REPLIKASI PADA
STANDBY DATABASE
MENGGUNAKAN
METODE
INCREMENTAL BACKUP
TESIS
DEFRY HAMDHANA
117038074
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
REPLIKASI PADA
STANDBY DATABASE
MENGGUNAKAN
METODE
INCREMENTAL BACKUP
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
DEFRY HAMDHANA
117038074
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
PENGESAHAN
Judul : Replikasi padaStandby DatabaseMenggunakan Metode Incremental Backup
Nama : Defry Hamdhana
Nomor Induk Mahasiswa : 117038074
Program Studi : Magister (S2) Teknik Informatika
Fakultas : Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara
Komisi Pembimbing :
Pembimbing 2, Pembimbing 1,
Dr. Erna Budhiarti Nababan, M.IT Prof. Dr. Herman Mawengkang
Diketahui/disetujui oleh
Program Studi S2 Teknik Informatika Ketua,
PERNYATAAN
REPLIKASI PADASTANDBY DATABASEMENGGUNAKAN METODEINCREMENTAL BACKUP
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan
dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 03 Januari 2014
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai civitas akademik Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini :
Nama : Defry Hamdhana
Nim : 117038074
Program Studi : Teknik Informatika
Demi pengembangan ilmu pengetahuan, menyetujui memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Ekslusif (Non-Exclusive Royalty Free Right) atas tesis saya yang berjudul:
REPLIKASI PADASTANDBY DATABASEMENGGUNAKAN METODEINCREMENTAL BACKUP
Beserta perangkat yang ada (jika diperlukan). Dengan hak bebas Royaliti Non-Exclusive ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 03 Januari 2014
Telah diuji pada
Tanggal: 03 Januari 2014
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Herman Mawengkang Anggota : 1. Dr. Erna Budhiarti Nababan, M.IT
2. Prof. Dr. Muhammad Zarlis 3. Prof. Dr. Tulus
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap : Defry Hamdhana, S.T
Tempat dan Tanggal Lahir : Lhokseumawe, 05 Mei 1987 Alamat Rumah : Jl. Pendidikan No. 6 Dusun III
Desa Tambon Tunong Kec. Dewantara Kab. Aceh Utara
Telepon Rumah/Faks/Hp : 0857 6136 2180
E-mail : [email protected]
Instansi Tempat Bekerja : SMK Tritech Informatika Medan
Alamat Kantor : Jl. Bhayangkara No. 488 Kel. Indra Kasih Kec. Medan Tembung
DATA PENDIDIKAN
SD : SD Swasta Iskandar Muda TAMAT : 1999 SMP : SMP Swasta Al-Azhar Medan TAMAT : 2002 SMA : SMA Negeri 1 Lhokseumawe TAMAT : 2005 S1 : Jurusan Teknik Informatika Unimal TAMAT : 2010
vii
KATA PENGANTAR
Alhamdulillah puji syukur kehadirat Allah SWT, yang telah memberikan rahmat dan
karunia-Nya kepada penulis, sehingga penulis dapat menyelesaikan tesis ini dengan judul:
Replikasi padaStandby DatabaseMenggunakan MetodeIncremental Backup.
Tesis ini disusun untuk melengkapi dan memenuhi persyaratan mencapai derajat
kesarjanaan Strata-2 pada Program Studi Teknik Informatika, Fakultas Ilmu Komputer
dan Teknologi Informasi Universitas Sumatera Utara. Penulis menyadari sepenuhnya,
bahwa tesis ini selesai karena adanya dukungan dan bantuan dari berbagai pihak. Untuk
itu pada kesempatan ini, penulis menyampaikan penghargaan dan ucapan terimakasih
yang sedalam-dalamnya kepada:
1. Bapak Prof. Dr. Herman Mawengkang, selaku Dosen Pembimbing Utama dan Ibu Dr.
Erna Budhiarti Nababan, M.IT selaku Dosen Pembimbing Kedua, dengan segala
perhatian dan kesabaran telah memberikan bimbingan baik selama mengikuti
pendidikan maupun dalam penyelesaian tesis ini.
2. Bapak Prof. Dr. Muhammad Zarlis selaku Ketua Prodi, Bapak Prof. Dr. Tulus dan
Bapak Dr. Marwan Ramli, M.Si, selaku Dosen Pembanding atas segala kritik dan
sarannya.
3. Seluruh Dosen Pengajar Pascasarjana Program Studi Teknik Informatika yang telah
memberikan bekal ilmu pengetahuan selama penulis mengikuti pendidikan.
4. Ayahanda H. Muhammad Yusuf Umar, Ibunda Hj. Ernawati Sulaiman, dan adik-adik
atas doa restu dan motivasinya yang telah diberikan selama ini.
5. Bapak Fadlisyah S.Si, M.T dan Bapak Sayed Fachrurrozi S.Si, M.Kom selaku Dosen
Jurusan Informatika Unimal, dan Bapak Nurdin, M.Kom selaku Ketua Jurusan
Informatika Unimal, yang selama ini telah banyak memberikan dukungan baik moril
viii
6. Segenap civitas akademika Program Studi Pascasarjana Teknik Informatika Sumatera
Utara yang selalu memberikan informasi dan pelayanan kepada penulis dengan tulus
dan tak kenal lelah.
7. Rekan-rekan seperjuangan pada program studi Teknik Informatika yang tergabung
dalam Kom C 2011 dan rekan-rekan lain yang tidak dapat disebutkan satu persatu,
yang telah banyak membantu selama perkuliahan maupun dalam penyelesaian tesis
ini.
Tentulah tiada yang sempurna di dunia ini begitu pula dalam penulisan tesis ini, untuk
itu penulis mengharapkan kritik dan saran dari pembaca demi kesempurnaan tesis ini
selanjutnya.
Akhir kata penulis berharap semoga tesis ini dapat bermanfaat bagi semua pihak,
khususnya dalam bidang pendidikan dan penyedia jasa internet.
Medan, 03 Januari 2014
ABSTRAK
Bagi beberapa lembaga pemerintahan atau perusahaan, data adalah salah satu aset yang harus dapat dijamin keberadaaannya. Akan tetapi resiko kehilangan data yang diakibatkan olehmaintenance, kerusakandatabase, kerusakan media, data corruption atau bahkan bencana alam dapat memberikan resiko yang besar terhadap keberadaan data yang semuanya itu dapat terjadi tanpa bisa diprediksi terlebih dahulu. Untuk itu dibutuhkan sebuah disaster recovery plan yang dapat menjamin data tetap konsisten walaupun database mengalami gangguan bahkan kerusakan. Adapun teknik penyelamatan data yang sering dilakukan adalah backup data. Pada kasus ini backup data harus dapat dilakukan secarareal time. Karenadisaster yang dapat terjadi kapan saja. Hal ini dapat dilakukan dengan menggunakan metode incremental backup. Namun solusi backup untuk beberapa instansi yang tetap harus melakukan transaksi data walaupun database primary rusak belum cukup. Server database slave tidak dapat langsung menggantikan server database primary. Untuk itu dibutuhkan sebuah teknik yang mampu mengatur server database slave menjadi pengganti server database primary untuk menjaga keberlangsungan transaksi data. Teknik tersebut adalah standby database. Dengan melakukan failover, standby database dapat menggantikan fungsiprimary database dalam waktu yang singkat. Dengan demikian proses transaksi data tetap dapat berjalan walaupun primary database mengalami kerusakan.
REPLICATION STANDBY DATABASE USING THE INCREMENTAL BACKUP METHOD
ABSTRACT
For some government agencies or companies, the data is one of the assets that must be guaranteed its existence. However, the risk of data loss caused by maintenance, database damage, damage to the media, corruption of data or even a natural disaster can provide a great risk to the existence of the data all of which can happen without being able to predict in advance. That requires a disaster recovery plan to ensure that data remains consistent even though the database to crash damage. The data rescue techniques is often done data backups. In this case the backup data must be done in real time. Because disaster can occur anytime. This can be done by using incremental backups. But backup solutions for some agencies still have to perform data transactions even if the primary database is not damaged enough. The slave database servers can not directly replace the primary database server. That requires a technique that is able to regulate the slave database server becomes a substitute for the primary database server to maintain the continuity of data transactions. The technique is a standby database. By doing failover, standby database can replace the function of the primary database in a short time. Thus the process of data transactions can still run even if the primary database is damaged.
xi
2.5. Primary DatabasedanStandby Database 9
2.5.1. Failover 10
2.5.2. Redo Log File 10
2.5.1. Archived Log File 10
2.6. MetodeStandby Database 11
2.6.1. Metode Standby Database secara Manual 11 2.6.2. Metode Standby Database secara Managed Recovery 11
2.6.3. Read-Only Mode untuk Query 12
BAB III METODOLOGI PENELITIAN 14
3.1. Rancangan Penelitian 15
3.2. Perangkat dan Data yang digunakan dalam penelitian 15
3.2.1. Perangkat 15
3.2.2.Data yang digunakan 15
3.3. Model Jaringan Untuk Simulasi 15
. 3.4. Langkah Kerja Jaringan 16
xii
3.6.1. Analisa Data 17
3.6.2. Rancangan Skenario Simulasi 17
3.6.2.1.Skenario I, Primary Database dan Standby
Database berada dalam keadaan normal 23 3.6.2.2.Skenario II, Standby Database dalam
keadaan normal tetapi Primary Database mati dalam keadaan proses menginput data 24 3.6.2.3.Skenario III, Primary Database dalam
keadaan normal tetapi dengan Standby Database
yang baru 24
BAB IV HASIL DAN PEMBAHASAN 25
4.1. Parameter ReplikasiDatabasepada Simulasi 25
4.2. Simulasi 27
4.1.1. Skenario I, Primary Database dan Standby Database
berada dalam keadaan normal 28
4.1.2. Skenario II, Standby Database dalam keadaan normal tetapi Primary Database mati dalam keadaan proses
menginput data 34
4.1.3.Skenario III, Primary Database dalam keadaan normal tetapi dengan Standby Database yang baru 36
BAB V KESIMPULAN DAN SARAN 40
5.1. Kesimpulan 40
5.2. Saran 41
DAFTAR PUSTAKA 42
xiii
DAFTAR TABEL
Hal.
Tabel 4.1. PengaturanIP address 28
Tabel 4.2. Contoh data barang yang terdapat di dalamprimary database 32
Tabel 4.3. Contoh data barang yang terdapat di dalamstandby database 32
Tabel 4.4. Hasil pengujian waktu respon danthroughputpada skenario I 34
Tabel 4.5. Hasil pengujian waktu respon pada skenario III 39
xiv
DAFTAR GAMBAR
Hal.
Gambar 2.1.Standby databasepada moderecovery manual 11
Gambar 2.2.Updatesecara otomatis pada sebuahstandby database 12
Gambar 2.3.Standby Databasedalam ModeRead Only 12
Gambar 3.1. Rancangan topologi jaringan yang dibagun untuk simulasi 16
Gambar 3.2.Flowchartsistem kerjastandby database 18
Gambar 3.3. Prosesstandby database 19
Gambar 3.4. Skema dari sistemstandby database 20
Gambar 3.5.Redo log files 21
Gambar 3.6. Proseslog File 23
Gambar 4.1. Arsitektur server pada simulasi 25
Gambar 4.2. MendaftarkanIP address primary databasepada komputer
klien 28
Gambar 4.3. Melakukan konfigurasiIP addresspada aplikasi master 29
Gambar 4.4. MendaftarkanIP server standby databasepada aplikasi
master 29
Gambar 4.5. Mengaktifkanreal time logging 30
Gambar 4.6.Inputdata 30
Gambar 4.7. (a) Data padaprimary database, (b) Data padastandby
database 31
Gambar 4.8. Tabellogging 31
Gambar 4.9. Skema replikasi pada sistem yang dibangun 32
Gambar 4.10. Proses replikasistandby databasesecaraincremental
backup 33
Gambar 4.11. KonfigurasiIP addressuntukprimary databaseyang baru 35
Gambar 4.12. Konfigurasifailover 35
Gambar 4.13. KonfigurasiIP addresspada aplikasi pergudangan 36
Gambar 4.14. Proses sinkronisasi data dengan menggunakan metodefull
xv
Gambar 4.15. Tabelreal time loggingtidak aktif 38
ABSTRAK
Bagi beberapa lembaga pemerintahan atau perusahaan, data adalah salah satu aset yang harus dapat dijamin keberadaaannya. Akan tetapi resiko kehilangan data yang diakibatkan olehmaintenance, kerusakandatabase, kerusakan media, data corruption atau bahkan bencana alam dapat memberikan resiko yang besar terhadap keberadaan data yang semuanya itu dapat terjadi tanpa bisa diprediksi terlebih dahulu. Untuk itu dibutuhkan sebuah disaster recovery plan yang dapat menjamin data tetap konsisten walaupun database mengalami gangguan bahkan kerusakan. Adapun teknik penyelamatan data yang sering dilakukan adalah backup data. Pada kasus ini backup data harus dapat dilakukan secarareal time. Karenadisaster yang dapat terjadi kapan saja. Hal ini dapat dilakukan dengan menggunakan metode incremental backup. Namun solusi backup untuk beberapa instansi yang tetap harus melakukan transaksi data walaupun database primary rusak belum cukup. Server database slave tidak dapat langsung menggantikan server database primary. Untuk itu dibutuhkan sebuah teknik yang mampu mengatur server database slave menjadi pengganti server database primary untuk menjaga keberlangsungan transaksi data. Teknik tersebut adalah standby database. Dengan melakukan failover, standby database dapat menggantikan fungsiprimary database dalam waktu yang singkat. Dengan demikian proses transaksi data tetap dapat berjalan walaupun primary database mengalami kerusakan.
REPLICATION STANDBY DATABASE USING THE INCREMENTAL BACKUP METHOD
ABSTRACT
For some government agencies or companies, the data is one of the assets that must be guaranteed its existence. However, the risk of data loss caused by maintenance, database damage, damage to the media, corruption of data or even a natural disaster can provide a great risk to the existence of the data all of which can happen without being able to predict in advance. That requires a disaster recovery plan to ensure that data remains consistent even though the database to crash damage. The data rescue techniques is often done data backups. In this case the backup data must be done in real time. Because disaster can occur anytime. This can be done by using incremental backups. But backup solutions for some agencies still have to perform data transactions even if the primary database is not damaged enough. The slave database servers can not directly replace the primary database server. That requires a technique that is able to regulate the slave database server becomes a substitute for the primary database server to maintain the continuity of data transactions. The technique is a standby database. By doing failover, standby database can replace the function of the primary database in a short time. Thus the process of data transactions can still run even if the primary database is damaged.
1
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Kebutuhan akan sistem database yang semakin meningkat menjadikan data menjadi
aset yang bernilai tinggi. Dengan demikian penting untuk menjaga data agar tetap ada
kapan saja dibutuhkan. Akan tetapi resiko terjadinya kerusakan (failure) pada
database yang mengakibatkan data tidak dapat diakses atau bahkan mengakibatkan
data loss dapat terjadi setiap saat. Gangguan tersebut dapat berupa maintenance,
kerusakandatabase, kerusakan media dandata corruption.Databasejuga dapat rusak
akibat adanya bencana alam seperti kebakaran, gempa bumi dan banjir.
Kerugian yang terjadi dari rusaknya database secara tiba-tiba akan sangat
besar. Hal ini dapat diatasi apabila database yang rusak dapat langsung digantikan
olehdatabasecadangan (secondary) sehingga sistem dapat berjalan dengan baik. Oleh
sebab itu dibutuhkan sebuah disaster recovery plan yang dapat menjamin data tetap
konsisten walaupundatabasemengalami gangguan bahkanfailure(kerusakan).
Adapun teknik penyelamatan data yang sering dilakukan, yaitu backup data.
Backup data adalah teknik menyalin data ke dalam media lain. Dalam penelitian ini
berarti data yang berada pada primary database (utama) disalin ke dalam secondary
database (cadangan). Jika primary database mengalami kerusakan maka data tetap
aman di dalam secondary database. Dan secondary database akan mengembalikan
(restore) data apabilaprimary databasesudah siap untuk digunakan kembali. Namun
demikian hal ini belum dapat menjadi solusi terbaik. Karena backup tidak
menggantikan kinerja primary database secara langsung yang mengakibatkan data
tidak dapat diakses sampai maintenance pada sistem primary database tersebut
berakhir.
Beberapa penelitian yang telah dilakukan oleh peneliti yang dituliskan dalam
2
melakukan penelitian teknik replikasi database dengan menggunakan klasifikasi tiga
parameter, yaitu arsitektur server, interaksi server, terminasi transaksi. Dengan
membandingkan ketiga parameter di atas kesimpulan yang bisa diambil adalahupdate
everywhere memiliki potensi yang baik untuk mereplikasi data. Sedangkan pada
interaksi linear kekurangannya adalah sumber biaya yang besar. Noraziah (2012)
meneliti tentang teknik replikasi di dalam Data Grid Environments. Dan
menghasilkan beberapa teknik yang dapat meningkatkan latency jaringan, konsumsi
bandwith maupun toleransi kesalahan dalam Data Grid Environments. Tawar &
Wahyuningsih (2011) menguji dua metode backup data yang terdapat pada server
database MySQL antara lain MySQLDump dan replikasi. Kedua metode tersebut
diuji dengan membandingkan pengukuran memori, penggunaan CPU dan waktu
proses pada server saat proses backup terjadi hampir bersamaan dengan proses
transaksi input data. Dan kesimpulannya adalah metodebackup menjadikan replikasi
lebih efisien dibandingkan dengan MySQLDump dari sisi penggunaan memory dan
CPU. Sementara Qian et al (2009) mempertimbangkan skema full backup dan
incrementaluntuk sistem database. Dari penelitian tersebut dihasilkan bahwa jumlah
optimal untuk meminimalkan biaya dalam melakukanbackupdapat dilakukan dengan
menggunakan teknikincremental.
Dari penelitian terdahulu penulis menyimpulkan bahwa replikasi merupakan
hal yang harus dilakukan oleh instansi yang tidak ingin kehilangan datanya. Replikasi
juga masih merupakan hot issue yang masih terus mengalami pengembangan. Salah
satunya adalah standby database. Kemampuan standby database adalah untuk
melakukanrecoverydan backuppadaprimary database (Singhet al : 2013).Standby
databasedapat melakukanbackupdata dari lingkungan geografis yang berbeda, maka
apabila terjadi hal-hal yang dapat menyebabkanprimary databaserusak karena suatu
hal, standby database dapat mengambil fungsi peran dari primary database yang
mengalami kerusakan. Pada DBMS Oracle, standby database merupakan fitur yang
sudah ada di dalam Oracle data guard. Wibowo et al (2007) melakukan analisa
standby databasedengan menggunakan Oracle dan menunjukkan tingkat availibilitas
yang tinggi karena dapat langsung diaktifkan dan beroperasi begitu terjadi failure
terhadap primary database. Dan oleh sebab itu penulis melakukan riset dan analisis
3
1.2. Perumusan Masalah
Berikut adalah Perumusan Masalah dari penelitian ini:
1. Membangun perangkat lunak yang mendukung konsep standby database pada
lingkungan DBMS MySQL.
2. Menganalisa kelemahan dari implementasi standby database pada lingkungan
DBMS MySQL.
3. Menguji sistemstandby databasebisa bekerja secarareal time.
4. Menguji waktu respon dan throughput pada replikasi dari server primary
databaseke serverstandby database.
1.3. Batasan Masalah
Dari Perumusan Masalah di atas penulis membatasi tesis ini dengan:
a. Simulasi skenario pengujian menggunakan jaringan yang telah terisolasi dengan
topologi star.
b. Parameter yang diuji adalah waktu respon dan throughput.
c. Failuresistem berupa matinya jaringan serverprimary database.
d. Simulasi hanya dilakukan pada sebuah serverstandby database.
1.4. Tujuan Penelitian
Tujuan penelitian ini adalah membuat standby database yang mampu melakukan
backup data secara realtime pada lingkungan DBMS MySQL dan menggantikan
primary database pada saat primary database mengalami kerusakan (failure) serta
menguji waktu respon dan throughput pada proses replikasi dari primary database
serverkestandby database serveryang diharapkan mampu mengatasi kehilangan data
jika terjadi gangguan seperti bencana alam, kerusakandatabasedan kerusakan media.
1.5. Manfaat Penelitian
Manfaat dari penelitian tesis ini, yaitu:
1. Memberikan uraian secara lebih terperinci tentang sistem kerja standby database
4
menjadiprimary database (failover) serta persiapanprimary database yang lama
menjadistandby databasedalam lingkungan DBMS MySQL.
2. Penelitian ini diharapkan dapat dijadikan sebagai salah satu solusi yang dapat
menangani kehilangan data sehingga data tetap dapat diakses kapan saja oleh
user.
3. Sebagai referensi bagi hasil studi dan peneliti selanjutnya yang diminati dan
5
BAB 2
TINJAUAN PUSTAKA
2.1. Data
Data adalah sesuatu yang mewakili objek dan peristiwa yang memiliki arti yang
sangat penting bagiuser (Hofferet al, 2005). Dalam pengertian yang lain data adalah
fakta yang dapat disimpan dan memiliki arti (Navathe & Elmasri, 2000). Sehingga
dapat disimpulkan bahwa data adalah fakta yang telah terjadi, memiliki arti, dan dapat
disimpan secara teratur sedemikian rupa sehingga menjadi sebuah form yang dapat
digunakan kembali suatu waktu. Data yang saling berhubungan akan dikumpulkan
dan disimpan dalam suatu database. Hal ini jelaskan oleh (Connolly, 2002) yang
menyatakan bahwa database adalah suatu koleksi data yang saling berhubungan
secara logikal, dan sebuah deskripsi data yang dirancang untuk memenuhi kebutuhan
informasi suatu organisasi. Database mempunyai sumber data dalam pengumpulan
data, bervariasi derajat interaksi kejadian dari dunia nyata, dirancang dan dibangun
agar dapat digunakan oleh beberapa user untuk berbagai kepentingan (Waliyanto,
2000). Untuk memasukkan, mengubah, menghapus, memodifikasi dan memperoleh
data/informasi dengan praktis dan efisien digunakan sebuah program komputer yang
disebut DBMS (Data Base Management System).
2.2. Disaster Recovery
Disaster recovery adalah proses, kebijakan dan prosedur yang berkaitan dengan
persiapan untuk pemulihan (recovery) atau kelanjutan pada infrastruktur teknologi
yang sangat penting (vital) bagi organisasi setelah bencana yang disebabkan oleh alam
maupun manusia. Bencana dapat diklasifikasikan ke dalam dua kategori, yaitu:
a. Yang pertama adalah bencana alam seperti banjir, angin topan, tornado atau
gempa bumi. Sementara mencegah bencana alam sangat sulit, memastikan
6
Langkah-langkah tersebut diharapkan mampu menghindari ataupun mengurangi
kerugian akibat bencana (disaster).
b. Bencana buatan manusia. Bencana juga dapat terjadi akibat perbuatan manusia.
Sebagai contoh kegagalan infrastruktur dan terorisme. Dalam hal ini pengawasan
dan perencanaan juga diharapkan dapat menghindari kerugian.
Menurut (Gregory, 2009) Disaster Recovery Plan (DRP) adalah bagian dari
sebuah proses yang lebih besar sebagai perencanaan kelangsungan bisnis dan
termasuk di dalamnya perencanaan untuk memulai kembali aplikasi, data, perangkat
keras (hardware), komunikasi elektronik (networking) dan infrastruktur teknologi
informasi lainnya. Langkah-langkah kontrol pemulihan (recovery) bencana teknologi
informasi dapat diklarifikasikan menjadi tiga jenis, yaitu:
1. Langkah preventive, kontrol yang dilakukan untuk mencegah sebuah bencana
yang akan terjadi.
2. Langkah deteksi, kontrol yang bertujuan untuk mendeteksi atau menemukan
kejadian yang tidak diinginkan.
3. Langkah korektif, kontrol yang ditujukan untuk memperbaiki atau memulihkan
sistem setelah bencana atau peristiwa.
Disaster recovery plan yang baik memastikan bahwa ketiga jenis kontrol
didokumentasikan dan diuji secara teratur.
2.3. KonsepBackup
Menurut (Tawar & Wahyuningsih, 2011) Proses backup dalam teknologi informasi
mengacu pada pembuatan salinan data, sehingga salinan tambahan tersebut dapat
digunakan untuk mengembalikan (restore) semula setelah peristiwa kehilangan data.
Backupdata merupakan salah satu pengelolaan data agar data tetap terjaga saat terjadi
perubahan atau kehilangan data.Backupsangat berguna terutama untuk dua tujuan:
a. Untuk memulihkan keadaan setelah bencana (disaster recovery)
b. Untuk mengembalikan sejumlah kecilfilesetelah sengaja dihapus atau rusak.
Konsistensi data dalam prosesbackupharus dijaga, sebelum melakukan backup data.
Secara umum tipebackupterbagi menjadi dua, yaitu:
a. Full Backup, yaitu tipe backup yang menyalin file secara keseluruhan dalam
7
maka archive bit dari file tersebut akan dihapus sampai file tersebut
dimodifikasi. Ketika archive bit diset kembali, ini menandakan bahwa file
tersebut telah berubah dan perlu di-backuplagi.
b. Incremental Backup, adalah backup data yang mengalami perubahan sejak
backupterakhir dilakukan. Hanya file denganarchive bityang akan di-backup.
Hal ini akan menghemat penggunaan pita tapi memerlukan waktu yang lama
untuk me-restore data karena data tersebar pada pita yang berbeda-beda.
Menurut (Elmasri & Rames : 2011) incremental backup sering digunakan
karena hanya mengganti perubahan yang terjadi sejak backup terakhir yang
telah disimpan.
2.4. Replikasi
Replikasi dicapai dengan memiliki sistem standby, yang merupakan duplikasi dari
database produksi. Replikasi standby diperbaharui setelah database produksi
memanipulasi data, sehingga membuat sistem standby sangat dekat dengan sistem
utama (Radulescu, 2002). Replikasi adalah suatu teknik untuk melakukan copy dan
pendistribusian data dan objek-objekdatabasedari satudatabasekedatabaselain dan
melakukan sinkronisasi antara database sehingga konsistensi data dapat terjamin
(Tawar & Wahyuningsih, 2011).
Pada dasarnya sistem replikasi membutuhkan minimal dua buah server untuk
digunakan sebagai master dan slave. Dengan menggunakan teknik replikasi, data
dapat didistribusikan ke lokasi yang berbeda melalui koneksi jaringan lokal maupun
internet.
Beberapa keuntungan dari replikasi adalah sebagai berikut:
1. Memungkinkan beberapa lokasi menyimpan data yang sama. Hal ini sangat
berguna pada saat lokasi-lokasi tersebut membutuhkan data yang sama atau
memerlukan server yang terpisah dalam pembuatan aplikasi laporan.
2. Aplikasi transaksi onlineterpisah dari aplikasi pembacaan seperti proses analisis
databasesecaraonline, datasmartsatau datawarehouse.
3. Memungkin otonomi yang besar. Pengguna dapat bekerja dengan meng-copy
data pada saat tidak terkoneksi kemudian melakukan perubahan untuk dibuat
8
4. Data dapat ditampilkan seperti layaknya melihat data tersebut dengan
menggunakan aplikasi berbasisWeb.
5. Meningkatkan kinerja pembacaan.
6. Membawa data mendekati lokasi individu atau kelompok pengguna. Hal ini akan
membantu mengurangi masalah karena modifikasi data dan pemrosesan query
yang dilakukan oleh banyak pengguna karena data dapat didistribusikan melalui
jaringan dan data dapat dibagi berdasarkan kebutuhan masing-masing unit atau
pengguna.
7. Penggunaan replikasi sebagai bagian dari strategistandby server.
8. Menyembunyikan perbedaan antara layananreplicateddan non-replicated.
Menurut (Wiesman et al, 2000) replikasi database memiliki tiga parameter
dalam menentukan karakteristik yang terbaik untuk mereplikasi data, yaitu:
1. Arsitektur Server
Parameter kunci pertama untuk dipertimbangkan adalah transaksi yang
dieksekusi pada tempat pertama. Ada dua kemungkinan identifikasi, yaitu
Replikasi copy primary yang memiliki situs yang spesifik untuk di copy oleh
setiap data yang saling terkait. Serta replikasi update everywhere yang
memungkinkan updateke item data yang akan dilakukan di mana saja dalam
sistem.
2. Interaksi Server
Untuk parameter ini terdapat dua hal yang harus dipertimbangkan, yaitu
interaksi konstan, protokol dalam kategori ini melakukan pesan tunggal per
transaksi dengan mengelompokkan semua operasi dari transaksi dalam satu
pesan. Selanjutnya adalah interaksi linear yang biasanya berkaitan dengan
teknik yang apabila sebuah server database merambat ke setiap operasi dari
sebuah transaksi pada basis per operasi.
3. Terminasi Transaksi
Sedangkan pada parameter terakhir juga terdapat dua hal yang harus
dipertimbangkan, yaitu terminasi voting yang membutuhkan babak tambahan
pesan untuk mengkoordinasi replika yang berbeda. Dan terminasi non-voting
yang menyiratkan bahwa situs dapat memutuskan sendiri apakah akan
9
Dengan membandingkan ketiga karakteristik tersebut Wiesman menyimpulkan bahwa
update everywherememiliki potensi yang baik untuk mereplikasi data.
Teknik replikasi di dalam Data Grid Environments menurut Noraziah (2012)
adalah:
1. A Weight-Based Dynamic Replica Replacement. Strategi ini dihitung
berdasarkan waktu akses dalam jendela waktu di masa depan, berdasarkan
akses padahistoryterakhir.
2. Distributed Popularity Based Replica Placement Algorithm. Dikembangkan
untuk jaringan data hirarkis. Strategi ini memanfaatkan history akses data
untuk mengenali file yang sering muncul dan menentukan lokasi replikasi
yang optimal untuk meningkatkan kinerja akses data dengan meminimalkan
replikasi yangoverheadpada pola jalur data yang diberikan.
3. A New Replication Strategy for Dynamic Data Grids diusulkan untuk
memperhitungkan situs yang dinamis. Strategi ini dapat meningkatkan
ketersediaan berkas, meningkatkan waktu respon dan dapat mengurangi
konsumsibandwidth.
4. Enhance Fast Spread Replication Strategy adalah versi yang disempurnakan
pada Fast Spread untuk strategi replikasi data grid. Strategi ini diusulkan
untuk meningkatkan total waktu respon dan total konsumsibandwidth.
5. A Value-Based Replication Strategy untuk mengurangi jaringan latency dan
sementara itu untuk meningkatkan kinerja keseluruhan sistem.
6. Agent Based Replica Placement Algorithmdiusulkan untuk menentukan calon
lokasi untuk penempatan replika yang mengurangi biaya akses,network traffic
dan agregat waktu respon untuk aplikasi.
2.5. Primary DatabasedanStandby Database
Primary database adalah database utama yang digunakan untuk menyimpan data.
Databaseini diharapkan mampu diakses setiap saat. Maka dari itu jika terjadi transisi
roledanprimary database mati, maka secara otomatis pengaksesan terhadap primary
databasetersebut juga tidak dapat dilakukan.
Standby database merupakan replikasi database yang terdiri dari backup data
10
database untuk standby database, sehingga data dapat disimpan di dalam server
database yang tersinkronisasi. Sebuah standby database memiliki tujuan utama
sebagai disaster recovery, backup, analisis, dan reporting (laporan). Jika primary
database hancur atau rusak, admin dapat melakukan failover ke standby database,
dalam kasus ini standby database menjadi primary database yang baru. Admin juga
dapat membuka standby database dengan opsi read only, sehingga dapat berfungsi
sebagai sebuahdatabase reportingindependen.
2.5.1. Failover
Failover yaitu mode backup operational pada saat fungsi komponen sistem (seperti
processor, server, network, atau database) dilakukan oleh secondary system
componentsketika komponen utama mengalami kegagalan atauscheduled down time.
Pada konfigurasi standby database semua pengguna aplikasi melakukan transaksi
pada primary database. Namun apabila server primary database mengalami
kegagalan secara tidak terduga, maka admin harus melakukan failover. Failover
adalah operasi yang mengubah standby databasemenjadiprimary database sehingga
dapat berjalan secara normal. Operasi ini juga disebut aktivasi standby database.
Penting untuk diperhatikan bahwa setelah melakukan failover, admin tidak dapat
mengembalikanstandby databaseyang saat ini telah menjadi primary databaseuntuk
menjadistandby databasekembali.
2.5.2. Redo Log File
Redo log file merupakan bagian terpenting dalam proses database untuk melakukan
proses recovery. Redo log files sebagai tempat catatan setiap transaksi yang terjadi.
Berisikan file yang digunakan untuk melakukan instance recovery ketika database
mengalami kegagalan.
2.5.3. Archived Log File
Tujuan utama archived log file adalah untuk melindungi database dari kegagalan
instance dan kerusakan media disk melalui pengarsipan secara online dengan
11
2.6. MetodeStandby Database
Standby databaseterdiri dari tiga metode. Masing-masing metode memiliki kelebihan
dan kelemahan. Oleh karena itu seorang admin harus mampu memilih metode
standby database yang sesuai dengan sistem yang ada. Berikut adalah tiga metode
standby database.
2.6.1. Metode Standby Database secara Manual
Admin memiliki pilihan untuk menempatkan database dengan menggunakan metode
manualrecovery. Untuk melakukan metode ini, adminharus terus menerus dan secara
manual mentransfer dan menerapkan archived redo log ke standby database untuk
tetap disinkronkan denganprimary database. Berikut adalah proses standby database
dengan menggunakan moderecoverymanual seperti pada gambar 2.1.
Gambar 2.1.Standby databasepada moderecoverymanual [Oracle : 1999]
Metode recovery manual berguna dalam lingkungan yang mana admin tidak
menghubungkan primary database dan standby database. Karena alasan tertentu
primary database tidak dapat secara otomatis mentransfer archived redo log ke
standby database untuk melakukan recovery data. Admin membutuhkan aksi secara
manual dalam halrecoveryuntuk memperbaharuistandby database.
2.6.2. Metode Standby Database secara Managed Recovery
Pada metode ini admin dapat menempatkan standby database dengan cara managed
recovery. Metode ini mengacu kepada standby database yang secara otomatis
menerima archived redo logs dari primary database. Keuntungan utama dari
12
archived redo logsecara manual. Di bawah ini adalah proses update secara otomatis
pada sebuahstandby databasepada gambar 2.2.
Gambar 2.2.Updatesecara otomatis pada sebuahstandby database[Oracle : 1999]
2.6.3. Read-Only Mode untuk Query
Admin juga dapat membukastandby database dalam mode read only setelah manual
terminasi atau managed recovery. Pada saat melakukan mode read only,admin dapat
melihatquery database bahkan menyimpan data di tablespacesementara selama data
sudah di dalam standby database tanpa mempengaruhi file data atau redo log.
Kemudian admin dapat mengembalikan standby database untuk mode recovery
manual atau managed recovery tanpa harus menutupnya. Berikut adalah proses
standby databasedalam moderead onlyyang ada pada gambar 2.3.
13
Dalam lingkunganmanaged standby, standbyserver terus menerimaarchived
redo log oleh primary database dan file kontrol trus diperbaharui (update) dengan
record yang ada. Akibatnya, pengarsipan terus berlanjut pada server standby,
meskipunstandby database tidak melakukanrecoverydalam moderead only.
Standby database yang menggunakan metoderead only berguna ketika admin
ingin mengurangi jumlah query yang ada pada primary database. Jika tablespace di
dalam sebuah primary database jarang berubah tetapi sering diakses, admin dapat
mengarahkan query ke standby database sehingga primary database tidak menjadi
14
BAB 3
METODOLOGI PENELITIAN
Standby database server merupakan sebuah server yang berfungsi mereplikasi
(menyalin) data dari sebuah database untuk menyediakan kontinuitas availability
primary database serversaatfailure(rusak) terjadi. Pada penelitian ini akan dilakukan
beberapa pengujian yang akan memperlihatkan cara kerja standby database
melakukan backup data terhadap primary database dan cara kerja standby database
servermenggantikanprimary database serverpada saat terjadi failure.
Pada tesis ini simulasi standby database yang dilakukan adalah dengan
menggunakan DBMS MySQL. MySQL adalah sebuah perangkat lunak sistem
manajemen basis data SQL yang multithread, multi-user, dengan 6 juta instalasi.
MySQL banyak digunakan untuk kepentingan penanganan database karena selain
handal juga bersifatopen source. Konsekuensi dari open source, perangkat lunak ini
dapat dipakai oleh siapa saja tanpa membayar dan source code-nya bisa diunduh oleh
siapa saja. Akan tetapi fungsi standby database tidak dimiliki oleh DBMS MySQL
secara default. Sehingga penulis harus membangun aplikasi yang dapat memberikan
fungsi yang sesuai dengan konsepstandby databasepada DBMS MySQL.
Pembahasan dalam tesis ini akan menggunakan struktur data inventori pada
sebuah gudang supermarket. Aplikasi yang dibangun merupakantools simulasi untuk
menganalisa sistem standby database dengan menggunakan metode managed
recovery sehingga tidak terlalu memperhatikan faktor pendukung seperti interface
yanguser friendly. Aplikasi ini berjalan dengan cara seorangadminmemasukkan data
barang dan kemudian menganalisis alur data yang berjalan dari aplikasi input barang
15
3.1. Rancangan Penelitian
Penelitian ini menggunakan metode penelitian eksperimen (Experimental Research).
Pengumpulan data dan informasi dengan menggunakan metode observasi yaitu
meninjau dan mengamati secara langsung pada server primary database dan server
standby database untuk mendapatkan gambaran tentang replikasi yang terjadi pada
saat admin melakukan transaksi serta mengamati aktifnya server standby database
pada saat serverprimary databaserusak pada lingkungan DBMS MySQL.
3.2. Perangkat dan Data yang digunakan dalam penelitian 3.2.1. Perangkat
Pada penelitian ini alat penelitian yang digunakan berupa perangkat keras dan
perangkat lunak sebagai berikut:
a. Perangkat keras (hardware)
1. Satu unitswitch hub.
2. Dua unit personal computer Processor Intel(R) Core(TM)2Duo 1.80 GHz
untukdatabase server.
3. Satu unit personal computer Processor Intel(R) Core(TM)2Duo 1.80 GHz
untuk klien.
b. Perangkat lunak (software)
1. Sistem Operasi Windows 7 untukdatabase serverdan klien.
2. Microsoft Visual Studio 2010 Professional
3. MySQL untukdatabase server.
4. XAMPP V 1.3.1 Win32
5. Bandwith Meter Pro V 2.6.0
3.2.2. Data yang digunakan
Data yang digunakan pada penelitian ini adalah berupa data acak pada sebuah gudang
supermarket yang penulis unduh dari internet.
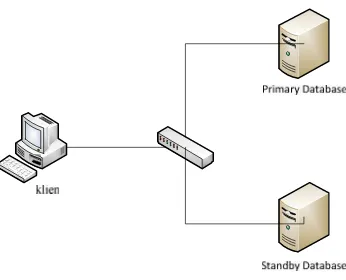
3.3. Model Jaringan untuk Simulasi
Adapun skenario jaringan untuk pengujian sistem ini adalah seperti pada gambar 3.1.
16
Gambar 3.1. Rancangan topologi jaringan yang dibangun untuk simulasi
3.4. Langkah Kerja Jaringan
Secara garis besar alur kerja jaringan ini adalah sebagai berikut:
1. Jaringan ini mempunyai dua server, yaitu server untuk primary database dan
server untuk standby database. Dan satu klien yang bertindak sebagai admin
pergudangan.
2. Pada saat admin pergudangan ingin meng-input data barang maka sistem akan
secara otomatis mengirim data tersebut ke server primary database. Setiap data
yang berada di dalam primary database akan dimasukkan ke dalam tabel_log
dan kemudian akan dikirimkan kestandby databasedalam proses replikasi data.
3. Topologi jaringan yang digunakan adalah topologi star untuk semua jaringan.
Dan pada setiap jaringan akan diberikan IP Static kelas C yang akan
menghubungkan ketiga jaringan.
3.5. Variabel Penelitian
Variabel dalam penelitian ini terdiri dari variabel dependen (terikat) dan variabel
independen (bebas). Variabel yang nilainya terikat tergantung dari variabel lain.
Variabel terikat pada penelitian ini adalah waktu respon (Y). Waktu respon adalah
waktu perjalanan data dari sebuah server database menuju server database lainnya
pada proses replikasi. Atribut yang mempengaruhi waktu respon dalam penelitian ini
adalah waktu respon danthroughput.
Sedangkan variabel bebas adalah yang nilainya tidak tergantung pada nilai
variabel lain. Variabel bebas pada penelitian ini yaitu incremental backup (X).
17
Keuntungan utama untuk backup secara incremental yaitu file yang lebih sedikit
disalin sehingga prosesbackupberjalan dengan cepat.
3.6. Proses Penelitian
Proses penelitian ini meliputi pengumpulan data, perancangan skenario simulasi,
pembuatan eksperimen simulasi berdasarkanflowchart, dan analisa data.
3.6.1. Analisa Data
Analisa data dilakukan melalui penelitian laboratorium dengan membuat jaringan
yang terisolasi menggunakan 1 (satu) unitswitchdan 2 (dua) unitdatabase serverdan
1 (satu) unit klien sesuai topologi yang dirancang untuk bisa mewakili jaringan nyata
dan juga diuji sesuai skenario simulasi yang dilakukan dengan beberapa kondisi dan
kemudian melakukan pengujian waktu yang diperlukan untuk mereplikasi dan
throughputyang dimiliki pada saat replikasi terjadi.
3.6.2. Rancangan Skenario Simulasi
Skenario simulasi pengujian secara umum terdiri atas dua bagian yaitu pengujian
tentang replikasi (logging) dan pengujian failover. Sebagai langkah awal
masing-masing laptop harus terhubung secaraLocal Area Network (LAN) pada kelas Internet
Protocol(IP) yang sama. Pada proses terjadinya replikasi, awalnya admin menginput
data yang ditujukan untuk primary database. Setelah itu admin mengaktifkan real
time logginguntuk mereplikasi data dari primary databaseke standby database.Real
time logging bertugas untuk membaca setiap perubahan yang terjadi pada primary
database. Semua perubahan baik ituinputdata baru, edit, ataupundeleteyang tercatat
pada real time logging akan diaplikasikan kepada standby database. Kemudian real
time logging akan memeriksa kembali apakah ada perubahan data lainnya di dalam
server primary database. Jika ada maka proses pereplikasian data masih akan terus
terjadi. Hal ini akan terus terjadi hinggareal time loggingmenyatakan bahwaprimary
database sudah tidak melakukan perubahan baik itu input data, edit data, ataupun
deletedata.
Secara default user akan mengakses data melalui primary database. Hal ini
18
apabila primary database mengalami kerusakan (failure), maka standby database
akan menggantikan fungsiprimary database.Standby databasemenjamin bahwa data
yang dimiliki tidak akan hilang ketika primary database rusak. Hal ini disebabkan
karena setiap transaksi yang terjadi antara klien danprimary database akan langsung
direplikasikan ke server standby database dengan cara mengumpulkan log file di
dalam archived log. Selama primary database dalam perbaikan, maka semua klien
masih dapat mengakses data secara normal menggunakan standby database. Proses
pengalihan (switch) standby database menjadi primary database disebut failover.
Failover diaktifkan oleh seorang admin pada saat server primary database rusak.
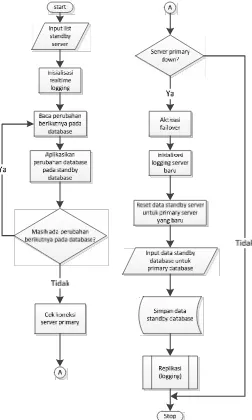
Untuk melihat gambaran kerja replikasi serta failover yang terjadi di dalam proses
standby databasedapat dilihat pada gambar 3.2.
19
Berikut adalahpseudocodedari metodeincremental backup:
a. Level 0 mem-backupsemua blok
b. Incremental Level 1 mem-backup blok yang telah berubah pada Level 1, 0 terakhir
c. Incremental Level 2 mem-backup blok yang telah berubah pada Level 2, 1, 0 terakhir
d. Incremental Level 3 mem-backup blok yang telah berubah pada Level 3, 2, 1, 0 terakhir
e. IncrementalLevel 4 mem-backupblok yang telah berubah pada Level 4, 3, 2, 1, 0 terakhir
f. Incremental Level n mem-backup blok yang telah berubah pada Level n – 1, 0
terakhir
Untuk dapat mengetahui gambaran umum proses standby database dapat
dilihat pada gambar 3.3.
Gambar 3.3. Prosesstandby database
Klien mengambil atau menginput data melalui primary database. Data yang
di-input ke primary database tereplikasi ke standby database. Pada saat primary
database rusak, standby database langsung menggantikan kerja sistem primary
database. Sehingga klien melakukan transaksi data ke standby database. Proses
transaksi data kembali keprimary databasepada saatprimary databasedapat berjalan
secara normal. Serta data yang ada pada standby database kembali direplikasi ke
20
Proses replikasi yang terjadi antara primary database dan standby database
hingga aktifnya redo logs di dalam standby database jika primary database
mengalami kerusakan seperti pada gambar 3.4.
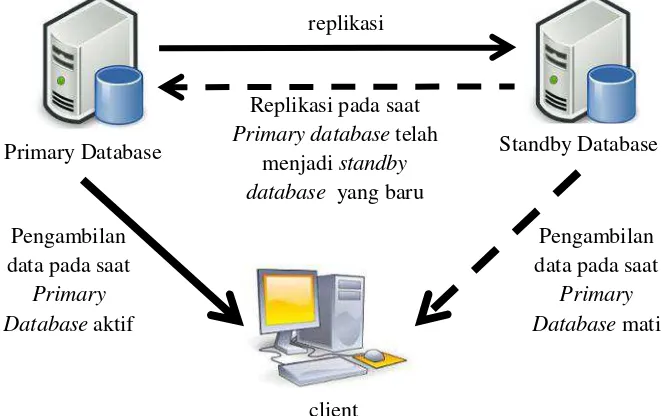
3.4. Skema dari sistemstandby database
Penjelasan dari Gambar 3.4. Skema dari sistem standby database di atas adalah sebagai berikut :
a. Primary Database
Primary database akan menulis data ke Redo logs. Kemudian isi dari Redo Logs
akan dituliskan ke Archived Logs. Lalu Archived Logs tersebut akan di-copy ke
Archived Logs dalam standby database jika logtime dalam keadaan aktif. Pada
simulasi ini tabel yang ada padaprimary databaseadalah sebagai berikut:
- tbl_barang adalah tabel yang berisikan data barang yang di-inputi oleh admin.
Ada 3 bagian penting yang harus terdaftar pada data barang yaitu kode barang,
nama barang dan harga.
- tbl_log ialah table yang berfungsi untuk menyimpan dan mengumpulkan log
yang tercipta dari transaksi data.
- tbl_server adalah tabel yang menyimpan beberapa data yang dimiliki oleh calon
standby database, diantaranya adalahIP Address,username,password, dan juga
databaseyang dimiliki oleh serverstandby database.
- tbl_status berfungsi untuk memberikan informasi kepada admin bahwa server
telah tersambung dengan baik atau tidak terhadap aplikasi.
21
- tbl_trans yaitu tabel yang mencatat jumlah barang yang terdapat di dalam
gudang.
b. Standby Database
Archived Logyang sudah di-copydariprimary database, akan dituliskan keArchieved
Logsdistandby database. Lalu Redo Logsdistandby databasehanya akan digunakan
jika primary database mati. Standby database memiliki tabel yang mutlak sama
denganprimary database. Ini karenastandby databasemerupakandatabasepengganti
apabila primary database rusak secara tiba-tiba. Oleh karena itu pada saat primary
database aktif,standby databasemelakukan backup data secara tersinkronisasi.
c. Redo Log Files
Redo log files digunakan sebagai tempat catatan setiap transaksi yang terjadi. Fungsi
utama redo log files digunakan untuk kebutuhan proses recovery. Jika pada saat
database mengalami kegagalan dan data yang diperbaharui belum tersimpan di data
file, redo log files akan melakukan recovery data yang telah diperbaharui dan
mengembalikan posisi transaksi terakhir saat database belum mengalami kegagalan.
Setiap transaksi yang dilakukan olehadminyang menuju ke primary database
akan disimpan pada sebuah redo log dan kemudian dikumpulkan oleh archive logs
dan kemudian direplikasi ke standby database. Redo log yang berfungsi untuk
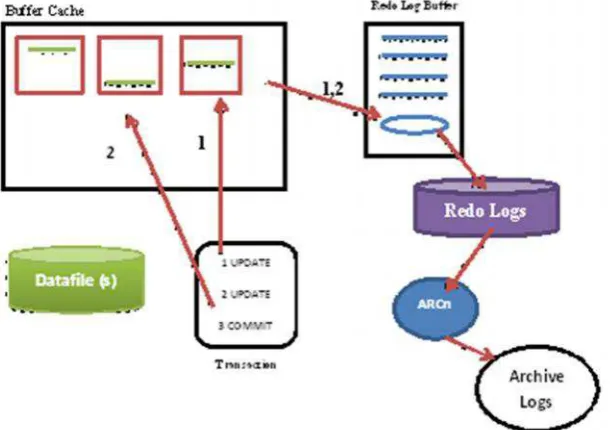
menyimpan log yang dikirimkan dariprimary databasedapat dilihat pada gambar 3.5.
22
Redo Log Buffer yang berisi cache redo informasi digunakan pada saat
terjadinyarecoverymenyimpan parsed version DDL (Data Definition Language) dan
DML (Data Manipulation Language) sebelum di-flush ke log file. DML adalah
kumpulan perintah SQL yang berhubungan dengan pekerjaan mengolah data di dalam
tabel. Sedangkan DDL adalah kumpulan perintah SQL yang dapat digunakan untuk
membuat dan mengubah struktur dan definisi tipe data dari objek-objek database
seperti tabel, index,triggerdanview.
Pada simulasi yang penulis lakukan dengan menggunakan DBMS MySQL,
archived log file disimulasikan dengan sebuah tabel log yang mencatat seluruh
kegiatan data yang terjadi diantara admin dan primary database. Isi dari tabel log
adalah sebagai berikut:
• Id_log sebagai primary key, yang berfungsi untuk memberikan nomor id setiap terjadinya transaksi data secara terurut.
• Log_tabel ialah log yang memberikan informasi tentang asal tabel yang merupakan tempat data melakukan transaksi data.
• Log_date adalah log yang mencatat tanggal terjadinya transaksi data antara admindenganprimary database.
• Log_time yaitu log yang mencatat waktu respon yang dimiliki standby database dalam mereplikasi data yang ada padaprimary database.
• Log_query adalah log yang mencatat transaksi yang dilakukan oleh admin terhadap primary database baik itu berupa data masukan, edit maupun hapus.
Apabila data yang telah di-input mengalami perubahan oleh admin, maka
log_query akan mencatat perubahan tersebut dengan log yang berbeda. Artinya
log yang berisikan tentang informasi admin meng-input barang tidak akan di
hapus apabila data barang tersebut mengalami perubahan kedepannya.
• Log_status ialah log yang mencatat status data yang ada pada primary database tereplikasi kestandby databaseatau tidak.
Log file adalah file yang mencatat peristiwa yang terjadi dalam pelaksanaan
sistem untuk memberikan jejak audit yang dapat digunakan untuk memahami aktivitas
sistem dan untuk mendiagnosis masalah. Prosesnya adalahDatabase Writer (DBWR)
bertugas untuk menuliskan data yang berubah ke data file. Kumpulan dari data file
23
memindahkan isi redo log buffer ke redo log file. Proses log file dapat dilihat pada
gambar 3.6.
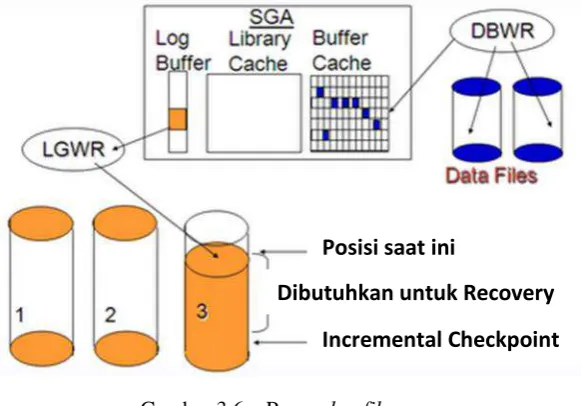
Pada log file terjadi proses checkpoint yaitu proses ketika DBWR menulis data ke
dalam datafile.Checkpointdilakukan apabila:
a. Log switch.
b. Alter tablespacexxxoffline/read only.
c. Shutdownselainabort.
d. Database bufferpenuh.
Selanjutnya diimplementasikan tiga model skenario simulasi dalam penelitian
ini. Ketiga simulasi tersebut dititikberatkan pada jumlah waktu respon yang dihasilkan
pada saatprimary databasedanstandby databasemelakukan proses replikasi.
3.6.2.1. Skenario I, Primary Database dan Standby Database berada dalam keadaan
normal
Pada skenario I ini primary database dan standby database berada dalam kondisi
hidup dan koneksi yang terhubung diantaranya (termasuk juga ke klien) dalam
keadaan hidup. Skenario simulasi I bertujuan untuk melihat primary database
melakukan proses replikasi dengan metode incremental backup terhadap standby
database. Hipotesa pada simulasi ini, proses replikasi akan berjalan secara real time.
Hal ini dapat terjadi karena metode incremental backup bekerja dengan mereplikasi
data yang diinput maupun dimanipulasi pada waktu yang hanya berselang dengan
ukuranms.
Posisi saat ini
Dibutuhkan untuk Recovery
Incremental Checkpoint
24
Simulasi ini akan dihitung jumlah waktu dan throughput saat primary
database melakukan replikasi ke standby database yang keduanya dalam keadaan
normal.
3.6.2.2. Skenario II, Standby Database dalam keadaan normal tetapi Primary
Database mati dalam keadaan proses menginput data
Sedangkan pada skenario II,primary database,standby databasedan klien terkoneksi
ke jaringan secara normal. Kemudian primary database akan dimatikan secara
tiba-tiba. Kondisi ini dibuat untuk melihat proses aktifnya failover di dalam standby
database sehingga secara langsung dapat menggantikan primary database sehingga
klien dapat tetap mengakses data. Pada saat standby database melakukan switching,
standby databaseakan menjadiprimary databaseyang baru.
3.6.2.3. Skenario III, Primary Database dalam keadaan normal tetapi dengan Standby
Database yang baru
Skenario III mewakili proses terbentuknya standby database yang baru. Karena
standby database yang lama telah menjadi primary database yang baru dan terjadi
kevakuman standby database. Dimana pada saat admin tetap melakukan transaksi
data pada primary database namun dengan kondisi belum ada standby database.
Skenario ini log file akan terkumpul di archived log menunggu untuk dikirimkan ke
standby database. Saat standby database yang baru dapat beroperasi kembali,
dibutuhkan waktu untuk mensinkronkan data yang ada pada primary database ke
standby database. Sehingga penulis akan menghitung jumlah waktu yang dibutuhkan
oleh standby database untuk melakukan replikasi terhadap primary database karena
pada saat standby database mati data pada primary database akan tetap terus
25
BAB 4
HASIL DAN PEMBAHASAN
4.1. Parameter ReplikasiDatabasepada Simulasi
Ada tiga parameter yang menjadi penilaian dalam mereplikasi data (Wiesman et al :
2000). Ketiga parameter terdapat pada simulasi yang dilakukan agar replikasi yang
terjadi baik. Parameter tersebut adalah arsitektur server, interaksi server dan terminasi
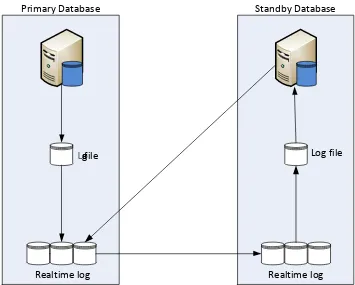
transaksi. Ketiga parameter tersebut dapat dijelaskan pada gambar 4.1 di bawah ini:
o
gfile Log file
Realtime log Realtime log
Primary Database Standby Database
Gambar 4.1. Arsitektur server pada simulasi
1. Arsitektur Server
Ada dua teknik yang harus dipertimbangkan dalam membangun arsitektur server.
Pertama adalah replikasiprimary copy, yaitu teknik yang membangun server dengan
26
adalahupdate everywhere, yaitu memungkinkan meng-update sebuah item data yang
akan dilakukan di mana saja di dalam sistem. Artinya,updatesecara bersamaan dapat
tiba di dua salinan yang berbeda dari item data yang sama (yang tidak dapat terjadi
denganprimary copy). Karena properti ini, di mana-mana memperbaharui pendekatan
yang lebih baik ketika berhadapan dengan kegagalan karena tidak ada protokol
pemilihan yang diperlukan untuk melanjutkan proses. Pada simulasi ini penulis
menggunakan teknikprimary copy, yaitu dengan membangun serverstandby database
yang mutlak sama dengan primary database. Data yang masuk ke primary database
akan tereplikasi ke dalam tabelstandby database yang susunan tabel tersebut mutlak
sama.
2. Interaksi Server
Parameter kedua yang perlu dipertimbangkan melibatkan tingkat komunikasi antara
serverdatabaseselama eksekusi transaksi. Ini menentukan jumlah lalu lintas jaringan
yang dihasilkan oleh algoritma replikasi dan overhead pada proses transaksi data.
Parameter ini mempertimbangkan dua kasus :
a. Interaksi terus-menerus (konstan), yang sesuai dengan teknik di mana sejumlah
data digunakan untuk mensinkronkan server untuk transaksi tertentu, terlepas
dari jumlah operasi dalam transaksi. Biasanya, protokol dalam kategori ini
bertukar pesan tunggal per transaksi dengan mengelompokkan semua operasi
dari transaksi dalam satu pesan.
b. Interaksi linier, yang biasanya berkaitan dengan teknik di mana sebuahdatabase
server merambat setiap operasi transaksi pada basis per operasi. Operasi dapat
dikirim baik sebagai pernyataan SQL atau sebagai catatan log yang berisi hasil
setelah dieksekusi operasi di server tertentu.
Berdasarkan simulasi yang telah dilakukan, parameter interaksi server yang terjadi
adalah interaksi linear. Standby database akan melakukan perubahan data apabila
admin melakukan traksaksi data terhadap primary database. Dan ini terjadi secara
per operasi. Setelah transaksi selesai, real time loggingdi aplikasiprimary database
akan memberikan status bahwa replikasi berhasil dilakukan dengan mencantumkan
tanggal dan jam terjadinya replikasi serta alamat server standby database (tujuan
27
3. Terminasi Transaksi
Replikasi yang baik adalah replikasi yang memiliki akhir di dalam prosesnya
(terminasi). Simulasi yang penulis lakukan juga memenuhi parameter ini. Karena
replikasi yang terjadi bersifat per operasi, maka setiap data yang telah tereplikasi di
dalam standby database akan berhenti setelah tabel log pada primary database
berstatus “logging”. Dan akan kembali melakukan replikasi apabila admin kembali
melakukan transaksi data terhadap primary database. Dari beberapa analisis di atas
dapat ditarik kesimpulan bahwa simulasi ini berjalan sesuai dengan parameter
replikasi database. Karena semua parameter telah terpenuhi. Sehingga dapat
disimpulkan bahwa replikasi standby database dengan metode incremental backup
adalah replikasi yang baik.
4.2. Simulasi
Penelitian pada simulasi ini dilakukan di laboraturium dengan menggunakan jaringan
LAN yang terisolasi dan melakukan penelitian terhadap tiga skenario. Tujuan simulasi
ini dilakukan untuk mengumpulkan data yang diperlukan, yaitu mengetahui proses
replikasi (logging) yang terjadi antaraprimary database danstandby database, proses
aktifnya failover untuk membuat standby database menjadi primary database yang
baru karena primary database yang sebelumnya mengalami kerusakan (failure), serta
menghitung jumlah waktu respon dan troughput yang dihasilkan pada saat primary
database mengirimkan archived log ke standby database dan jumlah waktu respon
serta throughput yang terjadi pada saat standby database yang baru melakukan
replikasi terhadapprimary database yang baru.
Ada dua buah aplikasi yang dilakukan pada simulasi. Dibuatkan aplikasi untuk
prosesstandby databasekarena DBMS MySQL tidak memiliki fiturstandby database
secara default. Aplikasi yang dibuat pertama untuk pengujian adalah aplikasi
pergudangan yang berfungsi untuk meng-input, edit ataupun men-delete data dari
sebuah PC klien (admin). Aplikasi yang kedua adalah aplikasi yang berada pada
primary database yang berfungsi untuk menghubungkan server primary database
dengan server standby database. Pada aplikasi ini juga menjadi tempat archived log
mengumpulkan log file pada primary database sebelum mengirimkannya ke server
standby database. Pengaturan IP Address untuk ketiga jaringan yang akan menjadi
28
4.1.1. Skenario I, Primary Database dan Standby Database berada dalam keadaan
normal
Langkah awal pada simulasi skenario I adalah membangun sebuah klien yang
terhubung pada serverprimary databasedan serverstandby databasesecara terisolasi.
Pada simulasi ini penulis akan memberikan Internet Protocol Address Static kepada
klien, server primary database dan juga server standby database yang semuanya
berada pada kelas C. Berikut adalah gambaran kerja pada simulasi I:
1) Konfigurasi IP serverprimary databasepada klien.
Aplikasi pergudangan yang berada pada komputer klien berfungsi untuk
melakukan transaksi data pada gudang supermarket seperti input, edit maupun
delete. Aplikasi pergudangan tersebut mendaftarkan alamat IP tujuan yaitu server
primary database. Hal ini dilakukan agar data yang di-input,edit maupun delete
akan diarahkan kepada server primary database sehingga data tersebut akan
tersimpan di dalam primary database. Seperti yang terlihat pada gambar 4.2 di
bawah ini:
29
2) Konfigurasi IP pada server primary database dengan menggunakan aplikasi
MasterStandby Database.
Setelah berhasil mengkonfigurasi IP pada aplikasi pergudangan, maka konfigurasi
IP selanjutnya pada aplikasi Master yang terdapat pada server primary database.
IP yang dimasukkan pada aplikasi Master adalah IP yang dimiliki oleh server
primary database. Dengan demikian log file data yang dikirimkan oleh admin
akan masuk ke dalam aplikasi master yang ada pada primary database. Berikut
adalah konfigurasi IP pada aplikasi master yang dapat dilihat pada gambar 4.3.
Gambar 4.3. Melakukan konfigurasiIP addresspada aplikasi master
3) Daftarkan IP serverstandby databasepada aplikasi Master.
Pada langkah ini daftarkan IP server standby databaseyang akan menjadi tujuan
replikasi dari serverprimary databasepada saat data di-input olehadminbarang.
Gambar 4.4 akan menjelaskan tentang daftar IPstandby database.
Gambar 4.4. MendaftarkanIP server standby databasepada aplikasi master
4) Jalankanreal time loggingpada aplikasi master.
Tabel real time logging ialah tabel yang penulis buat untuk menjadi sebuah
30
akhirnya akan dikirimkan ke server standby database. Tabel ini dibuat karena
MySQL tidak memiliki fitur archived log secara default. Jika tabel real time
loggingini tidak diaktifkan atau berada pada modus stop, makaredo log filepada
primary database tidak akan terkirim ke server standby database. Sehingga
mengakibatkan archived log file akan menyimpan banyak file redo log. Berikut
adalah proses mengaktifkan real time logging seperti pada gambar 4.5 di bawah
ini:
Gambar 4.5. Mengaktifkanreal time logging
5) Input data pada aplikasi klien.
Berikut adalah contoh seorangadminmemasukkan data barang ke dalam aplikasi
pergudangan yang akan di simpan di dalam primary database. Untuk lebih
![Gambar 2.1. Standby database pada mode recovery manual [Oracle : 1999]](https://thumb-ap.123doks.com/thumbv2/123dok/167104.12493/29.595.173.458.323.513/gambar-standby-database-pada-mode-recovery-manual-oracle.webp)
![Gambar 2.2. Update secara otomatis pada sebuah standby database [Oracle : 1999]](https://thumb-ap.123doks.com/thumbv2/123dok/167104.12493/30.595.194.436.528.714/gambar-update-secara-otomatis-sebuah-standby-database-oracle.webp)