1
BAB 1
PENDAHULUAN
1.1 Latar Belakang Masalah
Retina adalah selapis tipis sel yang terletak pada bagian belakang bola mata.
Retina mengandung banyak pembuluh darah yang membentuk pola yang unik
seperti pada sidik jari, oleh karena itu retina mata dapat digunakan sebagai alat
identifikasi. Sistem identifikasi retina bekerja dengan membaca pola retina mata
seseorang yang pindai menggunakan sinar inframerah berintensitas rendah, pola
ini kemudian disimpan dalam komputer untuk dijadikan identitas seseorang [1].
Sebelumnya dilakukan penelitian oleh Md. Amran Siddiqui, untuk identifikasi
retina mata yang melalui empat proses yaitu penentuan pusat deteksi, segmentasi
dan derivasi, ekstraksi, dan pencocokan didapatkan tingkat akurasi sebesar 80%
[2]. Pada penelitian yang yang dilakukan oleh Nurul Hikmah, identifikasi retina
mata menggunakan metode HSV dan ANFIS didapatkan tingkat akurasi 65%
untuk
membership function Trapesium
dan 80% untuk
membership function
Gaussian
[3].
Berdasarkan hal tersebut, diperlukan penelitian lebih lanjut tentang
identifikasi retina mata untuk meningkatkan akurasi dengan menggunakan metode
yang berbeda. Penelitian ini menggunakan metode ekstraksi Run Length untuk
proses ektraksi citra dan metode Naive Bayesian untuk klasifikasi. Metode Run
Length menggunakan distribusi suatu pixel dengan intensitas yang sama secara
berurutan dalam satu arah tertentu sebagai primitifnya. Ciri-ciri citra tekstur yang
didapat pada metode Run Length diantaranya adalah
Short Run Emphasis
(SRE),
Long Run Emphasis
(LRE),
Grey Level Uniformity
(GLU),
Run Length
Uniformity
(RLU), dan
Run Percentage
(RPC). Hasil dari ekstraksi ciri-ciri citra
merupakan sebuah metode pengklasifikasian probabilistik sederhana yang
menghitung sekumpulan probabilitas dengan menjumlahkan frekuensi dan
kombinasi nilai dari dataset yang diberikan.
Dari permasalahan dan solusi yang telah dijelaskan, maka penelitian ini akan
mengidentifikasi retina mata berdasarkan citra retina mata dengan menerapkan
metode Run Length untuk proses ekstraksi citra dan metode Naïve Bayesian
untuk proses klasifikasi citra, diharapkan metode Run Length dan Naïve Bayesian
dapat mengidentifikasi retina mata berdasarkan tekstur dan mengukur tingkat
keakuratan klasifikasinya.
1.2 Rumusan Masalah
Berdasarkan uraian latar belakang diatas terdapat beberapa masalah, yaitu :
1.
Bagaimana penerapan metode Run Length dan Naive Bayesian untuk
identifikasi retina mata.
2.
Bagaimana tingkat akurasi dalam mengidentifikasi citra retina mata
dengan menggunakan metode Run Length dan Naive Bayesian.
1.3 Maksud dan Tujuan
Berdasarkan permasalahan yang ada, maka maksud dari penelitian ini adalah
mengidentifikasi retina mata menggunakan metode Run Length dan Naive
Bayesian.
Sedangkan tujuan yang akan dicapai dalam penelitian ini adalah:
1.
Mengetahui bahwa metode Run Length dan Naive Bayesian dapat
digunakan dalam identifikasi retina mata.
2.
Mengetahui tingkat akurasi dalam identifikasi retina mata dengan
menggunakan metode Run Length dan Naive Bayesian.
1.4 Batasan Masalah
1.
Aplikasi yang dibangun berbasis desktop
2.
Citra yang akan diujikan adalah citra retina mata manusia yang sudah
tersedia di website
VARPA
[5].
3.
Database yang digunakan adalah MySQL.
4.
Metode ekstraksi yang digunakan adalah Run Length
5.
Fitur ciri yang digunakan adalah
Short Run Emphasis
(SRE),
Long
Run Emphasis
(LRE),
Grey Level Uniformity
(GLU),
run length
uniformity
(RLU),
Run Percentage
(RPC).
6.
Metode klasifikasi yang digunakan adalah Naive Bayesian.
7.
Metode analisis perancangan yang digunakan adalah analisis dan
perancangan perangkat lunak berorientasi objek, dengan menggunakan
pemodelan
Unified Modeling Language (UML).
1.5 Metodologi Penelitian
Metodologi penelitian adalah kesatuan metode-metode untuk memecahkan
masalah penelitian yang logis secara sistematis dan memerlukan data-data untuk
mendukung terlaksananya penelitian.
Metodologi penelitian yang digunakan dalam aplikasi ini adalah metode
deskriptif yaitu suatu metode yang bertujuan untuk mendapatkan gambaran yang
jelas tentang hal-hal yang diperlukan. Metodologi penelitian ini memiliki dua
tahapan, yaitu tahap pengumpulan data dan tahap pengembangan perangkat lunak.
1.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah studi
literatur. Studi literatur merupakan metode pengumpulan data dengan cara
mengumpulkan dan mempelajari data-data dari berbagai sumber referensi yang
berhubungan atau berkaitan dengan identifikasi retina mata menggunakan metode
Run Length dan Naive Bayesian.
1.5.2 Metode Pembangunan Perangkat Lunak
a.
Planning
Perencanaan dari keputusan pengguna/pembuat yang telah ditetapkan
prioritasnya.
Tahap
perencanaan
ini
dilakukan
dengan
pemodelan
menggunakan metode pemrograman berorientasi objek.
b.
Design
Perancangan dari pembangunan sistem untuk identifikasi retina mata
kedalam sebuah representasi software yang dapat diperkirakan untuk kualitas
sebelum dimulai pemunculan dan melakukan perancangan antar muka yang
akan tampil pada sistem yang akan dibangun.
c.
Coding
Pengkodean dilakukan dengan mengkonversi rancangan sistem kedalam
kode-kode bahasa pemrograman tertentu. Pada tahap ini dilakukan pembuatan
komponen-komponen sistem yang meliputi modul program antar muka.
d.
Testing
Pengujian dilakukan untuk mengetahui sistem yang sudah dibangun telah
sesuai dengan perancangan dan semua fungsi dapat berjalan dan dipergunakan
dengan baik tanpa ada kesalahan.
1.6 Sistematika Penulisan
Sistematika penulisan tugas akhir penelitian ini disusun untuk memberikan
gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan tugas
akhir ini adalah sebagai berikut:
BAB I PENDAHULUAN
Bab ini berisi penjelasan mengenai latar belakang masalah, identifikasi
masalah, maksud dan tujuan, batasan masalah, metodologi penelitian serta
sistematika penulisan.
BAB II LANDASAN TEORI
Bab ini membahas mengenai teori-teori yang digunakan dalam menganalisis
masalah dan teori yang dipakai dalam mengolah data penelitian yaitu teori
mengenai retina mata, teori mengenai biometrik, teori mengenai pengenalan pola,
teori mengenai pengolahan citra, teori mengenai tekstur, teori mengenai metode
Run Length, teori mengenai metode Naïve Bayesian, teori mengenai pengujian
blackbox
, teori mengenai pengujian
confusion matrix
, dan teori mengenai
pemrograman berorientasi objek.
BAB III ANALISIS DAN PERANCANGAN
Bab ini menguraikan penjelasan mengenai analisis masalah aplikasi, analisis
simulasi yang digunakan, analisis penyelesaian masalah, analisis simulasi yang
digunakan dan perancangan aplikasi yang akan dibangun.
BAB IV IMPLEMENTASI DAN PENGUJIAN
Bab ini menjelaskan mengenai implementasi dari hasil analisis dan
perancangan yang telah dibuat ke dalam bentuk aplikasi pemrograman serta
pengujian
blackbox
dan pengujian sistem yang meliputi pengujian parameter
algoritma yang akan diterapkan.
BAB V KESIMPULAN DAN SARAN
7
2.1 Kecerdasan Buatan
Kecerdasan buatan (
Artificial intelligence
) adalah salah satu cabang ilmu
pengetahuan yang berhubungan dengan pemanfaatan mesin untuk memecahkan
persoalan yang rumit dengan cara yang lebih manusiawi. Hal ini biasanya
dilakukan dengan mengikuti karakteristik dan analogi berpikir dari kecerdasan
manusia, dan menerapkannya sebagai algoritma yang dikenal oleh komputer.
Semakin
pesatnya
perkembangan
teknologi
menyebabkan
adanya
perkembangan dan perluasan lingkup yang membutuhkan kehadiran kecerdasan
buatan. Karakteristik cerdas sudah mulai dibutuhkan di berbagai disiplin ilmu dan
teknologi. Kecerdasan Buatan tidak hanya merambah di berbagai disiplin ilmu
yang lain. Irisan antara psikologi dan kecerdasan buatan melahirkan sebuah area
yang dikenal dengan nama
cognition
&
psycolinguistics
. Irisan antara teknik
elektro dengan kecerdasan buatan melahirkan berbagai ilmu seperti pengolahan
citra, teori kendali, pengenalan pola dan robotika.
Kecerdasan buatan digunakan untuk menganalisis pemandangan dalam citra
dengan perhitungan simbol-simbol yang mewakili isi pemandangan tersebut
setelah citra diolah untuk memperoleh ciri khas. Kecerdasan buatan bisa dilihat
sebagai tiga kesatuan yang terpadu yaitu persepsi, pengertian dan aksi. Persepsi
menerjemahkan sinyal dari dunia nyata dalam citra menjadi simbol-simbol yang
lebih sederhana, pengertian memanipulasi simbol-simbol tersebut untuk
memudahkan penggalian suatu informasi tertentu, dan aksi menerjemahkan
simbol-simbol yang telah dimanipulasi menjadi sinyal lain yang dapat merupakan
hasil akhir atau hasil antara sesuai dengan keperluan [7].
2.2 Retina Mata
manusia, cahaya masuk melalui pupil dan difokuskan pada retina dengan bantuan
lensa. Sel-sel saraf sensitif cahaya disebut
rod
(untuk kecerahan) dan
cone
(untuk
cahaya) yang beraksi terhadap cahaya. Keduanya berinteraksi satu dengan lainnya
dan mengirimkan pesan ke otak yang mengindikasikan kecerahan, warna, kontur.
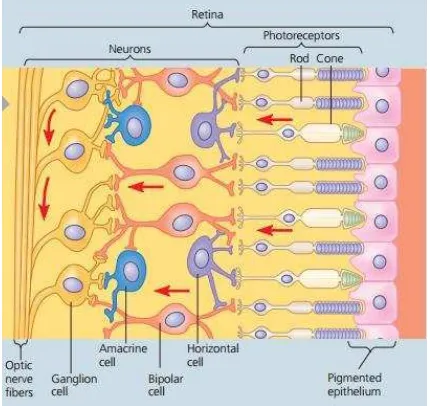
Retina adalah lapisan terdalam pada mata yang mengandung sel fotoreseptor
(
rod
dan
cone
) dan neuron yang berfungsi mentransmisikan bentuk benda yang
kita lihat yang dibentuk oleh lensa ke otak melalui saraf optik.
Cahaya masuk kedalam retina melewati sebagian besar lapisan transparan
neuron sebelum mencapai rod dan cone, dua jenis fotoreseptor yang berbeda
dalam bentuk dan fungsi. Neuron retina kemudian menyampaikan informasi
visual yang ditangkap oleh fotoreseptor ke saraf optik dan otak. Setiap sel bipolar
memerima informasi dari beberapa
rod
atau
cone
dan setiap ganglion sel
mengumpulkan hasil informasi dari beberapa bipolar sel, Horisontal dan
Amacrine sel mengintegrasikan informasi di retina. Salah satu daerah retina yaitu
optik disk tidak memiliki reseptor sebagai akibatnya dae
rah ini membentuk “
blind
spot
” dimana cahaya tidak terdeteksi [8].
2.3 Biometrik
Biometrik adalah suatu cabang keilmuan dengan menggunakan data unik
yang terdapat pada anggota tubuh atau tingkah laku manusia untuk tujuan
identifikasi. Teknologi biometrik sangat berguna untuk mencegah pemalsuan
identitas, karena menggunakan anggota tubuh atau tingkah laku manusia sebagai
identitas seseorang tersebut. Anggota tubuh atau tingkah laku manusia yang akan
dijadikan untuk sistem biometrik harus memenuhi beberapa syarat diantaranya
adalah :
a.
Universality
, bahwa setiap orang memiliki karakteristik.
b.
Uniqueness
, tidak ada kesamaan karakteristik.
c.
Permanence
, bahwa karakteristik konstan dengan waktu.
d.
Collectability
, karakteristik dapat diukur secara kuantitatif.
e.
Performance
, keakuratan dalam mengidentifikasi karakteristik.
f.
Acceptability
, sistem biometrik ini dapat diterima.
g.
Circumvention
, sistem tidak mudah untuk dicurangi.
Anggota tubuh atau tingkah laku yang bisa digunakan untuk sistem biometrik
ini diantaranya adalah Wajah, Sidik jari, Geometri tangan,
Keystrokes
, Vena
tangan, Iris mata, Retina mata, Tanda tangan, Suara,
Thermograms
, Bau, DNA,
Gaya berjalan, dan Telinga. Berikut adalah tabel tingkat kualitas anggota tubuh
atau tingkah laku pada sistem biometrik:
Tabel 2.1 Perbandingan Kualitas Biometrik [9]
Biometrik Universality Uniqueness Permanence Collectability Performance Acceptability Circumvention
Wajah High Low Medium High Low High Low
Sidik Jari Medium High High Medium High Medium High
Geometri Tangan
Medium Medium Medium High Medium Medium Medium
Keystrokes Low Low Low Medium Low Medium Medium
Vena Tangan Medium Medium Medium Medium Medium Medium High
Iris Mata High High High Medium High Low High
Retina Mata High High Medium Low High Low High
Tanda Tangan
Suara Medium Low Low Medium Low High Low
Thermograms High High Low High Medium High High
Bau High High High Low Low Medium Low
DNA High High High Low High Low Low
Gaya Berjalan
Medium Low Low High Low High Medium
Telinga Medium Medium High Medium Medium High Medium
2.4 Pengenalan Pola
Pengenalan pola adalah membedakan suatu objek dengan objek lain.
Pengenalan pola bertujuan untuk menentukan kelompok atau kategori pola
berdasarkan ciri-ciri yang dimiliki oleh pola tersebut. Terdapat dua pendekatan
yang dilakukan dalam pengenalan pola yaitu pendekatan secara statistik dan
pendekatan secara sintaktik atau struktural [10].
2.4.1 Pengenalan Pola Secara Statistik
Pengenalan pola dengan pendekatan statistik ini menggunakan teori-teori
dalam ilmu peluang dan statistik. . Ciri yang dimiliki oleh suatu pola ditentukan
distribusi statistiknya, pola yang berbeda memiliki distribusi yang berbeda pula.
Dengan menggunakan teori keputusan di dalam statistik, kita menggunakan
distribusi ciri untuk mengklasifikasikan pola. Sistem pengenalan pola dengan
pendekatan statistik ditunjukkan pada gambar 2.2.
Gambar 2.2 Pengenalan Pola Dengan Pendekatan Statistik [10].
klasifikasinya. Pada fase pengenalan, citra diambil cirinya kemudian ditentukan
kelas kelompoknya [10].
Pada penelitian ini termasuk sistem pengenalan pola dengan pendekatan
statistik, karena ciri-ciri yang dimiliki oleh citra retina mata memiliki pola yang
ditentukan distribusi statistiknya. Apabila polanya berbeda maka memiliki
distribusi yang berbeda pula. Distribusi ciri digunakan untuk mengklasifikasikan
pola dengan memanfaatkan teori keputusan di dalam statistik.
2.4.2 Pengenalan Pola Secara Sintaktik
Pengenalan pola dengan pendekatan sintaktik menggunakan teori bahasa
formal. Ciri yang terdapat pada suatu pola ditentukan primitif dan hubungan
struktural antara primitif kemudian menyusun tata bahasanya. Dari aturan
produksi pada tata bahasa tersebut kita dapat menentukan kelompok pola.
Pengenalan pola secara sintaktik lebih dekat ke strategi pengenalan pola yang
dilakukan manusia, namun secara praktek penerapannya relatif sulit dibandingkan
pengenalan pola secara statistik [10]. Sistem pengenalan pola dengan pendekatan
sintaktik ditunjukkkan pada gambar 2.3.
Gambar 2.3 Pengenalan Pola Dengan Pendekatan Sintaktik [10].
2.5 Pengolahan Citra
1.
Perbaikan atau memodifikasi citra perlu dilakukan untuk meningkatkan
kualitas penampakan atau untuk menonjolkan beberapa aspek informasi
yang terkandung di dalam citra.
2.
Elemen di dalam citra perlu dikelompokkan, dicocokkan, atau diukur.
3.
Sebagian citra perlu digabung dengan bagian citra yang lain.
Pengolahan citra bertujuan memperbaiki kualitas citra agar mudah
diinterpretasi oleh manusia atau mesin (dalam hal ini komputer). Teknik-teknik
pengolahan citra mentransformasikan citra menjadi citra lain. Jadi, masukannya
adalah citra dan keluarannya juga citra, namun citra keluaran mempunyai kualitas
lebih baik daripada citra masukan [10].
2.6 Operasi-operasi Pengolahan Citra
Operasi-operasi yang dilakukan di dalam pengolahan citra banyak ragamnya.
Namun, secara umum, operasi pengolahan citra dapat diklasifikasikan dalam
beberapa jenis sebagai berikut [10]:
1.
Perbaikan kualitas citra (
image enhancement
).
Jenis operasi ini bertujuan untuk memperbaiki kualitas citra dengan cara
memanipulasi parameter-parameter citra. Dengan operasi ini, ciri-ciri khusus
yang terdapat di dalam citra lebih ditonjolkan. Contoh operasi perbaikan citra
diantaranya adalah perbaikan kontras, perbaikan tepian objek (
edge
enhancement
),
penajaman
(
sharpening
),
pemberian
warna
semu
(
pseudocoloring
), dan penapisan derau (
noise filtering
).
2.
Pemugaran citra (
image restoration
).
Operasi ini bertujuan menghilangkan / meminimumkan cacat pada citra.
Tujuan pemugaran citra hampir sama dengan operasi perbaikan citra.
Bedanya, pada pemugaran citra penyebab degradasi gambar diketahui. Contoh
operasi pemugaran citra diantaranya adalah penghilangan kesamaran
(
deblurring
) dan penghilangan derau (
noise
).
3.
Pemampatan citra (
image compression
).
penting yang harus diperhatikan dalam pemampatan adalah citra yang telah
dimampatkan harus tetap mempunyai kualitas gambar yang bagus.
4.
Segmentasi citra (
image segmentation
).
Jenis operasi ini bertujuan untuk memecah suatu citra ke dalam beberapa
segmen dengan suatu kriteria tertentu. Jenis operasi ini berkaitan erat dengan
pengenalan pola.
5.
Pengorakan citra (
image analysis
)
Jenis operasi ini bertujuan menghitung besaran kuantitif dari citra untuk
menghasilkan deskripsinya. Teknik pengorakan citra mengekstraksi ciri-ciri
tertentu yang membantu dalam identifikasi objek. Proses segmentasi
kadangkala diperlukan untuk melokalisasi objek yang diinginkan dari
sekelilingnya. Contoh operasi pengorakan citra diantaranya adalah
pendeteksian tepi objek (
edge detection
), ekstraksi batas (
boundary
), dan
representasi daerah (
region
).
6.
Rekonstruksi citra (
image reconstruction
)
Jenis operasi ini bertujuan untuk membentuk ulang objek dari beberapa citra
hasil proyeksi. Operasi rekonstruksi citra banyak digunakan dalam bidang
medis. Misalnya beberapa foto rontgen dengan sinar X digunakan untuk
membentuk ulang gambar organ tubuh.
7.
Perubahan Model Warna
Warna adalah persepsi yang dirasakan oleh sistem visual manusia terhadap
panjang gelombang cahaya yang dipantulkan oleh objek [7]. Setiap warna
mempunyai panjang gelombang yang berbeda. Warna merah mempunyai
panjang gelombang paling tinggi, sedangkan warna ungu mempunyai panjang
gelombang paling rendah. Warna-warna yang diterima oleh mata merupakan
hasil kombinasi cahaya dengan panjang gelombang berbeda. Penelitian
memperlihatkan bahwa kombinasi warna yang memberikan rentang warna
yang paling lebar adalah red (R), green (G), blue (B).
a.
Citra RGB
Citra RGB yang biasa disebut juga citra true color, disimpan dalam citra
berukuran (m x n) x 3 yang mendefinisikan warna merah (red), hijau
(green) dan biru (blue) untuk setiap pikselnya. Warna pada setiap piksel
ditentukan berdasarkan kombinasi dari warna red, green dan blue (RGB).
RGB merupakan citra 24 bit dengan komponen merah, hijau, dan biru
yang masing-masing umumnya bernilai 8 bit sehingga intensitas kecerahan
warna sampai 256 level dan kombinasi warnanya kurang dari sekitar 16
juta warna.
b.
Citra Keabuan
Citra dengan derajat keabuan berbeda dengan citra RGB, citra ini
didefinisikan oleh satu nilai derajat warna. Umumnya bernilai 8 bit
sehingga intensitas kecerahan warna sampai 256 level dan kombinasi
warnanya 256 varian. Tingkat kecerahan paling rendah yaitu 0 untuk
warna hitam dan putih bernilai 255. Untuk mengkonversikan citra yang
memiliki warna RGB ke derajat keabuan bisa menggunakan persamaan :
Gray = 0.30 *
�
+ 0.59 *
�
+ 0.11 *
�
(2.1)
Dimana :
R = nilai
Red
G = nilai
Green
B = nilai
Blue
2.7 Tekstur
Secara umum tekstur mengacu pada repetisi elemen-elemen tekstur dasar
yang sering disebut primitif atau
texel
(
texture element
). Suatu
texel
terdiri dari
beberapa
pixel
dengan aturan posisi bersifat periodik, kuasiperiodik, atau acak.
Pengertian dari tekstur dalam hal ini adalah keteraturan pola-pola tertentu yang
terbentuk dari susunan piksel-piksel dalam citra digital [7].
1.
Terdiri dari satu atau lebih piksel yang membentuk pola-pola primitif
(bagian-bagian terkecil). Bentuk-bentuk pola primitif ini dapat berupa titik, garis lurus,
garis lengkung, luasan dan lain-lain yang merupakan elemen dasar dari sebuah
bentuk.
2.
Munculnya pola-pola primitif yang berulang-ulang dengan interval jarak dan
arah tertentu sehingga dapat diprediksi atau ditemukan karakteristik
perulangannya, untuk contoh dari beberapa citra tekstur dapat dilihat dari
gambar 2.4.
Gambar 2.4 Contoh Citra Tekstur [7]
Suatu citra memberikan interpretasi tekstur yang berbeda apabila dilihat
dengan jarak dan sudut yang berbeda, manusia memandang tekstur
berdasarkan deskripsi yang bersifat acak, seperti halus, kasar, teratur, tidak
teratur, dan lain sebgainya. Hal ini merupakan deskripsi yang tidak tepat dan
non-kuantitatif, sehingga diperlukan adanya suatu deskripsi yang kuantitatif
(matematis) untuk memudahkan analisis [7].
2.8 Analisis Tekstur
fourier, frekuensi tepi. Teknik struktural berkaitan dengan penyusupan
bagian-bagian terkecil suatu citra. contoh metode struktural adalah model fraktal. Metode
geometri berdasar atas perangkat geometri yang ada pada elemen tekstur. Contoh
model dasar adalah medan acak. Sedangkan metode pengolahan sinyal adalah
metode yang berdasarkan analisis frekuensi seperti transformasi gabor dan
transformasi wavelet [7].
2.9 Metode Run Length
Grey level run length matrix
yang biasa disingkat dengan GLRLM
merupakan salah satu metode untuk mengekstrak tekstur sehingga diperoleh ciri
statistik atau atribut yang terdapat dalam tekstur dengan mengestimasi
piksel-piksel yang memiliki derajat keabuan yang sama. Ekstraksi tekstur dengan metode
run-length dilakukan dengan membuat rangkaian pasangan nilai (
i,j
) pada setiap
baris piksel. Perlu diketahui maksud dari run-length
itu sendiri adalah jumlah
piksel berurutan dalam arah tertentu yang memiliki derajat keabuan/nilai
intensitas yang sama. Jika diketahui sebuah matriks run-length
dengan elemen
matriks
q
(
i, j
| θ) dimana i adalah derajat keabuan pada masing
-masing piksel, j
adalah nilai run-length
, dan θ adalah orientasi arah pergeseran tertentu yang
dinyatakan dalam derajat. Orientasi dibentuk dengan empat arah pergeseran
dengan interval 45
0
, yaitu 0
0
, 45
0
, 90
0
, dan 135
0
.
Terdapat beberapa jenis ciri tekstur yang dapat diekstraksi dari matriks
run-length [11]. Berikut variabel-variabel yang terdapat di dari ekstraksi citra dengan
menggunakan metode statistikal
Grey Level Run Length Matrix
:
i = nilai derajat keabuan
j = piksel yang berurutan (
run
)
M = Jumlah derajat keabuan pada sebuah gambar
N = Jumlah piksel berurutan pada sebuah gambar
r(j) = Jumlah piksel berurutan berdasarkan banyak urutannya (
run length)
g(i) = Jumlah piksel berurutan berdasarkan nilai derajat keabuannya
s = Jumlah total nilai
run
yang dihasilkan pada arah tertentu
n = jumlah baris * jumlah kolom.
Dimana varibel-variabel tersebut akan digunakan untuk mencari nilai dari
atribut-atribut tekstur sebagai berikut:
1.
Short Run Emphasis
(SRE)
SRE mengukur distribusi short run. SRE sangat tergantung pada banyaknya
short run dan diharapkan bernilai besar pada tekstur halus.
� ∑ ∑
∑
2.
Long Run Emphasis
(LRE)
LRE mengukur distribusi long run. LRE sangat bergantung pada banyaknya
long run dan diharapkan bernilai besar pada tekstur kasar.
� ∑ ∑
∑
3.
Grey Level Uniformity
(GLU)
GLU mengukur persamaan nilai derajat keabuan seluruh citra dan diharapkan
bernilai kecil jika nilai derajat keabuan serupa diseluruh citra.
� ∑ ∑ ∑
4.
Run Length Uniformity
(RLU)
RLU mengukur persamaan panjangnya run diseluruh citra dan diharapkan
bernilai kecil jika panjangnya run serupa diseluruh citra.
� ∑ ∑ ∑
5.
Run Percentage
(RPC)
RPC mengukur kebersamaan dan distribusi run dari sebuah citra pada arah
tertentu. RPC bernilai paling besar jika panjangnya run adalah 1 untuk semua
derajat keabuan pada arah tertentu.
� ∑ ∑ ∑
2.10 Metode Naive Bayesian
Naïve bayesian adalah suatu metode pengklasifikasian paling sederhana
dengan menggunakan peluang yang ada, dimana diasumsikan bahwa setiap
variable X bersifat bebas (
independence
) [4]. Karena asumsi variabel tidak saling
terikat, maka didapatkan :
(2.7)
Terdapat beberapa langkah dalam pengklasifikasian menggunakan metode naive
bayesian, berikut adalah langkah - langkahnya :
Training :
1.
Hitung rata-rata (
mean
) tiap fitur dalam dataset training dengan.
∑
(2.8)
Dimana:
= mean
= banyaknya data
∑
= jumlah nilai data
2.
Kemudian hitung nilai varian dari dataset training tersebut seperti pada.
∑
Dimana:
= varians
qi
P
X
iY
y
y
Y
X
µ= mean
= nilai data
banyaknya data
Testing :
1.
Hitung probabilitas (
Prior
) tiap kelas yang ada dengan cara menghitung jumlah
data tiap kelas dibagi jumlah total data secara keseluruhan.
2.
Selanjutnya
menghitung
densitas
probabilitasnya.
Fungsi
densitas
mengekspresikan probabilitas relatif. Data dengan mean μ dan standar deviasi
σ, fungsi densitas probabilitasnya adalah :
√
Dimana :
= data masukan
π = 3,14
standar deviasi
µ = mean
3.
Setelah didapatkan nilai densitas probabilitasnya, selanjutnya menghitung
posterior masing-masing kelas dengan menggunakan persamaan.
(2.11)
Atau bisa ditulis
| |
(2.12)
4.
Setelah didapat nilai posterior masing-masing kelas, maka kelas yang sesuai
untuk data masukan adalah kelas yang memiliki nilai posterior terbesar.
2.11 Pengujian
Confusion Matrix
matriks berkorespondensi kepada hasil klasifikasi dan setiap baris pada masukan.
Akurasi sebuah klasifikasi dimana i=j menerangkan akurasi dari klasifikasi pada
setiap kelas [12]. Berikut contoh
Confusion
Matrix
dapat dilihat pada tabel 2.2.
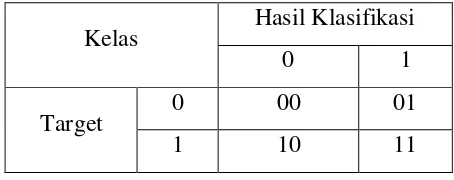
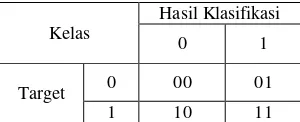
Tabel 2.2
Confusion Matrix
Kelas
Hasil Klasifikasi
0
1
Target
0
00
01
1
10
11
Untuk menghitung akurasinya digunakan formula :
2.12 Pemrograman Berorientasi Objek
Metodologi berorientasi objek adalah suatu strategi pembangunan perangkat
lunak yang mengorganisasikan perangkat lunak sebagai kumpulan objek yang
berisi data dan operasi yang diberlakukan terhadapnya. Metodologi berorientasi
objek merupakan suatu cara bagaimana sistem perangkat lunak dibangun melalui
pendekatan objek secara sistematis. Metode berorientasi objek didasarkan pada
penerapann prinsip-prinsip pengelolaan kompleksitas. Metode berorientasi objek
meliputi rangkaian aktifitas analisis beorientasi objek, perancangan berorientasi
objek, pemrograman berorientasi objek, dan pengujian berorientasi objek [13].
Keuntungan menggunakan metodologi berorientasi objek adalah sebagai
berikut :
a.
Meningkatkan Produktivitas
Karena kelas dan objek yang ditemukan dalam suatu masalah masih dapat
dipakai ulang untuk masalah lainnya yang melibatkan objek tersebut
(
reuseable
).
b.
Kecepatan Pengembangan
Karena sistem yang dibangun dengan baik dan benar pada saat analisis dan
perancangan akan mennyababkan berkurangnya kesalahan pada saat
pengkodean
c.
Kemudahan Pemeliharaan
Karena dengan model objek, pola-pola yang cendrung tetap dan stabil dapat
dipisahkan dan pola-pola yang mungkin sering diubah-ubah.
d.
Adanya Konsistensi
Karena sifat pewarisan dan penggunaan notasi yang sama pada saat analisis,
perancangan maupun pengkodean.
e.
Meningkatkan Kualitas Perangkat Lunak
Karena adanya pendekatan pengembangan lebih dekat dengan dunia nyata dan
adanya konsistensi pada saat pengambangannya, perangkat lunak yang
dihasilkan akan mampu memenuhi kebutuhan pemakai serta mempunyai
sedikit kesalahan.
Berikut
beberapa
contoh
bahasa
pemograman
yang
mendukung
pemrograman berorientasi objek adalah :
a.
Smalltalk
Smalltalk adalah salah satu bahasa pemograman yang diekmbangkan untuk
mendukung pemrograman beroirentasi objek.
b.
Bahasa Pemrograman Eiffel
c.
Bahasa Pemrograman (Web) PHP
Php dibuat pertama kali oleh seorang perekayasa perangkat (software
engineering) yang bernama Rasmus Lerdoff.
d.
Bahasa Pemrograman C++
C++ merupakan pengembangan lebih lanjut dari bahasa pemrograman C
untuk mendukung pemrograman berorientasi objek.
e.
Bahasa Pemrograman Java
Java dikembangkan oleh perusahaan Sun Microsystem. Java menurut definisi
dari Sun Microsystem adalah nama untuk sekumpulan teknologi untuk
membuat dan menjalankan perangkat lunak pada komputer
standalone
ataupun pada lingkungan jaringan.
2.12.1 Konsep Dasar Pemrograman Berorientasi Objek
Berikut adalah konsep dasar pemrograman berorientasi objek :
a.
Objek (
Object
)
Objek adalah abtraksi dan sesuatu yang mewakili dunia nyata seperti benda,
satuan organisasi, tempat, kejadian, struktur, status, atau hal-hal lain yang
bersifat abstrak. Objek merupakan suatu entitas yang mampu menyimpan
informasi dan mempunyai operasi yang dapat diterapkan atau dapat
berpengaruh pada status objeknya.
b.
Kelas (
Class
)
Kelas adalah kumpulan objek-objek dengan karakteristik yang sama. Kelas
merupakan definisi statik dan himpunan objek yang sama yang mungkin lahir
atau diciptakan dalam kelas tersebut.
c.
Pembungkusan (
Encapsulation
)
Pembungkusan atribut data dan layanan yang mempunyai objek untuk
menyembunyikan implementasi dan objek sehingga objek lain tidak
mengetahui cara kerjanya.
d.
Pewarisan (
Inheritance
) dan Generalisasi/Spesialisasi
e.
Metode
Operasi atau metode pada sebuah kelas hampir sama dengan fungsi atau
prosedur pada metodologi struktural.
f.
Polimorfisme
Kemampuan suatu objek untuk digunakan dibanyak tujuan yang berbeda
dengan nama yang sama sehingga menghemat baris program.
2.12.2 UML (Unified Modelling Language)
Unified Modelling Language
(UML) adalah sekumpulan spesifikasi yang
dikeluarkan oleh OMG. UML terbaru adalah UML 2.3 yang terdiri dari 4 macam
spesifikasi, yaitu :
Diagram Interchange Spesification,
UML
Infrastrukture,
UML
Superstrukture, dan Object Constraint Language
(OCL). Pada UML 2.3 terdiri 13
macam diagram yang dikelompokan pada 3 kategori, yaitu [14] :
A.
Struktur Diagram, yaitu kumpulan diagram yang digunakan untuk
menggambarkan suatu struktur statis dari sistem yang dimodelkan. Pada
Struktur Diagram dibagi menjadi 6 bagian :
1.
Diagam Kelas
Diagram kelas menggambarkan struktur sistem dari segi pendefinisian
kelas-kelas yang akan dibuat untuk membangun sistem. Kelas memiliki
apa yang disebut attribut dan metode atau operasi
.
2.
Diagram Objek
Diagram objek menggambarkan struktur sistem dari segi penamaan objek
dan jalannya objek dalam sistem.
3.
Diagram Komponen
Diagram
komponen
dibuat
untuk
menunjukan
organisasi
dan
ketergantungan diantara kumpulan komponen dalam sebuah sistem.
4.
Composite Structure Diagram
Composite Structure Diagram
baru mulai ada pada UML versi 2.0.
5.
Package Diagram
Package diagram
menyediakan cara mengumpulkan elemen-elemen yang
saling terkait dalam diagram UML. Hampir semua diagram dalam UML
dapat dikelompokan menggunakan
Package Diagram
.
6.
Deployment Diagram
Deployment diagram
menunjukan konfigurasi komponen dalam proses
eksekusi aplikasi.
B.
Behavior Diagram
, yaitu kumpulan diagram yang digunakan untuk
menggambarkan kelakuan sistem atau rangkaian perubahan yang terjadi pada
sebuah sistem. Pada
Behavior Diagram
dibagi menjadi 3 bagian :
1.
Use Case Diagram
Use case diagram
merupakan pemodelan untuk kelakuan (
behavior
)
sistem informasi yang akan dibuat,.
Use case
mendeskripsikan sebuah
interaksi antara satu atau lebih aktor dengan sistem informasi yang akan
dibuat.
2.
Activity Diagram
Activity diagram
menggambarkan
workflow
atau aktivitas dari sebuah
sistem atau proses bisnis atau menu yang ada pada perangkat lunak.
3.
State Machine Diagram
State machine diagram
digunakan untuk menggambarkan perubahan
status atau transisi status dari sebuah mesin atau sistem atau objek.
C.
Interactions Diagram
, yaitu kumpulan diagram yang digunakan untuk
menggambarkan interaksi antar subsistem pada suatu sistem. Pada Interactions
Diagram dibagi menjadi 4 bagian :
1.
Sequence Diagram
Sequence diagram
menggambarkan kelakuan objek pada
use case
dengan
mendeskripsikan waktu hidup objek dan message yang dikirimkan dan
diterima antar objek.
Communication
diagram menggambarkan interaksi antar bojek/bagian
dalam
bentuk
urutan
pengiriman
pesan.
Diagram
komunikasi
merepresentasikan informasi yang diperoleh dari diagram kelas, diagram
sequence
, dan diagram
use case
untuk mendeskripsikan gabungan antara
struktur statis dan tingkah laku dinamis dari suatu sistem.
3.
Timing Diagram
Timing diagram
merupakan diagram yang fokus pada penggambaran
terkait batas waktu.
4.
Interaction Overview Diagram
Interaction overview
diagram mirip dengan diagram aktivitas yang
berfungsi untuk menggarbarkan sekumpulan urutan aktivitas, diagram ini
adalah bentuk aktivias diagram yang setiap titik merepresentasikan
diagram interaksi.
2.12.3 Database
Istilah "basis data" berawal dari ilmu komputer. Meskipun kemudian artinya
semakin luas, memasukkan hal-hal di luar bidang elektronika, artikel ini mengenai
basis data komputer. Catatan yang mirip dengan basis data sebenarnya sudah ada
sebelum revolusi industri yaitu dalam bentuk buku besar, kuitansi dan kumpulan
data yang berhubungan dengan bisnis.
lain seperti model hierarkis dan model jaringan menggunakan cara yang lebih
eksplisit untuk mewakili hubungan antar tabel. Istilah
basis data
mengacu pada
koleksi dari data-data yang saling berhubungan, dan perangkat lunaknya
seharusnya mengacu sebagai
sistem manajemen basis data
(
database management
system/DBMS
). Jika konteksnya sudah jelas, banyak administrator dan programer
menggunakan istilah basis data untuk kedua arti tersebut [15].
2.12.3.1 MySQL
MySQL adalah sebuah perangkat lunak sistem manajemen basis data SQL
atau DBMS (
Database Management System
) yang
multithread
,
multi-user
,
dengan sekitar 6 juta instalasi di seluruh dunia. MySQL AB membuat MySQL
tersedia sebagai perangkat lunak gratis di bawah lisensi GNU
General Public
License
(GPL), tetapi mereka juga menjual dibawah lisensi komersial untuk
kasus-kasus dimana penggunaannya tidak cocok dengan penggunaan GPL.
Tidak seperti PHP atau Apache yang merupakan software yang
dikembangkan oleh komunitas umum, dan hak cipta untuk kode sumber dimiliki
oleh penulisnya masing-masing, MySQL dimiliki dan disponsori oleh sebuah
perusahaan komersial Swedia yaitu MySQL AB. MySQL AB memegang penuh
hak cipta hampir atas semua kode sumbernya. Kedua orang Swedia dan satu
orang Finlandia yang mendirikan MySQL AB adalah: David Axmark, Allan
Larsson, dan Michael "Monty" Widenius [15].
Fitur-fitur MySQL antara lain :
1.
Relational Database System. Seperti halnya software database lain yang ada
di pasaran, MySQL termasuk RDBMS.
2.
Arsitektur Client-Server. MySQL memiliki arsitektur client-server dimana
server database MySQL terinstal di server. Client MySQL dapat berada di
komputer yang sama dengan server, dan dapat juga di komputer lain yang
berkomunikasi dengan server melalui jaringan bahkan internet.
4.
Mendukung Sub Select. Mulai versi 4.1 MySQL telah mendukung select
dalam select (sub select).
5.
Mendukung Views. MySQL mendukung views sejak versi 5.0
6.
Mendukung Stored Prosedured (SP). MySQL mendukung SP sejak versi 5.0
7.
Mendukung Triggers. MySQL mendukung trigger pada versi 5.0 namun
masih terbatas. Pengembang MySQL berjanji akan meningkatkan
kemampuan trigger pada versi 5.1.
8.
Mendukung
replication
.
9.
Mendukung transaksi.
10.
Mendukung foreign key.
11.
Tersedia fungsi GIS.
12.
Gratis (bebas didownload)
13.
Stabil dan tangguh
14.
Fleksibel dengan berbagai pemrograman
15.
Security
yang baik, dukungan dari banyak komunitas
16.
Perkembangan software yang cukup cepat.
2.12.4 Bahasa Pemograman C#
C#
(tanda „#‟ dibaca “Sharp”) merupakan bahasa pemograman baru yang
diciptakan Microsoft secara khusus sebagai salah satu bahasa pemrograman dalam
teknologi .Net sebagai bahasa baru, C# tidak berevolusi dari bahasa C# versi
bukan teknologi .Net. dengan demikian C# dapat memaksimalkan kemampuannya
tanpa khawatir dengan masalah kompatibilitas dengan versi-versi sebelumnya.
Keharusan sebuah perangkat lunak untuk tetap dapat kompatibel dengan
versi-versi sebelumnya sebagaimana yang terjadi pada Visual Basic (VB) maupun
C++biasanya menghambat optimalitas kemampuan dari perangkat lunak tersebut
[16].
Sejak diluncurkan pada tahun 2000, C# dengan cepat merebut hati
progammer C++ bahkan VB. Dengan tata cara penulisan yang mirip C++ dan
interface
mirip VB 6.0 menurut wikipedia, sebuah ensiklopedia gratis di internet
91
5.1 Kesimpulan
Hasil yang didapat dari penelitian yang telah dilakukan dalam penyusunan
skripsi ini serta mengacu pada tujuan penelitian, maka dapat disimpulkan.
1.
Metode run length dan naive bayesian dapat digunakan untuk
mengidentifikasi retina mata berdasarkan citra.
2.
Tingkat akurasi metode run length dan naive bayesian dalam
mengidentifikasi retina mata berdasarkan citra adalah sebesar 100%.
5.2 Saran
Berdasarkan hasil dari penelitian yang telah tercapai saat ini, terdapat
beberapa saran yang mungkin bermanfaat jika ada yang akan melakukan
penelitian yang sejenis, yaitu :
1.
Dataset citra yang digunakan sebaiknya memiliki kelas yang lebih
beragam.
NIM
: 10111701
Jenis Kelamin
: Pria
Tempat / Tanggal Lahir
: Pemalang, 19 Desember 1993
Agama
: Islam
Alamat
: Jl D.I. No. 212, RT.02 RW.02, Kelurahan
Bojongbata, Kecamatan Pemalang, Kabupaten
Pemalang, Jawa Tengah.
Telepon / Hp
: 083861796865
RIWAYAT PENDIDIKAN
1999
–
2005
: SD Negeri Kebondalem 1 Pemalang,
2005
–
2008
: SMP Negeri 2 Pemalang,
2008
–
2011
: SMA Negeri 2 Pemalang,
2011
–
2016
: Program Strata 1 (S1) ,
Teknik Informatika,
Diajukan untuk Menempuh Ujian Akhir Sarjana
DICKY TANAGA PUTRA
10111701
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
v
ABSTRACT
... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR TABEL ... viii
DAFTAR GAMBAR ... x
DAFTAR SIMBOL ... xii
DAFTAR LAMPIRAN ... xvi
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah... 2
1.3 Maksud dan Tujuan ... 2
1.4 Batasan Masalah ... 2
1.5 Metodologi Penelitian ... 3
1.5.1 Metode Pengumpulan Data ... 3
1.5.2 Metode Pembangunan Perangkat Lunak ... 3
1.6 Sistematika Penulisan ... 5
BAB 2 TINJAUAN PUSTAKA ... 7
2.1 Kecerdasan Buatan ... 7
2.2 Retina Mata ... 7
2.3 Biometrik ... 9
2.4 Pengenalan Pola... 10
vi
2.7 Tekstur ... 14
2.8 Analisis Tekstur ... 15
2.9 Metode Run Length ... 16
2.10 Metode Naive Bayesian ... 18
2.11 Pengujian
Confusion Matrix
... 19
2.12 Pemrograman Berorientasi Objek ... 20
2.12.1 Konsep Dasar Pemrograman Berorientasi Objek ... 22
2.12.2 UML (Unified Modelling Language)... 23
2.12.3 Database ... 25
2.12.4 Bahasa Pemograman C# ... 27
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 29
3.1 Analisis Sistem ... 29
3.1.1 Analisis Masalah ... 29
3.1.2 Analisis Proses ... 29
3.1.3 Analisis Data... 36
3.1.4 Analisis Metode / Algoritma ... 38
3.1.5 Analisis Kebutuhan Basis Data ... 59
3.1.6 Analisis Kebutuhan Perangkat Lunak ... 59
3.2 Perancangan Sistem ... 68
3.2.1 Perancangan Basis Data ... 68
3.2.2 Perancangan Antarmuka ... 70
vii
4.1.1 Implementasi Perangkat Keras ... 75
4.1.2 Implementasi Perangkat Lunak ... 75
4.1.3 Implementasi Basis Data ... 76
4.1.4 Implementasi
Class
... 77
4.1.5 Implementasi Antarmuka ... 77
4.2 Pengujian ... 79
4.2.1 Pengujian Fungsionalitas... 79
4.2.2 Pengujian Metode ... 82
BAB 5 KESIMPULAN DAN SARAN ... 91
5.1 Kesimpulan ... 91
5.2 Saran ... 91
92
Butterworth Publishers, 1988.
[2] Md. Rounok Salehin, S. M. Hasan Sazzad Iqba, Md. Amran Siddiqui,
"Personal Authentication through Retinal Blood,"
International Journal of
Computer Applications
, vol. 33
–
No.9, November 2011.
[3]
Nurul Hikmah, “Identifikasi Retina Mata Manusia Menggunakan Sistem
Inferensi Neuro Fuzzy Adaptif,”
Tugas Akhir Teknik Elektro
, Universitas
Indonesia, Depok, 2008.
[4] Zanobya Nizar, Zahoor Jan, Rehanullah Khan, Rashid Jalal Quereshi,
“Palmprint Recognition: A Naïve Bayesian Approach,”
World Applied
Sciences Journal
, Mei 2014.
[5]
M. Ortega, “
VARIA Database
,”
VARPA Retinal Images for Authentication
Database, http://www.varpa.es/varia.html (diakses 14 Desember 2015).
[6] Pressman S. R.,
Rekayasa Perangkat Lunak
. Yogyakarta: Andi, 2010.
[7] Ahmad U.,
Pengolahan Citra Digital & Pemrogramannya
. Yogyakarta:
Graha Ilmu, 2005.
[8] Neil A. Campbell, Lisa A. Urry, Michael L. Cain, Jane B. Reece, Steven A.
Wasserman, Peter V. Minorsky, Robert B. Jackson,
Campbell Biology Ninth
Edition
. San Francisco: Benjamin Cummings, 2011.
[9] Anil K. Jain, Ruud Bolle, Sharath Pankanti,
Biometrics Personal
Identification in Network Society.
New York: Kluwer Academic Publishers,
2002.
[10] Munir R.,
Pengolahan Citra Digital.
Bandung: Informatika, 2002.
[11]
Galloway M., “Texture analysis using gray level run length”, Computer
Graphics Image Process., vol. 4, pp.172-179, juni 1975.
[12]
Anik A., “Sistem Pedukung Keputusan Berbasis Decision Tree Dalam
93
Yogyakarta: Graha Ilmu, 2005.
[15] Achmad S.,
MySql dari Pemula Hingga Mahir
. Jakarta: Achmatim, 2010.
Dicky Tanaga Putra
Teknik Informatika
–
Universitas Komputer Indonesia
Jl. Dipatiukur 112-114 Bandung
E-mail : [email protected]
ABSTRAK
Retina merupakan salah satu anggota tubuh manusia yang dapat digunakan sebagai identitas seseorang. Retina mengandung banyak pembuluh darah yang membentuk pola unik, setiap manusia memiliki pola yang berbeda. Cara membedakan suatu retina dengan yang lainnya yaitu dengan membedakan tekstur citra retina tersebut. Metode run length adalah suatu metode yang dapat mengekstrak ciri suatu citra berdasarkan tekstur, ciri yang didapat adalah Short Run Emphasis (SRE),
Long Run Emphasis (LRE), Grey Level Uniformity
(GLU), Run Length Uniformity (RLU), dan Run Percentage (RPC). Hasil dari ekstraksi ciri citra berdasarkan tekstur tersebut kemudian akan digunakan sebagai nilai masukan untuk menentukan hasil klasifikasi citra berdasarkan tekstur menggunakan metode naive bayesian. Metode naive
bayesian merupakan sebuah metode
pengklasifikasian probabilistik sederhana yang menghitung sekumpulan probabilitas dengan menjumlahkan frekuensi dan kombinasi nilai dari dataset yang diberikan.
Berdasarkan hasil penelitian yang telah dilakukan dapat diketahui identifikasi citra retina mata dapat dilakukan dengan klasifikasi berdasarkan tekstur menggunakan metode run length sebagai metode untuk ekstraksi tekstur pada citra retina mata dan metode naive bayesian sebagai metode untuk klasifikasi. Dari hasil pengujian yang telah dilakukan identifikasi citra retina mata berdasarkan tekstur menggunakan metode run length dan naive bayesian didapat tingkat akurasi sebesar 100%.
Kata Kunci : Identifikasi Retina, Run Length, Naive Bayesian, Kecerdasan Buatan.
1. PENDAHULUAN
Retina adalah selapis tipis sel yang terletak pada bagian belakang bola mata. Retina mengandung banyak pembuluh darah yang membentuk pola yang unik seperti pada sidik jari, oleh karena itu retina mata dapat digunakan sebagai alat identifikasi. Sistem identifikasi retina bekerja dengan membaca pola retina mata seseorang yang pindai menggunakan sinar inframerah berintensitas
rendah, pola ini kemudian disimpan dalam komputer untuk dijadikan identitas seseorang [1]. Sebelumnya dilakukan penelitian oleh Md. Amran Siddiqui, untuk identifikasi retina mata yang melalui empat proses yaitu penentuan pusat deteksi, segmentasi dan derivasi, ekstraksi, dan pencocokan didapatkan tingkat akurasi sebesar 80% [2]. Pada penelitian yang yang dilakukan oleh Nurul Hikmah, identifikasi retina mata menggunakan metode HSV dan ANFIS didapatkan tingkat akurasi 65% untuk membership function Trapesium dan 80% untuk membership function Gaussian [3].
Berdasarkan hal tersebut, diperlukan penelitian lebih lanjut tentang identifikasi retina mata untuk meningkatkan akurasi dengan menggunakan metode yang berbeda. Penelitian ini menggunakan metode ekstraksi Run Length untuk proses ektraksi citra dan metode Naive Bayesian untuk klasifikasi. Metode Run Length menggunakan distribusi suatu pixel dengan intensitas yang sama secara berurutan dalam satu arah tertentu sebagai primitifnya. Ciri-ciri citra tekstur yang didapat pada metode Run Length diantaranya adalah Short Run Emphasis (SRE), Long Run Emphasis (LRE), Grey Level Uniformity
(GLU), Run Length Uniformity (RLU), dan Run Percentage (RPC). Hasil dari ekstraksi ciri-ciri citra tekstur tersebut kemudian akan digunakan sebagai nilai masukan untuk menentukan hasil klasifikasi citra berdasarkan tekstur menggunakan metode Naive Bayesian. Pada penelitian yang dilakukan oleh Zanobya Nizar, metode Naive Bayesian digunakan untuk klasifikasi citra digital pada telapak tangan menghasilkan tingkat akurasi sebesar 97% [4]. Metode Naive Bayesian merupakan sebuah metode pengklasifikasian probabilistik sederhana yang menghitung sekumpulan probabilitas dengan menjumlahkan frekuensi dan kombinasi nilai dari dataset yang diberikan.
apakah lingkungan disekitarnya terang atau gelap. Dalam hal yang lebih kompleks mata dapat membedakan bentuk dan warna. Pada mata manusia, cahaya masuk melalui pupil dan difokuskan pada retina dengan bantuan lensa. Sel-sel saraf sensitif cahaya disebut rod (untuk kecerahan) dan cone (untuk cahaya) yang beraksi terhadap cahaya. Keduanya berinteraksi satu dengan lainnya dan mengirimkan pesan ke otak yang mengindikasikan kecerahan, warna, kontur.
Retina adalah lapisan terdalam pada mata yang mengandung sel fotoreseptor (rod dan cone) dan neuron yang berfungsi mentransmisikan bentuk benda yang kita lihat yang dibentuk oleh lensa ke otak melalui saraf optik.
Cahaya masuk kedalam retina melewati sebagian besar lapisan transparan neuron sebelum mencapai rod dan cone, dua jenis fotoreseptor yang berbeda dalam bentuk dan fungsi. Neuron retina kemudian menyampaikan informasi visual yang ditangkap oleh fotoreseptor ke saraf optik dan otak. Setiap sel bipolar memerima informasi dari beberapa rod atau cone dan setiap ganglion sel mengumpulkan hasil informasi dari beberapa bipolar sel, Horisontal dan Amacrine sel mengintegrasikan informasi di retina. Salah satu daerah retina yaitu optik disk tidak memiliki reseptor sebagai akibatnya daerah ini
membentuk “blind spot” dimana cahaya tidak
[image:38.595.311.524.412.578.2]terdeteksi [6].
Gambar 1 Bagian pada Retina
1.2 Biometrik
Biometrik adalah suatu cabang keilmuan dengan menggunakan data unik yang terdapat pada anggota tubuh atau tingkah laku manusia untuk tujuan identifikasi. Teknologi biometrik sangat berguna untuk mencegah pemalsuan identitas,
dijadikan untuk sistem biometrik harus memenuhi beberapa syarat diantaranya adalah :
a. Universality, bahwa setiap orang memiliki karakteristik.
b. Uniqueness, tidak ada kesamaan
karakteristik.
c. Permanence, bahwa karakteristik konstan dengan waktu.
d. Collectability, karakteristik dapat diukur secara kuantitatif.
e. Performance, keakuratan dalam
mengidentifikasi karakteristik.
f. Acceptability, sistem biometrik ini dapat diterima.
g. Circumvention, sistem tidak mudah untuk dicurangi.
Anggota tubuh atau tingkah laku yang bisa digunakan untuk sistem biometrik ini diantaranya adalah Wajah, Sidik jari, Geometri tangan,
[image:38.595.70.285.468.671.2]Keystrokes, Vena tangan, Iris mata, Retina mata, Tanda tangan, Suara, Thermograms, Bau, DNA, Gaya berjalan, dan Telinga. Berikut adalah tabel tingkat kualitas anggota tubuh atau tingkah laku pada sistem biometrik:
Tabel 1 Perbandingan Biometrik
1.3 Pengolahan Citra
Pengolahan citra adalah pemrosesan citra, khususnya dengan menggunakan komputer, menjadi citra yang kualitasnya lebih baik. Umumnya, operasi
–operasi pada pengolahan citra diterapkan pada citra bila :
1. Perbaikan atau memodifikasi citra perlu dilakukan untuk meningkatkan kualitas penampakan atau untuk menonjolkan beberapa aspek informasi yang terkandung di dalam citra.
2. Elemen di dalam citra perlu
dikelompokkan, dicocokkan, atau diukur. 3. Sebagian citra perlu digabung dengan
pengolahan citra mentransformasikan citra menjadi citra lain. Jadi, masukannya adalah citra dan keluarannya juga citra, namun citra keluaran mempunyai kualitas lebih baik daripada citra masukan [7].
1.4 Operasi Pengolahan Citra
Operasi-operasi yang dilakukan di dalam pengolahan citra banyak ragamnya. Namun, secara umum, operasi pengolahan citra dapat diklasifikasikan dalam beberapa jenis sebagai berikut [7]:
1. Perbaikan kualitas citra (image enhancement). Jenis operasi ini bertujuan untuk memperbaiki kualitas citra dengan cara memanipulasi parameter-parameter citra. Dengan operasi ini, ciri-ciri khusus yang terdapat di dalam citra lebih ditonjolkan. Contoh operasi perbaikan citra diantaranya adalah perbaikan kontras, perbaikan tepian objek (edge enhancement), penajaman (sharpening), pemberian warna semu (pseudocoloring), dan penapisan derau (noise filtering).
2. Pemugaran citra (image restoration).
Operasi ini bertujuan menghilangkan / meminimumkan cacat pada citra. Tujuan pemugaran citra hampir sama dengan operasi perbaikan citra. Bedanya, pada pemugaran citra penyebab degradasi gambar diketahui. Contoh operasi pemugaran citra diantaranya adalah penghilangan kesamaran (deblurring) dan penghilangan derau (noise).
3. Pemampatan citra (image compression). Jenis operasi ini dilakukan agar citra dapat direpresentasikan dalam bentuk yang lebih kompak sehingga memerlukan memori yang lebih sedikit. Hal penting yang harus diperhatikan dalam pemampatan adalah citra yang telah dimampatkan harus tetap mempunyai kualitas gambar yang bagus.
4. Segmentasi citra (image segmentation).
Jenis operasi ini bertujuan untuk memecah suatu citra ke dalam beberapa segmen dengan suatu kriteria tertentu. Jenis operasi ini berkaitan erat dengan pengenalan pola.
5. Pengorakan citra (image analysis)
Jenis operasi ini bertujuan menghitung besaran kuantitif dari citra untuk menghasilkan deskripsinya. Teknik pengorakan citra mengekstraksi ciri-ciri tertentu yang membantu dalam identifikasi objek. Proses segmentasi kadangkala diperlukan untuk melokalisasi objek yang diinginkan dari sekelilingnya. Contoh operasi pengorakan citra diantaranya adalah pendeteksian tepi objek (edge detection),
Jenis operasi ini bertujuan untuk membentuk ulang objek dari beberapa citra hasil proyeksi. Operasi rekonstruksi citra banyak digunakan dalam bidang medis. Misalnya beberapa foto rontgen dengan sinar X digunakan untuk membentuk ulang gambar organ tubuh.
7. Perubahan Model Warna
Warna adalah persepsi yang dirasakan oleh sistem visual manusia terhadap panjang gelombang cahaya yang dipantulkan oleh objek [5]. Setiap warna mempunyai panjang gelombang yang berbeda. Warna merah mempunyai panjang gelombang paling tinggi, sedangkan warna ungu mempunyai panjang gelombang paling rendah. Warna-warna yang diterima oleh mata merupakan hasil kombinasi cahaya dengan panjang gelombang berbeda. Penelitian memperlihatkan bahwa kombinasi warna yang memberikan rentang warna yang paling lebar adalah red (R), green (G), blue (B). Dalam pembentukan citra digital model warna yang umum digunakan antara lain sebagai berikut :
a. Citra RGB
Citra RGB yang biasa disebut juga citra true color, disimpan dalam citra berukuran (m x n) x 3 yang mendefinisikan warna merah (red), hijau (green) dan biru (blue) untuk setiap pikselnya. Warna pada setiap piksel ditentukan berdasarkan kombinasi dari warna red, green dan blue (RGB). RGB merupakan citra 24 bit dengan komponen merah, hijau, dan biru yang masing-masing umumnya bernilai 8 bit sehingga intensitas kecerahan warna sampai 256 level dan kombinasi warnanya kurang dari sekitar 16 juta warna.
b. Citra Keabuan
Citra dengan derajat keabuan berbeda dengan citra RGB, citra ini didefinisikan oleh satu nilai derajat warna. Umumnya bernilai 8 bit sehingga intensitas kecerahan warna sampai 256 level dan kombinasi warnanya 256 varian. Tingkat kecerahan paling rendah yaitu 0 untuk warna hitam dan putih bernilai 255. Untuk mengkonversikan citra yang memiliki warna RGB ke derajat keabuan bisa menggunakan persamaan :
Gray = 0.30 * � + 0.59 * � + 0.11 * � Dimana :
R = nilai Red
G = nilai Green
primitif atau texel (texture element). Suatu texel terdiri dari beberapa pixel dengan aturan posisi bersifat periodik, kuasiperiodik, atau acak. Pengertian dari tekstur dalam hal ini adalah keteraturan pola-pola tertentu yang terbentuk dari susunan piksel-piksel dalam citra digital [5].
Untuk membentuk suatu tekstur setidaknya ada dua persyaratan yang harus dipenuhi antara lain : 1 Terdiri dari satu atau lebih piksel yang
membentuk pola-pola primitif (bagian-bagian terkecil). Bentuk-bentuk pola primitif ini dapat berupa titik, garis lurus, garis lengkung, luasan dan lain-lain yang merupakan elemen dasar dari sebuah bentuk.
2 Munculnya pola-pola primitif yang berulang-ulang dengan interval jarak dan arah tertentu sehingga dapat diprediksi atau ditemukan karakteristik perulangannya, untuk contoh dari citra tekstur dapat dilihat dari gambar 2.
Gambar 2 Contoh Citra Tekstur Suatu citra memberikan interpretasi tekstur yang berbeda apabila dilihat dengan jarak dan sudut yang berbeda, manusia memandang tekstur berdasarkan deskripsi yang bersifat acak, seperti halus, kasar, teratur, tidak teratur, dan lain sebgainya. Hal ini merupakan deskripsi yang tidak tepat dan non-kuantitatif, sehingga diperlukan adanya suatu deskripsi yang kuantitatif (matematis) untuk memudahkan analisis [5].
1.6 Analisis Tekstur
Analisis tekstur merupakan dasar dari berbagai macam aplikasi, aplikasi dari analisis tekstur antara lain adalah penginderaan jarak jauh, pencitraan medis, identifikasi kualitas suatu bahan (kayu, kulit, tekstil dan lain-lain). Pada analisis citra, dikategorikan menjadi lima kategori utama yaitu statistis, struktural, geometri, model dasar dan pengolahan sinyal. Pendekatan statistis mempertimbangakan bahwa internsitas dibangkitkan oleh medan acak dua dimensi, metode ini berdasar pada frekuensi-frekuensi ruang. Contoh metode statistis adalah fungsi autokorelasi, run-length, matriks kookurensi, tranformasi fourier, frekuensi tepi. Teknik struktural berkaitan dengan penyusupan bagian-bagian terkecil suatu citra. contoh metode struktural adalah model fraktal. Metode geometri berdasar atas perangkat geometri yang ada pada elemen tekstur. Contoh model dasar adalah medan
1.7 Metode Run Length
Grey level run length matrix yang biasa disingkat dengan GLRLM merupakan salah satu metode untuk mengekstrak tekstur sehingga diperoleh ciri statistik atau atribut yang terdapat dalam tekstur dengan mengestimasi piksel-piksel yang memiliki derajat keabuan yang sama. Ekstraksi tekstur dengan metode run-length dilakukan dengan membuat rangkaian pasangan nilai (i,j) pada setiap baris piksel. Perlu diketahui maksud dari run-length itu sendiri adalah jumlah piksel berurutan dalam arah tertentu yang memiliki derajat keabuan/nilai intensitas yang sama. Jika diketahui sebuah matriks run-lengthdengan elemen matriks q ( i, j | θ) dimana
i adalah derajat keabuan pada masing-masing piksel, j adalah nilai run-length, dan θ adalah orientasi arah pergeseran tertentu yang dinyatakan dalam derajat. Orientasi dibentuk dengan empat arah pergeseran dengan interval 45
0
, yaitu 0
0
, 45
0
, 90
0
, dan 135
0
. Terdapat beberapa jenis ciri tekstur yang dapat diekstraksi dari matriks run-length [8]. Berikut variabel-variabel yang terdapat di dari ekstraksi citra dengan menggunakan metode statistikal Grey Level Run Length Matrix :
i = nilai derajat keabuan j = piksel yang berurutan (run)
M = Jumlah derajat keabuan pada sebuah gambar N = Jumlah piksel berurutan pada sebuah gambar r(j) = Jumlah piksel berurutan berdasarkan banyak
urutannya (run length)
g(i) = Jumlah piksel berurutan berdasarkan nilai derajat keabuannya
s = Jumlah total nilai run yang dihasilkan pada arah tertentu
p(i,j)= himpunan matrik i dan j n = jumlah baris * jumlah kolom.
Dimana varibel-variabel tersebut akan digunakan untuk mencari nilai dari atribut-atribut tekstur sebagai berikut:
1. Short Run Emphasis (SRE)
SRE mengukur distribusi short run. SRE sangat tergantung pada banyaknya short run dan diharapkan bernilai besar pada tekstur halus.
2. Long Run Emphasis (LRE)
3. Grey Level Uniformity (GLU)
GLU mengukur persamaan nilai derajat keabuan seluruh citra dan diharapkan bernilai kecil jika nilai derajat keabuan serupa diseluruh citra.
4. Run Length Uniformity (RLU)
RLU mengukur persamaan panjangnya run diseluruh citra dan diharapkan bernilai kecil jika panjangnya run serupa diseluruh citra.
5. Run Percentage (RPC)
RPC mengukur kebersamaan dan distribusi run dari sebuah citra pada arah tertentu. RPC bernilai paling besar jika panjangnya run adalah 1 untuk semua derajat keabuan pada arah tertentu.
1.8 Metode Naive Bayesian
Naïve bayesian adalah suatu metode pengklasifikasian paling sederhana dengan menggunakan peluang yang ada, dimana diasumsikan bahwa setiap variable X bersifat bebas (independence) [4]. Karena asumsi variabel tidak saling terikat, maka didapatkan :
Terdapat beberapa langkah dalam pengklasifikasian
menggunakan metode naive bayesian, berikut adalah langkah - langkahnya :
Training :
1.
Hitung rata-rata (mean) tiap fitur dalam dataset training dengan.∑
Dimana:
= mean
= banyaknya data
∑ = jumlah nilai data
2.
Kemudian hitung nilai varian dari dataset training tersebut seperti pada.= varians µ= mean
= nilai data
banyaknya data Testing :
1.
Hitung probabilitas (Prior) tiap kelas yang ada dengan cara menghitung jumlah data tiap kelas dibagi jumlah total data secara keseluruhan.2.
Selanjutnya menghitung densitas probabilitasnya.Fungsi densitas mengekspresikan probabilitas
relatif. Data dengan mean μ dan standar deviasi σ, fungsi densitas probabilitasnya adalah :
√
Dimana :
= data masukan
π = 3,14
standar deviasi µ = mean
3.
Setelah didapatkan nilai densitas probabilitasnya, selanjutnya menghitung posterior masing-masing kelas dengan menggunakan persamaan.
Atau bisa ditulis
| |
4.
Setelah didapat nilai posterior masing-masingkelas, maka kelas yang sesuai untuk data masukan adalah kelas yang memiliki nilai posterior terbesar.
1.9 Pengujian Confusion Matrix
Pengujian yang dilakukan pada metode klasifikasi terdapat pada bagian akurasi dari hasil klasifikasi. Akurasi sebuah klasifikasi berpengaruh terhadap performa dari suatu metode klasifikasi. Untuk melakukan pengujian akurasi dapat digunakan confusion matrix yaitu sebuah matriks dari prediksi yang akan dibandingkan dengan kelas yang asli dari data masukan. Setiap kolom dari matriks berkorespondensi kepada hasil klasifikasi dan setiap baris pada masukan. Akurasi sebuah klasifikasi dimana i=j menerangkan akurasi dari klasifikasi pada setiap kelas [9]. Berikut contoh
[image:41.595.343.493.699.760.2]ConfusionMatrix dapat dilihat pada tabel 2. Tabel 2 Confusion Matrix
Kelas
Hasil Klasifikasi
0 1
Target 0 00 01
1 10 11
qi
<![Gambar 1.1 Metode Agile, XP Process [6]](https://thumb-ap.123doks.com/thumbv2/123dok/434978.45957/4.595.109.484.474.709/gambar-metode-agile-xp-process.webp)
![Gambar 2.1 Bagian Pada Retina [8].](https://thumb-ap.123doks.com/thumbv2/123dok/434978.45957/8.595.150.440.446.725/gambar-bagian-pada-retina.webp)
![Tabel 2.1 Perbandingan Kualitas Biometrik [9]](https://thumb-ap.123doks.com/thumbv2/123dok/434978.45957/9.595.86.538.550.757/tabel-perbandingan-kualitas-biometrik.webp)
![Gambar 2.2 Pengenalan Pola Dengan Pendekatan Statistik [10].](https://thumb-ap.123doks.com/thumbv2/123dok/434978.45957/10.595.143.444.556.659/gambar-pengenalan-pola-dengan-pendekatan-statistik.webp)
![Gambar 2.3 Pengenalan Pola Dengan Pendekatan Sintaktik [10].](https://thumb-ap.123doks.com/thumbv2/123dok/434978.45957/11.595.177.467.459.576/gambar-pengenalan-pola-dengan-pendekatan-sintaktik.webp)