PENGGUNAAN FAKTOR HSINCHUN CHEN DALAM
ALGORITMA GENETIKA UNTUK MENEMUKAN
DOKUMEN YANG MIRIP
TESIS
Oleh
VERA WIJAYA
097038003/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
PROGRAM PASCASARJANA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PENGGUNAAN FAKTOR HSINCHUN CHEN DALAM
ALGORITMA GENETIKA UNTUK MENEMUKAN
DOKUMEN YANG MIRIP
TESIS
Oleh
VERA WIJAYA
097038003/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
PROGRAM PASCASARJANA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PENGGUNAAN FAKTOR HSINCHUN CHEN DALAM
ALGORITMA GENETIKA UNTUK MENEMUKAN
DOKUMEN YANG MIRIP
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar
Magister Ilmu Komputer dalam Program Studi
Magister Teknik Informatika pada Program Pascasarjana
Fakultas MIPA Universitas Sumatera Utara
Oleh
VERA WIJAYA
097038003/TINF
PROGRAM PASCASARJANA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PENGESAHAN TESIS
Judul Tesis :PENGGUNAAN FAKTOR HSINCHUN
CHEN DALAM ALGORITMA GENETIKA UNTUK MENEMUKAN DOKUMEN YANG MIRIP
Nama Mahasiswa : Vera Wijaya
Nomor Induk Mahasiswa : 09 70 38 003
Program Studi : Magister Teknik Informatika
Fakultas : Matematika dan Ilmu Pengetahuan Alam
Universitas Sumatera Utara
Menyetujui Komisi Pembimbing
Dr. Erna Budhiarti Nababan, MIT Dr. Poltak Sihombing, M.Kom
Pembimbing Anggota Pembimbing Utama
Ketua Program Studi, D e k a n,
Prof. Dr. Muhammad Zarlis
NIP.19570701198601 1003 NIP. 19631026199103 1001
PERNYATAAN ORISINALITAS
PENGGUNAAN FAKTOR HSINCHUN CHEN DALAM ALGORITMA GENETIKA UNTUK MENEMUKAN DOKUMEN YANG MIRIP
T E S I S
Dengan ini saya nyatakan bahwa saya mengakui semua karya tesis ini adalah hasil
kerja saya sendiri kecuali kutipan dan ringkasan telah di jelaskan sumbernya
dengan benar.
Medan, 13 Juni 2011
Vera Wijaya
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang telah bertanda
tangan di bawah ini :
Nama : Vera Wijaya
NIM : 097038003
Program Studi : Magister Teknik Informatika
Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada
Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive
Royalty Free Right) atas Tesis saya yang berjudul :
Penggunaan Faktor Hsinchun Chen Dalam Algoritma Genetika Untuk Menemukan Dokumen Yang Mirip
beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti
Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media,
memformat, mengelola dalam bentuk data-base, merawat dan mempublikasikan
Tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya
sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 13 Juni 2011
Telah diuji pada Tanggal : 28 Juli 2011
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Opim Salim Sitompul Anggota : 1. Prof. Dr. Muhammad Zarlis
RIWAYAT HIDUP
DATA PRIBADI
Nama lengkap berikut gelar : Vera Wijaya, S.Kom
Tempat dan Tanggal Lahir : Pematang Siantar, 2 Agustus 1983
Alamat Rumah : Kompleks Cemara Asri
Jl. Bungur No.120, Medan
Telepon/Faks/HP : 085261726988/
Instansi Tempat Bekerja : STMIK Kristenn Neumann Medan
Alamat Kantor : Jl. Jamin Ginting Km. 10,5 Medan
Telepon/Faks/HP :
DATA PENDIDIKAN
SD : Perguruan Kristen Methodist, P.Siantar Tamat : 1995
SMP : Perguruan Kristen Methodist, P.Siantar Tamat : 1998
SMA : Perguruan Kristen Methodist, P.Siantar Tamat : 2001
Strata-1 : Program Studi Sistem Informasi,
Universitas Bina Nusantara, Jakarta.
KATA PENGANTAR
Pertama-tama saya panjatkan puji syukur kehadirat Tuhan Yang Maha Esa atas segala limpahan rakhmadnya dan karunia-Nya sehingga tesis ini dapat diselesaikan.
Dengan selesainya tesis ini, perkenankanlah saya mengucapkan terima kasih yang sebesar-besarnya kepada yang terhormat :
• Rektor Universitas Sumatera Utara, Bapak Prof. Dr. dr. Syahril Pasaribu, DTM&H (CTM), Sp. A(K) atas kesempatan yang diberikan kepada kami untuk mengikuti dan menyelesaikan pendidikan Program Magister.
• Dekan Fakultas MIPA Universitas Sumatera Utara, Bapak Dr. Sutarman, M.Sc atas kesempatan menjadi mahasiswa Program Magister pada Program Pascasarjana FMIPA Universitas Sumatera Utara.
• Ketua Program Studi Magister Teknik Informatika, Bapak Prof. Dr. Muhammad Zarlis, Sekretaris Program Studi Magister Teknik Informatika, Bapak M.Andri Budiman, ST, M.Comp. Sc. MEM beserta seluruh Staf Pengajar Program Studi Magister Teknik Informatika Program Pascasarjana Fakultas MIPA Universitas Sumatera Utara.
Terimakasih yang tak terhingga dan penghargaan setinggi-tingginya kami ucapkan kepada Bapak Dr. Poltak Sihombing, M.Kom selaku Promotor/Pembimbing Utama yang dengan penuh perhatian dan telah memberikan dorongan, bimbingan dan tuntunan, demikian juga kepada Ibu Dr. Erna Budhiarti Nababan, MIT selaku Co. Promotor/Pembimbing Lapangan yang penuh kesabaran menuntun dan membimbing kami hingga selesainya penelitian ini.
Kepada Ayah Tukijan Sukardy dan Bunda Po Ing serta anakku terkasih Jasslyn. Terima kasih atas segala pergorbanan kalian baik berupa moril maupun materil, budi baik ini tidak dapat dibalas hanya diserahkan kepada Tuhan Yang Maha Esa.
PENGGUNAAN FAKTOR HSINCHUN CHEN DALAM ALGORITMA GENETIKA UNTUK MENEMUKAN DOKUMEN YANG MIRIP
ABSTRAK
Kecepatan pertumbuhan data dalam database sering menyebabkan data atau dokumen sulit ditemukan kembali. Hal ini berakibat pada dokumen yang ditemukan oleh suatu search engine tidak relevan (mirip) dengan kueri yang diberikan pada sistem. Tujuan penelitian ini mencoba untuk menjawab kebutuhan diatas dengan mengimplementasikan dan mengkaji penggunaan faktor Hsinchun chen dalam algoritma genetika untuk menemukan kembali dokumen yang diharapkan relevan dengan kueri yang diberikan oleh user. Teknik memanfaatkan faktor kemiripan Hsinchun chen untuk penemuan kembali dokumen dari suatu database. Metode penelitian ini secara garis besar terdiri dari 2 tahapan, yaitu tahapan text preprocessing secara offline kemudian tahapan mengukur nilai kemiripan dokumen dengan faktor hsinchun chen dalam algoritma genetika dan meretrieve dokumen tersebut. Hasil dari penelitian ini akan dibandingkan dengan sistem temu kembali jaringan syaraf tiruan metode Hopfiled dengan menggunakan dataset yang sama yang terdiri dari 600 dokumen sebagai ujicoba. Hasil pengujian nilai kemiripan dengan Hsinchun chen ini lebih tinggi jika dibandingkan dengan nilai kemiripan jaringan syaraf tiruan Hopfiled.
THE USE OF HSINCHUN CHEN FACTORS IN GENETIC
ALGORITHM TO RETRIEVE SIMILAR DOCUMENT
ABSTRACT
The speed of growth data in the database often cause data or documents hard to find again. This resulted in a document found by a search engine is not relevant (similar) with a given query on the system. The purpose of this study tries to answer the above needs by implementing and reviewing the use Hsinchun chen factor in the genetic algorithm to find the expected return of documents relevant to the query given by the user. Techniques take advantage of the similarity factor Hsinchun chen to the rediscovery of documents from a database. This research method largely consists of two phases, namely preprocessing stage of the text it offline later stages of document similarity measure value by a factor Hsinchun chen in genetic algorithms and retrieve document. The results of this study will be compared with the retrieval system Hopfiled neural network method using the same dataset consisting of 600 documents as testing. Test results by Hsinchun chen similarity value is higher if compared with the value of artificial neural networks Hopfiled similarity.
DAFTAR ISI
Halaman
KATA PENGANTAR i
ABSTRAK ii
ABSTRACT iii
DAFTAR ISI iv
DAFTAR TABEL vi
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN ix
BAB I PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Perumusan Masalah 3
1.3 Tujuan Penelitian 3
1.4 Manfaat Penelitian 4
1.5 Batasan Masalah 4
BAB II TINJAUAN PUSTAKA 6
2.1 Information Retrieval 6
2.2 Similarity (Kemiripan) 8
2.3 Similarity Measure (Ukuran Kemiripan) 9
2.4 Algoritma Genetika 10
2.4.1 Struktur Umum Algoritma Genetika 11
2.4.2 Pengkodean Algoritma Genetika 13
2.4.3 Operator Genetika 14
2.5 Teknik Yang Digunakan Sebelumnya 19
2.5.1 Pendekatan Jaringan Syaraf Tiruan untuk Temu
Kembali Informasi
19
Kembali Informasi
2.5.3 Pendekatan Bibliometrik untuk Temu Kembali
Informasi
22
BAB III METODE PENELITIAN 26
3.1 Data Penelitian 26
3.2 Keyword 27
3.3 Teknik Penelitian 27
3.3.1 Text Preprocessing 28
3.3.2 Ukuran Kemiripan Hsinchun Chen 30
3.3.3 Implementasi Faktor Hsinchun Chen dalam
Algoritma Genetika
31
3.4 Perancangan Sistem 36
3.4.1 Deskripsi Sistem 37
3.4.2 Perancangan Database 37
3.4.3 Perancangan Perangkat Lunak 40
BAB IV HASIL DAN PEMBAHASAN 44
4.1 Penggunaan Hsinchun Chen dalam Algoritma Genetika
untuk Menemukan Kembali Dokumen yang Mirip
44
4.1.1 Hasil Tahapan Text Preprocessing 44
4.1.2 Pencarian Kemiripan Dokumen dengan Algoritma
Genetika
45
4.2 Perbandingan Hasil Pencarian Kembali Dokumen
Menggunakan Algoritma Genetika dengan Jaringan
Syaraf Tiruan
58
BAB V KESIMPULAN DAN SARAN 67
5.1 Kesimpulan 67
5.2 Saran 68
DAFTAR PUSTAKA 70
DAFTAR TABEL
Nomor
Tabel
Judul
Halaman
2.1 Probabilitas Seleksi dan Nilai Fitness 15
2.2 Perbandingan Teknik dalam Sistem Temu Kembali
Informasi
24
3.1 Rancangan Halaman Perangkat Lunak 41
4.1 Hasil Tahapan Text Processing 47
4.2 Pemodelan Kromosom Solusi 47
4.3 Pembangkitan Populasi Awal 48
4.4.a Hasil Text Processing Dokumen Populasi Awal 49
4.4.b Hasil Text Processing Dokumen Populasi Awal 49
4.5 Hasil Perbandingan Keyword Query dengan Keyword
Populasi Awal
50
4.6 Hasil Pengkodean Kromosom Populasi 51
4.7 Hasil Perhitungan Nilai Fitness 52
4.8 Hasil Seleksi Kromosom 52
4.9 Populasi untuk Generasi Selanjutnya 54
4.10.a Hasil Tahapan Text Processing Generasi Selanjutnya 54
4.10.b Hasil Tahapan Text Processing Generasi Selanjutnya 55
4.11 Hasil Perbandingan Keyword Generasi Selanjutnya 55
4.12 Evaluasi Nilai Fitness Generasi Selanjutnya 56
4.13 Hasil Seleksi Generasi Selanjutnya 57
4.14 Hasil Perhitungan Kemiripan Dokumen 58
4.15 Hasil Pencarian Dokumen dengan Algoritma Genetika 58
4.16 Nilai Kemiripan Dokumen dengan Jaringan Syaraf
Tiruan (JST)
4.17 Nilai Kemiripan Dokumen dengan Algoritma Genetika 60
4.18 Kueri Jaringan Syaraf Tiruan 61
4.19 Kueri Algoritma Genetika 62
4.20 Hasil Kueri Algoritma Genetika 63
4.21 Hasil Perbandingan Nilai Kemiripan Dokumen
Menggunakan Algoritma Genetika dan Jaringan Syaraf
Tiruan
63
DAFTAR GAMBAR
Nomor
Gambar
Judul
Halaman
2.1 Diagram Alir Algoritma Genetika 12
2.2 Seleksi Roda Roulette 16
2.3.a Kueri dan Istilah Teraktivasi 20
2.3.b Dokumen Memuat Istilah Teraktivasi dan Kumpulan
Dokumen
20
3.1 Bagan Alir Teknik Pencarian Kembali Dokumen 28
3.2 Bagan Alir Tahapan Text Preprocessing 32
3.3 Bagan Alir Pencarian Kembali Dokumen dengan
Algoritma Genetika
35
3.4 Pseudocode Penerapan Algoritma Genetika dalam
Sistem Pencarian Kembali Dokumen
36
3.5 Rancangan Diagram ERD 40
3.6 Navigation Diagram Perancangan Perangkat Lunak 42
4.1 Perbandingan Jumlah Dokumen Pencarian 65
DAFTAR LAMPIRAN
Nomor
Lampiran
Judul
Halaman
A Hasil Perhitungan Nilai Fitness Algoritma Genetika L1
B Hasil Pencarian Nilai Kemiripan Dokumen
Menggunakan Algoritma Genetika
L2
C Hasil Pencarian Dokumen Menggunakan Jaringan
Syaraf Tiruan
L4
D Hasil Pencarian Dokumen Menggunakan Algoritma
Genetika
L8
E Perbandingan Nilai Kemiripan Algoritma Genetika
dengan Jaringan syaraf Tiruan
L12
F Daftar Keyword Hasil Tahapan Text Processing L13
G Daftar Stemming L14
H Daftar Stop Word L19
I Data Dokumen Penelitian L24
PENGGUNAAN FAKTOR HSINCHUN CHEN DALAM ALGORITMA GENETIKA UNTUK MENEMUKAN DOKUMEN YANG MIRIP
ABSTRAK
Kecepatan pertumbuhan data dalam database sering menyebabkan data atau dokumen sulit ditemukan kembali. Hal ini berakibat pada dokumen yang ditemukan oleh suatu search engine tidak relevan (mirip) dengan kueri yang diberikan pada sistem. Tujuan penelitian ini mencoba untuk menjawab kebutuhan diatas dengan mengimplementasikan dan mengkaji penggunaan faktor Hsinchun chen dalam algoritma genetika untuk menemukan kembali dokumen yang diharapkan relevan dengan kueri yang diberikan oleh user. Teknik memanfaatkan faktor kemiripan Hsinchun chen untuk penemuan kembali dokumen dari suatu database. Metode penelitian ini secara garis besar terdiri dari 2 tahapan, yaitu tahapan text preprocessing secara offline kemudian tahapan mengukur nilai kemiripan dokumen dengan faktor hsinchun chen dalam algoritma genetika dan meretrieve dokumen tersebut. Hasil dari penelitian ini akan dibandingkan dengan sistem temu kembali jaringan syaraf tiruan metode Hopfiled dengan menggunakan dataset yang sama yang terdiri dari 600 dokumen sebagai ujicoba. Hasil pengujian nilai kemiripan dengan Hsinchun chen ini lebih tinggi jika dibandingkan dengan nilai kemiripan jaringan syaraf tiruan Hopfiled.
THE USE OF HSINCHUN CHEN FACTORS IN GENETIC
ALGORITHM TO RETRIEVE SIMILAR DOCUMENT
ABSTRACT
The speed of growth data in the database often cause data or documents hard to find again. This resulted in a document found by a search engine is not relevant (similar) with a given query on the system. The purpose of this study tries to answer the above needs by implementing and reviewing the use Hsinchun chen factor in the genetic algorithm to find the expected return of documents relevant to the query given by the user. Techniques take advantage of the similarity factor Hsinchun chen to the rediscovery of documents from a database. This research method largely consists of two phases, namely preprocessing stage of the text it offline later stages of document similarity measure value by a factor Hsinchun chen in genetic algorithms and retrieve document. The results of this study will be compared with the retrieval system Hopfiled neural network method using the same dataset consisting of 600 documents as testing. Test results by Hsinchun chen similarity value is higher if compared with the value of artificial neural networks Hopfiled similarity.
BAB I
PENDAHULUAN
Pada bab ini akan dibahas latar belakang penelitian, perumusan masalah, tujuan penelitian, manfaat penelitian dan batasan masalah.
1.1
LATAR BELAKANGPerkembangan penggunaan informasi yang cukup tinggi khususnya informasi dalam bentuk teks dokumen menyebabkan kesulitan dalam proses menemukan kembali informasi, sehingga diperlukan suatu cara pendeteksian kemiripan dokumen untuk mendapatkan dokumen yang relevan dan sesuai dengan permintaan pengguna. Proses pendeteksian kemiripan dokumen merupakan pencarian kesamaan beberapa dokumen dengan membandingkan isi dokumen sehingga menghasilkan bobot atau nilai kemiripan dari dokumen yang dibandingkan. Salah satu kegunaan perbandingan isi dokumen adalah untuk membantu pengguna dalam pengelompokan dokumen dan juga memungkinkan pengguna mengetahui apakah isi dokumen yang satu merupakan dokumen yang pada dasarnya sama dengan dokumen yang lain. Menurut Rahman [25], pendeteksian kemiripan dokumen ini dapat dilakukan dengan beberapa teknik, misalnya teknik pencarian informasi (information retrieval), teknik penghitungan statistik, atau dengan menggunakan informasi sintaktik dari kalimat per kalimatnya.
antara lain Osinki [22], Prakasa [23], dan Widyantoro [34] pada hasil pencarian. Selain dari clustering dokumen yang telah dijelaskan sebelumnya, terdapat beberapa metode yang digunakan untuk pencarian kembali dokumen yaitu :
a. Proses parsing dokumen yaitu pengambilan kata-kata dari dokumen.
b. Proses stoplist yaitu pembuangan kata yang tidak mewakili isi dokumen
sehingga tidak dapat dijadikan sebagai indeks.
c. Proses steming kata yaitu proses penghilangan imbuhan yang tidak perlu
dari suatu kata turunan (berimbuhan).
d. Proses indexing yaitu pemilihan istilah (indeks) dilakukan oleh Tata[30].
e. Proses mencari hubungan antar dua istilah (similarity of terms).
f. Operasi Boolean terhadap istilah-istilah dalam kueri untuk penemuan
kembali dokumen yang diinginkan, dilakukan oleh Hasibuan dan Andri
[11].
Sihombing[27] telah melakukan penelitian pendeteksian kemiripan dokumen dengan menggunakan Jaringan Saraf Tiruan Hopfiled dengan memanfaatkan similarity measure Hsinchun Chen untuk mendapatkan nilai kemiripan dokumen yang dihasilkan dengan query yang diberikan.
Terdapat sejumlah metode untuk menghitung kesamaan antar dokumen, salah satunya dengan menggunakan ukuran kemiripan (similarity measure) Hsinchun Chen diperkenalkan oleh Chen et al [4]. Hsinchun Chen adalah seorang peneliti di bidang IT, pada tahun 1994 Chen dan teman-temannya melakukan penelitian sistem temu kembali dokumen dan menghasikan suatu formulasi pengukuran kemiripan dokumen, rumus ini dikenal dengan ukuran kemiripan (similarity measure) Hsinchun Chen.
Algoritma genetika adalah suatu algoritma pencarian yang berbasis pada mekanisme seleksi alam dan genetika. Masalah yang dapat diselesaikan dengan algoritma genetika adalah masalah yang mempunyai kemungkinan solusi yang jumlahnya tak berhingga. Pada sistem pencarian kembali dokumen, masalah yang dihadapi adalah tantangan meledaknya jumlah informasi, sehingga memungkinkan pemberian informasi sesuai kebutuhan semakin rumit.
Tiruan .
1.2 PERUMUSAN MASALAH
Berdasarkan latar belakang permasalahan yang telah dikemukakan di atas, maka perumusan masalah penelitian ini adalah :
• Bagaimana mendapatkan nilai kemiripan dokumen yang lebih tinggi dengan kueri yang diberikan?
• Bagaimana hasil nilai kemiripan dokumen yang diperoleh dalam penelitian ini jika dibandingkan dengan penelitian Sihombing [27]
dengan menggunakan jaringan syaraf tiruan ?
1.3 TUJUAN PENELITIAN
Tujuan yang akan dicapai dari penelitian ini adalah :
Mendapatkan nilai kemiripan dokumen dengan penerapan faktor Hsinchun Chen dalam algoritma genetika.
Objektif dari penelitian ini adalah :
a. Menjelaskan mekanisme sistem pencarian dokumen dengan mengunakan
algoritma genetika.
b. Membangun sebuah perancangan sistem temu kembali dokumen dengan
query yang diberikan.
c. Mendapatkan hasil perbandingan nilai kemiripan dokumen menggunakan
1.4 MANFAAT PENELITIAN
Manfaat dari penelitian ini adalah :
a. Memahami hal-hal yang perlu dilakukan dalam mengaplikasikan algoritma
genetika dalam mencari nilai kemiripan dokumen.
b. Memahami teknik yang dapat diterapkan dalam mencari nilai kemiripan
dokumen
c. Menjadi rujukan bagi peneliti yang lain sebagai teknik untuk melakukan
browsing guna menemukan dokumen yang relevan.
1.5 BATASAN MASALAH
Untuk mencegah pembahasan yang terlalu luas maka penulis membatasi ruang lingkup masalah pada penelitian ini adalah sebagai berikut :
a. Batasan model yaitu model algoritma genetika dengan faktor kemiripan
yang digunakan adalah Hsinchun Chen.
b. Penelitian ini berfokus pada implementasi algoritma genetika dalam
pencarian kembali dokumen, dimana bagian dokumen yang digunakan
adalah judul dari setiap dokumen.
c. Bagian dari dokumen yang digunakan untuk penerapan algoritma genetika
adalah keyword (kata kunci), dimana keyword tersebut diperoleh dari judul
setiap dokumen yang telah mengalami tahapan text preprocessing secara
sederhana.
d. Membandingkan nilai kemiripan dokumen yang didapatkan dengan
algoritma genetika dan algoritma jaringan syaraf tiruan Hopfield.
e. Dataset yang digunakan berjumlah 600 dokumen, dimana dokumen tersebut
berbentuk jurnal, makalah atau penelitian dalam Bahasa Indonesia, dimana
dataset tersebut merupakan data yang sama digunakan oleh peneliti
sebelumnya Sihombing[27], sehingga dapat dilakukan perbandingan nilai
kemiripan dokumen terhadap penelitian yang dilakukan sebelumnya dan
untuk penelitian di Universitas Indonesia (UI).
BAB II
TINJAUAN PUSTAKA
Pada bab ini akan dibahas mengenai information retrieval, similarity (kemiripan), similarity measure (ukuran kemiripan), algoritma genetika kemudian dilanjutkan dengan teknik-teknik yang telah digunakan sebelumnya.
2.1 INFORMATION RETRIEVAL
Rahman [25] mendefinisikan Information Retrieval (IR) sebagai tindakan, metode
dan prosedur untuk menemukan kembali data yang tersimpan, dan selanjutnya
menyediakan informasi mengenai subyek yang dibutuhkan. Tindakan tersebut
mencakup text indexing, inquiry analysis, dan relevance analysis. Data mencakup
teks, tabel, gambar, ucapan, dan video. Informasi yang ditemukan adalah
merupakan pengetahuan terkait yang dibutuhkan untuk mendukung penyelesaian
masalah dan akuisisi pengetahuan [7].
Sistem Temu Kembali Informasi merupakan sistem yang berfungsi untuk
menemukan informasi yang relevan dengan kebutuhan pemakai. Salah satu hal
yang perlu diingat adalah bahwa informasi yang diproses terkandung dalam
sebuah dokumen yang bersifat tekstual. Dalam konteks ini, temu kembali
informasi berkaitan dengan representasi, penyimpanan, dan akses terhadap
dokumen representasi dokumen. Dokumen yang ditemukan tidak dapat dipastikan
query. Pengguna Sistem Temu Kembali informasi sangat bervariasi dengan kebutuhan informasi yang berbeda-beda.
Tujuan dari sistem IR (Information Retrieval) adalah memenuhi kebutuhan
informasi pengguna dengan me-retrieve semua dokumen yang mungkin relevan,
pada waktu yang sama me-retrieve sesedikit mungkin dokumen yang tak-relevan.
Dokumen sebagai objek data dalam Sistem Temu Kembali Informasi
merupakan sumber informasi. Dokumen biasanya dinyatakan dalam bentuk
indeks atau kata kunci. Kata kunci dapat diekstrak secara langsung dari teks
dokumen atau ditentukan secara khusus oleh spesialis subjek dalam proses
pengindeksan yang pada dasarnya terdiri dari proses analisis dan representasi
dokumen. Pengindeksan dilakukan dengan menggunakan sistem pengindeksan
tertentu, yaitu himpunan kosa kata yang dapat dijadikan sebagai bahasa indeks
sehingga diperoleh informasi yang terorganisasi. Sementara itu, pencarian diawali
dengan adanya kebutuhan informasi pengguna. Dalam hal ini Sistem Temu
Kembali Informasi berfungsi untuk menganalisis pertanyaan (query) pengguna
yang merupakan representasi dari kebutuhan informasi untuk mendapatkan
pernyataan-pernyataan pencarian yang tepat. Selanjutnya pernyataan-pernyataan
pencarian tersebut dipertemukan dengan informasi yang telah terorganisasi
dengan suatu fungsi penyesuaian (matching function) tertentu sehingga ditemukan
dokumen atau sekumpulan dokumen.
Menurut Grossman and Ophir [10], sistem ini menggunakan fungsi
heuristik untuk mendapatkan dokumen-dokumen yang relevan dengan query
pengguna. Sistem IR yang baik memungkinkan pengguna menentukan secara
cepat dan akurat apakah isi dari dokumen yang diterima memenuhi kebutuhannya.
Dengan tujuan dokumen lebih baik dan lebih representasi, maka
dokumen-dokumen tersebut dikelompokkan secara bersama yang sesuai dengan topiknya
atau isi yang mirip dikelompokkan.
Menurut Frakes and Baeza-Yates [7], ada dua pekerjaan yang ditangani
oleh sistem ini, yaitu melakukan pre-processing terhadap database dan kemudian
menerapkan metode tertentu untuk menghitung kedekatan (relevansi atau
query pengguna. Pada tahapan preprocessing, sistem yang berurusan dengan dokumen semi-structured biasanya memberikan tag tertentu pada term-term atau
bagian dari dokumen; sedangkan pada dokumen tidak terstruktur proses ini
dilewati dan membiarkan term tanpa imbuhan tag.
Query yang dimasukkan oleh pengguna dikonversi sesuai aturan tertentu untuk mengekstrak term-term penting yang sejalan dengan term-term yang
sebelumnya telah diekstrak dari dokumen dan menghitung relevansi antara query
dan dokumen berdasarkan pada term-term tersebut [24]. Sebagai hasilnya, sistem
mengembalikan suatu daftar dokumen terurut descending (ranking) sesuai nilai
kemiripannya dengan query pengguna [18].
Menurut Tata [30], setiap dokumen (termasuk query) direpresentasikan
menggunakan model bag-of-words yang mengabaikan urutan dari kata-kata di
dalam dokumen, struktur sintaktis dari dokumen dan kalimat. Dokumen
ditransformasi ke dalam suatu “tas“ berisi kata-kata independen. Term disimpan
dalam suatu database pencarian khusus yang ditata sebagai sebuah inverted index.
Index ini merupakan konversi dari dokumen asli yang mengandung sekumpulan kata ke dalam daftar kata yang berasosiasi dengan dokumen terkait dimana
kata-kata tersebut muncul.
2.2 SIMILARITY (KEMIRIPAN)
Menurut Guo [13], definisi dari similarity adalah sesuatu yang penting dan
merupakan konsep yang digunakan secara luas. Similarity mempunyai beberapa
pendekatan, yaitu:
a. Perkiraan 1: kesamaan antara A dan B adalah berhubungan dengan
kesamaannya secara umum. Semakin banyak kesamaan umum yang
b. Perkiraan 2: kesamaan antara A dan B adalah berhubungan dengan
perbedaan-perbedaan yang dimilikinya. Semakin banyak perbedaan yang
dimiliki, semakin kecil tingkat kemiripannya.
c. Perkiraan 3: kesamaan maksimum antara A dan B akan tercapai ketika A
dan B adalah serupa atau identik, berapa banyak kesamaan umum yang
mereka bagikan tidak berpengaruh.
2.3 SIMILARITY MEASURE ( UKURAN KEMIRIPAN)
Menurut Salton [26], model ruang vektor dan pembobotan tf-idf digunakan untuk
merepresentasikan nilai numerik dokumen sehingga kemudian dapat dihitung
kedekatan antar dokumen. Semakin dekat dua vektor di dalam suatu ruang vektor
maka semakin mirip dua dokumen yang diwakili oleh vektor tersebut. Kemiripan
antar dokumen dihitung menggunakan suatu fungsi ukuran kemiripan (similarity
measure). Ukuran ini memungkinkan perankingan dokumen sesuai dengan kemiripan (relevansi)nya terhadap query. Setelah dokumen diranking, sejumlah
tetap dokumen top-scoring dikembalikan kepada pengguna.
Alternatifnya, suatu threshold dapat digunakan untuk memutuskan berapa
banyak dokumen akan dikembalikan. Threshold dapat digunakan untuk
mengontrol tarik-ulur antara presisi dan recall. Nilai threshold tinggi biasanya
akan menghasilkan presisi tinggi dan recall rendah.
Ada beberapa metode pengukuran kemiripan yaitu cosine, dice, hsinchun
chen, dan jaccard. Metode yang sering digunakan untuk pengukuran kemiripan adalah ukuran kemiripan (similarity measure) cosine.
Salah satu ukuran kemiripan dokumen adalah faktor Hsinchun Chen [32].
Menurut Chen et al [4] ukuran kemiripan dengan Hsinchun Chen adalah setiap
istilah dapat diwakili oleh satu simpul (node), dimana hubungan antar istilah ini
dapat dihitung dengan menggunakan rumusan yang diajukannya seperti pada
... (2.1)
Dengan
di
jk bernilai 1 (satu) apabila dokumen ke-i memuat istilah j danistilah k bersama-sama, dan bernilai 0 (nol) pada kasus lainnya. Nilai
di
j bernilai 1apabila dokumen ke-i memuat istilah j, dan 0 apabila dokumen ke-i tidak memuat
istilah j.
Rumus di atas menyatakan kemiripan antara istilah j dan istilah k yaitu
perbandingan antara jumlah dokumen yang memuat istilah j dan istilah k
bersama-sama, dengan jumlah dokumen yang memuat istilah j saja. Nilai n adalah jumlah
keseluruhan dokumen yang ada dalam koleksi.
Nilai kemiripan (Tj, Tk) mungkin berbeda dengan nilai kemiripan (Tk, Tj),
karena nilai pembagi dalam rumus di atas untuk kemiripan (Tk, Tj) adalah jumlah
dokumen yang memuat istilah k saja (dik). Ini berarti ada perbedaan nilai
keterhubungan dari istilah k ke istilah j dengan nilai keterhubungan dari istilah j
ke istilah k.
2.4 ALGORITMA GENETIKA
Menurut Kusumadewi [16] menyatakan bahwa algoritma genetika (AG) adalah
suatu algoritma pencarian yang berbasis pada mekanisme seleksi alam dan
genetika. Algoritma genetika merupakan salah satu algoritma yang sangat tepat
digunakan dalam menyelesaikan masalah optimasi kompleks, yang sulit dilakukan
oleh metode konvensional.
Menurut Desiani dan Arhami [6], sifat algoritma genetika adalah mencari
kemungkinan-kemungkinan dari calon solusi untuk mendapatkan yang optimal
(feasible), yaitu objek-objek diantara solusi yang sesuai, dinamakan ruang
pencarian (search space). Tiap titik dalam ruang pencarian merepresentasikan
satu solusi yang layak. Tiap solusi yang layak ditandai dengan nilai fitness-nya
bagi masalah.
Ciri-ciri permasalahan yang dapat dikerjakan dengan menggunakan
algoritma genetika adalah [1]:
• Mempunyai fungsi tujuan optimalisasi non linear dengan banyak kendala yang juga non linear.
• Mempunyai kemungkinan solusi yang jumlahnya tak berhingga.
• Membutuhkan solusi “real-time” dalam arti solusi bisa didapatkan dengan cepat sehingga dapat diimplementasikan untuk permasalahan yang
mempunyai perubahan yang cepat seperti optimasi pada pembebanan
kanal pada komunikasi seluller.
• Mempunyai multi-objective dan multi-criteria, sehingga diperlukan solusi yang dapat secara bijak diterima oleh semua pihak.
2.4.1 Struktur Umum Algoritma Genetika
Goldberg [9] mengemukakan bahwa algoritma genetika mempunyai
karakteristik-karakteristik yang perlu diketahui sehingga dapat terbedakan dari prosedur
pencarian atau optimasi yang lain, yaitu :
1. Algoritma genetika bekerja dengan pengkodean dari himpunan solusi
permasalahan berdasarkan parameter yang telah ditetapkan dan bukan
parameter itu sendiri.
2. Algoritma genetika melakukan pencarian pada sebuah populasi dari
sejumlah individu-individu yang merupakan solusi permasalahan bukan
3. Algoritma genetika merupakan informasi fungsi objektif(fitness), sebagai
cara untuk mengevaluasi individu yang mempunyai solusi terbaik bukan
turunan dari suatu fungsi.
Algoritma genetika secara umum dapat diilustrasikan dalam diagram alir gambar
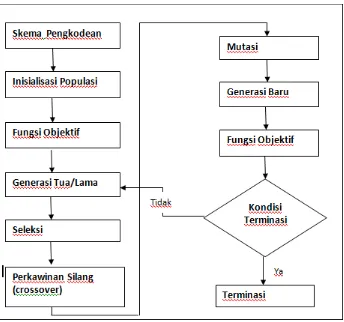
[image:31.595.115.459.223.545.2]2.1 berikut :
Gambar 2.1. Diagram Alir Algoritma Genetika
Kusumadewi dan Purnomo [17] menyatakan variabel dan parameter yang
digunakan pada algoritma genetika adalah :
1. Fungsi fitness (fungsi tujuan) yang dimiliki oleh masing-masing individu
untuk menentukan tingkat kesesuaian individu tersebut dengan kriteria
yang ingin dicapai.
3. Probabilitas terjadinya persilangan (crossover) pada suatu generasi.
4. Probabilitas terjadinya mutasi pada setiap individu
5. Jumlah generasi yang akan dibentuk menentukan lama penerapan
algoritma genetika.
Secara umum, Thiang et al. [31] mengemukakan bahwa struktur dari
suatu algoritma genetika dapat didefenisikan dengan langkah-langkah sebagai
berikut :
1. Membangkitkan populasi awal
Populasi awal ini dibangkitkan secara random sehingga didapatkan solusi
awal. Populasi ini sendiri terdiri atas sejumlah kromosom untuk
merepresentasikan solusi yang diinginkan.
2. Membentuk generasi baru
Untuk membentuk generasi baru, digunakan operator reproduksi/seleksi,
crossover dan mutasi. Proses ini dilakukan berulang-ulang sehingga didapatkan sejumlah kromosom yang cukup untuk membentuk generasi
baru di mana generasi baru ini merupakan representasi dari solusi baru.
Generasi baru in dikenal dengan istilah anak (offspring).
3. Evaluasi solusi
Pada tiap generasi, kromosom akan melalui proses evaluasi dengan
menggunakan alat ukur yang dinamakan fitness. Nilai fitness suatu
kromosom menggambarkan kualitas kromosom dalam populasi tersebut.
Proses ini mengevaluasi setiap populasi dengan menghitung nilai fitness
setiap kromosom dan mengevaluasinya dampai terpenuhi kriteria berhenti.
Bila kriteria berhenti belum terpenuhi maka akan dibentuk lagi generasi
baru dengan mengulang langkah 2. Beberapa kriteria berhenti yang sering
digunakan antara lain: berhenti pada generasi tertentu, berhenti setelah
tidak berubah, berhenti bila dalam n generasi berikut tidak didapatkan nilai
fitness yang lebih tinggi.
2.4.2 Pengkodean Algoritma Genetika
Pengkodean adalah suatu teknik untuk menyatakan populasi awal sebagai calon
solusi suatu masalah ke dalam suatu kromosom [8] sebagai suatu kunci pokok
persoalan ketika menggunakan algoritma genetika.
Berdasarkan jenis simbol yang digunakan sebagai nilai suatu gen, metode
pengkodean dapat diklasifikasikan sebagai berikut: pengkodean biner, bilangan
riil, bilangan bulat dan struktur data [8].
Pengkodean biner merupakan cara pengkodean yang paling umum
digunakan karena adalah yang pertama kali digunakan dalam algoritma genetika
oleh Holland. Keuntungan pengkodean ini adalah sederhana untuk diciptakan dan
mudah dimanipulasi.
Pengkodean biner memberikan banyak kemungkinan untuk kromosom
walaupun dengan jumlah nilai-nilai yang mungkin terjadi pada suatu gen yang
sedikit (0 atau 1). Di pihak lain, pengkodean biner ini sering tidak sesuai untuk
banyak masalah dan kadang pengkoreksian harus dilakukan setelah operasi
crossover dan mutasi.
Pengkodean bilangan riil adalah suatu pengkodean bilangan dalam bentuk
riil. Masalah optimasi fungsi dan optimalisasi kendala lebih tepat diselesaikan
dengan pengkodean bilangan riil karena struktur topologi ruang genotif untuk
pengkodean bilangan riil identik dengan ruang fenotifnya, sehingga mudah
membentuk operator genetika yang efektif dengan cara memakai teknik yang
Pengkodean bilangan bulat merupakan metode yang mengodekan bilangan
dalam bentuk bilangan bulat. Pengkodean ini baik digunakan untuk masalah
optimasi kombinational [8].
Pengkodean struktur data adalah model pengkodean yang menggunakan
struktur data. Pengkodean ini digunakan untuk masalah kehidupan yang lebih
kompleks seperti perencanaan jalur robot dan masalah pewarnaan grap [6].
2.4.3 Operator Genetika
Algoritma genetika merupakan proses pencarian yang heuristik dan acak sehingga
penekanan pemilihan operator yang digunakan sangat menentukan keberhasilan
algoritma genetika dalam menemukan solusi optimum suatu masalah yang
diberikan.
Operator genetika digunakan setelah proses evaluasi tahap pertama untuk
membentuk suatu populasi baru dari generasi sekarang. Operator-operator
tersebut adalah operator seleksi, crossover dan mutasi.
1. Seleksi
Seleksi bertujuan untuk memberikan kesempatan reproduksi yang lebih besar bagi
anggota populasi yang paling fit. Langkah pertama dalam seleksi ini adalah
pencarian nilai fitness. Masing-masing individu dalam wadah seleksi akan
menerima probailitas reproduksi yang bergantung pada nilai objektif dirinya
sendiri terhadap nilai objektif dari semua individu dalam wadah seleksi tersebut.
Nilai fitness inilah yang nantinya akan digunakan pada tahap-tahap seleksi
berikutnya [16].
a. Rank-based Fitness
Pada rank-based fitness, populasi diurutkan menurut nilai objektifnya.
Nilai fitness tiap-tiap individu hanya tergantung pada posisi individu
tersebut dalam urutan, dan tidak dipengaruhi oleh nilai objektifnya.
b. Seleksi Roda Roulette (Roulette Wheel Selection)
Pada metode ini, individu-individu dipetakan dalam sebuah segmen garis
secara berurutan sedemikian sehingga tiap-tiap segmen individu memiliki
ukuran yang sama dengan ukuran fitness-nya. Sebuah bilangan random
dibangkitkan dan individu yang memiliki segmen dalam kawasan bilangan
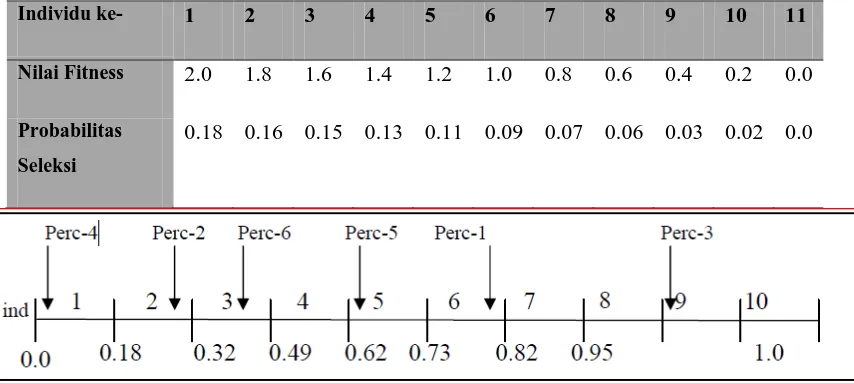
random tersebut akan terseleksi. Proses ini diulang hingga diperoleh sejumlah individu yang diharapkan. Pada tabel 2.1 dan gambar 2.2
menunjukkan probabilitas seleksi dari 11 individu. Individu pertama
memiliki fitness terbesar, dengan demikian dia juga memiliki individu
[image:35.595.117.544.484.676.2]terbesar. Sedangkan individu ke-10 memiliki fitness terkecil kedua.
Tabel 2.1 Probabilitas Seleksi Dan Nilai Fitness
Individu ke- 1 2 3 4 5 6 7 8 9 10 11
Nilai Fitness 2.0 1.8 1.6 1.4 1.2 1.0 0.8 0.6 0.4 0.2 0.0
Probabilitas
Seleksi
0.18 0.16 0.15 0.13 0.11 0.09 0.07 0.06 0.03 0.02 0.0
Setelah dilakukan seleksi, maka individu-individu yang terpilih adalah:
1 2 3 5 6 9
c. Stochastic universal sampling
Pada metode ini, individu-individu dipetakan dalam suatu segmen garis
secara berurutan sedemikian hingga tiap-tiap segmen individu memiliki
ukuran yang sama dengan ukuran fitnessnya seperti halnya pada seleksi
roda roulette. Kemudian diberikan sejumlah pointer sebanyak individu
yang ingin diseleksi pada garis tersebut. Andaikan N adalah jumlah
individu yang akan diseleksi, maka jarak antar pointer adalah 1/N, dan
posisi pointer pertama diberikan secara acak pada range [1,1/N].
d. Seleksi dengan pemotongan (Truncation selection)
Seleksi ini biasanya digunakan oleh populasi yang jumlahnya sangat besar.
Pada metode ini, individu-individu diurutkan berdasarkan nilai fitnessnya.
Hanya individu-individu yang terbaik saja yang akan diseleksi sebagai
induk. Parameter yang digunakan dalam metode ini adalah suatu nilai
ambang trunc yang mengindikasikan ukuran populasi yang akan diseleksi
sebagai induk yang berkisar antara 50%-10%. Individu-individu yang ada
di bawah nilai ambang ini tidak akan menghsilkan keturunan.
e. Seleksi dengan turnamen (Turnament Selection)
Pada metode seleksi dengan turnamen ini, akan ditetapkan suatu nilai tour
untuk individu-individu yang dipilih secara random dari suatu populasi.
Individu-individu yang terbaik dalam kelompok ini akan diseleksi sebagai
induk. Parameter yang digunakan pada metode ini adalah ukuran tour
yang bernilai 2 sampai N (jumlah individu dalam suatu populasi).
2. Crossover
Operator persilangan merupakan operasi yang bekerja untuk menggabungan dua
kromosom mengalami persilangan. Jumlah kromosom dalam populasi yang
mengalami persilangan ditentukan oleh paramater yang disebut dengan crossover
rate (probabilitas persilangan) .
Beberapa jenis crossover tersebut adalah
a. Crossover satu titik
Proses crossover dilakukan dengan memisahkan suatu string menjadi dua
bagian dan selanjutnya salah satu bagian dipertukarkan dengan salah satu
bagian dari string yang lain yang telah dipisahkan dengan cara yang sama.
Misalkan ada 2 kromosom dengan panjang 12 :
Induk 1 : 0 1 1 1 0 | 0 1 0 1 1 1 0
Induk 2 : 1 1 0 1 0 | 0 0 0 1 1 0 1
Posisi yang dipilih : 5
Kromosom baru yang terbetuk:
Anak 1 : 0 1 1 1 0 | 0 0 0 1 1 0 1
Anak 2 : 1 1 0 1 0 | 0 1 0 1 1 1 0
b. Crossover banyak titik
Proses crossover ini dilakukan dengan memisahkan suatu string menjadi
beberapa bagian dan selanjutnya dipertukarkan dengan bagian dari string
yang lain yang telah dipisahkan dengan cara yang sama sesuai dengan
urutannya.
Misalkan ada 2 kromosom dengan panjang 12 :
Induk 1 : 0 1 | 1 1 0 0 | 1 0 1 1 | 1 0
Induk 2 : 1 1 | 0 1 0 0 | 0 0 1 1 | 0 1
Kromosom baru yang terbetuk:
Anak 1 : 0 1 | 0 1 0 0 | 1 0 1 1 | 0 1
Anak 2 : 1 1 | 1 1 0 0 | 0 0 1 1 | 1 0
c. Crossover seragam
Kromosom seragam menghasilkan kromosom keturunan dengan menyalin
bit-bit secara acak dari kedua orang tuanya.
Misalkan ada 2 kromosom dengan panjang 12
Induk 1 : 0 1 1 1 0 0 1 0 1 1 1 0
Induk 2 : 1 1 0 1 0 0 0 0 1 1 0 1
Kromosom baru yang terbentuk:
Anak 1 : 0 1 0 1 0 0 0 0 1 1 1 0
Anak 2 : 1 1 1 1 0 0 1 0 1 1 0 1
3. Mutasi
Mutasi merupakan proses mengubah nilai dari satu atau beberapa gen dalam suatu
kromosom. Beberapa cara operasi mutasi diterapkan dalam algoritma genetika
menurut jenis pengkodean terhadap phenotype, antara lain:
a. Mutasi dalam pengkodean biner
Mutasi pada pengkodean biner merupakan operasi yang sangat sederhana.
Proses yang dilakukan adalah menginversi nilai bit pada posisi tertentu
yang dipilih secara acak (atau dengan menggunakan skema tertentu ) pada
kromosom, yang disebut inversi bit.
Kromosom sebelum mutasi : 1 0 0 1 0 1 1 1
Kromosom sesudah mutasi : 1 0 0 1 0 0 1 1
b. Mutasi dalam pengkodean permutasi
Proses mutasi yang dilakukan dalam pengkodean biner dengan mengubah
langsung bit-bit pada pada kromosom tidak dapat dilakukan pada
pengkodean permutasi karena konsistensi urutan permutasi harus
diperhatikan. Salah satu cara yang dapat dilakukan adalah dengan memilih
dua posisi (locus) dari kromosom dan kemudian nilainya saling
dipertukarkan.
Contoh mutasi dalam pengkodean permutasi
Kromosom sebelum mutasi : 1 2 3 4 6 5 8 7 9
Kromosom sesudah mutasi : 1 2 7 4 6 5 8 3 9
c. Mutasi dalam pengkodean nilai
Proses mutasi dalam pengkodean nilai dapat dilakukan dengan berbagai
cara, salah satunya yaitu dengan memilih sembarang posisi gen pada
kromosom, nilai yang ada tersebut kemudian ditambahkan atau
dikurangkan dengan suatu nilai kecil tertentu yang diambil secara acak.
Contoh mutasi dalam pengkodean nilai riil dengan nilai yang ditambahkan
atau dikurangkan adalah 0,1
Kromosom sebelum mutasi : 1,43 1,09 4,51 9,11 6,94
2.5 TEKNIK YANG DIGUNAKAN SEBELUMNYA
Terdapat beberapa teknik yang telah dikembangkan oleh para peneliti sebelumnya
untuk menyelesaikan permasalahan dalam sistem pencarian kembali dokumen.
Beberapa teknik yang telah dipergunakan sebelumnya adalah:
• Pendekatan jaringan syaraf tiruan untuk temu kembali informasi. • Pendekatan operator boolean untuk temu kembali informasi • Pendekatan bibliometrik untuk temu kembali informasi.
2.5.1 Pendekatan Jaringan Syaraf Tiruan Untuk Temu-Kembali Informasi
Jaringan syaraf tiruan terinspirasi dari sistem pengorganisasian otak manusia yang
terdiri dari beratus milyar sel syaraf dengan tipe yang bervariasi.
Sihombing [27,28] menerapkan jaringan syaraf tiruan untuk temu kembali
informasi dengan menggunakan beberapa ukuran kemiripan. Dalam terminologi
dan konsep jaringan syaraf tiruan untuk sistem temu kembali informasi, dibangun
node-node (neuron-neuron) yang merepresentasikan objek-objek dan links yang merepresentasikan hubungan objek-objek tersebut. Pendekatan sifat struktur JST
dibangun didasarkan pada pengertian sebagai berikut :
a. Objek: adalah sesuatu yang memiliki identitas atau entity konseptual untuk sistem temu kembali informasi.
b. Connection: menyatakan hubungan diantara dua objek, dimana keterhubungan ini dapat memiliki bobot, yang menentukan kekuatan
(kemiripan) hubungan diantara objek tersebut .
Pendekatan pada pengertian dasar struktur ini dapat dilihat pada gambar 2.3
Gambar 2.3 (a) kueri dan istilah aktivasi.
(b) dokumen memuat istilah teraktivasi dan kumpulan dokumen
Crestani and Rijsbergen [5]
Pada gambar 2.3 ditunjukkan bahwa dalam jaringan syaraf tiruan suatu
kueri ( ) bisa mengaktivasi beberapa istilah lain menjadi istilah teraktivasi ( ),
dan kueri yang berbeda dapat mengaktivasi istilah yang sama. Pada beberapa
dokumen yang memuat istilah teraktivasi, dapat memiliki persamaan dengan
suatu dokumen dari kumpulan dokumen.
Pendekatan jaringan syaraf tiruan dapat memformulasikan suatu istilah (j)
yang diwakili oleh suatu simpul (node atau neuron), dan hubungan antar istilah
diantara istilah (j) dengan istilah lain (k) dalam kumpulan dokumen yang dihitung
dengan menggunakan ukuran kemiripan (similarity measure).
Hasil dari penerapan jaringan syaraf tiruan pada sistem temu kembali
informasi adalah jaringan syaraf tiruan mampu mengakomodir istilah lain yang
tidak disajikan kueri dan dapat mengatasi kekakuan sistem kueri Boolean.
Dokumen yang diperoleh adalah dokumen yang sebagian relevan yang memuat
kueri dan yang memuat istilah teraktivasi yang terurut berdasarkan bobotnya.
Jumlah istilah teraktivasi berbanding lurus dengan dokumen yang memuat
pada peringkat atas, juga tetap berada pada range tersebut pada pengukuran
kemiripan lainnya, walaupun ada perubahan bobot.
2.5.2 Pendekatan Operator Boolean Untuk Kembali Informasi
Mustangimah [21] melakukan penelitian menggunakan operator boolean untuk
mengetahui efektivitas pencarian kembali dokumen, dengan cara mengajukan
pertanyaan-pertanyaan. Metode yang paling banyak digunakan dalam mengajukan
pertanyaan adalah logika aljabar Boole yaitu dengan melakukan operasi dengan
operator AND, OR, dan NOT. Kesederhanaan pengolahan data dan
kemampuannya dalam membangun konsep dari beberapa istilah merupakan
alasan dalam penggunaan logika Boole.
Salton [26] menjelaskan operasi dengan operator AND antara dua
himpunan atau lebih menghasilkan hasil logis (logical product), irisan
(intersection) atau disjungsi (disjunction) antara himpunan-himpunan
sebelumnya. Operasi dengan operator OR antara dua himpunan atau lebih
menghasilkan jumlah logis (logical sum), gabungan (union), atau konjungsi
(conjunction) antara himpunan-himpunan sebelumnya, sedangkan operasi dengan
operator NOT antara dua himpunan menghasilkan perbedaan logis (logical
difference) antara kedua himpunan sebelumnya.
Dalam proses temu-kembali informasi operator Boole digunakan untuk
membantu pembentukan konsep pencarian dari beberapa istilah pencarian. Namun
menunjukkan bahwa penggunaan operator AND, OR, dan NOT bervariasi antara
pemakai yang satu dengan yang lainnya. Ditemukan bahwa operator AND hampir
hanya sekali digunakan oleh pemakai, OR sangat banyak digunakan, dan NOT
hampir tidak pernah digunakan.
Mustangimah [21] menggunakan operator boolean untuk menggabungkan
pembentukan konsep pencarian, penggabungan istilah-istilah yang
menggambarkan konsep yang sama dilakukan dengan operator OR. Sedang
penggabungan istilah-istilah yang menggambarkan konsep yang berbeda
dilakukan dengan operator AND dan NOT.
Proses pencarian harus dilakukan dengan strategi tertentu yang
disesuaikan dengan fasilitas yang disediakan oleh sistem. Strategi pencarian
merupakan himpunan keputusan atau tindakan yang dilakukan dalam proses
pencarian, dengan tujuan untuk menemukan sejumlah cantuman yang relevan,
menghindari ditemukannya cantuman yang tidak relevan, menghindari
ditemukannya jumlah cantuman yang terlalu banyak, dan menghindari
ditemukannya jumlah cantuman yang terlalu sedikit atau tidak ditemukan
cantuman sama sekali. Dalam pencarian berbasis logika boolean, strategi
pencarian dibangun berdasarkan istilah pencarian yang telah dipilih yang
dikoordinasikan dengan AND, OR, atau NOT.
Pendekatan ini telah dikembangkan oleh peneliti lainnya seperti Hasibuan
dan Andri [11] dengan melakukan penerapan berbagai teknik sistem
temu-kembali informasi berbasis hiperteks seperti teknik Boolean biasa, teknik Boolean
berperingkat dan teknik Extended Boolean.
2.5.3. Pendekatan Bibiometrik Untuk Temu Kembali Informasi
Bibliometrika merupakan studi mengenai produksi dan penyebaran informasi
yang secara operasional dikaji melalui produksi dan penyebaran media yang
merekam informasi untuk disimpan dan disebarluaskan. Bibliometrik merupakan
bagian dari informatika yang mengkaji aspek kuantitatif informasi terekam
(recorded) dengan tujuan untuk mencari bentuk-bentuk keteraturan dalam proses
Metode bibliometrik banyak digunakan untuk mengukur kesamaan atau
hubungan antara pasangan dokumen. Menurut Ikpaahindi [14] metode
bibliometrik dapat dilakukan dengan cara perhitungan sitiran langsung (direct
citation counting), pasangan bibliografi (bibliograhic coupling), dan analisis ko-sitiran (co-citation analysis). Metode tersebut didasarkan pada hubungan antara
dokumen yang disisir dengan dokumen yang menyitir.
Hubungan antara dokumen yang disisr dengan dokumen yang menyitir
dapat ditelusuri melalui motivasi, tujuan, dan fungsi sitiran dalam berbagai jenis
ilmu. Liu [20] mengemukakan bahwa fungsi sitiran dalam bidang humaniora
dapat diklasifikasikan sebagai dokumentasi sumber primer dan sekunder untuk
baik di dalam maupun di luar topik dokumen yang menyitir, untuk menyatakan
kesetujuan atau ketidaksetujuan pengarang yang menyitir terhadap dokumen yang
disitir, dan untuk menyediakan informasi bibliografi.
Liu [20] mengidentifikasi indikator hubungan antara dokumen yang disitir
dengan dokumen yang menyitir yaitu sebagai penjelasan, memberikan informasi
umum, hubungan historis, hubungan “saudara kandung”, hubungan oposisional,
hubungan koroboratif, memberikan informasi spesifik, dokumentasi, hubungann
metodologis, dan hubungan korektif.
Menurut Liu [20] bahwa antara dokumen yang disitir dan dokumen yang
menyitir terdapat hubungan subjek pada tingkat tertentu. Berdasarkan hubungan
tersebut maka dapat dicari hubungan antara 2 (dua) dokumen yang menyitir
dokumen yang sama. Menurut Grosman and Ophir [10] bahwa hubungan dua
dokumen berdasarkan bibliografi yang digunakan bersama oleh kedua dokumen
dengan menggunakan konsep pasangan bibliografi (bibliographic coupling). Bila
2 dokumen menyitir paling sedikit satu dokumen yang sama, maka kedua
dokumen tersebut berpasangan secara bibliografi dengan pengindeksan subjek
diperoleh kesimpulan bahwa ada hubungan yang nyata antara pasangan
Banyaknya dokumen yang disitir secara bersama oleh pasangan dokumen
disebut sebagai frekuensi pasangan atau kekuatan pasangan (coupling strength).
Beberapa penelitian menunjukkan adanya hubungan antara kekuatan pasangan
dengan keterhubungan subjek.
Adanya hubungan antara pasangan pasangan bibliografi dengan
keterhubungan subjek dimanfaatkan untuk memperbaiki efektivitas temu kembali
informasi. Ditemukan bahwa efektivitas temu kembali informasi meningkat
dengan menggunakan pencarian berdasarkan kata kunci atau indeks dan pencarian
berdasarkan sitasi.
Dari uraian sebelumnya mengenai beberapa pendekatan dalam sistem
temu kembali informasi, maka dapat disimpulkan seperti tabel 2.2 di bawah ini:
Tabel 2.2 Perbandingan Teknik dalam Sistem Temu Kembali Informasi
Pendekatan Sistem Temu Kembali Informasi
Jaringan Syaraf Tiruan Operator Boolean Bibliometrik
•Sistem
memformulasikan
suatu istilah (j) yang
diwakili oleh suatu
simpul, dan hubungan
antar istilah
direpresentasikan oleh
neural network links.
• Sistem diformulasikan dengan mengajukan pertanyaan- pertanyaan, baik pertanyaan sederhana maupun pertanyaan kompleks.
• Sistem melakukan
perhitungan sitiran
langsung, pasangan
bibliografi, dan analisis
ko-sitiran, dan
didasarkan pada
hubungan antara
dokumen yang disitir
dengan dokumen yang
menyitir.
•Sistem yang diimplementasikan
mampu mengaktivasi
istilah-istilah lainnya
yang tidak dijadikan
kueri oleh pemakai.
• Hasil dari sistem adalah dokumen
yang memuat kueri
dan dokumen yang
memuat istilah
teraktivasi, dan
memuat nilai
ketepatan lebih baik
dari operator bolean.
• Sistem
menggunakan logika
aljabar boolean
dengan operator
AND,OR dan NOT
yang mampu
membantu
pembentukan
konsep pencarian
dari beberapa istilah
pencarian
• Hasil dari sistem adalah dokumen
memuat kueri
dengan nilai
ketepatan di atas 50
%, baik dengan
pertanyaan sederhana maupun kompleks diimplementasikan melalui pasangan bibliografi yang memberikan indikasi
hubungan antara dua
dokumen, bukan dalam
bentuk keterhubungan
subjek.
• Hasil dari sistem adalah dokumen yang memiliki
hubungan pasangan
bibliografi, sehingga
memberikan kontribusi
yang lemah terhadap
pemasangan dokumen
karena tidak berdasarkan
subjek dokumen.
Menurut Grossman and Ophir [10], sistem temu kembali informasi
menggunakan fungsi heuristik untuk mendapatkan dokumen-dokumen yang
relevan dengan query pengguna. Kekäläinen [15] melakukan penelitian pencarian
Penulis mencoba melakukan penelitian pencarian kembali dokumen
dengan salah satu metode optimasi heuristik yaitu algoritma genetika dan
memanfaatkan binary untuk pengkodean kromosom, dengan tujuan mampu
memberikan hasil yang efektif dalam pencarian kembali dokumen selain
pendekatan-pendekatan sistem temu kembali dokumen yang diuraikan
sebelumnya.
Pada bab selanjutnya akan dijelaskan tentang metode penelitian dari
pencarian kembali dokumen menggunakan algoritma genetika dengan
BAB III
METODE PENELITIAN
Pada bab ketiga ini dibahas metode penelitian yang mencakup data yang
digunakan dan teknik penelitian serta perancangan sistem dalam penggunaan
faktor hsinchun chen dalam algoritma genetika untuk penentuan nilai kemiripan
dokumen.
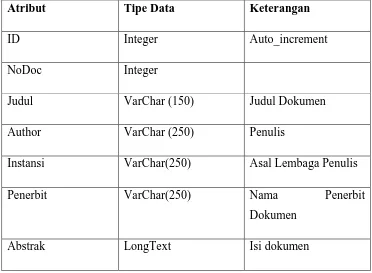
3.1 DATA PENELITIAN
Data penelitian dalam pencarian nilai kemiripan dokumen berbentuk teks koleksi
dokumen dan bersumber dari penelitian Sihombing [27]. Koleksi dokumen yang
digunakan adalah kumpulan dokumen abstrak penelitian dan karya ilmiah dalam
bidang sains dan teknologi nuklir yang dihasilkan oleh Badan Tenaga Atom
Nasional (BATAN), dan data penelitian yang digunakan merupakan data standard
penelitian di Universitas Indonesia. Naskah lengkap dokumen tersebut dimuat
dalam Majalah BATAN volume XIV tahun 1981 sampai dengan XXVII tahun
1995 dan Prosiding Pertemuan dan Presentasi Ilmiah Bahan Murni dan
Instrumentasi Nuklir tahun 1985, 1986, 1988, 1989, dan 1991. Pangkalan data ini
terdiri dari 600 dokumen yang terdiri dari Nomor dokumen (DOC), Judul (TIT).
Penelitian ini berfokus pada judul dari data dokumen, sehingga bagian dari
data yang diterapkan pada teknik pencarian kembali dokumen adalah judul dari
setiap dokumen.
3.2 KEYWORD (KATA KUNCI)
Menurut Trunojono[33], keyword adalah nama untuk term-term dalam word list
yang menginterpretasikan content (isi) dari item-item informasi. Keyword
biasanya disimpan dalam indeks pencarian, kata-kata umum dalam dokumen
(seperti suatu dan sebuah) dan konjungsi ( seperti dan, atau, dan tetapi) tidak
diperlukan sebagai kata kunci karena itu tidak efisien untuk melakukan pencarian
dokumen. Bahasa keyword adalah bahasa yang digunakan untuk menggambarkan
dokumen dan permintaan. Elemen dari keyword adalah istilah yang mungkin
berasal dari teks dokumen dan bersifat independen.
Masalah dalam pencarian keyword ada 2 yaitu :
1. Mungkin tidak meretrieve dokumen relevan yang menyertakan
synonymous terms (mempunyai pengertian yang sama). – “restaurant” vs. “café”
– “NDHU” vs. “National Dong Hwa University”
2. Mungkin meretrieve dokumen tak-relevan yang menyertakan ambiguous
terms.
– “bat” (baseball vs. mamalia)
– “Apple” (perusahaan vs. buah-buahan)
Penelitian ini berfokus pada keyword dokumen untuk penentuan kemiripan
dokumen, tetapi data penelitian keyword belum tersedia sehingga memerlukan
metode pencarian keyword. Metode pencarian keyword dokumen yang digunakan
adalah text preprocessing.
3.3 TEKNIK PENELITIAN
Teknik penelitian dalam sistem pencarian kembali dokumen adalah pemanfaatan
nilai kemiripan Hsinchun Chen dalam algoritma genetika , dengan tujuan untuk
menghasilkan dokumen yang relevan dengan dokumen kueri. Berikut adalah
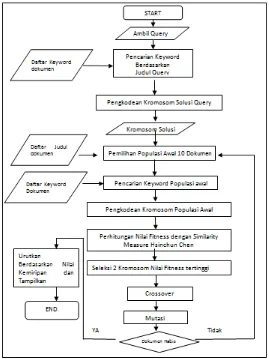
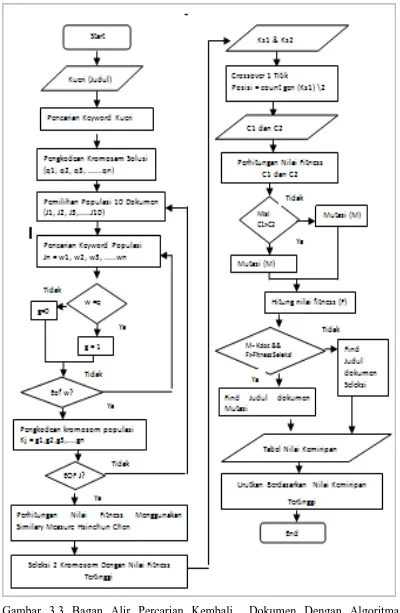
[image:50.595.112.381.359.718.2]diagram alir teknik penelitian pada gambar 3.1 :
Pada gambar 3.1 menunjukkan bahwa secara garis besar sistem pencarian
kembali dokumen terdiri dari 2 tahapan besar yaitu : text preprocessing dan
tahap mengukur kemiripan dokumen menggunakan ukuran kemiripan Hsinchun
Chen dan algoritma genetika.
3.3.1 Text Preprocessing
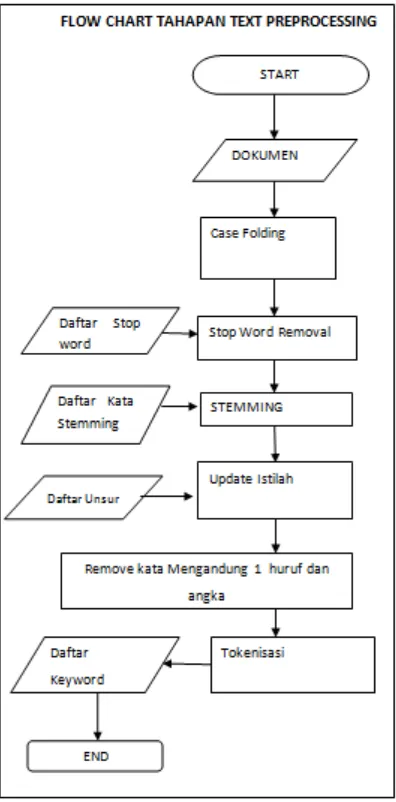
Pada tahapan text preprocessing, terdiri dari 6 proses yang dijalankan secara
offline, yaitu :
1. Menghilangkan tanda baca (case folding) dan mengubah judul setiap
dokumen menjadi huruf kecil.
Proses pertama dalam tahapan ini adalah menghilangkan tanda baca (case
folding), tanda baca yang akan dihilangkan dalam dokumen adalah
spasi. Selanjutnya akan melakukan proses lower yaitu mengubah seluruh
isi judul dokumen menjadi huruf kecil.
2. Menghilangkan stop word
Stop Word adalah kata yang sering muncul namun kata tersebut tidak relevan dengan sebuah artikel atau dokumen. Kata-kata tersebut
diantaranya kata sambung dan kata tanya. Dengan menghapus stop word,
hasil preprocessing dapat lebih baik karena proses perhitungan jumlah
kata tidak tecampur dengan jumlah dari stop word yang ada pada suatu
dokumen. Penyusunan daftar stop word ini dilakukan secara manual
dengan memperhatikan judul yang terdapat pada dokumen. Dalam
penelitian ini stop word yang digunakan sebanyak 144 kata. (data
terlampir pada lampiran H.)
3. Stemming
sebuah kata. Karena stemming menghilangkan imbuhan dari sebuah kata
dan tiap bahasa memiliki cara tersendiri dalam menambahkan imbuhan
didalamnya, sehingga jumlah ragam kata yang ada di dalam dokumen
dapat berkurang dan dapat mengoptimalkan text preprocessing. Proses
stemming ini bukan merupakan kajian utama dalam penelitian ini dan
dilakukan secara manual yaitu dengan mendaftarkan kata-kata berimbuhan
dan menggantinya dengan kata dasar dari kata berimbuhan tersebut.
Dalam penelitian ini kata berimbuhan yang digunakan sebanyak 353 kata.
(data terlampir pada lampiran G)
4. Update Istilah
Terdapat berbagai istilah kimia didalam data dokumen penelitian ini
karena data penelitian yang digunakan adalah dokumen dari BATAN dan
penulisan istilah kimia dalam dokumen tidak konsisten (ada judul
dokumen yang menggunakan simbol kimia dan ada yang menggunakan
nama kimia), maka memerlukan proses update istilah untuk mengatasi
masalah pada keyword yaitu term-term yang mempunyai pengertian yang
sama (synonymous terms).
Proses ini akan mendaftar istilah-istilah kimia ( unsur dan senyawa kimia),
sehingga apabila terdapat simbol-simbol kimia didalam dokumen akan
diganti menjadi nama kimia dari simbol yang ditemukan.
5. Remove kata yang mengandung 1 huruf dan angka
Proses ini akan menghapus kata-kata yang mengandung 1 huruf, karena
kata tersebut kurang efisien dijadikan sebagai keyword sebab
mengundung makna yang ambigu. Demikian halnya terhadap angka,
angka di dalam dokumen juga akan dihapus sebab mengandung makna
6. Tokenisasi
Tokenisasi merupakan proses terakhir pada tahapan text preprocessing dan
proses memecah dokumen menjadi kumpulan kecil, dengan mendapatkan
keyword-keyword dari setiap dokumen yang tersedia, keyword-keyword tersebut akan disimpan pada sebuah pangkalan data daftar keyword.
Keyword-keyword dokumen yang tersimpan pada daftar keyword akan
menjadi input dalam tahapan pencarian kembali dokumen selanjutnya
yaitu algoritma genetika.
Dari proses-proses tahapan text preprocessing yang telah dijelaskan sebelumnya,
[image:53.595.119.317.319.720.2]dapat disimpulkan dengan bagan alir (flowchart) pada gambar 3.2.
3.3.2 Ukuran Kemiripan Hsinchun Chen
Sihombing et al. (2005), melakukan penelitian menggunakan algoritma genetika
dan memanfaatkan ukuran kemiripan (similarity measure) Jaccard, untuk
pencarian kembali dokumen, dengan kesimpulan dari penelitian tersebut adalah
ukuran kemiripan Jaccard dapat memberikan hasil nilai kemiripan yang cukup
tinggi terhadap kueri.
Pada penelitian ini, sistem pencarian kembali dokumen yang dibangun
mencoba menerapkan ukuran kemiripan Hsinchun Chen dalam algoritma genetika
dengan harapan dapat menghasilkan nilai kemiripan dokumen yang optimal. Cara
implementasi dari ukuran kemiripan Hsinchun Chen dalam algoritma genetika
adalah rumus relevansi ukuran kemiripan Hsinchun Chen akan menjadi fungsi
fitness, dimana proses menghitung fungsi fitness merupakan salah satu tahapan
dari algoritma genetika. Keunggulan dari penerapan ini adalah nilai kemiripan
suatu dokumen terhadap kueri dapat diketahui pada tahapan perhitungan nilai
fitness. Ukuran kemiripan (similarity measure) dengan Hsinchun Chen yang
diterapkan dalam fungsi fitness seperti berikut ini :
...merujuk ke rumus (2.1)
Dari persamaan(1), menyatakan bahwa
di
jk bernilai 1 (satu) apabila dokumen ke-imemuat istilah j dan istilah k bersama-sama, dan bernilai 0 (nol) pada kasus
lainnya. Nilai
di
j bernilai 1 apabila dokumen ke-i memuat istilah j, dan 0 apabiladokumen ke-i tidak memuat istilah j.
3.3.3 Mengukur Kemiripan Dokumen Menggunakan Ukuran Kemiripan Hsinchun Chen Dalam Algoritma Genetika
Setelah menjalankan tahapan text preprocessing secara offline, akan diterapkan
adalah kueri dokumen dari user, dimana kueri dokumen tersebut berupa judul dari
dokumen. Pada tahapan ini terdiri dari proses sebagai berikut :
1. Pengkodean kromosom solusi
Pengkodean kromosom yang digunakan dalam penelitian ini adalah
pengkodean biner, gen yang digunakan menggunakan bit (0 dan 1). Pada
saat menerima input suatu kueri, akan dilakukan pencarian keyword
terhadap dokumen kueri. Setiap keyword yang didapatkan akan
diidentifikasikan dengan bit untuk inisial populasi.
2. Membangkitkan populasi awal
Pada proses populasi awal akan dipilih 10 dokumen dari database secara
acak dengan pertimbangan kinerja lebih efektif dibandingkan pemilihan
jumlah dokumen yang lebih kecil dari 10, dengan alasan jumlah
pengulangan generasi untuk pembangkitan populasi awal menjadi semakin
banyak. Sementara terdapat banyak jumlah dokumen dalam database yang
akan menjadi populasi awal untuk generasi selanjutnya.
Kemudian sistem akan mendapatkan keyword-keyword
masing-masing dokumen yang dipilh pada populasi awal. Keyword dari dokumen
kueri akan dibandingkan dengan keyword pada dokumen populasi awal
yang terpilih sebelumnya.
Setiap bit merepresentasikan secara unik untuk proses pencarian
dengan algoritma genetika. Ketika suatu keyword pada dokumen populasi
awal terdapat pada keyword dokumen query maka bit akan
direpresentasikan menjadi 1. Ketika keyword tersebut tidak terdapat maka
bit akan direpresentasikan menjadi 0, sehingga output dari proses ini
3. Menghitung nilai fitness dengan Hsinchun Chen
Proses ini merupakan implementasi ukuran kemiripan Hsinchun Chen
sebagai rumus relevansi perhitungan nilai fitness. Penerapan rumus nilai
kemiripan dokumen Hsinchun Chen dalam fungsi fitness sebagai berikut:
• dij : gen dari kromosom solusi yang direpresentasikan dengan
nilai 1
• ∑ dij : total perjumlahan gen pada kromosom solusi yang
bernilai 1.
• dijk : gen dari kromosom populasi yang bernilai 1 pada
pengkodean kromosom populasi
• ∑ dijk : total penjumlahan nilai 1 pada gen dari kromosom
populasi.
Sebagai contohnya dapat diilustarikan sebagai berikut Kromosom Solusi : 111111 ∑ dij = 6
Kromosom Populasi : 000101 ∑ dijk = 2
Sehingga dari ilustarsi diatas, nilai fitness hasil penerapan rumus Hsinchun
Chen adalah 0,25 (∑ dijk / ∑ dij artinya 2/6)
4. Seleksi
Dalam tahap seleksi ini akan memilih 2 kromosom dari populasi awal
untuk setiap generasi dengan nilai fitness paling besar. Nilai kromosom
yang lebih kecil akan diabaikan untuk proses pencarian kemiripan
dokumen.
5. Crossover
Metode crossover yang digunakan adalah crossover satu titik. Kromosom
dengan nilai fitness tertinggi hasil dari tahapan seleksi yang akan
total gen pada kromosom dengan pembulatan keatas, seperti pada contoh
dibawah ini :
Sebelum Crossover :
1011010100
0010010010 Posisi : 9 /2 = 5
Sesudah Crossover :
1011010010
0010010100
Kemudian akan dilakukan perhitungan nilai fitness, kromosom nilai
fitness terbesar yang akan mengalami tahapan mutasi.
6. Mutasi
Metode mutasi yang digunakan adalah mutasi pengkodean biner, dimana
kromosom yang akan dimutasi adalah kromosom dengan nilai fitness
tertinggi dari tahapan crossover. Posisi yang dipilih untuk mutasi adalah
median dari total gen pada kromosom dengan pembulatan keatas, seperti
pada contoh yang diuraikan di bawah ini :
Sebelum Mutasi :1011010010 <