3.1 Proses Penelitian
Dalam melakukan penelitian diperlukan suatu cara atau metode untuk menjadikan proses penelitian tersebut lebih terstruktur agar lebih mudah dipahami. Oleh sebab itu pada bab ini akan dibahas bagaimana tahapan-tahapan pada penelitian, teknik pengumpulan data, tahapan preprocessing, tahapan pembentukan kromosom dokumen, tahapan proses clustering dan tahapan proses optimasi dengan melibatkan algoritma genetika untuk menentukan pusat cluster awal k-means clustering yang menjadi pokok permasalahan pada penelitian ini.
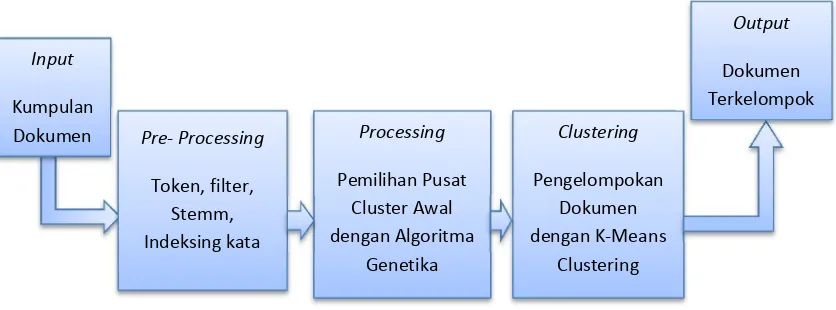
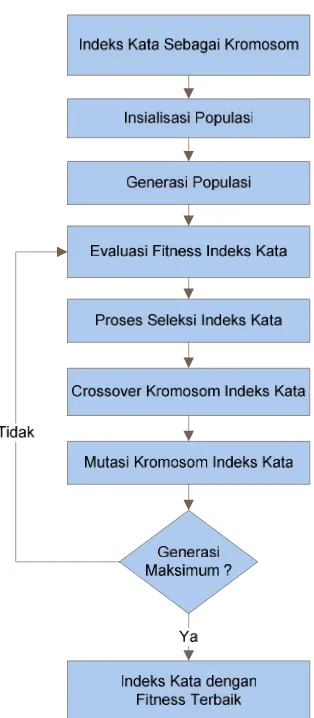
Pengelompokan dokumen teks pada penelitian ini dilakukan untuk menganalisis bagaimana suatu algoritma pengelompokan yaitu k-means clustering pada penentuan pusat cluster awalnya akan dioptimasi menggunakan algoritma genetika. Pada proses optimasi dengan algoritma genetika maka setiap dokumen akan direpresentasikan sebagai bentuk kromosom. Bentuk kromosom selanjutnya akan dikenai operator genetika yaitu selection, crossover dan mutation. Tahapan-tahapan proses yang dilakukan untuk menggambarkan proses pengelompokan dokumen tersebut dimulai dengan memasukkan kumpulan dokumen,pre-processing, clustering dan output hasil pengelompokan. Sebagaimana dapat dilihat pada gambar 3.1 berikut ini.
3.2 Tahapan Penelitian
Dalam penelitian ini dilakukan beberapa tahapan sebagai berikut : 1. Studi Literatur dan Bimbingan
Pada tahap ini dilakukan pengumpulan berbagai penelitian sebelumnya yang diambil dari jurnal, pustaka, prosiding dan sumber lain yang relevan. Dengan permasalahan mengenai algoritma k-means dan algoritma genetika dalam hal kaitannya dengan tujuan permasalahan penelitian ini. Kemudian mempelajarinya dan juga melakukan konsultasi dengan dosen pembimbing.
2. Pengumpulan Data
Data yang dikumpulkan pada penelitian ini bersumber dari beberapa media berita online. Kemudian menyimpannya ke dalam dokumen teks masing-masing berita tersebut untuk dilakukan pengujian pengelompokan.
3. Preproses Data
Pada tahap ini data berupa dokumen sebelum diproses dengan algoritma yang digunakan penelitian ini maka dilakukan preproses terlebih dahulu yaitu melakukan text mining pada dokumen sehingga menghasilkan ekstraksi pola dokumen yang dibutuhkan pada proses algoritma selanjutnya.
4. Penerapan Model Algoritma
Setelah dilakukan preproses maka tahapan selanjutnya yaitu menerapkan pola-pola dari dokumen tersebut pada algoritma genetika terlebih dahulu untuk mengoptimasi pusat cluster awal dari kumpulan dokumen dan selanjutnya mengelompokkannya dengan menggunakan algoritma k-means clustering berdasarkan pusat cluster awal yang telah dioptimasi sebelumnya.
5. Analisis Model Algoritma
6. Pengujian
Pengujian dilakukan menggunakan aplikasi yang dibangun dengan bahasa pemrograman visual c# berbasis net framework. Data masukan yang diproses untuk menguji algoritma pada penelitian ini berupa kumpulan dokumen teks. Kemudian data keluaran yang dihasilkan yaitu pengelompokan dokumen.
7. Hasil dan Kesimpulan
Mulai dari tahap studi literatur dan bimbingan sampai pada tahapan pengujian. semua hal yang berkaitan dengan penelitian didokumentasikan menjadi sebuah laporan berupa hasil penelitian, mulai dari teori pendukung, permbuatan aplikasi, pengujian dan hasil pengujian serta saran yang dapat dilakukan pada penelitian selanjutnya.
3.3 Jenis dan Sumber Data
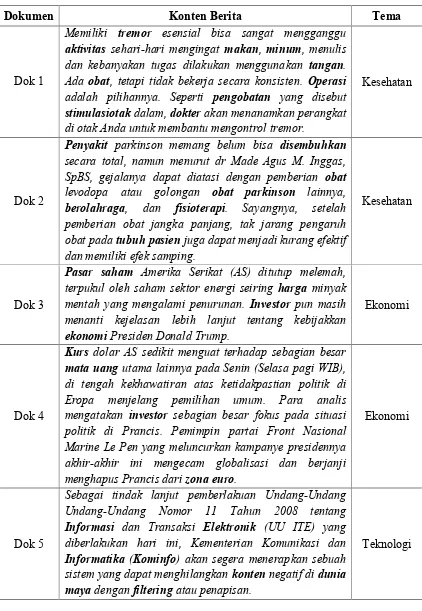
Jenis data yang digunakan pada penelitian ini adalah konten berita yang bersumber dari beberapa mediaonline dengan berbagai tema berita. Berikut merupakan rincian dari sumber data yang diambil dari penelitian ini.
Tabel 3.1 Tabel Sumber Berita Online
No. Konten Berita Sumber Berita
1
Memiliki tremor esensial bisa sangat mengganggu aktivitas sehari-hari mengingat makan, minum, menulis dan kebanyakan tugas dilakukan menggunakan tangan. Ada obat, tetapi tidak bekerja secara konsisten. Operasi adalah pilihannya. Seperti pengobatan yang disebut stimulasiotak dalam, dokter akan menanamkan perangkat di otak Anda untuk membantu mengontrol tremor.
http://health.liputan6.com/
2
Penyakit parkinson memang belum bisa disembuhkan secara total, namun menurut dr Made Agus M. Inggas, SpBS, gejalanya dapat
diatasi dengan pemberian obat levodopa atau golongan obat parkinson lainnya, berolahraga, dan fisioterapi. Sayangnya, setelah pemberian obat jangka panjang, tak jarang pengaruh obat pada tubuh pasien juga dapat menjadi kurang efektif dan memiliki efek samping.
3
Pasarsaham Amerika Serikat (AS) ditutup melemah, terpukul oleh saham sektor energi seiring harga minyak mentah yang mengalami penurunan. Investor pun masih menanti kejelasan lebih lanjut tentang kebijakkan ekonomi Presiden Donald Trump.
http://economy.okezone.com/
4
Kurs dolar AS sedikit menguat terhadap sebagian besar mata uang utama lainnya pada Senin (Selasa pagi WIB), di tengah kekhawatiran atas ketidakpastian politik di Eropa menjelang pemilihan umum. Para analis mengatakan investor sebagian besar fokus pada situasi politik di Prancis. Pemimpin partai Front Nasional Marine Le Pen yang meluncurkan kampanye presidennya akhir-akhir ini mengecam globalisasi dan berjanji menghapus Prancis dari zona euro.
http://economy.okezone.com/
5
Sebagai tindak lanjut pemberlakuan Undang-Undang Undang-Undang-Undang-Undang Nomor 11 Tahun 2008 tentang Informasi dan Transaksi Elektronik (UU ITE) yang diberlakukan hari ini, Kementerian Komunikasi dan Informatika (Kominfo) akan segera menerapkan sebuah sistem yang dapat menghilangkan konten negatif di dunia maya dengan filtering atau penapisan.
http://techno.okezone.com/
6
Media sosial masih menjadi alat paling efektif untuk menyebarkan hoax. Hal tersebut diakibatkan oleh rendahnya literasi informasi dan media, terlebih media sosial.Berdasarkan
Informatika (Kominfo) himpun, Google dan YouTube juga turut mendapatkan laporan sebanyak 1.204 sepanjang 2016 hingga 2017.
7
Regulasi yang mengatur pemain Over The Top (OTT) dipastikan rilis pada tahun ini. Menteri Komunikasi dan Informatika (Menkominfo) Rudiantara memastikan rilisnya peraturan menteri terkait bisnis OTT pada tahun ini. Rudiantara mengatakan, ada tiga aspek yang perlu diperhatikan. Aspek tersebut antara lain customer service, consumer data protection dan level playing field
http://techno.okezone.com/
3.4 Penentuan Tema Dokumen Berita
Penentuan tema dokumen berita dilakukan berdasarkan sumber berita dan kata yang sering muncul pada tema dokumen tersebut. Sehingga user secara manual dapat menentukan tema yang layak pada dokumen tersebut. Sebagai contoh berikut merupakan cara untuk menentukan tema dokumen berita :
Memilikitremoresensial bisa sangat mengganggu aktivitas sehari-hari mengingat makan, minum, menulis dan kebanyakan tugas dilakukan menggunakantangan. Ada obat, tetapi tidak bekerja secara konsisten.
Operasi adalah pilihannya. Seperti pengobatan yang disebut
stimulasiotak dalam, dokter akan menanamkan perangkat di otak
Anda untuk membantu mengontroltremor.
Pada contoh konten berita diatas berdasarkan kata-kata yang bercetak tebal dapat disimpulkan secara manual oleh user bahwa konten berita tersebut termasuk sebagai konten berita yang bertema kesehatan.
Tabel 3.2 Tabel Daftar Konten Berita
Dokumen Konten Berita Tema
Dok 1
Memiliki tremor esensial bisa sangat mengganggu
aktivitas sehari-hari mengingat makan, minum, menulis dan kebanyakan tugas dilakukan menggunakan tangan. Ada obat, tetapi tidak bekerja secara konsisten. Operasi
adalah pilihannya. Seperti pengobatan yang disebut
stimulasiotakdalam,dokterakan menanamkan perangkat di otak Anda untuk membantu mengontrol tremor.
Kesehatan
Dok 2
Penyakit parkinson memang belum bisa disembuhkan
secara total, namun menurut dr Made Agus M. Inggas, SpBS, gejalanya dapat diatasi dengan pemberian obat
levodopa atau golongan obat parkinson lainnya,
berolahraga, dan fisioterapi. Sayangnya, setelah pemberian obat jangka panjang, tak jarang pengaruh obat padatubuh pasienjuga dapat menjadi kurang efektif dan memiliki efek samping.
Kesehatan
Dok 3
Pasar saham Amerika Serikat (AS) ditutup melemah, terpukul oleh saham sektor energi seiring harga minyak mentah yang mengalami penurunan. Investor pun masih menanti kejelasan lebih lanjut tentang kebijakkan
ekonomiPresiden Donald Trump.
Ekonomi
Dok 4
Kurs dolar AS sedikit menguat terhadap sebagian besar
mata uangutama lainnya pada Senin (Selasa pagi WIB), di tengah kekhawatiran atas ketidakpastian politik di Eropa menjelang pemilihan umum. Para analis mengatakan investor sebagian besar fokus pada situasi politik di Prancis. Pemimpin partai Front Nasional Marine Le Pen yang meluncurkan kampanye presidennya akhir-akhir ini mengecam globalisasi dan berjanji menghapus Prancis darizona euro.
Ekonomi
Dok 5
Sebagai tindak lanjut pemberlakuan Undang-Undang Undang-Undang Nomor 11 Tahun 2008 tentang
Informasi dan Transaksi Elektronik (UU ITE) yang diberlakukan hari ini, Kementerian Komunikasi dan
Informatika (Kominfo) akan segera menerapkan sebuah sistem yang dapat menghilangkankontennegatif didunia
Dokumen Konten Berita Tema
Dok 6
Media sosial masih menjadi alat paling efektif untuk menyebarkan hoax. Hal tersebut diakibatkan oleh rendahnya literasi informasi dan media, terlebih media sosial.Berdasarkan data yang Kementerian Komunikasi dan Informatika (Kominfo) himpun, Google dan YouTube juga turut mendapatkan laporan sebanyak 1.204 sepanjang 2016 hingga 2017.
Teknologi
Dok 7
Regulasi yang mengatur pemain Over The Top (OTT) dipastikan rilis pada tahun ini. Menteri Komunikasi dan
Informatika (Menkominfo) Rudiantara memastikan rilisnya peraturan menteri terkait bisnis OTT pada tahun ini. Rudiantara mengatakan, ada tiga aspek yang perlu diperhatikan. Aspek tersebut antara lain customer service, consumerdata protectiondan level playing field
Teknologi
3.5 Teknik Pengumpulan Data
Pengumpulan data dilakukan dengan menyimpan isi dari masing-masing konten berita yang dipilih sebelumnya ke dalam file teks yang berekstensi.txt. Kemudian file teks tersebut ditempatkan pada satu folder yang selanjutnya kumpulan file teks tersebut menjadi sumber kumpulan dokumen yang akan diproses untuk dikelompokkan.
3.6 PreprocessingDokumen
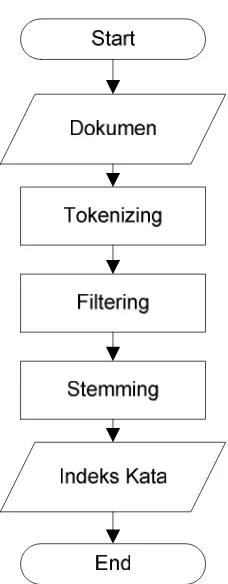
Gambar 3.2Flowchart PreProcessingDokumen
Dari Gambar 3.2 dimulai dengan memasukkan dokumen selanjutnya tokenizing yaitu menghilangkan karakter selain huruf pada teks dokumen, filtering yaitu mengambil kata-kata penting pada teks dokumen danstemming yaitu mengambil kata dasar dari teks dokumen. Kemudian mengindeksnya menjadi informasi yang berisi kata dan jumlah frekuensi.
3.8.1 Tokenizing
Pada tokenizing setiap kata pada masing-masing dokumen akan dihilangkan karakter selain huruf untuk memudahkan dalam proses pengindeksian kata-kata pada dokumen tersebut. Sebagai contoh berikut merupakan hasil tokenizing pada dokumen Dok1 :
Sebelum Tokenizing
secara konsisten. Operasi adalah pilihannya. Seperti pengobatan yang disebut stimulasi otak dalam, dokter akan menanamkan perangkat di otak Anda untuk membantu mengontrol tremor.
Sesudah Tokenizing
Memiliki tremor esensial bisa sangat mengganggu aktvitas sehari hari mengingat makan minum menulis dan kebanyakan tugas dilakukan menggunakan tangan Ada obat tetapi tidak bekerja secara konsisten Operasi adalah pilihannya Seperti pengobatan yang disebut stimulasi otak dalam dokter akan menanamkan perangkat di otak Anda untuk membantu mengontrol tremor
Pada hasil tokenizing di atas dapat dilihat beberapa tanda baca seperti tanda koma, titik dan tanda sambung kata telah dihilangkan pada hasil tokenizing tersebut.
3.8.2 Filtering
Setelah melewati proses tokenizing maka selanjutnya dilakukan proses filtering untuk mengambil kata-kata penting dari hasil tokenizing pada sebelumnya. Pada filtering tersebut setiap kata akan dicek dengan tabel stoplist dan apabila kata tersebut terdapat pada tabel stoplist maka kata tersebut dihapus. Berikut merupakan contoh dari hasil filtering pada dokumen Dok1 :
Sebelum Filtering
Sesudah Filtering
memiliki tremor esensial mengganggu aktvitas sehari makan minum menulis kebanyakan tugas tangan obat konsisten operasi pilihannya pengobatan stimulasi otak dokter menanamkan perangkat otak membantu mengontrol tremor
Pada hasil filtering di atas dapat dilihat beberapa kata dihilangkan dikarenakan kata tersebut terdapat pada tabel stoplist yang digunakan. Seperti contoh di atas kata yang dihilangkan yaitu bisa, ada, akan, untuk, dilakukan, anda, tetapi, tidak, secara, sangat, dan, adalah, disebut, yang, dalam . Tujuan dihilangkan kata-kata tersebut adalah untuk menyeleksi kata-kata yang memiliki makna dan mewakili ciri khas suatu tema dokumen.
3.8.3 Stemming
Langkah terkahir pada preprocessing ialah melakukan stemming yaitu mengambil kata dasar dari setiap kata pada dokumen dari hasil filtering dan juga mengembalikan kata dasar dari kata tersebut. Berikut merupakan contoh hasil stemming pada dokumen Dok1 :
Sebelum Stemming
memiliki tremor esensial mengganggu aktvitas sehari makan minum menulis kebanyakan tugas tangan obat konsisten operasi pilihannya pengobatan stimulasi otak dokter menanamkan perangkat otak membantu mengontrol tremor
Sesudah Stemming
Pada hasil stemming di atas dapat dilihat setiap kata pada hasil filtering sebelumnya akan dicari kata dasarnya untuk menghindari duplikat kata yang memiliki arti kata dasar yang sama. Seperti contoh di atas kata memiliki menjadi bentuk dasarnya milik .
3.7 Pembentukan Kromosom Dokumen
Pembentukan kromosom merupakan langkah awal dari terwujudnya proses pada algoritma genetika. Hal tersebut dikarenakan kromosom sebagai representasi penyelesaian dari masalah. Pada penelitian ini kromosom akan dibentuk dengan menggunakan kode biner yang merepresentasikan solusi dari pusatcluster awal pada k-means clustering.
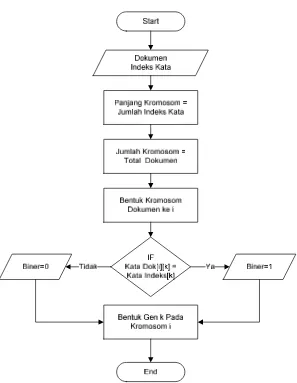
Gambar 3.3 Proses Pembentukan Kromosom Dokumen
Pada gambar 3.3 dapat dilihat panjang kromosom ditentukan dari jumlah indeks kata dan untuk jumlah kromosom berdasarkan banyaknya total dokumen. Kemudian untuk mengisi nilai biner dari masing-masing gen pada kromosom tersebut ditentukan dari ada tidaknya kata pada dokumen dengan indeks kata.
3.8 Optimasi Pusat Cluster Awal dengan Algoritma Genetika
Dengan algoritma genetika proses tersebut dapat digambarkan seperti pada Gambar 3.4 berikut ini.
Gambar 3.4 Proses Optimasi PusatClusterAwal
Dalam melakukan pemilihan k dokumen dengan algoritma genetika tersebut setiap dokumen yang berkompetisi akan melalui beberapa tahapan pada algoritma genetika. Tahapan-tahapannya berdasarkan gambar 3.4 adalah sebagai berikut :
1. Tahapan pertama yaitu mendefinisikan indeks kata keseluruhan pada dokumen dan membentuknya menjadi kromosom sebagai solusi dari dokumen yang akan terpilih.
3. Tahapan ketiga yaitu mengevaluasi nilai fitness pada setiap kromosom yang ada dalam populasi. Pada tahapan ini juga akan disimpan data populasi yang memiliki kromosom denganfitnessterbaik untuk dibawa pada proses selanjutnya.
4. Tahapan keempat yaitu membuat populasi baru. Membuat populasi baru dilakukan dengan mengulang proses seleksi, mutasi dan crossover sampai generasi maksimum tercapai. Pada akhir proses akan ditampilkan hasil k dokumen dari populasi dengan kromosomfitnessterbaik.
3.9 Pengelompokan Dokumen dengan K-Means
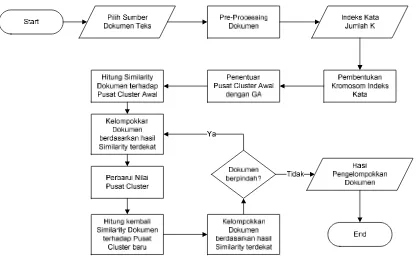
Algoritma k-means clustering merupakan algoritma pengelompokan iteratif yang mengelompokan data berdasarkan kedekatan jarak. Pada proses pengelompokan dokumen dengan algoritma k-means clustering akan melalui beberapa tahapan-tahapan untuk mencapai hasil pengelompokan yang maksimal. Sejumlah dokumen yang akan dikelompokan sebelumnya telah melewati rangkaian proses pada algoritma genetika untuk menentukan sejumlah k dokumen yang akan dijadikan sebagai pusat clusterawal pada k-means tersebut.
Gambar 3.5 Proses Pengelompokan Dokumen dengan K-Means
Pada Gambar 3.5 diatas dapat dilihat rangkaian proses dari pengelompokan dokumen dengan algoritma genetika. Tahap pertama yaitu memilih sumber dokumen yang dikelompokkan kemudian melakukanpreprocessingdokumen. Setelah didapat indeks kata dan menentukan jumlah k kelompok maka selanjutnya membentuk kromosom berdasarkan indeks kata dan melakukan proses algoritma genetika untuk mendapatkan pusat cluster awal. Kemudian proses selanjutnya yaitu melakukan langkah iteratif dengan mengelompokkan dokumen berdasarkan kemiripan dengan pusat cluster yang akan dibentuk berdasarkan hasil dari proses sebelumnya. Hal tersebut terus dilakukan sampai posisi dokumen tidak berpindah lagi yang artinya proses pengelompokan telah selesai dilakukan.
3.10 Tahapan Iterasi Pengelompokan K-Means
mendapatkan posisi cluster akan digabungkan berdasarkan posisi clusternya dan menjadikannya sebagai pusat cluster kembali.
Berikut merupakan tahapan-tahapan iterasi algoritma pengelompokan K-Means dalam pengelompokan dokumen :
1. Menentukan jumlah K cluster
Jumlah K cluster ditentukan berdasarkan pengetahuan user tentang jumlah kelompok dokumen yang berbeda pada sekumpulan dokumen tersebut.
2. Penentuan pusat cluster awal
Pusat cluster awal dapat ditentukan secara random ataupun dengan algoritma genetika yang pada penelitian ini akan dilihat perbedaannya. Jumlah pusat cluster awal disesuaikan jumlah K cluster yang sebelumnya sudah ditentukan terlebih dahulu.
3. Hitung kemiripan dokumen terhadap pusat cluster awal
Pada tahap ini masing-masing dokumen pada sekumpulan dokumen akan dinilai kemiripannya dengan pusat cluster awal. Metode yang digunakan untuk menghitung keimiripan dokumen tersebut ialah cosine similarity seperti yang sudah dijelaskan pada sub bab sebelumnya.
4. Penentuan kelompok dokumen
Menentukan kelompok dokumen berdasarkan nilai maksimum kemiripan yang diperoleh dari perhitungan ke masing-masing pusat cluster awal.
5. Menentukan pusat cluster baru
Setelah pada tahapan sebelumnya diperoleh hasil pengelompokan sementara dari nilai maksimum kemiripan, maka pada tahap ini pusat cluster baru yang terbentuk adalah kumpulan dari masing-masing cluster yang terbentuk.
6. Hitung kemiripan dokumen terhadap pusat cluster baru
7. Cek perubahan posisi cluster
4.1 Pembahasan
Pada bab ini akan membahas bagaimana melakukan pengujian dan hasil dari
pengelompokan dokumen tersebut. Pengelompokan dokumen yang akan diuji berupa
konten berita yang bertujuan untuk mengelompokkan dokumen yang memiliki konten
berita yang berbeda namun berada pada satu tempat yang sama, sehingga dengan
dilakukannya pengelompokan ( ) dapat memisahkan konten yang berbeda-beda tersebut berdasarkan karakteristik kata/tema konten beritanya masing-masing.
Dengan dapat dilakukannya proses pengelompokan dokumen tersebut oleh komputer
diharapkan dapat memudahkan kita dalam keperluan berbagai halnya seperti analisis
dokumen forensik.
Memodelkan algoritma genetika untuk dapat melakukan optimasi dokumen
sebagai pusat cluster awal tentu memiliki beberapa aturan yang disesuaikan dengan
masalah tersebut. Pada penelitian ini representasi kromosom yang digunakan adalah
representasi kode biner yaitu menggunakan nilai 1 dan 0 sebagai penyusun
kromosom yang dibuat seperti yang telah dijelaskan pada bab sebelumnya. Kemudian
untuk menghitung nilai dengan membandingkan keterhubungan setiap kromosom yang satu dengan yang lainnya pada pencocokan nilai biner yang ada pada
kromosom kemudian menghitung nilai rata-ratanya sebagai nilai fitness. Semakin
jauh perbedaan pencocokan kode biner setiap kromosom, maka kromosom tersebut
layak dijadikan sebagai solusi pada penentuan pusat cluster awal.
4.2 Pemilihan Dokumen
Pada pembahasan ini pengelompokan dokumen akan dilakukan dengan mengambil
sebanyak 7 konten berita. Masing-masing berita akan dikelompokkan berdasarkan isi
Dokumen yang berisi konten berita pada tabel 3.2 pada bab sebelumnya akan
melewati serangkaian proses pada untuk diekstraksi yaitu
(membuang karakter selain huruf), (menyaring kata-kata penting) dan (mengambil kata dasar). Sehingga hasil dari rangkaian proses tersebut dapat dilihat pada tabel 4.1 sebagai berikut.
Tabel 4.1 Hasil Ekstraksi Dokumen Konten Berita
Setelah diekstraksi maka selanjutnya setiap kata pada dokumen akan diindeks
untuk mendapatkan indeks kata sebagai representasi pada kromosom untuk tahap
selanjutnya. Berikut merupakan hasil indeks kata dari seluruh dokumen :
*+,- * ./ 0* 1 * .1/ 2/ 1*- * 3* 4/ * 3* 1 * 456/ .* * 7* 3/- *- *- 8 5. * 1, 6 0* 71, 0/ 9* . 0/- 7/-:;7- , 456 :,-1;45 6 <*-* 6 <* 1* < ;.1 56 < ;3* 6 < ;7* 3< <6 <, 7/* 5=5. 5=5. 1/= 5.;7;4/ 53 5.1 6;7/ . 57 56+/ 56;8* 5-57- /* 3 5, 6; =/ 53< =/ 3 156/ 7+ =/- /;156*8/ = ;.,- =6;71 +* 7++, + 5<, 7+ + 59 * 3* + 3;0* 3/ -*- / +;3;7+ +;;+ 3 5 >*8,- >* 6+* >* 1/ >/ 3* 7+ >/48, 7 >;*? / 7=;64*-/ / 7=;64* 1/.*/7++*-/72 5-1;6/ 6/7+/159 *.* 6 1*9 * 7+ .*9 * 79/ 9* 6* 7+9 53* 7+.*/1 .* 48* 7@ 5 .5:* 4 .51/<* .8*- 1/* 7 .>* A* 1/ 6 .;4/ 7=; .;4, 7/ .*- / .;7- /- 1 57 .;71 57 .;71 6;3 .,* 1 ., 6- 3*8;6 3 5 3 54*> 35253 352;< ;8* 3/ 1 56*- / 3, 7:, 6 4*<5 4*/ 7 4* .* 7 4* 6/ 754*@*4 5</*457 .;4/ 7=;4571*>4 57156/4 /3/.4/7, 44/7@* .7*-/;7* 375+* 1/= 7;4;6 ;0* 1 ;3*>6*+* ;8 56*- / ;1* . ;1 1 ;256 8*+/ 8* 6 ./ 7-;7 8* 6 1*/ 8*- * 6 8*- / 57 8 54 0563* .,* 7 857 8 57+ * 6,> 8 56* 7+ .* 1 8 51* 8/3/> 8/ 48/7 8 3*@/ 7+ 8;3/ 1/ . 8 6* 7:/ -8 65- /<578 6;15:1/;76* 0,65+, 3*- /657<*>6/ 3/-6,</* 71* 6*- *>* 4- *./ 1-* 48/ 7+- *@* 7+ - 50* 6 -5.1;6 -53*-* -54 0,> -57/ 7 -56/ .* 1 - 56 2/:5 -/ -154 - /1,*- / -;- /* 3 - 8 0- - 1/4, 3*-/ 1*>, 7 1* 7* 4 1* 7+* 71*8/- 1 57+*>156*8 1/7<* .1;8 1;1* 3 16* 7-* .- / 16 54;6 16, 48 1, 0,> 1,+*-1, 3/-1, 6, 71,1,8,*7+, 4, 4, 7<* 7+, 1* 4*,,A/ 0@;, 1, 05B;7*
Daftar indeks kata diatas ditentukan dengan mengambil setiap kata dari
masing-masing dokumen kemudian memunculkannya ke daftar indeks kata sebanyak
1 kali. Setiap terdapat kata yang sama di dokumen lain maka kata tetap hanya
dimunculkan sekali saja.
4.3 Representasi Kromosom Dokumen
Pada representasi kromosom dokumen, setiap dokumen akan dijadikan sebagai bentuk
kromosom dengan menggunakan representasi kode biner. Setiap kromosom dari
dokumen tersebut juga dibentuk dari indeks kata yang didapat dari hasil preprocessing
dokumen.
Panjang kromsom dokumen ditentukan dari panjang dari indeks kata. Kemudian
penentuan kode biner 1 dan 0 pada kromsom ditentukan dengan ada tidaknya kata
dari indeks kata dengan kata pada dokumen. Sebagai contoh dapat dilhat sebagai
Dok1
Hasil pada kode biner diatas diperoleh berdasarkan daftar indeks kata dengan
dokumen. Misalkan pada kode biner urutan ketiga berisi angka biner 1 yang pada
indeks kata merupakan kata M FG DTD GM K dan pada dokumen Dok1 terdapat kata tersebut di urutan ke 5. Untuk lebih lengkapnya berikut pada tabel 4.2 merupakan
hasil dari pembentukan kromosom dengan representasi kode biner.
Tabel 4.2 Representasi Kromosom Dokumen Kode Biner
Dokumen Kromosom Dokumen
Evaluasi fitness memiliki peranan penting dalam menentukan kualitas suatu
kromosom yang juga merupakan solusi pada algoritma genetika. Nilai fitness tertinggi
pada suatu generasi akan memiliki peluang lebih besar untuk terpilih kembali pada
generasi selanjutnya.
Proses perhitungan fitness dapat disesuaikan dengan masalah yang akan
diselesaikan. Pada penelitian ini akan dicari nilai fitness dari setiap kromosom yang
merupakan representasi kode biner dari setiap dokumen. Proses evaluasi dilakukan
untuk mendapatkan nilai fitness terbaik sebagai solusi cluster awal k-means pada
pengelompokan dokumen.
Pada proses pengelompokan, hal yang paling mendasar dalam menentukan pusat
cluster awal adalah nilai atau ciri dari masing-masing cluster tersebut harus memiliki
perbedaan yang memisahkan antara satu cluster dengan lainnya. Semakin tinggi
perbedaan yang dibentuk maka akan semakin baik pula dalam penentuan hasil cluster.
Oleh karena itu pada evaluasi fitness untuk pengelompokan dokumen ini dalam
menghitung fitness adalah menjumlahkan setiap perbedaan kode biner yang ada antara
Perhitungan fitness dilakukan dengan membandingkan perbedaan setiap
kromosom satu dengan yang lainnya kemudian menghitung nilai rata-ratanya sebagai
nilai fitness kromosom. Misalkan untuk menghitung nilai fitness pada Dok1 maka
kromosom Dok1 akan dibandingkan dengan kromosom Dok2 , Dok3 , Dok4 ,
Dok5 , Dok6 dan Dok7 kemudian menghitung rata-rata dari setiap fitness
tersebut. Sebagai contoh untuk menghitung fitness kromosom Dok1 dapat dilihat
sebagai berikut :
Jika nilai indeks kode biner tidak sama antara keduanya maka nilai bertambah 1
dan jika sama maka dilewatkan. Seperti pada kode biner diatas urutan biner pertama
kromosom Dok1 = 0 dan pada Dok2 = 1 maka nilai bertambah 1. Selanjutnya
untuk urutan biner kedua pada kromosom Dok1 = 0 sedangkan pada kromosom
Dok2 = 0 maka akan dilewatkan, seterusnya dengan cara yang sama kemudian
dijumlahkan. Berikut pada tabel 4.3 dapat dilihat hasil dari perhitungan nilai fitness
Dokumen Kromosom Dokumen Jumlah
Maka nilai fitness untuk kromosom Dok1 yaitu sebagai berikut :
Fitness = (20 + 19 + 29 + 18 + 22 + 24) / 6 = 22
Pada kromosom lainnya juga dikenai proses perhitungan fitness yang sama,
4.5 Proses Seleksi Pemilihan Kromosom
Dalam algoritma genetika terdapat proses yang mirip dengan proses seleksi alam yang
terjadi pada setiap generasi. Proses seleksi akan dipilih kromosom dengan fitness
terbaik untuk dapat dilanjutkan pada generasi berikutnya.
Dalam penelitian ini karena setiap penentuan nilai fitness kromosom sangat
dipengaruhi dengan kromosom yang lainnya maka untuk menyeleksi kromosom yang
terpilih adalah dengan membuang satu kromosom dengan nilai fitness terburuk pada
setiap generasi dan melanjutkan kromosom terbaik lainnya ke generasi
berikutnya.Berikut merupakan proses penyeleksian kromosom :
Fitness Dok1 22
Fitness Dok2 25
Fitness Dok3 23.83
Fitness Dok4 32.16
Fitness Dok5 21.33
Fitness Dok6 24
Fitness Dok7 26.33
Nilai fitness yang akan tereliminasi untuk dilanjutkan pada generasi berikutnya
adalah fitness pada Dok5 yang memiliki nilai fitness terendah yaitu 21.33 sedangkan 6
kromosom yang lainnya akan ikut pada generasi berikutnya. Untuk kromosom yang
sudah tereliminasi akan digantikan dengan UV VWXYZ [\ yang dihasilkan pada proses
]Y UW WU^_Y.
4.6 Crossover Kromosom
Pada penelitian ini jumlah parents yang akan dikenai operator penyilangan tidak
ditentukan berdasarkan probabilitas crossover melainkan terjadi hanya pada 2
kromosom sebagai parents dan menghasilkan 1 anak kromosom. Hal tersebut
dilakukan karena apabila proses crossover banyak terjadi terhadap kromosom atau
crossover dilakukan untuk mendapatkan `aab cd efg yang menggantikan kromosom yang telah dieleminasi pada proses seleksi sebelumnya. Berikut merupakan proses
crossover dengan induk dari kromosom Dok3 dan Dok6 untuk menggantikan
kromosom Dok1 yang sudah tereliminasi dengan posisi titik potong berada pada ghf ke 30 dari kromosom induk :
Makaijj klmn opyang dihasilkan adalah :
qj j klmn op= 0 0 0 1 0 1 0 1 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
qj j klm n op tersebut akan menggantikan kromosom Dok5 yang telah tereliminasi pada seleksi dan dengan kromsom yang lainnya yang terpilih dari proses seleksi akan dikenai pada
operator genetika selanjutnya.
4.7 Mutasi Kromosom
Pada penelitian ini proses mutasi dilakukan dengan probabilitas sebanyak 10 % yang
0 1 0 1 0 1 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 1 0 1
Jumlah tersebut dapat berubah-ubah sesuai dengan bilangan random t yang dibangkitkan dan probabilitas yang ditentukan. Untuk setiap kromosom jumlah mutasi
tidak terbatas dan bia terjadi lebih banyak daripada kromosom yang lain.
4.8 Penentuan Akhir Proses Genetika
Pada penelitian ini penentuan akhir untuk berhentinya proses genetika adalah banyak
generasi yang ditetapkan. Setiap hasil terbaik dari generasi akan disimpan untuk
diambil sebagai solusi pada penentuan pusat cluster awal. Jumlah solusi terbaik yang
diambil untuk pusat cluster awal berdasarkan dengan jumlah u yang ditentukan. Berikut pada tabel 4.6 dapat dilihat hasil kromosom terbaik pada generasi ke 98 dari
100 generasi yang diproses dengan jumlahuyaitu 3 cluster awal.
Tabel 4.6 Hasil Akhir Proses GA Cluster Awal
Cluster Kromosom Decode Kromosom Fitness bisnis consumer customer data donald efek efektif ekonomi eropa esensial euro gejala globalisasi google hapus hati himpun informatika investor ite jakarta kait lapor le lemah level literasi main marine media menkominfo milik nasional negatif obat operasi ott over partai pasar pen pengaruh perangkat playing presiden rudiantara sayang sebar service situasi spbs tengah terap transaksi tremor tutup uang umum undang utama uu youtube zona
Cluster Kromosom Decode Kromosom Fitness
agus aktivitas alat analis aspek atur bijak data dokter dolar donald dunia efek ekonomi energi eropa euro field fisioterapi front globalisasi harga hati hilang hoax informatika inggas janji jarang jelang kait kampanye kecam ketidakpastian khawatir kominfo komunikasi konsisten kontrol lapor le levodopa luncur main marine maya nasional nomor olahraga pagi partai pemberlakuan perangkat peta pimpin presiden rabu rudiantara saham sayang amerika analis atur bantu customer data dokter donald dunia efek efektif elektronik esensial euro fisioterapi fokus front ganggu gedung gejala golong google hapus harga hati hilang himpun hoax inggas iring jakarta janji jarang kait kecam ketidakpastian komunikasi konten kontrol lapor luncur made main maya menkominfo menteri minum minyak nasional negatif olahraga operasi otak ott parkinson partai pasar pasien pemberlakuan pilih politik presiden rabu regulasi rendah rilis rudiantara saham sakit samping sayang sektor sembuh senin situasi tahun tanam tapis total transaksi tremor tubuh tulis turun umum undang uu wib youtube zona
4.9.1 Menghitung Kemiripan Dokumen
Pada proses perhitungan kemiripan dokumen akan dilakukan dengan menggunakan
fungsi vwx yz{ x y| y} ~ y. Berikut merupakan tahap-tahapan dalam menghitung kemiripan dokumen Dok1 dengan pusat cluster awal sebanyak 3 cluster :
1) Daftar dokumen dan} x{ awal
Dokumen Dok1 akan dihitung kemiripannya dengan cluster 1, cluster 2 dan
cluster 3 dengan data yang telah diproses seperti pada tabel 4.7 sebagai berikut :
Dokumen Teks ¤quency) dan bobot kata (weigth document term) sehingga dapat dilakukan perhitungan kemiripan dengan cosine similarity berdasarkan hasil tersebut. Seperti
pada tabel 4.8 dapat dilihat perhitungan nilai idf (inverse document frequency) dan
nilai bobot kata(weigth document term).
Kata tf DF IDF wdt=tf.idf
ketidakpastian 0 0 1 1 2 0.301 0 0 0.301 0.301
khawatir 0 0 1 0 1 0.602 0 0 0.602 0
kominfo 0 0 1 0 1 0.602 0 0 0.602 0
komunikasi 0 0 1 1 2 0.301 0 0 0.301 0.301
levodopa 0 0 1 0 1 0.602 0 0 0.602 0
Keterangan :
tf =§ ¨© ª«©¨quency(frekuensi kata) D1 = dokumen Dok1
C1, C2, C3 = cluster dokumen hasil pusat cluster awal
DF =document frequency(jumlah kata dari setiap kata pada dokumen).
IDF =inverse document frequency
Wdt =weight document term( bobot kata pada dokumen).
3) Cosine Similarity
Berdasarkan nilai bobot pada tabel 4.8 maka untuk mencari nilai variabel pada
cosine similaritydapat dilihat pada tabel 4.9 dibawah ini :
Tabel 4.9 Perhitungan Nilai Variabel Pada Rumus Cosine Similarity
Kata (term)
C1 C2 C3 D1 C1 C2 C3
milik 0.091 0 0 0.091 0.091 0 0
tremor 0 0 0 0 0 0 0
esensial 0.016 0 0.016 0.016 0.016 0 0.016
ganggu 0 0 0.091 0.091 0 0 0.091
aktivitas 0 0.016 0.016 0.016 0 0.016 0.016
makan 0 0 0 0.362 0 0 0
konsisten 0 0.091 0 0.091 0 0.091 0
operasi 0.016 0 0.016 0.016 0.016 0 0.016
pilih 0 0 0.091 0.091 0 0 0.091
stimulasi 0 0.091 0 0.091 0 0.091 0
otak 0 0 0.091 0.091 0 0 0.091
dokter 0 0.016 0.016 0.016 0 0.016 0.016
tanam 0 0.016 0.016 0.016 0 0.016 0.016
perangkat 0.016 0.016 0 0.016 0.016 0.016 0
bantu 0 0 0.091 0.091 0 0 0.091
kontrol 0 0.016 0.016 0.016 0 0.016 0.016
agus 0 0 0 0.016 0.016 0.016 0.016
alami 0 0 0 0.091 0.091 0 0.091
Kata (term)
customer 0 0 0 0.091 0.091 0 0.091
data 0 0 0 0.016 0.016 0.016 0.016
donald 0 0 0 0.016 0.016 0.016 0.016
efek 0 0 0 0.016 0.016 0.016 0.016
globalisasi 0 0 0 0.091 0.091 0.091 0
google 0 0 0 0.091 0.091 0 0.091
hapus 0 0 0 0.091 0.091 0 0.091
hati 0 0 0 0.016 0.016 0.016 0.016
himpun 0 0 0 0.091 0.091 0 0.091
informatika 0 0 0 0.091 0.091 0.091 0
investor 0 0 0 0.362 0.362 0 0
ite 0 0 0 0.362 0.362 0 0
jakarta 0 0 0 0.091 0.091 0 0.091
kait 0 0 0 0.016 0.016 0.016 0.016
lapor 0 0 0 0.016 0.016 0.016 0.016
Le 0 0 0 0.091 0.091 0.091 0
menkominfo 0 0 0 0.091 0.091 0 0.091
nasional 0 0 0 0.016 0.016 0.016 0.016
negatif 0 0 0 0.091 0.091 0 0.091
ott 0 0 0 0.091 0.091 0 0.091
over 0 0 0 0.362 0.362 0 0
partai 0 0 0 0.016 0.016 0.016 0.016
pasar 0 0 0 0.091 0.091 0 0.091
pen 0 0 0 0.362 0.362 0 0
Kata (term)
C1 C2 C3 D1 C1 C2 C3
presiden 0 0 0 0.016 0.016 0.016 0.016
rudiantara 0 0 0 0.016 0.016 0.016 0.016
sayang 0 0 0 0.016 0.016 0.016 0.016
sebar 0 0 0 0.362 0.362 0 0
transaksi 0 0 0 0.091 0.091 0 0.091
tutup 0 0 0 0.091 0.091 0.091 0
uang 0 0 0 0.362 0.362 0 0
umum 0 0 0 0.016 0.016 0.016 0.016
undang 0 0 0 0.016 0.016 0.016 0.016
utama 0 0 0 0.362 0.362 0 0
fisioterapi 0 0 0 0.091 0 0.091 0.091
front 0 0 0 0.091 0 0.091 0.091
ketidakpastian 0 0 0 0.091 0 0.091 0.091
khawatir 0 0 0 0.362 0 0.362 0
kominfo 0 0 0 0.362 0 0.362 0
komunikasi 0 0 0 0.091 0 0.091 0.091
Kata (term)
C1 C2 C3 D1 C1 C2 C3
luncur 0 0 0 0.091 0 0.091 0.091
maya 0 0 0 0.091 0 0.091 0.091
nomor 0 0 0 0.362 0 0.362 0
olahraga 0 0 0 0.091 0 0.091 0.091
pagi 0 0 0 0.362 0 0.362 0
pemberlakuan 0 0 0 0.091 0 0.091 0.091
Keterangan :
= A¬®¯°¬±²®B (perkalian vektor A dengan vektor B) =³°´A (panjang vektor A )
=³°´B (panjang vektor B)
Selanjutnya menghitung kemiripan dokumen uji dengan dokumen sampel sebagai
berikut :
1. Cos(D1, C1)= 0.228/(27.651*9.465)= 0.00846 = (0.00871/1)*100 = 0.0871 %
2. Cos(D1, C2)= 0.259/(27.651*9.405)= 0.000997=(0.000997/1)*100 = 0.0997%
3. Cos(D1, C3)= 0.637/(27.651*12.955)=0.00177= (0.00177 /1)*100= 0.1779 %
Berdasarkan hasil perhitungan dengan fungsi cosine similarity tersebut dapat
diketahui bahwa nilai kemiripan dokumen yang tertinggi yaitu Dok1 (D1) dengan
dokumen cluster C3, sehingga dokumen Dok1 tersebut untuk iterasi pertama
terkelompok pada cluster C3. Berikut ini merupakan contoh hasil akhir dari
perhitungan kemiripan dari setiap dokumen ke masing-masing cluster :
Tabel 4.10 Hasil Pengelompokan Akhir K-Means Clustering
Dokumen Kemiripan Nilai
Maksimum
Anggota Cluster
C1 C2 C3
Dok1 3.975 % 44.352 % 3.115 % 44.352 % C2
Dok2 3.771 % 62.341 % 4.440 % 62.341 % C2
Dok3 59.387 % 8.096 % 2.414 % 59.387 % C1
Dok4 62.168 % 6.937 % 4.421 % 62.168 % C1
Dok5 9.579 % 5.213 % 41.550 % 41.550 % C3
Dok6 2.410 % 59.752 % 1.014 % 59.752 % C2
Dok7 5.346 % 6.0438 % 51.618 % 51.618 % C3
Pada tabel 4.10 dapat dilihat setiap dokumen dikelompokkan berdasarkan
kemiripannya terhadap 3 cluster yang sebelumnya telah dibentuk oleh algoritma
genetika. Penentuan 3 cluster tersebut berdasarkan pada jumlah jenis dokumen yang
4.9 Pengujian dan Hasil
Dalam melakukan pengujian pada pengelompokan dokumen akan membedakan hasil
pengelompokan dengan data pusat cluster awal secara random dengan pusat cluster
awal yang didapat dengan algoritma genetika.
4.10.1 Pengujian Pusat Cluster Awal Random
Pada pengujian ini dilakukan dengan mengambil pusat cluster awal dari dokumen
yang ada secara random. Pengujian dilakukan sebanyak 5 kali percobaan. Berikut
merupakan hasil pengujian :
Tabel 4.11 Hasil Pengujian Pusat Cluster Awal Random
Pengujian Dokumen Nilai Anggota
Cluster
1
Dok1 44.28 % C3
Dok2 48.27 % C2
Dok3 42.46 % C3
Dok4 55.39 % C2
Dok5 43.57 % C2
Dok6 100 % C1
Dok7 55.11 % C3
2
Dok1 35.73 % C2
Dok2 55.25 % C3
Dok3 34.97 % C2
Dok4 48.80 % C2
Dok5 39.86 % C2
Dok6 100 % C1
Dok7 63.49 % C3
3
Dok1 41.56 % C1
Dok2 44.93 % C2
Pengujian Dokumen Nilai Anggota Cluster
Dok4 57.80 % C2
Dok5 42.17 % C2
Dok6 41.55 % C2
Dok7 49.63 % C2
4
Dok1 49.25 % C3
Dok2 40.28 % C2
Dok3 32.81 % C2
Dok4 45.51 % C2
Dok5 46.27 % C3
Dok6 44.09 % C3
Dok7 43.01 % C2
5
Dok1 61.92 % C1
Dok2 39.90 % C2
Dok3 59.38 % C2
Dok4 45.30 % C2
Dok5 37.00 % C2
Dok6 36.58 % C2
Dok7 41.96 % C2
4.10.2 Pengujian Pusat Cluster Awal dengan GA
Pada pengujian ini menggunakan data pusat cluster awal yang diperoleh
menggunakan algoritma genetika. Pengujian dilakukan sebanyak 5 kali percobaan.
Berikut merupakan hasil pengujian :
Tabel 4.12 Hasil Pengujian Pusat Cluster Awal dengan GA
Pengujian Dokumen Nilai Anggota
Cluster
1 Dok1 51.92 % C3
Pengujian Dokumen Nilai Anggota Cluster
Dok4 57.13 % C2
Dok5 100 % C3
Dok6 37.66 % C2
Dok7 48.42 % C2
Berdasarkan hasil pengujian dapat diketahui bahwa pengelompokan dokumen
dengan menggunakan pusat cluster awal secara random banyak menghasilkan
pengelompokan yang tidak sesuai. Sedangkan dengan pusat cluster awal
menggunakan algoritma genetika hasil pengelompokan lebih banyak menghasilkan
pengelompokan yang sesuai. Berikut merupakan tingkat keberhasilan dari hasil
pengujian pengelompokan tersebut :
Tabel 4.13 Tingkat Keberhasilan Pengelompokan Dokumen
No. Penentuan Pusat Cluster Awal Perhitungan Tingkat
Keberhasilan
1 µ¶·¸¹ º 100% =
4
15 100% 26.66 %
2 »¼ ½¹¾¿ Àº¶Á ·ÂÀ¿Ã¶ 100% = 7
15 100% 46.66 %
4.10.3 Pengujian Aplikasi
Aplikasi digunakan untuk menguji bagaimana algoritma yang diterapkan dapat
bekerja untuk menyelesaikan permasalahan dalam penelitian ini. Berikut merupakan
1) Menentukan folder sumber dokumen yang akan di clustering.
Gambar 4.1 Menentukan sumber dokumen
3) Proses penentuan pusat cluster awal
Gambar 4.3 Proses penentuan pusat cluster awal
4) Memasukkan data hasil pusat cluster awal untuk clustering
5) Melakukan proses clustering