IDENTIFIKASI PEMBICARA PADA LINGKUNGAN YANG
MENGANDUNG
NOISE
MENGGUNAKAN
LEAST MEAN SQUARE
INGGIH PERMANA
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
CIPTA
*Dengan ini saya menyatakan bahwa tesis berjudul Identifikasi Pembicara
pada Lingkungan yang Mengandung
Noise
Menggunakan
Least Mean Square
adalah benar karya saya dengan arahan dari komisi pembimbing dan belum
diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber
informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak
diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam
Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut
Pertanian Bogor.
Bogor, Juni 2014
RINGKASAN
INGGIH PERMANA. Identifikasi Pembicara pada Lingkungan yang Mengandung Noise Menggunakan Least Mean Square. Dibimbing oleh AGUS BUONO dan BIB PARUHUM SILALAHI.
Identifikasi pembicara merupakan bagian dari pengenalan pembicara yang bertujuan untuk mengetahui siapa yang berbicara dari suara yang ada. Studi ini berfokus pada identifikasi pembicara di lingkungan yang mengalami noise. Hal ini menarik untuk dikaji karena sebagian besar penelitian identifikasi pembicara yang ada sekarang berhasil mendapatkan hasil identifikasi yang bagus dalam lingkungan yang sengaja dibuat baik tetapi belum tentu dalam lingkungan yang dipenuhi noise.
Studi ini menambahkan metode LMS (Least Mean Square) dalam praproses data agar bisa mengatasi masalah tersebut. LMS membuat proses identifikasi pembicara menjadi lebih baik karena sinyal suara yang dihasilkan setelah proses LMS adalah sinyal suara yang telah mengalami pengurangan noise.
Studi ini juga memodifikasi teknik pengukuran kemiripan pada identifikasi pembicara. Modifikasi dilakukan dengan cara memilih pembicara yang memiliki jumlah pasangan vektor terbanyak sebagai pembicara yang mewakili suara yang diuji. Pasangan vektor disini adalah jarak terkecil vektor masukan dengan salah satu vektor yang ada pada codebook (cetakan suara) pembicara.
Jumlah pembicara yang digunakan pada studi ini adalah 83 orang, yang terbagi menjadi 35 pembicara perempuan dan 48 pembicara laki-laki. Setiap pembicara memiliki 5 file suara dalam format wav. Panjang file suara adalah 1 sampai 39 detik. Perekaman dilakukan melalui telepon menggunakan sistem IVR (Interactive Voice Response). Sampling rate yang digunakan adalah 8000 Hz.
Noise yang digunakan pada studi ini adalah white noise.
Hasil percobaan menunjukan bahwa LMS berhasil membuat identifikasi pembicara menjadi lebih tahan terhadap noise. Akurasi identifikasi pembicara yang menggunakan LMS pada praproses data 77% lebih tinggi dari akurasi identifikasi pembicara yang tidak menggunakan LMS. Teknik pengukuran kemiripan yang ditawarkan berhasil menambah akurasi identifikasi pembicara diatas 15% pada suara yang mengandung noise.
SUMMARY
INGGIH PERMANA. Speaker Identification in Noisy Environment using Least Mean Square. Supervised by AGUS BUONO and BIB PARUHUM SILALAHI.
Speaker identification is part of the speaker recognition that aims to find out who is speaking from an existing sound. This research focuses on speaker identification in noisy environment. It is interesting to study because most of the research on speaker identification has performed successfully and obtained good accuracy on the environment that intentionally is made without noise, but not on the environment that full of noise.
This study added Least Mean Square (LMS) on data preprocessing to reduce noise in the voice. This study also modified the similarity measurement technique on speaker identification. The technique was modified by choosing a speaker that had the highest number of vector pair as speaker that representing tested voice. Vector pair in this case is the smallest distance between the input vector and the vector in the codebook.
This study used 83 speakers which consisted of 35 female speakers and 48 male speakers. Each speaker had 5 voice files in wav format. The durations of the voice files were 1 to 39 seconds. Recording was done by phone using an Interactive Voice Response (IVR) system. The voice sampling rate used in this study was 8000 Hz. Noise used in this study was white noise.
The experimental results showed that the LMS made speaker identification becoming more resistant to noise. The accuracy of the proposed method using LMS on data preprocessing was 77% higher than the accuracy of speaker identification without LMS. Moreover, the proposed similarity measurement technique could increase the accuracy of speaker identification up to 15% in noisy voice.
© Hak Cipta Milik IPB, Tahun 2014
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
IDENTIFIKASI PEMBICARA PADA LINGKUNGAN YANG
MENGANDUNG
NOISE
MENGGUNAKAN
LEAST MEAN SQUARE
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2014
Judul Tesis : Identifikasi Pembicara pada Lingkungan yang Mengandung Noise
Menggunakan Least Mean Square
Nama : Inggih Permana NIM : G651120011
Disetujui oleh Komisi Pembimbing
Dr Ir Agus Buono, MSi, MKom Ketua
Dr Ir Bib Paruhum Silalahi, MKom Anggota
Diketahui oleh
Ketua Program Studi Ilmu Komputer
Dr Eng Wisnu Ananta Kusuma, ST, MT
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Desember 2012 adalah Identifikasi Pembicara pada Lingkungan yang Mengandung Noise Menggunakan Least Mean Square,
Terima kasih penulis ucapkan kepada Bapak Dr Ir Agus Buono, MSi MKom dan Bapak Dr Ir Bib Paruhum Silalahi, MKom selaku pembimbing, Bapak Irman Hermadi, SKom MSi Phd selaku penguji, serta Bapak Dr Eng Wisnu Ananta Kusuma, ST, MT selaku moderator dalam ujian tesis. Terima kasih juga diucapkan kepada Bapak Toto Hartanto, MKom selaku dosen mata kuliah kolokium yang telah banyak memberi saran untuk penelitian ini. Di samping itu, penghargaan penulis sampaikan kepada Kementrian Agama atas beasiswa yang telah diberikan.
Terima kasih juga disampaikan kepada Bapak, Ibu serta adik-adik penulis Laska, Budi dan Rati atas segala doa dan kasih sayangnya. Semoga Allah SWT selalu merahmati kalian.
Terima kasih kepada pengelola pasca sarjana, seluruh dosen dan staf akademik Ilmu Komputer Institut Pertanian Bogor, teman-teman angkatan 13,5, 14 dan mahasiswa fast track. Terima kasih kepada Sdri. Fadhilah Syafria, Sdri. Lailan Sahrina Hasibuan, Sdr. Sanusi dan Sdri. Dhieka Avrillia Lantana sebagai teman diskusi penulis dalam menyelesaikan tesis ini. Program Studi Ilmu Komputer atas kebersamaan dan bantuannya selama kuliah dan penyelesaian penelitian ini.
Semoga karya ini dapat bermanfaat. Kritik dan saran sangat penulis harapkan demi kesempurnaan karya ini di kemudian hari.
Bogor, Juni 2014
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN viii
1 PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 3
Tujuan Penelitian 3
Manfaat Penelitian 4
Ruang Lingkup Penelitian 4
2 TINJAUAN PUSTAKA 4
Sinyal Suara 4
Digitasi Sinyal Suara 5
Identifikasi Pembicara 6
Noise 8
Self Organizing Map (SOM) 10
Mel Frequency Cepstral Coefficient (MFCC) 12
Least Means Square (LMS) 15
3 METODE PENELITIAN 16
Studi Pustaka 18
Data Suara 18
Perancangan Model Identifikasi Pembicara 19
Pengujian Identifikasi Pembicara 22
4 HASIL DAN PEMBAHASAN 24
Percobaan pada Data Uji yang Tidak Diberi Noise 24
Koefisien MFCC 13 25
Koefisien MFCC 15 25
Koefisien MFCC 20 26
Pengaruh Penambahan Jumlah Koefisien MFCC Terhadap
Peningkatan Akurasi Identifikasi Pembicara 27
Percobaan pada Data Uji yang Diberi Noise 28
Koefisien MFCC 13 28
Koefisien MFCC 15 29
Koefisien MFCC 20 30
Pengaruh Learning Rate LMS Terhadap Akurasi Identifikasi
Pembicara pada Teknik yang Ditawarkan 31
Pengaruh Learning Rate LMS Terhadap Akurasi Identifikasi
Pengaruh Learning Rate LMS Terhadap Akurasi Identifikasi
Pembicara pada Teknik yang Ditawarkan dari Teknik Sebelumnya 34 Pengaruh Koefisien MFCC Terhadap Akurasi Identifikasi Pembicara
pada Teknik yang Ditawarkan 35
Pengaruh Learning Rate LMS Terhadap Akurasi Identifikasi
Pembicara pada Teknik Sebelumnya 36
Pengaruh Learning Rate LMS Terhadap Akurasi Identifikasi
Pembicara pada Teknik yang Ditawarkan dari Teknik Sebelumnya 37
5 SIMPULAN DAN SARAN 38
Simpulan 38
Saran 39
DAFTAR PUSTAKA 40
LAMPIRAN 43
DAFTAR TABEL
1 Parameter-parameter yang akan dilihat pengaruhnya terhadap hasil
identifikasi 23
DAFTAR GAMBAR
1 Sistem suara manusia 52 Ilustrasi sampel dan kuantisasi 6
3 Ilustrasi fokus penelitian 7
4 Tingkatan informasi untuk pengenalan pembicara 8
5 White noise 9
6 Ilustrasi model jaringan SOM 10
7 Ilustrasi berbagi radius tetangga dan topologi pada jaringan SOM 11
8 Blok diagram tahapan MFCC 12
9 Ilustrasi frame blocking dan windowing 13
10 Ilustrasi DFT 14
11 Mel filter bank 15
12 Ilustrasi cara kerja ANC 16
13 Diagram alir tahapan penelitian 17
14 Ilustrasi data suara 19
15 Ilustrasi model identifikasi pembicara 19
16 Ilustrasi pembuatan codebook 20
17 Ilustrasi pengukuran kemiripan 21
18 Ilustrasi teknik pengukuran kemiripan sebelumnya 21
19 Ilustrasi teknik pengukuran kemiripan yang ditawarkan 22
20 Grafik perbandingan akurasi identifikasi pembicara pada data uji tanpa noise, koefisien MFCC 13 25
21 Grafik perbandingan akurasi identifikasi pembicara pada data uji tanpa noise, koefisien MFCC 15 26
22 Grafik perbandingan akurasi identifikasi pembicara pada data uji tanpa noise, koefisien MFCC 20 26
23 Pengaruh peningkatan MFCC terhadap akurasi identifikasi pembicara 27
24 Grafik perbandingan akurasi identifikasi pembicara, noise 20 dBkoefisien MFCC 13, LR ANC 0.7 29
25 Grafik perbandingan akurasi identifikasi pembicara, noise 20 dBkoefisien MFCC 20, LR ANC 0.7 30
26 Grafik perbandingan akurasi identifikasi pembicara, noise 20 dBkoefisien MFCC 20, LR ANC 0.7 31 27 Grafik pengaruh learning rate ANC/LMS terhadap akurasi identifikasi
pembicara pada teknik yang ditawarkan, noise 20 dB, koefesien MFCC 20 32 28 Grafik pengaruh learning rate ANC/LMS terhadap akurasi identifikasi pembicara pada teknik yang sebelumnya, noise 20 dB, koefesien MFCC 20
29 Grafik pengaruh learning rate ANC/LMS terhadap peningkatan akurasi identifkasi pembicara teknik yang ditawarkan dari teknik sebelumnya 34 30 Grafik pengaruh koefesien MFCC terhadap akurasi identifikasi pembicara pada teknik yang ditawarkan, noise 20 dB,learning rate ANC/LMS 0.7 35 31 Grafik pengaruh koefesien MFCC terhadap akurasi identifikasi pembicara
pada teknik sebelumnya, noise 20 dB, learning rate ANC/LMS 0.7 36 32 Grafik pengaruh koefesien MFCC terhadap peningkatan akurasi identifkasi pembicara teknik yang ditawarkan dari teknik sebelumnya 37
DAFTAR LAMPIRAN
1 Perbandingan akurasi identifikasi pembicara antara yang menggunakan ANC/LMC dengan yang tanpa ANC/LMS 43 2 Pengaruh learning rate terhadap akurasi identifikasi pembicara 49 3 Pengaruh learning rate LMS/ANC terhadap peningkatan akurasi identifikasi pembicara teknik yang ditawarkan dari teknik sebelumnya 51 4 Pengaruh MFCC Koefesien terhadap akurasi identifikasi pembicara 53 5 Pengaruh koefesien MFCC terhadap peningkatan akurasi identifikasi pembicara teknik yang ditawarkan dari teknik sebelumnya 57
6 Daftar data suara pembicara 61
Latar Belakang
Pengenalan pembicara (speaker recognition) merupakan bagian dari pengolahan suara (sound processing) yang bertujuan untuk mengetahui siapa yang berbicara. Pengenalan pembicara sendiri terbagi menjadi dua, yaitu identifikasi pembicara (speaker identification) dan verifikasi pembicara (speaker verification). Identifikasi pembicara adalah cara untuk mengidentifikasi seseorang dari suara yang ada, sedangkan verifikasi pembicara adalah cara untuk menverifikasi sebuah klaim terhadap sebuah identitas melalui kata-kata tertentu (Togneri dan Pullella 2011). Suara manusia dapat dikenali karena tidak ada suara antara manusia yang benar-benar sama persis. Hal ini dikarenakan bentuk saluran vokal, ukuran laring, irama, intonasi, pola pengucapan, pilihan kosa kata dan lain sebagainya pada manusia berbeda-beda (Kinnunen dan Li 2010).
Kemampuan manusia dalam mengenali suara manusia sangat terbatas, terlebih dengan begitu banyaknya keragamanan antara suara manusia yang satu dengan suara manusia yang lain. Oleh sebab itu, sistem identifikasi pembicara banyak diaplikasikan dalam kehidupan nyata. Aplikasi terpenting dari identifikasi pembicara adalah dalam bidang forensik (Kinnunen dan Li 2010), misalnya mengidentifikasi siapa yang berbicara pada rekaman percakapan telepon yang akan dijadikan bukti pada suatu kasus di persidangan. Dalam kehidupan sehari-hari pengenalan pembicara juga sangat penting, contohnya sebagai identitas dan akses kontrol untuk telephonbanking, shopping banking, membuka komputer pribadi dan lain sebagainya.
Penelitian ini akan berfokus pada identifikasi pembicara pada lingkungan yang mengalami noise. Hal ini menarik diteliti karena kebanyakan teknik-teknik identifikasi pembicara yang ada sekarang berhasil mendapat hasil identifikasi yang baik pada lingkungan yang sengaja dibuat tidak mengalami noise, tetapi belum tentu dalam keadaan yang dipenuhi noise (Kinnunen dan Li 2010).
Pengenalan pembicara berdasarkan kata-kata yang diucapkannya terbagi menjadi dua, yaitu dependent-text dan independent-text. Dependent-textadalah pengenalan pembicara dimana kata-kata yang diucapkan tetap (Furui 1996), biasanya dependent-text digunakan pada kata sandi, karena kata sandi selain harus bisa mengetahui siapa yang berbicara juga harus mampu mengenali kata yang diucapkan. Independent-text adalah pengenalan pembicara yang tidak ditentukan apa saja kata yang harus diucapkan. Pengenalan pembicara ini memiliki banyak sekali aplikasi, misalnya pada speaker diarization (Furui 1996), yaitu suatu cara untuk mengetehui siapa yang berbicara pada waktu tertentu. Contoh implementasi dari speaker diarization adalah untuk mengetahui siapa yang berbicara pada waktu tertentu pada suatu rapat. Mempertimbangkan banyaknya aplikasi dari pengenalan pembicara pada independent-text, maka penelitian ini juga akan berfokus pada hal tersebut.
format yang lebih sederhana dan jelas untuk diproses lebih lanjut. Salah satu metode ekstrasi ciri yang sering digunakan adalah metode MFCC (Mel Frequency Cepstral Coefficient). Cara kerja MFCC didasarkan pada perbedaan frekuensi yang dapat ditangkap oleh telinga manusia sehingga bisa merepresentasikan bagaimana manusia menerima sinyal suara (Muda et al. 2010). MFCC sering digunakan karena performanya dianggap lebih baik dari metode-metode lainnya, seperti dalam hal pengurangan tingkaterror. Tetapi MFFC memiliki kekurangan yaitu tidak terlalu tahan terhadap noise (Tyagi dan Wellekens 2005). Oleh sebab itu pada penelitian ini akan ditambahkan sebuah metode yang dapat menghilangkan noise untuk mengatasi masalah tersebut. Sehingga tujuan penelitian ini untuk membuat sebuah model identifikasi pembicara pada lingkungan yang mengalami noise bisa tercapai.
Data hasil ekstrasi ciri dengan menggunakan MFCC akan digunakan sebagai data masukan untuk membuat codebook masing-masing suara individu.
Codebook merupakan cetakan suara yang dihasilkan dari pelatihan data latih (Wisnudisastra dan Buono 2010). Pada penelitian ini algoritma yang akan digunakan sebagai pelatihan adalah SOM (Self Organizing Map). SOM adalah algoritmauntuk pengklusteran. SOM berhasil diterapkan pada data berdimensi tinggi (Yan et al. 2013), yang mana metode tradisional tidak dapat melakukan hal tersebut. Kemampuannya untuk menangani data berdimensi tinggi inilah yang menjadi pertimbangan untuk memilih metode ini untuk menghasilkan codebook. Data hasil dari MFCC mungkin saja menghasilkan dimensi yang tinggi, tergantung berapa koefesien yang ditetapkan pada saat proses MFCC. Dilihat dari penelitian sebelumnya (Wisnudisastra dan Buono 2010, Fruandta dan Buono 2011), semakin tinggi koefesien MFCC, yang berarti semakin tinggi juga dimensi data yang akan dikluster, maka akan semakin tinggi akurasi sebuah pengenalan suara. Hal ini semakin menguatkan alasan untuk memilih SOM sebagai teknik untuk pembuat codebook, agar bisa menangani keluaran MFCC ketika koefesien dibuat tinggi.
Penelitian ini akan menggunakan jarak Euclidean untuk pengukuran kemiripan. Sinyal suara yang akan diidentifikasi juga akan di lakukan proses ekstrasi ciri dengan MFCC. Data-data hasil MFCC tersebut akan diukur jaraknya dengan data-data pada codebook menggunakan jarak Euclidean, yang mana setiap individu mempunyai codebook masing-masing. Pada penelitian sebelumnya (Wisnudisastra dan Buono 2010, Fruandta dan Buono 2011), hasil penjumlahan jarak terkecil antara vektor-vektor masukan dengan vektor pada codebook tertentu yang paling minimal akan menjadi pemenang. Pembicara yang codebook menjadi pemenang tadi adalah pembicara yang mewakili suara yang dimasukan. Pada penelitian ini, teknik tersebut akan dimodifikasi dengan cara memilih codebook
yang memiliki jarak terkecil terbanyak dengan vektor-vektor masukan. Masing-masing vektor masukan hasil MFCC tersebut diukur jaraknya dengan semua vektor yang ada di kumpulan codebook, jarak terkecil akan dipilih sebagai pasangan vektor masukan tersebut. Setelah setiap vektor masukan mendapat pasangan vektor codebook, maka dihitung pembicara yang vektor pada codebook
memiliki pasangan terbanyak. Individu tersebut ditetapkan sebagai suara yang mewakili suara yang diidentifikasi.
tetapi model yang dihasilkan oleh penelitian tersebut tidak dirancang untuk identifikasi pembicara pada lingkungan yang mengalami noise. Sedangkan model yang diusulkan pada penelitian ini dirancang untuk identifikasi pembicara pada lingkungan yang mengalami noise. Sebagaimana yang telah dijelaskan sebelumnya bahwa ekstrasi ciri dengan menggunakan MFCC tidak terlalu tahan terhadap gangguan noise (Tyagi dan Wellekens 2005). Oleh sebab itu, pada penelitian akan ditambahkan metode activenoise canceling (ANC) pada bagian praproses data, agar dapat mengurangi noise pada suara sebelum dimasukan ke dalam proses MFCC. Secara sederhana ANC bekerja dengan cara memproduksi anti-noise untuk selanjutnya dikombinasikan dengan noise utama (Elliott 1999).
Metode ANC yang akan digunakan pada penelitian ini adalah Least Mean Square (LMS). Metode ini pertama kali dicetuskan oleh Widrow dan Hoff (1960). Metode LMS menjadi sangat populer karena kompleksitasnya yang rendah dan kemampuannya yang menjanjikan. Gorriz et al. (2009) pernah memodifikasi metode ini dengan mengkombinasikan dengan metode Lagrange. Hasilnya adalah LMS hasil modifikasi ini memiliki performa lebih baik dari LMS sebelumnya. Penelitian lainnya pernah dilakukan Takahashi (2010). Mereka meneliti tentang Difussion LMS, penelitian ini menawarkan strategi kombinasi adaptif pada permasalahan estimasi distribusi jaringan untuk meningkatkan ketahanan terhadap variasi spasial dari sinyal. Konsep minimum varian untuk estimasi digunakan untuk mendapatkan kombinasi yang adaptif. Hasil analisis secara teoritis, teknik ini memberikan approksimasi yang baik pada kinerja praktis.
Perumusan Masalah
Penelitian tentang identifikasi pembicara yang ada sekarang berhasil mendapatkan hasil yang akurat karena dilakukan pada lingkungan yang sengaja dibuat tidak mengalami noise, tetapi belum tentu mendapatkan hasil yang akurat jika dilakukan pada lingkungan yang dipenuhi noise. Oleh sebab itu, penelitian ini merancang model identifikasi pembicara yang tahan terhadap gangguan noise
dengan menggunakan metode MFCC sebagai ekstrasi ciri, SOM sebagai pembuat
codebook, LMS sebagai ANC dan jarak euclidean sebagai penghitung kemiripan. .
Tujuan Penelitian
Adapun tujuan penelitian ini sebagai berikut :
1. Merancang model identifikasi pembicara yang tahan terhadap gangguan noise dengan menambahkan metode ANC pada praproses data.
Manfaat Penelitian
Adapun ruang lingkup penelitian ini sebagai berikut:
1. Penelitian ini diharapkan dapat memberikan informasi mengenai pengaruh penggunaan ANC terhadap akurasi identifikasi pembicara pada lingkungan yang mengalami noise.
2. Penelitian ini diharapkan dapat memberikan model identifikasi pembicara yang tahan terhadap noise yang bisa diterapkan di dunia nyata.
Ruang Lingkup Penelitian
Adapun ruang lingkup penelitian ini sebagai berikut:
1. Jenis teks yang digunakan pada penelitian ini bersifatindependent. 2. Metode ekstrasi ciri yang digunakan pada penelitian ini adalah MFCC. 3. Metode untuk membuat codebook yang digunakan untuk penelitian ini
adalah SOM.
4. Metode ANC yang digunakan pada penelitian ini adalah LMS.
5. Metode untuk pengukuran kemiripan yang digunakan pada penelitian ini adalah jarak Euclidean.
6. Noise yang digunakan pada penelitian ini adalahwhite noisesebesar 20 dB.
2 TINJAUAN PUSTAKA
Sinyal Suara
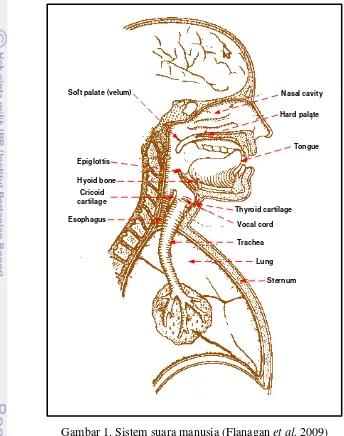
Bentuk saluran suara merupakan faktor pembeda fisik penting dari ucapan (Campbell 1997). Perbedaan dalam ukuran saluran suara antara individu berkontribusi pada perubahan gelombang ucapan (Eide dan Gish 1996). Saluran suara umumnya dianggap sebagai organ pembuat ucapan di atas pita suara. Seperti ditunjukkan dalam Gambar 2 (Flanagan et al. 2009), bagian-bagian saluran suara adalah faring laring (di bawah epiglotis), faring mulut (belakang lidah, antara epiglotis dan velum), rongga mulut (didepan velum dan dibatasi oleh bibir, lidah, dan langit-langit), faring hidung (di atas velum, bagian belakang rongga hidung), rongga hidung (di atas langit-langit dan membentang dari faring ke lubang hidung).
Pita suara atau vocal cord yang ditunjukkan pada Gambar 1 membentang antara kartilago tiroid dan kartilago arytenoid. Daerah antara pita suara disebut
dari cincin tulang rawan yang diikuti oleh jaringan ikat bergabung dengan paru-paru dan laring. Ketika pita suara dalam getaran, ada resonansi di atas dan di bawah pita. Resonansi subglotal (trakea dan paru-paru) sangat tergantung pada sifat dari trakea (Pentz 1990). Karena ketergantungan fisiologis ini, resonansi subglottal memiliki sifat yang tergantung pada pembicara. Sistem verifikasi suara biasanya menggunakan fitur yang berasal dari saluran suara ini (Campbell 1997).
Nasal cavity
Hard palate
Tongue
Thyroid cartilage Vocal cord
Trachea
Lung
Sternum Soft palate (velum)
Epiglottis
Hyoid bone Cricoid cartilage
Esophagus
Gambar 1. Sistem suara manusia (Flanagan et al. 2009)
Digitasi Sinyal Suara
Sampel
Kuantisasi
Waktu (t)
Amplitud
o
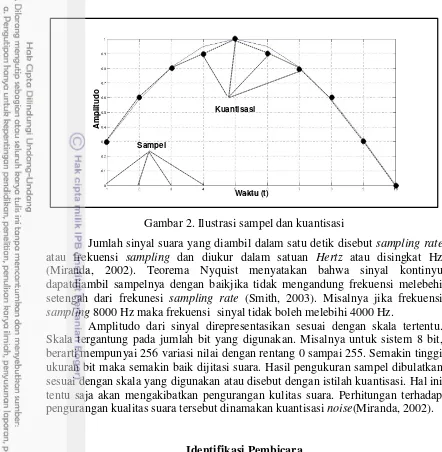
Gambar 2. Ilustrasi sampel dan kuantisasi
Jumlah sinyal suara yang diambil dalam satu detik disebut sampling rate
atau frekuensi sampling dan diukur dalam satuan Hertz atau disingkat Hz (Miranda, 2002). Teorema Nyquist menyatakan bahwa sinyal kontinyu dapatdiambil sampelnya dengan baikjika tidak mengandung frekuensi melebehi setengah dari frekunesi sampling rate (Smith, 2003). Misalnya jika frekuensi
sampling 8000 Hz maka frekuensi sinyal tidak boleh melebihi 4000 Hz.
Amplitudo dari sinyal direpresentasikan sesuai dengan skala tertentu. Skala tergantung pada jumlah bit yang digunakan. Misalnya untuk sistem 8 bit, berarti mempunyai 256 variasi nilai dengan rentang 0 sampai 255. Semakin tinggi ukuran bit maka semakin baik dijitasi suara. Hasil pengukuran sampel dibulatkan sesuai dengan skala yang digunakan atau disebut dengan istilah kuantisasi. Hal ini tentu saja akan mengakibatkan pengurangan kulitas suara. Perhitungan terhadap pengurangan kualitas suara tersebut dinamakan kuantisasi noise(Miranda, 2002).
Identifikasi Pembicara
Identifikasi pembicara (speaker identification) merupakan bagian dari pengolahan ucapan (speech processing). Pengolahan ucapan sendiri bisa digunakan untuk mengambil informasi sebagai berikut (Faundez-Zanuy dan Monte-Moreno 2005):
1. Pendeteksian ucapan (speech detection) : digunakan untuk mendeteksi ada atau tidaknya orang yang berbicara
2. Identifikasi jenis kelamin (sex identification) : digunakan untuk mengetahui jenis kelamin orang yang berbicara
3. Pengenalan bahasa (language recognition) : digunakan untuk mengetahui bahasa yang digunakan orang yang berbicara
4. Pengenalan ucapan (speech recognition) : digunakan untuk mengetahui kata apa yang diucapkan seorang pembicara
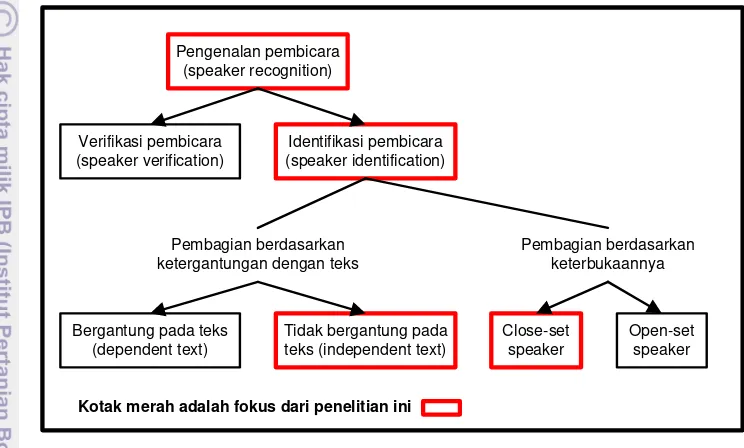
Dari informasi-informasi yang bisa didapat dari pengolahan ucapan di atas, identifikasi pembicara termasuk pada bagian pengenalan pembicara. Pengenalan pembicara adalah mengetahui siapa yang berbicara dari suara yang dikeluarkan (Tiwari 2010). Struktur anatomi saluran suara unik untuk setiap orang. Oleh sebab itu informasi suara yang tersedia di sinyal suara dapat digunakan untuk mengenali pembicara (Faundez-Zanuy dan Monte-Moreno 2005). Untuk lebih mempermudah bagian pengenalan pembicara yang menjadi fokus penelitian ini, perhatikan Gambar3 berikut ini.
Pengenalan pembicara
Kotak merah adalah fokus dari penelitian ini
Gambar 2. Ilustrasi fokus penelitian
Ilustrasi pada Gambar 3 menunjukkan bahwa pengenalan pembicara terbagi menjadi dua, yaitu verifikasi pembicara (speaker verification) dan identifikasi pembicara. Verifikasi pembicara digunakan untuk autentifikasi dan memonitor subjek manusia menggunakan sinyal ucapan (Fazel dan Chakrabartty 2011). Sedangkan identifikasi pembicara (speaker identification) bertujuan untuk mencari pembicara paling cocok untuk suara yang tidak diketahui pemiliknya dari
database pembicara(Kinnunen et al. 2011). Penelitian ini berfokus pada bagian identifikasi pembicara.
Berdasarkan ketergantungan pada teks, identifikasi pembicara terbagi menjadi dua, yaitu bergantung pada teks (dependent text) dan tidak bergantung pada teks (independent text). Pada identifikasi pembicara bergantung teks pembicara diharuskan menentukan kata-kata yang diucapkan terlebih dahulu (Singh 2003). Identifikasi pembicara dilakukan dengan kata-kata yang telah ditentukan tersebut. Sedangkan identifikasi pembicara tidak bergantung teks, pembicara tidak harus menetapkan kata-kata yang diucapkan terlebih dahulu (Singh 2003). Pada saat proses identifikasi, pembicara bebas mengucapkan kata apa saja. Penelitian ini akan menggunakan identifikasi pembicara tidak bergantung teks.
2012). Sedangkan identifikasi pembicara pada data tertutup hanya bisa menentukan identitas pembicara yang diuji jika pembicara tersebut telah terdaftar pada kelompok pembicara (Krothapalli et al. 2012). Penelitian ini akan lebih berfokus pada identifikasi pembicara pada data pembicara tertutup.
Gambar 4. Tingkatan informasi untuk pengenalan pembicara (Faundez-Zanuy dan Monte-Morento 2005)
Gambar 4 menunjukkan tingkatan informasi yang bisa digunakan untuk pengenalan pembicara. Bagian paling bawah adalah bagian yang paling mudah diekstrasi cirinya. Semakin atas, maka akan semakin sulit untuk mengektrasi cirinya. Ciri spectral bisa digunakan karena setiap manusia mempunyai spektrum yang berbeda untuk sebuah bunyi yang sama. Ciri prosodic adalah pengukuran terhadap tekanan, aksen dan intonasi. Ciri ini bisa estimasi dengan rata-rata nada, energi dan durasi suara. Ciri lain yang mungkin untuk diekstrasi adalah phonetic. Mencirikan pola berbicara dan pengucapkan sebuah fonem adalah hal yang memungkinkan. Sebuah fonem dapat diucapkan dengan cara yang berbeda oleh beberapa pembicara tanpa merubah makna. Tiga ciri lainnya yaitu ciri idiolectal
(hal yang berhubungan dengan sintaksis), dialogic dan ciri semantik lebih sulit diekstrasi. Tetapi ketiga ciri tersebut sangat berguna pada kasus-kasus tertentu. Misalnya untuk mempermudah pengenalan pembicara dengan ciri idiolectal. Hal ini dilakukan dengan menggunakan kata-kata yang sering pembicara gunakan (Doddington 2001).
Pada penelitian ini akan menggunakan fitur yang dihasilkan oleh spektrum ucapan. Fitur ini terbukti adalah cara yang paling efektif untuk pengenalan pembicara. Ini disebabkan spektrum mencerminkan geometri sistem yang membuat sinyal (Faundez-Zanuy dan Monte-Morento 2005). Oleh sebab itu keragaman dalam saluran suara dicerminkan oleh keragaman spektrum diantara para pembicara (Campbell et al. 2003).
Noise
Berdasarkan pada spektrum frekuensi noise dapat diklasifikasikan kategori sebagai berikut (Vaseghi, 2006):
1. White noise : noise yang secara murni diacak dan memiliki power
spektrum datar. Semua frekuensi dalam white noise secara teoritis memiliki intensitas yang sama.
2. Band limited white noise : noise dengan spektrum datar dan bandwidth yang terbatas, biasanya meliputi spektrum terbatas pada perangkat atau sinyal.
3. Narrow band noise : noise yang terjadi pada bandwidth yang sempit, contohnya 50-60 Hz.
4. Coloured noise: non white noise atau noise wideband yang spektrumnya memiliki bentuk tidak datar, contohnya adalah pink noise, brownnoise dan autoregressive noise.
5. Impulsive noise : terdiri dari durasi pendek sinyal dari amplitudo dan durasi acak.
6. Transient noise pulse : terdiri dari sinyal noise yang berdurasi relatif lama.
Penelitian ini akan menggunakan white noise yang dibuat dengan menggunakan Matlab 2010b. Noise yang digunakan adalah sebesar 20 dB. Fungsi yang digunakan adalah awgn. Cara kerja fungsi ini adalah dengan menambahkan
white noise dengan power sebesar power sinyal suara dikurangi dengan besar dB
noise yang diinginkan.Jika mode pada awgndibuat ‘measured’ makapower sinyal dihitung sebagai berikut:
� _ � � _ = log (�∑( � � _ � )
�=
)
N merupakan panjang sinyal suara. Tetapi jika mode awgn bukan ‘measured’ maka power sinyal suara dianggap 0. Penelitian ini menggunakan mode awgn yang bukan ‘measured’, sehingga power sinyal suara semuanya dianggap 0.Ilustrasi white noise dapat dilihat pada Gambar 5.
+
Sinyal suara asli
White noise
Sinyal suara asli + white noise
ANC (Active noise cancelling) membutuhkan noise referensi. Fungsi
awgn pada Matlab hanya mengeluarkan output sinyal suara asli yang sudah ditambah noise saja. Oleh sebab itu, pada penelitian inioutput darifungsi awgn
dimodifikasi agar bisa mengeluarkan noise. Noise tersebut digunakan sebagai
noise referensi ANC.
Self Organizing Map (SOM)
Self Organizing Map (SOM) pertama kali diusulkan oleh Teuvo Kohonen (1982). SOM atau juga dikenal dengan nama Kohonen, merupakan salah satu jenis dari jaringan syaraf tiruan (JST) atau artificial neural network (ANN) yang sistem pembelajarannya tidak terbimbing (unsupervised learning). SOM sangat efektif untuk menciptakan ruang representasi internal yang terorganisasi untuk berbagai fitur sinyal input (Kohonen 1990). SOM mengasumsikan struktur topologi diantara unit kluster, hal ini dijalankan oleh otak manusia tetapi tidak terdapat pada beberapa JST lainnya. Ilustrasi model SOM dapat dilihat pada Gambar 6.
Gambar 6. Ilustrasi model jaringan SOM (Haykin 1994)
Dalam pelatihan dengan menggunakan SOM harus ditentukan terlebih dahulu berapa jumlah kluster yang akan dihasilkan. Setelah itu dibuat vektor-vektor sejumlah kluster yang diinginkan. Vektor-vektor-vektor tersebut diberi bobot awal. Untuk setiap vektor latih dicari jarak terkecil dengan vektor-vektor kluster (atau vektor-vektor bobot). Vektor kluster yang jadi jarak terkecil tersebut merupakan vektor pemenang yang artinya vektor data latih termasuk pada sebuah kluster dimana vektor kluster terdapat. Setelah didapat jarak terkecil, perbaharui bobot vektor kluster tersebut beserta vektor-vektor kluster yang masih tetangganya. Lakukan hal-hal tersebut sampai kondisi berhenti terpenuhi. Kondisi berhenti adalah disaat tidak ada lagi perubahan kluster pada vektor latih atau telah mencapai iterasi maksimum. Untuk lebih jelasnya perhatikan Gambar 6. Algoritma (Fausett 2006) :
1. Inisialisasi bobot (w)
Atur parameter topologi dan fungsi ketetanggaan
Atur percepatan pembelajaran (α)
2. Ketika kondisi berhenti false (salah), lakukan langkah 2-8
dengan formula di bawah ini :)]
7. Perbaharui laju pembelajaran
8. Perbaharui radius fungsi ketetanggaan (pada waktu tertentu) 9. Uji kondisi berhenti
Pada algoritma diatas vektor-vektor bobot diinisialisasi dengan nilai acak kecil. Nilai laju pembelajaran tidak boleh terlalu besar karena jaringan SOM kemungkinan tidak akan belajar sehingga tidak konvergen, tetapi tidak boleh juga terkecil karena kemungkinan proses pembelajaran jaringan SOM akan lambat (Hecht-Nielsen 1990). Biasanya nilai laju pembelajaran adalah 0.1 ≤ α≤ 1.0.
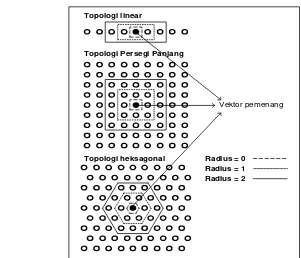
Ketetanggaan pada jaringan SOM ditentukan oleh radius dan topologi. Radius pada kasus jaringan SOM adalah berapa jumlah vektor setelah vektor pemenang yang akan diperbaharui bobotnya. Topologi jaringan SOM adalah cara penyusunan vektor-vektor kluster. Untuk lebih jelasnya perhatikan Gambar 6.
Pada Gambar 7 ada tiga buah topologi pada SOM, yaitu linear, persegi panjang dan heksagonal. Disana terlihat topologi tertentu dapat mempengaruhi jumlah tetangga vektor kluster pemenang yang diperbaharui nilainya meskipun radiusnya sama. Sebagai contoh dengan radius 1, jumlah tetangga yang diperbaharui pada topologi linear 2 buah, pada topologi persegi 8 buah dan pada topologi heksagonal 6 buah.
Topologi linear
Topologi Persegi Panjang
Topologi heksagonal Radius = 0 Radius = 1 Radius = 2
Vektor pemenang
Hasil dari pelatihan adalah vektor-vektor yang bobotnya telah disesuaikan dengan data latih. Jika ada data baru yang ingin diketahui klusternya, maka dihitung jaraknya dengan semua vektor-vektor kluster. Setelah itu pilih jarak terkecil sebagai kluster pemenang.
Mel Frequency Cepstral Coefficient (MFCC)
MFCC banyak digunakan sebagai ekstrasi ciri dalam berbagai bidang pengolahan sinyal suara (Muda et al. 2010, Nakagawa et al. 2012, Alam et al. 2012, Chen dan Luo 2009). Hal ini dikarenakan cara kerja MFCC didasarkan pada perbedaan frekuensi yang dapat ditangkap oleh telinga manusia sehingga bisa merepresentasikan bagaimana manusia menerima sinyal suara (Muda et al. 2010).
MFCC sendiri terdiri dari beberapa macam jenis, yaitu MFCC-FB20 (Davis dan Mermelstein 1980), HTK MFCC-FB24 (Young 1995), MFCC-FB40 (Slaney 1998) dan HFCC-E FB-29 (Skowronski dan Harris 2004). Pada penelitian ini akan menggunakan jenis MFCC-FB40 (selanjutnya akan ditulis MFCC saja) karena memiliki Equal Error Rate (EER) and Decision Cost Function (DCFopt) lebih rendah dari ketiga jenis MFCC lainnya (Ganchev et al. 2005). MFCC-FB40 adalah MFCC yang menerapkan 40 buah filter yang menangani frekuensi dara 133 Hz sampai 6854 Hz. Filter tersebut dibagi menjadi 2 bagian, 13 buah filter untuk ruang linear (200-1000 Hz) dan 27 buah untuk ruang logaritmik (1071-6400 Hz). Ilustrasi tahapan MFCC dapat dilihat pada Gambar 8.
mel
Gambar 8. Blok diagram tahapan MFCC (Patel dan Prasad 2013) Langkah ke 1 :Frame Blocking
Frame blocking adalah membagi sinyal yang masuk kedalam beberapa
frame. Pada tahap ini kita melakukan overlapping. Biasanya overlapping dimulai dari ukuran frame dibagi dengan dua yang disebut dengan istilah hop size. Untuk lebih jelasnya perhatikan Gambar 8. padaLangkah ke 2.
Langkah ke 2 :Windowing
Langkah selanjutnya adalah menghaluskan masing-masing frame untuk meminimalkan sinyal yang tidak kontinu pada awal dan akhir masing-masing
frame. Hal ini dilakukan dengan teknik hamming window. Teknik ini dipilih karena kesederhanaan formulanya (Buono 2009). Berikut rumus untuk hamming window (Patel dan Prasad 2013).
1
N = jumlah sample pada masing-masing frame
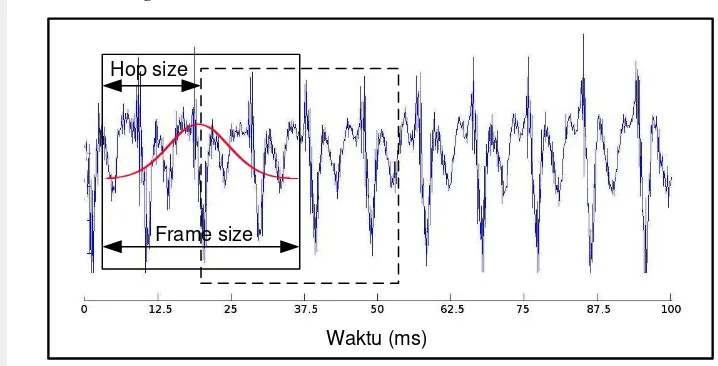
Gambar 9. memperlihatkan contoh frame blocking. Sumbu horizontal menerangkan suara yang masuk berdasarkan satuan waktu tertentu (ms/millisecond). Sedangkan sumbu vertikal menunjukan nilai amplitudo dari suara yang masuk. Pada gambar tersebut terlihat frame size adalah 30 ms dan hop size nya adalah 15 ms. Pada gambar tersebut juga terlihat garis melengkung yang disebut Hamming Window.
Hop size
Frame size
Waktu (ms)
Gambar 9. Ilustrasi frame blocking dan windowing
Langkah ke 3 :Fast Fourier Transform
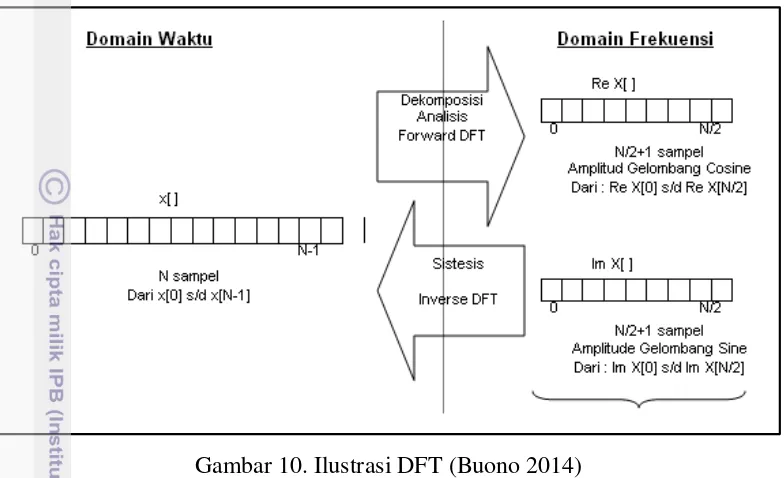
Langkah selanjutnya adalah Fast Fourier Transform (FFT). Hal ini dilakukan untuk mengubah frame dari domain waktu ke domain frekuensi. FFT adalah implementasi dari Discrete Fourier Transform (DFT). DFT sendiri adalah bagian dari transformasi Fourier. Berikut rumus DFT(Patel dan Prasad 2013).
sebagai input menjadi N/2+1 titik sinyal keluaran. Untuk lebih jelasnya perhatikan ilustrasi pada Gambar 10.
Gambar 10. Ilustrasi DFT (Buono 2014) Langkah 4 :Mel Frequency Wrapping
Peniruan cara kerja telinga manusia terjadi di bagian ini. Hal pertama yang harus dilakukan untuk mel frequency wrapping (MFW)adalah membuatmelfilter bank(MFB).Slaney (1998) menggunakan 40 buah MFB, yang terdiri dari 13 filter linear dan 27 buah filter logaritmik.MFB ini menangani frekuensi antara 133 Hz sampai 6854 Hz. Bobot segitiga dicari dengan cara sebagai berikut:
�� =
{
, < �− > �+ − �−
�− �− �+ − �−
, �− ≤ ≤ �
�+ −
�+ − � �+ − �−
, � ≤ ≤ �+
Hasil MFW didapat dengan cara melakukan log10 dari hasil perkalian
magnitudeFFTdengan MFB. Untuk lebih jelasnya perhatikan persamaan berikut ini:
� � = ∑ ��× ��
�=
, � … �
Gambar 11. Mel filter bank(Slaney 1998)
Terlihat pada Gambar 11mel filter bank merupakan segitiga tumpang tindih. Pada gambar tersebut sumbu horizontal adalah mewakili frekuensi dan sumbu vertikal mewakili db sinyal suara.
Langkah 5 : Cepstrum
Langkah terkahir dari proses ini adalah mengembalikan sinyal suara dari domain frekuensi ke domain waktu. Hasil dari langkah ini disebut MFCC. Berikut rumus untuk mencarinya (Patel dan Prasad 2013).
Least Means Square (LMS)
Pada penelitian ini akan digunakan NC jenis aktif atau yang lebih dikenal dengan active noise canceling (ANC). NC sebenarnya dapat dilakukan secara pasif maupun secara aktif. Secara pasif misalnya dengan menggunakan alat peredam suara, isolasi dan lain sebagainya. Tetapi noise canceling secara pasif tidak efektif pada frekuensi rendah (Kuo dan Morgan 1999, Eriksson et al. 1999) dan membutuhkan perangkat tambahan. Hal inilah yang menyebabkan penggunaan ANC lebih diminati. ANC adalah sebuah pendekatan untuk mengurangi noise menggunakan sumber noise sekunder yang secara destruktif menghilangkan suara yang tidak diinginkan (Oppenheim et al. 1994).Secara sederhana, ANC bekerja dengan cara memproduksi anti-noise untuk selanjutnya dikombinasikan dengan noise utama (Elliott 1999). Ilustrasi cara kerja ANC dapat dilihat pada Gambar 12.
Noise
Anti noise
Noise sisa
Gambar 12. Ilustrasi cara kerja ANC
Metode ANC yang akan digunakan pada penelitian ini adalah Least Mean Square (LMS). LMS adalah algoritma yang menerapkan gradient descent.
LMS menjadi popular karena kemudahannya untuk dimengerti, diprogram dan
di-debug (Widrow dan Stearns 1985). LMS memiliki kompleksitas yang rendah tetapi dengan hasil yang menjanjikan. Metode ini pertama kali dicetuskan oleh Widrow dan Hoff (1960). Steepest descent yang merupakan salah satu metode yang menerapkan gradient descent sebenarnya sudah sangat baik untuk menghasilkan bobot-bobot yang optimal, tetapi metode ini memerlukan gradien yang sesungguhnya pada setiap langkah. LMS bisa mengatasi kekurangan tersebut karena LMS secara instan bisa mengestimasi gradien pada setiap langkah (Widrow and Hoff 1960). Secara ringkas algoritma LMS adalah sebagai berikut.
1.Buat filter sejumlah M dan inisialisasi bobot koefisien (w) setiap filter 0, tentukan nilai learning rate (α) dan tentukan noise referensi (u).
2.Lakukan langkah 3 sampai 5 jika ada sinyal suara (d) masukan 3.Hitung anti noise dengan persamaan
3 METODE PENELITIAN
Mulai
Studi pustaka
- Sinyal suara - Identifikasi pembicara
- MFCC - SOM - Noise - LMS - Jarak Euclidean
Data latih
Pengumpulan data suara
Evaluasi
Selesai
Data uji
Praproses
-Penghilangan silent Penambahan Noise
Praproses -Penghilangan noise
-Penghilangan silent
Ekstrasi ciri
- MFCC
Ekstrasi ciri
- MFCC
Pembuatan codebook
- SOM
Pengukuran kemiripan
-Jarak euclidean
Dokumentasi dan laporan
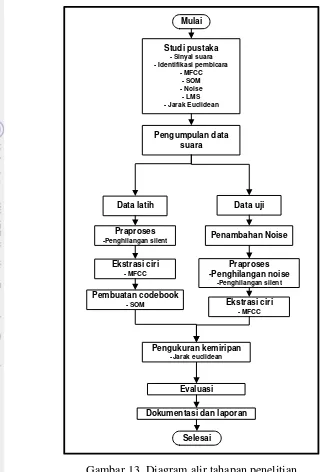
Gambar 13. Diagram alir tahapan penelitian
Tahap ketiga adalah membagi data suara menjadi data uji dan data latih. Pada data latih akan dilakukan proses penghilangan waktu diam, MFCC dan SOM sedangkan pada data uji akan dilakukan proses penambahan noise, penghilangan
Studi Pustaka
Bagian studi pustaka merupakan bagian untuk mengumpulkan teori-teori yang dibutuhkan untuk penelitian ini. Teori-teori dapat bersumber dari buku, jurnal atau apapun media yang dapat dijamin kebenarannya. Pada penelitian ini teori-teori yang diperlukan untuk dilakukan studi pustaka adalah teori tentang sinyal suara, identifikasi pembicara, noise, MFCC, SOM, LMS dan jarak
Euclidean.
Data Suara
Data suara yang digunakan adalah data suara yang pernah digunakan oleh Reda et. al (2011) dalam penelitian mereka tentang penelusuran seatu kehadiran. Data suara yang dikumpulkan memang ditujuan untuk identifikasi pembicara. Data suara terdiri dari 83 orang pembicara, yang terbagi menjadi 35 pembicara perempuan dan 48 pembicara laki-laki. Kata-kata yang diucapkan pembicara merupakan kombinasi dari angka-angka. Masing-masing pembicara memiliki 5
file data suara dalam bentuk wav. Panjang masing-masing file antara 1 detik sampai 39 detik, untuk lebih rincinya dapat dilihat pada Lampiran 6.
Pengumpulan data dilakukan dengan bekerja sama dengan Microsoft Research India. Perekaman dilakukan melalui telepon menggunakan sistem IVR (Interactive Voice Response) pada bulan Maret tahun 2011 di India. Sampling rate
yang digunakan adalah 8000 Hz. Para peserta adalah warga negara India dari berbagai latar belakang. Setiap peserta diberi beberapa deretan angka, dan diminta untuk membaca angka dengan menggunakan bahasa Inggris. Karena setiap pembicara memiliki 5 file suara, berarti ada 5 deretan angka yang masing-masing pembicara harus ucapkan. Berikut adalah contoh deretan angka yang diberikan kepada peserta.
File ke 1: 26503897147819045236217896345001376258948 File ke 2: 02154368
File ke 3: 6704352918719
File ke 4: 0635748219561047289
File ke 5: 7852934016275316948052843
Kode unik pembicara
Gambar 14. Ilustrasi data suara
Perancangan Model Identifikasi Pembicara
Secara garis besar model identifikasi pembicara yang dirancang oleh penelitian ini memiliki dua bagian utama, yaitu bagian pembuatan codebook dan bagian pengukuran kemiripan. Ilustrasi tentang model yang dibuat dapat dilihat pada Gambar 15.
Model identifikasi pembicara yang dibuat dimulai dengan tahapan pembuatan codebook. Codebook dibuat untuk masing-masing suara pembicara yang ada. Suara pembicara yang digunakan untuk membuat codebook adalah suara pembicara yang tanpa noise. Suara pembicara yang masuk dipraproses terlebih dahulu untuk menghilangkan waktu diam (silent). Waktu diam adalah waktu dimana tidak ada sinyal suara pembicara terdeteksi pada sinyal suara yang masuk. Cara ini akan membantu MFCC untuk menghasilkan ekstraksi ciri sinyal suara yang lebih baik. Hal ini disebabkan karena dengan cara ini sinyal suara yang diproses oleh MFCC adalah sinyal suara yang benar-benar berasal dari pembicara.
Suara
Codebook dibuat dengan menggunakan metode SOM. Hal pertama yang harus dilakukan untuk menggunakan SOM adalah menentukan berapa jumlah kluster yang diinginkan untuk vektor-vektor hasil MFCC. Setelah itu barulah vektor-vektor hasil MFCC milik masing-masing pembicara tersebut dilakukan proses SOM, sehingga untuk setiap pembicara dihasilkan sejumlah vektor pewakil sesuai dengan jumlah kluster yang ditentukan. Vektor-vektor pewakil tersebutlah yang akan dijadikan codebook. Vektor-vektor tersebut bisa juga disebut codeword. Sebenarnya semua vektor hasil MFCC bisa saja dijadikan codebook, tetapi tentu saja jumlah codeword pada codebook menjadi sebesar jumlah vektor.Dengan mengambil vektor-vektor centroid hasil SOM saja untuk dijadikan codebook, ini sama artinya mengurangi jumlah codeword, sehingga nantinya akan mempercepat proses perhitungan kemiripan pada saat mengidentifikasi suatu sinyal suara. Setiap codebook yang dihasilkan oleh setiap pembicara akan dikumpulan dalam suatu tempat yang disebut kumpulan codebook. Untuk lebih memperjelas cara kerja pembuatan codebook, perhatikan ilustrasi pada Gambar 16.
Suara pembicara ke 1
Gambar 16. Ilustrasi pembuatan codebook
Pengukuran kemiripan
Gambar 17. Ilustrasi pengukuran kemiripan
Seperti yang dijelaskan sebelumnya, pengukuran kemiripan dilakukan dengan menggunakan jarak Euclidean. Teknik penggunaan jarak Euclidean untuk pengukuran kemiripan yang dilakukan pada penelitian ini sedikit berbeda dengan penelitian sebelumnya (Wisnudisastra dan Buono 2010, Fruandta dan Buono 2011). Pada penelitian sebelumnya pengukuran kemiripan dilakukan dengan menggunakan hasil penjumlahan pasangan vektor. Setiap vektor hasil MFCC suara masukan yang akan diidentifikasi memiliki pasangan dengan sebuah vektor di setiap codebookpembicara yang ada. Pasangan vektor disini merupakan jarak terkecil suatu vektor masukan terhadap salah satu vektor yang ada pada codebook
tertentu. Pasangan yang berada pada codebook yang sama dijumlahkan jaraknya, sehingga setiap codebook memiliki hasil penjumlah jarak pasangan vektor. Lalu dipilih codebook yang hasil penjumlahannya terkecil sebagai pembicara yang mewakili suara yang diidentifikasi. Untuk lebih jelasnya perhatikan ilustrasi yang ada pada Gambar 18.
CB1
Setiap vektor hasil MFCC memiliki pasangan dengan sebuah vektor di setiap codebook yang ada. Pasangan merupakan jarak terkecil suatu vektor masukkan terhadap salah satu vektor pada yang ada pada codebook tertentu. Jarak pasangan yang berada pada codebook yang sama dijumlahkan, sehingga setiap codebook memiliki hasil penjumlah jarak pasangan. Lalu dipilih codebook yang hasil penjumlahannya terkecil sebagai pembicara yang mewakili suara yang dimasukkan
Teknik pengukuran kemiripan sebelumnya
Vektor masukkan hasil MFCC dari sebuah suara masukkan
Vektor yang ada di codebook
Jarak terkecil antara vektor masukkan hasil MFCC dengan vektor di suatu codebook tertentu
Pada penelitian ini pengukuran kemiripan dilakukan dengan cara memilih pembicara yang vektor-vektor pada codebook-nya memiliki pasangan dengan vektor-vektor hasil MFCC suara yang ingin diidentifikasi paling banyak. Pasangan vektor disini merupakan jarak terkecil yang didapat sebuah vektor hasil MFCC dengan salah satu vektor di kumpulan codebook. Pembicara yang vektor-vektor pada codebook-nya memiliki pasangan tersebut dipilih sebagai pembicara yang mewakili suara yang ingin didentifikasi. Jika jumlah pasangan vektor tersebar merata maka dipilih pasangan vektor yang mempuyai jarak terkecil. Untuk lebih jelasnya perhatikan ilustrasi pada Gambar 19.
Vektor masukkan hasil MFCC dari sebuah suara masukkan
Vektor yang ada di codebook
Jarak terkecil antara vektor masukkan hasil MFCC dengan vektor di kumpulan codebook
CB1
CB2
Setiap vektor hasil MFCC suara masukkan memiliki pasangan pada salah satu vektor yang ada di kumpulan codebook. Pasangan merupakan jarak terkecil yang didapat sebuah vektor hasil MFCC dengan salah sati vektor di kumpulan codebook. Dipilih codebook yang memiliki paling banyak pasangan sebagai pembicara yang mewakili suara yang dimasukkan
Teknik pengukuran kemiripan yang ditawarkan
Gambar 19. Ilustrasi teknik pengukuran kemiripan yang diusulkan
Pengujian Identifikasi Pembicara
Pengujian dilakukan untuk mengukur pengaruh beberapa parameter terhadap akurasi identifikasi pembicara. Parameter yang digunakan dapat dilihat pada Tabel 1. Akurasi identifikasi pembicara dihitung dengan cara berikut ini.
100
Tabel 1. Parameter-parameter yang akan dilihat pengaruhnya terhadap hasil identifikasi
Parameter Keterangan Ektrasi ciri (MFCC)
1 Panjang bingkai Panjang bingkai merupakan panjang waktu (biasanya millisecond) yang diinginkan untuk satu bingkai. Pada penelitian ini panjang bingkai yang akan diuji adalah 25 ms.
2 Overlap Overlap menjelaskan darimana bingkai selanjutnya dimulai. Nilai overlap harus lebih kecil dari 1.
Overlap yang digunakan adalah 0.4.
3 Koefesien cepstral Koefesien cepstral menjelaskan berapa jumlah spektrum yang dihasilkan untuk setiap bingkai. Koefesian yang digunakan pada penelitian ini adalah 13, 15 dan 20.
Pembuatan codebook
(SOM)
4 Jumlah kluster Jumlah kluster disini merupakan jumlah vektor yang ada pada setiap codebook pembicara. Jumlah kluster yang digunakan adalah 9, 16, 25, 36, 49, 64, 81 dan 100.
5 Radius tetangga Merupakan tetangga vektor pemenang yang akan ikut diperbaharui nilai bobotnya bersama vektor pemenang. Radius yang digunakan adalah 3.
6 Topologi Topologi yang akan digunakan pada SOM. Hal ini berpengaruh juga pada tetangga yang akan diperbaharui nilainya. Topologi yang akan digunakan pada penelitian ini adalahheksagonal.
Noise
7 dB noise Noise yang digunakan sebesar 20 dB terhadap suara asli.
Pra-proses 8 Learning rate pada
LMS
Pengujian ini dilakukan untuk mengukur pengaruh
learning rate pada LMS terhadap hasil akurasi identifikasi pembicara. Algoritma LMS digunakan pada suara yang telah diberi noise.
Pada bagian ini juga dibandingkan hasil identifikasi pembicara pada data yang mengalami noiseantara yang menggunakan LMS dengan yang tidak menggunakan LMS.
Nilai learning rate LMS yang dicoba adalah 0.1, 0.3, 0.5, 0.7 dan 0.9
Pengukuran kemiripan 9 Teknik penggunaan
jarak Euclidean
Seperti yang telah dijelaskan pada subbahasan tentang data suara bahwa jumlah file suara untuk setiap pembicara pada penelitian ini adalah lima, oleh karena itu untuk setiap kombinasi parameter dilakukan 5 kali percobaan. Pada setiap percobaan, satu buah file suara masing-masing pembicara akan dijadikan data untuk untuk membuat codebook dan semuafile suara yang ada akan dijadikan data pengujian. Hal ini dilakukan 5 kali hingga akhirnya semua file suara untuk masing-masing pembicara pernah menjadi data untuk membuat codebook. Misalnya untuk percobaan pertama file suara pertama dijadikan data pembuat
codebook, percobaan kedua file suara kedua yang dijadikan untuk pembuat
codebook, dan begitu seterusnya. Setiap percobaan dihitung akurasinya untuk selanjutnya hitung rata-rata akurasinya. Rata-rata akurasi tersebut digunakan sebagai pengukuran tingkat akurasi untuk sebuah kombinasi parameter tertentu.
4 HASIL DAN PEMBAHASAN
Bagian hasil dan pembahasan ini secara umum dibagi 2, yaitu percobaan pada data uji yang tidak diberi noise dan percobaan pada data uji yang telah diberi
noise. Pada percobaan data uji yang tidak diberi noise dikhususkan untuk membandingkan kemampuan teknik pengukuran kemiripan sebelumnya (Wisnudisastra dan Buono 2010, Fruandta dan Buono 2011) dengan teknik pengukuran kemiripan yang diusulkan dalam mengidentifikasi pembicara. Pada bagian pertama ini metode LMS belum digunakan karena belum ada noise yang ditambahkan pada data uji. Pada bagian kedua dilakukan percobaan pada data uji yang telah diberi noise. Bagian kedua ini bertujuan untuk membandingkan akurasi identifikasi pembicara antara data suara yang mengalami noise yang dilakukan praproses dengan LMS dan tanpa LMS. Selain itu pada bagian kedua ini juga dibandingkan kemampuan identifikasi pembicara pada data yang mengalami noise yang telah dilakukan praproses LMS antara teknik sebelumnya dan teknik yang diusulkan.
Percobaan pada Data Uji yang Tidak Diberi Noise
Koefesien MFCC 13
Grafik pada Gambar 20 menunjukkan pengaruh tingkat akurasi identifikasi pembicara dengan menggunakan koefisien MFCC 13 terhadap beberapa jumlah kluster SOM. Pada grafik tersebut terlihat bahwa pada saat jumlah kluster SOM 9 buah, akurasi teknik pengukuran kemiripan yang sebelumnya lebih baik daripada teknik pengukuran kemiripan yang diusulkan, yaitu 1.51% lebih tinggi. Tetapi pada saat jumlah kluster SOM ditingkatkan, maka teknik pengukuran kemiripan yang diusulkan menghasilkan nilai akurasi yang lebih baik. Peningkatan akurasi tertinggi terjadi pada jumlah kluster SOM 81 buah, yaitu 1.14%. Akurasi teknik yang diusulkan tetinggi terjadi pada jumlah kluster SOM 81 buah, yaitu 95.84%. Rata-rata peningkatan akurasi adalah 0,61%.
Gambar 20. Grafik perbandingan akurasi identifikasi pembicara pada data uji tanpa noise, koefisien MFCC13
Koefesien MFCC 15
Grafik pada Gambar 21 menunjukkan pengaruh tingkat akurasi identifikasi pembicara dengan menggunakan koefisien MFCC 15 terhadap beberapa jumlah kluster SOM. Pada grafik tersebut terlihat bahwa pada saat jumlah kluster SOM 9 buah, sama dengan saat koefisien MFCC 13, akurasi teknik pengukuran kemiripan yang sebelumnya lebih baik daripada teknik pengukuran kemiripan yang diusulkan, yaitu 0.42% lebih tinggi. Tetapi pada saat jumlah kluster SOM ditingkatkan, maka teknik pengukuran kemiripan yang diusulkanmenghasilkan nilai akurasi yang lebih baik. Peningkatan akurasi tertinggi terjadi pada jumlah kluster SOM 81 buah, yaitu 1.69%. Peningkatan ini lebih baik dari koefisien MFCC 13 sebelumnya yang hanya sebesar 1.14%. Akurasi teknik yang diusulkan tertinggi terjadi pada jumlah kluster SOM 49 buah dan 81 buah, yaitu 96.08%. Hal ini juga lebih baik dari MFCC 13 yang hanya mencapai akurasi tertinggi 95.84%. Rata-rata peningkatan akurasi dengan MFCC 15 adalah 0,98%, rata-rata ini lebih baik dari MFCC 13 sebelumnya yang hanya 0.61%.
Perbandingan Akurasi Percobaan (Koefesien MFCC = 13)
80
Teknik Sebelumnya 92.59 93.55 94.10 94.40 94.34 94.58 94.70 94.58
Teknik yang Ditawarkan 91.08 94.46 94.82 95.30 95.36 95.48 95.84 95.36
Gambar 21. Grafik perbandingan akurasi identifikasi pembicara pada data uji tanpa noise, koefisien MFCC 15
Koefesien MFCC 20
Grafik pada Gambar 22 menunjukkan pengaruh tingkat akurasi identifikasi pembicara dengan menggunakan koefisien MFCC 20 terhadap beberapa jumlah kluster SOM. Tidak seperti pada koefisien MFCC 13 dan 15, Pada saat jumlah kluster SOM 9 buah, akurasi teknik pengukuran kemiripan yang diusulkan sudah lebih baik daripada teknik pengukuran kemiripan sebelumnya, yaitu 0.72% lebih tinggi.
Gambar 22. Grafik perbandingan akurasi identifikasi pembicara pada data uji tanpa noise, koefisien MFCC 20
Peningkatan akurasi tertinggi terjadi pada jumlah kluster SOM 81 buah, yaitu 1.69%. Peningkatan ini sama dengan koefisien MFCC 15. Akurasi teknik yang diusulkan tertinggi terjadi pada jumlah kluster SOM 49 buah, yaitu 96.51%. Hal ini lebih baik dari koefesien MFCC 13 dan 15 yang hanya mencapai akurasi tertinggi masing-masing 95.84% dan 96.08%. Rata-rata peningkatan akurasi dengan MFCC dengan koefesien 20 adalah 1.27%, rata-rata ini lebih baik dari MFCC dengan koefesien 13 dan 15 yang masing-masing hanya 0.61% dan 0.98%.
Perbandingan Akurasi Percobaan (Koefesien MFCC = 15)
80
Teknik Sebelumnya 92.53 93.61 94.22 94.70 94.70 94.70 94.40 94.58
Teknik yang Ditawarkan 92.11 94.34 95.30 95.66 96.08 95.78 96.08 95.90
9 16 25 36 49 64 81 100
Perbandingan Akurasi Percobaan (Koefesien MFCC = 20)
80
Teknik Sebelumnya 93.37 94.10 94.94 94.82 94.88 94.88 94.70 94.94
Teknik yang Ditawarkan 94.10 95.00 95.84 96.45 96.51 96.20 96.39 96.33
Pengaruh Penambahan Jumlah Koefisien MFCC Terhadap Peningkatan Akurasi Identifikasi Pembicara
Gambar 23 merupakan grafik yang menunjukkan pengaruh penambahan jumlah koefisien MFCC terhadap peningkatan akurasi identifikasi pembicara disetiap jumlah kluster SOM pada penggunaan teknik pengukuran kemiripan yang diusulkan jika dibandingkan dengan teknik pengukuran kemiripan sebelumnya. Pada Gambar 21 tersebut terlihat bahwa dengan jumlah kluster SOM 9 dan jumlah koefesien MFCC sebesar 13 dan 15 teknik yang diusulkan tidak berhasil meningkatkan akurasi identifikasi pembicara. Pada jumlah kluster tersebut teknik yang diusulkan justru membuat penuruan akurasi, untuk koefesien MFCC 13 dan 15 masing-masing sebesar -1.51 dan -0.42. Tetapi pada saat jumlah koefesien MFCC dinaikan menjadi 20 penggunaan teknik yang diusulkan pada jumlah kluster SOM 9 telah berhasil meningkatkan akurasi identifikasi pembicara yaitu sebesar sebesar 0.72%.
Gambar 23. Pengaruh peningkatan MFCC terhadap akurasi identifikasi pembicara.
Grafik pada Gambar 23 memperlihatkan pada saat jumlah kluster SOM 16 dan 25, peningkatan jumlah koefesien MFCC tidak mengakibatkan peningkatan akurasi dalam identifikasi pembicara. Pada saat jumlah kluster SOM 25 peningkatan akurasi tertinggi justru terjadi pada jumlah koefesien MFCC 15 yaitu sebesar 1.08% sedangkan pada saat jumlah kluster SOM 16 peningkatan
jumlah koefesien baru terlihat dapat meningkatkan akurasi identifikasi pembicara pada saat jumlah kluster SOM besar sama 36. Tetapi meskipun begitu pada jumlah kluster SOM 81, MFCC dengan jumlah koefesien 15 dan 20 menghasilkan peningkatan akurasi yang sama yaitu sebesar 1.69%. Peningkatan akurasi tertinggi terjadi pada saat jumlah kluster SOM 81 dengan jumlah koefesien MFCC 15 dan 20 yaitu sebesar 1.69%.
Peningkatan akurasi juga bisa dilihat dari jumlah kluster SOM. Jika dilihat dari grafik pada Gambar 23, untuk semua jumlah koefesien MFCC yang sama, peningkatan jumlah kluster SOM tidak selalu menghasilkan peningkatan akurasi identifkasi pembicara. Tetapi meskipun begitu, grafik tersebut menunjukan peningkatan akurasi tertinggi selalu terjadi pada saat jumlah kluster SOM 81.
Percobaan pada Data Uji yang Diberi Noise
Percobaan ini dilakukan pada data uji yang telah diberi noise terlebih dahulu. Inti dari percobaan ini adalah untuk menguji pengaruh algoritma LMS dalam identifikasi pembicara pada data uji yang mengalami noise. Noise yang digunakan disini adalah sebesar 20 dB terhadap suara asli. Pada percobaan ini proses LMS dilakukan pada praproses data. Selain itu percobaan disini juga akan membandingkan kemampuan identifikasi pembicara antara teknik sebelumnya dan teknik yang diusulkan pada data uji yang diberi noise. Percobaan dilakukan dengan merubah beberapa nilai parameter. Parameter yang dirubah-rubah nilainya adalah learning rate LMS, koefisien MFCC dan jumlah kluster pada SOM. Learning rate ANC yang dicoba adalah 0.1, 0.3, 0.5, 0.7 dan 0.9. Koefisien MFCC yang dicoba adalah 13, 15 dan 20. Jumlah kluster SOM yang akan dicoba adalah 9, 16, 25, 36, 49, 64, 81 dan 100. Selain itu ada parameter yang dibuat tetap selama percobaan, yaitu panjang frame MFCC adalah 25 ms, overlap MFCC adalah 0.4, topologi SOM adalah heksagonal dan jumlah iterasi SOM adalah 1000.
Koefesien MFCC 13
Hasil percobaan koefesien MFCC 13 yang dibahas disini adalah hasil percobaan yang menggunakan nilai learning rate 0.7 pada LMS. Hasil percobaan ini dipilih karena akurasi identifikasi pembicara dengan menggunakan koefesien MFCC 13 tertinggi terjadi pada percobaan ini. Hasil percobaan lain dapat dilihat pada Lampiran 1.
Grafik pada Gambar 24 menunjukkan akurasi identifikasi pembicara tertinggi pada data uji noiseyang tidak menggunakan LMS pada praproses datanya sangat rendah, yaitu 1.45% pada teknik sebelumnya dan 1.63% pada teknik yang diusulkan. Kedua akurasi tersebut terjadi pada jumlah kluster SOM 9.
teknik sebelumnya pada data uji mengalami noise yang telah dilakukan proses LMS cukup signifikan, yaitu peningkatan paling tinggi 8.37%.
Gambar 24. Grafik perbandingan akurasi identifikasi pembicara, noise 20 dBkoefisien MFCC 13, LR ANC 0.7
Koefesien MFCC 15
Hasil percobaan koefesien MFCC 15 yang dibahas disini adalah hasil percobaan yang menggunakan nilai learning rate 0.7 pada LMS. Hasil percobaan ini dipilih karena akurasi identifikasi pembicara dengan menggunakan koefesien MFCC 15 tertinggi terjadi pada percobaan ini. Hasil percobaan lain dapat dilihat pada Lampiran 1.
Sama dengan pada koefesien MFCC 13, akurasi identifikasi pembicara pada koefesien MFCC 15 sebelum menggunakan LMS pada praproses data sangat rendah. Pada teknik sebelumnya akurasi tertinggi identifikasi pembicara hanya 1.93%, ini terjadi pada jumlah kluster SOM 9. Sedangkan pada teknik yang diusulkan akurasi tertinggi identifikasi pembicara hanya 1.99 %, ini terjadi pada jumlah kluster SOM 9 dan 16.
Grafik pada Gambar 25 menunjukkan akurasi identifikasi pembicara menjadi sangat meningkat setelah dilakukan algoritma LMS pada praproses data. Akurasi tertinggi dengan teknik sebelumnya adalah 83.13%. Akurasi ini terjadi pada jumlah kluster SOM 100. Perbedaan akurasi tidak terlalu jauh jika dibandingkan dengan MFCC kofesien 13, yaitu meningkat hanya 0,78%. Akurasi tertinggi dengan menggunakan teknik yang diusulkan adalah 91.33%. Akurasi ini terjadi pada jumlah kluster SOM 64. Sama dengan teknik sebelumnya, perbedaan akurasi teknik yang diusulkan jika dibandingkan dengan MFCC dengan koefesien 13 tidak jauh berbeda, yaitu hanya meningkat 0.61%. Jika dibandingkan antara
Perbandingan Akurasi, DB 20, MFCC 13, LR ANC 0.7
0.00
Teknik sebelumnya tanpa ANC 1.45 1.39 1.39 1.02 1.08 1.02 0.96 0.90
Teknik sebelumnya dngn ANC 78.19 81.20 82.23 82.17 82.05 82.35 82.29 81.99
Teknik ditawarkan tanpa ANC 1.63 1.39 1.33 1.08 1.08 0.96 1.02 1.02
Teknik ditawarkan dengan ANC 84.70 88.73 89.94 90.06 90.60 90.72 90.66 90.54
teknik sebelumnya peningkatan akurasi identifikasi pembicara teknik yang diusulkan pada koefesien MFCC 15 cukup signifikan yaitu 8.2%.
Gambar 25. Grafik perbandingan akurasi identifikasi pembicara, noise 20 dBkoefisien MFCC 20, LR ANC 0.7
Koefesien MFCC 20
Hasil percobaan koefesien MFCC 20 yang dibahas disini adalah hasil percobaan yang menggunakan nilai learning rate 0.7 pada LMS. Hasil percobaan ini dipilih karena akurasi identifikasi pembicara dengan menggunakan koefesien MFCC 20 tertinggi terjadi pada percobaan ini. Hasil percobaan lain dapat dilihat pada Lampiran 1.
Sama dengan pada koefesien MFCC 13 dan 15, akurasi identifikasi pembicara pada koefesien MFCC 20 sebelum menggunakan LMS pada prarposes data sangat rendah. Pada teknik sebelumnya akurasi tertinggi identifikasi pembicara hanya 2.11%, ini terjadi pada jumlah kluster SOM 9. Sedangkan pada teknik yang diusulkan akurasi tetinggi identifikasi pembicara hanya 1.93 %, ini terjadi pada jumlah kluster SOM 9.
Grafik pada Gambar 26 menunjukkan akurasi identifikasi pembicara pada koefesien MFCC 20 menjadi sangat meningkat setelah dilakukan algoritma LMS pada praproses data. Akurasi tertinggi dengan teknik sebelumnya adalah 84.64%. Akurasi ini terjadi pada jumlah kluster SOM 100. Perbedaan akurasi tidak terlalu jauh jika dibandingkan dengan MFCC kofesien 13 dan 15, yaitu masing-masing meningkat hanya 2.29% dan 1.51%. Akurasi tertinggi dengan menggunakan teknik yang diusulkan adalah 92.47%. Akurasi ini terjadi pada jumlah kluster SOM 64. Sama dengan teknik sebelumnya, perbedaan akurasi teknik yang diusulkan jika dibandingkan dengan MFCC dengan koefesien 13 dan 15 tidak jauh berbeda, yaitu masing-masing hanya meningkat 1.75% dan 1.14%.
Perbandingan Akurasi, DB 20, MFCC 15, LR ANC 0.7
0.00
Teknik sebelumnya tanpa ANC 1.93 1.75 0.96 0.96 1.33 0.78 1.20 1.14
Teknik sebelumnya dngn ANC 79.46 81.57 82.77 82.71 82.65 82.53 82.77 83.13
Teknik ditawarkan tanpa ANC 1.99 1.99 1.14 1.27 0.96 1.02 1.08 1.20
Teknik ditawarkan dengan ANC 86.81 89.46 91.14 91.27 91.20 91.33 91.08 90.84