SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
RESA TRESNADI
10110050
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
kepada Allah SWT atas berkat, rahmat, taufik dan hidayah-Nya, penyusunan skripsi yang berjudul “PENERAPAN DATA MINING PADA PENJUALAN PRODUK BAJU DI AIRPLANE SYSTM” dapat diselesaikan dengan baik.
Adapun tujuan dari penyusunan skripsi ini adalah untuk memenuhi salah satu syarat dalam menyelesaikan studi jenjang strata satu (S1) di Program Studi Teknik Informatika Universitas Komputer Indonesia.
Penulis menyadari bahwa dalam proses penulisan skripsi ini banyak mengalami kendala, namun berkat bantuan, bimbingan, kerjasama dari berbagai pihak dan berkah dari Allah SWT sehingga kendala-kendala yang dihadapi dapat diatasi. Untuk itu penulis menyampaikan rasa hormat dan terima kasih sebesar-besarnya kepada :
1. Allah SWT yang telah mencurahkan rahmat dan hidayah-Nya hingga detik ini.
2. Ibu Dian Dharmayanti, S.T., M.Kom. selaku dosen pembimbing serta dosen penguji 2 yang telah meluangkan waktu, tenaga, pikiran, memberikan motivasi, arahan dan saran serta ilmu pengetahuannya kepada penulis dalam penyusunan skripsi ini.
3. Bapak Andri Heryandi, S.T.,M.T. selaku dosen penguji 1 yang telah memberikan saran serta kritiknya dalam penyusunan skripsi ini.
4. Bapak Irfan Maliki, S.T., M.T. selaku dosen penguji 3 yang telah memberikan saran serta kritiknya dalam penyusunan skripsi ini.
5. Bapak Iskandar Ikbal, S.T., M.Kom. selaku ketua panitia skripsi yang telah memberikan bantuan dalam kelancaran penyusunan skripsi ini.
iv
tulus selalu mendoakan, memberikan dorongan moril dan materil, masukan, perhatian, dukungan sepenuhnya, dan kasih sayang yang tidak ternilai dan tanpa batas yang telah kalian memberikan yang terbaik untuk .
2. Kepada teman-teman kelas IF-2 angkatan 2010 atas dukungan dan kebersamaannya, terutama untuk M. Fajar Ramadhani yang telah bersedia meluangkan waktunya untuk berbagi pendapat dengan penulis dalam menyelesaikan skripsi ini.
3. Kepada teman-teman satu bimbingan Ibu Dian Dharmayanti, S.T., M.Kom. atas dukungan dan kebersamaannya untuk penulis dalam menyelesaikan skripsi ini.
4. Kepada Bang Putra atas dukungan nya dalam menyelesaikan skripsi ini dalam membantu pembuatan aplikasi.
5. Kepada Barudak HFFGODIN atas dukungan yang diberikan untuk penulis dalam menyelesaikan skripsi ini.
6. Semua pihak yang tidak dapat penulis sebut satu persatu yang telah membantu dalam penyelesaian penulisan skripsi ini.
Keterbatasan kemampuan, pengetahuan dan pengalaman penulis dalam pembuatan skripsi ini masih jauh dari kesempurnaan. Untuk itu penulis akan selalu menerima segala masukan yang ditujukan untuk menyempurnakan skripsi ini. Akhir kata penulis mengharapkan semoga skripsi ini dapat bermanfaat serta manambah wawasan pengetahuan baik bagi penulis sendiri maupun bagi pembaca pada umunya,
Bandung, 19 Agustus 2015
v
1.5.1 Metode Pengumpulan Data ...3
1.5.1.1 Studi Lapangan ...3
1.5.1.2 Studi Literatur...4
1.6 Metode Pengembangan Perangkat Lunak ...4
1.7 Metode Pembangunan Data Mining...5
1.8 Sistematika Penulisan ...8
BAB 2 TINJAUAN PUSTAKA ...9
2.1 Sekilas Tempat Penelitian ...9
2.1.1 Logo Perusahaan ...9
2.1.2 Visi dan Misi...10
2.1.3 Struktur Organisasi Perusahaan ...10
2.1.4 Deskripsi Kerja ...10
2.2 Landasan Teori...11
2.2.1 Pengertian Data, Informasi dan Knowledge ...11
2.2.2.1 Pengertian Data Mining...12
2.2.2.2 Pekerjaan Dalam Data Mining ...12
2.2.2.3 Konsep Data Mining...15
2.2.2.4 Tahapan Data Mining ...17
2.2.3 Association Rule ...18
2.2.4 Algoritma FP- Growth ...24
2.2.5 Alat-Alat Pemodelan Sistem...27
2.2.6 Microsoft Visual Studio ...29
2.2.7 MySQL ...30
BAB 3 ANALISIS DAN PERANCANGAN ...31
3.1 Analisis Sistem...31
3.1.1 Analisis Masalah ...31
3.1.2 Analisis Data Mining ...31
3.2 Analisis Spesifikasi Kebutuhan Perangkat Lunak ...81
3.2.1 Analisis Kebutuhan Non-Fungsional ...81
3.2.2 Analisis Kebutuhan Fungsional ...83
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM...101
4.1 Implementasi Sistem ...101
4.1.1 Perangkat Keras yang Digunakan ...101
4.1.2 Perangkat Lunak yang Digunakan ...102
4.1.3 Implementasi Basis Data...102
4.1.4 Implementasi Antarmuka...103
4.2 Pengujian Sistem...104
4.2.1 Pengujian Alpha...104
4.2.1.1 Kesimpulan Pengujian Alpha ...107
4.2.2 Pengujian Beta ...107
4.2.2.1 Kesimpulan Pengujian Beta...108
4.2.3 Pengujian Hasil ...108
4.2.3.1 Kesimpulan Pengujian Hasil ...112
BAB 5 KESIMPULAN DAN SARAN ...113
114
[2] S. M. A. S. Rosa, 2013. Rekayasa Perangkat Lunak Terstruktur dan Berorientasi Objek. Bandung: Informatika Bandung.
[3] Pate Chapman, 2000. [Online]. Available: http://the-modeling-agency.com/crisp-dm.pdf. [Accessed 21 Februari 2015].
[4] Prasetyo, Eko. 2012. DATA MINING: Konsep dan Aplikasi Menggunakan MATLAB, Yogyakarta: ANDI.
[5] Widiati, Elsa. 2014. Implementasi Data Mining Menggunakan Aturan association Rules Terhadap Penyusunan Layout Makanan dan Penentuan Paket Makanan Hemat Di RM. Roso Echo Dengan Algoritma Apriori, Bandung: Universitas Komputer Indonesia.
[6] Santosa, Budi. 2007. DATA MINING : Teknik Pemanfaatan Data Untuk Keperluan Bisnis, Yogyakarta,Graha Ilmu.
[7] Luthfi, K. d. E. T. 2009.ALGORITMA DATA MINING, Yogyakarta: Andi. [8] Witten, I, H. 2011. Data Mining : practical machine learning tools and
techniques.
[9] Ruldeviyani, Yova. 2008. Implementasi Algoritma-Algoritma Asociation Rules Sebagai Bagian Dari Pengembangan Data Mining Algorithms Collection, Universitas Indonesia.
[10] Arhami, Muhammad. 2010. Rekayasa Perangkat Lunak: DATA Flow Diagram (DFD) dan Kamus Data, Politeknik Negeri Lhokseumawe
[11] E. I. 2008. Belajar Pemograman C#, Yogyakarta : Andi.
[12] (sumber : An Introduction to Database System, Canada: ( Adision – Wessley Publishing Company, 181, Third Edition ), hal 237.).
1
1.1 Latar Belakang Masalah
AIRPLANE SYSTM adalah sebuah perusahaan yang sudah berdiri sejak tahun 1988 yang bergerak dibidang penjualan produk pakaian seperti baju,
sweater, celana dan lain sebagainya. AIRPLANE SYSTM memiliki beberapa agenretail outlet pendistribusian barang yang disebutspace dealer yang tersebar di beberapa kota besar yang ada di indonesia. Beberapa data penjualan yang diterima dari space dealer pada setiap bulannya dengan jumlah transaksi yang banyak dan memiliki variasi dari kebutuhan barang yang diminta oleh setiap
space dealerperbulannya. Dari waktu ke waktu data penjualan yang ada semakin banyak dan hanya menjadi arsip saja tanpa adanya pengolahan untuk mendapatkan informasi didalamnnya. Dalam perjalannanya AIRPLANE SYSTM merupakan distro yang paling diminati.
Tema desain mereka yang disebut art, biasanya selalu ditunggu para konsumen bahkan sebelum dirilis. Namun penjualan AIRPLANE SYSTM beberapa bulan ke belakang mengalami penurunan karena pemilihan art pada bulan tersebut tidak sebaik di bulan-bulan sebelumnya. Hal ini tentu saja akan mempengaruhi penjualan dalam beberapa waktu yang akan datang khususnya pada produk baju yang hampir setiap bulan diproduksi. Maka dari itu AIRPLANE SYSTM memerlukan suatu metode untuk dapat memanfaatkan data penjualan yang ada untuk dijadikan pola penjualan guna sebagai informasi bagi AIRPLANE SYSTM. Dengan menggunakan teknik data mining association rule diharapkan memberikan gambaran kepada pihak AIRPLANE SYSTM untuk menentukan pola dalam penjualan produk baju untuk setiap bulannya. Association rule
adalah salah satu metode data mining untuk menentukan pola dari suatu barang yang selalu dipilih dari setiap kejadiannya. Proses pemampatan data dengan model struktur data pohon untuk menghindari pengulangan scanning database
FP-Growth yang dapat langsung mengekstrak frequent itemset dari FP-Tree yang telah berbentuk dengan menggunakan prinsipdivide and conquer.
Dari pertimbangan atas penjelasan yang telah dipaparkan diatas, maka dibutuhkan suatu aplikasi “Penerapan Data Mining Association Rule Pada Penjualan Produk Baju di AIRPLANE SYSTM ” untuk mendapatkan pola barang yang tepat untuk meningkatkan penjualan dibulan selanjutnya.
1.2 Identifikasi Masalah
Berdasarkan latar belakang yang disebut di atas, permasalahan yang dapat diidentifikasi adalah :
Data penjualan produk hanya disimpan saja tanpa ada pemanfaatan data lebih lanjut untuk menghasilkan sebuah informasi yang berguna untuk menentukan strategi penjualan produk.
AIRPLANE SYSTM membutuhkan suatu sistem yang dapat memperoleh suatu pola dengan kecenderungan pemesanan produk baju dari setiapspace dealer
serta penjualan oleh pihak AIRPLANE SYSTM sendiri berdasarkan dari jumlah penjualan produk untuk melihat kecenderungan disetiap space dealer dan AIRPLANE SYSTM terhadap produk baju.
1.3 Maksud dan Tujuan
Berdasarkan permasalahan yang diteliti, maka maksud dari penulisan tugas akhir ini adalah untuk membangun sebuah aplikasi data mining pada data penjualan di AIRPLANE SYSTM dengan metodeAssociation rules.
Sedangkan tujuan dari penelitian ini adalah sebagai berikut :
1. Untuk mengolah dan memanfaatkan tumpukan data penjualan AIRPLANE SYSTM agar mendapatkan informasi didalam data penjualan tersebut.
2. Membantu pihak AIRPLANE SYSTM untuk mendapatkan informasi yang bermanfaat mengenai art apa harus diproduksi berdasarkan dari data penjualan yang sudah diolah berguna untuk meningkatkan penjualan dibulan berikutnya.
1.4 Batasan Masalah
a. Menggunakanassociation rule untuk menghasilkanrule dan algoritma FP –Growth untuk menemukan pola kombinasiitemsetyang telah dioptimasi. b. Data yang digunakan adalah data penjualan produk baju di AIRPLANE
SYSTM periode Januari–Desember 2014. c. Aplikasi yang akan dibuat berbasis desktop.
d. Bahasa pemograman yang digunakan adalah C# dan MySQL sebagai penyimpanandatabase.
1.5 Metodologi Penelitian
Metode penelitian merupakan cara utama yang digunakan peneliti untuk mencapai tujuan dan menentukan jawaban atas masalah yang diajukan [1]. Pada penelitian kali ini penulis akan menggunakan metode penelitian deskriptif.
Metode penelitian deskriptif adalah suatu metode untuk meneliti status sekelompok manusia, suatu objek, suatu set kondisi suatu sistem pemikiran ataupun suatu kelas peristiwa pada masa sekarang. Tujuan dari penelitian deskriptif ini adalah untuk membuat deskripsi, gambaran atau lukisan secara sistematis, faktual, dan akurat mengenai fakta-fakta, sifat-sifat serta hubungan antar fenomena yang diselidiki [1].
1.5.1 Metode Pengumpulan Data
Metodologi penelitian yang digunakan dalam pembangunan sistem untuk tugas akhir ini adalah sebagai berikut :
1. Studi Lapangan a. Observasi
Teknik pengumpulan data dengan mengadakan penelitian dan peninjauan langsung terhadap permasalahan yang diambil.
b. Wawancara
Mengadakan wawancara dengan pihak-pihak yang berkaitan langsung dengan permasalahan yang sedang dibahas pada tugas akhir ini untuk memperoleh gambaran dan penjelasan secara mendasar.
2. Studi Literatur
1.6 Metode Pengembangan Perangkat Lunak
Dalam pembangunan aplikasi ini menggunakan waterfall model sebagi tahapan pembangunan perangkat lunaknya. Adapun proses tersebut antara lain:
1. Requirement Analysis and Definition
Tahap requirement analysis and definition adalah tahap dimana pengumpulan kebutuhan telah terdefinisi secara lengkap kemudian dianalisis dan didefinisikan kebutuhan yang harus dipenuhi oleh program yang akan dibangun. Fase ini harus dikerjakan secara lengkap untuk bisa menghasilkan desain yang lengkap.
2. System and software design
Tahap system dan software design merupakan tahap mendesain perangkat lunak yang dikerjakan setelah kebutuhan selesai dikumpulkan secara lengkap.
3. Implementation and unit testing
Tahap implementation and unit testing merupakan tahap hasil desain program diterjemahkan ke dalam kode-kode dengan menggunakan bahasa pemograman yang sudah ditentukan. Program yang dibangun langsung diuji berdasarkan unit-unitnya.
4. Integration and System Testing
Tahapintegration and system testingmerupakan tahap penyatuan unit-unit program kemudian sistem diuji secara keseluruhan.
5. Operation and maintenance
Tahap operation and maintenance merupakan tahap mengoperasikan program dilingkungannya dan melakukan pemeliharaan, seperti penyesuaian atau perubahan karena adaptasi dengan situasi yang sebenarnya.
Gambar 1.1 MetodeWaterfall[2]
1.7 Metode PembangunanData Mining
Dalam penelitian ini mengikuti standar dariCross –Industry Standard for Data Mining (CRISP-DM) merupakan suatu standar yang telah dikembangkan pada tahun 1996 yang ditunjukan untuk melakukan proses analisis dari suatu industri sebagai strategi pemecahan masalah dari bisnis atau unit penelitian [3]. Untuk data yang dapat di proses dengan CRSP-DM ini, tidak ada ketentuan atau karakteristik tertentu, karena data tersebut akan diproses kembali pada fase–fase di dalamnya. Berikut ini adalah tahapan – tahapan yang akan dilakukan dalam penelitian ini sesuai dengan CRSP-DM :
1. Pemahaman bisnis
Pengimpelemntasian data mining pada penelitian ini adalah untuk melihat bagaimana kecenderungan pola dari setiap space dealer terhadap produk baju dengan memanfaatkan tumpukan data yang sudah ada, akan tetapi karena belum adanya suatu metode yang digunakan di AIRPLANE SYSTM untuk memanfaatkan kumpulan data tersebut menjadi sebuah informasi yang berharga, yang dapat digunakan untuk menentukan atau merancang strategi penjualan untuk produk baju dengan jumlah yang sesuai dengan kebutuhan
pengambilan keputusan seperti pemasaran produk, pemberian fasilitas dan pelayanan terhadap kantor cabang.
2. Pemahaman Data
Pada tahap pemahaman data ini terlebih dahulu akan mengumpulkan semua data yang diperlukan, data yang ada ini adalah data kantor cabang, data agen
retail outlet, dan data penjualan produk dari Desember tahun 2013–Desember 2014. Analisis data yang akan dilakukan mengenai bagaimana membuat sebuah atribut untuk melihat bagaiman pola penjualan ditiap bulannya, dengan melihat faktor-faktor yang mempengaruhinya, seperti tema, warna, ukuran baju. Bagaimana faktor–faktor tersebut dapat dijadikan acuan untuk mendapatkan informasi atau pengetahuan sesuai dengan pemahaman bisnis pada tahap sebelumnya.
3. Pengolahan Data
Pada tahapan ini akan dilakukan proses pemilihan dan pengolahan data yang nantinya akan diperlukan dalam tahap pemodelan sehingga pemodelan yang dilakukan dapat memberikan hasil yang maksimal sesuai dengan target yang diinginkan, data yang akan dipilih adalah data penjualan produk di AIRPLANE SYSTM perbulan.
4. Pemodelan
Dalam tahapan pemodelan ini akan dilakukan teknik association dengan menggunakan algoritma FP-Growth untuk mendapatkan hasil berupa atribut-atribut berdasarkan jumlah produk penjualan yang terdapat dalam space dealer
dan AIRPLANE SYSTM tersebut. 5. Evaluasi
6. Penyebaran
Setelah tahap evaluasi dimana menilai secara detail hasil dari pemodelan, maka dilakukan pengimplementasian dari keseluruhan model yang telah dirancang. Selain itu juga dilakukan penyesuaian dari model dengan sistem yang akan dibangun sehingga dapat menghasilkan suatu hasil yang sesuai dengan target pemahaman bisnis.
Gambar 1.
Gambar 1.2CRIPS-DM Model[3] 1.8 Sistematika Penulisan
Sistematika penulisan tugas akhir ini disusun untuk memberikan gambaran secara umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB 1 PENDAHULUAN
BAB 2 TINJAUAN PUSTAKA
Membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan dan hal-hal yang berguna dalam proses analisis permasalahan. Membahas tentang konsep dasar serta teori-teori yang berkaitan dengan topik penelitian dan yang melandasi penerapan data mining untuk menentukan strategi pasar.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Membahas tentang hasil analisis terhadap sistem yang sedang berjalan untuk mengetahui kekurangan dan kebutuhan sistem yang akan dibangun agar menjadi lebih baik. Menjelaskan tentang perencanaan sistem secara keseluruhan berdasarkan hasil dari analisis perancangan sistem ini mencakup perancangan basis data, perancangan menu, dan perancangan interface atau antarmuka sistem yang akan dibangun.
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi tentang implementasi dan pengujian sistem yang telah dikerjakan, yang terdiri dari menerapkan rencana implementasi, melakukan kegiatan implementasi, dan tindak lanjut implementasi. Selain itu juga berisi pengujian aplikasi yang dikerjakan.
BAB 5 KESIMPULAN DAN SARAN
9
2.1 Sekilas Tempat Penelitian
AIRPLANE SYSTM adalah salah satu pioneer distro di Bandung yang sudah berdiri sejak awal-awal distro sedang menjamur di tahun 1998. Perusahaan yang bergerak di dunia industri kreatif ini mengambil nama Airplane karena sebagai simbol tercepat layanan yang paling modern dan canggih untuk semua orang yang diangkut ke daerah sasaran di era modern. Dengan layanan dan material yang kuat seperti halnya dalam pembuatan pesawat terbang, perusahaan ini berusaha keras membangun citra yang baik dan selalu go public bagi mereka yang dinamis dan hidup di era modern ini. Desain produk merupakan komitmen untuk kerja keras dan rasa hormat terhadap detail yang rumit, kuat, dan modis, dengan desain kualitas tinggi dan bahan. Semua ini disajikan dan terintegrasi dalam keinginan untuk memberikan solusi bagi kebutuhan gaya hidup remaja.
2.1.1 Logo Perusahaan
Logo dari AIRPLANE SYSTM dapat dilihat pada gambar 2.1 dibawah ini:
2.1.2 Visi dan Misi
Visi AIRPLANE SYSTM adalah memberikan warna baru dalam industri kreatif dan menjadi perusahaan desain produk distro terkemuka di Indonesia. Semua ini disajikan dan terintegrasi dalam keinginan untuk memberikan solusi bagi kebutuhan gaya hidup remaja.
AIRPLANE SYSTM mempunyai misi untuk memberikan karya-karya terbaik dengan sentuhan ide-ide kreatif agar dapat memenuhi kebutuhan di bidang
fashionyang semakin lama semakin berkembang.
2.1.3 Struktur Organisasi Perusahaan
Berikut adalah struktur organisasi dari perusahaan AIRPLANE SYSTM, dapat dilihat pada gambar 2.2 dibawah ini :
Gambar 2.2 Struktur Organisasi Perusahaan
2.1.4 Deskripsi Kerja
Berikut ini adalah deskripsi kerja pada struktur organisasi yang nantinya akan terlibat didalam sistem. Hanya terdapat satu bagian yang terlibat dalam sistem yang akan dibangun, yaitu Manajer Pemasaran. Berikut adalah tugas dari Manajemen Pemasaran, yaitu :
3. Mengadakan evaluasi, menganalisa dan mengawasi rencana tersebut dalam pelaksanaannya. (untuk mengukur hasil dan penyimpangannya serta untuk mengendalikan aktivitas).
2.2 Landasan Teori
Bagian ini berisi tentang beberapa teori-teori yang mendukung dalam proses analisis dan implementasi berdasarkan masalah yang diangkat dalam pembangunan sistem.
2.2.1 Pengertian Data, Informasi danKnowledge
Data merupakan fakta yang dikumpulkan, disimpan, dan diproses oleh sebuah sistem informasi. Saat ini, akumulasi pertumbuhan jumlah data berjalan dengan cepat dalam format dan basis data yang berbeda. Data-data tersebut, antara lain [3]:
1. Data operasional atau transaksional, seperti penjualan, inventaris, penggajian, akuntansi, dan sebagainya.
2. Data nonoperasional, seperti industri penjualan (supermarket), peramalan, dan data ekonomi makro.
3. Metadata, adalah data mengenai data itu sendiri, seperti desain logika basis data atau definisi kamus data.
Sementara informasi adalah pola, asosiasi, atau hubungan antara semua data yang dapat memberikan informasi. Sebagai contoh, analisis titik eceran (retail point) data transaksi penjualan dapat menghasilkan informasi mengenai produk apa yang sebaiknya dijual dan kapan menjualnya.
2.2.2 Data Mining
Berikut akan dijelaskan beberapa hal yang bersangkutan dengan data mining.
2.2.2.1 PengertianData Mining
Tan (2006) mendefinisikan data mining sebagai proses untuk mendapatkan informasi yang berguna dari gudang basis data yang besar. Data mining juga dapat diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan keputusan.
Salah satu teknik yang dibuat dalam data mining adalah bagaimana menelusuri data yang ada untuk membangun sebuah model, kemudian menggunakan model tersebut agar dapat mengenali pola data yang lain yang tidak berada dalam basis data yang tersimpan. Kebutuhan untuk prediksi juga dapat memanfaatkan teknik ini. Dalam data mining pengelompokan data juga bisa dilakukan. Tujuannya adalah agar kita dapat mengetahui pola universal data-data yang ada. Anomaly data transaksi juga perlu dideteksi untuk dapat mengetahui tindak lanjut berikutnya yang dapat diambil. Semua hal tersebut bertujuan mendukung kegiatan operasional perusahaan sehingga tujuan akhir perusahaan diharapkan dapat tercapai.
2.2.2.2 Pekerjaan DalamData Mining
Gambar 2.3 Pekerjaan Utama Data Mining
1. Model prediksi
Model prediksi berkaitan dengan pembuatan sebuah model yang dapat melakukan pemetaan dari setiap himpunan variabel ke setiap targetnya, kemudian menggunakan model tersebut untuk memberikan nilai target pada himpunan baru yang didapat. Ada dua jenis model, yaitu klasifikasi dan regresi. Klasifikasi digunakan untuk variabel target diskret, sedangkan regresi untuk variabel target kontinu.
ketiga, nilai penjualaan bulan kedua harus didapatkan dan untuk mendapatkan nilai penjualan bulan kedua, nilai penjualan bulan pertama harus didapatkan. Di sini ada nilai deret waktu yang harus dihitung untuk sampai pada target akhir yang diinginkan, ada nilai kontinu yang harus dihitung untuk mendapatkan nilai target akhir yang diingingkan.
2. Analisis Kelompok
Contoh pekerjaan yang berkaitan dengan analisis kelompok (cluster analysis) adalah bagaimana caranya mengetahui pola pembelian barang oleh para konsumen pada waktu-waktu tertentu. Dengan mengetahui pola kelompok pembelian tersebut, perusahaan/pengecer dapat menentukan jadwal promosi yang dapat diberikan sehingga omset penjualan bisa ditingkatkan.
Analisis kelompok melakukan pengelompokan data-data ke dalam sejumlah kelompok (cluster) berdasarkan kesamaan karakteristik masing-masing data pada kelompok-kelompok yang ada. Data-data yang masuk dalam batas kesamaan dengan kelompoknya akan bergabung dalam kelompok tersebut, dan akan terpisah dalam kelompok yang berbeda jika keluar dari batas kesamaan dengan kelompok tersebut.
3. Analisis asosiasi
Analisis asosiasi (association analysis) digunakan untuk menentukan pola yang menggambarkan kekuatan hubungan fitur dalam data. Pola yang ditemukan biasanya merepresentasikan bentuk aturan implikasi atau subset fitur. Tujuannya adalah untuk menemukan pola yang menarik dengan cara yang efisien.
minyak, telur, dan tidak mungkin atau jarang membeli barang lain seperti topi atau buku. Dengan mengetahui hubungan yang lebih kuat antara beras dengan telur daripada beras dengan topi, pengecer dapat menentukan barang-barang yang sebaiknya disediakan dalam jumlah yang cukup banyak.
4. Deteksi Anomali
Pekerjaan deteksi anomali (anomaly detection) berkaitan dengan pengamatan sebuah data dari sejumlah data yang secara signifikan mempunyai karakteristik yang berbeda dari sisa data yang lain. Data-data yang karakteristiknya menyimpang (berbeda) dari Data-data yang lain disebutoutlier. Algoritma deteksi anomali yang baik harus mempunyai laju deteksi yang tinggi dan laju eror yang rendah. Deteksi anomali dapat diterapkan pada sistem jaringan untuk mengetahui pola data yang memasuki jaringan sehingga penyusupan bisa ditemukan, jika pola kerja data yang datang berbeda. Perilaku kondisi cuaca yang mengalami anomali juga dapat dideteksi dengan algoritma ini.
2.2.2.3 KonsepData Mining
Gambar 2.4KonsepData Mining
Berikut adalah tahap-tahap dalamData Mining:
1. Data cleaningyaitu untuk menghilangkannoise data yang tidak konsisten.
2. Data integrationyaitu menggabungkan beberapafileatau database.
3. Data selection yaitu data yang relevan dengan tugas analisis dikembalikan ke dalam database untuk prosesdata mining.
4. Data transformationyaitu data berubah atau bersatu menjadi bentuk yang tepat untuk menambang dengan ringkasan performa atau operasi agresi. 5. Data miningyaitu proses esensial dimana metode yang intelejen digunakan
untuk mengekstrak pola data.
6. Knowledge Discoveryyaitu proses esensial dimana metode intelejen digunakan untuk mengekstrak pola data.
7. Pattern evolutionyaitu untuk mengidentifikasi pola yang benar-benar menarik yang mewakili pengetahuan berdasarkan atas beberapa tindakan yang menarik.
2.2.2.4 TahapanData Mining
Tahapan dalam melakukan data mining salah satunya adalah
preprocessing data. Tahapan ini biasanya diperlukan karena data yang akan digunakan belum baik, yang disebabkan oleh beberapa faktor berikut ini [4]: 1. Incomplete: tidak lengkapnya nilai suatu atribut, tidak lengkapnya
atribut-atribut yang penting, atau hanya mempunyai data yang merupakan rekapitulasi.
Contoh : pekerjaan=” ‘’
Hal tersebut dapat disebabkan oleh perbedaan kebijakan ketika dapat dianalisa, bias juga disebabkan oleh permasalahan yang ditimbulkan oleh manusia,hardware,atausoftware.
2. Noisy: mengandungerroratau merupakanvalueyang tidak wajar.
Contoh : gaji ”-100’’
Timbul karena kesalahan entry oleh manusia atau computer error, atau karena terdapat kesalahan ketika proses pengiriman data.
3. Inconsisten:mengandung nilai yang saling bertentangan.
Contoh : umur =”42” dan ulang tahun = “02/10/1981”
Masalah ini muncul karena perbedaan sumber data, karena pada data mining
data didapatkan dari banyak sumber dan sangat mungkin terdapat perbedaan persepsi pengelolahan data. Seail itu, perbedaan ini muncul karena pelanggaran terhadap fungsional dependency, misalnya melakukan perubahan pada data yang terhubung dengan data lain.
Sebenarnya data yang bisa diterima untuk bisa diproses menjadi informasi atauknowledgeadalah data yang mempunyai kualitas diantaranya :
7. Kemudahan untuk dimengerti
Jika data tidak dalam kualitas seperti yang telah diuraikan diatas, maka kualitas analisis data menjadi kurang sehingga hasilnya pun kurang bermakna. Hal tersebut harus dihindarkan karena hasil analisa yang salah dapat berujung pada solusi yang salah. Untuk itu, perlu dilakukan preprocessing data yangbertujuan untuk agar membuat data menjadi lebih berkualitas. Adapun tahapan-tahapannya adalah sebagai berikut :
1. Data Cleaning: mengisi/mengganti nilai-nilai yang hilang, menghaluskan data yangnoisy,mengidentifikasi dan menghilangkan data yang tidak wajar, dan menyelesaikan masalahinconsistensidata.
2. Data Integration: menggabungkan beberapadatabasedanfile menjadi satu sehingga didapatkan sumber data yang besar.
3. Data Transformation :normalisasi dan agregasi data.
4. Data Reduction : mengurangivolumedata namun tetap mempertahankan arti dalam hal hasil analisis data.
5. Data Discretization :merupakan bagian dari datareduction dengan memperhitungkan data yang signifikan, khususnya padadata numeric.
2.2.3 Association Rule
Aturan asosiasi (Association rule) adalah salah satu teknik tentang ‘apa bersama apa’. Ini bisa berupa transaksi di supermarket, misalnya seseorang yang
membeli susu bayi juga membeli sabun mandi. Di sini berarti susu bayi bersama sabun mandi. Karena awalnya berasal dari studi tentang database transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama produk apa, maka aturan asosiasi juga sering dinamakanMarket Basket[5].
Jika diasumsikan bahwa barang yang dijual di swalayan adalah semesta, maka setiap barang akan memiliki Boolean variable yang akan menunjukan keberadaannya atau tidak barang tersebut dalam satu transaksi atau satu keranjang belanja. Pola Boolean yang didapat digunakan untuk menganalisa barang yang dibeli secara bersamaan. Pola tersebut dirumuskan dalam sebuah association rule.
Sebagai contoh konsumen biasanya akan membeli kopi dan susu yang ditujukan sebagai berikut :
Kopi→ susu [support= 2%,confidence= 60%]
Nilai support 2% menunjukan bahwa keseluruhan dari total transaksi konsumen membeli kopi dan susu secara bersamaan yaitu sebanyak 2%. Sedangkan confidence 60% yaitu menunjukan bila konsumen membeli kopi dan pasti membeli susu sebesar 60%.
Penting tidaknya suatu aturan asosiatif dapat diketahui dengan dua parameter, yaitu support dan confidence. Support (nilai penunjang) adalah presentase kombinasi item tersebut dalam database, sedangkan confidence (nilai kepastian) adalah kuatnya hubungan antar-itemdalam aturan asosiasi.
Dalam menentukan suatu association rule, terdapat suatu ukuran kepercayaan yang didapat dari hasil pengelolahan data dengan perhitungan tertentu. Umumnya ada dua ukuran, yaitu:
a. Support: suatu ukuran yang menunjukan seberapa besar tingkat dominasi suatu
itemset dari keseluruhan transaksi. Ukuran ini menentukan apakah suatu
itemsetlayak untuk dicariconfidence-nya ( misal, dari keseluruhan transaksi yang ada, seberapa besar tingkat dominasi suatuitemyang menunjukan bahwa
itemA danitemB dibeli bersamaan).
b. Confidence: suatu ukuran yang menunjukan hubungan antara 2itemsecara
conditional(misal, menghitung kemungkinan seberapa seringitemB dibeli oleh pelanggan jika pelanggan tersebut membeli sebuahitemA).
minimum untuk support (minimum support) dan syarat minimum untuk
confidence(minimum confidence).
Nilaisupportsebuahitem diperoleh dengan rumus sebagai berikut[6] : x100%….. Persamaan (2.1)
Sementara itu, nilaisupportdari 2itemdiperoleh dari rumus berikut:
x100%..Persamaan (2.2)
Sedangkan nilai confidencedapat dicari setelah pola frekuensi munculnya sebuah
item ditemukan.Rumus untuk menghitungconfidenceadalah sebagai berikut:
x100%…..Persamaan(2.3)
Berikut adalah contoh penerapan metodeassociation rule:
Misalkan diberikan tabel data transaksi sebagai berikut dengan minimum support count= 2
Tabel 2.1 Data Transaksi
TID Items
1 B
2 B, D
3 A, C, D, E
4 A, D, E
5 B, C
6 A, C
7 A
Yang mana nilaisupport countdidapat dari : x 100% = 2.14≈ 2
Frekuensi kemunculan tiap item dapat dilihat pada tabel berikut:
Tabel 2. 2 Frekuensi Kemunculan Tiap Karakter
Item Frekuensi
B 3
C 3
D 3
E 2
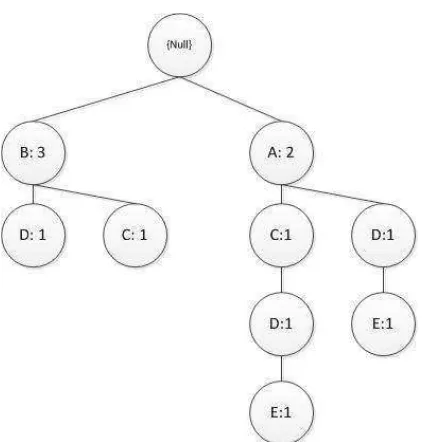
Karena contoh kasus dalam kemunculan itemsudah frequentdalam setiap transaksi, sudah diurut berdasarkan frekuensi yang paling tinggi. Selanjutnya pada gambar di bawah ini memberikan ilustrasi mengenai pembentukan FP-Tree setelah pembacaan TID 2
Gambar 2.6 Hasil PembentukanFP-Treesetelah pembacaan TID 5
Gambar 2.7 Hasil pembentukanFP-Treesetelah pembacaan TID 7
Setelah FP-Tree terbentuk dari sekumpulan data transaksi maka, proses pencarian frequent itemset dengan menggunakan algoritma FP-Growth akan dilakukan yang dibagi menjadi tiga tahapan utama, yaitu:
a. Tahap pembangkitanconditional pattern base
Merupakan subdata yang berisi prefix path (lintasan awal) dan suffix pattern
(pola akhiran). Pembangkitan conditional pattren basedidapatkan melalui FP-Tree yang telah dibangun sebelumnya.
b. Tahap pembangkitanconditionalFP-Tree
Pada tahap ini, support count dari setiap item pada setiap conditional pattern base dijumlahkan, lalu setiap item yang memiliki jumlah support count lebih besar atau sama dengan minimum support count akan dibangkitkan dengan
conditionalFP-Tree seperti pada tabel 2.3 dibawah ini.
Tabel 2.3 Hasil Perhitungan Conditional Pattern Base dan Conditional FP-Tree
Item Conditional Pattern Base ConditionalFP Tree E {{A,C,D:1}, {A,D:1}} {<A:2,D:2>}
D {{B:1}, {A,C:1}, {A:1}} {A:2}
C {B:1}, {A:2} {A:2}
c. Tahap pencarianfrequent itemset.
Apabila conditional FP-Tree merupakan lintasan tunggal(single-path), maka didapatkan frequent itemset dengan melakukan kombinasi item untuk setiap
Tabel 2.4HasilFrequent Itemset Suffix Frequent Itemset
E E, A-E, D-E, A-D-E
D D, A-D
C C, A-C
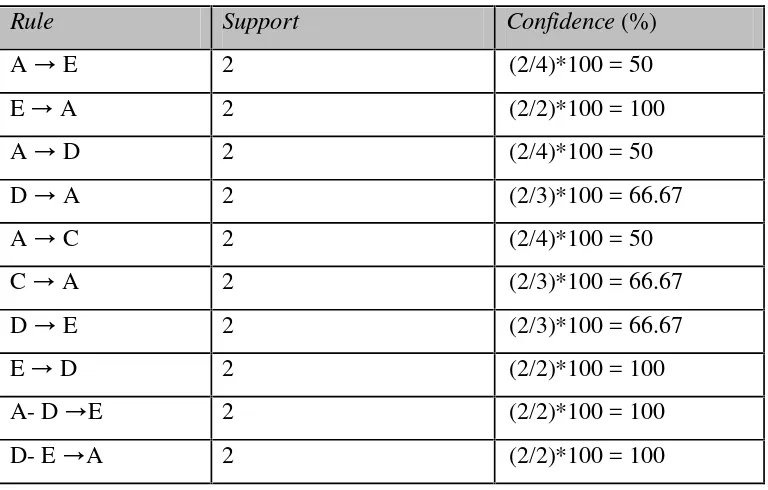
Tabel 2.5HasilGenerate Rule
Rule Support Confidence(%)
Algoritma yang sama dengan Apriori, FP-Growth mulai dengan menghitung item tunggal sesuai dengan jumlah kemunculan item yang ada didalam dataset. Setelah proses penghitungan selesai maka akan dibuat struktur pohon pada tahap kedua. Pohon yang dibuat mulanya kosong yang nanti akan diisi dengan hasil dari dataset yang telah didapat sebelumnya. Kunci untuk mendapatkan struktur pohon yang bisa didapatkan dengan proses lebih cepat untuk mencari item set yang besar menjadi sedikit dengan di urutkan secara
Tree merupakan struktur penyimpanan data yang dimampatkan. FP-Tree dibangun dengan memetakan setiap data transaksi ke dalam setiap lintasan tertentu dalam FP-Tree. Karena dalam setiap transaksi yang dipetakan, mungkin ada transaksi yang memiliki item yang sama, maka lintasannya memungkinkan untuk saling menimpa. Semakin banyak data transaksi yang memiliki item yang sama, maka proses pemampatan dengan struktur data FP-Tree semakin efektif. Kelebihan dari FP-Tree adalah hanya memerlukan dua kali pemindaian data transaksi yang terbukti sangat efisien.
Adapun FP-Tree adalah sebuah pohon dengan definisi sebagai berikut:
a. FP-Tree dibentuk oleh sebuah akar yang diberi labelnull, sekumpulan berupa pohon yang beranggotakan item-item tertentu, dan sebuah tabel
frequent header.
b. Setiap simpul dalam FP- Tree mengandung tiga informasi penting, yaitu label item, menginformasikan jenis item yang direpresentasikan simpul tersebut,support count, merepresentasikan jumlah lintasan transaksi yang melalui simpul tesebut, danpointerpenghubung yang menghubungkan simpul-simpul dengan label item sama antar-lintasan, ditandai dengan garis panah putus-putus.
2.2.4.1 Langkah-Langkah Proses Perhitungan Association Rule Dengan Algoritma FP-Growth
Proses perhitungan association rule terdiri dari beberapa tahap adalah sebagai berikut [9] :
1. MembuatHeader Item
Headerdalam hal ini selain sebagaiheader suatuitemke FP-Tree juga sebagai jenis item dasar yang memenuhi minimum support. Setelah mendapatkanitemdan nilaisupport-nya, makaitemyang tidakfrequent
untuk item, disiapkan pada suatuarraytertentu dan ditambahkan ketika membuat FP-Tree.
2. Membuat FP-Tree
FP-Tree dibangun dengan mencari item sesuai urutan pada item yang
frequent. Data transaksi tidak perlu diurutkan, dan untuk tiapitem yang ditemukan bisa langsung dimasukkan ke dalam FP-Tree. Sesudah membuatroot, tiap itemyang ditemukan dimasukkan berdasarkan path
pada FP-Tree. Jikaitemyang ditemukan sudah ada, maka nilai support item tersebut yang ditambahkan. Namun jika path belum ada, maka dibuat nodebaru untuk melengkapi path baru pada FP-Tree tersebut. Hal ini dilakukan selama item pada transaksi masih ada yang
qualified, artinya memenuhi nilai minimum support. Jadi, item-item
yang ditemukan dalam transaksi akan berurutan memanjang ke bawah. Dalam struktur FP-Tree, diterapkan alurpath darichildhingga ke root. Jadi, suatupath utuh dalam FP-Tree adalah dari child terbawah hingga keroot. Tiap node pada FP-Tree memilikipointer ke parent, sehingga pencarian harus dimulai dari bawah.
3. Pattern Extraction
Pattern extraction dilakukan berdasarkan keterlibatan item pada suatu path. Di setiap path, diperiksa semua kombinasi yang mungkin dimana item tersebut terlibat. Di iterasi berikutnya dilakukan dengan melibatkanitemberikutnya, tanpa melibatkan itemsebelumnya, sehingga pattern yang sama tidak akan ditemukan dua kali pada path
yang sama. Bilaitempertama suatu hasil kombinasi bukanitemterakhir (sebelum root), maka kombinasi itemset tersebut masih bisa dikembangkan lagi.
4. Memasukkan setiap pattern yang ditemukan ke dalamPatternTree
di Pattern Tree merepresentasikan dan menyimpan frekuensi suatu
pattern. Pattern Tree terdiri atas Pattern TreeNode yang menyimpan nilai item, nilaisupport dan dilengkapi dengan duapointer yaitu untuk horisontal dan vertikal.
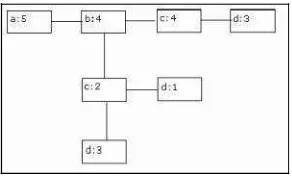
Misalnya pada node d:1 di atas, berarti terdapat pattern a-c-d bernilai
support1. Kemudian bila ada pattern a-c-d lagi bernilaisupportn yang ditemukan dari FP-Tree maka nilai support 1 tersebut menjadi n+1. Contoh hasil lengkap dariPatternTreetersebut:
1. a:5 menggambarkan bahwa ada pattern a sebanyak 5 2. b:4 menggambarkan bahwa ada pattern a-b sebanyak 4 3. c:4 menggambarkan bahwa ada pattern a-b-c sebanyak 4 4. d:3 menggambarkan bahwa ada pattern a-b-c-d sebanyak 3 5. c:2 menggambarkan bahwa ada pattern a-c sebanyak 2 6. d:1 menggambarkan bahwa ada pattern a-c-d sebanyak 1 7. d:3 menggambarkan bahwa ada pattern a-d sebanyak 3 5. Mengurutkan dan MenyeleksiPattern
Pattern yang tidak memenuhi minimum support, dihapus dari daftar
pattern. Pattern-pattern yang tersisa kemudian diurutkan untuk memudahkan pembuatanrules.
2.2.5 Alat-Alat Pemodelan Sistem
Berikut ini adalah penjelasan dari alat-alat yang digunakan dalam pemodelan sistem yang akan dibangun.
2.2.5.1Entity Relation Diagram(ERD)
ERD adalah suatu model jaringan yang menggunakan susunan data yang disimpan dalam sistem secara abstrak. Basis data relasional adalah kumpulan dari relasi-relasi yang mengandung seluruh informasi berkenaan suatu entitas/objek yang akan disimpan di dalam database. Tiap relasi disimpan sebagai sebuah file
tersendiri. Perancangan basis data merupakan suatu kegiatan yang setidaknya bertujuansebagai berikut :
1. Menghilangkan redudansi data.
2. Meminimumkan jumlah relasi di dalam basis data. 3. Membuat relasi berada
4. Dalam bentuk normal, sehingga dapat meminimumkan permasalahan berkenaan dengan penambahan, pembaharuan dan penghapusan.
2.2.5.2 Diagram Konteks
Diagram konteks adalah diagram yang terdiri dari suatu proses dan menggambarkan ruang lingkup suatu sistem. Diagram konteks merupakan level tertinggi dari Data Flow Diagram yang menggambarkan seluruh input ke sistem atau output dari sistem. Diagram konteks memberi gambaran tentang keseluruan sistem. Sistem dibatasi oleh boundary (dapat digambarkan dengan garis putus). Dalam diagram konteks hanya ada satu proses [10].
2.2.5.3 Data Flow Diagram
Data flow diagram atau DFD adalah alat untuk menggambarkan komponen-komponen sebuah sistem, aliran data pada sistem, dimana data berasal, tujuan data serta penyimpanan data. Ada 4 komponen utama dalam DFD yaitu [9]:
1. Entitas eksternal (External Entity) 2. Arus data (Data Flow)
3. Proses (Process)
4. Penyimpanan data (Data Store)
seterusnya. Penjelasan simbol pada diagram konteks dan DFD dapat dilihat di daftar simbol.
2.2.5.4 Spesifikasi Proses
Spesifikasi proses digunakan untuk mendeskripsikan proses yang terjadi pada level yang paling dasar dalam DFD. Spesifikasi proses berfungsi mendeskripsikan tahapan yang dilakukan untuk merubah masukan menjadi keluaran. Spesifikasi proses ditampilkan dalam bentuk form, logika proses yang ditulis pada spesifikasi proses harus jelas [10]. Berikut adalah poin yang dideskripsikan pada spesifikasi proses :
1. No Proses : Menyatakan nomor proses 2. Nama Proses : Menyatakan nama proses
3. Sumber : Menyatakan sumber data yang menuju ke proses 4. Input: Menyatakan isi data yang masuk ke proses
5. Output: Menyatakan informasi yang keluar dari proses 6. Tujuan : Menyatakan tujuan informasi keluaran dari proses 7. Logika Proses : Menyatakan algoritma dari proses
2.2.5.5 Kamus Data
Kamus data adalah deskripsi formal mengenai seluruh komponen-komponen yang ada pada data flow diagram. Pada tahap perancangan, komponen-komponen pada kamus data akan menjadi bahan untuk menyusun basis data[10]. Berikut adalah poin yang dideskripsikan pada kamus data :
1. Nama aliran data : Data yang digunakan 2. How used: Proses apa saja yang digunakan 3. Keterangan : Uraian singkat data yang digunakan
4. Struktur data : Daftar komponen yang ada pada data yang digunakan
5. Deskripsi : Jenis data dalam representasi komputer untuk masing-masing data
2.2.6 Microsoft Visual Studio
perangkat lunak lengkap (suite) yang dapat digunakan untuk melakukan pengembangan aplikasi, baik itu aplikasi bisnis, aplikasi personal, ataupun komponen aplikasinya, dalam bentuk aplikasiconsole, aplikasi Windows, ataupun aplikasi Web. Microsoft Visual Studio dapat digunakan untuk mengembangkan aplikasi dalam native code (dalam bentuk bahasa mesin yang berjalan di atas Windows) ataupun managed code (dalam bentuk Microsoft Intermediate Language di atas .NET Framework).
C# sering dianggap sebagai bahasa penerus C++ atau versi canggih dari C++. C# adalah sebuah bahasa pemrograman yang dikembangkan oleh Microsoft dan menjadi salah satu bahasa pemrograman yang mendukung .Net programming melalui Visual Studio. C# didasarkan pada bahasa pemrograman C++, C# juga memiliki kemiripan dengan beberapa bahasa pemrograman seperti Visual Basic, Java, Delphi dan tentu saja C++.
2.2.7 MySQL
MySQL adalah multiuser database yang menggunakan bahasastructured Query Language (SQL). MySQL dalam operasi client server melibatkan server daemon MySQL di sisi server dan berbagai macam program serta library yang berjalan di sisi client. MySQL mampu menangani data yang cukup besar. Perusahaan yang mengembangkan MySQL yaitu TcX, mengaku bahwa MySQL yang mampu menyimpan data lebih dari 40 database, 10.000 tabel dan sekitar 7 juta baris, totalnya kurang lebih 100Gigabytedata [12].
31
Analisis sistem didefinisikan sebagai penguraian suatu sistem informasi yang utuh kedalam beberapa bagian dengan tujuan untuk mengidentifikasi dan mengevaluasi permasalahan-permasalahan, kesempatan-kesempatan ataupun hambatan-hambatan yang terjadi untuk menghasilkan sebuah solusi guna melakukan perbaikan-perbaikan terhadap sistem yang sedang berjalan. Dalam analisa sistem ini meliputi beberapa bagian, yaitu :
1. Analisis Masalah 2. AnalisisData Mining
3. Analisis Spesifikasi Kebutuhan Perangkat Lunak 4. Analisis Kebutuhan Non-Fungsional
5. Analisis Kebutuhan Fungsional
3.1.1 Analisis Masalah
Berdasarkan hasil wawancara dengan pihak AIRPLANE SYSTM, dapat disimpulkan bahwa permasalahannya yakni:
1. Banyaknya art-art yang dihasilkan oleh AIRPLANE SYSTM pada setiap bulannya membuat bagian produksi kurang hati-hati dalam memilih art untuk diproduksi pada bulan berikutnya.
2. Menentukan art yang akan diproduksi berdasarkanhistorypenjualan dibeberapa pemesanan olehspace dealerdan pihak AIRPLANE SYSTM sendiri yang beberapa bulan kebelakang mengalami penurunan karena kesalahan pemilihan art yang kurang tepat.
3.1.2 AnalisisData Mining
3.1.2.1 Pemahaman Bisnis
Tahapan prmahaman bisnis merupakan tahapan pertama yang dilakukan dalam kerangka kerja CRISP-DM. dalam tahapan bisnis ini terdapat beberapa tahapan lainnya, yaitu :
1. Identifikasi Tujuan Bisnis
Dalam proses bisnisnya AIRPLANE SYSTM memasarkan produk-produknya langsung kepada konsumen dan kepada space dealer (sebutan agen retail). Untuk membuat strategi bisnis perusahaan, pihak marketing harus menganalisa data penjualan. Tujuan dari menganalisa data penjualan yakni untuk mengetahui kecenderungan pemilihan produk yang sering dibeli dengan cara mengetahui pola pemesanan space dealer agar produk yang diproduksi tepat sasaran.
2. Penentuan SasaranData Mining
Tujuan data mining untuk perusahaan adalah menggali pengetahuan (discovering knowledge) tentang pola (pattern) produk-produk apa saja yang sering dibeli space dealer secara bersaman dalam sebuah transaksi penjualan sehingga diketahui produk mana saja yang sering dipesan space dealer secara bersamaan agar pihak perusahaan mendapatkan gambaran dalam menentukan produk mana saja yang akan diproduksi.
3.1.2.2 Pemahaman Data
Tahapan pemahaman data merupakan tahapan kedua yang dilakukan setelah tahapan bisnis dalam kerangka kerja CRISP-DM. dalam tahap pemahaman data ini terdapat beberapa langkah diantaranya :
a. Pengumpulan data awal
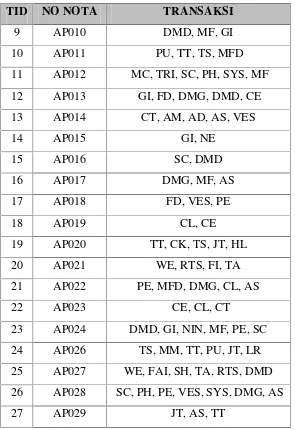
Data yang digunakan dalam penelitian ini yakni data penjualan produk berdasarkan pesanan dari beberapa space dealer pada bulan Januari sampai dengan bulan Desember 2014. Data yang terlibat dalam data penjualan produk ini adalah data space dealer outlet, data yang digunakan untuk proses analisis berupa file Excel dengan format *.csv atau *.xlsx.
selanjutnya. Adapun detail informasi mengenai data transaksi yang digunakan dapat dilihat dalam table 3.1 dibawah ini.
Tabel 3.1 Struktur Data Penjualan
Berikut adalah contoh data penjualan pada bulan Desember yang didapat dari pesanan dari space dealer yang ada di AIRPLANE SYSTM yang akan digunakan untuk proses perhitungan metode association rule dengan algoritma FP-Growth, dimana atribut-atribut yang terdapat dalam data penjualan tersebut antara lain no nota, tanggal, brand, sex, art, colour, size, qty, price, amount. Untuk lebih jelasnya, dapat dilihat pada lampiran tabel D-1 di lembar lampiran.
3.1.2.3 PreprocessingData
Preprocessing data adalah hal yang harus dilakukan dalam proses data mining,karena tidak semua data atau atribut data dalam data digunakan pada data
mining. Proses ini dilakukan agar data yang akan digunakan sesuai dengan kebutuhan. Adapun tahapan-tahapan preprocessing data dalam penelitian ini adalah sebagai berikut :
1. Ekstraksi data
selanjutnya ataupun untuk menyimpan data hasil ekstrak tersebut. Dalam penelitian ini, data yang berasal dari flat file berupa microsoft excel (.xlsx) diekstrak, kemudian disimpan ke dalam sebuah database agar memudahkan dalam proses pengolahan data.
2. Pembersihan data
Proses menghilangkan noise dan menghilangkan data tidak relevan atau inkonsisten disebut dengan pembersihan data. Dalam penelitian ini data yang dihilangkan yaitu data yang pada kadang-kadang diproduksi seperti wallet, jacket, pants, belt, sweater. Berikut adalah hasil proses pembersihan data pada tabel D-2 di lembar lampiran.
3. Pemilihan atribut
Pemilihan atribut adalah proses pemilihan atribut data yang akan digunakan, sehingga data tersebut dapat diproses sesuai dengan kebutuhan data mining. Dalam penelitian ini, atribut yang akan digunakan yakni no nota dan Art, karna penelitian ditujukan pada pola mengenai art, dapat dilihat pada lampiran tabel D-3 di lembar lampiran.
4. Setelah semua proses telah berhasil dilalui dan data transaksi telah sesuai dengan kebutuhan yang diperlukan dalam proses data mining,maka data penjualan tersebut sudah dapat digunakan untuk diproses dalam sistemdata miningseperti terlihat dalam tabel 3.2.
Tabel 3.2 Hasil PenggabunganItemPer Nota
TID NO NOTA ART
Pemodelan merupakan tahap pembuatan model yang akan digunakan dalam prosesdata mining. Tahap ini dilakukan dengan menggunakan metode
association ruleyang akan memasuki ke dalam dua tahap yaitu : a. Frequent Itemset
b. Generate Rule
yang telah diketahui sebelumnya untuk memproses informasi selanjutnya. Dalam kasus ini sebelum melanjutkan ke proses selanjutnnya, untuk mempermudah pembentukan frequent itemset maka dibuatlah inisialisasi terhadap data yang digunakan. Berikut adalah hasil inisialisasi pada tabel 3.3 di bawah ini:
Algoritma FP-Growth dibagi menjadi tiga langkah utama, namun terlebih dahulu dilakukan pembentukan pohon dengan menggunakan algoritma FP-Tree. Langkah-langkah algoritma FP-Growth yaitu:
1. Pembentukan pohon dengan FP-Tree
FP-Tree merupakan struktur penyimpanan data yang dimapatkan. FP-Tree dibangun dengan memetakan setiap data transaksi ke dalam setiap lintasan tertentu dalam FP-Tree. Karena dalam setiap transaksi yang dipetakan, mungkin ada transaksi yang memiliki item yang sama, maka lintasannya memungkinkan untuk saling menimpa. Semakin banyak data transaksi yang memiliki item yang sama, maka proses pemampatan dengan struktur data FP-Tree semakin efektif. Kelebihan dari FP-FP-Tree adalah hanya memerlukan dua kali pemindaian data transaksi yang terbukti sangat efisien.
2. Langkah pertama adalah menentukanminimum supportdari data yang digunakan yakni ada pada tabel 3.2 yang mana hasil dari penyederhanaan dalam lampiran tabel D-3. Dalam tahap yang selanjutnya nilai minimum support= 3 yang diambil dari hasil perhitungan rata-rata 1itemsetdi bawah :
Dari hasil penyederhanaan data yang dilakukan pada setiap item yang ditunjukan pada tabel 3.4.
Tabel 3.4 Tabel yang telah disederhanakan
TID NO NOTA TRANSAKSI
Berikut ini adalah frekuensi kemunculan tiap item yang ada pada atribut art pada table 3.5 di bawah ini :
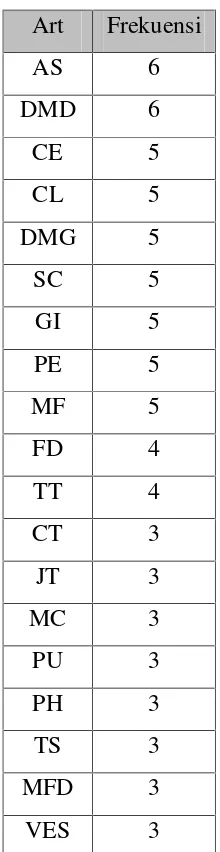
Tabel 3.5 Frekuensi Kemunculan Tiap Art
Art Frekuensi Art Frekuensi
AS 6 MC 3
AD 2 MF 5
AM 2 MFD 3
Art Frekuensi Art Frekuensi
CK 2 NE 2
CE 5 PE 5
CL 5 PX 1
CT 3 PU 3
DMD 6 PH 3
DMG 5 RTS 3
DA 1 SC 5
FAI 1 SH 1
FI 1 SYS 2
FD 4 TT 4
GI 5 TA 2
HL 2 TS 3
JT 3 TON 1
LR 1 TRI 1
LN 1 VES 3
MCH 1 WE 2
MM 1 RTS 3
3. Setelah frekuensi didapatkan untuk tiap item maka pemberian prioritas untuk setiap item dilakukan untuk memulai proses pembentukantree,hasil
Tabel 3.6 Pengurutan Berdasarkan Frekuensi dan ditentukan nilai support =
Tabel 3.7 Pemberian Skala Prioritas
Art Frekuensi Prioritas
4. Setelah data diberi skala prioritas sesuai urutan secaradescending pada tabel 3.7, maka selanjutnya adalah mengurutkan item transaksi berdasarkan prioritas yang telah ditentukan sebelumnya. Berikut adalah hasil pengurutan
berdasarkan skala priotitas tiap item
Tabel 3.8 Data Yang Sudah Di Urutkan Berdasarkan Prioritas
TID TRANSAKSI ORDER ITEM
5. Setelah pengurutan pada setiap transaksi sesuai item, selanjutnya masuk pada pembentukan FP-Tree. Berikut adalah tahap-tahap dalam pembuatan FP-Tree yaitu:
a. Lakukan pembacaan pada data pertama yang akan diproses.
c. Jika data yang keluar berikutnya sama dengan data yang pertama, maka itu bukan anak kedua dariroot, tetapi tetap anak darirootyang sebelumnya keluar, yang berubah adalahsupport count-nya menjadi bertambah 1. d. Lakukan pengecekan padaroot, jikarootsudah mempunyai anak, maka
data yang dibaca atau data yang keluar berbeda dengan data yang kelaur sebelumnya maka itu menjadi anak terakhir darirootdan menjadi sibling darinodedata pertama. Dansupport countdarinodetersebut bertambah 1. e. Lakukan langkah tersebut hingga semua data yang keluar.
f. Jika ada data yang sama setelah pembacaan, namun berbedalintasanmaka
node padalaintasanyang lain tidak bertambahsupportcount-nya, hanya data yang dibaca saja yang bertambahsupport count-nya. Pembentukan FP-Tree lengkap dapat dilihat pada lampiran D-4.
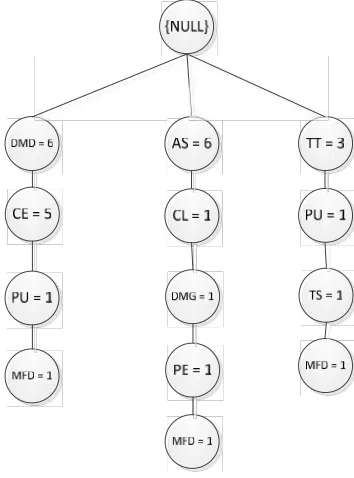
Gambar 3.1 Hasil Pembentukan FP-Tree Setelah TID 1
Gambar 3.2 Hasil Pembentukan FP-Tree Setelah TID 2
Gambar 3.4 Hasil Pembentukan FP-Tree Setelah TID 8
Setelah proses pembacaan TID 27 yaitu AS, TT, JT, maka terbentuklahtree
dari semua transaksi yang akan digunakan seperti pada gambar 3.5 dibawah ini.
Gambar 3.5 Hasil Pembentukan FP-Tree Setelah TID 27
a. Tahap pembangkitanconditional pattern base
Pembangkitan conditional pattern base didapatkan melalui hasil FP-Tree seluruhnya, dengan mencari support count terkecil sesuai dengan hasil pengurutanpriority. Dan telah didapatkan yaitu : VES, MFD, PH, CT, MF, RTS, MC, PE, GI, DMG, TS, PU, JT, CL, TT, CE, SC, DMD dan AS. Berikut adalah hasil tabel dariconditional pattern base :
Tabel 3.9Conditional Pattern base
Items Conditional Pattren Base
RTS { MFD:2, PU:2, CE:2, DMD:2}, {DMD:1}
MC {SC:1},{ MF:2, FD:2, GI: 2}
PE {SC:2}.{ GI:1, SC:1, DMD:1 },{ SC:1, DMG:1, AS:1 },{ DMG:1, CL:1, AS:1 }
GI {NULL},{ MF:1, CE:1, DMD:1 },{DMD:1},{ SC:1, DMD:1}
DMG { CL:1, CE:1, DMD:1 },{AS:2},{ CL:1, AS:1 }
SC {NULL},{DMD:2},{ DMG :1, AS:1}
b. Tahap pembangkitanconditionalFP-Tree
Pada tahap ini, support count dari setiap item pada setiap conditional pattern base dijumlahkan, lalu setiap item yang memiliki jumlah
support count lebih besar atau sama dengan minimum support count
akan dibangkitkan dengan conditional FP-Tree. Tahap pembentukan
ConditionalFP-Tree untuk itemVES dengan Conditional Pattern Base
karena walaupun memenuhisupport count ≥ 3 dan frequent, tapi pada proses pembangkitan tidak ada yang memenuhi minimum support count.
{NULL}
SC = 2
PE = 2
AS = 6
CT = 1
VES = 1
DMG = 2
FD = 1
VES = 1
SC = 1
PE = 1
PH = 1
VES = 1
Gambar 3.6 Lintasan Mengandung Simpul VES
ConditionalFP-Tree untukitem MFD denganConditional pattern base
Gambar 3.7 Lintasan Mengandung Simpul MFD
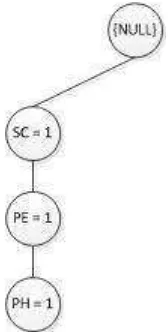
Conditional FP-Tree untuk item PH dengan Conditional Pattern Base
{SC,PE:1},{SC,MC:1},{AS,DMG,SC,PE:1} yang setelah dijumlahkan berdasarkansupport count =3 telah memenuhi minimumsupport≥ 3.
{NULL}
SC = 2
PH = 1 PE = 2
AS = 6
MC = 1
PH = 1
DMG = 2
SC = 1
PE = 1
PH = 1
Berikut adalah tahap-tahapannya :
1. Jumlahsupport countyang memenuhiminimum supportakan dibangkitkan denganconditionalFP-Tree.
- DalamconditionalFP-Tree untuk PH, ada 3 lintasan yaitu :
o Lintasan pertama : {SC,PE,PH:1}
o Lintasan kedua : {SC,MC, PH:1}
o Lintasan ketiga : {AS,DMG,SC,PE,PH:1}
- Pada lintasan yang berakhiran {PH:1} dengansupport count
adalah 1 akan dihilangkan dansupport countyang melewati lintasan pertama yang berakhiran PH, akan disamakan dengan
support countPH yaitu sesuai dengansupport countyang dimilikinya.
- Proses selanjutnya adalah apabila dalam suatu lintasan, melintasi dua atau lebih, makasupport count-nya akan selalu bertambah 1.
2. Setelah proses pembangkitan, maka proses terakhir adalah mencari
frequent itemsetyang keluar yang memenuhiminimum support. SC:3 adalah satu-satunya yang keluar yang dapat memenuhi
minimum.Danfrequent itemsetyang didapatkan adalah {PH, SC:3}
Gambar 3.10 Conditional FP-TreePH,SC:3HasilFrequent Itemset
ConditionalFP-Tree untukitemCT denganConditional pattern base
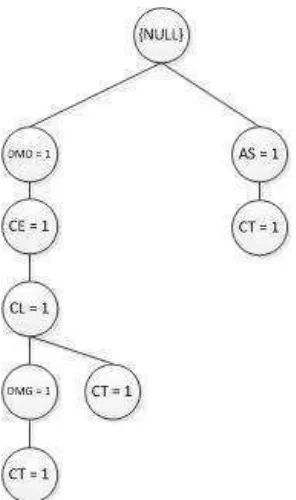
{ DMG:1, CL:1, CE:1, DMD:1},{ CL:1, CE:1, DMD:1},{AS:1} yaitu null karena walaupun memenuhi support count ≥ 3 dan
Gambar 3.11Lintasan Mengandung Simpul CT
Conditional FP-Tree untuk item MF dengan Conditional Pattern Base {SC:1}, {GI:1}, {DMD,GI:1}, {DMD,SC,GI,PE:1}, {AS,DMG:1} yang setelah dijumlahkan berdasarkan support count =5telah memenuhi minimumsupport≥ 3.
Berikut adalah tahap-tahapannya :
1. Jumlahsupport countyang memenuhiminimum supportakan dibangkitkan denganconditionalFP-Tree.
- DalamconditionalFP-Tree untuk MF, ada 5 lintasan yaitu :
o Lintasan pertama : {SC, MF:1}
o Lintasan kedua : {GI, MF:1}
o Lintasan ketiga : {DMD, GI, MF:1}
o Lintasan keempat : {DMD, SC, GI, PE, MF:1}
o Lintasan kelima : {AS,DMG, MF:1}
- Pada lintasan yang berakhiran {MF:1} dengansupport countadalah 1 akan dihilangkan dansupport countyang melewati lintasan pertama yang berakhiran MF, akan disamakan dengansupport countMF yaitu sesuai dengan
support countyang dimilikinya.
-Gambar 3.13 Conditional FP-TreeMF Setelah Dibangkitkan
2. Setelah proses pembangkitan, maka proses terakhir adalah mencari
frequent itemsetyang keluar yang memenuhiminimum support. DMD:3 adalah satu-satunya yang keluar yang dapat memenuhi
minimum.Danfrequent itemsetyang didapatkan adalah {PH, GI:3}
Gambar 3.14 Conditional FP-Tree MF,GI:3 HasilFrequent Itemset
ConditionalFP-Tree untukitemFD denganConditional pattern base
Gambar 3.15 Lintasan Mengandung Simpul FD
Berikut adalah tahap-tahapannya :
1. Jumlahsupport countyang memenuhiminimum supportakan dibangkitkan denganconditionalFP-Tree.
-DalamconditionalFP-Tree untuk FD, ada 3 lintasan yaitu :
o Lintasan pertama : {SC, PE, FD:1}
o Lintasan kedua : { GI, MF, FD:2}
o Lintasan ketiga : {DMD, CE, MF, GI, FD:1}
- Pada lintasan yang berakhiran {FD:1} dan{FD:2} dengansupport countadalah 1,2 akan dihilangkan dansupport countyang melewati lintasan pertama yang berakhiran MF, akan disamakan dengansupport countFD yaitu sesuai dengansupport countyang dimilikinya.
Gambar 3.16ConditionalFP-Tree FD Setelah Dibangkitkan
2. Setelah proses pembangkitan, maka proses terakhir adalah mencari
frequent itemsetyang keluar yang memenuhiminimum support. DMD:3 adalah satu-satunya yang keluar yang dapat memenuhi
minimum.Danfrequent itemsetyang didapatkan adalah {FD, GI, MF:3}
Gambar 3.17ConditionalFP-TreeFD,GI:3 dan MF:3 Hasil Frequent Itemset
- Tahap pembentukanConditionalFP-Tree untukitemRTS denganConditional Pattern Base{DMD,CE,PU,MFD:2}, {DMD:1} yang setelah dijumlahkan berdasarkansupport count =3 telah memenuhi minimumsupport≥ 3.
Gambar 3.18 Lintasan Mengandung Simpul RTS
Berikut adalah tahap-tahapannya :
1. Jumlahsupport countyang memenuhiminimum support
akan dibangkitkan denganconditionalFP-Tree.
- DalamconditionalFP-Tree untuk RTS, ada 2 lintasan yaitu:
o Lintasan pertama : {DMD, CE, PU, MFD, RTS:2}
o Lintasan kedua : {DMD, RTS:1}
- Pada lintasan yang berakhiran {RTS:2} dan {RTS:1} dengansupport countadalah 2dan 1 akan dihilangkan dansupport countyang melewati lintasan pertama yang berakhiran RTS, akan disamakan dengansupport count
- Proses selanjutnya adalah apabila dalam suatu lintasan, melintasi dua atau lebih, makasupport count-nya akan selalu bertambah 1.
Gambar 3.19ConditionalFP-Tree RTS Setelah Dibangkitkan
2. Setelah proses pembangkitan, maka proses terakhir adalah mencarifrequent itemset yang keluar yang memenuhi
minimum support. DMD:3 adalah satu-satunya yang keluar yang dapat memenuhiminimum.Danfrequent itemsetyang didapatkan adalah {RTS, DMD:3}
- ConditionalFP-Tree untukitemMC denganConditional pattern base{SC:1},{ MF:2, FD:2, GI: 2} yaitunull
karena tidak memenuhisupport count≥ 3danfrequent, tapi pada proses pembangkitan tidak ada yang memenuhi minimumsupport count.
Gambar 3.21Lintasan Mengandung Simpul MC
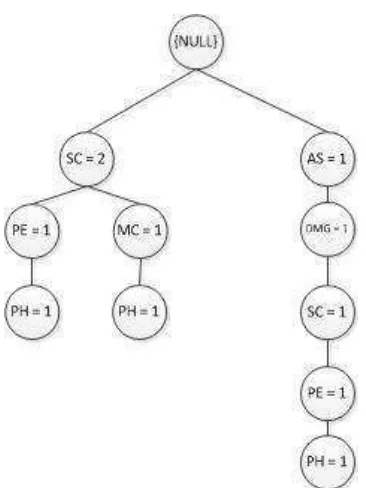
- ConditionalFP-Tree untukitemPE denganConditional Pattern Base{SC:2}.{DMD,SC,GI:1}, {AS,DMG,SC:1}, {AS,CL,DMG:1} yang setelah dijumlahkan berdasarkan
Gambar 3.22 Lintasan Mengandung Simpul PE
Berikut adalah tahap-tahapannya :
1. Jumlahsupport countyang memenuhiminimum supportakan dibangkitkan denganconditionalFP-Tree.
-DalamconditionalFP-Tree untuk PE, ada 4 lintasan yaitu :
o Lintasan pertama : {SC, PE:2}
o Lintasan kedua : {DMD, SC,GI,PE:1}
o Lintasan ketiga : {AS, DMG,SC,PE:1}
o Lintasan keempat : {AS,CL,DMG,PE:1}
-Pada lintasan yang berakhiran {PE:2},{PE:1} dengansupport countadalah 2 dan 1 akan dihilangkan dansupport count yang melewati lintasan pertama yang berakhiran PE, akan disamakan dengansupport countPE yaitu sesuai dengansupport countyang dimilikinya.
Gambar 3.23ConditionalFP-Tree PE Setelah Dibangkitkan
2. Setelah proses pembangkitan, maka proses terakhir adalah mencari
frequent itemsetyang keluar yang memenuhiminimum support. SC:4 adalah satu-satunya yang keluar yang dapat memenuhi
minimum.Danfrequent itemsetyang didapatkan adalah {PE, SC:4}
Gambar 3.24ConditionalFP-Tree PE, SC:3 HasilFrequent Itemset
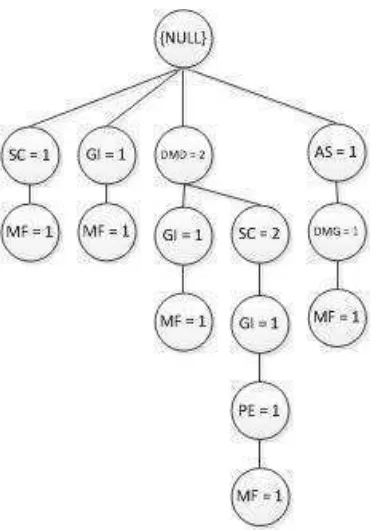
- ConditionalFP-Tree untukitemGI denganConditional Pattern Base{NULL},{DMD,CE,MF:1},{DMD:1},{DMD,SC:1} yang setelah dijumlahkan berdasarkansupport count =3 telah
Gambar 3.25 Lintasan Mengandung Simpul GI
Berikut adalah tahap-tahapannya :
1. Jumlahsupport countyang memenuhiminimum supportakan dibangkitkan denganconditionalFP-Tree.
- DalamconditionalFP-Tree untuk PH, ada 4 lintasan yaitu :
o Lintasan pertama : { GI:2}
o Lintasan kedua : {DMD, CE, MF, GI:1}
o Lintasan ketiga : {DMD,GI:1}
o Lintasan keempat : {DMD,SC, GI:1}
- Pada lintasan yang berakhiran {GI:1} dengansupport count
adalah 1 akan dihilangkan dansupport countyang melewati lintasan pertama yang berakhiran GI, akan disamakan dengan
support countGI yaitu sesuai dengansupport countyang dimilikinya.
Gambar 3.26ConditionalFP-Tree GI Setelah Dibangkitkan
2. Setelah proses pembangkitan, maka proses terakhir adalah mencari
frequent itemsetyang keluar yang memenuhiminimum support. DMD:3 adalah satu-satunya yang keluar yang dapat memenuhi
minimum.Danfrequent itemsetyang didapatkan adalah {GI, DMD:3}
Gambar 3.27ConditionalFP-Tree GI, DMD:3 HasilFrequent Itemset
Gambar 3.28 Lintasan Mengandung Simpul DMG
Berikut adalah tahap-tahapannya :
1. Jumlahsupport countyang memenuhiminimum supportakan dibangkitkan denganconditionalFP-Tree.
- DalamconditionalFP-Tree untuk DMG, ada 4 lintasan yaitu:
o Lintasan pertama : {DMD, CE, CL, DMG:1}
o Lintasan kedua : {DMD, CE, DMG:1}
o Lintasan ketiga : {AS, DMG:2}
o Lintasan empat : {AS, CL, DMG:1}
- Pada lintasan yang berakhiran {DMG:1} dan {DMG:2} dengansupport countadalah 1 dan 2 akan dihilangkan dan
support countyang melewati lintasan pertama yang berakhiran DMG, akan disamakan dengansupport count
DMG yaitu sesuai dengansupport countyang dimilikinya. - Proses selanjutnya adalah apabila dalam suatu lintasan,
Gambar 3.29ConditionalFP-Tree DMG Setelah Dibangkitkan
2. Setelah proses pembangkitan, maka proses terakhir adalah mencari
frequent itemsetyang keluar yang memenuhiminimum support. AS:3 adalah satu-satunya yang keluar yang dapat memenuhi
minimum.Danfrequent itemsetyang didapatkan adalah {DMG, AS:3}
Gambar 3.30ConditionalFP-Tree DMG, AS:3 HasilFrequent Itemset