PENERAPAN METODE CLUSTERING K-MEANS PADA HASIL
PROSES DATA MINING TRANSAKSI PENJUALAN PRODUK
Rini Nuraini Sukmana1 , Indriyanto2 STMIK BANDUNG
Sekolah Tinggi Manajemen Informatika dan Komputer Bandung JL. Phh. Mustofa No. 39 SUCORE M-19 Bandung – 40192
[email protected]
1, [email protected]
2ABSTRAK
Data mining adalah proses menemukan pola atau informasi yang menarik dari data dalam jumlah besar, data dapat disimpan dalam database, data warehouse, atau penyimpanan informasi lainnya. Clustering termasuk metode yang sudah cukup dikenal dan banyak dipakai dalam data mining. Clustering tidak mengklasifikasikan, meramalkan, atau memprediksi nilai dari sebuah data, melainkan digunakan untuk menentukan segmen keseluruhan himpunan data menjadi subgroup yang relatif sama.
Metodologi pembangunan perangkat lunak menggunakan metode waterfall terhadap permasalahan yang timbul dalam penerapan data mining dengan metode clustering k-means. Untuk perancangan sistem menggunakan UML (Unified Modeling Language).
Pada laporan ini dirancang sebuah penerapan data mining dengan metode clustering k-means yang dibangun menggunakan bahasa pemrograman PHP dan MySQL sebagai database, serta framework CodeIgniter untuk mendukung dalam pembuatan aplikasi data mining.
Kata Kunci : Data Mining, Clustering, K-Means, MySQL, CodeIgniter
ABSTRACT
Data mining is a process of finding and pulling patterns or informations in large amount, which can be saved in database, data warehouse, or any other information storage drives. Clustering is one of the well-known data mining methods, which frequently used in the process. Clustering method doesn't classify, foresee or predict values of the data, as its purpose is to determine overall segments of the data collection into similar subgroups.
To solve the problems in implementing data mining by k-means clustering method, waterfall method is used as software development methodology basis, and UML (Unified Modeling Language) is used for building the system. In this report, an implementation of data mining by k-means clustering method is created with PHP programming language and MySQL database, elaborated with CodeIgniter framework as supporting module in purpose of creating data mining application.
Keywords: Data Mining, Clustering, K-Means, MySQL, CodeIgniter
1. PENDAHULUAN
Semakin besar suatu perusahaan, tentunya semakin besar data yang dimiliki. Semua data tersebut biasanya akan tersimpan dalam Database Center. Namun banyak perusahaan yang tidak menyadari betapa berharganya tumpukan data-data lama yang dihasilkan perusahaan dalam bertransaksi. Kebanyakan informasi hanya dipandang sebagai arsip yang sudah menjadi berkas-berkas tidak terpakai dan bisa dihancurkan kapan saja. Hal tersebut tentu saja merupakan pandangan yang salah, sebab dengan
penanganan yang baik maka data-data tersebut dapat diberdayakan dengan Data Mining, sehingga nantinya dapat digunakan untuk meramalkan strategi bisnis dan masa depan perusahaan.
Perusahaan berskala menengah ke atas memang sudah berkewajiban untuk memanfaatkan data mining jika memang ingin sukses dalam bisnis, khususnya didalam bagian penjualan produk-produknya. Data mining adalah sebuah metode yang digunakan untuk mengekstraksi informasi prediktif tersembunyi pada database yang mampu memprediksi tren, prilaku,
sehingga perusahaan semakin proaktif dan memperkaya pengetahuan atau informasi dalam membuat keputusan.
2. PENELITIAN TERKAIT
Penelitian terkait dengan riset ini adalah sebagai berikut
a. Datamining dengan algoritma Apriori
Pada jurnal yang dimuat oleh Dewi Kartika Pane yang berjudul “Implementasi DataMining Pada Penjualan Produk Elektronik Dengan Algoritma
Apriori(Studi Kasus : Kreditplus)” dijelaskan Datamining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan didalam database. Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar.
Aplikasi yang dibuat oleh Dewi Kartika Pane adalah implementasi datamining pada penjualan produk elektronik dengan algoritma Apriori
berbasis web. Pada aplikasi ini dapat mengetahui sejauh mana algoritma Apriori dapat membantu pengembangan strategi pemasaran dan membantu perusahaan untuk mengetahui produk elektronik yang paling banyak terjual.
b. Datamining dengan metode clustering
Pada jurnal yang dimuat oleh Sutrisno, Afriyudi, Widiyanto yang berjudul “Penerapan Data Mining Pada Penjualan Menggunakan Metode
Clustering Study Kasus Pt. Indomarco
Palembang” dijelaskan data penjualan yang sudah ada akan diolah atau dianalisis untuk mengetahui tingkat kecenderungan konsumen di setiap tempat tujuan pemasaran produk pada faktor ketertarikannya. Dari pengolahan data
tersebut akan diperoleh suatu pola konsumsi masyarakat terhadap produk dari perusahaan tersebut. Ketersediaan data yang cukup banyak, kebutuhan akan informasi (atau pengetahuan) sebagai pendukung pengambilan keputusan untuk membuat bussinessolution serta dukungan infrastruktur di bidang teknologi informasi merupakan lahirnya suatu teknologi datamining.
Datamining yang dimaksud untuk memberikan solusi nyata bagi para pengambil keputusan di dunia bussines untuk mengembangkan bisnis mereka.
Aplikasi yang dibuat oleh Sutrisno dan kawan-kawan adalah untuk menerapkan Data Mining
pada penjualan produk makanan dan minuman di PT. Indomarco Palembang menggunakan
metode clustering dengan bahasa pemrograman
PHP. Aplikasi ini dapat melihat penjualan yang paling banyak diminati konsumen khususnya penjualan makanan dan minuman serta menampilkan grafik yang menununjukkan tingkat penjualan yang tinggi terhadap penjualan makanan dan minuman.
Berdasarkan jurnal yang telah dibahas diatas dapat disimpulkan bahwa data mining merupakan proses untuk menggali nilai atau informasi tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data yang besar. Metode clustering k-means pada transaksi penjualan dapat membantu dalam mengolah dan menganalisa tingkat penjualan disetiap cabang dan tingkat kecenderungan konsumen. Oleh karena itu metode
clustering k-means diambil dalam pembuatan skripsi ini.
3. METODOLOGI PENELITIAN
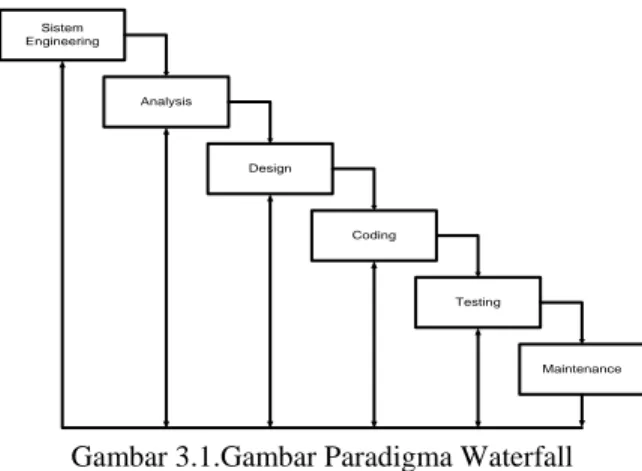
Metode yang digunakan dalam pengembangan sistem ini adalah paradigma Waterfall (Classic Life Cycle) yang terdiri dari :
1. System Engineering, yaitu melakukan pengumpulan data dan penetapan kebutuhan semua elemen sistem.
2. Sistem Analysis, yaitu melakukan analisis dan menetapkan kebutuhan perangkat lunak, fungsi performansi dan interfacing.
3. Design, yaitu tahap penterjemahan dari permasalahan yang telah dianalisis ke dalam bentuk yang lebih mudah dimengerti. 4. Coding, yaitu pengkodean yang
mengimplementasikan hasil desain kedalam kode atau bahasa yang dimengerti oleh mesin komputer dengan menggunakan bahasa pemograman tertentu.
5. Testing, yaitu setelah program selesai dibuat, maka tahap berikutnya adalah uji coba terhadap program tersebut.
6. Maintence, yaitu menangani kemungkinan kekurangan perangkat lunak baik itu berupa kesalahan atau ada hal-hal yang akan ditambahahkan ke dalam perangkat lunak.
Sistem Engineering Testing Coding Design Analysis Maintenance
Gambar 3.1.Gambar Paradigma Waterfall
4. OVERVIEW CLUSTERING K-MEANS
K-means merupakan suatu metode untuk melakukan pengalokasian data ke masing-masing cluster. Alokasi
data tersebut didasarkan perbandingan jarak antara
data dengan centroid setiap cluster (Yudi Agusta, 2007).
Metode clustering mempartisi data ke dalam kelompok sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama (Refaat, 2007). Tujuan dari clustering ini adalah untuk meminimalisasi fungsi tujuan yang ditetapkan dalam proses clustering, yang umumnya berusaha meminimalisasi variasi dalam suatu cluster dan memaksimalisasi variasi antar cluster.
5. PEMBAHASAN
Penerapan metode clustering k-means pada hasil proses data mining transaksi penjualan produk merupakan sebuah aplikasi yang digunakan untuk mengolah data transaksi penjualan di perusahaan-perusahaan dan menghasilkan sebuah informasi atau
knowledge dari data transaksi penjualan, sehingga dapat membantu perusahaan dalam menentukan jumlah produksi dan distribusi dalam bisnisnya.
5.1. Data Mining
Data mining adalah kegiatan menemukan pola yang menarik dari data dalam jumlah besar, data dapat disimpan dalam database, data warehouse, atau penyimpanan informasi lainnya.
5.2. Gudang Data (Data Warehouse)
Data warehouse merupakan kumpulan data dari berbagai sumber yang disimpan dalam suatu gudang data (repository) dalam kapasitas besar dan digunakan untuk proses pengambilan keputusan (Prabhu, 2007).
5.3. Metode Clustering K-means
Metode clustering mempartisi data ke dalam kelompok sehingga data yang memiliki karakteristik
yang sama dikelompokkan ke dalam satu cluster yang sama (Refaat, 2007). Tujuan dari clustering ini adalah untuk meminimalisasi fungsi tujuan yang ditetapkan dalam proses clustering, yang umumnya berusaha meminimalisasi variasi dalam suatu cluster dan memaksimalisasi variasi antar cluster. K-means merupakan suatu metode untuk melakukan pengalokasian data ke masing-masing cluster. Alokasi data tersebut didasarkan perbandingan jarak antara data dengan centroid setiap cluster (Yudi Agusta, 2007).
Secara umum algoritma K-means adalah : 1. Menentukan banyaknya cluster (k). 2. Menentukan centroid.
3. Apakah centroid-nya berubah?
a. Jika ya, hitung jarak data dari centroid. Rumus untuk menghitung data dengan
centroid:
d = jarak
j = banyaknya data c = centroid
x = data
b. Jika tidak, selesai.
4. Mengelompokkan data berdasarkan jarak yang terdekat.
5. Kembali ke langkah 3.
6. PERANCANGAN
berikut ini merupakan arsitektur sistem yang diusulkan dari penerapan metode clustering k-means
pada hasil proses data mining :
Hasil Mining Database Load Extract Transform Data transaksi penjualan Data hasil transform (.xls) Sumber Data Proses mining
Berikut penjelasan dari arsitektur sistem yang diajukan :
1. Data hasil transform berupa file excel yang telah disaring dan diubah sesuai format yang telah ditentukan yang nantinya akan diimpor kedalam
database melalui aplikasi.
2. Proses selanjutnya adalah proses mining dimana
data yang telah masuk kedalam database akan diolah dengan menggunakan metode clustering k-means dengan parameter yang telah ditentukan. 3. Setelah proses mining selesai maka dihasilkan
berikut ini merupakan use case diagram dari penerapan metode clustering k-means pada hasil proses data mining dalam bentuk Use Case:
Data Mining Clustering K-Means
Operator Administrator Kelola Data Customer Kelola Transaksi Penjualan Kelola Data Produk
Kelola User Autentikasi Kelola Data Kategori Manager Clustering K-Means << include >> << include >> << include >> << include >> << include >>
Pada use case diagram ini terdapat 3 aktor yang berperan dalam menjalankan aplikasi. Berikut peran masing – masing dari setiap actor pada aplikasi ini : a. Manager, ialah pengguna yang melakukan proses
miningdata transaksi penjualan.
b. Operator, hanya dapat merekam data master
seperti datacustomer, data kategori, data produk, dan data transaksi penjualan.
c. Administrator, ialah pengguna tertinggi level admin. Fungsinya ialah melakukan maintenance (perawatan) terhadap sistem . Memiliki semua hak akses.
7. IMPLEMENTASI SISTEM
Berikut ini merupakan beberapa implementasi dari penerapan metode clustering k-means pada hasil proses data mining :
Gambar 5.1 Form Proses Clustering
Pada halaman proses mining pengguna dapat melakukan proses data mining dengan metode clustering k-means pada data transaksi penjualan yang hasil akhirnya berupa tabel hasil clustering dan grafik penjualan serta fasilitas ekspor hasil clustering ke dalam file pdf. Pada halaman proses mining ini yang dapat mengakses adalah manager saja.
8. PENGUJIAN
Pengujian metode clustering k-means pada hasil proses data mining transaksi penjualan produk berikut menggunakan data uji berupa pengolahan data, pengolahan proses dan pengolahan laporan serta informasi kelengkapannya. Pada pengujian yang dilakukan pada aplikasi ini menggunakan pengujian
black box, berikut merupakan pengujian dari metode
clustering k-means pada hasil proses data mining
transaksi penjualan produk :
Pengujian proses data mining dengan metode
clustering k-means dilakukan untuk mengecek fungsional dari proses data mining dengan metode clustering k-means.
Tabel 6.1 Pengujian Proses Clustering
9. KESIMPULAN
Setelah dilakukan analisa terhadap aplikasi yang akan dibuat maupun sistem usulan dapat disimpulkan sebagai berikut :
1. Dengan diterapkannya metode clustering k-means pada data mining sistem mampu mengolah data transaksi penjualan menjadi sebuah informasi atau knowledge.
2. Dengan dibuatnya aplikasi data mining ini perusahaan dapat mengolah data transaksi penjualan, sehingga perusahaan dapat melihat perkembangan penjualan disuatu customer. 3. Dengan penyajian hasil clustering berupa tabel
dan grafik, maka membantu perusahaan dalam menentukan produksi dan distribusi produknya.
10. SARAN
Agar sebuah aplikasi dapat berjalan dengan baik dan dapat mencapai tujuan secara maksimal, maka dibutuhkannya hal-hal pendukung. Menyangkut hal ini maka rekomendasi yang diusulkan diantaranya: 1. Penerapan metode clustering k-means masih
memungkinkan dikembangkan tidak hanya pada transaksi penjualan.
2. Menerapkan beberapa metode pendukung proses
clustering untuk optimalisasi algoritma k-means.
11. DAFTAR PUSTAKA
1. Davies, and Paul Beynon. 2004. Database Systems Third Edition. Palgrave Macmillan. New York. 2. Han, J. and Kamber, M. 2006. Data Mining
Concepts and Techniques Second Edition. Morgan Kauffman. San Francisco.
3. Kimball, R. 2004. The Data Warehouse ETL Toolkit. Wiley Publishing Inc.
4. Prabhu, S., Venatesan, N. 2007. Data Mining and Warehousing. New Age International (P) Limited, Publishers.
5. Pramudiono, I. 2007. Pengantar Data Mining : Menambang Permata Pengetahuan di Gunung Data. http://www.ilmukomputer.org/wp-content/uploads/2006/08/iko-datamining.zip Diakses pada tanggal 9 februari 2015 jam 10:40. 6. Refaat, M. 2007. Data Preparation for Data
Mining Using SAS. Diane D Cerra. San Francisco. 7. Santosa, Budi. 2007. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Graha Ilmu. Yogyakarta.
8. Witten, I. H and Frank, E. 2005. Data Mining : Practical Machine Learning Tools and Techniques Second Edition. Morgan Kauffman. San Francisco. 9. Yudi Agusta, P. 2007. K-Means Penerapan
Permasalahan dan Metode terkait. Jurnal Sistem dan Informatika vol.3, pp. 47-60.