ABSTRACT
EKA MARLIANA. Information Retrieval for RSS News Document in Bahasa Indonesia. Supervised by FIRMAN ARDIANSYAH.
RSS (Really Simple Syndication) is a language derived from XML (Extensible Markup Language). The use of RSS as a syndication on Indonesian news sites has become widespread, as well as a syndicated news by news websites will continue to evolve in time, so it requires a search facility that can return information that explore the RSS data efficiently and effectively. Several studies have been conducted related to information retrieval, one of it was developed by Rahman (2006) which measured performance and compared the equality of returned XML document.
This research tries to implement the information retrieval using VSM (Vector Space Model) to build an RSS search facility and to analyze and compare the effects of the use of additional title weighting with normal weighting.
Test results show that the use of the normal weighting performs better than the use of weighting in the title. This is explained by the average precision value gotten from the test. At recall levels between 10% until 30% the average precision has the same value, at recall level 60% the average precision value of title weighting is higher than normal weighting, but between 40%, 50%, 70% until 100% the normal weighting precision is greater that of the title weighting.
TEMU KEMBALI INFORMASI BERITA BERBAHASA
INDONESIA BERBASIS RSS
EKA MARLIANA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
TEMU KEMBALI INFORMASI BERITA BERBAHASA
INDONESIA BERBASIS RSS
EKA MARLIANA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
TEMU KEMBALI INFORMASI BERITA BERBAHASA
INDONESIA BERBASIS RSS
EKA MARLIANA
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
EKA MARLIANA. Information Retrieval for RSS News Document in Bahasa Indonesia. Supervised by FIRMAN ARDIANSYAH.
RSS (Really Simple Syndication) is a language derived from XML (Extensible Markup Language). The use of RSS as a syndication on Indonesian news sites has become widespread, as well as a syndicated news by news websites will continue to evolve in time, so it requires a search facility that can return information that explore the RSS data efficiently and effectively. Several studies have been conducted related to information retrieval, one of it was developed by Rahman (2006) which measured performance and compared the equality of returned XML document.
This research tries to implement the information retrieval using VSM (Vector Space Model) to build an RSS search facility and to analyze and compare the effects of the use of additional title weighting with normal weighting.
Test results show that the use of the normal weighting performs better than the use of weighting in the title. This is explained by the average precision value gotten from the test. At recall levels between 10% until 30% the average precision has the same value, at recall level 60% the average precision value of title weighting is higher than normal weighting, but between 40%, 50%, 70% until 100% the normal weighting precision is greater that of the title weighting.
Judul : Temu Kembali Informasi Berita Berbahasa Indonesia Berbasis RSS Nama : Eka Marliana
NIM : G64066010
Menyetujui:
Pembimbing,
Firman Ardiansyah., S.Kom.,M.Si NIP. 19790522 200501 1 003
Mengetahui: Ketua Departemen,
Dr. Ir. Sri Nurdiati, M.Sc NIP. 19601126 198601 2 001
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 5 Maret 1984 dari pasangan Ahmad Sobari dan Nuriah. Penulis merupakan anak kedua dari enam bersaudara.
PRAKATA
Bismillahirrahmanirrahim,
Segala puji bagi Allah SWT, atas limpahan rahmat dan karunia-Nya dan semoga shalawat dan salam tetap tercurahkan kepada Nabi Muhammad SAW. Penulis mengucapkan Alhamdulillahi rabbal ‘alamin, atas selesainya skripsi dengan judul Temu Kembali Informasi Berita Berbahasa Indonesia Berbasis RSS. Skripsi ini merupakan salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Terlalu banyak pihak-pihak yang menjadikan penulis bisa mencapai hasil dan keadaan seperti sekarang ini. Dengan tidak bermaksud mengecilkan peran mereka semua dengan tidak menuliskannya pada bagian ini, penulis ingin menyampaikan penghargaan sebesar-besarnya kepada mereka semua. Bapak Firman Ardiansyah, S.Kom, M.Si selaku pembimbing atas seluruh saran, koreksi maupun bimbingan selama pengerjaan tugas akhir ini. Bapak Ahmad Ridha, S.Kom, M.S dan Sony Hartono Wijaya, S.Kom, M.Kom selaku penguji atas saran dan koreksinya. Seluruh anggota keluarga besar Departemen Ilmu Komputer atas kerja sama yang telah diberikan.
Rasa terima kasih juga ingin penulis sampaikan kepada teman-teman seperjuangan yang telah banyak membantu. Mas Sukma Agung atas bantuan dan dukungannya, Ana, Rika, Holili, Harry, Wenny, Dede, Ajis, Dimas, Rico dan teman-teman ILKOM Ekstensi IPB yang tidak dapat disebutkan satu persatu, atas dukungan dan kebersamaannya.
The last but not least, untuk keluargaku, Bapak, Mamah, Abang, Adik-adik atas cinta, dukungan, kesabaran, serta do’a yang selalu menyertai penulis. Terima kasih telah memberikan yang terbaik untuk penulis.
Bogor, Desember 2009
DAFTAR ISI
Halaman
DAFTAR TABEL ...viii
DAFTAR GAMBAR...viii
DAFTAR LAMPIRAN...viii
PENDAHULUAN ...1
Latar Belakang ...1
Tujuan ...1
Ruang Lingkup...1
Manfaat ...1
TINJAUAN PUSTAKA ...1
Temu Kembali Informasi ...1
RSS ...1
Parsing...1
Stemming...1
Pembobotan tf-idf...1
Vector Space Model...2
Recall Precision...2
Average Precision...2
Hash Function...3
METODOLOGI PENELITIAN...3
Koleksi Dokumen...3
Pemilihan Ukuran Kesamaan ...3
Tahap-tahap Penelitian...3
Text Operation...3
Indexing...5
Searching...5
Ranking...5
User Interface...5
Evaluasi Sistem ...5
Asumsi-asumsi ...5
Lingkup Implemental ...6
HASIL DAN PEMBAHASAN...6
Koleksi Dokumen...6
Tahap-tahap Penelitian...6
Text Operation...6
Indexing...9
Searching...10
Ranking...10
User Interface...10
Evaluasi Sistem ...10
KESIMPULAN DAN SARAN...11
Kesimpulan ...11
Saran ...11
DAFTAR PUSTAKA ...11
DAFTAR TABEL
Halaman
1 Daftar imbuhan untuk proses stemming hasil adopsi Tala stemmer...4
2 Penambahan aturan pemotongan...4
3 Situs berita dan jumlah RSS yang diunduh ...6
4 Daftar kueri untuk pengujian sistem...6
5 Average precision dengan pembobotan judul ...11
6 Average precision dengan pembobotan normal ...11
DAFTAR GAMBAR
Halaman 1 Sistem temu kembali informasi ...32 Desain dasar dari Tala stemmer untuk bahasa Indonesia ...4
3 Lima aturan pemotongan imbuhan ...5
4 Representasi berita dalam dokumen RSS ...7
5 Stemming tanpa penyisipan huruf...8
6 Stemming dengan penyisipan huruf...9
7 Tabel posting...9
8 Tabel dictionary...9
9 Hasil pembobotan tf-idf...9
10 Nilai cosine untuk kueri uji coba ”nuklir Iran” ...10
11 Daftar dokumen dan nilai cosine yang telah terurut berdasarkan kueri masukan ”nuklir Iran” ...10
12 User interface dari sistem temu kembali ...10
13 Grafik average precision...12
DAFTAR LAMPIRAN
Halaman 1 Contoh dokumen RSS yang diperoleh dari situs berita Okezone ...142 Hasil proses parsing tahap satu ...15
3 Daftar hasil ujicoba kueri ...16
4 Recall, precision dan nilai recall vs precision yang digunakan untuk membuat grafik sebelas standar recall setiap kueri. ...17
PENDAHULUAN
Latar Belakang
Beberapa situs berita di Indonesia seperti Kompas, Okezone, Tempo, Antara dan lain sebagainya telah menggunakan RSS dalam menyajikan sindikasi berita.
Jumlah berita yang disindikasikan oleh situs berita tersebut akan terus berkembang seiring dengan berjalannya waktu. Oleh karena itu perlu dikembangkan sebuah fasilitas temu kembali informasi yang dapat mengeksplorasi data tesebut secara efisien. Hal ini bertujuan untuk memudahkan pengguna mendapatkan berita yang relevan dengan yang diinginkan.
Tujuan
1. Mengimplementasikan temu kembali informasi untuk dokumen berita berbahasa Indonesia dengan format RSS.
2. Menelaah kinerja sistem yang dibangun dalam mengembalikan jawaban yang relevan dari kumpulan dokumen berita berbahasa Indonesia.
Ruang Lingkup
Korpus terdiri atas dokumen berita berbahasa Indonesia dengan format RSS 2.0, berjumlah 173 dokumen RSS. Untuk pengujian sistem digunakan 10 kueri percobaan.
Manfaat
Dari penelitian ini diharapkan terbentuk sebuah engine yang dapat menemukembalikan dokumen berita dengan format RSS berdasarkan kueri yang diberikan pengguna.
TINJAUAN PUSTAKA
Temu Kembali Informasi
Temu kembali informasi berkaitan dengan representasi, penyimpanan, pengorganisasian dan pengaksesan informasi. Sistem temu kembali informasi menyediakan kemudahan akses informasi bagi pengguna. Pengguna harus menerjemahkan kebutuhan informasinya ke dalam bentuk kueri. Dengan adanya kueri yang diberikan oleh pengguna, tujuan utama dari sistem temu kembali informasi adalah mengembalikan informasi yang relevan dengan kueri dan informasi yang tidak relevan sesedikit mungkin (Baeza-Yates & Ribeiro-Neto 1999).
RSS
Really Simple Syndication (RSS)
merupakan turunan dari bahasa XML.
Extensible Markup Language (XML) adalah format teks yang sederhana dan sangat fleksibel yang diambil dari SGML (ISO 8879). RSS adalah suatu format yang digunakan untuk sindikasi berita dan isi dari situs seperti berita, termasuk situs berita besar seperti Wired, situs komunitas yang berorientasi berita seperti Slashdot, dan weblog pribadi. Maksud dari sindikasi di sini adalah sebuah situs yang memiliki RSS Feed dapat dibaca isinya tanpa harus mengunjungi situs yang bersangkutan. RSS tidak hanya untuk berita. Hampir semua hal yang bisa dipilah-pilah menjadi bagian-bagian diskret dapat disindikasi melalui RSS: halaman "recent changes" dari sebuah wiki,
changelog dari CVS checkins, bahkan juga sejarah revisi dari sebuah buku. (XML 2002).
Parsing
Untuk pemrosesan, dokumen dipilih menjadi unit-unit yang lebih kecil contohnya berupa kata, frasa atau kalimat. Unit hasil pemrosesan disebut sebagai token. Dalam proses ini biasanya juga digunakan sebuah daftar kata yang tidak digunakan (stoplist) karena tidak signifikan dalam membedakan dokumen atau kueri, misalnya kata-kata tugas seperti yang, hingga, dan dengan. Proses
parsing akan menghasilkan daftar istilah beserta informasi tambahan seperti frekuensi dan posisi yang akan digunakan dalam proses selanjutnya (Ridha 2002).
Stemming
Stemming adalah proses penghilangan prefiks dan sufiks dari kueri dan istilah-istilah dokumen (Grossman 2002). Stemming
dilakukan atas dasar asumsi bahwa kata-kata yang sama memiliki makna yang serupa. Dalam hal keefektifan stemming dapat meningkatkan
recall dengan mengurangi bentuk-bentuk kata ke bentuk kata dasarnya. Selain itu proses
stemming juga dapat mengurangi ruang
penyimpanan indeks (Ridha 2002).
Pembobotan tf-idf
Pada saat pengindeksan, dokumen RSS diekstrak melalui proses parsing untuk mendapatkan istilah-istilah dari masing-masing dokumen. Untuk setiap pasangan istilah dan dokumen tersebut diberikan pembobotan tf-idf:
i idf j i tf j i idf
Untuk pembobotan istilah dalam dokumen dihitung dengan rumus berikut:
j i freq i j i freq j i tf , max , , = ,
di mana bobot kemunculan istilah dalam dokumen merupakan hasil bagi antara tingkat kepentingan istilah tersebut dalam dokumen
j i
tf, dengan tingkat kepentingannya pada keseluruhan dokumen dalam koleksi
( )
idft . Dengan(
freqi,j)
= banyaknya kemunculan istilah( )
i dalam dokumen, danj i freq
i ,
max =
kemunculan terbanyak
( )
f dari istilah dalam dokumen. Ukuran maxi freqi,j digunakan sebagai faktor normalisasi karena dokumen yang panjang cenderung memiliki lebih banyak istilah dan frekuensi istilah yang lebih tinggi. Tingkat kepentingan istilah terhadap keseluruhan dokumen dalam koleksi dihitung dengan rumus berikut:=
i n
N i
idf log ,
dengan Nadalah banyaknya dokumen dalam koleksi dan
( )
ni adalah banyaknya dokumen yang mengandung istilah( )
i .Selain pembobotan istilah pada dokumen, pembobotan juga dilakukan pada istilah kueri. Berikut ini adalah pembobotan yang digunakan untuk istilah kueri.
× × + = t df N q i freq i q i freq q i w log , max , 5 . 0 5 . 0 , ,
dengan freqi,q = banyaknya kemunculan istilah
( )
f dalam kueri, danq i freq
i ,
max =
kemunculan terbanyak
( )
f dari istilah dalam kueri (Baeza-Yates & Ribeiro-Neto 1999).Vector Space Model
Vector Space Model (VSM) merupakan salah satu model matematika yang digunakan untuk merepresentasikan sistem dan prosedur penemukembalian informasi yang merepresentasikan kueri dan dokumen dengan gugus istilah dan menghitung kesamaan global antara kueri dan dokumen (Salton 1989).
Dalam temu kembali informasi pada dokumen, VSM digunakan untuk memodelkan tingkat kesamaan antara dokumen dengan kueri. Pada umumnya pengukuran tingkat kesamaan dilakukan dengan cara menghitung kosinus sudut antara vektor kueri dengan dokumen. Kueri dan dokument dapat dinyatakan dalam vektor istilah sebagai berikut:
Q = (WQ(t1), WQ(t2), WQ(t3), ..., WQ(tn)),
D = (WD(t1), WD(t2), WD(t3), ..., WD(tn)),
dengan WQ(ti) adalah bobot istilah t dalam kueri
dan WD(ti) adalah bobot istilah t dalam
dokumen. Nilai WD(ti) adalah nilai tf-idf(ti).
Selanjutnya derajat kesamaan ρ
(
Q,D)
antara dokumen dan kueri dapat dihitung menggunakan kosinus sudut antara vektor D dan Q dengan rumus sebagai berikut: (Rahman 2006)
(
,)
|( )
( )
. D Q i t D W i t Q W D Q ti D Q ∗ ∗ ∈ = ρRecall – Precision
Recall dan Precision adalah dua ukuran yang umum digunakan untuk mengevaluasi kualitas dari temu kembali informasi.
Dalam temu kembali informasi precision
didefinisikan sebagai jumlah dari dokumen relevan yang ditemukembalikan dibagi dengan jumlah total dokumen yang ditemukembalikan dari hasil pencarian, sedangkan recall
didefinisikan sebagai jumlah dari dokumen relevan ditemukembalikan dibagi dengan jumlah total dokumen relevan yang ada dalam koleksi.
Recall dan precission dapat dinyatakan sebagai berikut (Baeza-Yates & Ribeiro-Neto 1999). , Re R R A call= , Pr A R A ecision=
dengan A adalah jumlah dokumen yang ditemukembalikan, R adalah jumlah dokumen yang relevan dalam koleksi, dan A R adalah
jumlah dokumen relevan yang
ditemukembalikan.
Average Precision
berbagai tingkat recall, biasanya digunakan sebelas tingkat recall standar yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.
Adakalanya tingkat recall yang diperoleh tiap kueri berbeda dengan sebelas tingkat recall
standar yang ada. Untuk kasus yang seperti ini dibutuhkan prosedur interpolasi. Jika rj,
}
{
0,1,2,...,10∈
j adalah tingkat recall standar ke-
j
maka :1
max ≤ ≤ +
= r rj
j r j
r
P P
( )
r ,dengan demikian, precision interpolasi pada tingkat recall standar ke-j adalah precision
tertinggi pada setiap tingkat recall antara j
hingga
(
j+1)
(Baeza-Yates & Ribeiro-Neto 1999).Hash Function
Hash function adalah suatu metode yang digunakan untuk mengubah data yang ada menjadi sebuah bilangan yang relatif kecil (small number) yang akan menjadi “sidik jari” (fingerprint) dari data terebut. Fungsi ini memecah dan mengolah data untuk menghasilkan kode atau nilai hash-nya. Nilai dari suatu fungsi hash akan memiliki panjang yang tetap untuk masukan dengan panjang yang sembarang. Secara umum, fungsi hash memiliki beberapa sifat utama, yaitu : fungsi satu arah, artinya untuk suatu nilai fungsi hash y, sulit menemukan nilai input x yang memenuhi persamaan H(x)=y, dan collision free/resistant, artinya sulit untuk menemukan 2 buah nilai input yang memunyai nilai fungsi hash yang sama.
Salah satu fungsi hash yang banyak digunakan adalah Message Digest 5 (MD5). Algoritme MD-5 secara garis besar adalah mengambil pesan yang memunyai panjang variabel diubah menjadi ‘sidik jari’ atau ‘intisari pesan’ yang memunyai panjang tetap yaitu 128 bit.
METODE PENELITIAN
Koleksi Dokumen
Dokumen berita yang akan digunakan pada penelitian berasal dari beberapa situs berita di Indonesia seperti Antara, Detik, Liputan 6, Kompas, Okezone, dan Tempo. Data yang digunakan adalah data dengan format RSS versi 2.0.
Pemilihan ukuran kesamaan
Beberapa ukuran kesamaan yang dapat digunakan dalam VSM di antaranya inner product, cosine, dice, jaccard, overlap dan
asymmetric.
Pada penelitian yang dilakukan oleh Rorvig (1999), dibandingkan lima ukuran kesamaan (cosine, dice, jaccard, overlap, dan asymetric) hasil uji menunjukkan bahwa ukuran kesamaan
cosine dan overlap memiliki kinerja temu kembali yang lebih baik dibanding yang lain. Hasil penelitian yang dilakukan oleh Rahman (2006) yang melakukan perbandingan kinerja empat ukuran kesamaan (cosine, dice, jaccard, dan overlap), hasil uji menunjukkan bahwa ukuran kesamaan cosine memberikan kinerja temu kembali yang lebih baik dibandingkan dengan tiga ukuran kesamaan lainnya. dice dan
jaccard tidak jauh berbeda sedangkan overlap
memiliki kinerja yang paling rendah.
Merujuk kepada hasil kedua penelitian tersebut maka ukuran kesamaan yang akan digunakan dalam penelitian ini adalah ukuran
cosine.
Tahap-tahap Penelitian
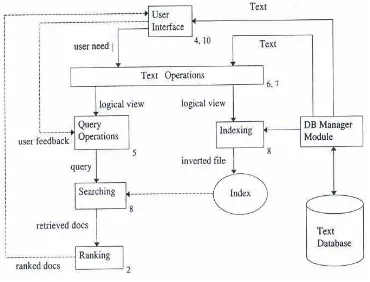
Gambar 1 menunjukkan gambaran sistem secara umum yang akan dibuat dalam penelitian ini
Gambar 1 Sistem temu kembali informasi (Baeza & Ribeiro 1999).
Tahapan-tahapan yang dilakukan dalam penelitian ini adalah :
Text operation
Proses yang dilakukan dalam text operation
adalah proses parsing dan stemming.
1. Parsing
Parsing dilakukan dengan
proses ini yang termasuk ke dalam stoplist
(daftar kata-kata buangan) akan diabaikan.
Parsing dilakukan dalam dua tahap yaitu :
• Parsing tahap satu
Parsing pada tahap satu bertujuan untuk mengambil dan memisahkan setiap berita menjadi token berita. Setiap token berita dalam dokumen RSS direpresentasikan dalam elemen item. Untuk mencegah adanya duplikasi berita maka digunakan
hash function MD5 yang bertujuan untuk menghasilkan identitas yang unik untuk setiap token berita berdasarkan isi dari token tersebut.
• Parsing tahap dua
Parsing tahap dua bertujuan untuk
parsing isi token berita yang didapat dari proses parsing tahap satu. Pada tahapan ini dilakukan parsing terhadap isi dari setiap token berita sehingga dihasilkan token istilah. Token istilah beserta identitas token berita digunakan dalam proses
indexing.
2. Stemming
Stemming adalah proses pemotongan kata untuk mengembalikan kata ke bentuk dasarnya sehingga dapat meningkatkan hasil recall. Algoritme stemmer yang digunakan dalam penelitian ini diadopsi dari Tala stemmer. Tala stemmer
memodifikasi algoritme Porter stemmer
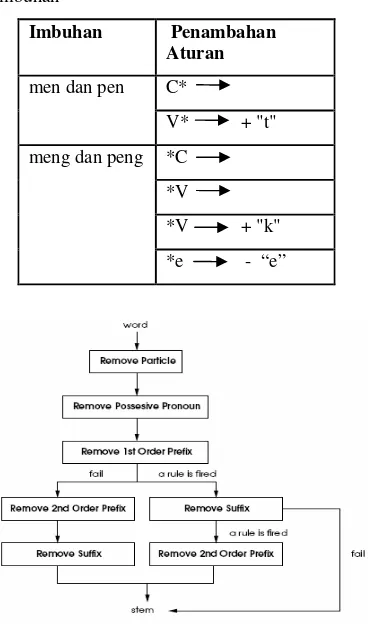
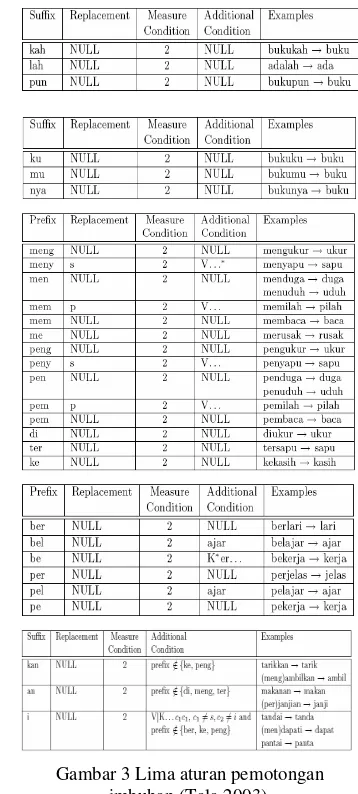
untuk bahasa Indonesia. Selain menggunakan daftar imbuhan dan aturan yang ada pada Tala stemmer, pada penelitian ini dilakukan penambahan aturan pemotongan dan imbuhan yang dapat dilihat pada Tabel 1 dan 2.
Bahasa Indonesia memiliki Struktur morfologi sebagai berikut:
[prefiks1] + [prefiks2] + kata dasar + [sufiks] + [kata ganti kepunyaan] + [partikel]
dengan tanda [ ] menunjukkan pilihan. Struktur tersebut dapat digunakan sebagai panduan dalam proses stemming. Desain dasar dari proses stemming dapat dilihat pada Gambar 2.
Pemotongan kata dilakukan dengan menghilangkan partikel, kata ganti kepunyaan, prefiks (awalan), infiks (sisipan), sufiks (akhiran), dan konfiks (gabungan antara prefiks dan sufiks).
Hanya saja pemotongan imbuhan yang berupa sisipan sulit dilakukan untuk itu dalam penelitian ini sisipan atau infiks diabaikan. Daftar imbuhan dapat dilihat pada Tabel 1, sedangkan aturan pemotongan imbuhan dapat dilihat pada Gambar 3. Tabel 1 Daftar imbuhan untuk proses stemming
hasil adopsi Tala stemmer
Tabel 2 Penambahan aturan pemotongan imbuhan
Imbuhan Penambahan
Aturan
C* men dan pen
V* + "t" *C
*V *V + "k" meng dan peng
*e - “e”
Gambar 2 Desain dasar dari Tala stemmer
untuk bahasa Indonesia (Tala 2003).
Imbuhan Porter Stemmer tambahan
Partikel kah, lah, pun, tah Kata ganti
kepunyaan
ku, mu, nya
Sufiks kan, an, i Prefiks be, di, ke, me, pe,
bel, ber, mem, men, pel, per, pem, pen, ter, meng, meny, peng, peny
Sebagaimana algoritme Tala, digunakan suatu fungsi penghitung ukuran kata untuk mencegah stemming menghasilkan stem
yang terlalu pendek. Diasumsikan minimal
stem hasil berukuran dua kecuali jika token berukuran kurang dari dua. Jumlah vokal dalam kata akan digunakan sebagai penentu ukuran kata kecuali kata-kata tanpa vokal yang terdiri atas tiga karakter atau lebih dianggap memiliki ukuran dua untuk mengakomodasi singkatan yang hanya terdiri atas konsonan (Ridha 2002).
Selain menggunakan daftar imbuhan proses stemming dalam penelitian ini menggunakan aturan gugus konsonan dalam proses pemotongannya, serta menggunakan kamus kata dasar bahasa Indonesia untuk melakukan pemeriksaan apakah kata yang dihasilkan merupakan kata dasar atau bukan.
Gambar 3 Lima aturan pemotongan imbuhan (Tala 2003).
Indexing
Pada tahapan ini dibangun sebuah indeks kata dari hasil text operation, dengan menggunakan teknik inverted index.
Searching
Proses pencarian kueri dilakukan dengan menghitung tingkat relevansi kueri dengan dokumen yang ada. Algoritme pencarian yang digunakan pada inverted index adalah
Vocabulary search, yaitu kueri dicari di dalam perbendaharan kata yang terdapat pada indeks. Hal yang perlu ditekankan adalah kueri harus dipisahkan per kata (parsing).
Ranking
Pada tahapan ini dilakukan pengurutan dokumen berdasarkan tingkat relevansi antara kueri dan dokumen.
User Interface
Perancangan dan pembuatan user interface
dari sistem yang akan menjembatani pengguna dengan sistem itu sendiri.
Evaluasi Sistem
Evaluasi dilakukan dengan mengukur kinerja temu kembali dengan menggunakan pendekatan recall–precission. Sistem akan mengembalikan daftar dokumen terurut menurun berdasarkan hasil fungsi kesamaan kueri dan dokumen.
Batasan dan asumsi
Batasan dan asumsi yang akan digunakan dalam penelitian ini adalah sebagai berikut :
1. Dokumen dan kueri menggunakan karakter ASCII.
2. Dokumen yang digunakan adalah dokumen berekstensi XML dengan format RSS versi 2.0.
3. Pengindeksan hanya dilakukan untuk isi dari elemen title dan description. Tag, atribut dan elemen lain seperti link dan
pubdate tidak diindeks karena diangggap tidak terlalu penting dalam RSS berita. 4. Tidak ada kesalahan penulisan XML dalam
dokumen RSS.
5. Pengujian dilakukan dengan membandingkan kinerja sistem yang menggunakan pembobotan judul dengan pembobotan normal.
6. Istilah yang terdapat pada elemen title
besar dibandingkan dengan istilah yang berada pada description.
Lingkup Implemental
Lingkungan implementasi yang akan digunakan adalah sebagai berikut:
Perangkat Lunak :
• Sistem operasi Windows XP Professional
• Java 1.6
• Apache Tomcat 6
• MySQL 5 Perangkat Keras :
• Processor Intel dual core 1.6 GB
• RAM 1 GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen
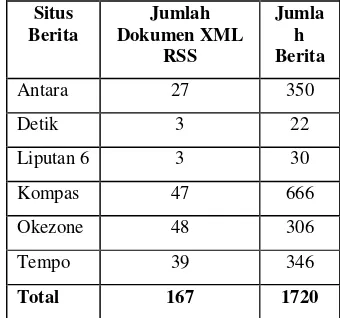
Penelitian ini menggunakan koleksi dokumen RSS versi 2.0 yang didapatkan dari beberapa situs berita berbahasa Indonesia di antaranya situs berita Antara, Detik, Kompas, Liputan6, Okezone, dan Tempointeraktif, yang diunduh pada tanggal 22, 23 dan 27 Agustus 2009. Contoh dari salah satu dokumen RSS berita dapat dilihat pada Lampiran 1.
Untuk menguji kinerja sistem temu kembali informasi digunakan koleksi dokumen sebanyak 173 dokumen RSS. Dari 173 dokumen RSS yang dipergunakan hanya 167 dokumen yang terindeks oleh sistem dan diperoleh 1720 buah berita (Tabel 3). Hal ini dikarenakan beberapa dokumen RSS tidak memenuhi aturan penulisan XML yang benar.
Untuk melakukan uji coba, dibentuk daftar pasangan kueri dan jumlah dokumen yang relevan yang akan dipergunakan untuk mengukur kinerja sistem temu kembali informasi yang dibuat. Adapun daftar kueri yang akan diujikan terhadap dokumen dapat dilihat pada Tabel 4.
Tahap-tahap Penelitian
Text Operation
1.Parsing
Dokumen masukan diproses secara sekuensial dan menghasilkan sebuah token. Proses parsing dilakukan dalam dua tahapan yaitu:
Tabel 3 Situs berita dan jumlah RSS yang diunduh Situs Berita Jumlah Dokumen XML RSS Jumla h Berita
Antara 27 350
Detik 3 22
Liputan 6 3 30
Kompas 47 666
Okezone 48 306
Tempo 39 346
Total 167 1720
Tabel 4 Daftar kueri untuk pengujian sistem
No Kueri Dokumen
Relevan
1 Kebakaran 7
2 Gempa bumi 5
3 Inter Milan 15
4 Kebakaran hutan 5
5 Nuklir Iran 4
6 Pembunuhan Nasrudin 5
7 Tari pendet 29
8 Virus komputer 6
9 Pemakaman Michael
Jackson 7
10 Pemilu di Afghanistan 7 a. Parsing tahap satu
Proses parsing tahap satu adalah sebagai berikut:
Gambar 4 Representasi berita dalam dokumen RSS.
• Setiap token berita yang diperoleh dibentuk sebuah identitas yang unik yang akan digunakan sebagai nama berkas dari token berita tersebut dengan menggunakan teknik enkripsi MD5. Nama file dan token berita disimpan ke dalam basis data. Hasil dari proses parsing tahap satu dapat dilihat pada Lampiran 2.
Dari proses parsing tahap satu dihasilkan 1720 berita dari 167 dokumen RSS. b. Parsing tahap dua
Setiap token berita yang diperoleh dari tahap satu diproses kembali, parsing di sini bertujuan untuk mendapatkan token istilah (satuan perkata) dari token berita.
Tidak semua informasi yang ada pada token berita dipergunakan, hanya informasi yang tersimpan dalam elemen title dan
description yang diolah, di mana elemen
title dan description merepresentasikan judul dan deskripsi berita. Berikut ini adalah proses parsing tahap dua:
• Dengan menggunakan JDOM isi dari elemen item dan description diambil.
• Proses pengambilan token istilah dengan cara membaca satu persatu karakter. Sebuah karakter dapat berupa salah satu dari tiga jenis berikut:
o whitespace, berarti karakter ini merupakan karakter pemisah token
o alphanumeric, berarti karakter ini merupakan huruf atau angka
o other, berarti karakter ini tidak termasuk jenis-jenis di atas.
• Jika karakter yang ditemukan merupakan huruf atau angka maka karakter tersebut menjadi karakter pertama dari istilah.
• Karakter-karakter selanjutnya menjadi bagian dari istilah tersebut hingga ditemukan karakter whitespace atau akhir dari istilah.
Istilah yang didapatkan dari hasil
parsing tahap kedua disebut token istilah, yang kemudian diubah ke dalam bentuk
lower case (Ridha 2002).
2. Stemming
Mekanisme stemming digunakan untuk mengatasi masalah variasi dalam bentuk kata yang sebenarnya memiliki makna yang sama. Penelitian ini menggabungkan metode Tala stemmer yang telah diadopsi dengan penggunaan kamus kata dasar bahasa Indonesia dan gugus konsonan.
Beberapa fungsi pendukung yang digunakan dalam stemming antara lain a. isBasicWord(s), mengembalikan true bila
kata s adalah kata dasar selainnya false; b. isVocal(c), mengembalikan true bila
karakter c termasuk ke dalam huruf vokal (a, i, u, e, o) selainya false;
c. substring(i, n), mengembalikan potongan karakter dimulai dari indeks ke i sampai indeks ke n dari karakter token istilah;
d. numberOfVocals(s), mengembalikan
jumlah huruf vokal dalam kata.
berikut adalah aturan dan proses pemotongan untuk tiap imbuhan yang diadopsi dari aturan pemotongan pada penelitian Aries (2005): a. partikel - lah
(M>2) lah b. partikel - kah
(M>2) kah c. partikel - tah
(M>2) tah d. partikel - pun
(M>2) pun
e. kata ganti kepunyaan - ku (M>2) ku
f. kata ganti kepunyaan - mu (M>2) mu
g. kata ganti kepunyaan - nya (M>2) nya
h. sufiks - i (M>2) i i. sufiks - an
(M>2) an j. sufiks - kan
k. prefiks - di (M>2) di l. prefiks - ke
(M>2) ke m. prefiks - se
(M>2) se n. prefiks - ter
(M>2) ter o. prefiks - ber
be (M>2 and C* and er*) bel (ajar*) ajar ber (M>2)
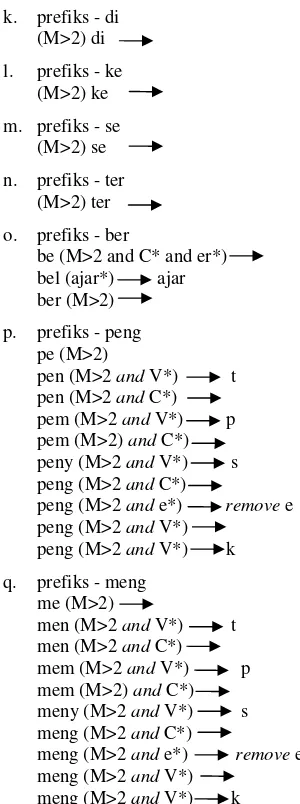
p. prefiks - peng pe (M>2)
pen (M>2 and V*) t pen (M>2 and C*) pem (M>2 and V*) p pem (M>2) and C*) peny (M>2 and V*) s peng (M>2 and C*)
peng (M>2 and e*) remove e peng (M>2 and V*)
peng (M>2 and V*) k q. prefiks - meng
me (M>2)
men (M>2 and V*) t men (M>2 and C*) mem (M>2 and V*) p mem (M>2) and C*) meny (M>2 and V*) s meng (M>2 and C*)
meng (M>2 and e*) remove e meng (M>2 and V*)
meng (M>2 and V*) k
Dalam hal ini V* : diawali dengan huruf vokal, C* : diawali dengan huruf konsonan, dan e* : diawali dengan huruf e, dan M adalah jumlah minimal ukuran hasil stem.
Proses stemming dilakukan dengan langkah-langkah sebagai berikut :
a. Kata yang akan di-stemming pertama kali dicari ke dalam kamus. Jika kata tersebut ditemukan, maka kata tersebut adalah kata dasar, dan proses stemming dihentikan, b. Kata asli, kata hasil pemotongan dan
imbuhan yang dipotong dicatat ke dalam koleksi hasil potong,
c. Daftar kata pada koleksi hasil potong diiterasi untuk proses pengecekan dan pemotongan imbuhan,
d. Penghilangan partikel. Langkah ini dilakukan untuk menghilangkan partikel,
e. Penghilangan kata ganti kepunyaan. Langkah ini dilakukan untuk menghilangkan kata ganti kepunyaan,
f. Penghilangan sufiks. Langkah ini dilakukan untuk menghilangkan sufiks,
g. Penghilangan prefiks. Untuk prefiks terdapat tambahan aturan berupa penyisipan dan penghilangan karakter. Dilanjutkan dengan pemeriksaan apakah masih ada prefiks yang tersisa, jika ada maka dihilangkan. Jika tidak ada lagi maka lakukan langkah selanjutnya, h. Setelah tidak ada lagi imbuhan yang tersisa,
kemudian kata-kata yang ada pada koleksi hasil potong dicari ke dalam kamus kata dasar, urutan pengecekan dilakukan berdasarkan ukuran pemotongan imbuhan yang terbesar. Jika kata dasar tersebut ditemukan maka kata hasil proses stemming
tersebut dikembalikan dan proses dihentikan,
i. Jika semua langkah telah dilakukan tetapi kata dasar tersebut tidak ditemukan pada kamus maka kata asli sebelum dilakukan proses stemming yang akan dikembalikan.
Sebelum menggunakan stemming istilah unik yang dihasilkan oleh proses Indexing
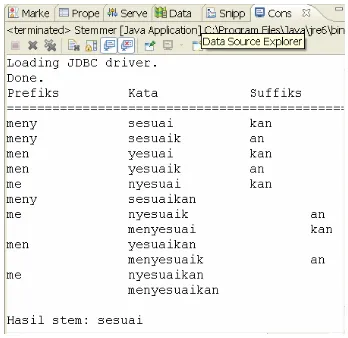
sebesar 10.053. Hal ini berbeda ketika stemming
ditambahkan pada saat proses pengindexan ke dalam sistem, jumlah istilah unik menjadi sebesar 7.459. Hasil pengujian menunjukkan bahwa stemming dapat mengurangi jumlah token istilah dalam penelitian sebesar 25.08 %. Contoh penerapan stemming yang telah diurutkan berdasarkan ukuran imbuhan yang terbesar dapat dilihat pada Gambar 5 dan 6.
Gambar 6 Stemming dengan penyisipan huruf.
Indexing
Proses pengindeksan dokumen dilakukan sebagai berikut:
1. proses pengekstrakan token-token istilah yang didapat dari hasil text operation,
2. jika token istilah termasuk ke dalam daftar kata buang maka token dilewati,
3. token istilah diubah ke dalam bentuk kata dasar (stemming),
4. untuk setiap pasang token istilah dan token berita, ditambahkan informasi ke dalam
posting (Gambar 7) dan dictionary
(Gambar 8) yang bersesuaian,
5. proses token item berikutnya hingga seluruh dokumen dalam koleksi ditambahkan ke dalam indeks,
6. setelah semua dokumen terindeks proses pembobotan tf-idf dilakukan terhadap masing-masing pasangan token istilah dan token berita. Untuk token istilah yang terdapat pada tubuh berita pembobotan dilakukan secara normal, sedangkan untuk token istilah yang merupakan bagian dari judul dilakukan pembobotan dengan memodifikasi nilai frekuensi. Contoh hasil dari pembobotan yang dilakukan terhadap token istilah yang telah terindeks dapat dilihat pada Gambar 9.
Pembobotan terhadap token istilah yang merupakan bagian dari judul adalah sebagai berikut :
j i freq i
title i freq title i freq j i freq
j i tf
, max
) 2 , ( ) , ,
( ,
× +
−
= ,
di mana besaran angka dua adalah asumsi penulis untuk memboboti token istilah yang
terdapat pada judul, dengan asumsi bahwa token istilah yang terdapat pada judul berita dianggap lebih penting dari pada tubuh berita. Untuk token istilah yang tidak berada pada judul maka nilai freqi,tittle=0.
Gambar 7 Tabel posting.
Gambar 8 Tabel dictionary.
Gambar 9 Hasil pembobotan tf-idf.
Untuk pengindeksan teks kueri digunakan tahap satu, dua, empat dan lima. Tahap tiga dilewati karena pada saat pengindeksan teks kueri tidak akan dimasukkan ke dalam tabel
diboboti dengan menggunakan pembobotan sebagai berikut: × × + = t df N q i freq i q i freq q i w log , max , 5 . 0 5 . 0 , . Searching
Pada tahap ini dilakukan pencarian kata kueri ke dalam inverted index untuk menemukan dokumen mana saja yang mengandung kata kueri.
Setelah ditemukan, kemudian dilakukan proses pengukuran tingkat kedekatan antara kueri dan dokumen dengan menggunakan ukuran kesamaan cosine, sehingga setiap dokumen memiliki nilai kedekatan dengan kueri. Contoh hasil penghitungan nilai cosine
sebelum diurutkan dengan menggunakan kueri uji coba ”nuklir Iran” dapat dlihat pada Gambar 10.
Gambar 10 Nilai cosine untuk kueri uji coba ”nuklir Iran".
Gambar 11 Daftar dokumen dan nilai cosine yang telah terurut berdasarkan kueri
masukan ”nuklir Iran”.
Ranking
Pengurutan atau ranking dilakukan berdasarkan nilai kesamaan yang dimiliki setiap dokumen dari hasil penghitungan cosine pada tahap searching. Pengurutan nilai kesamaan tersebut dilakukan secara asscending untuk mendapatkan urutan dokumen yang memiliki tingkat kesamaan mulai dari yang paling tinggi sampai yang terendah.
Hasil dari pengurutan inilah yang akan dikembalikan kepada pengguna sebagai hasil dari pencarian berdasarkan teks kueri yang diinputkan oleh pengguna.
Pengurutan yang dilakukan oleh sistem berdasarkan nilai cosine hasil dari tahap
searching dapat dilihat pada Gambar 11.
User Interface
User interface dari sistem temu kembali pada penelitian ini dapat dilihat pada Gambar 12.
Gambar 12 User interface dari sistem temu kembali.
Evaluasi sistem temu kembali informasi
Evaluasi yang digunakan dalam penelitian ini adalah evaluasi untuk mengukur keefektifan sistem dalam menemukan dokumen yang relevan terhadap kueri masukan pengguna.
Pengujian dilakukan sebanyak dua kali, pengujian pertama dilakukan dengan memberikan bobot lebih pada judul dan yang kedua adalah pengujian dengan menggunakan pembobotan secara normal.
Dari hasil pengujian (Lampiran 3), dapat dilihat bahwa jumlah dokumen relevan dan jumlah dokumen yang ditemukembalikan pada masing-masing pembobotan hasilnya sama.
Perbedaan dapat terjadi pada urutan dokumen relevan yang ditemukembalikan oleh sistem. Hal ini dikarenakan dokumen yang tidak relevan tetapi mengandung kata kueri pada judul dokumen, dapat memiliki nilai cosine yang lebih tinggi dari pada dokumen yang relevan tetapi tidak mengandung kata kueri pada judul.
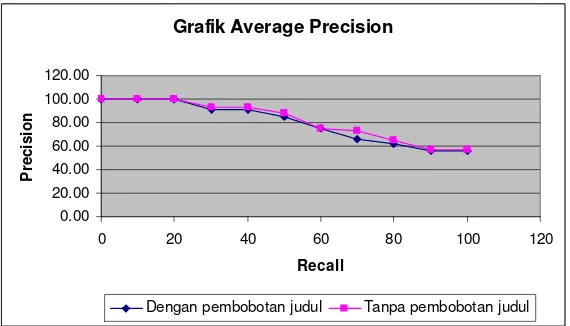
Dari tabel recall precision kesepuluh kueri pada Lampiran 4 dan grafik average precision
pada Lampiran 5 terlihat bahwa 90% hasil pencarian mengembalikan recall sebesar 100%, salah satunya pada kueri pengujian kesatu, dan
Penurunan recall ini terjadi pada kueri kesepuluh yaitu ”pemilu di Afghanistan” setelah dilakukan pengamatan, yang menjadi faktor penyebabnya adalah dari sisi penulisan. Masalah penulisan terjadi pada saat dokumen relevan yang tidak ditemukembalikan memiliki cara penulisan nama negara yang berbeda dengan kueri, pada dokumen relevan yang tidak dapat ditemukembalikan oleh sistem tertulis ”Afganistan” hal ini tentunya akan dianggap berbeda dengan kata ”Afghanistan” pada kueri.
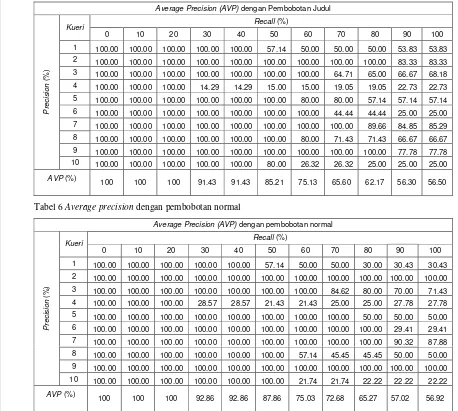
Untuk melihat kinerja sistem berdasarkan nilai average precision masing-masing pengujian dapat dilihat pada Tabel 5, dan
grafik average precision pada Gambar 13. Pada tabel dan grafik average precision terlihat bahwa dengan pembobotan normal pada tingkat recall
30% sampai dengan 50% dan 70% sampai dengan 100%, sistem memiliki tingkat precision
rata-rata lebih tinggi dibandingkan dengan yang menggunakan pembobotan lebih pada judul, hanya pada saat tingkat recall 60% sistem dengan pembobotan lebih pada judul memiliki nilai
precision rata-rata lebih tinggi dari pembobotan normal. Dengan demikian dapat disimpulkan bahwa penggunaan pembobotan normal memberikan hasil yang lebih baik dari pada penggunaan pembobotan judul.
Tabel 5 Average precision dengan pembobotan judul
Average Precision (AVP) dengan Pembobotan Judul
Recall (%)
Kueri
0 10 20 30 40 50 60 70 80 90 100
1 100.00 100.00 100.00 100.00 100.00 57.14 50.00 50.00 50.00 53.83 53.83
2 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 83.33 83.33
3 100.00 100.00 100.00 100.00 100.00 100.00 100.00 64.71 65.00 66.67 68.18
4 100.00 100.00 100.00 14.29 14.29 15.00 15.00 19.05 19.05 22.73 22.73
5 100.00 100.00 100.00 100.00 100.00 100.00 80.00 80.00 57.14 57.14 57.14
6 100.00 100.00 100.00 100.00 100.00 100.00 100.00 44.44 44.44 25.00 25.00
7 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 89.66 84.85 85.29
8 100.00 100.00 100.00 100.00 100.00 100.00 80.00 71.43 71.43 66.67 66.67
9 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 77.78 77.78
P
rec
is
ion
(
%)
10 100.00 100.00 100.00 100.00 100.00 80.00 26.32 26.32 25.00 25.00 25.00
AVP (%)
100 100 100 91.43 91.43 85.21 75.13 65.60 62.17 56.30 56.50
Tabel 6 Average precision dengan pembobotan normal
Average Precision (AVP) dengan pembobotan normal
Recall (%)
Kueri
0 10 20 30 40 50 60 70 80 90 100
1 100.00 100.00 100.00 100.00 100.00 57.14 50.00 50.00 30.00 30.43 30.43
2 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00
3 100.00 100.00 100.00 100.00 100.00 100.00 100.00 84.62 80.00 70.00 71.43
4 100.00 100.00 100.00 28.57 28.57 21.43 21.43 25.00 25.00 27.78 27.78
5 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 50.00 50.00 50.00
6 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 29.41 29.41
7 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 90.32 87.88
8 100.00 100.00 100.00 100.00 100.00 100.00 57.14 45.45 45.45 50.00 50.00
9 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00
Pre
c
is
ion
(
%)
10 100.00 100.00 100.00 100.00 100.00 100.00 21.74 21.74 22.22 22.22 22.22
AVP (%)
Grafik Average Precision
0.00 20.00 40.00 60.00 80.00 100.00 120.00
0 20 40 60 80 100 120
Recall
P
re
c
is
io
n
Dengan pembobotan judul Tanpa pembobotan judul
Gambar 13 Grafik average precision.
KESIMPULAN DAN SARAN
Kesimpulan
1. Proses stemming dan penggunaan daftar kata buang yang digunakan pada penelitian ini dapat mengurangi jumlah istilah sebesar 25.08%.
2. Berdasarkan hasil pengujian sepuluh kueri pada sistem temu kembali yang dibuat mampu mengembalikan recall
maksimum yaitu 100% dengan minimum
recall 85.71%.
3. Nilai average precision dari hasil pengujian antara penggunaan pembobotan judul dan pembobotan normal menunjukkan bahwa penggunaan pembobotan normal memberikan hasil yang lebih baik dibandingkan dengan penggunaan pembobotan judul.
4. Hasil temu kembali informasi dari sebuah sistem tidak hanya bergantung pada metode yang digunakan tetapi juga faktor-faktor yang dapat menurunkan hasil temu kembali seperti masalah penulisan dan penggunaan kata yang berbeda tetapi memiliki makna yang sama.
Saran
1. Untuk mengatasi masalah kesalahan penulisan dapat ditambahkan sebuah sistem yang dapat mengecek kesalahan penulisan dan dapat mengembalikan satu atau beberapa kata alternatif yang mendekati kata tersebut, sehingga hasil temu kembali dapat lebih ditingkatkan.
2. Pembobotan ekstra dapat ditambahkan pada tanggal berita dipublikasikan sehingga penyajian hasil temu kembali berita bisa dapat lebih terurut berdasarkan waktu.
DAFTAR PUSTAKA
Baeza-Yates, Ribeiro-Neto. 1999. Modern Information Retrieval. England: Addison-Wesly Publishing Company.
Cummins R, O’Riordan. Determining General Term Weighting Schemes for the Vector Space Model of Information Retrieval Using Genetic Programing. Departement of Information Technology, National University of Ireland. Manning CD, Raghavan P, Schutze H. 2008.
Introduction to Information Retrieval. Cambridge University
Ridha A. 2002. Pengindeksan Otomatis dengan Istilah Tunggal untuk Dokumen Berbahasa Indonesia. Skripsi. Departemen Ilmu Komputer IPB, Bogor.
Rahman A. 2006. Perbandingan Kinerja Beberapa Ukuran Kesamaan pada Temu Kembali Informasi Dokumen XML. Skripsi. Departemen Ilmu Komputer IPB, Bogor. Salton G. 1989. Automatic Teks Processing: The
Transformation, Analysis, and Retrieval of Information by Computer. Addison-Wesley. Tala F Z. 2003. A Study of Stemming Effects on
Information Retrieval in Bahasa Indonesia. Institute for Logic, Language and Computation, Universiteit van Amsterdam, Netherlands Wandari FA. 2005. Evaluasi Stemmer Berbasis
Menggunakan Kamus Kata Dasar. Skripsi. Departemen Ilmu Komputer IPB, Bogor
[XML]. What is RSS.
http://www.xml.com/pub/a/2002/12/18/dive /-into-xml.html. [17 July 2009].
[XML]. What is RSS.
Lampiran 1 Contoh dokumen RSS yang diperoleh dari situs berita Okezone <?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0">
<channel>
<title>Sindikasi autos.okezone.com</title>
<description>Berita-berita Okezone pada kanal Autos</description>
<link>http://autos.okezone.com</link>
<lastBuildDate>Thu, 27 Aug 2009 17:27:01 +0700</lastBuildDate>
<generator>Okezone RSS 2.0 Generator</generator>
<image>
<url>http://sindikasi.okezone.com/image/template/okezone_rss.gif</url>
<title>Sindikasi autos.okezone.com</title>
<link>http://autos.okezone.com</link>
<description>Berita-berita Okezone pada kanal Autos</description>
</image>
<item>
<title>Lebaran, Harga Motor Juga Stabil</title>
<link>http://autos.okezone.com/read/2009/08/27/53/252043/lebaran-harga-motor-juga-stabil</link>
<guid>http://autos.okezone.com/read/2009/08/27/53/252043/lebaran-harga-motor-juga-stabil</guid>
<description>Serupa dengan roda empat, harga sepeda motor menjelang Hari Raya Idul Fitri juga cenderung stabil. Bahkan beberapa dealer menawarkan berbagai promosi menjelang Lebaran. </description>
<category>breaking news - Motor</category>
<pubDate>Thu, 27 Aug 2009 17:24:10 +0700</pubDate>
</item>
<item>
<title>BMW Yakin Bisa Menjual 1.000 Unit Tahun Ini</title>
<link>http://autos.okezone.com/read/2009/08/27/52/251900/bmw-yakin-bisa-menjual-1-000-unit-tahun-ini</link>
<guid>http://autos.okezone.com/read/2009/08/27/52/251900/bmw-yakin-bisa-menjual-1-000-unit-tahun-ini</guid>
<description>Hadirnya banyak tipe-tipe terbaru membuat PT BMW Indonesia yakin tahun ini bisa menembus angka penjualan hingga 1.000 unit. </description>
<category>breaking news - Mobil</category>
<pubDate>Thu, 27 Aug 2009 12:06:10 +0700</pubDate>
</item>
</channel>
Lampiran 3 Daftar hasil uji coba kueri
Dengan Pembobotan Judul
Dengan Pembobotan Normal
No Kueri
( )
R
(
A
R
)
( )
A
(
A
R
)
( )
A
1 Kebakaran 7 7 25 7 25
2 Gempa bumi 5 5 15 5 15
3 Inter Milan 15 15 32 15 32
4 Kebakaran hutan 5 5 40 5 40
5 Nuklir Iran 4 4 11 4 11
6 Pembunuhan Nasrudin 5 5 30 5 30
7 Tari pendet 29 29 36 29 36
8 Virus komputer 6 6 13 6 13
9 Pemakaman Michael
Jackson 7
7 20 7 20
Lampiran 4 Recall, Precision dan nilai Recall vs Precision yang digunakan untuk membuat grafik sebelas standar recall setiap kueri.
Di mana: A = hasil temu kembali dengan menggunakan pembobotan judul, sedangkan B = hasil temu kembali menggunakan pembobotan normal.
Kueri : Kebakaran
Recall Precision (%) Recall vs Precision (sebelas
standar recall) (%) Hasil Temu
Kembali
A B A B
Urutan hasil
pencarian Recall Precision Recall Precision
Recall
Precision Precision
1 14.29 100.00 14.29 100.00 0.00 100.00 100.00
2 28.57 100.00 28.57 100.00 10.00 100.00 100.00
3 42.86 100.00 42.86 100.00 20.00 100.00 100.00
7 57.14 57.14 57.14 57.14 30.00 100.00 100.00
10 71.43 50.00 71.43 50.00 40.00 100.00 100.00
12 85.71 50.00 50.00 57.14 57.14
13 100.00 53.85 60.00 50.00 50.00
20 85.71 30.00 70.00 50.00 50.00
23 100.00 30.43 80.00 50.00 30.00
25 90.00 53.83 30.43
100.00 53.83 30.43
Kueri : Gempa bumi
Recall Precision (%) Recall vs Precision (sebelas
standar recall) (%) Hasil Temu
Kembali
A B A B
Urutan hasil
pencarian Recall Precision Recall Precision
Recall
Precision Precision
1 20.00 100.00 20.00 100.00 0.00 100.00 100.00
2 40.00 100.00 40.00 100.00 10.00 100.00 100.00
3 60.00 100.00 60.00 100.00 20.00 100.00 100.00
4 80.00 100.00 80.00 100.00 30.00 100.00 100.00
5 100.00 100.00 40.00 100.00 100.00
6 100.00 83.33 50.00 100.00 100.00
9 60.00 100.00 100.00
10 70.00 100.00 100.00
15 80.00 100.00 100.00
90.00 83.33 100.00
Lampiran 4 Lanjutan
Kueri : Inter Milan
Recall Precision (%) Recall vs Precision (sebelas
standar recall) (%) Hasil Temu
Kembali
A B A B
Urutan hasil
pencarian Recall Precision Recall Precision
Recall
Precision Precision
1 6.67 100.00 666.67 100.00 0 100.00 100.00
2 13.33 100.00 666.67 100.00 10 100.00 100.00
3 20.00 100.00 666.67 100.00 20 100.00 100.00
4 26.67 100.00 666.67 100.00 30 100.00 100.00
5 33.33 100.00 666.67 100.00 40 100.00 100.00
6 40.00 100.00 666.67 100.00 50 100.00 100.00
7 46.67 100.00 666.67 100.00 60 100.00 100.00
8 53.33 100.00 666.67 100.00 70 64.71 84.62
9 60.00 100.00 666.67 100.00 80 65.00 80.00
12 66.67 83.33 90 66.67 70.00
13 73.33 84.62 100 68.18 71.43
15 80.00 80.00
16 66.67 62.50
17 73.33 64.71
18 86.67 72.22
19 80.00 63.16
20 86.67 65.00 93.33 70.00
21 93.33 66.67 100.00 71.43
22 100.00 68.18
32
Kueri : Kebakaran hutan
Recall Precision (%) Recall vs Precision (sebelas
standar recall) (%) Hasil Temu
Kembali
A B A B
Urutan hasil
pencarian Recall Precision Recall Precision
Recall
Precision Precision
1 20.00 100.00 20.00 100.00 0.00 100.00 100.00
7 40.00 28.57 10.00 100.00 100.00
14 40.00 14.29 60.00 21.43 20.00 100.00 100.00
16 80.00 25.00 30.00 14.29 28.57
18 100.00 27.78 40.00 14.29 28.57
20 60.00 15.00 50.00 15.00 21.43
21 80.00 19.05 60.00 15.00 21.43
22 100.00 22.73 70.00 19.05 25.00
40 80.00 19.05 25.00
90.00 22.73 27.78
Lampiran 4 Lanjutan
Kueri : Nuklir Iran
Recall Precision (%) Recall vs Precision (sebelas
standar recall) (%) Hasil Temu
Kembali
A B A B
Urutan hasil
pencarian Recall Precision Recall Precision
Recall
Precision Precision
1 25.00 100.00 25.00 100.00 0.00 100.00 100.00
2 50.00 100.00 50.00 100.00 10.00 100.00 100.00
3 75.00 100.00 20.00 100.00 100.00
5 75.00 80.00 100.00 30.00 100.00 100.00
7 100.00 57.14 100.00 40.00 100.00 100.00
8 100.00 50.00 50.00 100.00 100.00
11 60.00 80.00 100.00
70.00 80.00 100.00
80.00 57.14 50.00
90.00 57.14 50.00
100.00 57.14 50.00
Kueri : Pembunuhan Nasrudin
Recall Precision (%) Recall vs Precision (sebelas
standar recall) (%) Hasil Temu
Kembali
A B A B
Urutan hasil
pencarian Recall Precision Recall Precision
Recall
Precision Precision
1 20.00 100.00 20.00 100.00 0.00 100.00 100.00
2 40.00 100.00 40.00 100.00 10.00 100.00 100.00
3 60.00 100.00 60.00 100.00 20.00 100.00 100.00
4 80.00 100.00 30.00 100.00 100.00
9 80.00 44.44 40.00 100.00 100.00
17 100.00 29.41 50.00 100.00 100.00
20 100.00 25.00 60.00 100.00 100.00
30 70.00 44.44 100.00
80.00 44.44 100.00
90.00 25.00 29.41
Lampiran 4 Lanjutan
Kueri : Tari Pendet
Recall Precision (%) Recall vs Precision (sebelas
standar recall) (%) Hasil Temu
Kembali
A B A B
Urutan hasil
pencarian Recall Precision Recall Precision
Recall
Precision Precision
1 3.45 100.00 3.45 100.00 0.00 100.00 100.00
2 6.90 100.00 6.90 100.00 10.00 100.00 100.00
3 10.34 100.00 10.34 100.00 20.00 100.00 100.00
4 13.79 100.00 13.79 100.00 30.00 100.00 100.00
5 17.24 100.00 17.24 100.00 40.00 100.00 100.00
6 20.69 100.00 20.69 100.00 50.00 100.00 100.00
7 24.14 100.00 24.14 100.00 60.00 100.00 100.00
8 27.59 100.00 27.59 100.00 70.00 100.00 100.00
9 31.03 100.00 31.03 100.00 80.00 89.66 100.00
10 34.48 100.00 34.48 100.00 90.00 84.85 90.32
11 37.93 100.00 37.93 100.00 100.00 85.29 87.88
12 41.38 100.00 41.38 100.00
13 44.83 100.00 44.83 100.00
14 48.28 100.00 48.28 100.00
15 51.72 100.00 51.72 100.00
16 55.17 100.00 55.17 100.00
17 58.62 100.00 58.62 100.00
18 62.07 100.00 62.07 100.00
19 65.52 100.00 65.52 100.00
20 68.97 100.00 68.97 100.00
21 72.41 100.00 72.41 100.00
22 75.86 100.00 75.86 100.00
23 79.31 100.00 79.31 100.00
24 82.76 100.00
26 86.21 96.15
27 82.76 88.89
28 89.66 92.86
29 93.10 89.66
30 86.21 86.21
31 89.66 89.66 96.55 90.32
32 93.10 84.38
33 96.55 84.85 100.00 87.88
34 100.00 85.29
Lampiran 4 Lanjutan
Kueri : Virus komputer
Recall Precision (%) Recall vs Precision (sebelas
standar recall) (%) Hasil Temu
Kembali
A B A B
Urutan hasil
pencarian Recall Precision Recall Precision
Recall
Precision Precision
1 16.67 100.00 16.67 100.00 0.00 100.00 100.00
2 33.33 100.00 33.33 100.00 10.00 100.00 100.00
3 50.00 100.00 50.00 100.00 20.00 100.00 100.00
5 66.67 80.00 30.00 100.00 100.00
7 83.33 71.43 66.67 57.14 40.00 100.00 100.00
9 100.00 66.67 50.00 100.00 100.00
11 83.33 45.45 60.00 80.00 57.14
12 100.00 50.00 70.00 71.43 45.45
13 80.00 71.43 45.45
90.00 66.67 50.00
100.00 66.67 50.00
Kueri : Pemakaman Michael Jackson
Recall Precision (%) Recall vs Precision (sebelas
standar recall) (%) Hasil Temu
Kembali
A B A B
Urutan hasil
pencarian Recall Precision Recall Precision
Recall
Precision Precision
1 14.29 100.00 14.29 0.00 0.00 100.00 100.00
2 28.57 100.00 28.57 0.00 10.00 100.00 100.00
3 42.86 100.00 42.86 0.00 20.00 100.00 100.00
4 57.14 100.00 57.14 0.00 30.00 100.00 100.00
5 71.43 100.00 71.43 0.00 40.00 100.00 100.00
6 85.71 100.00 85.71 0.00 50.00 100.00 100.00
7 100.00 100.00 60.00 100.00 100.00
9 100.00 77.78 70.00 100.00 100.00
10 80.00 100.00 100.00
20 90.00 77.78 100.00
100.00 77.78 100.00
Lampiran 4 Lanjutan
Kueri : Pemilu di Afghanistan
Recall Precision (%) Recall vs Precision (sebelas
standar recall) (%) Hasil Temu
Kembali
A B A B
Urutan hasil
pencarian Recall Precision Recall Precision
Recall
Precision Precision
1 14.29 100.00 14.29 100.00 0.00 100.00 100.00
2 28.57 100.00 28.57 100.00 10.00 100.00 100.00
3 42.86 100.00 42.86 100.00 20.00 100.00 100.00
4 57.14 100.00 30.00 100.00 100.00
5 57.14 80.00 40.00 100.00 100.00
19 71.43 26.32 50.00 80.00 100.00
23 71.43 21.74 60.00 26.32 21.74
24 85.71 25.00 70.00 26.32 21.74
27 85.71 22.22 80.00 25.00 22.22
33 90.00 25.00 22.22
Lampiran 5 Grafik sebelas standar recall untuk setiap hasil kueri yang diujicobakan Di mana : Precision A adalah hasil pencarian dengan pembobotan judul
Precision B adalah hasil pencarian dengan pembobotan normal
Kueri : Kebakaran
0.00 20.00 40.00 60.00 80.00 100.00 120.00
0.00 20.00 40.00 60.00 80.00 100.00 120.00
Recall
P
re
c
is
io
n
Precision A Precision B
Kueri : Gempa bumi
0.00 20.00 40.00 60.00 80.00 100.00 120.00
0.00 20.00 40.00 60.00 80.00 100.00 120.00
Recall
P
re
c
is
io
n
Precision A Precision B
Kueri : Inter Milan
0.00 20.00 40.00 60.00 80.00 100.00 120.00
0 20 40 60 80 100 120
Recall
P
re
c
is
io
n
Lampiran 5 Lanjutan
Kueri : Kebakaran hutan
0.00 20.00 40.00 60.00 80.00 100.00 120.00
0.00 20.00 40.00 60.00 80.00 100.00 120.00
Recall
P
re
c
is
io
n
Precision A Precision B
Kueri : Nuklir Iran
0.00 20.00 40.00 60.00 80.00 100.00 120.00
0.00 20.00 40.00 60.00 80.00 100.00 120.00
Recall
P
re
c
is
io
n
Precision A Precision B
Kueri : Pembunuhan Nasrudin
0.00 20.00 40.00 60.00 80.00 100.00 120.00
0.00 20.00 40.00 60.00 80.00 100.00 120.00
Recall
P
re
c
is
io
n
Lampiran 5 Lanjutan
Kueri : Tari pendet
84.00 86.00 88.00 90.00 92.00 94.00 96.00 98.00 100.00 102.00
0.00 20.00 40.00 60.00 80.00 100.00 120.00
Recall
P
re
c
is
io
n
Precision A Precision B
Kueri : Virus komputer
0.00 20.00 40.00 60.00 80.00 100.00 120.00
0.00 20.00 40.00 60.00 80.00 100.00 120.00
Recall
P
re
c
is
io
n
Precision A Precision B
Kueri : Pemakaman Michael Jackson
0.00 20.00 40.00 60.00 80.00 100.00 120.00
0.00 20.00 40.00 60.00 80.00 100.00 120.00
Recall
P
re
c
is
io
n
Lampiran 5 Lanjutan
Kueri : Pemilu di Afghanistan
0.00 20.00 40.00 60.00 80.00 100.00 120.00
0.00 20.00 40.00 60.00 80.00 100.00 120.00 Recall
P
re
c
is
io
n
besar dibandingkan dengan istilah yang berada pada description.
Lingkup Implemental
Lingkungan implementasi yang akan digunakan adalah sebagai berikut:
Perangkat Lunak :
• Sistem operasi Windows XP Professional
• Java 1.6
• Apache Tomcat 6
• MySQL 5 Perangkat Keras :
• Processor Intel dual core 1.6 GB
• RAM 1 GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen
Penelitian ini menggunakan koleksi dokumen RSS versi 2.0 yang didapatkan dari beberapa situs berita berbahasa Indonesia di antaranya situs berita Antara, Detik, Kompas, Liputan6, Okezone, dan Tempointeraktif, yang diunduh pada tanggal 22, 23 dan 27 Agustus 2009. Contoh dari salah satu dokumen RSS berita dapat dilihat pada Lampiran 1.
Untuk menguji kinerja sistem temu kembali informasi digunakan koleksi dokumen sebanyak 173 dokumen RSS. Dari 173 dokumen RSS yang dipergunakan hanya 167 dokumen yang terindeks oleh sistem dan diperoleh 1720 buah berita (Tabel 3). Hal ini dikarenakan beberapa dokumen RSS tidak memenuhi aturan penulisan XML yang benar.
Untuk melakukan uji coba, dibentuk daftar pasangan kueri dan jumlah dokumen yang relevan yang akan dipergunakan untuk mengukur kinerja sistem temu kembali informasi yang dibuat. Adapun daftar kueri yang akan diujikan terhadap dokumen dapat dilihat pada Tabel 4.
Tahap-tahap Penelitian
Text Operation
1.Parsing
Dokumen masukan diproses secara sekuensial dan menghasilkan sebuah token. Proses parsing dilakukan dalam dua tahapan yaitu:
Tabel 3 Situs berita dan jumlah RSS yang diunduh Situs Berita Jumlah Dokumen XML RSS Jumla h Berita
Antara 27 350
Detik 3 22
Liputan 6 3 30
Kompas 47 666
Okezone 48 306
Tempo 39 346
[image:37.612.333.503.107.266.2]Total 167 1720
Tabel 4 Daftar kueri untuk pengujian sistem
No Kueri Dokumen
Relevan
1 Kebakaran 7
2 Gempa bumi 5
3 Inter Milan 15
4 Kebakaran hutan 5
5 Nuklir Iran 4
6 Pembunuhan Nasrudin 5
7 Tari pendet 29
8 Virus komputer 6
9 Pemakaman Michael
Jackson 7
10 Pemilu di Afghanistan 7 a. Parsing tahap satu
Proses parsing tahap satu adalah sebagai berikut:
[image:37.612.327.505.297.580.2]Gambar 4 Representasi berita dalam dokumen RSS.
• Setiap token berita yang diperoleh dibentuk sebuah identitas yang unik yang akan digunakan sebagai nama berkas dari token berita tersebut dengan menggunakan teknik enkripsi MD5. Nama file dan token berita disimpan ke dalam basis data. Hasil dari proses parsing tahap satu dapat dilihat pada Lampiran 2.
Dari proses parsing tahap satu dihasilkan 1720 berita dari 167 dokumen RSS. b. Parsing tahap dua
Setiap token berita yang diperoleh dari tahap satu diproses kembali, parsing di sini bertujuan untuk mendapatkan token istilah (satuan perkata) dari token berita.
Tidak semua informasi yang ada pada token berita dipergunakan, hanya informasi yang tersimpan dalam elemen title dan
description yang diolah, di mana elemen
title dan description merepresentasikan judul dan deskripsi berita. Berikut ini adalah proses parsing tahap dua:
• Dengan menggunakan JDOM isi dari elemen item dan description diambil.
• Proses pengambilan token istilah dengan cara membaca satu persatu karakter. Sebuah karakter dapat berupa salah satu da