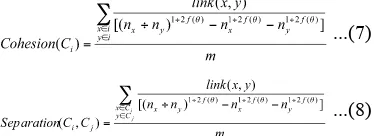Kategorik (Studi Kasus : Data Sponge). Dibimbing oleh ANNISA, dan HARI AGUNG.
Sponge adalah hewan laut berpori yang memompa air melalui tubuhnya untuk menyaring partikel–partikel sebagai makanannya. Beberapa ahli taksonomi berpendapat adanya kelas baru dari sponge. Iosune Uriz dan Marta Domingo melakukan riset dan pengumpulan data sponge jenis
O.Hadromerida (Demospongiae. Porifera) yang termasuk kelas Demospongiae di Laut Atlantik pada tahun 1993. Tujuan riset dan pengumpulan data tersebut adalah untuk mengetahui model
cluster berdasarkan anatomy dan phisiology sponge. Model cluster tersebut diharapkan dapat direpresentasikan pada klasifikasi taksonomi sehingga dapat memprediksi ada atau tidaknya kemungkinan species atau kelas baru dari data sponge tersebut. Sebagian besar atribut data sponge
tersebut merupakan data kategorik.
Clustering adalah proses data mining untuk melihat pola pendistribusian data yang akan digunakan untuk melihat karakteristik dari data. Pada penelitian ini data riset Iosune Uriz dan Marta Domingo akan dikelompokkan oleh algoritme ROCK dan QROCK. Algoritme ROCK digunakan karena memiliki kualitas dan penanganan data kategorik yang lebih baik dari algoritme
clustering distance pada umumnya, sedangkan algoritme QROCK merupakan perbaikan dari algoritme ROCK karena dari segi waktu lebih efisien dan dapat mendeteksi outlier pada ROCK. Algoritme ROCK yaitu algoritme clustering hirarki aglomeratif untuk mengelompokkan data kategorik yang membangun link untuk menggabungkan cluster-cluster-nya. QROCK adalah perbaikan dari algoritme ROCK yang memiliki metode yang lebih efisien untuk menghasilkan
cluster akhir algoritme ROCK ketika ROCK sudah tidak memiliki link antar cluster-nya.
Pada penelitian ini cluster yang dihasilkan merepresentasikan pola data sponge. Cluster hasil dari algoritme ROCK dan QROCK untuk data sponge akan dibandingkan. Total cohesion dari
cluster yang dihasilkan ROCK lebih kecil dibandingkan separation-nya, sedangkan total cohesion
dari cluster yang dihasilkan QROCK lebih besar dibandingkan nilai separation-nya. Hal tersebut membuktikan bahwa cluster yang dihasikan QROCK lebih baik dari ROCK. Dibuktikan pula bahwa algoritme QROCK dapat mendeteksi outlier dari algoritme ROCK pada saat nilai threshold
0,9.
(STUDI KASUS : DATA
SPONGE)
MARISA ANGGRAENI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
(STUDI KASUS : DATA
SPONGE)
MARISA ANGGRAENI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
(STUDI KASUS : DATA
SPONGE)
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh :
MARISA ANGGRAENI
G64104037
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Kategorik (Studi Kasus : Data Sponge). Dibimbing oleh ANNISA, dan HARI AGUNG.
Sponge adalah hewan laut berpori yang memompa air melalui tubuhnya untuk menyaring partikel–partikel sebagai makanannya. Beberapa ahli taksonomi berpendapat adanya kelas baru dari sponge. Iosune Uriz dan Marta Domingo melakukan riset dan pengumpulan data sponge jenis
O.Hadromerida (Demospongiae. Porifera) yang termasuk kelas Demospongiae di Laut Atlantik pada tahun 1993. Tujuan riset dan pengumpulan data tersebut adalah untuk mengetahui model
cluster berdasarkan anatomy dan phisiology sponge. Model cluster tersebut diharapkan dapat direpresentasikan pada klasifikasi taksonomi sehingga dapat memprediksi ada atau tidaknya kemungkinan species atau kelas baru dari data sponge tersebut. Sebagian besar atribut data sponge
tersebut merupakan data kategorik.
Clustering adalah proses data mining untuk melihat pola pendistribusian data yang akan digunakan untuk melihat karakteristik dari data. Pada penelitian ini data riset Iosune Uriz dan Marta Domingo akan dikelompokkan oleh algoritme ROCK dan QROCK. Algoritme ROCK digunakan karena memiliki kualitas dan penanganan data kategorik yang lebih baik dari algoritme
clustering distance pada umumnya, sedangkan algoritme QROCK merupakan perbaikan dari algoritme ROCK karena dari segi waktu lebih efisien dan dapat mendeteksi outlier pada ROCK. Algoritme ROCK yaitu algoritme clustering hirarki aglomeratif untuk mengelompokkan data kategorik yang membangun link untuk menggabungkan cluster-cluster-nya. QROCK adalah perbaikan dari algoritme ROCK yang memiliki metode yang lebih efisien untuk menghasilkan
cluster akhir algoritme ROCK ketika ROCK sudah tidak memiliki link antar cluster-nya.
Pada penelitian ini cluster yang dihasilkan merepresentasikan pola data sponge. Cluster hasil dari algoritme ROCK dan QROCK untuk data sponge akan dibandingkan. Total cohesion dari
cluster yang dihasilkan ROCK lebih kecil dibandingkan separation-nya, sedangkan total cohesion
dari cluster yang dihasilkan QROCK lebih besar dibandingkan nilai separation-nya. Hal tersebut membuktikan bahwa cluster yang dihasikan QROCK lebih baik dari ROCK. Dibuktikan pula bahwa algoritme QROCK dapat mendeteksi outlier dari algoritme ROCK pada saat nilai threshold
0,9.
Nama : Marisa Anggraeni
NIM : G64104037
Menyetujui:
Pembimbing I,
Annisa, S.Kom, M.Kom
NIP 132 311 930
Pembimbing II,
Hari Agung, S.Kom, M.Si
NIP 132 311 918
Mengetahui:
Dekan Fakultas Matematika Dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. drh. Hasim, DEA
NIP 131 578 806
dari pasangan O.Ridwan dan Metini. Tahun 2004, penulis lulus dari SMU Negeri 1 Cimalaka, Sumedang dan pada tahun yang sama penulis diterima sebagai mahasiswa S1 Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk Institut Pertanian Bogor (USMI).
limpahan rahmat dan hidayah-Nya sehingga tugas akhir dengan judul Perbandingan Algoritme
Clustering ROCK dan QROCK untuk Data Kategorik dapat diselesaikan. Shalawat serta salam juga penulis ucapkan kepada junjungan kita Nabi Muhammad SAW beserta seluruh sahabat dan umatnya hingga akhir zaman.
Dalam menyelesaikan tugas akhir ini penulis mendapatkan banyak sekali bantuan, bimbingan dan dorongan dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih kepada semua pihak yang telah membantu dalam penyelesaian tugas akhir ini, antara lain:
1 Ketiga orangtua tersayang, Bapak Deden dan Mama Metini serta Mpah O.Ridwan atas segala do’a, kasih sayang, dan dukungannya.
2 Aa Geri Ridwandini dan Ade Silvie Delasani tersayang yang selalu memberikan do’a, semangat dan motivasi dalam penyelesaian tugas akhir ini.
3 Ibu Annisa, S.Kom, M.Kom selaku pembimbing pertama atas bimbingan dan arahannya selama pengerjaan tugas akhir ini.
4 Bapak Hari Agung, S.Kom, M.Si selaku pembimbing kedua atas bimbingan dan arahannya selama pengerjaan tugas akhir ini.
5 Bapak Endang, S.Kom, M.Kom selaku moderator dan penguji tugas akhir ini.
6 Efrian Muharrom yang telah memberi dukungan, semangat, bantuan dan do’a saat penulis merasa jenuh dan kesulitan dalam penyelesaian tugas akhir ini.
7 Anizza, Popi, Ineza, Fathimah, Gananda, Imam, Henri, Lewe, Denny dan Maulana atas semangat dan dukungannya.
8 Ayudya Paramita, Nurdian Setiawan, dan Riza Mahendra atas semangat dan do’a selama bimbingan bersama.
9 Imam Abu Daud, Irfan Sidqon, M.Syadid, Rizki Peburdi, dan Arif Nurwidiantoro atas bantuan dan ilmu yang telah dibaginya.
10 Seluruh teman-teman Program Studi Ilmu Komputer angkatan 41 yang tidak dapat disebutkan namanya satu-persatu.
Penulis juga mengucapkan terima kasih kepada semua pihak yang telah membantu selama pengerjaan penyelesaian tugas akhir ini yang tidak dapat disebutkan satu-persatu. Semoga penelitian ini dapat memberikan manfaat.
Bogor, Agustus 2008
v
DAFTAR ISI
Halaman
DAFTAR TABEL... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN... vi_Toc208994323
PENDAHULUAN ... 1
Latar Belakang ...1
Tujuan ...1
Ruang Lingkup...1
Manfaat Penelitian ...1
TINJAUAN PUSTAKA ... 1
Knowledge Discovery in Database (KDD)...1
Data Mining...2
Clustering...2
Agglomerative Hirarchical Clustering...3
Data Kategorik ...3
ROCK (RObust Clustering using linKs) ...3
QROCK (Quick RObust Clustering using linKs)...4
Evaluasi Cluster...5
Outlier...5
METODE PENELITIAN ... 5
Proses Knowledge Discovery in Database...5
Lingkungan Pengembangan ...8
HASIL DAN PEMBAHASAN ... 8
Preprocessing Data...8
Data Mining...8
Evaluasi Pola ...10
Ukuran Cluster dan Nilai Cohesion...11
Nilai Threshold dan Nilai Cohesion...12
Mendeteksi Outlier...13
KESIMPULAN DAN SARAN ... 14
Kesimpulan ...14
Saran...14
vi
DAFTAR TABEL
Halaman
1 Cluster hasil algoritmeROCK untuk ukuran k = 8 dan = 0,7 ... 8
2 Persentase dan jumlah anggota cluster algoritme ROCK untuk ukuran k = 8 dan = 0,7 ... 9
3 Cluster yang dihasilkan oleh algoritmeQROCK pada ukuran k = 6 dan = 0,85... 9
4 Persentase dan jumlah anggota cluster algoritme QROCK pada ukuran k = 6 dan = 0,85 9
5 Nilai cohesion dan nilai separation algoritme ROCKuntuk cluster delapan dan = 0.7 ... 10
6 Nilai cohesion dan nilai separation algoritme QROCK untuk cluster enam dan = 0.85 .. 11
7 Nilai total cohesion dan ukuran cluster algoritme ROCK pada nilai threshold 0.7 ... 11
8 Hubungan antar nilai threshold dan nilai cohesion pada algoritme ROCK pada ukuran cluster delapan ... 12
DAFTAR GAMBAR
Halaman 1 Tahapan dalam KDD (Han & Kamber, 2006). ... 2
2 Langkah-langkah KDD dalam penelitian. ... 6
3 Proses algoritme (a) ROCK dan (b) QROCK... 7
4 Grafik nilai cohesion terhadap nilai k pada algoritme ROCK. ... 11
5 Grafik nilai cohesion terhadap nilai k pada algoritme QROCK. ... 12
6 Perbandingan nilai cohesion terhadap ukuran cluster untuk ROCK dan QROCK. ... 12
7 Grafik nilai threshold terhadap nilai cohesion pada algoritme ROCK... 13
8 Grafik nilai threshold terhadap nilai cohesion pada algoritme QROCK. ... 13
9 Perbandingan nilai cohesion terhadap nilai threshold untuk ROCK dan QROCK. ... 13
DAFTAR LAMPIRAN
Halaman 1 Keterangan anggota ...162 Struktur dari 27 atribut non numeric, 15 atribut boolean, dan tiga atribut numeric...18
3 Nilai total cohesion untuk clustering algoritme ROCK dari setiap kombinasi ukuran k dan nilai threshold...19
4 Nilai total cohesion untuk clustering algoritme QROCK dari setiap nilai threshold yang dicobakan....20
1
PENDAHULUAN
Latar Belakang
Sponge atau poriferans berasal dari bahasa Latin yaitu porus yang artinya pori dan ferre
yang artinya memiliki. Sponge adalah hewan berpori, pada umumnya terdapat di lautan, yang memompa air melalui tubuhnya untuk menyaring partikel–partikel sebagai makanannya. Berdasarkan tipe spicules dari kerangka tubuhnya bunga karang dikelompokan menjadi tiga kelas yaitu
Calcarea, Hexactenellida, dan
Demospongiae. Beberapa ahli taksonomi berpendapat adanya kelas lain yaitu
Sclerospongiae. Ditemukannya kelas dan
species baru mendorong ilmuwan–ilmuwan ahli taksonomi untuk melakukan penelitian lebih lanjut terhadap bunga karang berdasarkan anatomy, phisiology, geological history, dan lineage untuk memperoleh kemungkinan mendapatkan kelas dan species
baru.
Iosune Uriz dan Marta Domingo melakukan riset dan pengumpulan data terhadap bunga karang (sponge) di Lautan Atlantik. Jenis bunga karang pada data tersebut adalah O.Hadromerida (Demospongiae. Porifera) dan berdasarkan taksonominya termasuk kelas Demospongiae.
Salah satu tujuan riset dan pengumpulan data tersebut adalah untuk mengetahui model
cluster berdasarkan anatomy dan phisiology
sponge. Model cluster tersebut diharapkan dapat direpresentasikan pada klasifikasi taksonomi sehingga dapat memprediksikan ada atau tidaknya kemungkinan species atau bahkan kelas baru dari data sponge tersebut.
Data mining merupakan proses ekstraksi informasi atau pola yang penting dalam basis data yang berukuran besar (Han & Kamber, 2006). Data mining yang diterapkan pada data bunga karang tersebut diharapkan mampu menggali informasi pola cluster data tersebut.
Clustering adalah proses data mining untuk melihat pola pendistribusian data yang akan digunakan untuk melihat karakteristik dari data (Han & Kamber 2006). Pola yang dihasilkan adalah pengelompokan himpunan objek ke dalam kelas-kelas berdasarkan nilai maksimal kemiripan data antar cluster.
Sebagian besar data bunga karang adalah data kategorik. Algoritme ROCK dan QROCK merupakan algoritme clustering
hirarki aglomeratif untuk data kategorik, oleh karena itu algoritme yang digunakan adalah
algoritme ROCK dan QROCK. ROCK
(RObust Clustering using linKs) adalah algoritme yang membangun link untuk menggabungkan cluster-cluster-nya dan tidak menggunakan jarak (distance) seperti pada algoritme clustering pada umumnya. Algoritme ROCK tidak hanya menghasilkan kualitas yang lebih baik daripada algoritme
clustering distance tetapi juga memiliki penanganan data kategorik yang lebih baik (Guha et al 2000). QROCK adalah perbaikan dari algoritme ROCK karena dari segi waktu iterasi lebih efisien dan dapat mendeteksi
outlier dari hasil proses algoritme ROCK (M.Dutta et al. 2005).
Tujuan
Tujuan dari penelitian ini adalah :
1 Menerapkan teknik clustering ROCK dan QROCK pada data kategorik dari bunga karang.
2 Membandingkan kualitas cluster yang dihasilkan oleh algoritme ROCK dan QROCK pada data kategorik dari bunga karang.
Ruang Lingkup
Penelitian ini dibatasi pada penggunaan teknik clustering untuk data kategorik dengan menggunakan algoritme ROCK dan QROCK. Data yang digunakan adalah data bunga karang jenis O.Hadromerida (Demospongiae. Porifera) yang terdapat di Lautan Atlantik hasil penelitian Iosune Uriz dan Marta Domingo pada tahun 1993. Data dapat
diunduh pada situs
http://archive.ics.uci.edu/ml/dataset/Sponge.
Manfaat Penelitian
Penelitian ini diharapkan dapat bermanfaat bagi pihak-pihak yang membutuhkan informasi tentang penjelasan cara kerja ROCK dan QROCK, serta perbandingan diantara keduanya.
TINJAUAN PUSTAKA
Knowledge Discovery in Database (KDD)
2
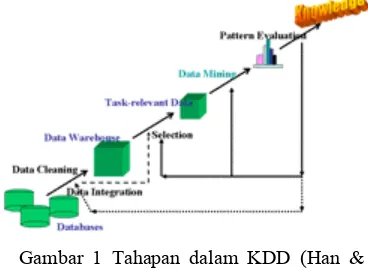
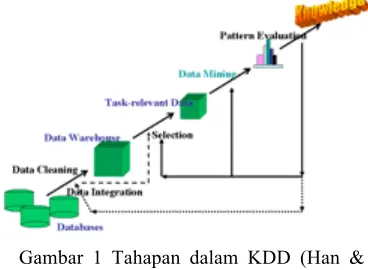
Data mining merupakan salah satu langkah dalam prosess KDD. Tahapan proses KDD dapat dilihat pada Gambar 1.
Gambar 1 Tahapan dalam KDD (Han & Kamber, 2006).
Tahapan proses KDD menurut Han & Kamber (2006) terdiri dari :
1 Pembersihan data
Pembersihan data dilakukan untuk menghilangkan data yang tidak konsisten dan mengandung noise.
2 Integrasi data
Proses integrasi data dilakukan untuk menggabungkan data dari berbagai sumber menjadi bentuk sebuah penyimpanan data yang saling berhubungan, seperti dalam data warehousing.
3 Seleksi data
Proses seleksi data mengambil data yang relevan digunakan untuk proses analisis. 4 Tranformasi data
Proses ini mentransformasikan atau menggabungkan data ke dalam bentuk yang tepat untuk dilakukan proses mine
dengan cara melakukan peringkasan atau operasi agregasi. Dalam beberapa kasus proses tranformasi dilakukan sebelum proses seleksi, misalnya dalam kasus data warehouse.
5 Data mining
Data mining merupakan proses yang penting, di mana metode-metode cerdas diaplikasikan untuk mengekstrak pola-pola dalam data.
6 Evaluasi pola
Evaluasi pola diperlukan untuk mengidentifikasi beberapa pola yang menarik dalam merepresentasikan pengetahuan.
7 Presentasi pengetahuan
Penggunaan visualisasi dan teknik representasi untuk menunjukan pengetahuan hasil penggalian dari tumpukan data kepada pengguna.
Data Mining
Data mining merupakan suatu proses untuk menemukan pola-pola yang menarik dari data berukuran besar yang disimpan di basis data, data warehouse, atau sarana penyimpanan yang lain (Han & Kamber, 2006).
Proses data mining dapat dibedakan menjadi dua tujuan utama yaitu (Kantardzic 2003) :
1 Descriptive data mining
Deskripsi konsep atau task-relevan data dalam bentuk yang ringkas, informatif, dan diskriminatif.
2 Predictive data mining
Dari hasil analisis data dibuat model untuk dijadikan alat prediksi tren dan data yang tidak diketahui nilainya.
Clustering
Clustering merupakan proses dari data mining untuk mengelompokkan kumpulan objek ke dalam kelas-kelas atau cluster
sehingga objek-objek dalam satu cluster
memiliki kemiripan yang tinggi tetapi tidak mirip terhadap objek dari cluster lain (Han & Kamber, 2006). Ukuran kemiripan dan ketidakmiripan dinilai berdasarkan nilai atribut yang mendeskripsikan objek. Metode yang umum digunakan dalam clustering dapat diklasifikasikan sebagai berikut (Han & Kamber, 2006) :
1 Metode partisi
Metode yang membangun berbagai partisi (bagian) kemudian mengevaluasinya dengan beberapa kriteria. Metode ini akan memindahkan objek dari satu kelompok ke kelompok lain.
2 Metode hirarki
Metode yang membangun dekomposisi hirarki dari himpunan data (objek) menggunakan beberapakriteria.
3 Metode berdasarkan kepekatan
3 4 Metode berdasarkan grid
Metode yang berdasarkan kepada struktur
multiple levelgranularity.
5 Metode berdasarkan model
Metode yang menjadikan sebuah model merupakan patokan bagi setiap cluster
mendapatkan model yang tepat terhadap suatu data dengan model yang diberikan. Agglomerative Hirarchical Clustering
Agglomerative hirarchical clustering
adalah metode clustering hirarki yang pada langkah awal menganggap masing-masing objek adalah cluster, cluster digabungkan pada coarser partition atau partisi yang lebih kasar dan proses penggabungan tersebut berlangsung sampai trivial partition terbentuk yaitu ketika semua objek berada pada satu
cluster (Kantardzic 2003).
Sebagian besar algoritme agglomerative hirarchical clustering terdiri dari algoritme
single link atau algoritme complete link. Pada
single link method jarak antara dua cluster
adalah minimum jarak antardua objek dari dua
cluster (minimum jarak antardua cluster). Sedangkan complete link method jarak antardua cluster adalah maksimum jarak antara dua objek dari dua cluster (maksimum jarak antardua cluster) (Kantardzic 2003).
Data Kategorik
Data kategorik yaitu data non-numeric (symbolic) yang variabelnya memiliki dua relasi. Contoh dari data kategorik seperti warna mata, jenis kelamin, dan kewarganegaraan (Kantardzic 2003). Biasanya data kategorik adalah data hasil pengamatan. Data numerik adalah data metric
atau data yang merupakan hasil pengukuran. Data kategorik diklasifikasikan menjadi dua yaitu :
1. Data nominal yaitu data kategorik yang tak dapat dinyatakan bahwa kategori yang satu lebih baik dari kategori lainnya. Contoh dari data nominal yaitu pria–wanita, ungu– biru.
2. Kategorik ordinal, yaitu data kategorik yang mempunyai urutan tertentu namun jarak antar kategori sulit untuk dinyatakan sama. Contoh dari data ordinal yaitu keadaan baik, sedang, dan buruk.
ROCK (RObust Clustering using linKs)
ROCKadalah algoritme clustering hirarki aglomeratif untuk mengelompokkan data kategorik (Guha et al. 2000).
ROCK merupakan algoritme yang membangun link untuk menggabungkan
cluster-cluster-nya dan tidak menggunakan
distance seperti algoritme clustering pada umumnya (Guha et al. 2000). Link antar dua
tuple pada ROCK adalah nilai common neighbor yang mereka miliki dari data set.
Common neighbor yaitu jumlah tetangga yang sama diantara dua objek data. Algoritme ROCK akan berhenti ketika (M.Dutta et al. 2005) :
1 Jumlah dari cluster yang diharapkan sudah terpenuhi,
2 Tidak ada lagi link antar
cluster-cluster-nya.
Langkah-langkah dalam algoritme ROCK yaitu (M.Dutta et al. 2005) :
1 Menentukan inisialisasi untuk masing-masing data poin sebagai cluster pada awalnya.
2 Menghitung similaritas antarcluster
dengan cluster lainnya dengan menggunakan persamaan :
...(1)
dan adalah pasangan cluster yang akan dihitung similaritasnya, k merupakan nomor atribut dan | | adalah jumlah kandidat atribut ke k. Penjumlahan satu perjumlah kandidat atribut dilakukuan untuk atribut yang bukan anggota atribut irisan dan . 3 Mencari nilai nbrlist antarcluster dengan
cluster lainnya. Nbrlist yaitu matrik nilai tetangga yang didapat dari threshold yang diberikan (nilai threshold antara 0 dan 1). Suatu objek dan bertetangga jika ...(2) 4 Menghitung link antarcluster dengan
4 bernilai besar maka kemungkinan besar
dan berada pada cluster yang sama. 5 Menentukan local heap. Local heap yaitu
nilai goodness measure untuk setiap
cluster dengan cluster lainnya jika link
0. Goodness measure yaitu persamaan yang menghitung jumlah link dibagi dengan kemungkinan link yang akan terbentuk dilihat dari ukuran cluster-nya. Persamaan untuk mencari goodness measure :
...(3)
adalah jumlah common
neighbor dari dan , adalah
jumlah anggota cluster i dan adalah jumlah anggota cluster j, dengan persamaan :
...(4)
6 Menentukan global heap. Global heap
yaitu nilai maksimum goodness measure
antar kolom di baris ke i.
7 Ulangi langkah 5 dan 6 hingga mendapat kan nilai maksimum di global heap dan
local heap.
8 Selama ukuran data > k, dengan k adalah jumlah kelas yang ditentukan lakukan penggabungan cluster yang memiliki nilai
local heap terbesar dengan global heap
terbesar menjadi satu cluster, tambahkan
link antar cluster yang digabungkan, hapus
cluster yang digabungkan dari local heap
dan update global heap dengan nilai hasil penggabungan.
9 Lakukan langkah 8 hingga menemukan jumlah cluster yang diharapkan (k) atau cluster akan dibangkitkan secara otomatis ketika tidak ada lagi link antar clusternya.
Time complexity pada saat worst case
yaitu dengan
n adalah jumlah data, maksimum jumlah
neighbor, dan nilai rata-rata jumlah
neighbor.
QROCK (Quick RObust Clustering using linKs)
QROCK adalah algoritme yang memiliki metode yang lebih efisien untuk menghasilkan
cluster akhir algoritme ROCK ketika ROCK sudah tidak memiliki link antar cluster-nya (M.Dutta, et al. 2005). QROCK tidak lagi menggunakan link untuk menggabungkan
cluster-cluster-nya tetapi menggunakan primitif tipe data abstrak MFSET. MFSET
(Merge Find Set) atau disjoint set adalah suatu struktur data yang menggunakan dua operasi yaitu :
1 Find: menentukan himpunan yang berisi elemen khusus. Digunakan untuk menentukan dua elemen yang berada pada himpunan yang sama.
2 Merge: menggabungkan dua himpunan menjadi satu himpunan.
MFSET yang digunakan pada QROCK yaitu (M.Dutta et al. 2005 ):
1 Merge (A,B) : menggabungkan komponen A dan B.
2 Find (x) : mencari komponen yang salah satu anggota dari komponen tersebut adalah x.
3 Initial (x) : membuat komponen yang hanya berisi elemen x.
Langkah-langkah dalam algoritme QROCK yaitu (M.Dutta et al. 2005 ) :
1 Menentukan inisialisasi untuk masing-masing data poin sebagai cluster pada awalnya.
2 Menghitung similaritas antar cluster
dengan cluster lainnya dengan menggunakan persamaan (1).
3 Mencari nilai nbrlist antar cluster dengan
cluster lainnya.
4 Inisialisasi MFSET yang terdiri dari
count, first element, set name, next element.
5 Inisialisasi elemen x adalah anggota himpunan data.
6 Inisialisasi elemen y adalah semua nilai
nbrlist x = 1.
7 Find nilai A sebagai first element nilai x.
8 Find nilai B sebagai first element nilai y.
9 Jika nilai A B maka merge A dan B, selainnya passed.
5
Time complexity dari algoritme QROCK yaitu .
Evaluasi Cluster
Cluster validation adalah kemampuan untuk mendeteksi ada atau tidaknya suatu stuktur tidak acak dalam data. Beberapa aspek penting dalam cluster validation yaitu (Tan et al. 2006) :
1 Menentukan clustering tendency dari data. Clustering tendency yaitu kecenderungan sifat dari suatu cluster.
2 Menentukan jumlah cluster yang tepat. 3 Mengevaluasi seberapa baik hasil analisis
cluster tanpa diberikan informasi eksternal.
4 Membandingkan hasil analisis cluster
terhadap hasil eksternal yang diketahui, misalnya label kelas eksternal.
5 Membandingkan dua himpunan cluster
untuk menentukan yang lebih baik. Pada aspek satu, dua dan tiga tidak diperlukan informasi eksternal yang merupakan teknik unsupervised, sedangkan aspek empat membutuhkan informasi eksternal. Aspek empat termasuk teknik
supervised. Aspek lima dapat dilakukan pada teknik supervised atau unsupervised.
Perhitungan evaluasi dapat digolongkan menjadi tiga jenis yaitu (Tan et al. 2006) : 1 Unsupervised. Mengukur goodness dari
struktur clustering tanpa informasi eksternal. Besaran unsupervised dibagi dua yaitu : cluster cohesion (seberapa dekat suatu objek dalam suatu cluster) dan cluster separation atau isolation
(perbedaan atau seberapa jauh suatu
cluster dengan cluster lainnya).
2 Supervised. Mengukur kecocokan struktur clustering dengan struktur eksternal.
3 Relative. Membandingkan clustering
yang beda. Besaran evaluasi cluster relative merupakan teknik unsupervised
atau supervised yang digunakan untuk perbandingan.
Algoritme ROCK dan QROCK merupakan teknik unsupervised dan graph-base sehingga cohesion didapatkan dengan menjumlahkan bobot link dari proximity graf yang terhubungkan pada cluster dengan persamaan (Tan et al. 2006) :
..(5)
Demikian juga dengan separation antar dua cluster dapat dihitung dari jumlah bobot
link suatu objek data dalam suatu cluster ke objek data di cluster lain dengan persamaan :
...(6)
Fungsi proximity dapat berupa similarity, dissimilarity atau fungsi kuantitas lainnya. Dikarenakan fungsi kuantitas dari algoritme ROCK dan QROCK adalah fungsi goodness
pada persamaan (3) maka persamaan yang digunakan untuk menghitung nilai evaluasi cluster-nya adalah persamaan goodness measure dibagi m yaitu cluster yang terbentuk. Persamaan cohesion dan separation
tersebut yaitu :
...(7)
...(8) Dengan sama dengan persamaan (4).
Semakin tinggi nilai total cohesion dan semakin minimum nilai separation maka semakin baik suatu cluster terhadap yang lainnya. Karena fungsi yang digunakan adalah fungsi goodness measure yang semakin besar nilai goodness-nya maka semakin dekat suatu objek cluster dengan objek lainnya.
Outlier
Outlier menurut ilmu statistik adalah data yang terdapat di atas batas atas atau di bawah batas bawah rentangan data (Huntsbergen 1987).
Outlier adalah data yang tidak mengikuti tingkahlaku umum sebagian besar data, perbedaan yang penting atau sesuatu yang tidak konsisten dalam himpunan data (Kantardzic 2003).
METODE PENELITIAN
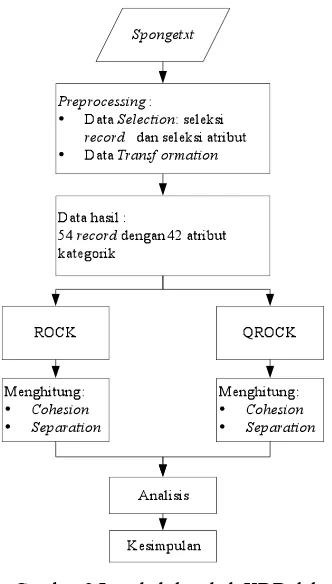
ProsesKnowledge Discovery in Database
6 Gambar 2 Langkah-langkah KDD dalam
penelitian. 1 Preprocessing data
Praproses data meliputi pembersihan data, integrasi data, seleksi data, dan transformasi data.
2 Data mining
Dalam penelitian ini digunakan algoritme ROCK dan QROCK. Algoritme ROCK dan QROCK digunakan untuk mengelompokan data bunga karang
(sponge) sehingga didapatkan pola-pola
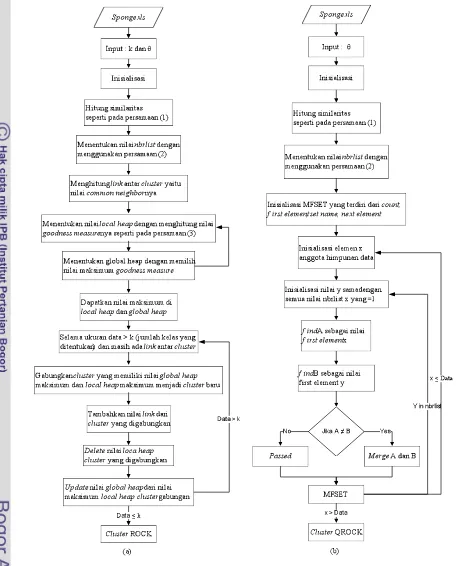
cluster bunga karang jenis O.Hadromerida (Demospongiae. Porifera) berdasarkan anatomi dan fisiologinya. Perbandingan langkah-langkah algoritme ROCK dan QROCK digambarkan pada Gambar 3.
Penjelasan dari tahapan algoritme ROCK yaitu :
1 Menentukan inisialisasi untuk masing-masing data poin sebagai
cluster pada awalnya.
2 Menghitung similaritas antar cluster
dengan cluster lainnya
3 Mencari nilai nbrlist antar cluster
dengan cluster lainnya. 4 Menghitung link antar cluster dengan
cluster lainnya. antar
objek diperoleh dari jumlah common neighbor dan .
5 Mengitung nilai goodness measure
untuk setiap cluster dengan cluster
lainnya jika link 0 yang disebut
local heap.
6 Memilih nilai maksimum goodness measure antar kolom di baris ke i
yang disebut global heap.
7 Ulangi langkah 5 dan 6 hingga mendapatkan nilai maksimum di
global heap dan local heap.
8 Selama ukuran data > k, dengan k
adalah jumlah kelas yang ditentukan lakukan penggabungan cluster yang memiliki nilai local heap terbesar dengan global heap terbesar menjadi satu cluster, tambahkan link antar
cluster yang digabungkan, hapus
cluster yang digabungkan dari local heap dan update nilai global heap
dengan nilai hasil penggabungan. 9 Lakukan langkah 8 hingga
menemukan jumlah cluster yang diharapkan atau tidak ada lagi link
antar clusternya.
Langkah-langkah dari algoritme QROCK tersebut yaitu :
1 Menentukan inisialisasi untuk masing-masing data poin sebagai
cluster pada awalnya.
2 Menghitung similaritas antarcluster
dengan cluster lainnya.
3 Mencari nilai nbrlist antar cluster
dengan cluster lainnya. 4 Inisialisasi MFSET yang terdiri dari
count, first element, set name, next element.
5 Inisialisasi elemen x adalah anggota himpunan data.
6 Inisialisasi elemen y adalah semua nilai nbrlist x = 1.
7 Find nilai A sebagai first element
nilai x.
8 Find nilai B sebagai first element
nilai y.
7 Gambar 3 Proses algoritme (a) ROCK dan (b) QROCK.
10 Ulangi langkah 5 dan 6 selama y berada dalam nbrlist.
3 Evaluasi pola
Pada tahap ini dipergunakan persamaan (7) untuk menghitung cohesion dan persamaan (8) untuk menghitung separation.
4 Presentasi pengetahuan
8 Setelah dilakukan analisis clustering maka
algoritme tersebut akan dibandingkan berdasarkan cluster yang terbentuk dari hasil analisis cluster-nya. Hasil perbandingan diharapkan dapat membuktikan bahwa algoritme QROCK lebih baik dari ROCK.
Lingkungan Pengembangan
Aplikasi ini dibangun dengan menggunakan perangkat keras dan lunak dengan spesifikasi sebagai berikut :
Perangkat keras :
• Processor Intel Pentium 4
• RAM 512 MB DDR 1
• HDD 80 GB
• Monitor 14”
• Mouse dan keyboard
Perangkat lunak :
• Sistem operasi Windows XP SP 2
• Bahasa Pemrograman Matlab 7
• Microsoft Excel 2007
HASIL DAN PEMBAHASAN
Preprocessing Data
Data yang digunakan pada penelitian ini adalah data bunga karang atau sponge jenis
O.Hadromerida (Demospongiae. Porifera) yang terdapat di Lautan Atlantik. Data diperoleh dari hasil penelitian Iosune Uriz dan Marta Domingo pada tahun 1993. Data ini memiliki 76 record dan 45 atribut. Format awal data adalah format txt.
Tahap praproses data dilakukan terhadap data bunga karang meliputi:
1 Data selection
Pada proses ini dilakukan dua tahapan : a Seleksi record. Dari 76 record data
terdapat 22 missingdata pada atribut ke 39, oleh karena itu diperlukan pemilihan record yang sesuai sehingga data yang hilang tidak mempengaruhi hasil. Pada penelitian ini seleksi record dilakukan dengan cara membuang 22 record missing
data, sehingga dihasilkan 54 record
data. Data sponge tersebut dapat dilihat pada Lampiran 1.
b Seleksi atribut. Dalam data yang digunakan terdapat 45 atribut yang terdiri dari 27 atribut non-numerik, 15 atribut boolean, dan tiga atribut
numeric. Karena tiga atribut numeric
dalam bentuk bilangan diskret maka diasumsikan bahwa nilai dari atribut
tersebut merupakan hasil pengamatan yang didiskretkan sehingga dapat dijadikan kategori. Oleh karena semua atribut yang ada berhubungan dengan struktur anatomidan fisiologi dari bunga karang maka semua atribut digunakan dalam proses data mining. Atribut yang digunakan dapat dilihat pada Lampiran 2. 2 Data transformation
Pada tahapan proses ini dilakukan tranformasi data dari format .txt ke format
.xls agar dapat diproses dengan mudah oleh MATLAB. Kemudian dilakukan inisialisasi untuk setiap data kedalam bentuk integer untuk mempermudah proses perhitungan similaritas.
Data Mining
Pada tahap ini dilakukan clustering
menggunakan langkah-langkah dari algoritme ROCK dan QROCK. Pada langkah pertama akan dilakukan proses clustering
menggunakan algoritme ROCK. Percobaan
clustering dilakukan untuk ukuran cluster dua sampai 13 (k = 2…13). Untuk masing–masing ukuran cluster dilakukan percobaan dengan nilai threshold diambil pada selang 0 sampai 1 (0:0.1:1). Cluster hasil ditentukan sedemikian sehingga cluster hasil memiliki nilai cohesion
yang tinggi dan telah merepresentasikan pola anatomi dari sponge.
Cluster yang dihasilkan oleh algoritme ROCK berjumlah tujuh cluster dengan nilai
threshold 0.6. Hasil algortme ROCK tersebut disajikan pada Tabel 1.
Tabel 1 Cluster hasil algoritmeROCK untuk ukuran k = 7 dan = 0,6
Cluster Anggota
9 Tabel 2 Persentase dan jumlah anggota cluster
algoritme ROCK untuk ukuran k = 7 dan = 0,6
Cluster Jumlah
anggota Persentase (%)
1 6 11
2 8 15
3 8 15
4 8 15
5 8 15
6 8 15
7 8 15
Pola anatomi yang direpresentasikan dari
cluster hasilalgoritme ROCK yaitu :
1 Anggota cluster satu merupakan sponge
yang tidak memiliki bagian dalam cortex, tidak memiliki espicula, megasclera tipe satu dan warnanya selain warna biru, kuning dan orange permukaan halus. 2 Anggota cluster dua merupakan sponge
yang memiliki cortex, tidak memiliki tipe
espicula, megasclera tipe tiga, dan bentuk lapisan permukaannya keras.
3 Cluster tiga merupakan sponge yang tidak memiliki cortex, tidak memiliki espicula,
megasclera tipe satu, berwarna kuning dan lapisan permukaan kasar.
4 Anggota cluster empat merupakan sponge
yang tidak memiliki cortex, tidak memiliki
espicula, megasclera tipe satu dan dua, berwarna kuning, selain biru dan orange, memiliki lapisan permukaan halus namun keras.
5 Cluster lima merupakan sponge yang memiliki cortex, memiliki espicula,
megasclera tipe tiga dan satu, warnanya selain warna biru dan orange, bentuk lapisan permukaannya beragam dan keras.
6 Cluster enam merupakan sponge yang tidak memiliki cortex, tidak memiliki
espicula, megasclera tipe satu, dua, dan tiga, berwarna kuning, selain biru dan
orange, memiliki lapisan permukaan halus dan kasar serta keras.
7 Cluster tujuh merupakan sponge yang memiliki cortex, tidak memiliki espicula
dan memiliki espicula, megasclera tipe satu, dua, dan tiga, berwarna kuning,
selain biru dan orange, memiliki permukaan yang keras.
Pada percobaan untuk algoritme QROCK tidak diperlukan penentuan ukuran cluster
karena ukuran cluster akan dibangkitkan otomatis oleh algoritme QROCK. Pada algoritme ini hanya diperlukan masukan data dan nilai threshold.
Nilai threshold pada percobaan ini diambil pada selang 0 sampai dengan 1 (0:0.05:1). Percobaan clustering dilakukan dengan memasukan nilai threshold yang bervariasi hingga menghasilkan cluster yang memiliki nilai cohesion yang tinggi dan telah merepresentasikan pola anatomi dari sponge.
Cluster yang dihasilkan oleh algoritme QROCK berjumlah enam cluster dengan nilai
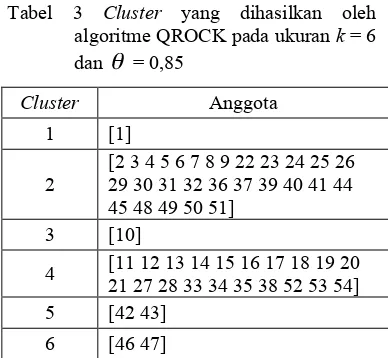
threshold 0.85. Hasil algoritme QROCK tersebut disajikan pada Tabel 3.
Tabel 3 Cluster yang dihasilkan oleh algoritmeQROCK pada ukuran k = 6 dan = 0,85
Cluster Anggota
1 [1]
2
[2 3 4 5 6 7 8 9 22 23 24 25 26 29 30 31 32 36 37 39 40 41 44 45 48 49 50 51]
3 [10]
4 [11 12 13 14 15 16 17 18 19 20 21 27 28 33 34 35 38 52 53 54] 5 [42 43]
6 [46 47]
Persentase dan jumlah anggota masing-masing cluster algoritme QROCK pada ukuran k = 6 dan threshold = 0,85 disajikan dalam Tabel 4.
Tabel 4 Persentase dan jumlah anggota cluster
algoritme QROCK pada ukuran k = 6 dan = 0,85
Cluster Jumlah
anggota Persentase (%)
1 1 2
2 28 52
3 1 2
4 20 37
5 2 4
10 Pola anatomi yang direpresentasikan dari
cluster hasilalgoritme QROCK yaitu : 1 Anggota cluster satu merupakan sponge
yang memiliki cortex, tidak ada espicula, megasclera tipe satu, warna selain kuning, biru dan orange, permukaannya kasar. 2 Cluster dua sponge yang memiliki cortex,
megascleras tipe satu dan dua, tidak memiliki espicula, warna kuning dan selain biru dan orange, permukaan halus dan keras.
3 Anggota cluster tiga sponge yang memiliki cortex dan espicula, megasclera
tipe tiga, permukaannya halus dan warnanya kuning.
4 Cluster empat sponge yang memiliki
cortex dan tidak memiliki espicula,
megasclera tipe tiga, warna selain kuning, biru dan orange, permukaan halus tapi keras.
5 Cluster lima sponge yang tidak memiliki
cortex namun memiliki espicula, megasclera tipe tiga, warna kuning, lapisan permukaan halus dan kasar. 6 Cluster enam merupakan sponge yang
memiliki cortex dan tidak memiliki
espicula, tidak memiliki megasclera, warna selain kuning, biru dan orange,
permukaannya berbentuk poligon besar dan kasar.
Pada kasus algoritme ROCK yang membutuhkan dua parameter ukuran cluster
dan nilai threshold, algoritme berhenti setelah mendapatkan kcluster yang ditentukan maka
k > untuk nilai threshold . Cluster
tambahan (| | buah) tidak lain merupakan calon anggota cluster, namun karena nilai k terpenuhi maka proses merge
tidak sempat dikerjakan. Selain itu, kondisi data dalam jumlah besar dan kemungkinan memiliki outliers sangat sulit untuk menentukan nilai k. Algoritme QROCK lebih mudah dan natural karena tidak harus menentukan ukuran k dibandingkan algoritme ROCK.
Evaluasi Pola
Hasil clustering dari setiap kombinasi ukuran cluster dan nilai threshold dievaluasi menggunakan total cohesion dengan menggunakan persamaan (7) dan nilai
separation dengan menggunakan persamaan
(8). Nilai total cohesion untuk clustering
algoritme ROCK disajikan pada Lampiran 3. Pada algoritme ROCK pola anatomi
sponge dapat direpresentasikan setelah ukuran cluster tujuh. Pada tabel di Lampiran 3 dapat terlihat bahwa untuk ukuran cluster
tujuh dengan nilai cohesion yang paling tinggi terdapat pada nilai threshold 0.6, maka
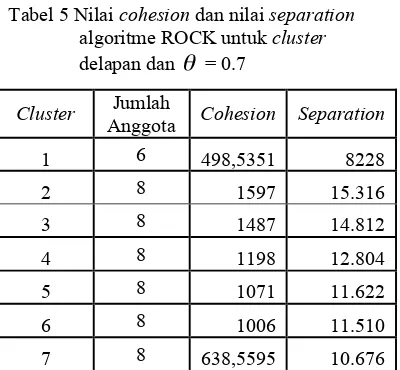
cluster yang dipilih untuk algoritme ROCK adalah ukuran cluster tujuh dengan = 0.6.
Nilai cohesion dan nilai separation untuk
cluster tujuh dan = 0.6 tersebut disajikan pada Tabel 5.
Tabel 5 Nilai cohesion dan nilai separation
algoritme ROCKuntuk cluster
delapan dan = 0.7
Cluster Jumlah
Anggota Cohesion Separation
1 6 498,5351 8228
2 8 1597 15.316
3 8 1487 14.812
4 8 1198 12.804
5 8 1071 11.622
6 8 1006 11.510
7 8 638,5595 10.676
Nilai total cohesion untuk clustering dari setiap kombinasi nilai threshold bagi algoritme QROCK disajikan pada Lampiran 4.
Pada algoritme QROCK pola anatomi
sponge dapat direpresentasikan pada ukuran
cluster enam. Pada tabel di Lampiran 4 dapat dilihat bahwa untuk nilai (threshold) = 0.85 total cohesion memiliki nilai cohesion
yang tinggi dibandingkan dengan cluster
sembilan yang dihasilkan oleh nilai threshold
= 0.87, maka cluster yang dipilih untuk algoritme QROCK adalah cluster ukuran enam dengan = 0.85.
11 Tabel 6 Nilai cohesion dan nilai separation
algoritme QROCK untuk cluster
enam dan = 0.85
Cluster Jumlah
anggota Cohesion Separation
1 1 0 0
2 28 13946 0
3 1 0 0
4 20 1517.3 0
5 2 0 0
6 2 0 0
Semakin besar nilai cohesion (intracluster) menunjukkan kemiripan (similaritas) objek-objek tersebut semakin besar (Mali & Mitra, 1998). Semakin kecil nilai separation yang menggunakan persamaan similaritas maka perbedaan atau jarak suatu cluster dengan cluster lainnya semakin besar (Tan et al. 2006). Dengan demikian suatu cluster dikatakan baik jika nilai cohesion lebih besar dari nilai
separation-nya.
Dari Tabel 5 dapat dilihat bahwa algoritme ROCK memiliki nilai total cohesion 7.498,6 dan nilai separation 84.969. Nilai separation
lebih besar dibandingkan nilai cohesion-nya. Sedangkan dari Tabel 6 terlihat bahwa algoritme QROCK memili ki nilai cohesion
15.463,3 dan nilai total separation 0. Nilai
separation algoritme QROCK lebih kecil dibandingkan nilai cohesion-nya. Dengan demikian berdasarkan hasil penelitian ini,
cluster yang dihasilkan algoritme QROCK lebih baik dibandingkan cluster yang dihasilkan algoritme ROCK.
Ukuran Cluster dan Nilai Cohesion
Nilai cohesion menentukan kualitas suatu
cluster sementara ukuran cluster menentukan nilai total cohesion. Nilai cohesion
menentukan kualitas suatu cluster karena dengan semakin tinggi nilai cohesion maka semakin baik kualitas suatu cluster. Ukuran
cluster menentukan nilai total cohesion karena semakin banyak cluster yang terbentuk maka semakin sedikit anggota suatu cluster dan semakin sedikit pula nilai total cohesion-nya.
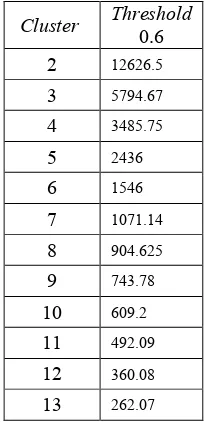
Hubungan antar ukuran cluster dan nilai
cohesion pada algoritme ROCK dapat dilihat pada Lampiran 3. Nilai total cohesion dan ukuran cluster pada nilai threshold 0.7 untuk algoritme ROCK dapat dilihat pada Tabel 7.
Tabel 7 Nilai total cohesion dan ukuran
cluster algoritme ROCK pada nilai
threshold 0.6
Cluster Threshold
0.6 2 12626.5
3 5794.67
4 3485.75
5 2436
6 1546
7 1071.14
8 904.625
9 743.78
10 609.2
11 492.09
12 360.08
13 262.07
Berdasarkan Tabel 7 dapat dilihat grafik nilai k terhadap nilai total cohesion pada Gambar 4.
Gambar 4 Grafik nilai cohesion terhadap nilai k pada algoritme ROCK. Nilai total cohesion dan ukuran cluster
pada algoritme QROCK dapat dilihat pada Lampiran 4. Nilai k terhadap total cohesion
12 Gambar 5 Grafik nilai cohesion terhadap
nilai k pada algoritme QROCK. Dari grafik Gambar 4 dan 5 dapat disimpulkan bahwa semakin besar jumlah k
maka semakin kecil nilai total cohesion-nya, hal ini disebabkan semakin banyak cluster
mengakibatkan jumlah anggota suatu cluster
semakin sedikit sehingga menyebabkan nilai total cohesion menjadi kecil.
Perbandingan nilai cohesion terhadap ukuran cluster antara algoritme ROCK dan QROCK dapat dilihat pada Gambar 6.
Gambar 6 Perbandingan nilai cohesion
terhadap ukuran cluster untuk ROCK dan QROCK.
Pada algoritme QROCK menurunnya nilai
cohesion lebih dipengaruhi oleh nilai
threshold dibandingkan oleh ukuran cluster
karena ukuran clusternya ditentukan secara otomatis oleh algoritme QROCK berdasarkan nilai threshold yang ditentukan.
Nilai Threshold dan Nilai Cohesion
Nilai threshold pada algoritme ROCK menentukan kepadatan dari graf L (graf yang dibangkitkan oleh algoritme ROCK), sehingga menentukan hasil akhir algoritme ROCK. Pada saat nilai k tidak diberikan, algoritme ROCK akan berhenti secara otomatis dengan
kumpulan cluster sebagai sekumpulan komponen graf L (M.Dutta et al. 2005).
Misalkan adalah jumlah cluster akhir graf L berdasarkan . Nilai dapat diambil pada rentang 0 sampai dengan 1, sedemikian sehingga nilai konstan. Sehingga jika maka nbrlist dari nbrlist , jumlah anggota cluster jumlah anggota
cluster , cluster cluster (M.Dutta
et al. 2005).
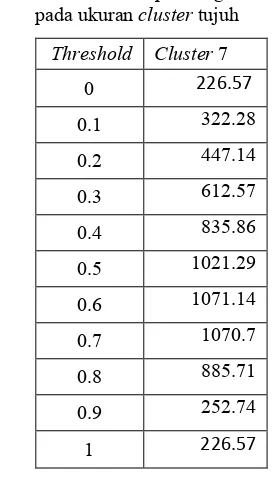
Hubungan antar nilai threshold dan nilai
cohesion pada algoritme ROCK dapat dilihat pada Tabel 8.
Tabel 8 Hubungan antar nilai threshold dan nilai cohesion pada algoritme ROCK pada ukuran cluster tujuh
Threshold Cluster 7 0 226.57
0.1 322.28
0.2 447.14
0.3 612.57
0.4 835.86
0.5 1021.29
0.6 1071.14
0.7 1070.7
0.8 885.71
0.9 252.74
1 226.57
13 Gambar 7 Grafik nilai threshold terhadap
nilai cohesion pada algoritme ROCK.
Pada algoritme QROCK, cluster akhir hanya ditentukan oleh nilai threshold sehingga proses algoritme dapat berhenti secara natural (M.Dutta et al 2005). Nilai total cohesion dan ukuran cluster pada algoritme QROCK dapat dilihat pada Lampiran 4. Nilai k terhadap total
cohesion dari Lampiran 4 digambarkan pada grafik dalam Gambar 8.
Gambar 8 Grafik nilai threshold terhadap nilai cohesion pada algoritme QROCK.
Dari grafik Gambar 7 dan 8 dapat disimpulkan bahwa semakin besar nilai
threshold maka semakin kecil nilai total
cohesion-nya ini dikarenakan nilai nbrlist
semakin kecil mengakibatkan jumlah anggota suatu cluster semakin sedikit sehingga menyebabkan nilai total cohesion menjadi kecil.
Perbandingan nilai cohesion terhadap nilai
threshold antara algoritme ROCK dan QROCK dapat dilihat pada Gambar 9.
Gambar 9 Perbandingan nilai cohesion
terhadap nilai threshold untuk ROCK dan QROCK.
Mendeteksi Outlier
Algoritme ROCK akan berhenti ketika : jumlah cluster yang diharapkan terpenuhi atau tidak ada lagi link diantara cluster-cluster-nya. Pada suatu kasus algoritme ROCK berhenti ketika tidak ada lagi link antar cluster-nya dikarenakan sudah tidak memiliki link yang tidak nol antara mereka, namun ketika kasus yang sama diproses oleh algoritme QROCK ternyata masih memiliki link antar
cluster-nya.
Teorema 1 : Jika cluster akhir hasil algoritme ROCK sudah tidak memiliki
link yang tidak nol antara mereka maka cluster tersebut tidak lain adalah sebuah link graf L yang komponen-komponennya saling berhubung (M.Dutta et al. 2005).
Pembuktian dari teorema tersebut ada dua yaitu :
1 Jika algoritme ROCK berhenti karena tidak ada lagi link yang tidak nol (global heap semuanya nol proses algoritme ROCK berhenti), maka cluster yang terbentuk merupakan komponen terhubung dari graf L.
2 Komponen terhubung tersebut sebenarnya adalah cluster itu sendiri yang merupakan hasil algoritme ROCK (M.Dutta et al. 2005).
Pembuktian pertama terjadi pada saat nilai
threshold 0.9 untuk kombinasi ukuran cluster
14 ketika nilai threshold 0.9 cluster yang
terbentuk adalah 19 cluster, dimana data ke 14 masih dapat digabungdengan data ke 19, data ke 42 digabung dengan data ke 43, data ke 46 masih bisa digabung dengan data ke 47, dan data ke 18 digabung dengan data ke 27. Dari hasil penelitian tersebut terbukti bahwa algoritme QROCK dapat mendeteksi outlier
pada algoritme ROCK. Perbandingan hasil
cluster algoritme ROCK dan QROCK pada nilai threshold 0.9 dapat dilihat pada Lampiran 5.
KESIMPULAN DAN SARAN
Kesimpulan
Pada penelitian ini dilakukan proses
clustering menggunakan algoritme ROCK dan QROCK untuk data bunga karang (sponge).
Percobaan clustering untuk algoritme ROCK dilakukan untuk ukuran cluster dua sampai 13 (k = 1…13) untuk masing–masing ukuran
cluster dilakukan percobaan dengan nilai
threshold diambil pada selang 0 sampai 1 (0:0,1:1). Pada algoritme QROCK ukuran
cluster akan dibangkitkan otomatis oleh algoritmenya, algoritme QROCK hanya membutuhkan nilai threshold untuk menghasilkan cluster. Percobaan cluster pada algoritme QROCK dilakukan berdasarkan variasi nilai threshold pada selang 0 sampai 1 (0:0,05:1). Algoritme QROCK terbukti lebih mudah dibandingkan algoritme ROCK karena tidak perlu menentukan ukuran dari cluster.
Dari percobaan diperoleh hasil clustering
terbaik untuk algoritme ROCK adalah
clustering dengan ukuran cluster tujuh dan nilai threshold 0.6, memiliki nilai total
cohesion 7.498,6 dan nilai separation 84.969.
Clustering terbaik untuk algoritme QROCK yaitu cluster berukuran enam dan nilai
threshold 0.85. Nilai total cohesion 15.463,3 dan nilai total separation 0.
Dilihat dari nilai cohesion dan separation
algoritme ROCK memiliki nilai cohesion
lebih kecil dibandingkan nilai separationnya. Sedangkan untuk algoritme QROCK nilai
cohesion lebih besar dari pada nilai
separationnya. Dengan demikian dapat disimpulkan algoritme QROCK lebih baik dibandingkan algoritme ROCK.
Pada percobaan untuk nilai threshold 0.9 algoritme ROCK menghasilkan 23 cluster
karena sudah tidak ada lagi nilai link yang tak nol, sedangkan pada algoritme QROCK dengan nilai threshold 0.9 dihasilkan 19
cluster. Dengan demikian dapat disimpulkan bahwa algoritme QROCK dapat mendeteksi
outlier pada algoritme ROCK.
Algoritme ROCK dan QROCK dapat digunakan untuk data kategorik, namun menurut hasil dari penelitian ini algoritme QROCK lebih baik dari pada algoritme ROCK.
Saran
Penelitian ini dapat dilanjutkan dengan menentukan klasifikasi taksonomi dari data sponge dari cluster-cluster yang telah dihasilkan.
Perbandingan hasil clustering algoritme QROCK dapat dilakukan dengan algoritme lain yang berbeda base misal algoritme
conceptual clustering yaitu COWEB dan ITERATE, sehingga dari perbandingan tersebut dapat diketahui algoritme mana yang lebih efektif digunakan untuk data kategorik.
DAFTAR PUSTAKA
Goharian & Grossman. 2003. Introduction to
Data Mining.
http://ir.iit.edu/~nazli/cs422/CS422-Slide/DM-Introduction.pdf. [Juni 2008].
Guha S, Rajeev R, & Kyuseok S. 2000.
ROCK: A Robust Clustering Algorithm for Categorical Attributes. Proceedings of the IEEE International Conference on Data Engineering, Sydney, Maret 1999.
Han J dan Kamber M. 2006. Data Mining Concepts and Techniques Edisi Ke-2. San Francisco: Morgan Kaufmann Publisher.
Huntsbergen . 1987. Elemen of Statistical Inference. Edisi Ke-6. New York : Allyn and Balon, Inc.
Kantardzic M. 2003. Data Mining: Concepts, Model, Methods, and Algorithm. New Jersey: John Wiley & Sons inc.
Mali K, Mitra S. 2003. Clustering Validation
In A Symbolic Framework.
http://www.dis.uniromal.it/~sassano/ST AG E/Fast.Clustering.pdf. [juli 2008]. M.Dutta, A.Kakoti M & Arun K. 2005.
15 IEEE International Conference on Data
Engineering, 2004.
Tan P, Michael S, & Vipin K. 2006.
17 Lampiran 1 Keterangan anggota
No Nama sponge
1 AAPTOS_AAPTOS
2 CLIONA_CARTERI
3 CLIONA_CELATA
4 CLIONA_LABYRINTHICA
5 CLIONA_SCHMIDTI
6 CLIONA_VIRIDIS
7 DIPLASTRELLA_BISTELLATA
8 LAXOSUBERITES_FERRERHERNANDEZI
9 LAXOSUBERITES_RUGOSUS
10 OXYCORDYLA_PELLITA
11 POLYMASTIA_AGGLUTINARIS
12 POLYMASTIA_ECTOFIBROSA
13 POLYMASTIA_FUSCA
14 POLYMASTIA_INFLATA
15 POLYMASTIA_INFRAPILOSA
16 POLYMASTIA_MAMMILLARIS
17 POLYMASTIA_MARTAE
18 POLYMASTIA_RADIOSA
19 POLYMASTIA_SPINULA
20 POLYMASTIA_TENAX
21 POLYMASTIA_TISSIERI
22 PROSUBERITES_EPIPHYTUM
23 PROSUBERITES_LONGISPINA
24 PROSUBERITES_RUGOSUS
25 PSEUDOSUBERITES_HYALINUS
26 PSEUDOSUBERITES_SULFUREUS 27 QUASILINA_INTERMEDIA 28 QUASILINA_RICHARDII 29 RHIZAXINELLA_BISETA
30 RHIZAXINELLA_ELONGATA
31 RHIZAXINELLA_PYRIFERA 32 RHIZAXINELLA_UNISETA
33 SPHAEROTYLUS_ANTARCTICUS
34 SPHAEROTYLUS_CAPITATUS
35 SPINULARIA_SPINULARIA 36 SPIRASTRELLA_CUNCTATRIX
37 SPIRASTRELLA_MINAX
38 SUBERITES_CAMINATUS
39 SUBERITES_CARNOSUS_V.INCRUSTANS
40 SUBERITES_CARNOSUS_V.RAMOSUS
41 SUBERITES_CARNOSUS_V.TYPICUS 43 SUBERITES_FICUS
42 SUBERITES_DOMUNCULA
44 SUBERITES_GIBBOSICEPS
45 TERPIOS_FUGAX
46 TETHYA_AURANTIUM
18 Lampiran 1 Lanjutan
No Nama sponge
48 TIMEA_HALLEZI
49 TIMEA_MIXTA
50 TIMEA_STELLATA
51 TIMEA_UNISTELLATA
52 TRICHOSTEMA_HEMISPHAERICUM
53 WEBERELLA_BURSA
19 Lampiran 2 Struktur dari 27 atribut non numeric, 15 atribut boolean, dan tiga atribut numeric
No Atribut Non Numeric Atribut Boolean Atribut numeric
1 Lapisan Cortex Cortex Jumlah Papilas
2 Struktur Bagian Dalam Cortex Tiang Espiculas Dalam Pompon di Cortex
Panjang Megascleras
3 Jenis Serat Cortex Tipe Akar Espicula Deactina
Ketebalan Cortex
4 Bentuk Tangen Espiculas Dalam
Cortex
Jenis Tipe Espicula
5 Bagian Aneh Dalam Cortex Jenis Tipe Espiculas
Ukuran 2
6 Penambahan Tilostilo Jenis Tipe Espiculas Tilostilo
7 Tipe Jumlah Megascleras Tipe Espiculas Estrongiloxa
8 Jenis Spicula Tipe Espiculas Tilostilo
9 Jenis Spicula Tilostilo Microscleras
10 Bentuk Dasar Tilostilo Aster
11 Bentuk Dasar Tilostilo Ectosomico Papilas
12 Bentuk Megasclera Ectosomica Tempat Tinggal Sementara
13 Tipe Megasclera Ectosomica Lapisan Tajam
14 Tipe Exostilo Peseudoraices
15 Bentuk Lapisan Tengah Megasclera Jenis Tipe Espiculas Oxas
16 Tipe Lapisan Tengah Megasclera
17 Tipe Microsclera
18 Diameter Esferaster
19 Tipe Aster
20 Tipe Diplaster
21 Tipe Esferaster
22 Bentuk Dasar
23 Bentuk Permukaan
24 Warna
25 Struktur Kerangka Espicular
26 Bentuk Lapisan
27
Susunan Megascleras EctosilasDalam Etosoma
20 Lampiran 3 Nilai total cohesion untuk clustering algoritme ROCK dari setiap kombinasi ukuran k
dan nilai threshold dan grafiknya
θ
K θ = 0 θ = 0.1 θ = 0.2 θ = 0.3 θ = 0.4 θ = 0.5 θ = 0.6 θ = 0.7 θ = 0.8 θ = 0.9 θ = 1
k = 2 3150 4481.5 6218.5 8518 11600 13851.5 12626.5 14960 11723 252.74 0
k = 3 1360 1935.67 2685.67 3679 4999 5953.67 5794.67 6214.3 4636.67 252.74 0
k = 4 777.75 1106.5 1535.25 2103 2864.25 3515.25 3485.75 3784.25 3085 252.74 0
k = 5 511.4 727.4 1009.2 1382.6 1881.2 2383.2 2436 2585.2 2029.6 252.74 0
k = 6 333.67 4746.67 658.5 902.17 1226 1519.5 1546 1554.33 1444.67 252.74 0
k = 7 226.57 322.28 447.14 612.57 835.86 1021.29 1071.14 1070.7 885.71 252.74 0
k = 8 180.87 257.37 357 489.13 666.75 840.38 904.625 927 763.75 252.74 0
k = 9 145.44 206.78 287 393.11 535.78 684 743.78 765 642.11 252.74 0
k = 10 117 166.4 230.9 316.3 430.9 555 609.2 630.8 542.8 252.74 0
k = 11 93.73 133.36 185 253.45 345.09 441.73 492.09 495.36 422.45 252.74 0
k = 12 74.38 105.75 146.83 201.08 298.55 345.92 360.08 410.08 297.16 252.74 0
21 Lampiran 4 Nilai total cohesion untuk clustering algoritme QROCK dari setiap nilai threshold
yang dicobakan
Threshold Cluster Cohesion
0 1 12402
0.1 1 17643
0.15 1 20831
0.2 1 24480
0.25 1 28677
0.3 1 33533
0.35 1 39193
0.4 1 45599
0.45 1 50907
0.5 1 54241
0.55 1 53841
0.6 1 49983
0.65 1 40963
0.7 1 37520
0.75 1 32617
0.8 1 23756
0.85 6 2577.17
0.86 9 1562.89
0.87 10 1335.9
0.88 12 948.92
0.89 17 501.88
0.9 19 305.95
0.91 20 209.6
0.92 26 107.69
0.93 27 74.33
0.94 29 52.45
0.95 34 26
0.96 41 6.37
0.97 43 3.81
0.98 48 2.21
0.99 54 0
22 Lampiran 5 Perbandingan hasil cluster algoritme ROCK dan QROCK pada nilai threshold 0.9
Cluster hasil algoritme ROCK Cluster hasil algoritme QROCK
Cluster Anggota
1 1
2 4
3 6
4 10
5 11
6 12
7 13
8 14
9 15
10 18
11 19
12 27
13 28
14 30
15 35
16 42
17 43
18 46
19 47
20 52
21 [54 38 53]
22 [17 33 16 21 20 34]
23
[8 25 26 44 31 22 24 2 7 36 3 5 51 37 50 48 49 23 32 40 41 9 29 39 45]
Cluster Anggota
1 1
2
[8 3 5 36 37 9 2 24 32 48 26 44 31 39 7 22 40 41 45 23 29 49 50 51 25]
3 4
4 6
5 10
6 11
7 12
8 13
9 [14 19]
10 15
11 [17 20 21 33 16 34] 12 [18 27]
13 28
14 30
15 35
16 [38 53 54] 17 [42 43] 18 [46 47]
17 Lampiran 1 Keterangan anggota
No Nama sponge
1 AAPTOS_AAPTOS
2 CLIONA_CARTERI
3 CLIONA_CELATA
4 CLIONA_LABYRINTHICA
5 CLIONA_SCHMIDTI
6 CLIONA_VIRIDIS
7 DIPLASTRELLA_BISTELLATA
8 LAXOSUBERITES_FERRERHERNANDEZI
9 LAXOSUBERITES_RUGOSUS
10 OXYCORDYLA_PELLITA
11 POLYMASTIA_AGGLUTINARIS
12 POLYMASTIA_ECTOFIBROSA
13 POLYMASTIA_FUSCA
14 POLYMASTIA_INFLATA
15 POLYMASTIA_INFRAPILOSA
16 POLYMASTIA_MAMMILLARIS
17 POLYMASTIA_MARTAE
18 POLYMASTIA_RADIOSA
19 POLYMASTIA_SPINULA
20 POLYMASTIA_TENAX
21 POLYMASTIA_TISSIERI
22 PROSUBERITES_EPIPHYTUM
23 PROSUBERITES_LONGISPINA
24 PROSUBERITES_RUGOSUS
25 PSEUDOSUBERITES_HYALINUS
26 PSEUDOSUBERITES_SULFUREUS 27 QUASILINA_INTERMEDIA 28 QUASILINA_RICHARDII 29 RHIZAXINELLA_BISETA
30 RHIZAXINELLA_ELONGATA
31 RHIZAXINELLA_PYRIFERA 32 RHIZAXINELLA_UNISETA
33 SPHAEROTYLUS_ANTARCTICUS
34 SPHAEROTYLUS_CAPITATUS
35 SPINULARIA_SPINULARIA 36 SPIRASTRELLA_CUNCTATRIX
37 SPIRASTRELLA_MINAX
38 SUBERITES_CAMINATUS
39 SUBERITES_CARNOSUS_V.INCRUSTANS
40 SUBERITES_CARNOSUS_V.RAMOSUS
41 SUBERITES_CARNOSUS_V.TYPICUS 43 SUBERITES_FICUS
42 SUBERITES_DOMUNCULA
44 SUBERITES_GIBBOSICEPS
45 TERPIOS_FUGAX
46 TETHYA_AURANTIUM
18 Lampiran 1 Lanjutan
No Nama sponge
48 TIMEA_HALLEZI
49 TIMEA_MIXTA
50 TIMEA_STELLATA
51 TIMEA_UNISTELLATA
52 TRICHOSTEMA_HEMISPHAERICUM
53 WEBERELLA_BURSA
19 Lampiran 2 Struktur dari 27 atribut non numeric, 15 atribut boolean, dan tiga atribut numeric
No Atribut Non Numeric Atribut Boolean Atribut numeric
1 Lapisan Cortex Cortex Jumlah Papilas
2 Struktur Bagian Dalam Cortex Tiang Espiculas Dalam Pompon di Cortex
Panjang Megascleras
3 Jenis Serat Cortex Tipe Akar Espicula Deactina
Ketebalan Cortex
4 Bentuk Tangen Espiculas Dalam
Cortex
Jenis Tipe Espicula
5 Bagian Aneh Dalam Cortex Jenis Tipe Espiculas
Ukuran 2
6 Penambahan Tilostilo Jenis Tipe Espiculas Tilostilo
7 Tipe Jumlah Megascleras Tipe Espiculas Estrongiloxa
8 Jenis Spicula Tipe Espiculas Tilostilo
9 Jenis Spicula Tilostilo Microscleras
10 Bentuk Dasar Tilostilo Aster
11 Bentuk Dasar Tilostilo Ectosomico Papilas
12 Bentuk Megasclera Ectosomica Tempat Tinggal Sementara
13 Tipe Megasclera Ectosomica Lapisan Tajam
14 Tipe Exostilo Peseudoraices
15 Bentuk Lapisan Tengah Megasclera Jenis Tipe Espiculas Oxas
16 Tipe Lapisan Tengah Megasclera
17 Tipe Microsclera
18 Diameter Esferaster
19 Tipe Aster
20 Tipe Diplaster
21 Tipe Esferaster
22 Bentuk Dasar
23 Bentuk Permukaan
24 Warna
25 Struktur Kerangka Espicular
26 Bentuk Lapisan
27
Susunan Megascleras EctosilasDalam Etosoma
20 Lampiran 3 Nilai total cohesion untuk clustering algo