PENERAPAN KLASIFIKASI DECISION TREE DENGAN
ALGORITMA C4.5 UNTUK MENENTUKAN
CALON DOSEN DAN DOSEN TETAP
(STUDI KASUS DI FAKULTAS KEDOKTERAN
UNIVERSITAS MUHAMMADIYAH YOGYAKARTA)
Skripsi
Untuk memenuhi sebagian persyaratan Mencapai derajat S-1
Diajukan oleh DEDE HARDIANSAH
2012 014 0074
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK
PERNYATAAN
Dengan ini saya menyatakan bahwa dalam skripsi ini tidak terdapat karya yang pernah diajukan untuk memperoleh gelar kesarjanaan di suatu Perguruan Tinggi dan sepanjang pengetahuan saya juga tidak terdapat karya atau pendapat yang pernah ditulis atau diterbitkan oleh orang lain, kecuali yang secara tertulis dikutip dalam naskah ini dan disebutkan dalam daftar pustaka.
Yogyakarta, 07 Februari 2017
Dede Hardiansah
PRAKATA
Assalamu’alaikum Wr. Wb.
Alhamdulillah, segala puji dan syukur atas khadirat Allah SWT yang telah
melimpahkan rahmat, karunia dan hidayah-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul “Penerapan Klasifikasi Decision Tree Dengan
Algoritma C4.5 Untuk Menentukan Calon Dosen Dan Dosen Tetap (Studi Kasus Di Fakultas Kedokteran Universitas Muhammadiyah Yogyakarta)”. Skripsi ini
disusun untuk memenuhi persyaratan dalam memperoleh gelar sarjana pada Fakultas Teknik Jurusan Teknologi Informasi Universitas Muhammadiyah Yogyakarta.
Dalam menyelesaikan skripsi ini, penulis banyak mendapatakan bantuan serta dukungan dari berbagai pihak. Penulis ingin mengucapkan terimakasih yang tidak terhingga kepada:
1. Keluarga tercinta ayahanda Bapak Khaidir, dan Ibunda Ibu Nurhasanah, serta kakakku Hady N. Panduwinata, dan adik – adikku Deny Asmar Wahyudin, Shifa Himah Nur’aila yang telah menyemangati, memberikan doa, dukungan yang sangat tulus dan ikhlas kepada penulis, sehingga penulis dapat menyelesaikan kuliah dan meraih gelar sarjana.
3. Bapak dan ibu dosen serta karyawan Fakultas Teknik Universitas Muhammadiyah Yogyakarta yang telah banyak membantu dalam proses pendidikan selama penulis belajar di Universitas Muhammadiyah Yogyakarta. 4. Sri Utami Lestari, S.p., yang telah memberikan bimbingannya kepada penulis,
berupa saran, masukan, nasehat dan dukungan kepada penulis.
5. Teman seperjuangan Wahyudi S, Andri G, Joko F, teman angkatan 2012 jurusan Teknologi Informasi UMY khususnya kelas B.
6. Semua pihak yang tidak dapat penulis sebutkan satu per satu, yang telah banyak membantu hingga menyelesaikan skripsi ini.
Penulis menyadari bahwa penyusunan skripsi ini masih jauh dari kesempurnaan, maka dengan penuh kerendahan hati penulis senantiasa mengharapkan kritik dan saran yang membangun demi kesempurnaan skripsi ini.
Akhir kata, penulis berharap semoga skripsi ini dapat memberikan informasi yang bermanfaat bagi pembaca dan semoga Allh SWT selalu meridhoi setiap langkah dan senantiasa membalas budi kebaikan Bapak/Ibu/sdr sekalian.
Wassalamualaikum Wr.Wb
Yogyakarta, 07 Februari 2017
DAFTAR ISI
HALAMAN PENGESAHAN I ... iii
HALAMAN PENGESAHAN II ... ii
PERNYATAAN ... iii
1.1.Latar Belakang ... 1
1.2.Rumusan Masalah... 2
1.3.Tujuan Penelitian ... 2
1.4.Batasan Masalah ... 2
1.5.Manfaaat Penelitian ... 3
1.6.Sistematika Penulisan ... 3
BAB II ... 5
TINJAUAN PUSTAKA DAN LANDASAN TEORI ... 5
2.1. Tinjauan Pustaka ... 5
2.2. Landasan Teori ... 7
2.2.1. Data Mining ... 7
2.2.2. Klasifikasi ... 12
2.2.3. Decision Tree (Pohon Keputusan) ... 12
2.2.4. Algoritma C4.5 ... 15
BAB III ... 17
METODE PENELITIAN ... 17
3.1. Lokasi Penelitian ... 17
3.2.2. Bahan ... 18
3.3.Metodologi Penelitian... 18
3.3.1. Studi Literatur ... 19
3.3.2. Identifikasi Masalah ... 20
3.3.3. Pengumpulan Data ... 20
3.3.4. Analisis Data ... 20
3.3.5. Pengujian ... 20
BAB IV ... 21
HASIL DAN PEMBAHASAN ... 21
4.1. Identifikasi Masalah ... 21
4.2. Pengumpulan Data ... 21
4.3. Analisis Data ... 28
4.3.1. Pre-Processing Data ... 28
4.3.2. Memilih Attribut ... 32
4.3.3. Menghitung Entropy dan Gain ... 33
4.4. Pengujian dalam RapidMiner 7.2 ... 36
BAB V ... 50
KESIMPULAN DAN SARAN ... 50
5.1. Kesimpulan ... 50
5.2. Saran ... 50
DAFTAR PUSTAKA ... 52
DAFTAR GAMBAR
Gambar 1. Tahapan Data Mining (Han dan Kamber, 2006) ... 9
Gambar 2. Konsep Pohon Keputusan ... 13
Gambar 3. Konsep Dasar Pohon Keputusan ... 14
Gambar 4. Alur Penelitian ... 19
Gambar 5. Tampilan Antar Muka Microsoft Sql Server 2014 ... 22
Gambar 6. Tampilan Login ... 22
Gambar 7. Tampilan Database dan membuat view baru ... 23
Gambar 8. Tampilan Pemilihan Tabel ... 24
Gambar 9. Tampilan Pemilihan Attribut ... 25
Gambar 10. Tampilan Data Baru ... 25
Gambar 11. Tampilan Filter Data ... 26
Gambar 12. Tampilan Data Setelah di Filter ... 27
Gambar 13. Tampilan Pemberian Nama pada Tabel Baru ... 27
Gambar 14. RapidMiner 7.2 ... 36
Gambar 15. Tampilan Awal RapidMiner 7.2 ... 37
Gambar 16. Tampilan utama New Process ... 38
Gambar 17. Operators Read CSV pada Main Process ... 38
Gambar 18. Importing Data ... 39
Gambar 19. Pencarian Data ... 39
Gambar 20. Memilih Comma ... 40
Gambar 21. Memilih Annotasi ... 41
Gambar 22. Pemilihan Attribut dan Variabel ... 42
Gambar 23. Menghubungkan port Read CSV dengan port Validation ... 43
Gambar 24. Tampilan Panel Process Validation ... 44
Gambar 25. Tampilan Operators Decision Tree pada tabel Training ... 44
Gambar 26. Tampilan Operator Apply Model pada table Testing ... 45
Gambar 27. Tampilan operator performance pada tabel testing ... 45
Gambar 28. Tampilan menghubungkan port Decision tree, Apply Model dan Performance ... 46
Gambar 29. Tampilan Decision Tree (Pohon Keputusan) Akhir ... 47
Gambar 30. Tampilan Deskripsi Decision Tree ... 48
DAFTAR TABEL
Tabel 1. Frekuensi Penggunaan Algoritma Pohon Keputusan ... 14
Tabel 2. Perangkat lunak (Software)yang digunakan ... 17
Tabel 3. Spesifikasi perangkat keras (Hardware) ... 18
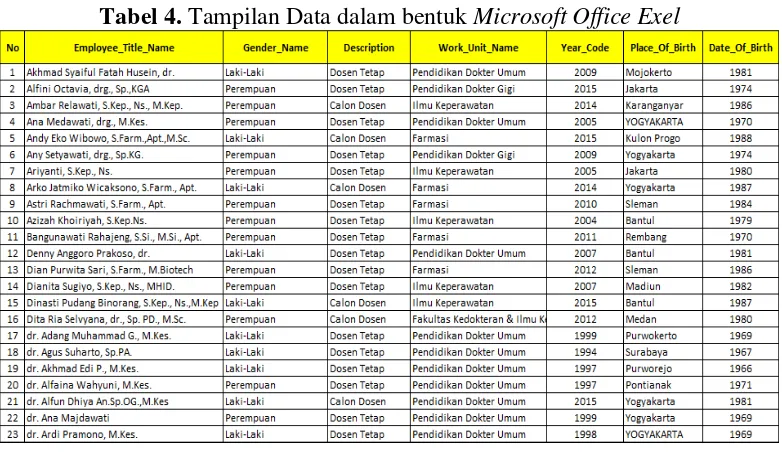
Tabel 4. Tampilan Data dalam bentuk Microsoft Office Exel ... 28
Tabel 5. Data setelah Transformasi ... 30
Tabel 6. Tabel Attribut ... 33
INTISARI
Permasalahan yang sering dijumpai adalah Database yang ada belum dimanfaatkan dan dikelola dengan baik dan belum diterapkannya sebuah teknik
data mining atau metode klasifikasi dalam mengelolaan data pada Fakultas
Kedokteran Unversitas Muhammadiyah Yogyakarta untuk mengetahui status calon dosen atau dosen tetap. Penelitian ini bertujuan untuk mengetahui kriteria calon dosen dan dosen tetap dan menerapkan teknik klasifikasi data mining dengan Algoritma C4.5. Penelitian ini dilakukan menggunakan metode klasifikasi decision
tree atau pohon keputusan dengan data sebanyak 137 dosen yang diperoleh dari
database server BSI (Biro Sistem Informasi) Universitas Muhammadiyah
Yogyakarta. Adapun pengambilan data dosen dengan bantuan perangkat lunak
Microsoft SQL Server 2014 yaitu data Dosen Fakultas Kedokteran Universitas
Muhammadiyah Yogyakarta. Hasil Penelitian dengan menggunakan Klasifikasi
Decision Tree dengan Algoritma C4.5 dan diimplementasikan ke RapidMiner
mampu menentukan status calon dosen dan dosen tetap dengan tingkat akurasi 92.68%.
ABSTRACT
Problems often encountered is that there is untapped Database and well run and not the implementation of a data mining technique or method of classification in mengelolaan data at the Medical Faculty of University of Muhammadiyah Yogyakarta to know the status of candidate lecturer or professor. This study aims to determine the criteria for lecturers and professors remain and apply data mining techniques with classification algorithm C4.5. This research was conducted using the method of decision tree classification or decision tree with as much data as 137 lecturers obtained from the database server BSI (Bureau of Information Systems) University of Muhammadiyah Yogyakarta. As for data retrieval software lecturer with the help of Microsoft SQL Server 2014 is the data Lecturer at the Faculty of Medicine, University of Muhammadiyah Yogyakarta. Results using classification C4.5 Decision Tree Algorithm and implemented to RapidMiner is able to determine the status of candidate for lecturers and professors remained at 92.68% accuracy rate.
INTISARI
Permasalahan yang sering dijumpai adalah Database yang ada belum dimanfaatkan dan dikelola dengan baik dan belum diterapkannya sebuah teknik
data mining atau metode klasifikasi dalam mengelolaan data pada Fakultas
Kedokteran Unversitas Muhammadiyah Yogyakarta untuk mengetahui status calon dosen atau dosen tetap. Penelitian ini bertujuan untuk mengetahui kriteria calon dosen dan dosen tetap dan menerapkan teknik klasifikasi data mining dengan Algoritma C4.5. Penelitian ini dilakukan menggunakan metode klasifikasi decision
tree atau pohon keputusan dengan data sebanyak 137 dosen yang diperoleh dari
database server BSI (Biro Sistem Informasi) Universitas Muhammadiyah
Yogyakarta. Adapun pengambilan data dosen dengan bantuan perangkat lunak
Microsoft SQL Server 2014 yaitu data Dosen Fakultas Kedokteran Universitas
Muhammadiyah Yogyakarta. Hasil Penelitian dengan menggunakan Klasifikasi
Decision Tree dengan Algoritma C4.5 dan diimplementasikan ke RapidMiner
mampu menentukan status calon dosen dan dosen tetap dengan tingkat akurasi 92.68%.
ABSTRACT
Problems often encountered is that there is untapped Database and well run and not the implementation of a data mining technique or method of classification in mengelolaan data at the Medical Faculty of University of Muhammadiyah Yogyakarta to know the status of candidate lecturer or professor. This study aims to determine the criteria for lecturers and professors remain and apply data mining techniques with classification algorithm C4.5. This research was conducted using the method of decision tree classification or decision tree with as much data as 137 lecturers obtained from the database server BSI (Bureau of Information Systems) University of Muhammadiyah Yogyakarta. As for data retrieval software lecturer with the help of Microsoft SQL Server 2014 is the data Lecturer at the Faculty of Medicine, University of Muhammadiyah Yogyakarta. Results using classification C4.5 Decision Tree Algorithm and implemented to RapidMiner is able to determine the status of candidate for lecturers and professors remained at 92.68% accuracy rate.
BAB I
PENDAHULUAN
1.1. Latar Belakang
Data mining merupakan serangkaian proses untuk mendapatkan informasi
yang berguna dari gudang basis data yang besar. Data mining juga dapat diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan keputusan.Universitas Muhammadiyah Yogyakarta menyimpan begitu banyak data di data server, mulai data mahasiswa, alumni dan data karyawan dan Dosen. Jika data ini dimanfaatkan dengan mencari informasi tersembunyi dari data tersebut mungkin bisa memberikan informasi penting bagi Universitas Muhammadiyah Yogyakarta. Di Universitas Muhammadiyah Yogyakarta khususnya yang belum menerapkan metode data mining dalam penggalian informasi, ini merupakan langkah awal yang besar dan tidak menutup kemungkinan banyak Perguruan Tinggi mengikuti langkah ini dalam penggalian informasi.
Banyak metode dan teknik yang sudah dilakukan dalam model prediksi, teknik klasifikasi misalnya, teknik klasifikasi adalah sebuah metode dari data
mining yang digunakan untuk memprediksi kategori atau kelas dari suatu data
instance berdasarkan sekumpulan atribut-atribut dari data tersebut dan algoritma
1.2. Rumusan Masalah
Berdasarkan latar belakang masalah diatas dapat diambil rumusan masalah sebagai berikut:
1. Database yang ada belum dimanfaatkan dan dikelola dengan baik.
2. Belum diterapkannya sebuah teknik data mining atau metode klasifikasi dalam mengelolaan data Fakultas Kedokteran Unversitas Muhammadiyah Yogyakarta untuk mengetahui status calon dosen atau dosen tetap.
1.3. Tujuan Penelitian
Tujuan yang ingin dicapai dalam penelitian ini adalah:
1. Mengetahui kriteria dari calon dosen dan dosen tetap seperti, Jenis Kelamin, Lama Kerja, Tempat Asal dan Usia.
2. Menerapkan dan melakukan analisis teknik klasifikasi data mining dengan Algoritma C4.5 pada Fakultas Kedokteran Universitas Muhammadiyah Yogyakarta.
1.4. Batasan Masalah
Adapun batasan masalah dalam penelitian ini adalah sebagai berikut: 1. Data yang digunakan dalam penelitian ini adalah data sekunder (Secondary
Data) yang diperoleh dari database server BSI (Biro Sistem Informasi) Universitas Muhammadiyah Yogyakarta.
2. Data yang diambil untuk keperluan penelitian adalah data Calon Dosen dan Dosen Tetap Fakultas Kedokteran Universitas Muhammadiyah Yogyakarta. 3. Menerapkan metode klasifikasi data mining dengan algoritma C4.5 untuk
4. Data yang diambil dari tahun 1994-2016.
5. Pengembangan aplikasi menggunakan RapidMiner sebagai perangkat lunak bantuan untuk mentukan calon dosen dan dosen tetap dan sql server 2012 sebagai database.
1.5. Manfaaat Penelitian
Dalam penelitian ini akan menghasilkan keluaran berupa karakteristik calon dosen dan dosen tetap.
Adapun manfaat yang didapat dalam penelitian ini adalah:
1. Manfaat untuk IPTEK yaitu sebagai bahan analisis untuk membantu dalam pengambilan keputusan proses data dalam jumlah yang besar dan penerapan Teknik data mining.
2. Manfaat untuk user adalah untuk mempermudah system dalam penentuan status dosen dalam sebuah perguruan tinggi.
1.6. Sistematika Penulisan
Dalam penulisan skripsi ini, untuk memudahkan dalam hal penyusunan, penulis membaginya kedalam beberapa bab. Adapun sistematika penulisan skripsi ini adalah sebagai berikut:
BAB I PENDAHULUAN
Bab I menjelaskan mengenai latar belakang, rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, dan sistematika penulisan.
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI
ini menjelaskan mengenai penelitian-penelitian yang pernah dilakukan sebelumnya serta teori-teori yang berkaitan dengan sistem Data Mining yang digunakan. BAB III METODE PENELITIAN
Bab III berisi penjelasan mengenai alat bahan dan metode yang digunakan dalam melakukan penelitian dengan mengacu pada teori-teori penunjang yang telah dijelaskan pada Bab II.
BAB IV HASIL DAN PEMBAHASAN
Bab IV menjelaskan hasil dari tahapan-tahapan yang telah dilaksanakan, dan setiap hasil yang ada akan dibahas secara rinci dan jelas. Dan pada tahap akhir dilakukan pengujian, apakah hasil dari penelitian sesuai dengan yang diharapkan. BAB V KESIMPULAN DAN SARAN
BAB II
TINJAUAN PUSTAKA DAN LANDASAN TEORI
2.1. Tinjauan Pustaka
Sistem data mining akan lebih efektif dan efisiensi dengan komputerisasi yang tepat. Sistem data mining mampu memberikan informasi yang tepat dan pengelohan data yang akurat sehingga bisa langsung digunakan dan dilaporkan.
Penelitian mengenai data mining sebelumnya sudah banyak dilakukan, tetapi tempat dan program aplikasi yang digunakan berbeda – beda. Adapun sistem
data mining yang berkaitan yang pernah dibuat adalah sebagai berikut:
Menurut penelitian yang dilakukan oleh Swastina. L. (2013), yang berjudul “Penerapan Algoritma C4.5 Untuk Penentuan Jurusan Mahasiswa”. Metode yang
digunakan dalam penelitian ini adalah Algoritma C4.5, Algoritma C4.5 digunakan untuk menentukan jurusan yang akan diambil oleh mahasiswa sesuai dengan latar belakang, minat dan kemampuannya sendiri. Parameter pemilihan jurusan adalah Indeksi Prestasi Kumulatif Semester 1 dan 2. Hasil eksperimen dan evaluasi dari penelitian tersebut menunjukan bahwa Algoritma Decision Tree C4.5 akurat diterapkan untuk penentuan kesesuaian jurusan mahasiswa dengan tingkat akurasi 93,31% dan akurasi rekomendasi jurusan sebesar 82,64%.
Andriani. A. (2013), melakukan penelitian tentang “Sistem Pendukung
Keputusan Berbasis Decision Tree dalam Pemberian Beasiswa (Studi Kasus: AMIK “BSI Yogyakarta”). Tujuan penelitian ini adalah membuat klasifikasi
Matrix dan Kurva ROC untuk mengetahui tingkat akurasi Decision Tree dalam membuat klasifikasi beasiswa. Hasil klasifikasi digunakan untuk membuat sistem pendukung keputusan dalam pemberian beasiswa. Sistem yang digunakan dibuat dengan Microsoft Visual Basic 6.0. Dengan adanya sistem pendukung keputusan ini dapat mempermudah dan mempercepat pengambilan keputusan untuk pemberian beasiswa.
Julianto. W. et al (2014), penelitian yang pernah mereka lakukan adalah “Algoritma C4.5 untuk Penilaian Kinerja Karyawan”. Dengan menggunakan
algoritma C4.5 yang menggunakan teknik data mining untuk membuat pohon keputusan, algoritma ini dimulai dengan memasukkan data training ke dalam simpul akar pada pohon keputusan. Data training adalah sampel yang digunakan untuk membangun model classifier dalam hal ini pohon keputusan. Adapun hasil analisis sebagai berikut: berdasarkan evaluasi yang dilakukan dapat diketahui bahwa proses pembentukan pohon menggunakan teknik pruning memiliki kecepatan yang lebih tinggi karena penyederhanaan pohon, tetapi tidak selalu memliki akurasi yang lebih besar, dan perbedaan pohon keputusan yang dihasilkan disebabkan oleh perbedaan jumlah data training yang digunakan pada masing-masing partisi.
keputusan bagi pihak Universitas dalam menentukan status dosen, sehingga mempermudah pihak universitas dalam menentukan status dosen. Adapun perbedaan yang ada yaitu dalam penelitian ini, data yang digunakan data yang tersimpan didalam database server dan pengambilan data menggunakan software
Sql Server 2014.
2.2. Landasan Teori
2.2.1. Data Mining
Menurut Gunadi dan Sensuse (2012) Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Data mining merupakan proses analisa data untuk menemukan suatu pola dari kumpulan data tersebut. Data mining mampu menganalisa data yang besar menjadi informasi berupa pola yang mempunyai arti bagi pendukung keputusan.
Menurut Hermawati (2013) Data mining adalah proses yang mempekerjakan satu atau lebih teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksi pengetahuan secara otomatis.
Menurut Kursini dan Luthfi (2009) Data Mining merupakan suatu proses otomatis terhadap data yang sudah ada. Dan data yang akan diproses berupa data yang sangat besar.
Menurut Han dan Kamber (2006), rancangan bangun dari data mining yang khas memiliki beberapa komponen utama yaitu:
Database, data warehouse, atau tempat penyimpanan informasi lainnya.
Knowledge base.
Data mining engine.
Pattern evolution module.
Graphical user interface.
Tahap-tahap data mining salah satu tuntutan dari data mining ketika diterapkan pada data berskala besar adalah diperlukan metodologi sistematis tidak hanya ketika melakukan analisa saja tetapi juga ketika mempersiapkan data dan juga melakukan interpretasi dari hasilnya sehingga dapat menjadi aksi ataupun keputusan yang bermanfaat. Karenanya data mining seharusnya dipahami sebagai suatu proses, yang memiliki tahapantahapan tertentu dan juga ada umpan balik dari setiap tahapan ke tahapan sebelumnya.
Pada umumnya proses data mining berjalan interaktif karena tidak jarang hasil data mining pada awalnya tidak sesuai dengan harapan analisnya sehingga perlu dilakukan desain ulang prosesnya (Kusnawi, 2007).
Gambar 1. Tahapan Data Mining (Han dan Kamber, 2006)
Keterangan:
1. Pembersihan Data (Data Cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isianisian yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak relevan dengan hipotesa data mining yang dimiliki.
Data-data yang tidak relevan itu juga lebih baik dibuang. Pembersihan data juga akan mempengaruhi performasi dari teknik data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
2. Integrasi Data (Data Integration)
tidak hanya berasal dari satu database tetapi juga berasal dari beberapa database atau file teks. Integrasi data dilakukan pada atribut-aribut yang mengidentifikasikan entitas-entitas yang unik seperti atribut nama, jenis produk, nomor pelanggan dan lainnya. Integrasi data perlu dilakukan secara cermat karena kesalahan pada integrasi data bisa menghasilkan hasil yang menyimpang dan bahkan menyesatkan pengambilan aksi nantinya.
Sebagai contoh bila integrasi data berdasarkan jenis produk ternyata menggabungkan produk dari kategori yang berbeda maka akan didapatkan korelasi antar produk yang sebenarnya tidak ada.
3. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database.
Sebagai contoh, sebuah kasus yang meneliti faktor kecenderungan orang membeli dalam kasus market basket analisis, tidak perlu mengambil nama pelanggan, cukup dengan id pelanggan saja.
4. Transformasi Data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining. Beberapa metode data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan.
5. Proses Mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi Pola (Pattern Evaluation)
Untuk mengidentifikasi pola-pola menarik kedalam knowledge base yang ditemukan. Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai hipotesa ada beberapa alternatif yang dapat diambil seperti menjadikannya umpan balik untuk memperbaiki proses data mining, mencoba metode data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat.
7. Presentasi Pengetahuan (Knowledge Presentation)
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisis yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami data mining. Karenanya presentasi hasil data
mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu
2.2.2. Klasifikasi
Klasifikasi adalah suatu fungsionalitas data mining yang menghasilkan model untuk memprediksi kelas atau kategori dari objek - objek didalam basis data. Klasifikasi merupakan proses yang terdiri dari dua tahap, yaitu tahap pembelajaran dan tahap pengklasifikasian.
Pada tahap pembelajaran, sebuah algoritma klasifikasi akan membangun sebuah model klasifikasi dengan cara menganalisis training data. Tahap pembelajaran dapat juga dipandang sebagai tahap pembentuakan fungsi atau pemetaan Y=F(X) dimana Y adalah kelas hasil prediksi dan X adalah tuple yang ingin diprediksi kelasnya. Selanjutnya pada tahap pengklasifikasian, model yang telah dihasilkan akan digunakan untuk melakukan pengklasifikasian.
Menurut Herman Aldino, Naam, Julfriadif (2012), klasifikasi adalah proses pencarian sekumpulan model yang menggambarkan dan membedakan kelas data dengan tujuan agar model tersebut dapat digunakan untuk memprediksi kelas dari suatu obyek yang belum diketahui kelasnya.
2.2.3. Decision Tree (Pohon Keputusan)
Pohon (tree) adalah sebuah struktur data yang terdiri dari simpul (node) dan rusuk (edge). Simpul pada sebuah pohon dibedakan menjadi tiga, yaitu simpul akar
(root node), simpul percabangan/internal (branch/ internal node) dan simpul daun
(leaf node), (Hermawati, 2013).
mungkin dan simpul daun ditandai dengan kelas-kelas yang berbeda (Hermawati, 2013).
Gambar 2. Konsep Pohon Keputusan
Proses pada pohon keputusan adalah mengubah bentuk data (tabel) menjadi model pohon, mengubah model pohon menjadi rule, dan menyederhanakan rule. Manfaat utama dari penggunaan pohon keputusan adalah kemampuannya untuk
membreak down proses pengambilan keputusan yang kompleks menjadi lebih simpel
sehingga pengambil keputusan akan lebih menginterpretasikan solusi dari permasalahan. Pohon Keputusan juga berguna untuk mengeksplorasi data, menemukan hubungan tersembunyi antara sejumlah calon variabel input dengan sebuah variabel target.
Gambar 3. Konsep Dasar Pohon Keputusan
Bagian awal dari pohon keputusan ini adalah titik akar (root), sedangkan setiap cabang dari pohon keputusan merupakan pembagian berdasarkan hasil uji, dan titik akhir (leaf) merupakan pembagian kelas yang dihasilkan.
Pohon keputusan banyak mengalami perkembangan, beberapa algoritma yang populer dan sering dipakai adalah ID3, C4.5 dan CART.
Tabel 1. Frekuensi Penggunaan Algoritma Pohon Keputusan
Algoritma Pohon Keputusan Frekuensi
2.2.4. Algoritma C4.5
Menurut Luthfi (2009), algoritma C4.5 adalah algoritma klasifikasi data dengan teknik pohon keputusan yang memiliki kelebihan-kelebihan. Kelebihan ini misalnya dapat mengolah data numerik (kontinyu) dan diskret, dapat menangani nilai atribut yang hilang, menghasilkan aturan - aturan yang mudah diintrepetasikan dan tercepat diantara algoritma-algoritma yang lain.
Keakuratan prediksi yaitu kemampuan model untuk dapat memprediksi label kelas terhadap data baru atau yang belum diketahui sebelumnya dengan baik. Dalam hal kecepatan atau efisiensi waktu komputasi yang diperlukan untuk membuat dan menggunakan model. Kemampuan model untuk memprediksi dengan benar walaupun data ada nilai dari atribut yang hilang. Dan juga skalabilitas yaitu kemampuan untuk membangun model secara efisien untuk data berjumlah besar (aspek ini akan mendapatkan penekanan). Terakhir interpretabilitas yaitu model yang dihasilkan mudah dipahami.
Dalam algoritma C4.5 untuk membangun pohon keputusan hal pertama yang dilakukan yaitu memilih atribut sebagai akar. Kemudian dibuat cabang untuk tiap-tiap nilai didalam akar tersebut. Langkah berikutnya yaitu membagi kasus dalam cabang. Kemudian ulangi proses untuk setiap cabang sampai semua kasus pada cabang memiliki kelas yang sama.
��� �, � = � �� � � − ∑|�|�|�|
Sehingga akan diperoleh nilai gain dari atribut yang paling tertinggi. Gain adalah salah satu atribute selection measure yang digunakan untuk memilih test
atribute tiap node pada tree. Atribut dengan information gain tertinggi dipilih
sebagai test atribute dari suatu node.
Sementara itu, penghitungan nilai entropi dapat dilihat pada persamaan 2.
BAB III
METODE PENELITIAN
3.1. Lokasi Penelitian
Penelitian dilaksanakan di Universitas Muhammadiyah Yogyakarta (UMY) yang berlokasi Jl. Lingkar Selatan, Kasihan, Bantul, Yogyakarta.
3.2. Alat dan Bahan Penelitian
Dalam penelitian dibutuhkan beberapa alat dan bahan untuk mendukung berjalannya penelitian.
3.2.1. Alat
Alat yang digunakan berupa perangkat lunak dan perangkat keras. a. Perangkat Lunak (software)
Perangkat lunak, versi, dan fungsi dapat dilihat pada tabel 2. Tabel 2. Perangkat lunak (Software)yang digunakan
Software Versi Fungsi
SQL Server 2014
Management Studio
2014 Digunakan untuk
menghubungkan pengguna dan mengambil data yang ada pada server.
Microsoft Exel 2013 Untuk mengfilter dan
menyimpan data.
RapidMiner 7.2 Digunakan untuk melakukan
analisis data mining.
b. Perangkat keras (hardware)
Selain Perangkat Lunak (Software), dibutuhkan pula Perangkat Keras
(Hardware) yang digunakan untuk mendukung penelitian data mining, yaitu
Tabel 3. Spesifikasi perangkat keras (Hardware)
Spesifikasi Hardware Spesifikasi
Processor Intel(R)
Operating System Windows 10
3.2.2. Bahan
Dalam penelitian ini data yang digunakan bersumber dari database calon dosen dan dosen tetap Fakultas Kedokteran Universitas Muhammadiyah Yogyakarta. Data tersebut didapat dari Biro Sistem Informasi (BSI).
3.3. Metodologi Penelitian
Metode yang digunakan dalam penelitian ini adalah System Development
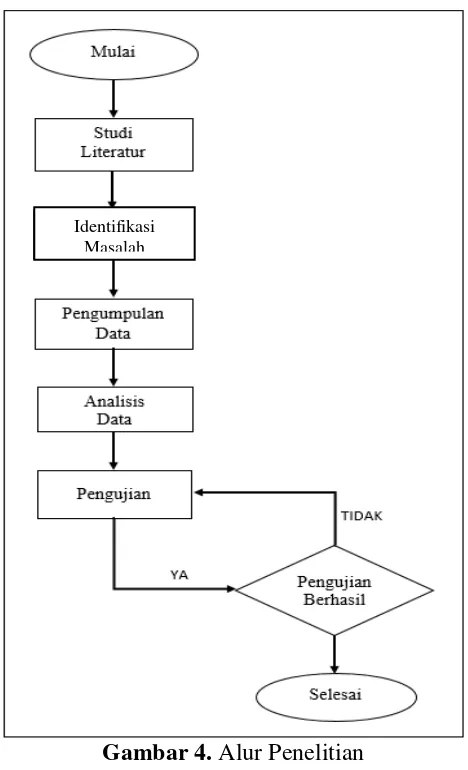
Life Cyle (SDLC), model Watelfall.
Gambar 4. Alur Penelitian
Gambar 4 menjelaskan bahwa alur dalam penelitian ini menggunakan metode waterfall, dan tahapan yang digunakan mencakup 5 tahap. Masing-masing dari tahapan tersebut mempunyai detail proses dan fungsi yang berbeda-beda, yang diuraikan dibawah ini.
3.3.1. Studi Literatur
Langkah pertama yang dilakukan dalam penelitian ini adalah studi literatur. Studi Literatur dilakukan untuk mengumpulkan informasi yang diperlukan dalam penelitian ini. Informasi tersebut diperoleh dengan mempelajari dan membaca
obyek penelitian seperti buku, jurnal, skripsi, publikasi maupun artikel yang terkait dengan Data Mining.
3.3.2. Identifikasi Masalah
Tahap Identifikasi Masalah dilakukan untuk mengetahui permasalahan yang terjadi pada saat ini. Tahap ini perlu dilakukan agar penelitian yang dilakukan memiliki tujuan yang jelas.
3.3.3. Pengumpulan Data
Tahap pengumpulan data dilakukan untuk memperoleh informasi yang dibutuhkan dalam rangka mencapai tujuan penelitian, jenis data yang digunakan adalah Data Skunder. Data diperoleh dari Biro Sistem Informasi (BSI) Universitas Muhammadiyah Yogyakarta.
3.3.4. Analisis Data
Langakah berikutnya adalah Analisis Data, tahap Analisis Data bertujuan untuk menentukan kebutuhan data penulis. Seperti pemilihan atribut penentu dalam pembentukan pohon keputusan. Pemilihan atribut ini dilakukan dengan mempertimbangkan bahwa nilai atribut tidak banyak. Karena tidak semua data bisa digunakan.
3.3.5. Pengujian
BAB IV
HASIL DAN PEMBAHASAN
4.1. Identifikasi Masalah
Dalam menentukan status calon dosen dan dosen tetap terdapat masalah-masalah dan fakor-faktor penyebab masalah-masalah tersebut bisa terjadi diantaranya sebagai berikut:
Data di dalam database Universitas Muhammadiyah Yogyakarta belum
dimanfaatkan dan dikelola dengan baik.
Belum diterapkannya sebuah teknik Data Mining atau metode klasifikasi
dalam mengelolaan data perguruan tinggi untuk mengetaui calon dosen dan dosen tetap.
4.2. Pengumpulan Data
Data yang digunakan dalam penelitian ini merupakan data sekunder yaitu data yang didapat dari database server Universitas Muhammadiyah Yogyakarta, data yang digunakan adalah data calon dosen dan dosen tetap Fakultas Kedokteran, pengambilan data penelitian menggunakan perangkat lunak (software) microsoft
sql server 2014.
Sql Server 2014 merupakan Relation Database Management System
Menjalankan microsoft sql server 2014 pertama kali, jalankan microsoft sql
server 2014.
Gambar 5. Tampilan Antar Muka Microsoft Sql Server 2014
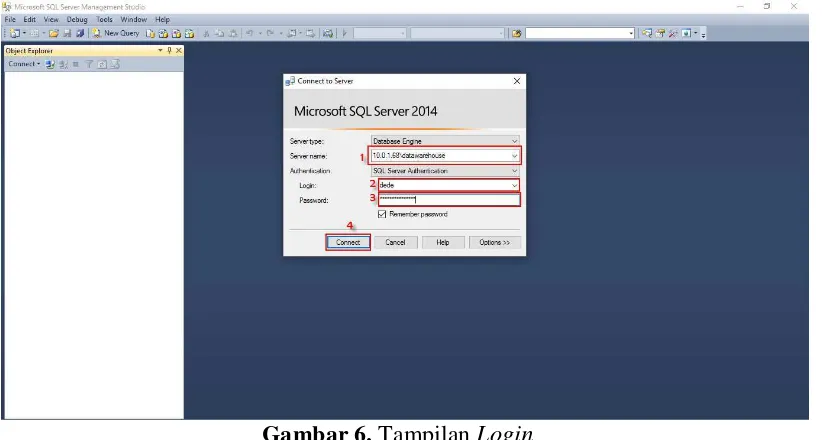
Setelah tampilan awal muncul, masukkan Server name, User name dan
Password yang telah diperoleh dari pihak Biro Sistem Informasi (BSI), untuk lebih
jelas dapat dilihat pada Gambar 6, kemudian klik Connect.
Gambar 6. Tampilan Login
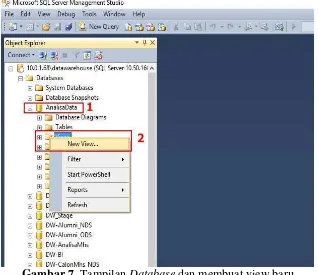
analisa, yaitu di database AnnalisaData. Selanjutnya peneliti membuat sebuah data baru dari data yang sudah ada agar lebih mudah dan bisa digunakan jika sewaktu-waktu dibutuhkan. klik kanan pada folderView pilih New View.
Gambar 7. Tampilan Database dan membuat view baru
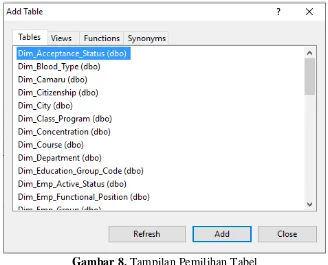
Setelah tampil halaman add table seperti Gambar 8 langkah selanjutnya memilih tabel-tabel yang akan digunakan. Tabel yang digunakan dalam penelitian ini adalah tabel Dim_Employee, Dim_Emp_Mork_Unit, Dim_Gendr,
Dim_Emp_Status, Dim_Year dan Fact_Employment sebagai penghubung tabel.
Gambar 8. Tampilan Pemilihan Tabel
Setelah tampil seperti Gambar 9, langkah selanjutnya mencentang atribut-atribut yang akan digunakan yaitu, Employee_Title_Name, Place_Of_Birth,
Date_Of_Bith dari tabel Dim_Emlployee, Work_Unit,Name dari tabel
Dim_Emp_Work_Unit, Gender_Name dari tabel Dim_Gender, Description dari
Gambar 9. Tampilan Pemilihan Attribut
Maka akan di dapatkan data terlihat pada Gambar 10yaitu, data dari seluruh karyawan Universitas Muhammadiyah Yogyakarta.
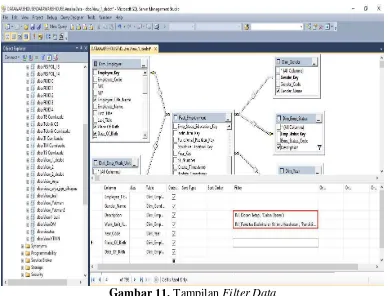
Terlihat pada Gambar 10 adalah data seluruh karyawan Universitas Muhammadiyah Yogyakarta, maka peneliti perlu memfilter data yang akan digunakan saja yaitu dengan cara menuliskan Dosen Tetap dan Calon Dosen pada tabel filter Column Description dan Fakultas Kedokteran pada Column
Work_Unit_Name kemudian eksekusi atau menekan tombol F5 pada keyboard.
Gambar 11. Tampilan Filter Data
Gambar 12. Tampilan Data Setelah di Filter
Selanjutnya memberi nama pada tabel baru yaitu, Data dosen FK Kedokteran kemudian pilih OK.
Gambar 13. Tampilan Pemberian Nama pada Tabel Baru
Tabel 4. Tampilan Data dalam bentuk Microsoft Office Exel
4.3. Analisis Data
Analisis data yang digunakan untuk proses klasifikasi dapat menggunakan
Knowledge Discovery in Database (KDD). KDD diartikan sebagai proses
terorganisir untuk mengidentifikasi pola dalam data yang besar dan kompleks dimana pola data tersebut ditemukan yang bersifat sah dan dapat bermanfaat serta dapat dimengerti. Ada beberapa tahapan-tahapan dalam KDD yang digunakan dalam analisis data untuk klasifikasi yaitu:
4.3.1. Pre-Processing Data
Pre-Processing Data merupakan salah satu langkah yang digunakan untuk
1. Employee_Title_Name
Untuk nama attributEmployee_Title_Name menjadi Nama
2. Gender_Name
Untuk nama attributGender_Name Menjadi Jenis Kelamin
3. Work_ Unit_Name
Untuk nama attribut Work_Unit_Name manjadi Prodi
4. Year_Code
Untuk nama attributYear_Code menjadi Lama Kerja dan diklasifikasikan menjadi:
1 apabila tahun pertama kerja ”2015” 2 apabila tahun pertama kerja ”2014”
3 apabila tahun pertama kerja ”2013” dan seterusnya.
5. Place_Of_Birt
Untuk nama attribut Place_Of_Birt menjadi Tempat Asal
6. Date_Of_Birth
7. Untuk nama attribut Date_Of_Birth menjadi Usia dan diklasifikasikan menjadi:
28 apabila tahun lahir ”1988”
29 apabila tahun lahir ”1997”
30 apabila tahun lahir ”1996” dan seterusnya.
(Lanjutan) Tabel 5. Data setelah Transformasi
4.3.2. Memilih Attribut
Tabel 6. Tabel Attribut
Attribut Nilai yang ada pada Attribut
Jenis Kelamin Laki-Laki, Perempuan
Lama Kerja 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21,
Descriprtion Calon Dosen, Dosen Tetap ( target Attribut )
4.3.3. Menghitung Entropy dan Gain
Setelah menentukan attribut dan target attribut kemudian menghitung jumlah kasus, jumlah kasus untuk keputusan Calon Dosen, jumlah kasus untuk keputusan Dosen Tetap, dan Entropy dari semua kasus. Setelah itu, lakukan penghitungan Gain untuk setiap attribut, dapat dilihat sebagai berikut:
Tabel 7. Hasil Penghitungan Node 1
Baris Total dan Jenis Kelamin kolom Entropy pada Tabel 7 dihitung dengan persamaan 1 sebagai berikut:
Entropy (S) = ∑��= − � ∗ log ��
Jadi, Entropy (Total) = − ∗ log + − ∗ log
= 0.730601213
Entropy (Jenis Kelamin):
a. Entropy (Laki-Laki) = − ∗ log + − ∗ log
= 0.773226674
b. Entropy (Perempuan) = − ∗ log + − ∗ log
= 0.708835673
Sementara itu, nilai Gain pada baris Jenis Kelamain dihitung dengan menggunakan persamaan 2 sebagai berikut:
Gain (S, A) = Entropy (Total) - ∑��= | S� |
| S | * Entropy (S� )
Jadi, Gain (Total, Jenis Kelamin)
= 0.730601213-( ∗ . + ∗ . ) = 0.001085219 Dan akan didapatkan hasil seperti terlihat pada Tabel 1 (Lampiran).
Dari hasil Tabel 1 (Lampiran), dapat diketahui bahwa atribut dengan Gain tertinggi adalah Lama Kerja, yaitu sebesar 0.481430674. Dengan demikian, “Lama
Kerja” dapat menjadi node akar. Ada 21 nilai atribut dari Lama Kerja, yaitu
yaitu keputusannya Dosen Tetap, sehingga tidak perlu dilakukan perhitungan lebih lanjut, tetapi untuk nilai atribut 1 masih perlu dilakukan perhitungan lagi, kemudian menghitung jumlah kasus, jumlah kasus untuk keputusan Calon Dosen, jumlah kasus untuk keputusan Dosen Tetap, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut Jenis Kelamin, Tempat Asal dan Usia yang dapat menjadi node akar dari nilai atribut ≥2.500. Kemudian melakukan penghitungan
Gain untuk tiap-tiap atribut dengan rumus yang sama seperti sebelumnya. Hasil
perhitungan terlihat pada Tabel 2 (Lampiran).
Dari hasil pada Tabel 2 (Lampiran),dapat diketahui bahwa atribut dengan
Gain tertinggi adalah Usia, yaitu sebesar 0.274934445. Dengan demikian Usia
dapat menjadi node cabang dari nilai atribut ≥2.500. Ada sembilan nilai atribut dari Usia, Yaitu 28, 29, 30, 32, 33, 35, 36, 38 dan 42. Dari kesembilan nilai atribut tersebut, nilai atribut 28, 29, 30, 32 dan 33 sudah mengklasifikasikan kasus menjadi satu, yaitu keputusannya Calon Dosen dan nilai atribut 36, 38 dan 42 sudah mengklasifikasikan kasus menjadi satu dengan keputusan Dosen Tetap, sehingga tidak perlu dilakukan perhitungan lebih lanjut, tetapi untuk nilai atribut 35 masih perlu dilakukan perhitungan lagi. Hasil perhitungan terlihat pada Tabel 3 (Lampiran).
Dari hasil pada Tabel 3 (Lampiran), dapat diketahui bahwa atribut dengan
Gain tertinggi adalah Jenis Kelamin, yaitu sebesar 1. Dengan demikian Jenis
keputusan Calon Dosen dan nilai atribut Perempuan sudah mengklasifikasikan kasus menjadi satu dengan keputusan Dosen Tetap, sehingga tidak perlu dilakukan perthitungan lebih lanjut untuk nilai atribut ini.
4.4. Pengujian dalam RapidMiner 7.2
RapidMiner 7.2 merupakan software tool Open Source untuk Data Mining.
RapidMiner 7.2 menyediakan prosedur data mining dan machine learning
termasuk: ETL (extraction, transformation, loading), data preprocessing, visualisasi, modelling dan evaluasi. Data dosen Fakultas Kedokteran yang diperoleh dari Biro Sistem Informasi (BSI) Universitas Muhammadiyah Yogyakarta yang sudah dimiliki dan telah dianalisis kemudian diolah menggunakan aplikasi
RapidMiner 7.2 untuk mengetahui klasifikasi status dosen Fakultas Kedokteran
Universitas Muhammadiyah Yogyakarta menggunakan Decision Tree. Menjalankan RapidMiner 7.2 pertama kali, jalankan RapidMiner 7.2.
Setelah halaman awal tampil, untuk membuat proses baru pilih new process lalu pilih blank.
Gambar 15. Tampilan Awal RapidMiner 7.2
Gambar 16.Tampilan utama New Process
Tahap selanjut menuju panel operators, karena tipe file yang digunakan dalam penelitian ini menggunakan format CSV, lakukan Drag dan Drop Read CSV pada menu Operators kedalam proses View hingga muncul dalam View,
Gambar 17. Operators Read CSV pada Main Process
Gambar 18. Importing Data
Setelah itu, akan muncul window baru yaitu, step 1 dari 4 step data import
wizard. Cari file CSV yang telah dipersiapkan sebelumnya seperti Gambar 19,
selanjutnya klik Next.
Pada step ini, penulis pilih Comma ”,” (sesuai kebutuhan) kemudian klik next.
Gambar 20. Memilih Comma
Apabila nilai atribut pada data sudah lengkap (tidak ada yang kosong) maka
Gambar 21. Memilih Annotasi
Pada step terakhir yaitu, memilih Atribut yang akan di gunakan dan
Variabel. Atribut yang digunakan yaitu, Jenis Kelamin, Lama Kerja, Tempat Asal
dan Usia, sedangkan yang menjadi Variabel adalah Description yang berisi data
Gambar 22. Pemilihan Attribut dan Variabel
Setelah importing data selesai, tahap berikutnya untuk testing lakukan Drag
dan Drop Split Validation pada menu Operators kedalam proses View, hingga
muncul dalam View. Selanjutnya hubungkan port operators Read Csv dengan
Operators Validation dengan menarik garis dari operators Read Csv ke Operators
Validation dan menarik garis dari operators Validation ke result disisi kanan,
seperti terlihat pada Gambar 23.
Pada operators validation terdapat port input training yang berfungsi membuat exampleset untuk dijadikan pelatihan data training (model) dimana
exampleset yang sama akan digunakan oleh subproses untuk menguji model apabila
tidak ada kumpulan data lain yang disediakan. Output port model berfungsi mengambil exampleset yang telah dilatih pada input training sebelumnya. Output
training berfungsi untuk mengambil data training dari input training yang melalui
port ini tanpa merubah output, dan output averagable berfungsi mengembalikan
vector kinerja yang telah diuji oleh subproses pengujian.
Gambar 23. Menghubungkan port Read CSV dengan port Validation
Setelah port terhubung antara satu sama lain, selanjutnya double klik pada
operators Validation hingga tampil subpocess training dan testing sepertiGambar
Gambar 24. Tampilan Panel Process Validation
Pada tabel Training lakukan Drag dan Drop algoritma yang akan digunakan yaitu, Decision Tree.
Gambar 26. Tampilan Operator Apply Model pada table Testing
Kemudian lakukan Drag dan Drop Performance classification pada table
testing. Performance digunakan untuk evaluasi statistik dari kinerja klasifikasi dan
memberikan daftar nilai kriteria dari kinerja klasifikasi tersebut.
Gambar 27. Tampilan operator performance pada tabel testing
Selanjutnya hubungkan port-port dari operator decision tree, operator
seperti pada Gambar 28, untuk menampilkan hasil. Tunggu beberapa saat hingga
rapidminer menampilkan hasil.
Gambar 28. Tampilan menghubungkan port Decision tree, Apply Model dan Performance
Gambar 29. Tampilan Decision Tree (Pohon Keputusan) Akhir
Berdasarkan pohon keputusan pada Gambar 29, dapat dilihat bahwa tingkat dominan status dosen adalah berdasarkan Lama Kerja, yaitu Lama Kerja >2.500 (diatas dua tahun setengah). Sedangkan tingkat status dosen pada node terakhir adalah berdasarkan Jenis Kelamin sebagai pertimbangan akhir. Apabila Jenis Kelamin Perempuan sebagian besar Dosen Tetap, yaitu masing-masing sebanyak 75 orang. Sedangkan apabila jenis kelamin laki-laki yang berstatus dosen tetap sebanyak 34 orang dosen. Dapat dilihat pada Gambar 30 menunjukkan deskripsi lengkap dari pohon keputusan (decision tee) yang terbentuk dari 137 data dosen untuk menentukan status calon dosen dan dosen tetap.
Keterangan:
Gambar 30. Tampilan Deskripsi Decision Tree
Gambar 30 menunjukkan hasil deskripsi secara lengkap dari pohon keputusan (decision tree) yang telah terbentuk dengan menggunakan algoritma C4.5. Dari hasil deskripsi pada Gambar 30 juga menunjukkan bahwa penggunaan
data mining algoritma C4.5 baik digunakan dalam proses menggali data (data
mining process) untuk menarik beberapa kesimpulan yang divisualisasikan dengan
BAB V
KESIMPULAN DAN SARAN 5.1. Kesimpulan
Berdasarkan seluruh hasil tahapan penelitian yang telah dilakukan pada Penerapan Klasifikasi Decision Tree dengan Algoritma C4.5 untuk menentukan Calon Dosen dan Dosen Tetap di Fakultas Kedokteran Universitas Muhammadiyah Yogyakarta dapat disimpulkan sebagai berikut.
1. Permasalahan menentukan status dosen di Fakultas Kedokteran Universitas Muhammadiyah Yogyakarta dapat diselesaikan menggunakan teknik data
mining, yaitu dengan Algoritma C4.5. Tingkat akurasi yang dihasilkan oleh
metode tersebut adalah 92.68%.
2. Dengan adanya penerapan data mining algoritma C4.5 diharapkan mampu memberikan solusi dalam menentukan status dosen pada Fakultas Kedokteran Universitas Muhammadiyah Yogyakarta.
5.2. Saran
Adapun saran-saran yang disampaikan berdasarkan hasil pengamatan dan analisa selama melakukan penelitian data dosen Fakultas Kedokteran Universitas Muhammadiyah Yogyakarta adalah:
1. Peneliti selanjutnya sebaiknya menggunakan data yang lebih banyak agar menghasilkan Rules yang lebih akurat.
DAFTAR PUSTAKA
Andriani, A. 2013. “Sistem Pendukung Keputusan Berbasis Decision Tree Dalam Pemberian Beasiswa”. Program Studi Manajemen Informatika. Jakarta. 163-168.
Gunadi & Sensuse. 2012. Penerapan Metode Data Mining Market Basket
Analysis terhadap Data Penjualan Produk Buku dengan Menggunakan
Algoritma Apriori dan Frequent Pattern-Growth (Fp-Growth): Studi Kasus Percetakan Pt.Gramedia. Volume 4 No.1, Hal 121.
Han, J., & Kamber, M. 2006. Data Mining Concep and Tehniques. Morgan Kaufman: San Fransisco.
Herman, Aldino & Naam, Julfriadif. 2012. Penerapan Kata Kunci Dokumen Teks Surat Kabar Singgalang Dengan Menggunakan Metode Algoritma
Naïve Bayes. Singgalang.
Hermawati, F. A., 2013. Data Mining. Andi: Yogyakarta.
Julianto, W., Yunitarini, R., & Sophan, K, M. 2014. “Algoritma C4.5 Untuk Penilaian Kinerja Karyawan”. Universitas Trunojoyo Madura. Hal 33- 39 Kusnawi. 2007. Pengantar Solusi Data Mining. Seminar Nasional Teknologi,
Yogyakarta, pp 1-5.
Kusrini, & Luthfi, E. T., 2009. Algoritma Data Mining. Andi: Yogyakarta. Swastina, L. 2013. “Penerapan Algoritma C4.5 Untuk Penentuan Juruasan Mahasiswa”. Jurnal GEMA AJTUALITA, Vol. 2 No. 1. Sekolah Tinggi Manajemen Informatika dan Komputer (STMIK) Indonesia. Banjarmasin. Hal 93-98.
LAMPIRAN
Lampiran 1. Hasil Perhitungan Node 1, Node 1.1 dan Node 1.1.2 Tabel 1 Hasil Perhitungan Node 1
(Lanjutan) Tabel 1 Hasil Perhitungan Node 1
Tabel 2 Hasil Perhitungan Node 1.1
(Lanjutan) Tabel 2 Hasil Perhitungan Node 1.1
Tabel 3 Hasil Perhitungan Node 1.1.2
Lampiran 2. Perhitungan Nilai Entropy Node 1, Node 1.1 dan Node 1.1.2 Tabel 4 Perhitungan Entropy Node 1 Attribut Lama Kerja
Attribut
Lama Kerja
Perhitungan Nilai Entropy
(Lanjutan) Tabel 4 Perhitungan Entropy Node 1 Attribut Lama Kerja
Attribut
Lama Kerja
Perhitungan Nilai Entropy
Entropy
Tabel 5 Perhitungan Entropy Node 1 Attribut Tempat Asal
Attribut
Tempat Asal Perhitungan Nilai Entropy
(Lanjutan) Tabel 5 Perhitungan Entropy Node 1 Attribut Tempat Asal
Attribut
Tempat Asal
Perhitungan Nilai Entropy
(Lanjutan) Tabel 5 Perhitungan Entropy Node 1 Attribut Tempat Asal
Attribut
Tempat Asal
Perhitungan Nilai Entropy
(Lanjutan) Tabel 5 Perhitungan Entropy Node 1 Attribut Tempat Asal
Attribut
Tempat Asal
Perhitungan Nilai Entropy
(Lanjutan) Tabel 5 Perhitungan Entropy Node 1 Attribut Tempat Asal
Attribut
Tempat Asal
Perhitungan Nilai Entropy
(Lanjutan) Tabel 5 Perhitungan Entropy Node 1 Attribut Tempat Asal
Attribut
Tempat Asal
Perhitungan Nilai Entropy
Entropy
Tabel 6 Perhitungan Entropy Node 1 Attribut Usia
Attribut
Usia Perhitungan Nilai Entropy
(Lanjutan) Tabel 6 Perhitungan Entropy Node 1 Attribut Usia
Attribut
Usia Perhitungan Nilai Entropy
(Lanjutan) Tabel 6 Perhitungan Entropy Node 1 Attribut Usia
Attribut
Usia Perhitungan Nilai Entropy
Entropy (50) = − ∗ log + − ∗ log = 0
Entropy (51) = − ∗ log + − ∗ log = 0
Entropy (52) = − ∗ log + − ∗ log = 0
Entropy (53) = − ∗ log + − ∗ log = 0
Tabel 7 Perhitungan Entropy Node 1.1 Attribut Jenis Kelamin
Attribut
Jenis Kelamin Perhitungan Nilai Entropy
Entropy
(Laki-Tabel 8 Perhitungan Entropy Node 1.1 Attribut Jenis Kelamin
Attribut
Tempat Asal Perhitungan Nilai Entropy
(Lanjutan) Tabel 8 Perhitungan Entropy Node 1.1 Attribut Jenis Kelamin
Attribut
Tempat Asal Perhitungan Nilai Entropy
Entropy
Tabel 9 Perhitungan Entropy Node 1.1 Attribut Usia
Attribut
Tempat Asal Perhitungan Nilai Entropy
Tabel 10 Perhitungan Entropy Node 1.1.2 Attribut Jenis Kelamin
Attribut
Jenis Kelamin Perhitungan Nilai Entropy
Entropy
(Laki-Laki)
= − ∗ log + − ∗ log = 0
Entropy (Perempuan)
= − ∗ log + − ∗ log = 0
Tabel 11 Perhitungan Entropy Node 1.1.2 Attribut Tempat Asal
Attribut
Tempat Asal Perhitungan Nilai Entropy
Entropy Yogyakartai)
Lampiran 3. Perhitungan GainNode 1, Node 1.1, dan Node 1.1.2 Tabel 12 Perhitungan Gain Node 1 Attribut Lama Kerja
Attribut
Jenis Kelamin
Gain (Total, Jenis Kelamin)
Perhitungan
= 0.730601213 –( ∗ . + ∗
. + ∗ . + ∗
. + ∗ + ∗ + ∗ +
∗ + ∗ + ∗ + ∗ + ∗ +
∗ + ∗ + ∗ + ∗ + ∗ +
∗ + ∗ + ∗ + ∗ )
Tabel 13 Perhitungan Gain Node 1 Attribut Tempat Asal
Attribut
Tempat Asal Gain (Total, Tempat Asal)
Perhitungan
= 0.730601213 –( ∗ + ∗ + ∗ +
∗ + ∗ . + ∗ + ∗ +
∗ + ∗ + ∗ + ∗ + ∗ +
∗ + ∗ + ∗ + ∗ + ∗ +
∗ + . + ∗ + ∗ +
∗ + ∗ + ∗ + ∗ + + ∗ +
∗ + ∗ + ∗ + ∗ + ∗ +
∗ + ∗ + ∗ + ∗ + ∗ +
∗ + ∗ + ∗ + ∗ + ∗
. + ∗ + ∗ + ∗ +
∗ + ∗ + ∗ + ∗ + ∗
. )
Tabel 14 Perhitungan Gain Node 1Attribut Usia
Nilai Gain = 0.338393706
Tabel 15 Perhitungan Gain Node 1.1 Attribut Jenis Kelamin Attribut
Jenis Kelamin
Gain (Lama Kerja 1, Jenis Kelamin)
Perhitungan = 0.485460761 –( ∗ + ∗ . )
Tabel 16 Perhitungan Gain Node 1.1 Attribut Tempat Asal
Attribut
Tempat Asal Gain (Lama Kerja 1, Tempat Asal)
Perhitungan
= 0.485460761 –( ∗ + ∗ + ∗ + ∗ +
∗ + ∗ + ∗ + ∗ + ∗ +
∗ . )
Nilai Gain = 0.174927365
Tabel 17 Perhitungan Gain Node 1.1 Attribut Usia
Attribut
Usia Gain (Lama Kerja 1, Usia)
Perhitungan = 0.485460761 –( ∗ + ∗ + ∗ + ∗ +
∗ + ∗ + ∗ + ∗ + ∗ )
Nilai Gain = 0.274934445
Tabel 18 Perhitungan Gain Node 1.1.2 Attribut Jenis Kelamin
Attribut
Jenis Kelamin
Gain (Usia 35, Jenis Kelamin)
Perhitungan = 1 –( ∗ + ∗ )
Tabel 19 Perhitungan Gain 1.1.2 Attribut Tempat Asal
Attribut
Tempat asal Gain (Usia 35, Tempat Asal)
Perhitungan = 1 –( ∗ )