KLASIFIKASI PENENTUAN JENIS KANKER PAYUDARA DAN PARU-PARU BERDASARKAN SUSUNAN PROTEIN
DENGAN ALGORITMA DECISION TREE ABSTRAK
Angka kematian di Indonesia karena penyakit kanker menurut WHO pada
tahun 2014 mencapai 195.300 orang dengan kematian terbanyak pada laki-laki
sebanyak 103.100 dengan penyakit kanker paru-paru pada tingkat pertama sebesar
21,8% dan pada wanita sebanyak 92.200 dengan penyakit kanker payudara pada
tingkat pertama sebesar 21.4%. Ilmu informatika dapat membantu menganalisa
masalah ini dengan mengunakan cabang ilmu bioinformatika, yang merupakan
penerapan teknis komputasional untuk mengolah dan menganalisa informasi
biologi seperti data DNA, RNA dan Protein.
Penelitian ini membahas tentang pendeteksian jenis kanker payudara dan
paru-paru berdasarkan susunan protein berupa asam amino. Data protein yang
digunkan berformat .fasta yang diambil dari database protein yaitu UniProt dan
NCBI (National Center for Biotechnology Information). Metode klasifikasi
digunakan untuk mendekteksi secara dini penyakit kanker berdasakan susunan
protein. Algoritma yang digunakan pada penelitian ini adalah decision tree, yaitu
salah satu algoritma yang digunakan dalam bidang bioinformatika.
Sebelum tahap klasifikasi dilakukan tahap pre-processing data sekuen
protein bertipe String ditransformasikan terlebih dahulu menggunakan EIIP
(Electron-Ion Interaction Potential) based protein value. Data sekuen protein yang telah ditransformasikan menjadi numerik selanjutnya diektraksi ciri menjadi
sinyal frequency based dengan menggunakan FFT (Fast Fourier Transform) dan
LPC (Linear Prediction Coding) dan turunan dari LPC dengan order 8 dan 12.
Klasifikasi dengan decision tree dilakukan setelah proses ekstraksi ciri
selesai. Pada penelitian ini dilakukan pengujian kombinasi feature LPC pada saat
proses ekstraksi ciri. Dari seluruh pengujian (16 pengujian) yang dilakukan,
didapatkan hasil akurasi terbesar yaitu 79,85% dan waktu yang diperlukan untuk
membuat tree 29,09 detik dengan akurasi rata-rata sebesar 74.82% pada feature
THE CLASSIFFICATION OF BREAST CANCER AND LUNG CANCER TYPE BASED ON PROTEIN STRUCTURE
USING DECISION TREE ALGORITM ABSTRACT
The death rate from cancer in Indonesia by WHO in 2014 reached 195.300
people with the number of death in men at 103.100 from lung cancer at the first
level by 21.8% and in women at 92.200 from breast cancer at the first level by
21.4%. Science of Informatics can help analyze this problem by using a branch of
bioinformatics, which is the computational technique application to process and
analyze the data of biological information such as DNA, RNA and Protein.
This research discusses the detection of breast cancer and lung cancer
based on the composition of proteins in the form of amino acids. The protein data
used the format of .fasta derived from the protein database UniProt and NCBI
(National Center for Biotechnology Information). The classification method that
used for early detection of cancer based on protein structure. The algorithm used
in this study is a decision tree, which is one of the algorithms used in
bioinformatics.
Before classification phase, pre-processing phase of protein sequence data
of String type are transformed beforehand using EIIP (Electron-Ion Interaction
Potential) based on protein value conducted. Protein sequence data that have been transformed into numeric, then the feature extracted to become frequency based
signal by using FFT (Fast Fourier Transform) and LPC (Linear Prediction
Coding) and a derivative of LPC with order of 8 and 12.
Classification by decision tree is happened after the feature extraction
process is complete. In this research, testing the combination of LPC feature
during the process of feature extraction conducted. From all the tests (16 tests)
were conducted, showed the greatest accuracy is 79.85% and time to build tree
KLASIFIKASI PENENTUAN JENIS KANKER PAYUDARA DAN PARU-PARU BERDASARKAN SUSUNAN PROTEIN
DENGAN ALGORITMA DECISION TREE
SKRIPSI
Ditujukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana
Program Studi Teknik Informatika
Oleh :
ANDHINI AYU SUSANTI
10 5314 097
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNVERSITAS SANATA DHARMA YOGYAKARTA
THE CLASSIFFICATION OF BREAST CANCER AND LUNG CANCER TYPE BASED ON PROTEIN STRUCTURE
USING DECISION TREE ALGORITM
A THESIS
Presented Partial Fulfillment of the Requirements To Obtain the Sarjana Komputer Degree In Informatics Engineering Department
By:
Andhini Ayu Susanti
10 5314 097
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCINCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
HALAMAN PERSEMBAHAN
“By three methods we may learn wisdom: First, by reflection, which is noblest; Second, by imitation, which is easiest; and third by experience,
which is the bitterest” _Confucius_
“Jangan mencari yang besar-besar, cukup mengerjakan yang kecil-kecil dengan cinta yang besar”
_Mother Teresa_
“Scared is what you’re feeling. Brave is
What you’re doing”
_Emma Donoghue_
Skripsi ini kupersembahkan untuk :
Tuhan Yang Maha Esa
Keluargaku
PERNYATAAN KEASLIAN KARYA
Saya yang bertanda tangan dibawah ini menyatakan bahwa, saya menyatakan
dengan sungguh-sungguh bahwa skripsi yang saya tulis ini karya atau bagian dari
karya orang lain, kecuali yang telah disebutkan dalam kutipan atau daftar pustaka,
sebagaimana layaknya karya ilmiah
Yogyakarta, 29 Februari 2016
Penulis,
KLASIFIKASI PENENTUAN JENIS KANKER PAYUDARA DAN PARU-PARU BERDASARKAN SUSUNAN PROTEIN
DENGAN ALGORITMA DECISION TREE ABSTRAK
Angka kematian di Indonesia karena penyakit kanker menurut WHO pada
tahun 2014 mencapai 195.300 orang dengan kematian terbanyak pada laki-laki
sebanyak 103.100 dengan penyakit kanker paru-paru pada tingkat pertama sebesar
21,8% dan pada wanita sebanyak 92.200 dengan penyakit kanker payudara pada
tingkat pertama sebesar 21.4%. Ilmu informatika dapat membantu menganalisa
masalah ini dengan mengunakan cabang ilmu bioinformatika, yang merupakan
penerapan teknis komputasional untuk mengolah dan menganalisa informasi
biologi seperti data DNA, RNA dan Protein.
Penelitian ini membahas tentang pendeteksian jenis kanker payudara dan
paru-paru berdasarkan susunan protein berupa asam amino. Data protein yang
digunkan berformat .fasta yang diambil dari database protein yaitu UniProt dan
NCBI (National Center for Biotechnology Information). Metode klasifikasi
digunakan untuk mendekteksi secara dini penyakit kanker berdasakan susunan
protein. Algoritma yang digunakan pada penelitian ini adalah decision tree, yaitu
salah satu algoritma yang digunakan dalam bidang bioinformatika.
Sebelum tahap klasifikasi dilakukan tahap pre-processing data sekuen
protein bertipe String ditransformasikan terlebih dahulu menggunakan EIIP
(Electron-Ion Interaction Potential) based protein value. Data sekuen protein yang telah ditransformasikan menjadi numerik selanjutnya diektraksi ciri menjadi
sinyal frequency based dengan menggunakan FFT (Fast Fourier Transform) dan
LPC (Linear Prediction Coding) dan turunan dari LPC dengan order 8 dan 12.
Klasifikasi dengan decision tree dilakukan setelah proses ekstraksi ciri
selesai. Pada penelitian ini dilakukan pengujian kombinasi feature LPC pada saat
proses ekstraksi ciri. Dari seluruh pengujian (16 pengujian) yang dilakukan,
didapatkan hasil akurasi terbesar yaitu 79,85% dan waktu yang diperlukan untuk
membuat tree 29,09 detik dengan akurasi rata-rata sebesar 74.82% pada feature
THE CLASSIFFICATION OF BREAST CANCER AND LUNG CANCER TYPE BASED ON PROTEIN STRUCTURE
USING DECISION TREE ALGORITM ABSTRACT
The death rate from cancer in Indonesia by WHO in 2014 reached 195.300
people with the number of death in men at 103.100 from lung cancer at the first
level by 21.8% and in women at 92.200 from breast cancer at the first level by
21.4%. Science of Informatics can help analyze this problem by using a branch of
bioinformatics, which is the computational technique application to process and
analyze the data of biological information such as DNA, RNA and Protein.
This research discusses the detection of breast cancer and lung cancer
based on the composition of proteins in the form of amino acids. The protein data
used the format of .fasta derived from the protein database UniProt and NCBI
(National Center for Biotechnology Information). The classification method that
used for early detection of cancer based on protein structure. The algorithm used
in this study is a decision tree, which is one of the algorithms used in
bioinformatics.
Before classification phase, pre-processing phase of protein sequence data
of String type are transformed beforehand using EIIP (Electron-Ion Interaction
Potential) based on protein valueconducted. Protein sequence data that have been transformed into numeric, then the feature extracted to become frequency based
signal by using FFT (Fast Fourier Transform) and LPC (Linear Prediction
Coding) and a derivative of LPC with order of 8 and 12.
Classification by decision tree is happened after the feature extraction
process is complete. In this research, testing the combination of LPC feature
during the process of feature extraction conducted. From all the tests (16 tests)
were conducted, showed the greatest accuracy is 79.85% and time to bulid tree
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma :
Nama : Andhini Ayu Susanti
NIM : 105314097
Demi pengembangan ilmu pengetahuan, saya memberikan kepada perpustakaan
Univesitas Sanata Dharma karya ilmiah saya yang berjudul :
KLASIFIKASI PENENTUAN JENIS KANKER PAYUDARA DAN PARU-PARU BERDASARKAN SUSUNAN PROTEIN
DENGAN ALGORITMA DECISION TREE
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan
kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan,
mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan
data, mendistribusikannya secara terbatas dan mempublikasikannya di internet
atau media lain demi kepentingan akademis tanpa perlu meminta ijin dari saya
maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya
sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di Yogyakarta,
Pada tanggal :
Yang menyatakan,
KATA PENGANTAR
Puji syukur kepada Tuahn Yang Maha Esa atas karunia, berkat dan
rahmat-Nya yang melimpah sehingga penulis dapat menyelesaikan skripsi dengan judul “Klasifikasi Penentuan Jenis Kanker Payudara dan Paru-Paru Berdasarkan Susunan Protein Dengan Algoritma Decision Tree”. Dalam kesempatan ini, penulis ingin mengucapkan terima kasih yang sebesar- besarnya
kepada semua pihak yang turut memberikan semangat, dukungan dan bantuan
sehingga selesainya skripsi ini :
1. Tuhan Yang Maha Esa atas segala berkat dan rahmatNya.
2. Romo Dr. Cyprianus Kuntoro Adi, S.J., M.A., M.Sc. selaku dosen
pembimbing, terima kasih atas bimbingan, saran, waktu, dan
kesabaranya dalam membimbing dan mengarahkan penulis dalam
menyelesaikan tugas akhir ini.
3. Bapak Sudi Mungkasi, S.Si., M.Math. Sc., Ph.D selaku Dekan
Fakultas Sains dan Teknologi Universitas Sanata Dharma
Yogyakarta.
4. Ibu Dr. Anastasia Rita Widiarti M.Kom selaku Kaprodi dan Dosen
Penguji
5. Bapak Eko Hari Parmadi, S.Si., M.Kom. selaku Dosen Penguji
6. Ibu P.H. Prima Rosa, S.Si., M.Sc. selaku dosen pembimbing
akademik.
7. Seluruh staff pengajar Prodi Teknik Informatika Fakultas Sains dan
Teknologi Universitas Sanata Dharma Yogyakarta.
8. Kedua orang tua saya, Ganeshan dan Harjanti Kusumawati, terima
kasih atas doa, semangat dan perhatian yang diberikan serta
dukungan material selama perkulihan.
9. Keluarga besar saya, terima kasih atas semangat, doa dan motivasi
yang diberikan.
11. Teman-teman seperjuangan skripsi, Lutgardis Festidita, Renny
Nita dan Stella Filensia atas semangat dan segala waktu untuk
belajar dan berdiskusi bersama.
12.Amelia Endah, Karl Haryo, Sepen Mulyani, dan Gregorius
Airlangga atas motivasi dan dorongan semangat untuk penulis
yang tak pernah lelah diberikan untuk menyelesaikan tugas akhir
ini.
13.Temen-teman “second home” dan “ccp”, Maria Fernandez, Ria
Regina, Fransisca Novia, Yovita Metty, Fa Febrian, Yohanes
Teddy, Theodorus Adi Nugraha, I Nyoman Rama, Wisnu Yoga,
Alfonsus Doni, Christan Ardy dan Eduardus Hardika yang
berjuang bersama baik suka maupun duka dalam menyusun tugas
akhir ini.
14.Ratna Yani, Reti Erwiyanti, Astrian, Leslie, Adita, Pradita Eka,
Neva, Mario, Merry, Artha dan Ayu atas semangatnya.
15.Teman-teman Teknik Informatika angakatan 2010 atas
kebersamaan dan dukungnya.
16.Terima kasih kepada semua pihak yang tidak dapat penulis
sebutkan secara langsung dan tidak langsung.
Penulis menyadari bahwa tugas akhir ini jauh dari
sempurna, oleh karena itu kritik dan saran yang sifatnya
membangun sangat penulis harapkan. Akhir kata, semoga skripsi
ini bermanfaat bagi pembaca dan pikah yang membutuhkan.
Yogyakarta, 29 Februari 2016
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN PERSETUJUAN ... Error! Bookmark not defined. HALAMAN PENGESAHAN ... Error! Bookmark not defined. HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... vi
ABSTRAK ... vii
ABSTRACT ... viii
LEMBAR PERNYATAAN PERSETUJUAN ... ix
DAFTAR ISI ... xii
BAB I ... 1
PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Tujuan Penelitian ... 3
1.4 Batasan Masalah ... 3
1.5 Luaran yang Diharapkan ... 3
1.6 Metodelogi ... 4
1.7 Sistematis Penulisan ... 4
BAB II ... 5
LANDASAN TEORI ... 5
2.1 Kanker ... 5
2.2.1. Kanker Payudara ... 6
2.1.2. Kanker Paru - paru ... 7
2.2 Bioinformatika ... 8
2.2.1. Protein ... 9
2.2.2. Asam Amino ...10
2.4.1. Electron- Ion Interaction Potential (EIIP) ...11
2.4.2. Fast Fourier Transform (FFT) ...13
2.4.3. Linier Predictive Coding (LPC) ...14
2.5 Algoritma Decision Tree ...15
2.6 K-Fold Cross Validation ...17
BAB III ...19
METODOLOGI ...19
3.1 Data ...19
3.2 Metode Penelitian ...20
3.2.1 Preprocessing ...21
3.2.2 Ekstraksi Ciri ...22
3.2.3 Proses Training ...25
3.2.4 Tahap Klasifikasi Decision Tree ...26
3.2.5 Pengujian ...28
BAB IV ...30
ANALISIS HASIL DAN IMPLEMENTASI SISTEM ...30
4.1 Analisis Hasil ...30
4.2 Analisis Coding ...32
4.2.1. Ekstraksi Ciri ...32
4.2.2. Algoritma Decision Tree ...38
4.2.3. Akurasi Tree ...42
4.3 User interface ...43
BAB V ...47
KESIMPULAN DAN SARAN ...47
5.1 Kesimpulan ...47
5.2 Saran ...48
DAFTAR PUSTAKA ...49
DAFTAR TABEL
TABEL 2.1EIIP VALUE AMINO ACID ... 12
DAFTAR GAMBAR
GAMBAR 2.1GAMBAR PRESENTASE KANKER PAYUDARA... 7
GAMBAR 2.2MEKANISME PENGENALAN POLA ... 10
GAMBAR 2.3 BLOK DIAGRAM PROSES PREPROCESSING DAN EKSTRAKSI CIRI ... 11
GAMBAR 2.4BLOK DIAGRAM ANALISIS LPC ... 15
GAMBAR 2.5CONTOH POHON KEPUTUSAN ... 16
GAMBAR 3.1DIAGRAM PROSES TRAINING DAN TESTING ... 21
GAMBAR 3.2DIAGRAM PREPROCESSING ... 22
GAMBAR 3.3GRAFIK SEKUEN PROTEIN ASAM AMINO A2KUC3 ... 22
GAMBAR 3.4DIAGRAM EKSTRAKSI CIRI ... 23
GAMBAR 3.5SINYAL STEM EKSTRAKSI CIRI DENGAN ... 23
GAMBAR 3.6SINYAL STEM LPC, DELTA LPC, ... 24
GAMBAR 3.7SINYAL STEM LPC, DELTA LPC, ... 25
GAMBAR 3.8CONTOH DATA TRAINING 1 ... 26
GAMBAR 3.9 DECISION TREE KOSONG ... 27
GAMBAR 3.10 ENTROPY DARI VARIABEL BINARI ... 27
GAMBAR 3.11CONTOH LEVEL PERTAMA DECISION TREE ... 28
GAMBAR 3.12HASIL TREE YANG TERBENTUK DARI TRAINING 3 ... 28
GAMBAR 4.1TABEL HASIL PERBANDINGAN AKURASI DAN WAKTU ... 30
GAMBAR 4.2GRAFIK AKURASI RATA-RATA FEATURE LPC ... 31
GAMBAR 4.3 USER INTERFACE HALAMAN UTAMA ... 44
GAMBAR 4.4HALAMAN EKSTRAKSI CIRI ... 44
GAMBAR 4.5PROSES PREPROSES DAN EKSTRAKSI CIRI ... 45
GAMBAR 4.6HALAMAN TREE ... 45
GAMBAR 4.7HALAMAN AKURASI TREE ... 46
BAB I PENDAHULUAN
1.1Latar Belakang
Penyakit Kanker merupakan salah satu penyakit pembunuh teratas di
dunia. Pada tahun 2012, sekitar 8,2 juta kematian disebabkan oleh kanker, dengan
spesifikasi kanker paru, hati, perut, kolorektal, dan kanker payudara adalah
penyebab terbesar kematian akibat kanker setiap tahunnya (INFODATIN, 2014).
Berdasarkan data profil mortalitas Kanker (Cancer Mortality Profile) yang dirilis
oleh WHO pada tahun 2014, menyebutkan angka kematian yang disebabkan oleh
kanker di Indonesia mencapai 195.300 orang dengan prevalensi kematian
terbanyak pada laki-laki sebanyak 103,100 dengan penyakit kanker paru-paru
pada tingkat pertama sebesar 21,8% orang dan perempuan mencapai 92,200
orang dengan penyakit kanker payudara pada tingkat pertama sebesar 21,4 %.
Penyakit kanker adalah penyakit yang timbul akibat pertumbuhan tidak
normal sel jaringan tubuh yang berubah menjadi sel kanker, sedangkan tumor
adalah kondisi dimana pertumbuhan sel tidak normal sehingga membentuk suatu
lesi atau dalam banyak kasus, benjolan di tubuh. Tumor terbagi menjadi dua, yaitu
tumor jinak dan tumor ganas. Tumor jinak memiliki ciri-ciri, yaitu tumbuh secara
terbatas, memiliki selubung, tidak menyebar bila dioperasi,dapat dikeluarkan
secara utuh sehingga dapat sembuh sempurna, sedangkan tumor ganas memiliki
ciri-ciri, yaitu dapat menyusup ke jaringan sekitarnya, dan sel kanker dapat
ditemukan pada pertumbuhan tumor. Penyakit kanker tidak dapat diketahui
secara langsung dalam satu kali pemeriksaan yang dilakukan oleh dokter.
Diperlukan serangkaian uji laboratorium yang berguna untuk mendeteksi sel-sel
kanker tersebut dalam tubuh manusia (Infodatin,2015).
Bioinformatika adalah ilmu yang mempelajari penerapan teknis
komputasional untuk mengelola dan menganalisa informasi biologis. Bidang ini
mencakup penerapan metode-metode matematika, statistika, dan informatika
sekuen DNA dan asam amino serta infomasi yang terkaitan.
Peranan bioinformatika dalam penelitian ini untuk membantu dalam
proses mendeteksi penyakit kanker payudara dan kanker paru-paru. Dengan
menggunakan data sekuen protein dari tubuh manusia, maka mendeteksi secara
dini penyakit kanker dan mengklasifikasikan jenis kanker dapat dilakukan.
Pendeteksian penyakit kanker secara dini di dalam tubuh penderita salah
satu data yang dapat digunakan adalah data sekuen protein. Protein yang
digunakan dalam penelitian ini adalah asam amino. Data sekuen protein
berformat .fasta dan bertipe String. Tahap awal dalam mengolah data sekuen
protein yaitu asam amino dalam penelitian ini adalah tahap pre-processing yaitu
data sekuen protein yang berupa string akan ditransformasikan menjadi data
numerik untuk mempermudah perhitungan dan panjang sekuen protein tidak harus
sama.
Pada peneilitian ini jenis kanker yang diteliti berdasarkan susunan sekuen
protein (asam amino) adalah kanker payudara dan kanker paru-paru yang
dibandingkan dengan manusia sehat atau non-cancer. Data sekuen protein berasal
dari bank protein dunia yang dapat diakses melalui website antara lain UniProt
(www.UniProt.org) dan National Center for Biotechnology Information
(www.ncbi.nlm.nih.gov).
Tahap pre-processing data sekuen protein ditransformasikan terlebih
dahulu menggunakan EIIP (Electron-Ion Interaction Potential) based protein
value. Data sekuen protein yang telah ditransformasikan menjadi numerik selanjutnya diektraksi ciri menjadi sinyal frequency based dengan menggunakan
FFT (Fast Fourier Transform) dan LPC (Linear Prediction Coding) dan turunan
dari LPC dengan order 8 dan 12 untuk nyeragamkan panjang data dan
mendapatkan ciri data.
Berdasarkan pada penelitian sebelumnya yaitu menentukan jenis kanker
berdasarkan susunan protein metode yang digunakan adalah pengelompokan
menggunakan K-Means dan klasifikasi KNN. Metode yang digunakan merupakan
gabungan antara pengelompokan dan klasifikasi yang bertujuan agar proses
klasifikasi KNN dapat dilakukan dengan mudah dan optimal, namun pada
yaitu sekitar 52,00% .
Pada penelitian ini hanya menggunakan satu algoritma saja untuk proses
Klasifikasi. Ada beberapa metode dan algoritma yang dapat digunakan untuk
mengklasifikasi menentukan jenis kanker berdasarkan susunan protein. Algoritma
yang digunakan dalam penelitian ini adalah algoritma decission tree. Algoritma
decision tree akan menghasilkan tree atau pohon keputusan. Algoritma decision tree yang telah digunakan dalam beberapa penelitian lain dan menghasilkan tingkat keakurasian yang baik yaitu sekitar 70% - 85%.
1.2Rumusan Masalah
Masalah yang dirumuskan dalam penelitian ini adalah :
Bagaimana klasifikasi dengan menggunakan algoritma decision tree mampu
mengenal jenis kanker payudara dan kanker paru-paru cepat dan tepat?
1.3Tujuan Penelitian
Penelitian ini bertujuan untuk melakukan klasifikasi terhadap susunan protein
yaitu asam amino untuk mendeteksi kanker payudara dan kanker paru-paru
dengan cepat dan tepat.
1.4Batasan Masalah
Batasan-batasan dalam penelitian ini adalah :
1. Ekstrasi ciri yang digunakan FFT, LPC dan turunan LPC (delta LPC dan
delta delta LPC) dengan order 8 dan 12.
2. Pre-processing yang digunakan adalah EIIP based value protein
3. Metode klasifikasi yang digunakan adalah greedy decision tree.
1.5Luaran yang Diharapkan
Luaran yang dihasilkan dari penelitian ini adalah prototype yang bisa
menentukan apakah seseorang menderita penyakit kanker payudara,
1.6 Metodelogi
Metodologi penelitian yang digunakan antara lain :
1. Studi literatur untuk mempelajari bioinformatika khususnya mengenai
susunan asam amino.
2. Studi literatur untuk mempelajari mengenai EIIP ,FFT dan LPC.
3. Studi literatur untuk mempelajari data mining klasifikasi yaitu
algoritma Decision Tree.
4. Analisis data untuk mengetahui bagaimana cara mendapatkan data
susunan protein yang akan digunakan dalam penelitian ini.
5. Implementasi merupakan proses membuat model yang telah dibuat
dalam bentuk yang dapat diesksekusi. Implementasi mengunakan
MATLAB 2010.
6. Pengujian menggunakan k-fold cross validation untuk mengetahui
akurasi dari algoritma decision tree yang digunakan.
1.7 Sistematis Penulisan
BAB I PENDAHULUAN
Bab ini berisi latar belakang, rumusan masalah, tujuan, batasan masalah,
keluaran yang dihasilkan, metodologi dan sistematika penulisan.
BAB II LANDASAN TEORI
Bab ini berisi landasan teori yang dipakai untuk pembahasan tugas akhir.
BAB III ANALISIS DAN PERANCANGAN SISTEM Bab ini berisi analisis dan perancangan sistem yang akan
diimplementasikan.
BAB IV IMPLEMENTASI SISTEM DAN ANALISIS HASIL Bab ini berisi tentang proses implementasi sistem dan analisis hasil
Implementasi sistem.
BAB II
LANDASAN TEORI
Bab ini menjelaskan tentang dasar teori yang digunakan dalam penyusunan
tugas akhir ini untuk memperjelas materi-materi yang sedikit sudah dijelaskan
mulai dari kanker, bioinformatika, dan pengenalan pola yang meliputi ekstraksi
fitur yaitu EIIP, FFT dan LPC, algoritma decision tree dan cross-validation. Teori
–teori tersebut dijelaskan sebagai berikut :
2.1Kanker
Kanker atau neoplasma adalah suatu penyakit sel dengan ciri gangguan atau
kegagalan mekanisme multiplikasi dan fungsi homeostasis lainnya pada
organisme multiseluler sehingga terjadi pertumbuhan jaringan yang tak terkontrol
(van Cauteren, et al,1996). Kadang istilah kanker sering di kacaukan dengan
tumor, padahal ada perbedaan yang mendasar. Perbedaan utama yaitu kanker
adalah neoplasma yang menyebar dan ganas (Malignant neoplasm) dan tumor
adalah neoplasma yang tidak menyebar dan tidak ganas (benigh neoplasm).
Kanker dapat menyerang berbagai sel pada seluruh organ dalam tubuh, dari
kepala sampai ujung kaki. Dalam keadaan normal sel hanya akan membelah diri
bila tubuh membutuhkan, misalnya ada sel-sel yang perlu diganti karena mati atau
rusak. Sedangkan sel kanker akan membelah meskipun tidak diperlukan, sehingga
terjadi sel-sel baru yang berlebihan. Sel-sel baru mempunyai sifat seperti
induknya yang sakit yaitu tidak mempunyai daya atur.
Dalam daftar Badan Kesehatan Dunia (WHO) penyakit kanker masuk dalam
urutan teratas dari kelompok penyakit. Hal ini dapat dimengerti, karena penyakit
ini merupakan penyakit yang paling mematikan di dunia. Kalau penyakit kanker
di dunia menempati urutan kedua, setelah penyakit jantung , di Indonesia kanker
termasuk urutan ke-6 sebagai penyakit kematian. Penyakit kanker diperkirakan
diidap oleh 15 orang per 100.000 penduduk di dunia (Saffiot dalam
Jenis kanker yang sering terjadi pada kelompok pria adalah kanker paru-paru,
prostat dan kolon (usus besar). Sedangkan pada kelompok wanita adalah kanker
payudara, servix uteri, paru-paru dan kolon. Pada kelompok anak-anak jenis
kanker yang paling sering adalah leukemia(kanker darah) (Sunarto,1997:82-84).
2.1.1. Kanker Payudara
Kanker payudara adalah kanker yang banyak menyerang kaum wanita dan
merupakan kanker penyebab kematian kedua bagi wanita di dunia. Kanker ini
banyak menyerang wanita umur antara 35 – 50 tahun. Berdasarkan laporan
dari Pathology of Breast Cancer in New South Wales Women pada tahun 1995
ditemukan bahwa 60% dari kaum wanita mempunyai benjolan pada
payudaranya yang berdiameter kurang dari 2cm yang dikenal sebagai kanker
panyudara stadium awal (dini). Kanker payudara umunnya terjadi pada kaum
wanita namun dapat pula menyerang kaum pria, pria dengan Klinefelter
Syndrome mempunyai resiko 60 kali lebih besar dibandingkan dengan pria
normal(Sri Hartati Yuliani. 2000).
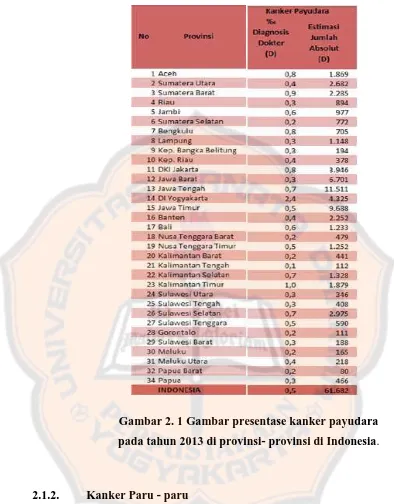
Menurut data GLOBOCAN (IARC) pada tahun 2012 diketahui bahwa
penyakit kanker payudara merupakan penyakit kanker dengan presentase
kasus baru tertinggi pada wanita yaitu sebesar 43.3% dan presentase kematian
Gambar 2. 1 Gambar presentase kanker payudara pada tahun 2013 di provinsi- provinsi di Indonesia.
2.1.2. Kanker Paru - paru
Kanker paru-paru adalah tumor mengancam (malignant tumour) pada
paru-paru. Paling biasa adalah bronchogenic carcinoma (sekitar 90%).Kanker
paru-paru adalah tumor mengancam yang paling bahaya di seluruh dunia,
menyebabkan sampai 3 juta kematian setiap tahun.
Pengungkapan kepada karsinogen, seperti diakibatkan asap tembakau,
menyebabkan perubahan kecil pada selaput jaringan pada bronkus di
paru-paru (bronchial mucous membrane). Efek ini akan menyebabkan jaringan
akan menghalangi jalur udara menyebabkan sulit bernafas. Paru-paru akan
runtuh dan akan terkena infeksi dan menyebabkan bisul paru-paru (lung
abscess). Penderita akan mulai batuk dan mengeluarkan lendir berdarah.
Namun jika tumor membesar ke luar paru-paru, penderita tidak menyadarinya
sehingga mulai menginfeksi bagian tubuh yang lain[3].
Menurut data GLOBOCAN (IARC) pada tahun 2012 diketahui bahwa
penyakit kanker paru- paru merupakan penyakit kanker dengan presentase
kasus baru tertinggi pada laki-laki yaitu sebesar 34,2% dan presentase
kematian akibat penyakit kanker paru-paru sebesar 30,0%. Penyakit kanker
paru-paru tidak hanya diderita oleh kaum laki-laki saja namun kaum
perempuan penderita penyakit kanker paru-paru dengan presentase kasus baru
sebesar 13,6% dan presentase kematian akibat penyakit kanker paru-paru
sebesar 11,1%. (infoDatin. 2015).
Penyakit kanker payudara dan paru-paru dapat dideteksidengan
menggunakan data sekuen protein yaitu data asam amino dari penderita
penyakit tersebut cabang ilmu yang digunakan adalah Bioinfomatika adalah
ilmu yang mempelajari penerapan teknis komputasional untuk mengelola dan
menganalisa informasi biologis. Data yang digunakan biasanya berupa DNA
dan asam amino.
2.2Bioinformatika
Bioinformatika merupakan bidang ilmu pengetahuan baru dimana biologi
molekular dan ilmu komputer saling berhubungan untuk mengembangkan
cara-dara yang lebih baik dalam mengeksplor, menganalisis dan memahami data-data
genetis (St. Clair, Caroline dan Jonathan Visick. 2010).Data yang digunakan
adalah data DNA dan protein atau asam amino. Data-data tersebut digunakan
antara lain untuk mendapatkan informasi genetik, mengetahui struktur molekul,
menentukan fungsi biokimia. Selanjutnya informasi-informasi yang ada
digabungkan dan di analisis yang kemudian hasilnya digunakan untuk penemuan
obat maupun prediksi suatu penyakit.Data dalam bioinformatika ini merupakan
data yang sangat besar sehingga dibutuhkan database untuk menyimpannya.
dan Inggris. Para peneliti sering mencari informasi dari database yang ada seperti
susunan asam amino, struktur gen atau protein.
Ada satu alat yang sering dalam bioinformatika yaitu The Basic Alignment
Search Tool (BLAST). BLAST melakukan perbandingan antara input sekuen
dengan seluruh sekuen yang ada dalam database untuk mendapatkan sekuen yang
paling mirip.
2.2.1. Protein
Protein merupakan komponen utama dalam semua sel hidup. Fungsinya
terutama adalah sebagai unsur pembentuk struktur sel, misalnya dalam
rambut, wol, kolagen, jaringan penghubung, membran sel dan lain-lain. Selain
itu dapat pula berfungsi sebagai protein yang aktif, seperti misalnya enzim,
yang berperan sebagai katalis segala proses biokimia dalam sel. Protein aktif
selain enzim yaitu hormone, pembawa O2 (hemoglobin), protein yang terkait
pada gen, toksin, antibodi/antigen, dan lain-lain. Beberapa ciri utama molekul
protein yaitu:
1. Berat molekulnya besar, ribuan sampai jutaan, sehingga merupakan suatu
markro molekul.
2. Umumnya terdiri atas 2 asam amino. Asam amino berikatan (secara
kovalen) satu dengan yang lain dalam variasi urutan yang
bermacam-macam, membentuk suatu rantai polipeptida. Ikatan polipeptida merupakan ikatan antara gugus α-karboksil dari asam amino yang satu dengan gugus α-amino dari asam amino yang lain.
3. Terdapat ikatan kimia lain, yang menyebabkan terbentuknya
lengkungan-lengkungan rantai polipeptida menjadi struktur tiga dimensi protein.
Sebagai contoh misalnya ikatan hidrofob (ikatan apolar), ikatan ion atau
elektrostatik dan ikatan Van der Waals.
4. Strukturnya tidak stabil terhadap beberapa factor seperti pH, radiasi,
temperature, medium pelarut organic dan deterjen.
5. Umumnya reaktif dan sangat spesifik, disebabkan terdapatnya gugus
samping yang reaktif dan susunan khas struktur makro
molekulnya.berbagai macam gugus samping yang biasa terdapat adalah
hoterosiklik.
2.2.2. Asam Amino
Asam Amino merupakan bagian struktur protein dan menentukan banyak
sifatnya yang penting. Gilisin merupakan asam amino pertama yang telah
diisolasi dari hidrolisat protein, sedangkan teronin adalah asam amino
pembentuk protein yang paling akhir dapat diisolasi, yaitu dari hidrolisat
fibrin. Ke-20 macam amino berserta simbol kependekannya yaitu Alamin (A),
Arginin (R), Asparagin (N), Asam Aspartat (D), Sistein (C), Glutamin (Q),
Asam Glutamat (E), Glisin (G), Histidin (H), Isolesin (I), Lesin (L), Lisin (K),
Metionim (M), Femilalanim (F), Prolin (P), Serin (S), Treonin (T), Triptofan
(W), Tirosin (Y), Valin (V) (Muhamad Wirawadikusma. 1977).
2.3Pengenalan Pola
Secara umum pengenalan pola (pattern recognition) adalah ilmu untuk
mengklasifikasikan atau menggambarkan sesuatu berdasarkan kuantitatif fitur
(ciri) atau sifat utama dari suatu objek. Pola sendiri adalah suatu entitas yang
terdefinisi dan didefinisikan serta dapat diberi nama. Sidik jari adalah suatu
contoh pola. Pola biasanya merupakan hasil kumpulan hasil suatu pengukuran
atau pemantauan dan bisa dinyatakan dalam notasi vector atau matrik. (Putra,
2010).
Gambar 2. 2 Mekanisme Pengenalan Pola
Pengenalan pola berkaitan dengan menemukan algoritma dan metode atau alat
yang bisa membuata implementasi komputer yang digunakan untuk berbagai
macam tugas pengenalan yang biasa dilakukan oleh manusia. Tujuan dari
mengerjakan apa yang tidak bisa dilakukan oleh manusia seperti membaca
barcode, dan membuat proses pembuatan keputusan menjadi otomatis yang
mengarah ke pengenalan klasifikasi. (Sankar K. Pal and Pabita Mitra. 2004).
Pra-pengolahan n
Pencarian dan seleksi fitur
Terdapat tiga tahapan dalam pengenalan pola yaitu yaitu pre-processing,
ekstraksi ciri atau seleksi fitur dan klasifikasi. Pre-processing merupakan tahapan
awal dalam mengolah data inputan sebelum masuk pada proses klasifiksi. Data
pre-processing kemudian masuk pada tahap ekstraksi ciri. Ekstraksi ciri adalah
suatu pengambilan ciri atau fitur dari suatu data, dimana nilai yang didapatkan
dianalisis untuk proses klasifikasi. Tahap terakhir adalah klasifikasi, data yang
sudah diekstrak akan digunakan untuk klasifikasi yang mengevaluasi informasi
yang masuk dan menghasilkan keputusan akhir.
2.4Preprocessing dan Ekstraksi Ciri
Ekstraksi ciri merupakan proses mendapatkan ciri tertentu dari data yang
sudah dikumpulkan. Tujuan dari proses ekstraksi ciri ini adalah mencari
karakteristik penting yang berguna untuk proses pengenalan dan mengurangi
dimesi (reduksi dimensi) pengukuran ruang sehingga efektif dan algoritma dengan
komputasi yang mudah bisa digunakan untuk klasifikasi yang efektif.
Gambar 2. 3 Blok diagram Proses Preprocessing dan Ekstraksi Ciri Langkah Pertama untuk mendapatkan ciri dari data sekuen protein
adalah tahap pre-processing yaitu mengubah data .fasta yang bertipe String
menjadi bertipe numerik dengan memberikan nilai Electron- Ion Interaction
Potential (EIIP), lalu diproses menggunakan Fast Fourier Transform (FFT) untuk mengubah data dari numerik menjadi data sinyal dan Linier Predictive
Coding (LPC) mendapatkan ciri dari setiap data.
2.4.1. Electron- Ion Interaction Potential (EIIP)
EIIP adalah salah satu paremeter asam amino yang digunakan untuk
mengubah data sekuen asam amino menjadi sekuen numerik dimana setiap Data Sekuen
Protein
asam amino akan diberikan nilai konstanta berdasarkan EIIP value.
Perhitungan dalam EIIP value adalah menggunakan energi dari elektron
valensi dan dihitung untuk setiap asam amino menggunakan model umum dari
pseudopotensial adalah sebagai berikut.
W = . 5Z∗ π. 4πZ∗ (2.1)
Dimana Z* memwakili dari rata-rata nilai equevalensi, dengan rumus
dibawah ini:
Z∗ =
N∑ n= Z (2.2)
Dimana Zi adalah nomer valensi dari i-komponen atom, ni adalah nomer
dari i-komponen atom, m adalah nomer komponen atom di monekul, dan N
adalah total nomer atom. Seperti telah menunjukan bahwa perioditas dari
EIIP disepanjang sekuen protein berkorelasi dengan biologis protein,
terutama dengan interaksi spesifik dengan ligan dan protein lainnya.
(Branislava Gemovic et al . 2013).
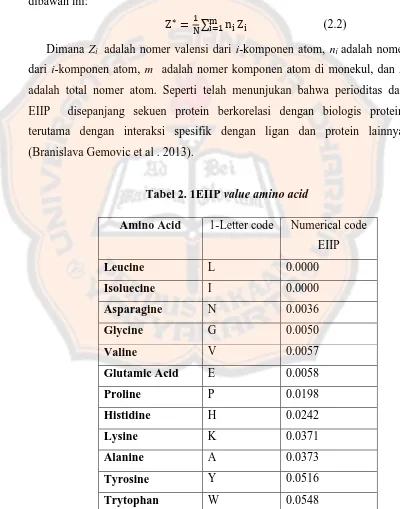
Tabel 2. 1EIIP value amino acid
Amino Acid 1-Letter code Numerical code EIIP
Leucine L 0.0000
Isoluecine I 0.0000
Asparagine N 0.0036
Glycine G 0.0050
Valine V 0.0057
Glutamic Acid E 0.0058
Proline P 0.0198
Histidine H 0.0242
Lysine K 0.0371
Alanine A 0.0373
Tyrosine Y 0.0516
Glutamine Q 0.0761
Methionine M 0.0823
Serine S 0.0829
Cysteine C 0.0829
Threonine T 0.0941
Phenylalanine F 0.0954
Arginine R 0.0956
Aspartic Acid D 0.1263
2.4.2. Fast Fourier Transform (FFT)
Algoritma Alihragam Fourier Cepat atau Fast Fourier Transform (FFT)
merupakan prosedur penghitungan DFT yang efisien sehingga akan
mempercepat proses penghitungan DFT. Bila diterapkan pada kawasan waktu
maka algoritma ini disebut juga sebagai FFT penipisan dalam waktu atau
decimation-in-time (DIT). Penipisan kemudian mengarah pada pengurangan yang signifikan dalam sejumlah perhitungan yang dilakukan pada data
kawasan waktu. Persamaanya menjadi :
H k = ∑N− h n WN , untuk ≤ k ≤ N −
= (2.3)
Dimana faktor �−�2�� akan ditulis sebagai :
WN= e− π⁄N = cos π⁄ − j sin(N π⁄ )N (2.4)
Akhiran n pada Persamaan (2.4) diperluas dari n=0 sampai dengan n=N-1,
bersesuaian dengan nilai data h(0), h(1), h(2), h(3)...h(N-1). Runtun bernomor
genap adalah h(0), h(2), h(4)....h(N-2) dan runtun bernomor ganjil adalah h(1),
h(3)....h(N-1). Kedua runtun berisi N/2-titik. Runtun genap dapat ditandakan h(2n) dengan n=0 sampai n=N/2-1, sedangkan runtun ganjil menjadi h(2n-1). Kemudian Persamaan selanjutnya dapat ditulis ulang menjadi :
H k = ∑ h n WN + ∑ h n − WN +
N⁄ − = N⁄ −
=
untuk ≤ k ≤ N − (2.5)
Selanjutnya dengan menganti � ��� menjadi � �⁄�� maka persamaan
selanjutnya menjadi : (Nandra Pradipta. 2011)
H k = ∑ h n W N⁄ + WN∑ h n − W N⁄ N⁄ −
= N⁄ −
= (2.6)
Untuk melakukan analisis frekuensi di dalam MATLAB, telah tersedia
command “Fast Fourier Transform” (FFT) sebagai berikut:
y = fft x (2.7)
2.4.3. Linier Predictive Coding (LPC)
Analisa Linear Predictive Coding (LPC) adalah salah satu cara untuk
mendapatkan sebuah pendekatan mengenai spektrum bunyi. Prinsip dasar dari
pemodelan sinyal dengan menggunakan LPC adalah bahwa pencuplikan
sinyal ucapan s(n) pada waktu ke-n dapat diperkirakan sebagai kombinasi
linear dari p cuplikan sinyal ucapan sebelumnya yaitu :
s n ≈ a s n − + a s n − + ⋯ + aps n − p , p < � (2.8)
Dimana koefisien a1, a2,…,ap diasumsikan konstan selama analisi frame
suara (Novi Aryanto, 2011).
Secara umum metode yang digunakan utuk mendapatkan informasi dari
ciri yang dinamis biasa disebut dengan delta-feature. Turunan watu dari ciri
dapat dihitung dengan beberapa metode, hasil dari perhitungan delta akan
ditambahkan ke vector ciri, sehingga menghasilkan vector ciri yang lebih
besar.
∆y =y+D− y −D (2.9)
Dimana D mewakili jumlah dari frame untuk menutup kedua sisi frame
saat ini dan dengan demikian dapat mengontrol window y dengan pembedaan
operasi. D diset bernilai 1 atau 2. ∆y adalah koefisien delta yang dihitung
dari frame t untuk vektor fitur LPC (F.Z. Chelali, etc, 2015).
Nilai dari delta akan diturunkan sekali lagi terhadpa waktu menjadi nilai
percepatan, kerena nilai tersebut turunan dari kuadrat waktu dari koefisien.
∆∆y =∆y+D− ∆y −D (2.10)
Pengukuran energi merupakan salah satu cara untuk menambah nilai
koefisien yang dihitung dari LPC, nilai tersebut merupakan log energy signal.
Ini berarti pada setiap frame tredapat nilai energi yang ditambahkan, berikut
rumus untuk menghitung nilai energi :
E = log ∑ − x_windowed
= k; m (2.11)
Dimana x_windowed adalah sinyal hasil windowing, k adalah jumlah
frame dan m adalah panjang frame (Muslim Sidiq, etc, 2015).
Analisis LPC pada dasarnya digunakan untuk mendapatkan koefisien LPC
[image:32.595.99.524.160.599.2]yang diperlihatkan pada gambar 2.4.
Gambar 2. 4 Blok diagram analisis LPC
2.5Algoritma Decision Tree
Pohon keputusan (decision tree) merupakan metode penambangan data
meodel klasifikasi. Salah satu metode data mining yang umum digunakan adalah
decision tree. Konsep decision tree adalah suatu struktur flowcart yang menyerupain tree (pohon), dimana setiap simpul internal menandakan suatu tes
pada atribut, setiap cabang mempresentasikan hasil tes dan simpul daun
mempresentasikan kelas atau distribusi kelas. Alur pada decision tree di telusuri
dari simpul akar ke simpil daun yang memegang prekdisi kelas untuk untuk
contoh tersebut. (Jiawei Han dan Micheline Kamber. 2006). Sinyal ucap
diskret
Pembingkian sinyal (Frame)
Penjendelaan Metode
Autokorelasi
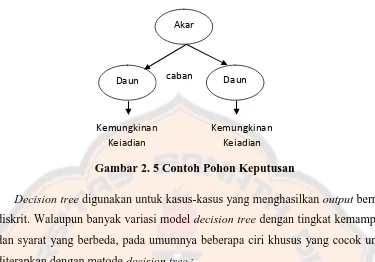
Gambar 2. 5 Contoh Pohon Keputusan
Decision tree digunakan untuk kasus-kasus yang menghasilkan output bernilai diskrit. Walaupun banyak variasi model decision tree dengan tingkat kemampuan
dan syarat yang berbeda, pada umumnya beberapa ciri khusus yang cocok untuk
diterapkan dengan metode decision tree :
1. Data dinyatakan dengan pasangan atribut dan nilainya.
2. Label /output data biasanya bernilai diskrit.
3. Data mempunyai missing value.
Dalam decision tree setiap atribut ditanyakan disimpul. Jawaban dari atribut
ini dinyatakan dalam cabang sampai akhirnya ditemukan kategori/jenis dari suatu
objek disimpul akhir .Untuk membuat decision tree perlu diperhatikan beberapa
syarat berikut : (Budi Santoso. 2007)
1. Atribut mana yang akan dipilih untuk memisahan objek
2. Urutan atribut mana yang akan dipilih terlebih dahulu
3. Struktur tree
4. Kriteria pemberhentian
5. Pruning
Masalah pertama pada decision tree adalah atribut manakah yang digunakan
sebagai akar atau root dari tree yang akan dibentuk. Akar yang dimaksud adalah
pemisah pertama dari decision tree. Dikenal dengan istilah Bayesian Score yang
menilai suatu atribut atau dalam decision tree disebut dengan entropy. Entropy
dihitung dengan rumus sebagai berikut: (Prabowo, Rahmadya dan Herlawati. Akar
Daun Daun
Kemungkinan Kejadian
Kemungkinan Kejadian caban
2013)
Entropy S = − ∑= p ∗ log p (2.12)
Keterangan :
S = Himpunan Kasus
n = jumlah partisi atribut S
pi = proporsi Si terhadap S
Setelah mendapatkan nilai entropy untuk suatu kumpulan sampel data, maka
dapat melakukan pengukuran efektoivitas suatu atribut dalam pengklasifikasikan
data. Ukuran efektivitas ini yang disebut dengan information gain. Information
Gain adalah salah satu alat ukur seleksi atribut yang digunakan untuk memilih
data test atribut tiap node pada tree. Atribut dengan information Gain tertinggi
dipilih sebagai data test atribut dari suatu node selanjutnya. Rumus untuk
information Gain adalah: (Kantardzic. 2003)
Gain S, A = Entropy S − ∑ |Si|
|S| ∗ Entropy S
= (2.10)
Keterangan :
S = Himpunan Kasus
A = Fiture
n = jumlah partisi atributA
│Si│ = proporsi Si terhadap S
│S│ = jumlah kasus pada S
2.6K-Fold Cross Validation
Cross validation adalah metode statistic yang mengevaluasi dan membandingkan algoritma pembelajaran dengn membagi data menjadi dua yaitu
data training dan data testing. Bentuk dari cross validation adalah k-fold cross
bagian kelompok data yang selanjutnya, data tersebut secara bergantian akan
[image:35.595.106.513.172.598.2]digunakan untuk training dan testing sejumlah k pengujian.
Tabel 2. 2 3-Fold cross validation
Training Testing
2,3 1
1,3 2
1,2 3
Misalkan untuk 3-fold cross validation data dibagi menjadi 3 bagian. Setiap
bagian yang akan digunakan unruk training dan testing secara bergantian. Dua
dari tiga bagian data digunakan untuk training maka bagian data ketiga digunakan
untuk testing (Ian H., Frank Eibe, Mark A. Hall . 2010). Jika bagian data pertama
dan kedua digunakan untuk training maka data kedua digunakan untuk testing.
Jiaka bagian data kedua dan ketiga yang digunakan untuk training maka bagian
BAB III METODOLOGI
Bab metodologi ini berisi gambaran proses yang akan dilakukan dalam
penilitian dan penjelasan cara kerja sistem, serta data sekuen protein yang
digunakan dalam penilitian.
3.1Data
Dalam penelitian ini, data yang digunakan untuk klasifikasi kanker
paru-paru dan kanker payudara dengan algoritma decision tree adalah data sekuen
protein yang berupa sekumpulan asam amino. Data sekuen protein diperoleh
dari salah satu bank protein dunia yaitu Uniprot.org dan NCBI. Data sekuen
protein yang digunakan berformat .fasta. Sekuen protein yang terdiri dari
sekumpulan asam amino. Asam amino memiliki 20 macam yaitu Alamin (A),
Arginin (R), Asparagin (N), Asam Aspartat (D), Sistein (C), Glutamin (Q),
Asam Glutamat (E), Glisin (G), Histidin (H), Isolesin (I), Lesin (L), Lisin (K),
Metionim (M), Femilalanim (F), Prolin (P), Serin (S), Treonin (T), Triptofan
(W), Tirosin (Y), Valin (V). Data sekuen protein yang digunakan bertipe
String dengan panjang sekuen yang beda-beda pada setiap data.
Data sekuen protein yang digunakan dipre-processing dan diekstraksi ciri
terlebih dahulu sebelum digunakan dalam proses klasifikasi dengan algoritma
decision tree. Tahap pertama dilakukan adalah pre-prosesing yaitu dengan mentrasformasikan data asam amino yang bertipe String menjadi numerik
menggunakan EIIP based protein value tahap kedua adalah ektraksi ciri yaitu
mengubah data bertipe numeric yang berupa time based menjadi sinyal
frequency based mengunakan FFT dan tahap yang terakhir ekstraksi ciri menggunakan LPC dan turunan LPC dengan order 8 dan 12 untuk
dicleaning yaitu dengan menganti data yang memiliki missing value berupa
nilai NaN dengan nilai 0.
Untuk penelitian ini data yang digunakan sebanyak 417 sekuen protein
asam amino yang terdiri dari :
a. 37 sekuen protein asam amino manusia sehat
b. 255 sekuen protein asam amino kanker paru-paru (lung cancer)
c. 125 sekuen protein asam amino kanker payudara (breast cancer)
[image:37.595.102.516.182.647.2]Contoh data sekuen protein asam amino jenis lung cancer yang digunakan:
Tabel 3 1 Contoh data sekuen protein
>sp|O14672|ADA10_HUMAN Disintegrin and metalloproteinase
domain-containing protein 10 OS=Homo sapiens GN=ADAM10 PE=1
SV=1
MVLLRVLILLLSWAAGMGGQYGNPLNKYIRHYEGLSYNVDSL
HQKHQRAKRAVSHEDQFLRLDFHAHGRHFNLRMKRDTSLFSD
EFKVETSNKVLDYDTSHIYTGHIYGEEGSFSHGSVIDGRFEGFIQ
TRGGTFYVEPAERYIKDRTLPFHSVIYHEDDINYPHKYGPQGGC
ADHSVFERMRKYQMTGVEEVTQIPQEEHAANGPELLRKKRTT
SAEKNTCQLYIQTDHLFFKYYGTREAVIAQISSHVKAIDTIYQTT
DFSGIRNISFMVKRIRINTTADEKDPTNPFRFPNIGVEKFLELNSE
QNHDDYCLAYVFTDRDFDDGVLGLAWVGAPSGSSGGICEKSK
LYSDGKKKSLNTGIITVQNYGSHVPPKVSHITFAHEVGHNFGSP
HDSGTECTPGESKNLGQKENGNYIMYARATSGDKLNNNKFSL
CSIRNISQVLEKKRNNCFVESGQPICGNGMVEQGEECDCGYSD
QCKKRRRPPQPIQQPQRQRPRESYQMGHMRR
3.2Metode Penelitian
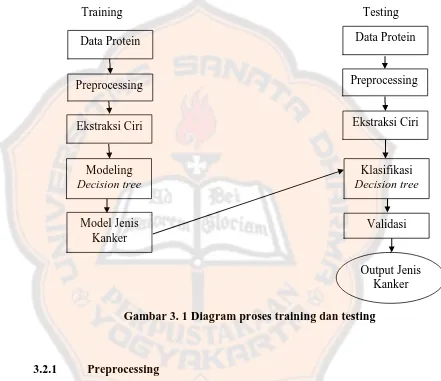
Metode penelitian menjelaskan urutan proses yang dilakukan dalam sistem
dengan dataset masukan berupa data protein berformat .fasta. Proses pelatihan
berupa tree. Proses pengujian sistem atau testing bertujuan sebagai pengenalan
atau penentuan jenis kanker. Proses training terdiri dari ekstraksi ciri dan
klasifikasi decision tree untuk membentuk model. Proses testing terdiri dari
ekstraksi ciri, klasifikasi dan validasi sehingga terbentuk presentase akurasi.
[image:38.595.98.539.195.576.2]Alur proses dari sistem bisa dilihat pada block diagram pada gambar 3.1 :
Gambar 3. 1 Diagram proses training dan testing
3.2.1 Preprocessing
Tahap pre-processing merupakan tahapan awal dalam mengolahan data
inputan sebelum masuk pada proses klasifikasi. Data yang
diprocessing kemudian akan masuk dalam tahap ekstraksi ciri. Tahap
pre-processing pada penelitian ini menggunakan Electron- Ion Interaction
Potential (EIIP) yang merupakan based protein value. Data Protein
Ekstraksi Ciri
Training Testing
Modeling Decision tree
Model Jenis Kanker
Data Protein
Ekstraksi Ciri
Klasifikasi Decision tree
Validasi
Output Jenis Kanker
Preprocessing Preprocessing
Data Sekuen
Protein
Gambar 3. 2 Diagram Preprocessing
Langkah pertama tahap pre-processing adalah data sekuen protein dengan
format .fasta memilki dua bagian yaitu header dan sequence, bagian sequence
yang berupa 1-latter code dari asam amino yang akan digunakan dalam tahap
pre-processing menggunakan EIIP based protein value. Fungsi dari EIIP
adalah mentransformasikan sequence yang bertipe String menjadi numerik
berdasarkan nilai asam amino yang telah ditetapkan pada tabel 2. EIIP value
amino acid. Berikut ini adalah contoh sequence yang telah ditransformasikan, yang divisualisasikan pada grafik seperti gambar 3.3 :
Gambar 3. 3Grafik sekuen protein asam amino A2KUC3 yang telah ditrasformasikan dengan EIIP based protein value
3.2.2 Ekstraksi Ciri
Ekstraksi ciri merupakan proses mendapatkan ciri dari data yang sudah
dikumpulkan, tujuan ekstraksi ciri ini adalah mendapatkan ciri penting dari
[image:39.595.172.490.727.788.2]Gambar 3. 4 Diagram ekstraksi ciri
Sekuen protein asam amino yang telah ditransformasikan menjadi
numerik menggunakan EIIP based protein value , selanjutnya masuk kedalam
proses ekstraksi ciri dengan menggunakan Fast Fourier Transform (FFT)
yaitu mengubah sinyal time base (hasil pre-processing) menjadi sinyal
[image:40.595.101.504.193.609.2]frequency based. Hasil dari proses FFT bisa dilihat pada grafik steam gambar dibawah ini :
Gambar 3. 5 Sinyal stem ekstraksi ciri dengan FFT pada sekuen protein A2KUC3
Data yang telah diubah menjadi sinyal frequency based, selanjutnya
ekstraksi ciri lagi dengan LPC. Fungsi LPC adalah untuk mendapatkan ciri
dari setiap data yaitu dengan menghapus redundansi pada sinyal. Order yang
digunakan dalam penelitian ini adalah order 8 dan order 12. Pemilihan order
LPC berhubungan dengan pole, dimana pole yang berhubungan pada
frekuensi. Pole yang biasa digunakan adalah pole 3 dan 4. Penelitian ini
merupakan nilai order pole kedua (8+4). Nilai order yang dipilih pada
penelitian ini berpengaruh pada nilai turunan LPC. Jika nilai order semakin
besar, maka nilai ciri pada turuanan dari LPC semakin kecil. Pada penelitian
ini, menggunakan 3 feature LPC yaitu LPC, delta LPC dan delta delta LPC.
Delta LPC adalah turunan pertama dari LPC dan delta delta LPC adalah
turunan kedua dari LPC. Turunan LPC digunakan untuk mendapatkan
informasi dari ciri yang dinamis dari fitur statis.
Pada order 8, setiap feature menghasilkan 8 ciri dan 1 energi. Jika semua
feature (LPC, deltaLPC, delta delta LPC) digabungkan menjadi satu, maka panjang data yang terbentuk sebanyak 27, dimana panjang data akan menjadi
atribut dari data dalam proses klasifikasi. Hasil dari proses LPC dengan
order 8 feature LPC, delta LPC dan delta delta LPC pada gambarr dibawah ini
[image:41.595.103.507.268.591.2]:
Gambar 3. 6 Sinyal stem LPC, delta LPC, delta delta LPC order 8 sekuen protein A2KUC3
Sedangkan, untuk order 12, setiap feature LPC menghasilkan 12 ciri dan
1 energi. Jika semua feature (LPC, deltaLPC, delta delta LPC) digabungkan
menjadi satu, maka panjang data yang terbentuk sebanyak 39, dimana panjang
data akan menjadi atribut dari data dalam proses klasifikasi. Hasil dari proses
LPC dengan order 12 dengan feature LPC, delta LPC dan delta delta LPC
Gambar 3. 7 Sinyal stem LPC, delta LPC, delta delta LPC order 12 sekuen protein A2KUC3
Setelah proses ektraksi ciri selasai, maka dilakukan cleaning data dari
hasil ekstraksi ciri yang memiliki missing value. Pada penelitian ini missing
value berupa nilai NaN akan diberi nilai baru yaitu nilai 0, untuk menormalisasikan nilai data tanpa merubah nilai. Proses ini melooping semua
data yang dimiliki nilai NaN pada setiap baris dan kolom.
Pada proses ini juga penambahan label data berupa kelas 1 sampai 3.
Dimana kelas 1 berupa data sehat, kelas 2 berupa data kanker paru-paru dan
kelas 3 berupa data kanker payudara. Pemberian label dilakukan secara
otomatis berdasarkan banyaknya data dari folder class (sehat, kanker
paru-paru, dan kanker payudara). Label ditaruh dibagian kolom pertama dari data
dan kolom selanjutnya berupa atribut.
3.2.3 Proses Training
Pada proses training, data dari tahap ekstraksi ciri akan diklasifikasi
dengan menggunakan algoritma decision tree. Data sekuen protein yang telah
dilakukan ekstraksi ciri akan disimpan dalam format .mat. K-fold cross
3-fold cross-validation. Proses pembagian data mengunakan cv partition milik matlab dimana data akan dipartisi sebanyak k, dimana nilai k adalah 3, data
dipartisi menjadi 3 bagian untuk data training dan 3 bagian untuk data data
testing. Data sebanyak 417 akan dibagi menjadi 3 bagian masing-masing 278 untuk training 1, 278 untuk training 2, dan 278 untuk training 3. Proses
training digunakan untuk mendapatkan model dari klasifikasi dengan menggunakan algoritma decision tree yaitu berupa tree. Berikut ini contoh
[image:43.595.105.539.235.604.2]data training 1 pada feature LPC dengan order 8.
Gambar 3. 8 Contoh data training 1 feature LPC dengan order 8
3.2.4 Tahap Klasifikasi Decision Tree
Data sekuen protein yang sudah diekstraksi ciri, selanjutnya masuk dalam
proses klasifikasikan menggunakan algoritma decision tree. Data yang telah
dipartisi menjadi training 1, training 2, dan training 3, selanjutnya tiap training
dan feature LPC dengan order 8 dan 12 akan dibuat model atau tree. Pada
penelitian ini menghasilkan 18 tree yang terbentuk berdasarkan kombanasi
greedy decision tree. Langkah membuat tree dengan algoritma greedy decision tree:
[image:44.595.99.513.130.624.2]a. Dimulai dari membuat decision tree kosong
Gambar 3. 9 decision tree kosong
b. Pisahkan pada yang memiliki atribut terbaik.
1. Hitung nilai entropy untuk semua atribut.
Entropy S = − ∑= p ∗ log p (3.1)
Lalu cari nilai binari untuk setiap atribut terhadap kelas,
nilai binary digunakan untuk perhitungan entropy terhadap
komposisi kelas.
Entropy S = −p log p − − p log − p (3.2) Dimana nilai p = 0.5 merupakan nilai p terbaik untuk
variabel binary.
Gambar 3. 10 entropy dari variabel binari
2. Hitung nilai entropy untuk semua data terhadap komposisi
kelas
Entropy S|A = ∑ |Si|
|S| ∗ Entropy S
= (3.3)
Gain S, A = Entropy S − ∑ |Si|
|S| ∗ Entropy S
[image:45.595.91.565.150.576.2]= (3.4)
Gambar 3. 11 Contoh level pertama decision tree
c. Ulangi (rekursif) langkah 2 untuk setiap daun
Gambar 3. 12 Hasil Tree yang terbentuk dari training 3
3.2.5 Pengujian
Pengujian dilakukan untuk mengetahui akurasi dari proses klasifikasi.
Akurasi merupakan presentase data yang terklasifikasi dengan benar. Dari
tahap pengujian dapat dibuktikan bahwa jenis kanker paru-paru, kanker
payudara dan sehat dapat dikenali dengan benar sesuai label. Pengujian dan
training menggunakan 3-fold cross-validation yaitu dengan membagi data Att b
menjadi tiga bagian. Data sebanyak 417 akan dibagi menjadi 3 bagian (untuk
testing) masing-masing 139, 139, 139. Dua bagian data akan digunakan untuk
training dan satu bagian digunakan untuk testing. Proses akurasi untuk menghitung nilai akurasi dengan mencocokan label kelas data testing dengan
prediksi kelas, lalu hitung data yang sama antara label kelas data testing
dengan prediksi lalu dibagi dengan jumlah data testing dan dikalikan 100 %.
Berikut ini contoh tabel validasi yaitu data pencocokan data testing.
Gambar3. 1 Contoh data pencocokan data testing
Dari tabel validasi diatas, dapat dihitung akurasi dari percobaan
yang telah dilakukan.
Akurasi =∑∑data benartotal data × % (3.5)
Keterangan :
∑ data benar = jumlah data yang benar pada kelas prediksi
BAB IV
ANALISIS HASIL DAN IMPLEMENTASI SISTEM
Pada bab ini akan dibahas hal-hal yang berkaitan dengan implentasi
sistem, hasil yang akan didapatkan dari pengujian-pengujian yang akan dilakukan,
serta analisis dari hasil pengujian.
4.1Analisis Hasil
Berdasarkan hasil pengujian yang dilakukan dengan menggunakan model
dari klasifikasi yaitu berupa tree dengan kombinasi feature LPC dan
kombinasi order dengan ketiga data training. Dari proses pengujian ini
dihasilkan nilai akurasi, nilai akurasi rata-rata, waktu pembuatan tree dan nilai
pembuatan tree rata-rata yang berbeda-beda pada setiap feature LPC. Hasil
pengujian tree yang dilakukan dengan kombinasi feature LPC dan kombinasi
order dihadirkan secara keseluruhan pada tabel yang ditunjukan pada gambar
[image:47.595.115.523.266.726.2]berikut ini.
Dari kedelapan belas pengujian feature LPC dengan data training yang
berbeda didapatkan tree yang berbeda-beda, hasil akurasi rata-rata yang paling
baik sebesar 74,82% dengan waktu rata-rata 28,34 detik dengan feature LPC
order 8 dengan nilai akurasi training yang paling baik sebesar 79.85 % dengan
waktu 29.09 detik dan feature LPC, Delta LPC order 8 memiliki nilai akurasi
rata-rat terendah yaitu sebesar 68,70% dengan waktu rata-rata 33,64 detik
dengan nilai akurasi training terrendah sebesar 64.02 dengan waktu 32,2 detik
Grafik hasil akurasi rata-rata pengujian tree ditunjukan melalui grafik dibawah
[image:48.595.101.501.247.588.2]ini :
Gambar 4. 2 Grafik akurasi rata-rata feature LPC
Nilai akurasi tree merupakan pengaruh dari besarnya range data yang
digunakan pada proses klasifikasi, dimana data berasal dari hasil ekstraksi ciri.
Range nilai atribut yang besar berpengaruh pada perhitungan entrory dan
information gain yang digunakan dalam perhitungan untuk membuat tree. Lamanya waktu pembuatan tree merupakan pengaruh dari banyaknya atribut
yang digunakan pada proses klasifikasi, dimana banyaknya atribut berasal
4.2 Analisis Coding
2.1.1. Ekstraksi Ciri
Proses Ekstraksi ciri diawali dengan tahap pre-processing data sekuen
protein, dan dilanjutkan dengan proses ekstraksi ciri. Proses ekstraksi ciri
berjalan jika tombol proses diklik kemudian semua data sekuen yang akan
digunakan dilooping satu persatu. Data sekuen protein yang tersimpan
dalam sebuah folder, untuk melakukan looping nilai i diset untuk folder
yang menunjukkan banyaknya kelas yang dimiliki, dalam penelilitian ini
ada 3, dalam setiap folder terdapat data sekuen protein yang berbeda-
beda, untuk data sehat 37 data sekuen protein, data kanker paru-paru 254
data sekuen protein dan data kanker payudara 125 data sekuen protein.
Data sekuen protein harus berformat .fasta, untuk proses looping
ditunjukan pada potongan source code berikut.
for i=1:3
folder=['C:\Users\quadran\Documents\MATLAB\decision
tree\class ',num2str(n),'\'];
j = 1;
file = [folder,'class ',num2str(n),' (',num2str(j),').fasta']; Kode Program 4. 1 Looping data sekuen protein
Proses pre-processing data sekuen protein menggunakan EIIP
based protein value, yaitu mentransformasikan data sekuen protein berformat String menjadi berformat numerik, untuk proses pre-processing
ditunjukan pada potongan source kode berikut.
while exist(file, 'file') == 2 %ekstraksi ciri
[f,databaru] = preprosses(file);
Kode Program 4. 2 Pre-processing data sekuen protein
Proses transformasi dengan EIIP based protein value. Tahap
pertama yang dilakukan membaca data sekuen protein berformat .fasta
dengan menggunakan fungsi fastaread milik matlab, bagian data yang
digunakan adalah bagian sequence yang berisi single letter-code dari asam
EIIP based protein value. Berikut ini potongan source code transformasi
EIIP.
a=fastaread(x); s=a.Sequence; l = length(s);
ds = [];
for i = 1:l hr = s(i); if hr == 'L'
ds(i)=0.0000; elseif hr == 'I'
ds(i)=0.0000; elseif hr == 'N'
ds(i)=0.0036; elseif hr == 'G'
ds(i)=0.0050; elseif hr == 'V'
ds(i)=0.0057; elseif hr == 'E'
ds(i)=0.0058; elseif hr == 'P'
ds(i)=0.0198; elseif hr == 'H'
ds(i)=0.0242; elseif hr == 'K'
ds(i)=0.0371; elseif hr == 'A'
ds(i)=0.0373; elseif hr == 'Y'
ds(i)=0.0516; elseif hr == 'W'
ds(i)=0.0548; elseif hr == 'Q'
ds(i)=0.0761; elseif hr == 'M'
ds(i)=0.0823; elseif hr == 'S'
ds(i)=0.0829; elseif hr == 'C'
ds(i)=0.0829; elseif hr == 'T'
ds(i)=0.0941; elseif hr == 'F'
ds(i) =0.0956; elseif hr == 'D'
ds(i)=0.1263; end
end
f=ds;
Kode Program 4. 3 Transformasi sekuen protein menggunakan EIIP based value protein
Proses selanjutnya adalah ektraksi ciri menggunakan FFT. Data sekuen
protein ditransformasikan menjadi data bertipe numerik diekstraksi ciri menjadi
sinyal frequency based dengan menggunakan FFT. FFT berfungsi mengubah
sinyal dari time-base menjadi frequency-base (Yan-Zhi GUO, Meng-Long L, et
al. 2005). Proses ini menggunakan function FFT milik matlab, yang ditunjukan
pada potongan source code berikut.
%fft
FreqBase = fft(ds);
plot(1:l,abs(FreqBase(1:l)));figure(gcf);
Kode Program 4. 4 Proses FFT data sekuen protein
Data sekuen protein yang telah menjadi sinyal frequency-base selanjutnya
diekstraksikan ciri kembali dengan mengunakan LPC dan turunan dari LPC (delta
LPC dan delta delta LPC). LPC digunakan untuk menyeragamkan panjang sinyal
yang ditentukan berdasarkan order dan mendapatkan ciri dari setiap data. Pada
penelitian ini order yang digunakan adalah order 8 dan order 12. Berikut ini
adalah potongan source code dari function dolpc.m dan deltas.m
[nbands,nframes] = size(x);
if nargin < 2 modelorder = 8;
end
% Calculate autocorrelation
r = real(ifft([x;x([(nbands-1):-1:2],:)])); % First half only
r = r(1:nbands,:);
% Find LPC coeffs by durbin [y,e] = levinson(r, modelorder); % Normalize each poly by gain y = y'./repmat(e',(modelorder+1),1);
end
if nargin < 2 w = 9;
end
[nr,nc] = size(x);
if nc == 0
% empty vector passed in; return empty vector d = x;
else
% actually calculate deltas
% Define window shape
hlen = floor(w/2); w = 2*hlen + 1; win = hlen:-1:-hlen;
% pad data by repeating first and last columns
xx = [repmat(x(:,1),1,hlen),x,repmat(x(:,end),1,hlen)];
% Apply the delta filter
d = filter(win, 1, xx, [], 2); % filter along dim 2 (rows)
% Trim edges
d = d(:,2*hlen +