KLASIFIKASI FORMULA JAMU BERDASARKAN KHASIAT
MENGGUNAKAN
OBLIQUE DECISION TREE
DENGAN
OPTIMASI MENGGUNAKAN ALGORITME GENETIKA
DELLY FAHLEVI MEIDIKA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Formula Jamu Berdasarkan Khasiat Menggunakan Oblique Decision Tree Dioptimasi Algoritme Genetika adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2014
Delly Fahlevi Meidika
ABSTRAK
DELLY FAHLEVI MEIDIKA. Klasifikasi Formula Jamu Berdasarkan Khasiat Menggunakan Oblique Decision Tree dengan Optimasi Menggunakan Algoritme Genetika. Dibimbing oleh WISNU ANANTA KUSUMA dan RUDI HERYANTO.
Indonesia kaya akan keragaman hayati termasuk berbagai macam tanaman obat yang dapat digunakan sebagai jamu. Penggunaan tanaman sebagai bahan pengobatan atau jamu masih terbatas. Hal ini disebabkan masih sulitnya akses terhadap informasi tanaman obat yang umumnya didapat dari buku/dokumen teks dan pengetahuan yang didapat secara turun temurun. Salah satu informasi penting yang dibutuhkan adalah khasiat yang dimiliki oleh jamu berdasarkan tanaman obat yang menyusunnya. Penelitian ini bertujuan melakukan klasifikasi khasiat jamu berdasarkan komposisi tanaman menggunakan oblique decision tree dengan optimasi menggunakan Algoritme Genetika. Hasil dari metode ini berupa sebuah pohon keputusan yang merepresentasikan penciri jenis tanaman terhadap suatu khasiat. Pendekatan menggunakan data 231 tanaman mampu memberikan akurasi sebesar 94.47%.
Kata kunci: algoritme genetika, jamu, khasiat, klasifikasi, oblique decision tree
ABSTRACT
DELLY FAHLEVI MEIDIKA. Classification of Jamu Formulas Based on Efficacy Using Oblique Decision Tree Optimized by Genetic Algorithm. Supervised by WISNU ANANTA KUSUMA and RUDI HERYANTO.
Indonesia is rich in biodiversity, consisting of a wide variety of medicinal plants. However, the use of plants as a medicinal or herbal medicine is still limited. It is difficult to find the information of medicinal plants which are generally obtained from a rare book/text document or inherited knowledge from generation to generation. One of the most important information is to determine the efficacy of an herbal formula based on medicinal plants that composing it. This research aims to develop a classification system based on the composition of medicinal efficacy of plants using oblique decision tree optimized by Genetic Algorithm. The result of decision tree determine plant identifier for each efficacy. The proposed method with data set of 231 plants is able to obtain 94.47% accuracy.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI FORMULA JAMU BERDASARKAN KHASIAT
MENGGUNAKAN
OBLIQUE DECISION TREE
DENGAN
OPTIMASI MENGGUNAKAN ALGORITME GENETIKA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Klasifikasi Formula Jamu Berdasarkan Khasiat Menggunakan
Oblique Decision Tree dengan Optimasi Menggunakan Algoritme Genetika
Nama : Delly Fahlevi Meidika NIM : G64100041
Disetujui oleh
Dr Wisnu Ananta Kusuma, MT Pembimbing I
Rudi Heryanto, MSi Pembimbing II
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah yang berjudul “Klasifikasi Formula Jamu Berdasarkan Khasiat Menggunakan Oblique Decision Tree dengan Optimasi Menggunakan Algoritme Genetika” ini berhasil diselesaikan. Tema yang dipilih dalam penelitian ini merupakan pengembangan dari proyek Praktik Kerja Lapangan (PKL) Departemen Ilmu Komputer yang penulis lakukan di Pusat Studi Biofarmaka LPPM IPB.
Terima kasih penulis ucapkan kepada Bapak Dr Wisnu Ananta Kusuma, MT dan Bapak Rudi Haryanto, MSi selaku pembimbing, Bapak Dr Heru Sukoco, SSi MT selaku penguji, serta seluruh dosen dan staf di Departemen Ilmu Komputer. Di samping itu, penulis menyampaikan terima kasih kepada teman-teman terdekat penulis, rekan-rekan Ilkomerz khususnya Pixels 47, teman-teman satu bimbingan (Alfat, Yuda, Gerry, Huda dan Bang Dan) yang telah saling memberi semangat dan bantuannya untuk menyelesaikan penelitian. Ungkapan terima kasih yang terutama penulis sampaikan kepada kedua orang tua penulis, Nanang Kusmana dan Sri Suprihatin, kakak dan adik penulis serta seluruh keluarga, atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2014
Delly Fahlevi Meidika
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Data Penelitian 2
Tahapan Penelitian 3
Akuisisi Data 3
Praproses Data 3
Proses Booleanize 5
Pembagian data 5
Oblique Decision Tree – Genetic Algorithm 5
Evaluasi 7
Lingkungan Pengembangan 7
HASIL DAN PEMBAHASAN 7
Hasil 7
Pembahasan 11
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 13
DAFTAR PUSTAKA 13
LAMPIRAN 15
DAFTAR TABEL
1 Data I khasiat formula jamu 4
2 Data II khasiat formula jamu 4
3 Ilustrasi proses booleanize 5
4 Nilai parameter percobaan 7
5 Nilai akurasi set data 8
6 Confusion matrix Data I 8 7 Confusion matrix Data II 9
DAFTAR GAMBAR
1 Skema tahapan penelitian 3
2 Skema optimasi algoritme genetika 6
3 Ilustrasi proses crossover 6
4 Grafik akurasi tiap khasiat pada Data I dan Data II 9 5 Perbandingan akurasi metode PLS-DA, SVM dan ODT-GA 10 6 Tree keluaran hasil proses ODT-GA 11 7 Contoh potongan tree setelah divisualkan dalam bentuk asli 11
8 Contoh potongan tree hasil pruning 12
DAFTAR LAMPIRAN
1 Screenshot aplikasi 15
2 Pengkodean tanaman 17
3 Contoh sebagian data formula jamu 19
4 Decision tree hasil ODT-GA 20
PENDAHULUAN
Latar Belakang
Pengetahuan tentang obat herbal tradisional yang diolah menjadi jamu menjadi warisan budaya yang telah turun temurun diwariskan antar generasi. Bahan alami penyusun jamu dapat berupa akar, daun, kayu dan buah-buahan. Menurut Mahady (2001), penggunaan jamu sebagai pengobatan alternatif mengalami peningkatan. Orang-orang mulai mempertimbangkan jamu sebagai obat yang aman dan manjur yang telah terbukti secara empiris selama ratusan tahun.
Upaya sistematis dengan menggunakan pendekatan statistik untuk menemukan hubungan antara komposisi dan khasiat jamu telah dilakukan oleh Afendi et al. (2012). Penelitian ini menunjukan bahwa formula jamu dengan khasiatnya memiliki aktivitas farmakologi tertentu. Dikembangkan pula hipotesis dalam penelitian ini bahwa suatu formula jamu terdiri atas tanaman utama dengan khasiat utamanya dan tanaman pendukung dengan sekurangnya harus memiliki karakteristik analgesik, antimikroba, dan anti-peradangan. Dalam penelitian tersebut digunakan metode Partial Least Squares Discriminant Analysis (PLS-DA) untuk mengembangkan model klasifikasi formula jamu.
Dalam penelitian lain yang dilakukan oleh Fitriawan (2013), dikembangkan sistem klasifikasi formula jamu dengan khasiatnya menggunakan teknik Support Vector Machine (SVM). SVM adalah salah satu teknik machine learning yang mampu mengklasifikasikan masalah di dunia nyata dengan hasil akurasi yang tinggi (Byun dan Lee 2003). Penelitian ini memberikan hasil yang lebih baik dibandingkan dengan metode PLS-DA pada data yang melalui data cleaning.
Pada penerapan kedua metode diatas dalam melakukan klasifikasi formula jamu, masih sering terdapat perbedaan dalam hasil klasifikasinya, sehingga dibutuhkan satu cara klasifikasi formula jamu dengan metode lain untuk menghasilkan pendekatan sistem yang lebih akurat. Salah satu metode yang dapat diterapkan adalah Oblique Decision Tree optimized by Genetic Algorithm (ODT-GA). Metode ini menghasilkan aturan-aturan atau rules yang terangkum menjadi sebuah pohon keputusan. Metode ini juga memiliki beberapa kelebihan, seperti fleksibel dalam skala hingga dimensi besar dan dapat diimplementasikan secara paralel (Cantú-Paz dan Kamath 2003).
Hasil dari penelitian ini akan dibandingkan dengan penelitian sebelumnya yang menggunakan PLS-DA (Afendi et al. 2012) dan SVM (Fitriawan 2013). Juga akan dilakukan perbandingan antara daftar tanaman yang berpengaruh terhadap suatu khasiat tertentu hasil keluaran dari metode VFI5. Diharapkan dengan adanya metode ini dapat menjadi dasar untuk mengembangkan sistem klasifikasi khasiat formula jamu baru yang lebih akurat.
Perumusan Masalah
Adapun masalah yang akan diangkat dalam penelitian ini adalah pencarian
2
metode ODT-GA dapat menjadi sebuah metode yang baik untuk memprediksi khasiat formula jamu baru.
Tujuan Penelitian
Tujuan dari penelitian ini adalah membuat model klasifikasi tanaman berdasarkan khasiat jamu dengan menggunakan metode ODT-GA. Nilai akurasi model yang diperoleh akan dibandingkan dengan nilai akurasi dari metode PLS-DA dan SVM. Selanjutnya menganalisis model tersebut dan membandingkan dengan hasil dari keluaran metode VFI5.
Manfaat Penelitian
Hasil dari dilakukannya penelitian ini diharapkan dapat menjadi sebuah teknik baru dalam pengembangan sistem untuk menentukan formula jamu berdasarkan khasiat. Pada akhirnya, hasil dari penelitian ini dapat digunakan sebagai model penentuan formula jamu beserta khasiatnya.
Ruang Lingkup Penelitian
Ruang lingkup dalam penelitian ini adalah:
1 Menggunakan data yang sama dengan penelitian sebelumnya (Fitriawan 2013) yaitu data reduksi yang terdiri atas 2748 formula jamu dari 231 jenis tanaman. 2 Implementasi metode menggunakan metode ODT-GA menggunakan perangkat
lunak Keel Tool 2.0.
METODE
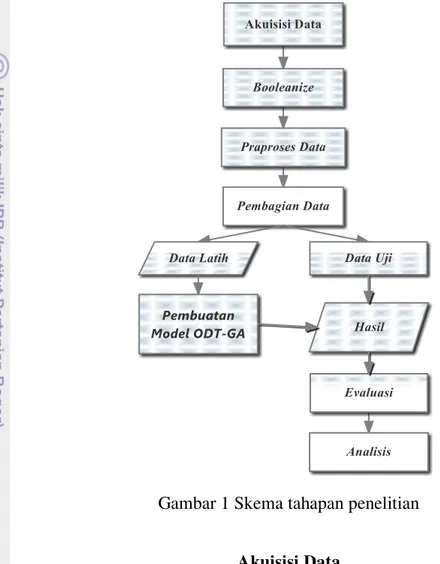
Penelitian ini menggunakan metode ODT-GA sebagai pembuat model untuk klasifikasi. Tahapan pada penelitian ini terdiri atas akuisisi data, booleanize, praproses data, pembagian data, ODT-GA dan evaluasi.
Data Penelitian
3
Tahapan Penelitian
Tahapan-tahapan yang dilakukan pada penelitian ini terdiri atas akuisisi data,
booleanize, praproses data, pembagian data, pembuatan model dengan metode ODT-GA dan evaluasi. Alur penelitian dapat dilihat pada Gambar 1.
Akuisisi Data
Data terdiri atas 2748 formula jamu yang terdaftar di Badan Pengawasan Obat dan Makanan (Badan POM) dengan disertai komposisi masing-masing jamu dari 231 jenis tanaman. Keseluruhan data jamu masuk kedalam tepat satu kelas khasiat dari total 9 kelas khasiat. Keseluruhan kelas khasiat dapat dilihat pada Tabel 1. Data ini kemudian disebut sebagai Data I atau data asli.
Praproses Data
Pada data penelitian ini ditemukan masalah imbalance data, yaitu tidak seimbangnya persebaran jumlah data pada masing-masing kelas. Ini dapat mempengaruhi ketepatan dalam proses klasifikasi (Chawla et al. 2002). Untuk itu akan dilakukan praproses data untuk over-sampling dengan metode Synthetic Minority Over-sampling Technique (SMOTE). Digunakannya metode ini untuk
4
over-sampling karena dengan metode ini dapat menambah akurasi proses klasifikasi untuk kelas yang memiliki jumlah data sedikit (kelas minor). Penggunaan metode SMOTE dikombinasikan dengan random under-sampling
akan menghasilkan hasil klasifikasi yang lebih baik dibandingkan hanya under-sampling biasa (Chawla et al. 2002).
Tahapan pertama dari proses ini adalah dengan membangkitkan data buatan pada kelas minor. Data dibangkitkan dengan memilih beberapa tetangga terdekat secara acak dari kelas minor, selanjutnya dilakukan proses perhitungan terhadap beberapa data pilihan tersebut hingga didapatkan data buatan baru. Proses tersebut dilakukan sampai seluruh kelas minor mencapai jumlah kelas minimal yang ditentukan. Setelah proses pembangkitan data buatan, dilakukan proses penghapusan secara acak terhadap kelas yang memiliki data melebihi jumlah yang telah ditentukan. Proses ini disebut random under-sampling.
Pada penerapan SMOTE dan under-sampling digunakan bantuan perangkat lunakWeka 3.6. Data yang telah dilakukan praproses ini kemudian disebut Data II dan ditunjukan seperti pada Tabel 2.
Tabel 2 Data II khasiat formula jamu
Nama Khasiat Kode
Khasiat
Jumlah formula jamu
Urinary related problems Disorder of apetite
Disorder of mood and behavior Gastrointestinal disorders
Female reproductive organ problems
Muskuloskeletal and connective tissue disorders Pain and inflammation
Espiratory disease
Wounds and skin infections
E1
Tabel 1 Data I khasiat formula jamu
Nama Khasiat Kode
Khasiat
Jumlah formula jamu
Urinary related problems Disorder of apetite Disorder of mood and behavior
Gastrointestinal disorders Female reproductive organ problems Muskuloskeletal and connective tissue disorders
Pain and inflammation Espiratory disease Wounds and skin infections
5
Proses Booleanize
Dalam proses booleanize dikodekan atribut jenis tanaman yang terdiri 231 tanaman dari P001 sampai P465 dengan biner 0 dan 1 pada setiap formula jamu. Pengkodean ini mengikuti pengkodean penelitian sebelumnya (Fitriawan 2013). Angka 0 menunjukan di dalam formula jamu tidak terdapat tanaman tersebut sebaliknya angka 1 menunjukan adanya tanaman tersebut dalam formula jamu seperti ditunjukan pada Tabel 3.
Pembagian data
Data dibagi menjadi data latih dan data uji pada setiap set data. Pembagian data menggunakan k-fold cross validation dengan nilai k=5 dan k=10. Untuk nilai
k=5, data dibagi menjadi 5 subset, yaitu fold 1, fold 2, fold 3, fold 4 dan fold 5.
Pelatihan data dilakukan dengan 4 subset fold dan diuji dengan 1 subset fold.
Dilakukan pengulangan sebanyak 5 kali sampai setiap subset telah menjadi fold
pelatih dan fold penguji. Begitu pula dengan nilai k=10 data akan dibagi menjadi 10 subset dan diproses mirip seperti k=5.
Oblique Decision Tree – Genetic Algorithm
Decision tree atau pohon keputusan merupakan salah satu metode machine learning yang cukup popular untuk melakukan klasifikasi. Kebanyakan algoritme pohon keputusan dalam proses pemisahan node menggunakan hyperplane yang paralel dengan salah satu sumbu, sehingga sering disebut axis-parallel. Berbeda dengan oblique decision tree, hyperplane yang dibentuk tidak selalu paralel dengan sumbu. Dalam beberapa kasus hal ini membuat tree yang dihasilkan lebih akurat.
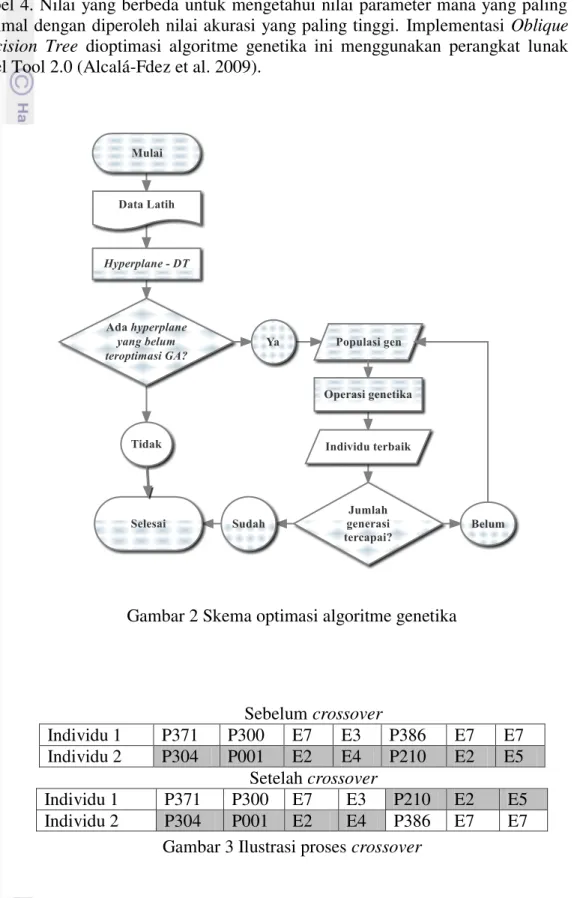
Pendekatan algoritme genetika digunakan pada pembuatan pohon keputusan untuk menemukan pemisah node atau hyperplane yang cocok. Pada kebanyakan algoritme, proses penentuan pemisah ditentukan melalui proses heuristik Greedy Search. Pada kasus ini dilakukan optimasi dengan algoritme genetika untuk mengganti proses greedy search. Tree direpresentasikan dalam bentuk gen yang memiliki nilai berupa node untuk selanjutnya dilakukan proses sesuai dengan algoritme genetika. Alur optimasi menggunakan algoritme genetika ditunjukan oleh Gambar 2.
Tabel 3 Ilustrasi proses booleanize
6
Pada penelitian ini digunakan algoritme genetika dengan prinsip pairwise tournament selection tanpa adanya replacement atau penggantian. Digunakan juga
uniform crossover dengan nilai 1 tanpa adanya proses mutasi. Ilustrasi proses
crossover ditunjukan oleh Gambar 3. Sedangkan nilai parameter yang akan diujikan adalah nilai k pada fold validation dan nilai jumlah generasi seperti ditunjukan pada Tabel 4. Nilai yang berbeda untuk mengetahui nilai parameter mana yang paling optimal dengan diperoleh nilai akurasi yang paling tinggi. Implementasi Oblique Decision Tree dioptimasi algoritme genetika ini menggunakan perangkat lunak Keel Tool 2.0 (Alcalá-Fdez et al. 2009).
Gambar 2 Skema optimasi algoritme genetika
Sebelum crossover
Individu 1 P371 P300 E7 E3 P386 E7 E7 Individu 2 P304 P001 E2 E4 P210 E2 E5
Setelah crossover
Individu 1 P371 P300 E7 E3 P210 E2 E5 Individu 2 P304 P001 E2 E4 P386 E7 E7
7
Evaluasi
Evaluasi dilakukan untuk menentukan nilai akurasi atau kinerja dari model klasifikasi yang dihasilkan. Nilai akurasi didapat dari jumlah benar hasil prediksi dibandingkan dengan jumlah data uji. Proses evaluasi ini menggunakan confusion matrix.
akurasi =∑data uji benar
∑data uji ×100%
Selain dihitung nilai akurasinya, dari model klasifikasi berupa decision tree
yang dihasilkan juga akan diperiksa nilai kedekatannya dengan data tanaman yang paling berpengaruh terhadap suatu khasiat tertentu dari metode VFI5. Decision tree
yang akan digunakan, sebelumnya telah dilakukan proses pruning, untuk menghilangkan atau mengurangi noise yang kemungkinan ada saat training data
(Han dan Kamber 2006).
Lingkungan Pengembangan
Proses analisis dilakukan menggunakan perangkat lunak Weka 3.6 dan library komputasi Keel Tool 2.0(Alcalá-Fdez et al. 2009). Implementasi Sistem klasifikasi Formula Jamu Berdasarkan Khasiat Menggunakan Oblique Decision Tree
Dioptimasi Algoritme Genetika pada penelitian ini berbasis web dengan menggunakan PHP sebagai bahasa pemrograman dan menggunakan MySQL sebagai database management system.
HASIL DAN PEMBAHASAN
Hasil
Setiap set data yang telah dilakukan percobaan dengan penggantian nilai parameter memberikan hasil berupa akurasi yang ditunjukan pada Tabel 5. Nilai akurasi tertinggi untuk Data I (data tanpa praproses data) adalah 94.47% dengan nilai parameter k=10 dan jumlah generasi=50; nilai akurasi tertinggi untuk Data II (data dengan praproses data) adalah 95.19% dengan nilai parameter k=10 dan jumlah generasi=50. Masing-masing parameter dengan nilai akurasi tertinggi pada
Tabel 4 Nilai parameter percobaan
Parameter Nilai parameter
k-fold validation Jumlah generasi
8
tiap set data akan digunakan untuk analisis selanjutnya.
Nilai akurasi dari Data I dengan nilai parameter yang telah ditentukan dapat dihitung dari confusion matrix yang disajikan pada Tabel 6.
akurasi =5 +217+8+719+346+763+281+82+1242748 ×100%=94.47%
Nilai akurasi yang didapatkan pada Data I adalah sebesar 94.47%, nilai yang sudah cukup baik untuk membuat model klasifikasi. Confusion matrix untuk Data II disajikan pada Tabel 7.
Dari perhitungan akurasi pada Tabel 7, didapat nilai akurasi sebesar 95.19%. Nilai akurasi ini lebih tinggi dari Data I karena pada Data II telah dilakukan telah dilakukan praproses balancing data dari data asli. Data yang persebarannya belum merata diseimbangkan dengan metode SMOTE dan under-sampling. Praproses ini berhasil meningkatkan nilai akurasi dibandingkan dengan Data I.
akurasi =303+289+304+291+273+283+284+2952748 ×100%=9 .19% Tabel 6 Confusion matrix Data I Tabel 5 Nilai akurasi set data
Data Nilai k Jumlah generasi
9
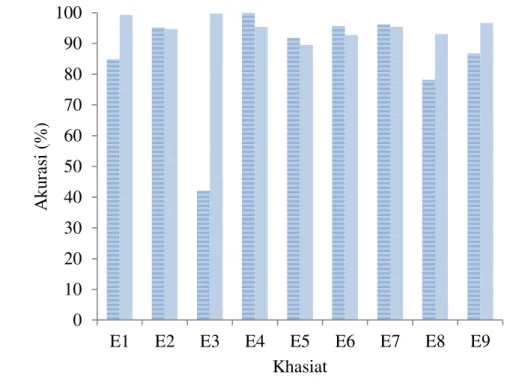
Pada Gambar 4 terlihat kedua penyebaran akurasi masing-masing khasiat dari Data I dan Data II. Data I memiliki akurasi lebih baik pada 5 dari 9 khasiat dibanding Data II. Tapi ketika akurasi khasiat Data II yang lebih baik, selisih akurasinya cukup jauh. Bisa dilihat seperti pada khasiat Disorder of mood and behavior Data I hanya memberikan nilai akurasi kurang dari setengah dari nilai akurasi yang diberikan Data II. Ini dikarenakan pada khasiat Disorder of mood and behavior termasuk kelas minor, atau kelas yang memiliki jumlah formula jamu sedikit dengan hanya 19 formula jamu. Pada Data II yang telah dilakukan proses
balancing SMOTE, berhasil menaikan nilai akurasi dari kelas Disorder of mood and behavior yang merupakan kelas minor.
Tabel 7 Confusion matrix Data II Khasiat
10
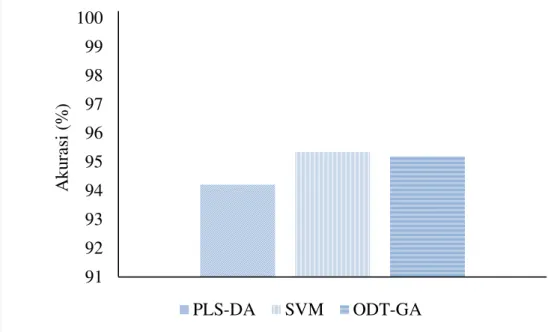
Ketika dilakukan perbandingan akurasi antar metode seperti pada Gambar 5, nilai akurasi metode SVM masih yang tertinggi dengan 95.34%, selanjutnya tertinggi kedua adalah metode ODT-GA dengan akurasi 95.19% dan terakhir metode PLS-DA dengan akurasi 94.21%. Akurasi dari ketiga metode tidak begitu terlampau jauh, selisih terbesar hanya 1.13% ini membuat akurasi ketiga metode tidak berbeda nyata. Meskipun nilai akurasi metode ODT-GA masih kalah ketika dibandingkan akurasi metode SVM, tapi dalam hal ini metode ODT-GA memiliki kelebihan yaitu dapat memberikan daftar tanaman yang berpengaruh terhadap suatu khasiat tertentu yang tidak dapat diberikan oleh SVM. Hal ini dapat membantu dalam pengambilan pilihan tanaman awal apa saja untuk suatu khasiat tertentu.
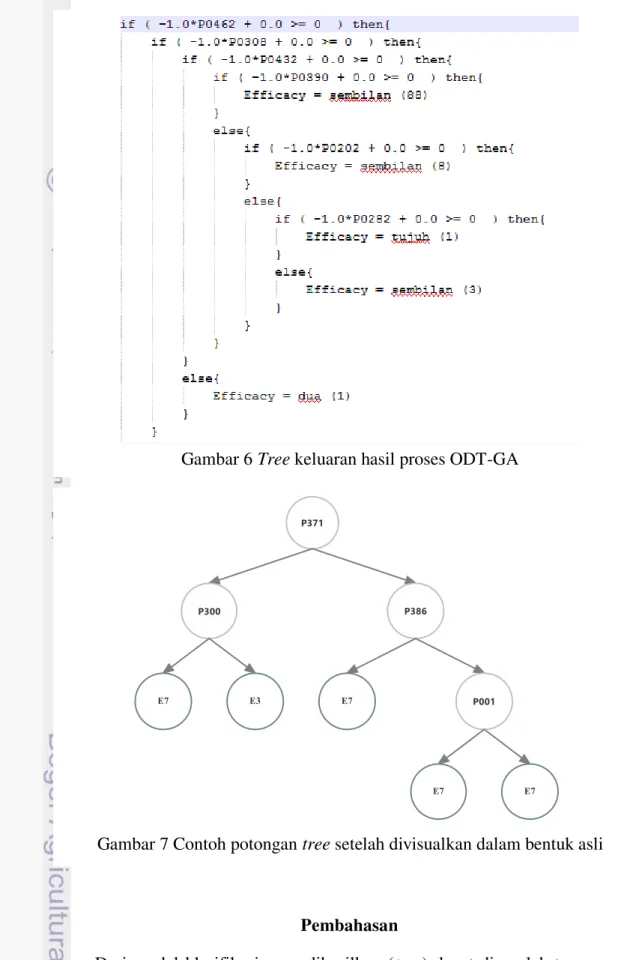
Model klasifikasi yang dihasilkan dari metode ODT-GA adalah pohon keputusan dalam bentuk teks. Tree yang dihasilkan berbentuk binary tree sehingga setiap node selain leaf pasti memiliki tepat 2 node anak. Tree ini dibentuk dari aturan IF-Else yang bersarang. Contoh potongan tree yang dihasilkan dapat dilihat pada Gambar 6.
Tree yang berbentuk teks kemudian diolah menjadi bentuk visual tree asli secara manual sehingga akan didapatkan bentuk tree seperti pada Gambar 6. Tree
yang dihasilkan memiliki kedalaman=38 dan jumlah leaf=141. Pada tree yang dihasilkan masih perlu dilakukan proses pruning atau pemangkasan, karena masih didapat node-node yang tidak efektif. Seperti pada Gambar 4, karena anak-kiri dari
node P386 berupa leaf (E7), kedua anak P001 berupa leaf (E7 dan E7), dan kesemua
leaf dalam satu keturunan tertentu memiliki nilai yang sama, maka satu keturunan tersebut dapat dihilangkan dan diganti dengan nilai pada leaf-nya. Contoh, setelah dilakukan pruning, maka potongan tree pada Gambar 6 akan menjadi seperti potongan tree pada Gambar 7. Tree hasil pruning memiliki kedalaman=30 dan jumlah leaf = 94.
11
Pembahasan
Dari model klasifikasi yang dihasilkan (tree) dapat diperoleh tanaman apa saja yang berpengaruh dalam suatu khasiat tertentu. Hal itu dapat diketahui dengan
Gambar 6 Tree keluaran hasil proses ODT-GA
12
melihat tanaman apa yang merupakan induk dari leaf-kiri suatu khasiat. Contoh sederhana bisa dilihat dari Gambar 5, induk dari leaf-kiri E7 adalah P300, ini berarti salah satu tanaman yang berpengaruh di khasiat Pain and inflammation (E7) adalah
Panax pseudoginseng (P300).
Daftar tanaman yang berpengaruh pada suatu khasiat tertentu yang dihasilkan lalu dibandingkan dengan daftar tanaman yang berpengaruh pada suatu khasiat tertentu yang dihasilkan oleh metode Voting Feature Interval 5 (VFI5) yang telah ditemukan sebelumnya. Dari hasil perbandingan, kesemua tanaman yang berpengaruh hasil dari metode ODT-GA terdapat di tanaman yang berpengaruh hasil dari metode VFI5.
Evaluasi menggunakan data tanaman yang berpengaruh di suatu khasiat hasil dari metode VFI5 juga dilakukan pada tree hasil pemodelan ODT-GA. Dari 94
leaves yang ada dalam tree terdapat 11 perbedaan dalam penentuan tanaman yang berpengaruh atau tidak terhadap suatu khasiat, atau dapat dikatakan metode ODT-GA memiliki kesamaan dalam klasifikasi dengan metode VFI5 sebesar 86.17%.
Selain menghasilkan daftar tanaman yang berpengaruh terhadap suatu khasiat, model tree ini juga dapat menghasilkan beberapa tanaman yang tidak berpengaruh signifikan atau tidak direkomendasikan terhadap suatu khasiat. Ini dimungkinkan karena pada data formula jamu, tanaman tersebut tidak pernah dipakai atau sangat sedikit sekali dipakai untuk tujuan khasiat tertentu. Terdapat 14 tanaman yang diindikasikan tersebut. Itu ditunjukan dengan suatu tanaman menjadi induk dari
leaf-kanan suatu khasiat. Ketika dibandingkan dengan hasil dari metode VFI5, hanya ada 5 tanaman yang beririsan atau diindikasikan sama. Kelima tanaman itu adalah tanaman Areca catechu dan Ficus deltoidea pada khasiat Disorder of apetite, Panax pseudoginseng pada khasiat Disorder of mood and behavior, Trigonella foenum-graecum pada khasiat Muskuloskeletal and connective tissue disorders, dan
Imperata cylindrical pada khasiat Espiratory disease.
13
SIMPULAN DAN SARAN
Simpulan
Penelitian ini berhasil membuat model klasifikasi formula jamu berdasarkan khasiat dengan metode oblique decision tree dengan optimasi menggunakan algoritme genetika. Akurasi yang didapat dari metode ini sebesar 94.47% dan dengan data yang telah dilakukan proses penyeimbangan data, nilai akurasi menjadi bertambah menjadi 95.19 %. Dari hasil model klasifikasi yang berupa tree, didapat sejumlah tanaman yang berpengaruh dan yang tidak berpengaruh signifikan terhadap suatu khasiat tertentu. Ini dapat menjadi salah satu rujukan dalam formulasi jamu berdasarkan komposisi tanaman untuk mencapai suatu khasiat.
Saran
Saran untuk penelitian selanjutnya adalah menambah jumlah data latih untuk setiap kelas sampai pada batas yang cukup atau memadai untuk membuat suatu model, sehingga dapat meningkatkan nilai akurasi keseluruhan sistem. Selanjutnya dengan melakukan perbaikan pada saat melakukan praproses data, seperti menggunakan metode SMOTEBoost.
Penelitian selanjutnya tentang metode ODT-GA bisa juga dilakukan dengan memakai set data yang variabel penciri tiap kelasnya merupakan mayoritas atau dominan dibanding variabel yang bukan penciri. Sehingga ODT-GA dapat lebih baik dalam membuat model, tree yang dihasilkan pun akan lebih sederhana.
DAFTAR PUSTAKA
Afendi FM, Darusman LK, Morita AH, Altaf-Ul-Amin M, Takahashi H, Nakamura K, anaka K, Kanaya S. 2012. Efficacy prediction of jamu formulations by PLS Modeling. Curr Comput Aided Drug Des. 9(1):46-59. PubMed PMID: 23106776.
Alcalá-Fdez J, Sánchez L, García S, del Jesus MJ, Ventura S, Garrell JM, Otero J, Romero C, Bacardit J, Rivas VM, Fernández JC, Herrera F. KEEL: A Software Tool to Assess Evolutionary Algorithms to Data Mining Problems. Soft Computing 13:3 (2009) 307-318
Byun H, Lee SW. 2003. A survey on pattern recognition application of support vector machines. Int J Patt Recogn Artif Intell. 17(3):459-486.
14
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer PW. 2002. SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research 16: 321-357.
Fitriawan A. 2013. Sistem Klasifikasi Khasiat Formula Jamu dengan Metode Support Vector Machine [Skripsi]. Bogor (ID) : Institut Pertanian Bogor.
Han J, Kamber M. 2006. Data Mining Concepts and Techniques 2nd Ed. San
Francisco (US) : Morgan Kaufmann Pub.
15 Lampiran 1 Screenshot aplikasi
Tampilan memilih efikasi/khasiat
16
Tampilan hasil yang formula yang diharapkan sesuai dengan khasiat
17 Lampiran 2 Pengkodean tanaman
P001 Foeniculum vulgare P176 Amomum compactum P321 Prunus persica
P002 Clausena anisum-olens P180 Sauropus androgynus P322 Stachytarpheta jamaicensis
P003 Litsea chinensis P181 Usnea misaminensis P323 Hydrocotyle asiatica
P004 Glycyrrhiza uralensis P182 Aquilaria sinensis P324 Illicium verum
P006 Imperata cylindrica P183 Cinnamomum camphora P325 Carica papaya
P007 Phellodendron chinense P185 Cinnamomum cullilawan P328 Areca catechu
P008 Zanthoxylum acanthopodium P187 Cinnamomum cassia P329 Pinus merkusii
P013 Elaeocarpus grandiflora P188 Melaleuca leucadendra P332 Pygeum africanum
P020 Garcinia atroviridis P189 Parameria laevigata P333 Prunus armeniaca
P021 Tamarindus indica P190 Caesalpinia sappan P334 Mentha arvensis
P026 Atractylodis Macrocephala P191 Grewia salutaris P336 Euchresta horsfieldii
P029 Zingiber purpureum P193 Psophocarpus tetragonolobus P339 Lepiniopsis ternatensis
P031 Allium fistulosum P194 Elettaria speciosa P340 Alstonia scholaris
P033 Allium cepae P198 Parkia roxburghii P342 Pimpinella pruatjan
P034 Allium sativum P199 P345 Helicteres isora
P040 Pluchea indica P200 Strobilanthes crispus P347 Notopterygium incisum
P042 Pachyrrhizus erosus P201 Typhonium flagelliforme P349 Ceiba pentandra
P044 Strychnos ligustrina P202 Cocos nucifera P351 Rubia cordifolia
P045 Merremia mammosa P203 Rheum tanguticum P352 Trifolium pratense
P048 Cimicifuga racemosa P206 Carthamus tinctorius P355 Hibiscus sabdariffa
P053 Tinospora tuberculata P207 Aleurites moluccana P360 Laminaria japonica
P055 Pandanus conoideus P209 Phyllanthus emblica P362 Hedyotis corymbosa
P059 Clerodendron squamatum P210 Piper cubeba P363 Abrus precatorius
P061 Piper retrofractum P211 Murraya paniculata P364 Syzygium polyanthum
P066 Santalum album P212 Canangium odoratum P366 Salvia coccinea
P067 Cordyceps sinensis P214 Kaempferia galanga P367 Cistanches salsa
P068 Syzygium aromaticum P215 Tagetes erecta P369 Hemigraphis colorata
P072 Prunus cerasus P218 Terminalia catappa P370 Andrographis paniculata
P073 Phyllanthus acidus P220 Cassia alata P371 Moschosma polystachium
P075 Clematis chinensis P221 Coriandrum sativum P374 Symplocos odoratissima
P080 Cibotium barometz P223 Cinchona succirubra P375 Serenoa repens
P081 Theobroma cacao P224 Trigonella foenum-graecum P377 Brassica nigrae
P082 P226 Cola acuminata P378 Nasturtium indicum
P091 Gynura segetum P231 Portulaca oleracea P379 Schisandra chinensis
P095 Achillea santolina P233 Orthosiphon stamineus P382 Apium graveolens
P096 Graptophyllum pictum P234 Kaempferia angustifolia P386 Blumea balsamifera
P097 Plantago major P236 Curcuma longa P389 Cassia angustifolia
P098 Punica granatum P239 Cucurbita pepo P390 Cymbopogon nardus
P099 Glochidion rubrum P241 Piper nigrum P392 Crataegus pinnatifida
P101 Harpagophytum procumbens P243 Ocimum sanctum P397 Sida rhombifolia
P106 Syzygium cumini P244 Alpinia galanga P400 Silybum marianum
P107 Echinacea purpurea P245 Vetiveria zizanioides P403 Cinnamomum sintok
P110 Forsythia suspensa P247 Lavandula angustifolia P404 Piper betle Cola nitida
18
P111 Dioscorea opposite P250 Vitex trifolia P407 Talinum paniculatum
P112 Smilax zeylanica P252 Zingiber zerumbet P409 Sparganium stoloniferum
P113 Polygonum multiflorum P254 Zingiber aromaticum P410
P115 Gaultheria punctata P255 Languas galanga P411 Nyctanthes arbor-tritis
P116 Justicia gendarussa P256 Leucas lavandulifolia P415 Spatholobus suberectus
P118 Ligusticum acutilobum P258 Polygala glomerata P418 Ficus deltoidea
P119 Garcinia cambogia P259 P421 Elephantopus scaber
P120 Sanguisorba officinalis P263 Eriobotrya japonica P424 Theae sinensis
P122 Borreria hispida P266 Phaleria papuana P426 Melaleuca alternifolia
P123 Commiphora myrrha P269 Galla lusitania P427 Cyperus rotundus
P126 Panax ginseng P270 Quercus lusitanica P428 Thymus vulgaris
P128 Angelica sinensis P276 Massoia aromatica P429 Lantana camara
P129 Eleutherococcus senticosus P277 Pistacia lentiscus P431 Sonchus arvensis
P132 Equisetum debile P278 Rosa chinensis P432 Curcuma heyneana
P136 Asarum sieboldii P279 Jasminum sambac P434 Curcuma aeruginosa
P138 Magnolia officinalis P280 Morinda citrifolia P435 Kaempferia pandurata
P139 Coleus scutellarioides P281 Phyllanthus urinaria P436 Curcuma xanthorrhiza
P140 Ruta angustifolia P282 Mentha piperita P438 Curcuma zedoaria
P142 P283 Cucumis sativus P439 Fritillaria cirrhosa
P144 Zingiber officinale P292 Artemisia cina P440 Solanum verbacifolium
P145 Zingiber officinale P295 Messua ferrea P443 Solanum lycopersicum
P147 Psidium guajava P299 Pogostemon cablin P444 Tetranthera brawas
P149 Anacardium occidentale P300 Panax pseudoginseng P445 Paeonia suffruticosa
P155 Guazuma ulmifolia P303 Eclipta prostrata P446 Cassia fistula
P159 Citrus amblycarpa P307 Costus speciosus P447 Tribulus terrestris
P160 Citrus sinensis P308 Oryza sativa P449 Wolfiporia extensa
P161 Citrus aurantium P309 Sophora japonica P450 Sesbania grandiflora
P162 Citrus hystrix P311 Myristica fragrans P452 Valeriana javanica
P166 Nigella sativa P314 Pandanus amaryllifolius P456 Salix alba
P167 Cassia siamea P315 Vanilla planifolia P459 Daucus carota
P168 Terminalia bellirica P316 Momordica charantia P462 Epimedium brevicornum
P171 Baeckea frutescens P318 Eurycoma longifolia P463 Pausinystalia yohimbe
P173 Phaseolus radiatus P319 Euphorbia thymifolia P464 Olea europaea
P175 Ipomoea reptana P320 Euphorbia hirta P465 Alisma orientalis
Zea mays
Spirulina
19 Lampiran 3 Contoh sebagian data formula jamu
P444 P445 P446 P447 P449 P450 P452 P456 P459 P462 P463 P464 P465 Efficacy
20
21
Khasiat Tanaman yang berpengaruh
Urinary related problems
Disorder of apetite Disorder of mood and behavior
Wounds and skin infections
Imperata cylindrica, Plantago major, Smilax zeylanica, Zea mays, Strobilanthes crispus, Serenoa repens, Sonchus arvensis, Solanum lycopersicum, Paeonia suffruticosa
Guazuma ulmifolia, Laminaria japonica, Curcuma heyneana, Curcuma aeruginosa
Baeckea frutescens, Ipomoea reptana, Leucas lavandulifolia, Carica papaya, Valeriana javanica Pluchea indica, Punica granatum, Ligusticum
acutilobum, Baeckea frutescens, Parameria laevigata, Kaempferia angustifolia, Ocimum sanctum, Quercus lusitanica, Artemisia cina, Trifolium pratense, Piper betle, Nyctanthes arbor-tritis, Ficus deltoidea Justicia gendarussa, Zingiber officinale, Massoia aromatica, Myristica fragrans, Euchresta horsfieldii, Cyperus rotundus, Epimedium brevicornum
Foeniculum vulgare, Syzygium aromaticum, Graptophyllum pictum, Zingiber officinale, Parkia roxburghii, Typhonium flagelliforme, Cinchona succirubra, Panax pseudoginseng, Helicteres isora Clausena anisum-olens, Glycyrrhiza uralensis, Echinacea purpurea, Amomum compactum, Piper cubeba, Kaempferia galanga, Eriobotrya japonica, Euphorbia hirta, Illicium verum, Abrus precatorius, Nasturtium indicum, Thymus vulgaris, Salix alba Tinospora tuberculata, Santalum album, Aleurites moluccana, Trigonella foenum-graecum, Aloe vera, Mentha piperita, Curcuma heyneana
22
RIWAYAT HIDUP
Penulis lahir di Kota Bandung pad 30 Mei 1992. Penulis merupakan putra kedua dari tiga bersaudara pasangan Nanang Kusmana dan Sri Suprihatin. Penulis menamatkan sekolah menengah di Kabupaten Indramayu yaitu SMAN 1 Sindang pada tahun 2010 dan kemudian melanjutkan pendidikan di Institut Pertanian Bogor pada tahun yang sama melalui jalur Undangan Seleksi Masuk IPB (USMI).