i
IMPLEMENTASI ALGORITMA REDUCT BASED DECISION TREE UNTUK MENGENALI POLA KLASIFIKASI MAHASISWA YANG TERKENA SISIP
PROGRAM
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Hariyo Koco NIM : 075314005
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
IMPLEMENTATION OF REDUCT BASED DECISION TREEALGORITHM TO IDENTIFY DROP OUT STUDENTS
A Thesis
Presented as Partial Fullfillment of the Requirements
To Obtain the Sarjana Komputer Degree In Informatics Engineering Study Program
By:
Hariyo Koco NIM : 075314005
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENTS OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
HALAMAN PERSEMBAHAN
“
KEGAGALAN BUKANLAH HAL YANG MEMBUAT SAYA
MENYERAH UNTUK MERAIH MIMPI TETAPI
MERUPAKAN SEBUAH MOTIVASI UNTUK DAPAT
BANGKIT KEMBALI MERAIH MIMPI “
SEMANGAT !!!!!
KEBERHASILAN Skripsi ini aku persembahkan untuk ....
Tuhan Yesus Kristus , atas Bantuan, Persetujuan dan berkatNya
Bunda Maria, atas rahmatNya yang diberikan berlimpah kepadaku
Semua Keluargaku , Sahabat , dan Teman-teman, atas dukungan dan
doa yang telah mereka berikan kepadaku.
vii
ABSTRAK
Algoritma Reduct Based Decision Tree (RDT) adalah salah satu algoritma penambangan data yang dapat digunakan untuk menemukan pola klasifikasi dari data yang berjumlah besar. Algoritma ini mengkombinasikan teori himpunan kasar dan algoritma pohon keputusan. Tujuan dari penelitian ini adalah mengenali pola klasifikasi mahasiswa yang terkena sisip program. Pada penelitian ini algoritma RDT digunakan untuk menemukan pola klasifikasi mahasiswa yang diperkirakan terkena sisip program. Data yang digunakan dalam penelitian ini adalah data PMB Universitas Sanata Dharma (USD) Yogyakarta jalur reguler tahun 2007- 2009 dengan jumlah data sebanyak 2436 record. Komponen data PMB tersebut meliputi jenis kelamin, asal kabupaten, asal sekolah, asal kabupaten sekolah, nilai penaralan verbal, nilai kemampuan numerik, nilai penalaran mekanik, nilai hubungan ruang, nilai bahasa inggris, prioritas pilihan program studi, dan gelombang masuk. Penelitian ini menghasilkan 1258 pola klasifikasi. Dari pola yang dihasilkan ternyata mahasiswa yang berasal dari Mimika lebih banyak mengalami sisip program. Sistem yang dibangun telah diuji dengan menggunakan teknik 10-fold cross validation dan menghasilkan akurasi sebesar 56.527096 %.
viii ABSTRACT
Reduct algorithm Based Decision Tree (RDT) is one of data mining algorithms that can be used to discover the pattern classification of large amounts of data. This algorithm combines the rough set theory and decision tree algorithm. The purpose of this study is to identify drop out student in Sanata Dharma University by implementing the RDT algorithm. The data used in this research is the student admission data of Sanata Dharma University (SDU) Yogyakarta through regular line which consist of 2436 records. The data components include sex, home district, high school, school districts, the score of verbal reasoning test, numerical ability test, mechanical reasoning test, space relations test, English language test, chosen study program, and registration periods. The results of this study are 1258 classification pattern. From the resulting pattern turned out to students from Mimika more likely to "Sisip Program". The system has been tested by using 10-fold cross validation and produces an accuracy of 56,527096 %.
x
KATA PENGANTAR
Puji dan syukur kehadirat Tuhan Yang Maha Esa, karena pada akhirnya penulis dapat menyelesaikan penelitian tugas akhir ini yang berjudul “Implementasi Algoritma Reduct Based Decision Tree Untuk Mengenali Pola Klasifikasi Mahasiswa Yang Terkena Sisip Program”.
Penelitian ini tidak akan selesai dengan baik tanpa adanya dukungan, semangat, dan motivasi yang telah diberikan oleh banyak pihak. Untuk itu, penulis ingin mengucapkan terima kasih kepada:
1. Ibu P.H. Prima Rosa, S.Si., M.Sc. selaku dosen pembimbing serta dekan Fakultas Sains dan Teknologi yang telah membantu dan membimbing dalam penulisan tugas akhir.
2. Ibu Ridowati Gunawan, S.Kom., M.T. selaku ketua program studi Teknik Informatika yang bertindak sebagai dosen penguji yang telah berkenan memberikan motivasi, kritik, dan saran yang telah diberikan kepada penulis.
3. Ibu Sri Hartati Wijono, S.Si., M.Kom. selaku dosen penguji atas motivasi, kritik dan saran yang telah diberikan kepada penulis.
4. Kedua orang tua, bapak Yakobus Poniyo Ratmo dan ibu Sri Mustani atas perhatian, kasih sayang, semangat dan dukungan yang tak henti-hentinya diberikan kepada penulis.
5. Kakak, Hendrikus Adven Wicaksono yang telah memberikan doa, semangat dan dukungan sehingga penulis dapat menyelesaikan tugas akhir ini.
xi
TI angkatan 2007. Terima kasih atas segala bantuan, semangat, dan kesedianaan untuk berbagi solusi dalam penyelesaian tugas akhir ini. 7. Para sahabat Edo Barata, Feby Dwi Septiono, Nur Fikri Pratama, Rhidky
Oktavian, Benzario Khaula, Indra Prasetyo, Sunar Wibowo, Adhit, Topan, Arip, Gilang Prasetyo (almarhum) dan seluruh teman-teman. Terimakasih atas semangat dan doa yang telah diberikan.
8. Serta semua pihak yang tidak dapat disebutkan satu persatu yang telah membantu penulis dalam menyelesaikan tugas akhir ini.
xii
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN JUDUL (INGGRIS) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... vi
ABSTRAK ... vii
ABSTRACT ... viii
LEMBAR PERSETUJUAN PUBLIKASI ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR TABEL ... xv
DAFTAR GAMBAR ... xvii
BAB I PENDAHULUAN ... 1
I.1 Latar Belakang ... 1
I.2 Rumusan Masalah ... 2
I.3 Tujuan ... 2
I.4 Batasan Masalah ... 2
I.5 Metodologi Penelitian ... 3
I.6 Sistematika Penulisan ... 4
BAB II LANDASAN TEORI ... 6
II.1 Penambangan Data (Data Mining) ... 6
II.2 Himpunan Kasar (Rough Sets) ... 8
II.2.1 Pendahuluan ... 9
II.2.2 Pengertian Dasar ... 9
II.2.3 Relasi Ekuivalensi ... 11
II.2.4 Kelas Ekuivalensi... 12
II.2.5 Ruang Hampiran Dan Himpunan Kasar ... 13
xiii
II.3 Pohon Keputusan (Decision Tree) ... 18
II.3.1 Pengertian Pohon Keputusan ... 18
II.3.2 Kelebihan Pohon Keputusan ... 18
II.3.3 Kekurangan Pohon Keputusan ... 19
II.3.4 Jenis-jenis Pohon Keputusan ... 20
II.4 Algoritma C4.5 ... 20
II.5 Algoritma Reduct Based Decision Tree (RDT) ... 23
II.5.1 Pendahuluan ... 23
II.5.2 Reduct Computation dan Pembentukan Pohon Keputusan ... 23
II.6 K-fold Cross Validation ... 29
II.7 Mengukur Tingkat Keakuratan Penggolong (Classifier) ... 29
II.8 Perkiraan Interval ... 31
BAB III ANALISIS DAN PERANCANGAN ... 32
III.1 Identifikasi Sistem ... 32
III.2 Analisis Sistem ... 32
III.2.1 Analisis Data Awal ... 32
III.2.2 Pemrosesan Awal ... 38
III.2.2.1 Pembersihan Data (Data Cleaning) ... 38
III.2.2.2 Integrasi Data (Data Integration) ... 38
III.2.2.3 Seleksi Data (Data Selection) ... 43
III.2.2.4 Transformasi Data (Data Transformation) ... 43
III.3 Analisis Kebutuhan Sistem ... 44
III.3.1 Diagram Use Case ... 44
III.3.2 Narasi Use Case... 44
III.4 Perancangan Umum Sistem ... 47
III.4.1 Masukan Sistem ... 47
III.4.2 Proses Sistem ... 51
III.4.3 Keluaran Sistem ... 59
III.4.4 Diagram Aktivitas... 60
xiv
III.6 Diagram Kelas Analisis dan Diagram Sekuen ... 64
III.7 Diagram Kelas Disain ... 74
III.8 Perancangan Struktur Data ... 76
III.9 Perancangan Antarmuka ... 78
BAB IV IMPLEMENTASI SISTEM ... 80
IV.1 Spesifikasi Perangkat Lunak dan Perangkat Keras ... 80
IV.2 Uji Validasi Sistem ... 80
IV.3 Implementasi Antar Muka Dengan Pengguna ... 81
IV.4 Implementasi Diagram Kelas... 88
BAB V ANALISIS HASIL ... 98
V.1 Evaluasi Pola ... 98
V.3 Presentasi Pengetahuan ... 108
BAB VI PENUTUP ... 109
VI.1 Kesimpulan ... 109
VI.2 Saran ... 110
DAFTAR PUSTAKA ... 111
LAMPIRAN ... 113
LAMPIRAN 1 ... 114
LAMPIRAN 2 ... 125
LAMPIRAN 3 ... 155
LAMPIRAN 4 ... 161
LAMPIRAN 5 ... 182
LAMPIRAN 6 ... 195
xv
DAFTAR TABEL
Tabel 2.1 Sistem Informasi (Hvidsten,2006:13)...9
Tabel 2.2 Sistem Keputusan (Hvidsten,2006:13)...10
Tabel 2.3 Kelas ekuivalensi (Hvidsten,2006:15)...12
Tabel 2.4 Data 18 pasien kanker (Hvidsten,2006:15) ...14
Tabel 2.5 Contoh basis data ...16
Tabel 2.6 Discernibility matrix untuk data dalam Tabel 2.5...17
Tabel 2.7 Matriks Boolean untuk data pada Tabel 2.4...17
Tabel 2.8 Data Input Tabel Keputusan T1...24
Tabel 2.9 Tabel Keputusan T1 Diurutkan Secara Ascending...24
Tabel 2.10 Tabel Keputusan T1...25
Tabel 2.11 Discernibility matrix untuk tabel 2.10...25
Tabel 2.12 Matrik Boolean Untuk Tabel 2.10...26
Tabel 2.13 Proses Menghapus Matrik Boolean (MB) Untuk Tabel 2.12...26
Tabel 2.14 Hasil Proses Hapus MB Untuk Tabel 2.13...27
Tabel 2.15 Proses Menghapus Matrik Boolean (MB) Untuk Tabel 2.14...27
Tabel 2.16 Hasil Proses Hapus MB Untuk Tabel 2.15...28
Tabel 2.17 Proses Menghapus Matrik Boolean (MB) Untuk Tabel 2.16...28
Tabel 2.18 Matrik Boolean (MB) Null...28
Tabel 2.19 confusion matrix......30
Tabel 3.1 Daftar atribut data PMB jalur reguler...32
Tabel 3.2 Contoh data PMB jalur reguler...34
Tabel 3.3 Daftar atribut data KRS mahasiswa...36
Tabel 3.4 Contoh data KRS mahasiswa...36
Tabel 3.5 Contoh data awal setelah proses integrasi dan pembersihan...40
Tabel 3.6 Aturan Transformasi Data Nilai Tes Potensi Akademik......43
Tabel 3.7 Narasi Use Case Transformasi Data...45
Tabel 3.8 Narasi Use Case Reduct Data...45
Tabel 3.9 Narasi Use Case Bentuk Aturan...46
Tabel 3.10 Narasi Use Case Simpan Aturan...46
xvi
Tabel 3.12 Deskripsi uji...48
Tabel 3.13 Pembagian data untuk setiap fold......49
Tabel 3.14 Struktur Data Tabel Hasil Transformasi...64
Tabel 3.15 Struktur Data Tabel Hasil Reduct...65
Tabel 3.16 Struktur Data Tabel Atribut Remove...67
Tabel 3.17 Struktur Data Tabel HAP...67
Tabel 3.18 Daftar Kelas Use Case Transformasi Data...68
Tabel 3.19 Daftar Kelas Use Case Reduct Data...69
Tabel 3.20 Daftar Kelas Use Case Bentuk Aturan...71
Tabel 3.21 Daftar Kelas Use Case Simpan Aturan...73
Tabel 3.22 Bentuk penyimpanan dalam Vector.......76
Tabel 5.1 Komposisi Data Asal SMA Mahasiswa...100
Tabel 5.2 Detail Pola Klasifikasi Mahasiswa Sisip Program Untuk Tabel 5.1...101
Tabel 5.3 Hasil Penelusuran Atribut Program Studi Terhadap Data Input...103
Tabel 5.4 Tabel pengujian cross-validation dengan bervariasi nilai fold...104
Tabel 5.5 Pembagian data untuk setiap fold...105
Tabel 5.6 Tabel Confusion Matrix untuk Pengujian pada Fold 1...106
xvii
DAFTAR GAMBAR
Gambar 2.1 Tahapan dalam Penambangan Data (Jiawei Han, 2006:6)...8
Gambar 2.2 Himpunan kasar dengan hampiran atas dan bawah(Susilo,2006:3)...15
Gambar 2.3 Gambaran Pohon Keputusan...18
Gambar 2.4 Algoritma C45...21
Gambar 3.1 Diagram Use Case...44
Gambar 3.2 Proses alur yang terjadi di dalam sistem secara umum...51
Gambar 3.3 Diagram Konteks...59
Gambar 3.4 Diagram Aktifitas Transformasi Data...60
Gambar 3.5 Diagram Aktivitas Reduct Data...61
Gambar 3.6 Diagram Aktifitas Bentuk Aturan...61
Gambar 3.7 Diagram Aktifitas Simpan Aturan...62
Gambar 3.8 ER Diagram...63
Gambar 3.9 Diagram Kelas Analisis Use Case Transformasi Data...68
Gambar 3.10 Diagram Sekuen Transformasi Data...69
Gambar 3.11 Diagram Kelas Analisis Use Case Reduct Data...70
Gambar 3.12 Diagram Sekuen Reduct data...70
Gambar 3.13 Diagram kelas Analisis Use Case Bentuk Aturan...72
Gambar 3.14 Diagram Sekuen Bentuk Aturan...72
Gambar 3.15 Diagram Kelas Analisis Use Case Simpan Aturan...73
Gambar 3.16 Diagram Sekuen Simpan Aturan...73
Gambar 3.17 Diagram Kelas Keseluruhan...75
Gambar 3.18 Contoh Pohon Keputusan...77
Gambar 3.19 Contoh Ilustrasi Bentuk Penyimpanan Dalam Vector...77
Gambar 3.20 Halaman Utama...78
Gambar 3.21 Halaman Transformasi dan Reduct Data...78
Gambar 3.22 Halaman Bentuk Aturan...79
Gambar 3.23 Halaman Hasil Aturan...79
Gambar 4.1Implementasi Halaman Utama...81
xviii
Gambar 4.3 File Chooser untuk mengambil data...82
Gambar 4.4 Implementasi Halaman Transformasi dan Reduct (2)...83
Gambar 4.5 Pesan data sudah dimasukkan...84
Gambar 4.6 Implementasi Halaman Transformasi dan Reduct (3)...84
Gambar 4.7 Pesan data berhasil dimasukkan...84
Gambar 4.8 Implementasi Halaman Bentuk Aturan...85
Gambar 4.9 Pesan proses reduct berhasil...85
Gambar 4.10 Implementasi Halaman Hasil Aturan...86
Gambar 4.11 pesan pohon sudah terbentuk...86
Gambar 4.12 File Chooser untuk memilih letak penyimpanan file....87
Gambar 4.13 Pesan Data berhasil disimpan...87
1
BAB I
PENDAHULUAN
I.1.
Latar Belakang
Universitas Sanata Dharma (USD) merupakan lembaga akademik yang setiap tahunnya melakukan proses Penerimaan Mahasiswa Baru (PMB). Proses seleksi PMB dapat ditempuh melalui berbagai jalur dan salah satunya adalah jalur reguler. Dalam proses tersebut akan menghasilkan informasi berupa data PMB yang digunakan untuk melakukan penyeleksian terhadap calon mahasiswa baru. Komponen yang terdapat dalam data PMB jalur reguler berupa jenis kelamin, asal kabupaten, asal sekolah, asal kabupaten sekolah, nilai penalaran verbal, nilai kemampuan numerik, nilai penalaran mekanik, nilai bahasa inggris, nilai hubungan ruang, prioritas pilihan program studi, dan gelombang masuk.
Mahasiswa yang dinyatakan diterima di jalur reguler adalah mahasiswa yang lulus penilaian komponen PMB sesuai dengan standar yang ditetapkan USD. Seluruh mahasiswa yang diterima di jalur reguler diharapkan dapat menjalankan perkuliahan dengan lancar dan tidak sisip program. Namun kenyataannya tidak demikian, masih ada mahasiswa yang terkena sisip program. Dari hal tersebut timbul pertanyaan bagaimana mengetahui pola klasifikasi mahasiswa yang terkena sisip program?
atribut yang relevan untuk pembentukan pola dengan demikian diharapkan akurasi dari pola yang terbentuk dapat ditingkatkan.
I.2.
Rumusan Masalah
Berdasarkan latar belakang masalah yang telah dikemukakan diatas maka perumusan masalah dalam penelitian ini adalah:
1. Bagaimana mengenali pola klasifikasi mahasiswa USD hasil PMB jalur Reguler yang terkena sisip program menggunakan algoritma RDT ? 2. Berapa kinerja akurasi dalam pembentukan pola klasifikasi mahasiswa
yang terkena sisip program menggunakan algoritma RDT ?
I.3.
Tujuan
Tujuan dari penelitian ini yaitu :
1. mengenali pola klasifikasi mahasiswa yang terkena sisip program menggunakan algoritma RDT.
2. Mengukur akurasi dalam pembentukan pola klasifikasi mahasiswa yang terkena sisip program menggunakan algoritma RDT.
I.4.
Batasan Masalah
Dalam penelitian ini ada beberapa batasan masalah yaitu:
1. Penelitian ini hanya menerapkan algoritma Reduct Based Decision Tree (RDT).
2. Pada penelitian ini pembentukan pola klasifikasi berupa pohon keputusan dengan menggunakan algoritma C4.5.
3. Data yang digunakan dalam penelitian ini adalah data Penerimaan Mahasiswa Baru (PMB) tahun 2007 – 2009 jalur reguler.
5. Pada penelitian ini pembentukan dalam pembentukan pola klasifikasi tidak dikenai metode pemangkasan pohon (pruning).
I.5.
Metodologi Penelitian
Metodologi yang digunakan untuk menyelesaikan masalah pada penelitian tugas akhir ini Knowledge discovery in database (KDD) menurut Han dan Kamber (2006) :
1. Pembersihan data (Data Cleaning)
Pada proses ini dilakukan penghilangan noise dan data yang tidak konsisten atau data yang tidak relevan.
2. Integrasi Data (Data Integration)
Pada proses ini dilakukan penggabungan data dari berbagai sumber agar seluruh data terangkum dalam satu tabel utuh (denormalisasi).
3. Seleksi Data (Data Selection)
Pada proses ini dilakukan penyeleksian data dimana data yang relevan diambil dari database.
4. Transformasi Data (Data Transformation)
Pada proses ini Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam penambangan data.
5. Penambangan Data (Data Mining)
Pada proses ini dilakukan penerapan teknik penambangan data untuk mengekstrak pola. Dalam penilitian Tugas Akhir ini, teknik yang digunakan adalah Reduct Based Decision Tree (RDT).
6. Evaluasi Pola (Pattern Evaluation)
Proses ini dilakukan untuk mengidentifikasi pola-pola menarik yang dalam arti tertentu menyatakan basis pengetahuan.
7. Presentasi Pengetahuan (Knowledge Presentation)
Merupa visualisasi dan teknik representasi pengetahuan untuk menyajikan pengetahuan yang ditambang kepada pengguna.
I.6.
Sistematika Penulisan
Sistematika penulisan penelitian ini adalah sebagai berikut : BAB I. PENDAHULUAN
Bab ini berisi latar belakang masalah, rumusan masalah, tujuan penelitian, batasan masalah, metodologi penelitian, dan sistematika penulisan.
BAB II . LANDASAN TEORI
Bab ini berisi dasar-dasar teori yang digunakan dalam Penelitian.
BAB III . ANALISIS DAN PERANCANGAN
Bab ini berisi analisis dan perancangan aplikasi penambangan data yang akan dibangun. Dalam tahap analisis terdapat empat proses KDD meliputi pembersiahan data, integrasi data, seleksi data, dan transformasi data.
BAB IV. IMPLEMENTASI PROGRAM
Bab ini berisi implementasi penerapan proses penambangan data
menggunakan algoritma RDT kedalam bentuk aplikasi.
BAB V . ANALISIS HASIL
Bab ini berisi tentang analisis dari hasil output proses penambangan
BAB VI. PENUTUP
Bab ini berisi tentang kesimpulan dari hasil penelitian dan saran-saran
6
BAB II
LANDASAN TEORI
Untuk mendukung penelitian ini diperlukan beberapa landasan teori dan konsep-konsep yang relevan. Landasan teori dalam penelitian ini meliputi pengertian Penambangan Data (Data Mining), Himpunan Kasar (Rough Sets), Pohon Keputusan(Decision Tree), Algoritma C.45, Algoritma Reduct Based Decision Tree (RDT), dan k-fold Cross Validation.
II.1.
Penambangan Data(
Data Mining
)
Definisi tentang penambangan data menurut beberapa penulis adalah sebagai berikut:
1. Definisi penambangan data menurut Yudho (2003:1) adalah “ekstraksi informasi atau pola yang penting atau menarik dari data yang ada di database yang besar”.
2. Penambangan data menurut Mitra dan Acharya (2003:1) adalah “suatu data percobaan untuk memperoleh informasi yang berguna yang tersimpan dalam basisdata yang sangat besar”.
3. Penambangan data menurut Lee dan Santana (2010:17) adalah “metoda yang digunakan untuk mengekstraksi informasi prediktif tersembunyi pada database”.
yang harus dilakukan terhadap tumpukan data tersebut? Salah satu solusinya adalah dilakukannya teknik Penambangan Data (Data Mining) agar data yang sedemikian banyak tersebut tidak menjadi sampah atau kuburan data.
Penambangan data merupakan proses yang tidak dapat dipisahkan dengan dengan Knowledge Discovery in Database (KDD), karena penambangan data adalah salah satu tahap dari proses KDD yang menggunakan analisa data serta penggunaan algoritma, sehingga menghasilkan pola-pola khusus dalam data yang besar. Berikut ini merupakan urutan langkah-langkah dalam membangun penambangan data menurut Han dan Kamber (2006):
1. Pembersihan Data (Data Cleaning)
Pembersihan data merupakan proses untuk menghilangkan noise dan data yang tidak konsisten atau data yang tidak relevan.
2. Integrasi Data (Data Integration)
Integrasi data merupakan proses penggabungan data dari berbagai sumber.
3. Seleksi Data (Data Selection)
Seleksi data merupakan proses menyeleksi data dimana data yang relevan diambil dari database.
4. Transformasi Data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam penambangan data.
5. Penambangan Data (Data Mining)
Penambangan data merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi Pola (Pattern Evaluation)
Proses ini dilakukan untuk mengidentifikasi pola-pola menarik yang dalam arti tertentu menyatakan basis pengetahuan.
7. Presentasi Pengetahuan (Knowledge Presentation)
Tahapan atau urutan langkah-langkah dalam membangun penambangan data dapat diilustrasikan kedalam gambar berikut :
Gambar 2.1 Tahapan dalam Penambangan Data (Han, 2006:6)
Ada banyak teknik algoritma dalam penambangan data. Pada penelitian ini teknik algoritma penambangan data yang digunakan adalah Reduct Based Decision Tree (RDT). Teknik RDT mengkombinasikan teori himpunan kasar (Rough Set) dan induksi algorima pohon keputusan (Ramadevi,2008).
II.2.
Himpunan Kasar (
Rough Set
)
II.2.1Pendahuluan
elemen-elemen tertentu dalam semestanya tidak dapat dibedakan satu sama lain karena keterbatasan atau ketidaklengkapan pengetahuan atau informasi dalam elemen-elemen tersebut.
II.2.2Pengertian dasar
Himpunan kasar (Rough set) adalah teknik matematika yang biasanya digunakan untuk menangani masalah Uncertainty, (Mising data, Incompleted Data dan Inconsistency Data, Imprecision dan Vagueness) dalam apliksi Artificial Intelligence (AI). Selain itu teknik himpunan kasar (Rough set) merupakan teknik yang efisien dalam Database (KDD) proses dan Data Mining. Didalam Rough Set data dapat direpresentasikan kedalam 2 bentuk yaitu:
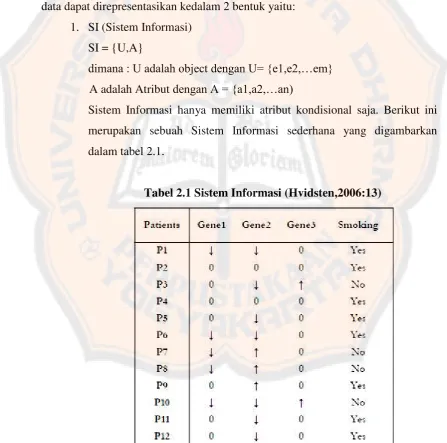
1. SI (Sistem Informasi) SI = {U,A}
dimana : U adalah object dengan U= {e1,e2,…em} A adalah Atribut dengan A = {a1,a2,…an)
Sistem Informasi hanya memiliki atribut kondisional saja. Berikut ini merupakan sebuah Sistem Informasi sederhana yang digambarkan dalam tabel 2.1.
Tiap-tiap baris pada tabel diatas merepresentasikan objek sedangkan tiap-tiap kolom merepresentasikan atribut. Tabel Sistem Informasi diatas hanya terdiri dari m obyek,seperti P1, P2, P3..., Pm dan n atribut seperti Patients, Gene1, Gene2, Gene3, moking.
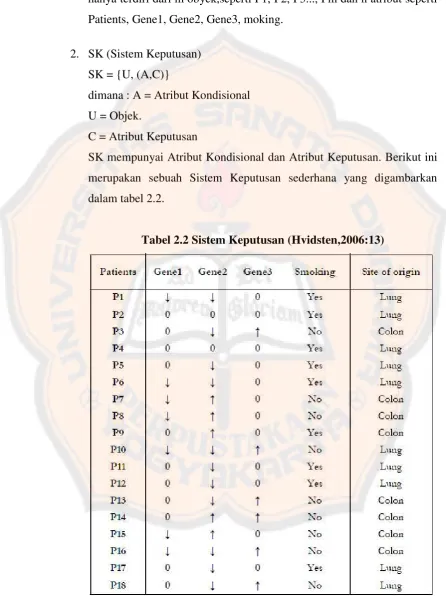
2. SK (Sistem Keputusan) SK = {U, (A,C)}
dimana : A = Atribut Kondisional U = Objek.
C = Atribut Keputusan
SK mempunyai Atribut Kondisionaldan Atribut Keputusan. Berikut ini merupakan sebuah Sistem Keputusan sederhana yang digambarkan dalam tabel 2.2.
Tabel 2.2 memperlihatkan sebuah sistem keputusan yang terdiri dari m objek, seperti P1, P2 , …, Pm, dan n attribute, seperti Patients, Gene1, Gene2, Gene3, Smoking dan Site of Origin. Dalam tabel ini, n-1 atribut Patients, Gene1, Gene2, Gene3, Smoking adalah attribute kondisi, sedangkan Site of Origin adalah atribut keputusan.
Awalnya himpunan kasar dikembangkan untuk menangani keridakpastian dan ketidaktegasan dalam analisis data. Asumsi yang menjadi dasar pengembangan teori himpunan kasar yaitu bahwa setiap elemen dalam semesta wacananya terkait dengan informasi elemen itu, dan elemen-elemen dengan informasi yang takterbedakan. Pendekatan terhadap himpunan kasar adalah suatu hampiran dari suatu himpunan tak tegas berdasarkan suatu partisi pada semesta himpunan tersebut. Partisi pada semesta himpunan tak tegas tersebut diambil dari
partisi yang terimbas relasi ekuivalensi “takterbedakan” antara elemen-elemen semesta tersebut. Dengan demikian kelas-kelas ekivalensi dalam partisi itu memuat elemen-elemen semesta yang takterbedakan satu sama lain. Relasi ekivalensi adalah model matematik paling sederhana yang dapat dipergunakan untuk merepresentasikan keadaan di mana elemen-elemen tertentu dalam suatu semesta tidak dapat dibedakan satu sama lain, dengan mengingat bahwa relasi
“takterbedakan” itu pada dasarnya adalah suatu relasi ekivalensi, yaitu bersifat refleksif, simetrik, dan transitif. Sehingga konsep himpunan kasar adalah perampatan konsep himpunan tegas, dalam arti bahwa himpunan tegas adalah kejadian khusus dari himpunan kasar.
II.2.3Relasi Ekuivalensi
Suatu relasi R pada himpunan S dikatan ekuivalen jika memenuhi ketiga hal berikut ini :
1. Reflektif , xRx
2. Simetris, jika xRy maka yRx
Misalkan Diberikan himpunan S={1,2,3....,20}dan relasi R pada S didefinisikan 4|( x – y ). Akan ditunjukan R merupakan relasi ekivalensi ( a | b artinya a membagi b ).
1. Refleksif. Untuk sebarang xS diperoleh x – x = 0, Jelas s | 0 , terbukti R bersifat Refleksif.
2. Simetris. Diketahui xRy maka 4 | ( x – y ), yang artinya x – y = 4n. Diperoleh y – x = - 4n maka 4 | ( y – x = - 4n ). Dapat disimpulkan yRx 3. Transitif. Diketaui xRy dan yRz yang artinya x– y = 4n dan y– z = 4m
Diperoleh x – ( z + 4m ) = 4n kemudian x – z = 4n + 4m = 4( n + m ). Itu artinya xRz. Maka terbukti bahwa R Transitif.
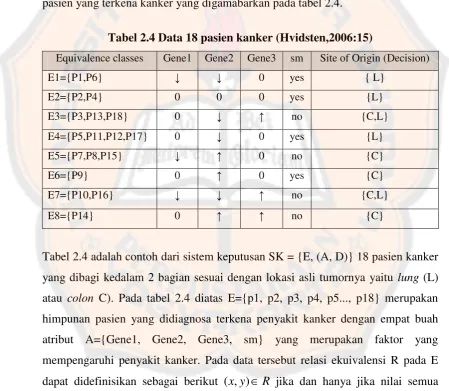
II.2.4Kelas Ekuivalensi
Dalam relasi ekuivalensi pasti terdapat kelas ekuivalensi. Misalkan diberikan R relasi ekuivalen pada S maka untuk semua aS terdapat suatu himpunan yang berisikan semua anggota S yang berelasi ke a, dinotasikan [a] = {
S
a | a R x}. Berikut ini merupakan contoh sebuah tabel dengan objectnya adalah kelas ekuivalensi.
Tabel 2.3Kelas ekuivalensi (Hvidsten,2006:15)
Equivalence classes Gene1 Gene2 Gene 3 sm Site of Origin (Decision)
E1={P1,P6} ↓ ↓ 0 yes { L}
E2={P2,P4} 0 0 0 Yes {L}
E3={P3,P13,P18} 0 ↓ ↑ no {C,L}
E4={P5,P11,P12,P17} 0 ↓ 0 yes {L}
E5={P7,P8,P15} ↓ ↑ 0 No {C}
E6={P9} 0 ↑ 0 yes {C}
E7={P10,P16} ↓ ↓ ↑ No {C,L}
E8={P14} 0 ↑ ↑ No {C}
II.2.5Ruang Hampiran dan Himpunan Kasar
Dimisalkan X adalah suatu semesta yang takkosong, R adalah suatu relasi ekivalensi pada X, [x]R {yX|(x,y)R} adalah kelas ekivalensi yang memuat
X
Selisih hampiran atas dan hampiran bawah dari himpunan A dalam K, yaitu BK(A)K(A)K(A), disebut daerah batas dari himpunan A dalam K. Jika
, ) (A
BK yaitu K(A)K(A) A, maka A merupakan gabungan himpunan elementer dalam K dan disebut himpunan yang dapat dideskripsikan secara tepat dalam K (atau himpunan tegas dalam K). Jika BK(A), maka A tidak dapat dideskripsikan secara tepat dalam K dan disebut himpunan kasar dalam K. Dengan perkataan lain, himpunan kasar adalah himpunan bagian dari semesta yang mempunyai daerah batas yang tak kosong. Berikut ini akan diberikan ilustrasi pengimplementasian himpunan kasar dan ruang hampiran menggunakan data 18 pasien yang terkena kanker yang digamabarkan pada tabel 2.4.
Tabel 2.4Data 18 pasien kanker (Hvidsten,2006:15)
Equivalence classes Gene1 Gene2 Gene3 sm Site of Origin (Decision)
E1={P1,P6} ↓ ↓ 0 yes { L}
E2={P2,P4} 0 0 0 yes {L}
E3={P3,P13,P18} 0 ↓ ↑ no {C,L}
E4={P5,P11,P12,P17} 0 ↓ 0 yes {L}
E5={P7,P8,P15} ↓ ↑ 0 no {C}
E6={P9} 0 ↑ 0 yes {C}
E7={P10,P16} ↓ ↓ ↑ no {C,L}
E8={P14} 0 ↑ ↑ no {C}
E5={P7, P8, P15}, E6={P9}, E7={P10, P16} dan E8={P14} adalah himpunan elementer yaitu himpunan pasien-pasien yang tak terbedakan dalam K karena menunjukkan faktor penyebab penyebab penyakit yang sama. Pasien dengan Decision class lung(L) dan colon(C) {C,L} merupakan himpunan kasar karena tidak dapat didefinisikan secara unik menggunakan kelas ekuivalensi. Data Pasien tersebut hanya dapat didefinisikan dengan hampiran atas K dan hampiran bawah K. Dalam kasus ini A = {E1, E2, E3, E4, E7} merupakan himpunan kelas ekuivalensi pasien yang didiagnosa menderita penyakit kanker paru-paru (lung). Maka hampiran bawah dari A, yaitu himpunan pasien yang pasti menderita kanker
paru-paru, adalah
) (A
K E1E2E4 = {P1, P2, P4, P5, P6, P11, P12, P17}
Hampiran atas dari A, yaitu himpunan kelas ekuivalensi pasien yang mungkin menederita kanker paru-paru adalah
K(A) = E1E2E3E4E7= {P1, P2, P4, P5, P6, P11, P12, P17}
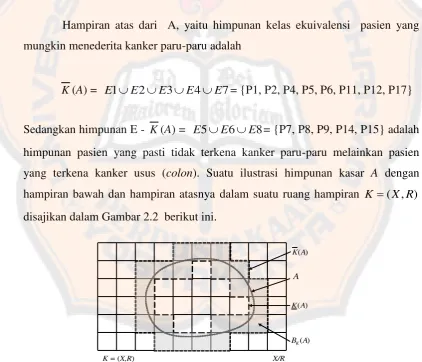
Sedangkan himpunan E - K(A) = E5E6E8= {P7, P8, P9, P14, P15} adalah himpunan pasien yang pasti tidak terkena kanker paru-paru melainkan pasien yang terkena kanker usus (colon). Suatu ilustrasi himpunan kasar A dengan hampiran bawah dan hampiran atasnya dalam suatu ruang hampiran K (X,R)
disajikan dalam Gambar 2.2 berikut ini.
Gambar 2.2 Himpunan kasar dengan hampiran atas dan bawah (Susilo,2006:3)
A
) (A K
) (A K
X/R
) (A BK
Kualitas hampiran dalam suatu ruang hampiran dinyatakan dengan suatu ukuran ketepatan. Bila K(X,R) adalah suatu ruang hampiran dan A suatu himpunan bagian dari X, maka banyaknya atom dalam K(A) dan K(A), yang disajikan dengan (A) dan (A), berturut-turut disebut ukuran dalam dan ukuran luar dari A dalam K. Jika (A)(A), maka A dikatakan terukur dalam K. Ketepatan hampirandari A dalam K didefinisikan sebagai bilangan real
( ) K. Dalam kasus ini ketepatan hampiran dari A1 dalam ruang hampiran K tersebut
adalah
Pada himpunan kasar discernibilty matrix digunakan untuk mengekstrak minimal reduct . Hasil dari reduct tersebut berupa atribut yang dapat digunakan untuk membuat sebuah decision rules. Discernibility matrix yang sesuai dengan contoh basis data dalam Tabel 2.5 dengan U = {X1, X2, …, X7}, C = {a, b, c, d},
D = {E} dimana U adalah himpunan Objek, C himpunan atribut kondisional dan E himpunan atribut keputusan ditunjukkan dalam Tabel 2.6.
Tabel 2.5Contoh basis data
M(X1,X3) = {b, c, d}, X1 dan X3 mempunyai nilai keputusan yang berbeda,
perbedaannya di atribut b, c dan d.
Tabel 2.6Discernibility matrix untuk data dalam Tabel 2.5
X1 X2 X3 X4 X5 X6
X2 -
X3 b, c, d b, c
X4 b b, d c, d
X5 a, b, c, d a, b, c - a, b, c, d
X6 a, b, c, d a, b, c - a, b, c, d -
X7 - - a, b, c, d a, b c, d c, d
Reduct untuk data dari tabel 2.4 adalah {b, c} dan {b, d}. Matriks Boolean (MB) untuk data pada Tabel 2.4 ditunjukkan pada Tabel 2.6 di bawah ini :
Tabel 2.7Matriks Boolean untuk data pada Tabel 2.5
a b c d
X1X3 0 1 1 1
X1X4 0 1 0 0
X1X5 1 1 1 1
X1X6 1 1 1 1
X2X3 0 1 1 0
X2X4 0 1 0 1
X2 X5 1 1 1 0
X2 X6 1 1 1 0
X3X4 0 0 1 1
X3X7 1 1 1 1
X4X5 1 1 1 1
X4X6 1 1 1 1
X4X7 1 1 0 0
X5X7 0 0 1 1
II.3.
Pohon Keputusan (
Decision Tree
)
II.3.1Pengertian Pohon Keputusan
Pohon keputusan (Decision Tree) merupakan metode penambangan data model klasifikasi. Menurut Jiawei Han dan Micheline Kamber (2006), salah satu metode data mining yang umum digunakan adalah decision tree. Konsep decision tree adalah suatu struktur flowchart yang menyerupai tree (pohon), dimana setiap simpul internal menandakan suatu tes pada atribut, setiap cabang merepresentasikan hasil tes, dan simpul daun merepresentasikan kelas atau distribusi kelas. Alur pada decision tree di telusuri dari simpul akar ke simpul daun yang memegang prediksi kelas untuk contoh tersebut. Gambar 2.3 berikut ini merupakan bentuk gambaran dari pohon keputusan.
Gambar 2.3Gambaran Pohon Keputusan.
Pohon keputusan memiliki merupakan model keputusan yang banyak digunakan dalam proses penambangan data kerena memiliki beberapa kelebihan
II.3.2Kelebihan Pohon Keputusan
Menurut Said, Fairuz. El. (2009) kelebihan dari metode pohon keputusan adalah :
2. Eliminasi perhitungan-perhitungan yang tidak diperlukan, karena ketika menggunakan metode pohon keputusan maka sample diuji hanya berdasarkan kriteria atau kelas tertentu.
3. Fleksibel untuk memilih fitur dari node internal yang berbeda, fitur yang terpilih akan membedakan suatu kriteria dibandingkan kriteria yang lain dalam node yang sama. Kefleksibelan metode pohon keputusan ini meningkatkan kualitas keputusan yang dihasilkan jika dibandingkan ketika menggunakan metode penghitungan satu tahap yang lebih konvensional 4. Dalam analisis multivariat, dengan kriteria dan kelas yang jumlahnya
sangat banyak, seorang penguji biasanya perlu untuk mengestimasikan baik itu distribusi dimensi tinggi ataupun parameter tertentu dari distribusi kelas tersebut. Metode pohon keputusan dapat menghindari munculnya permasalahan ini dengan menggunakan criteria yang jumlahnya lebih sedikit pada setiap node internal tanpa banyak mengurangi kualitas keputusan yang dihasilkan.
Pohon keputusan bukanlah satu-satunya model penambangan data yang paling baik karena selain memiliki kelebihan pohon keputusan juga memiliki kekurangan.
II.3.3Kekurangan Pohon Keputusan
Menurut Said, Fairuz. El. (2009) kekurangan dari metode pohon keputusan adalah :
1. Terjadi overlap terutama ketika kelas-kelas dan criteria yang digunakan jumlahnya sangat banyak. Hal tersebut juga dapat menyebabkan meningkatnya waktu pengambilan keputusan dan jumlah memori yang diperlukan.
2. Pengakumulasian jumlah eror dari setiap tingkat dalam sebuah pohon keputusan yang besar.
3. Kesulitan dalam mendesain pohon keputusan yang optimal.
Dari beberapa kekurangan tersebut pohon keputusan memiliki beberapa penyempurnaan dan pengembangan.
II.3.4Jenis-jenis Pohon Keputusan
Beberapa jenis model pohon keputusan yang sudah dikembangkan antara lain ID3, C4.5 dan CART (Classification and Regression Tree).
1. CART
Dalam CART, setiap simpul dipecah menjadi 2 cabang. Ada dua langkah penting yang harus diikuti untuk mendapatkan pohon (tree) dengan performansi yang optimal. Yang pertama adalah pemecahan obyek secara berulang berdasarkan atribut tertentu. Yang kedua, pemangkasan (pruning) dengan menggunakan data validasi (Santoso,2007).
2. ID3 dan C4.5
ID3 menggunakan kriteria information gain untuk memilih atribut yang akan digunakan untuk pemisahan obyek. Atribut yang mempunyai information gain paling tinggi dibanding atribut yang lain relatif terhadap set y dalam suatu data, dipilih untuk melakukan pemecahan. Sedangkan C4.5 merupakan pengembangan dari ID3. Perbaikan dilakukan dalam hal :
1. Dapat mengatasi data yang hilang 2. Dapat mengatasi data kontinyu. 3. Pemangkasan.
4. Aturan.
Dalam penelitian Tugas akhir ini algoritma yang digunakan untuk membentuk pohon keputusan adalah algoritma C4.5.
II.4.
Algoritma C4.5
Gambar 2.4 Algoritma C.45
http://fairuzelsaid.files.wordpress.com/2009/11/image004.gif?w=443&h=311
Pohon dibangun dengan cara membagi data secara rekursif hingga tiap bagian terdiri dari data yang berasal dari kelas yang sama. Bentuk pemecahan (split) yang digunakan untuk membagi data tergantung dari jenis atribut yang digunakan dalam split. Algoritma C4.5 dapat menangani data numerik (kontinyu) dan diskret. Split untuk atribut numerik yaitu mengurutkan contoh berdasarkan atribut kontiyu A, kemudian membentuk minimum permulaan (threshold) M dari contoh-contoh yang ada dari kelas mayoritas pada setiap partisi yang bersebelahan, lalu menggabungkan partisi-partisi yang bersebelahan tersebut dengan kelas mayoritas yang sama. Split untuk atribut diskret A mempunyai bentuk value (A) ε X,dimana X ⊂domain(A).
𝐸 𝑆 = −𝑝+𝑙𝑜𝑔2𝑝+ − 𝑝−𝑙𝑜𝑔2𝑝−
Keterangan :
S : ruang (data) sampel yang digunakan untuk pelatihan
p+ : jumlah yang bersolusi positif (mendukung pada data sampel untuk kriteria tertentu)
p- : jumlah yang bersolusi negatif (tidak mendukung pada data sampel untuk kriteria tertentu).
Catatan :
1. Entropi(S) = 0, jika semua contoh pada S berada dalam kelas yang sama. 2. Entropi(S) = 1, jika jumlah contoh positif dan negatif dalam S adalah sama. 3. 0 < Entropi(S) < 1, jika jumlah contoh positif dan negatif dalam S tidak
sama.
Entropi split yang membagi S dengan n record menjadi himpunan-himpunan S1 dengan n1baris dan S2dengan n2 baris adalah :
𝐸(𝑆1,𝑆2) = 𝑛1
𝑛 𝐸 𝑆1 + 𝑛2
𝑛 𝐸(𝑆2)
Kemudian menghitung perolehan informasi dari output data atau variabel dependenty yang dikelompokkan berdasarkan atribut A, dinotasikan dengan gain (y,A). Perolehan informasi, gain (y,A), dari atribut A relatif terhadap output data y adalah:
𝐺𝑎𝑖𝑛 𝑦,𝐴 = 𝑒𝑛𝑡𝑟𝑜𝑝𝑖 𝑦 − 𝑦𝑐
𝑦
𝑐=𝑛𝑖𝑙𝑎𝑖(𝐴) 𝑒𝑛𝑡𝑟𝑜𝑝𝑖 𝑦𝑐
Nilai (A) adalah semua nilai yang mungkin dari atribut A, dan yc adalah subset dari y dimana A mempunyai nilai c. Term pertama dalam persamaan di atas adalah entropitotal y dan term kedua adalah entropi sesudah dilakukan pemisahan data berdasarkan atribut A.
Untuk menghitung rasio perolehan perlu diketahui suatu term baru yang disebut pemisahan informasi (Split Info). Pemisahan informasi dihitung dengan cara :
...…(2.6)
...…(2.5)
𝑆𝑝𝑙𝑖𝑡𝐼𝑛𝑓𝑜 𝑆,𝐴 =− 𝑆𝑡
𝑆 𝑐
𝑡=1 𝑙𝑜𝑔2 𝑆𝑆𝑡
bahwa S1 sampai Sc adalah c subset yang dihasilkan dari pemecahan S dengan menggunakan atribut A yang mempunyai sebanyak c nilai. Selanjutnya rasio perolehan (gain ratio) dihitung dengan cara :
𝐺𝑎𝑖𝑛𝑅𝑎𝑡𝑖𝑜 𝑆,𝐴 = 𝐺𝑎𝑖𝑛 𝑆,𝐴
𝑆𝑝𝑙𝑖𝑡𝐼𝑛𝑓𝑜 𝑆,𝐴
II.5.
Algoritma
Reduct Based Decision Tree
(RDT)
II.5.1Pendahuluan
Dalam Algoritma penambangan data Reduct Based Decision Tree (RDT) terdapat dua langkah penting yaitu Reduct Computation dan pembentukan pohon keputusan. Reduct Based Decision Tree(RDT)mengkombinasikan teori himpunan kasar (Rough Set) dan induksi algoritma pohon keputusan, yang meningkatkan efisiensi dan sederhana. Datasets dapat diskret ataupun kontinyu.
II.5.2 Reduct Computation dan Pembentukan Pohon Keputusan
Di dalam proses Reduct Computation Algorithm (RCA), tabel keputusan diberikan sebagai input dan atribut utama (predominant attributes) yang disebut reduct diperoleh sebagai output. Jika data yang digunakan besar, digunakan fragmentasi vertikal. Atribut keputusan ditambahkan ke tiap fragmen dan RCA dipergunakan. Predominant attributes untuk semua fragmen diperoleh dan dikelompokkan bersama dengan informasi fragmen dan atribut keputusan. Selanjutnya RCA digunakan lagi. Himpunan baru dari atribut disebut composite reduct. Menurut Ramadevi (2008) langkah-langkah dalam Reduct Computation Algorithm (RCA) adalah sebagai berikut.
...…(2.8)
Algoritma RCA (input : Tabel Keputusan; output : Reduct): 1. Baca tabel keputusan T1. Berikut ini
Tabel 2.8 Data Input Tabel Keputusan T1
ID a b c d E
X1 1 0 2 1 1
X2 1 0 2 0 1
X3 1 2 0 0 2
X4 1 2 2 1 0
X5 2 1 0 0 2
X6 2 1 1 0 2
X7 2 1 2 1 1
2. Urutkan baris secara ascending berdasarkan atribut keputusan.
Tabel 2.9 Tabel Keputusan T1 Diurutkan Secara Ascending
ID a b c d E
X4 1 2 2 1 0
X1 1 0 2 1 1
X2 1 0 2 0 1
X7 2 1 2 1 1
X3 1 2 0 0 2
X5 2 1 0 0 2
X6 2 1 1 0 2
3. InisialisasiHimpunan Atribut Predominan (HAP) sebagai Null. 4. Buatlah Matriks Boolean (MB), seperti dijelaskan pada langkah 5,
dengan membuat (generate) baris untuk setiap pasangan dari baris yang nilai atribut keputusannya berbeda.
beri nilai dengan „0‟ jika nilai atributnya sama. Proses langkah 5 secara detail ditunjukkan pada tabel 2.10 dan 2.11 dibawah ini :
Tabel 2.10 Discernibility matrix untuk tabel 2.9
X4 X1 X2 X7 X3 X5
X1 b
X2 b, d -
X7 a, b -
X3 c,d b, c, d b, c a, b, c, d
X5 a, b, c, d a, b, c, d a, b, c c,d -
X6 a, b, c, d a, b, c, d a, b, c c,d - -
Tabel 2.11 Matrik Boolean Untuk Tabel 2.10
a b c d
X4 X1 0 1 0 0
X4 X2 0 1 0 1
X4 X7 1 1 0 0
X4 X3 0 0 1 1
X4 X5 1 1 1 1
X4 X6 1 1 1 1
X1 X3 0 1 1 1
X1 X5 1 1 1 1
X1 X6 1 1 1 1
X2 X3 0 1 1 0
X2 X5 1 1 1 0
X2 X6 1 1 1 0
X7 X3 1 1 1 1
X7 X5 0 0 1 1
X7 X6 0 0 1 1
Reduct 1 : {b, c}
6. Ulangi langkah 7 kemudian langkah 8 sampai jumlah dari baris dalam MBadalah nol atau null matriks.
7. Pilih atribut „a‟, dimana a mempunyai jumlah maksimum dan tambahkan atribut tersebut ke dalam HAP.
8. Hapus semua baris dari MB yang berhubungan terhadap „a‟
dimana elemennya adalah „1‟. Proses menhapus matrik boolean ditunjukkan pada tabel 2.12 sampai dengan tabel 2.16 berikut ini :
Tabel 2.12 Proses Menghapus Matrik Boolean (MB) Untuk Tabel 2.11
a b c d
X4 X1 0 1 0 0
X4 X2 0 1 0 1
X4 X7 1 1 0 0
X4 X3 0 0 1 1
X4 X5 1 1 1 1 x
X4 X6 1 1 1 1 x
X1 X3 0 1 1 1 x
X1 X5 1 1 1 1 x
X1 X6 1 1 1 1 x
X2 X3 0 1 1 0 x
X2 X5 1 1 1 0 x
X2 X6 1 1 1 0 x
X7 X3 1 1 1 1 x
X7 X5 0 0 1 1
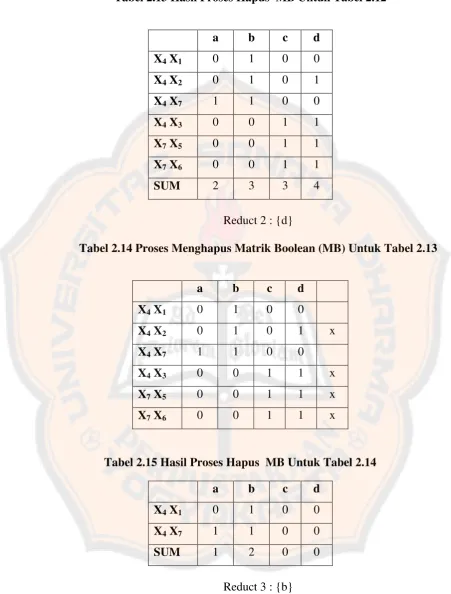
Tabel 2.13 Hasil Proses Hapus MB Untuk Tabel 2.12
a b c d
X4 X1 0 1 0 0
X4 X2 0 1 0 1
X4 X7 1 1 0 0
X4 X3 0 0 1 1
X7 X5 0 0 1 1
X7 X6 0 0 1 1
SUM 2 3 3 4
Reduct 2 : {d}
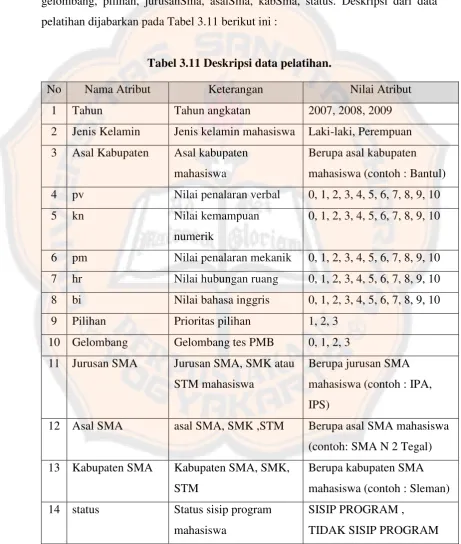
Tabel 2.14 Proses Menghapus Matrik Boolean (MB) Untuk Tabel 2.13
a b c d
X4 X1 0 1 0 0
X4 X2 0 1 0 1 x
X4 X7 1 1 0 0
X4 X3 0 0 1 1 x
X7 X5 0 0 1 1 x
X7 X6 0 0 1 1 x
Tabel 2.15 Hasil Proses Hapus MB Untuk Tabel 2.14
a b c d
X4 X1 0 1 0 0
X4 X7 1 1 0 0
SUM 1 2 0 0
Tabel 2.16 Proses Menghapus Matrik Boolean (MB) Untuk Tabel 2.15
a b c d
X4 X1 0 1 0 0 x
X4 X7 1 1 0 0 x
Tabel 2.16 Matrik Boolean (MB) Null
a b c d
Reduct 1 : {b,c} , Reduct 2: {d} , Reduct 3 :{ b}, HAP= b,c,d
9. Jika MB tidak null, kemudian cetak, HAP secara kasar menjelaskan tentang atribut keputusan.
10. Himpunan Atribut Predominan dikelompokkan dan ditetapkan sebagai hasil reduct.
Dalam Reduct Based Decision Tree (RDT) setelah data melewati proses RCA maka diperoleh dataset yang telah direduksi. Dataset yang telah direduksi merupakan data yang memiliki atribut sesuai dengan anggota dari Himpunan Atribut Predominan (HAP). Dataset yang telah direduksi tersebut kemudian dibentuk pohon keputusan. Menurut Ramadevi (2008) langkah-langkah dalam membuat pohon keputusan adalah sebagai berikut.
Algoritma RDT (input : Data Pelatihan T1; output : Aturan Keputusan): 1. Masukkan data pelatihan T1.
2. Diskretkan atribut yang kontinyu jika ada dan beri nama dataset baru sebagai T2.
3. Hitung reduct dari T2, yaitu R menggunakan RCA.
5. Buat pohon keputusan dari T3 dengan menggunakan reduct R, ambil satu atribut dalam satu waktu dan gunakan atribut tersebut untuk memecah (splitting) secara breadth first (semua nodes dalam level yang sama). 6. Buat aturan keputusan dengan menelusuri semua path dari akar sampai
node daun dalam pohon keputusan.
II.6.
K-Fold Cross Validation
Dalam penelitian ini metode yang akan digunakan untuk menguji pola klasifikasi yang diperoleh menggunakan metode k-fold cross validation. K-fold cross validation merupakan teknik yang membagi data kedalam k bagian untuk kemudian masing bagian data akan dilakukan proses klasifikasi topik. Dengan menggunakan k-fold cross validation kita dapat melakukan percobaan sebanyak k buah. Tiap percobaan tersebut akan menggunakan satu buah data testing dan k-1 bagian menjadi data training,dan kemudian data testing tersebut akan ditukar dengan satu buah data training sehingga untuk setiap percobaan akan didapatkan testing yang berbeda-beda. Data training yaitu data yang akan dipakai dalam melakukan pembelajaran untuk memperoleh pola klasifikasi. Sedangkan data testing yaitu data yang akan digunakan untuk pengujian akurasi dari hasil pembelajaran tersebut. Pada k-fold cross validation untuk pengukuran keakurasian dapat dihitung dengan cara seluruh jumlah klasifikasi yang benar dari k iterasi, dibagi dengan seluruh data.
II.7.
Mengukur Tingkat Keakuratan Penggolong (
Classifier
)
Tabel 2.19 confusion matrix
Jika diberikan dua kelas, ada terminologi tuple positif dan tuple negatif. Benar positif merujuk pada tuple positif yang dilabeli oleh penggolong secara benar. Benar negatif merujuk pada tuple negatif yang dilabeli oleh penggolong secara benar. Salah positif merujuk pada tuple negatif yang dilabeli dengan tidak benar. Maka, Salah negatif merujuk pada tuple positif yang dilebeli dengan tidak benar. Sensitivitas (sensitivity) juga merujuk pada angka benar positif. Angka benar positif adalah ukuran dari tuple positif yang diidentifikasi dengan benar. Spesifikasi (specificity) merujuk pada angka benar negatif. Angka benar negatif adalah ukuran dari tuple negatif yang diidentifikasi dengan benar. Sebagai tambahan, diperlukan perhitungan ketelitian (precision) untuk mendapatkan persentasi dari tuple yang dilabeli sebagai „a‟ yang sebenarnya adalah „a‟.
...(2.10)
...(2.11)
...(2.12)
Dimana :
Dengan demikian untuk menghitung keakuratan sebuah penggolong adalah
..….(2.13 )
II.8.
Perkiraan Interval
Dalam penelitian ini sebelum data melalui proses penambangan data diperlukan proses transformasi terhadap data nilai tes Penerimaan Mahasiswa Baru (PMB) jalur reguler agar mudah mudah dikelola. Transformasi data untuk setiap nilai tes PMB jalur reguler menggunakan aturan perkiraan interval dengan rumus sebagai berikut (Supranto, 1992) :
n
Z = nilai galat standar (koefisien reliabilitas)
n = jumlah data
Dalam penelitian ini diasumsikan selang kepercayaannya adalah 95% jadi didapatkan untuk nilai
adalah 5% (didapatkan dari : 100% - selang kepercayaan). Jadi didapatkan nilai2 α
Z adalah 1,96. Nilai tersebut didapatkan dari
32
BAB III
ANALISIS DAN PERANCANGAN
III.1.Identifikasi Sistem
Dalam penelitian ini akan dibangun sistem yang mampu mengenali pola klasifikasi mahasiswa yang terkena sisip program dan mampu menghitung kinerja akurasi dan kecepatan komputasi dalam membangun pola klasifikasi tersebut berdasarkan data Penerimaan Mahasiswa Baru (PMB) jalur reguler. Algoritma yang akan digunakan dalam membangun sistem ini adalah Reduct Based Decision Tree (RDT). Masukan dari sistem ini berupa data PMB Universitas Sanata Dharma (USD) jalur reguler dengan format File berupa .csv. Sistem akan memproses masukan tersebut menggunakan algoritma RDT untuk menghasilkan suatu pola klasifikasi.
III.2.Analisis Sistem
III.2.1 Analisis Data Awal
Dalam penelitian ini data yang akan digunakan adalah data PMB jalur reguler USD tahun 2007 – 2009. Data PMB didapat dari BAPSI Universitas Sanata Dhrama. Data tersebut berupa file dengan format .xml Document yang terdiri dari 2506 record dengan atribut seperti pada tabel 3.1 berikut ini:
Tabel 3.1Daftar atribut data PMB jalur reguler.
Nama atribut Keterangan
Tahun Tahun angkatan mahasiswa
ProgramStudi Program studi mahasiswa JenisKelamin (JK) Jenis kelamin mahasiswa AsalKabupaten (AK) Asal kabupaten mahasiswa
pv Nilai penalaran verbal
kn Nilai kemampuan numerik
hr Nilai hubungan ruang
bi Nilai bahasa inggris
pilihan (P) Pilihan program studi yang diterima dari hasil tes PMB
Gelombang (G) Gelombang pendaftaran saat tes PMB JenisSMA (JS) Jenis jurusan SMA mahasiswa
AsalSMA (AS) Asal SMA mahasiswa
KeteranganSMA (KS) Keterangan SMA (negeri/swasta) AsalKabupatenSMA (AKS) Asal kabupaten SMA mahasiswa
Tabel 3.2Contoh data PMB jalur reguler
tahun ProgramStudi (PS)
JenisKelami
RTUS_YOGYAKARTA swasta Sleman
2007 ILMU_SEJARAH Laki-Laki
Banjarma
KAEL_WARAK swasta Sleman
2010 AKUNTANSI Perempuan Kebumen 7 4 4 5 5 pilihan_1
NTIAE_JAMBU swasta Semarang
2010 TEKNIK_MESIN Laki-Laki Magelang 7 6 7 7 6 pilihan_2
Gelomba ng_1
SMU/MA
_IPA SMA_N_1_SLEMAN negeri Sleman
2009 PEND._SEJARAH Perempuan
Purbaling
NGGA negeri Purbalingga
2008
HUR_SEDAYU swasta Bantul
2010 PEND._EKONOMI Laki-Laki Sleman 2 2 5 1 1 pilihan_2
Tabel 3.2Contoh data PMB jalur reguler (Lanjutan).
tahun ProgramStudi (PS)
JenisKelami
2010 PEND._MATEMATIKA Laki-Laki
Tulang_Ba
HUR_SEDAYU swasta Bantul
2007 PEND._BAHASA_INGGRIS Laki-Laki Manggarai 7 3 3 2 8 pilihan_1
ABUAN_BAJO swasta Manggarai
2009 PEND._BAHASA_INGGRIS Perempuan Kebumen 6 5 8 7 8 pilihan_1
ANYAR negeri Kebumen
2009 MANAJEMEN Laki-Laki Sleman 4 3 5 2 1 pilihan_2
Gelomba ng_2
SMU/MA
_IPS SMA_N_1_GODEAN negeri Sleman
2007 FARMASI Perempuan Yogyakarta 8 8 7 7 7 pilihan_1
ARTA negeri Yogyakarta
2009 PEND._BAHASA_INGGRIS Laki-Laki Sleman 7 6 6 5 8 pilihan_1
ARTA negeri Yogyakarta
2009 PEND._BAHASA_INGGRIS Laki-Laki Magelang 7 6 9 6 8 pilihan_1
MAGELANG swasta Magelang
2009
HUR_SEDAYU swasta Bantul
2007 PEND._AKUNTANSI Laki-Laki Sleman 6 4 9 5 3 pilihan_1
HUR_SEDAYU swasta Bantul
2009 PEND._BAHASA_INGGRIS Perempuan Kulonprogo 7 6 6 5 7 pilihan_1
Selain menggunakan data PMB jalur reguler digunakan juga data nilai KRS mahasiswa USD angkatan 2007 – 2009. Data KRS mahasiswa mahasiswa USD angkatan 2007 – 2009 digunakan untuk memperoleh status sisip program mahasiswa. Data tersebut diperoleh dari dari BAPSI Universitas Sanata Dhrama berupa file dengan format .xml Document dengan atribut seperti pada tabel 3.3 berikut ini:
Tabel 3.3Daftar atribut data KRS mahasiswa. Nama atribut Keterangan
Nomor (no) Nomor urut Mahasiswa
Ambil Tahun dan semester mahasiswa saat mengambil sks.
sks Merupakan sks dari matakuliah yang diambil mahasiswa.
nilai nilai dari matakuliah yang diambil mahasiswa.
Kd_mtk Kode matakuliah.
Nama_mtk Nama matakuliah.
Contoh data KRS mahasiswa yang akan digunakan dalam penelitian ini dijabarkan pada tabel 3.4 berikut ini :
Tabel 3.4Contoh data KRS mahasiswa. Nomor Ambil sks Nilai Kd_mtk Nama_mtk 1113000 20071 2 A MKK132 Komputer
1113000 20071 2 A MKK116 Dasar-dasar Pemahaman Perilaku 1113000 20071 2 B MKK126 Bahasa Indonesia
1113000 20071 2 B KPBF103 Dasar-dasar Bimbingan dan Konseling
Data status sisip program ditentukan dari data nilai KRS mahasiswa yang mengikuti tes PMB jalur reguler Universitas Sanata Dharma (USD) tahun 2007 – 2009 yang diperoleh dari BAPSI USD. Penentuan status sisip program dilakukan berdasarkan aturan evaluasi sisip program yang ada pada buku panduan akademik USD tahun 2007. Aturan penentuan status sisip program yaitu bahwa mahasiswa boleh dinyatakan tidak sisip program apabila pada akhir semester 4 dapat mengumpulkan sekurang-kurangnya 40 sks dengan ipk sekurang-kurangnya 2,00. Apabila dalam waktu empat semester tersebut mahasiswa mampu mengumpulkan lebih dari 40 sks, maka untuk evaluasi tersebut diambil 40 sks dengan nilai tertinggi.
1113000 20071 2 B MKK128 Antropobiologi 1113000 20071 2 B USD120 Pendidikan Agama 1113000 20071 2 B USD123 Pendidikan Pancasila 1113000 20072 2 A MKK121 Pskologi Pendidikan
1113000 20072 2 B MKK121 Pendidikan Kewarganegaraan 1113000 20072 2 A USD224 Teologi Moral
1113000 20072 2 A USD121 Sosioantropologi Pendidikan 1113000 20072 2 B MKK112 Psikologi Remaja
1113000 20072 3 B KPBF201 Perkembangan Anak 1113000 20072 2 A MKK118 Perilaku Sosial
1113000 20072 2 C MKK117 Pengembangan Pribadi Konselor 1113000 20072 2 B MKK115 Dasar-Dasar BK (Pengantar BK) 1113000 20072 2 A MKK111 BK Perkembangan
1113000 20081 2 B USD325 Filsafat Ilmu Pengetahuan 1113000 20081 2 B MKB234 Dinamika Kelompok 1113000 20081 2 B MKB235 BK Pribadi-Sosial 1113000 20081 2 A MKK233 Statistika I
1113000 20081 2 C MKK220 Psikologi Konseling
1113000 20081 3 B MKK219 Perkembangan Orang Dewasa dan Lanjut Usi
III.2.2 Pemrosesan Awal
Dalam penelitian ini sebelum dilakukan proses penambangan data, data mentah melewati pemrosesan awal terlebih dahulu. Langkah-langkah dalam pemrosesan awal menggunakan empat tahapan yang ada pada Knowledge discovery in database (KDD) yaitu pembersihan data, integrasi data, seleksi data dan transfomasi data.
III.2.2.1 Pembersiha Data (Data Cleaning)
Tahap pembersihan yang pertama dilakukan terhadap data mahasiswa yang memiliki nilai PMB jalur reguler null atau kosong. Pembersihan tersebut dilakukan apabila pada kolom nilai penalaran verbal, nilai kemampuan numerik, nilai penalaran mekanik, nilai hubungan ruang dan nilai bahasa inggris keseluruhanya bernilai null atau kosong. Dalam tahap ini diasumsikan apabila keseluruhan nilai pada kolom tersebut bernilai null atau kosong, terjadi kesalahan pada saat menyimpan data.
Data mentah sebelum proses pembersihan data sebanyak 2506 data. Dari 2506 data, terdapat 70 data yang memiliki nilai null atau kosong pada nilai penalaran verbal, nilai kemampuan numerik, nilai penalaran mekanik, nilai hubungan ruang dan nilai bahasa inggris sehingga 70 data tersebut dihapus. Data mentah yang diperoleh dari proses pembersihan data sebanyak 2436 data. Data mentah yang telah melalui proses pembersihan data akan digunakan dalam tahap selanjutnya.
III.2.2.2 Integrasi Data (Data Integration)
Tabel 3.5Contoh data awal setelah proses integrasi dan pembersihan.
Ta
hun ProgramStudi (PS)
JenisK
MIKAEL_WARAK swasta Sleman
SISIP_PROGRAM
UHUR_SEDAYU swasta Bantul
SISIP_PROGRAM
UHUR_SEDAYU swasta Bantul
SISIP_PROGRAM
UHUR_SEDAYU swasta Bantul
Tabel 3.5Contoh data awal setelah proses integrasi dan pembersihan (Lanjutan).
ABUAN_BAJO swasta Manggarai
TIDAK_SISIP_PRO
ANYAR negeri Kebumen
TIDAK_SISIP_PRO
ARTA negeri Yogyakarta
TIDAK_SISIP_PRO
ARTA negeri Yogyakarta
TIDAK_SISIP_PRO
_MAGELANG swasta Magelang
Tabel 3.5Contoh data awal setelah proses integrasi dan pembersihan (Lanjutan).
HUR_SEDAYU swasta Bantul
TIDAK_SISIP_PRO
HUR_SEDAYU swasta Bantul
TIDAK_SISIP_PRO
HUR_SEDAYU swasta Bantul
III.2.2.3 Seleksi Data (Data Selection)
Pada tahap ini dilakukan tahap pembuangan data-data yang tidak diperlukan atau dibutuhkan seperti data-data yang kurang relevan dalam penelitian. Pada penelitian ini tahap seleksi data dilakukan pada proses Reduct Computation Algoritm (RCA) yang ada pada algoritma RDT. Contoh proses seleksi data mengunakan algoritma Reduct Computation Algoritm (RCA) dalam penelitian ini dapat dilihat pada lampiran 1.
III.2.2.4 Transformasi Data (Data Transformation)
Pada tahapan transformasi data pengubahan data mentah menjadi data yang mudah dikelola dalam proses penambangan data. Dalam penelitian ini tahapan transformasi data dilakukan terhadap data yang berupa nilai angka. Sedangkan data yang bukan berupa nilai angka tidak dilakukan transformasi data. Proses transformasi akan dilakukan terhadap atribut nilai tes potensi akademik yang meliputi: penalaran verbal (pv), kemampuan numerik (kn), penalaran mekanik (pm), bahasa inggris (bi), dan hubungan ruang (hr). Dengan mengasumsikan data nilai tes potensi akademik tersebut terdistribusi normal, maka dalam penelitian ini diterapkan aturan transformasi sebagai berikut (Supranto, 1992) :
Tabel 3.6 Aturan Transformasi Data Nilai Tes Potensi Akademik.
Interval Formula
D nilai tes < X nilai tes – 1.96 * σnilai tes / n C X nilai tes – 1.96 * σ
nilai tes / n ≤ nilai tes ˂ X nilai tes
B X nilai tes ≤ nilai tes˂ X
nilai tes + 1.96 * σnilai tes / n
III.3.Analisis Kebutuhan Sistem
III.3.1 Diagram Use Case
Transformasi Data
Reduct Data
Bentuk Aturan
Simpan Aturan Pencarian Pola
<< depends on >>
<< depends on >>
<< depends on >>
Pengguna
Gambar 3.1 Diagram Use Case .
III.3.2 Narasi Use Case
ID Use Case : SPRDT-01
Nama Use Case : Transformasi Data. Aktor : Pengguna.
Tabel 3.7Narasi Use Case Transformasi Data.
Aksi Actor Reaksi Sistem
1. Menekan tombol browse untuk memasukkan data pelatihan.
2. Menampilkan tabel data pelatihan (data PMB) beserta jumlah data. 3. Menekan tombol transformasi.
4. Melakukan proses transformasi data, menampilkan pesan bahwa transformasi selesai dilakukan dan menampilkan hasil transformasi.
ID Use Case : SPRDT-02 Nama Use Case : Reduct Data. Aktor : Pengguna.
Deskripsi : Use case ini menggambarkan proses dimana pengguna melakukan proses Reduct atribut.
Tabel 3.8Narasi Use Case Reduct Data.
Aksi Actor Reaksi Sistem
1. Menekan tombol Reduct.
2. Melakukan proses reduct data, menampilkan pesan bahwa proses reduct selesai dilakukan dan menampilkan hasil reduct.
ID Use Case : SPRDT-03 Nama Use Case : Bentuk Aturan. Aktor : Pengguna.
Tabel 3.9Narasi Use Case Bentuk Aturan.
Aksi Actor Reaksi Sistem
1. Menekan tombol bentuk aturan.
2. Melakukan proses pembentukan aturan kemudian menampilkan hasil pembentukan aturan berupa pohon keputusan.
ID Use Case : SPRDT-04 Nama Use Case : Simpan Aturan. Aktor : Pengguna.
Deskripsi : Use case ini menggambarkan proses dimana pengguna melakukan proses menyimpan aturan yang diperoleh dari proses bentuk aturan.
Tabel 3.10Narasi Use Case Simpan Aturan.
Aksi Actor Reaksi Sistem
1. Menekan tombol simpan aturan.
2. Menampilkan halaman file chooser.
3. Memilih letak penyimpanan yang ada pada halaman file chooser, memberi nama file yang akan disimpan dan menekan tombol save.
III.4.Perancangan Umum Sistem
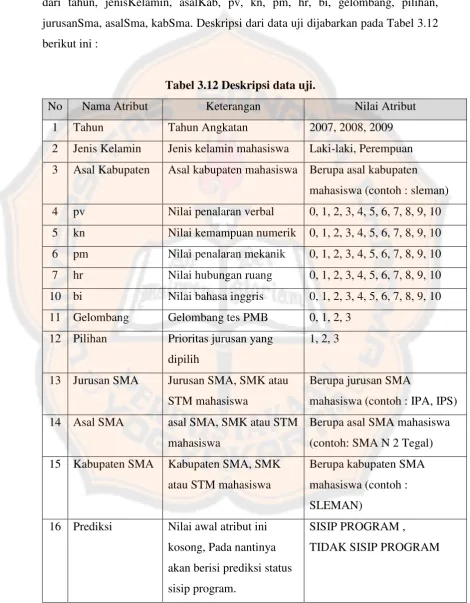
III.4.1 Masukan Sistem
Data yang akan menjadi masukan sistem dalam penelitian ini berupa data pelatihan dan data uji. Format data yang akan menjadi masukan sistem berupa file .csv. Data pelatihan terdiri dari tahun, jenisKelamin, asalKab, pv, kn, pm, hr, bi, gelombang, pilihan, jurusanSma, asalSma, kabSma, status. Deskripsi dari data pelatihan dijabarkan pada Tabel 3.11 berikut ini :
Tabel 3.11 Deskripsi data pelatihan.
No Nama Atribut Keterangan Nilai Atribut 1 Tahun Tahun angkatan 2007, 2008, 2009 2 Jenis Kelamin Jenis kelamin mahasiswa Laki-laki, Perempuan 3 Asal Kabupaten Asal kabupaten
mahasiswa
Berupa asal kabupaten mahasiswa (contoh : Bantul) 4 pv Nilai penalaran verbal 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 mahasiswa (contoh : IPA, IPS)
12 Asal SMA asal SMA, SMK ,STM Berupa asal SMA mahasiswa (contoh: SMA N 2 Tegal) 13 Kabupaten SMA Kabupaten SMA, SMK,
STM
Berupa kabupaten SMA mahasiswa (contoh : Sleman) 14 status Status sisip program
mahasiswa
Untuk masukan data uji hampir sama dengan masukan data pelatihan, tetapi untuk atribut status diganti dengan atribut prediksi yang nantinya digunakan untuk menyimpan hasil prediksi dan sebagai keluaran. Masukan data uji terdiri dari tahun, jenisKelamin, asalKab, pv, kn, pm, hr, bi, gelombang, pilihan, jurusanSma, asalSma, kabSma. Deskripsi dari data uji dijabarkan pada Tabel 3.12 berikut ini :
Tabel 3.12 Deskripsi data uji.
No Nama Atribut Keterangan Nilai Atribut 1 Tahun Tahun Angkatan 2007, 2008, 2009 2 Jenis Kelamin Jenis kelamin mahasiswa Laki-laki, Perempuan 3 Asal Kabupaten Asal kabupaten mahasiswa Berupa asal kabupaten
mahasiswa (contoh : sleman) 4 pv Nilai penalaran verbal 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
12 Pilihan Prioritas jurusan yang dipilih
1, 2, 3
13 Jurusan SMA Jurusan SMA, SMK atau STM mahasiswa
Berupa jurusan SMA
mahasiswa (contoh : IPA, IPS) 14 Asal SMA asal SMA, SMK atau STM
mahasiswa
Berupa asal SMA mahasiswa (contoh: SMA N 2 Tegal) 15 Kabupaten SMA Kabupaten SMA, SMK
atau STM mahasiswa
Berupa kabupaten SMA mahasiswa (contoh : SLEMAN)
16 Prediksi Nilai awal atribut ini kosong, Pada nantinya akan berisi prediksi status sisip program.