PENERAPAN DECISION TREE UNTUK PENENTUAN POLA DATA PENERIMAAN MAHASISWA BARU
Aradea, Satriyo A., Ariyan Z., Yuliana A.
Teknik Informatika Universitas Siliwangi Tasikmalaya Ilmu Komputer Universitas Diponegoro Semarang
Abstrak
Penerimaan mahasiswa baru (PMB) adalah proses penyaringan calon mahasiswa yang diterima pada suatu perguruan tinggi. Mengidentifikasi pola dari PMB dapat memberikan informasi yang bermanfaat baik kepada perguruan tinggi dalam hal ini program studi atau calon mahasiswa yang mendaftar pada suatu program studi.
Penentuan pola tersebut dapat dilakukan dengan model klasifikasi, model klasifikasi dibuat dengan cara menganalisis training data, model yang dihasilkan nantinya dapat digunakan untuk memprediksi kelas dari unknown data. Model klasifikasi dapat digambarkan dalam berbagai bentuk, salah satunya adalah dengan menggunakan Decision Tree. Dalam makalah ini akan dibahas model klasifikasi menggunakan Decision Tree dengan algoritma Interactive Dichotomicer 3 (ID3), untuk penentuan pola dari sebuah data PMB dengan mengacu pada parameter atribut yang digunakan pada saat calon mahasiswa tersebut mendaftar dan melaksanakan ujian masuk. Dari hasil pembahasan studi kasus didapatkan atribut yang berpengaruh pada penentuan pola data PMB terdiri dari tiga atribut, yaitu prioritas pilihan program studi, skor ujian masuk dan jurusan saat SMA.
Kata Kunci : Data Mining, Model Klasifikasi, Decision Tree, Algoritma ID3, Penerimaan Mahasiswa Baru
1. PENDAHULUAN
Suatu hal penting yang seharusnya dilakukan perguruan tinggi pada saat melakukan PMB, yaitu dengan mengidentifikasi pola dari data PMB yang sudah dilaksanakan, dengan melakukan klasifikasi dari paramenter atribut yang ditentukan. Informasi yang dapat diterima program studi dari penentuan pola tersebut dapat dijadikan dasar penentuan kebijakan sistem PMB yang akan datang untuk kriteria penilaian calon mahasiswanya. Informasi yang dihasilkan juga bermanfaat bagi calon
mahasiswa yang akan mendaftar pada suatu program studi, informasi tersebut dapat dijadikan dasar untuk pemilihan program studi dengan informasi kriteria penilaian suatu program studi terhadap calon mahasiswanya.
Klasifikasi adalah suatu fungsionalitas yang akan menghasilkan model yang mampu memprediksi kelas atau kategori dari objek-objek. Dalam permsalahan ini klasifikasi dapat digunakan oleh suatu program studi untuk menentukan atau mengidentifikasi pola dari data PMB yang sudah
dilaksanakan. Pada kasus ini model klasifikasi dibuat untuk mengidentifikasi pola data untuk kelas status “diterima”
atau “tidak diterima”, dari hasil penentuan pola training data. Pola atau model dari training data tersebut selanjutnya diuji dengan menggunakan test set data. Singkatnya Model klasifikasi dibuat dengan cara menganalisis training data (terdiri dari variable variabel yang kelasnya sudah diketahui). Model yang dihasilkan kemudian akan digunakan untuk memprediksi kelas dari unknown data (variable-variabel yang kelasnya belum diketahui), test set data digunakan untuk pengujian dari model yang telah didapatkan pada training data. Model klasifikasi yang digunakan dalam kasus ini adalah Decision Tree. Perangkat lunak bantu yang digunakan untuk implementasi adalah WEKA 36.2.
Diharapakan dengan dilakukannya model klasifikasi ini program studi akan menemukan pola dari data PMB yang sudah dilaksanakan, sebagai dasar untuk penentuan kebijakan bagi PMB yang akan datang.
2. LANDASAN TEORI Data Mining
Data Mining (DM) adalah salah satu bidang yang berkembang pesat karena
besarnya kebutuhan akan nilai tambah dari database dengan skala besar. DM adalah serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data. DM memiliki hubungan dari bidang ilmu seperti artificial intelligent, machine learning, statistik dan database. Beberapa teknik DM antara lain: clustering, classification, association rule mining, neural network, genetic algorithm dan lain-lain.
Proses Data Mining
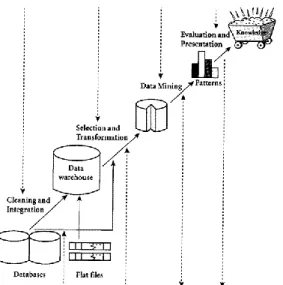
DM dapat dibagi menjadi beberapa tahap yang diilustrasikan pada Gambar 1
Gambar 1 Tahapan Data Mining Klasifikasi
Klasifikasi adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk
dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui.
Model itu sendiri bisa berupa aturan
“jika-maka”, berupa decision tree, formula matematis atau neural network.
Proses classification biasanya dibagi menjadi dua fase: learning dan test. Pada fase learning, sebagian data yang telah diketahui kelas datanya diumpankan untuk membentuk model perkiraan.
Kemudian pada fase test model yang sudah terbentuk diuji dengan sebagian data lainnya untuk mengetahui akurasi dari model tersebut. Bila akurasinya mencukupi model ini dapat dipakai untuk prediksi kelas data yang belum diketahui.
3. METODOLOGI
Metode yang digunakan untuk menangani permasalahan yang ada bertujuan untuk memperlihatkan bagaimana sebuah model data mining dapat digunakan untuk membantu mengetahui pola Penerimaan Mahasiswa Baru (PMB) di salah satu Program Studi X di Perguruan Tinggi Z berdasarkan atribut-atribut dari data mahasiswa yang mendaftar pada program studi tersebut.
Dari berbagai model klasifikasi yang ada digunakan model Decision Tree, yaitu dengan menggunakan algoritma Iterative Dichotomiser 3 (ID3) merupakan sebuah metode yang
digunakan untuk membangkitkan Decision Tree yang mendapatkan informasi berdasarkan entropy yang merupakan sistem pengukuran statistik.
Sample data yang digunakan oleh ID3 memiliki beberapa syarat, yaitua tribut yang sama harus mendeskripsikan tiap contoh dan memiliki jumlah nilai yang sudah ditentukan. Pemillihan atribut pada ID3 dilakukan dengan properti statistik, yang disebut dengan information gain. Gain mengukur seberapa baik suatu atribut memisahkan training example ke dalam kelas target. Atribut dengan informasi tertinggi akan dipilih. Dengan tujuan untuk mendefinisikan gain, pertama-tama digunakanlah ide dari teori informasi yang disebut entropi. Entropi mengukur jumlah informasi yang ada pada atribut. Rumus entropi adalah:
Rumus untuk menghitung gain adalah:
Setelah mendapatkan informasi dari semua atribut yang dihitung, atribut dengan information gain tertinggi dipilih sebagai atribut node awal (root node) serta cabang-cabangnya di buat sesaui nilai-nilai kemungkinan. Proses ini terus berulang sepanjang/ pada setiap cabang
4. HASIL DAN PEMBAHASAN Arsitektur Sistem
Pada makalah ini, data yang digunakan merupakan data calon mahasiswa yang mendaftar pada suatu program studi di Universitas X. Jumlah data yang diproses adalah 1458 sampel data. Yang dibagi kedalam 7 attribut Atribut-atribut tersebut adalah :
a) Jurusan pilihan.
Dibagai kedalam 2 label, yaitu : 1. Ilmu Pengetahuan Sosial (IPS) 2. Ilmu Pengetahuan Campuran (IPC).
b) Jurusan sewaktu SMA.
Attribut jurusan sewaktu SMA dibagi menjadi 3 label, yaitu :
1. Ilmu Pengetahuan Alam (IPA).
2. Ilmu Pengetahuan Sosial (IPS).
3. Kejuruan.
c) Daerah asal.
Attribut daerah asal siswa dibagi menjadi 5 label, yaitu :
1. Banten.
2. DKI.
3. Jawa Barat.
4. Jawa Tengah.
5. Jawa Timur.
d) Rata-rata nilai Ujian Nasional (UN).
Attribut rata-rata nilai UN dibagi menjadi 3 label, yaitu :
1. Rataan < 6.
2. Rataan >= 6 dan < 8 3. Rataan >= 8 dan <= 10.
e) Prioritas pilihan Program Studi.
Attribut ini dibagi menjadi 3 label, yaitu :
1. Pilihan 1.
2. Pilihan 2.
3. Pilihan 3.
f) Skor ujian masuk.
Attribut skor ujian masuk dibagi menjadi 4 label, yaitu :
1. Skor ujian < 25.
2. Skor ujian >= 25 dan <50.
3. Skor ujian >= 50 dan <75.
4. Skor ujian >= 75 dan <=100.
g) Status diterima atau tidak diterimanya siswa tersebut.
Attribut ini dibagi menjadi 2 label, yaitu :
1. Diterima 2. Tidak diterima.
Dari total sampel yang digunakan kemudian dibagi menjadi 2 subset, subset 1 untuk training dengan jumlah sampel data 972 dan subset 2 untuk testing dengan jumlah sampel data 486.
Pembahasan
Penelitian ini menggunakan data sejumlah 1.458 yang dibagi menjadi dua subset yaitu :
1. S1 = 972 data sebagai training set 2. S2 = 486 data sebagai test set
Dengan metode yang digunakan, maka perhitungan entropi dan nilai information
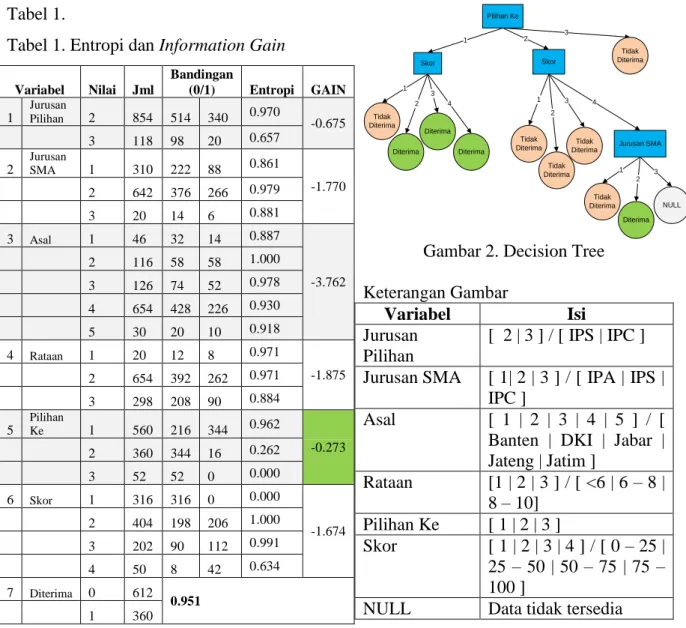
gain masing-masing variabel dengan menggunakan data subset S1 (972 data) sebagai training set dapat dilihat pada Tabel 1.
Tabel 1. Entropi dan Information Gain
Variabel Nilai Jml
Bandingan
(0/1) Entropi GAIN 1
Jurusan
Pilihan 2 854 514 340 0.970
-0.675
3 118 98 20 0.657
2
Jurusan
SMA 1 310 222 88 0.861
-1.770
2 642 376 266 0.979
3 20 14 6 0.881
3 Asal 1 46 32 14 0.887
-3.762
2 116 58 58 1.000
3 126 74 52 0.978
4 654 428 226 0.930
5 30 20 10 0.918
4 Rataan 1 20 12 8 0.971
-1.875
2 654 392 262 0.971
3 298 208 90 0.884
5 Pilihan
Ke 1 560 216 344 0.962
-0.273
2 360 344 16 0.262
3 52 52 0 0.000
6 Skor 1 316 316 0 0.000
-1.674
2 404 198 206 1.000
3 202 90 112 0.991
4 50 8 42 0.634
7 Diterima 0 612 0.951
1 360
Berdasarkan hasil yang didapatkan pada tabel 1, maka sebagai langkah pertama variabel Pilihan Ke menjadi NODE pertama dalam Decision Tree karena memiliki nilai information gain paling tinggi. Pada langkah selanjutnya adalah menentukan NODE kedua dan seterusnya hingga Decision Tree didapatkan dengan perhitungan cara yang sama pada langkah
pertaman. Sehingga deskripsi dari Decision Treenya dapat dilihat pada Gambar 2.
Pilihan Ke
1 2 3
Skor
1 2
3 4
Skor
1 2
3 4
Tidak Diterima
Diterima Diterima
Diterima
Tidak Diterima
Tidak Diterima
Tidak Diterima
Tidak
Diterima Jurusan SMA
1 2
3
Tidak Diterima
Diterima NULL
Gambar 2. Decision Tree Keterangan Gambar
Variabel Isi Jurusan
Pilihan
[ 2 | 3 ] / [ IPS | IPC ] Jurusan SMA [ 1| 2 | 3 ] / [ IPA | IPS |
IPC ]
Asal [ 1 | 2 | 3 | 4 | 5 ] / [ Banten | DKI | Jabar | Jateng | Jatim ]
Rataan [1 | 2 | 3 ] / [ <6 | 6 – 8 | 8 – 10]
Pilihan Ke [ 1 | 2 | 3 ]
Skor [ 1 | 2 | 3 | 4 ] / [ 0 – 25 | 25 – 50 | 50 – 75 | 75 – 100 ]
NULL Data tidak tersedia Berdasarkan Decision Tree yang terbentuk, variabel-variabel yang berpengaruh pada penerimaan mahasiswa baru adalah :
1. Pilihan Ke (1 atau 2 atau 3) 2. Skor (1 atau 2 atau 3 atau 4) 3. Jurusan SMA (1 atau 2 atau 3)
Variabel-variabel yang tidak mempengaruhi diantaranya :
1. Jurusan pilihan (2 atau 3)
2. Asal (1 atau 2 atau 3 atau 4 atau 5) 3. Rataan (1 atau 2 atau 3)
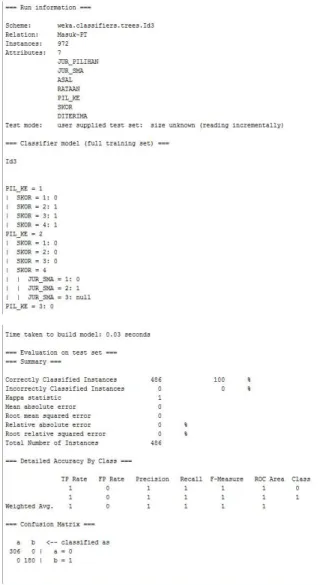
Dalam aturan klasifikasi yang telah dilakukan dengan metode Decision Tree menggunakan algoritma ID3 untuk menghasilkan output dari penentuan pola pada training data dan hasil evaluasi test set data digunakan perangkat lunak bantu WEKA. Dan hasil yang diperoleh seperti ditunjukan pada gambar 3.
Gambar 3. Output Decision Tree.
Pada gambar 3 output dari hasil pengolahan diketahui bahwa dari semua
atribut yang ada, teridentifikasi bahwa atribut yang berpengaruh pada penentuan status akhir dari data terdapat tiga atribut yaitu atribut prioritas pilihan program studi, skor ujian masuk dan jurusan saat SMA. Hasil evaluasi dari data test set, didapatkan bahwa nilai keakuratan penentuan dari pola menunjukan hasil maksimal yaitu 100%, artinya setiap data pada status akhir/ kelas tujuan semuanya terpasang dengan benar. Dari data confusion matrix data test set menunjukan nilai klasifikasi sesuai dan tidak terdapat kesalahan klasifikasi yaitu a = 306 data dan b= 108 data untuk total 486 data tes set.
5. KESIMPULAN
Penentuan pola data PMB pada pembahasan studi kasus penelitian ini dapat diidentifikasi dengan model klasifikasi menggunakan model Decision Tree dengan algoritma ID3. Dari pembahasan studi kasus pada penelitian ini klasifikasi yang dilakukan mengacu pada enam atribut data PMB, dan setelah melakukan pengolahan atribut yang berpengaruh pada penentuan pola untuk mendapatkan status data final hanya diperoleh tiga atribut saja yaitu : prioritas pilihan program studi, skor ujian masuk dan jurusan saat SMA. Akurasi hasil dari studi kasus yang dibahas mencapai nilai
keakuratan yang maksimal yaitu 100%.
Penelitian lanjutan perlu dilakukan untuk menambah cakupan atribut yang dapat dijadikan penentu peningkatan nilai dari status akhir data yang dibutuhkan, misalnya dengan penambahan kelompok atribut dari atribut hasil atau skor test masuk, yang didekomposisi menjadi beberapa atribut baru, misalnya skor nilai kemampuan verbal, skor nilai kemampuan kuantitatif, skor nilai kemampuan logika, skor nilai test psikologis, dan lain lain.
DAFTAR PUSTAKA
Ayu Purwarianti, (2010). Sistem Informasi Inteligen. Magister Informatika STEI ITB.
Han, Jiawei, Micheline Kamber, (2006), Data Mining Concept and Techniques (2nd edition), Morgan Kaufmann Publish.
Ian H. Witten, Eibe Frank,(2005), Data Mining : Practical Machine Learning Tools and Techniques, Second Edition, Morgan Kaufmann Publishers.
Jian Wang Bo Yuan Wenhuang Liu.
(2008). Application of Decision Trees in Mining High-Value Credit Card Customers. Proceedings of the 11th Joint Conference on Information Sciences.
Q. Wang, Y. Wu, J. Xiao, and F. Guang, (2007). The Applied Research Based on Decision Tree of Data Mining In Third- Party Logistics”, IEEE International Conference on Logistics, pp. 1540-1544.