vii
MODEL FONEM DENGAN PENDEKATAN DISTRIBUSI NORMAL
UNTUK PENGENALAN KATA MENGGUNAKAN MFCC
SEBAGAI EKSTRAKSI CIRI
ADITYA DWI HAPSARI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
vii
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
MODEL FONEM DENGAN PENDEKATAN DISTRIBUSI NORMAL
UNTUK PENGENALAN KATA MENGGUNAKAN MFCC
SEBAGAI EKSTRAKSI CIRI
ADITYA DWI HAPSARI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
vii
ABSTRACT
ADITYA DWI HAPSARI. Phoneme
Model with Normal Distribution Approach to
Word Recognition Using MFCC as Feature Extraction.
Supervised by AGUS
BUONO.
Voice recognition is a field study in voice processing. Research on voice signal
has several methods of processing, one of them is the Mel Frequency Cepstrum
Coefficients (MFCC). The purpose of MFCC is to extract voice features. The goal of
this research is to apply MFCC as a feature extraction and the normal distribution as
a method for word recognition. The first step of the research is data reprocessing, and
then data extraction using MFCC. Afterwards, the normal distribution method is used
to process the data.
From the result, it can be concluded that the normal distribution method can be
used for word recognition.The results obtained from the word recognition using
normal distribution and MFCC as feature extraction have the highest accuracy of
100% for the phonemes /g/, /n/, /p/, /v/, /x/, /y/ and the lowest accuracy of 67% for
the phonemes /a/ and /k/.
viii
Judul Skripsi : Model Fonem dengan Pendekatan Distribusi Normal untuk
Pengenalan Kata Menggunakan MFCC sebagai Ekstraksi Ciri
Nama : Aditya Dwi HapsariNIM : G64086031
Menyetujui:
Pembimbing
Dr. Ir. Agus Buono, M.Si.,M.Kom.
NIP. 19660702 199302 1 001
Mengetahui:
Ketua Departemen
Dr. Ir. Agus Buono, M.Si.,M.Kom.
NIP. 19660702 199302 1 0010
RIWAYAT HIDUP
Penulis bernama Aditya Dwi Hapsari dilahirkan di Wamena pada tanggal 24 Juni 1987
sebagai anak kedua dari 2 bersaudara dari pasangan Bapak Tri Suharyono dan Ibu Siti Nur Fatimah Tri Sutanti. Penulis menyelesaikan pendidikan lanjutan atas di SMU Negeri 2 Bogor pada tahun 2005. Pada tahun yang sama, penulis diterima sebagai mahasiswa di Institut Pertanian Bogor (IPB) pada Program Studi Diploma Manajemen Informatika, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam melalui jalur reguler.iv
PRAKATA
Alhamdulillaahirabbil ‘aalamiin, puji serta syukur penulis panjatkan ke
hadirat Allah Subhanahu wata’ala atas segala curahan rahmat dan karunia-Nya
sehingga penelitian ini berhasil diselesaikan. Karya tulis ini merupakan salah satu
syarat memperoleh gelar Sarjana Komputer di Departemen Ilmu Komputer,
Fakultas Matematika dan Ilmu Pengetahuan Alam. Judul dari karya ilmiah ini
adalah Model Fonem dengan Pendekatan Distribusi Normal untuk Pengenalan
Kata Menggunakan MFCC sebagai Ekstraksi Ciri.
Penyelesaian penelitian ini tidak luput dari dukungan dan bantuan berbagai
pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih sebesar-besarnya
kepada:
1
Kedua orang tua tercinta Ayahanda Tri Suharyono dan Ibunda Siti Nur Fatimah
Tri Sutanti, kakak penulis yang bernama Indri Iriana Prameswari, dan segenap
keluarga besar penulis atas do’a, dukungan dan semangat yang tidak pernah
berhenti diberikan selama ini sehingga penulis dapat menyelesaikan studi di
Departemen Ilmu Komputer IPB.
2
Bapak Dr.Ir. Agus Buono M.Si M.Kom selaku dosen pembimbing. Bapak
Ahmad Ridha SKom dan Bapak Toto Haryanto SKom MSi selaku dosen
penguji, atas waktu, ilmu, saran, nasihat, dan masukan yang diberikan.
3
Teman-teman penulis di Ekstensi Ilmu Komputer khususnya angkatan 3, serta
teman-teman lain yang tidak dapat penulis sebutkan satu per satu atas bantuan,
motivasi, serta semangat kepada penulis.
4
Departemen Ilmu Komputer, Bapak/Ibu Dosen dan Tenaga Kependidikan yang
telah begitu banyak membantu baik selama pelaksanaan penelitian ini maupun
sebelumnya.
Kepada semua pihak lainnya yang telah memberikan kontribusi yang besar
selama pengerjaan penelitian ini yang tidak dapat disebutkan satu-persatu, penulis
ucapkan terima kasih banyak. Segala kesempurnaan hanya milik Allah Subhanahu
wata’ala. Semoga hasil penelitian ini dapat bermanfaat, Amin.
Bogor, Juni 2012
v
DAFTAR ISI
Halaman
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup Penelitian ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA ... 1
Fonem ... 1
Sinyal ... 2
Data Suara Digital ... 2
Mel Frequency Cepstrum Coefficients (MFCC) ... 2
Distribusi Normal ... 3
METODOLOGI PENELITIAN ... 4
Pengambilan Data ... 4
Penghapusan Silence ... 4
Normalisasi ... 5
Segmentasi Sinyal ... 5
Data Latih dan Data Uji ... 5
Proses Ekstraksi Ciri ... 5
Perata-rataan Hasil MFCC ... 5
Pemodelan Distribusi Normal ... 5
Pengujian ... 5
Perhitungan Nilai Akurasi ... 5
HASIL DAN PEMBAHASAN ... 5
Praproses ... 5
Hasil Pengujian dengan MFCC ... 6
KESIMPULAN DAN SARAN ... 7
Kesimpulan ... 7
Saran ... 7
vi
DAFTAR TABEL
Halaman
1 Daftar kata dan fonem dalam penelitian ... 4
2 Hasil pengujian dengan ekstraksi ciri MFCC ... 6
DAFTAR GAMBAR
Halaman 1 Diagram alur MFCC ... 22 Distribusi normal. ... 3
3 Diagram alur penelitian. ... 4
4 Pemotongan silence. ... 4
5 Grafik hasil pengujian dengan ekstraksi... 6
6 Proses pada sinyal suara ‘n’ dan ‘o’. ... 6
7 Proses pada sinyal suara ‘v’ dan ‘e’. ... 6
1
PENDAHULUAN
Latar Belakang
Salah satu cara interaksi manusia dengan komputer adalah melalui suara. Dalam beberapa hal, cara ini memiliki beberapa kelebihan dibandingkan dengan interaksi melalui gerakan mekanis. Agar interaksi melalui suara berjalan baik, salah satu kemampuan yang harus dimiliki oleh komputer adalah kemampuan mengenali suara manusia, yaitu tersusun dari fonem-fonem apa saja suara tersebut.
Pengucapan fonem-fonem tersebut akan membentuk kata yang dikenal dengan pengenalan kata. Pengenalan kata termasuk ke dalam speech to text yang merupakan bagian dari speech recognition karena dibutuhkan proses mengubah sinyal akustik yang ditangkap oleh mikrofon untuk setiap fonem yang dimasukan.
Pengenalan suara atau yang sering disebut dengan Automatic Speech Recogniton (ASR) adalah pengembangan teknik dan sistem yang memungkinkan komputer untuk menerima masukan berupa kata yang diucapkan. Kata-kata yang diucapkan diubah bentuknya menjadi sinyal digital dengan cara mengubah gelombang suara menjadi sekumpulan angka yang kemudian disesuaikan dengan kode-kode tertentu untuk mengidentifikasikan kata-kata tersebut. Hasil dari identifikasi kata yang diucapkan dapat ditampilkan dalam bentuk tulisan atau dapat dibaca oleh perangkat teknologi sebagai sebuah komando untuk melakukan suatu pekerjaan, misalnya penekanan tombol pada telepon genggam yang dilakukan secara otomatis dengan komando suara.
Penelitian ini menggunakan metode pendekatan distribusi normal dengan menggunakan Mel Frequency Cepstrum Coefficients (MFCC) sebagai ekstrakasi ciri, dengan ditambahkan proses Noise Canceling
untuk mengetahui kualitas suara. Tujuan Penelitian
Penelitian ini bertujuan memberikan informasi akurasi model kata berbasis fonem dengan pendekatan distribusi normal menggunakan Mel Frequency Cepstrum Coefficients (MFCC) sebagai ekstraksi ciri. Ruang Lingkup Penelitian
Ruang lingkup permasalahan pada penelitian ini ialah:
1 Penelitian dilakukan untuk mengenali fonem. Proses pengambilan suara dilakukan dengan menggunakan mikrofon. 2 Data yang digunakan diambil dari satu
orang pembicara.
3 Kata-kata yang diucapkan pembicara telah ditentukan. Terdapat 19 kata, yaitu: aqidah, autentik, bacem, bahasa, bayem, cendol, efektif, gerigi, jejer, novel, payet, pepes, rezeki, survei, tipx, waqaf, wesel, xilem, dan zebra.
4 Masing-masing kata diucapkan sebanyak 30 kali.
5 Menggunakan Mel Frequency Cepstrum Coefficients (MFCC) sebagai ekstraksi ciri.
6 Penelitian difokuskan dengan menggunakan pendekatan distribusi normal.
7 Pengembangan penelitian ini
menggunakan Matlab. Manfaat Penelitian
Penelitian ini diharapkan dapat memberikan informasi keakuratan pengenalan fonem dari kata yang telah diucapkan oleh pembicara dengan menggunakan pendekatan distribusi normal dan Mel Frequency Cepstrum Coefficients (MFCC) sebagai ekstraksi ciri .
TINJAUAN PUSTAKA
Fonem
Fonem merupakan satuan bunyi terkecil yang mampu menunjukkan kontras makna (KBBI). Fonem dibagi menjadi empat, yaitu: 1 Fonem vokal merupakan bunyi ujaran
akibat adanya udara yang keluar dari paru-paru dan tidak terkena hambatan atau halangan. Jumlah fonem vokal ada lima, yaitu: a, i, u, e, dan o
2 Fonem konsonan merupakan bunyi ujaran akibat adanya udara yang keluar dari paru-paru yang mendapatkan hambatan atau halangan. Jumlah fonem konsonan ada 21 buah yaitu: b, c, d, f, g, h, j, k, l, m, n, p, q, r, s, t, v, w, x, y, dan z.
3 Fonem vokal rangkap adalah gabungan dua fonem vokal yang menghasilkan bunyi rangkap, yaitu: ai, au.
4 fonem konsonan rangkap adalah gabungan dua buah konsonan, yaitu : ny, ng, kh, dan sy.
2
Sinyal
Sinyal suara merupakan gelombang yang tercipta dari tekanan udara yang berasal dari paru-paru yang berjalan melewati lintasan suara menuju mulut dan rongga hidung dengan bentuk artikulator yang senantiasa berubah. Manusia mendengar bunyi saat gelombang bunyi, yaitu getaran di udara atau medium lain, sampai ke gendang telinga manusia. Batas frekuensi bunyi yang dapat didengar oleh manusia berkisar antara frekuensi 20 Hz sampai dengan 20 KHz, dan frekuensi yang dapat didengar dengan baik dan jelas oleh telinga manusia yaitu di atas 10000 Hz (Pelton 1993).
Data Suara Digital
Suara merupakan gelombang analog yang dapat ditangkap oleh mikrofon. Sinyal analog tersebut dapat diubah menjadi sinyal digital melalui proses sampling, yaitu proses untuk memperoleh nilai dari sinyal analog dalam waktu diskret.
Sinyal analog harus diubah menjadi sinyal digital yang disebut proses digitalisasi. Proses digitalisasi terdiri atas dua tahap, yaitu
sampling dan kuantisasi. (Jurafsky & Martin 2000). Sampling adalah proses pengambilan nilai setiap jangka waktu tertentu. Nilai ini menyatakan amplitudo volume suara pada saat itu. Hasilnya adalah sebuah vektor yang menyatakan nilai-nilai hasil sampling. Panjang vektor data ini tergantung pada panjang atau lamanya suara yangdidigitasikan serta sampling rate yang digunakan pada proses digitasinya. Sampling rate sendiri adalah banyaknya nilai yang diambil setiap detik. Sampling rate yang biasa digunakan ialah 8000 Hz dan 16000 Hz. Hubungan antara panjang vektor data yang dihasilkan dengan sampling rate dan panjangnya data suara yang didigitasikan dapat dinyatakan secara sederhana sebagai berikut:
S = Fs * T
dengan,
S = panjang vektor.
Fs = sampling rate yang digunakan (Hertz).
T = panjang suara (detik).
Setelah melalui tahap sampling, proses digitasi suara selanjutnya adalah kuantisasi, yaitu menyimpan nilai amplitudo ke dalam representasi nilai 8 bit atau 16 bit (Jurafsky & Martin 2000).
Mel Frequency Cepstrum Coefficients
(MFCC)
Ekstraksi ciri merupakan proses menentukan suatu nilai atau vektor yang dapat digunakan sebagai penciri objek atau individu. Pada pemrosesan suara, ciri yang biasa digunakan adalah nilai koefisien cepstral dari sebuah frame. Salah satu teknik ekstraksi ciri sinyal suara adalah teknik Mel Frequency
Cepstrum Coefficients (MFCC) yang
menghitung koefisien cepstral dengan mempertimbangkan persepsi sistem pendengaran manusia terhadap frekuensi suara.
Teknik MFCC dapat merepresentasikan sinyal lebih baik dibanding LPC, LPCC, dan teknik lainnya dalam pengenalan suara. Teknik MFCC sebagai ekstraksi ciri dan teknik parameterisasi sinyal suara telah banyak digunakan pada berbagai bidang area pemrosesan suara. Gambar 1 merupakan ilustrasi MFCC.
Gambar 1 Diagram alur MFCC (Buono 2009).
WINDOWING Y(t) = X(t) * W(n), 0<n<N-1 W(n)= 0.54 – 0.46 cos (2 n/(N-1))
Fast Fourier Transform (FFT)
Mel Frequency Wrapping: mel(f)=2595 log(1+f/700) Spektrum Mel:
H(k) adalah nilai filter segitiga ke-i
3
Tahap-tahap dalam teknik MFCC lebih jelasnya ialah sebagai berikut:
a Frame Blocking
Untuk keperluan pemrosesan, sinyal analog yang sudah melalui proses sampling
dan kuantisasi (digitasi suara) dibaca dari
frame demi frame dengan lebar tertentu yang saling tumpang tindih (overlap). Proses ini dikenal dengan frame blocking.
b Windowing
Setiap frame mengandung satu unit informasi sehingga barisan frame akan menyimpan suatu informasi yang lengkap dari sebuah sinyal suara. Untuk itu, distorsi
antar-frame harus diminimalisasi. Salah satu teknik untuk meminimalkan distorsi antar-frame
adalah dengan melakukan proses filtering
pada setiap frame. Pada penelitian kali ini, jenis filter yang digunakan ialah Windowing
karena pemrosesan sinyal akan dilakukan dalam domain frekuensi. Proses windowing
dilakukan pada setiap frame. Dalam hal ini, sinyal digital dikalikan dengan fungsi window
tertentu yang berukuran sama dengan ukuran
frame. Jika sinyal digital frame ke-i adalah xi
dan fungsi window yang digunakan adalah wi,
outputwindowing frame ke-i adalah perkalian skalar antara vektor xi dan wi. Fungsi window
yang digunakan pada penelitian ini ialah
Hamming karena memiliki ekspersi
matematika yang cukup sederhana. c Fast Fourier Transform (FFT)
Analisis Fourier merupakan suatu teknik matematika untuk mendekomposisi sinyal menjadi sinyal-sinyal sinusoidal. Analisis Fourier terdiri atas dua versi, yaitu versi real
dan versi imajiner. Untuk dapat melihat perbedaan sinyal suara yang berbeda-beda, harus dilihat dari domain frekuensi karena, jika dilihat dari domain waktu, perbedaannya sulit terlihat. Untuk itu, sinyal suara yang berada pada domain waktu diubah ke domain frekuensi dengan Fast Fourier Transform
(FFT). FFT merupakan suatu algoritme untuk mengimplementasikan Discrete Fourier Transform (DFT) (Do 1994).
d Mel frequency Wrapping
Studi psikofisik menunjukkan bahwa persepsi manusia terhadap frekuensi sinyal suara tidak berupa skala linier. Oleh karena itu, untuk setiap nada dengan frekuensi aktual
f (dalam Hertz), tinggi subjektifnya diukur dengan skala mel (Melody). Skala mel-frequency adalah selang frekuensi di bawah
1000 Hz dan selang logaritmik untuk frekuensi di atas 1000 Hz (Do 1994).
e Tranformasi Kosinus
Langkah terakhir ialah mengonversikan log mel spectrum ke domain waktu. Hasilnya disebut mel frequency cepstrum coefficients.
Cara untuk mengonversikan log mel spectrum
ke bentuk domain waktu yaitu dengan menggunakan Discrete Cosine Transform
(DCT) (Fazriah 2010). Distribusi Normal
Distribusi normal sering disebut sebaran
Gauss. Penulisan notasi dari peubah acak yang berdistribusi normal umum adalah N(x;µ,σ²). Artinya, peubah acak X
berdistribusi normal umum dengan mean µ dan varians σ². Peubah acak X yang berdistribusi normal dengan mean µ dan
variansσ².
Peubah acak X dikatakan berdistribusi normal umum jika dan hanya jika fungsi densitasnya berbentuk seperti persamaan berikut (Herrhyanto dan Gantini 2009)
Dalam persamaan ini, X merupakan data yang digunakan sebagai data uji, µ merupakan nilai rata-rata dari data latih. Distribusi normal (Gauss) multivariate N(µ, ∑) didefinisikan
sebagai :
Dalam hal ini, d adalah dimensi dari variabel,
X merupakan koefisien data uji hasil ekstraksi ciri, µ adalah nilai rata-rata dari data latih, dan ∑ merupakan nilai matriks kovarian dari data latih.
-
Gambar 2 Distribusi normal.
4
Jika x mempunyai bentuk - , variabel acak X disebut berdistribusi normal. Suatu peubah acak X yang distribusinya berbentuk lonceng seperti pada gambar, disebut peubah acak normal. Distribusi peluang peubah normal kontinu bergantung pada dua parameter µ dan σ, yaitu rataan dan simpangan baku. Jadi, fungsi padat X
dinyatakan dengan n(x;µ,σ).
METODOLOGI PENELITIAN
Berikut akan dijelaskan mengenai tahapan yang dilakukan dalam penelitian. Tahapan yang dimulai dari pengumpulan data suara sampai dengan pengujian dapat dilihat pada Gambar 3. Berikut adalah tahapan metodologi diagram alur penelitian yang dilakukan beserta penjelasannya: Data Suara Segmentasi Normalisasi Hapus Silence Data
Latih Data Uji
Ekstraksi Ciri (MFCC) Perata-rataan hasil MFCC Pemodelan Distribusi Normal Pengujian Perhitungan Akurasi Dokumentasi
dan laporan Selesai
Ekstraksi Ciri (MFCC)
Perata-rataan hasil MFCC Mulai
Gambar 3 Diagram alur penelitian.
Pengambilan data
Data yang digunakan pada penelitian ini berupa data rekaman suara dari satu orang pembicara. Kata yang direkam ada sebanyak
19 kata (aqidah, autentik, bacem, bahasa, bayem, cendol, efektif, gerigi, jejer, novel, payet, pepes, rezeki, survei, tipx, waqaf, wesel, xilem, zebra). Pemilihan kata yang direkam didasarkan untuk memenuhi jumlah fonem sebanyak 26 fonem. Pengambilan suara menggunakan perangkat lunak Audacity. Setiap pembicara direkam selama 1 detik dengan sampling rate 44100 Hz. Kata yang digunakan dapat dilihat pada Tabel 1.
Tabel 1 Daftar kata dan fonem dalam penelitian Kata Fonem aqidah /a/,/d/,/i/,/h/,//q/ autentik /a/,/e/,/i/,/k/,/n/,/t/,/u/ bacem /a/,/b/,/c/,/e/,/m/ bahasa /a/,/b/,/h/,/s/ bayem /a/,/b/,/e/,/m/,/y/ cendol /c/,/d/,/e/,/l/,/n/,/o/ efektif /e/,/f/,/i/,/k/,/t/ gerigi /e/,/g/,/i/,/r/ jejer /e/,/j/,/r/ novel /e/,/l/,/n/,/o/,/v/ payet /a/,/e/,/p/,/t/,/y/ pepes /e/,/p/,/s/ rezeki /e/,/i/,/k/,/r/,/z/ survei /e/,/i/,/r/,/s/,/u/,/v/ tipx /i/,/p/,/t/,/x/ Waqaf /a/,/f/,/q/,/w/ Wesel /e/,/l/,/s/,/w/ Xilem /e/,/l/,/m/,/x/,/y/ zebra /a/,/b/,/e/,/r/,/z/
Penghapusan Silence
Setelah koleksi data suara didapatkan, tahapan selanjutnya adalah penghapusan
silence. Silence sangat mungkin terjadi pada saat perekaman dan biasanya bagian silence
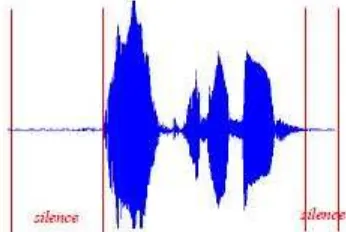
terdapat pada saat awal dan akhir perekaman suara pembicara. Gambar 4 adalah ilustrasi gambar suara yang memiliki silence :
5
Suara yang sudah melalui tahap pemotongan silence disimpan di data suara. Normalisasi
Normalisasi dilakukan dengan mengabsolutkan nilai-nilai data suara dan mencari nilai maksimumnya, kemudian setiap nilai data tersebut dibagi dengan nilai maksimumnya. Normalisasi dilakukan untuk menghasilkan amplitudo maksimum dan minimum yang normal, yaitu maksimum satu dan minimum minus satu sehingga tingkat kekerasan suara menjadi normal.
Segmentasi Sinyal
Pada proses segmentasi, sinyal dipotong sehingga setiap potongan (segmen) sinyal akan menjadi beberapa fonem dari masing-masing kata yang diucapkan. Proses pemotongan masing-masing fonem dilakukan secara manual dengan menggunakan audacity
sehingga diperoleh fonem yang terdiri atas a sampai z.
Data Latih dan Data Uji
Data suara yang telah direkam dibagi menjadi dua bagian, yaitu data latih dan data uji. Jumlah data masing-masing fonem terdapat 60 data. Dengan proporsi 75% data latih dan 25% data uji.
Proses Ekstraksi Ciri
Setiap kata yang telah disegmentasi diekstraksi ciri menggunakan MFCC. Ekstraksi ciri adalah proses untuk menentukan suatu nilai atau vektor yang digunakan sebagai penciri suatu objek. Ekstraksi ciri dengan menggunakan MFCC tidak akan menghilangkan sebagian besar ciri atau informasi setiap data suara pembicara. Selain itu, ukuran data suara menjadi tidak terlalu besar.
Proses yang dilakukan pada tahap ini adalah Framing, Windowing, Fast Fourier Transform, Mel-Frequency Wrapping, dan
Cepstrum. Proses MFCC membutuhkan lima parameter, yaitu:
1 Input. Suara yang merupakan masukan dari pembicara.
2 Sampling rate. Banyaknya nilai yang diambil dari setiap detik. Penelitian ini menggunakan sampling rate sebesar44100 Hz.
3 Time frame. Waktu yang digunakanuntuk satu frame (dalam milidetik). Time frame
yang digunakan adalah 30ms.
4 Lap yaitu Overlaping yang diinginkan (harus kurang dari 100%). Lap yang digunakan pada penelitian ini adalah50%. 5 Cepstral coeffient yaitu jumlah cepstrum
yang diinginkan sebagai output. Cepstral coeffient yang digunakan sebanyak 13. Perata-rataan Hasil MFCC
Hasil ekstraksi ciri menggunakan MFCC memiliki hasil berupa matriks ciri nxk, n
adalah jumlah frame dan k adalah koefisien. Untuk menghasilkan matriks yang berukuran sama di setiap suara, yaitu matriks berukuran
lxk, dilakukan perata-rataan koefisien pada setiap baris. Data latih yang digunakan dalam penelitian untuk satu fonem ada 45 data maka matriks yang dihasilkan berukuran 45xk. Dari matriks tersebut, kemudian dihitung nilai
mean untuk fonem tersebut. Pemodelan Distribusi Normal
Setelah hasil perata-rataan MFCC didapat dilakukan tahap pemodelan dengan metode Distribusi Normal (Gauss). Pada tahap ini dicari nilai rata-rataሺߤሻ dan nilai matriks kovarian dari data latih untuk masing-masing fonem. Matriks kovarian didapat dengan menghitung nilai rata-rata dari data latih. Pengujian
Tahap pengujian dilakukan setelah didapat data uji yang telah melalui proses perata-rataan dan nilai maximum dari metode distribusi normal. Setiap data uji dilihat apakah data tersebut teridentifikasi pada fonem yang seharusnya.
Perhitungan Nilai Akurasi
Setelah tahap pengujian, dilakukan perhitungan nilai akurasi dari penelitian untuk mengetahui tingkat akurasi dari pengenalan fonem ini. Persentase nilai akurasi dihitung dengan persamaan berikut:
Akurasi =
HASIL DAN PEMBAHASAN
Praproses
Kata yang digunakan pada penelitian ini sebanyak 19 kata yang masing-masing direkam sebanyak 30 kali oleh satu orang pembicara. Data tersebut selanjutnya dipraproses. Karena data yang direkam masih merupakan data asli yang masih terdapat
6
segmentasi manual. Tahapan praproses menghasilkan 26 fonem dari fonem /a/ sampai /z/. Kemudian, ditetapkan 75% data latih dan 15% data uji. Masing-masing fonem yang digunakan pada penelitian ini memiliki sebanyak 45 data latih dan 15 data uji sehingga total data latih sebanyak 1170 data dan data uji sebanyak 390 data. Tahapan setelah praproses ialah proses ekstraksi ciri dengan menerapkan MFCC pada semua data. Proses ekstraksi ciri dengan MFCC meliputi beberapa tahapan, yaitu input suara,
sampling rate, time frame, overlap, dan
cepstral coefficient. Data latih adalah data hasil praproses dan ekstraksi ciri yang sebelumnya dibuatkan modelnya terlebih dahulu dengan menghitung mean dan sigma dari masing-masing fonem dengan 13 koefisien. Data latih yang telah diolah dan dilakukan praproses digunakan untuk membangun model pengenalan kata dengan distribusi normal. Model ini yang selanjutnya diuji dengan data uji yang telah diolah. Hasil Pengujian dengan MFCC
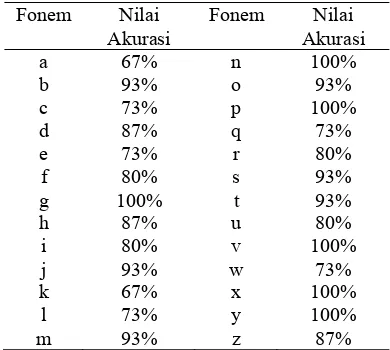
Hasil pengujian dengan ekstraksi ciri MFCC dan distribusi normal untuk masing-masing fonem dapat dilihat pada Gambar 5. Pada gambar terlihat fonem yang dikenal baik oleh sistem dengan akurasi 100%, yaitu fonem /g/, /n/, /p/, /v/, /x/, /y/. Fonem /b/, /j/, /m/, /o/, /s/, /t/ memiliki akurasi 93%. Fonem /d/, /h/, /z/ akurasi 87%. Fonem /f/, /i/, /r/, /u/ memiliki akurasi 80%. Fonem /c/, /e/, /l/, /q/, /w/ memiliki akurasi 73%. Fonem yang dikenali oleh sistem dengan akurasi terendah, yaitu sebesar 67%, ialah fonem /a/ dan /k/. Lebih jelasnya hasil pengujian dengan MFCC dapat dilihat pada Tabel 2.
Gambar 5 Grafik hasil pengujian dengan ekstraksi Ciri MFCC.
Tabel 2 Hasil pengujian dengan ekstraksi ciri MFCC
Fonem Nilai Akurasi
Fonem Nilai Akurasi a 67% n 100% b 93% o 93% c 73% p 100% d 87% q 73% e 73% r 80% f 80% s 93% g 100% t 93% h 87% u 80% i 80% v 100% j 93% w 73% k 67% x 100% l 73% y 100% m 93% z 87%
Gambar 6 merupakan grafik sinyal suara yang diambil dari kata “novel”.
Gambar 6 Proses pada sinyal suara ‘n’ dan ‘o’.
Gambar 7 Proses pada sinyal suara ‘v’ dan ‘e’.
7
KESIMPULAN DAN SARAN
Kesimpulan
Dari penelitian yang dilakukan, dapat disimpulkan bahwa metode distribusi normal dapat digunakan untuk pengenalan fonem. Nilai akurasi tertinggi yang didapat dari pengenalan fonem dengan menggunakan metode distribusi normal dan MFCC sebagai ekstraksi ciri ialah 100% untuk fonem /g/, /n/, /p/, /v/, /x/, /y/. Fonem dengan akurasi terendah, yaitu sebesar 67%, didapat pada fonem /a/ dan /k/. Akurasi fonem /a/ dan /k/ terendah kemungkinan terjadi karena pemotongan fonem yang dilakukan secara manual.
Saran
Penelitian ini dimungkinkan untuk dilakukan pengembangan lebih baik. Saran untuk pengembangan selanjutnya ialah: 1 Penelitian pengenalan fonem ini sangat
memungkinkan untuk dikembangkan lebih lanjut ke tahap pengenalan kata.
2 Jumlah pembicara yang lebih banyak. 3 Menggunakan metode dan algoritme lain
untuk dibandingkan hasilnya dengan metode distribusi normal.
DAFTAR PUSTAKA
Buono A. 2009. Representasi nilai hos dan model MFCC sebagai ekstraksi ciri pada sistem indentifikasi pembicara di lingkungan ber-noise menggunakan HMM [disertasi]. Depok: Program Studi Ilmu Komputer, Universitas Indonesia. Do MN. 1994. Digital Signal Processing
Mini- Project: An Automatic Speaker Recognition System Audio Visual Communications Laboratory. Lausanne: Swiss Federal Institute of Technology. Fazriah. 2010. Identifikasi Pembicara dengan
MFCC sebagai Ekstraksi Ciri dan Codebook untuk pengenalan pola
[skripsi]. Bogor: Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Herrhyanto N, Tuti G. 2009. Pengantar Statistika Matematis. Bandung: Yrama Widya.
Jurafsky D, Martin JH. 2000. Speech and Language Processing an Introduction to Natural Language Processing, Computational Linguistic, and Speech Recognition. New Jersey: Prentice Hall. Pelton GE. 1993. Voice Processing.