UNTUK MEMPREDIKSI FAKTOR DOMINAN INJURY
SEVERITY PADA KECELAKAAN LALU LINTAS
SKRIPSI
TIKA YUNITA
071402008
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEMPREDIKSI FAKTOR DOMINAN INJURY SEVERITY PADA KECELAKAAN LALU LINTAS
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Teknologi Informasi
TIKA YUNITA 071402008
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : JARINGAN SARAF TIRUAN RESILIENT
BACKPROPAGATION UNTUK MEMPREDIKSI FAKTOR DOMINAN INJURY SEVERITY PADA KECELAKAAN LALU LINTAS
Kategori : SKRIPSI
Nama : TIKA YUNITA
Nomor Induk Mahasiswa : 071402008
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI
Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI (Fasilkom-TI) UNIVERSITAS SUMATERA UTARA
Diluluskan di Medan, Juni 2012
Komisi Pembimbing :
Pembimbing II Pembimbing I
Mohammad Fadly Syahputra, M.Sc.IT. Drs. Suyanto, M.Kom. NIP 198301292009121003 NIP 195908131986011002
Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
PERNYATAAN
JARINGAN SARAF TIRUAN RESILIENT BACKPROPAGATION UNTUK MEMPREDIKSI FAKTOR DOMINAN INJURY SEVERITY
PADA KECELAKAAN LALU LINTAS
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juni 2012
PENGHARGAAN
Alhamdulillah, puji dan syukur penulis panjatkan kehadirat Allah SWT serta shalawat dan salam senantiasa terlimpah curah kepada Rasulullah Muhammad SAW, karena atas berkah, rahmat dan hidayahNya penulis dapat menyelesaikan penyusunan skripsi ini. Rasa terima kasih yang tidak terhingga kepada Allah SWT yang selalu menuntun dan mengajarkan penulis makna dari tanggung jawab, pengorbanan, keikhlasan dan kesabaran yang sesungguhnya selama penyusunan skripsi ini.
Dalam penulisan skripsi ini, penulis banyak mendapat bantuan moril maupun materil dari berbagai pihak. Dalam kesempatan ini dengan segala kerendahan hati penulis ingin mengucapkan rasa terimakasi kepada:
1. Orang tua penulis yaitu Ibunda Wagini. Terima kasih yang tidak pernah terhenti penulis ucapkan kepada ibunda atas segala doa, kesabaran, pengertian dan pengorbanan moril dan materil yang telah ibunda berikan selama ini. Serta kakak-kakak penulis Lia Aprina, S.Pd., Supriyanto Sahputra, S.E.,Yuni Darmawani, S.Sos., Juliani P, S.IK., yang selalu memberikan motivasi dan bantuan moril maupun materil kepada penulis selama ini, serta seluruh keluarga besar atas segala perhatian yang selalu diberikan kepada penulis. 2. Ketua Program Studi Teknologi Informasi, Bapak Prof. Dr. Opim Salim
Sitompul, M.Sc dan Sekretaris Program Studi Teknologi Informasi Bapak Sawaluddin, M.IT, Dekan dan Pembantu Dekan Fakultas Ilmu Komputer dan Teknologi Informasi, Seluruh dosen pada Program Studi Teknologi Informasi beserta para staf tata usaha Teknologi Informasi.
4. Bapak M. Anggia Muchtar, ST.MM.IT dan Bapak Dedy Arisandi, S.T.M.Kom
selaku dosen pembanding yang telah memberikan banyak masukan berupa saran maupun kritik yang membangun dalam menyelesaikan skripsi ini . 5. Sahabat-sahabat saya Putri Liyoni Suci, S.Ked., Anna Kesuma Daulay, S.TI.,
Guntur Alamsyah, S.Sos., Siska Budiarti S.Pd., Harfa’i dan Seluruh rekan mahasiswa Teknologi Informasi angkatan 2007 khususnya Nurul Hayati, Shifa Sihotang, Maspin Sahputra, Adinda Reni, Boy Utomo Manalu, Andreni Menovita Ginting, dan Faisal Amri atas segala bentuk bantuan baik diskusi, masukan, doa, semangat maupun hiburan selama proses penyelesaian skripsi ini.
ABSTRAK
Kecelakaan lalu lintas merupakan suatu kejadian yang sering sekali terjadi disekitar kita. Kecelakaan lalu lintas dapat menyebabkan berbagai risiko dan juga kerugian baik materi maupun jiwa. Besarnya risiko kecelakaan yang dialami tiap orang berbeda-beda dalam setiap kejadian. Hal tersebut dapat diberbeda-bedakan dalam beberapa kategori risiko kecelakaan lalu lintas atau lebih sering dikenal dengan injury severity. Oleh karena itu pada penulisan ini penulis akan menjelaskan pengaplikasian metode Jaringan Saraf Tiruan Resilient Backpropagation untuk memprediksi injury severity tersebut. Metode ini digunakan untuk menghindari perubahan gradien yang terlalu kecil selama proses update dengan fungsi aktivasi Sigmoid yang menyebabkan pembentukan jaringan menjadi lambat. Hasil dari penelitian ini menunjukkan bahwa proses pembelajaran yang dihasilkan lebih baik dan cepat memprediksi faktor dominan injury severity kecelakaan lalu lintas.
NEURAL NETWORK RESILIENT BACKPROPAGATION FOR
PREDICT DOMINANT FACTOR INJURY SEVERITY
OF TRAFFICT ACCIDENT
ABSTRACT
Traffic accidents is an event that often occure around us. Traffic accident cause a variety of risks. The risks of accidents experienced by each person is different in each event. It can be divided into several categories of risk of traffic accidents or commonly known as the injury severity. In this study explains about the application of the method Resilient Backpropagation Neural Network to predict the severity of injury. This method is used to avoid a small gradient changes during the update process with Sigmoid activation function that causes the formation of a slow network. The result of this paper are resulting learning process more faster and better to predict the dominant factor of injury severity of traffic accidents.
DAFTAR ISI
Daftar Gambar xii
Bab 1 PENDAHULUAN
Bab 2 LANDASAN TEORI
2.1. Jaringan Saraf Biologi 7
2.2. Jaringan Saraf Tiruan 8
2.1.1. Arsitektur Jaringan Saraf Tiruan 8
2.2.2. Fungsi Aktivasi 11
2.2.3. Bias 12
2.2.4. Laju Pembelajaran / learning rate (η) 12
2.3. Metode Backpropagation 13
2.3.1. Arsitektur Backpropagation 14
2.3.3. Inisialisasi Bobot Awal dan Bias 29
2.3.3.1. Inisialisasi Acak 30
2.3.3.2. Inisialisasi Nguyen-Widrow 30
2.3.4. Momentum (α) 31
2.3.5. Perhitungan Error 32
2.3.6. Penggantian bobot 33
2.3.7. Testing 34
2.3.8. Metode Resilient Backpropagation 35
Bab 3 ANALISIS DAN PERANCANGAN SISTEM
3.1. Rancangan Sistem 37
3.2. Pemilihan Variabel Input 38
3.3. Pemilihan Variabel Output 41
3.4. Normalisasi Data 41
3.5. Arsitektur Jaringan Saraf Tiruan 43
3.6. Training 45
3.7. Perhitungan Error 47
3.8. Testing 47
Bab 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
4.1. Lingkungan Implementasi 50
4.2. Pencarian Arsitektur Jaringan Terbaik 51
4.2.1. Variasi Jumlah Hidden Layer 51
4.2.2. Variasi Jumlah Neuron 53
4.2.3. Pengujian Jaringan 54
4.2.4. Pengujian Menggunakan Data yang Pernah Dilatih 54 4.2.5. Hasil Prediksi Mengunakan Data yang Pernah Dilatih 57 4.2.6. Pengujian Menggunakan Data yang Belum Pernah Dilatih 58 4.2.7. Hasil Prediksi Menggunakan Data yang Belum Pernah Dilatih 61 4.2.8. Analisis Faktor Dominan Berdasarkan Hasil Prediksi Jaringan 62
Bab 5 PENUTUP
5.2. Saran 71
DAFTAR PUSTAKA 72
LAMPIRAN A 75
DAFTAR TABEL
Halaman
Tabel 2.1 Bobot dari input layer ke hidden layer 25
Tabel 2.2 Bobot dari hidden layer ke output layer 25
Tabel 2.3 Suku Perubahan Bobot Hidden Neuron 28
Tabel 2.4 Perubahan Bobot Hidden Neuron 29
Tabel 3.1 Variabel Input Jaringan Saraf Tiruan 38
Tabel 3.2 Variabel Output Jaringan Saraf Tiruan 39
Tabel 3.3 Pembagian data kecelakaan lalu lintas 42
Tabel 3.4 Contoh Data Normalisasi 42
Tabel 4.1 Menggunakan Satu Hidden Layer 51
Tabel 4.2 Percobaan Beberapa Variasi Neuron 53
DAFTAR GAMBAR
Halaman
Gambar 2.1 Sel Saraf Biologi 7
Gambar 2.2 Single Layer Network 9
Gambar 2.3 Multilayer Network 10
Gambar 2.4 Competitive layer network 10
Gambar 2.5 Arsitektur Backpropagation 15
Gambar 2.6 Propagasi Sinyal ke Neuron Pertama Pada Input Layer 17 Gambar 2.7 Propagasi Sinyal ke Neuron Kedua Pada Input Layer 17 Gambar 2.8 Propagasi Sinyal ke Neuron Ketiga Pada Input Layer 17 Gambar 2.9 Propagasi Sinyal ke Neuron Pertama Pada Hidden Layer 18 Gambar 2.10 Propagasi Sinyal ke Neuron Kedua Pada Hidden Layer 18
Gambar 2.11 Propagasi Sinyal ke Neuron Output 18
Gambar 2.12 Perbandingan Sinyal Keluaran dan Target 19
Gambar 2.13 Propagasi Sinyal Error Δ Ke F4(E) 20
Gambar 2.14 Propagasi Sinyal Error Δ Ke F5(E) 20
Gambar 2.15 Propagasikan Sinyal Error Δ Ke f1(E) 20 Gambar 2.16 Propagasikan Sinyal Error Δ Ke f2(E) 21 Gambar 2.17 Propagasikan Sinyal Error Δ Ke f3(E) 22
Gambar 2.18 Modifikasi Bobot Δ1 22
Gambar 2.19 Modifikasi Bobot Δ2 22
Gambar 2.20 Modifikasi Bobot Δ3 22
Gambar 2.21 Modifikasi Bobot Δ4 23
Gambar 2.22 Modifikasi Bobot Δ5 23
Gambar 2.23 Modifikasi Bobot Δ6 23
ABSTRAK
Kecelakaan lalu lintas merupakan suatu kejadian yang sering sekali terjadi disekitar kita. Kecelakaan lalu lintas dapat menyebabkan berbagai risiko dan juga kerugian baik materi maupun jiwa. Besarnya risiko kecelakaan yang dialami tiap orang berbeda-beda dalam setiap kejadian. Hal tersebut dapat diberbeda-bedakan dalam beberapa kategori risiko kecelakaan lalu lintas atau lebih sering dikenal dengan injury severity. Oleh karena itu pada penulisan ini penulis akan menjelaskan pengaplikasian metode Jaringan Saraf Tiruan Resilient Backpropagation untuk memprediksi injury severity tersebut. Metode ini digunakan untuk menghindari perubahan gradien yang terlalu kecil selama proses update dengan fungsi aktivasi Sigmoid yang menyebabkan pembentukan jaringan menjadi lambat. Hasil dari penelitian ini menunjukkan bahwa proses pembelajaran yang dihasilkan lebih baik dan cepat memprediksi faktor dominan injury severity kecelakaan lalu lintas.
NEURAL NETWORK RESILIENT BACKPROPAGATION FOR
PREDICT DOMINANT FACTOR INJURY SEVERITY
OF TRAFFICT ACCIDENT
ABSTRACT
Traffic accidents is an event that often occure around us. Traffic accident cause a variety of risks. The risks of accidents experienced by each person is different in each event. It can be divided into several categories of risk of traffic accidents or commonly known as the injury severity. In this study explains about the application of the method Resilient Backpropagation Neural Network to predict the severity of injury. This method is used to avoid a small gradient changes during the update process with Sigmoid activation function that causes the formation of a slow network. The result of this paper are resulting learning process more faster and better to predict the dominant factor of injury severity of traffic accidents.
BAB I
PENDAHULUAN
1.1. Latar Belakang
Kecelakaan lalu lintas merupakan suatu kejadian yang sering sekali terjadi disekitar kita. Meskipun telah banyak sistem keamanan pada kendaraan yang sengaja dirancang oleh pihak industri kendaraan untuk mengurangi tingkat terjadinya kecelakaan, namun kecelakaan tetap saja tidak dapat dihindari. Banyak faktor yang menyebabkan terjadinya kecelakaan lalu lintas, diantaranya adalah faktor cuaca, kendaraan, kondisi jalan maupun kebiasaan pengendara kendaraan (Akin & Akbas, 2010).
Kecelakaan lalu lintas dapat menyebabkan berbagai risiko dan juga kerugian baik materi maupun jiwa. Besarnya risiko kecelakaan yang dialami tiap orang berbeda-beda dalam setiap kejadian. Hal tersebut dapat dibedakan dalam beberapa kategori risiko kecelakaan lalu lintas atau lebih sering dikenal dengan injury severity, seperti fatal (fatal injury), luka parah (severe injury), luka ringan dan lainnya (other injury) atau hanya kerusakan pada material saja (Property demage only) (Chong et al, 2005). Namun terdapat kesulitan untuk memprediksi injury severity tersebut dikarenakan faktor penyebab kecelakaan lalu lintas merupakan peristiwa yang tidak linear. Oleh karena itu diperlukan suatu metode khusus yang dapat digunakan untuk memprediksi injury severity tersebut
(Sulaiman, 2010). Hal ini dikarenakan JST memiliki kemampuan belajar dari data yang dilatihkan serta memiliki toleransi yang tinggi terhadap data yang mengandung noise (Maharani, 2009).
JST memiliki beberapa metode yang dapat digunakan seperti Hopfield, Perceptron, Adaline dan Backpropagation. Diantara metode-metode tersebut, Backpropagation merupakan metode yang paling sering digunakan karena metode ini menurunkan gradien untuk meminimalkan penjumlahan error kuadrat dari output jaringan (Puspitaningrum, 2006). Namun metode Backpropagation ini memiliki kelemahan yaitu proses pelatihan yang memerlukan waktu yang cukup lama karena membutuhkan banyak iterasi untuk mencapai keadaan stabil. Oleh karena itu diperlukan modifikasi pada proses Backpropagation.
Resilient Backpropagation (Rprop) merupakan modifikasi dari Backpropagation yang dikembangkan untuk menghindari perubahan gradien yang terlalu kecil selama proses update dengan fungsi aktivasi Sigmoid yang menyebabkan pembentukan jaringan menjadi lambat. Metode ini dapat digunakan untuk mempercepat laju pembelajaran dan telah terbukti sebagai metode yang memiliki kecepatan pembelajaran yang baik (Fajri, 2011).
1.2. Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan, maka rumusan masalahnya adalah: 1. Sulitnya menentukan faktor-faktor dominan yang mempengaruhi tingkat
injury severity kecelakaan lalu lintas.
2. Bagaimana menentukan arsitektur JST yang tepat sehingga dapat dengan cepat memprediksi faktor dominan injury severity kecelakaan lalu lintas.
1.3. Batasan Masalah
Penelitian ini dilakukan dengan beberapa batasan, diantaranya:
1. Diasumsikan bahwa kondisi kendaraan yang digunakan masih dalam kondisi baik.
2. Kondisi cuaca yang digunakan dalam penelitian tidak digambarkan secara detail untuk setiap variabelnya.
3. Dalam penelitian ini tidak mempertimbangkan faktor human error seperti pelanggaran lalu lintas ataupun kondisi psikologi pengendara.
4. Arsitektur yang digunakan adalah 11 input neuron, 2 hidden layer dan 3 output neuron.
1.4. Tujuan Penelitian
Tujuan dari penelitian ini adalah membuat system yang mampu memprediksi faktor dominan injury severity kecelakaan lalu lintas.
1.5. Manfaat Penelitian
1. Diharapkan dapat memberikan informasi mengenai tingkat akurasi Resilient Backpropagation dalam bidang prediksi, terutama untuk masalah data yang kompleks dan memiliki tingkat nonlinear yang tinggi.
2. Memberikan informasi mengenai faktor dominan penyebab risiko kecelakaan lalu lintas berdasarkan hasil prediksi jaringan.
1.6. Metode Penelitian
Metodologi penelitian yang dilakukan oleh penulis dalam skripsi ini melalui beberapa tahap, yaitu:
1. Studi Literatur
Pada tahap ini penulis mengumpulkan literatur dan referensi lainnya baik dari buku, artikel, paper, jurnal, makalah maupun situs internet yang mendukung penelitian, diantaranya:
a. Referensi mengenai jaringan syaraf tiruan.
b. Referensi mengenai algoritma backpropagation dan Resilient Propagation.
c. Referensi mengenai prediksi kecelakaan lalu lintas. d. Data mengenai kecelakaan lalu lintas.
2. Pengolahan Data
Pada tahap ini penulis akan mengolah dataset yang telah diperoleh dengan memilih variable-variabel yang akan digunakan menjadi variabel input dan membagi dataset kedalam dua bagian yaitu data pelatihan (data training) dan data pengujian (data testing).
3. Analisis dan Rancangan Sistem
4. Implementasi dan Pengujian Sistem
Pada tahap ini penulis akan mengimplementasikan hasil analisis dan rancangan sistem pada Matlab 2009. Selanjutnya akan dilakukan dua tahapan yaitu pelatihan jaringan dan pengujian untuk mengetahui apakah sistem yang dibangun telah sesuai dengan hasil yang diharapkan.
5. Penulisan Laporan
Pada tahap ini akan dilakukan penulisan dokumentasi hasil analisis dan implementasi dari sistem yang telah dibangun sebagai laporan tugas akhir.
1.7. Sistematika Penulisan
Penulisan skripsi ini terdiri dari lima bab dengan masing-masing bab secara singkat dijelaskan sebagai berikut:
BAB1 PENDAHULUAN
Bab ini berisi berisikan latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian dan sistematika penulisan.
BAB2 LANDASAN TEORI
Bab ini akan dibahas mengenai teori-teori pendukung yang berkaitan dengan Jaringan Saraf Tiruan dan algoritma Backpropragation.
BAB3 ANALISIS DAN PERANCANGAN SISTEM
Bab ini akan membahas bagian yang berkaitan dengan penjelasan algoritma Backpropagation untuk prediksi injury severity kecelakaan lalu lintas.
BAB4 IMPLEMENTASI DAN PENGUJIAN SISTEM
BAB5 KESIMPULAN DAN SARAN
BAB II
LANDASAN TEORI
Bab ini akan dibahas mengenai teori-teori pendukung pada penelitian ini. Adapun teori tersebut yaitu teori jaringan saraf tiruan dan algoritma backpropragation.
2.1. Jaringan Saraf Biologi
Jaringan saraf biologi merupakan kumpulan dari sel-sel saraf (neuron) yang memiliki tugas untuk mengolah informasi (Puspitaningrum, 2006). Komponen-komponen utama dari sebuah neuron dapat dikelompokkan menjadi 3 bagian, yaitu:
1. Dendrit yang bertugas untuk menerima informasi.
2. Badan sel (soma) yang berfungsi sebagai tempat pengolahan informasi. 3. Akson (neurit) yang bertugas mengirimkan impuls-impuls ke sel saraf lainnya.
Gambar 2.1 Sel Saraf Biologi
dengan dendrit dari sel saraf lainnya dengan cara mengirimkan impuls melalui sinapsis, yaitu penghubung antara dua buah sel saraf. Sinapsis memiliki kekuatan yang dapat meningkat dan menurun tergantung seberapa besar tingkat propagasi yang diterimanya.
2.2. Jaringan Saraf Tiruan
Jaringan saraf tiruan (JST) merupakan sistem pemrosesan informasi yang mengadopsi cara kerja otak manusia (Fausset, 1994). JST memiliki kecenderungan untuk menyimpan pengetahuan yang bersifat pengalaman dan membuatnya siap untuk digunakan. Ada tiga elemen penting dalam JST (Rojas, 1996), yaitu:
1. Arsitektur jaringan beserta pola hubungan antar neuron.
2. Algoritma pembelajaran yang digunakan untuk menemukan bobot-bobot jaringan.
3. Fungsi aktivasi yang digunakan.
JST terdiri dari sejumlah besar elemen pemrosesan sederhana yang sering disebut neurons, cells atau node. Proses pengolahan informasi pada JST terjadi pada neuron – neuron. Sinyal antara neuron – neuron diteruskan melalui link – link yang saling terhubung dan memiliki bobot terisolasi. Kemudian setiap neuron menerapkan fungsi aktivasi terhadap input jaringan.
2.2.1 Arsitektur Jaringan Saraf Tiruan
Arsitektur jaringan yang sering dipakai dalam JST antara lain : 1. Jaringan layar tunggal (single layer network)
Gambar dibawah menunjukkan arsitektur jaringan dengan n neuron input (X1, X2, X3, ..., Xn) dan m buah neuron output (Y1, Y2, Y3, ..., Ym). Semua neuron input dihubungkan dengan semua neuron output, meskipun memiliki bobot yang berbeda-beda. Tidak ada neuron input yang dihubungkan dengan neuron input lainnya. Begitu juga dengan neuron output.
X1
Gambar 2.2 Single Layer Network
Besaran Wji menyatakan bobot hubungan antara ubit ke-i dalam input dengan neuron ke-j dalam output. Bobot-bobot ini saling independen. Selama proses pelatihan, bobot – bobot saling dimodifikasi untuk menigkatkankeakuratan hasil. Metode ini tepat digunakan untuk pengenalan pola karena kesederhanaannya.
2. Jaringan Layar Jamak (multi layer network)
Gambar 2.3 Multilayer Network
Pada gambar diatas jaringan dengan n buah neuron input (X1, X2, ..., Xn), sebuah layer tersembunyi yang terdiri dari p buah neuron (Z1, Z2, .. Zp) dan m buah neuron output (Y1,Y2, ... Ym).
3. Competitive layer network
Jaringan ini mirip dengan jaringan layar tunggal ataupun ganda. Hanya saja, ada neuron output yang memberikan sinyal pada neuron input (sering disebut feedback loop). Sekumpulan neuron bersaing untuk mendapatkan hak menjadi aktif.
2.2.2. Fungsi Aktivasi
Fungsi aktivasi pada jaringan saraf tiruan digunakan untuk memformulasikan output dari setiap neuron. Argumen fungsi aktivasi adalah net masukan (kombinasi linier masukan dan bobotnya). Jika net = XiWi, maka fungsi aktivasinya adalah =
( ).
Fungsi aktivasi dalam jaringan Backpropagation memiliki beberapa karakteristik penting, yaitu fungsi aktivasi harus bersifat kontinu, terdiferensial dengan mudah dan tidak turun (Fausset, 1994). Beberapa fungsi aktivasi yang sering dipakai adalah sebagai berikut :
1. Fungsi aktivasi linier
= (1)
Fungsi aktivasi linier sering dipakai apabila keluaran jaringan yang diinginkan berupa sembarang bilangan riil (bukan hanya pada range [0,1] atau [-1,1]. Fungsi aktivasi linier umumnya digunakan pada neuron output.
2. Fungsi aktivasi sigmoid biner
= 1
1+ − (2)
Fungsi aktivasi sigmoid atau logistik sering dipakai karena nilai fungsinya yang terletak antara 0 dan 1 dan dapat diturunkan dengan mudah.
′ = (1− ) (3)
3. Fungsi aktivasi sigmoid bipolar.
= 2
Fungsi aktivasi ini memiliki nilai yang terletak antara -1 dan 1 dengan turunannya sebagai berikut:
′ = 1+ (1− )
2 (5)
4. Fungsi aktivasi tangen hiperbola
Fungsi aktivasi ini juga memiliki nilai yang terletak antara -1 dan 1. Formulanya yaitu:
=( − − )
( + − )= 1− −2
1+ −2 (6)
dengan rumus turunannya sebagai berikut:
′ = 1 + tanh (1−tanh ) (7)
2.2.3. Bias
Bias dapat ditambahkan sebagai salah satu komponen dengan nilai bobot yang selalu bernilai 1. Jika melibatkan bias, maka fungsi aktivasi menjadi:
(8) Dimana:
2.2.4. Laju Pembelajaran / learning rate (�)
Penggunaan parameter learning rate memiliki pengaruh penting terhadap waktu yang dibutuhkan untuk tercapainya target yang diinginkan. Secara perlahan akan mengoptimalkan nilai perubahan bobot dan menghasilkan error yang lebih kecil (Fajri, 2011). Variabel learning rate menyatakan suatu konstanta yang bernilai antara 0.1-0.9. Nilai tersebut menunjukkan kecepatan belajar dari jaringannya.
Jika nilai learning rate yang digunakan terlalu kecil maka terlalu banyak epoch yang dibutuhkan untuk mencapai nilai target yang diinginkan, sehingga menyebabkan proses training membutuhkan waktu yang lama. Semakin besar nilai learning rate yang digunakan maka proses pelatihan jaringan akan semakin cepat, namun jika terlalu besar justru akan mengakibatkan jaringan menjadi tidak stabil dan menyebabkan nilai error berulang bolak-balik diantara nilai tertentu, sehingga mencegah error mencapai target yang diharapkan. Oleh karena itu pemilihan nilai variable learning rate harus seoptimal mungkin agar didapatkan proses training yang cepat (Hermawan, 2006).
2.3. Metode Backpropagation
Backpropagation adalah salah satu bentuk dari jaringan saraf tiruan dengan pelatihan terbimbing. Ketika menggunakan metode pelatihan terbimbing, jaringan harus menyediakan input beserta nilai output yang diinginkan. Nilai output yang diinginkan tersebut kemudian akan dibandingkan dengan hasil output aktual yang dihasilkan oleh input dalam jaringan.
Pelatihan jaringan Backpropagation meliputi tiga langkah, yaitu langkah maju (feedforward) dari pola pelatihan input, perhitungan langkah mundur (Backpropagation) dari error yang terhubung dan penyesuaian bobot-bobot (Fausset, 1994). Langkah maju dan langkah mundur dilakukan pada jaringan untuk setiap pola yang diberikan selama jaringan mengalami pelatihan.
2.3.1. Arsitektur Backpropagation
Jaringan Backpropagation memiliki beberapa neuron yang berada dalam satu atau lebih lapisan tersembunyi (hidden layer). Setiap neuron yang berada dilapisan input terhubung dengan setiap neuron yang berada di hidden layer. Begitu juga pada hidden layer, setiap neuronnya terhubung dengan setiap neuron yang ada di output layer.
Jaringan saraf tiruan Backpropagation terdiri dari banyak lapisan (multi layer), yaitu:
1. Lapisan masukan (input layer)
Input layer sebanyak 1 lapis yang terdiri dari neuron – neuron input, mulai dari neuron input pertama sampai neuron input ke-n. Input layer merupakan penghubung yang mana lingkungan luar memberikan sebuah pola kedalam jaringan saraf. Sekali sebuah pola diberikan kedalam input layer, maka output layer akan memberikan pola yang lainnya (Heaton, 2008). Pada intinya input layer akan merepresentasikan kondisi yang dilatihkan kedalam jaringan. Setiap input akan merepresentasikan beberapa variabel bebas yang memiliki pengaruh terhadap output layer.
2. Lapisan tersembunyi (hidden layer)
Hidden layer berjumlah minimal 1 lapis yang terdiri dari neuron-neuron tersembunyi mulai dari neuron tersembunyi pertama sampai neuron tersembunyi ke-p. Menentukan jumlah neuron pada hidden layer merupakan bagian yang sangat penting dalam arsitektur jaringan saraf.
hasil yang baik dalam jaringan, namun pada dasarnya jumlah hidden neuron yang digunakan dapat berjumlah sampai dengan tak berhingga (~). Sedangkan menurut Heaton (2008), ada beberapa aturan yang dapat digunakan untuk menentukan banyaknya jumlah neuron pada hidden layer yaitu:
a. Jumlah hidden neuron harus berada diantara ukuran input layer dan output layer.
b. Jumlah hidden neuron harus 2 3 dari ukuran input layer, ditambah ukuran
output layer.
c. Jumlah hidden neuron harus kurang dari dua kali jumlah input layer.
Aturan-aturan tersebut hanya berupa pertimbangan dalam menentukan arsitektur jaringan saraf tiruan. Bagaimanapun, penentuan arsitektur jaringan akan kembali pada trial and error sesuai dengan masalah yang ditangani oleh jaringan. 3. Lapisan keluaran (output layer)
Output layer berjumlah satu lapis yang terdiri dari neuron-neuron output mulai dari neuron output pertama sampai neuron output ke-m. Output layer dari jaringan saraf adalah pola yang sebenarnya diberikan oleh lingkungan luarnya (external environment). Pola yang diberikan output layer dapat secara langsung ditelusuri kembali ke input layernya. Jumlah dari neuron output tergantung dari tipe dan performa dari jaringan saraf itu sendiri.
X1
Gambar 2.5 Arsitektur Backpropagation
yang menghubungkan bias di neuron input ke neuron layar tersembunyi Zj). Wkj merupakan bobot dari neuron layar tersembunyi Zj ke neuron keluaran Yk ( Wk0 merupakan bobot dari bias di layar tersembunyi ke neuron keluaran Yk). Pelatihan Backpropagation meliputi tiga fase, yaitu :
1. Fase I: Propagasi maju
Selama propagasi maju, sinyal masukan dipropagasikan ke hidden layer menggunakan fungsi aktivasi yang telah ditentukan hingga menghasilkan keluaran jaringan. Keluaran jaringan dibandingkan dengan target yang harus dicapai. Selisih antara target dengan keluaran merupakan kesalahan yang terjadi. Jika kesalahan lebih kecil dari batas toleransi, maka iterasi dihentikan. Akan tetapi jika kesalahan lebih besar, maka bobot setiap garis dalam jaringan akan dimodifikasi untuk mengurangi kesalahan yang terjadi.
2. Fase II: Propagasi mundur
Kesalahan yang terjadi di propagasi mundur mulai dari garis yang berhubungan langsung dengan neuron-neuron dilayar keluaran.
3. Fase III: Perubahan bobot
Pada fase ini, bobot semua garis dimodifikasi secara bersamaan. Ketiga fase tersebut diulang- ulang terus hingga kondisi penghentian dipenuhi. Kondisi penghentian yang sering dipakai adalah jumlah maksimal iterasi (epoch) atau minimal kesalahan (error).
2.3.2. Algoritma Pelatihan Backpropagation
Berikut adalah algoritma pelatihan Backpropagation dengan arsitektur satu hidden layer (Fausset, 1994):
Langkah 0 Inisialisasi bobot (set dengan bilangan acak kecil)
Langkah 1 Jika kondisi berhenti masih belum terpenuhi, lakukan langkah 2-9. Langkah 2 Untuk setiap pasang pelatihan, lakukan langkah 3-8
Feedforwad
neuron). Berikut merupakan ilustrasi bagaimana sinyal dipropagasikan keseluruh input layer. ( ) merupakan bobot penghubung pada input layer.
Gambar 2.6 Propagasi sinyal ke neuron pertama pada input layer (www.home.agh.edu.pl)
Gambar 2.7 Propagasi sinyal ke neuron kedua pada input layer (www.home.agh.edu.pl)
Gambar 2.8 Propagasi sinyal ke neuron ketiga pada input layer (www.home.agh.edu.pl)
Langkah 4 Setiap hidden neuron ( , = 1,…,�) menjumlahkan bobot dari sinyal-sinyal inputnya.
_ = 0 + =1 (10)
= ( _ ) (11)
Dan kirimkan sinyal ini ke semua neuron yang berada pada lapisan diatasnya (output neuron). Gambar berikut merupakan ilustrasi bagaimana sinyal dipropagasikan keseluruh hidden layer.
merupakan bobot penghubung pada hidden layer.
Gambar 2.9 Propagasi sinyal ke neuron pertama pada hidden layer (www.home.agh.edu.pl)
Gambar 2.10 Propagasi sinyal ke neuron kedua pada hidden layer (www.home.agh.edu.pl)
Langkah 5 Setiap output neuron ( , = 1,…, ) menjumlahkan bobot dari sinyal-sinyal inputnya.
_ = 0 + �=1 (12)
Dan menerapkan fungsi aktivasinya untuk menghitung nilai sinyal outputnya.
= ( ) (13)
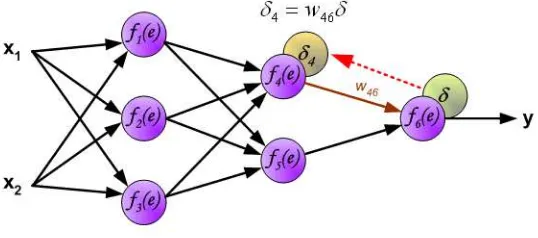
Gambar 2.11 Propagasi sinyal ke neuron output (www.home.agh.edu.pl)
Backpropagation error
Langkah 6 Setiap neuron output ( , = 1,…, ) menerima sebuah pola target yang sesuai pada input pola pelatihan, kemudian menghitung informasi kesalahannya.
= − ′( _ ) (14)
Hitung koreksi bobot (yang nantinya akan dipakai untuk merubah bobot )
∆ = (15)
Hitung koreksi bias (yang nantinya akan digunakan untuk merubah bobot 0
∆ 0 = (16)
Dan kirim ke neuron pada lapisan dibawahnya. Berikut ini adalah ilustrasi dari prosesnya.
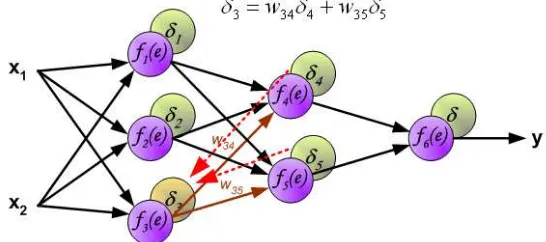
Gambar 2.12 Perbandingan sinyal keluaran dan target (www.home.agh.edu.pl) Langkah 7 Setiap hidden neuron ( , = 1,…,�) menjumlahkan delta input (dari
neuron yang berada dilapisan bawahnya),
Mengalikan dengan turunan dari fungsi aktivasinya untuk menghitung informasi errornya.
= _ ′( _ ) (18)
Hitung koreksi bobotnya (yang nantinya akan digunakan untuk mengupdate
∆ = (19)
Dan hitung koreksi biasnya (yang nantinya akan digunakan untuk mengupdate 0 .
∆ 0 = (20)
Prosesnya dapat dilihat dari ilustrasi gambar 2.13 dan 2.14 berikut ini:
Gambar 2.13 Propagasi sinyal error Δ Ke f4(E) (www.home.agh.edu.pl)
Gambar 2.14 Propagasi sinyal error Δ Ke f5(E) (www.home.agh.edu.plx)
(sinyal di propagasikan dari keluaran ke masukan). Teknik ini digunakan untuk semua lapisan jaringan. Apabila propagasikan error datang dari beberapa neuron, seperti yang terlihat pada gambar 2.14 sampai 2.16 berikut:
Gambar 2.15 Propagasikan Sinyal Error Δ Ke f1(E) (www.home.agh.edu.pl)
Gambar 2.16 Propagasikan Sinyal Error Δ Ke f2(E) (www.home.agh.edu.pl)
Update weight and bias
Langkah 8 Setiap neuron output ( , = 1,…, ) mengupdate bias dan bobot-bobotnya ( j=0, . . . ,p):
= +∆ (21)
Setiap hidden neuron ( , = 1,…,�) mengupdate bias dan bobot-bobotnya (i= 0, . . ., n)
= +∆ (22)
Gambar 2.17 sampai dengan gambar 2.22 merupakan ilustrasi dari proses pengupdate-an bobot:
Gambar 2.18 Modifikasi Bobot Δ1 (www.home.agh.edu.pl)
Gambar 2.20 Modifikasi Bobot Δ3 (www.home.agh.edu.pl)
Gambar 2.21 Modifikasi Bobot Δ4 (www.home.agh.edu.pl)
Gambar 2.23 Modifikasi Bobot Δ6 (www.home.agh.edu.pl)
Langkah 9 Tes kondisi berhenti dapat dilakukan ketika error yang dihasilkan oleh jaringan berada pada nilai yang lebih kecil sama dengan (≤) error target yang diharapkan atau ketika telah mencapai iterasi (epoch) maksimal yang telah ditetapkan.
Berikut ini adalah contoh perhitungan sederhana dari arsitektur Backpropagation yang dilakukan secara manual:
X2
Gambar 2.24 Contoh Arsitektur Backpropagation
buah output layer. Nilai target pada jaringan adalah 1 dan learning rate = 0.25. Mula-mula bobot diberi nilai acak pada range [-1, 1]. Misal terdapat bobot seperti tabel 2.1 (bobot dari input layer ke hidden layer = ) dan tabel 2.2 (bobot dari hidden layer ke output layer = ).
Tabel 2.1 Bobot dari input layer ke hidden layer
� � �
Tabel 2.2 Bobot dari hidden layer ke output layer
Y
� 0.1
� 0.03
� 0.5
b=1 0.1
Normalisasi data input kedalam range [0, 1] dengan menggunakan rumus berikut:
x′ =0.8 x−min
Maka didapatkan hasil input normalisasi dengan nilai minimum = 4 dan nilai
Hitung nilai output dari masing-masing hidden neuron dengan persamaan (10):
_ = 0 + =1
Kemudian terapkan fungsi aktivasi untuk masing-masing neuronnya menggunakan persamaan (11), dalam soal ini diterapkan fungsi aktivasi sigmoid biner.
= _ = 1
1=
Hitung nilai output dari neuron Y menggunakan persamaan (12)seperti berikut:
_ = 0 + �=1
Karena jaringan hanya memiliki sebuah output Y, maka
= 1 0.1 + 1.23 0.1 + 1.19 0.03 + 1.42(0.5)
Hitung faktor pada neuron output Y sesuai dengan persamaan (14)
= − ′( _ )= − (1− )
= 1−1.38 1.38 1−1.38
= 0.20
Suku perubahan bobot (dengan = 0.25) adalah sebagai berikut: ∆ = ; = 0,1…3
∆ 10 = 0.25 0.20 1 = 0.05 ∆ 11 = 0.25 0.20 1.23 = 0.01 ∆ 12 = 0.25 0.20 1.19 = 0.06 ∆ 13 = 0.25 0.20 1.42 = 0.07
Hitung penjumlahan kesalahan di hidden neuron (= ):
_ = =1 karena jaringan hanya memiliki sebuah neuron output maka
_ = 1
1 = 0.20 0.1 = 0.20
_ 2 = 0.20 0.03 = 0.01
Faktor kesalahan di hidden neuron:
Tabel 2.3 Suku Perubahan Bobot Hidden Neuron
Perubahan bobot neuron output: Perubahan bobot hidden neuron:
= +∆ = 1; = 0,…,5
Tabel 2.4 Perubahan Bobot Hidden Neuron
� � �
2.3.3. Inisialisasi Bobot Awal dan Bias
Bobot merupakan salah satu faktor penting agar jaringan dapat melakukan generalisasi dengan baik terhadap data yang dilatihkan kedalamnya (Fitrisia dan Rakhmatsyah, 2010). Pemilihan inisialisasi bobot awal akan menentukan apakah jaringan mencapai global minimum atau hanya lokal minimum dan seberapa cepat konvergensi jaringannya.
Peng-update-an antara dua buah neuron tergantung dari kedua turunan fungsi aktivasi yang digunakan pada neuron yang berada pada lapisan diatasnya dan juga fungsi aktivasi neuron yang berada pada lapisan bawahnya. Nilai untuk inisialisasi bobot awal tidak boleh terlalu besar, atau sinyal untuk setiap hidden atau output neuron kemungkinan besar akan berada pada daerah dimana turunan dari fungsi sigmoid memiliki nilai yang sangat kecil. Dengan kata lain, jika inisialisasi bobot awal terlalu kecil, input jaringan ke hidden atau output neuron akan mendekati nol, yang mana akan menyebabkan pelatihan akan menjadi sangat lambat (Fausset, 1994). Ada beberapa metode inisilisasi bobot yang dapat digunakan, yaitu:
2.3.3.1. Inisialisasi Acak
Prosedur umum yang digunakan adalah menginisialisasi bobot dan bias (baik dari input neuron ke hidden neuron maupun dari hidden neuron ke output neuron) dengan nilai acak antara -0.5 dan 0.5 atau antara -1 dan 1 (atau dengan menggunakan interval
tertentu – dan . Nilai bobot menggunakan nilai posotif atau negatatif karena nilai bobot akhir setelah pelatihan juga dapat bernilai keduanya.
2.3.3.2. Inisialisasi Nguyen-Widrow
Bobot-bobot dari hidden neuron ke output neuron (dan bias pada output neuron) diinisialisasikan dengan nilai acak antara -0.5 dan 0.5.
Inisialisasi bobot-bobot dari input neuron ke hidden neuron didesain untuk meningkatkan kemampuan hidden neuron untuk belajar. Inisialisasi bobot dan bias secara acak hanya dipakai dari input neuron ke hidden neuron saja, sedangkan untuk bobot dan bias dari hidden neuron ke output neuron digunakan bobot dan bias diskala khusus agar jatuh pada range tertentu. Faktor skala Nguyen-Widrow didefinisikan sebagai berikut:
= 0.7(�)1 (23)
Keterangan:
n : Banyak input neuron p : Banyak hidden neuron β : Faktor skala
Prosedur Inisialisasi Nguyen-Widrow terdiri dari langkah-langkah sederhana sebagai berikut:
Untuk setiap hidden neuron ( j = 1, ..., p):
= −0.5 0.5 ( − )
Hitung = 1 ( )2 +
2 ( )2+ …+ ( )2 (24)
Bobot yang dipakai sebagai inisialisasi:
= ( )
| | (25)
Bias yang dipakai sebagai inisialisasi:
2.3.4. Momentum (�)
Pada standard Backpropagation, perubahan bobot didasarkan atas gradient yang terjadi untuk pola yang dimasukkan pada saat itu. Modifikasi yang dapat dilakukan adalah dengan menggunakan momentum yaitu dengan melakukan perubahan bobot yang didasarkan atas arah gradient pola terakhir dan pola sebelumnya yang dimasukkan. Penambahan momentum dimaksudkan untuk menghindari perubahan bobot yang mencolok yang diakibatkan oleh adanya data yang sangat berbeda dengan yang lain. Variabel momentum dapat meningkatkan waktu pelatihan dan stabilitas dari proses pelatihan (Al-Allaf, 2010). Berikut merupakan rumus dari Backpropagation:
∆ = � ∗ ∗ (26)
Keterangan:
η
: learning rate. Nilainya 0.25 atau 0.5 : nilai dari neuron ke i
Perubahan bobot dilakukan dengan cara menambahkan bobot yang lama
dengan
∆
w. Akan tetapi, bobot pada iterasi sebelumnya memberikan pengaruh besarterhadap performa jaringan saraf. Oleh karena itu, perlu ditambahkan dengan bobot yang lama dikalikan momentum, menjadi :
∆ = � ∗ ∗ + ∗ Δ ′ (27)
Keterangan :
α
: momentum faktor, nilainya antara 0 dan 1. ∆w’: bobot pada iterasi sebelumnya.
2.3.5. Perhitungan Error
Perhitungan error bertujuan untuk pengukuran keakurasian jaringan dalam mengenali pola yang diberikan. Ada tiga macam perhitungan error yang sering digunakan, yaitu Mean Square Error (MSE), Mean Absolute Error (MAE) dan Mean Absolute Percentage Error (MAPE).
MSE merupakan error rata–rata kuadrat dari selisih antara output jaringan dengan output target. Tujuan utama adalah memperoleh nilai errorsekecil-kecilnya dengan secara iterative mengganti nilai bobot yang terhubung pada semua neuron pada jaringan. Untuk mengetahui seberapa banyak bobot yang diganti, setiap iterasi memerlukan perhitungan error yang berasosiasi dengan setiap neuron pada output dan hidden layer. Rumus perhitungan MSE adalah sebagai berikut (Bayata et al, 2011):
��= 1 =1( − )2 (28)
Keterangan:
= nilai output target = nilai output jaringan N = jumlah output dari neuron
MAE merupakan perhitungan error hasil absolute dari selisih antara nilai hasil system dengan nilai aktual. Rumus perhitungan MAE adalah sebagai berikut:
��= 1 =1| − | (29)
MAPE hampir sama dengan MAE, hanya hasilnya dinyatakan dalam persentase. Rumus perhitungan MAPE adalah sebagai berikut:
���= 1 =1| − | x 100% (30)
2.3.6. Penggantian bobot
dengan menjumlahkan bobot yang lama dengan ∆ . Rumus untuk mengganti bobot adalah sebagai berikut:
∆ = η ∗ δi∗ (31)
Keterangan:
η = learning rate
δi = error yang berasosiasi dengan neuron yang dihitung = nilai error dari neuron yang dihitung
Berikut adalah rumus penggantian bobot tanpa momentum:
+ 1 = + ∆ (32)
Rumus penggantian bobot menggunakan momentum:
+ 1 = + ∆ +η∆wjk ( −1) (36)
Pada proses testing JST hanya akan diterapkan tahap propagasi maju. Setelah training selesai dilakukan, maka bobot-bobot yang terpilih akan digunakan untuk menginisialisasi bobot pada proses testing JST. Adapun tahapannya adalah sebagai berikut:
1. Masukkan nilai input dari data testing.
= 0 + =1 . (40)
3. Hitung hasil output dari masing-masing hidden layer dengan menerapkan kembali fungsi aktivasi.
= ( ) (41)
=
11+ − _ (42)
Sinyal tersebut kemudian akan diteruskan kesemua neuron pada lapisan berikutnya yaitu output layer.
4. Setiap neuron pada output layer (Yk, k=1,..,5) menjumlahkan sinyal-sinyal output beserta bobotnya:
= 0 + =1 . (43)
5. Menerapkan kembali fungsi aktivasi untuk menghitung sinyal output
= ( _ ) (44)
=
11+ − _ (45)
2.3.8. Metode Resilient Backpropagation
Rprop melaksanakan dua tahap pembelajaran yaitu tahap maju (forward) untuk mendapatkan error output dan tahap mundur (backward) untuk mengubah nilai bobot-bobot. Proses pembelajaran pada algoritma RPROP diawalai dengan definisi masalah, yaitu menentukan matriks masukan (P) dan matriks target (T). kemudian dilakukan proses inisialisasi yaitu menentukan bentuk jaringan, MaxEpoch, Target_Error, delta_dec, delta_inc, delta0, deltamax, dan menetapkan nilai-nilai bobot sinaptik vij dan wjk secara acak.
BAB III
ANALISIS DAN PERANCANGAN SISTEM
3.1. Rancangan Sistem
Rancangan sistem terdiri dari preprocessing data yaitu tahap normalisasi data kedalam range [0-1]. Kemudian dilakukan pemilihan arsitektur yang tepat pada jaringan saraf tiruan untuk mendapatkan hasil prediksi yang optimal. Setelah arsitektur jaringan ditentukan maka dilakukan proses training, dimana sistem akan dilatih sehingga dapat mengenali pola pasangan data input dan data target. Testing dilakukan untuk mengetahui apakah sistem mampu memberikan hasil yang benar terhadap pasangan data input dan target yang belum pernah dilatih kedalam sistem. Sedangkan pada tahap postprocessing dilakukan denormalisasi dari data yang telah dinormalisasi untuk menjadi nilai output dari jaringan. Gambar 3.1 adalah rancangan umum dari sistem yang akan dibangun pada penelitian ini, yaitu:
Mulai
Preprocessing
Arsitektur JST
Training
P1
Testing
Selesai
Postprocessing
Gambar 3.1 Rancangan Sistem
3.2. Pemilihan Variabel Input
Input variabel merupakan faktor-faktor yang mempengaruhi terjadinya kecelakaan lalu lintas. Berikut adalah variabel input yang telah dipilih:
Table 3.1 Variabel Input Jaringan Saraf Tiruan
Variabel
Input
Definisi Representasi
X1 Weather 1. Clear
2. Cloudy 3. Raining 4. Snowing 5. Fog 6. Wind 7. Other
2. Dusk dawn
3. Dark – street light 4. Dark – no street light
5. Dark – street light no functioning
X3 Vehicle Type 1. Passanger car
2. Passanger car with trailer 3. Motor cycle
4. Pick up or panel truck
5. Pick up or panel truck with trailer 6. Truck or truck tractor
7. Truck or truck tractor with 1 trailer 8. School bus
9. Other bus
10. Emergency vehicle
11. Highway construction equipment 12. Other motor vehicle
13. Truck or truck tractor with 2 trailer 14. Truck/trailer and 1 tank trailer
X4 Accident type 1. Head on 7. Auto pedestrian 8. Other
X5 Movement
preceding collision
4. In roadway – include shoulder 5. Not in roadway
6. Stopped
7. Proceeding straight 8. Ran off road
9. Making right turn 10. Making left turn
11. Making ‘U’ turn
12. Backing
13. Slowing, stopping 14. Passing other vehicle 15. Changing lanes 16. Parking maneuver
17. Entering traffic from shoulder, median, parking strip or private drive
18. Other unsave turning 19. Crossed into opposing lane 20. Parked
21. Merging
X8 Driver Safety 5. Shoulder harnest used 6. Shoulder harness not used 7. Lap/shoulder harnest used 8. Lap/shoulder harnest not used 9. Passive restrant used
10. Passive restrant not used 11. Air bag deployed
12. Air bag not deployed 13. Other
X11 Vehicle year 1. 1920 – 1929 2. 1930 – 1939 3. 1940 – 1949 4. 1950 – 1959 5. 1960 – 1969 6. 1970 – 1979 7. 1980 – 1989 8. 1990 – 1999 9. ≥ 2000
3.3. Pemilihan Variabel Output
Variabel output merupakan risiko kecelakaan lalu lintas yang terjadi berdasarkan faktor-faktor penyebab kecelakaan lalu lintas yang telah diuraikan sebagai variabel input. Variabel output akan dikelompokkan menjadi 5 kategori yang mempunyai pola yang ditunjukkan pada tabel 3.3:
Table 3.3 Variabel Output Jaringan Saraf Tiruan
Risiko Kecelakaan Pola Output Target
T[1] T[2] T[3]
Fatal 0 0 0
Severe Injury 0 0 1
Other Injury 0 1 0
Complaint of pain 0 1 1
3.4. Normalisasi Data
Data yang digunakan dalam penelitian ini merupakan database kecelakaan lalu lintas California pada tahun 2007 yang diperoleh dari HSIS (Highway Safety Information System). Data kemudian disusun dan dipilih variabel faktor-faktor kecelakaan lalu lintas dengan record data yang memiliki informasi paling lengkap. Berdasarkan data kecelakaan tersebut, kemudian digunakan sebanyak 400 kasus untuk masing-masing kategori injury severity dari beberapa kasus kecelakaan lalu lintas. Data tersebut kemudian akan di bagi menjadi 2 bagian, yaitu data pelatihan (training), data pengujian (testing). Sebanyak 80% data digunakan untuk proses training dan 20% data digunakan untuk proses testing. Tabel 3.3 adalah tabel pembagian data kecelakaan lalu lintas yang akan digunakan:
Table 3.3 Pembagian data kecelakaan lalu lintas
No Kategori Jumlah data Set training
(80%)
Data yang telah dianalisis kemudian dinormalisasi sehingga dapat dikenali oleh fungsi aktifasi yang akan digunakan. Pada penelitian ini, data di normalisasi kedalam range [0-1] berdasarkan rumus:
x′ =0.8 x−min
max = nilai maksimum dari seluruh data
Berikut merupakan contoh beberapa data yang telah di normalisasi dengan nilai minimum = 1 dan nilai maksimum = 23.
Tabel 3.4 Contoh Data Normalisasi
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11
0.1 0.209 0.209 0.209 0.282 0.245 0.1 0.464 0.136 0.173 0.355
0.1 0.1 0.1 0.173 0.282 0.136 0.1 0.5 0.391 0.245 0.391
0.173 0.209 0.1 0.318 0.209 0.318 0.1 0.5 0.1 0.245 0.355
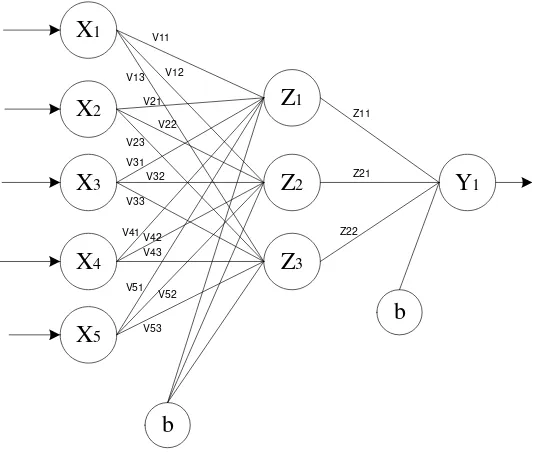
3.5. Arsitektur Jaringan Saraf Tiruan
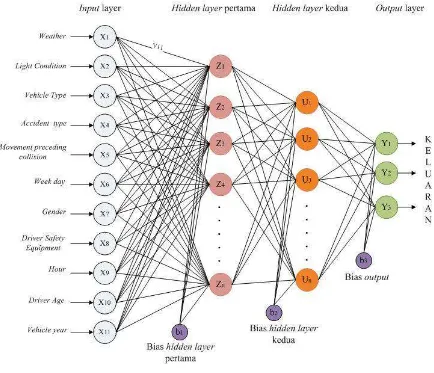
Arsitektur jaringan saraf tiruan terdiri dari lapisan input (input layer), lapisan tersembunyi (hidden layer) dan lapisan output (output layer). Berikut adalah rincian arsitektur jaringan saraf tiruan yang digunakan:
1. Lapisan masukan (input layer) terdiri 11 neuron dan ditambah sebuah bias. 2. Lapisan tersembunyi (hidden layer) terdiri dari dua lapis. Banyaknya jumlah
neuron pada hidden layer yang akan digunakan ditentukan berdasarkan percobaan yang dilakukan beberapa kali untuk mendapat arsitektur terbaik, Setiap masing-masing hidden layer akan ditambah dengan sebuah bias.
3. Lapisan keluaran (output layer) yang digunakan sebanyak satu lapis dengan 3 neuron.
Gambar 3.2 Arsitektur JST
Keterangan:
X = input neuron pada input layer Z = hidden neuron pada hidden layer Y = output neuron pada output layer
V11,..Vn = bobot dari input layer ke hidden layer pertama
W11,..Wn = bobot dari hidden layer pertama ke hidden layer kedua
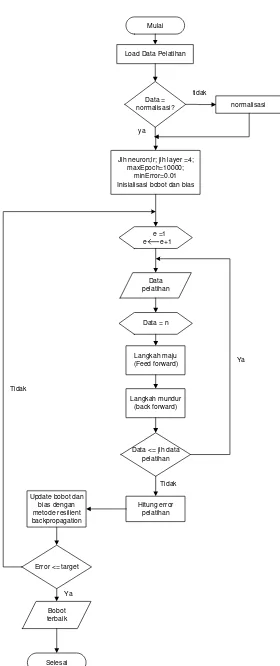
3.6. Training
Proses training pada JST memerlukan data input dan data target. Training meliputi proses iteratif dari data input yang dimasukkan ke dalam jaringan sehingga jaringan dapat belajar dan menyesuaikan data yang dilatih dengan data target yang diinginkan. Training dilakukan untuk mencari nilai bobot yang menghubungkan semua neuron sehingga meminimalkan error yang dihasilkan oleh output jaringan.
Proses training JST menggunakan sebanyak 80% jumlah data yang terdiri dari input data dan output target, kemudian data training dinormalisasi sebelum diproses kedalam jaringan. Pada proses ini akan dilakukan pelatihan dengan arsitektur JST dari jumlah hidden neuron yang berbeda-beda. Setiap arsitektur yang diuji tersebut akan menghasilkan bobot pelatihan yang nantinya akan digunakan sebagai bobot awal pada proses testing. Kemudian inisialisasi bobot dan bias untuk menghitung nilai output dari setiap neuron yang akan dikalikan dengan fungsi aktivasi dan learning rate.
Mulai
Jlh neuron;lr; jlh layer =4; maxEpoch=10000;
3.7. Perhitungan Error
Perhitungan error digunakan untuk menguji keakurasian jaringan. Tujuannya yaitu memperoleh nilai error seminimal mungkin dengan cara mengganti nilai bobot yang terhubung pada semua neuron secara iteratif. Pada penelitian ini, perhitungan error yang digunakan adalah Mean Square Error (MSE) yang merupakan rata-rata kuadrat dari selisih antara output jaringan dengan output target. Rumus dari MSE sebagai berikut:
��= 1 − 2
=1 Keterangan:
= nilai output target = nilai output jaringan N = jumlah output dari neuron
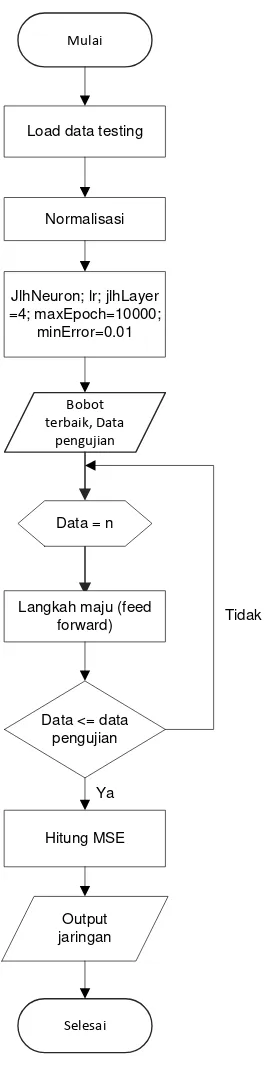
3.8. Testing
Proses testing JST menggunakan sebanyak 20% dari jumlah kasus kecelakaan lalu lintas yang telah dipilih untuk masing-masing kategori. Pada tahap ini jaringan akan di testing dengan data baru yang belum pernah dilatih kedalam jaringan untuk mengetahui kemampuan jaringan melakukan generalisasi kasus yang dihadapi dan kemudian menarik kecenderungan terhadap output tertentu.
Mulai
Selesai JlhNeuron; lr; jlhLayer =4; maxEpoch=10000;
minError=0.01
Bobot terbaik, Data
pengujian Load data testing
Normalisasi
Data = n
Langkah maju (feed forward)
Data <= data pengujian
Hitung MSE
Output jaringan Ya
Tidak
Gambar 3.4 Flowchart Testing
Adapun tahapannya adalah sebagai berikut:
1. Masukkan nilai input dari data testing.
= 0 + . 11
=1
3. Hitung hasil output dari masing-masing hidden layer dengan menerapkan kembali fungsi aktivasi.
= ( )
= 1 1 + − _
Sinyal tersebut kemudian akan diteruskan kesemua neuron pada lapisan berikutnya yaitu output layer.
4. Setiap neuron pada output layer (Yk, k=1,..,5) menjumlahkan sinyal-sinyal output beserta bobotnya:
= 0 + . 5
=1
5. Menerapkan kembali fungsi aktivasi untuk menghitung sinyal output
= ( _ )
= 1 1 + − _
Setelah proses testing selesai, maka kemampuan generalisasi jaringan dapat diukur dari berapa banyak pola yang dikenali. Hal tersebut dihitung menggunakan rumus berikut:
= 100% (3.1)
BAB IV
IMPLEMENTASI DAN PENGUJIAN SISTEM
Pada bab ini akan dilakukan implementasi dan pengujian sistem. Sistem dibuat dengan menggunakan Matlab R2009b. Pengujian sistem untuk memrepresentasikan review akhir dari analisis dan implementasi.
4.1. Lingkungan Implementasi
Lingkungan implementasi yang akan dijelaskan merupakan lingkungan perangkat keras (hardware) dan perangkat lunak (software) yang digunakan dalam penulisan skripsi ini.
Spesifikasi perangkat keras (hardware) yang digunakan adalah sebagai berikut: 1. Prosesor Intel(R) core (TM) i3 CPU M380 @ 2.53GHz (4CPUs), ~2.5GHz. 2. RAM 2048 MB.
3. Hard disk 500 GB. 4. Keyboard.
5. Mouse.
Spesifikasi perangkat lunak (software) yang digunakan adalah sebagai berikut: 1. Operating System Windows 7 Ultimate 64-bit (6.1, Build 7600). 2. Software Matlab R2009b.
4.2. Pencarian Arsitektur Jaringan Terbaik
beserta parameter-parameter yang digunakan. Adapun langkah-langkah yang dilakukan oleh penulis adalah sebagai berikut:
1. Dilakukan serangkaian percobaan untuk variasi jumlah hidden layer dan jumlah hidden neuron untuk mencari arsitektur jaringan terbaik. Dari seluruh variasi jumlah neuron pada hidden layer yang dicoba akan dipilih satu variasi yang memberikan nilai MSE pelatihan paling minimum.
2. Setelah arsitektur jaringan terbaik diperoleh, kemudian dilakukan beberapa kali percobaan untuk mencari bobot terbaik pelatihan yang menghasilkan nilai MSE paling minimum sesuai dengan iterasi yang telah ditetapkan.
3. Nilai bobot terbaik disimpan untuk diuji kembali dengan menggunakan nilai learning rate antara 0.1 sampai dengan 0.9.
4. Menampilkan hasil prediksi menggunakan data testing yang pernah dilatih dan juga data testing yang belum pernah dilatih kedalam jaringan.
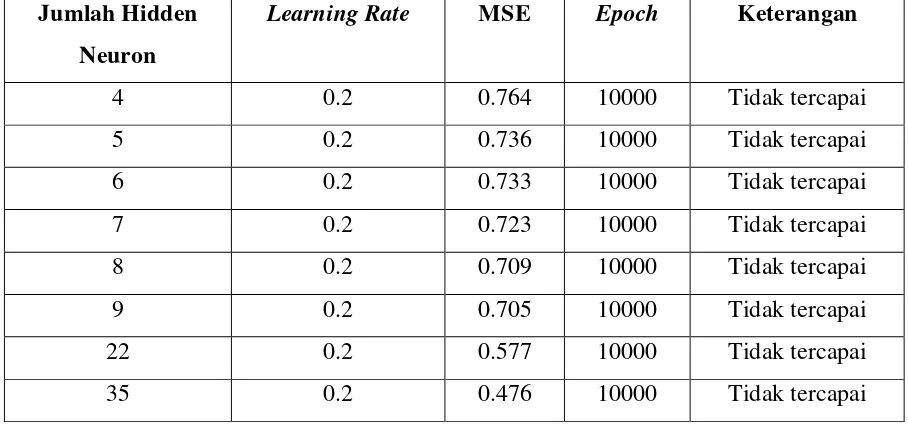
4.2.1. Variasi Jumlah Hidden Layer
Percobaan pertama yang dilakukan yaitu dengan menggunakan satu hidden layer dengan beberapa variasi jumlah neuron. Nilai learning rate yang digunakan adalah 0.2 dan epoch maksimal adalah 10000 dengan error maksimal 0.1. Hasil percobaan dapat dilihat pada tabel 4.1 berikut ini:
Tabel 4.1 Menggunakan Satu Hidden Layer
Jumlah Hidden
Neuron
Learning Rate MSE Epoch Keterangan
Berdasarkan hasil percobaan yang dapat dilihat dari tabel 4.1 maka dapat diketahui bahwa arsitektur jaringan dengan menggunakan satu hidden layer ternyata tidak mampu mencapai nilai MSE yang telah ditetapkan yaitu 0.01. Adapun hasil dari prosesnya dapat dilihat melalui gambar 4.1 berikut ini:
Gambar 4.2 MSE tidak tercapai
4.2.2. Variasi Jumlah Neuron
Setelahpercobaan dengan menggunakan satu hidden layer tidak dapat mencapai nilai MSE yang ditentukan, maka pada percobaan selanjutnya dilakukan dengan menggunakan dua hidden layer dengan variasi jumlah neuron untuk masing-masing layer. Percobaan dilakukan beberapa kali untuk mencari arsitektur terbaik, untuk masing-masing variasi jumlah iterasi (epoch) maksimal yang digunakan yaitu sebanyak 10000 dan nilai MSE sebesar 0.01. Berdasarkan percobaan yang telah dilakukan, jaringan memiliki nilai MSE minimum dengan jumlah neuron pada masing-masing hidden layer ditunjukkan pada tabel 4.1.
Tabel 4.2 Percobaan Beberapa Variasi Neuron
Jumlah Neuron
Learning rate MSE Epoch hidden layer ke-1 hidden layer ke-2
22 22 0.2 0.336 10000
0.5 0.343 10000
0.5 0.242 10000
50 35 0.2 0.137 10000
0.5 0.129 10000
50 50 0.2 0.094 10000
0.5 0.104 10000
75 75 0.2 0.025 10000
0.5 0.026 10000
100 75 0.2 0.016 10000
0.5 0.015 10000
100 100 0.2 0.012 10000
0.5 0.012 10000
100 125 0.2 0.013 10000
0.5 0.013 10000
100 150 0.2 0.010 9775
0.5 0.010 9626
Berdasarkan hasil percobaan yang telah dilakukan, maka didapatkan arsitektur terbaik dengan menggunakan jumlah neuron pada hidden layer pertama sebanyak 100 neuron dan pada hidden layer kedua sebanyak 150 neuron.
4.2.3. Pengujian Jaringan
Pengujian jaringan dilakukan dalam dua tahap, yaitu pengujian (testing) dengan menggunakan data yang pernah dilatih kedalam jaringan dan pengujian (testing) dengan menggunakan data yang belum pernah dilatih kedalam jaringan.
4.2.4. Pengujian Menggunakan Data yang Pernah Dilatih
pola data yang pernah dilatih kedalam jaringan. Hasil pengujian dapat dilihat pada tabel 4.2.
Tabel 4.3 Hasil Pengujian Data yang Pernah Dilatih Jumlah neuron Learning
rate
MSE Epoch Waktu yang dibutuhkan Layer pertama Layer kedua
100 150 0.1 0.010 9626 13:21
100 150 0.2 0.010 9626 13:35
100 150 0.3 0.010 9626 13:26
100 150 0.4 0.010 9626 13:52
100 150 0.5 0.010 9626 14:26
100 150 0.6 0.010 9626 13:36
100 150 0.7 0.010 9626 13:44
100 150 0.8 0.010 9626 13:45
100 150 0.9 0.010 9626 13:45
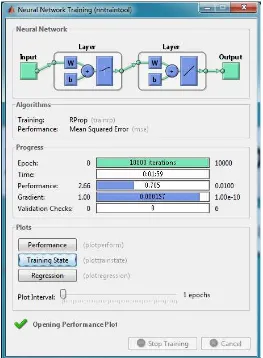
Hasil pengujian pada tabel 4.2 menunjukkan bahwa performansi terbaik dari jaringan adalah dengan menggunakan nilai parameter learning rate 0.1 dengan waktu pelatihan yang dibutuhkan yaitu 13 menit 21 detik.
Gambar 4.4 Performansi Pelatihan dengan learning rate 0.1
Gambar 4.6 Hasil Pengujian Data yang Pernah Dilatih
4.2.5. Hasil Prediksi Mengunakan Data yang Pernah Dilatih
Tabel 4.3 merupakan beberapa hasil dari prediksi yang dihasilkan oleh jaringan dengan menggunakan data yang pernah dilatih kedalam jaringan. Hasil prediksi selengkapnya dapat dilihat pada bagian lampiran.
Tabel 4.4 Hasil Prediksi Menggunakan Data yang Pernah Dilatih
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 Output
Target Jaringan
2 4 1 5 23 1 2 12 24 2 8 0 0 0 0 0 0
1 4 1 3 7 7 1 13 1 4 9 0 0 0 0 0 0
1 4 1 3 7 7 2 11 1 5 9 0 0 0 0 0 0
1 3 1 3 7 2 2 7 1 3 9 0 0 0 0 0 0
3 4 1 5 7 2 1 11 1 2 9 0 0 0 0 0 0
1 4 1 5 7 1 1 12 1 1 8 0 1 0 0 1 0
Berdasarkan hasil prediksi yang dihasilkan secara keseluruhan, maka dapat diketahui bahwa jaringan mampu mengenali data yang pernah dilatih kedalam jaringan dengan prosentasi kebenaran mencapai 100%.
4.2.6. Pengujian Menggunakan Data yang Belum Pernah Dilatih
Tahap kedua adalah melakukan pengujian menggunakan data yang belum pernah dilatih kedalam jaringan. Tujuannya adalah untuk mengetahui keandalan dari jaringan memprediksi output target untuk data yang serupa tetapi tidak sama. Hasil Pengujian dapat dilihat dari tabel 4.4 berikut:
Tabel 4.5 Hasil Pengujian Data yang Belum Pernah Dilatih
Jumlah neuron Learning
rate
MSE Epoch Waktu
yang
dibutuhkan Layer pertama Layer kedua
100 150 0.2 0.010 9626 13:52
100 150 0.3 0.010 9626 13:29
100 150 0.4 0.010 9626 13:36
100 150 0.5 0.010 9626 13:39
100 150 0.6 0.010 9626 13:44
100 150 0.7 0.010 9626 14:04
100 150 0.8 0.010 9626 14:54
100 150 0.9 0.010 9626 14:01
Hasil pengujian pada tabel 4.5 menunjukkan bahwa performansi terbaik dari jaringan adalah dengan menggunakan nilai parameter learning rate 0.3 dengan waktu pelatihan yang dibutuhkan yaitu 13 menit 29 detik.
Gambar 4.8 Performansi Pelatihan dengan learning rate 0.3
Gambar 4.10 Hasil Pengujian Data yang Belum Pernah Dilatih
4.2.7. Hasil Prediksi Menggunakan Data yang Belum Pernah Dilatih
Tabel 4.5 merupakan beberapa hasil dari prediksi yang dihasilkan oleh jaringan dengan menggunakan data yang pernah dilatih kedalam jaringan. Hasil prediksi selengkapnya dapat dilihat pada bagian lampiran.
Tabel 4.6 Hasil Prediksi Menggunakan Data yang Belum Pernah Dilatih
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11
Output
Keterangan
Target Jaringan
1 1 6 2 6 2 1 12 15 2 9 1 0 0 1 0 0 Cocok
1 3 1 3 6 2 1 12 17 5 7 1 0 0 1 0 0 Cocok
1 1 1 3 6 3 1 11 7 2 9 0 1 1 0 1 1 Cocok
1 1 1 3 6 7 1 11 12 4 8 0 0 1 0 0 1 Cocok
2 2 1 3 6 4 1 11 15 32 9 0 1 0 0 1 0 Cocok
1 3 1 3 6 2 1 7 17 3 9 0 1 0 0 1 0 Cocok
Berdasarkan hasil prediksi yang dihasilkan secara keseluruhan, maka dapat diketahui bahwa jaringan mampu mengenali data yang belum pernah dilatih kedalam jaringan dengan prosentasi kebenaran mencapai 70.25%.
4.2.8. Analisis Faktor Dominan Berdasarkan Hasil Prediksi Jaringan
prosentasi (%), 1 hingga 11 merupakan variabel faktor kecelakaan lalu lintas yang dapat dilihat seperti pada tabel 3.1 sedangkan nilai 1 hingga 24 merupakan representasi dari nilai masing-masing variabel faktor kecelakaan lalu lintas yang juga dapat dilihat penjelasannya pada tabel 3.1.
Gambar 4.1 Faktor Risiko Fatal Injury (a)
Gambar 4.2 Faktor Risiko Fatal Injury (b)
0
Variabel Faktor Kecelakaan Lalu lintas
Gambar 4.1 dan Gambar 4.2 menunjukkan faktor kecelakaan lalu lintas dengan risiko fatal injury. Berdasarkan gambar tersebut dapat dilihat bahwa faktor paling dominan dapat diketahui melalui intensitas terjadinya kasus kecelakaan berisiko fatal injury, yaitu:
1. weather(x1) yaitu clear, risiko fatal sering terjadi meskipun cuaca cerah.
2. Light condition (x2) yaitu Dark-No Street Light, Kondisi gelap tanpa penerangan jalan dapat berisiko kecelakaan fatal.
3. Vehycle Type (x3) yaitu Passanger Car. 4. Accident Type (x4) yaitu Broadside.
5. Movement Preceeding Collision (x5) yaitu Proceeding straight. 6. Week day (x6) yaitu Friday.
7. Gender (x7) yaitu male.
8. Drive Safety Equipment (x8) yaitu Air bag deployed.
9. Hour (x9) yaitu sekitar pukul 05.00 sampai dengan 05.59 pagi.
10. Driver Age (x10) yaitu pengendara dengan rentang usia 21 sampai 30 tahun. 11. Vehicle year (x11) yaitu 1990 - 1999.
Gambar 4.3 Faktor Risiko Severe Injury (a)
0
Variabel Faktor Kecelakaan Lalu Lintas
Gambar 4.4 Faktor Risiko Severe Injury (b)
Gambar 4.3 dan Gambar 4.4 menunjukkan faktor kecelakaan lalu lintas dengan risiko severe injury. Berdasarkan gambar tersebut dapat dilihat bahwa faktor paling dominan dapat diketahui melalui intensitas terjadinya kasus kecelakaan berisiko severe injury, yaitu:
1. weather(x1) yaitu clear, risiko fatal sering terjadi meskipun cuaca cerah. 2. Light condition (x2) yaitu Day Light.
3. Vehycle Type (x3) yaitu Motor Cycle. 4. Accident Type (x4) yaitu Over turned.
5. Movement Preceeding Collision (x5) yaitu Proceeding straight. 6. Week day (x6) yaitu Saturday.
7. Gender (x7) yaitu male.
8. Drive Safety Equipment (x8) yaitu Air bag Deployed.
9. Hour (x9) yaitu sekitar pukul 14.00 – 14.59 dan 17.00 – 17.59.
10. Driver Age (x10) yaitu pengendara dengan rentang usia 21 sampai 30 tahun. 11. Vehicle year (x11) yaitu kenderaan diatas tahun 2000.
0
Gambar 4.5 Faktor Risiko Other Injury (a)
Gambar 4.6 Faktor Risiko Other Injury (b)
0
Variabel Faktor Kecelakaan Lalu Lintas
Other Injury (a)
Variabel Faktor Kecelakaan Lalu Lintas