1
Bahasa dalam sebuah tulisan merupakan alat komunikasi untuk menerjemahkan sebuah pikiran yang ingin diungkapkan oleh seorang penulis. Dalam sebuah tulisan seorang penulis tidak hanya menyampaikan sebuah keterangan dari suatu informasi, tetapi juga berisi informasi tentang perilaku manusia termasuk emosi [1]. Emosi yang tersembunyi dibalik tulisan sangat sulit untuk ditafsirkan oleh pembaca dikarenakan pengaruh oleh sudut pandang yang berbeda antara penulis dan pembaca [2]. Maka dari itu untuk memudahkan pembaca mengetahui emosi dari sebuah tulisan bisa menggunakan cara klasifikasi.
Banyak metode yang bisa digunakan dalam klasifikasi teks diantaranya yaitu metode naive bayes, k-nearest neighbor (KNN), support vector machine (SVM) decision tree, neural network dan sebagainya. Masing – masing metode mempunyai kelebihan dan kekurangan masing – masing dan tingkat akurasi yang berbeda-beda. Seperti pada penelitian yang berjudul “Review on Comporation Between Text Classification Algorithms” dari hasil perbandingan algoritma naive bayes, k-nearest neighbor (KNN), dan support vector machine (SVM), diketahui bahwa algoritma K-nearest neighbor (KNN) memiliki kinerja yang bagus dengan nilai akurasi sampai 86% [3].
Pada penelitian yang sudah dilakukan sebelumnya dengan judul “Klasifikasi Emosi Untuk Teks Berbahasa Indonesia Dengan Menggunakan K-Nearest Neighbor” dijelaskan tahapan untuk mengenali emosi pada lirik lagu dilakukan beberapa proses. Adapun tahapan yang dilakukan sebelum proses klasifikasi dengan k-nearest neighbor (KNN) adalah tahapan preprocessing dan tahapan pembobotandengan menggunakan metode TF.IDF, hasil akurasi yang didapatkan adalah sekitar 50% – 60% [4]. Hasil tersebut dipengaruhi oleh metode pembobotan yang digunakan, seperti dalam penelitian “Text Categorization Based on Weighted
TF.IDF mempunyai kelemahan yaitu semua text yang berisi term tertentu diperlakukan sama, sehingga IDF tidak memperhitungkan jumlah kemunculan suatu term pada suatu dokumen. Sehingga untuk metode pembobotan term yang akan digunakan dalam penelitian ini adalah metode WIDF (Weighted Inverse Document Frequency), metode ini memiliki kinerja yang lebih baik dibanding dengan TF.IDF dengan memberikan peningkatan akurasi pada IDF sebesar 7.4% Maksimum [5].
Berdasarkan gambaran yang telah dijelaskan, dalam penelitian ini digunakan metode K-nearest neighbor (KNN) dengan metode pembobotan term WIDF untuk mengklasifikasikan emosi pada teks bahasa Indonesia dan mengetahui besar akurasi yang didapatkan.
1.2Perumusan Masalah
Berdasarkan penjelasan dari latar belakang masalah, maka rumusan masalah yang dapat teridentifikasi adalah bagaimana K-nearest neighbor dengan pembobotan WIDF dalam mengklasifikasikan emosi pada sebuah teks bahasa Indonesia dan mengetahui seberapa besar akurasi yang didapatkan.
1.3Maksud dan Tujuan
Berdasarkan permasalahan yang akan diteliti, maka maksud penelitian ini adalah mengklasifikasikan emosi pada teks bahasa Indonesia menggunakan metode K-nearest neighbor dengan pembobotan WIDF
Tujuan yang ingin dicapai dalam simulasi pengenalan emosi pada teks bahasa Indonesia adalah :
1. Untuk mengklasifikasikan emosi pada teks bahasa Indonesia
2. Untuk mengetahui besar akurasi yang didapatkan dari pengklasifikasian emosi pada teks bahasa Indonesia menggunakan metode K-nearest neighbor dengan pembobotan WIDF.
1.4Batasan Masalah
Ada pun batasan masalah dalam penelitian ini adalah sebagai berikut :
1. Data latih digunakan adalah dari ISEAR (International Survey On Emotion Antecedents And Reaction)
3. Kategori emosi senang, takut, marah, sedih dan bersalah yang disesuaikan dengan penelitian sebelumnya.
1.5Metodologi Penelitian
Metodologi penelitian merupakan sekumpulan peraturan, kegiatan dan prosedur yang digunakan oleh peneliti untuk memecahkan suatu masalah agar lebih efisien. Metode penelitian yang digunakan adalah metode deskriptif. Metode deskriptif bertujuan untuk mendapatkan gambaran yang jelas tentang hal-hal yang diperlukan, melalui tahapan sebagai berikut:
1.5.1 Metode Pengumpulan Data
Dalam tahapan ini pengumpulan data yang dilakukan adalah : a. Studi Literatur
Pada tahap ini akan dilakukan pengumpulan informasi yang berhubungan dengan Tugas Akhir ini khususnya pada metode yang diterapkan K-Nearset Neighbor (KNN)melalui sumber-sumber seperti jurnal penelitian, buku-buku teori, dan sumber-sumber lain.
b. Observasi
Observasi merupakan metode pengumpulan data dengan cara mengamati objek yang berkaitan dengan penelitian secara langsung terhadap permasalahan yang diambil. Di mana observasi yang dilakukan adalah dengan menggunakan data dari ISEAR (International Survey On Emotion Antecedents And Reaction)untuk data latihnya dan data uji mengggunakan lirik lagu yang akan diteliti.
1.5.2 Metode Pembangunan Perangkat Lunak
1. Analisis Metode
Dalam tahapan ini dilakukan untuk mempelajari konsep dan analisi mengenai klasifikasi teks, metode K-Nearest Neighbor, dan pembobotan WIDF yang akan diimplementasikan dalam sistem
2. Perancangan Desain
Pada tahap ini dilakukan perancangan desain dari simulasi klasifikasi emosi pada teks bahasa indonesia yang akan dibuat dengan analisis yang telah dilakukan pada tahap sebelumnya.
3. Pembangunan simulasi
Pada tahap ini dilakukan proses implementasi metode K-Nearest Neighbor dengan pembobotan WIDF ke dalam simulasi yang akan dibangun sesuai dengan desain yang telah dibuat pada tahap sebelumnya. 4. Pengujian simulasi
Pada tahap ini simulasi yang telah dibangun akan diuji oleh penguji, penguji menilai apakah simulasi yang dibangun sudah sesuai dengan tujuan dari penelitian.
Adapun gambaran dari tahapan pembangunan perangkat lunak yang akan dilakukan dalam penelitian ini dapat dilihat pada gambar 1.1
Analisis Metode Perancangan Desain Pembangunan Simulasi Pengujian Simulasi Pengumpulan Data
Gambar 1.1 Tahapan Pembangunan Perangkat Lunak
1.6Sistematika Penulisan
Penulisan skripsi ini terbagi menjadi beberapa bab yang masing – masing bab membahas tentang :
BAB 1 PENDAHULUAN
BAB 2 LANDASAN TEORI
Di dalam bab ini membahas tentang konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan dan hal-hal yang berguna dalam proses analisis permasalahan serta tinjauan terhadap penelitian.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Bab ini menjelaskan analisis dan perancangan sistem. Analisis yang dilakukan berupa analisis masalah, analisis penyelesaian masalah, analisis data masukan, analisis kebutuhan non fungsional dan analisis kebutuhan fungsional. Perancangan yang dilakukan berupa perancangan data, perancangan antarmuka, dan perancangan prosedural.
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Bab ini menjelaskan mengenai implementasi dari hasil tahapan analisis dan perancangan sistem yang dibangun. Serta berisi pengujian perangkat lunak seperti pengujian black box, pengujian precision, recall.
BAB 5 KESIMPULAN DAN SARAN
7
Emosi adalah suatu perasaan yang mendorong individu untuk merespon atau bertingkah laku terhadap stimulus, baik yang berasal dari dalam maupun dari luar dirinya. Emosi cenderung terjadi dalam kaitannya dengan perilaku yang mengarah (approach) atau menyingkiri (avoidance) terhadap sesuatu, dan perilaku tersebut pada umumnya disertai adanya ekspresi kejasmanian, sehingga orang lain dapat mengetahui bahwa seseorang sedang mengalami emosi.
Beberapa studi tentang emosi manusia telah dilakukan sehingga ada kesepakatan tentang emosi dasar yaitu, takut digambarkan sebagai ancaman fisik atau sosial bagi diri sendiri, kemarahan sebagai ketidakpuasan atau frustrasi dari peran atau tujuan yang dicapai oleh orang lain, jijik saat yang jarak, kelalaian, atau penolakan dari ide untuk diri sendiri, kesedihan sebagai kegagalan atau penderitaan pada peran dan tujuan, kebahagiaan atau sukacita sebagai keberhasilan atau gerakan untuk prestasi peran berharga [6].
2.2ISEAR (International Survey On Emotion Antecedents And Reaction)
ISEAR adalah sebuah data tentang emosi yang selama bertahun-tahun dimulai pada tahun 1990-an, sebuah kelompok besar psikolog di seluruh dunia mengumpulkan data dalam proyek ISEAR, dipimpin oleh Klaus R. Scherer dan Harald Wallbott. Mahasiswa responden, baik psikolog dan non-psikolog, diminta untuk melaporkan situasi di mana mereka mengalami semua 7 emosi utama (senang, takut, marah, sedih, jijik, malu, dan rasa bersalah). Dalam setiap kasus, pertanyaan-pertanyaan meliputi cara mereka telah mengenali situasi dan bagaimana mereka bereaksi. Data akhir ini memuat laporan tentang tujuh emosi masing-masing sekitar 3000 responden di 37 negara di 5 benua [7].
sebanyak 1000 data dengan banyak masing – masing emosi adalah 250 data karena ada empat emosi yang akan diklasifikasikan.
2.3Text Mining
Teks mining adalah salah satu bidang khusus dari data mining. Teks mining merupakan sebuah teknologi baru yang dapat digunakan untuk menambang data yang telah ada dalam sebuah database dengan membuat suatu data berupa teks yang tidak terstruktur menjadi data yang dapat dianalisa. Text mining juga dapat didefinisikan sebagai proses mendapatkan informasi secara intensif dimana pengguna berinteraksi dengan koleksi-koleksi dokumen menggunakan seperangkat tools analisis [8].
Secara umum, proses-proses pada text mining adalah mengadopsi dari proses data mining. Oleh karena itu, text mining dan data mining mempunyai banyak kesamaan arsitekturnya. Proses-proses yang ada pada text mining juga hampir sama dengan data mining. Proses-proses utama pada text mining diantaranya pemrosesan awal (text preprocessing), penemuan pola (pattern discovery), transformasi teks (text transformation), dan pemilihan fitur (feature selection).
2.4Preprocessing
Text preprocessing adalah tahapan untuk mempersiapkan teks menjadi data yang akan diolah di tahapan berikutnya. Inputan awal pada proses ini adalah berupa dokumen teks. Teks yang akan dilakukan proses text mining pada umumnya memiliki beberapa karakteristik, diantaranya adalah memiliki dimensi yang tinggi, terdapat noise pada data, dan terdapat struktur teks yang tidak baik. Agar dapat dihasilkan fitur yang baik dan mewakili data dengan baik, perlu dilakukan tahapan preprocessing [10].
Adapun tahapan preprocessing yang akan dilakukan antara lain case folding, tokenizing, stopword removal dan stemming.
1. CaseFolding
Pada tahap ini dilakukan perubahan pada semua huruf dalam dokumen menjadi huruf kecil dan menghilangkan karakter selain a-z, dengan tujuan untuk menyeragamkan karakter dalam dokumen tersebut
Convert Negation merupakan proses konversi kata-kata negasi yang terdapat pada suatu kalimat, karena kata negasi mempunyai pengaruh dalam merubah nilai emosi pada sebuah kalimat. Jika terdapat kata negasi maka akan disatukan dengan kata setelahnya. Kata - kata negasi tersebut meliputi kata
“bukan”, “tidak”, “tak”, “tanpa” dan “jangan”.
Langkah – langkah pada tahap convert negation adalah sebagai berikut : a. Kata yang digunakan adalah hasil dari case folding
b. Jika ditemukan lirik yang mengandung kata – kata negasi maka akan disatukan kata negasi tersebut dengan kata setelah kata negasi tersebut. 3. Tokenizing
Tokenizing merupakan tahap pemotongan kalimat berdasarkan tiap kata yang menyusunnya. Proses ini melakukan penguraian deskripsi yang semula berupa kalimat-kalimat menjadi kata-kata dan menghilangkan simbol seperti titik(.), tanda seru(!), tanda tanya (?), koma(,), spasi, emoticon.
4. Stopword removal
Tahapan ini bertujuan untuk menghilangkan kata yang dianggap tidak dapat memberikan pengaruh dalam menentukan suatu kategori tertentu dalam suatu dokumen. Proses ini dilakukan karena kata tersebut sering muncul hampir disetiap dokumen sehingga dianggap tidak dapat menjadi pembeda yang baik dalam membedakan kategori yang satu dengan kategori yang lain.
Setiap kata akan diperiksa apakah masuk dalam daftar stopword, jika sebuah kata masuk di dalam daftar stopword maka kata tersebut tidak akan diproses lebih lanjut dan kata tersebut akan dihilangkan. Sebaliknya apabila sebuah kata tidak termasuk di dalam daftar stopword maka kata tersebut akan masuk keproses berikutnya.
5. Stemming
Stemming merupakan tahap untuk mentransformasi kata-kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu. Dengan menggunakan stemming dapat mengurangi variasi kata yang sebenarnya memiliki kata dasar yang sama. Salah satu algoritma stemming yaitu Algoritma Nazief dan Adriani.
Algoritma stemming Nazief dan Adriani menggunakan morfologi imbuhan sebagai berikut :
a. Inflection suffixes merupakan kumpulan akhiran (suffixes) yang tidak
merubah kata dasar. Seperti : ‘-lah’, ‘-kah’, ‘-nya’, ‘-mu’
b. Derivation suffixes (DS) merupakan kumpulan akhiran (suffixes) yang
langsung menempel pada kata dasar, seperti : ‘-i’, ‘-an’ dan ‘kan’.
c. Derivation prefixes (DP) merupakan himpunan awalan (prefixes) yang menempel langsung pada kata dasar maupun terhadap kata yang telah
mempunyai sampai dua derivation prefixes. Seperti : ‘mem-‘ dan ‘per-‘.
2.5Pembobotan (Term Weighting)
Term weighting merupakan tahapan untuk memberikan suatu nilai/bobot pada
term yang terdapat pada suatu dokumen yang telah berhasil diekstrak. Metode yang akan digunakan dalam penelitian dalam pembobotan adalah pembobotan WIDF. Metode WIDF (Weighted Inverse Document Frequency) adalah sebuah metode pengembangan dari metode Inverse Document Frequency (IDF), IDF adalah proses mengukur term yang jarang muncul pada corpus. Penilaiannya menggunakan seluruh dokumen latih yang digunakan. Jika sebuah term sering muncul, maka term tersebut tidak bisa dianggap sebagai term yang mewakili dokumen tersebut. Sebaliknya, jika term yang jarang muncul pada corpus, maka term tersebut dikatakan memiliki hubungan dengan dokumen. Inverse Document Frequency merupakan perhitungan dari jumlah seluruh dokumen (D) dibagi dengan Frekuensi Dokumen (DF) dari kata (ti), dapat dituliskan dengan persamaan sebagai berikut [11]
IDF = log (
Dfi
N
Keterangan :
IDF = inverse document frequency N = Jumlah kalimat yang berisi term(t) Dfi = Jumlah kemunculan term terhadap D
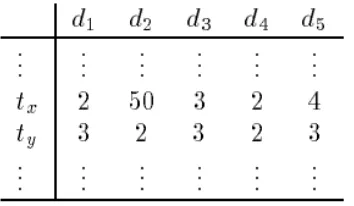
Kelemahan dari metode IDF adalah semua teks yang berisi term tertentu diperlakukan sama. Artinya, IDF tidak memperhitungkan jumlah kemunculan suatu term pada suatu dokumen. Contohnya pada tabel 2.1 berikut, dimana d (kolom) adalah text dan t (row) adalah term yang dicari, pertemuan antara di dan tj adalah termfrequency dari term tj di dalam text di
Gambar 2.1 Contoh Perhitungan Kemunculan Term
Dapat dilihat dari persamaan (2.1) bahwa IDF (tx) dan IDF (ty) masing-masing bernilai 0, karena term yang dicari muncul pada semua text. Sedangkan, distribusi frekuensi tx dan ty terhadap d1 sampai d5 berbeda, IDF tidak dapat mengidentifikasi perbedaannya, karena bersifat binary counting. Sehingga, tidak dapat menentukan jumlah frekuensi dari term.
IDF mengasumsikan bahwa term berbanding terbalik dengan jumlah text yang mengandung term tersebut. Oleh karena itu, bagian penting dari persamaan (1) di atas adalah faktor 1/df(t). Metode WIDF menghitung factor ini dengan term frekuensi. Sebagai contoh, 1/df(t) dari tabel 2.1 di atas menjadi
+ + + +
untuk semua text. Kemudian angka “1” diganti dengan frekuensi dari masing-masing term, menjadi
pada kasus d2. Faktor inilah yang yang disebut WIDF. Tidak seperti IDF, WIDF dapat membedakan masing-masing text d1…d5. Sehingga, WIDF dengan term t dalam text d dapat dituliskan sebagai persamaan (2) berikut :
���� �, � =∑�� ,�� �,
��� (2.2)
dimana TF(d,t) adalah term frequency dari term t di dalam text d dan i menyatakan jumlah text. WIDF dari term t menjumlahkan semua term frequency dari dari semua kumpulan text. Dengan kata lain WIDF adalah bentuk normalisasi term frequency dari semua kumpulan text [5].
2.6K-NN
K-Nearest Neighbor (KNN) adalah suatu metode yang menggunakan algoritma supervised dimana hasil dari query instance yang baru diklasifikan berdasarkan mayoritas dari kategori pada KNN. Tujuan dari algoritma ini adalah mengklasifikasikan obyek baru berdasarkan atribut dan training sample. Classifier tidak menggunakan model apapun untuk dicocokkan dan hanya berdasarkan pada memori. Diberikan titik query, akan ditemukan sejumlah k obyek atau (titik training) yang paling dekat dengan titik query. Klasifikasi menggunakan voting terbanyak diantara klasifikasi dari k obyek. algoritma KNN menggunakan klasifikasi ketetanggaan sebagai nilai prediksi dari query instance yang baru.
Nilai k yang terbaik untuk algoritma ini tergantung pada data training. k dipilih dengan nilai ganjil akan mendapatkan hasil yang lebih baik dibandingkan dengan k dengan nilai genap, karena akan relevan terhadap kasus, dengan kategori yang sama nilai jumlahnya. Nilai k yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi semakin kabur. Ketepatan algoritma KNN sangat dipengaruhi oleh ada atau tidaknya fitur-fitur yang tidak relevan atau jika bobot fitur tersebut tidak setara dengan relevansinya terhadap klasifikasi. Riset terhadap algoritma ini sebagian besar membahas bagaimana memilih dan memberi bobot terhadap fitur agar performa klasifikasi menjadi lebih baik.
KNN memiliki beberapa kelebihan yaitu ketangguhan terhadap training data yang memiliki banyak noise dan efektif apabila training data-nya besar. Sedangkan, kelemahan KNN adalah KNN perlu menentukan nilai dari parameter k (jumlah dari tetangga terdekat), training berdasarkan jarak tidak jelas mengenai jenis jarak apa yang harus digunakan dan atribut mana yang harus digunakan untuk mendapatkan hasil terbaik, dan biaya komputasi cukup tinggi karena diperlukan perhitungan jarak dari tiap query instance pada keseluruhan training sample.
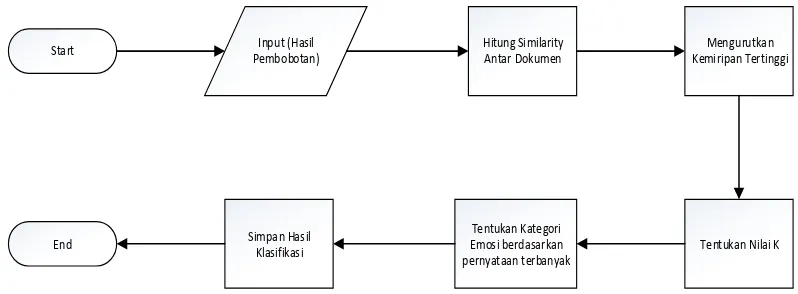
Adapun algortima k-NN dapat digambarkan dalam diagram alir K-Nearest Neighbor sebagai berikut.
Start Input (Hasil
Pembobotan)
Hitung Similarity Antar Dokumen
Mengurutkan Kemiripan Tertinggi
Tentukan Nilai K Tentukan Kategori
Emosi berdasarkan pernyataan terbanyak Simpan Hasil
Klasifikasi End
1. Hitung jarak antara data sampel (data uji) dengan data latih yang telah dibangun. Salah satu persamaan dalam menghitung jarak kedekatan dapat menggunakan persamaan 2.3 Cosine Similarity.
2. Menentukan parameter nilai k = jumlah tetanggaan terdekat bebas. 3. Mengurutkan jarak terkecil dari data uji
4. Pasangkan kategori sesuai dengan kesesuaian
5. Cari jumlah terbanyak dari tetanggaan terdekat kemudian tetapkan kategori. Jarak yang digunakan dalam penelitian ini adalah Cosine Similarity.
Pemrogramman berorientasi objek pertama kali muncul pada pertengahan 60-an deng60-an bahasa pemgrogramm60-an y60-ang disebut Simula d60-an terus berkemb60-ang higga pada tahun 2002 microsoft memperkenalkan bahasa pemgoramman yaitu C# yang benar-benar merupakan bahasa pemrograman berorientasi objek. Pemrograman berorientasi objek adalah sebuah pendekatan yang berdasarkan kepada interaksi antar objek dalam menyelesaikan tugas [12]. Terdapat karakteristrik pada pemrograman berorientasi objek yaitu:
1. Objects
2. Abstraction
Saat objek berinteraksi dengan objek lain perlu diperhatikan mengenai bagian dari property objek tersebut. Sebagai contoh abstraksi jika suatu objek berinteraksi dengan 2 objek lain di mana 2 objek tersebut memiliki atribut yang sama dan nilainya berbeda maka akan berbeda pula hasil interaksi tersebut. 3. Encapsulation
Enkapsulasi yaitu proses di mana transaksi dengan sebuah data dilakukan secara tidak langsung, contohnya jika kita ingin berinteraksi data mahasiswa maka kita harus berinteraksi melalui objek mahasiswa tersebut, jika kita ingin melihat data mahasiswa maka kita mengirimkan pesan kepada objek mahasiswa lalu objek tersebut membaca pesan kita dan memberikan respon. Hal ini membuat program lebih mudah dan menyederhanakan proses debugging. 4. Polymorphism
Dengan polymorphism, 2 objek yang berbeda dapat menerima pesan yang sama namun dengan aksi yang berbeda. Dalam pemrograman berorientasi objek kita dapat menerapkan jenis polymorphism yang bernama overloading yaitu penerapan metode atau aksi yang berbeda pada objek yang memiliki nama yang sama. Objek tersebut dapat membedakan dari objek yang memiliki nama yang sama tersebut mana objek yang harus dijalankan seperti membedakan berdasarkan parameter.
5. Inheritance
Sebuah pewarisan fungsi dan karakteristik dari objek yang umum pada objek yang lebih spesifik seperti objek orangtua ke objek anak sehingga objek anak tersebut mewarisi fungsi dan karakteristik yang ada pada objek orangtua dan menggunakannya. Contohnya yaitu objek bangun datar sebagai objek orangtua yang memiliki fungsi luas dan keliling, dan objek segitiga menjadi objek anak yang mempunyai karakteristik alas dan tinggi, sehingga dengan inheritance objek segitiga dapat memakai fungsi luas dan keliling.
6. Agregation
2.8UML (Unified Modeling Language)
UML merupakan suatu alat dalam memodelkan analisis dan desain berorientasi objek. UML adalah sebuah bahasa pemodelan standar untuk perangkat lunak dan pengembangan sistem. Desain sistem dengan skala besar merupakan hal yang sulit, bagaimana pengembang perangkat lunak dan timnya menjaga komponen yang dibutuhkan, bagaimana membagi komponen-komponen kedalam beberapa bagian agar dapat dikerjakan bersama secara tim dan terdapat pemahaman yang sabar dalam pembangunan sistem tersebut sehingga detail pekerjaan tidak disalahartikan. Agar desain model lebih efektif maka diperlukan bahasa pemodelan yang dapat menjelaskan kompleksitas tersebut yang disebut UML. Berikut adalah beberapa diagram pada UML beserta apa yang dimodelkannya [13].
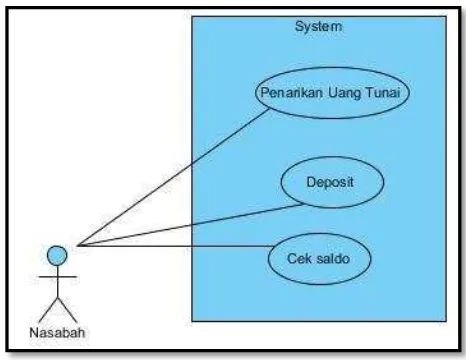
1. Use Case Diagram
Use Case Diagram menggambarkan fungsionalitas yang diharapkan dari sebuah sistem. Di dalam use case diagram ini sendiri lebih ditekankan kepada apa yang diperbuat sistem dan bagaimana sebuah sistem itu bekerja. Sebuah use case merepresentasikan sebuah interaksi antara aktor dengan sistem. Use case merupakan bentuk dari sebuah pekerjaan tertentu, misalnya login ke dalam sistem, posting, dan sebagainya, sedangkan seorang aktor adalah sebuah entitas manusia atau mesin yang berinteraksi dengan sistem untuk melakukan pekerjaan-pekerjaan tertentu [13]. Adapun komponen-komponen dalam use case diagram diantaranya: a. Aktor
b. Use Case
Use case merupakan gambaran umum dari fungsi atau proses utama yang menggambarkan tentang salah satu perilaku sistem. Perilaku sistem ini terdefinisi dari proses bisnis sistem yang akan dimodelkan. Tidak semua proses bisnis digambarkan secara fungsional pada use case, tetapi yang digambarkan hanya fungsionalitas utama yang berkaitan dengan sistem. Use case menitik beratkan bagaimana suatu sistem dapat berinteraksi baik antar sistem maupun diluar sistem. Contoh use case diagram dapat dilihat pada gambar 2.3 berikut.
Gambar 2.3 Contoh Use Case Diagram
2. Use Case Scenario
Use case description digunakan untuk menunjukkan use case dan actor, mungkin menjadi titik awal yang bagus tapi ini tidak memberikan cukup detail untuk desainer sistem agar benarbenar memahami persis bagaimana sistem akan dipenuhi [13].
Tidak ada aturan baku untuk apa yang masuk ke dalam use case description menurut UML, tetapi beberapa contoh jenis informasi yang ditampilkan dalam tabel 2.1
Tabel 2.1 Contoh Use Case Scenario
Use case name Create a new Blog Account Related
Requirements
Goal In Context A new or existing author requests a new blog account from the Administrator.
Preconditions The system is limited to recognized authors and so the author needs to have appropriate proof of identity.
Successful End Condition
A new blog account is created for the author.
Failed End
Condition
The application for a new blog account is rejected.
Primary Actors Adminidtrator
Secondary Actors
Author Credentials Database.
Trigger The Administrator asks the CMS to create a new blog
account.
Main Flow Step Action
1 The Administrator asks the system to create a new blog
account.
2 The Administrator selects an account type.
3 The Administrator enters the author's details.
4 The author's details are verified using the Author
Credentials Database.
5 The new blog account is created.
6 A summary of the new blog account's details are
emailed to the author.
Extensions Step Branching Action
4.1 The Author Credentials Database does not verify the
author's details.
4.2 The author's new blog account application is rejected.
3. Activity Diagram
Gambar 2.4 Contoh Activity Diagram
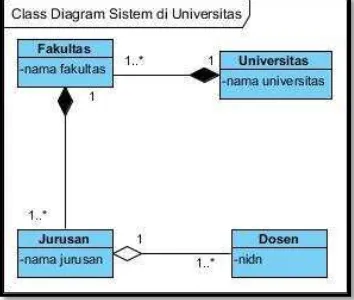
4. Class Diagram
Class Diagram adalah sebuah class yang menggambarkan struktur dan penjelasan class, paket, dan objek serta hubungan satu sama lain. Class diagram juga menjelaskan hubungan antar class secara keseluruhan di dalam sebuah sistem yang sedang dibuat dan bagaimana caranya agar mereka saling berkolaborasi untuk mencapai sebuah tujuan [13]. Contoh class diagram dapat dilihat pada berikut.
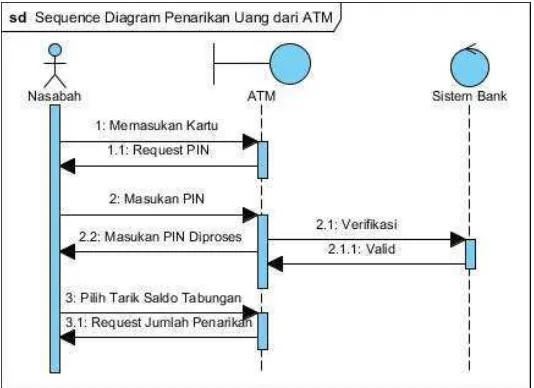
5. Sequence Diagram
Sequence Diagram digunakan untuk menggambarkan perilaku pada sebuah skenario. Diagram jenis ini memberikan kejelasan sejumlah objek dan pesan-pesan yang diletakkan diantaranya di dalam sebuah use case. Komponen utamanya adalah objek yang digambarkan dengan kotak segi empat atau bulat, message yang digambarkan dengan garis penuh, dan waktu yang ditunjukkan dengan progress vertical. Manfaat dari sequence diagram adalah memberikan gambaran detail dari setiap use case diagram yang dibuat sebelumnya [13]. Contoh sequence diagram dapat dilihat pada berikut.
Gambar 2.6 Contoh Sequence Diagram
1.9Pengujian
Pengujian yang dilakukan pada penelitian ini menggunakan precision, recall, dan F-measure.
1. Precision
Precision =
+ =
�� � � �
� � � (2.4)
Istilah positive dan negative mengacu pada prediksi yang dilakukan oleh sistem. Sedangkan istilah true dan false mengacu pada prediksi yang dilakukan oleh pihak luar atau pihak yang melakukan observasi. Pembagian kondisi tersebut dapat dilihat pada Tabel 2.2
Tabel 2.2 Pembagian Kondisi Hasil
Relevant Non relevant
Retrieved True positif (tp) False positive (fp)
Not retrieved False negatif (fn) True negatif (tn)
2. Recall
Recall digunakan sebagai ukuran dokumen yang relevan yang dihasilkan oleh sistem. False negative (fn) merupakan semua item relevan yang tidak dihasilkan oleh sistem. Dalam evaluasi information retrival system, recall dihitung dengan persamaan 2.5 [14]
Recall =
+ =
�� � � �
�� � (2.5)
3. F-measure
F-measure merupakan nilai tunggal hasil kombinasi antara nilai precision dan nilai recall. F-measure dapat digunakan untuk mengukur kinerja dari recommendation system ataupun information retrival system. Karena merupakan rata-rata harmonis dari precision dan recall, F-measure dapat memberikan penilaian kinerja yang lebih seimbang. Persamaan (2.6) merupakan persamaan untuk menghitung F-measure [14]
F-measure = . � � . �
91
BAB 5
KESIMPULAN DAN SARAN
1.1 Kesimpulan
Berdasarkan penelitian yang telah dilakukan mengenai klasifikasi emosi pada teks bahasa Indonesia menggunakan metode k-nearest neighbor dengan pembobotan WIDF dapat disimpulkan sebagai berikut :
1. Simulator yang dibuat untuk pengklasifikasian emosi pada teks bahasa Indonesia menggunakan metode k-nearest neighbor dengan mengimplementasikan lirik lagu berbahasa Indonesia sebagai data ujinya berhasil dilakukan, dengan memberikan kategori emosi yang sesuai dengan kandungan lirik lagu tersebut.
2. Keberhasilan mengkalsifikasikan emosi pada lirik lagu dipengaruhi oleh nilai K dalam proses k-nearest neighbor dan data latih yang digunakan.
3. Penggunaan metode pembobotan WIDF dalam proses pengklasifikasian emosi memberikan nilai akurasi yang meningkat dari penelitian sebelumnya dengan besar akurasi yang didapatkan sebesar 73.3%.
4. Untuk nilai relevansi dari setiap kategori emosi dengan menggunakan precision dan recall menghasilkan nilai maksimum sebesar 100%. Nilai tersebut didapatkan di kategori “Takut” untuk precision, dan kategori “Marah” untuk recallnya.
1.2 Saran
Nama Lengkap : Wildan Abdul Gani
Jenis Kelamin : Laki-laki
Tempat, Tanggal Lahir : Garut, 12 Januari 1994
Agama : Islam
Kewarganegaraan : Indonesia
Status : Belum Menikah
Anak ke : 4 dari 4 bersaudara
Alamat : Kp. Pasir Cibolang No.171 Rt.01 Rw.03 Desa. Karanganyar Kec. Leuwigoong Kab. Garut
No. Telepon : 085794024412
Email : [email protected]
2. RIWAYAT PENDIDIKAN
1 SD Negeri Karanganyar 2 1999 -2005
2 MTs. Persis 76 Tarogong – Garut 2005-2008
3 SMK Negeri 1 Garut (Jurusan Multimedia) 2008-2011
4 Universitas Komputer Indonesia 2011-2016
Demikian riwayat hidup ini saya buat dengan sebenar-benarnya dalam keadaan sadar dan tanpa paksaan.
Bandung, 27 Februari 2016
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
WILDAN ABDUL GANI
10111402
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
v
DAFTAR ISI
ABSTRAK ... i
ABTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ...v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ...x
DAFTAR SIMBOL ... xiii
DAFTAR LAMPIRAN ... xvii
BAB 1 ...1
1.1 Latar Belakang Masalah ...1
1.2 Perumusan Masalah ...2
1.3 Maksud dan Tujuan ...2
1.4 Batasan Masalah ...2
1.5 Metodologi Penelitian ...3
1.5.1 Metode Pengumpulan Data ...3
1.5.2 Metode Pembangunan Perangkat Lunak ...3
1.6 Sistematika Penulisan ...4
BAB 2 ...7
2.1 Emosi ...7
2.2 ISEAR (International Survey On Emotion Antecedents And Reaction) ..7
2.3 Text Mining ...8
2.4 Preprocessing ...8
2.5 Pembobotan (Term Weighting) ... 10
vi
2.7 Pemrograman Beorientasi Objek...14
2.8 UML (Unified Modeling Language) ...16
2.9 Pengujian ...20
BAB 3 ...23
3.1 Analisis Masalah ...23
3.2 Analisis Data Masukan ...23
3.3 Analisis Proses ...23
3.3.1 Analisis Preprocessing ...25
3.3.2 Analisis Pembobotan(WIDF) ...40
3.3.3 Analisis Penerapan Algoritma K-Nearest Neighbor ...45
3.4 Analisis Kebutuhan Non-Fungsional ...48
3.4.1 Analisis Kebutuhan Perangkat Keras ...48
3.4.2 Analisis Kebutuhan Perangkat Lunak ...49
3.4.3 Analisis Pengguna ...49
3.5 Analisis Kebutuhan Fungsional ...49
3.5.1 Use Case Diagram...49
3.5.1.1 Definisi Actor ...50
3.5.1.2 Definisi Use Case ...50
3.5.1.3 Use Case Skenario ...51
3.5.2 Activity Diagram ...54
3.5.3 Class Diagram ...57
3.5.4 Sequence Diagram ...58
3.6 Perancangan Arsitektur Sistem ...60
3.6.1 Perancangan Data ...60
vii
3.6.3 Perancangan Antarmuka ...64
3.6.4 Perancangan Antarmuka Pesan ...64
3.6.5 Jaringan Simantik ...67
BAB 4 ...69
4.1 Implementasi Sistem ...69
4.1.1 Implementasi Perangkat Keras...69
4.1.2 Implementasi Perangkat Lunak ...69
4.1.3 Implementasi Data ...70
4.1.4 Implementasi Antarmuka ...72
4.1.5 Implementasi Class ...73
4.2 Pengujian Sistem ...73
4.2.1 Rencana Pengujian ...73
4.2.2 Skenario Pengujian ...73
4.2.3 Hasil Pengujian ...75
4.2.4 Evaluasi ...90
BAB 5 ...91
5.1 Kesimpulan ...91
5.2 Saran ...91
93 University of Sydney, 2011, p. 26.
[3] J. A. Vaibhav C.Gandhi, "Review on Comparison between Text Classification Algorithms," International Journal of Emerging Trends & Technology in Computer Science (IJETTCS) , vol. 1, no. 3, 2012.
[4] M. I. Takenobu Tokunage, "Text Categorization Based on Weighted Inverse Document Frequency," in ISSN 0918-2802, Ookayama, Meguro Tokyo Japang, Department Of Computer Science Tokyo Institute Of Technology , 1994.
[5] L. Sofiyana, "Klasifikasi Emosi Untuk Teks Berbahasa Indonesia Dengan Menggunakan K-Nearest Neighbor," Saintek UIN Maliki Malang, 2014. [6] K. E. P. Arifin, "Classification of Emotions in Indonesia Text," Internasional
Journal of Information and Electronics Engineering , vol. 2, no. 6, 2012. [7] "emotion-research.net," AAAC (The Association for the Advancement of
Affective Computing), [Online]. Available: http://emotion-research.net/toolbox/toolboxdatabase.2006-10-13.2581092615. [Accessed 25 Oktober 2015].
[8] R. d. J. S. Fieldman, The Text Mining Handbook., Cambridge: Cambridge University , 2007.
94
[11] R. A. d. N. H. Rahmi Pratiwi, "Penerapan Metode Neighbor Weighted-K Nearest Neighbor (NW-KNN) Pada Pengklasifikasian Spam Email.," Program Studi Informatika/Ilmu Komputer PTIIK Universitas Brawijaya. , 2013.
[12] D. Clark, Beginning C# Object-Oriented Programming, New YorkSpringer: Springer Science+Business Media, 2011.
[13] K. Hamilton and M. Russell, Learning UML 2.0, Sebastopol: O'Reilly Media, 2006.
[14] P. R. Christopher D. Manning, "An Introduction to Information Retrieval," Cambridge, England, Cambridge University Press, 2009, pp. 155 - 156. [15] N. Fajrin, "PENERAPAN METODE FK-NN UNTUK
PENGKLASIFIKASIAN SPAM EMAIL DENGAN PEMBOBOTAN WIDF," 2013.
PEMBOBOTAN WIDF
Wildan Abdul Gani
Teknik Informatika – Universitas Komputer Indonesia Jl. Dipatiukur 112-114 Bandung
ABSTRAK
Emosi merupakan sebuah ekspresi dari suatu keadaaan yang berkaitan dengan perasaan seseorang
yang dipengaruhi berbagai faktor baik internal
maupun eksternal. Dalam mengekpresikan sebuah
emosi seseorang biasanya menggunakan berbagai cara salah satunya dalam sebuah tulisan. Sebuah tulisan yang mengandung emosi sangat sulit untuk ditafsirkan oleh pembaca karena dipengaruhi oleh sudut pandang yang berbeda antara penulis dan pembaca. Maka dari itu untuk memudahkan pembaca mengetahui emosi dari sebuah tulisan bisa menggunakan cara klasifikasi.
Pada penelitian ini metode yang digunakan dalam mengklasifikasikan emosi pada teks yaitu K-Nearest Neighbor, pemilihan metode ini didasarkan pada penelitian yang dilakukan yang menjelaskan bahwa metode ini memiliki kinerja yang baik dengan
hasil akurasi sampai 86%. Pada penelitian
sebelumnya yang telah dilakukan dengan tahapan proses dari mulai preprocessing, pembobotan TF.IDF dan pengklasifikasian hasil akurasi yang didapat masih kurang sekitar 60%, hal ini dipengaruhi oleh beberapa kelemahan salah satunya dalam metode pembobotan yang digunakan. Oleh karena itu dalam penelitian ini metode pembobotan yang akan digunakan adalah WIDF yang memiliki kinerja yang baik dan pengembangan dari TF.IDF.
Berdasarkan hasil pengujian dari penelitian ini yang mengimplementasikan lirik lagu bahasa Indonesia dalam mengklasifikasikan emosi dengan
metode K-Nearest Neighbor dan pembobotan WIDF
ke dalam lima kategori yaitu senang, takut, marah, sedih dan bersalah, menghasilkan akurasi sebesar 73.3% pada nilai K = 5. Untuk nilai relevansi dari
setiap kategori emosi dengan menggunakan precision
dan recall menghasilkan nilai rata-rata terbaik pada
kategori “Takut” untuk precision, dan kategori
“Marah” untuk recall.
Kata kunci : Emosi, Klasifikasi, K-Nearest
Neighbor, Pembobotan WIDF
1. PENDAHULUAN
1.1 Latar Belakang
Bahasa dalam sebuah tulisan merupakan alat komunikasi untuk menerjemahkan sebuah pikiran yang ingin diungkapkan oleh seorang penulis. Dalam sebuah tulisan seorang penulis tidak hanya menyampaikan sebuah keterangan dari suatu informasi, tetapi juga berisi informasi tentang perilaku manusia termasuk emosi [1]. Emosi yang tersembunyi dibalik tulisan sangat sulit untuk ditafsirkan oleh pembaca dikarenakan pengaruh oleh sudut pandang yang berbeda antara penulis dan pembaca [2]. Maka dari itu untuk memudahkan pembaca mengetahui emosi dari sebuah tulisan bisa menggunakan cara klasifikasi.
Banyak metode yang bisa digunakan dalam klasifikasi teks diantaranya yaitu metode naive bayes,
k-nearest neighbor (KNN), support vector machine
(SVM) decision tree, neural network dan sebagainya.
Masing – masing metode mempunyai kelebihan dan
kekurangan masing – masing dan tingkat akurasi yang berbeda-beda. Seperti pada penelitian yang
berjudul “Review on Comporation Between Text
Classification Algorithms” dari hasil perbandingan
algoritma naive bayes, k-nearest neighbor (KNN), dan support vector machine (SVM), diketahui bahwa
algoritma K-nearest neighbor (KNN) memiliki
kinerja yang bagus dengan nilai akurasi sampai 86% [3].
Pada penelitian sebelumnya dalam pengolahan
teks dalam metode pembobotan term sering
menggunakan metode TF.IDF. metode ini memiliki kelemahan seperti yang disebutkan dalam penelitian
yang berjudul “Text Categorization Based on
Weighted Inverse Document Frequency”
menjelaskan yaitu semua text yang berisi term
tertentu diperlakukan sama, sehingga IDF tidak memperhitungkan jumlah kemunculan suatu term pada suatu dokumen. Sehingga untuk metode pembobotan term yang akan digunakan dalam
penelitian ini adalah metode WIDF (Weighted
WIDF untuk mengklasifikasikan emosi pada teks bahasa Indonesia dan mengetahui besar akurasi yang didapatkan.
1.2Maksud dan Tujuan
Berdasarkan permasalahan yang akan diteliti,
maka maksud penelitian ini adalah
mengklasifikasikan emosi pada teks bahasa Indonesia
menggunakan metode K-nearest neighbor dengan
pembobotan WIDF
Tujuan yang ingin dicapai dalam simulasi pengenalan emosi pada teks bahasa Indonesia adalah :
1. Untuk mengklasifikasikan emosi pada teks
bahasa Indonesia
2. Untuk mengetahui besar akurasi yang didapatkan
dari pengklasifikasian emosi pada teks bahasa
Indonesia menggunakan metode K-nearest
neighbor dengan pembobotan WIDF.
1.3Tahapan Pembangunan Sistem Sistem klasifikasi emosi yang akan dibangun akan melewati tahapan-tahapan sebagai berikut :
a. Analisis Sumber Data
Data latih yang digunakan berasal dari data
ISEAR (International Survey On Emotion
Antecedents and Reaction) yang berbahasa inggris kemudian diterjemahkan ke dalam bahasa indonesia tanpa mengurangi maksud dari kalimat – kalimat dalam ISEAR.
Sedangkan untuk data uji yang akan digunakan adalah data lirik lagu berbahasa Indonesia dengan format (.txt)
b. Preprocessing
Pada tahap ini, data yang terkumpul akan diproses sehingga data yang didapat menjadi lebih terstruktur dan mudah untuk diolah. Langkah - langkah preprocessing terdiri dari case folding, convert
negation, tokenizing, stopword removal dan
stemming.
c. Pembobotan Kata
Pada tahap ini akan dilakukan proses pengekstrakan
keyword menggunakan nilai WIDF (Weighted
Inverse Document Frequency). Term (kata) di ambil dari hasil proses prepocessing terakhir yaitu stemming. Nilai dari hasil pembobotan akan
digunakan sebagai tahapan pengklasifikasian
menggunakan metode k-nearest neigbor. d. Klasifikasi
Langkah selanjutnya adalah proses pengklasifikasian yang akan diproses menggunakan metode k-nearest neighbor untuk menentukan kandungan emosi dari data uji yang dimasukan.
menemukan model yang menjelaskan atau
membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang kelasnya tidak diketahui. Di dalam klasifikasi diberikan sejumlah record yang dinamakan training set, yang terdiri dari beberapa artibut, artibut dapat berupa kontinyu ataupun kategoris, salah satunya artibut menunjukan kelas untuk record.
2.2Preprocessing
Preprocessing merupakan proses menggali,
mengolah, mengatur informasi dengan cara
menganalisis hubungannya, aturan-aturan yang ada di data tekstual semi terstruktur atau tidak terstruktur. bagian – bagian tahapan dari preprocessing, dapat dijelaskan dengan menggunakan flowchart berjenis Flowchart Sistem, yaitu bagan yang menunjukkan alur kerja atau apa yang sedang dikerjakan di dalam sistem secara keseluruhan dan menjelaskan urutan dari prosedur-prosedur yang ada di dalam sistem.
1. Case Folding
Pada tahap ini, semua huruf akan diubah menjadi huruf kecil.
2. Convert Negation
Convert Negation merupakan proses konversi kata-kata negasi yang terdapat pada suatu pernyataan, karena kata negasi mempunyai pengaruh dalam merubah nilai sentimen pada suatu tweet. Jika terdapat kata negasi maka akan disatukan dengan kata setelahnya. Kata - kata negasi tersebut meliputi kata
“bukan”, “tidak”, “tak”, “ga”,”gak”, “enggak”, “jangan”, dan ”nggak”.
3. Tokenizing
Tokenizing merupakan tahap pemotongan
kalimat berdasarkan tiap kata yang menyusunnya. Proses ini melakukan penguraian deskripsi yang semula berupa kalimat-kalimat menjadi kata-kata dan menghilangkan simbol seperti titik(.), tanda seru(!), tanda tanya (?), koma(,), spasi, emoticon.
4. Stopword Removal
Stopword didefinisikan sebagai term yang tidak berhubungan dengan subyek utama dari database meskipun kata tersebut sering kali hadir di dalam dokumen dan kata yang dianggap tidak dapat memberikan pengaruh dalam menentukan suatu kategori sentimen..
5. Stemming
Stemming merupakan tahap untuk
mentransformasi kata-kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan
menggunakan aturan-aturan tertentu. Dengan
Frequency (WIDF). WIDF merupakan sebuah metode pengembangan dari metode IDF. Inverse Document Frequency (IDF) adalah proses mengukur term yang jarang muncul pada corpus. Penilaiannya
menggunakan seluruh dokumen latih yang
digunakan. Jika sebuah term sering muncul, maka term tersebut tidak bisa dianggap sebagai term yang mewakili dokumen tersebut. Sebaliknya, jika term yang jarang muncul pada corpus, maka term tersebut dikatakan memiliki hubungan dengan dokumen.
Inverse Document Frequency merupakan
perhitungan dari jumlah seluruh dokumen (D) dibagi dengan Frekuensi Dokumen (DF) dari kata (ti), dapat dituliskan dengan persamaan sebagai berikut.
IDF = log (
N = Jumlah kalimat yang berisi term(t)
Dfi = Jumlah kemunculan term terhadap D
Kelemahan dari metode IDF adalah semua teks yang berisi term tertentu diperlakukan sama. Artinya, IDF tidak memperhitungkan jumlah kemunculan suatu term pada suatu dokumen. Contohnya pada tabel 2.1 berikut, dimana d (kolom) adalah text dan t (row) adalah term yang dicari, pertemuan antara di dan tj adalah termfrequency dari term tj di dalam text di
Gambar 1. Contoh Perhitungan Kemunculan Term
Dapat dilihat dari persamaan (2.1) bahwa IDF (tx) dan IDF (ty) masing-masing bernilai 0, karena
term yang dicari muncul pada semua text. Sedangkan, distribusi frekuensi tx dan ty terhadap d1 sampai d5 berbeda, IDF tidak dapat mengidentifikasi perbedaannya, karena bersifat binary counting. Sehingga, tidak dapat menentukan jumlah frekuensi dari term.
IDF mengasumsikan bahwa term berbanding
terbalik dengan jumlah text yang mengandung term tersebut. Oleh karena itu, bagian penting dari persamaan (1) di atas adalah faktor 1/df(t). Metode WIDF menghitung factor ini dengan term frekuensi. Sebagai contoh, 1/df(t) dari tabel 2.1 di atas menjadi
+ + + +
+ + + +
pada kasus d2. Faktor inilah yang yang disebut WIDF. Tidak seperti IDF, WIDF dapat membedakan
masing-masing text d1…d5. Sehingga, WIDF dengan
term t dalam text d dapat dituliskan sebagai persamaan (2) berikut :
���� �, � =∑ �� �, ��� �, �
���
dimana TF(d,t) adalah term frequency dari term t di dalam text d dan i menyatakan jumlah text. WIDF dari term t menjumlahkan semua term frequency dari dari semua kumpulan text. Dengan kata lain WIDF adalah bentuk normalisasi term frequency dari semua kumpulan text [4].
2.4 K-Nearest Neighbor
K-Nearest Neighbor (KNN) adalah suatu metode yang menggunakan algoritma supervised dimana hasil dari query instance yang baru diklasifikan berdasarkan mayoritas dari kategori pada KNN. KNN memiliki beberapa kelebihan yaitu ketangguhan terhadap training data yang memiliki banyak noise dan efektif apabila training data-nya besar. Sedangkan, kelemahan KNN adalah KNN perlu menentukan nilai dari parameter k (jumlah dari tetangga terdekat), training berdasarkan jarak tidak jelas mengenai jenis jarak apa yang harus digunakan dan atribut mana yang harus digunakan untuk mendapatkan hasil terbaik, dan biaya komputasi cukup tinggi karena diperlukan perhitungan jarak dari tiap query instance pada keseluruhan training sample.
Start Pembobotan)Input (Hasil Hitung Similarity Antar Dokumen Kemiripan TertinggiMengurutkan
Tentukan Nilai K
Gambar 2. Diagram Alur K-Nearest Neighbor
Langkah – langkah metode KNN :
1. Hitung jarak antara data sampel (data uji) dengan data latih yang telah dibangun. Salah satu persamaan dalam menghitung jarak kedekatan Cosine Similarity.
k : data latih ke-j
2. Menentukan parameter nilai k = jumlah
tetanggaan terdekat bebas.
3. Mengurutkan jarak terkecil dari data uji
4. Pasangkan kategori sesuai dengan kesesuaian
Cari jumlah terbanyak dari tetanggaan terdekat Kemudian tetapkan kategori.
2.5 Pengujian
Pengujian dalam penelitian ini dilakukan dengan menguji sebanyak 30 lirik lagu bahasan Indonesia dengan nilai K yang digunakan adalah 2, 3, 4, 5 dan kategori klasifikasi yang ditentukan adalah emosi senang, sedih, tahut, marah, dan bersalah.
Berdasarkan pengujian yang telah dilakukan maka akurasi yang didapatkan sebagi berikut :
Tabel 1. Hasil Akurasi
Sedangkan untuk nilai relevansi dari setiap kategori
emosi dengan menggunakan pengujian precision dan
recall. Berikut hasil pengujian relevansi dari setiap kategori :
Tabel 2. Hasil Nilai Precesion
2 3 4 5 Rata-rata
Tabel 3. Hasil Nilai Recall
2 3 4 5 Rata-rata
Berdasarkan penelitian yang telah dilakukan mengenai klasifikasi emosi pada teks bahasa
Indonesia menggunakan metode k-nearest neighbor
dengan pembobotan WIDF dapat disimpulkan sebagai berikut ;
1. Simulator yang dibuat untuk pengklasifikasian emosi pada teks bahasa Indonesia menggunakan
metode k-nearest neighbor dengan
mengimplementasikan lirik lagu berbahasa
2. Keberhasilan mengkalsifikasikan emosi pada
lirik lagu dipengaruhi oleh nilai K dalam proses k-nearest neighbor dan data latih yang digunakan.
3. Penggunaan metode pembobotan WIDF dalam
proses pengklasifikasian emosi memberikan nilai akurasi yang meningkat dari penelitian
sebelumnya dengan besar akurasi yang
didapatkan sebesar 73.3%.
4. Untuk nilai relevansi dari setiap kategori emosi dengan menggunakan precision dan recall menghasilkan nilai maksimum sebesar 100%.
Nilai tersebut didapatkan di kategori “Takut”
untuk precision, dan kategori “Marah” untuk recallnya.
3.2 Saran
Berdasarkan penelitian yang telah dilakukan ada
kekurangan yang didapat yaitu proses
pengklasifikasian yang memerlukan waktu lama, sehingga penulis memberikan saran untuk penelitian selanjutnya untuk bisa menyempurnakan lagi dan data latih yang digunakan untuk bisa menggunakan data asli berbahasa Indonesia agar hasil yang didapatkan lebih relevan.
DAFTAR PUSTAKA
[1] C. Z.-j. H.W, "Multimodal Emotion Recognation From Speech," p. 1, 2004.
[2] S. M. Kim, "Recognising Emotions and Sentiments in Text," Sydney, The University of Sydney, 2011, p. 26.
[3] J. A. Vaibhav C.Gandhi, "Review on Comparison
between Text Classification Algorithms,"
International Journal of Emerging Trends & Technology in Computer Science (IJETTCS) , vol. 1, no. 3, 2012.
Wildan Abdul Gani
Teknik Informatika – Universitas Komputer Indonesia Jl. Dipatiukur 112-114 Bandung
ABSTRAK
Emotion is an expression of an event related to the feeling of someone who is influenced by a variety of factors, both internal and external. In expressing a person's emotions typically use a variety of ways one of which in his writing. An inscription containing the emotions are very difficult to be interpreted by the reader because it is influenced by the different points of view between the writer and the reader. Therefore to make it easier for the reader to know the emotions of piece of writing can use the method of with accuracy results up to 86%. In previous research that has been done with the stages of the process from the start preprocessing, weighting TF.IDF and the classification accuracy of obtained results is still lacking around 60%, it is influenced by some of the weaknesses of one in the method of weighting is used. Therefore, in this study the method of weighting to be used is the WIDF which has good performance and development of the TF. IDF.
Based on the test results of this research are implemented in Indonesia language lyrics classify emotions with the K-Nearest Neighbor method and weighting WIDF into five categories, namely happy, fear, anger, sadness and guilt, produce the accuracy of 73.3% on the value of K = 5. To value the relevance of each category of emotions with the use of precision and recall the average value produces a best in category "Fear" for precision, and the category of "angry" for a recall.
Keywords: Emotion, Classification, K-Nearest Neighbor, WIDF Weighting.
1. INTRODUCTION
1.1Background
Language in an article is a communication tool to translate a thought expressed by an author. In an
article a writer not only convey a description of the information, but also provides information about human behavior, including emotions [1]. Emotions are hidden behind the writing is very difficult to be
Many methods can be used in the text of which is the method of classification Naive Bayes, k-nearest neighbor (KNN), support vector machine (SVM) decision tree, neural network and so forth. Each - each method has advantages and disadvantages of each - each and accuracy vary. As in the study entitled
"Review on Comporation Between Text
Classification Algorithms" of the comparison algorithm Naive Bayes, k-nearest neighbor (KNN), and support vector machine (SVM), it is known that the algorithm K-nearest neighbor (KNN) has performance great value accuracy up to 86% [3].
In previous studies of text processing in term weighting method frequently used method TF.IDF. This method has a drawback as mentioned in the study entitled "Text Categorization Based on Weighted Inverse Document Frequency" explaining that all the text that contain certain terms are treated equally, so that the IDF does not take into account the number of occurrences of a term in a document. So for term weighting method that will be used in this research is the method WIDF (Weighted Inverse Document Frequency), this method has better performance than TF.IDF by providing increased accuracy in the IDF by 7.4% Maximum [4].
Based on an idea that has been described, in this study used methods of K-nearest neighbor (KNN) with WIDF term weighting method to classify the emotion in the Indonesian language text and know the great accuracy obtained.
1.2Purpose and objectives
text
2. To determine the great accuracy obtained from the classification of emotions in the Indonesian language text using the K-nearest neighbor weighted WIDF.
1.3Stages of Development System Emotion classification system to be built will pass through the stages as follows:
a. Data Sources Analysis
Training data used comes from the data ISEAR (International Survey On Emotion antecedents and Reaction) who speak English and then translated into Indonesian without reducing the meaning of the sentence - the sentence in ISEAR.
As for the test data to be used is the data speak Indonesian song format (.txt)
b. Preprocessing
At this stage, the collected data will be processed so that the data obtained become more structured and easy to prepare. Step - a preprocessing step consists of folding case, convert negation, tokenizing, stopword removal and stemming.
c. Weighting words
At this stage the keyword extraction process will be conducted using values WIDF (Weighted Inverse Document Frequency). Term (words) taken from the results of the last prepocessing are stemming. The value of the weighting of the results will be used as a stage classification using k-nearest neigbor.
d. Classification
The next step is the classification process will be processed using k-nearest neighbor method to determine the emotional content of the test data object whose class is unknown. In the classification given number of records called training set, which consists of several attributes, attributes can be either continuous or categorical, one of which shows the attributes for the class record.
2.2 Preprocessing
Preprocessing the digging process, process,
organize the information by analyzing the
relationship, the rules that exist in the textual data semi-structured or unstructured. part - part of a preprocessing stage, can be explained by using a flowchart Flowchart manifold system, which is a chart showing the workflow or what is being done within the overall system and explain the sequence of procedures that exist in the system.
2. Convert negation
Negation Converter is a conversion process of negation words contained in a statement, because of the word negation have an influence in changing the value of sentiment in a tweet. If there is a negation said it will be merged with the word thereafter. Said - said the negation includes the word "not", "no", "no", "ga", "not", "baseball", "do not" and "no".
3. Tokenizing
Tokenizing a sentence based on the cutting stage that compose each word. This process did the original description decomposition in the form sentences into words and removes symbols like a period (.), Exclamation mark (!), The question mark (?), Comma (,), space, emoticons.
4. Removal Stopword
Stopword defined as a term that is not related to the main subject of the database even though the word is often present in the document and words that are considered not to provide influence in determining a category sentiment.
5. Stemming
Stemming is the stage to transform the words contained in a document to word roots (root word) by using certain rules. By using stemming can reduce the variation of the word has the same root. One stemming algorithms are algorithms Nazief and Adriani.
2.3 WIDF Weighting
Word weighting method used in this system is Weighted Inverse Document Frequency (WIDF). WIDF is a method of the development of the method of the IDF. Inverse Document Frequency (IDF) is the process of measuring term which is rarely present in the corpus. Assessment using the trainer used the entire document. If a term frequently appears, then the term could not be considered a term that represents the document. Conversely, if the term rarely appears on the corpus, then the term is said to have ties with the document. The inverse Document Frequency is a calculation of the total number of documents (D) divided by the frequency of the document (DF) of the word (it), can be expressed with the following equations.
IDF = inverse document frequency
in the text in.
Figure 1. Example Calculation Of The Emergence Of The Term
It can be seen from equation (2.1) that IDF (tx) and IDF (ty) each is worth 0, because the search term appears on all the text. Frequency distribution, while the tx and ty against d1 to d5 is different, the IDF cannot identify the difference, because the binary nature of the counting. So, unable to determine the number of frequency of term.
IDF assumes that the term is inversely proportional to the amount of text that contain the term. Therefore, an important part of the equation (1) above is a factor 1/df (t). This method of calculating WIDF factor with the term frequency. For example, 1/df (t) from table 2.1 above into
+ + + +
for all text. Then the number "1" is replaced with the frequency of each term, be
+ + + +
in the case of d2. It is this factor which is called WIDF. Unlike the IDF, WIDF can distinguish each text d1 ... d5. So, with the term t WIDF in text d can be written as an equation (2) below:
���� �, � =∑ �� �, ��� �, �
���
where TF (d, t) is the term frequency of the term in the text t d and i stated the amount of text. Term of WIDF t add up all term frequency of collection of all text. In other words the WIDF is a form of normalization term frequency of all batches of text [4].
2.4 K-Nearest Neighbor
K-Nearest Neighbor (KNN) is a method that uses a supervised algorithm which results from query instance new remedies based on the majority of categories on KNN. KNN has several advantages, namely toughness against training data that has a lot of noise and effective when training his big data. Meanwhile, the weakness of KNN is KNN need to determine the value of the parameter k (the number of nearest neighbors), based on distance training was not
the required calculation of the distance of each query instance on the overall training sample.
Start Pembobotan)Input (Hasil Hitung Similarity Antar Dokumen Kemiripan TertinggiMengurutkan
Tentukan Nilai K
Figure 2. Flowchart Of K-Nearest Neighbor Steps-steps: KNN method
1. Calculate the distance between the sample data (test data) with data training that has been built. One equation in calculating the distance of the proximity of the Cosine Similarity.
number of the nearest tetanggaan.3. Sort the smallest distance from the test data 4. Attach the category in accordance with the conformity
Search for the most of the nearby tetanggaan and then set the category.
2.5 Testing
Testing in this study was done by testing as many as 30 song lyrics discussion of Indonesia with a value of K is 2, 3, 4, 5 and category classification prescribed is happy, sad, emotional tahut, anger, and guilt.
Based on the testing that has been done then accuracy is obtained as follows:
No Nilai K Akurasi
1 2 60%
2 3 63.3%
3 4 70%
4 5 73.3%
2 3 4 5 Rata-rata classification of emotions in the Indonesian language text using k-nearest neighbor method with weighting WIDF can be summarized as follows;
1. Simulator made for the classification of emotions in the Indonesian language text using k-nearest neighbor method by implementing the song lyrics in Indonesian language the test was successful, by providing emotional categories that correspond to the content of the lyrics of the song.
2. The success of the classification of emotions in the lyrics of songs influenced by the value of K in the k-nearest neighbor and training data are used..
3. Using the methods of weighting WIDF in the process of classifying emotions provide increased accuracy values from previous studies with great accuracy obtained amounted to 73.3%.
4. To value the relevance of each category of emotion by using precision and recall generate maximum value of 100%. The value obtained in the category of "Fear" for precision, and the category of "Angry" to recallnya.
3.2 Suggestion
Based on the research that has been done there is a shortage obtained that the classification process takes a long time, so the authors provide suggestions for future research in order to further enhance and training data used to be able to use the original data in Indonesian language so that the results obtained are more relevant
BIBLIOGRAPHY
[1] C. Z.-j. H.W, "Multimodal Emotion Recognation From Speech," p. 1, 2004.
[3] J. A. Vaibhav C.Gandhi, "Review on Comparison
between Text Classification Algorithms,"
International Journal of Emerging Trends & Technology in Computer Science (IJETTCS) , vol. 1, no. 3, 2012.
iii
KATA PENGANTAR
Assalamu’alaikum Warahmatullahi Wabarakatuh.
Puji dan syukur penulis panjatkan kehadirat Tuhan Yang Maha Esa Allah SWT karena atas rahmat dan karunia-Nya penulis dapat menyelesaikan penelitian dengan judul “Klasifikasi Emosi Pada Teks Bahasa Indonesia Menggunakan Metode K-Nearest Neighbor dengan Pembobotan WIDF” sebagai syarat untuk menyelesaikan program studi Strata 1 Jurusan Teknik Informatika Fakultas Teknik dan Ilmu Komputer di Universitas Komputer Indonesia.
Dalam penyusunan penelitian ini penulis memiliki banyak kekurangan, untuk itu penulis ingin mengucapkan terima kasih kepada pihak yang telah banyak membantu penulis sehingga penulis dapat menyelesaikan penelitian ini dengan baik. Oleh karena itu penulis mengucapkan terima kasih kepada:
1. Tuhan Yang Maha Esa Allah SWT yang telah memberikan rizki dan karunia-Nya sehingga penulis dapat menyelesaikan penelitian ini.
2. Ayah tercinta Idi Supardi, S.Pd.I dan ibu tercinta Wiwi Lasmini, S.Pd yang telah memberikan dukungan moral dan materi khususnya pengarahan ilmu yang sangat berguna dalam merangsang pola pikir penulis sehingga penulis selalu semangat dalam menyelesaikan penelitian.
3. Ibu Ednawati Rainarli, S.Si., M.Si selaku dosen pembimbing yang senantiasa memberikan pengarahan, penjelasan ilmu dan motivasi yang bermanfaat untuk menyelesaikan penilitian dengan kualitas baik.
4. Ibu Dian Dharmayanti, S.T., M.Kom selaku reviewer yang telah memberikan pengarahan dan pembenaran mengenai penelitian penulis sehingga penelitian dapat lebih baik.
iv
6. Seluruh Dosen dan Staff Program Studi Teknik Informatika Universitas Komputer Indonesia.
7. Dzikry Pramanda, Dika Muhammad Fazar, Argi Sugiyarsa, Dimas Hamdani, Alih Purwandi, Nizar Assegaf, Hilman Herlambang, selaku sahabat terdekat penulis di Universitas Komputer Indonesia.
8. Teman-teman kelas IF 9 angkatan 2011 yang telah berjuang bersama selama 4 tahun.
9. Teman-teman dari Earth Hour Bandung Champions 2015 khususnya divisi multimedia yang telah memberikan ilmu untuk cinta dan peduli terhadap lingkungan dan pengalaman – pengalaman seru lainnya.
10. Teman-teman dari Sahabat Museum Konperensi Asia Africa khususnya Young Announcer Club yang memberikan semangat penulis agar menyelesaikan tugas akhir ini.
11. Teman-teman anak bimbing Ibu Ednawati Rainarli, S.Si., M.Si yang selalu saling membantu dan berbagi ilmu dan informasi.
12. Semua pihak yang telah membantu penulis dalam menyelesaikan penelitian ini. Penulisan laporan penelitian ini memiliki banyak kekurangan, untuk itu penulis mengharapkan kritik dan saran pembangun sehingga penulis dapat lebih baik lagi untuk kedepannya. Semoga penelitian ini dapat memberikan manfaat baik bagi pembaca maupun penulis sendiri.
Wassalaamu’alaikum Warahmatullahi Wabarakatuh.
Bandung, 27 Februari 2016