Fakultas Ilmu Komputer
Universitas Brawijaya
8293
Klasifikasi Tweets Pada Twitter Menggunakan Metode K-Nearest
Neighbour (K-NN) Dengan Pembobotan TF-IDF
Rakhman Halim Satrio1, Mochammad Ali Fauzi2, Indriati3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Twitter termasuk mikroblog yang sedang diminati oleh banyak orang dan menjelma menjadi penyiar informasi yang amat cepat saat ini. Informasi yang dikeluarkan serta bersirkulasi via media ini amat bebas serta banyak ragam, layaknya berita, pendapat, pertanyaan, kritikan, komentar baik bersifat positif ataupun negatif. Klasifikasi ialah kaidah di teks mining yang menghimpunkan muatan mengacu pada kesamaan skripnya. Lewat kaidah ini membolehkan tweets yang tersedia di Twitter digolongkan jadi satu bersandarkan jenisnya. Misalkan, substansi sepakbola, voli, serta tenis diguguskan pada kategori olahraga. Prosedur pada klasifikasi dimulai memakai preprocessing, selanjutnya dilakukan pembobotan kata, lalu kategorisasi yang terdiri dari kalkulasi cosine similarity. Preprocessing sendiri terdiri dari beberapa tahapan, yakni pembersihan dokumen, tokenizing, stopword removal, serta stemming. Metode pembobotan kata yang dipergunakan dalam skripsi ini ialah Term Frequency–Inverse Document Frequency (TF-IDF) & memakai K-Nearest Neighbor (K-NN) untuk metode klasifikasinya. Metode KNN merupakan klasifikasi terhadap sekumpulan data berdasarkan pembelajaran data yang sudah terklasifikasikan sebelumya. Pengujian akurasi dari klasifikasi tweets pada Twitter dengan memakai metode K-Nearest Neighbor (K-NN) menghasilkan akurasi dimana total data berjumlah 140, dengan uraian 100 data latih & 40 data uji serta angka k yang dimasukkan ialah 1, 3, 5, serta 7, masing-masing hasilnya k = 1, akurasi sebesar 75,0%; k = 3, ketepatan 72,5%; k = 5, ketepatan 62,5%; k = 7, ketepatan 55,0%.
Kata kunci:K-Nearest Neighbor (K-NN), Text Mining, Preprocessing
Abstract
Twitter is a microblog that is currently favored by many people and has turned out to be a very fast spreader of information at this time. Information released and circulates through this media is very free and has many variations, like news, opinions, questions, criticisms, comments either positive or negative. Classification is a rule in text mining that collects content based on the similarity of the script. With this classification allows a tweets on Twitter to be grouped into one based on the category. For example, football, basketball and chess content are grouped into sports categories. Prosedure of classification begins using preprocessing, then term weighting is done, then categorization consists of cosine similarity calculations. Preprocessing itself consists of several phases, that is document cleaning, tokenizing, stopword removal, and stemming. The word weighting method used in this thesis is Term Frequency - Inverse Document Frequency (TF-IDF) & using K-Nearest Neighbor (K-NN) for its classification method. The KNN method is a classification of a set of data based on data learning that has been previously classified. Accuracy testing of the classification of tweets on Twitter with step of K-Nearest Neighbor (K-NN) theorem resulted in accuracy where the total data amounted to 140, with descriptions of 100 training data and 40 testing data and the values of k entered were 1, 3, 5, and 7, each the result is when k = 1, the accuration is 75.0%; k = 3, accuration is 72.5%; k = 5, accuration is 62.5%; k = 7, accuration is 55.0%.
Keywords:K-Nearest Neighbor (K-NN), Text Mining, Preprocessing
1. PENDAHULUAN
Salah satu diantara jejaring sosial berbentuk
microblog yang sekarang sedang digemari khalayak luas ialah Twitter, yang mana membolehkan pemakainya berkirim serta menyimak pesan pendek, dinamakan tweets.
Tweets sanggup dibaca bebas, tetapi juga bisa diatur hanya sanggup diamati pemakai lain yang mengikuti Twitter-nya, dapat dikatakan follower. Twitter berperan sebagai media penyebar informasi yang amat cepat sejalan meningkatnya pemakai Twitter. Info yang didapatkan serta bersirkulasi lewat media ini amat bebas serta banyak ragam layaknya berita, pendapat, pertanyaan, perkataan, kritikan apakah yang bernilai positif ataupun negatif. Kita boleh menyaksikan bagaimana opini orang lain pada semacam kasus melewati analisis sentimen, hingga sanggup membantu kita ketika memilih suatu pertimbangan dengan lebih cepat & tepat (Putri, 2013). Kala pemakai hendak membaca buletin atau liputan yang tersedia pada pelataran (home) Twitter, mereka menjumpai kendala, yakni tak tersedianya kategorisasi tweets. Tweets di home seluruhnya berbaur, alhasil pemakai yang hendak menyimak tweets definit jadi kepelikan mendapatinya.
Klasifikasi ialah kaidah di teks mining yang menghimpunkan muatan mengacu pada kesamaan skripnya. Lewat kaidah ini membolehkan tweets yang tersaji di Twitter diguguskan jadi satu bersandarkan jenisnya, misalkan, substansi sepakbola, voli, serta tenis diguguskan ke dalam kategori olahraga. Dengan mempraktikkan mekanisme klasifikasi kepada tweets di Twitter sanggup menolong pemakai menyimak sebuah buletin atau laporan kian gampang, dikarenakan buletin dan liputan yang berada di Twitter diguguskan berlandaskan kategorinya (Sriram et al., 2010).
Kaidah yang digunakan untuk klasifikasi adalah K-Nearest Neighbour (KNN). KNN yaitu salah satu kaidah machine learning yang melaksanakan klasifikasi kepada objek mengacu pada data pembelajaran yang jaraknya terdekat dengan objek yang dimaksud.
Tujuan dari observasi ini dialokasikan jadi dua bagian, yakni tujuan umum serta tujuan spesifik. Tujuan umumnya adalah memaksimalkan kaidah klasifikasi tweets di Twitter memakai metode K-Nearest Neighbour.
Sedangkan tujuan khususnya
mengklasifikasikan tweets pada Twitter dengan menggunakan metode KNN. Berdasarkan kajian yang dilakukan penulis dengan melihat permasalahan yang dilakukan peneliti lainnya pada penelitian klasifikasi twitter, maka penulis tertarik untuk melakukan penelitian klasifikasi tweets di Twitter dengan menggunakan metode K-Nearest Neighbour. Implementasi dari sistem ini adalah dengan menggunakan bahasa
pemrograman Java.
2. DASAR TEORI 2.1 Klasifikasi
Klasifikasi teks yakni prosedur text mining yang bermaksud guna membubuhkan teks kepada kelas yang sinkron dengan ciri khusus dari teks itu seraya memakai kaidah-kaidah definit. Melalui tersedianya klasifikasi teks, sanggup mempersembahkan gambaran secara terkonsep berkenaan dengan tahap penggolongan arsip yang menyandang kontribusi krusial kepada kehidupan sebenarnya (Sriram et al., 2010).
Algoritma klasifikasi yang banyak digunakan yaitu Naïve Bayes, Artificial Neural Networks (ANN), Support Vector Machine (SVM), Algoritma Genetika, K-Nearest Neighbour, dan Fuzzy C-means.
2.2 Twitter
Twitter ialah satu diantara banyak jejaring sosial yang membolehkan pemakainya bertukar kabar, dinamakan kicauan (tweets) berjumlah 280 karakter. Tweets yang tampak pada linimasa (timeline) tiap pemakai Twitter tak bakal sama, disebabkan per pemakai Twitter boleh memutuskan pemakai yang diikutinya. Tweets yang keluar hanyalah tweets bersumber dari pemakai yang diikutinya (Perdana, 2013). Fiturnya antara lain:
1. Followers & following
Followers (pengikut) ialah akun/orang yang mengikuti akun lainnya, following (mengikuti) ialah akun/orang yang diikuti akun lain.
2. Direct Message
Twitter memperbolehkan mengirim pesan personal ke pengguna yang mengikuti akun tersebut.
2.3 Text Preprocessing
Prosedur text preprocessing bermaksud menyediakan teks jadi data yang hendak diolah pada proses kemudian. Didapati beberapa step pada prosedur ini, yakni tokenizing, filtering, stemming, serta term weighting.
2.3.1. Tokenizing
Tokenizing ialah tahapan pemenggalan string input bersandarkan setiap kata yang menyusunnya (Sulhan, 2014). Tiap-tiap huruf input akan dikonversi jadi huruf kecil. Seluruh tanda baca serta tanda hubung dihilangkan, juga
semua karakter.
2.3.2. Filtering
Filtering merupakan tahapan memperoleh kata-kata pokok dari produk token (Sulhan, 2014). Dalam tahapan ini ditetapkan sebutan yang mewakili isi dokumen tersebut yang kemudian layak dipergunakan untuk menjelaskan maksud dokumen tersebut dan memisahkan dengan dokumen lainnya dalam koleksi. Pada tahapan ini pula dikerjakan penghilangan kosakata yang tidak bermanfaat atau dikenal dengan istilah stoplist atau istilah lainnya lagi stopword, yaitu daftar kata yang kerap dipakai, tetapi bukan mendeskripsikan konten dokumen, seperti kata ”yang”, “dan”, “di”, “dari” dan yang lainnya.
2.3.3. Stemming
Stemming ialah fase mencari dasar kata yang berasal dari langkah sebelumnya, yakni filtering. Di fase stemming ini apabila memakai bahasa Inggris, yang dilaksanakan yakni operasi pembuangan suffix, namun pada bahasa Indonesia mekanisme stemming yang dihilangkan mencakup prefix, suffix, konfix serta infix (Asian, 2007).
2.3.4. Weighting
Step keempat pada text preprocessing ialah term weighting, yakni sebuah klasifikasi dokumen memakai metode TF-IDF (Frekuensi Term-Frekuensi Dokumen Invers).
TF-IDF yakni kaidah pembobotan lazim, dipergunakan bertujuan mengilustrasikan sebuah dokumen pada model ruang vektor (vector space model). Di klasifikasi teks, ada dua kaidah pembelajaran mesin (machine learning) dimana kerap digunakan dengan metode TF-IDF, yakni k-NN serta SVM.
Term Frequency (TF) adalah faktor yang menentukan bobot term pada suatu dokumen berdasarkan jumlah kemunculannya dalam dokumen tersebut. Inverse Document Frequency (IDF) dilaksanakan guna mereduksi dominasi kata yang kerap keluar pada kumpulan dokumen. Persamaan TF-IDF yaitu:
w(t, d) tf(t, d) idf (1) 𝑖𝑑𝑓 = 𝑙𝑜𝑔 (𝑁
𝑑𝑓) (2)
Keterangan:
tf(t, d) : intensitas keluarnya term t di dokumen d
N : jumlah total dokumen latih
df : banyaknya dokumen yang mengandung
term t.
2.4. K-Nearest Neighbour
K-Nearest Neighbor (KNN) ialah salah satu metode amat sederhana guna memecahkan masalah klasifikasi (Adeniyi, Wei, & Yongquan, 2016). Algoritma ini kerap dipakai untuk klasifikasi teks & data (Samuel, Delima, & Rachmat, 2014). Pada metode ini dilaksanakan klasifikasi terhadap obyek berlandaskan data yang jaraknya terdekat dengan obyek tersebut (Hardiyanto & Rahutomo, 2016). Jarak antara dua titik x1 dan x2 didefinisikan sebagai berikut.
𝑑(𝑥1, 𝑥2) = √(𝑥11− 𝑥21)2+ ⋯ + (𝑥1𝑝− 𝑥2𝑝) 2
= √∑𝑝 (𝑥1𝑗− 𝑥2𝑗)2
𝑗=1 (3)
Keterangan:
d(x1,x2) : jarak antara variabel x1 dan x2
x : variabel
p : jumlah dimensi variabel
2.4.1. Cosine Similarity
Metode Cosine Similarity ialah metode untuk mengkalkulasi kesamaan antara dua dokumen. Penetapan kecocokan dokumen dengan query dilihat sebagai pengukuran (similarity measure) antara vector dokumen (D) dengan vector query (Q). Kian sama suatu vector dokumen dengan vector query, dokumen bisa dilihat kian cocok dengan query (Putri, 2013). Rumusnya adalah:
𝑐𝑜𝑠𝑆𝑖𝑚(𝑋, 𝑑𝑗) = ∑ 𝑥𝑖.𝑑𝑗𝑖 𝑚 𝑖=1 √(∑𝑚𝑖=1𝑥𝑖) 2 .√(∑𝑚𝑖=1𝑑𝑗𝑖) 2 (4) Keterangan: X : dokumen uji dj : dokumen training
xi dan dji: nilai bobot yang diberikan pada setiap
term pada dokumen.
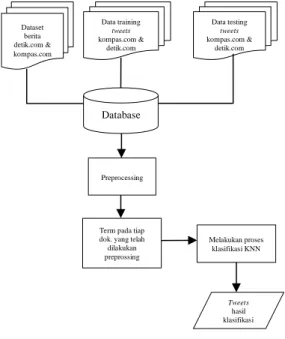
3. METODOLOGI
Mulai
Data latih 200 tweet berlabel, data uji 50 tweet
tak berlabel Selesai Preprocessing Pembobotan TF-IDF Menghitung kesamaan cosin Klasifikasi menggunakan metode KNN
Gambar 1. Diagram alir K-NN
4. PERANCANGAN 4.1. Diagram Sistem
Gambar 2. Deskripsi Umum Sistem
4.2. K-Nearest Neighbour
K-Nearest Neighbor (KNN) ialah salah satu metode amat sederhana guna memecahkan masalah klasifikasi (Adeniyi, Wei, & Yongquan, 2016). Pada metode ini dilakukan pengelompokan terhadap obyek berdasarkan data, dimana jaraknya terdekat dengan obyek yang dimaksud (Hardiyanto & Rahutomo, 2016).
Prosedur menggolongkan dokumen uji X dengan algoritme K-Nearest Neighbor ialah:
1. Menetapkan parameter k (jumlah tetangga terdekat)
2. Mengkalkulasi kuadrat jarak euclidean objek kepada data training yang disuguhkan 3. Mengurutkan hasil no. 2 secara ascending
(berurutan mulai nilai besar ke kecil)
4. Menggabungkan kategori Y (Klasifikasi nearest neighbor berlandaskan tetapan k)
Gambar 3. Proses Metode K-Nearest Neighbour
5. IMPLEMENTASI
5.1. BATASAN IMPLEMENTASI
Di fase ini diterangkan tentang batasan terkait dengan cara bekerjanya sebuah sistem yang mengacu pada perancangan yang sudah dibahas di bagian terdahulu. Makna daripada batasan ini supaya sistem yang dikembangkan sejalan dan tak menyimpang dari maksud utamanya. Batasan yang dimaksud meliputi:
1. Penggunaan Metode K-Nearest Neighbour dalam klasifikasi Tweets pada Twitter, dirancang & dijalankan dengan aplikasi berbahasa JAVA.
2. Metodologi pengerjaan permasalahan yang dipakai ialah K-Nearest Neighbour.
3. Data yang dipergunakan selaku data training & data testing adalah cuitan (tweets) yang diambil sumbernya dalam akun resmi portal kompas & detik.
4. Output yang ditunjukkan adalah produk klasifikasi yang ada dalam kategori teknologi, kesehatan, ekonomi, olahraga, serta otomotif. Dataset berita detik.com & kompas.com Data training tweets kompas.com & detik.com Data testing tweets kompas.com & detik.com Database Preprocessing Melakukan proses klasifikasi KNN Tweets hasil klasifikasi Term pada tiap
dok. yang telah dilakukan preprossing Klasifikasi KNN Mulai Selesai Nilai k (jumlah tetangga terdekat)
Mengurutkan hasil cosine
similarity secara ascending
Menetapkan kelompok dokumen
testing X berlandaskan produk
kalkulasi. Dokumen X digolongkan kepada kategori yang mepunyai nilai
5.2. IMPLEMENTASI ANTARMUKA
Antarmuka (Interface) program bertujuan agar user dan sistem dapat berinteraksi langsung. Interface yang dapat ditampilkan antara lain preprocessing, penghitungan kemunculan jumlah term, pembobotan, dan proses klasifikasi.
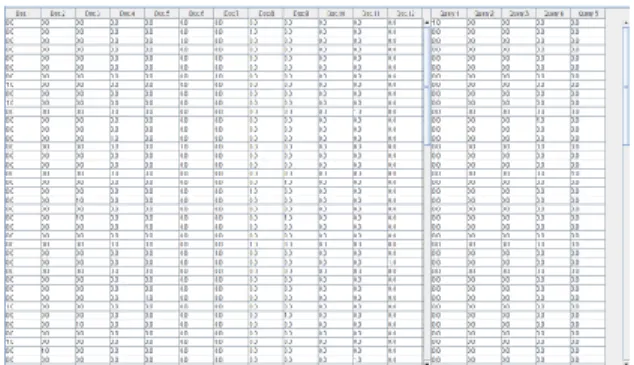
Halaman ini menampilkan data training serta data testing yang dipergunakan pada pengujian. Implementasinya yaitu ditunjukkan di Gambar 4.
Gambar 4. Antarmuka Data training & testing Laman ini menyajikan perhitungan proses Tf-Idf dan input besaran data training, data testing, beserta tetapan k. Implementasinya yakni disajikan di Gambar 5.
Gambar 5. Gambaran Input
Halaman ini menyajikan model ruang vektor output preprocessing & kalkulasi Frekuensi Term (dilambangkan TFi), Frekuensi Dokumen
(dilambangkan DFi), Frekuensi Dokumen Invers
(disingkat IDF) yang dipakai pada tahap pembobotan TF-IDF. Implementasinya disajikan di Gambar 6.
Gambar 6. Tampilan frekuensi term Laman ini menunjukkan model ruang vektor produk kalkulasi pembobotan TF-IDF. Implementasinya disajikan di Gambar 7.
Gambar 7. Tampilan Kalkulasi TF.IDF Berikutnya adalah tampilan vector space model sebagai konsekuensi dari hitungan cosine similarity yang dihitung yang mengacu pada data testing dan data training yang berasal dari pembobotan TF.IDF yang selanjutnya menetapkan besaran dari variabel k. Implementasinya ditunjukkan pada Gambar 8.
Gambar 8. Tampilan Cosine Similarity Halaman di bawah ini menampilkan hasil klasifikasi. Implementasinya ditunjukkan pada Gambar 9.
Gambar 9. Tampilan hasil klasifikasi Tingkat keakuratan dari kalkulasi K-Nearest Neighbor yang dihasilkan. Implementasinya ditunjukkan pada Gambar 10.
Gambar 10. Tampilan akurasi
6. PENGUJIAN DAN ANALISIS 6.1. PENGUJIAN METODE K-NN 6.1.1 PENGUJIAN DENGAN 50 DATA
LATIH
Untuk mengetahui keakuratan dari metode ini, maka dilakukan skenario pengujian dengan mengambil total data ada 65, dengan rincian data uji yang dipakai sejumlah 15 data untuk keseluruhan kategori, dengan data random. Sedangkan untuk data latih yang dipakai sejumlah 10 data dari setiap kategori, atau 50 data untuk keseluruhan kategori. Lalu tetapan k yang dimasukkan yaitu 1,3, 5, dan 7.
K = 1, Presentase 93,3%, Dokumen benar terklasifikasi ada 14
K = 3, Presentase 86,7%, Dokumen benar terklasifikasi ada 13
K = 5, Presentase 66,7%, Dokumen benar terklasifikasi ada 10
K = 7, Presentase 53,3%, Dokumen benar terklasifikasi ada 8
Gambar 11. Grafik produk pengujian dengan total 50 data training
6.1.2. PENGUJIAN DENGAN 75 DATA LATIH
Pengujian selanjutnya memakai total data berbeda, yakni total datanya 100, dengan uraian 75 data latih, 15 data untuk tiap kategori, dan 25 data uji . Selanjutnya nilai k yang dimasukkan yakni 1, 3, 5, dan 7.
K = 1, Presentase 80,0 %, Dokumen benar terklasifikasi ada 20
K = 3, Presentase 76,0%, Dokumen benar terklasifikasi ada 19
K = 5, Presentase 60,0%, Dokumen benar terklasifikasi ada 15
K = 7, Presentase 60,0%, Dokumen benar terklasifikasi ada 15
Gambar 12. Grafik produk pengujian dengan jumlah 75 data latih
6.1.3. PENGUJIAN MEMAKAI 100 DATA LATIH
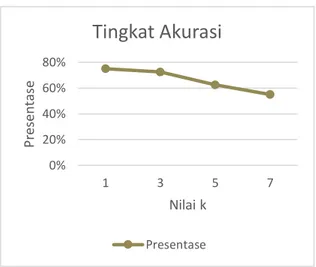
Data yang digunakan dalam pengujian berikutnya jumlahnya lebih banyak, yakni total data 140, dengan uraian 100 data training & 40 data testing. Berikutnya, nilai k dimasukkan 1, 3, 5, serta 7. 0,00% 20,00% 40,00% 60,00% 80,00% 100,00% 1 3 5 7 Pr es en tas e Nilai k
Tingkat Akurasi
0,00% 20,00% 40,00% 60,00% 80,00% 100,00% 1 3 5 7Tingkat Akurasi
Nilai kK = 1, Presentase 75,0%, Dokumen benar terklasifikasi ada 30
K = 3, Presentase 72,5%, Dokumen benar terklasifikasi ada 29
K = 5, Presentase 62,5%, Dokumen benar terklasifikasi ada 25
K = 7, Presentase 55,0%, Dokumen benar terklasifikasi ada 22
Gambar 13. Grafik hasil pengujian dengan data latih sebanyak 100
Analisis pengujiannya sebagai berikut. Keakuratan hasil uji penggunaan metode K-Nearest Neighbour (K-NN), menunjukkan bahwasannya keakuratan menurun dibarengi bersama semakin besarnya nilai k dan bertambahnya jumlah data. Seperti percobaan pertama dengan total data sebanyak 65, dimana jumlah data latih sebesar 50 data serta data uji sebesar 15 data. Dari pengujian tersebut menunjukkan tingkat akurasi ketika nilai k = 1 lebih besar dibandingkan dengan nilai k = 3 dan nilai k yang lebih besar lainnya. Hal ini membuktikan bahwasannya nilai k memiliki pengaruh terhadap prosedur klasifikasi memakai metode K-Nearest Neighbour (K-NN), lantaran bisa disebabkan oleh penyebaran data yang berbeda dan dalam hal tertentu kelas asli mendominasi nilai k atau bahkan kebalikannya.
7. PENUTUP 7.1. KESIMPULAN
Kesimpulan atas penggunaan kaidah K-Nearest Neighbour (K-NN) memakai pembobotan TF-IDF untuk menguji dan menganalisis klasifikasi tweets pada Twitter dapat disajikan sebagai berikut:
1. Penerapan metode K-NN pada tweets
pengguna Twitter yakni dengan memasukkan tweets tersebut pada dokumen uji, lalu selanjutnya dibandingkan dengan data yang ada pada dokumen latih. Kemudian akan diketahui hasil klasifikasi dari tweets tersebut. 2. Cara memaksimalkan klasifikasi memakai
metode K-NN yaitu menginputkan k values dengan nilai yang tidak terlalu besar, karena bila tetapan k bertambah besar, jumlah dokumen terklasifikasi benar ikut berkurang. 3. Semakin kecil penggunaan nilai k, maka
semakin akurat penggunaan metode K-NN. Begitu pula sebaliknya, jika penggunaan nilai k bertambah besar, maka tingkat akurasi yang dihasilkan akan cenderung menurun.
7.2. SARAN
Saran yang sanggup ditambahkan guna pengembangan observasi mendatang, diantaranya yakni:
1. Diperlukan pengujian klasifikasi menggunakan algoritme klasifikasi lain atau modifikasi, seperti kaidah Modified K-Nearest Neighbour (MK-NN), Fuzzy C-Means, Naive Bayes, atau metode lain untuk mengetahui metode mana yang memiliki akurasi lebih baik.
2. Direkomendasikan perlunya penelitian lanjutan dalam rangka menghasilkan klasifikasi yang semakin presisi dengan penggunaan algoritme stemming yang semakin sempurna, karena text preprocessing yang diterapkan dalam penelitian ini dirasakan masih belum optimal, misalnya proses stemming belum cukup efektif menghilangkan awalan & akhiran pada dokumen.
DAFTAR PUSTAKA
Adeniyi, D., Wei, Y., & Yongquan, Y. 2016. Automated web usage data mining and recommendation system using. Applied Computing and Informatics, 12, 90– 108.
Asian, J. 2007. Effective Techniques for Indonesian Text Retrieval. S3. School of Computer Science and Information Technology, Science, Engineering, and Technology Portfolio, RMIT
University, Melbourne, Victoria, Australia.
Hardiyanto, E., & Rahutomo, F. 2016. Studi
0% 20% 40% 60% 80% 1 3 5 7 Pr es en tas e Nilai k
Tingkat Akurasi
PresentaseAwal Klasifikasi Artikel Wikipedia Bahasa Indonesia Dengan
Menggunakan Metoda K-Nearest Neighbor. Seminar Nasional Terapan Riset Inovatif Semarang. Semarang. Nurjanah, W. Perdana, S. Dan Fauzi, M. 2017.
Analisis Sentimen Terhadap Tayangan televisi Berdasarkan Opini Masyarakat pada Media Sosial Twitter
menggunakan Metode K-Nearest Neighbor dan Pembobotan Jumlah Retweet. Fakultas Ilmu Komputer. Universitas Brawijaya Malang. Perdana, R.S. 2013. Pengkategorian Pesan
Singkat Berbahasa Indonesia Pada Jejaring Sosial Twitter Dengan Metode Klasifikasi Naïve Bayes. S1. Program Teknologi Informasi dan Ilmu Komputer, Universitas Brawijaya. Phuvipadawat, S. and Murata, T. 2010.
Breaking News Detection and Tracking in Twitter. In: Proceedings of the 2010 IEEE/WIC/ACM International
Conference on Web Intelligence and Intelligent Agent Technology. 31 Agustus – 3 September 2010. Washington DC: IEEE Computer Society.
Putri, P.A., 2013. Implementasi Metode Improved K-Nearest Neighbor pada Analisis Sentimen Twitter Berbahasa Indonesia. S1. Program Teknologi Informasi dan Ilmu Komputer, Universitas Brawijaya.
Samuel, Y., Delima, R., & Rachmat, A. 2014. Implementasi Metode K-Nearest Neighbor dengan Decision Rule untuk Klasifikasi Subtopik Berita. 10, hal. 1-15.
Sriram, B., Fuhry, D., Demir, E.,
Ferhatosmanoglu, H., dan Demirbas, M., 2010. Short Text Classification in Twitter to Improve Information Filtering. In: Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval. Geneva, Switzerland, 19 – 23 July 2010. New York: Association for Computing Machinery.
Sulhan, Moh. 2014. Metode Stemming Sebagai Preprocessing Pada Filter Kata Porno Melalui Aspek Pendidikan. Yogyakarta: