PENERAPAN METODE SODA
(SIMPLE OBJECT DATABASE ACCESS)
PADA APLIKASI BERBASIS WEB
DENGAN MULTIPLE DBMS
(STUDI KASUS DATABASE WEB FAABULA PT TELKOM)
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana Program Strata Satu Jurusan Teknik Informatika
Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia
ARIFANI HELGA
10108974
JURUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS KOMPUTER INDONESIA
BANDUNG
i
PENERAPAN METODE SODA (SIMPLE OBJECT DATABASE ACCESS) PADA APLIKASI BERBASIS WEB DENGAN MULTIPLE DBMS
(STUDI KASUS DATABASE WEB FAABULA PT TELKOM) Oleh
Arifani Helga 10108974
Setiap perusahaan yang menggunakan database yang berbeda-beda memiliki kebutuhan yang sama dalam pengambilan informasi dari data yang ada di database yang berbeda-beda. Salah satu permasalahan yang muncul adalah proses penggabungan data dari banyak sistem yang masing-masing menggunakan Database Management System (DBMS) yang berbeda-beda. Simple Object Database Access (SODA) adalah metode yang dapat diterapkan pada suatu objek yang digunakan untuk berkomunikasi dengan satu atau lebih DBMS.
Berdasarkan permasalahan tersebut di atas, maka diperlukan suatu perangkat lunak berbasis web yang menggunakan metode SODA untuk mengatasi permasalahan dalam melakukan penggabungan data dari database dengan DBMS yang berbeda. Aplikasi berbasis web yang dibangun menggunakan bahasa pemrograman PHP. Dengan satu perintah SQL query aplikasi dapat melakukan penggabungan data antar DBMS yang berbeda dengan menjalankan fungsi operation set (union,minus,intersect).
Berdasarkan hasil penelitian, dapat disimpulkan bahwa perangkat lunak yang dibangun yang dapat membantu pengguna dalam melakukan penggabungan data antar database dengan DBMS yang berbeda dan memudahkan developer atau programmer dalam mengembangkan aplikasi web dengan single or multiple DBMS.
ii
ABSTRACT
SODA (SIMPLE OBJECT DATABASE ACCESS)
METHOD IMPLEMENTATION
ON WEB BASED APPLICATION USING MULTIPLE DBMS
(CASE STUDIES ON PT TELKOM’S WEB FAABULA DATABASE)
By
Arifani Helga
10108974
Every company that uses a different database have the similar needs in the retrieval of information from data contained in different databases. One issue that comes up is the process of merging data from many systems, each system using different Database Management System (DBMS). Simple Object Database Access (SODA) is a method that can be applied to an object that is used to communicate with one or more DBMS.
Based on the above issues, we need a web-based software that uses the SODA method to solve problems in merging data from the database with the different DBMS. Web-based applications are built using the PHP programming language. By using a single SQL query command, the application can merge data between different DBMS to perform the set operation functions (union, minus, intersect).
Based on the research, it can be concluded that the software can help the user to merging data between databases with different DBMS and facilitate developers or programmers to develop web applications with single or multiple DBMS.
iv
Puji dan syukur senantiasa penulis panjatkan kepada Allah SWT yang telah
melimpahkan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan
skripsi dengan judul “Penerapan Metode SODA (Simple Object Database Access)
pada Aplikasi Berbasis Web dengan Multiple DBMS (studi kasus database web
Faabula PT Telkom)” ini. Skripsi ini dibuat sebagai salah satu persyaratan untuk
memperoleh gelar Sarjana Program Strata Satu (S1) pada jurusan Teknik
Informatika Fakultas Teknik dan Ilmu Komputer Universitas Komputer
Indonesia. Dengan segenap motivasi, kesabaran, kerja keras, dukungan, dan doa,
penulis berhasil menjalani tahap demi tahap dalam kehidupan akademik penulis di
jurusan Teknik Informatika Universitas Komputer Indonesia.
Di dalam penyusunan skripsi ini tidak lepas dari berbagai kesulitan dan
rintangan yang dialami oleh penulis, namun berbagai pihak telah banyak
membantu penulis dalam penyelesaian skripsi ini. Pada kesempatan ini, dengan
segala kerendahan hati penulis mengucapkan terima kasih yang sebesar-besarnya
kepada semua pihak yang telah membantu penulis, terutama kepada:
1. Ibu Mira Kania Sabariah, S.T., M.T. ketua jurusan Teknik
Informatika Universitas Komputer Indonesia, yang telah berkenan
membimbing saya dalam penulisan skripsi ini. Terimakasih atas
segala arahan, kritik, saran, petunjuk, dan bimbingan selama ini.
2. Bapak Andri Heryandi, S.T., M.T. selaku dosen wali sekaligus
v
penguji dalam sidang skripsi ini. Terimakasih atas masukan dan
saran untuk perbaikan skripsi ini.
3. Segenap tim sekretariat jurusan Teknik Informatika Universitas
Komputer Indonesia. Terimakasih kepada mas Hendar, mbak Shanti,
dan mbak Hani atas kesabaran, pelayanan dan bantuannya selama ini
kepada kami para Mahasiswa khususnya kepada penulis.
4. Segenap dosen jurusan Teknik Informatika Universitas Komputer
Indonesia. Terimakasih banyak atas segala ilmu dan pengalaman
yang telah diberikan kepada kami sebagai modal dalam menjalani
kehidupan ini.
5. Ibu Endang Kristyawati ibu yang sangat saya sayangi, yang telah
membesarkan dan mendidik saya. Saya mutlak berterima kasih dan
sekaligus meminta maaf kepada beliau karena hanya dengan
dukungan beliau, saya dapat melanjutkan pendidikan saya hingga
perguruan tinggi. Kepada adik-adik saya: Gilang Bayu Sukma dan
Sike Ferensia terimakasih atas dukungannya.
6. Shinta Taufani Novitasari, S.Sos istri yang sangat saya sayangi, yang
tak kenal lelah dan setia mendukung, mendoakan dan menyayangi
saya. Juga kepada bapak Drs. H. Maman Rohmana dan ibu Hj. Euis
Aisyah, S.Pd., M.M.Pd, teh Ega, bebe, a Dodi, dan iyank atas doa
dan dukungannya selama ini.
7. Teman-teman di kantor, mbak ui, mas Dharma, Shandy, Faris, Anis,
Arif, Randi, bapak Armansyah, dan rekan-rekan di FBCC
vi
yang lain yang tidak dapat dituliskan satu persatu disini.
Terimakasih atas kebersamaan yang tak terlupakan selama ini.
Dan kepada semua pihak lainnya yang tidak dapat disebutkan satu persatu
yang telah memberikan dukungan dan bantuan dalam hal moril maupun materi
sehingga penulis dapat menyelesaikan skripsi ini.
Semoga apa yang ada di dalam skripsi ini dapat bermanfaat bagi semua
pihak yang telah membaca skripsi ini.
Bandung, Agustus 2011
1
BAB I
PENDAHULUAN
1.1 Latar belakang masalah
Setiap perusahaan ataupun institusi yang menggunakan database yang
berbeda-beda secara bersamaan, akan dihadapkan pada permasalahan yang
beragam. Secara umum, setiap perusahaan memiliki kebutuhan yang sama dalam
pengambilan informasi dari data yang ada di dalam database yang berbeda-beda.
Salah satu permasalahan yang muncul adalah masalah penggabungan data dari
banyak sistem yang masing-masing menggunakan Database Management System
(DBMS) yang berbeda-beda. Untuk mendapatkan data dari database dari aplikasi
yang berbasis web, cara akses ke database harus didefinisikan dalam web
tersebut. Cara akses ke database berbeda-beda jika menggunakan DBMS yang
berbeda. Sehingga dalam satu aplikasi web harus menggunakan lebih dari satu
cara akses ke dalam database. Data dari database yang akan digabungkan harus
memiliki arti atau maksud yang sama, akan tetapi tidak semua data mempunyai
format data yang sama. Kendala inilah yang menimbulkan permasalahan dalam
mengolah data yang akan digabungkan ke dalam format data yang sama.
Berdasarkan observasi, salah satu perusahaan yang mempunyai
permasalahan tersebut adalah PT Telekomunikasi Indonesia, Tbk (Telkom).
Telkom memiliki arsitektur database yang tersebar di masing-masing regional.
Banyak aplikasi yang digunakan untuk mendukung operasional dalam mengelola
data pelanggan Telkom. Telkom menggunakan banyak database dengan DBMS
strategis dalam pengelolaan pelanggan, manajemen Telkom memerlukan data
yang lengkap dan dapat diakses dari aplikasi web di lingkungan kerja Telkom.
Pada dasarnya hal inilah yang menimbulkan permasalahan di Telkom, yaitu dalam
mengkaji dan memanfaatkan banyaknya data dalam sistem tersebut dengan
melakukan penggabungan data ke dalam sebuah format data yang sama. Karena
dibutuhkan komunikasi di tingkat database melalui aplikasi berbasis web untuk
dapat melakukan penggabungan data.
Simple Object Database Access (SODA) adalah metode yang dapat
diterapkan pada suatu objek yang digunakan untuk berkomunikasi dengan satu
atau lebih DBMS. SODA menyimpan semua cara koneksi dan akses ke dalam
database yang berbeda dalam suatu library tertentu dan membuat satu cara
koneksi dan akses ke dalam semua database. Meskipun cara koneksi ke
masing-masing DBMS berbeda-beda, terdapat kesamaan dalam hal pengambilan data
yaitu dengan menggunakan query yang biasa kita kenal dengan menggunakan
SQL (Structured Query Language) query. Hal inilah yang menjadi dasar metode
SODA dalam melakukan penggabungan data dari bermacam-macam database.
Berdasarkan permasalahan tersebut di atas, maka diperlukan suatu
perangkat lunak berbasis web yang menggunakan metode SODA untuk mengatasi
permasalahan dalam melakukan penggabungan data dari database dengan DBMS
yang berbeda. Dengan adanya sistem menggunakan metode SODA ini,
mempermudah pengguna dalam melihat data atau informasi yang berasal dari
3
1.2 Rumusan masalah
Dari latar belakang masalah yang dijelaskan sebelumnya maka dapat
dirumuskan permasalahan yaitu bagaimana menerapkan SODA (Simple Object
Database Access) pada aplikasi berbasis web dengan multiple DBMS dengan
tujuan untuk mengatasi permasalahan dalam melakukan penggabungan data
dalam lingkungan heterogenous database.
1.3 Maksud dan Tujuan
Maksud dari penelitian ini adalah bagaimana mengatasi permasalahan
Heterogenous Database yang terjadi.
Sedangkan tujuan dari penelitian ini adalah sebagai berikut :
1. Memudahkan pengguna dalam melakukan koneksi dan akses data dari
aplikasi berbasis web ke dalam database dengan DBMS yang berbeda.
2. Membantu pengguna dalam melakukan penggabungan data antar
database dengan DBMS yang berbeda.
3. Memudahkan developer atau programmer dalam mengembangkan
1.4 Batasan Masalah atau Ruang Lingkup Kajian
Untuk dapat mencapai tujuan penelitian ini, ruang lingkup dan batasan
masalah yang ada dalam penelitian ini adalah sebagai berikut :
1. Pengujian dilakukan dengan menggunakan dua buah DBMS, yaitu :
Oracle dan MySQL.
2. Pemrograman pada kelas Simple Object Database Access menggunakan
bahasa pemrograman PHP.
3. Dalam penelitian ini, masing-masing data yang akan digabungkan
berasal dari table, view dan SQL query.
4. Dalam proses penggabungan data, syarat dan prosedur yang akan
dijalankan adalah sebagai berikut :
a. Data yang akan digabungkan berasal dari table, view, dan SQL
query. Sistem mengenali ketiganya dengan SQL query. Sistem
belum dapat menerima SQL query yang terdapat query join antara
table dengan view.
b. Untuk dapat melakukan proses penggabungan data, jumlah field
dan urutan field-nya harus sama antara query satu dengan yang
lainnya, tiap field yang didefinisikan harus memiliki tipe data
yang sama atau sejenis di setiap field.
c. Format SQL query mengikuti aturan produksi yang akan
dijelaskan pada Bab III.
d.Penulisan set operator yang diterima adalah union, unionall,
intersect, dan minus.
5
1.5 Metodologi Penelitian
Metodologi penelitian yang digunakan dalam penulisan skripsi ini adalah :
1. Pengumpulan data
a. Observasi
Merupakan teknik pengumpulan data dengan mengadakan
pengamatan atau penelitian secara langsung dari objek penelitian,
seperti perangkat keras yang ada, pengguna aplikasi, dan
sebagainya.
b. Studi Kepustakaan
Merupakan kegiatan pengumpulan data dengan mempelajari
buku-buku, karya ilmiah, koleksi perpustakaan, dan browsing via internet
yang berkaitan erat dengan materi bahasan dalam penulisan laporan
ini.
c. Wawancara
Merupakan teknik pengumpulan data dengan melakukan
wawancara secara langsung dengan karyawan atau teknisi yang ada
2. Pembangunan perangkat lunak
Tahapan yang akan dilakukan dalam pembangunan perangkat lunak,
akan menggunakan metode waterfall yang terdiri dari System
Requirement, Analysis, Design, Coding, Testing dan Maintenance.
Seperti dalam gambar berikut ini :
Gambar 1.1 Diagram Waterfall
1.6 Sistematika Penulisan
Sistematika penulisan dalam penyusunan skripsi ini adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisi tentang latar belakang masalah, identifikasi masalah, maksud
dan tujuan, batasan masalah, metodologi penelitian, dan sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini menjelaskan mengenai teori apa saja yang digunakan dalam
7
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi analisis dan perancangan yang dilakukan dalam membangun
perangkat lunak dengan menggunakan metode Object Oriented Unified Process
dengan notasi Unified Modelling Language (UML).
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini menjelaskan tentang implementasi hasil dari analisis dan
perancangan sistem ke dalam bentuk bahasa pemrograman. Serta kebutuhan
perangkat keras dan perangkat lunak yang diperlukan dalam membangun sistem.
Bab ini juga berisi tentang pengujian pada sistem yang sudah lengkap dan telah
memenuhi semua persyaratan sistem.
BAB V KESIMPULAN DAN SARAN
Dalam bab ini berisi kesimpulan dari setiap tahapan yang dilalui dalam
8
2.1 DBMS (Database Management System)
DBMS merupakan perangkat lunak yang dirancang untuk dapat melakukan
utilisasi dan mengelola koleksi data dalam jumah yang besar. DBMS juga
dirancang untuk dapat melakukan manipulasi data secara lebih mudah. Sebelum
adanya DBMS maka data pada umumnya disimpan dalam bentuk flat file, yaitu
file teks yang ada pada sistem operasi. Sampai sekarangpun masih ada aplikasi
yang menyimpan data dalam bentuk flat secara langsung. Menyimpan data dalam
bentuk flat file mempunyai kelebihan dan kekurangan. Penyimpanan dalam
bentuk ini akan mempunyai manfaat yang optimal jika ukuran filenya relatif kecil,
seperti file password. File password pada umumnya hanya digunakan untuk
menyimpan nama yang jumlahnya tidak lebih dari seribu orang. Selain dalam
bentuk flat file, penyimpanan data juga dapat dilakukan dengan menggunakan
program bantu seperti spreadsheet. Penggunaan perangkat lunak ini memperbaiki
beberapa kelemahan dari flat file, seperti bertambahnya kecepatan dalam
pengolahan data. Namun demikian metode ini masih memiliki banyak kelemahan,
9
2.1.1 Pengertian DBMS
Berikut ini adalah beberapa pengertian tentang DBMS menurut para ahli di
bidang database.
1. Menurut C.J. Date : DBMS adalah merupakan software yang
menghandel seluruh akses pada database untuk melayani kebutuhan
user.
2. Menurut S, Attre : DBMS adalah software, hardware, firmware dan
prosedur-prosedur yang mengelola database. Firmware adalah
software yang telah menjadi modul yang tertanam pada hardware
(ROM).
3. Menurut Gordon C. Everest : DBMS adalah manajemen yang efektif
untuk mengorganisasi sumber daya data.
Jadi dapat disimpulkan bahwa DBMS adalah semua peralatan komputer
(Hardware, Software, dan Firmware) yang dilengkapi dengan bahasa yang
berorientasi pada data (High level data language) yang sering disebut juga sebagai
bahasa generasi ke-4 (fourth generation language). Peralatan untuk menetapkan
atau menentukan pendekatan database disebut DBMS. DBMS merupakan
software (dan hardware) yang didesain khusus untuk melindungi dan mengelola
database.
2.1.2 Fungsi dan Kegunaan DBMS
DBMS memiliki beberapa fungsi diantaranya sebagai berikut
:
1. Definisi data dan hubungannya
2. Memanipulasi data
4. Recovery atau perbaikan dan concurency data
5. Data dictionary
6. Unjuk kerja atau performance
Kegunaan DBMS antara lain :
1. Mendefinisikan data dan hubungannya.
2. Mendokumentasikan struktur dan definisi data
3. Menggambarkan, mengorganisasikan dan menyimpan data untuk akses
yang selektif dan efisien.
4. Hubungan yang sesuai antara user dengan sumber daya data.
5. Perlindungan terhadap sumber daya data akan terjamin, dapat diandalkan,
konsisten dan benar.
6. Memisahkan masalah logical dan physical sehingga mengubah
implementasi database secara fisik tidak menghendaki user untuk
mengubah maksud data (Logical).
7. Menentukan pembagian data kepada para user untuk mengakses secara
concurent pada sumber daya data.
2.1.3 Keuntungan Dan Kerugian Penggunaan DBMS
Beberapa keuntungan penggunaan DBMS adalah sebagai berikut:
1. Kebebasan data dan akses yang efisien
2. Mereduksi waktu pengembangan aplikasi
3. Integritas dan keamanan data
4. Administrasi keseragaman data
5. Akses bersamaan dan perbaikan dari terjadinya crashes (tabrakan/error
11
6. Mengurangi data redundancy : Data redundansi dapat direduksi atau
dikurangi, tetapi tidak dapat dihilangkan sama sekali (untuk kepentingan
keyfield)
Beberapa kerugian penggunaan DBMS adalah sebagai berikut:
1. Memperoleh perangkat lunak yang mahal (teknologi DBMS, Operation,
Conversion, Planning, Risk). DBMS mainframe masih sangat mahal.
DBMS berbasis mikro biayanya mencapai beberapa ratus dolar, dapat
menggambarkan suatu organisasi yang kecil secara berarti.
2. Memperoleh konfigurasi perangkat keras yang besar. DBMS sering
memerlukan kapasitas penyimpanan primer dan sekunder yang lebih besar
daripada yang diperlukan oleh program aplikasi lain. Juga, kemudahan
yang dibuat oleh DBMS dalam mengambil informasi mendorong lebih
banyak terminal pemakai yang disertakan dalam konfigurasi daripada jika
sebaliknya.
3. Mempekerjakan dan mempertahankan seorang DBA DBMS memerlukan
pengetahuan khusus agar dapat memanfaatkan kemampuan secara penuh.
2.1.4 Macam-macam DBMS
Banyak sekali DBMS yang dikembangkan saat ini untuk mengimbangi
kebutuhan pengguna akan manajemen basis data. Beberapa DBMS yang sering
dipakai oleh pengguna adalah sebagai berikut:
1. Microsoft SQL Server
Microsoft SQL Server adalah program Sistem Manajemen Basis Data
Relasional. Susunan dari Microsoft SQL Server dibagi menjadi tiga
komponen:
a. SQL OS yang melakukan layanan utama pada SQL Server,
misalnya mengatur aktifitas, pengaturan memori, dan
pengaturan Input atau Output;
b. Relational Engine yang bekerja sebagai penghubung komponen
database, table, query, dan perintah tersimpan;
c. Protocol Layer yang mengatur fungsi-fungsi SQL Server.
2. Oracle
Oracle adalah salah satu software sistem manajemen basis data
relasional yang cukup diminati, dikenal, dan dipakai saat ini. Software ini
biasa digunakan untuk pengaksesan data yang dilakukan secara online dan
sangat baik dalam pengelolaan data dalam jumlah record yang sangat besar.
Oracle adalah Relational Database Management System (RDBMS) untuk
mengelola informasi secara terbuka, komprehensif dan terintegrasi. Oracle
merupakan DBMS yang dirancang khusus untuk organisasi berukuran besar,
bukan untuk ukuran kecil dan menengah. Kebutuhan organisasi berukuran
13
akan berkembang menjadi besar. Organisasi yang berukuran besar
membutuhkan fleksibilitas dan skalabilitas agar dapat memenuhi tuntutan
akan data dan informasi yang bervolume besar dan terus menerus bertambah
besar.
3. MySQL
MySQL adalah perangkat lunak sistem manajemen basis data yang
diciptakan untuk dapat dilakukan instalasi secara gratis (open source).
MySQL AB membuat MySQL tersedia sebagai perangkat lunak gratis di
bawah lisensi GNU General Public Licency (GPL), tetapi mereka juga
menjual di bawah lisensi komersial untuk kasus-kasus dimana
penggunaannya tidak cocok dengan penggunaan GPL.
Beberapa contoh DBMS lainnya : Microsoft Visual Fox Pro, dBase, DB2,
Microsoft Office Access, Ingres, Arago, Force, dbFast, dbXL, Quicksilver,
Clipper, Xbase++, Flagship, Codebase, Harbour/Xharbour.
2.2 Data Agregation dan Data Integration
Data Agregation adalah sebuah sistem atau konsep yang digunakan untuk
menghubungkan berbagai macam database atau lebih dari satu database ke dalam satu aplikasi. Perbedaan mendasar dari kedua sistem tersebut adalah data
2.2.1 DataAgregation
Data agregation mengambil konsep dari agregasi, yakni suatu konsep yang
menghubungkan lebih dari satu entitas. Apabila dalam implementasi suatu aplikasi pengambilan data yang berasal dari database dengan lokasi yang berbeda
beda, pengguna aplikasi tidak perlu tahu lokasi fisik data tersebut disimpan. Keuntungan dari Data Agregation adalah :
1. Menghemat tempat penyimpanan data, tidak perlu repository
2. Tidak perlu sinkronisasi, karena akses langsung terhadap data source. 3. Data akan selalu real time
Namun konsep Data Agregation memiliki kelemahan antara lain :
1. Data yang digunakan tidak normal, berbeda-beda tergantung pada
sistem yang ada pada datasource-nya. 2. Mengurangi efektifitas dan kecepatan akses. 3. Sedikit banyaknya akan merubah struktur query.
Agregasi DBMS dapat dilakukan pada level SQL Query, artinya DBMS yang dapat diagregasikan juga terbatas pada DBMS yang sudah mengimplementasikan standar query.
2.2.2 Data Integration
Sampai saat ini, definisi data integration masih abstrak, namun secara garis
besarnya data integration adalah solusi umum untuk menyelesaikan permasalahan heterogenous database. Data integration biasanya diimplementasikan ke dalam suatu aplikasi, konsep data integration umumnya mengambil data dari data
15
repository, karenanya lahirlah konsep data integration. Kemampuan data
integration masih terbatas pada Extract, Transform, Load.
Data Integration System secara formal didefinisikan sebagai tripel [G,S,M],
dimana G adalah global skema. S adalah heterogenous data source, dan M adalah
pemetaan yang memetakan permintaan antara sumber dan skema global. Baik G
dan S dinyatakan dalam bahasa lebih abjad terdiri dari simbol-simbol untuk setiap
hubungan masing-masing. Pemetaan M terdiri dari pernyataan antara G dan
pertanyaan atas pertanyaan di atas S. Sedangkan untuk implementasi data
integration dalam aplikasi ditandai dengan kode ETL. Elemen dari integrasi data
diantaranya adalah sebagai berikut:
- perpindahan data secara realtime
- transformasi atau perubahan bentuk
- sinkronisasi dan kualitas data
- manajemen data dan data services
Kelebihan dari konsep data integration adalah
1. Data yang ditaruh dalam repository sudah diperbaharui dan dinormalisasikan sesuai dengan kebutuhan penggunanya.
2. Akses ke dalam data dapat lebih cepat, karena user langsung
mengakses ke dalam repository. Kekurangannya adalah
1. Data tidak sepenuhnya realtime.
2. Sistem perlu melakukan sinkronisasi dengan data source yang sebenarnya.
3. Karena menggunakan repository maka data integration membutuhkan DBMS temporary
2.3 SODA (Simple Object Database Access)
SODA (Simple Object Database Access) adalah metode yang dapat
digunakan untuk berkomunikasi dengan DBMS. Metode ini bertujuan untuk
menyatukan komponen untuk mengakses lebih dari satu DBMS, membuatnya
lebih sederhana dan lebih terstruktur.
SODA dapat diimplementasikan dalam sebuah class yang nantinya dapat
digunakan dalam beberapa aplikasi berbasis objek, dan dapat dibentuk ke dalam
sebuah prosedur untuk diimplementasikan ke dalam aplikasi berbasis prosedural.
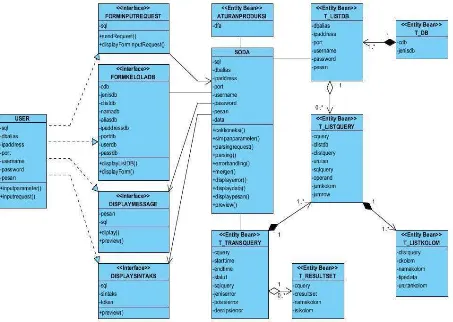
Komponen dasar dari SODA terdiri dari :
1. User Access
2. Event Notifier
17
4. Data Source Map
5. Data Access Library
6. Data Access
7. Event Publisher
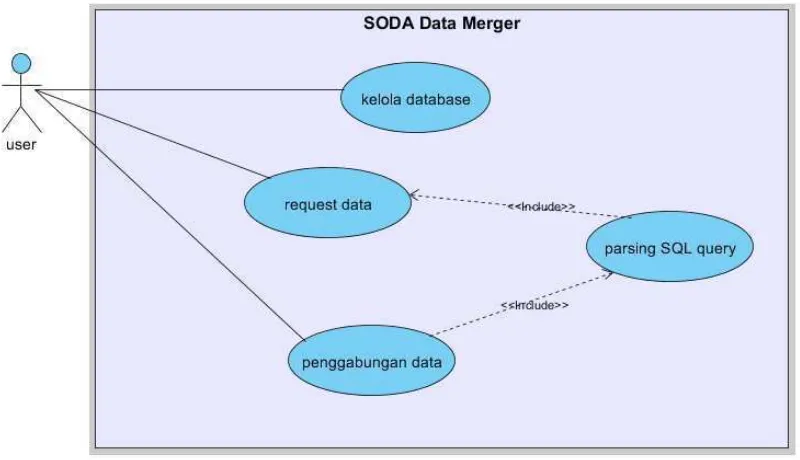
Gambar 2.2 Ilustrasi SODA pada web application dengan multiple DBMS
Komponen-komponen yang mendukung SODA pada gambar di atas
dijelaskan sebagai berikut :
1. User Access
User access adalah komponen bagian depan dari data agregator yang
digunakan untuk membaca dan mengkategorikan masukan. User access juga
berfungsi sebagai keluaran data hasil eksekusi query data agregator dengan user
Komponen ini memiliki format yang telah ditentukan sebelumnya baik
untuk masukan maupun keluaran, tujuan format tersebut adalah agar algoritma
dibelakangnya dapat membaca dan mengkategorikan inputan.
Bentuk masukan pada komponen ini digambarkan sebagai berikut:
Gambar 2.3 Ilustrasi masukan
Alias : jenis alias koneksi ke DBMS yang digunakan
Query : SQL queryselect data dari table atau table-table pada database
Format keluarannya adalah array hasil eksekusi query berupa data yang
didefinisikan dalam SQL query.
Gambar 2.4 Ilustrasi array data hasil keluaran
19
2. Event Notifier
Event notifier adalah komponen bagian depan yang digunakan untuk
merubah format dari format standart input kedalam format yang lebih dikenal oleh
controller sesuai dengan data source map. Komponen ini sangat membantu
memudahkan controller untuk membaca masukan dengan cara memisahkan
komponen masukan ke dalam beberapa bagian.
Ilustrasinya dapat digambarkan sebagai berikut:
Gambar 2.5 Pemecahan format masukan
Alias : jenis alias koneksi database yang digunakan
Query : SQL queryselect data dari table atau view pada database
DB Name : nama database yang diakses
DB Connection : jenis koneksi database yang digunakan
Perubahan format ini dimaksudkan agar komponen controller dapat
menemukan lokasi, jenis koneksi dan nama database yang akan diakses dengan
menggunakan entitas database_name dan menyesuaikannya dengan data source
map sehingga dapat ditentukan data access mana yang akan digunakan pada data
3. Controller
Controller adalah komponen terpenting dalam Simple Object Database
Access, dimaksudkan sebagai sentral dan letak dari implementasi algoritma pada
Simple Object Database Access. Controller bertugas membaca inputan SQL query
setelah di transformasi dan mencari lokasi, jenis dan nama database dalam data
source map berdasarkan entitas aliasnya. Untuk kemudian memutuskan dengan
data access yang mana DBMS tersebut akan diakses.
4. Data Source Map
Data source map adalah komponen yang memetakan bentuk, lokasi dan
jenis database. Data source map memiliki format yang sudah didefinisikan,
sehingga user bisa dengan bebas menambahkan lokasi, jenis DBMS dan nama
database yang akan diakses dengan menambahkan indeks ke dalam
masing-masing source yang ditambahkan.
5. Data Access Library
Data access library adalah komponen yang menyimpan tata cara akses ke
dalam DBMS dengan cara yang sudah didefinisikan sebelumnya. Data access
library dapat ditambahkan sesuai dengan koneksi yang akan diakses sesuai
dengan format yang digunakan oleh controller. Misalnya adalah cara akses ke
mysql, cara akses ke sql-server,cara akses ke oracle.
6. Data Access
Data access adalah komponen yang umum digunakan dalam mengakses
database. Data access secara global disimpan dalam data access library. Di
dalam SODA, data access dikendalikan oleh controller karena jenis DBMS yang
21
7. Event Publisher
Event publisher adalah komponen bagian depan yang digunakan untuk
meneruskan keluaran dari data access kepada user access. Event publisher
memiliki format yang sama dengan keluaran hasil eksekusi query pada user
access. Event publisher dapat juga dimanfaatkan sebagai transformator dari data
access ke dalam sebuah array dengan format keluaran.
2.4 UML (Unified Modelling Language)
UML adalah bahasa untuk spesifikasi, visualisasi, konstruksi dan
dokumentasi pembuatan perangkat lunak yang berorientasi objek. UML
dapat membantu kita untuk :
1. Memudahkan berpikir dan mendokumentasikan sistem sebelum
mengimplementasikannya
2. Merencanakan dan menganalisa logika atau perilaku sistem
3. Membuat keputusan yang benar sedini mungkin (sebelum
melangkah ke tahap coding)
4. Lebih mudah untuk memodifikasi atau mengelola sistem yang
Diagram UML digambarkan dalam tree di bawah ini :
Gambar 2.6 Diagram UML
Dalam gambar 2.6 terdapat banyak macam diagram UML seperti :
1. Use Case (relation of actors to system functions)
2. Class (static class structure)
3. Object (same as class - only using class instances – i.e. objects)
4. State (states of objects in a particular class)
5. Sequence (Object message passing structure)
6. Collaboration (same as sequence but also shows context - i.e.
objects and their relationships)
7. Activity (sequential flow of activities i.e. action states)
8. Component (code structure)
23
2.5 Teori Bahasa dan Otomata
Arti menurut American Heritage Dictionary:
1. a robot
2. one that behaves in an automatic or mechanical fashion
Arti dalam dunia matematika
Berkaitan dengan teori mesin abstrak, yaitu mesin sekuensial yang
menerima input, dan mengeluarkan output, dalam bentuk diskrit.
Contoh :
1. Mesin Jaja / vending machine
2. Kunci kombinasi
3. Parser/compiler
Teori Otomata dan bahasa formal, berkaitan dalam hal :
1. Pembangkitan kalimat / generation : menghasilkan semua kalimat dalam
bahasa L berdasarkan aturan yang dimilikinya
2. Pengenalan kalimat / recognition : menentukan suatu string (kalimat)
2.5.1 Bahasa Formal
Suatu kalimat dibentuk dengan menerapkan serangkaian aturan produksi
pada sebuah simbol ‘akar’. Proses penerapan aturan produksi dapat digambarkan
sebagai suatu diagram pohon.
Teori dasar dari bahasa formal adalah sebagai berikut:
1. Def. 1 : Sebuah string dengan panjang n yang dibentuk dari himpunan A
adalah barisan dari n simbol
Panjang string x dituliskan dengan |x|
2. Def 2 : String kosong (null string), dilambangkan dengan ε adalah untaian
dengan panjang 0 dan tidak berisi apapun. Panjang string x dituliskan
dengan |x|
3. Def 3 : Dua buah string a = a1a2...am dan b = b1b2...bndapat disambungkan
menjadi string c dengan panjang m+n sebagai berikut c = a1a2...am
b1b2...bn. Operasi penyambungan tersebut dapat pula diterapkan pada
himpunan
4. Def 4 : (Closure) . An adalah himpunan string dengan panjang n yang
dibentuk dari simbol-simbol di himpunan simbol/alfabet A: Transitif
Closure atau Kleen Closure adalah himpunan seluruh string yang dapat
25
Jika string kosong dikeluarkan , akan
diperoleh positiveclosure
2.5.2 Tata Bahasa
Aturan yang disebutkan pada proses pengenalan dan pembangkitan kalimat.
Secara formal, tata bahasa terdiri dari 4 komponen yaitu :
1. Himpunan berhingga, tidak kosong dari simbol-simbol non terminal
2. Himpunan berhingga, dari simbol-simbol non-terminal N
3. Simbol awal S ∈ N, yang merupakan salah satu anggota dari himpunan
simbol nonterminal.
4. Himpunan berhingga aturan produksi P yang setiap elemennya dituliskan
dalam bentuk : α → β dimana α dan β adalah string yang dibentuk dari
himpunan dan α harus berisi paling sedikit satu simbol
non-terminal.
Keempat komponen tersebut sering dituliskan sbb : G = (T,N,S,P). Bahasa
yang dihasilkan oleh G ditulis sebagai L(G), yaitu himpunan string yang dapat
diturunkan dari simbol awal S dengan menerapkan aturan-aturan produksi yang
2.5.3 Aturan Produksi
Aturan produksi α→β yang diterapkan pada suatu string w=aαc mengganti
kemunculan α menjadi β, sehingga string tersebut berubah menjadi w=aβc,
sehingga dapat dituliskan aαc ⇒ aβc (aαc memproduksi aβc).
Produksi tersebut dapat diterapkan berkali-kali
atau dapat dituliskan
jika minimal harus ada 1 aturan produksi yang diterapkan :
Contoh 1
Tatabahasa G = {{S} , {a,b}, S , P } dengan aturan produksi P adalah
S → aSb
S →ε
maka dapat dihasilkan suatu string S ⇒ aSb ⇒ aaSbb ⇒aabb
sehingga dapat dituliskan S ⇒* aabb
Bahasa yang dihasilkan dari tatabahasa tersebut adalah
L(G) = { ε , ab, aabb , aaabbb , aaaabbbb, ... }
atau dapat pula dituliskan
27
Contoh 2
Tatabahasa G = {{S,A} , {a,b}, S , P } dengan aturan produksi P adalah
S → Ab
A → aAb
A →ε
maka dapat dihasilkan suatu string
S ⇒ Ab ⇒b
S ⇒ Ab ⇒ aAbb ⇒ abb
S ⇒ Ab ⇒ aAbb ⇒ aaAbbb ⇒ aaAbbb
Bahasa yang dihasilkan dari tatabahasa tersebut adalah
L(G) = { b , abb, aabbb , aaabbbb , aaaabbbbb, ... }
atau dapat pula dituliskan
2.5.4 Finite State Automata (FSA)
Ciri-ciri dari Finite State Automata diantaranya adalah
1. Model matematika yang dapat menerima input dan mengeluarkan output
2. Memiliki state yang berhingga banyaknya dan dapat berpindah dari satu
state ke state lainnya berdasar input dan fungsi transisi
3. Tidak memiliki tempat penyimpanan atau memory, hanya bisa mengingat
state terkini.
4. Mekanisme kerja dapat diaplikasikan pada : elevator, text editor, analisa
leksikal, pengecek parity.
Contoh pengecek parity ganjil
Misal input : 1101
29
diterima mesin
Misal input : 1100
Genap 1 Ganjil 1 Genap 0 Genap 0 Genap
ditolak mesin
Finite State Automata dinyatakan oleh lima tuple
M = (Q , Σ , δ , S , F )
Q = himpunan state
Σ = himpunan simbol input
δ = fungsi transisi δ : Q × Σ
S = state awal / initial state , S ∈ Q
F = state akhir, F ⊆ Q
Pada contoh diatas,
Q = {Genap, Ganjil}
Σ = {0,1}
S = Genap
F = {Ganjil }
atau
δ(Genap,0) = Genap
δ(Genap,1) = Ganjil
δ(Ganjil,0) = Ganjil
2.5.5 Jenis FSA
Deterministic Finite Automata (DFA) : dari suatu state ada tepat satu state
berikutnya untuk setiap simbol masukan yang diterima.
Non-deterministic Finite Automata (NFA) : dari suatu state ada 0, 1 atau
lebih state berikutnya untuk setiap simbol masukan yang diterima.
2.5.5.1 Deterministic Finite Automata
1. Contoh : pengujian parity ganjil.
2. Contoh lain : Pengujian untuk menerima bit string dengan banyaknya 0
genap, serta banyaknya 1 genap.
3. 0011 : diterima.
4. 10010 : ditolak, karena banyaknya 0 ganjil
5. Diagram transisi-nya :
6. DFA nya
Q = {q0 , q1 , q2 , q3 }
Σ = {0,1}
S = q0
31
fungsi transisi
δ( q0,011)= δ( q2,11) =δ( q3,1)= q2 Ditolak
δ( q0,1010)= δ( q1,010) =δ( q3,10)=δ( q2,0)= q0 Diterima
2.5.5.2 Nondeterministic Finite Automata
1. Perbedaan dengan NFA: fungsi transisi dapat memiliki 0 atau lebih fungsi
transisi
2. String diterima NFA bila terdapat suatu urutan transisi berdasar input, dari
state awal ke state akhir.
4. Contoh : string 01001
Dua buah FSA disebut ekuivalen apabila kedua FSA tersebut menerima
bahasa yang sama. Contoh : FSA yang menerima bahasa {an | n≥0 }
Dua buah state dari FSA disebut indistinguishable (tidak dapat dibedakan)
apabila : δ(q,w)∈F sedangkan δ(p,w)∉F dan δ(q,w) ∉F sedangkan δ(p,w) ∈F
untuk semua w ∈Σ*.
Dua buah state dari FSA disebut distinguishable (dapat dibedakan) bila
terdapat w ∈Σ * sedemikian hingga:
δ(q,w)∈F sedangkan δ(p,w)∉F dan
33
Prosedur menentukan pasangan status indistinguishable
1. Hapus semua state yang tak dapat dicapai dari state awal.
2. Catat semua pasangan state (p,q) yang distinguishable, yaitu {(p,q) | p ∈ F
∧ q ∉ F}
3. Untuk setiap pasangan (p,q) sisanya, untuk setiap a∈ Σ, tentukan δ(p,a)
dan δ(q,a)
Contoh :
1. Hapus state yang tidak tercapai -> tidak ada
2. Pasangan distinguishable (q0,q4), (q1,q4), (q2,q4), (q3,q4).
Prosedur Reduksi DFA
1. Tentukan pasangan status indistinguishable.
2. Gabungkan setiap group indistinguishable state ke dalam satu state
dengan relasi pembentukan group secara berantai : Jika p dan q
indistingishable dan jika q dan r indistinguishable maka p dan r
indistinguishable, dan p,q serta r indistinguishable semua berada
dalam satu group.
35
2.6 Notasi BNF (Backus-Naur Form)
Di dalam ilmu komputer, BNF (Backus Normal Form atau Backus-Naur
Form) adalah notasi untuk tata bahasa CFG (Context-free Grammar), yang sering
dipakai untuk mendiskripsikan sintaks tata bahasa yang digunakan, contoh:
bahasa pemrograman, format dokumen, set intruksi, dan protokol komunikasi.
Notasi BNF ini diterapkan dimanapun saat deskripsi dari tata bahasa diperlukan,
misalnya dalam spesifikasi tata bahasa resmi, dalam buku manual, dan di buku
teori bahasa pemrograman.
Banyak ekstensi dan varian dari notasi asli yang digunakan, beberapa yang
pasti didefinisikan termasuk EBNF (Extended Backus-Naur Form) dan ABNF
(Augmented Backus-Naur Form).
Sebuah spesifikasi BNF adalah serangkaian aturan derivasi, ditulis :
Dimana <symbol> adalah sebuah non-terminal, dan __expression__
terdiri dari satu atau lebih barisan simbol. Barisan yang dipisahkan oleh simbol |
mempunyai arti sebuah pilihan. Semua simbol pada sisi kanan menjadi subtitusi
bagi simbol non-terminal pada sisi kiri. Simbol terminal tidak boleh ada pada sisi
kiri. Sisi kiri selalu diisi oleh satu simbol non-terminal yang diapit oleh simbol <
dan >.
Berikut ini adalah aturan sintaks pada BNF yang sering dipakai :
- Untuk menandakan item yang opsional (bisa ada atau bisa tidak
ada), ditandai dengan diapit dua buah kurung siku, yaitu [ dan ].
Contoh: <kalimat> ::= <subjek> <predikat> [ <objek> ]
- Simbol terminal diapit oleh simbol < dan >. Simbol
non-terminal selalu ada di sisi kiri. Untuk simbol non-terminal biasanya
diapit oleh tanda kutip ‘. Contoh : <angkasatu> ::= ‘1’
- Item yang berulang sebanyak 0 kali atau lebih, diapit oleh kurung
kurawal. Atau diapit dengan tanda kurung dengan diakhiri dengan
tanda superscript bintang *.
Contoh 1 : <word> ::= <letter> {<letter>}
Contoh 2 : <word> ::= <letter> (<letter>)*
- Item yang berulang sebanyak 1 kali atau lebih, diapit dengan tanda
kurung dengan diakhiri dengan tanda superscript tambah +.
Contoh : <word> ::= (<letter>)+
- Simbol terminal bisa ditulis dengan cetak tebal (bold) dan simbol
non-terminal bisa ditulis dengan cetak biasa (plain text)
Contoh : <angkasatu> ::= ‘1’
- Untuk menandakan pilihan, biasanya digunakan tanda ‘|’
Contoh : <angkabiner> ::= ‘1’ | ‘0’
- Untuk mengelompokkan simbol-simbol ke dalam group simbol bisa
37
BAB III
ANALISA DAN PERANCANGAN SISTEM
3.1 Analisis Sistem
Tahap analisis sistem dilakukan sebelum tahap perancangan sistem. Tahap
analisis sistem merupakan tahap yang kritis dan sangat penting karena kesalahan
di dalam tahap ini akan menyebabkan kesalahan pada tahap selanjutnya. Proses
analisis sistem merupakan suatu prosedur yang dilakukan untuk pemeriksaan
masalah dan penyusunan alternatif pemecahan masalah yang timbul serta
membuat spesifikasi sistem yang baru atau sistem yang akan diusulkan dan
dimodifikasi. Hasil akhir dari tahap analisis sistem adalah suatu laporan yang
dapat menggambarkan sistem yang telah dipelajari dan diketahui bentuk
permasalahannya serta rancangan sistem baru yang akan dikembangkan.
3.1.1 Analisis Masalah
Salah satu kendala dalam proses pengolahan data dari database yang
tersebar adalah proses penggabungan data dari database yang berbeda. Tidak
semua DBMS memiliki fitur database link seperti pada DBMS Oracle sehingga
dalam proses penggabungan data akan mengalami kendala dalam hal akses data
antar DBMS yang berbeda.
Proses penggabungan data akan lebih mudah jika data yang akan
digabungkan mempunyai format data yang sama. Karena hal ini merupakan syarat
Yang dimaksud dengan format data yang sama ini adalah sebagai berikut :
1. Memiliki jumlah field atau kolom yang sama
2. Memiliki nama-nama field atau kolom yang sama.
3. Memiliki tipe data dan ukuran yang sama di setiap field atau kolomnya.
Dalam kenyataannya tidak semua data yang akan digabungkan pasti
memiliki format data yang sama. Informasi yang akan diambil tidak hanya berasal
dari satu tabel, tetapi dapat juga berasal dari banyak tabel, maka harus dilakukan
query dahulu ke dalam masing-masing database yang digunakan. Hasil dari query
tersebut juga harus memiliki format data yang sama dengan data (hasil query)
yang lain jika akan dilakukan penggabungan data.
Pada umumnya cara yang sering dipakai adalah dengan membuat spool data
tersebut ke dalam text file dengan delimiter tertentu. Setelah itu semua text file
yang ada digabungkan dengan menggunakan text editor atau menggunakan
command prompt menjadi satu text file. Kemudian data gabungan di dalam file
tersebut diolah menjadi sebuah informasi.
Dari permasalahan yang sudah dijelaskan sebelumnya maka dapat
disimpulkan beberapa kendala yang ada, diantaranya sebagai berikut:
1. Tidak ada aplikasi yang mempunyai fungsi untuk melakukan koneksi
dan menghubungkan database dengan DBMS yang berbeda.
2. Data yang akan digabungkan tidak selalu memiliki format data yang
sama.
3. Proses penggabungan data dilakukan secara manual dengan mengolah
39
3.1.2 Blok Diagram Model Aplikasi
Aplikasi yang akan dibangun dimaksudkan untuk menyelesaikan
permasalahan dalam penggabungan data dari database yang berbeda. Secara
umum dapat dimodelkan dalam block diagram berikut ini.
Gambar 3.1 Blockdiagram model aplikasi
Block Diagram pada gambar 3.1 di atas adalah gambaran umum model
aplikasi. Aplikasi berbasis web yang akan dibangun memiliki fungsi utama yaitu
melakukan penggabungan data antar database dengan DBMS yang berbeda.
Pengabungan data yang dimaksud adalah dengan menggunakan fungsi set operasi
atau operation set (Union, Intersect, Minus) antar tabel dalam database dengan
DBMS yang berbeda dalam satu perintah atau sintaks SQL query.
Penjelasan dari block diagram di atas adalah sebagai berikut :
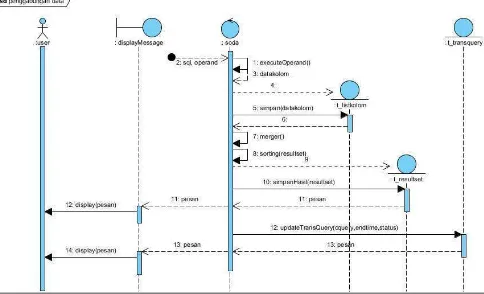
a. Input SQL Query
- SQL query dipakai sebagai masukan aplikasi.
- Query data dipakai sebagai metode untuk mengambil data dari
masing-masing database.
- Format query yang diterima oleh aplikasi ini sesuai dengan aturan
- Sintaks blok SQL query yang diterima adalah SQL query yang
diterima oleh masing-masing DBMS yang diakses.
b. Scanning SQL Query
Proses scanning (analisis leksikal) melakukan pemeriksaan terhadap
SQL query dengan cara membaca satu per satu karakter yang ada pada
kode sumber tersebut, kemudian dikelompokkan menjadi token/leksik
yang mempunyai arti tertentu.
c. Parsing SQL Query
Proses parsing (analisis sintaksis) memeriksa kebenaran sintaks dari
SQL query dan menangani kesalahan sintaks berdasarkan tata bahasa
(grammar) SQL query. Proses ini dilakukan oleh masing-masing
DBMS yang diakses.
d. Identifying SQL Query Block
Proses ini mengidentifikasi elemen-elemen pada SQL query, seperti
jumlah kolom, nama kolom, alias kolom, nama table, dan alias table.
Kolom-kolom yang didefinisikan dapat juga berupa fungsi yang
memiliki tipe data keluaran tertentu sesuai dengan daftar fungsi-fungsi
yang ada dalam SQL Query.
e. Comparing (Pembandingan format data).
- Validasi data dilakukan untuk mengecek nama kolom dan tipe data
kolom yang didefinisikan dalam SQL query. Nama kolom yang
dipakai adalah nama-nama kolom yang didefinisikan dalam blok
SQL query yang pertama.
41
- Jika format data sama, aplikasi akan melakukan penggabungan data
berdasarkan fungsi yang didefinisikan oleh pengguna (Union,
Intersect, atau Minus) dalam SQL Query.
f. Data Merging Process (Union, Intersect, atau Minus).
- Fungsi ini dapat dieksekusi jika format data yang akan digabungkan
memiliki format yang sama.
- Hasil dari penggabungan data dapat disimpan dalam teks file atau
disimpan dalam sebuah tabel di dalam database.
3.1.3 Analisis Proses Parsing pada Masukan SQL Query
Proses parsing terhadap inputan SQL query ini terdari dari dua bagian.
Bagian pertama adalah yang menggabungkan karakter demi karakter untuk
membuat token (biasanya dilakukan oleh bagian yang disebut scanner atau lexer),
dan bagian kedua adalah yang menentukan apakah token-token tersebut
memenuhi grammar (dilakukan oleh bagian yang disebut parser).
Analisis leksikal (scanner) melakukan pemeriksaan terhadap SQL query
dengan cara membaca satu per satu karakter yang ada pada kode sumber tersebut,
kemudian dikelompokkan menjadi token atau leksik yang mempunyai arti
tertentu. Scanner berperan sebagai antar muka antara source code dengan proses
analisis sintaksis (parser).
Analisis sintaksis (parser) menerima masukan dari scanner (dalam bentuk
token) dan membentuk parse tree sesuai dengan sintaks dan tata bahasanya.
Dengan kata lain parser memeriksa kebenaran sintaks dari SQL query dan
3.1.3.1Aturan produksi sintaks dan Diagram sintaks
Aturan produksi sintaks pada SQL query ditulis dalam format BNF (Backus
Nour Form). Aturan produksi ini mengacu pada Final Committee Draft (FCD) of
ISO/IEC 9075-2:2003. Dalam penelitian ini, aturan produksi yang dipakai dapat
dilihat pada table 3.1 di halaman ini. Aturan produksi ini dipakai untuk memeriksa
kebenaran sintaks. Untuk sintaks query ke database akan ditangani oleh
masing-masing DBMS yang diakses.
Aturan produksi yang dimaksud dapat dilihat pada table 3.1 berikut ini:
Tabel 3.1 Tabel BNF SQL Query
1 <s> ::= <expression><semicolon>
3 <term> ::= <lroundbrackets>
<expression>
5 <dbidentifier> ::= 'db-'<alphabet>
{ <alphabet> | <numeral> }
43
Diagram sintaks memberikan gambaran yang jelas mengenai BNF yang
telah dirancang dalam bentuk grafis. Masing-masing diagram sintaks
memudahkan pembaca untuk melihat masing-masing aturan produksi yang ada.
Diagram-diagram sintaks pada gambar 3.2 sampai dengan gambar 3.14 berikut ini
menggambarkan BNF (13 aturan produksi) yang telah dirancang pada tabel 3.1 di
halaman 42.
Simbol <s> pada gambar 3.2 adalah sebuah simbol variabel (simbol non
terminal) yang menghasilkan urutan variable <expression><semicolon>.
Gambar 3.2 Diagram sintaks S
Simbol <expression> pada gambar 3.3 adalah sebuah simbol variabel
(simbol non terminal) yang menghasilkan variable <term>. Variabel <expression>
juga menghasilkan urutan variable <expression><set_operator><term>.
Simbol <term> pada gambar 3.4 adalah sebuah simbol variabel (simbol non
terminal) yang menghasilkan variabel <expression> atau <squery> atau urutan
variable <lroundbrackets><expression><rroundbrackets>.
Gambar 3.4 Diagram sintaks TERM
Simbol <squery> pada gambar 3.5 adalah sebuah simbol variabel (simbol
non terminal) yang menghasilkan urutan variabel <dbidentifier>
<lsquarebrackets> <rsquarebrackets>. SQL query ke masing-masing DBMS
diletakkan diantara variable <lsquarebrackets> dan <rsquarebrackets>. SQL query
tidak diparsing oleh aplikasi ini, akan tetapi diparsing oleh masing-masing DBMS
yang dipanggil sesuai dengan variabel <dbidentifier> yang didefinisikan.
45
Simbol <dbidentifier> pada gambar 3.6 adalah sebuah simbol variabel
(simbol non terminal) yang menghasilkan urutan terminal ‘db-’ (urutan karakter d,
b, dan -) variabel <alphabet> diikuti iterasi variable <alphabet> atau <numeral>.
Contoh string yang diterima oleh variabel <dbidentifier> : best, ora90,
db-mssql2011, dsb.
Gambar 3.6 Diagram sintaks DBIDENTIFIER
Simbol <set_operator> pada gambar 3.7 adalah sebuah simbol variabel
(simbol non terminal) yang menghasilkan terminal ‘union’ atau ‘union all’ atau
‘intersect’ atau ‘minus’.
Simbol <alphabet> pada gambar 3.8 adalah sebuah simbol variabel (simbol
non terminal) yang menghasilkan terminal karakter alphabet ‘a’ sampai dengan
‘z’.
Gambar 3.8 Diagram sintaks ALPHABET
Simbol <numeral> pada gambar 3.9 adalah sebuah simbol variabel (simbol
non terminal) yang menghasilkan terminal karakter number ‘0’ sampai dengan
‘9’.
Gambar 3.9 Diagram sintaks NUMERAL
Simbol <lsquarebrackets> pada gambar 3.10 adalah sebuah simbol variabel
(simbol non terminal) yang menghasilkan terminal karakter ‘[’ (kurung siku
buka).
47
Simbol <rsquarebrackets> pada gambar 3.11 adalah sebuah simbol variabel
(simbol non terminal) yang menghasilkan terminal karakter ‘]’ (kurung siku
tutup).
Gambar 3.11 Diagram sintaks RSQUAREBRACKETS
Simbol <lroundbrackets> pada gambar 3.12 adalah sebuah simbol variabel
(simbol non terminal) yang menghasilkan terminal karakter ‘(’ (kurung buka).
Gambar 3.12 Diagram sintaks LROUNDBRACKETS
Simbol <rroundbrackets> pada gambar 3.13 adalah sebuah simbol variabel
(simbol non terminal) yang menghasilkan terminal karakter ‘(’ (kurung tutup).
Simbol <semicolon> pada gambar 3.14 adalah sebuah simbol variabel
(simbol non terminal) yang menghasilkan terminal karakter ‘;’ (titik koma).
Variable ini menandakan akhir dari string SQL query yang diterima oleh aplikasi
ini.
Gambar 3.14 Diagram sintaks SEMICOLON
3.1.3.2Diagram FSA (Finite State Automata) untuk analisis leksikal (scanner)
Pada sub bab sebelumnya sudah dijelaskan mengenai aturan produksi dan
diagram sintaks pada SQL query. Aturan produksi tersebut digunakan sebagai
pedoman dalam proses parsing pada saat proses penggabungan data dilakukan.
Proses penggabungan data dapat dilakukan jika SQL query yang diberikan oleh
pengguna sudah sesuai dengan aturan produksi tersebut. Aturan produksi tersebut
menggunakan tata bahasa bebas konteks. Proses parsing merupakan tahapan yang
berfungsi untuk memeriksa urutan kemunculan token.
Token dihasilkan oleh parser (yang melakukan proses scanning) dengan
cara menguraikan kode sumber (source code) menjadi unit-unit kecil yang
mempunyai arti. Proses parsing (analisis leksikal) lebih mudah
diimplementasikan pada FSM (Finite State Machine) atau FSA (Finite State
49
matematika dari suatu sistem yang menerima masukan dan mengeluarkan
keluaran dalam bentuk diskrit. FSA terdiri dari sejumlah state berhingga.
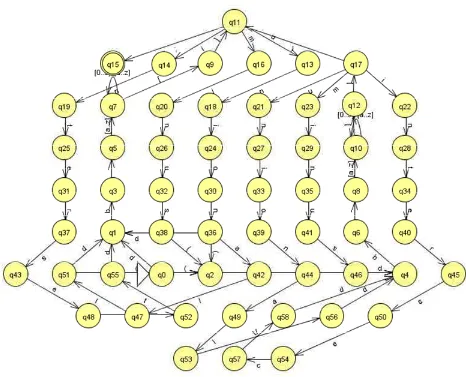
Pada gambar 3.15 dapat dilihat sebuah state diagram dalam bentuk DFA
(Non-Deterministic State Automata) yang menggambarkan proses scanning dalam
penelitian ini. FSA dalam bentuk DFA akan memudahkan pembuatan algoritma
pada tahap implementasi nantinya karena dalam DFA dari suatu state ada tepat
satu state berikutnya untuk setiap simbol masukan.
Tuple yang ada dalam gambar 3.15 adalah sebagai berikut :
Q = {q0,q1,q2,q3,q4,q5,q6,q7,q8,q9,q10,q11,q12,q13,q14,q16,q17,q18,q19,q20,
Keterangan simbol yang dipakai sebagai simbol masukan dapat dilihat pada
tabel 3.2 berikut ini.
Tabel 3.2 Keterangan simbol masukan
Tabel transisi untuk DFA pada gambar 3.15 dapat dilihat pada tabel 3.3 dan
tabel 3.4 berikut ini.
Tabel 3.3 Tabel transisi DFA (bagian 1)
δ - ( ) ; [ ] 0 1 2 3 4 5 6 7 8 9 a b c d e
q10 q12 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10
51
Tabel 3.4 Tabel transisi DFA (bagian 2)
δ f g h i j k l m n o p q r s t u v w x y z
q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10 q10
Gambar berikut ini adalah sebuah diagram DFA yang dipakai sebagai acuan
untuk melakukan proses scanning.
Gambar 3.15 DFA untuk scanner pada aplikasi SODA Data Merger
3.1.3.3Metode parsing
Terdapat dua buah metode parsing yaitu Top-Down Parsing dan Bottom-Up
Parsing. Metode Top-Down Parsing melakukan penelusuran dari puncak menuju
daun. LL parser merupakan top-down parser, yang akan membaca masukan dari
kiri ke kanan dan melakukan parsing secara penurunan terkiri (left-most
derivation). Kelas grammar yang bisa diturunkan dengan menggunakan LL
53
kiri (left recursive), contoh : A Abc. LL grammar tidak boleh mengandung
faktorisasi kiri (left factorization), yaitu dalam sebuah aturan produksi yang
memiliki ruas kiri yang sama tidak boleh ada alternatif penurunan (ruas kanan)
yang diawali simbol yang sama, contoh : B a | aC.
Metode Bottom-Up Parsing melakukan penelusuran dari daun menuju
puncak. Metode ini lebih general dari metode Top-Down Parsing dan dapat
menangani aturan produksi yang mengandung rekursif kiri. Hampir semua kelas
bahasa CFG (Context Free Grammar) dapat diselesaikan oleh metode ini. Metode
ini akan mereduksi string masukan menjadi simbol awal dengan menggunakan
aturan produksi yang ada. Parser yang digunakan dalam metode ini adalah LR
Parser. LR Parser akan membaca input dari kiri ke kanan dan melakukan parsing
secara penurunan terkanan (right-most derivation). Kelas grammar yang bisa
diturunkan dengan menggunakan LR parser dinamakan LR grammar. Aturan
produksi yang memenuhi bentuk CFG merupakan LR grammar. Metode ini akan
mereduksi string masukan (input) menjadi simbol awal dengan menggunakan
aturan produksi yang ada. Dalam metode Bottom-Up Parsing terdapat dua buah
aksi yang dilakukan dalam proses parsing, yaitu Shift (membaca string masukan
berikutnya) dan Reduce (mengubah string menjadi simbol variabel yang dapat
menurunkan string tersebut). Hasil akhir dari metode ini dapat berupa accepted
(jika string masukan sudah habis dibaca dan state mampu mencapai state awal)
atau error (jika string masukan sudah habis dibaca tetapi tidak dapat mencapai
state awal, atau state awal mampu dicapai tapi masih ada string masukan yang
3.1.3.4Proses scanning dan parsing yang dilakukan dalam aplikasi ini
State diagram DFA dan aturan produksi BNF yang digunakan dalam proses
scanning dan parsing mempunyai tujuan yang sama yaitu memeriksa kebenaran
sintaks pada string masukan. Dalam penelitian ini, kebenaran sintaks ditangani di
dalam proses scanning yaitu dengan memeriksa apakah string sudah sesuai
dengan state diagram DFA atau tidak. Hasil proses scanning berupa token
dbidentifier dan block SQL query akan dibaca, diidentifikasi dan dieksekusi.
Pada Tabel BNF SQL Query pada tabel 3.1 di halaman 45, variabel
<set_operator> dapat kita sebut sebagai sebuah operator dan variabel
<expression> dapat kita sebut sebagai sebuah operand. Scanner akan
mengidentifikasi string masukan SQL query ke dalam variabel <set_operator>
dan <expression>. Sehingga menghasilkan suatu format dengan urutan tertentu
yang akan dijalankan oleh aplikasi ini.
Diagram DFA yang digunakan sebagai acuan dalam proses scanning dapat
dilihat pada gambar 3.15 di halaman 56. Untuk memastikan bahwa DFA tersebut
sudah benar sesuai dengan kebutuhan untuk melakukan scanning pada SQL
query, maka berikut ini adalah pembuktian dengan melakukan penelusuran string
SQL query ke dalam DFA tersebut.
SQL Query :
db-alias1[select x.kolom1as col1 from tablex x] union
(db-alias2[select y.kolom2 from tabley y] minus
55
Hasil tracing dari SQL Query di atas dapat dilihat pada table 3.5 berikut ini.
Sebelum aplikasi melakukan proses scanning, string masukan SQL query tersebut
harus diubah menjadi huruf kecil (menggunakan fungsi strtolower pada php) dan
membagi string masukan per baris menjadi string-string dan disimpan ke dalam
sebuah array variable. Sehingga string masukan tersebut (dalam array variable)
menjadi:
Array[0]: db-alias1[select x.kolom1 as col1 from tablex x]
Array[1]: union
Array[2]: (db-alias2[select y.kolom2 from tabley y]
Array[3]: minus
Array[4]: db-alias3[select z.kolom3 as col1 from tablez z]);
Variabel tersebut digunakan agar setiap ada kesalahan sintaks, aplikasi dapat
menunjukkan letak kesalahan dengan jelas yaitu pada baris tertentu yang terjadi
kesalahan.
Proses scanning dilakukan pada tiap-tiap karakter mulai dari baris pertama
sampai dengan baris terakhir. Ada beberapa kondisi dimana karakter digolongkan
ke dalam golongan sintaks dan ke dalam golongan block SQL query.
Kriteria masing-masing golongan tersebut adalah sebagai berikut:
1. Golongan sintaks.
- Karakter-karakter pada golongan ini adalah karakter yang
akan diperiksa apakah sesuai dengan DFA atau tidak.
- Karakter-karakter ini berada di posisi sebelum karakter ‘[‘
dan berada di posisi setelah karakter ‘]’. Dengan catatan
bahwa karakter ‘[’ dan ‘]’ bukan merupakan bagian dari
- Menghasilkan sebuah token yang disebut dbidentifier yang
berarti sebuah alias database yang didefinisikan dalam
inputan SQL query. Setiap menemukan karakter ‘]’ (dengan
catatan bahwa karakter tersebut bukan bagian dari sebuah
string yang berada di antara simbol kutip), proses scanning
akan menghasilkan sebuah token dbidentifier dan sebuah
block SQL query.
- Setiap token dbidentifier yang ditemukan akan dicek apakah
sudah didefinisikan dalam aplikasi atau belum. Jika belum
ada maka proses scanning akan menghasilkan pesan error
dan menunjukkan letak kesalahan tersebut.
2. Golongan block SQL query.
- Karakter-karakter pada golongan ini adalah serangkaian
karakter yang menjadi sebuah SQL query. Karakter pada
golongan ini tidak diperiksa atau dilakukan proses parsing
oleh aplikasi. Proses parsing dilakukan oleh masing-masing
DBMS yang didefinisikan pada sintaks (dbidentifier)
sebelumnya.
- Karakter-karakter pada golongan ini berada pada posisi
diantara karakter ‘[‘ dan karakter ‘]’. Dengan catatan bahwa
karakter ‘[’ dan ‘]’ bukan merupakan bagian dari sebuah