ANALISIS KLASIFIKASI SENTIMEN TWITTER TERHADAP KINERJA
LAYANAN
PROVIDER
TELEKOMUNIKASI MENGGUNAKAN
VARIAN NAÏVE BAYES
AISAH RINI SUSANTI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis Analisis Klasifikasi Sentimen Twitter Terhadap Kinerja Layanan Provider Telekomunikasi Menggunakan Varian Naïve Bayes benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
RINGKASAN
AISAH RINI SUSANTI. Analisis Klasifikasi Sentimen Twitter Terhadap Kinerja Layanan Provider Telekomunikasi Menggunakan Varian Naïve Bayes. Dibimbing oleh TAUFIK DJATNA dan WISNU ANANTA KUSUMA.
Pengguna telekomunikasi di Indonesia dari tahun ke tahun terus tumbuh dengan pesat. Seiring dengan kebutuhan publik yang terus meningkat akan komunikasi baik melalui layanan sms, telepon, maupun data mengakibatkan terjadi persaingan para provider telekomunikasi untuk menarik atau mempertahankan pelanggannya. Opini Pelanggan menunjukkan tingkat kualitas layanan yang dilakukan oleh provider. Berbagai opini yang dikemukakan oleh pelanggan tentang provider telekomunikasi dapat diketahui melalui media sosial Twitter. Salah satu teknik yang dapat digunakan untuk menganalisis opini ini adalah dengan melakukan klasifikasi pada data mentah dari Twitter. Salah satu metode klasifikasi yang dapat digunakan adalah Multinomial Naive Bayes Tree.
Metode Multinomial Naïve Bayes Tree merupakan adaptasi dari Metode Multinomial Naïve Bayes dan Metode Decision Tree. Metode Multinomial Naïve Bayes merupakan metode Naïve Bayes untuk menangani teks atau dokumen. Multinomial naïve bayes mengembangkan klasifikasi teks di setiap node pada pohon keputusan. Dokumen yang digunakan dalam penelitian ini adalah komentar dari pengguna Twitter tentang provider telekomunikasi GSM Indonesia.
Penelitian ini menggunakan metode Multinomial Naïve Bayes Tree untuk mengkategorikan opini sentimen pelanggan terhadap penyedia telekomunikasi di Indonesia. Analisis sentimen hanya mencakup kelas positif, negatif dan netral. Hasil analisis klasifikasi sentimen Twitter terhadap penyedia layanan kinerja telekomunikasi menggunakan Multinomial Naïve Bayes Tree menghasilkan akar pohon keputusan pada kata "Aktif" di mana probabilitas dari kata "Aktif" dalam metode Multinomial Naive Bayes diperoleh pada kelas positif. Tingkat akurasi tertinggi dalam mengevaluasi hasil klasifikasi sentimen Twitter / evaluasi dengan menggunakan dataset yang sama menggunakan metode Multinomial Naïve Bayes Tree (MNBTree) pada 145 fitur adalah 16,26 % sedangkan metode Multinomial Naïve Bayes (MNB) memberikan akurasi tertinggi pada data keseluruhan 1665 fitur yaitu 73,15%. Manfaat yang diharapkan dalam penelitian ini bahwa penyedia telekomunikasi dapat mengevaluasi kinerja dan layanan untuk mencapai kepuasan pelanggan dari berbagai keluhan yang dihadapi.
Kata kunci: Kinerja layanan, Multinomial Naïve Bayes Tree, Naïve Bayes, Opini Sentimen, Provider Telekomunikasi Indonesia, Twitter.
SUMMARY
AISAH RINI SUSANTI. A Classification Analysis of Sentiment Opinion on Twitter Towards Performance of Indonesian Telecommunication Service Providers By Using Varian Naïve Bayes. Supervised By TAUFIK DJATNA And WISNU ANANTA KUSUMA.
Telecommunication users in Indonesia are rapidly growing from year to year which are consistent to the increasing public need for communication services through sms, telephone, or data transfer. As consequence, Indonesian telecommunication providers tightly compete in pursue of winning customers preference and loyalty. Customers opinions indicate the level of service quality performed by the providers. Customers express their opinions about how each provider delivers its services through social media such as Twitter. Analysis of sentiment opinion can be conducted by classifying of raw data from Twitter. One of the classification methods that can be used in this problem is Multinomial Naive Bayes Tree.
Multinomial Naïve Bayes Tree is an adaptation of multinomial naïve Bayes and Decision Tree methods. Multinomial naïve Bayes method used specifically addressing frequency in the text of the sentence or document. Documents used in this study are comments from the users Twitter on the GSM telecommunications provider in Indonesia.
This Research used Multinomial Naïve Bayes Tree classification technique to categorize customers sentiment opinion towards telecommunication providers in Indonesia. Sentiment analysis only includes the class of positive, negative and neutral. This research produced a Decision Tree roots in the word "aktif" in which the probability of the word "aktif" in Multinomial Naive Bayes method obtained in the positive class. The evaluation research showed that the highest accuracy of classification using Multinomial Naïve Bayes Tree (MNBTree) method was obtained using 145 features with the value of 16,26%. Moreover, the Multinomial Naïve Bayes (MNB) yield the highest accuracy of 73,15% by using all dataset with 1665 features The expected benefits in this research that the Indonesian telecommunications provider can evaluate the performance and services to reach customer satisfaction of various complaints encountered.
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Ilmu Komputer
pada
Program Studi Ilmu Komputer
ANALISIS KLASIFIKASI SENTIMEN TWITTER TERHADAP KINERJA
LAYANAN
PROVIDER
TELEKOMUNIKASI MENGGUNAKAN
VARIAN NAÏVE BAYES
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
Judul Tesis : Analisis Klasifikasi Sentimen Twitter Terhadap Kinerja Layanan Provider Telekomunikasi Menggunakan Varian Naïve Bayes Nama : Aisah Rini Susanti
NIM 651130704j G651130704 :
Disetujui oleh Komisi Pembimbing
Dr Eng Ir Taufik Djatna, MSi Ketua
Dr Eng Wisnu Ananta Kusuma, ST MT Anggota
Diketahui oleh
Ketua Program Studi Ilmu Komputer
Dr Ir Sri Wahjuni, MT
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
Tanggal Ujian: 02 Agustus 2016 Tanggal Lulus:
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah Ta’ala atas segala karunia dan hidayahNya sehingga penulis dapat menyelesaikan penelitian ini. Penelitian ini berjudul Analisis Klasifikasi Sentimen Twitter Terhadap Kinerja Layanan Provider Telekomunikasi Menggunakan Varian Naïve Bayes.
Terima kasih penulis ucapkan kepada Bapak Dr Eng Taufik Djatna, STP MSi dan Bapak Dr Eng Wisnu Ananta Kusuma, ST MT selaku pembimbing yang telah memberikan arahan dan masukan selama penelitian ini. Terima kasih kepada Dr Imas Sukaesih Sitanggang SSi, MKom selaku penguji luar atas saran dan masukannya.
Terima kasih penulis ucapkan kepada kedua orangtua, suami dan anak tercinta serta keluarga yang telah mendukung dengan sepenuh hati dan keridhoannya serta memberikan motivasi sehingga penelitian ini dapat terlaksana dengan baik. Terima kasih juga penulis juga ucapkan kepada teman- teman seperjuangan yang telah berbagi ilmu, memberikan dukungan, saran dan masukan dalam penelitian ini : Husnul Khotimah, Ibu Puspa Oesina, Lira Ruhwinaningsih, Fery Dergantoro, Irwan Adriansyah, Andita Wahyuningtyas, Sodik Kirono, Mulyati, Tengku Khairil Ahsyar, Arini Pekuwali, Fathur Rohman, Ahmad Luky Ramdani, M Rake Linggar Anggoro, Irfan Wahyudin, Heri Bambang Santoso, Lailan sahrina, Rossy Nurhasanah Thoe, Rohmah Luthfianti dan semua rekan-rekan ILKOM angkatan 2013.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
Penelitian Terkait 2
2 TINJAUAN PUSTAKA 3
Metode Naïve Bayes 3
Metode Multinomial Naive Bayes 4
Praproses Data 6
Metode Naïve Bayes Tree 6
Metode Multinomial Naïve Bayes Tree (MNB Tree) 7
3 METODE 7
Praproses 8
Metode Multinomial Naïve Bayes Tree (MNB Tree) 12
Evaluasi Model 14
Peralatan Penelitian 15
4 HASIL DAN PEMBAHASAN 15
Persiapan Data 15
Metode Multinomial Naïve Bayes Tree 16
Penerapan metode Multinomial Naïve Bayes Tree 17
Evaluasi Model 19
Kelebihan dan kekurangan metode MNBTree 19
5 SIMPULAN DAN SARAN 20
Simpulan 20
Saran 20
DAFTAR PUSTAKA 21
LAMPIRAN 23
DAFTAR TABEL
1 Kata dalam korpus kata kunci sentimen positif dan negatif 9
2 Beberapa kata yang dijadikan stopword 10
3 Beberapa kata yang dilakukan Normalisasi 10
4 Beberapa daftar kata opini sentimen positif pada kamus Lexicon 11 5 Beberapa daftar kata opini sentimen negatif pada kamus Lexicon 12 6 Kamus Lexicon opini sentimen positif dalam bahasa Indonesia 13 7 Kamus Lexicon opini sentimen negatif dalam bahasa Indonesia 14
8 Confusion Matrix 15
9 Ukuran dan formula Confusion Matrix 18
10 Hasil akurasi terhadap evaluasi model klasifikasi opini sentimen Twitter
dengan metode MNBTree 18
11 Hasil akurasi terhadap evaluasi model klasifikasi opini sentimen Twitter
dengan metode MNB dan metode MNBTree 19
DAFTAR GAMBAR
1 Hasil skoring untuk pelabelan kelas positif, negatif dan netral 6
2 Tahapan Penelitian 8
3 Hasil tahapan praproses 10
4 Flowchart proses training 11
5 Hasil pengambilan data Twitter melalui API 16
6 Kolom text yang berisi komentar dari pengguna Twitter 16
7 Tahapan Metode Multinomial Naive Bayes Tree 17
DAFTAR LAMPIRAN
1 Tampilan hasil running metode MNB 1665 fitur di Weka 23
2 Tampilan Netbeans IDE 8.0.2 26
3 Tampilan hasil running data training metode MNBTree 145 fitur pada k-fold
1 di Netbeans 26
4 Tampilan hasil running data testing metode MNBTree 145 fitur pada k-fold 1
di Netbeans 28
5 Tampilan data berupa fitur dan frekuensinya dalam bentuk file .csv bentuk
file .csv 29
6 Tampilan komentar Twitter sebanyak 5210 komentar disimpan dalam file .csv 30 7 Tampilan fungsi pada R untuk pengambilan data Twitter sampai dengan
tokenisasi 30
8 Tampilan GUI untuk training dan testing data menggunakan metode
Multinomial Naïve Bayes Tree 34
9 Tampilan proses training data menggunakan metode Multinomial Naive 35 10 Tampilan hasil testing data menggunakan metode Multinomial Naive Bayes
1
PENDAHULUAN
Latar Belakang
Analisis sentimen merupakan teknik yang digunakan untuk melakukan evaluasi dan mengindentifikasi emosi dan opini baik positif maupun negatif (Wilson et al. 2009). Penelitian analisis sentimen telah banyak dilakukan pada media dokumen, Twitter sebagai salah satu media sosial populer di mana penggunanya dapat mengekspresikan opini yang objektif tentang topik yang berbeda (Coletta et al. 2014). Sebanyak 19% pengguna media sosial Twitter memberikan berbagai opini mengenai merk dan produk (Jansen et al. 2009). serta ekspresi perasaan mereka terhadap operator seluler dengan akurasi memprediksi sentimen mencapai 80% (Wijaya et al. 2013). Perusahaan operator seluler merupakan perusahaan penyedia jasa (provider) telekomunikasi. Beberapa perusahaan operator seluler GSM (Global System for Mobile communications) antara lain : Telkomsel (PT. Telekomunikasi Seluler), Indosat Ooredoo (PT. Satelit Indonesia / Satelindo), XL Axiata (PT XL Axiata Tbk), Hutchison (PT. Hutchison CP Telecommunications Indonesia / HCPT). Masing-masing provider mempunyai produk berbeda-beda, misalnya Telkomsel (Simpati dan Halo), Indosat Ooredoo (Im3 dan Mentari), XL Axiata (XL), Hutchison (Tri).
Pengguna telekomunikasi di Indonesia dari tahun ke tahun terus tumbuh pesat. Hal itu seiring dengan kebutuhan publik akan komunikasi yang terus meningkat baik melalui SMS (Short Message Service), telepon maupun data. Dengan demikian terjadi persaingan para provider telekomunikasi Indonesia untuk menarik atau mempertahankan pelanggannya. Berbagai opini yang dikemukakan oleh pelanggan tentang provider telekomunikasi dapat diketahui melalui media sosial Twitter.
2
Perumusan Masalah
Berdasarkan latar belakang masalah yang diteliti maka rumusan masalah dari penelitian ini adalah :
1. Bagaimana mengidentifikasi atribut dan menyusun praproses evaluasi kinerja layanan provider GSM
2. Bagaimana mengimplementasi klasifikasi opini sentimen Twitter terhadap kinerja layanan provider GSM menggunakan metode Multinomial Naïve Bayes dan Multinomial Naïve Bayes Tree
3. Bagaimana mengevaluasi hasil klasifikasi opini sentimen Twitter menggunakan metode Multinomial Naïve Bayes dan Multinomial Naïve Bayes Tree
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1. Mengidentifikasi atribut dan menyusun praproses evaluasi kinerja layanan provider GSM
2. Mengimplementasi klasifikasi opini sentimen Twitter terhadap kinerja layanan provider GSM menggunakan metode Multinomial Naïve Bayes dan Multinomial Naïve Bayes Tree
3. Melakukan evaluasi hasil klasifikasi opini sentimen Twitter menggunakan metode Multinomial Naïve Bayes dan Multinomial Naïve Bayes Tree
Manfaat Penelitian
Manfaat yang diharapkan dari penelitian ini adalah provider GSM yang ada di Indonesia dapat menganalisis sentimen komentar Twitter konsumen untuk mengevaluasi kinerja dan pelayanannya sehingga tercapai kepuasan konsumen terhadap berbagai keluhan yang dihadapi.
Ruang Lingkup Penelitian
1. Objek penelitian diambil dari tiga provider GSM yaitu Telkomsel, Indosat dan XL akun masing-masing provider mengenai kinerja layanan provider yang dibatasi pada aliran data Twitter berbahasa Indonesia
2. Analisis sentimen hanya mencakup kelas positif, negatif dan netral 3. Kalimat yang digunakan hanya mempunyai asumsi satu kategori kelas
Penelitian Terkait
3
metode Naïve Bayes diperoleh akurasi 72,22 % (Wijaya et al. 2013). Analisis kualitas layanan provider telepon seluler pada media sosial Twitter menggunakan Naïve Bayes menunjukan provider dengan tingkat kepuasan pelanggan tertinggi (Calvin dan Setiawan 2014). Pada koleksi data 400 kalimat dilaporkan akurasi kinerja yang sangat tinggi dalam klasifikasi dokumen yaitu 97% (Yu dan Hatzivassiloglou 2003) dan memiliki hasil yang baik untuk klasifikasi sentimen menggunakan N-gram dan POS-tag sebagai fitur (Pak dan Paroubek 2010). Pada koleksi data yang besar, metode Naïve Bayes menghasilkan akurasi 97%. Dengan demikian Naïve Bayes adalah salah satu teknik klasifikasi yang akurat, efisien, dan mudah diinterpretasi (Wu et al. 2008; Rennie et al 2003).
Salah satu varian dari metode Naïve Bayes untuk menangani data Multinomial yang digunakan dalam klasifikasi teks adalah metode Naïve Bayes Multinomial. Model Multinomial menghasilkan akurasi lebih baik daripada model Multi-variate Bernoulli untuk klasifikasi teks pada data dengan kosakata dalam jumlah besar sedangkan Multi-variate Bernoulli sebaliknya (McCallum dan Nigam 1998). Metode Multinomial Naïve Bayes merupakan metode Naïve Bayes untuk menghitung frekuensi kata atau istilah (term frequency) dalam dokumen. Salah satu kelemahan dari metode Naïve Bayes adalah asumsi independen di antara fitur padahal fitur saling terkait dan tergantung satu sama lain (Domingos dan Pazzani 1997; Zheng dan Webb 2005). Oleh sebab itu, diajukan metode Naive Bayes Tree. Metode Naïve Bayes Tree merupakan metode gabungan antara Naïve Bayes dan Decision Tree. Metode Naïve Bayes Tree secara efektif dapat mengurangi waktu komputasi dengan cara melakukan penghapusan redudansi data asli sehingga menghasilkan akurasi lebih baik dari metode Naïve Bayes dan metode Decision Tree (Veeraswamy et al. 2013). Mengadaptasi dari algoritme naïve bayes tree, untuk pengklasifikasian teks maka lahirlah metode Multinomial Naïve bayes Tree (MNBTree) yang menunjukan tingkat akurasi lebih baik dari Metode Naïve Bayes Tree (Wang et al. 2014). Metode MNBTree merupakan gabungan dari metode Multinomial Naïve Bayes (MNB) dan metode Decision Tree. Standar MNB secara substansi dapat ditingkatkan dengan menerapkan transformasi TF-IDF (Term Frequency-Inverse Document Frequency) untuk fitur kata dan normalisasi vektor fitur yang dihasilkan dengan panjang vektor rata-rata yang diamati dalam data (Kibriya et al. 2005).
2
TINJAUAN PUSTAKA
Metode Naïve Bayes
Naïve Bayes merupakan metode yang digunakan untuk melakukan klasifikasi dengan menggunakan metode statistik dan probabilistik. Metode ini dikemukakan oleh ilmuwan Inggris Thomas Bayes untuk memprediksi peluang masa depan berdasarkan pengalaman masa lalu yang selanjutnya disebut Teorema Bayes yang dikombinasikan dengan naïve dan mempunyai asumsi kondisi atribut saling bebas. Teorema Bayes mempunyai persamaan seperti persamaan 1 (Manning et al. 2009) :
� │� =P X|H , P HP X ... (1)
4
(Prior probability), dimana P(X/H) adalah probabilitas X menurut kondisi hipotesis H, sedangkan P(X) adalah Probabilitas X.
Pada proses ekstraksi fitur terdapat pembobotan kata berdasarkan kemunculan kata. Fungsi klasifikasi yang digunakan adalah fungsi klasifikasi dengan basis peluang (Azis 2013). Setelah dilakukan tahapan ekstraksi fitur pada data maka dilakukan tahapan algoritme Naïve Bayes.
Metode Naive Bayes telah berhasil untuk mendokumentasikan klasifikasi dalam banyak upaya penelitian. Metode Bayes merupakan metode dalam machine learning berdasarkan data training dengan probabilitas bersyarat. Klasifikasi Bayes merupakan klasifikasi statistik untuk memprediksi kelas suatu anggota probabilitas. Klasifikasi Naïve Bayes diasumsikan bahwa efek suatu nilai atribut dalam sebuah kelas bersifat bebas dari atribut lain. Asumsi ini disebut class conditional independence yang dibuat untuk memudahkan perhitungan-perhitungan. Pengertian ini dianggap “Naive”, dalam bahasa lebih sederhana naïve itu mengasumsikan bahwa kemunculan suatu term kata dalam suatu kalimat tidak dipengaruhi kemungkinan kata-kata yang lain dalam kalimat. Padahal dalam kenyataannya bahwa kemungkinan kata dalam kalimat sangat dipengaruhi kemungkinan keberadaan kata-kata yang dalam kalimat. Beberapa metode varian dari metode Naïve Bayes antara lain : Complement Naïve Bayes, Naïve Bayes Multinomial, Naïve Bayes Bernouli, Multiclass Multinomial Naïve (MMNB), Naïve Bayes Tree, Discriminatively Weighted Multinomial Naive Bayes (DWMNB), Multiclass Multinomial Naive Bayes Tree (MMNB) dan Multinomial Naïve Bayes Tree (Wang et al. 2014).
Metode Multinomial Naive Bayes
Multinomial Naïve Bayes merupakan algoritme Naïve Bayes yang menangani data multinomial yang digunakan dalam klasifikasi teks. Data dalam Multinomial Naïve Bayes direpresentasikan sebagai jumlah vektor kata. Sehingga Multinomial naïve bayes merupakan metode naïve bayes untuk menghitung frekuensi kata atau istilah (term frequency) dalam dokumen. Dalam multinomial naïve bayes pertama dilakukan penghitungan probabilitas kata dalam kelas (prior) menggunakan persamaan 2 berikut (Manning et al. 2009):
� | ∝ � ∏ � �|
≤�≤�
………. (2)
� �| adalah peluang istilah (term) � yang muncul dalam sebuah dokumen
dengan kelas . � adalah peluang suatu dokumen dalam kelas . Nilai peluang dokumen d pada kelas c dihitung menggunakan persamaan 3 (Manning et al. 2009):
�̂ = ��� ………. (3)
5
�̂ | = ��
∑�′∈�� �′′ ………. (4)
��� merupakan jumlah kemunculan istilah dalam dokumen training dari kelas . ∑�′∈����′′ adalah jumlah seluruh istilah yang terdapat pada seluruh dokumen di kelas termasuk istilah yang muncul berulang kali pada dokumen yang sama. Istilah yang tidak muncul dalam dokumen menghasilkan nilai frekuensi � �| adalah nol sehingga demikian algoritme Multinomial Naïve Bayes untuk tahapan pelatihan seperti berikut (Manning et al. 2009) :
MULTINOMIAL NB TRAINING (C,D) 1 V ← ekstrak kosa kata (D) 11 return V, prior, condprob
Proses training pada algoritme Multinomial Naïve Bayes adalah tahapan dilakukannya pelatihan terhadap data yang menjelaskan bahwa � adalah semua jumlah kosa kata dalam data training kemudian N adalah jumlah banyaknya data yaitu kalimat komentar Twitter. Untuk setiap kelas dari data dihitung banyaknya data pada masing-masing kelas (��) dibagi banyaknya jumlah data (��
�) seperti yang tercantum dalam
persamaan 3 kemudian untuk setiap fitur teks (t) pada � dihitung peluangnya pada masing-masing kelas menggunakan persamaan 4. Jika kondisi t terdapat nilai nol maka dilakukan laplace smoothing seperti persamaan 5. Tahap selanjutnya adalah menerapkan tahapan pengujian seperti berikut (Manning et al. 2009) :
6
Pada tahapan pengujian diterapkan data testing untuk masing-masing kelas dengan menghitung skor menggunakan persamaan 3, kemudian untuk setiap fitur teks dilakukan penghitungan menggunakan persamaan 4. Jika terdapat fitur bernilai nol maka diterapkan persamaan 5. Penerapan tahap pengujian menghasilkan nilai peluang masing-masing kelas sehingga nilai peluang tertinggi adalah pemenang yaitu peluang terbesar kelas tersebut pada masing-masing dokumen.
Praproses Data
Tahapan praproses yang dilakukan pada data mentah Twitter menghasilkan 5182 komentar dengan label seperti pada Gambar 1. Untuk score angka negatif (contoh : -1) mengidentifikasikan kelas negatif sedangkan score angka positif (contoh: 1) mengidentifikasikan kelas positif dan angka nol (0) mengidentifikasikan kelas netral. Hasil tahapan praproses dapat dilihat seperti pada Gambar 3, di mana kata sebagai fitur dan angka sebagai frekuensi kata tersebut dalam dokumen (Lampiran 5). jika diterapkan kedalam data, maka probabilitas masing-masing kelas menjadi sebagai berikut :
P (Positif) = 1616 / 5182 = 0.311849 P (Negatif) = 2321 / 5182 = 0.447897 P (Netral) = 1245 / 5182 = 0.240255
Selanjutnya data dibagi menjadi data training dan data testing. Fase training merupakan pembentukan model Multinomial Naïve Bayes Tree terhadap dokumen yang digunakan. Fase selanjutnya adalah proses testing yaitu penerapan model Multinomial Naïve Bayes Tree terhadap data baru. Pembagian data training dan data testing adalah 80-20 yaitu 80% untuk data training dari seluruh data dan 20% untuk data testing dari seluruh data.
Gambar 1 Hasil skoring untuk pelabelan kelas positif, negatif dan netral
Metode Naïve Bayes Tree
Tahapan algoritme NBTree dijelaskan seperti berikut (Kohavi 1996) :
Algoritme: Metode Naïve Bayes Tree
Input : himpunan T berisi instance dengan label.
Output : pohon keputusan dengan pengkategorian Naïve Bayes pada daun
1. Hitung utility untuk setiap atribut Xi, buat threshold untuk menangani atribut kontinyu.
2. Misalkan j = arg maxi(ui) sebagai atribut dengan utility tertinggi.
3. Jika uj tidak lebih tinggi dari utility dari node yang dimiliki sekarang, buat model naïve
7
4. Mempartisi T menurut pengujian di Xj.. Jika Xj kontinyu maka menggunakan threshold;
jika Xj adalah diskrit, multi-way split dibuat untuk semua nilai yang mungkin.
5. Untuk setiap child, panggil algoritme secara rekursif untuk membagi T yang sesuai dengan pengujian yang mengarah ke child.
Input algoritme NBTree adalah himpunan T yang terdiri atas instance dengan labelnya sedangkan output adalah metode Decision Tree dengan dengan pengkategorian Naïve Bayes pada setiap daun dari pohon keputusannya.
Metode Multinomial Naïve Bayes Tree (MNB Tree)
Mengadaptasi dari algoritme naïve bayes tree, untuk pengklasifikasian teks maka lahirlah metode Multinomial Naïve bayes Tree yang menunjukan tingkat akurasi lebih baik dari metode Naïve Bayes Tree (Wang et al. 2014). Metode Multinomial Naïve Bayes Tree mengembangkan klasifikasi teks naïve bayes multinomial di setiap node pada pohon keputusan. Metode Multinomial Naïve Bayes Tree terinspirasi dari metode Naïve Bayes Tree yang mempunyai kompleksitas waktu yang tinggi dalam tahapannya. Dalam penerapannya, algoritme Multinomial Naïve Bayes Tree merupakan adaptasi metode Decision Tree dan metode Multinomial Naïve Bayes. Decision Tree merupakan metode yang digunakan untuk klasifikasi yang menghasilkan bentuk struktur pohon yang terdiri dari akar (root node) dan daun (leaf node). Metode Decision Tree dapat menangani data kategorik dan numerik.
3
METODE
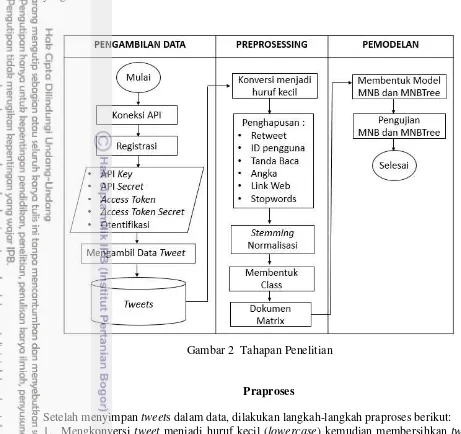
Tahapan yang ditempuh dalam penelitian ini pertama dilakukan persiapan data yang akan diambil, kedua melakukan praproses pada data pesan Twitter, ketiga melakukan pemodelan klasifikasi sentimen pada opini pesan Twitter, seperti yang ditampilkan oleh Gambar 2.
Pada tahapan pertama, dilakukan koneksi dengan API (Application Programming Interface). Tahap kedua praproses data sebagai tahapan yang dilakukan sebelum data utama diproses mencakup mengkonversi tweet menjadi huruf kecil (lowercase) kemudian membersihkan tweet dari : ReTweet, ID Pengguna (user ID), tanda baca, angka, link web, stopwords, stemming, normalisasi dan pelabelan . Setelah tahapan praproses, data dibuat menjadi dokumen matrix yaitu representasi kata dan frekuensi kata dalam dokumen. Tahap terakhir yaitu pembentukan model menggunakan Multinomial Naïve Bayes menggunakan Weka 3.6 (Lampiran 1) dan Multinomial Naïve Bayes Tree menggunakan Netbeans IDE 8.0.2 (Lampiran 2,8,9 ). Selanjutnya dilakukan pengujian terhadap model yang digunakan.
Persiapan Data
8
mengenai status pengguna Twitter berbahasa Indonesia tentang provider telekomunikasi yang ada di Indonesia.
Gambar 2 Tahapan Penelitian
Praproses
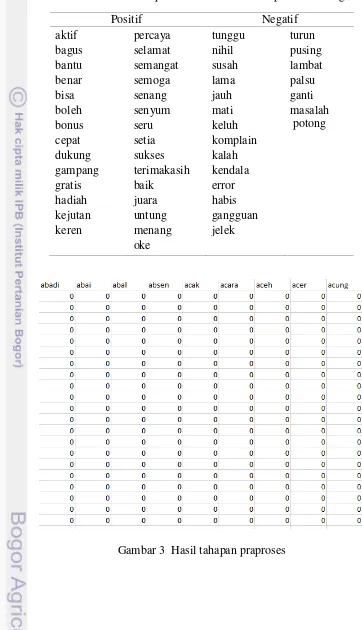
Setelah menyimpan tweets dalam data, dilakukan langkah-langkah praproses berikut: 1. Mengkonversi tweet menjadi huruf kecil (lowercase) kemudian membersihkan tweet
dari : ReTweet, ID Pengguna (user ID), tanda baca, angka, link web, stopwords (Tabel 2) serta dilakukan stemming dan normalisasi. Tabel 3 menampilkan beberapa kata yang dilakukan normalisasi menjadi kata baku Bahasa Indonesia. Stemming adalah mengubah kata menjadi kata dasarnya sedangkan normalisasi yaitu mengubah kata menjadi bentuk yang diinginkan dalam hal ini bahasa “gaul” dan Bahasa daerah yang dirubah kedalam bentuk kata baku Bahasa Indonesia. Hasil tahapan tersebut disimpan dalam fail. Tahap ini menghasilkan kata kunci sentimen positif dan negatif yang kemudian disimpan dalam korpus. Adapun kata kunci yang mempunyai nilai sentimen positif dan negatif dapat dilihat pada Tabel 1 sebagai bahan korpus kata opini sentimen untuk melakukan pelabelan pada masing-masing tweet.
9
3. Melakukan tokenisasi yaitu input teks dalam kalimat dipecah ke dalam kata tunggal kemudian diubah menjadi matriks menggunakan Bahasa pemrograman R (Tampilan 7) seperti pada Gambar 3.
Gambar 3 Hasil tahapan praproses
Tabel 1 Kata dalam korpus kata kunci sentimen positif dan negatif
10
Tabel 2 Beberapa kata yang dilakukan Normalisasi Normalisasi
11
Praproses data dilakukan menggunakan Bahasa pemrograman R sampai dengan penentuan label kelas pada masing-masing dokumen atau kalimat komentar Twitter. Pada pelabelan menggunakan kamus Lexicon yang diterjemahkan kedalam Bahasa Indonesia dan korpus seperti pada Tabel 1. Cara menentukan label adalah menghitung skor jumlah kata positif dikurangi skor jumlah kata negatif dalam kalimat tersebut . Selanjutnya data dibagi menjadi 2, yakni data latih (training) dan data uji (testing). Data training digunakan untuk memberi pengetahuan tentang ciri-ciri suatu kelas. Untuk mengambil ciri-ciri suatu kelas, dilakukan proses seperti yang diilustrasikan pada Gambar 4. Penerapan metode MNBTree menggunakan Netbeans IDE 8.0.2 untuk data training (Lampiran 3) dan testing (Lampiran 4, 10).
Gambar 4 Flowchart proses training
Sumber : Twitter Sentiment Tracking for Predicting Marketing Trends (Esiyok dan Albayrak)
Tabel 4 Beberapa daftar kata opini sentimen positif pada kamus Lexicon Opini positif kamus Lexicon
12
Metode Multinomial Naïve Bayes Tree (MNB Tree)
Dalam tekniknya, Multinomial Naïve Bayes Tree membangun sebuah pohon biner, di mana nilai-nilai atribut perpecahan hanya dibagi menjadi nol dan bukan nol dan menggunakan ukuran information gain untuk membangun pohon untuk mengurangi konsumsi waktu.
Algoritme: Metode MNBTree (D) (Wang et al. 2014) Input: Contoh data training D
Output: Pembelajaran metode MNBTree teks klasifikasi 1. Atur ukuran minimum leaf l menjadi | D | * 40%
2. Jika | D | kurang dari l maka buat leaf node dan membangun metode MNB menggunakan contoh-contoh yang ada dalam leaf node tersebut, dan kemudian kembali
3. Untuk setiap atribut Wi, menggunakan Persamaan 6, untuk mendapatkan information Tabel 5 Beberapa daftar kata opini sentimen negatif pada kamus Lexicon
13
Di mana D adalah Himpunan dokumen atau data, � adalah fitur yang berupa masing-masing kata dalam dokumen, │ �│ adalah Jumlah dokumen pada partisi ke v sedangkan
│ │adalah Jumlah dokumen dalam himpunan dokumen.
4. Tetapkan Wmax menjadi atribut dengan maksimum informasi gain Gmax
5. Jika Gmax= 0 buat leaf node dan bangun algoritme MNB menggunakan contoh ke leaf
node ini, dan kemudian kembali 6. Selainnya untuk setiap contoh d di D
(A) Tetapkan Vwmax (d) menjadi nilai Wmax dalam d
(B) Jika Vwmax (d) = 0 kemudian tetapkan d ke left child Dl
(C) Selainnya, tetapkan d untuk right child Dr 7. Tetapkan D = Dl dan kembali ke langkah 2 8. Tetapkan D = Dr dan kembali ke langkah 2 9. Kembali ke klasifikasi teks metode MNBTree
Di mana | Dv | adalah jumlah contoh yang nilai atribut wi adalah v (v ∈ {0, ̅}), Entropi (D) adalah Entropi D, yang dapat dihitung dengan persamaan 7 (Wang et al. 2014).
= − ∑ � ∗ � ��
�∈�
……….. (7)
dimana adalah himpunan dokumen sedangkan P (c) adalah probabilitas kelas c di D. Tabel 6 Kamus Lexicon opini sentimen positif dalam bahasa Indonesia
14
Apabila nilai information gain yang dihasilkan adalah nol atau jumlah fitur kurang dari 40% dari jumlah data (dokumen) maka penghitungan dilakukan dengan menggunakan Mutinomial Naïve Bayes. Nilai minimum daun (leaf) yaitu l dipilih nilai empiris | D | * 40% sebagai nilai minimum ukuran daun sebagai upaya agar mengurangi konsumsi waktu, overfitting, dan mengurangi kompleksitas node daun pada data training (Wang et al. 2014). Minimal ukuran daun mempengaruhi ukuran pohon yang dibangun.
Setelah diketahui ukuran minimum daun kemudian dihitung information gain pada tiap atribut Wi. Di mana Wi adalah atribut yaitu fitur kata ke i dihitung menggunakan
persamaan 6. Selanjutnya menetapkan Wmax menjadi atribut dengan nilai informasi gain
tertinggi (Gmax). Jika Gmax bernilai nol dijadikan cabang sisi kiri (child left) yaitu Dl
dilakukan penghitungan menggunakan metode MNB namun jika Gmax bernilai bukan nol
dijadikan cabang sisi kanan (child right) yaitu Dr dilakukan penghitungan menggunakan metode Decision Tree.
Evaluasi Model
Penelitian ini menggunakan evaluasi model Confusion Matrix untuk mengetahui hasil akurasi klasifikasi terhadap metode yang digunakan. Ukuran dan formula Confusion Matrix yang digunakan disajikan pada Tabel 8 (Han et al. 2012).
Tabel 7 Kamus Lexicon opini sentimen negatif dalam bahasa Indonesia Lexicon Negatif Bahasa Indonesia
berwajah 2
15
TP (True Positif) adalah positif sejati yaitu label pada data sama dengan hasil prediksi model, sedangkan TN (True Negatif) adalah negatif sejati sejati yaitu label pada data berbeda dengan hasil prediksi model. FP (False Positif) adalah positif palsu, sedangkan FN (False Negatif) adalah negatif palsu seperti yang dijelaskan oleh Tabel 9 (Han et al. 2012).
Peralatan Penelitian
Spesifikasi peralatan perangkat keras dalam penelitian ini menggunakan Prosesor Intel Core i5 – 3337U 1.8 GHz, RAM 4 GB, HDD 750 GB. Adapun spesifikasi perangkat lunak dalam penelitian ini menggunakan sistem operasi Windows 8 64-bit. Alat bantu dalam tahapan pengambilan data, praproses, dan pelabelan data menggunakan RStudio versi 0.99.903 (2009-2016) dengan R versi 3.2.3. Perangkat server web yang digunakan adalah XAMPP versi 3.2.1, sedangkan server basis data yang digunakan adalah MySQL versi 5.6.16. Metode Multinomial Naïve Bayes diimplementasikan menggunakan Weka versi 3.6.10 sedangkan pada tahapan penerapan metode Multinomial Naïve Bayes Tree menggunakan Netbeans IDE 8.0.2 dan Java versi 1.8 (http://www.oracle.com).
4
HASIL DAN PEMBAHASAN
Persiapan Data
Pada tahapan pertama, dilakukan koneksi dengan API (Application Programming Interface) yaitu dengan cara registrasi terlebih dahulu untuk mendapatkan akun dalam pengambilan data Twitter untuk mendapatkan API Key, API Secret, Access Token, Access Token Secret. Setelah mendapatkan API Key, API Secret, Access Token, Access Token Secret kemudian melakukan otentifikasi dan registrasi. Hasil pada tahapan pertama didapatkan data berupa komentar pengguna Twitter. Selanjutnya dilakukan pengambilan data berdasarkan kata kunci yang diperlukan. Data yang telah diambil kemudian disimpan dalam bentuk frame pada Bahasa pemrograman R (Lampiran 7), lalu disimpan dalam file format CSV (Comma Delimited) seperti yang digambarkan oleh Gambar 5. Fitur yang terdapat dalam data antara lain : text, favorited, favoriteCount, replyToSN, created, truncated, replyToSID, id, replyToUID, statusSource, screenname, retweetCount, isRetweet, retweeted, longitude, latitude. Fitur yang diambil dalam penelitian ini hanya kolom text yang merupakan isi dari komentar pengguna Twitter seperti yang digambarkan oleh Gambar 6.
Tabel 8 Confusion Matrix Aktualisasi Kelas Prediksi
Kelas = ya Kelas = tidak
Kelas = ya tp fn
16
Gambar 5 Hasil pengambilan data Twitter melalui API
Gambar 6 Kolom text yang berisi komentar dari pengguna Twitter
Data yang digunakan dalam penelitian ini adalah data tweet komentar pengguna Twitter berbahasa Indonesia yang diambil dari API mengenai status pengguna Twitter berbahasa Indonesia tentang provider telekomunikasi yang ada di Indonesia. Akun masing-masing provider yaitu Telkomsel (@Telkomsel, @kartuas, @simpati), Indosat (@Indosat, @Indosatcare, @Indosatmania), XL (@XL, @XLandme, @XLcare). Pengumpulan data menghasilkan 5210 komentar (Lampiran 6) yang terdiri dari iklan provider dan komentar pengguna Twitter. Komentar yang berhasil ditambang dari tanggal 5 Januari 2016 sampai tanggal 3 Januari 2016.
Metode Multinomial Naïve Bayes Tree
17
Mulai
Data Training
Atur ukuran minimum leaf, | D | * 40% menjadi nilai Wmax di d
Vwmax (d) = 0
Gambar 7 Tahapan Metode Multinomial Naive Bayes Tree
Penerapan metode Multinomial Naïve Bayes Tree
18
Dalam tahapannya, yang pertama perlu dilakukan adalah penerapan metode Decision Tree. Pertama, dihitung jumlah nilai nol dan bukan nol pada masing-masing fitur kata dalam dokumen. Kedua dihitung Probabilitas kelas terhadap nilai nol pada kelas positif, negatif, netral serta nilai entropy masing-masing kata dalam dokumen kemudian dihitung Probabilitas kelas terhadap nilai bukan nol pada kelas positif, negatif, netral serta nilai entropy masing-masing kata dalam dokumen. Ketiga, dihitung nilai information gain pada masing-masing fitur kata (Wi) dalam dokumen dengan menggunakan persamaan 6,
kemudian didapatkan nilai information gain tertinggi 0.035136 pada kata “aktif” (Wmax).
Setelah diperoleh kata dengan nilai information gain tertinggi maka kata tersebut dijadikan sebagai akar dari pohon keputusan (Gmax).
Kata “aktif” sebagai nilai information gain tertinggi akan dijadikan sebagai akar dari pohon keputusan. Setelah mendapatkan akar pada pohon keputusan kemudian dilakukan iterasi untuk mencari daun dari fitur kata yang mempunyai nilai nol (sebanyak 581 fitur) yang dijadikan cabang sisi kiri (child left) yaitu Dl menggunakan Multinomial Naïve Bayes
Tabel 10 Hasil akurasi terhadap evaluasi model klasifikasi opini sentimen Twitter dengan metode MNBTree
Tabel 9 Ukuran dan formula Confusion Matrix
19
menghasilkan kelas negatif sebagai probabilitas tertinggi yaitu 2.718463. Adapun untuk fitur yang mempunyai nilai bukan nol dijadikan cabang sisi kanan (child right) yaitu Dr (sebanyak 4601 dokumen) menggunakan penghitungan ukuran information gain tertinggi menghasilkan kata “untung” dengan nilai 0.025782.
Evaluasi Model
Hasil akurasi terhadap evaluasi model klasifikasi opini sentimen Twitter dengan metode MNBTree ditampilkan oleh Tabel 10. Berdasarkan Tabel 10, evaluasi model metode MNBTree dilakukan dengan 5 kali cross validasi dengan pembagian 80% data training dan 20 data testing dengan hasil akurasi tertinggi pada fitur 145 dengan rata-rata 21.652%. Sedangkan Evaluasi model metode Multinomial Naive Bayes hasil akurasi tertinggi pada fitur 1665 dengan rata-rata 73.15%. metode Multinomial Naive Bayes dan metode MNBTree jika dibandingkan maka menghasilkan akurasi seperti pada Tabel 11. Pertimbangan pembagian jumlah fitur dari 145 hingga 1665 adalah upaya untuk mencari nilai akurasi tertinggi, adapun penentuan jumlahnya tidak terpaku pada suatu metode tertentu. Berdasarkan Tabel 11 dapat disimpulkan bahwa metode MNB akurasi cenderung meningkat saat fitur bertambah sedangkan metode MNBTree akurasi cenderung meningkat saat fitur berkurang.
Kelebihan dan kekurangan metode MNBTree
Kelebihan metode MNBTree dapat mengurangi konsumsi waktu karena menggunakan ukuran information gain bukan ukuran akurasi klasifikasi untuk membangun pohon keputusan dan dapat menangani data numerik sebagai jawaban dari kelemahan NBTree yang handal pada data nominal (Wang et al., 2014). Adapun kekurangan dalam penelitian ini pada penerapan pelabelan dengan menggunakan kamus Lexicon Bahasa Inggris yang diterjemahkan kedalam Bahasa Indonesia menggunakan google translate menghasilkan beberapa kata yang masih keliru dalam terjemahannya. Selanjutnya dalam tahapan normalisasi masih kurang dalam penerapannya karena keragaman bahasa “gaul” dan bahasa daerah dan ruang lingkup pelabelan kalimat pada penelitian ini hanya mencakup satu kategori kelas.
Tabel 11 Hasil akurasi terhadap evaluasi model klasifikasi opini sentimen Twitter dengan metode MNB dan MNBTree
Fitur 145 181 231 381 1665
20
5
SIMPULAN DAN SARAN
Simpulan
Berdasarkan hasil analisis klasifikasi sentimen Twitter terhadap kinerja layanan provider telekomunikasi menggunakan metode Multinomial Naïve Bayes Tree dapat diambil kesimpulan bahwa dihasilkan root dengan information gain tertinggi pada kata “aktif”, di mana pada metode Multinomial Naïve Bayes probabilitas tertinggi kata “aktif” pada kelas positif. Berdasarkan evaluasi hasil klasifikasi opini sentimen Twitter menggunakan metode MNBTree dihasilkan akurasi tertinggi pada 145 fitur yaitu sebesar 21.65 %. Adapun untuk metode MNB akurasi tertinggi diperoleh dengan menggunakan data lengkap 1665 fitur yaitu sebesar 73.15 %.
Saran
21
DAFTAR PUSTAKA
Aziz A. 2013. Sistem Pengklasifikasian Entitas Pada Pesan Twitter Menggunakan Ekspresi Regular Dan Naïve Bayes. Bogor (ID): Institut Pertanian Bogor.
Bollen J, Mao H, Zeng X. 2011. Twitter mood predicts the stock market. Journal of Computational Science, 2(1), 1–8. http://doi.org/10.1016/j.jocs.2010.12.007
Calvin, Setiawan J. 2014. Using Text Mining to Analyze Mobile Phone Provider Service Quality (Case Study: Social Media Twitter). International Journal of Machine Learning and Computing, 4(1), 106–109. http://doi.org/10.7763/IJMLC.2014.V4.395 Chamlertwat W, Bhattarakosol P. 2012. Discovering Consumer Insight from Twitter via
Sentiment Analysis. J. Ucs, 18(8), 973–992.
http://doi.org/10.1016/j.pragma.2013.12.003
Coletta LFS, De Silva NFF, Hruschka ER, Hruschka ER. 2014. Combining classification and clustering for tweet sentiment analysis. Proceedings - 2014 Brazilian Conference on Intelligent Systems, BRACIS 2014, 210–215. http://doi.org/10.1109/BRACIS.2014.46
DiGrazia J, McKelvey K, Bollen J, Rojas F. 2013. More tweets, more votes: Social media as a quantitative indicator of political behavior. PLoS ONE, 8(11). http://doi.org/10.1371/journal.pone.0079449
Gamallo P, Garcia M, Technology CL. 2014. Citius: A Naive-Bayes Strategy for Sentiment Analysis on English Tweets. Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), (SemEval), 171–175. Retrieved from http://www.aclweb.org/anthology/S14-2026
Hawwash B. 2014. From Tweets to Stories : Using Stream-Dashboard to weave the Twitter data stream into dynamic cluster models, 182–197.
J Han, J Pei, M Kamber. 2012. Data Mining: Concepts and Techniques. Journal of Chemical Information and Modeling (Vol. 3). http://doi.org/10.1017/CBO9781107415324.004
Jansen BJ, Zhang M, Sobel K, Chowdury A. 2009. Twitter power: Tweets as electronic word of mouth. Journal of the American Society for Information Science and Technology, 60(11), 2169. http://doi.org/10.1002/asi.21149
Jiang L, Li C. 2011. Scaling up the accuracy of decision-tree classifiers: A naive-bayes combination. Journal of Computers, 6(7), 1325–1331. http://doi.org/10.4304/jcp.6.7.1325-1331
Kibriya A, Frank E, Pfahringer B, Holmes G. 2005. Multinomial Naive Bayes for Text Categorization Revisited. In AI 2004: Advances in Artificial Intelligence, 488–499. http://doi.org/10.1007/978-3-540-30549-1_43
Kohavi R. 1996. Scaling Up the Accuracy of Naive-Bayes Classifiers: A Decision-Tree Hybrid. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (Vol. 7, pp. 202–207). http://doi.org/citeulike-article-id:3157868
Liu B, Street SM. 2005. Opinion Observer : Analyzing and Comparing Opinions on the Web. Proceedings of the 14th International Conference on World Wide Web, 342– 351. http://doi.org/10.1145/1060745.1060797
Veeraswamy A, Alias SA, E Kannan P. 2013. An Implementation of Efficient Datamining Classification Algorithm using Nbtree. International Journal of Computer Applications, 67(12), 26–29.
Wang S, Jiang L, Li C. 2014. Adapting naive Bayes tree for text classification. Knowledge and Information Systems. http://doi.org/10.1007/s10115-014-0746-y
22
Insight for Indonesian Mobile Operators. In Information Systems International Conference (ISICO) (p. 367).
Wilson TA, Wiebe J, Hoffmann P. 2009. Recognizing Contextual Polarity: an exploration of features for phrase-level sentiment analysis. Computational Linguistics, 35(3), 399–433. http://doi.org/10.1162/coli.08-012-R1-06-90
Wu X, Kumar V, Ross QJ, Ghosh J, Yang Q, Motoda H, Steinberg D. 2008. Top 10 algorithms in data mining. Knowledge and Information Systems, 14(1), 1–37. http://doi.org/10.1007/s10115-007-0114-2
Yu H, Hatzivassiloglou V. 2003. Towards answering opinion questions: separating facts from opinions and identifying the polarity of opinion sentences. Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, 129–136. http://doi.org/10.3115/1119355.1119372
23
24
Lampiran 1 Tampilan hasil running metode MNB 1665 fitur di Weka === Run information ===
Scheme:weka.classifiers.bayes.NaiveBayesMultinomial Relation: transposeNew
Instances: 5182 Attributes: 1665
[list of attributes omitted]
Test mode:5-fold cross-validation
=== Classifier model (full training set) === The independent probability of a class --- positif 0.3118611378977821 negatif 0.4478302796528447 netral 0.2403085824493732
The probability of a word given the class ---
positif negatif netral
abadi 1.8301610541727683E-4 5.8068637129086584E-5 1.2985326580963519E-4
abai 9.15080527086384E-5 1.7420591138725964E-4 2.5970653161927037E-4
abal 9.15080527086384E-5 1.1613727425817317E-4 1.2985326580963519E-4
absen 9.15080527086384E-5 1.1613727425817317E-4 1.2985326580963519E-4
acak 9.15080527086384E-5 5.8068637129086584E-5 2.5970653161927037E-4
acara 9.15080527086384E-5 2.3227454851634636E-4 3.8955979742890534E-4
aceh 9.15080527086384E-5 1.1613727425817317E-4 1.2985326580963519E-4
xperia 9.15080527086384E-5 1.1613727425817317E-4 1.2985326580963519E-4
xxi 9.15080527086384E-5 1.1613727425817317E-4 1.2985326580963519E-4
yahoo 1.8301610541727683E-4 5.8068637129086584E-5 1.2985326580963519E-4
yahud 9.15080527086384E-5 5.8068637129086584E-5 2.5970653161927037E-4
yakin 1.8301610541727683E-4 1.7420591138725964E-4 1.2985326580963519E-4
yogya 9.15080527086384E-5 4.645490970326928E-4 1.2985326580963519E-4
25
youtube 9.15080527086384E-5 6.968236455490387E-4 1.2985326580963519E-4
zalora 9.15080527086384E-5 1.1613727425817317E-4 2.5970653161927037E-4
zenfone 9.15080527086384E-5 1.7420591138725964E-4 1.2985326580963519E-4
zona 9.15080527086384E-5 1.7420591138725964E-4 3.8955979742890534E-4
zone 9.15080527086384E-5 1.1613727425817317E-4 1.2985326580963519E-4
zte 9.15080527086384E-5 1.7420591138725964E-4 1.2985326580963519E-4
Time taken to build model: 0.34 seconds === Stratified cross-validation === === Summary ===
Correctly Classified Instances 3791 73.1571 % Incorrectly Classified Instances 1391 26.8429 % Kappa statistic 0.5765
Mean absolute error 0.2009 Root mean squared error 0.3455 Relative absolute error 46.7673 % Root relative squared error 74.5444 % Total Number of Instances 5182 === Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class 0.786 0.052 0.873 0.786 0.827 0.937 positif
0.839 0.242 0.738 0.839 0.785 0.903 negatif 0.46 0.131 0.527 0.46 0.491 0.829 netral Weighted Avg. 0.732 0.156 0.729 0.732 0.728 0.896 === Confusion Matrix ===
26
Lampiran 2 Tampilan Netbeans IDE 8.0.2
Lampiran 3 Tampilan hasil running data training metode MNBTree 145 fitur pada k-fold 1 di Netbeans
file path : C:\Users\A46CB\Documents\Rdata\140416\fitur 145\trainingset1.csv file name : trainingset1.csvCategory root : ketik
Gains Max-Min : 45 -> ketik = 0.015110 47 -> kirim = 0.014898 28 -> iring = 0.012632 105 -> serbu = 0.011389 46 -> khusus = 0.010924 118 -> spasi = 0.008848 Last Not Zero data (>0) : 339 Next Zero data (=0) : 3865 Changes to Left
Left MNB
MNB Summary Class : negatif (2.707241) Changes to Right
Right
Category root : serbu Gains Max-Min :
27
Changes to Left Left
MNB
MNB Summary Class : netral (2.747058) Changes to Right
Right
Category root : tekan Gains Max-Min :
125 -> tekan = 0.008378 48 -> klik = 0.006100 96 -> pusat = 0.005667 7 -> batas = 0.005251 104 -> sensasi = 0.003944 4 -> aplikasi = 0.003766 Last Not Zero data (>0) : 265 Next Zero data (=0) : 3505 Changes to Left
Left MNB
MNB Summary Class : positif (2.765207) Changes to Right
Right
Category root : klik Gains Max-Min : 48 -> klik = 0.006747 96 -> pusat = 0.005583 104 -> sensasi = 0.004366 4 -> aplikasi = 0.004131 23 -> Indosat = 0.003702 108 -> simcard = 0.003496 Last Not Zero data (>0) : 93 Next Zero data (=0) : 3412 Changes to Left
Left MNB
MNB Summary Class : netral (2.786860) Changes to Right
Right
28
MNB
MNB Summary Class : netral (2.800666) Changes to Right
Right
Category root : aplikasi Gains Max-Min :
4 -> aplikasi = 0.004447 23 -> Indosat = 0.004149 --dan seterusnya--
Processing time : 00:01:26:02
Lampiran 4 Tampilan hasil running data testing metode MNBTree 145 fitur pada k-fold 1 di Netbeans
file path : C:\Users\A46CB\Documents\Rdata\140416\fitur 145\testset1.csv file name : testset1.csv
Statistic Classed Prediction : positif : 199
negatif : 133 netral : 710
================================================== Testing Result Summary :
True Positive on matching to Positive Sentiment : tp_positive = 27 True Positive on matching to Negative Sentiment : tp_negative = 16 True Positive on matching to Neutral Sentiment : tp_neutral = 200 True Negative on matching to Positive Sentiment : tn_positive = 216 True Negative on matching to Negative Sentiment : tn_negative = 227 True Negative on matching to Neutral Sentiment : tn_neutral = 43 False Positive Actual Data on Positive Prediction : fp_positive = 172 False Positive Actual Data on Negative Prediction : fp_negative = 117 False Positive Actual Data on Neutral Prediction : fp_neutral = 510 False Negative Prediction on Positive Actual Data : fn_positive = 407 False Negative Prediction on Negative Actual Data : fn_negative = 304 False Negative Prediction on Neutral Actual Data : fn_neutral = 88
Total True Positive = tp_positive + tp_negative + tp_neutral = 27 + 16 + 200 = 243 Total False Positive = fp_positive + fp_negative + fp_neutral = 172 + 117 + 510 = 799 Total False Negative = fn_positive + fn_negative + fn_neutral = 407 + 304 + 88 = 799 True Prediction : 243
False Prediction : 799
29
---Positive---
Precision = tp_positive / (tp_positive + fp_positive) = 27 / (27 + 172) = 0.135678 Sensitivity = tp_positive / (tp_positive + fn_positive) = 27 / (27 + 407) = 0.062212 Specificity = tn_positive / (tn_positive + fp_neutral) = 216 / ( 216 + 510 ) = 0.556701 F-Score = (2 * tp_positive) / ((2 * tp_positive) + fp_positive + fn_positive) = (2 * 27) / ((2 * 27) + 172 + 407) = 0.085308
---Negative---
Precision = tp_negative / (tp_negative + fp_negative) = 16 / (16 + 117) = 0.120301 Sensitivity = tp_negative / (tp_negative + fn_negative) = 16 / (16 + 304) = 0.050000 Specificity = tn_negative / (tn_negative + fp_negative) = 227 / ( 227 + 117 ) = 0.659884 F-Score = (2 * tp_negative) / ((2 * tp_negative) + fp_negative + fn_negative) = (2 * 16) / ((2 * 16) + 117 + 304) = 0.070640
---Neutral---
Precision = tp_neutral / (tp_neutral + fp_neutral) = 200 / (200 + 510) = 0.281690 Sensitivity = tp_neutral / (tp_neutral + fn_neutral) = 200 / (200 + 88) = 0.694444 Specificity = tn_neutral / (tn_neutral + fp_neutral) = 43 / ( 43 + 510 ) = 0.077758
F-Score = (2 * tp_neutral) / ((2 * tp_neutral) + fp_neutral + fn_neutral) = (2 * 200) / ((2 * 200) + 510 + 88) = 0.400802
================================================== Processing time : 00:00:18:09
30
Lampiran 6 Tampilan komentar Twitter sebanyak 5210 komentar disimpan dalam file .csv
Lampiran 7 Tampilan fungsi pada R untuk pengambilan data Twitter sampai dengan tokenisasi
# Pengambilan data Twitter
data <- read.csv(file="gabungan.csv",head=TRUE,sep=";") library(Twitter)
library(tm)
source('singkatan.R')
myCorpus <- Corpus(VectorSource(data$text)) myCorpus <- tm_map(myCorpus, tolower) for(j in seq(myCorpus))
{
myCorpus[[j]] <- gsub("\\S*(\\S)\\1\\1\\S*\\s?", "", myCorpus[[j]])
myCorpus[[j]] <- gsub("(RT|via)((?:\\b\\W*@\\w+)+)", "" , myCorpus[[j]]) myCorpus[[j]] <- gsub("(@)[[:graph:]]+", "", myCorpus[[j]])
myCorpus[[j]] <- gsub("(http)[[:graph:]]+", "", myCorpus[[j]]) myCorpus[[j]] <- gsub("(#)[[:graph:]]+", "", myCorpus[[j]]) myCorpus[[j]] <- gsub("<-"," ", myCorpus[[j]])
myCorpus[[j]] <- gsub("<-"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("[[:punct:]]", " ", myCorpus[[j]]) myCorpus[[j]] <- gsub("[[:digit:]]", " ", myCorpus[[j]]) }
myCorpus <- tm_map(myCorpus, tolower)
myCorpus <- tm_map(myCorpus, stripWhitespace) for(j in seq(myCorpus))
{
myCorpus[[j]] <- gsub("â™ xâ™"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("™ â˜"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("™ â™"," ", myCorpus[[j]])
31
myCorpus[[j]] <- gsub("”"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("‡"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("™"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("‹"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("˜"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("‚"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("•"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("ï"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("ž"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("„"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("‰"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("ÿ"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("š"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("…"," ", myCorpus[[j]]) myCorpus[[j]] <- gsub("†"," ", myCorpus[[j]]) }
myCorpus <- tm_map(myCorpus, stripWhitespace) library(qdap)
a <- data.frame(myCorpus)
names(a)[names(a)=="text"] <- "text" names(a)[names(a)=="class"] <- "class"
splitsaya<-strsplit(as.character(a$text), split = " ") splitsaya <- lapply(splitsaya, unique)
unlistsaya<-unlist(splitsaya) ok<-NULL
for (i in unlistsaya){
normal<- cari.singkatan(i) ok<-c(ok, normal)
} ---
ok2<-NULL for (i in ok){
normal3<- stemming(i) ok2<-c(ok2, normal3) }
ok2 ---
Length <- sapply(splitsaya, length) for(i in Length){
hasilnormal<-split(ok, rep(seq_along(Length), Length)) }
max.length<-max(sapply(hasilnormal,length))
hasilnormal<-lapply(hasilnormal,function(v) {c (v, rep("",max.length-length(v)))}) hasilnormal<-do.call(rbind,hasilnormal)
hasilnormal<-data.frame(hasilnormal) library(stringr)
newdat <- data.frame(text=str_trim(do.call(paste, hasilnormal)), stringsAsFactors=FALSE)
----
32
stopword <- tolower(stopword[, 1])
stopword <- c(stopword, "", "a", "-", "rt", "...", "&", "|") hasilnormal=tm_map(hasilnormal,removeWords,stopword) hasilnormal1 <- tm_map(hasilnormal1, stripWhitespace) for(j in seq(hasilnormal1))
{
hasilnormal1[[j]] <- gsub("^\\s+|\\s+$", "", hasilnormal1[[j]]) }
write.csv(baru, file = "pascaSingkatan.csv") #skoring
positif <- scan("C:/Users/A46CB/Documents/Rdata/140416/korpus positif.txt",what="character",comment.char=";")
negatif <- scan("C:/Users/A46CB/Documents/Rdata/140416/korpus negatif.txt",what="character",comment.char=";")
kata.positif = c(positif, "terima kasih banyak") kata.negatif = c(negatif, "tidak bisa")
score.sentiment = function(kalimat2, kata.positif, kata.negatif, .progress='none') {
require(plyr) require(stringr)
scores = laply(kalimat2, function(kalimat, kata.positif, kata.negatif) { kalimat = gsub('[[:punct:]]', '', kalimat)
positif.matches = match(kata2, kata.positif) negatif.matches = match(kata2, kata.negatif) positif.matches = !is.na(positif.matches) negatif.matches = !is.na(negatif.matches)
score = sum(positif.matches) - sum(negatif.matches) return(score)
}, kata.positif, kata.negatif, .progress=.progress ) scores.df = data.frame(score=scores, text=kalimat2) return(scores.df)
}
v <- Corpus(VectorSource(baru$text))
hasil = score.sentiment(v, kata.positif, kata.negatif) hasil
33
hasil.scores = score.sentiment(v, kata.positif, kata.negatif, .progress='text') View(hasil.scores)
write.csv(hasil, file = "skor.csv") #frekuensi
tdm <- TermDocumentMatrix(v) tdm
temp<-inspect(tdm)
DF <- data.frame(inspect(TermDocumentMatrix(v))) %>% add_rownames() %>%
mutate_each(funs(replace(., . > 1, 1)), -rowname) %>% mutate(DF = rowSums(.[-1])) %>%
#ambil data frekuensi yang sudah di transpose
34
1746:1753,1757:1758,1762,1764:1767,1769:1770,1772:1774,1776,1779:1780,1782,1787 ,1790:1791,1793,1796:1799,1801:1803,1805,1807:1808,1810,1814:1822)]
write.csv(transpose.new, file="transposeNew.csv")
35
Lampiran 9 Tampilan proses training data menggunakan metode Multinomial Naive
36