ANALISIS KOMPONEN UTAMA KERNEL:
SUATU STUDI EKSPLORASI PEMBAKUAN PEUBAH
PUTRI THAMARA
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Analisis Komponen Utama Kernel: Suatu Studi Eksplorasi Pembakuan Peubah adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, November 2014
Putri Thamara
ABSTRAK
PUTRI THAMARA. Analisis Komponen Utama Kernel: Suatu Studi Eksplorasi Pembakuan Peubah. Dibimbing oleh SISWADI dan TONI BAKHTIAR.
Analisis Komponen Utama Kernel (AKUK) merupakan perluasan dari Analisis Komponen Utama (AKU) yang berguna untuk menyelesaikan masalah data yang takterpisah atau taklinear. AKUK adalah AKU yang diterapkan di ruang fitur, yang merupakan ruang hasil pemetaan objek-objek dari ruang asal. Pada AKUK, data asal dipetakan ke ruang fitur. Namun tidak semua hasil pemetaannya diketahui, sehingga nilai eigen dan vektor eigen hanya dapat diperoleh dari matriks dual hasil pemetaan tersebut di ruang fitur, tidak dari matriks primalnya. Hasil kali dalam dari pemetaan di ruang fitur disebut dengan fungsi kernel. Fungsi kernel polinom memiliki hasil pemetaan yang jelas sehingga pembakuan peubah di ruang fitur dapat dieksplorasi. Pada karya tulis ini, eksplorasi pembakuan peubah diterapkan pada data pengenalan anggur (Forina 1991). Eksplorasi pembakuan peubah tersebut memberikan gambaran bahwa ada perbedaan pada waktu pembakuan dilakukan terhadap konfigurasi yang terbentuk dan terhadap nilai salah klasifikasinya. Perbedaan hasil pembakuan peubah tercermin dari ukuran kemiripan dan nilai salah klasifikasinya.
Kata kunci: Analisis Komponen Utama, Analisis Komponen Utama Kernel, Fungsi Kernel Polinom, Pembakuan Peubah
ABSTRACT
PUTRI THAMARA. Kernel Principal Component Analysis: an Exploratory Study on Standardization of Variables. Supervised by SISWADI and TONI BAKHTIAR.
Kernel Principal Component Analysis (KPCA) is an extension of the Principal Component Analysis (PCA) which are useful to solve the problem of data which are unseparable or nonlinear. The KPCA is also considered as a PCA applied in the feature space. In the KPCA, the original data were mapped into the feature space. However, if they are mapping results are unknown, therefore the eigenvalues and eigenvectors can only be obtained from the dual matrix mapping results in the feature space, not from the primal matrix. An inner product of the mapping in the feature space called the kernel function. The Polynomial kernel function has a clear mapping results, so that standardization of variables in the feature space could be explored. In this paper, exploratory on standardization of variables were applied into the wine recognition datasets (Forina 1991). Exploratory on standardization of the variables illustrate that there is a difference on time of standardization conducted into the configuration and to the missclassification error. The difference in the results of standardization of variables reflected goodness of fit and value of the missclassification error.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Sains
pada
Departemen Matematika
ANALISIS KOMPONEN UTAMA KERNEL:
SUATU STUDI EKSPLORASI PEMBAKUAN PEUBAH
PUTRI THAMARA
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Analisis Komponen Utama Kernel: Suatu Studi Eksplorasi Pembakuan Peubah
Nama : Putri Thamara NIM : G54100050
Disetujui oleh
Prof Dr Ir Siswadi, MSc Pembimbing I
Dr Toni Bakhtiar, MSc Pembimbing II
Diketahui oleh
Dr Toni Bakhtiar, MSc Ketua Departemen
PRAKATA
Alhamdulillaahirabbil’aalamiin. Puji dan syukur Penulis panjatkan ke hadirat Alloh SWT atas segala nikmat dan karunia-Nya sehingga karya ilmiah ini dapat diselesaikan. Penulis karya ilmiah ini juga tidak lepas dari bantuan dan dukungan dari berbagai pihak. Untuk itu Penulis mengucapkan terimakasih kepada Prof Dr Ir Siswadi, MSc dan Dr Toni Bakhtiar, MSc sebagai dosen pembimbing I dan dosen pembimbing II, serta kepada Bapak Ir Ni Komang Kutha Ardhana, MSc sebagai dosen penguji atas semua ilmu, nasihat, kesabaran, motivasi, dan bimbingannya selama penulisan skripsi ini. Selain itu, Penulis juga mengucapkan terimakasih kepada Kak Wirdania yang telah bersedia manjadi tempat untuk bertanya, Pak Deni yang membantu menginstal software-software
yang diperlukan, dan tentunya kepada Mamah dan Bapak yang setiap hari selalu mengingatkan dan mendoakan agar karya tulis ini dapat segera diselesaikan.
Semoga karya ilmiah ini dapat bermanfaat dan menjadi inspirasi bagi penelitian-penelitian selanjutnya.
Bogor, November 2014
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 1
TINJAUAN PUSTAKA 2
METODE 11
Sumber Data 11
Prosedur Analisis Data 11
HASIL DAN PEMBAHASAN 13
SIMPULAN DAN SARAN 19
Simpulan 19
Saran 19
DAFTAR PUSTAKA 20
LAMPIRAN 21
DAFTAR TABEL
1 Klasifikasi kelompok 13
2 Deskripsi data pengenalan anggur 13
3 Proporsi total varians yang ditampilkan oleh dua komponen utama pertama15 4 Nilai perbedaan minimum matriks X terhadap matriks Y dari berbagai
kondisi dengan seluruh komponen utama 16
5 Nilai perbedaan minimum matriks X terhadap matriks Y dari berbagai
kondisi dengan dua komponen utama pertama 16
6 Ukuran kesesuaian matriks X terhadap Y dari berbagai kondisi dengan
seluruh komponen utama 17
7 Ukuran kesesuaian matriks X terhadap Y dari berbagai kondisi dengan
dua komponen utama pertama 17
8 Klasifikasi kelompok data asal tanpa pembakuan (I) 18 9 Klasifikasi kelompok data asal terkoreksi atau baku (II) 18 10 Klasifikasi kelompok menggunakan metode kernel (III) 18
DAFTAR GAMBAR
1 Ilustrasi pemetaan data ke ruang fitur 6
2 Konfigurasi AKUK primal dengan data asal tanpa pembakuan (I) 14 3 Konfigurasi AKUK primal dengan data asal terkoreksi atau baku (II) 14
4 Konfigurasi AKU Kernel dual dengan data asal baku (III) 15
DAFTAR LAMPIRAN
1 Data Pengenalan Anggur (Wine Recognition Data) 21
2 Data dua komponen utama pertama dari berbagai kondisi 25 3 Fungsi yang digunakan untuk memperoleh nilai perbedaan minimum
antarkonfigurasi 29
4 Fungsi yang digunakan untuk memperoleh matriks komponen utama
PENDAHULUAN
Latar Belakang
Permasalahan yang sering muncul dalam penelitian ialah banyaknya peubah yang terlibat sehingga terlalu kompleks untuk langsung diinterpretasikan. Oleh karena itu, diperlukan suatu teknik untuk menyederhanakannya. Dalam statistika, masalah semacam itu umumnya diselesaikan dengan menggunakan analisis peubah ganda. Salah satu jenis analisis peubah ganda adalah Analisis Komponen Utama (AKU), yaitu suatu analisis statistika yang digunakan untuk mereduksi dimensi data berukuran besar dengan mempertahankan sebanyak mungkin informasi yang terkandung pada data asalnya dengan membentuk peubah baru yang tidak berkorelasi yang merupakan kombinasi linear dari peubah-peubah asalnya dan beragam terurut. Peubah baru ini disebut dengan komponen utama.
Meskipun AKU sering dan baik digunakan untuk mereduksi dimensi data, namun AKU juga masih memiliki keterbatasan. Keterbatasan yang paling menonjol dari AKU adalah ketidakmampuannya dalam mengatasi masalah data yang taklinear dan tak terpisah. Untuk itu ditemukan perluasan dari AKU, yaitu AKU Kernel. Pada dasarnya, AKU merupakan AKU Kernel dengan fungsi kernel polinom berderajat satu. Pada AKU Kernel ini, terlebih dahulu dilakukan pemetaan data ke ruang fitur sehingga membentuk vektor-vektor baru di ruang fitur. Hasil kali dalam dari vektor-vektor tersebut disebut dengan fungsi kernel. AKU Kernel ini merupakan AKU yang diterapkan di ruang fitur.
Pada AKU Kernel, matriks komponen utama dapat diperoleh dari formula primal dan formula dual. Namun pada fungsi kernel yang hasil pemetaan di ruang fiturnya tidak diketahui, formula primal tidak dapat digunakan. Salah satu fungsi kernel yang sering digunakan adalah fungsi kernel polinom. Untuk fungsi kernel ini, hasil pemetaan di ruang fiturnya jelas, sehingga matriks komponen utama dapat diperoleh melalui formula primalnya.
Bila peubah asal memiliki varians yang jauh berbeda akan menyebabkan adanya peubah yang memberikan kontribusi varians yang dominan sebagai penentu komponen utama. Salah satu upaya untuk mengendalikannya adalah dengan melakukan pembakuan peubah. Dalam karya tulis ini, akan dilakukan eksplorasi mengenai pengaruh pembakuan peubah yang dilakukan di ruang asal, atau ruang fitur, atau keduanya (ruang asal dan ruang fitur) terhadap konfigurasi yang terbentuk dan terhadap salah klasifikasi yang diperoleh.
Untuk menelusuri seberapa jauh berbeda, konfigurasi titik yang diperoleh dari setiap pembakuan perlu dibandingkan. Salah satu teknik analisis yang digunakan untuk membandingkan suatu konfigurasi terhadap konfigurasi yang lainnya ialah Analisis Procrustes (Procrustes Analysis) sehingga menghasilkan
suatu ukuran kesesuaian. Selain itu, pengaruh pembakuan peubah juga akan dilihat dari nilai salah klasifikasinya.
Tujuan Penelitian
2
TINJAUAN PUSTAKA
Nilai Eigen dan Vektor Eigen
Misalkan adalah suatu matriks . Skalar disebut sebagai nilai eigen atau nilai karakteristik dari jika terdapat suatu vektor taknol , sehingga
. Vektor disebut vektor eigen atau vektor karakteristik matriks yang
bersesuaian dengan . (Leon 2014)
Nilai Singular
Misalkan adalah suatu matriks . Nilai-nilai singular dari adalah akar dari nilai eigen yang positif dari matriks atau . (Leon 2014)
Teras
Misalkan Y ( ) adalah suatu matriks . Teras (trace) dari matriks Y atau ditulis tr Y merupakan jumlah elemen-elemen diagonal utama dari Y:
tr Y ∑ . (Leon 2014) Jarak Euclid
Jarak Euclid antara dan dari matriks didefinisikan sebagai
( ) √( ) ( ) . (Jolliffe 2002)
Analisis Komponen Utama
Analisis Komponen Utama (AKU) adalah analisis peubah ganda yang paling tua dan sudah banyak digunakan. Analisis ini pertama kali diperkenalkan oleh Pearson pada tahun 1901 kemudian oleh Hotelling pada tahun 1935 (SchÖlkopf dan Smola 2002). Ide pokok analisis ini ialah mereduksi dimensi data
berukuran besar dari data dengan p peubah yang saling berkorelasi dengan mempertahankan sebanyak mungkin variasi yang terdapat pada data. Meskipun dibutuhkan p komponen untuk menunjukkan keseluruhan variasi data, namun
seringkali variasi ini dapat diwakili oleh k komponen utama pertama, dengan
(Jollife 2002), sehingga data asal yang mengandung n objek dengan p
peubah dapat direduksi menjadi n objek dengan k komponen utama.
Misalkan adalah vektor dengan p peubah acak, ( ) memunyai matriks kovarians Σ dengan nilai eigen . Misalkan kombinasi linear memiliki varians terbesar, dengan merupakan vektor koefisien . Kombinasi linear dapat dituliskan sebagai berikut
∑ .
Kombinasi linear kedua, , tidak berkorelasi dengan . Kombinasi linear ini memiliki varians terbesar kedua, dan seterusnya, sehingga kombinasi linear ke-k,
3
Untuk menentukan komponen utama pertama, pandang kombinasi linear pertama dan vektor yang memaksimumkan . Nilai
dapat terus membesar bila dikalikan dengan suatu konstanta yang lebih
besar dari satu maka dibutuhkan batasan , yaitu jumlah kuadrat elemen sama dengan 1. Untuk komponen utama pertama yang ingin memaksimumkan
[ ] dengan kendala dapat diselesaikan
melalui persamaan Lagrange berikut
dengan adalah pengganda Lagrange, kemudian mencari titik kritis dari persamaan Lagrange dapat dilakukan dengan cara mencari turunan pertama terhadap sebagai berikut: adalah nilai eigen dari dan merupakan vektor eigen yang bersesuaian. Untuk menentukan vektor eigen yang memberikan kombinasi linear dengan varians terbesar, kuantitas yang akan dimaksimumkan ialah
.
Dengan demikian agar maksimum maka haruslah merupakan nilai eigen terbesar dari matriks kovarians dan merupakan vektor eigen yang bersesuaian dengan nilai eigen terbesar dari .
4
Jika persamaan (2) dikalikan dengan didapatkan
.
merupakan persamaan eigen dari matriks . Dengan demikian merupakan nilai eigen dan merupakan vektor eigen yang bersesuaian. Untuk menentukan vektor eigen yang memberikan kombinasi linear dengan varians terbesar, kuantitas yang akan dimaksimumkan ialah
.
Karena nilai eigen terbesar pertama merupakan varians dari komponen utama pertama maka dipilih nilai eigen terbesar kedua dari matriks . Demikian juga dengan vektor eigen merupakan vektor eigen yang bersesuaian dengan nilai eigen terbesar kedua .
Berdasarkan uraian sebelumnya, dapat ditunjukkan bahwa komponen utama ketiga, keempat sampai ke-p, vektor koefisien merupakan vektor
eigen yang bersesuaian dengan nilai eigen , secara berturut-turut. Secara umun, komponen utama ke-k dari X adalah dan
] untuk , ,…,
dengan merupakan nilai eigen terbesar ke-k dan adalah vektor eigen yang
bersesuaian.
Apabila varians antarpeubah memiliki perbedaan cukup besar akan mengakibatkan salah satu peubah menjadi dominan dalam menentukan komponen utama, maka biasanya digunakan matriks korelasi
ρ
. Bila peubah telah dibakukan sebagai berikutApabila matriks kovarians populasi dan matriks korelasi dari populasi
ρ
tidak diketahui, maka dapat diduga dengan matriks kovarians contoh S5
⁄ (
√ √ √ ), dalam hal ini adalah matriks data yang
sudah terkoreksi nilai tengahnya.
Formulasi primal dianalisis dengan ⁄ yang berukuran . Formulasi primal memiliki permasalahan persamaan eigen sebagai berikut
Formulasi primal sangat baik digunakan saat ukuran , sehingga dapat meringkas dalam menyelesaikan masalah persamaan eigen. Selain formulasi primal dijelaskan pula tentang formulasi dual. Formulasi dual dianalisis dengan
⁄ yang berukuran dalam amatan dapat menjadi sangat besar.
Formulasi dual memiliki permasalahan persamaan eigen sebagai berikut
dengan adalah nilai eigen dan adalah vektor eigen yang bersesuaian dengan . Jika persamaan ini dikalikan dari kiri maka akan diperoleh
proporsional dengan , atau dilambangkan dengan , yaitu sebuah vektor eigen dari matriks kovarians S dengan nilai eigen . Dalam hal ini nilai
eigen yang diperoleh dari kedua formulasi adalah sama-sama , dan dengan mengasumsikan vektor eigen adalah vektor satuan ( ) diperoleh
√ .
Jika dan berpangkat , ⁄ dan
⁄ memunyai r nilai eigen taknol yang sama dan bahwa vektor
eigennya saling terkait yaitu ⁄√ dan ⁄√ . Total varians yang dijelaskan oleh komponen utama adalah ∑ yang merupakan total varians peubah asal, sehingga proporsi total varians dari k
komponen utama pertama (Pk) ialah
di mana k≤ p .
Analisis Komponen Utama Kernel
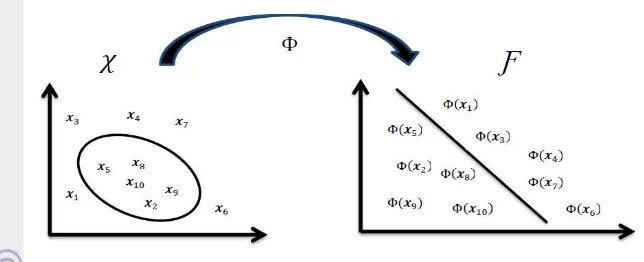
Analisis Komponen Utama Kernel (AKUK) adalah suatu analisis yang dapat menunjukkan bentuk taklinear dari AKU. Dengan menggunakan fungsi kernel dapat diperoleh komponen utama secara lebih efisien dalam dimensi yang lebih tinggi di ruang fitur. Dalam AKUK dikenal kernel trick, yaitu suatu cara yang memberikan kemudahan karena hanya cukup mengetahui fungsi kernel yang digunakan dan tidak perlu mengetahui wujud dari fungsi pemetaan taklinearnya.
Misalkan dinotasikan pemetaan Φ dari ruang input ke ruang fitur dengan
Φ : → Ƒ
6
Gambar 1 Ilustrasi pemetaan data ke ruang fitur
di mana data asal berada dalam ruang dan fitur dalam Ƒ. Permasalahan muncul karena bentuk konkret dan dimensi dari Ƒ tidak semua diketahui. Namun permasalahan tersebut dapat diselesaikan menggunakan kernel trick.
Hasil kali dalam dari pemetaan data merupakan fungsi kernel. Kernel adalah sebuah fungsi k di mana memenuhi
k( , ) . (Shen 2007)
Dimensi Ƒ dapat memunyai perubahan dimensi yang besar dan mungkin tak
terbatas (Shen 007). Pemetaan Φ mungkin taklinear dan tak dapat dijelaskan secara eksplisit. Matriks data hasil pemetaan di ruang fitur adalah sebagai berikut :
Φ di ruang fitur dan nilainya bisa sangat besar atau tak terbatas.
Asumsikan bahwa data dalam ruang fitur memunyai rata-rata nol, yaitu
∑ 0 , sehingga matriks kovarians memiliki bentuk
S
∑ yang bersesuaian dengan formulasi primal sebagai berikut
.
Untuk formulasi dual yang bersesuaian diperoleh
,
di mana digunakan kembali simbol sebagai nilai eigen dan vektor eigen secara berturut-turut. Seperti pada AKU, nilai eigen taknol untuk formulasi primal dan dual adalah sama dan vektor eigen dihubungkan dengan
7
Pada kenyataannya tidak dapat diasumsikan bahwa data pada ruang fitur sudah terkoreksi terhadap nilai tengahnya. Oleh karena itu agar matriks terkoreksi nilai tengah, digunakan di mana
√ .
Untuk mendapatkan skor komponen utama kernel dari permasalahan nilai eigen, proyeksikan pemetaan x atas vektor eigen primal
⁄√
⁄√
⁄√
⁄√ .
Berikut merupakan tiga fungsi kernel yang biasa digunakan
Gauss : k( exp( ‖ ‖ ,
Polinom : k( ( ) ,
Sigmoid : k( tanh(k( ) + θ) .
Sebelum menggunakan fungsi kernel, harus ditentukan terlebih dahulu fungsi k( , ) untuk memastikan bahwa fungsi tersebut adalah fungsi kernel untuk beberapa ruang fitur. Oleh karena itu, perlu diketahui beberapa hal yang berhubungan dengan fungsi kernel, yaitu:
1. Fungsi kernel harus simetrik
( , ) k( , ) .
2. Memenuhi ketaksamaan Cauchy-Schwarz
‖ ‖ ‖ ‖
.
Misalkan pemetaan ke ruang fitur diberikan sebagai berikut
: x = ( , ) → (x) = ( √ ) .
Pemetaan mengambil data dari ruang input dua dimensi dan memetakan ke ruang fitur tiga dimensi. Komposisi dari pemetan fitur dengan hasil kali dalam pada ruang fitur dapat dievaluasi sebagai berikut:
( √ ) √
.
Karenanya, fungsi
8
3)
merupakan sebuah fungsi kernel dengan ruang fitur yang bersesuaian. Hal tersebut berarti dapat menghitung hasil kali dalam antara proyeksi dari dua titik ke dalam ruang fitur tanpa mengevaluasi koordinatnya secara eksplisit.
Dekomposisi Nilai Singular (DNS) atas vektor eigen yang ortonormal dan berpadanan dengan nilai eigen taknol i
dari matriks dalam bentuk
(√ √ √ ) .
Matriks adalah matriks yang kolom-kolomnya merupakan vektor eigen yang ortonormal dan berpadanan dengan nilai eigen taknol i dari matriks dalam bentuk
( √ √ √ ) .
Dekomposisi Nilai Singular Bentuk Lengkap (DNSBL)
Setiap matriks berdimensi dapat dinyatakan sebagai bentuk Dekomposisi Nilai Singular Bentuk Lengkap (DNSBL) sebagai berikut:
di mana dengan adalah matriks identitas berukuran n,
dengan adalah matriks identitas berukuran , dan
(√ √ √ )
.
Dalam hal ini merupakan pangkat matriks dengan . Matriks
9
Analisis Procrustes
Misalkan adalah matriks berukuran dan berukuran yang masing-masing merupakan representasi konfigurasi yang akan dibandingkan. Koordinat titik ke- pada ruang Euclid diberikan oleh nilai-nilai pada baris ke-Procrustes menggunakan jumlah kuadrat jarak antartitik yang bersesuaian, yaitu:
∑ ∑( )
. (3)
Nilai perbedaan minimum dihitung dengan menggunakan tiga transformasi geometris yaitu translasi, rotasi, dan dilasi yang diberikan oleh Bakhtiar dan Siswadi (2011).
1. Translasi
Misalkan ( ), maka sentroid kolom dari matriks dinotasikan sebagai
, di mana ∑ , .
Dalam analisis Procrustes, translasi diartikan sebagai proses pemindahan seluruh titik dengan jarak yang tetap dan arah yang sama.
∑ ∑ [( ) ( )] kuadrat dari kedua sentroid kolom dan . Penyesuaian optimal dengan translasi dapat dilakukan dengan menghimpitkan sentroid kolom dan sehingga
. Dengan demikian, nilai perbedaan minimum dari konfigurasi dan setelah dilakukan penyesuaian optimal dengan translasi ialah
∑ ∑ [( ) ( )] .
2. Rotasi
10
8)
terhadap dilakukan dengan mengalikan matriks dengan matriks ortogonal , dengan .
Nilai perbedaan minimum dari konfigurasi dan setelah dilakukan penyesuaian dengan rotasi ialah
.
Berdasarkan persamaan (3), nilai perbedaan pada penyesuaian dengan rotasi dapat dituliskan sebagai
.
Nilai yang maksimum akan meminimumkan . Jadi, harus dipilih matriks ortogonal yang memaksimumkan . adalah matriks ortogonal yang diperoleh dari Dekomposisi Nilai Singular Bentuk Lengkap (DNSBL) matriks . Jika DNSBL matriks adalah , maka
Q .
Dengan menggunakan matriks Q tersebut, nilai perbedaan minimum dari
konfigurasi dan setelah dilakukan penyesuaian optimal dengan rotasi ialah
.
3. Dilasi
Dilasi merupakan proses penskalaan data melalui pembesaran/pengecilan jarak setiap titik dalam konfigurasi terhadap sentroidnya. Dilasi terhadap dilakukan dengan cara mengalikan konfigurasi dengan suatu skalar . Nilai perbedaan minimum dari dua konfigurasi dan setelah dilakukan penyesuaian dengan dilasi ialah
.
Berdasarkan persamaan (3), nilai perbedaan pada penyesuaian dengan dilasi dapat dituliskan sebagai
. (5) Persamaan (5) merupakan bentuk fungsi kuadrat dengan variabel sehingga untuk meminimumkan nilai , turunan pertamanya harus sama dengan nol dan turunan keduanya lebih besar dari nol.
Dengan menyubstitusikan nilai , nilai perbedaan minimum setelah penyesuaian optimal dengan dilasi menjadi
( )
11
Dengan menggunakan aljabar sederhana, secara analitik telah dibuktikan bahwa dalam analisis Procrustes, urutan pengerjaan yang menghasilkan jarak paling minimum adalah translasi-rotasi-dilasi. Bukti dapat dilihat di Bakhtiar dan Siswadi (2011).
Ukuran kesesuaian analisis Procrustes diberikan sebagai berikut
adalah hasil analisis kimia dari anggur yang tumbuh di daerah yang sama di Italia, tetapi berasal dari tiga budidaya/kultivar yang berbeda. Data tersebut terdiri atas 178 objek dan 13 peubah yaitu kadar alkohol (alcohol), kadar asam malat (malic acid), banyaknya abu (ash), banyaknya alkali pada abu (alcanity of ash), kadar magnesium (magnesium), kadar fenol (total phenols), kadar flavonoid
(flavonoids), kadar fenol bukan flavonoid (nonflavonoids phenols), kadar
proanthosianin (proanthocyanins), intensitas warna (color intensity), warna
berdasarkan tingkat kecerahannya (hue), anggur yang diencerkan pada OD280/OD315 (OD280/OD315 of diluted wines), dan kadar prolina (proline).
Dari 178 objek terbagi ke dalam 3 kelompok yaitu kelompok anggur yang berasal dari budidaya 1, budidaya 2, dan budidaya 3 yang banyaknya objek dari tiap kelompok berturut-turut adalah 59, 71, dan 48 objek.
Prosedur Analisis Data
Pada karya tulis ini, matriks data di ruang asal yang bedimensi 178 13 diperluas menjadi matriks data berdimensi 178 105 di ruang fitur. Perluasan ini didasarkan pada pemetaan kernel polinom berderajat 2 dengan parameter . Hal tersebut menyebabkan matriks data hasil pemetaan di ruang fitur merupakan komposisi dari bentuk konstanta, linear, cross product, dan kuadratik dari peubah-peubah asalnya.
Secara umum, matriks berukuran 178 105 tersebut dibakukan, selanjutnya dicari model primalnya (bersesuaian dengan matriks korelasi di ruang fitur) kemudian didapatkan nilai eigen dan vektor eigen yang merupakan solusi dari persamaan nilai eigennya. Kemudian untuk menggambarkan konfigurasi, diambil dua komponen utama yang diperoleh dari dua nilai eigen terbesar pertama.
Eksplorasi dilakukan terhadap tiga kondisi, yaitu:
12
II. Matriks data asli terkoreksi atau baku dipetakan ke ruang fitur. Setelah itu hasil pemetaan di ruang fitur dibakukan. Selanjutnya matriks data baku di ruang fitur dikerjakan menggunakan AKU.
(Catatan: Matriks data hasil pembakuan di ruang fitur baik pada matriks data asal terkoreksi maupun matriks data asal baku adalah sama).
III. Matriks data asal yang sudah baku dikerjakan menggunakan metode Kernel dengan fungsi kernel polinom berderajat 2 dan parameter . Berikut adalah tahapan yang dilakukan untuk mengerjakan menggunakan metode kernel:
1. Menentukan fungsi kernel yang akan digunakan, dalam hal ini fungsi kernel polinom berderajat 2 dengan parameter . Kemudian menghitung matriks kernel yang elemen-elemennya adalah fungsi kernel = k( = ( ) yang merupakan hasil kali dalam dari vektor-vektor di ruang fitur.
2. Mengoreksi matriks kernel dengan di mana
√ .
3. Menyelesaikan permasalahan nilai eigen dari matriks dengan persamaan . Dua vektor eigen yang bersesuaian dengan dua nilai eigen terbesar pertama kemudian dijadikan sebagai koefisien-koefisien pada komponen utama 1 dan komponen utama 2. 4. Untuk menemukan skor komponen utama kernel dari permasalahan nilai
eigen, proyeksikan pemetaan x atas vektor eigen primal
/√
√ ,
di mana i 1, 2 .
Setelah diperoleh matriks-matriks komponen utamanya, kemudian divisualisasikan menjadi konfigurasi atau plot pencaran menggunakan software
Minitab. Dari konfigurasi-konfigurasi tersebut akan diperoleh gambaran bagaimana perbedaan plot pencaran dari masing-masing pembakuan secara visual. Untuk memperoleh ukuran kesesuaiannya, pertama-tama dicari terlebih dahulu nilai perbedaan minimum antar konfigurasi dengan melakukan penyesuaian translasi, rotasi, dan dilasi . Selanjutnya adalah mencari ukuran kesesuaian (goodness of fit) dari analisis Procrustes yaitu
) 100% .
Salah satu tolok ukur dalam menentukan keberhasilan suatu klasifikasi adalah dengan melihat nilai salah klasifikasinya (misclassification error). Semakin kecil nilai salah klasifikasinya maka semakin baik. Pengklasifikasian yang dilakukan dalam karya tulis ini menggunakan jarak Euclid untuk ruang dimensi dua dengan menghitung kuadrat jarak terkecil antara objek baru ( , ) menggunakan dua komponen utama pertama terhadap rataan dari setiap kelompok, yaitu rataan kelompok 1 ( ̅ ), rataan kelompok 2 ( ̅ ), dan rataan kelompok 3 ( ̅ ) sebagai berikut
̅ ̅ ̅ di mana k = .
Objek masuk ke dalam kelompok k jika .
13
Tabel 1 Klasifikasi kelompok
Kelompok asal (k) 1 Kelompok Prediksi (2 j) 3 Total
1
2
3
Total
Salah Klasifikasi (SK) ( ∑ ) , dengan banyaknya anggota kelompok k yang diklasifikasikan ke dalam kelompok j.
HASIL DAN PEMBAHASAN
Data yang digunakan dalam karya ilmiah ini adalah data sekunder yang diperoleh dari internet, yaitu data pengenalan anggur (Forina 1991). Data ini adalah hasil analisis kimia dari anggur yang tumbuh di daerah yang sama di Italia, tetapi berasal dari tiga budidaya/kultivar yang berbeda. Data tersebut terdiri atas 178 objek dan 13 peubah yaitu kadar alkohol (alcohol), kadar asam malat (malic acid), banyaknya abu (ash), banyaknya alkali pada abu (alcanity of ash), kadar
magnesium (magnesium), kadar fenol (total phenols), kadar flavonoid
(flavonoids), kadar fenol bukan flavonoid (nonflavonoids phenols), kadar
proanthosianin (proanthocyanins), intensitas warna (color intensity), warna
berdasarkan tingkat kecerahannya (hue), anggur yang diencerkan pada OD280/OD315 (OD280/OD315 of diluted wines), dan kadar prolina (proline).
Dari 178 objek terbagi ke dalam 3 kelompok yaitu kelompok anggur yang berasal dari budidaya 1, budidaya 2, dan budidaya 3 yang banyaknya objek dari tiap kelompok berturut-turut adalah 59, 71, dan 48 objek.
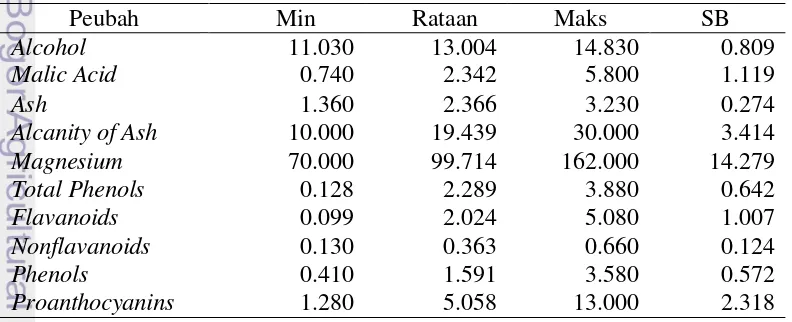
Berikut ini ditampilkan tabel yang berisi deskripsi data pengenalan anggur secara ringkas. Tabel tersebut menggambarkan nilai minimum, rataan, nilai maksimum, dan simpangan baku (SB) dari setiap peubah.
Tabel 2 Deskripsi data pengenalan anggur
Peubah Min Rataan Maks SB
Alcohol 11.030 13.004 14.830 0.809
Malic Acid 0.740 2.342 5.800 1.119
Ash 1.360 2.366 3.230 0.274
Alcanity of Ash 10.000 19.439 30.000 3.414
Magnesium 70.000 99.714 162.000 14.279 Total Phenols 0.128 2.289 3.880 0.642
Flavanoids 0.099 2.024 5.080 1.007
Nonflavanoids 0.130 0.363 0.660 0.124
Phenols 0.410 1.591 3.580 0.572
14
Tabel tersebut memberikan informasi bahwa peubah proline memiliki simpangan baku paling besar. Simpangan baku antara peubah tersebut dengan peubah yang lain memiliki perbedaan yang cukup besar. Sehingga peubah tersebut akan dominan dalam menentukan komponen utama. Rata-rata dan SB pada tabel tersebut akan digunakan untuk pembakuan pada data asal.
Dalam penelitian ini, fungsi kernel yang digunakan adalah fungsi kernel polinom berderajat 2. Alasan pemilihan fungsi kernel tersebut karena hasil pemetaan di ruang fiturnya diketahui dengan jelas sehingga dapat dilakukan eksplorasi pembakuan peubah di ruang fiturnya, yang selanjutnya dapat dijadikan sebagai pembanding dengan hasil yang diperoleh melalui metode kernel untuk melihat seberapa jauh berbeda, karena dengan menggunakan metode kernel artinya nilai eigen dan vektor eigen hanya dapat diperoleh dari matriks yang setara dengan matriks kovarians ruang fiturnya, tidak dari matriks korelasinya.
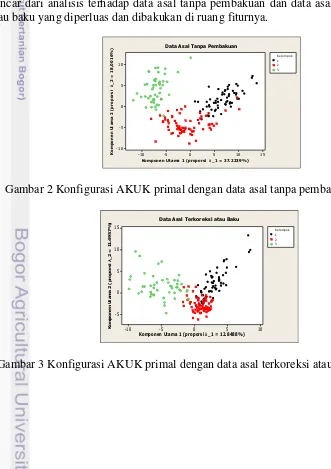
Gambar 2 dan 3 di bawah ini merupakan visualisasi konfigurasi atau plot pencar dari analisis terhadap data asal tanpa pembakuan dan data asal terkoreksi atau baku yang diperluas dan dibakukan di ruang fiturnya.
Gambar 2 Konfigurasi AKUK primal dengan data asal tanpa pembakuan (I)
Gambar 3 Konfigurasi AKUK primal dengan data asal terkoreksi atau baku (II)
15
Komponen Utama 1 (proporsi λ_1 = 37.2239%)
15
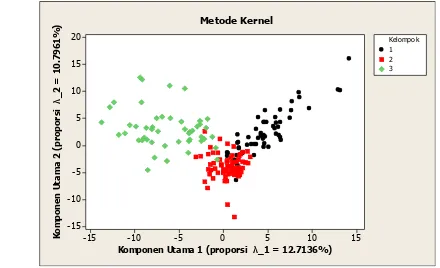
Konfigurasi yang diperoleh dengan menggunakan metode kernel dapat dilihat pada Gambar 4.
Komponen Utama 1 (proporsi λ_1 = 12.7136%)
K
Gambar 4 Konfigurasi AKUK dual dengan data asal baku (III)
Berikut ini adalah tabel yang memberikan informasi mengenai proporsi varians yang ditampilkan oleh dua komponen utama pertama.
Tabel 3 Proporsi total varians yang ditampilkan oleh dua komponen utama tanpa pembakuan dan terkoreksi atau baku yang dikerjakan menggunakan AKU Kernel dalam formula primal baku atau setara dengan matriks korelasi di ruang fiturnya.
Berdasarkan Tabel 3, saat data asal tidak dibakukan, proporsi nilai eigen yang ditampilkan adalah 55.2255% sedangkan proporsi nilai eigen yang ditampilkan saat data asal dibakukan adalah sebesar 24.3445%.
16
Dalam karya tulis ini, setiap konfigurasi titik yang terbentuk dibandingkan menggunakan analisis Procrustes. Sebelum ditemukan ukuran kemiripannya, dicari terlebih dahulu nilai perbedaan minimum antar konfigurasi dengan melakukan penyesuaian konfigurasi dari dua konfigurasi yang akan dibandingkan. Penyesuaian tersebut diawali dengan penyesuaian translasi, rotasi, kemudian dilasi.
Berikut ini diberikan tabel-tabel yang berisi informasi mengenai nilai perbedaan minimum dari matriks seluruh komponen utama dan dua komponen utama pertamanya.
Namun pada kenyataannya, representasi komponen utama yang dapat digambarkan umumnya hanya dua atau tiga saja. Dalam karya ilmiah ini, konfigurasi hanya digambarkan oleh dua komponen utama pertama. Nilai perbedaan minimum yang digambarkan oleh dua komponen utama pertama ditampilkan dalam tabel di bawah ini. semakin besar matriks pembagi yang bersesuaian maka dapat dikatakan antar konfigurasi tersebut semakin mirip.
Pada perbandingan seluruh komponen utama, konfigurasi tanpa pembakuan memiliki nilai perbedaan minimum sebesar 10488 dan 10454 terhadap konfigurasi terkoreksi atau baku dan kernel. Konfigurasi terkoreksi atau baku memiliki nilai perbedaan minimum sebesar 10488 dan 135.73 terhadap konfigurasi tanpa pembakuan dan kernel. Sedangkan konfigurasi kernel memiliki nilai perbedaan minimum sebesar 19985 dan 259.48 terhadap konfigurasi tanpa pembakuan dan terkoreksi atau baku.
17
nilai perbedaan minimum sebesar 3814.5 dan 200.3489 terhadap konfigurasi tanpa pembakuan dan terkoreksi atau baku.
Tabel 6 dan Tabel 7 menunjukkan ukuran kesesuaian Procrustes. Ukuran kesesuaian memperlihatkan seberapa besar kemiripan antara dua konfigurasi. Dalam hal ini, jika ukuran kesesuaian semakin besar artinya konfigurasi-konfigurasi yang dibandingkan semakin mirip.
Berdasarkan pada penelitian ini, jika dua matriks yang dibandingkan telah terkoreksi terhadap rataan kolomnya atau dengan kata lain rataan kolomnya menjadi nol maka ukuran kesesuaian Procrustes yang diperoleh adalah simetrik, artinya ukuran kesesuaian matriks X terhadap matrik Y sama dengan matriks Y
terhadap matriks X. Setelah ditelusuri melalui sejumlah percobaan ternyata
kesimetrikan ini terjadi jika matriks yang dianggap tetap adalah matriks yang sudah ditranslasikan. Sedangkan matriks yang menyesuaikan telah melalui proses translasi saat mencari nilai perbedaan minimumnya.
Tabel 6 Ukuran kesesuaian matriks X dan Y dari berbagai kondisi dengan seluruh komponen utama konfigurasi yang sama bernilai 100%. Semakin mendekati 100% maka semakin mirip. Pada ukuran kesesuaian dari seluruh komponen utama, yang paling mendekati 100% adalah ukuran kemiripan untuk pasangan konfigurasi dengan pembakuan di ruang asal dan ruang fiturnya (II) dengan konfigurasi yang diperoleh menggunakan metode kernel (III), yaitu sebesar 99.26%. Begitu pun pada ukuran kemiripan dari dua komponen utama pertama, yang mendekati nilai 100% adalah pasangan konfigurasi antara primal terkoreksi atau baku dengan konfigurasi yang diperoleh dari metode kernel, yaitu sebesar 97.58%.
18
menggambarkan data baku yang dikerjakan menggunakan AKU korelasi di ruang fitur. Nilai persentase tersebut menggambarkan keseluruhan komponen utama. Sedangkan untuk matriks komponen utama yang sudah tereduksi atau dua komponen utama pertamanya saja, metode kernel menggambarkan sebesar 97.58% AKU korelasi di ruang fitur.
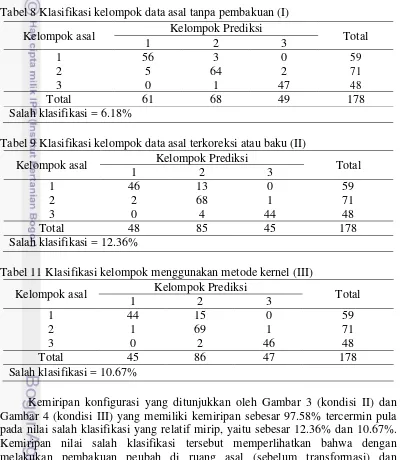
Salah satu tolok ukur untuk melihat keberhasilan dalam menggunakan AKU Kernel adalah terpisahnya objek ke dalam kelompok aslinya. Oleh karena itu, untuk melihat pembakuan mana yang paling baik, dicari nilai salah klasifikasinya. Tabel 8 Klasifikasi kelompok data asal tanpa pembakuan (I)
Kelompok asal Kelompok Prediksi Total
1 2 3
Tabel 9 Klasifikasi kelompok data asal terkoreksi atau baku (II)
Kelompok asal Kelompok Prediksi Total
1 2 3
Tabel 11 Klasifikasi kelompok menggunakan metode kernel (III)
Kelompok asal Kelompok Prediksi Total
19
SIMPULAN DAN SARAN
Simpulan
Eksplorasi pembakuan peubah dalam Analisis Komponen Utama (AKU) Kernel menggunakan data pengenalan anggur (wine recognition) memberikan
gambaran bahwa terdapat perbedaan hasil kapan pembakuan dilakukan terhadap konfigurasi dan salah klasifikasi.
Perbedaan hasil pembakuan peubah tercermin dari ukuran kemiripan dan nilai salah klasifikasinya. Kemiripan antara konfigurasi yang dilakukan pembakuan di ruang asal dan ruang fiturnya (II) terhadap konfigurasi yang pembakuannya dilakukan di ruang asal dan hanya terkoreksi nilai tengah di ruang fiturnya (III) adalah sebesar 97.58%. Kemiripan tersebut tercermin pula pada nilai salah klasifikasinya yang relatif mirip, yaitu 12.36% dan 10.67%. Kemiripan antara konfigurasi yang dilakukan pembakuan di ruang asal dan ruang fiturnya (II) terhadap konfigurasi yang pembakuannya hanya dilakukan di ruang fiturnya (I) adalah sebesar 54.54%. Kemiripan yang hanya 54.54% tersebut tercermin pula pada nilai salah klasifikasinya yang relatif berbeda, yaitu 12.36% dan 6.18%.
Saran
Eksplorasi pembakuan peubah hanya dapat dilakukan pada AKU Kernel dengan fungsi kernel yang hasil pemetaan di ruang fiturnya diketahui, yaitu fungsi kernel polinom. Pada penelitian selanjutnya, diharapkan dapat melakukan pembakuan peubah pada fungsi kernel secara umum.
DAFTAR PUSTAKA
Bakhtiar T, Siswadi. 2011. Orthogonal Procrustes Analysis: Its Transformation Arrangement and Minimal Distance. International Journal of Applied Mathematics and Statistics 20:16 24.
Forina M. 1991. Wine Recognition Data. [internet]. Tersedia pada: http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data. Jolliffe IT. 2002. Principal Component Analysis. New York (US):
Springer-Verlag.
Leon SJ. 2014. Linear Algebra with Application. 8th Ed. Edinburg Gate (UK):
Pearson.
SchÖlkopf B, Smola AJ. 2002. Learning with Kernels. London (UK): The MIT
Press.
Shen Y. 2007. Outlier Detection Using the Smallest Kernel Principal Component.
[Disertasi]. Philadelphia (US): Temple University Graduate Board. Siswadi, Bakhtiar T, Maharsi R. 2012. Procrustes Analysis and the
21
Lampiran 1
Data Pengenalan Anggur (Wine Recognition Data)
24
3 13.58 2.58 2.69 24.5 105 1.55 0.84 0.39 1.54 8.66 0.74 1.8 750 3 13.4 4.6 2.86 25 112 1.98 0.96 0.27 1.11 8.5 0.67 1.92 630 3 12.2 3.03 2.32 19 96 1.25 0.49 0.4 0.73 5.5 0.66 1.83 510 3 12.77 2.39 2.28 19.5 86 1.39 0.51 0.38 0.64 9.89 0.57 1.63 470 3 14.16 2.51 2.48 20 91 1.68 0.7 0.44 1.24 9.7 0.62 1.71 660 3 13.71 5.65 2.45 20.5 95 1.68 0.61 0.52 1.06 7.7 0.64 1.74 740 3 13.4 3.91 2.48 23 102 1.8 0.75 0.43 1.41 7.3 0.7 1.56 750 3 13.27 4.28 2.26 20 120 1.59 0.69 0.43 1.35 10.2 0.59 1.56 835 3 13.17 2.59 2.37 10 120 1.65 0.68 0.53 1.46 9.3 0.6 1.62 840 3 14.13 4.1 2.74 24.5 96 2.05 0.76 0.56 1.35 9.2 0.61 1.6 560
Keterangan :
Kel : Kelompok P7 : Flavanoids
P1 : Alcohol P8 : Nonflavanoids
P2 : Malic Acid P9 : Phenols
P3 : Ash P10 : Proanthocyanins
P4 : Alcanity of Ash P11 : Color Intensity
P5 : Magnesium P12 : OD280/OD315 of Diluted Wines
25
Lampiran 2
Data dua komponen utama pertama dari berbagai kondisi
I II III
KU 1 KU 2 KU 1 KU 2 KU 1 KU 2
26
27
28
29
Lampiran 3 Fungsi yang digunakan untuk memperoleh nilai perbedaan minimum antarkonfigurasi
function E=eproc(X,Y) E=sum(sum((X-Y).^2));
function E=TRD(X,Y)
[rx,cx]=size(X); [ry,cy]=size(Y); CX=mean(X); CY=mean(Y);
X=X-ones(rx,1)*CX; Y=Y-ones(ry,1)*CY; [U,S,V]=svd(X'*Y);
Q=V*U'; Y=Y*Q;
c=trace(X’*Y)/trace(Y’*Y);
Y=c*Y;
30
Lampiran 4 Fungsi yang digunakan untuk memperoleh matriks komponen utama menggunakan metode kernel
function Z = polinom2(X,r,ho) [rx,cx] = size(X);
if r > cx
error('Number of principal component must be smaller than that
of variables.')
end
K = zeros (rx,rx);
for i = 1:rx,
for j=1:i,
K(i,j) = (X(i,:)*X(j,:)'+ho).^2; K(j,i)=K(i,j);
end
end
vector1 = ones (size(K))/rx; K = K - repmat(mean(K),rx,1); [v,lambda]=eig(K);
for j = 1:size(v,2)
v(:,j)=v (:,j)./(sqrt(lambda(j,j)));
end
[l,k] = sort(diag(lambda),'descend');
v = v(:,k);
Z = zeros(rx,r);
for j = 1:r
Z(:,j) = K*v(:,j);
31
RIWAYAT HIDUP
Penulis dilahirkan di Sumedang, Jawa Barat pada tanggal 28 April 1992 sebagai anak pertama dari tiga bersaudara dari pasangan Wawan Rohendi dan Yeni Widayani.
Pendidikan formal yang ditempuh penulis yaitu di TK Gelatik Kabupaten Sumedang lulus tahun 1998, SD Negeri Cikubang Kabupaten Sumedang lulus pada tahun 2004, SMP Negeri 1 Tanjungsari Kabupaten Sumedang lulus pada tahun 2007, dan SMA Negeri Tanjungsari lulus pada tahun 2010 kemudian di tahun yang sama penulis diterima di Departemen Matematika Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor melalui jalur USMI.