ANALISIS KINERJA SUPPORT VECTOR MACHINE (SVM) DAN
PROBABILISTIC NEURAL NETWORK (PNN) PADA SISTEM
IDENTIFIKASI TUMBUHAN OBAT DAN TANAMAN HIAS
BERBASIS CITRA
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2012
PERNYATAAN MENGENAI TESIS DAN SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis Analisis Kinerja Support Vector Machine
(SVM) dan Probabilistic Neural Network (PNN) pada Sistem Identifikasi Tumbuhan Obat dan Tanaman Hias Berbasis Citra adalah karya saya dengan arahan komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir dari tesis ini.
Bogor, April 2012
Dewi Kania Widyawati
ABSTRACT
DEWI KANIA WIDYAWATI. Perfomance Analysis of Support Vector Machine (SVM) and Probabilistic Neural Network (PNN) on Identification System of Medicinal Plant and House Plant Based on Image. Under the supervision of YENI HERDIYENI and ANNISA
This research analyzed perfomance of clasification for plant identification using Support Vector Machine (SVM) and Probabilistic Neural Network (PNN). In this research we used kernel linear, polynomial and RBF for clasifier SVM. In thus research, we use 1.440 medicinal plant images and 300 house plant images belong to 30 are extracted using Fuzzy Local Binary Patern based on texture feature.The expermental result shows that SVM kernel polynomial is superior compare to PNN with accuracy 73.57% to medicinal plant identification and SVM kernel RBF is superior compare to PNN with accuracy 81.11% to house plant identification. The proposed system is promising to improve identification medicinal plant and house plant.
Keywords : support vector machine, probabilistic neural network, fuzzy local binary patern, medicinal plant identification, house plant identification
RINGKASAN
Indonesia merupakan salah satu negara tropis yang kaya akan flora dan fauna. Indonesia memiliki lebih dari 3.800 spesies tanaman, oleh karena itu negara ini dikenal dengan sebutan megabiodiversity country. Ada 940 jenis tumbuhan yang dapat dimanfaatkan sebagai obat alternatif yang cukup potensial untuk menyembuhkan berbagai jenis penyakit. Mengingat banyaknya jenis tumbuhan obat dan tanaman hias yang ada maka diperlukan klasifikasi yang bermanfaat untuk mempercepat dan mempermudah proses pencarian data dalam mengidentifikasi tumbuhan obat dan tanaman hias.
Klasifikasi Support Vector Machine (SVM) dan Probabilistic Neural Network
(PNN) memiliki kelebihan masing-masing. SVM memiliki kelebihan diantaranya adalah dalam menentukan jarak menggunakan support vector sehingga proses komputasi menjadi cepat. Adapun klasifikasi PNN memiliki kelebihan memiliki struktur sederhana dan training data yang cepat karena tidak perlu memperbaharui bobot. Berdasarkan kelebihan yang dimiliki oleh klasifikasi PNN dan SVM, oleh karena itu penelitian ini mengusulkan menggunakan kedua klasifikasi tesebut untuk mengidentifikasi tumbuhan obat dan tanaman hias.
Penelitian ini bertujuan untuk menganalisa kinerja klasifikasi PNN dan SVM pada objek citra tumbuhan obat dan tanaman hias dengan menggunakan fitur tekstur FLBP. Penelitian ini diawali dengan pengambilan objek citra dengan menggunakan kamera digital, objek citra yang diambil adalah 30 spesies tumbuhan obat yang berasal dari Biofarmaka IPB dan Gunung Leutik dan 30 spesies tanaman hias yang berasal dari Kebun Raya Bogor.
Data citra tumbuhan obat tidak memiliki latar belakang dan data citra tanaman hias memiliki latar belakang hal ini bertujuan untuk menganalisis kinerja FLBP. Setelah dilakukan pengumpulan data citra tahap selanjutnya adalah tahap praproses, dimana dalam tahap ini dilakukan perbaikan pada citra tumbuhan obat dan citra tanaman hias. Selanjutnya, citra tersebut diubah menjadi mode grayscale untuk diproses pada tahap ekstraksi. Proses yang dilakukan pada ekstraksi tekstur dalam penelitian ini menggunakan metode . Citra akan dibagi kedalam beberapa blok (local region) sesuai dengan operator circular neighborhood (sampling points dan radius) yang digunakan. Penelitian ini menggunakan dua ukuran circular neighborhood yaitu (8,1) dan (8,2). Nilai LBP akan direpresentasikan melalui histogram FLBP yang
merupakan gambaran frekuensi dari kontribusi nilai LBP yang muncul pada sebuah citra. Masing-masing blok diektraksi menggunakan metode .
Setelah proses ekstraksi citra selesai dilakukan, diperoleh hasil vektor histogram untuk setiap operator, untuk tumbuhan obat diperoleh 1.440 vektor histogram dan tanaman hias diperoleh 300 vektor histogram. Tahap selanjutnya adalah menglasifikasi vektor-vektor histogram tersebut dengan SVM dan PNN. Klasifikasi baik untuk data tumbuhan obat dan tanaman hias dilakukan dengan membagi data latih dan data uji masing-masing 70% dan 30%. Klasifikasi SVM menggunakan tiga jenis kernel yaitu:
Linear, Polynomial dan RBF.
Hasil penelitian menunjukkan untuk identifikasi tumbuhan obat kernel polynomial
lebih bagus dibandingkan dengan kernel lainnya dengan tingkat akurasi 73.57%, kernel polynomial memiliki kinerja yang lebih baik dari PNN. PNN menghasilkan tingkat akurasi 64.53%. Klasifikasi SVM kernel polynomial dengan menggunakan ekstraksi FLBP mampu mengidentifikasi kelas-kelas yang memiliki warna yang bergradasi dan citra yang memiliki variasi warna, walapun akurasinya tidak tinggi. Kelas citra tumbuhan obat yang selalu terklasifikasi dengan benar memiliki warna yang seragam dan kualitas citra yang baik dari segi pencahayaan maupun kontras.
Kernel RBF lebih bagus dibandingkan kernel lainnya dalam mengidentifikasi tanaman hias dengan tingkat akurasi 81.11%. Kinerja kernel RBF pun lebih baik dibandingkan PNN. Klasifikasi PNN menghasilkan tingkat akurasi 77.78%. Klasifikasi SVM kernel RBF dengan ekstraksi FLBP mampu mengindentifikasi citra yang memiliki background yang berbeda-beda.
Kata kunci: support vector machine, probabilitas neural network, fuzzy local binary
Hak Cipta Milik IPB, Tahun 2012 Hak Cipta dilindungi Undang-undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik atau tinjauan suatu masalah. Pengutipan tidak merugikan kepentingan yang wajar IPB.
Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis dalam bentuk apapun tanpa izin IPB.
ANALISIS KINERJA SUPPORT VECTOR MACHINE (SVM) DAN
PROBABILISTIC NEURAL NETWORK (PNN) PADA SISTEM
IDENTIFIKASI TUMBUHAN OBAT DAN TANAMAN HIAS
BERBASIS CITRA
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Ilmu Komputer pada
Program Studi Magister Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2012
Judul Penelitian : Analisis Kinerja Support Vector Machine (SVM) Dan
Probabilistic Neural Network (PNN) Pada Sistem Identifikasi
Tumbuhan Obat Dan Tanaman Hias Berbasis Citra Nama : Dewi Kania Widyawati
NIM : G651090041
Disetujui Komisi Pembimbing
Dr. Yeni Herdiyeni, S.Si, M.Kom Annisa, S.Kom, M.Kom Ketua Anggota
Diketahui
Ketua Program Studi Dekan Sekolah Pascasarjana Ilmu Komputer
Dr. Yani Nurhadryani, S.Si, M.T Dr. Ir. Dahrul Syah, M.Sc.Agr
PRAKATA
Puji syukur penulis panjatkan kepada Alloh SWT yang telah melimpahkan kasih sayang, rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan tesis ini yang berjudul Analisis Kinerja Support Vector Machine (SVM) dan Probabilistic Neural
Network (PNN) pada Sistem Identifikasi Tumbuhan Obat dan Tanaman Hias Berbasis
Citra.
Penulis mengucapkan terima kasih sebesar-besarnya kepada Ibu Dr. Yeni Herdiyeni, S.Si, M.Kom selaku ketua komisi pembimbing dan Ibu Annisa, S.Kom, M.Kom selaku anggota komisi pembimbing, yang senantiasa membimbing penulis dengan sabar dan teliti, semoga Alloh SWT selalu melimpahkan rahmat dan hidayah-Nya serta membalas segala kebaikannya. Penulis mengucapkan terima kasih juga kepada:
1. Suami tercinta, yang tak henti-henti nya mendo’akan, memberikan semangat, memberikan masukan-masukan dan selalu sabar menjaga anak-anak.
2. Bapak, mamah, mamah mertua dan adik-adik, yang tak henti-henti nya mendo’akan, dan memberikan semangat serta anak-anak tercinta, atas kesabarannya menunggu penulis menyelesaikan tesis ini.
3. Ketua Departemen Ilmu Komputer, Ketua Program Studi Ilmu Komputer, beserta Dosen dan staff yang banyak membimbing penulis selama perkuliahan. 4. Direktur, Pembantu Direktur I, II, III, serta Ketua Jurusan Ekonomi dan Bisnis
Politeknik Negeri Lampung yang telah memberikan kesempatan pada penulis untuk melanjutkan kuliah.
5. Sahabat-sahabatku Zuriati, Rico, Shinta, Arie, Retno, Damayanti, Evi, Rima, Nurmala, Sri, Anna, Fitriani, Annita, Dian, Fadila, Linda terimakasih atas masukan-masukannya.
6. Para tetangga yang senantiasa menjaga anak-anak selama penulis kuliah. Penulis menyadari dalam penulisan tesis ini masih banyak kekurangan, oleh karena itu penulis menerima saran dan kritik yang membangun demi pengembangan ilmu pengetahuan.
Bogor, April 2012
RIWAYAT HIDUP
Penulis Dilahirkan di Bandung pada tanggal 24 Juni 1972, sebagai anak pertama pasangan Ir. H.Mochammad Jusuf Tardjadimadja, S.E, M.Sc dan Hj.Nunah Salamah. Pada saat masih kecil, penulis memulai pendidikan di TK. Angkasa Bandung dan SDN Ungaran 1 Yogyakarta. Kemudian, penulis melanjutkan pendidikan menengahnya pada SMP Muhammadyah 3 Yogyakarta dan melanjutkan ke SMA Negeri 3 Bandung. Setelah Lulus SMA, penulis kuliah di STMIK Bandung, Program Studi Manajemen Informatika. Saat ini penulis merupakan staff pengajar Program Studi Manajemen Informatika, Politeknik Lampung. Matakuliah yang diampu penulis diantaranya adalah Analisis dan Perancangan Sistem Informasi, Sistem Basis Data, Aljabar Linear, Matematika dan pemrograman Java. Penulis berkesempatan melanjutkan jenjang pascasarjana (S2) Ilmu Komputer, Institut Pertanian Bogor sejak tahun 2009.
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... xx
DAFTAR TABEL... xx
DAFTAR LAMPIRAN... xxi
1 PENDAHULUAN ... Error! Bookmark not defined. 1.1 Latar Belakang ... Error! Bookmark not defined. 1.2 Tujuan Penelitian ... 3
1.3 Ruang Lingkup Penelitian ... 3
2 TINJAUAN PUSTAKA ... 4
2.1 Ekstraksi Fitur dan Fitur ... 4
2.2 Local Binary Pattern ... 4
2.3 Fuzzy Local Binary Pattern (FLBP) ... 6
2.4 Support Vector Machine (SVM) ... 8
2.5 Probabilistic Neural Network (PNN) ... 12
2.6 Confusion Matrix ... 14
2.7 Tumbuhan Obat ... 15
3 METODE PENELITIAN ... 16
3.1 Tahapan Penelitian ... 16
3.1.1 Pengumpulan Citra dan Praposes ... 17
3.1.2 Ekstraksi Fitur Tekstur dengan Metode FLBP P,R ... 17
3.1.3 Klasifikasi Support Vector Machine (SVM) ... 19
3.1.4 Klasifikasi Probabilistic Neural Network (PNN) ... 19
3.1.5 Pengujian dengan Sistem ... 20
3.1.6 Evaluasi Hasil Klasifikasi SVM dan PNN ... 20
3.2 Kebutuhan Alat dan Bahan Penelitian ... 20
3.3 Waktu dan Tempat Penelitian ... 20
4 HASIL DAN PEMBAHASAN ... 21
4.1 Hasil Praproses dan Ekstraksi Fitur dengan FLBP ... 21
4.2 Hasil Klasifikasi Support Vector Mechine (SVM) ... 21
4.2.1 Citra Tumbuhan Obat dengan SVM ... 21
4.2.1.1 Pemilihan Parameter Kernel Tumbuhan Obat ... 22
4.2.1.2 Model Klasifikasi KernelPolynomial untuk Tumbuhan Obat ... 23
4.2.1.3 Identifikasi Akurasi Setiap Kelas Tumbuhan Obat dengan Fungsi Kernel Polynomial ... 25
4.2.2 Citra Tanaman Hias dengan SVM ... 26
4.2.2.1 Pemilihan Parameter Kernel Tanaman Hias ... 27
4.2.2.2 Model Klasifikasi Kernel RBF untuk Tanaman Hias ... 28
4.2.2.3 Identifikasi Akurasi Setiap Kelas Tanaman Hias dengan Fungsi Kernel RBF ... 29
4.3 Hasil Klasifikasi Probabilistic Neural Network (PNN) ... 31 4.3.1 Citra Tumbuhan Obat dengan PNN ... 31 4.3.1.1 Model Klasifikasi PNN untuk Tumbuhan Obat ... 31 4.3.1.2 Identifikasi Akurasi Setiap Kelas Tumbuhan Obat dengan PNN 34 4.3.2 Citra Tanaman Hias dengan PNN ... 35 4.3.1.1 Model Klasifikasi PNN untuk Tanaman Hias ... 35 4.3.1.2 Identifikasi Akurasi Setiap Kelas Tanaman Hias dengan PNN ... 37 4.4 Perbandingan Klasifikasi SVM Fungsi Kernel Polynomial dan PNN untuk
Tumbuhan Obat ... 39 4.5 Perbandingan Klasifikasi SVM Fungsi Kernel RBF dan PNN untuk
Tanaman Hias ... 40 4.6 Pengembangan Sistem ... 41
5 KESIMPULAN DAN SARAN ... Error! Bookmark not defined.
5.1 Kesimpulan ... Error! Bookmark not defined.
5.2 Saran ... ... Error! Bookmark not defined.
DAFTAR PUSTAKA ... 43 LAMPIRAN... 45
DAFTAR GAMBAR
Halaman
1 Skema komputasi LBP. ...4
2 Ukuran circular neighborhood...6
3 Keanggotaan fungsi m0() dan m1() sebagai fungsi dari pi-pcenter. ...6
4 Skema komputasi FLBP. ...8
5 Struktur SVM. ...8
6 SVM untuk klasifikasi tiga kelas. ...11
7 Struktur PNN. ...13
8 Tahapan Penelitian. ...16
9 Proses Fuzzy thresholding. ...18
10 Citra Lavendula Afficinalis Chaix teridentifikasi ke kelas Pandanus Amaryllifolius Roxb ...24
11 Kelas 24 teridentifikasi pada kelas 4,12,15 dan 18...24
12 Grafik akurasi masing-masing kelas SVM kernel polynomial dalam mengidentifikasi tumbuhan obat FLBP(8+2). ...25
13 Citra tumbuhan obat menghasilkan akurasi 100% dengan SVM kernel polynomial ...25
14 Citra tumbuhan obat menghasilkan akurasi antara 85% - 92.56% dengan SVM kernel polynomial. ...26
15 Citra tumbuhan obat menghasilkan akurasi antara 60% - 80% dengan SVM kernel polynomial. ...26
16 Citra tumbuhan obat menghasilkan akurasi dibawah 60% dengan SVM kernel polynomial. ...26
17 Citra tanaman hias yang teridentifikasi ke kelas lain (a) Dendrobium (b) Chaopraya Moonlight, Calathea sp. (c) Piper decumanum ...29
18 Grafik Akurasi masing-masing kelas SVM Kernel RBF dalam mengidentifikasi tanaman hias dengan FLBP(8+2)...30
19 Citra Tanaman Hias menghasilkan akurasi 100% dengan SVM Kernel RBF....30
20 Citra Tanaman Hias menghasilkan akurasi 66,67% dengan SVM Kernel RBF.31 21 Citra Tanaman Hias menghasilkan akurasi 33.33% dengan SVM Kernel RBF.31 22 Citra lavendula Afficinalis Chaix yang teridentifikasi ke kelas pandanus amaryllifolius roxb, clinacanthus nurans, dan barleria lupulina lindl...33
23 Citra ficus deloidea L paling banyak mengalami kesalahan klasifikasi (a) citra latih (b) citra uji ...33
24 Grafik akurasi masing-masing kelas PNN dalam mengidentifikasi tumbuhan obat FLBP(8+2)... 34
25 Citra tumbuhan obat menghasilkan akurasi 100% dengan PNN... 34
26 Citra tumbuhan obat menghasilkan akurasi antara 85% - 92.56% dengan PNN... 34
27 Citra tumbuhan obat menghasilkan akurasi antara 60% - 80% dengan PNN. ...35
28 Citra tumbuhan obat menghasilkan akurasi dibawah 60% dengan PNN ...35
29 Citra Calathea sp. yang paling banyak mengalami kesalahan klasifikasi dengan menggunakan PNN.. ...36
30 Citra tanaman hias hanya dapat chaopraya moonlight mengidentifikasi 1 citra uji (a) Dendrobium(b) Calathea rufibarba . ...37
31 Grafik Akurasi Masing-Masing Kelas PNN dalam mengidentifikasi tanaman hias FLBP(8+2) ...37
32 Citra Tanaman Hias menghasilkan akurasi 100% dengan PNN...38
33 Citra Tanaman Hias menghasilkan akurasi 66.67% dengan PNN...38
34 Citra Tanaman Hias menghasilkan akurasi dibawah 50% dengan PNN.. ...38
35 Perbandingan Akurasi dengan Klasifikasi SVM Fungsi Kernel Polynomial dan PNN identifikasi tumbuhan obat dengan FLBP(8+1) dan FLBP(8+2). ...39
36 Perbandingan Akurasi dengan Klasifikasi SVM Fungsi Kernel RBF dan PNN identifikasi tanaman hias dengan FLBP(8+1) dan FLBP(8+2)...40
DAFTAR TABEL
Halaman
1 Confusion matrix ...14 2 Akurasi fungsi kernel tumbuhan obat ... 2Error! Bookmark not defined.
3 Kelas tumbuhan obat yang teridentifikasi pada kelas lain dengan fungsi kernel polynomial. ... 2Error! Bookmark not defined.
4 Akurasi fungsi kernel tanaman hias. ...27 5 Kelas tanaman hias yang teridentifikasi pada kelas lain dengan fungsi kernel RBF
...28 6 Kelas tumbuhan obat yang teridentifikasi pada kelas lain dengan PNN. ...32 7 Kelas tanaman hias yang teridentifikasi pada kelas lain dengan PNN. ...36
DAFTAR LAMPIRAN
Halaman
1 Tiga puluh citra tumbuhan obat. ...47
2 Tiga puluh citra tanaman hias. ...50
3a Antar Muka Sistem Perfect-Pro Ekstraksi Database Citra Tumbuhan Obat ... 5Error! Bookmark not defined. 3b Antar Muka Sistem Perfect-Pro Hasil Identifikasi Citra Queri Tumbuhan Obat. ... 5Error! Bookmark not defined. 4a Antar Muka Sistem Perfect-Pro Ekstraksi Database Citra Tanaman Hias.5Error! Bookmark not defined. 4b Antar Muka Sistem Perfect-Pro Hasil Identifikasi Citra Queri Tanaman Hias.54 5 Confusion matrix tumbuhan obat dengan fungsi kernel polynomial...55
6 Confusion matrix tanaman hias dengan fungsi kernel RBF. ...56
7 Confusion matrix tumbuhan obat dengan PNN. ...57
1 PENDAHULUAN
1.1 Latar Belakang
Indonesia merupakan salah satu negara tropis yang memiliki lebih dari 3.800 spesies tanaman menurut Bappenas (2003), oleh karena itu negara ini dikenal dengan sebutan megabiodiversity country. Diantara ribuan spesies tanaman yang tumbuh di Indonesia, terdapat tanaman hias yang memiliki nilai estetika dan tumbuhan obat. Ada 940 jenis tumbuhan yang dapat dimanfaatkan sebagai obat alternatif yang cukup potensial untuk menyembuhkan berbagai jenis penyakit (Nugroho 2010). Beberapa diantara jenis tumbuhan obat tersebut sudah dikenal dan dipergunakan oleh masyarakat secara turun temurun, namun sebagian lainnya belum dikenal dan ada juga yang masih dalam tahap penelitian. Mengingat banyaknya jenis tumbuhan obat dan tanaman hias yang ada maka diperlukan klasifikasi yang bermanfaat untuk mempercepat dan mempermudah proses pencarian data dalam mengidentifikasi tumbuhan obat dan tanaman hias.
Kulsum (2010) telah melakukan penelitian mengidentifikasi tanaman hias dengan menggunakan klasifikasi Probabilistic Neural Networks (PNN) dan ekstraksi fitur dengan Descriptor Local Binary Pattern. Hasil dari penelitian menunjukkan bahwa klasifikasi PNN dapat mengidentifikasi tanaman hias secara automatis, sehingga proses identifikasi dilakukan dengan cepat dan menghasilkan tingkat akurasi 73,33%. Nurafifah (2010) melakukan penelitian dengan klasifikasi PNN dalam mengidentifikasi daun dengan beberapa teknik penggabungan ciri yaitu product
decision rule (PDR), sum decision rule (SDR), max decision rule (MDR), dan
majority vote rule (MVR). Hasil percobaan menunjukkan teknik PDR merupakan
teknik terbaik dalam mengidentifikasi daun dengan tingkat akurasi sebesar 83.33%. Selain itu penelitian PNN juga dilakukan oleh Wu et al. (2007) untuk melakukan identifikasi daun tanaman liar yang ada di Jepang. Pada penelitian ini dilakukan reduksi matrik citra dengan menggunakan Principal Component Analysis (PCA).
2
Hasil percobaan menunjukkan dengan melakukan reduksi matrik dan klasifikasi tersebut menghasilkan tingkat akurasi sebesar 90%.
Kerami dan Murfi (2004) telah melakukan penelitian dengan menggunakan klasifikasi Support Vector Mechine (SVM) untuk mengenali jenis splice site pada suatu barisan DNA. Pengenalan jenis splice site ini diperlukan dalam pemindahan
intron-intron yang berakibat bergabungnya exon-exon (donor) yang diperlukan dalam
pembentukan protein. Percobaan yang dilakukan untuk menentukan barisan DNA tersebut merupakan splice site berjenis donor atau bukan. Hasil percobaan menunjukkan SVM dapat memprediksi data uji dengan kemampuan generalisasi 95.4%.
Penelitian dengan melakukan perbandingan kinerja klasifikasi telah dilakukan oleh Rustam et al. (2003), yaitu dengan melakukan perbandingan klasifikasi K-Nearest
Neighborhood (KKN) dan SVM untuk menentukan jenis dan kelas aroma,
percobaaan ini terdiri dari 3 jenis aroma, masing-masing aroma terdiri atas 6 kelas. Pembagian kelas ini berdasarkan pada konsentrasi alkohol yang dicampurkan pada masing-masing aroma. Hasil percobaan menunjukkan kinerja SVM dengan menggunakan kernel polynomial memiliki kemampuan untuk mengenal dan mengklasifikasikan aroma, dengan tepat dan sesuai dengan jenis atau kelas.
Widyanto dan Fatichah (2008) melakukan penelitian membandingkan SVM
dan boosting untuk mendeteksi objek manusia. Hasil yang diperoleh dari penelitian
tersebut adalah kinerja dari SVM memiliki tingkat konsistensi 35% lebih baik dari
Boosting.
Iakovidis et al. (2008) telah melakukan penelitian dengan menggunakan fuzzy logic untuk mengatasi ketidakpastian pada representasi tekstur LBP, yang dikenal sebagai metode Fuzzy Local Binary Pattern (FLBP). Metode tersebut digunakan untuk karakterisasi tekstur ultrasound dengan akurasi mencapai 84%.
Menurut Vapnik dan Cortes (1995), SVM memiliki kelebihan diantaranya adalah dalam menentukan jarak menggunakan support vector sehingga proses komputasi menjadi cepat. Adapun klasifikasi PNN menurut Duda, R.O et al. (2000) memiliki
3
kelebihan memiliki struktur sederhana dan training data yang cepat karena tidak perlu memperbaharui bobot.
Berdasarkan kelebihan yang dimiliki oleh klasifikasi PNN dan SVM, oleh karena itu penelitian ini mengusulkan menggunakan kedua klasifikasi tesebut untuk mengidentifikasi tumbuhan obat dan tanaman hias.
1.2 Tujuan Penelitian
Penelitian ini bertujuan untuk menganalisa kinerja klasifikasi PNN dan SVM pada objek citra tumbuhan obat dan tanaman hias dengan menggunakan fitur tekstur FLBP.
1.3 Ruang Lingkup Penelitian
Data penelitian diperoleh dari hasil pengambilan citra dengan menggunakan kamera digital, objek citra yang diambil adalah 30 species tumbuhan obat yang berasal dari kebun Biofarmaka IPB Cikabayan dan rumah kaca Pusat Konservasi Ex-situ Tumbuhan Obat Hutan Tropika Indonesia, Fahutan IPB dan 30 species tanaman hias yang berasal dari Kebun Raya Bogor.
1.4 Manfaat Penelitian
Manfaat penelitian ini adalah mempercepat proses pencarian data pada identifikasi tumbuhan obat dan tanaman hias.
4
2 TINJAUAN PUSTAKA
2.1 Ekstraksi Fitur dan Tekstur
Ekstraksi fitur merupakan proses mendapatkan penciri atau fitur dari suatu citra. Fitur dari suatu citra dapat berupa warna, bentuk, dan tekstur. Acharya dan Ray (2005) mendefinisikan fitur sebagai pendeksripsi suatu objek yang bebas terhadap posisi, orientasi, dan ukuran. Fitur tekstur didefinisikan sebagai pengulangan pola yang ada pada suatu daerah bagian citra.
Tekstur merupakan gambaran visual dari sebuah permukaan. Permukaan tekstur berasal dari keragaman bentuk, iluminasi, bayangan, absorbsi dan refleksi, untuk citra digital, tekstur dicirikan dengan variasi intensitas atau warna. Variasi intensitas disebabkan oleh perbedaan warna pada suatu permukaan. Properti-properti dari tekstur citra meliputi: keseragaman, kepadatan, kekasaran, keberaturan, linearitas, keberarahan, frekuensi (Mäenpää2003).
2.2 Local Binary Pattern
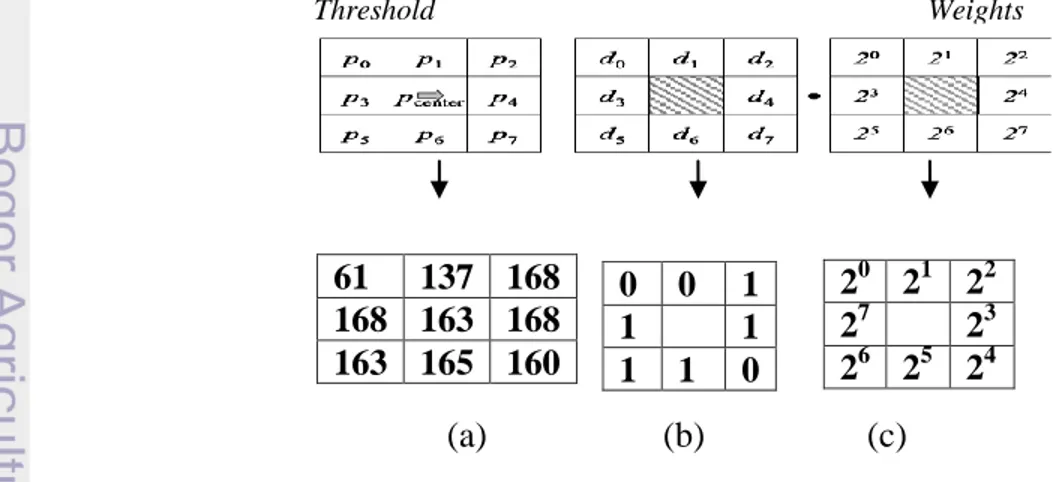
Ojala pada tahun 1996 pertama kali memperkenalkan Local Binary Pattern (LBP) untuk mendeskripsikan tekstur dalam mode grayscale. Operator LBP dengan ukuran piksel 3 3 merepresentasikan tekstur lokal di sekitar pusat piksel seperti yang di ilustrasikan pada Gambar 1.a. (Iakovidis et al 2008).
(a) (b) (c) Nilai LBP : 4+8+32+64+128 = 236
Gambar 1 Skema komputasi LBP.
61 137 168 168 163 168 163 165 160 0 0 1 1 1 1 1 0 20 21 22 27 23 26 25 24 Threshold Weights
5
Setiap pola tekstur LBP direpresentasikan oleh sembilan elemen , dimana merepresentasikan nilai intensitas pada piksel pusat dan (0 7) merepesentasikan nilai piksel sekelilingnya (circular
sampling). Nilai delapan ketetanggaan yang mengelilingi pusat piksel dapat
dicirikan oleh nilai biner (0 7) seperti pada Gambar 1.b, dimana menurut (Iakovidis et al 2008):
dengan,
Berdasarkan nilai biner tersebut, setiap ketetanggan memiliki nilai LBP yang dihasilkan oleh formula berikut :
Dengan, adalah nilai biner
Nilai yang dihasilkan menunjukan kode Local Binary Pattern. Kemudian kode-kode LBP tersebut akan direpresentasikan melalui histogram. Histogram akan menunjukan frekuensi kejadian berbagai nilai LBP. Untuk ukuran citra N×M, keseluruhan nilai LBP dapat direpresentasikan dengan membentuk histogram sebagai berikut:
dengan, K merupakan nilai LBP terbesar.
(2)
(3) (1)
6
Operator LBP juga dapat dikembangkan dengan menggunakan berbagai ukuran
sampling points dan radius yang disajikan pada Gambar 2. Pada piksel ketetanggaan
akan digunakan notasi (P,R) dimana P merupakan sampling points dan R merupakan
radius (Ahonen 2008).
(8,1) (8,2)
Gambar 2 Ukuran circular neighborhood.
2.3 Fuzzy Local Binary Pattern
Fuzzy pada pendekatan LBP meliputi transformasi input variabel untuk variabel
fuzzy masing-masing, sesuai dengan seperangkat aturan fuzzy, dua aturan fuzzy yang
digunakan untuk menggambarkan hubungan antara nilai pada circular sampling
dan piksel pusat pcenter dalam ketetanggaan 3 × 3 menurut Iakovidis et al (2008)
adalah sebagai berikut:
RuleR0 : Semakin negatif nilai , maka nilai kepastian terbesar dari adalah 0. RuleR1 : Semakin positif nilai , maka nilai kepastian terbesar dari adalah 1.
Gambar 3 Keanggotaan fungsi m0() dan m1() sebagai fungsi dari pi-pcenter (Iakovidis et al 2008).
Membership function m0() dan m1() ditentukan oleh rule R0 dan rule R1
(Iakovidis et al 2008).. Membership function m0() adalah fungsi menurun yang
didefinisikan pada persamaan 4 dan membership function m1() mendefinisikan
7 F p if F p F if F p if F p F i m i i i i . 2 1 0 ) ( 0 F p if F p F if F p if F p F i m i i i i . 2 0 1 ) ( 1
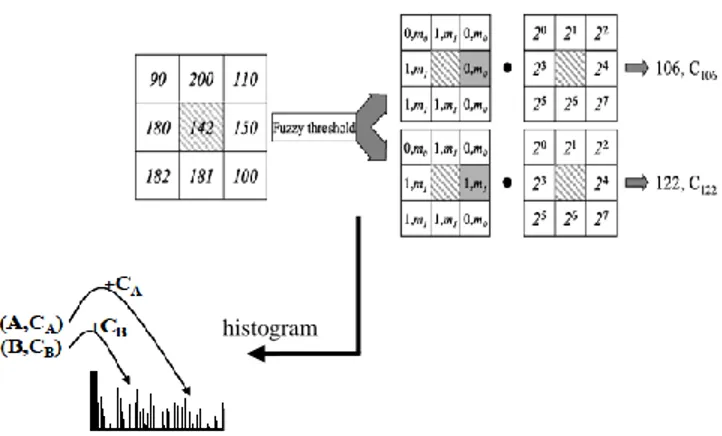
dengan, F adalah nilai fuzzy. Metode LBP menghasilkan hanya satu kode LBP saja, akan tetapi dengan menggunakan metode FLBP akan menghasilkan satu atau lebih kode LBP. Ilustrasi pendekatan FLBP di sajikan pada Gambar 4, dimana dua kode LBP (A,B) mencirikan ketetanggaan 3x3. Masing-masing nilai LBP yang dihasilkan memiliki tingkat kontribusi (CA, CB) yang berbeda, hal ini tergantung pada nilai-nilai fungsi
keanggotaan m0() dan m1() yang dihasilkan. Untuk ketetanggaan 3 3, kontribusi CLBP
dari setiap kode LBP pada histogram FLBP didefinisikan sebagai berikut (Iakovidis
et al 2008):
Total kontribusi ketetanggaan 3 3 ke dalam bin histogram FLBP yaitu :
Ilustrasi pendekatan FLBP menghasilkan dua kode LBP sebagai penciri ketetanggaan 3x3 disajikan pada Gambar 4 dimana kode LBP tersebut akan direpresentasikan dengan histogram yang dihitung dengan menjumlahkan kontribusi dari setiap nilai LBP.
(4)
(5)
(7) (6)
8
Gambar 3 Skema komputasi FLBP (Iakovidis et al 2008).
2.4 Support Vector Machine
Support Vector Machine (SVM) merupakan sistem pembelajaran untuk mengklasifikasikan data menjadi dua kelompok data yang menggunakan ruang hipotesis berupa fungsi-fungsi linear dalam sebuah ruang fitur berdimensi tinggi. Strategi dari SVM adalah berusaha menemukan hyperplane yang terbaik pada input
space (Nugroho et al. 2003). Cara kerja SVM melakukan transformasi data pada
input space ke ruang yang berdimensi lebih tinggi, dan optimisasi dilakukan pada ruang vektor yang baru dengan menerapkan strategi Structural Risk Minimization
(SRM). Structural Risk Minimization (SRM) bertujuan untuk mengestimasi suatu fungsi dengan cara meminimalkan batas atas dari generalization error (Santosa 2007). Ilustrasi SVM untuk data yang terpisahkan secara linier menurut Vapnik dan Cortes (1995), disajikan pada Gambar 5.
Gambar 5 Struktur SVM.
9
Gambar 5 mengilustrasikan dua kelas dapat dipisahkan oleh sepasang bidang pembatas yang sejajar. Bidang pembatas pertama membatasi kelas pertama sedangkan bidang pembatas kedua membatasi kelas kedua, sehingga diperoleh persamaan 8 (Vapnik dan Cortes 1995):
Dengan,
xi = data set
yi = label kelas dari data
w = vektor bobot yang tegak lurus terhadap hyperplane (bidang normal) b = menentukan lokasi fungsi pemisah relatif terhadap titik asal.
Bidang pemisah (hyperplane) terbaik adalah hyperlane yang terletak ditengah-tengah antara dua bidang pembatas kelas, untuk mendapatkan hyperlane terbaik dengan memaksimalkan margin atau jarak antara dua set objek dari kelas yang berbeda. Nilai margin antara bidang pembatas adalah . Memaksimalkan nilai margin ekuivalen dengan meminimumkan nilai . Persamaan yang digunakan untuk pencarian bidang pemisah terbaik dengan nilai margin terbesar pada permasalahan linear di dalam primal space, disajikan pada persamaan 9(Vapnik dan Cortes 1995):
Pada kasus yang tidak feasible, dimana beberapa data tidak dapat dikelompokkan secara benar maka persamaan yang digunakan adalah sebagai berikut (Vapnik dan Cortes 1995):
(8)
(9)
(2)
10
dengan,
= variabel slack
C = parameter yang menentukan besar pinalti akibat kesalahan klasifikasi.
Permasalahan ini akan lebih mudah diselesaikan jika diubah ke dalam formulasi
Lagrange dengan menggunakan Lagrange multiplier ( ). Dengan demikian
permasalahan optimasi konstrain dapat diubah menjadi (Vapnik dan Cortes 1995):
Vektor seringkali bernilai besar (mungkin tak terhingga), tetapi nilai terhingga. Untuk itu formulasi Lagrange (primal problem) diubah ke dalam
Lagrange (dual problem). Dengan demikian persamaan Lagrange hasil modifikasi
menjadi persamaan 12 (Vapnik dan Cortes 1995):
. Jadi persoalan pencarian bidang pemisah terbaik dapat dirumuskan sebagai berikut (Vapnik dan Cortes 1995):
Persamaan 13 akan menghasilkan nilai untuk setiap data pelatihan. Nilai tersebut digunakan untuk menentukan . Data pelatihan yang memiliki nilai
adalah support vector sedangkan sisanya memiliki nilai , support vector adalah data yang memiliki jarak paling dekat dengan hyperplane.
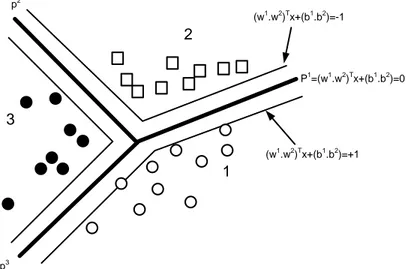
Ilustrasi SVM untuk data multiclass menurut Santosa (2007), disajikan pada Gambar 6.
(11)
(12)
11 p2 p3 3 P1 =(w1 .w2 )T x+(b1 .b2 )=0 1 2 (w1 .w2 )T x+(b1 .b2 )=+1 (w1.w2)Tx+(b1.b2)=-1
Gambar 6 SVM untuk klasifikasi tiga kelas.
Gambar 6 mengilustrasikan klasifikasi untuk tiga kelas, teknik yang digunakan untuk mengklasifikasi tiga kelas adalah satu lawan semua (SLA). Cara kerja teknik satu lawan semua, pada saat melakukan training P1, semua data dalam kelas satu diberi label +1 dan data yang lain dari kelas dua dan tiga diberi label -1, sebaliknya jika melatih P2, semua data dalam kelas dua diberi label +1 dan data yang lain dari kelas satu dan tiga diberi label -1, begitu pun pada saat melakukan training P3, semua data dalam kelas tiga diberi label +1 dan data yang lain dari kelas satu dan dua diberi label -1, maka fungsi pemisah ke–i menyelesaikan permasalahan optimisasi berikut (Santosa 2007).
Setelah menyelesaikan persamaan 10 diperoleh k fungsi pemisah, kemudian kelas dari suatu objek baru x ditentukan berdasarkan nilai terbesar dari fungsi pemisah (Santosa 2007):
Jika data terpisah secara non linier, SVM dimodifikasi dengan memasukkan fungsi . Langkah yang dilakukan, data dipetakan oleh fungsi ke ruang vektor baru yang berdimensi lebih tinggi. Selanjutnya pada ruang vektor yang baru ini, SVM mencari hyperplane yang memisahkan kedua kelas secara linier. Pencarian ini hanya bergantung pada dot product dari data yang sudah dipetakan pada ruang baru (14)
12
yang berdimensi lebih tinggi, yaitu . Pada umumnya transformasi ini tidak diketahui dan sangat sulit untuk dipahami sehingga perhitungan dot product
dapat digantikan dengan fungsi kernel yang dirumuskan menurut Vapnik dan Cortes (1995) sebagai berikut:
Sehingga persamaan menjadi sebagai berikut:
Fungsi hasil pembelajaran yang dihasilkan disajikan pada persamaan 16.
Dengan:
ns = banyaknya data pelatihan yang termasuk support vector.
x = data yang diklasifikasikan
Kernel yang yang digunakan pada SVM diantaranya adalah :
1. Linear :
2. Polynomial :
3. Gaussian (radial-basis function) :
dengan:
γ , r dan d merupakan parameter kernel.
2.5 Probabilistic Neural Network (PNN)
Probabilistic neural network (PNN) merupakan jaringan syaraf tiruan yang
dibangun berdasar kaidah keputusan Bayes dan dikembangkan oleh Donald Specht pada tahun 1988. PNN merupakan ANN yang menggunakan radial basis function
(18) (19) ( 20) (15) (16) (17)
13
(RBF). RBF adalah fungsi yang berbentuk seperti bel yang menskalakan variabel
non-linear (Wu et al. 2007). Kelebihan menggunakan arsitektur PNN adalah training
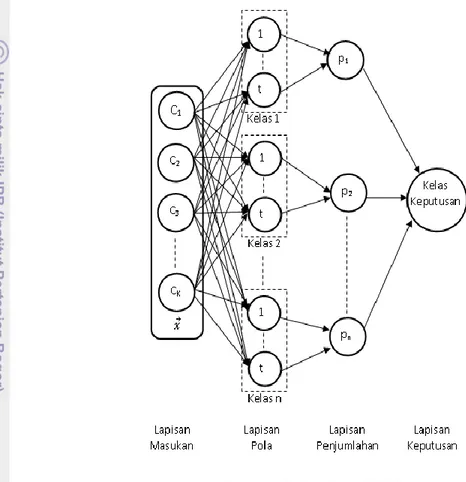
data mudah dan sangat cepat, hal ini karena dilakukan hanya satu tahap. Struktur PNN menurut Wu et al. (2007) disajikan pada Gambar 7.
Gambar 7 Struktur PNN.
Struktur PNN ditunjukkan pada Gambar 6 yang terdiri atas empat lapisan yaitu lapisan masukan, lapisan pola, lapisan penjumlahan, dan lapisan keputusan/keluaran (Wu et al. 2007).
1 Lapisan masukan, merupakan objek terdiri atas k nilai ciri yang akan diklasifikasikan pada n kelas.
2 Lapisan pola (pattern layer), digunakan 1 node pola untuk setiap data pelatihan yang digunakan. Setiap node pola menghasilkan Zi = . Bobot
merupakan nilai data latih ke-i pada kelas ke-j. Nilai Zi kemudian dibagi
14
yaitu radbas(n) = exp (-n)2. Dengan demikian persamaan yang digunakan pada lapisan pola seperti pada Persamaan 21.
3 Lapisan penjumlahan (summation layer), menerima masukan dari node lapisan pola yang terkait dengan kelas yang ada. Persamaan yang digunakan pada lapisan ini adalah:
dengan k merupakan dimensi vektor ciri, σ merupakan bias dan t merupakan jumlah data latih pada kelas tertentu.
4 Lapisan keluaran (output layer), menghasilkan keputusan input masuk ke dalam suatu kelas. Input akan masuk kelas Y jika nilai pY(x) paling besar dibandingkan
kelas yang lainnya.
2.6 Confusion Matrix
Confusion Matrix merupakan sebuah tabel yang terdiri atas banyaknya baris data
yang diuji yang diprediksi benar dan salah oleh model klasifikasi, hal ini bertujuan untuk menentukan kinerja dari suatu model kalsifikasi yang digunakan (Tan PN 2005). Tabel Confusion Matrix disajikan pada Tabel 1 .
Tabel 1 Confusion Matrix
Assigned Class Class=1 Class=0 True Class Class=1 F11 F10 Class=0 F01 F00 (21) (22)
15
F11 merupakan jumlah citra dari kelas 1 yang benar diklasifikasikan sebagai kelas 1, F00 merupakan jumlah citra dari kelas 1 yang benar diklasifikasikan sebagai kelas 0, adapun F01 merupakan jumlah citra dari kelas 0 yang salah diklasifikasikan sebagai kelas 1, F10 merupakan jumlah citra dari kelas 1 yang benar diklasifikasikan sebagai kelas 0.
2.7 Tumbuhan Obat
Tumbuhan obat memiliki khasiat untuk menyembuhkan berbagai penyakit. Kemajuan dari ilmu pengetahuan dan teknologi yang semakin modern dan berkembang secara pesat tidak dapat menggeser obat-obatan tradisional yang telah ada sejak nenek moyang, obat-obatan tradisional mampu saling berdampingan dan saling melengkapi dengan obat-obatan yang terbuat secara kimiawi (Thomas 1993). Informasi yang dapat digali dari tanaman obat diantaranya nama botani, nama lokal, familia, daerah asal tumbuhan, spesifikasi tumbuhan, komposisi kandungan kimia, khasiat, dan cara menggunakannya.
16
3 METODE PENELITIAN
3.1 Tahapan Penelitian
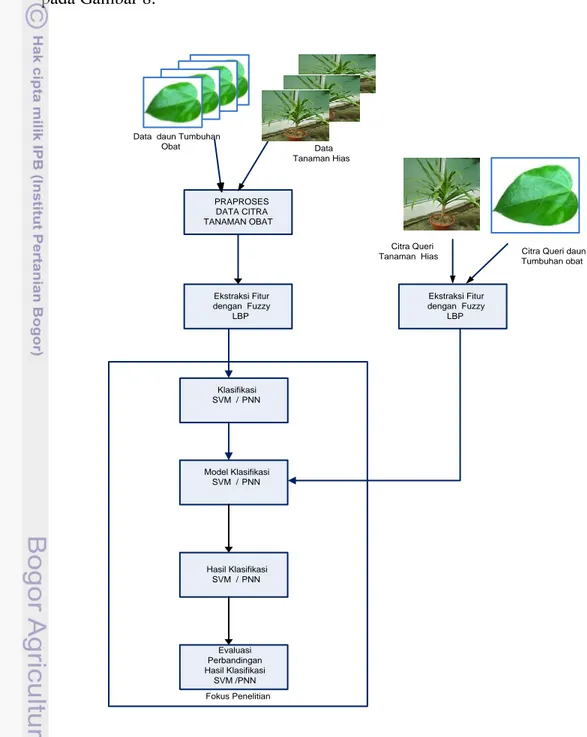
Penelitian ini dilakukan dalam beberapa tahap. Tahap-tahap tersebut disajikan pada Gambar 8. Ekstraksi Fitur dengan Fuzzy LBP Model Klasifikasi SVM / PNN PRAPROSES DATA CITRA TANAMAN OBAT Evaluasi Perbandingan Hasil Klasifikasi SVM /PNN Data daun Tumbuhan
Obat Hasil Klasifikasi SVM / PNN Citra Queri Tanaman Hias Fokus Penelitian Ekstraksi Fitur dengan Fuzzy LBP Data Tanaman Hias
Citra Queri daun Tumbuhan obat
Klasifikasi SVM / PNN
17
3.1.1 Pengumpulan Citra dan Praposes
Penelitian ini menggunakan citra tumbuhan obat dan tanaman hias yang diperoleh dari pemotretan. Citra tumbuhan obat terdiri dari tiga puluh species yang terdapat di kebun Biofarmaka IPB Cikabayan dan rumah kaca Pusat Konservasi Ex-situ Tumbuhan Obat Hutan Tropika Indonesia, Fahutan IPB. Masing- masing species terdiri 48 citra, dimana setiap species daun terdiri atas 24 pose citra bagian depan dan 24 pose citra bagian belakang, sehingga total 1.440 citra daun tumbuhan obat .
Citra tanaman hias terdiri dari tiga puluh species citra dari Kebun Raya Bogor, yang digunakan oleh Kulsum (2010). Data citra tumbuhan obat tidak memiliki latar belakang dan data citra tanaman hias memiliki latar belakang hal ini bertujuan untuk menganalisis kinerja FLBP. Setelah dilakukan pengumpulan data citra tahap selanjutnya adalah tahap praproses, dimana dalam tahap ini dilakukan perbaikan pada citra tumbuhan obat dan citra tanaman hias. Selanjutnya, citra tersebut diubah menjadi mode grayscale untuk diproses pada tahap ekstraksi.
3.1.2 Ekstraksi Fitur Tekstur dengan Metode FLBP P,R
Proses yang dilakukan pada ekstraksi tekstur dalam penelitian ini menggunakan metode . Citra akan dibagi kedalam beberapa blok (local region) sesuai dengan operator circular neighborhood (sampling points dan radius) yang digunakan. Penelitian ini menggunakan dua ukuran circular neighborhood yaitu (8,1) dan (8,2). Nilai LBP akan direpresentasikan melalui histogram FLBP yang merupakan gambaran frekuensi dari kontribusi nilai LBP yang muncul pada sebuah citra. Masing-masing blok diektraksi menggunakan metode .
Ekstraksi tekstur dilakukan dengan mengolah setiap untuk mencari selisih dari piksel tetangga dengan piksel pusat. Dari setiap blok yang didapat, akan menghasilkan satu atau lebih nilai LBP dan nilai kontribusinya. Blok yang berisikan nilai , selanjutnya akan melalui proses fuzzy tresholding berdasarkan rule R0 dan rule R1.
18
Parameter fuzzifikasi (F) yang digunakan berdasarkan penelitian yang dilakukan Valerina (2012). Citra tumbuhan obat dan tanaman hias memiliki nilai parameter F berbeda . Citra tanaman hias 0 sampai 40 dan untuk citra tumbuhan obat berkisar antara 0 sampai 20. Penggunaan parameter F>0 sebagai hasil dari metode FLBP, proses fuzzy tresholding akan dihasilkan nilai LBP sebanyak 2n, dimana n merupakan banyaknya nilai piksel yang berada direntang fuzzy antara –F sampai F, contoh proses fuzzy tresholding dengan nilai fuzzy 4 disajikan pada Gambar 9.
Gambar 9 Proses Fuzzy thresholding.
Hasil yang diperoleh dari ilustrasi pada Gambar 8 terdapat tiga nilai yang berada diantara rentang fuzzy (-4 < < 4), sehingga diperoleh kombinasi sebanyak 23 = 8, nilai biner yang diperoleh dari masing-masing kombinasi adalah 00111111, 00111101, 00111011, 00111001, 00110111, 00110101, 00110011, dan 00110001. Kedelapan nilai biner ini akan menghasilkan nilai LBP sebagai dasar untuk menentukan perhitungan masuknya nilai ke membership function.
3.1.3 Klasifikasi Support Vector Machine (SVM)
61 137 168 168 163 168 163 165 160 -102 -26 5 5 5 0 2 -3 -102 -26 5 5 -3 2 0 5 0 0 1 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 1 1 1 1 1 1 1
19
Setelah proses ekstraksi citra selesai dilakukan, diperoleh hasil vektor histogram untuk setiap ukuran circular neighborhood, untuk tumbuhan obat diperoleh 1.440 vektor histogram dan tanaman hias diperoleh 300 vektor histogram. Tahap selanjutnya adalah menglasifikasi vektor-vektor histogram tersebut dengan SVM. Klasifikasi baik untuk data tumbuhan obat dan tanaman hias dilakukan dengan membagi data latih dan data uji masing-masing 70% dan 30%.
SVM pada penelitian ini menggunakan fungsi Kernel , yang berfungsi untuk mengatasi kesulitan yang timbul karena tidak diketahuinya suatu fungsi non linear dan cara memilih fungsi yang tepat dalam mencari hyperplane yang terbaik. Fungsi
kernel yang digunakan yaitu fungsi kernel Linear, Polynomial dan RBF. Fungsi
kernel terbaik akan digunakan sebagai pembanding dengan klasifikasi PNN, yang
bertujuan untuk menganalisa model klasifikasi masing-masing klasifikasi tersebut. Pada penggabungan ukuran circular neighborhood maupun tanpa penggabungan ukuran circular neighborhood harus diekstraksi terlebih dahulu. Hasil identifikasi citra tumbuhan obat menggunakan FLBP akan dibandingkan dengan hasil identifikasi citra tanaman hias.
3.1.4 Klasifikasi Probabilistic Neural Network (PNN)
Sama seperti klasifikasi SVM, setelah proses ekstraksi citra selesai dilakukan, diperoleh hasil vektor histogram untuk setiap ukuran circular neighborhood, untuk tumbuhan obat diperoleh 1.440 vektor histogram dan tanaman hias diperoleh 300 vektor histogram. Tahap selanjutnya adalah menglasifikasi vektor-vektor histogram tersebut dengan PNN. Klasifikasi baik untuk data tumbuhan obat dan tanaman hias dilakukan dengan membagi data latih dan data uji masing-masing 70% dan 30%.
Klasifikasi dengan menggunakan PNN dengan menerapkan bias yang berbeda-beda untuk setiap ukuran circular neighborhood karena dimensi vektor histogram setiap ukuran circular neighborhood berbeda-beda.
20
Pengujian data dilakukan oleh sistem, yaitu dengan penilaian tingat keberhasilan klasifikasi terhadap citra kueri. Evaluasi dari kinerja model klasifikasi didasarkan pada banyaknya data uji yang diprediksi secara benar dan tidak benar oleh model. Hal ini dapat dihitung menggunakan akurasi yang didefinisikan sebagai berikut:
3.1.6 Evaluasi Hasil Klasifikasi SVM dan PNN
Evaluasi kinerja yang dilakukan adalah :
1 Menganalisa model klasifikasi yang disajikan dalam bentuk Confusion Matrix.
2 Menganalisa akurasi hasil identifikasi klasifikasi setiap kelas citra tumbuhan obat dan tanaman hias yang disajikan dalam bentuk grafik.
3.2 Kebutuhan Alat dan Bahan Penelitian
Perangkat lunak yang digunakan MS Window XP Professional Version 2002 SP2 dan Microsoft Visual Studio 2010 adapun perangkat keras yang digunakan:
Processor intel® core ™ 2 duo CPU T57550, memori DDR2, RAM 2,99 GB,
Library OpenCv 2.1, dan Visual C++.
3.3 Waktu dan Tempat Penelitian
Penelitian dilaksanakan di Laboratorium Computational Intelligence
Pascasarjana Departemen Ilmu Komputer IPB di mulai bulan Januari 2011 .
21
4 HASIL DAN PEMBAHASAN
4.1 Hasil Praposes dan Ekstraksi Tekstur
Perbaikan data citra tumbuhan obat pada tahap praproses dilakukan dengan menyeleksi objek satu daun dan memperkecil ukuran citra menjadi 270x240 piksel. Pada data citra pohon, Kulsum (2010) melakukan tahap praproses dengan memotong citra untuk mendapatkan objek tanaman hias dan memperkecil ukuran citra menjadi 270x210 piksel. Mode warna citra pohon dan citra daun kemudian diubah menjadi
grayscale untuk proses ekstraksi selanjutnya. Hasil praproses data bertujuan untuk mengurangi waktu pemrosesan data (running time).
Berdasarkan penelitian yang dilakukan Valerina (2012), pada citra tumbuhan obat dihasilkan 20 fitur FLBP yang diekstrak menggunakan rentang F [0,20]. Sedangkan, pada citra tanaman hias dihasilkan 40 fitur FLBP yang diekstrak menggunakan rentang F [0,40]. Besarnya rentang parameter fuzzifikasi yang digunakan untuk menghasilkan fitur dan identifikasi terbaik, dipengaruhi oleh sebaran distribusi pi yang dihasilkan. Nilai F=4 digunakan untuk tumbuhan obat dan
nilai F=19 digunakan untuk tanaman hias.
4.2 Hasil Klasifikasi Support Vector Mechine (SVM)
Langkah pertama yang dilakukan dalam klasifikasi SVM adalah pemilihan parameter kernel yang bertujuan untuk menentukan kernel terbaik. Kernel terbaik ini sebagai dasar untuk menganalisa model klasifikasi dan menganalisa hasil akurasi perkelas. Selain itu kernel terbaik digunakan sebagai pembanding dengan klasifikasi PNN.
4.2.1 Citra Tumbuhan Obat dengan SVM
Citra data uji tumbuhan untuk setiap kelas yang digunakan adalah empat belas citra data uji , yang digunakan untuk mengidentifikasi citra tumbuhan obat ini oleh sistem.
22
4.2.1.1 Pemilihan Parameter Kernel Tumbuhan Obat.
Fungsi kernel yang digunakan yaitu fungsi Linear, Polynomial dan RBF, masing-masing fungsi kernel ini memiliki parameter yang berbeda-beda. Pada Fungsi kernel Linear nilai parameter C yang diujicobakan adalah [ 212,211, 210,29, ..,2-1, 2-2] . Pada fungsi kernel Polynomial nilai parameter C yang diujicobakan sama dengan fungsi
linear , adapun nilai parametr γ dan r adalah [ 24,23, 22 ,...,2-10], untuk nilai degree
(d) pada penelitian ini di ujicobakan 2 , sehingga dihasilkan 153 =3.375 kombinasi. Pada fungsi kernel linear, nilai parameter C dan γ sama dengan fungsi kernel
polynomial dan linear , sehingga dihasillan 152 = 225 kombinasi yang diujicobakan.
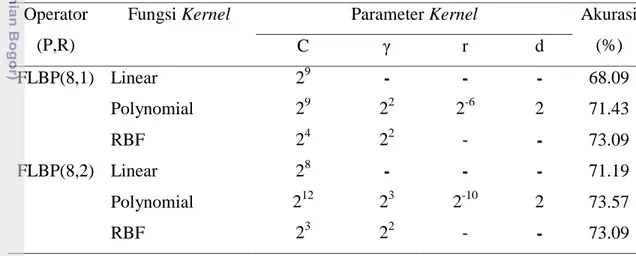
Ukuran circular neighborhood yang digunakan pada FLBP adalah (8,1) dan (8,2), nilai akurasi masing-masing dari fungsi kernel tersebut disajikan pada Tabel 2 dan
screen shoot hasil ekstraksi tumbuhan obat disajikan pada Lampiran 3.
Tabel 2 Akurasi Fungsi Kernel Tumbuhan Obat Operator
(P,R)
Fungsi Kernel Parameter Kernel Akurasi (%) C γ r d FLBP(8,1) Linear 29 - - - 68.09 Polynomial 29 22 2-6 2 71.43 RBF 24 22 - - 73.09 FLBP(8,2) Linear 28 - - - 71.19 Polynomial 212 23 2-10 2 73.57 RBF 23 22 - - 73.09
Ukuran circular neighborhood (8,2) pada penelitian ini menghasilkan tingkat akurasi lebih baik dibandingkan ukuran circular neighborhood (8,1), hal ini dikarenakan semakin besarnya ukuran blok piksel semakin mampu mengambil nilai piksel-piksel ketetanggaan melingkar yang berbeda-beda sehingga pola-pola nilai LBP pun menjadi berbeda, hal ini menjadi penciri yang baik dalam ekstraksi tekstur. Fungsi kernel terbaik untuk mengidentifkasi tumbuhan obat adalah fungsi kernel
23
memiliki variasi warna kernel polynomial memiliki tingkat akurasi lebih tinggi dibandingkan kernel RBF dan kernel linear.
4.2.1.2 Model Klasifikasi Kernel Polynomial untuk Tumbuhan Obat
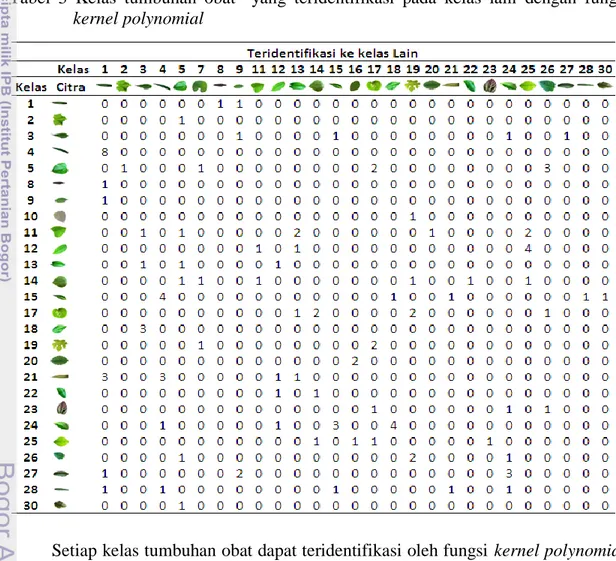
Model klasifikasi dari Fungsi kernel polynomial disajikan dalam bentuk Confusion
Matrix secara lengkap yang disajikan pada Lampiran 5. Tabel 3 menyajikan
kelas-kelas yang teridentifikasi pada kelas-kelas lain.
Tabel 3 Kelas tumbuhan obat yang teridentifikasi pada kelas lain dengan fungsi
kernel polynomial
Setiap kelas tumbuhan obat dapat teridentifikasi oleh fungsi kernel polynomial. Kelas 4 (Lavendula Afficinalis Chaix) merupakan kelas yang mengalami kesalahan klasifikasi, terdapat delapan citra data uji teridentifikasi ke kelas 1 (Pandanus Amaryllifolius Roxb), hal ini dikarenakan kelas 4 dan kelas 1 memiliki kemiripan
24
tekstur pada permukaan belakang daun, Gambar 10 menyajikan kesalahan klasifikasi kelas 4 yang teridentifikasi pada kelas 1.
Gambar 10 Citra Lavendula Afficinalis Chaix teridentifikasi ke kelas Pandanus Amaryllifolius Roxb.
Kelas 24 (Orthosiphon Aristatus (B1) Miq ), merupakan kelas yang menghasilkan akurasi terendah dimana kelas ini hanya mampu mengidentifikasi lima citra data uji, terdapat sembilan citra teridentifikasi kedalam kelas yang berbeda-beda diantaranya adalah satu citra masing-masing teridentifikasi ke kelas 4 (Lavendula afficinalis Chaix) dan kelas 12 (Quisqualis Indica), tiga citra teridentifikasi ke kelas 15
(clinacanthus nurans) dan empat citra teridentifikasi ke kelas 18 (Talinum
paniculatum) , citra kelas 24 disajikan pada Gambar 11.
25
4.2.1.3 Identifikasi Akurasi Setiap Kelas Tumbuhan Obat dengan Fungsi
Kernel Polynomial.
Hasil akurasi perkelas dari uji coba identifikasi tumbuhan obat dengan fungsi
kernel polynomial pada FLBP(8,2) disajikan pada Gambar 12.
Gambar 12 Grafik akurasi masing-masing kelas SVM kernel polynomial dalam mengidentifikasi tumbuhan obat FLBP(8+2).
Klasifikasi SVM kernel polynomial dengan menggunakan ekstraksi FLBP mampu mengidentifikasi kelas-kelas yang memiliki warna yang bergradasi dan citra yang memiliki variasi warna, walapun akurasinya tidak tinggi, sebagai contoh kelas
24 (Orthosiphon Aristatus (B1) Miq). Kelas 24 hanya mampu mengidentifikasi 5 citra
data testing. Kelas citra tumbuhan obat yang selalu terklasifikasi dengan benar memiliki warna yang seragam dan kualitas citra yang baik dari segi pencahayaan maupun kontras, terdapat 4 kelas yang selalu terklasifikasikan dengan benar dengan akurasi 100% dari 30 kelas yang ada, keempat kelas tersebut adalah kelas 6 (Acanthus ilicifolius L), kelas 7 (Centella asiatica), kelas 16 (Clitoria ternatea L.), dan kelas 29 (Psidium guajava L.), citra-citra ini disajikan pada Gambar 13.
Gambar 13 Citra tumbuhan obat menghasilkan akurasi 100% dengan SVM kernel polynomial. 0 20 40 60 80 100 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 A ku ra si ( % ) Kelas
26
Dari 30 kelas terdapat delapan kelas yang mampu mengklasifikasikan dengan tingkat akurasi 85% - 92.86%, hal ini disajikan pada Gambar 14.
Gambar 14 Citra tumbuhan obat menghasilkan akurasi antara 85% - 92.56% dengan
SVM kernel polynomial.
Terdapat delapan kelas yang mampu mengklasifikasikan dengan tingkat akurasi antara 60% - 80% disajikan pada Gambar 15.
Gambar 15 Citra tumbuhan obat menghasilkan akurasi antara 60% - 80% dengan
SVM kernel polynomial.
Citra-citra yang menghasilkan tingkat akurasi dibawah 60% terdapat pada kelas 4,5,11,12,14,15,17,21,24 dan kelas 27 dapat dilihat pada Gambar 16.
Gambar 16 Citra tumbuhan obat menghasilkan akurasi dibawah 60% dengan SVM
kernel polynomial.
4.2.2 Citra Tanaman Hias dengan SVM.
Citra data uji tanaman hias untuk setiap kelas yang digunakan adalah tiga citra data uji, yang digunakan untuk mengidentifikasi citra tanaman hias ini oleh sistem.
27
4.2.2.1 Pemilihan Parameter Kernel Tanaman Hias
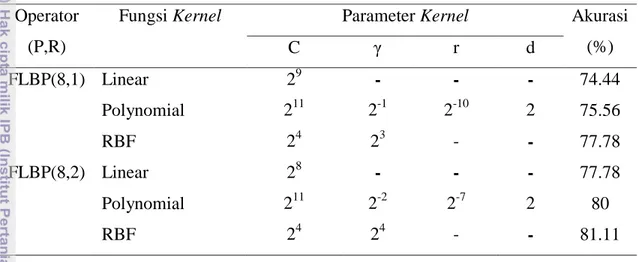
Fungsi kernel dan nilai parameter yang digunakan untuk identifikasi tanaman hias sama dengan tumbuhan obat, nilai akurasi yang dihasilkan dengan menggunakan ketiga fungsi kernel disajikan pada Tabel 4.
Tabel 4 Akurasi Fungsi Kernel Tanaman Hias Operator
(P,R)
Fungsi Kernel Parameter Kernel Akurasi (%) C γ r d FLBP(8,1) Linear 29 - - - 74.44 Polynomial 211 2-1 2-10 2 75.56 RBF 24 23 - - 77.78 FLBP(8,2) Linear 28 - - - 77.78 Polynomial 211 2-2 2-7 2 80 RBF 24 24 - - 81.11
Ukuran circular neighborhood (8,2) pada penelitian ini menghasilkan tingkat akurasi untuk semua fungsi kernel lebih baik dibandingkann ukuran circular
neighborhood (8,1), hal ini dikarenakan semakin besarnya ukuran blok piksel
semakin mampu mengambil nilai piksel-piksel ketetangaan melingkar yang berbeda-beda sehingga pola-pola nilai LBP juga menjadi berberbeda-beda hal ini menjadi penciri yang baik dalam ekstraksi tekstur. Fungsi kernel yang menghasilkan nilai akurasi tertinggi untuk mengidentifikasi tanaman hias adalah fungsi kernel RBF pada ukuran circular
neighborhood (8,2). Fungsi kernel RBF akan digunakan untuk mengevaluasi model
klasifikasi dan identifikasi tanaman hias. Kelas-kelas yang memiliki corak tekstur
28
4.2.2.2 Model Klasifikasi Kernel RBF untuk Tanaman Hias .
Pada citra tanaman hias diambil tiga data uji pada setiap kelas untuk mengidentifikasi citra oleh sistem Fungsi kernel RBF digunakan untuk model klasifikasi disajikan dalam bentuk Confusion Matrix yang disajikan pada Lampiran 6.6 dan Tabel 5 menyajikan kelas-kelas yang teridentifikasi ke dalam kelas lain. Tabel 5 Kelas tanaman hias yang teridentifikasi pada kelas lain dengan fungsi kernel
RBF
Dari 30 kelas terdapat tiga kelas yang menghasilkan nilai akurasi terendah, dimana ketiga kelas ini hanya mampu mengidentifikasi satu citra uji saja dari tiga citra data uji, kelas tersebut adalah kelas 15 (Dendrobium Chaopraya Moonlight) ,
kelas 24 (Calathea sp.) dan kelas 30 (Piper decumanum). Kelas 15 (Dendrobium
Chaopraya Moonlight) mengalami kesalahan klasifikasi teridentifikasi ke kelas 1
(Dracena Draco) dan kelas 13 (Philodendron Bifinnatifidum). Kelas 24 ( Calathea sp) teridentifikasi ke kelas 11 ( Dendrobium sp.) dan kelas 19 ( Begonia sp). Pada kelas 30 ( Piper decumanum ) teridentifikasi ke kelas 8 ( Dendrobium sp.) dan kelas 10 (Dendrobium sp.).
29
Citra-citra yang teridentifikasi ke kelas lain disajikan pada Gambar 17.
(a)
(b)
(c)
Gambar 17 Citra tanaman hias yang teridentifikasi ke kelas lain (a) Dendrobium (b)
Chaopraya Moonlight,Calathea sp. (c) Piper decumanum.
4.2.2.3 Identifikasi Akurasi Setiap Kelas Tanaman Hias dengan Fungsi Kernel
RBF.
Identifikasi tanaman hias dengan menggunakan fungsi kernel RBF menghasilkan tingkat akurasi tertinggi yaitu 81.11%. Tingkat akurasi tanaman hias lebih baik daripada tumbuhan obat karena metode FLBP sangat cocok pada citra yang memiliki tekstur yang kompleks. Akurasi masing-masing kelas disajikan pada Gambar 17.
30
Gambar 18 Grafik Akurasi masing-masing kelas SVM Kernel RBFdalam mengidentifikasi tanaman hias FLBP(8+2).
Hasil Ekstraksi FLBP(8,2) dengan menggunakan fungsi Kernel RBF pada
tanaman hias , dari 30 kelas terdapat enam belas kelas yang mampu mengidentifikasi semua citra uji sehingga menghasilkan tingkat akurasi 100%, citra-citra yang memiliki akurasi tinggi dikarenakan citra-citra tersebut memiliki jenis daun dengan warna yang bergradasi, memiliki tekstur unik yaitu citra yang kemiripan teksturnya cukup jauh berbeda dengan citra kelas lain, dan citra yang memiliki kualitas yang baik dari segi pencahayaan maupun kontras serta memiliki komposisi background
yang hampir seragam, citra-citra ini disajikan pada Gambar 19.
Gambar 19 Citra Tanaman Hias menghasilkan akurasi 100% dengan SVM Kernel
RBF.
Dari 30 kelas terdapat sebelas kelas yang mampu mengklasifikasikan dengan tingkat akurasi 66.67% yang disajikan pada Gambar 20.
Gambar 20 Citra Tanaman Hias menghasilkan akurasi 66,67% dengan SVM Kernel
RBF. 0 20 40 60 80 100 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 A ku ra si ( % ) Kelas
31
Dari 30 kelas terdapat tiga kelas yang mampu mengklasifikasikan dengan tingkat akurasi 33.33% yang disajikan pada Gambar 21.
Gambar 21 Citra Tanaman Hias menghasilkan akurasi 33.33% dengan SVM Kernel
RBF.
4.3 Hasil Klasifikasi Probabilistic Neural Network (PNN)
Pembagian data uji dan data latih untuk identifikasi tumbuhan obat pada klasifikasi PNN sama dengan klasifikasi SVM. Uji coba yang dilakukan pada PNN dengan menerapkan bias yang berbeda-beda untuk mendapatkan akurasi dari masing-masing ekstraksi
4.3.1 Citra Tumbuhan Obat dengan Probabilistic Neural Network (PNN)
Hasil uji coba klasifikasi PNN dengan menggunakan FLBP(8,1) memiliki ukuran
blok (piksel) 3x3 menghasilkan tingkat akurasi 64.29%, dengan menggunakan
FLBP(8,2) nilai akurasi mengalami peningkatan menjadi 64.52%
4.3.1.1 Model Klasifikasi PNN untuk Tumbuhan Obat.
Model klasifikasi PNN disajikan dalam bentuk confusion matrix yang disajikan pada Lampiran 7. Tabel 6 menyajikan kelas-kelas yang teridentifikasi ke dalam kelas lain.
32
Tabel 6 Kelas tumbuhan obat yang teridentifikasi pada kelas lain dengan PNN
Setiap kelas dengan klasifikasi PNN dapat mengidentifikasi tumbuhan obat. Pada kelas 4 ( Lavendula Afficinalis Chaix)mampu mengidentifikasi delapan citra data uji, pada kelas ini mengalami kesalahan klasifikasi teridentifikasi ke dalam beberapa kelas, dimana terdapat empat citra teridentifikasi ke kelas 1 (Pandanus Amaryllifolius
33
citra teridentifikasi ke kelas 28 (Barleria lupulina Lindl), citra-citra ini disajikan pada Gambar 22.
.
Gambar 22 Citra lavendula Afficinalis Chaix yang teridentifikasi ke kelas pandanus amaryllifolius roxb , clinacanthus nurans, dan barleria lupulina lindl. Kelas yang paling banyak mengalami kesalahan dalam klasifikasi terdapat pada kelas 14 (Ficus deloidea ), kelas ini hanya mampu mengidentifikasi dua citra uji dari empat belas citra uji yang ada, hal ini dikarenakan kelas ini memiliki kualitas citra yang tidak baik, dari segi pencahayaan maupun kontras, sehingga berpengaruhi pada tingkat kesalahan. Kelas 14 (Ficus deloidea L) mengalami kesalahan klasifikasi dengan rincian tiga citra data uji teridentifikasi ke kelas 7, dua citra data uji masing-masing teridentifikasi ke kelas 2 dan kelas 19, satu citra data uji masing-masing-masing-masing teridentifikasi ke kelas 13, kelas 16, kelas 20, kelas 22, dan kelas 23, citra kelas 14 disajikan pada Gambar 23.
(a) (b)
Gambar 23 Citra ficus deloidea L paling banyak mengalami kesalahan klasifikasi (a) citra latih (b) citra uji .
34
4.3.1.2 Identifikasi Akurasi Setiap Kelas Tumbuhan Obat dengan klasifikasi PNN
Identifikasi tumbuhan obat dengan menggunakan klasifikasi PNN disajikan dalam bentuk grafik, akurasi masing-masing kelas disajikan pada Gambar 24.
Gambar 24 Grafik akurasi masing-masing kelas PNN dalam mengidentifikasi tumbuhan obat FLBP(8+2) .
Hasil ekstraksi FLBP(8,2) setiap kelas memiliki kemampuan mengidentifikasi citra
data testing. Dari 30 kelas hanya terdapat dua kelas yang mengidentifikasi 100% data uji yaitu kelas 7 (Centella asiatica (Linn)Urban) dan kelas 29 (Psidium Guajava L), citra-citra ini memiliki kualitas citra yang baik, dari segi pencahayaan maupun kontras , hal ini dapat dilihat pada Gambar 25.
Gambar 25 Citra tumbuhan obat menghasilkan akurasi 100% dengan PNN . Dari 30 kelas terdapat tujuh kelas yang mampu mengklasifikasikan dengan tingkat akurasi antara 85% - 92.86% disajikan pada Gambar 26.
Gambar 26 Citra tumbuhan obat menghasilkan akurasi antara 85% - 92.56% dengan PNN. 0 10 20 30 40 50 60 70 80 90 100 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 A ku ra si ( % ) Kelas
35
Dari 30 kelas terdapat sembilan kelas yang mampu mengklasifikasikan dengan tingkat akurasi antara 60% - 80% disajikan pada Gambar 27.
Gambar 27 Citra tumbuhan obat menghasilkan akurasi antara 60% - 80% dengan PNN.
Dari 30 kelas terdapat sebelas kelas yang mampu mengklasifikasikan dengan tingkat akurasi dibawah 60% disajikan pada Gambar 28.
Gambar 28 Citra tumbuhan obat menghasilkan akurasi dibawah 60% dengan PNN.
4.3.2 Citra Tanaman Hias dengan Probabilistic Neural Network (PNN)
Uji coba Klasifikasi PNN untuk tanaman hias menerapkan bias yang berbeda-beda untuk mendapatkan akurasi dari masing-masing ekstraksi dengan menggunakan
FLBP(8,1) memiliki ukuran blok (piksel) 3x3 menghasilkan tingkat akurasi cukup
baik yaitu 75.56% , dan pada FLBP(8,2) nilai akurasi mengalami peningkatan
menjadi 77.78%.
4.3.2.1 Model Klasifikasi PNN untuk Tanaman Hias
Model klasifikasi PNN disajikan dalam bentuk confusion matrix yang disajikan pada Lampiran 8. Tabel 7 menyajikan kelas-kelas yang teridentifikasi ke dalam kelas lain.
36
Tabel 7 Kelas tanaman hias yang teridentifikasi pada kelas lain dengan PNN
Tidak semua citra uji dapat dikenali oleh setiap kelas, dari model klasifikasi dapat dilihat kelas 24 ( Calathea sp) sama sekali tidak dapat mengenali data uji, hal ini dikarenakan data testing dan data training memiliki background yang sangat berbeda, klasifikasi PNN tidak mampu mengidentifikasi citra data testing tersebut. Kelas ini mengalami kesalahan klasifikasi dengan teridentifikasi ke kelas 14 (Agave attenuata)
sebanyak satu citra dan dua citra teridentifikasi ke kelas 19 (Begonia sp), hal ini dapat dilihat pada Gambar 29.
Gambar 29 Citra Calathea sp. yang paling banyak mengalami kesalahan klasifikasi dengan menggunakan PNN.
Citra kelas 15 (Dendrobium chaopraya moonlight) dan kelas 20 (Calathea
37
chaopraya moonlight) teridentifikasi ke kelas 1 ( Dracena draco ) dan kelas 13
(Philodendron bifinnatifidum). Kelas 20 ( Calathea rufibarba)teridentifkasi ke dalam
kelas 19 ( Begonia sp). Citra-citra tersebut dapat dilihat pada Gambar 30.
(a)
(b)
Gambar 30 Citra tanaman hias hanya dapat mengidentifikasi 1 citra uji (a)
Dendrobium chaopraya moonlight (b) Calathea rufibarba.
4.3.2.2 Identifikasi Akurasi Setiap KelasTanaman Hias dengan Klasifikasi PNN
Identifikasi tanaman hias dengan menggunakan klasifikasi PNN disajikan dalam bentuk grafik, akurasi masing-masing kelas disajikan pada Gambar 31.
.
Gambar 31 Grafik Akurasi Masing-Masing Kelas PNN Dalam Mengidentifikasi tanaman hias FLBP(8+2) . 0 20 40 60 80 100 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 A ku ra si ( % ) Kelas
38
Pada FLBP(8,2) dengan klasifikasi PNN, dari 30 kelas terdapat empat belas kelas
yang dapat mengidentifikasi semua citra uji hal ini dikarenakan citra-citra ini memiliki latar belakang yang seragam dan memiliki jenis daun dengan warna yang bergradasi, sehingga menghasilkan akurasi tinggi, citra-citra tersebut disajikan pada Gambar 32.
Gambar 32 Citra Tanaman Hias menghasilkan akurasi 100% dengan PNN.
Dari 30 kelas terdapat tiga belas kelas yang mampu mengklasifikasikan dengan tingkat akurasi 66.67% disajikan pada Gambar 33.
Gambar 33 Citra Tanaman Hias menghasilkan akurasi 66,67% dengan PNN.
Dari 30 kelas terdapat tiga kelas yang mampu mengklasifikasikan dengan tingkat akurasi dibawah 50% disajikan pada Gambar 34.