ANALISIS CLUSTER UNTUK PENGELOMPOKAN NILAI UJIAN NASIONAL SMP DI DAERAH ISTIMEWA YOGYAKARTA DENGAN
METODE WARD Tugas Akhir
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Matematika
Program Studi Matematika
Oleh:
Sisilia Caturingrum 173114014
PROGRAM STUDI MATEMATIKA, JURUSAN MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
i
ANALISIS CLUSTER UNTUK PENGELOMPOKAN NILAI UJIAN NASIONAL SMP DI DAERAH ISTIMEWA YOGYAKARTA DENGAN
METODE WARD Tugas Akhir
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Matematika
Program Studi Matematika
Oleh:
Sisilia Caturingrum 173114014
PROGRAM STUDI MATEMATIKA, JURUSAN MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
CLUSTER ANALYSIS FOR GROUPING OF JUNIOR HIGH SCHOOL NATIONAL EXAM SCORE IN DAERAH ISTIMEWA YOGYAKARTA
USING WARD METHOD Thesis
Presented as a Partial Fulfillment of the Requirements To Obtain the Degree Sarjana Mathematics
Mathematics Study Program
By:
Sisilia Caturingrum 173114014
MATHEMATICS STUDY PROGRAM, DEPARTMENT OF MATHEMATICS FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
vi MOTTO
Barang siapa yang bertakwa kepada Allah niscaya Dia akan mengadakan baginya jalan keluar. Dan memberinya rezeki dari arah yang tiada disangka-sangkanya. Dan
barang siapa yang bertawakal kepada Allah niscaya Allah akan mencukupkan (keperluan)nya. Sesungguhnya Allah melaksanakan urusan yang (dikehendaki)-Nya.
Sesungguhnya Allah telah mengadakan ketentuan bagi tiap-tiap sesuatu (Q.S. Ath-Thalaq: 2-3)
vii
HALAMAN PERSEMBAHAN
Karya ini kupersembahkan untuk:
Allah SWT, kedua orangtuaku, keluarga besar Suhada dan Adi Wikarto, serta almamaterku.
viii
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma: Nama : Sisilia Caturingrum
NIM : 173114014
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
ANALISIS CLUSTER UNTUK PENGELOMPOKAN NILAI UJIAN NASIONAL SMP DI DAERAH ISTIMEWA YOGYAKARTA DENGAN
METODE WARD
beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengolahnya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta izin kepada saya maupun memberi royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya. Dibuat di Yogyakarta
Pada tanggal 29 Juli 2021 Yang menyatakan
ix ABSTRAK
Ujian nasional adalah kegiatan pengukuran capaian kompetensi lulusan pada mata pelajaran tertentu secara nasional dengan mengacu pada Standar Kompetensi Lulusan. Salah satu kegunaan hasil ujian nasional adalah untuk pemetaan serta analisis tingkat pencapaian hasil belajar siswa. Ujian nasional juga dapat digunakan sebagai barometer minimal bagi sekolah di seluruh Indonesia, di mana barometer ini sebagai pengontrol mutu sekolah di Indonesia.
Dalam memantau mutu pendidikan yang ada di Indonesia khususnya DIY, dapat menggunakan analisis cluster untuk mengelompokkan sekolah-sekolah berdasarkan rerata nilai ujian nasional yang diperoleh (tertinggi, menengah, atau terendah). Tujuan dari penelitian ini adalah untuk mengelompokkan SMP yang ada di Daerah Istimewa Yogyakarta menjadi tiga cluster dengan menggunakan metode
Ward, pada tahun pelajaran 2017/2018 dan tahun pelajaran 2018/2019, serta
mengamati sekolah-sekolah yang mengalami pergeseran atau perpindahan cluster. Berdasarkan hasil analisis, didapat tiga cluster, yaitu cluster 1, cluster 2, dan
cluster 3. Cluster-cluster tersebut berbeda secara signifikan. Banyaknya sekolah
yang tetap berada pada cluster yang sama pada tahun pelajaran 2017/2018 dan tahun pelajaran 2018/2019 ada sebanyak 88.08%. Lalu hanya sedikit sekolah yang mengalami perpindahan keanggotaan cluster, yaitu ada sebanyak 11.92% .
Oleh karena itu, pemerintah bisa memetakan peringkat sekolah-sekolah dengan menggunakan nilai UN sebagai dasar meningkatkan mutu pendidikan sekolah.
Kata kunci: Ujian nasional, clustering, metode Ward, ANOVA, MANOVA, peringkat.
x ABSTRACT
The national examination is an activity to measure the achievement of graduates competencies in certain subjects nationally by referring to the Graduate Competency Standards. One of the uses of the national exam results is to map and analyze the level of achievement of student learning outcomes. The national exam can also be used as a minimum barometer for schools throughout Indonesia, where this barometer is a control of the quality of education in Indonesia.
In controlling the quality of schools in Indonesia, especially DIY, a cluster analysis can be used to classify schools based on the average national exam scores obtained (highest, middle, or lowest). The purpose of this study was to group SMP in the Region Special of Yogyakarta into three clusters using the Ward method, in the academic year of 2017/2018 and 2018/2019, as well as observing schools that shift to other cluster.
Based on the results of the analysis, three clusters were obtained, namely cluster 1, cluster 2, and cluster 3. The clusters were significantly different. The number of schools that remained in the 2017/2018 school year and the 2018/2019 school year were 88.08%. There were only a few schools shifting to other cluster membership, namely 11.92%.
Therefore, the government may map the ranking of schools using the average national examination score as the bases of improving the quality of education.
Keywords: national examination, clustering, Ward method, ANOVA, MANOVA, ranking.
xi
KATA PENGANTAR
Puji syukur penulis panjatkan kepada Allah SWT yang telah memberikan rahmat dan karunia-Nya, sehingga penulis dapat menyelesaikan tugas akhir ini dengan tepat waktu dan sangat baik. Tugas akhir ini dibuat dengan tujuan memenuhi syarat untuk memperoleh gelar Sarjana Matematika pada Program Studi Matematika, Fakultas Sains dan Teknologi, Universitas Sanata Dharma.
Dalam penulisan tugas akhir ini, banyak pihak yang membantu penulis dalam menghadapi berbagai macam persoalan sekaligus tantangan yang ada. Oleh karena itu, pada kesempatan ini penulis ingin mengucapkan terimakasih kepada:
1. Bapak Ir. Ig. Aris Dwiatmoko, M.Sc. selaku Dosen Pembimbing Tugas Akhir yang sangat baik dan sabar, serta banyak membantu penulis dalam proses perkuliahan dan penyusunan tugas akhir, hingga akhirnya penulis dapat menyelesaikan tugas akhir ini dengan baik.
2. Bapak Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D. selaku Dekan Fakultas Sains dan Teknologi yang telah memberikan banyak ilmu selama proses perkuliahan.
3. Bapak Hartono, S.Si., M.Sc., Ph.D. selaku Ketua Program Studi Matematika sekaligus Dosen Pendamping Akademik yang senantiasa memberikan motivasi serta telah banyak memberikan banyak ilmu selama proses perkuliahan.
4. Romo Prof. Dr. Frans Susilo SJ., Bapak Dr. rer. nat. Herry P. Suryawan, S.Si., M.Si., Bapak Ricky Aditya, M.Sc., Ibu Lusia Krismiyati Budiasih, S.Si., M.Si., Ibu M. V. Any Herawati, S.Si., M.Si., selaku dosen-dosen Prodi Matematika yang telah memberikan banyak ilmu pengetahuan kepada penulis selama proses perkuliahan.
xii
5. Bapak/Ibu/karyawan Fakultas Sains dan Teknologi yang telah memberikan waktu dan informasi kepada penulis selama proses perkuliahan.
6. Bapak dan Mamak (Heribertus Subandi & Sunartiwi), kakakku (Gigih S., Ferry S. P., & Karunia Tri P.), adikku Putri Mutiara Sari, mba, ponakan-ponakan bibi yang senantiasa mendoakan dan mendukung penulis hingga penulis dapat menyelesaikan kuliah serta tugas akhir ini dengan baik. Beribu-ribu terimakasih penulis ucapkan untuk Bapak dan Mamak atas segala limpahan kasih sayang yang diberikan, yang tidak pernah berhenti memberikan semangat kepada penulis, dan yang tak pernah lelah memberikan segala sesuatu yang terbaik untuk penulis.
7. Sahabatku tercinta sekaligus saudariku Cintya Rachman, yang selalu memberikan doa dan dukungan kepada penulis, yang selalu ada buat penulis dalam keadaan apapun, yang senantiasa memberikan senyuman terbaiknya sehingga penulis termotivasi untuk selalu maju.
8. Sahabatku terkasih sekaligus saudariku Agrippina, yang selalu memberikan doa dan semangat selama proses perkuliahan, yang tak pernah lelah membantu penulis dalam hal apapun, dan yang tak pernah bosan mendengar segala keluh-kesah yang penulis sampaikan, serta yang selalu ada buat penulis dalam keadaan suka & duka.
9. Sahabatku tersayang sekaligus saudaraku Veronica Aprilia, Chatarina Wahyu Trirenfi H., Maria Christiana N. Maran, Elisabeth Patricia, Juli Turnip, Maria Immaculata, Novernatus, Setyandri Rimanda, Ardila Grastika, Nyoman Dina, Saiful Anwar, Pandu Prasetiyo, dan Dwi Agung yang selalu memberikan doa dan semangat kepada penulis.
10. Marchelina, Nathania, Mydia, Oliv, Yasinta, Prisca, Kak Vanessa, Kak Diani, Mba Ghina, dan Mas Denis yang selalu memberikan semangat kepada penulis.
xiv DAFTAR ISI
HALAMAN JUDUL ... i
TITLE PAGE ... ii
HALAMAN PERSETUJUAN PEMBIMBING ... iii
HALAMAN PENGESAHAN ... iv
PERNYATAAN KEASLIAN KARYA ... v
MOTTO... vi
HALAMAN PERSEMBAHAN... vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI... viii
ABSTRAK ... ix
ABSTRACT ... x
KATA PENGANTAR ... xi
DAFTAR ISI ... xiv
BAB I PENDAHULUAN A. Latar Belakang ... 1 B. Rumusan Masalah ... 4 C. Batasan Masalah... 4 D. Tujuan Penulisan ... 4 E. Manfaat Penulisan ... 5 F. Metode Penulisan ... 5 G. Sistematika Penulisan... 5
BAB II LANDASAN TEORI A. Variabel Acak... 7
xv
B. Pengukuran ... 8
C. Data dan Jenisnya ... 9
1. Berdasarkan Cara Memperolehnya ... 9
2. Berdasarkan Skala Pengukurannya ... 10
3. Berdasarkan Sifatnya ... 11
4. Berdasarkan Banyaknya Variabel ... 12
D. Teorema Limit Pusat ... 15
E. Analisis Variansi Multivariat ... 16
1. Analysis of Variance (ANOVA) ... 16
2. Multivariate Analysis of Variance (MANOVA) ... 18
F. Penambangan Data (Data Mining)... 23
1. Pembersihan Data... 24
2. Integrasi Data ... 26
3. Reduksi Data ... 26
4. Transformasi ... 26
G. Ujian Nasional ... 26
H. Ukuran Kesamaan Antar Obyek ... 28
1. Ukuran Korelasi ... 28
2. Ukuran Asosiasi ... 31
3. Ukuran Jarak ... 33
BAB III ANALISIS CLUSTER A. Analisis Cluster ... 43
1. Merumuskan Masalah ... 45
2. Memilih Ukuran Jarak ... 46
3. Memilih Metode Pengclusteran ... 46
4. Menentukan Banyaknya Cluster ... 46
5. Menginterpretasi dan Membuat Profil Cluster ... 46
xvi
B. Metode-metode dalam Analisis Cluster ... 47
1. Metode Hirarki ... 58
2. Metode Non-hirarki ... 63
BAB IV IMPLEMENTASI METODE WARD DAN HASIL ANALISIS A. Metode Ward ... 69
B. Sumber Data dan Metode Pengambilannya ... 78
C. Praproses Data ... 89
D. Implementasi Metode Ward ... 85
1. Merumuskan Masalah ... 85
2. Memilih Ukuran Jarak... 85
3. Memilih Metode Pengclusteran ... 86
4. Menentukan Banyaknya Cluster dan Keanggotaannya ... 86
5. Hasil Analisis Cluster ... 87
E. Hasil Analisis ... 95 BAB V PENUTUP A. Kesimpulan ... 102 B. Saran ... 103 DAFTAR PUSTAKA ... 104 LAMPIRAN ... 108
1 BAB I PENDAHULUAN
A. Latar Belakang
Dalam kehidupan sehari-hari seringkali ditemukan pengelompokan suatu obyek (pengamatan), baik berupa benda maupun yang lainnya. Pengelompokan tersebut biasanya didasarkan atas kemiripan obyek. Misal di bidang sosial, pengelompokan tingkat kesejahteraan masyarakat bisa berdasarkan beberapa hal, seperti pekerjaannya, pendidikannya, dan sebagainya. Pengelompokan tersebut dapat dibuat karena masing-masing faktor yang mempengaruhi tingkat kesejahteraan masyarakat mempunyai karakteristik yang menjadi dasar dalam pengelompokan. Dalam tugas akhir ini akan dibahas mengenai pengelompokan dalam bidang pendidikan, yaitu dengan menggunakan analisis cluster.
Analisis cluster adalah suatu analisis statistika yang mencari pola dalam kumpulan data dengan mengelompokkan obyek (pengamatan) ke dalam cluster. Tujuan dari analisis cluster adalah mengelompokkan obyek-obyek berdasarkan kesamaan karakteristik di antara obyek-obyek-obyek-obyek tersebut. Ada dua pendekatan secara umum untuk vektor pengamatan dalam
clustering, yaitu metode hirarki dan metode non-hirarki.
Metode hirarki adalah pendekatan alternatif untuk partisi cluster dalam mengelompokkan obyek berdasarkan kesamaan mereka (Kassambra, 2017). Dalam metode hirarki terdapat dua tipe dasar metode, yaitu agglomerative dan
divisive (Everitt, et al., 2011:71). Metode agglomerative memiliki beberapa
macam metode, salah satunya adalah metode Ward. Dalam metode Ward, jarak antara dua cluster didasarkan pada jumlah kuadrat total (total sum of
Dalam tugas akhir ini, akan dibahas mengenai analisis cluster dalam pengelompokan sekolah menengah pertama berdasarkan nilai ujian nasional di Daerah Istimewa Yogyakarta dengan metode Ward. Berikut ini merupakan penelitian-penelitian yang membahas mengenai pengelompokan yang berkaitan dengan dunia pendidikan, serta penelitian menggunakan metode
Ward.
1. Penelitian yang dilakukan oleh Aloysius Ari Kurniawan (2017) yang berjudul Implementasi Algoritma Agglomerative Hierarchical Clustering untuk Mengelompokkan Capaian Belajar Siswa SD. Dalam penelitian ini, peneliti menggunakan tiga metode dari agglomerative hierarchical
clustering, yaitu single linkage, complete linkage, dan average linkage.
Salah satu kesimpulan yang diperoleh dalam penelitian ini adalah metode
agglomerative hierarchical clustering dapat dengan baik mengelompokkan data nilai capaian belajar siswa.
2. Penelitian yang dilakukan oleh Kresentia Nita Kurniadewi (2016) yang berjudul Pengelompokan Sekolah Menengah Atas di Provinsi Daerah Istimewa Yogyakarta Berdasarkan Nilai Ujian Nasional Menggunakan Algoritma K-Means Clustering. Kesimpulan yang diperoleh salah satunya adalah algoritma K-Means dapat digunakan untuk mengelompokkan nilai hasil ujian nasional SMA jurusan IPA dan IPS tahun ajaran 2014/2015 di Daerah Istimewa Yogyakarta dengan cara melakukan proses awal pembersihan data, integrasi data dan seleksi data.
3. Penelitian yang dilakukan oleh Sofya Laeli (2014) yang berjudul Analisis
Cluster dengan Average Linkage Method dan Ward’s Method untuk Data
yang telah dilakukan, salah satu kesimpulan yang diperoleh adalah nilai rasio simpangan baku dalam cluster dan antar cluster bisa digunakan untuk menilai perbandingan kinerja metode pengclusteran. Berdasarkan nilai rasio simpangan baku, metode average linkage merupakan metode terbaik.
Pendidikan merupakan salah satu hal penting dalam keberlangsungan hidup manusia. Jika berbicara mengenai pendidikan, maka tidak akan terlepas dari konsep sekolah. Dalam dunia pendidikan, sekolah menjadi tempat yang berfungsi untuk memberikan pendidikan kepada siswa. Sekolah memberikan keterampilan dasar bagi para siswa yaitu kemampuan membaca, menulis, dan juga berhitung. Sekolah menengah pertama (SMP) merupakan tingkatan kedua yang harus ditempuh oleh para siswa ketika sudah menyelesaikan pendidikan di sekolah dasar. Pendidikan di tingkat SMP menjadi jembatan untuk mengenyam pendidikan pada tingkat selanjutnya. Pada tingkat SMP, siswa dididik untuk menjadi generasi yang siap menghadapi era perkembangan zaman.
Pentingnya pengelompokan sekolah-sekolah menengah pertama di DIY berdasarkan nilai ujian nasional adalah untuk memetakan peringkat sekolah-sekolah di DIY pada tahun pelajaran 2017/2018 dan tahun pelajaran 2018/2019. Dengan adanya pengelompokan ini, bisa diketahui apakah terjadi perubahan peringkat (perpindahan cluster) berdasarkan nilai UN, sehingga diharapkan sekolah bisa mengevaluasi dan meningkatkan mutu pendidikan sekolah untuk para siswanya. Pengelompokan SMP di DIY beradasarkan nilai UN ini akan dilihat dari aspek nilai rerata yang diperoleh sekolah, yaitu rerata nilai mata pelajaran yang diujikan seperti nilai ujian bahasa Indonesia, bahasa Inggris, matematika, dan ilmu pengetahuan alam. Hasil pengelompokan selanjutnya dianalisis dan diinterpretasikan menggunakan metode statistika.
B. Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan, rumusan masalah yang akan dibahas adalah:
1. Bagaimana landasan matematis analisis cluster dengan metode Ward? 2. Bagaimana analisis cluster dengan metode Ward dapat diterapkan dalam
pengelompokan SMP berdasarkan nilai UN di DIY?
C. Batasan Masalah
Batasan masalah dalam tugas akhir ini adalah:
1. Metode yang digunakan dalam pengelompokan adalah metode Ward. 2. Pengumpulan dan pengolahan data dibatasi hanya untuk sekolah
menengah pertama di DIY.
3. Pengelompokan kemampuan siswa dilihat dari aspek nilai rerata ujian nasional SMP, yaitu nilai ujian bahasa Indonesia, bahasa Inggris, matematika, dan IPA.
4. Tidak semua materi prasyarat dijelaskan dalam tugas akhir ini.
D. Tujuan Penulisan
Berdasarkan rumusan masalah di atas, tujuan penulisan tugas akhir ini adalah sebagai berikut:
1. Mengetahui landasan matematis analisis cluster khususnya dengan menggunakan metode Ward.
2. Mengetahui bagaimana penerapan analisis cluster dengan metode Ward dapat diterapkan dalam pengelompokan SMP berdasarkan nilai UN di DIY.
E. Manfaat Penulisan
Manfaat penulisan tugas akhir ini adalah sebagai berikut:
1. Memperluas wawasan penulis mengenai analisis cluster untuk pengelompokan SMP berdasarkan nilai UN di DIY dengan metode Ward. 2. Menambah pengetahuan pembaca tentang penerapan analisis cluster dan
salah satu penerapannya dalam bidang pendidikan.
F. Metode Penulisan
Metode penulisan yang digunakan dalam menyusun tugas akhir ini adalah metode studi pustaka, yaitu dengan membaca dan mempelajari buku-buku dan jurnal-jurnal yang berkaitan dengan analisis cluster, serta praktik menggunakan perangkat lunak R.
G. Sistematika Penulisan BAB 1 PENDAHULUAN A. Latar Belakang B. Rumusan Masalah C. Batasan Masalah D. Tujuan Penulisan E. Manfaat Penulisan F. Metode Penulisan G. Sistematika Penulisan BAB II LANDASAN TEORI
A. Variabel Acak B. Pengukuran C. Data dan Jenisnya D. Teorema Limit Pusat
F. Penambangan Data (Data Mining) G. Ujian Nasional
H. Ukuran Kesamaan Antar Obyek BAB III ANALISIS CLUSTER
A. Analisis Cluster
B. Metode-metode dalam Analisis Cluster
BAB IV IMPLEMENTASI METODE WARD DAN HASIL ANALISIS A. Metode Ward
B. Sumber Data dan Metode Pengambilannya C. Praproses Data
D. Implementasi Metode Ward E. Hasil Analisis BAB V PENUTUP A. Kesimpulan B. Saran DAFTAR PUSTAKA LAMPIRAN
7 BAB II
LANDASAN TEORI
A. Variabel Acak
Definisi 2.1 Variabel Acak
Variabel acak adalah suatu fungsi bernilai real yang domainnya merupakan ruang sampel.
Contoh 2.1
Berikut ini merupakan diagram panah yang menunjukkan nilai matematika empat siswa sekolah menengah pertama.
Gambar 2.1 Pemetaan Nilai Siswa
Contoh 2.2
Suatu percobaan dilakukan dengan melemparkan dua buah dadu sebanyak satu kali. Variabel acak menyatakan banyaknya mata dadu 6 yang muncul, maka nilai yang menyatakan nilai dari yang mungkin adalah 0,1, atau 2.
1 2 3 4 5 6 1 (1,1) (1,2) (1,3) (1,4) (1,5) (1,6) 2 (2,1) (2,2) (2,3) (2,4) (2,5) (2,6) 3 (3,1) (3,2) (3,3) (3,4) (3,5) (3,6) 4 (4,1) (4,2) (4,3) (4,4) (4,5) (4,6) 5 (5,1) (5,2) (5,3) (5,4) (5,5) (5,6) 6 (6,1) (6,2) (6,3) (6,4) (6,5) (6,6)
Variabel acak dibedakan menjadi dua, yaitu variabel acak diskrit dan variabel acak kontinu.
Definisi 2.2 Variabel Acak Diskrit
Variabel acak dikatakan variabel acak diskrit jika semua nilai yang mungkin dari membentuk himpunan bilangan terbilang.
Definisi 2.3 Variabel Acak Kontinu
Variabel acak dikatakan variabel acak kontinu jika semua nilai yang mungkin dari membentuk himpunan bilangan tak terbilang.
B. Pengukuran
Dalam kehidupan sehari-hari seringkali kita mendengar bahkan melakukan kegiatan pengukuran. Pengukuran merupakan suatu proses memberikan lambang bilangan atau variabel pada obyek penelitian.
Definisi 2.4 Pengukuran
Pengukuran adalah kegiatan memberikan lambang-lambang bilangan pada obyek penelitian menurut aturan tertentu.
Proses pengukuran akan menghasilkan data yang mengandung suatu informasi. Ada banyak contoh pengukuran, misal mengukur tinggi badan, menimbang berat badan, mengukur capaian hasil belajar siswa sekolah menengah pertama, dan lain sebagainya. Pengukuran dapat dilakukan pada hal apapun. Misalnya pada pengukuran capaian hasil belajar, pengukuran dilakukan dengan melihat keberhasilan dalam proses pembelajaran baik dari segi nilai yang diperoleh maupun yang lainnya.
Contoh 2.3
Panjang dua buah kayu diukur dengan menggunakan alat ukur berturut-turut adalah 120 cm dan 3 m.
C. Data dan Jenisnya
Data adalah nilai dari variabel yang merupakan hasil suatu pengukuran atau observasi (Bluman, 2011). Data dapat dikategorikan menjadi beberapa jenis, yaitu berdasarkan cara memperolehnya, sifatnya, dan skala pengukurannya, dan lain sebagainya.
1. Berdasarkan Cara Memperolehnya
Berdasarkan cara memperolehnya data dibedakan menjadi dua, yaitu data primer dan data sekunder.
a. Data Primer
Data primer adalah data yang diperoleh secara langsung berdasarkan obyek yang diteliti. Misalnya data hasil wawancara dengan responden.
b. Data Sekunder
Data sekunder diperoleh secara tidak langsung dari obyek yang diteliti. Data sekunder umumnya diperoleh dari instansi-instansi yang menyediakan kumpulan data untuk keperluan penelitian. Contoh data sekunder adalah data jumlah pengunjung perpustakaan Universitas Sanata Dharma yang diperoleh dari daftar hadir (pengunjung).
2. Berdasarkan Skala Pengukurannya a. Skala Nominal
Skala nominal merupakan skala yang hanya memberikan informasi yang cukup untuk membedakan satu obyek dari yang lain. Contoh dengan mempertimbangkan variabel jenis kelamin, laki-laki dan perempuan. Misalkan dengan menggunakan angka untuk mewakili subjek jenis kelamin. Sebagai contoh bisa ditentukan dengan menetapkan sembarang nomor, misal nomor 1 untuk subjek laki-laki dan nomor 2 untuk subjek perempuan. Angka yang ditetapkan tersebut tidak memiliki arti apapun karena angka tersebut hanya untuk mengkategorikan subjek ke dalam kelompok yang berbeda.
b. Skala Ordinal
Skala ordinal merupakan skala yang mengkategorikan suatu obyek berdasarkan tingkatan atau urutan. Pada skala ordinal, lambang-lambang bilangan hasil pengukuran menunjukkan tingkatan atau urutan obyek-obyek yang diukur menurut dari karakteristik yang dipe lajari. Hal yang dipentingkan pada skala ordinal adalah urutannya, sementara jarak antar urutan tidak menjadi persoalan. Contoh dari skala ordinal adalah status gizi, di mana status gizi dapat diurutkan ke dalam gizi buruk, gizi kurang cukup, atau gizi baik.
c. Skala Interval
Skala interval merupakan skala pengukuran yang mempunyai sifat seperti skala ordinal, yaitu adanya urutan tertentu dalam hasil pengukuran, namun ditambah satu sifat khas yaitu adanya satuan skala. Artinya, perbedaan karakteristik antara obyek yang berpasangan dengan lambang bilangan yang satu dengan obyek yang berpasangan dengan lambang bilangan berikutnya selalu tetap sama. Salah satu contoh dari skala interval adalah suhu yang diukur dalam derajat celcius.
d. Skala Rasio
Skala rasio merupakan skala yang menghasilkan data dengan mutu tertinggi. Perbedaan antara skala rasio dan skala interval terletak pada keberadaan nilai nol pada skala tersebut. Jika skala interval nilai nolnya tidak bersifat mutlak, maka pada skala rasio nilai nolnya bersifat mutlak, di mana nilai nol mutlak ini dapat menunjukkan ketiadaan karakteristik yang diukur. Contohnya adalah perbedaan nilai nol derajat pada variabel suhu dan nilai nol pada variabel berat badan.
3. Berdasarkan Sifatnya a. Data Kualitatif
Data kualitatif tidak dapat diukur maupun dicacah secara langsung, karena data kualitatif bersifat deskriptif. Data kualitatif bisa juga disebut dengan data kategorikal, di mana data kualitatif terdiri dari nama atau label bukan angka yang mewakili hasil perhitungan maupun pengukuran. Contohnya adalah kualitas udara di Jakarta memburuk seiring dengan volume kendaraan yang meningkat.
b. Data Kuantitatif
Data kuantitatif merupakan data yang terdiri atas bilangan-bilangan yang merupakan hasil dari perhitungan maupun pengukuran. Data kuantitatif dapat dibedakan menjadi dua, yaitu data diskrit dan data kontinu.
a) Data Diskrit
Data diskrit adalah data yang diperoleh dari hasil pencacahan atau membilang variabel random diskrit. Salah satu contoh data diskrit adalah data jumlah penduduk di kota X.
b) Data Kontinu
Data kontinu adalah data yang diperoleh dari hasil pengukuran variabel random kontinu. Data kontinu dihasilkan dari banyak kemungkinan nilai kuantitatif yang tak berhingga di mana kumpulan nilainya tak terbilang. Salah satu contoh dari data kontinu adalah data tinggi badan.
4. Berdasarkan Banyaknya Variabel a. Data Univariat
Data univariat merupakan data hasil pengukuran dari sebuah variabel. Pada prinsipnya, kita dihadapkan dengan data sampel berukuran yang menghasilkan pengamatan , di mana variabelnya hanya satu yaitu dengan pengamatan.
Contoh 2.4
Berikut ini merupakan tabel data hasil observasi variabel tinggi badan 5 siswa.
Siswa Tingggi Badan (cm) 1 98 2 105 3 103 4 89 5 110 b. Data Multivariat
Data multivariat merupakan data hasil pengukuran dari dua atau lebih variabel. Analisis multivariat terdiri dari sekumpulan metode yang dapat digunakan ketika beberapa pengukuran dilakukan oleh satu individu atau obyek dalam sampel. Analisis multivariat bertujuan untuk menganalisis data yang terdiri atas banyak variabel yang saling berhubungan satu sama lain. Secara umum data multivariat dapat disajikan dalam bentuk matriks. Misal terdapat deretan bilangan yang akan disusun sebagai matriks dengan baris dan kolom adalah sebagai berikut (Johnson and Wichern, 2007:54).
[ ] di mana:
: banyaknya obyek pengamatan : banyaknya variabel diamati
: data hasil pengamatan obyek ke-i untuk variabel ke-j, dengan dan
Contoh 2.5
Di bawah ini merupakan data penilaian tengah semester 20 siswa kelas 6, SDN 01 Tanjung Serupa tahun ajaran 2019/2020.
Siswa 1 83 79 78 75 84 74 78 86 80 2 79 82 82 78 79 75 77 79 77 3 88 90 89 86 85 87 78 88 85 4 77 78 79 73 84 73 78 78 76 5 78 81 80 73 83 76 78 79 77 6 77 78 82 74 80 73 79 78 77 7 80 76 79 74 77 72 78 80 77 8 83 88 85 80 83 82 80 88 80 9 78 76 84 74 83 78 80 85 78 10 82 89 83 78 85 80 79 80 80 11 80 80 81 75 84 76 79 79 77 12 84 85 85 76 87 87 79 82 79 13 79 83 84 72 90 80 78 81 77 14 80 79 81 72 80 76 79 79 76 15 80 87 84 74 86 82 79 86 77 16 76 80 82 77 79 72 77 77 76 17 78 79 79 79 85 79 78 82 77 18 86 84 84 77 83 88 79 86 80 19 78 77 84 77 80 81 78 88 79 20 81 89 84 77 83 90 80 83 78 dengan
nilai pendidikan agama dan budi pekerti nilai pendidikan kewarganegaraan nilai bahasa indonesia
nilai matematika
nilai ilmu pengetahuan alam nilai ilmu pengetahuan sosial
nilai pendidikan jasmani, olahraga, dan kesehatan nilai seni budaya
nilai bahasa Lampung D. Teorema Limit Pusat
Apabila suatu sampel acak diambil dari populasi yang distribusinya sembarang dengan rata-rata dan variansi , maka distribusi sampling dari ̅ memiliki
( ̅) ( ̅)
Secara umum, distribusi sampling dari ̅ akan selalu normal bila berdistribusi normal. Tetapi, bila tidak berdistribusi normal, maka tidak ada jaminan bahwa distribusi sampling dari ̅ adalah normal. Bila distribusi dari populasi tidak normal, maka distribusi sampling dari ̅ akan normal hanya bila ukuran sampelnya cukup besar (biasanya nilai lebih besar dari 30).
Teorema 2.1 Teorema Limit Pusat
Misalkan merupakan variabel acak independen dan berdistribusi identic dengan ( ) dan ( ) . Didefinisikan
∑ √ ̅ √ ⁄ di mana ̅ ∑
maka fungsi distribusi dari konvergen ke fungsi distribusi Normal Standar untuk .
( ) ∫√
Bukti dapat dilihat pada buku Mathematical Statistics with Application 7th
Edition (Wackerly, et al., 2008).
E. Analisis Variansi Multivariat
Dalam tugas akhir ini, analisis variansi univariat dan analisis variansi multivariat akan digunakan untuk memvalidasi hasil clustering. Analisis variansi multivariat atau yang lebih dikenal dengan MANOVA merupakan perluasan dari analisis variansi univariat atau lebih dikenal dengan ANOVA. MANOVA digunakan untuk menguji perbedaan untuk dua atau lebih variabel dependen yang berskala metrik berdasarkan kumpulan variabel independen yang berskala non-metrik.
Dalam pengujian MANOVA, asumsi-asumsi yang harus dipenuhi adalah sebagai berikut:
1. adalah sampel acak berukuran dari populasi dengan rata-rata ( ). Sampel acak dari populasi yang berbeda bersifat independen.
2. Masing-masing populasi berdistribusi normal multivariat 3. Matriks-matriks kovarian homogen
1. Analysis of Variance (ANOVA)
ANOVA digunakan untuk menguji hipotesis perbedaan rata-rata lebih dari dua populasi. Asumsi yang harus dipenuhi untuk menguji ANOVA untuk buah populasi adalah sebagai berikut:
1. Normalitas data tiap populasi
2. Homogenitas variansi dari populasi
Diasumsikan terdapat buah populasi yang independen dan berdistribusi normal dengan rata-rata , hipotesis yang digunakan adalah
: sekurang-kurangnya dua rata-rata tidak sama
(2.1)
Populasi biasanya akan sesuai dengan rangkaian kondisi perulangan yang berbeda, dan oleh karena itu, akan lebih mudah untuk menyelidiki deviasi yang terkait dengan populasi (perlakuan). Hipotesis nol menjadi
Variabel respon yang berdistribusi normal ( ), dapat ditulis dalam bentuk
(2.2) di mana adalah variabel acak yang berdistribusi normal ( ) yang independen.
Berdasakaran dekomposisi dalam persamaan (2.2), ANOVA didasarkan pada dekomposisi pengamatan yang analog
̅ ( ̅ ̅) ( ̅ ) (2.3) di mana:
̅ : penduga rata-rata ( ̅ ̅) : penduga efek perlakuan ( ̅): penduga galat
2. Multivariate Analysis of Variance (MANOVA)
Terdapat beberapa statistik uji yang dapat digunakan dalam pengujian MANOVA, yaitu Wilks’ Lambda, Roy‟s, Pillai, dan
Lawley-Hotelling. Dalam tugas akhir ini, hanya akan dibahas mengenai analisis
variansi multivariat satu arah (one-way MANOVA).
One-Way MANOVA
Berikut ini merupakan persamaan model MANOVA untuk membandingkan vektor rata-rata populasi.
(2.4)
dengan dan , di mana adalah variabel dari ( ) yang independen, parameter vektor adalah rata-rata keseluruhan, dan merepresentasikan efek perlakuan ke- dengan ∑ . Selanjutnya vektor pengamatan dapat diuraikan menjadi
̅ ( ̅ ̅) ( ̅) (2.5) di mana:
: pengamatan ke- dari populasi ke- ̅ : rata-rata sampel penduga
( ̅ ̅) : penduga efek perlakuan ( ̅) : penduga galat
Di bawah ini merupakan tabel MANOVA untuk membandingkan vektor rata-rata populasi.
Tabel 2.2 Tabel MANOVA
Sumber Variasi Matriks Jumlah Kuadrat dan Perkalian Silang Derajat Bebas Perlakuan ∑ ( ̅ ̅)( ̅ ̅) Galat ∑ ∑( ̅ )( ̅ ) ∑ Total ∑ ∑( ̅)( ̅) ∑
Berikut ini langkah-langkah dalam pengujian hipotesis MANOVA. 1.
atau juga dapat ditulis dalam bentuk vektor dengan populasi dan variabel pengamatan [ ] [ ] [ ]
2. setidaknya ada , di mana 3. Memilih Tingkat Signifikansi
4. Statistik Uji
Dalam pengujian MANOVA terdapat asumsi-asumsi yang harus dipenuhi, yaitu variabel pengamatan berdistribusi normal multivariat dan matriks kovarian homogen. Statistik uji yang digunakan dalam pengujian MANOVA pada tugas akhir ini dibatasi, yakni hanya menggunakan statistik uji Wilks’ Lambda ( ) dan uji Pillai ( ( )).
Berikut ini merupakan rumus statistik uji Wilks’ Lambda | |
| | dan rumus statistik uji Pillai
( ) ,( ) - dengan ∑ ∑( ̅ )( ̅) ∑ ( ̅ ̅)( ̅ ̅) di mana:
: ukuran sampel atau jumlah sampel kelompok ke- ̅ : rata-rata dari sampel ke-
̅ : rata-rata keseluruhan : vektor pengamatan
Dalam hal ini jika asumsi matriks kovarian homogen dipenuhi, statistik uji yang digunakan adalah statistik uji Wilks’ Lambda ( ). Sedangkan jika asumsi matriks kovarian homogen tidak dipenuhi, maka statistik uji yang digunakan adalah statistik uji Pillai ( ).
5. Wilayah Kritis (Daerah penolakan ) Untuk statistik uji Wilk‟s Lambda,
ditolak apabila dengan
( )
di mana:
: derajat bebas untuk hipotesis : derajat bebas untuk galat Untuk statistik uji Pillai
ditolak bila ( ) ( ) 6. Melakukan Perhitungan
Pada tahap ini, perhitungan dapat dilakukan dengan menggunakan bantuan perangkat lunak-R pada komputer, menggunakan fasilitas yang terdapat pada Microsoft Excel, maupun perangkat-perangkat lunak yang lain yang sesuai dengan statistik uji yang telah dipilih sebelumnya. 7. Membuat Kesimpulan
Berdasarkan hasil yang diperoleh pada tahap perhitungan, maka dapat ditarik suatu kesimpulan apakah vektor rata-rata dari dua populasi atau lebih berbeda secara signifikan.
Contoh 2.6
Dalam percobaan klasik yang dilakukan dari tahun 1918 sampai 1934, Andrews dan Herberg (1985) melaporkan hasil penelitiannya terhadap 6 ladang pohon apel yang berbeda, di mana setiap ladang akan diteliti 8 pohon apel dengan ketentuan variabel pengukuran sebagai berikut
lingkar batang pohon berumur 4 tahun (dalam 10 cm) pertumbuhan pohon berumur 4 tahun (dalam m)
lingkar batang pohon berumur 15 tahun (dalam 10 cm)
berat batang pohon di atas permukaan tanah pada pohon berumur 15 tahun (dalam 1000 pon)
data dari penelitian tersebut dapat dilihat pada Lampiran 1.
Akan diuji apakah vektor rata-rata ukuran dari keenam ladang yang diteliti berbeda secara signifikan. Berikut ini merupakan rumusan hipotesis yang digunakan.
1. Merumuskan hipotesis nol dan alternatif :
: setidaknya ada , di mana 2. Memilih tingkat signifikansi 3. Statistik uji
Statistik uji yang digunakan dalam contoh ini adalah statistik uji Wilk‟s
Lambda. Dalam contoh ini keenam ladang diasumsikan berdistribusi
normal multivariat dan matriks kovarian homogen. | | | | 4. Wilayah kritis Dengan ( ) ( ) sehingga ditolak apabila 5. Perhitungan ( ) ( )
( ) | | | |
Karena , maka dapat disimpulkan bahwa ditolak.
6. Kesimpulan
ditolak, maka terbukti bahwa ada perbedaan rata-rata ukuran dari keenam ladang yang diteliti secara signifikan.
F. Penambangan Data (Data Mining)
Penambangan data atau yang lebih dikenal dengan istilah data mining sangat erat kaitannya dengan analisa data (Kumar, et al., 2006). Data mining
adalah proses menemukan informasi yang berguna secara otomatis dalam repositori data yang besar. Definisi lain dari data mining adalah bagian integral dari Knowledge Discovery in Databases (KDD), yang merupakan keseluruhan proses mengubah data mentah menjadi informasi yang berguna. Kegunaan data mining dibagi menjadi dua, yaitu prediktif dan deskriptif. Prediktif berarti data mining digunakan untung memprediksi nilai variabel tertentu berdasarkan nilai variabel lainnya. Sedangkan deskriptif berarti data
mining digunakan untuk mendapatkan pola baik itu korelasi, cluster, maupun
yang lainnya, yang menjelaskan karakteristik data.
Seiring dengan kemajuan zaman, jumlah data yang ada saat ini meningkat secara eksponensial. Hal ini tentunya menimbulkan permasalahan tersendiri dalam era big data, di mana sangat rentan terhadap data yang berisik (noisy), hilang, dan tidak konsisten dikarenakan ukuran data yang
sangat besar. Prapemrosesan data (data preprocessing) dalam data mining sangat diperlukan dalam hal ini. Tujuan dari prapemrosesan data adalah untuk mempermudah memahami data sehingga mempermudah pemilihan teknik dan metode data mining yang tepat, meningkatkan kualitas data sehingga hasil data mining menjadi lebih baik, meningkatkan efisiensi dan kemudahan proses penambangan data. Pada bagian prapemrosesan data, data dikatakan memiliki kualitas jika memenuhi persyaratan yang dimaksudkan. Prapemrosesan data diperlukan karena data di dunia nyata cenderung kotor, tidak lengkap, berisi gangguan, kesalahan atau pencilan (outliers), tidak konsisten, dan lain sebagainya. Berikut ini merupakan tugas utama dari prapemrosesan data.
1. Pembersihan Data
Pembersihan data atau data cleaning berfungsi untuk membersihkan data dengan mengisi nilai yang hilang, menghaluskan data yang menyimpang (noisy data), mengidentifikasi atau menghapus pencilan (outlier), dan mengatasi ketidakonsistenan.
a. Data Hilang/Kosong (Missing Values)
Jika terdapat sebuah data yang mengandung tuple dengan satu atau lebih atribut tanpa nilai (kosong), maka dapat dibersihkan dengan cara: 1) Abaikan tuple tersebut: cara ini biasanya digunakan jika tuple tersebut tidak memiliki label kelas (dalam kasus klasifikasi data). Metode ini kurang efektif untuk data yang memiliki banyak tuple dengan sedikit atribut kosong. Karena dengan mengabaikan
tuple-tuple tersebut, banyak atribut lain yang memiliki nilai tidak
dipergunakan sama sekali.
2) Isi atribut kosong secara manual: cara ini dapat digunakan untuk mengatasi kelemahan metode pertama. Namun, cara ini
memerlukan banyak waktu dan seringkali tidak layak untuk digunakan pada himpunan data besar yang memilik banyak atribut kosong.
3) Gunakan sebuah konstanta global untuk mengisi atribut kosong: dalam metode ini, dapat dilakukan dengan mengisi semua atribut kosong dengan nilai yang berupa sebuah konstanta yang sama. 4) Gunakan sebuah nilai tendensi sentral (misal rata-rata atau median)
untuk mengisi atribut kosong: rata-rata biasanya digunakan untuk himpunan data yang berdistribusi normal (simetris), sedangkan median umumnya digunakan untuk himpunan data yang memiliki distribusi condong ke kiri atau ke kanan (asimetris).
5) Gunakan rata-rata atau median dari suatu atribut untuk mengisi semua sampel dalam kelas yang sama dengan tuple tersebut.
6) Gunakan nilai yang paling mungkin untuk mengisi atribut kosong.
b. Noisy Data
Kebisingan atau noise dalam himpunan data bisa berupa kesalahan atau variasi yang bersifat acak, misalnya suatu nilai yang jauh lebih kecil atau lebih besar dibanding yang lain. Jika memiliki sebuah data yang bising, maka dapat dibersihkan dengan cara:
1) Binning: metode ini dilakukan dengan cara mengurutkan nilai-nilai
pada suatu atribut, lalu membaginya ke dalam sejumlah interval secara merata, dan penghalusan dapat dilakukan dengan tiga cara, yaitu rata-rata, median, atau batas nilai minimum dan maksimum.
2) Regresi: suatu regresi linear biasa mencari persamaan garis terbaik
yang paling mendekati nilai-nilai dari dua buah atribut sedemikian hingga suatu atribut dapat digunakan untuk memprediksi atribut yang lain.
3) Analisis outliers (pencilan): outliers (pencilan) dapat dideteksi
dengan berbagai metode yang tidak dibahas dalam tugas akhir ini.
2. Integrasi Data
Dalam data mining seringkali membutuhkan integrasi data (penggabungan data dari beberapa penyimpanan data). Integrasi data yang dilakukan secara hati-hati dapat membantu mengurangi dan menghindari redundansi inkonsistensi di antara kumpulan data yang dihasilkan. Suatu atribut dikatakan redundan jika atribut bisa diturunkan dari atribut atau sekumpulan atribut lainnya.
3. Reduksi Data
Data dapat direduksi menjadi jauh lebih kecil dengan tetap menjaga keutuhan data asli. Artinya, menambang pada himpunan data yang direduksi harus lebih efisien namun menghasilkan hasil analisis yang sama.
4. Transformasi
Transformasi adalah proses pentransferan data dalam bentuk standar. Bentuk standar yang dimaksud adalah bentuk data yang akan dicapai oleh algoritma penambangan data. Bentuk standar ini biasanya dalam bentuk
spreadsheet.
G. Ujian Nasional
Dalam pendidikan dasar dan menengah, untuk mengukur pencapaian kompetensi siswa dalam proses pembelajaran salah satunya adalah dengan menyelenggarakan ujian bagi siswa. Ujian adalah kegiatan yang dilakukan untuk mengukur pencapaian kompetensi peserta didik sebagai pengakuan
prestasi belajar dan/atau penyelesaian dari suatu Satuan Pendidikan (permendikbud No. 43 Tahun 2019). Ujian yang diselenggarakan oleh Satuan Pendidikan merupakan penilaian hasil belajar oleh Satuan Pendidikan yang bertujuan untuk menilai pencapaian standar kompetensi lulusan untuk semua mata pelajaran. Sedangkan ujian nasional merupakan ujian yang diselenggarakan secara nasional pada tingkat akhir sekolah dasar dan menengah.
Ujian Nasional yang selanjutnya disingkat UN adalah kegiatan pengukuran capaian kompetensi lulusan pada mata pelajaran tertentu secara nasional dengan mengacu pada Standar Kompetensi Lulusan (permendikbud No. 43 Tahun 2019). Di Indonesia sendiri UN dilaksanakan untuk anak-anak dalam pendidikan dasar hingga dalam pendidikan menengah. UN biasanya dilaksanakan pada akhir semester genap untuk siswa kelas VI sekolah dasar, kelas IX sekolah menengah pertama, dan kelas XII sekolah menengah atas. UN dapat menentukan tingkat kemampuan peserta didik di seluruh Indonesia berdasarkan standar nasional yang telah ditetapkan. Nilai perolehan UN siswa dapat dibandingkan dengan siswa lain antarsekolah, antar-kabupaten, dan antar provinsi di seluruh Indonesia karena menggunakan kisi-kisi UN berstandar nasional. Salah satu kegunaan hasil UN adalah untuk pemetaan serta analisis tingkat pencapaian hasil belajar siswa.
UN dapat digunakan sebagai barometer minimal bagi sekolah di seluruh Indonesia, di mana barometer ini sebagai pengontrol mutu sekolah di Indonesia. UN sebagai barometer minimal bagi sekolah karena UN dapat digunakan untuk mengelompokkan sekolah-sekolah berdasarkan nilai ujian terbaik yang diperoleh. Pada UN SMP terdapat empat mata pelajaran yang diujikan, yaitu bahasa Indonesia, bahasa Inggris, matematika, dan IPA.
H. Ukuran Kesamaan Antar Obyek
Dalam analisis cluster ukuran kedekatan atau kesamaan merupakan hal yang paling mendasar, sebagai upaya untuk menghasilkan struktur kelompok yang agak sederhana dari kumpulan data yang kompleks. Untuk memilih ukuran kesamaan, penting mempertimbangkan beberapa hal yang meliputi sifat variabel (diskrit, kontinu, biner), skala pengukuran (nominal, ordinal, rasio, interval), dan lain sebagainya. Berikut ini terdapat tiga metode yang dapat diterapkan dalam memilih ukuran kesamaan, yaitu ukuran korelasi, ukuran asosiasi, dan ukuran jarak.
1. Ukuran Korelasi
Dalam kehidupan sehari-hari banyak variabel yang saling berhubungan satu dengan yang lain. Hubungan antar variabel tersebut disebut dengan korelasi. Tujuan dari analisis korelasi adalah untuk mengukur kekuatan hubungan antara dua variabel dan menguji apakah kekuatan hubungan tersebut signifikan atau tidak signifikan. Dalam korelasi, ukuran kekuatan hubungan antar variabel memerlukan ukuran korelasi.
Kekuatan hubungan antar variabel dinyatakan dengan ukuran yang disebut koefisien korelasi atau koefisien asosiasi. Mengukur kesamaan antar obyek dapat dilihat dari koefisien korelasi antar sepasang obyek pada beberapa variabel yang diukur. Ukuran korelasi dapat diterapkan pada data yang berskala metrik. Korelasi dalam populasi biasanya disimbolkan dengan (rho), sedangkan korelasi dalam sampel disimbolkan dengan . Dalam tugas akhir ini, untuk mengukur kekuatan hubungan linear antara dua variabel dan menggunakan korelasi Pearson. Berikut ini merupakan langkah-langkah uji korelasi Pearson.
1. Menetapkan Hipotesis Nol dan Hipotesis Alternatif
: (ada korelasi antara variabel dan variabel ) 2. Menetapkan tingkat signifikansi
3. Statistik Uji √ √ dengan ∑ (∑ )(∑ ) √, ∑ (∑ ) -, ∑ (∑ ) -di mana:
: koefisien korelasi sampel
: banyaknya pasangan pengamatan ( ) 4. Wilayah Kritis (Daerah penolakan )
ditolak apabila | | , dengan derajat bebas 5. Melakukan Perhitungan
Pada tahap ini, perhitungan dapat dilakukan dengan menggunakan bantuan perangkat lunak-R pada komputer, menggunakan fasilitas yang terdapat pada Microsoft Excel, maupun perangkat-perangkat lunak yang lain yang sesuai dengan statistik uji yang telah dipilih sebelumnya. 6. Membuat Kesimpulan
Berdasarkan hasil yang diperoleh pada tahap perhitungan, maka dapat ditarik suatu kesimpulan apakah terdapat korelasi yang signifikan antara variabel dan variabel .
Contoh dari koefisien korelasi adalah korelasi antara tinggi badan dan berat badan.
Contoh 2.7
Berikut ini merupakan data tinggi dan berat badan lima mahasiswa Universitas Sanata Dharma.
Individu Tingggi Badan (cm) Berat Badan (kg) 1 155 47 2 157 49 3 159 52 4 160 44 5 160 42
Berdasarkan data tersebut, dapat diketahui apakah ada korelasi yang signifikan atau tidak signifikan antara variabel tinggi badan dan variabel berat badan. Berikut ini merupakan hasil pengujian variabel tinggi badan dan variabel berat badan menggunakan uji korelasi Pearson.
1. Menetapkan Hipotesis Nol dan Hipotesis Alternatif
: (tidak terdapat korelasi yang signifikan antara variabel tinggi badan dan variabel berat badan)
: (terdapat korelasi yang signifikan antara variabel tinggi badan dan variabel berat badan)
2. Menetapkan tingkat signifikansi 3. Statistik Uji
Statistik uji yang digunakan dalam contoh ini adalah uji-t. Dalam contoh ini kedua variabel diasumsikan berdistribusi Normal bivariat.
√ √ dengan .
4. Wilayah Kritis (Daerah penolakan )
ditolak apabila | | , dengan derajat bebas . 5. Melakukan Perhitungan
Dengan melakukan perhitungan menggunakan Microsoft Excel, diperoleh hasil perhitungan sebagai berikut.
sehingga
√
√ ( )
Karena | | ( ), maka dapat disimpulkan diterima.
6. Membuat Kesimpulan
Berdasarkan hasil yang diperoleh pada tahap perhitungan, maka dapat ditarik suatu kesimpulan bahwa tidak terdapat korelasi yang signifikan antara variabel tinggi badan dan variabel berat badan pada data tersebut.
2. Ukuran Asosiasi
Ukuran asosiasi mirip dengan ukuran korelasi, bedanya ukuran asosiasi diterapkan pada data berskala nonmetrik (nominal).
Contoh 2.8
Dengan mempertimbangkan jenis kelamin, seberapa kuat faktor jenis kelamin dalam mempengaruhi pemilihan warna dalam membeli telepon seluler. Misalnya apakah perempuan lebih dominan memilih warna-warna cerah, sedangkan laki-laki dominan memilih warna gelap. Misalkan dengan mengambil sampel sebanyak 30 orang, yaitu 13 orang berjenis kelamin laki-laki dan sisanya berjenis kelamin perempuan. Dalam hal ini terdapat dua
variabel pengukuran, yaitu variabel jenis kelamin dan variabel pemilihan warna telepon. Variabel-variabel tersebut adalah
jenis kelamin
pemilihan warna telepon seluler
Variabel-variabel tersebut dapat didefinisikan sebagai berikut
{ {
Dengan mempertimbangkan definisi variabel-variabel di atas, dapat dibuat tabel yang menunjukkan seberapa kuat faktor jenis kelamin dalam mempengaruhi pemilihan warna dalam membeli telepon seluler.
Variabel Jumlah 1 0
1 3 10 13 0 12 5 17 Jumlah 15 15 30
Berdasarkan tabel di atas, dapat dilihat bahwa laki-laki lebih dominan memilih warna gelap dalam membeli telepon seluler dan perempuan dominan memilih warna cerah. Hal ini berarti bahwa salah satu faktor yang mempengaruhi pemilihan warna dalam membeli telepon seluler adalah jenis kelamin.
Dalam beberapa aplikasinya ketika variabelnya berbentuk biner, data dapat disusun dalam bentuk tabel kontingensi. Untuk setiap pasangan variabel, ada item yang dikategorikan dalam tabel. Dengan memberikan pengkodean dan , tabel kotingensinya adalah sebagai berikut.
Tabel 2.1 Skema Tabel Kontingensi Variabel Jumlah Variabel 1 0 1 0 Jumlah
Tabel di atas merepresentasikan frekuensi variabel dan variabel yang bernilai 1 ada sebanyak , frekuensi variabel yang bernilai 1 dan variabel yang bernilai 0 ada sebanyak , frekuensi variabel yang bernilai 0 dan variabel yang bernilai 1 ada sebanyak , serta frekuensi variabel dan variabel yang bernilai 0 ada sebanyak .
Rumus korelasi product moment yang biasa digunakan pada variabel biner dalam Tabel 2.1 adalah sebagai berikut.
,( )( )( )( )- ⁄
Nilai yang diperoleh dapat diambil sebagai ukuran kesamaan antara dua variabel.
3. Ukuran Jarak
Secara umum jarak didefinisikan sebagai hasil pengukuran (nilai) yang menunjukkan seberapa jauh posisi suatu obyek dengan obyek lainnya. Dalam ilmu fisika jarak merupakan panjang lintasan suatu benda. Misalkan sebuah mobil berjalan dari titik menuju titik m. Setelah itu mobil berjalan lagi menuju titik m. Maka jarak yang ditempuh mobil tersebut adalah m.
Dalam ilmu matematika dengan menggunakan konsep geometri, misalkan diambil sebarang titik ( ) dalam bidang, jarak garis lurus
dari P ke titik asal ( ) menurut teorema Pitagoras adalah
( ) √ (2.6)
Jarak Titik ke Titik
Jarak antara dua buah titik dapat dicari dengan menarik suatu garis lurus yang menghubungkan kedua titik tersebut.
Jarak Titik ke Garis
Jarak titik ke garis merupakan panjang ruas garis yang ditarik dari suatu titik secara tegak lurus terhadap suatu garis.
Jarak Titik ke Bidang
Jarak titik ke bidang dapat dinyatakan sebagai jarak titik ke proyeksi titik pada suatu bidang.
Secara geometri, jika titik P mempunyai koordinat ( ) dalam ruang berdimensi p, jarak dari P ke titik asal ( ) adalah
( ) √ (2.7)
Lalu jarak antara dua sembarang titik ( ) dan ( ) adalah
( ) √( ) ( ) ( ) (2.8) Hal tersebut yang akan mendasari pembahasan mengenai ukuran kesamaan dalam analisis cluster. Jarak Euclidean antara dua pengamatan berdimensi p, misal ( ) dan ( ), maka berdasarkan persamaan (2.8) adalah
( ) √( ) ( ) ( )
√( )( ) (2.9) a. Jarak untuk Data Kontinu
Ukuran kesamaan atau ketidaksamaan obyek-obyek pengamatan dapat disajikan dalam bentuk matriks D dengan obyek.
[
]
Berikut ini merupakan ukuran ketidaksamaan dan jarak pengukuran untuk data kontinu.
Metrik merupakan suatu fungsi yang mendefinisikan jarak antara setiap pasang elemen titik pada suatu himpunan.
Definisi 2.6 Metrik
Misalkan adalah suatu himpunan. Suatu fungsi disebut metrik pada , jika untuk setiap berlaku:
a. ( ) (tak negatif)
b. ( ) jika dan hanya jika c. ( ) ( ) (simetri)
d. ( ) ( ) ( ) (ketaksamaan segitiga)
1) Jarak Euclidean
Jarak Euclidean merupakan kasus khusus atau bentuk khusus dari metrik minkowski untuk . Jarak ini sering digunakan untuk perhitungan dengan menggunakan data numerik.
Definisi 2.7 Jarak Euclidean
Jarak garis lurus antara dua titik manapun disebut sebagai jarak
Euclidean antar dua titik (Sharma, 1996). Jarak Euclidean antara dua
sembarang titik pada ruang dimensi p dinyatakan dengan
( ) √∑( )
(2.10)
dengan dan adalah koordinat dari titik x dan y.
2) Jarak Manhattan (city-block)
Jarak manhattan antara dua titik didefinisikan sebagai
( ) ∑|( )|
(2.11)
3) Metrik Minkowski
Metrik minkowski merupakan metrik yang bisa dianggap sebagai generalisasi dari jarak manhattan (city-block) dan jarak
Euclidean.
( ) [∑| |
] (2.12)
Dalam hal ini, untuk ( ) akan menjadi jarak city-block (manhattan) antara dua titik di dimensi p. Sedangkan untuk ( ) akan menjadi jarak Euclidean.
4) Jarak Chebyshev
Jarak chebychev adalah nilai mutlak dari selisih antara sepasang obyek.
( ) | | (2.13)
5) Jarak Canberra
Jarak Canberra antara dua titik didefinisikan sebagai
( ) ∑ | | ( ) (2.14) 6) Jarak Mahalanobis
Definisi 2.8 Jarak Mahalanobis
Jarak Mahalanobis didefinisikan sebagai jarak statistik antara dua titik yang memperhitungkan kovariansi dan korelasi antar variabel (Sharma, 1996).
( ) ( ) (2.15) dengan dan adalah vektor dan S adalah matriks variansi-kovariansi sampel.
Contoh 2.9
Misal diketahui tiga vektor ( ) ( ) dan ( ). Ketiga vektor tersebut dapat disusun menjadi matriks A, yaitu
[ ]
Akan dicari matriks jarak dengan menggunakan beberapa jarak yang telah dibahas sebelumnya.
Penyelesaian:
Pertama, akan dihitung dengan menggunakan jarak Euclidean setiap pasangan data yang ada.
( ) √( ) ( ) √ √ ( ) √( ) ( ) √ √ ( ) √( ) ( ) √ √ ( ) √( ) ( ) √ √ ( ) √( ) ( ) √ √ ( ) √( ) ( ) √ √ dari hasil perhitungan di atas, diperoleh hasil yang dapat dinyatakan dengan matriks jarak
[
]
Kedua, akan dihitung dengan menggunakan jarak manhattan ( ) | | | | ( ) | | | | ( ) | | | | ( ) | | | | ( ) | | | | ( ) | | | | sehingga matriks jarak yang diperoleh adalah
[
]
Ketiga, akan dihitung dengan menggunakan jarak chebychev
( ) *| | | | | | | | | | | |+ * +
b. Jarak untuk Data Biner
Ketika obyek-obyek tidak dapat diwakili oleh pengukuran p-dimensi, pasangan obyek sering dibandingkan atas ada tidaknya kemiripan maupun karakteristik tertentu. Ukuran kesamaan atau similaritas antara obyek yang hanya berisi atribut biner disebut dengan koefisien kesamaan atau similaritas, dan biasanya memiliki nilai antara 0 dan 1. Ada atau tidaknya suatu karakteristik maupun kemiripan pasangan obyek, dapat digambarkan secara matematis dengan melibatkan variabel biner yang mengasumsikan nilai 1 jika karakteristik tersebut ada dan nilai 0 jika karakteristik tersebut tidak ada (Johnson & Wichern, 2007).
Berikut ini merupakan tabel beberapa koefisien similaritas yang analog dengan Tabel 2.1 yaitu tabel kontingensi untuk variabel biner, satu-satunya perubahan yang diperlukan adalah substisusi (jumlah item) untuk (jumlah variabel).
Tabel 2.2 Beberapa Koefisien Similaritas Nama Koefisien Koefisien
Jaccard Sorensen Tanimoto ( ) Sokal-Sneath ( )
Contoh 2.10
Berikut ini merupakan data 5 individu dengan 6 variabel yang digunakan untuk menunjukkan karakteristik yang akan dinilai. Variabel-variabel tersebut adalah
tinggi badan berat badan warna mata warna rambut
kebiasaan penggunaan tangan jenis kelamin
Obyek
Individu 1 68 140 Hijau pirang kanan perempuan Individu 2 73 185 Coklat coklat kanan laki-laki Individu 3 67 165 Biru pirang kanan laki-laki Individu 4 64 120 Coklat coklat kanan perempuan Individu 5 76 210 Coklat coklat Kiri laki-laki
Misalkan data biner akan dihitung dari data yang ada pada tabel di atas dengan definisi sebagai berikut:
{ { { { { {
Berdasarkan definisi tersebut diperoleh data biner sebagai berikut Individu 1 0 0 0 1 1 1 2 1 1 1 0 1 0 3 0 1 0 1 1 0 4 0 0 1 0 1 1 5 1 1 1 0 0 0
1) Tabel kontingensi individu 1 dan individu 2 Individu 2 Jumlah Individu 1 1 0 1 1 2 3 0 3 0 3 Jumlah 4 2 6
dengan menggunakan koefisien Jaccard diperoleh
2) Tabel kontingensi individu 1 dan individu 3
Individu 3 Jumlah Individu 1 1 0 1 2 1 3 0 1 2 3 Jumlah 3 3 6
dengan menggunakan koefisien Jaccard diperoleh
Proses ini dilanjutkan hingga selesai, hingga diperoleh matriks similaritas di mana elemen dengan nomor baris ke- dan nomor kolom ke- akan sama dengan elemen dengan nomor baris ke- dan nomor kolom ke- atau dapat ditulis dengan .
[ ]
43 BAB III
ANALISIS CLUSTER
A. Analisis Cluster
Analisis cluster merupakan suatu teknik analisis multivariat yang digunakan untuk mengelompokkan obyek-obyek. Pengelompokan tersebut dilakukan didasarkan pada kesamaan karakteristik atau jarak (perbedaan) obyek-obyek tersebut. Karakteristik obyek-obyek dalam suatu kelompok memiliki tingkat kemiripan yang tinggi (bersifat homogen), sedangkan karakteristik antar obyek pada suatu kelompok dengan kelompok yang lain memiliki tingkat kemiripan yang rendah. Analisis cluster mengelompokkan obyek data hanya berdasarkan pada informasi yang ditemukan dalam data yang menjelaskan obyek dan hubungannya. Tujuannya adalah agar obyek dalam suatu kelompok menjadi serupa satu sama lain dan berbeda dari obyek kelompok yang lain. Analisis cluster juga berfungsi untuk menyederhanakan data, dengan membentuk kelompok yang sederhana dari kumpulan data yang kompleks. Pemilihan variabel dalam analisis cluster didasarkan pada tujuan pengelompokan yang akan dilakukan.
Analisis cluster kadang disebut juga sebagai klasifikasi tanpa supervisi (unsupervised classification), di mana klasifikasi merupakan teknik multivariat yang berkaitan dengan pemisahan kumpulan obyek (observasi) yang berbeda dan dengan mengalokasikan obyek baru (observasi). Contoh sederhana mengenai analisis cluster adalah andaikan dari setumpuk kartu remi, 52 kartu dapat dikelompokkan menggunakan beberapa skema yang berbeda. Misal skema pertama mengelompokkan semua kartu berwarna
merah ke dalam satu kelompok dan semua kartu berwarna hitam menjadi satu kelompok ke dalam kelompok lain, atau skema kedua misal pemain blackjack ingin mengelompokkan kartu ke dalam kelompok yang berisi semua kartu berwajah dan kelompok lain berisi sisa kartu. Dari contoh tersebut jelas bahwa pengelompokan obyek dapat berbeda-beda, bergantung dengan tujuan pengelompokan yang dilakukan. Berikut ini merupakan gambaran skema pengelompokan dari contoh di atas.
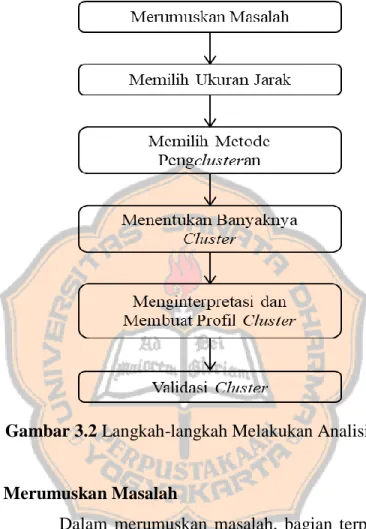
Langkah-langkah dalam melakukan clustering adalah sebagai berikut (Malhotra, Naresh K., et al., 2017).
Gambar 3.2 Langkah-langkah Melakukan Analisis Cluster
1. Merumuskan Masalah
Dalam merumuskan masalah, bagian terpenting dari prosedur pengelompokan (clustering) ini adalah memilih variabel yang menjadi dasar pengelompokan. Menyertakan satu atau dua variabel yang tidak relevan dapat mendistorsi hasil dari pengclusteran yang kemungkinan bermanfaat. Pada dasarnya, himpunan variabel yang dipilih harus menggambarkan kemiripan antar obyek dalam hal yang relevan dengan masalah yang akan dilakukan clustering. Variabel harus dipilih berdasarkan penelitian sebelumnya, teori atau pertimbangan hipotesis yang sedang dikembangkan atau diuji.
2. Memilih Ukuran Jarak
Tujuan dari pengelompokan (clustering) adalah untuk mengelompokkan obyek yang serupa, sehingga diperlukan beberapa ukuran untuk menilai seberapa mirip atau seberapa berbeda obyek tersebut. Pada umumnya, pendekatan yang sering digunakan adalah mengukur kesamaan dalam hal jarak antara pasangan obyek. Obyek dengan jarak yang lebih kecil (paling mirip) di antara obyek-obyek tersebut lebih mirip satu sama lain daripada yang berada pada jarak yang lebih jauh.
3. Memilih Metode Pengclusteran
Setelah dilakukan pemilihan jarak, langkah selanjutnya adalah menentukan metode yang akan digunakan dalam pengclusteran. Dalam prosedur ini, pemilihan metode pengclusteran didasarkan pada kebutuhan penguji.
4. Menentukan Banyaknya Cluster
Masalah utama dalam analisis cluster adalah menentukan banyaknya cluster, meskipun tidak ada aturan yang tegas mengenai penentuan banyaknya cluster. Namun, dalam menentukan banyaknya
cluster salah satunya dapat mengacu pada pertimbangan teoritis,
konseptual, maupun praktis.
5. Menginterpretasi dan Membuat Profil Cluster
Menginterpretasi dan membuat profil cluster melibatkan pemeriksaan terhadap centroid cluster. Centroid mewakili nilai rata-rata dari obyek yang terdapat dalam cluster pada masing-masing variabel. Centroid memungkinkan kita untuk mendeskripsikan setiap
6. Validasi Cluster
Validasi cluster bertujuan untuk menjamin dan memastikan bahwa solusi yang dihasilkan dari proses clustering dapat mewakili populasi dan dapat digeneralisasi untuk obyek lain.
Dalam analisis cluster, misalkan terdapat sampel obyek yang ma-sing-masing memiliki nilai pada variabel. Ide dari analisis cluster adalah menggunakan nilai-nilai variabel untuk membuat skema pengelompokan obyek ke dalam kelas, sehingga obyek yang serupa akan berada di kelas yang sama. Metode yang digunakan dalam analisis cluster harus numerik dan jumlah kelas biasanya tidak diketahui.
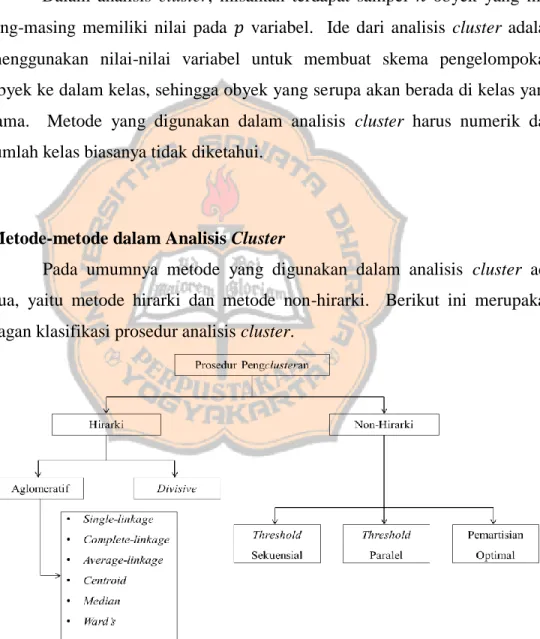
B. Metode-metode dalam Analisis Cluster
Pada umumnya metode yang digunakan dalam analisis cluster ada dua, yaitu metode hirarki dan metode non-hirarki. Berikut ini merupakan bagan klasifikasi prosedur analisis cluster.