SISTEM KLASIFIKASI SURAT MASUK
MENGGUNAKAN
MULTINOMIAL NAIVE BAYES
STUDI KASUS :
FAKULTAS SAINS DAN TEKNOLOGI UNIVERSITAS SANATA DHARMA
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer (S.Kom.)
Program Studi Teknik Informatika
Oleh:
Fran Sandy Herlin Hanopo NIM : 075314045
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
CLASSIFICATION SYSTEM FOR
ARCHIVE LATTERS USING
MULTINOMIAL NAIVE BAYES
STUDY CASE :
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
A THESIS
Presented as Partial Fulfillment of the Requirements to Obtain Sarjana Komputer Degree (S.Kom.)
In Department of Informatics Engineering
By:
Fran Sandy Herlin Hanopo NIM : 075314045
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
vii
KATA PENGANTAR
Puji dan syukur penulis panjatkan ke hadirat Tuhan Yang Maha Esa atas berkat dan penyertaan yang diberikan-Nya dalam berbagai wujud yang kadang tidak disadari sehingga penulis dapat menyelesaikan penelitian yang berjudul “Sistem Klasifikasi Surat Masuk Menggunakan Multinomial Naive Bayes”.
Penulis juga berterima kasih kepada pihak – pihak yang telah berjasa membantu menyelesaikan penelitian ini. Kepada Ibu Sri Hartati Wijono, S.Si., M.Kom. atas bimbingannya berupa pengarahan dan solusi dalam melaksanakan penelitian ini hingga selesai. Kepada Bapak Puspaningtyas Sanjoyo Adi, S.T., M.T. dan Bapak Drs. Johanes Eka Priyatma, M.Sc., Ph.D. sebagai dosen penguji atas kerjasama dan apresiasinya memberikan penilaian yang baik atas usaha penulis. Kepada Bapak Zaerilus Tukija yang telah berbaik hati bersedia menjadi narasumber untuk informasi dan data yang digunakan dalam penelitian ini. Kepada pihak sekretariat fakultas sains dan teknologi, dan juga Bapak Bele yang telah membantu mempersiapkan ujian tugas akhir. Kepada para programer yang berkontribusi di internet atas pengetahuan telah yang mereka bagi dengan cuma – cuma. Kepada teman – teman yang telah memberikan dukungan dan bantuan yang sangat berarti. Dan akhirnya kepada keluarga yang tak pernah lelah untuk terus memberikan dukungan sehingga penulis dapat melakukan penelitian ini dengan sebaik mungkin.
Penulis menyadari bahwa hasil dari penelitian ini jauh dari kata sempurna, namun penulis berharap semoga kerja yang telah penulis lakukan ini dapat berguna bagi pihak yang membutuhkan dan dapat menjadi jalan bagi penelitian lain yang lebih baik.
viii
ABSTRAK
Penelitian ini bertujuan untuk membangun sebuah sistem pengelolaan surat masuk yang dikelola oleh sekretariat Fakultas Sains dan Teknologi Informatika Universitas Sanata Dharma. Sistem yang dibangun memiliki fungsi klasifikasi dan pencarian surat. Data yang digunakan dalam penelitian adalah arsip (surat) fisik. Surat – surat tersebut akan diproses menjadi arsip digital untuk kemudian dapat diolah oleh sistem yang akan dibangun. Arsip digital yang dimaksudkan adalah berupa file PDF dan teks.
Fungsi klasifikasi yang dimiliki sistem mengelompokkan surat ke dalam delapan kategori. Kedelapan kategori tersebut, yaitu Administrasi Umum, Akademik, Kemahasiswaan, Kepegawaian, Keuangan, Perlengkapan, Yayasan, dan Lain – lain. Proses klasifikasi surat pada sistem menggunakan algoritma Multinomial Naive Bayes. Melalui pengujian menggunakan 3-fold cross validation terhadap 278 data didapat persentase rata – rata benar sebesar 79% dan salah sebesar 20%. Kemudian pada pengujian menggunakan 5-fold terhadap data yang sama didapat persentase rata – rata benar sebesar 83% dan salah sebesar 16%. Kesalahan klasifikasi yang terjadi dapat disebabkan oleh penentuan kelas terhadap data training yang mungkin mengalami kesalahan. Hal ini dikarenakan penentuan kelas tersebut tidak dilakukan oleh pakar.
ix
ABSTRACT
This research aims to build a management system of archive letters, which are managed by the secretariat of Science and Technology Faculty of Sanata Dharma University. The system has functions to classify and search the letter. The data that will be used in this research are physical archives (letters). These letters will be made into digital archives for which can be processed by the system. The digital archives will be in the form of PDF and text file.
The classification function of the system will classify letters into eight categories. Those eight categories are Administrasi Umum, Akademik, Kemahasiswaan, Kepegawaian, Keuangan, Perlengkapan, Yayasan, dan Lain – lain. The process of these letters classification is using Multinomial Naive Bayes algorithm. The average percentage results based on the validation using 3-fold cross validation to 278 data are 79% of correct classification and 20% of wrong classification. Then, based on the validation using 5-fold cross validation to same data, the average percentage results are 83% of correct classification and 16% of wrong classification. Those false classifications could be caused by uncorrectly classified training data. The classification of training data was not performed by expert.
x
HALAMAN PERSETUJUAN...iii
HALAMAN PENGESAHAN...iv
HALAMAN KEASLIAN KARYA...v
HALAMAN PERSETUJUAN PUBLIKASI...vi
KATA PENGANTAR ... vii
ABSTRAK ... viii
ABSTRACT ... ix
DAFTAR ISI ... x
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xiv
BAB 1 PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 2
1.3. Batasan Masalah ... 3
1.4. Tujuan Penelitian ... 3
1.5. Metodologi Penelitian ... 3
1.6. Sistematika Penulisan ... 5
BAB 2 LANDASAN TEORI ... 7
1.1. Pemerolehan Informasi ... 7
1.2. Indexing ... 9
1.3. Porter Stemmer ... 10
1.3.1. Tentang Porter Stemmer ... 10
1.3.2. Porter Stemmer untuk Bahasa Indonesia ... 11
1.4. Klasifikasi Teks ... 14
1.5. Naive Bayes ... 15
1.5.1. Multinomial Naive Bayes atau Multinomial NB ... 16
1.6. Evaluasi Sistem Pemerolehan Informasi (menggunakan K-fold Cross-Validation dan Precision) ... 18
1.6.1. K-fold Cross-Validation ... 18
1.6.2. Precision ... 19
1.8.2. Pemrosesan Data Testing ... 34
1.8.3. Hitung Precision ... 38
BAB 3 PERANCANGAN SISTEM ... 39
3.1. Gambaran Umum Sistem ... 39
3.2. Analisis Masalah ... 41
3.3. Analisis Kebutuhan Sistem ... 42
3.4. Desain Logikal ... 43
3.4.1. Desain Penyimpanan Data ... 43
3.4.2. Diagram Dekomposisi ... 44
3.4.3. Diagram Arus Data (DAD) ... 44
3.5. Desain Fisikal ... 51
3.5.1. Desain Antarmuka ... 51
3.5.2. Algoritma Proses Klasifikasi ... 53
BAB 4 IMPLEMENTASI ... 56
4.1. Antarmuka Menu Utama / Pencarian Surat ... 56
4.2. Antarmuka Simpan Surat ... 60
4.3. Antarmuka Training ... 64
BAB 5 PENGUJIAN ... 73
5.1. Pengujian ... 73
5.1.1. Pengujian Penerapan Algoritma ... 73
5.1.2. Pengujian Akurasi Sistem ... 76
5.2. Analisis Pengujian ... 78
BAB 6 KESIMPULAN DAN SARAN ... 80
6.1. Kesimpulan ... 80
6.2. Saran ... 81
DAFTAR PUSTAKA ... 82
xii
Tabel 2.1 Aturan 1. Aturan untuk inflectional particles. ... 12
Tabel 2.2 Aturan 2. Aturan untuk inflectional possessive pronouns. ... 12
Tabel 2.3 Aturan 3. Aturan untuk first order of derivational prefixes. ... 13
Tabel 2.4 Aturan 4. Aturan untuk second order of derivational prefixes. ... 13
Tabel 2.5 Aturan 5. Aturan untuk derivational suffixes. ... 14
Tabel 2.6 Contoh suku kata dalam Bahasa Indonesia. ... 14
Tabel 2.7 Daftar surat beserta kelasnya. ... 21
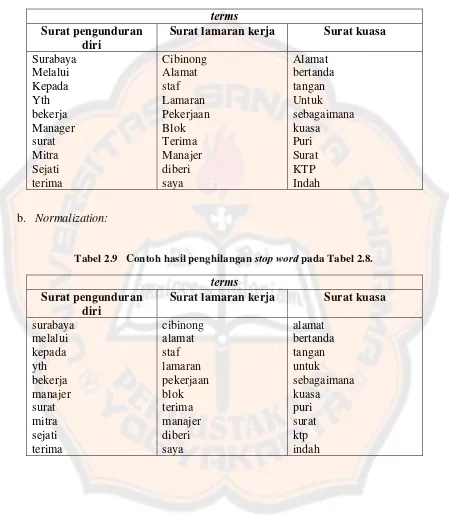
Tabel 2.8 Contoh hasil tokenization. ... 26
Tabel 2.9 Contoh hasil penghilangan stop word pada Tabel 2.8. ... 26
Tabel 2.10 Contoh hasil proses normalisasi terhadap Tabel 2.9. ... 27
Tabel 2.11 Contoh hasil stemming dari Tabel 2.10. ... 27
Tabel 2.12 Daftar term berserta frekuensi kemunculannya. ... 28
Tabel 2.13 Hasil sorting secara ascending. ... 29
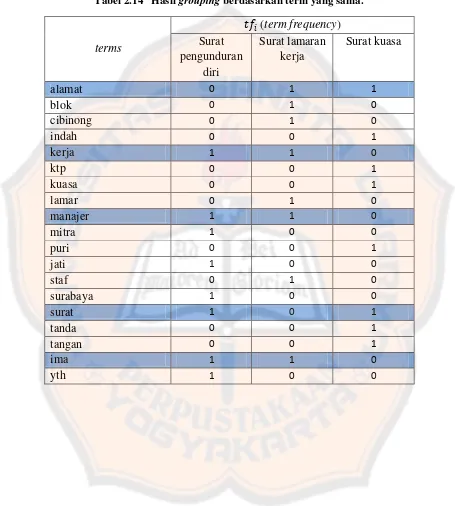
Tabel 2.14 Hasil grouping berdasarkan term yang sama. ... 30
Tabel 2.15 Hasil perhitungan prior probabilities untuk tiap kelas. ... 31
Tabel 2.16 Contoh penghitungan conditional probabilities. ... 31
Tabel 2.17 Model. ... 32
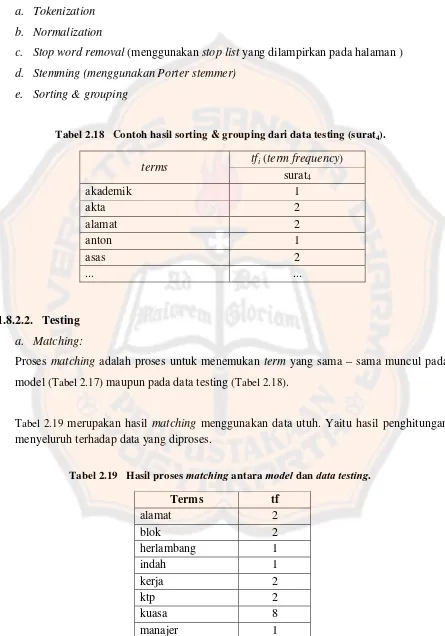
Tabel 2.18 Contoh hasil sorting & grouping dari data testing (surat4). ... 35
xiv
Gambar 2.1 Proses pemerolehan informasi menurut (Davies & Goker, 2009). ... 7
Gambar 2.2 Proses dasar dari Porter stemmer untuk Bahasa Indonesia (Tala, 2003). ... 12
Gambar 2.3 Contoh proses dari three-fold cross-validation. ... 19
Gambar 3.1 Diagram Blok untuk proses klasifikasi. ... 40
Gambar 3.2 Diagram Use Case. ... 42
Gambar 3.3 Diagram Dekomposisi. ... 44
Gambar 3.4 Diagram Konteks. ... 44
Gambar 3.5 Diagram Arus Data Level 1. ... 45
Gambar 3.6 Diagram Arus Data Level 2 Proses 1. ... 46
Gambar 3.7 Diagram Arus Data Level 2 Proses 2. ... 46
Gambar 3.8 Diagram Arus Data Level 3 Proses 1.1. ... 47
Gambar 3.9 Diagram Arus Data Level 3 Proses 1.2. ... 48
Gambar 3.10 Diagram Arus Data Level 3 Proses 2.1. ... 49
Gambar 3.11 Diagram Arus Data Level 3 Proses 2.2. ... 50
Gambar 3.12 Antarmuka Menu Utama / Menu Pencarian Surat. ... 51
Gambar 3.13 Antarmuka Menu Simpan Surat. ... 52
Gambar 4.1 Antarmuka untuk menu utama juga pencarian. ... 56
Gambar 4.2 Antarmuka untuk penyimpanan surat. ... 60
Gambar 4.3 Antarmuka untuk proses training. ... 65
Gambar 5.1 Output Hasil Training Pada Pengujian Penerapan Algoritma. ... 74
Gambar 5.2 Output Hasil Testing Pada Pengujian Penerapan Algoritma. ... 74
1
BAB 1
PENDAHULUAN
1.1.
Latar Belakang
Setiap fakultas di Universitas Sanata Dharma memiliki tanggung jawab untuk mengelola semua surat yang mereka miliki. Pengelolaannya dilaksanakan oleh pihak sekretariat dari masing – masing fakultas. Surat – surat yang dikelola tersebut dikategorikan ke dalam tiga kategori, yaitu surat masuk, surat keluar dan surat keputusan. Surat – surat tersebut kemudian akan disimpan sebagai arsip dan digunakan kembali saat dibutuhkan. Hingga saat tulisan ini dibuat, pengelolaan surat keluar, surat masuk, dan surat keputusan tersebut masih dilakukan secara manual. Hal ini dikarenakan pihak fakultas tidak memiliki sistem yang mendukung pengelolaan yang terkomputerisasi. Sistem yang berjalan secara manual memiliki kelemahan pada alokasi ruang dan waktu yang tidak efisien. Penyimpanan arsip yang besar secara fisik membutuhkan media simpan dengan kapasitas yang besar pula. Seiring dengan bertambahnya arsip yang dikelola maka akan semakin banyak ruang yang dibutuhkan. Melakukan backup terhadap arsip fisik juga sulit untuk dilaksanakan karena besarnya biaya dan tenaga dalam pelaksanaannya. Pencarian suatu arsip fisik pada penyimpanan yang besar kadang juga memerlukan waktu yang lama. Adanya sistem yang secara khusus ditujukan untuk mengelola surat diharapkan dapat mempermudah proses pengelompokkan dan pencarian surat – surat tersebut oleh sekretariat dan pejabat fakultas.
untuk mengubah hasil scanning yang dapat berupa PDF atau file gambar menjadi file teks. File teks dibutuhkan untuk mengekstrak informasi di dalam surat. Informasi tersebut kemudian digunakan dalam menghasilkan klasifikasi dan melakukan pencarian surat. PDF dari hasil scanning akan berguna sebagai view untuk menampilkan isi surat.
Sistem yang hendak dibangun akan menerapkan teknik klasifikasi teks menggunakan algoritma Multinomial Naïve Bayes. Klasifikasi teks adalah proses mengelompokkan dokumen ke dalam kategori-kategori atau kelas-kelas yang berbeda (Joachims, 1997). Beberapa penggunaan teknik klasifikasi teks misalnya untuk menyaring e-mail, memprediksi keinginan user, dan pengorganisasian konten / isi web (Schneider, 2004). Algoritma Multinomial Naïve Bayes adalah pengembangan dari algoritma Naïve Bayes yang memiliki keunggulan dalam memproses teks. Naive Bayes (Witten & Frank, 2005) yaitu salah satu teknik klasifikasi yang banyak digunakan untuk klasifikasi teks karena metode ini sangat cepat dan cukup akurat.
1.2.
Rumusan Masalah
1. Bagaimana membangun sebuah sistem yang dapat mengelompokkan surat masuk dan surat keputusan ke dalam kategori – kategori tertentu secara otomatis, kemudian menyimpan file surat tersebut dan metadatanya ke dalam database.
2. Melakukan pencarian file surat yang telah tersimpan di database dengan memanfaatkan metadata dari file surat maupun berdasarkan kategori surat untuk mempercepat proses pencarian surat.
1.3.
Batasan Masalah
Batasan dari sistem pemerolehan informasi surat masuk dan surat keputusan yang hendak dibangun adalah sebagai berikut :
1. Tipe surat yang dikelola adalah surat masuk.
2. Bentuk surat yang diproses adalah hasil scan yang kemudian dikonversi menjadi file text (*.txt).
3. User dari sistem adalah sekretariat dan pejabat fakultas. 4. Proses - proses utama yang dimiliki sistem:
a. Mengelompokkan surat masuk dan surat keputusan yang dimiliki sekretariat ke dalam kategori – kategori tertentu yang kemudian disimpan ke dalam database.
b. Mencari surat yang telah disimpan di dalam database berdasarkan suatu kategori tertentu atau berdasarkan kata kunci dari user.
1.4.
Tujuan Penelitian
Tujuan dari penelitian ini adalah membangun sebuah sistem yang dapat membantu pihak sekretariat dan pejabat fakultas dalam mengelola surat masuk yang telah digitalisasi (berbentuk file digital).
1.5.
Metodologi Penelitian
Langkah-langkah dari metodologi penelitian yang digunakan dalam penelitian ini adalah sebagai berikut:
1. Studi Pustaka
2. Observasi
Observasi bertujuan untuk mengetahui segala sesuatu mengenai sistem pengelolaan surat yang sedang berjalan di Fakultas Sains dan Teknologi. Seperti untuk mengetahui bagaimana cara kerjanya, siapa yang bertugas mengelola dan bertanggung jawab, dan apa saja yang benar – benar dibutuhkan untuk memaksimalkan pengelolaan surat tersebut.
3. Analisis dan Perancangan Sistem
Melakukan analisis terhadap masalah dan kebutuhan sistem yang akan dibangun. Kemudian dilakukan perancangan umum sistem sesuai dengan kebutuhan user. Metode yang akan digunakan dalam merancang sistem pengklasifikasian surat ini adalah metode FAST (Framework for the Application of Sistem Thinking) yang meliputi :
a. Fase Definisi Ruang Lingkup (Scope Definition Phase)
Pada fase ini akan dilakukan analisis terhadap batasan – batasan sistem, yaitu menentukan kebutuhan – kebutuhan yang dapat ditangani oleh sistem. Fase ini juga akan menganalisis siapa saja yang akan menjadi user dari sistem.
b. Fase Analisis Masalah (Problem Analysis Phase)
Mempelajari sistem yang telah ada dan sedang berjalan untuk menemukan masalah – masalah dan solusi dari sistem yang sedang berjalan tersebut. c. Fase Analisis Kebutuhan (Requirements Analysis Phase)
Mendefinisikan kemampuan yang akan disediakan sistem kepada usernya. Mengalisis kebutuhan user atau yang diharapkan user dari sistem yang baru.
d. Fase Desain Logikal (Logical Design Phase)
e. Fase Desain Fisikal (Physical Design Phase)
Menerjemahkan Desain Logikal yang menggambarkan kebutuhan pengguna ke dalam sebuah model yang menggambarkan implementasi teknis dari sistem yang akan dibuat.
f. Fase pembangunan dan pengujian (Construction & Testing Phase)
Membangun dan menguji sistem yang telah dirancang melalui fase – fase terdahulu dalam memenuhi kebutuhan pengguna. Membuat dokumetasi dari sistem yang berguna untuk membantu user memahami sistem baru.
4. Pembuatan Sistem
Pembuatan sistem akan berdasarkan hasil analisis dan perancangan sistem yang telah dilakukan pada tahap sebelumnya.
5. Implementasi dan pengujian
Sistem yang telah dibuat kemudian dijalankan dan dilakukan uji coba untuk mengetahui kinerja sistem secara khusus yang meliputi keakuratan klasifikasi dan keberhasilan melakukan pencarian. Kinerja sistem secara umum meliputi berjalan atau tidaknya setiap fungsi dan keberhasilan setiap fungsi tersebut menjalankan tugasnya.
6. Evaluasi
Menganalisis hasil implementasi dan pengujian untuk kemudian disimpulkan sejauh mana sistem telah mengakomodasi kebutuhan user secara keseluruhan.
1.6.
Sistematika Penulisan
BAB I PENDAHULUAN
BAB II LANDASAN TEORI
Berisi dasar teori yang berkaitan dengan penelitian yang dilakukan, yaitu metode klasifikasi Naive Bayes, klasifikasi teks, dan pemerolehan informasi.
BAB III PERANCANGAN
Berisi perancangan sistem dari penelitian yang dilakukan.
BAB IV IMPLEMENTASI
Berisi penjelasan tentang implementasi hasil perancangan yang telah dibuat ke dalam bentuk program.
BAB V PENGUJIAN DAN ANALISIS
Berisi pengujian terhadap hasil implementasi dan analisis dari hasil pengujian.
BAB VI KESIMPULAN DAN SARAN
7
BAB 2
LANDASAN TEORI
1.1.
Pemerolehan Informasi
Pemerolehan informasi (Manning, Raghavan, & Schutze, 2008) adalah menemukan bahan (umumnya dokumen) dari sebuah sifat yang tidak terstruktur (umumnya teks) untuk memenuhi kebutuhan informasi dari dalam koleksi yang besar (biasanya disimpan dalam komputer).
Menurut (Davies & Goker, 2009), terdapat tiga proses utama yang harus didukung oleh sebuah sistem pemerolehan informasi, yaitu indexing, query formulation, dan matching.
Pada Gambar 2.1, kotak persegi mewakili data dan kotak yang melingkar mewakili proses.
Information need Documents
Query Indexed documents
Retrieved documents
Query formulation Indexing
Matching
Feedback
1. Indexing
Proses indexing menghasilkan representasi dari dokumen. Proses ini tidak melibatkan user secara langsung. Proses indexing dapat memasukkan keseluruhan isi dokumen ke dalam sistem. Namun yang lebih sering dilakukan adalah menyimpan sebuah dokumen hanya per bagian, misalnya, hanya judul dan ringkasan, ditambah dengan lokasi sebenarnya dari dokumen yang disimpan. Tahap – tahap dalam proses indexing akan dibahas pada sub bab 2.2.
2. Query formulation
Query formulation adalah proses merepresentasikan informasi yang dibutuhkan oleh user. Hasil dari proses representasi tersebut adalah query. Dalam arti yang lebih luas, query formulation dapat berarti sebuah hubungan timbal balik antara komputer dan user, yang tidak hanya menghasilkan query yang sesuai, namun memungkinkan untuk memperoleh hasil yang dapat memandu user untuk lebih memahami informasi yang mereka butuhkan. Hal ini dinyatakan pada proses feedback pada Gambar 2.1.
3. Matching
Matching adalah proses membandingkan query dengan indexed document yang diperoleh melalui dua proses di atas. Proses ini bertujuan untuk menemukan dokumen yang cocok dengan keinginan user. Proses matching biasanya menghasilkan daftar peringkat (ranking) dokumen. Daftar dokumen tersebut nantinya akan digunakan oleh user untuk mencari informasi yang mereka inginkan. Peringkat pencarian juga diharapkan akan meletakkan dokumen yang relevan di posisi puncak pada daftar peringkat, sehingga meminimalkan waktu yang dibutuhkan user dalam mencari dokumen yang tepat.
1.2.
Indexing
Tahap – tahap dalam membangun sebuah index (Manning, Raghavan, & Schutze, 2008) adalah sebagai berikut:
1. Tokenization
Tokenization adalah proses memotong rangkaian kata yang terdapat dalam sebuah dokumen menjadi potongan – potongan kata yang berdiri sendiri, yang disebut token, dan dalam waktu bersamaan juga menghilangkan karakter – karakter tertentu, seperti tanda baca.
Input: Friends, Romans, Countrymen, lend me yours ears; Output:
2. Normalzation
Normalization adalah proses menyamakan ejaan sebuah kata yang mewakili makna yang sama. Misalnya, e-mail, E-mail, Email, dan email; keempat kata tersebut mewakili makna yang sama namun memiliki penulisan yang berbeda. Dalam melakukan proses normalisasi dapat digunakan salah satu kata sebagai acuan, misalnya dipilih kata email sebagai acuan, maka penulisan kata e-mail, E-mail, dan Email akan diubah menjadi email.
3. Stop words removal
Stop words removal adalah proses menghilangkan stop words dari kumpulan kata yang didapat dari hasil tokenization. Stop words adalah beberapa kata yang sangat umum yang kurang membantu / kurang berpengaruh dalam proses klasifikasi. Penghilang stopword diharapkan dapat mengefisienkan dan meningkatkan akurasi proses klasifikasi.
Contoh stop words:
dan atau lagi ada akan agar akhir
bahkan baik begini dahulu cukup guna entah
ingat hampir hanya itu jadi jangan hendak
4. Stemming
Stemming adalah proses menghilangkan imbuhan, seperti awalan, sisipan, dan akhiran, pada sebuah kata untuk mendapatkan kata dasarnya. Dalam penelitian ini, algoritma stemming yang akan digunakan adalah algoritma Porter.
5. Membangun index melalui proses sorting dan grouping.
Tahap utama dalam membangun sebuah index adalah mengurutkan (sorting) hasil stemming sehingga daftar term tersebut terurut berdasarkan abjad. Term yang sama kemudian dikelompokkan (grouping) menjadi satu dan dihitung frekuensi kemunculannya di tiap – tiap dokumen.
1.3.
Porter Stemmer
1.3.1.
Tentang Porter Stemmer
kata dasar yang dihasilkan. Panjang minimal ini disebut measure. Contoh kondisi lain yaitu apakah sebuah kata dasar diakhiri dengan huruf mati atau apakah mengandung huruf hidup.
Saat semua kondisi dari sebuah aturan terpenuhi, maka aturan tersebut dijalankan, yang menyebabkan penghilangan akhiran; dan kemudian proses dilanjutkan pada tahap berikutnya. Bila kondisi dari sebuah aturan pada suatu tahap tidak terpenuhi, maka kondisi dari aturan berikutnya akan diuji, hingga aturan tersebut dijalankan atau hingga aturan pada tahap tersebut habis.
1.3.2.
Porter Stemmer untuk Bahasa Indonesia
Tabel 2.1 Aturan 1. Aturan untuk inflectional particles.
Akhiran Replacement Measure Condition
Additional Condition
Contoh
-kah NULL 2 NULL bukukah buku
-lah NULL 2 NULL adalah ada
-pun NULL 2 NULL bukupun buku
Tabel 2.2 Aturan 2. Aturan untuk inflectional possessive pronouns.
Akhiran Replacement Measure Condition
Additional Condition
Contoh
-ku NULL 2 NULL bukuku buku
-mu NULL 2 NULL bukumu buku
-nya NULL 2 NULL bukunya buku
fail a rule is fired
a rule is fired fail
Word
Remove Particle
Remove Possessive
Remove 1st Order Prefix
Remove 2nd Order Prefix Remove Suffix
Remove Suffix Remove 2nd Order Prefix
Stem
Tabel 2.3 Aturan 3. Aturan untuk first order of derivational prefixes.
Awalan Replacement Measure Condition
Additional Condition
Contoh
meng- NULL 2 NULL mengukur ukur
meny- s 2 V…* menyapu sapu
men- t 2 V… menduga duga
menuduh tuduh
mem- p 2 V… memilah pilah
me- NULL 2 NULL merusak rusak
peng- NULL 2 NULL pengukur ukur
peny- s 2 V… penyapu sapu
pen- NULL 2 NULL penduga duga
pem- p 2 V… pemilah pilah
pem- NULL 2 NULL pembaca baca
di- NULL 2 NULL diukur ukur
ter- NULL 2 NULL tersapu sapu
ke- NULL 2 NULL kekasih kasih
* kata hasil pemotongan diawali dengan huruf hidup (vokal).
Tabel 2.4 Aturan 4. Aturan untuk second order of derivational prefixes.
Awalan Replacement Measure Condition
Additional Condition
Contoh
ber- NULL 2 NULL berlari lari
bel- NULL 2 ajar belajar ajar
be- NULL 2 K* er bekerja kerja
per- NULL 2 NULL perjelas jelas
pel- NULL 2 ajar pelajar ajar
pe- NULL 2 NULL pekerja kerja
Tabel 2.5 Aturan 5. Aturan untuk derivational suffixes.
Akhiran Replacement Measure Condition
Additional Condition Contoh
-kan NULL 2 awalan ∉ {ke, peng} tarikkan tarik ambilkan ambil
-an NULL 2 awalan ∉ {di, meng, ter} makanan makan (per)janjian janji
-i NULL 2 V|K…�1�1, �1 ≠ �, �2 ≠ �,
dan awalan ∉ {ber, ke, peng}
tandai tanda (men)dapati dapat
Tabel 2.6 Contoh suku kata dalam Bahasa Indonesia.
Measure Contoh Suku Kata
0 kh, ng, ny kh, ng, ny
1 ma, af, nya, nga ma, af, nya, nga
2 maaf, kami, rumpun, kompleks ma-af, ka-mi, rum-pun, kom-pleks
3 mengapa, menggunung, tandai mang-a-pa, meng-gu-nung, tan-da-i
1.4.
Klasifikasi Teks
diberi label dan beberapa tidak. Ini dilakukan karena suatu alasan, khususnya untuk menyaring atau mengarahkan dokumen sesuai dengan kapan dan bagaimana dokumen tersebut mungkin dibutuhkan.
Klasifikasi teks adalah bagian dari konteks penggunaan yang lebih luas yang berbeda dari beberapa area dari pemerolehan informasi. Poin – poin utama yang dapat diringkas adalah sebagai berikut:
1. Klasifikasi teks dimaksudkan untuk membuat sekumpulan dokumen lebih mudah dikelola dalam beberapa cara.
2. Pengelolaan yang efektif dari dokumen bergantung dari tujuan yang dimaksudkan dari pengelolaan tersebut, baik dari pengirim dan penerima. 3. Tujuan yang dimaksudkan dari sebuah dokumen tercermin dalam struktur dan
susunan dokumen tersebut, serta dalam penggunaan bahasanya.
Beberapa pendekatan dan contoh metode yang digunakan dalam proses klasifikasi teks, yaitu:
• Defining features. Contoh: ID3 dan COBWEB.
• Spatial boundaries. Contoh: support vector machines (SVM).
• Prototypes. Contoh: Rocchio’s relevance feedback.
• Probabilistic models. Contoh: Bayes’ rule.
• Exemplar models. Contoh: k-nearest neighbour algorithm (kNN).
• Hidden dependency models. Contoh: neural networks.
1.5.
Naive Bayes
pengklasifikasi jaringan saraf (neural network) tertentu. Pengklasifikasi Bayesian juga menunjukkan akurasi dan kecepatan yang tinggi saat diterapkan pada basisdata yang besar.
Pengklasifikasi naive Bayesian mengasumsikan bahwa pengaruh dari nilai atribut pada kelas tertentu tidak bergantung pada nilai atribut lainnya. Asumsi ini disebut class conditional independence. Asumsi ini dibuat untuk menyederhanakan perhitungan yang rumit dan, dalam arti ini, dianggap “naive”.
1.5.1.
Multinomial Naive Bayes atau Multinomial NB
Menurut (Manning, Raghavan, & Schutze, 2008), probabilitas sebuah dokumen d berada di kelas c dihitung dengan:
�
(
�
|
�
)
∝ �
(
�
)
� �
(
�
�|
�
)
1≤�≤��
( 1 )
• �(��|�), adalah conditional probability dari term �� yang terdapat dalam sebuah dokumen dari kelas c. �(��|�) diinterpretasikan sebagai ukuran dari seberapa banyak petunjuk �� membantu dalam menentukan bahwa c adalah kelas yang tepat.
• �(�), adalah prior probability dari sebuah dokumen yang terdapat dalam kelas c. Bila term dari sebuah dokumen tidak memberikan petunjuk yang jelas untuk satu kelas dibandingkan dengan kelas lainnya, maka dipilih satu kelas yang memiliki prior probability yang tertinggi.
〈Beijing, Taipei, join, WTO〉, dengan �� = 4, jika termand dan the dianggap sebagai stop words.
Untuk memperkirakan prior probability ��(�) digunakan persamaan sebagai berikut:
�
(
�
) =
��
�
( 2 )
• �� = jumlah dari dokumen training dalam kelas c.
• N = jumlah keseluruhan dokumen training dari seluruh kelas.
Untuk memperkirakan conditional probability��(�|�) persamaan yang digunakan, yaitu:
�
(
�
�|
�
) =
�
��∑
�′∈��
��′
( 3 )
• Tct = jumlah kemunculan termt dalam sebuah dokumen training dari kelas c.
• ∑�′∈����′′ = jumlah total dari keseluruhan term yang terdapat dalam sebuah dokumen training dari kelas c.
�
(WTO|
��
) = 0
Untuk menghilangkan nilai nol, digunakan add-one atau Laplace smoothing. Proses ini menambahkan nilai satu (1) pada setiap nilai Tct dari perhitungan
conditional probabilities. Sehingga persamaan untuk conditional probabilities menjadi:
�
(
�
�|
�
) =
�
��+ 1
(
∑
�′∈��
��′) +
�
′( 4 )
• B’ = jumlah keseluruhan term unik dari seluruh kelas.
1.6.
Evaluasi Sistem Pemerolehan Informasi (menggunakan
K-fold Cross-Validation dan Precision)
1.6.1.
K-fold Cross-Validation
Gambar 2.3 Contoh proses dari three-fold cross-validation.
Dalam setiap pengulangan, akan diukur performa dari masing-masing model yang terbentuk. Hal ini berfungsi untuk menentukan model mana yang terbaik / paling efektif untuk diaplikasikan ke dalam sistem. Untuk mengukur performa sebuah model, akan digunakan perhitungan precision untuk mengetahui tingkat akurasinya.
1.6.2.
Precision
Untuk menilai keefektifan dari sebuah sistem pemerolehan informasi (kualitas dari hasil klasifikasi), perlu dilakukan perhitungan untuk mengetahui precision dan recall dari hasil klasifikasi sistem tersebut. Dalam penelitian ini, yang akan dihitung hanyalah precision, karena yang hendak dicari tahu adalah tingkat akurasi dari sebuah model.
Precision adalah rasio dari jumlah dokumen relevan yang diperoleh dibagi oleh jumlah dari dokumen yang diperoleh.
��������� (�) = ������������������������������
Sehingga:
�
=
��
(
��
+
��
)
( 5 )
tp (true positives) : hasil prediksi tepat, kedua kategori cocok.
fp (false positives) : hasil prediksi mengatakan kedua kategori cocok, tapi ternyata salah.
1.7.
Pencarian file menggunakan Apache Lucene 4.1.0
Apache Lucene adalah library mesin pencari teks yang berkinerja tinggi, kaya fitur yang ditulis sepenuhnya menggunakan Java. Ini adalah sebuah teknologi yang cocok untuk hampir semua aplikasi yang membutuhkan pencarian penuh terhadap file teks, khususnya lintas platform (Apache Foundation).
Secara garis besar Lucene memiliki dua proses utama, yaitu indexing dan searching. Proses indexing akan memotong kalimat menjadi kata yang berdiri sendiri, kemudian memilah antara kata dan tanda baca, mengubah semua huruf menjadi huruf kecil, dan menghilangkan stopword.
Di dalam proses indexing terdapat proses scoring yang merupakan inti dari proses indexing dan juga Lucene. Proses scoring menentukan performa dari Lucene dalam melakukan pencarian. Proses ini memberikan bobot pada setiap kata dalam dokumen, sehingga memungkinkan untuk menemukan kemiripan antara keyword dan dokumen yang dicari.
Lucene memberikan kemampuan kepada user untuk menentukan bagaimana sebuah dokumen akan diindeks. Bagaimana sebuah dokumen diindeks akan mempengaruhi proses scoring.
1.8.
Penerapan Multinomial Naive Bayes Pada Klasifikasi Teks
Diketahui terdapat empat file surat: surat1, surat2, surat3, dan surat4. Surat1,
surat2, dan surat3 akan menjadi data training yang digunakan untuk membangun model, sedangkan surat4 akan menjadi data testing untuk menguji model yang
dibangun. Keempat surat tersebut akan dikategorikan ke dalam tiga kategori, yaitu surat pengunduran diri, surat lamaran kerja, dan surat kuasa. Kategori untuk ketiga data training telah diketahui terlebih dahulu, yaitu surat
[image:36.595.70.521.277.740.2]pengunduran diri untuk������, surat lamaran kerja untuk������, dan surat kuasa untuk������.
Tabel 2.7 Daftar surat beserta kelasnya.
surat kelas
�����1 surat pengunduran diri
�����2 surat lamaran kerja
�����3 surat kuasa
�����4 ???
Keseluruhan tahap yang akan dilalui dalam melakukan klasifikasi yaitu: I. Pemrosesan data training:
1. Indexing data training (Indexing, hal.9): a. Tokenization.
b. Normalization.
c. Stopword removal (menggunakan stop words dari (Tala, 2003)). d. Stemming (Porter Stemmer untuk Bahasa Indonesia, hal.11). e. Sorting and grouping.
2. Training:
II. Pemrosesan data testing:
3. Indexing data testing (Indexing, hal.9): a. Tokenization.
b. Stopword removal (menggunakan stop words dari (Tala, 2003)). c. Normalization.
d. Stemming (Porter Stemmer untuk Bahasa Indonesia, hal.11). e. Sorting and grouping.
4. Testing: a. Matching.
b. Kalikan nilai Conditional Probabilities. c. Hitung probabilitas.
III. Mengukur keberhasilan klasifikasi:
5. K-fold Cross Validation (K-fold Cross-Validation, hal.18). 6. Precision (Precision, hal.19)
1.8.1.
Pemrosesan Data Training
Data training yang akan digunakan dalam membangun model adalah
sebagai berikut:
Surat1 (masuk ke dalam kategori surat pengunduran diri):
Surabaya 29 Maret 2011
Kepada Yth. HRD Manager PT. Mitra Sejati
Jl. Raya Semangka No. 20 Surabaya
Dengan hormat,
Melalui surat ini saya Gunawan Soeprapto mengajukan permohonan
Saya menghaturkan terima kasih atas kesempatan yang telah diberikan untuk belajar dan bekerja di PT. Mitra Sejati sebagai suatu perusahaan besar di bidang percetakan sebagai Kepala Gudang selama kurang lebih 3 tahun.
Tak lupa saya mohon maaf kepada jajaran manajemen PT. Mitra Sejati apabila terdapat hal-hal yang tidak baik yang telah saya lakukan selama bekerja di PT. Mitra Sejati.
Saya berharap dan berdo'a agar PT. Mitra Sejati dapat terus berkembang dan selalu mendapatkan yang terbaik.
Hormat saya,
Gunawan Soeprapto
Email : Goesoe20@yahoo.com Mobile phone : 081111222878
Surat2 (masuk ke dalam kategori surat lamaran kerja):
Cibinong, 10 Juni 2011 Hal: Lamaran Pekerjaan
Kepada Yth.,
Manajer Sumber Daya Manusia PT. Hand's Parmantindo
Jl. Raya Bumi Sentosa No. 5 Cibinong
Dengan hormat,
Bpk. Bambang Satrio, seorang asisten editor di PT. Hand's Parmantindo, menginformasikan kepada saya tentang rencana pengembangan Departemen Finansial PT. Hand's Parmantindo.
Sehubungan dengan hal tersebut, perkenankan saya mengajukan diri (melamar kerja) untuk bergabung dalam rencana pengembangan PT. Hand's Parmantindo.
Mengenai diri saya, dapat saya jelaskan sebagai berikut :
Nama : Florentina Putri
Tempat & Tanggal Lahir : Probolinggo, 5 Agustus 1979
Pendidikan Akhir : Sarjana Akuntansi Universitas Pancasila - Jakarta Alamat : Perum Bojong Depok Baru 1, Blok ZT No. 3, Cibinong 16913
Telepon / HP / E-mail : 021-87903802 / 08179854203 / putri.flo@gmail.com
Saat ini saya bekerja di PT. Flamboyan Bumi Singo, sebagai staf akuntasi dan perpajakan, dengan fokus utama pekerjaan di bidang finance dan perpajakan.
Sebagai bahan pertimbangan, saya lampirkan :
1. Daftar riwayat hidup. 2. Fotocopy ijazah S-1.
3. Fotocopy setifikat kursus / pelatihan. 4. Pas foto terbaru.
Besar harapan saya untuk diberi kesempatan wawancara, dan dapat menjelaskan lebih mendalam mengenai diri saya. Seperti yang tersirat di resume (riwayat hidup), saya mempunyai latar belakang pendidikan, pengalaman, potensi dan seorang pekerja keras.
Demikian saya sampaikan. Terima kasih atas perhatian Bapak.
Hormat saya,
Florentina Putri
Surat3 (masuk ke dalam ketegori surat kuasa):
Yang bertanda tangan di bawah ini
Nama : Joko Susanto Jenis Kelamin : Pria
Tempat Tanggal Lahir : Medan, 21 Juni 1973 Alamat : Cipondoh Makmur Blok E. IV/01
RT 07/05 Kel. Cipondoh Makmur. Kec. Cipondoh No. KTP : 32.75.02.1002.08617
Memberikan kuasa kepada
Nama : EKO HERLAMBANG
Alamat : Puri Dewata Indah Blok. Ag. No. 27 RT. 03/02 Cipondoh Tangerang.
No. KTP : 367.105.13.00.02
Untuk pengambilan :
Satu Unit : BPKB Mobil Honda Genio Nopol : B. 2628 YH
Warna : Abu-abu Metalik No. Mesin : G168-ID- 602036
Demikianlah Surat Kuasa ini saya buat untuk dipergunakan sebagaimana mestinya.
Tanggal, 26 Oktober 2010
Yang Diberi Kuasa Yang Memberikan
a. Tokenization:
Tabel 2.8 Contoh hasil tokenization.
terms
Surat pengunduran diri
Surat lamaran kerja Surat kuasa
Surabaya Cibinong Alamat
Melalui Alamat bertanda
Kepada staf tangan
Yth Lamaran Untuk
bekerja Pekerjaan sebagaimana
Manager Blok kuasa
surat Terima Puri
Mitra Manajer Surat
Sejati diberi KTP
terima saya Indah
[image:41.595.73.522.153.669.2]b. Normalization:
Tabel 2.9 Contoh hasil penghilangan stop word pada Tabel 2.8.
terms
Surat pengunduran diri
Surat lamaran kerja Surat kuasa
surabaya cibinong alamat
melalui alamat bertanda
kepada staf tangan
yth lamaran untuk
bekerja pekerjaan sebagaimana
manajer blok kuasa
surat terima puri
mitra manajer surat
sejati diberi ktp
Tabel 2.10 Contoh hasil proses normalisasi terhadap Tabel 2.9.
terms
Surat pengunduran diri
Surat lamaran kerja Surat kuasa
surabaya cibinong alamat
yth alamat bertanda
bekerja staf tangan
manajer lamaran indah
surat pekerjaan ktp
mitra blok kuasa
sejati terima puri
terima manajer surat
[image:42.595.71.521.132.664.2]d. Stemming:
Tabel 2.11 Contoh hasil stemming dari Tabel 2.10.
terms
Surat pengunduran diri
Surat lamaran kerja Surat kuasa
surabaya cibinong alamat
yth alamat tanda
kerja staf tangan
manajer lamar indah
surat kerja ktp
mitra blok kuasa
jati ima puri
Kumpulan term pada Tabel 2.11 kemudian disusun ke dalam satu kolom dan dihitung frekuensi kemunculannya pada masing – masing surat.
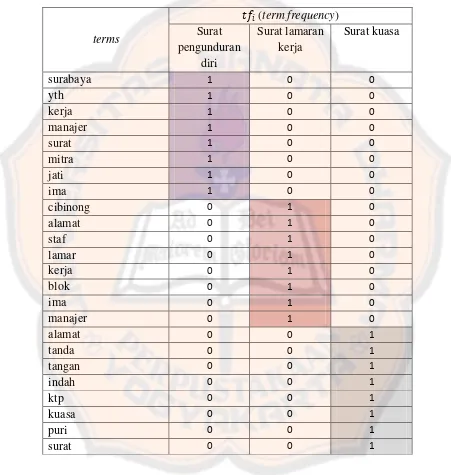
Tabel 2.12 Daftar term berserta frekuensi kemunculannya.
terms
��� (term frequency) Surat
pengunduran diri
Surat lamaran kerja
Surat kuasa
surabaya 1 0 0
yth 1 0 0
kerja 1 0 0
manajer 1 0 0
surat 1 0 0
mitra 1 0 0
jati 1 0 0
ima 1 0 0
cibinong 0 1 0
alamat 0 1 0
staf 0 1 0
lamar 0 1 0
kerja 0 1 0
blok 0 1 0
ima 0 1 0
manajer 0 1 0
alamat 0 0 1
tanda 0 0 1
tangan 0 0 1
indah 0 0 1
ktp 0 0 1
kuasa 0 0 1
puri 0 0 1
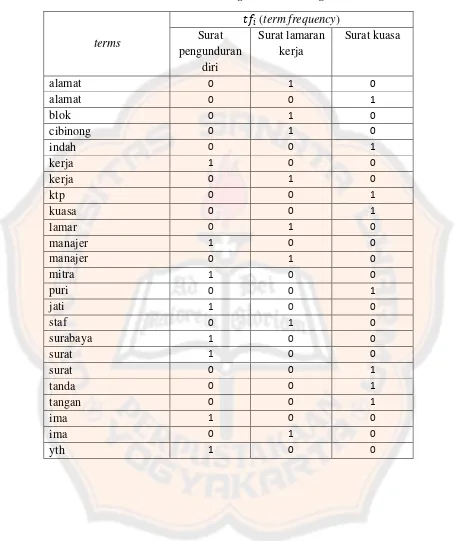
Tabel 2.13 Hasil sorting secara ascending.
terms
��� (term frequency) Surat
pengunduran diri
Surat lamaran kerja
Surat kuasa
alamat 0 1 0
alamat 0 0 1
blok 0 1 0
cibinong 0 1 0
indah 0 0 1
kerja 1 0 0
kerja 0 1 0
ktp 0 0 1
kuasa 0 0 1
lamar 0 1 0
manajer 1 0 0
manajer 0 1 0
mitra 1 0 0
puri 0 0 1
jati 1 0 0
staf 0 1 0
surabaya 1 0 0
surat 1 0 0
surat 0 0 1
tanda 0 0 1
tangan 0 0 1
ima 1 0 0
ima 0 1 0
satu.
Tabel 2.14 Hasil grouping berdasarkan term yang sama.
terms
��� (term frequency) Surat
pengunduran diri
Surat lamaran kerja
Surat kuasa
alamat 0 1 1
blok 0 1 0
cibinong 0 1 0
indah 0 0 1
kerja 1 1 0
ktp 0 0 1
kuasa 0 0 1
lamar 0 1 0
manajer 1 1 0
mitra 1 0 0
puri 0 0 1
jati 1 0 0
staf 0 1 0
surabaya 1 0 0
surat 1 0 1
tanda 0 0 1
tangan 0 0 1
ima 1 1 0
a. Hitung prior probabilities:
Contoh perhitungan prior probabilities terhadap kelas surat pengunduran diri:
��(��������������������) =1 3
[image:46.595.74.524.225.768.2]Nilai 1 adalah jumlah dokumen training dalam kelas surat pengunduran diri. Nilai 3 adalah jumlah keseluruhan dokumen training dari seluruh kelas.
Tabel 2.15 Hasil perhitungan prior probabilities untuk tiap kelas.
b. Hitung conditional probabilities:
Contoh perhitungan conditional probabilities untuk term ‘alamat’ pada kelas surat lamaran kerja:
��(������ | surat lamaran kerja) = 1 122
Tabel 2.16 Contoh penghitungan conditional probabilities.
terms Surat pengunduran diri
Surat lamaran kerja
Surat kuasa
alamat 0 / 68 1 / 122 2 / 65
blok 0 / 68 1 / 122 2 / 65
cibinong 0 / 68 3 / 122 0 / 65
ima 1 / 68 1 / 122 0 / 65
indah 0 / 68 0 / 122 1 / 65
jati 6 / 68 0 / 122 0 / 65
kerja 0 / 68 4 / 122 0 / 65
ktp 0 / 68 0 / 122 2 / 65
kuasa 0 / 68 0 / 122 4 / 65
atribut kelas P(class)
surat pengunduran diri 1/3
surat lamaran kerja 1/3
mitra 6 / 68 0 / 122 0 / 65
puri 0 / 68 0 / 122 1 / 65
staf 0 / 68 1 / 122 0 / 65
surabaya 2 / 68 0 / 122 0 / 65
surat 1 / 68 0 / 122 1 / 65
tanda 0 / 68 0 / 122 1 / 65
tangan 0 / 68 0 / 122 1 / 65
yth 1 / 68 1 / 122 0 / 65
c. Laplace smoothing:
Laplace smoothing digunakan untuk menghilangkan nilai nol (term tanpa bobot) pada term dari Tabel 2.16. Laplace smoothing merupakan tahap akhir dari proses training menggunakan algoritma Multinomial Naive Bayes. Hasil yang didapat dari proses ini akan menjadi Model untuk melakukan klasifikasi.
Contoh perhitungan conditional probabilities untuk term ‘alamat’ pada kelas surat lamaran kerja:
��(������ | surat lamaran kerja) = 1 + 1
122+ 255= 0.005305
[image:47.595.89.512.70.292.2]Nilai 255 adalah jumlah term di dalamTabel 2.16.
Tabel 2.17 Model.
terms Surat pengunduran diri
Surat lamaran kerja
Surat kuasa
alamat 0.003096 0.005305 0.009375
blok 0.003096 0.005305 0.009375
cibinong 0.003096 0.01061 0.003125
ima 0.006192 0.005305 0.003125
indah 0.003096 0.002653 0.00625
jati 0.021672 0.002653 0.003125
kerja 0.003096 0.013263 0.003125
ktp 0.003096 0.002653 0.009375
kuasa 0.003096 0.002653 0.015625
lamar 0.003096 0.007958 0.003125
staf 0.003096 0.005305 0.003125
surabaya 0.009288 0.002653 0.003125
surat 0.006192 0.002653 0.00625
tanda 0.003096 0.002653 0.00625
tangan 0.003096 0.002653 0.00625
Data Testing:
Surat4
Yang bertanda tangan dibawah ini :
Nama : Bambang Suprapto
Umur : 37
No. KTP / SIM : 243.115.25.98.78
Alamat : Perumahan Cemara Indah Blok C No. 30 Pekerjaan : Wiraswasta
Untuk selanjutnya disebut sebagai Pemberi Kuasa
Dengan ini menerangkan dan memberi kuasa kepada :
Nama : Anton Herlambang
Umur : 32
No. KTP / SIM : 872.308.61.90.83
Alamat : Puri Cendrawasih Blok Cb No. 33 Pekerjaan : Manager Keuangan
Untuk selanjutnya disebut sebagai Penerima Kuasa
---KUASA KHUSUS---
Untuk menghadap kepada Notaris di Bandung guna menyelesaikan pembuatan akta notaris pembentukan Asosiasi Staf Akademik Seluruh Indonesia (ASASI).
Penerima kuasa dapat melakukan tindakan-tindakan lainnya yang penting dan berguna untuk kepentingan pembuatan akta notaris ASASI dan melakukan hal-hal yang selayaknya dilakukan oleh seorang penerima kuasa sesuai dengan peraturan perundang-undangan.
Surat kuasa ini diberikan dengan hak substitusi baik sebagian maupun seluruhnya.
Bandung, 01 Oktober 2005
Penerima Kuasa Pemberi Kuasa
1.8.2.1. Indexing data testing
indexing pada data testing adalah sebagai berikut: a. Tokenization
b. Normalization
c. Stop word removal (menggunakan stop list yang dilampirkan pada halaman ) d. Stemming (menggunakan Porter stemmer)
[image:50.595.75.520.130.766.2]e. Sorting & grouping
Tabel 2.18 Contoh hasil sorting & grouping dari data testing (surat4).
terms tfi (term frequency) surat4
akademik 1
akta 2
alamat 2
anton 1
asas 2
... ...
1.8.2.2. Testing
a. Matching:
Proses matching adalah proses untuk menemukan term yang sama – sama muncul pada model (Tabel 2.17) maupun pada data testing (Tabel 2.18).
Tabel 2.19 merupakan hasil matching menggunakan data utuh. Yaitu hasil penghitungan menyeluruh terhadap data yang diproses.
Tabel 2.19 Hasil proses matching antara model dan data testing.
Terms tf
alamat 2
blok 2
herlambang 1
indah 1
kerja 2
ktp 2
kuasa 8
Hasil matching tersebut kemudian digabungkan dengan nilai conditional probabilities -nya.
Tabel 2.20 Hasil matching beserta dengan nilai conditional probabilities-nya.
Terms
tf (term frequency)
surat pengunduran
diri
surat lamaran
kerja
surat kuasa
surat1 surat2 surat3
alamat 2 0.003096 0.005305 0.009375
blok 2 0.003096 0.005305 0.009375
herlambang 1 0.003096 0.002653 0.00625
indah 1 0.003096 0.002653 0.00625
kerja 2 0.003096 0.013263 0.003125
ktp 2 0.003096 0.002653 0.009375
kuasa 8 0.003096 0.002653 0.015625
manajer 1 0.006192 0.005305 0.003125
nama 2 0.003096 0.005305 0.009375
nomor 4 0.006192 0.007958 0.01875
puri 1 0.003096 0.002653 0.00625
staf 1 0.003096 0.005305 0.003125
surat 1 0.006192 0.002653 0.00625
tanda 1 0.003096 0.002653 0.00625
tangan 1 0.003096 0.002653 0.00625
puri 1
staf 1
surat 1
tanda 1
Untuk memudahkan kalkulasi pada bagian ∏1≤�≤���(��|�), maka persamaan tersebut
akan dihitung terlebih dahulu dalam bentuk tabel seperti di bawah.
Untuk sebuah term yang kemunculannya lebih dari satu kali, pangkatkan nilai conditional probabilities-nya pada Tabel 2.20 dengan term frequency masing - masing.
Kemudian jumlahkan nilainya untuk masing-masing kelas.
Contoh, term ‘alamat’ memiliki term frequency sebanyak 2 kali. Pangkatkan nilainya untuk menyederhanakan penghitungan.
[image:52.595.71.521.205.703.2]�(������|surat lamaran kerja) =0.0053052 = 2.8143E−05
Tabel 2.21 Hasil perkalian nilai conditional probabilities dengan term frequency-nya.
Terms
surat pengunduran
diri
surat lamaran
kerja
surat kuasa
surat1 surat2 surat3
alamat 9.58522E-06 2.8143E-05 8.78906E-05
blok 9.58522E-06 2.8143E-05 8.78906E-05
herlambang 0.003096 0.002653 0.00625
indah 0.003096 0.002653 0.00625
kerja 9.58522E-06 0.00017591 9.76563E-06
ktp 9.58522E-06 7.0384E-06 8.78906E-05
kuasa 8.44127E-21 2.4541E-21 3.55271E-15
manager 0.006192 0.005305 0.003125
nama 9.58522E-06 2.8143E-05 8.78906E-05
no 1.47002E-09 4.0107E-09 1.23596E-07
puri 0.003096 0.002653 0.00625
staf 0.003096 0.005305 0.003125
surat 0.006192 0.002653 0.00625
tanda 0.003096 0.002653 0.00625
tangan 0.003096 0.002653 0.00625
masing – masing kelas.
Probabilitas dari surat4 terhadap kelas surat pengunduran diri:
P(surat pengunduran diri|surat4) = 1/3 * 3.39007E-74 = 1.12991E-74
Probabilitas dari surat4 terhadap kelas surat lamaran kerja: P(surat lamaran kerja|surat4) = 1/3 * 2.6655E-72 = 8.8841E-73
Probabilitas dari surat4 terhadap kelas surat kuasa:
P(surat kuasa|surat4) = 1/3 * 1.48941E-61 = 4.96422E-62
Dari hasil perhitungan probabilitas di atas diketahui bahwa probabilitas surat4 terhadap kelas suratkuasa memiliki nilai yang paling tinggi, yaitu 4.96422E-62. Sehingga �����
4
masuk ke dalam kelas suratkuasa.
1.8.3.
Hitung Precision
Jumlah data testing : 1 Jumlah klasifikasi yang tepat : 1
� =1 1= 1
39
BAB 3
PERANCANGAN SISTEM
3.1.
Gambaran Umum Sistem
Gambar 3.1 Diagram Blok untuk proses klasifikasi.
index
Indexing
Data testing
Tokenizing
Stop word removal Normalization
Matching
Pangkatkan Nilai Conditional Probabilities
Hitung Probabilitas Tiap Kelas
Testing
index
Data training
Tokenizing
Stopword removal Normalization
Tentukan kategori
Indexing
Hitung Prior Probabilities
Hitung Conditional Probabilities
Laplace Smoothing
Model
Training
Modeling
Classification
Stemming
Sorting & Grouping
Stemming
Sorting & Grouping
Pada Gambar 3.1, proses indexing pada tahap modeling menghasilkan inverted index yang adalah kumpulan term yang telah terseleksi beserta dengan term frequency dari masing – masing term. Inverted index inilah yang kemudian akan diolah melalui proses training dari algoritma Multinomial Naïve Bayes untuk mendapatkan model yang digunakan dalam klasifikasi.
Pada tahap testing / klasifikasi, surat yang akan diklasifikasi akan melalui proses indexing namun tanpa diketahui kategorinya. Setelah melalui proses indexing tersebut, maka akan dihasilkan pula sebuah inverted index untuk proses testing. Dari inverted index tersebut kemudian dilakukan proses matching untuk mendapatkan daftar term yang sama-sama muncul pada inverted index dan model. Hasil proses matching kemudian digunakan untuk menjalankan proses klasifikasi dari Multinomial Naïve Bayes.
3.2.
Analisis Masalah
Sistem pengarsipan surat yang dimiliki pihak fakultas saat ini sebagian besar masih dijalankan secara manual. Meskipun beberapa surat telah memiliki softcopy, namun terbatas untuk beberapa surat tertentu. Sistem yang secara khusus mengelolanya juga belum tersedia. Sehingga softcopy tersebut tetap harus dicari secara manual.
Masalah dari pengelolaan manual tersebut adalah kecepatan dalam menemukan kembali sebuah surat dan kebutuhan ruang penyimpanan. Seiring dengan peningkatan jumlah arsip yang terus berlangsung, masalah – masalah tersebut akan semakin membebani.
3.3.
Analisis Kebutuhan Sistem
Dalam fase ini, kebutuhan sistem akan dideskripsikan dalam bentuk diagram use case.
Diagram Use Case
Diagram use case dari sistem pengklasifikasian surat ini dapat dilihat pada Gambar 3.2.
Tabel 3.1 Deskripsi Use Case.
No
Use Case
Deskripsi
1. Mengklasifikasikan surat
Sistem mengklasifikasikan surat ke dalam 8 kategori dengan algoritma Multinomial Niave Bayes menggunakan model yang telah dibangun melalui proses training.
2. Mencari surat Sistem melakukan pencarian surat menggunakan library Apache Lucene terhadap surat – surat yang telah diklasifikasi.
3. Menampilkan surat Sistem menampilkan file surat hasil pencarian menggunakan aplikasi pdf reader.
Sekretariat / Pejabat fakultas
<<extend>>
Mengklasifikasikan surat
Mencari surat
[image:57.595.70.522.237.707.2]Menampilkan surat
3.4.
Desain Logikal
3.4.1.
Desain Penyimpanan Data
Media penyimpanan data yang dikelola oleh sistem adalah berupa file plain text yang disimpan dengan ekstensi .txt. Setiap satu file mewakili satu surat. File – file tersebut kemudian disimpan dalam folder yang mewakili masing – masing kategori.
Penjabaran folder dan file yang digunakan oleh sistem: 1. data_storage
Menyimpan file hasil klasifikasi yang dilakukan oleh user melalui sistem. 2. model
Menyimpan file hasil training yang kemudian menjadi model untuk melakukan klasifikasi.
3. preprocessed_file
Menyimpan file hasil preprocessing yang merupakan tahap awal dari proses training.
4. search_index
Menyimpan index yang dihasilkan oleh Apache Lucene untuk proses searching.
5. stopwords.txt
File yang berisi stopwords. 6. synonym.txt
3.4.2.
Diagram Dekomposisi
3.4.3.
Diagram Arus Data (DAD)
[image:59.595.74.518.162.721.2]3.4.3.1. Diagram Konteks
Gambar 3.3 Diagram Dekomposisi.
Gambar 3.4 Diagram Konteks.
hasil pencarian, info hasil klasifikasi kata kunci pencarian, file surat
User
Sistem Klasifikasi Surat Masuk Fakultas Sains
dan Teknologi Sistem Klasifikasi Surat
Masuk Fakultas Sains dan Teknologi
2
Cari Surat 1
Simpan Surat
1.1
Ambil Surat
1.2
Simpan
1.3
Reset
2.1
Cari
2.2
3.4.3.2. Level 1
hasil indexing index file surat file surat
hasil pencarian
1 Mengklasifikasi
kan surat
2 Mencari surat menggunakan
Apache Lucene User
file surat
Koleksi Surat stoplist
model file surat
Model Stopword
Data Training
Lucene_index
[image:60.595.70.536.142.669.2]Keywords, file surat
3.4.3.3. Level 2 Proses 1
3.4.3.4. Level 2 Proses 2
file surat model stopwords file surat
file surat User
1.1
Training
1.2
Testing
Model
Data training Stopwords
Koleksi Surat
file surat Hasil pencarian,
file surat
index hasil indexing file surat
Keywords
User
2.1
Indexing
2.2
Searching
Lucene_index
[image:61.595.68.522.146.669.2]Koleksi Surat
Gambar 3.6 Diagram Arus Data Level 2 Proses 1.
3.4.3.5. Level 3 Proses 1.1
Conditional probabilities file surat
Prior probabilities
kumpulan token yang terurut & dikelompokan
[image:62.595.70.524.152.665.2]kumpulan token dalam bentuk kata dasar kumpulan token ternormalisasi kumpulan token tanpa stopword kumpulan token stoplist file surat 1.1.1 Tokenizing 1.1.2 Normalization 1.1.3 Stopwords removal 1.1.4 Stemming 1.1.5 Sorting & Grouping 1.1.7 Laplace smoothing Model Stopword Data training 1.1.6 Hitung nilai conditional probabillities 1.1.8 Hitung prior probabilities
3.4.3.6. Level 3 Proses 1.2
file surat
Conditional probabilities Prior probabilities
kumpulan token yang terurut & dikelompokan
kumpulan token dalam bentuk kata dasar
kumpulan token ternormalisasi kumpulan token tanpa stopword
kumpulan token
stoplist file surat
1.1.1
Tokenizing
1.1.2
Normalization
1.1.3
Stopwords removal
1.1.4
Stemming
1.1.5
Sorting & Grouping
Model
Stopword
1.1.6 Hitung probabilitas file
surat
User Koleksi
[image:63.595.69.520.163.681.2]Surat
3.4.3.7. Level 3 Proses 2.1
index
kumpulan token dalam bentuk kata dasar
kumpulan token ternormalisasi
kumpulan token tanpa stopword kumpulan token file surat
2.1.1
Tokenizing
2.1.2
Normalization
2.1.3
Stopwords removal
2.1.4
Stemming 2.1.5
Scoring
User
[image:64.595.73.522.157.683.2]Lucene_index
3.4.3.8. Level 3 Proses 2.2
file surat yang sesuai dengan
keywordsuser
Hasil pencarian file surat
Koleksi Surat
index
kumpulan token dalam bentuk kata dasar
kumpulan token ternormalisasi
kumpulan token tanpa stopword kumpulan token keywords
2.2.1
Tokenizing
2.2.2
Normalization
2.2.3
Stopwords removal
2.2.4
Stemming
2.2.6
Scoring
User
Lucene_index 2.2.5
[image:65.595.67.523.158.671.2]Matching
3.5.
Desain Fisikal
3.5.1.
Desain Antarmuka
3.5.1.1. Menu Utama / Menu Pencarian Surat
SISTEM MANAJEMEN SURAT
Pencarian Surat
Simpan Surat
Cari Reset
Filter pencarian berdasarkan
[image:66.595.74.539.220.642.2]Tabel hasil
3.5.1.2. Menu Simpan Surat
SISTEM MANAJEMEN SURAT
Pencarian Surat
Simpan Surat
[image:67.595.73.540.150.666.2]Ambil Surat Simpan
Tabel daftar surat yang akan
Reset Kategorikan Surat
3.5.2.
Algoritma Proses Klasifikasi
Algoritma yang akan dijabarkan dalam sub bab ini adalah algoritma yang berhubungan dengan proses klasifikasi. Sedangkan proses pencarian tidak ikut dijelaskan karena bukan merupakan bahasan utama dalam penelitian.
3.5.2.1Preprocessing untuk proses training
input: file surat yang terbagi dalam 8 folder yang mewakili masing – masing kelas, stopword, synonym
loop: semua folder n...i dari data training {
loop: semua file surat dari folder n {
read: satu per satu file surat dari folder n
loop - tokenization: setiap term j...k dalam file surat {
normalization: term j
check_stopwords: term j
stemming: term j
count: jumlah kemunculan term j }
} }
3.5.2.2Preprocessing untuk proses testing
input: file surat, stopword, synonym
read: file surat
loop - tokenization: setiap term j...k dalam file surat {
normalization: term j
check_stopwords: term j
stemming: term j }
3.5.2.3Hitung Prior Probabilities
input: file surat yang terbagi dalam 8 folder yang mewakili masing – masing kelas
loop: semua folder n...i dari data training {
loop: semua file surat dari folder n {
count: file surat yang ada dalam folder n }
count: file surat yang ada dalam semua folder }
calculate: nilai prior probabilities dari tiap – tiap kelas (folder)
3.5.2.4Hitung Conditional Probabilities
input: hasil preprocessing, jumlah term dalam keseluruhan kelas, jumlah term unik dari keseluruhan kelas
loop: semua folder n...i dari hasil preprocessing {
read: satu per satu file hasil preprocessing dari folder n
calculate: nilai conditional probabilities dari masing – masing kelas }
3.5.2.5Training
execute: preprocessing method
execute: prior probabilities method
execute: conditional probabilities method
3.5.2.6Matching
input: indeks term hasil preprocessing data testing, indeks term dari model
loop – read: indeks term data testing{ tt = term data testing
loop: indeks term dari model{ tm = term dari model
compare: tt with: tm
store: match term, term frequency }
3.5.2.7Testing
get: prior probabilities, conditional probabilities, hasil proses matching
loop: indeks matching{
m = term frequency dalam indeks hasil matching
loop: conditional prob{
c = term frequency dalam conditional prob{
calculate: n = c m }
}
calculate: n * prior probabilities
56
BAB 4
IMPLEMENTASI
Pada sub bab ini akan dijabarkan hasil implementasi berupa antarmuka (interface) beserta dengan method – method utama yang digunakannya.
[image:71.595.70.524.213.717.2]4.1.
Antarmuka Menu Utama / Pencarian Surat
Gambar 4.1 Antarmuka untuk menu utama juga pencarian.
1. Method: createIndex(String filesToIndex)
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_41); File dir = new File(filesToIndex);
FileInputStream fis = null;
FieldType type1 = new FieldType(); type1.setIndexed(true);
type1.setStored(true);
type1.setStoreTermVectors(true);
type1.setStoreTermVectorOffsets(true); type1.setStoreTermVectorPositions(true);
if (dir.isDirectory()) {
for (final File folder : dir.listFiles()) { String classname = folder.getName(); File index_dir = new
File("C:/Users/Fran/Documents/KULIAH/Skripsi/De2n/Program/Sy
stem/se arch_index/" + classname.toLowerCase());
IndexWriterConfig conf = new
IndexWriterConfig(Version.LUCENE_41, analyzer);
Directory directory = FSDirectory.open(index_dir);
IndexWriter indexWriter = new IndexWriter(directory, conf);
File[] files = folder.listFiles(); for (File file : files) {
if (file.toString().endsWith("txt")) { fis = new FileInputStream(file);
Document doc = new Document();
String fileContent = readFile(file); if (fileContent != null) {
String path = file.getPath();
doc.add(new StringField("path", path, Field.Store.YES));
BufferedReader reader = new BufferedReader(new InputStreamReader(fis, "UTF-8"));
doc.add(new Field("contents", fileContent, type1));
if (!index_dir.exists()) {
indexWriter.addDocument(doc); } else {
indexWriter.updateDocument(new Term("path", file.getPath()), doc);
} } } }
fis.close();
indexWriter.close(); }
}
2. Method: searchIndex(String searchString, String[] kategori)
System.out.println("Searching for '" + searchString + "'"); String index_path;
if (kategori != null) {
for (int i = 0; i < kategori.length; i++) { String kelas = kategori[i];
index_path =
"C:/Users/Fran/Documents/KULIAH/Skripsi/De2n/Program/System/
search_ index/" + kelas;
File dir = new File(index_path); if (dir.isDirectory()) {
HashMap<String, String> hasilPencarian = new HashMap<>(); Directory directory = FSDirectory.open(dir);
IndexReader reader = DirectoryReader.open(directory); IndexSearcher searcher = new IndexSearcher(reader);
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_41);
QueryParser parser = new QueryParser(Version.LUCENE_41,
"contents", analyzer);
Query query = parser.parse(searchString);
ScoreDoc[] hits = searcher.search(query, null, 1000).scoreDocs;
Highlighter highlighter = new Highlighter(new QueryScorer(query));
jumlah_hits = jumlah_hits + hits.length;
for (int j = 0; j < hits.length; j++) { String highlight = "";
String t = "";
Document doc = searcher.doc(hits[j].doc); String content = doc.get("contents"); String path = doc.get("path");
TokenStream tokenStream =
TokenSources.getAnyTokenStream(searcher.getIndexReader(), hits[j].doc, "contents", analyzer);
TextFragment[] frag =
highlighter.getBestTextFragments(tokenStream, content, false, 10);
for (int p = 0; p < frag.length; p++) {
if ((frag[p] != null) && (frag[p].getScore() > 0)) {
t = frag[p].toString(); highlight = highlight + t; }
} }
directory.close();
pencarian.put(kelas, hasilPencarian); }
} } else {
index_path =