Pencarian Kelompok Profil Mahasiswa Menggunakan
Metode K-Means di Universitas Muhammadiyah Gresik
Eko Prasetyo
1, Mursyidul Umam
2, Deni Sutaji
31
Program Studi Teknik Informatika, Fakultas Teknik, Universitas Bhayangkara Surabaya Jl. Ahmad Yani 114, Surabaya, Indonesia, 60231
2
Program Studi Teknik Informatika, Fakultas Teknik, Universitas Muhammadiyah Gresik Jl. Sumatera 101 GKB, Gresik, Indonesia, 61121
eko@ubhara.ac.id
1, umam2407@gmail.com
2, sutaji.deni@umg.ac.id
3Abstract— University of Muhammadiyah Gresik (UMG) is a growing university where the number of new students always increases from year to year. A very important need for promotion teams to promote campus is the profile of prospective students that has the potential to study at UMG. By using new student registration data, the K-Means method can help to find the profile of the prospective student. This study uses student biodata as variables, namely: gender, age, school majors, parents' income, school, hometown, class, test status and student work. The clustering results indicate that the profile of prospective students who have the potential to study at UMG are those who when they take the test, do not work, attend to the morning class, and parent’s income > 1 million rupiahs.
Keywords- clustering; profiles; prospective students; campus promotions; K-Means
Abstrak— Universitas Muhammadiyah Gresik (UMG) merupakan perguruan tinggi yang sedang berkembang dimana jumlah mahasiswa baru selalu bertambahn dari tahun ke tahun. Kebutuhan yang sangat penting bagi tim promosi untuk menyampaikan promosi kampus adalah profil calon mahasiswa seperti apa yang punya potensi untuk belajar di UMG. Dengan menggunakan data pendaftaran mahasiswa baru, maka metode K-Means clustering dapat membantu menemukan profil calon mahasiswa tersebut. Penelitian ini menggunakan biodata mahasiswa sebagai variabel yaitu: jenis kelamin, usia, jurusan sekolah, penghasilan orang tua, sekolah, daerah asal, kelas, status test dan pekerjaan mahasiswa. Hasil pengelompokan menunjukkan bahwa profil calon mahasiswa yang berpotensi belajar di UMG adalah mereka yang ketika pendaftaran mengikuti tes, belum bekerja, masuk kelas pagi, dan penghasilan orang tua > 1 juta.
Kata kunci- pengelompokan; profil; calon mahasiswa; promosi kampus; K-Means
I. PENDAHULUAN
Universitas Muhammadiyah Gresik (UMG) sebagai institusi pendidikan telah memiliki data akademik dan administrasi dalam jumlah yang banyak, namun hanya sebagaian kecil data tersebut dimanfaatkan, termasuk data profil mahasiswa. Setiap mahasiswa berasal dari sekolah, jurusan dan daerah yang berbeda. Data mahasiswa dapat diproses menjadi informasi, selanjutnya dapat digunakan untuk membantu dalam kegiatan sehari – hari atau dapat digunakan lebih lanjut pada bidang yang lain. Hal ini
sejalan dengan konsep data mining untuk menemukan informasi baru dari kumpulan data besar [1].
UMG setiap tahun melakukan penerimaan mahasiswa baru, hal ini akan berdampak terhadap penumpukan data yang berjumlah besar. Dengan jumlah data yang besar UMG kesulitan untuk mengelompokan profil mahasiswa. Dengan volume data yang berkembang pesat, baik dari jumlah record atau jumlah field maka diperlukan penerapan data mining untuk membantu menganalisa data yang diperoleh dari transaksi pada sistem informasi penerimaan mahasiswa baru.
Penelitian yang dilakukan adalah sistem pencarian kelompok profil mahasiswa calon mahasiswa. Untuk keperluan tersebut, digunakan metode K-Means Clustering dengan ukuran ketidakmiripan adalah Euclidean [2]. Dengan menggunakan metode K-Means, data di kelompokan menjadi beberapa cluster berdasarkan kemiripan dari data-data tersebut, sehingga data-data yang memiliki karakteristik yang berbeda akan berkumpul kedalam cluster yang lain dengan karakteristik serupa. Dengan adanya pengelompokan – pengelompokan data seperti ini, diharapkan dapat membantu mengetahui daerah mana yang berpotensi banyak calon mahasiswa, atau profil seperti apa calon mahasiswa dari daerah tertentu. Hal ini menjadi informasi baru atau pengetahuan baru untuk strategi bagian promosi kampus.
II. RISET SEBELUMNYA
Penelitian yang dilakukan oleh [3] menggunakan variabel – variabel : nilai mata kuliah Algoritma dan Pemrograman, Fisika Dasar, Kalkulus dan Indek Prestasi Kumulatif (IPK) untuk menentukan pilihan beberapa mahasiswa yang akan mengikuti lomba tingkat nasional. Dengan menggunakan metode K-Means, sistem berhasil mengelompokkan 124 mahasiswa menjadi 5 kelompok. Hasilnya didapatkan ada 5 mahasiswa terpilih untuk mengikuti lomba. Penelitian lain yang juga mengolah data mahasiswa adalah [4]. Dalam penelitian ini, sistem pembagian kelas kuliah yang dikembangkan bertujuan untuk mendapatkan kelompok-kelompok mahasiswa dengan kemampuan yang homogen, dimana mahasiswa dengan kemampuan tinggi akan berkumpul bersama dengan mahasiswa dengan kemampuan tinggi juga,
demikian pula untuk kelompok mahasiswa
pengelompokan ini agar proses pembelajaran menjadi efektif dan mempermudah tenaga pendidik dalam menentukan metode atau strategi pembelajaran yang sesuai. Penelitian ini menggunakan nilai tugas, nilai ujian tengah semester, nilai ujian akhir semester, dan indeks prestasi kumulatif (IPK) untuk mengelompokkan mahasiswa menggunakan K-Means. Penelitian ini juga melakukan prediksi kelulusan mahasiswa pada mata kuliah tersebut menggunakan K-Nearest Neighbor. Hasil pengujian menunjukkan bahwa pengelompokan 100 data mahasiswa menjadi 10 kelompok mempunyai kualitas terbaik dimana nilai evaluasi Silhouette sebesar 0.534 [4].
Penelitian ini menggunakan K-Means untuk mengelompokkan data mahasiswa berdasarkan latar belakang biodata mahasiswa yang diisikan ketika proses pendaftaran. Variabel-variabel tersebut sebagai berikut: jenis kelamin, usia, jurusan sekolah, penghasilan orang tua, asal sekolah, daerah asal, kelas, status test, pekerjaan mahasiswa. Hasil pengelompokan nantinya adalah profil kelompok calon mahasiswa sebagai strategi promosi.
III. ANALISIS DAN PERANCANGAN SISTEM
Sistem yang dibuat bertujuan untuk mencari kelompok profil mahasiswa, dimana variabel yang digunakan yaitu : jenis kelamin, usia, jurusan sekolah, penghasilan orang tua, sekolah, daerah asal, kelas, status test dan pekerjaan mahasiswa. Dengan adanya pengelompokan ini diharapkan dapat diketahui pola-pola potensi calon mahasiswa baru sebagai informasi baru untuk bagian promosi UMG. Sistem pengelompokan yang dibangun menggunakan metode K-Means. Sistem menghasilkan keluaran berupa kelompok – kelompok profil mahasiswa. Variabel yang digunakan dalam penelitian ini disajikan pada Tabel I.
TABEL I. VARIABEL YANG DIGUNAKAN
No Variabel Keterangan
1 Jenis Kelamin Laki-laki, Perempuan 2 Usia Usia ketika masuk 3 Jurusan Sekolah Kejuruan, IPA, IPS, Teknik 4 Penghasilan Orang
Tua
<1.000.000, >1.000.000 5 Sekolah SMK, SMA, MA
6 Daerah Asal Manyar, Menganti, Surabaya, Lamongan
7 Kelas Sore, Pagi 8 Status Test Test, Bebas test 9 Pekerjaan
Mahasiswa
Belum bekerja, Bekerja <2 th, Bekerja >2th
Alur sistem pencarian kelompok profil mahasiswa disajikan pada Gambar 1.
Nilai data variabel yang digunakan dalam penelitian ini bertipe kategorikal, sedangkan K-Means hanya dapat mengolah data bertipe numerik, maka sebelum proses pengelompokan, data harus dilakukan pra-pemrosesan berupa inisialisasi dari tipe data kategorikal ke tipe data
numerik [5]. Data yang bertipe kategorikal seperti jenis kelamin, penghasilan orang tua, jurusan sekolah, daerah asal, sekolah, status test, pekerjaan mahasiswa dan kelas harus dilakukan proses inisialisasi data terlebih dahulu kedalam bentuk angka atau numerik. Inisialisasi dilakukan dengan memberikan nilai numerik pada tiap variasi nilai kategori berdasarkan frekuensi data yang digunakan. Proses inisialisasi ini melibatkan 40 data mahasiswa. Selanjutnya, untuk tiap nilai variabel diurutkan berdasarkan frekuensi kemunculan pada data, urutan pemberian nilai inisial dimulai dari frekuensi tertinggi. Hasilnya disajikan pada Tabel II-IX.
Gambar 1. Diagram Alur Sistem Pencarian Kelompok Profil Mahasiswa TABEL II. INISIALISASI JENIS KELAMIN
Jenis Kelamin Frekuensi Inisial
Perempuan 21 1 Laki - Laki 19 2
TABEL III. INISIALISASI PENGHASILAN ORANG TUA Penghasilan Orang Tua Frekuensi Inisial
>1 juta 32 1 <1 juta 8 2
TABEL IV. INISIALISASI JURUSAN SEKOLAH Jurusan Sekolah Frekuensi Inisial
Kejuruan 17 1 IPS 14 2 IPA 9 3 TABEL V. INISIALISASI JURUSAN SEKOLAH
Sekolah Frekuensi Inisial
SMK 17 1 SMA 16 2 MA 7 3
TABEL VI. INISIALISASI DAERAH ASAL Daerah Asal Frekuensi Inisial
Manyar 15 1 Cerme 11 2 Kebomas 6 3 Menganti 4 4 Lamongan 2 5 Jember 1 6 Singosari 1 7 Balungpanggang 1 8
TABEL VII. INISIALISASI KELAS Kelas Frekuensi Inisial
Pagi 21 1 Sore 19 2 TABEL VIII. INISIALISASI STATUS TES Status Test Frekuensi Inisial
Test 34 1 Bebas Test 6 2 TABEL IX. INISIALISASI PEKERJAAN MAHASISWA
Pekerjaan Mahasiswa Frekuensi Inisial
Belum Bekerja 26 1 Bekerja <2 th 11 2 Bekerja >2 th 3 3
Penulis juga melakukan evaluasi pada cluster yang terbentuk. Evaluasi ini bertujuan untuk menilai kualitas cluster apakah sudah memenuhi syarat kualitas cluster yang baik. Pada penelitian ini penulis menggunakan
Purity untuk evaluasi kualitas cluster [2]. Purity adalah metrik untuk mengukur sejauh mana kemurnian cluster berisi obyek dari kelas tunggal. Nilainya adalah rentang [0,1], nilai 1 berarti cluster hanya berisi obyek dari satu kelas, semakin mendekati 0 berarti cluster berisi obyek dari banyak kelas [2]. Pada penelitian digunakan hasil
Purity tertinggi dari beberapa kali pengujian, Purity tertinggi digunakan sebagai hasil cluster, selanjutnya dilakukan karakterisasi.
IV. HASIL DAN PEMBAHASAN
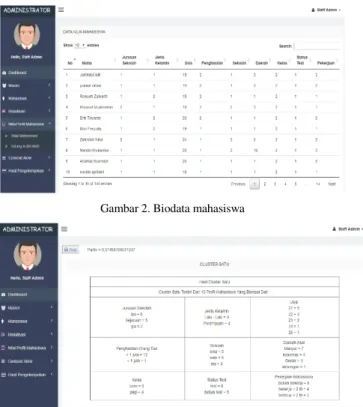
Hasil implementasi sistem pencarian profil mahasiswa berbasis web disajikan pada Gambar 2 dan 3. Pada Gambar 2 disajikan tampilan data mahasiswa yang sudah melalui proses inisialisasi semua variabel, dimana semua nilai sudah berupa angka numerik. Sistem diterapkan pada 140 sampel biodata mahasiswa dari calon mahasiswa.
Pada Gambar 3 disajikan tampilan untuk cluster 1 dimana sistem menampilkan frekuensi nilai variabel. Nilai
variabel dan frekuensi inilah yang menjadi informasi baru bagi tim promosi kampus.
Gambar 2. Biodata mahasiswa
Gambar 3. Hasil pengelompokan menggunakan K-Means TABEL X. DATA DI CLUSTER 1
Hasil Cluster Satu 18 profil mahasiswa Jurusan Sekolah Kejuruan = 6 IPA = 10 IPS = 2 Jenis Kelamin Perempuan = 6 Laki-Laki = 12 Usia 18 = 6 19 = 6 21 = 3 20 = 3 Penghasilan Orang tua >1 juta = 15 <1 juta = 3 Sekolah SMK = 6 SMA = 8 MA = 2 Daerah Asal Cerme = 5 Balung panggang = 4 Sedayu = 3 Benjeng = 2 Jember = 1 Menganti = 1 Dawar = 1 Bungah = 1 Kelas Pagi = 12 Sore = 6 Status Test Test = 13 Bebas Test = 5 Pekerjaan Mahasiswa Belum Bekerja = 11 Bekerja <2 th = 5 Bekerja >2 th = 2
Dari 3 kali pengujian yang dilakukan, nilai Purity tertinggi pada semua cluster yang dicapai sebesar 0,5883. Berdasarkan hasil evaluasi cluster tersebut maka penulis menggunakannya sebagai hasil pengelompokan. Nilai ini
menyatakan bahwa rata-rata 58.83% data dalam satu kelompok merupakan data dari kelas yang sama.
Hasil pengujian menggunakan 5 cluster disajikan pada Tabel X-XIV. Tabel X menyajikan data mahasiswa yang tergabung di cluster 1. Variabel yang cukup dominan dalam menyajikan data adalah penghasilan orang tua, dimana ada 15 data untuk penghasilan > 1 juta, hasil membuktikan bahwa kemampuan finansial orang tua dalam mendukung biaya kuliah mahasiswa masih tinggi. Hasil ini juga didukung oleh variabel status tes, kelas pagi, dan status pekerjaan belum bekerja, masing-masing memberikan nilai dominan pada kelas pagi, tes dan belum bekerja.
TABEL XI. DATA DI CLUSTER 2 Hasil Cluster Dua 23 profil mahasiswa Jurusan Sekolah IPS = 6 Kejuruan = 11 IPA = 6 Jenis Kelamin Laki-Laki = 10 Perempuan = 13 Usia 19 = 9 18 = 8 20 = 5 21 = 1 Penghasilan Orang tua >1 juta = 17 <1 juta = 6 Sekolah SMA = 8 SMK = 11 MA = 4 Daerah Asal lamongan = 9 Manyar = 6 Surabaya = 5 Duduk Sampean = 3 Kelas Sore = 5 Pagi = 18 Status Test Test = 22 Bebas Test = 1 Pekerjaan Mahasiswa Belum Bekerja = 21 Bekerja <2 th = 2
TABEL XII. DATA DI CLUSTER 3 Hasil Cluster Tiga
17 profil mahasiswa Jurusan Sekolah IPA = 5 IPS = 7 Kejuruan = 5 Jenis Kelamin Laki-Laki = 12 Perempuan = 5 Usia 22 = 8 23 = 6 21 = 2 24 = 1 Penghasilan Orang tua >1 juta = 11 <1 juta = 6 Sekolah SMA = 6 MA = 6 SMK = 5 Daerah Asal Gresik = 8 Manyar = 3 Surabaya = 2 lamongan = 2 Duduk Sampean = 1 kebomas = 1 Kelas Pagi = 5 Sore = 12 Status Test Test = 13 Bebas Test = 4 Pekerjaan Mahasiswa Belum Bekerja = 6 Bekerja <2 th = 7 Bekerja >2 th = 4
Tabel XI menyajikan data yang tergabung di cluster 2. Variabel yang mendominasi adalah status tes, pekerjaan, kelas, dan penghasilan orang tua, dimana masing-masing bernilai tes, tidak bekerja, pagi, dan > 1 juta.
Pada cluster 3, seperti disajikan pada Tabel XII, ada 17 data mahasiswa yang bergabung. Dominasi terjadi pada variabel status tes, kelas dan jenis kelamin, dimana masing-masing bernilai tes, sore, dan laki-laki.
TABEL XIII. DATA DI CLUSTER 4 Hasil Cluster Empat 71 profil mahasiswa Jurusan Sekolah IPS = 14 Kejuruan = 32 IPA = 14 Jenis Kelamin Laki-Laki = 27 Perempuan = 44 Usia 19 = 35 20 = 22 18 = 10 21 = 4 Penghasilan Orang tua >1 juta = 55 <1 juta = 16 Sekolah SMK = 32 SMA = 30 MA = 9 Daerah Asal Gresik = 57 kebomas = 14 Kelas Sore = 35 Pagi = 36 Status Test Test = 64 Bebas Test = 7 Pekerjaan Mahasiswa Belum Bekerja = 56 Bekerja <2 th = 10 Bekerja >2 th = 5 TABEL XIV. DATA DI CLUSTER 5
Hasil Cluster Lima 11 profil mahasiswa Jurusan Sekolah Kejuruan = 2 IPA = 3 IPS = 6 Jenis Kelamin Laki-Laki = 6 Perempuan = 5 Usia 27 = 4 25 = 3 28 = 2 26 = 1 30 = 1 Penghasilan Orang tua >1 juta = 9 <1 juta = 2 Sekolah SMA = 5 SMK = 2 MA = 4 Daerah Asal Gresik = 5 Bungah = 1 Surabaya = 1 kebomas = 1 lamongan = 1 Duduk Sampean = 1 Manyar = 1 Kelas Sore = 8 Pagi = 3 Status Test Test = 6 Bebas Test = 5 Pekerjaan Mahasiswa Belum Bekerja = 3 Bekerja <2 th = 4 Bekerja >2 th = 4
Hasil berbeda diberikan oleh cluster 4, disajikan pada Tabel XIII, dimana ada 71 data yang tergabung,
didominasi oleh variabel status tes, daerah asal, pekerjaan, dan penghasilan orang tua, masing-masing bernilai tes, Gresik, belum bekerja, dan > 1 juta.
Data yang disajikan pada Tabel XIV adalah data yang bergabung di cluster 5. Dari 11 data yang bergabung, variabel yang mendominasi adalah penghasilan orang tua, dan kelas, dimana masing-masing bernilai > 1 juta dan pagi.
Dari hasil clustering yang sudah dilakukan, didapatkan informasi profil bahwa dominasi calon mahasiswa yang berpotensi kuliah di UMG adalah status tes, status pekerjaan, kelas, dan penghasilan orang tua, dimana masing-masing bernilai tes, belum bekerja, pagi, dan penghasilan orang tua > 1 juta. Informasi ini mempunyai arti bahwa potensi calon mahasiswa yang layak untuk dilakukan promosi adalah mereka yang mengikuti tes saat pendaftaran, biasanya dilakukan oleh calon mahasiswa di pendaftaran gelombang 2 dan 3. Potensi juga ada pada calon yang belum bekerja, dan biasanya masuk kelas pagi. Potensi besar juga ada pada calon mahasiswa dimana penghasilan orang tua > 1 juta.
V. KESIMPULAN
Berdasarkan penelitian yang sudah dilakukan, dapat disimpulkan bahwa sistem berhasil mengelompokkan profil mahasiswa yang mendaftar kuliah di UMG. Profil potensi calon mahasiswa adalah mereka yang ketika pendaftaran mengikuti tes, belum bekerja, masuk kelas pagi, dan penghasilan orang tua > 1 juta. Saran yang dapat
diberikan dari hasil penelitian adalah masih ada variabel yang belum dilibatkan dalam pencarian profil, seperti status menikah dan domisili selama kuliah (kos atau pulang pergi), dengan penambahan variabel maka diharapkan ada informasi potensi calon mahasiswa yang lebih luas dan jelas.
DAFTAR PUSTAKA
[1] P. Tan, Steinbach, M., Kumar, V., Introduction to Data Mining. Boston San Fransisco New York: Pearson Education, 2006. [2] E. Prasetyo, Data Mining – Mengolah Data Menjadi Informasi
Menggunakan Matlab. Yogyakarta: Andi Offset, 2014.
[3] A. Asroni, Adrian, R., "Penerapan Metode K-Means Untuk Clustering Mahasiswa Berdasarkan Nilai Akademik Dengan Weka Interface Studi Kasus Pada Jurusan Teknik Informatika UMM Magelang," Semesta Teknika, vol. 18, pp. 76-82, 2015.
[4] G. A. Pradnyana, Permana, A.A.J., "Sistem Pembagian Kelas Kuliah Mahasiswa dengan Metode K-means dan K-Nearest Neighbors untuk Meningkatkan Kualitas Pembelajaran," JUTI: Jurnal Ilmiah Teknologi Informasi, vol. 16, pp. 59-68, 2018. [5] R. Setiawan, "Penerapan Data Mining Menggunakan Algoritma
K-Means Clustering Untuk Menentukan Strategi Promosi Mahasiswa Baru (Studi Kasus : Politeknik LP3I Jakarta )," Jurnal Lentera ICT, vol. 3, pp. 76-92, 2016.