KLASIFIKASI PENYAKIT DEMAM BERDARAH DENGUE MENGGUNAKAN ALGORITMA NAÏVE BAYES PADA RUMAH SAKIT
BUDI ASIH
SKRIPSI
Diajukan untuk memenuhi salah satu syarat dalam Program Studi Strata Satu (S1) Teknik Informatika
Disusun Oleh :
MOCH MUSLIH 311410579
SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA CIKARANG
i
LEMBAR PERSETUJUAN SKRIPSI
KLASIFIKASI PENYAKIT DEMAM BERDARAH DENGUE MENGGUNAKAN ALGORITMA NAÏVE BAYES PADA RUMAH SAKIT
BUDI ASIH
MOCH MUSLIH NIM : 311410579
Disetujui dan disahkan Oleh :
Pembimbing I Pembimbing II
Wahyu Hadikristanto S.Kom, M.Kom Akhmad Akromusyuhada, S.T, M.Pd.I
NIDN : 0415088207 NIDN : 0427057408
Mengetahui
Ketua Prodi Teknik Informatika
Aswan Supriyadi Sunge, S.E, M.Kom NIDN : 0426018003
ii
PENGESAHAN
SKRIPSI
KLASIFIKASI PENYAKIT DEMAM BERDARAH DENGUE MENGGUNAKAN ALGORITMA NAÏVE BAYES PADA RUMAH SAKIT
BUDI ASIH
Yang disusun oleh
MOCH MUSLIH NIM: 311410579
Telah dipertahankan di depan Dewan Penguji Pada tanggal 8 November 2018
Susunan Dewan Penguji
Nama Penguji Tanda Tangan
Yoga Religia, M.Kom ( )
NIDN : 0419089301
Basuki Edi Priyo, M.Pd ( )
NIDN : 0421068205
Mengetahui
Kaprodi Teknik Informatika
Aswan Supriyadi Sunge, S.E, M.Kom NIDN : 0426018003
Ketua STT Pelita Bangsa
Dr. Ir. Supriyanto, M.P NIDN : 0401066605
iii
SURAT PERNYATAAN KEASLIAN SKRIPSI
Dengan ini saya yang bertandatangan dibawah ini,
Nama : MOCH MUSLIH
NIM : 311410579
Perrguruan Tinggi : STT Pelita Bangsa Program Studi : Teknik Informatika
Dengan ini menyatakan bahwa skripsi yang telah saya buat dengan judul :
“KLASIFIKASI PENYAKIT DEMAM BERDARAH DENGUE
MENGGUNAKAN ALGORITMA NAÏVE BAYES PADA RUMAH SAKIT BUDI ASIH“, adalah merupakan hasil karya saya sendiri dan segala kutipan dalam
bentuk apapun telah mengikuti kaidah dan etika yang berlaku. Mengenai isi dan tulisan adalah merupakan tanggung jawab penulis, bukan STT Pelita Bangsa.
Demikian pernyataan ini dibuat dengan sebenar-benarnya dan dengan keadaan sadar tanpa paksaan dari pihak manapun.
Cikarang, Oktober 2018 Yang membuat pernyataan.
iv
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Kampus Pelita Bangsa :
Nama : Moch. Muslih
NIM : 311410579
Program pendidikan : Strata Satu (S1) Program Studi : Teknik Informatika
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Kampus Pelita Bangsa skripsi saya yang berjudul : “KLASIFIKASI
PENYAKIT DEMAM BERDARAH DENGUE MENGGUNAKAN
ALGORITMA NAÏVE BAYES PADA RUMAH SAKIT BUDI ASIH” beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Kampus Pelita Bangsa hak untuk menyimpan, me-ngalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di Internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis. Demikian pernyataan ini yang saya buat dengan sebenarnya.
Dibuat di Cikarang
Pada tanggal : 30 Oktober 2018 Yang menyatakan
v
ABSTRAK
Demam Berdarah Dengue (DBD) merupakan penyakit infeksi virus yang disebabkan oleh gigitan nyamuk Aedes aegypti betina. Penyakit demam berdarah masih termasuk dalam kategori penyakit yang berbahaya, bahkan dapat menyebabkan kematian. Lamanya proses diagnosis penyakit tersebut menjadi hambatan bagi seseorang untuk mendapatkan diagnosis akan penyakit yang diderita secara dini. Penelitian ini dilakukan guna memprediksi penyakit demam berdarah menggunakan metode algoritme naïve bayes yang di implementasikan pada data pasien penyakit demam berdarah. Dari hasil analisis menggunakan Split Validation diperoleh nilai akurasi 90,74%.
vi
KATA PENGANTAR
Dengan memanjatkan puji dan syukur kehadirat Allah SWT atas segala Rahmat, Taufiq, serta Hidayah-Nya sehingga penulis dapat menyelesaikan Skripsi ini dengan judul “Klasifikasi Penyakit Demam Berdarah Dengue Menggunakan Algoritma Naïve Bayes Pada Rumah Sakit Budi Asih”. Yang merupakan syarat dalam menyelesaikan Program Studi Sl pada Program Studi Teknik Informatika, Sekolah Tinggi Teknologi Pelita Bangsa.
Selama penulisan skripsi ini penulis mendapat banyak bantuan dan bimbingan dari berbagai pihak, untuk itu pada kesempatan ini penulis mengucapkan terima kasih yang sebesar-besarnya. pada :
1. Ayah dan Ibu saya telah banyak memberikan dukungan maupun do'a kepada saya sehingga semua dapat berjalan dengan lancar.
2. Dr. Ir. Supriyanto, M.P., selaku Ketua Sekolah Tinggi Teknologi Pelita Bangsa. 3. Aswan Supriyadi Sunge, S.E, M.Kom., selaku Ketua Program Studi Teknik
Informatika Sekolah Tinggi Teknologi Pelita Bangsa.
4. Bapak Wahyu Hadikristanto, S.Kom, M.Kom. selaku Dosen Pembimbing I. 5. Bapak Akhmad Akromusyuhada, S.T, M.Pd.I. selaku Dosen Pembimbing II. 6. Seluruh Dosen Teknik Informatika.
7. Teman-teman STT Pelita Bangsa angkatan 2014.
8. Semua pihak yang telah menbantu penulis dalam menyelesaikan Skripsi. Penulis sadar bahwa tentunya dalam penulisan skripsi ini masih banyak terdapat kekurangan untuk itu saran dan kritik dari pembaca yang sifatnya membangun sangat diharapkan, demi pengembangan kemampuan penulis ke depan.
vii
DAFTAR ISI
LEMBAR PERSETUJUAN... i
SURAT PERNYATAAN KEASLIAN SKRIPSI ... iii
ABSTRAK ... v
KATA PENGANTAR ... vi
DAFTAR ISI ... vii
DAFTAR GAMBAR ... x DAFTAR TABEL ... xi BAB I ... 1 1.1 Latar belakang ... 1 1.2 Identifikasi Masalah ... 3 1.3 Rumusan Masalah ... 4 1.4 Batasan Masalah... 4 1.5 Tujuan Penelitian ... 5 1.6 Manfaat Penelitian ... 5 BAB II ... 7 2.1 Kerangka Pemikiran... 7 2.1 Sistem Diagnosis ... 9 2.1.1 Pengertian Sistem ... 9 2.1.2 Pengertian Diagnosis ... 10
2.1.3 Pengertian Sistem Diagnosis ... 11
2.2 Pengertian Penyakit Demam Berdarah Dengue (DBD) ... 11
2.3 Data Mining ... 13
2.3.1 Pengertian Data Mining ... 13
2.3.2 Tugas – Tugas Data Mining... 14
2.4 Arsitektur Sistem Data Mining ... 16
2.5 Penyimpanan Data dalam Data Mining ... 18
2.6 Tahap – Tahap Data Mining ... 19
2.7 Teknik – Teknik Data Mining ... 21
viii
2.7.2 Teknik Classification menggunakan Naïve Bayes ... 23
2.8 Implementasi (Penerapan Data Mining) ... 23
2.9 Metode Penelitian Data Mining ... 25
2.9.1 Teori Naïve Bayes Classifier ... 25
2.9.2 Naïve Bayes Untuk Klasifikasi... 26
2.9.3 Model Klasifikasi ... 28
2.10 Metode – Metode Pilihan dan Klasifikasi ... 30
2.11 Penelitian Terdahulu ... 32
2.11.1 Kajian jurnal pertama ... 32
2.11.2 Kajian jurnal kedua ... 33
2.11.3 Kajian jurnal ketiga ... 33
2.11.4 Kajian jurnal keempat ... 34
2.11.5 Kajian jurnal kelima ... 35
2.12 Spesifikasi Kebutuhan Software dan Hardware ... 35
2.13 Pengujian Confusion Matrix... 37
BAB III ... 40
3.1 Sekilas Tentang Rumah Sakit Budi Asih ... 40
3.2 Metode Pengumpulan Data ... 41
3.3 Hasil Wawancara ... 41
3.4 Desain Penelitian ... 42
3.5 Analisa Sistem yang Berjalan... 42
3.6 Akuisisi Pengetahuan ... 43
3.7 Analisa Sistem ... 44
3.8 Metode Algoritma Naïve Bayes ... 45
3.9 Pengumpulan Data ... 46
3.10 Model yang Diusulkan ... 47
BAB IV ... 48
4.1 Persiapan dan Perhitungan Data... 48
4.2 Seleksi Data ... 49
4.3 Model dan Metode yang diusulkan ... 50
ix
4.4.1 Prediksi Menggunakan Perhitungan Manual ... 53
4.4.2 Prediksi Menggunakan Rapid Miner... 56
4.5 Evaluasi dan Validasi... 57
4.6 Hasil Klasifikasi Class ... 58
4.6.1 Simple Distribution Model ... 58
4.6.2 Distribution Label ... 59
4.7 Perhitungan Menentukan Akurasi, Presisi, dan Recall ... 60
4.7.1 Accuracy (Akurasi)... 60
4.7.2 Precision (Presisi) ... 61
4.7.3 Recall ... 61
4.8 Analisa Hasil Pengujian ... 62
BAB V... 64
5.1 Kesimpulan ... 64
5.2 Saran ... 64
DAFTAR PUSTAKA ... 65
x
DAFTAR GAMBAR
Gambar 2.1 Tahapan Proses Data Mining ... 22
Gambar 2.2 Diagram Alir Naive Bayes ... 25
Gambar 2.3 Proses Klasifikasi... 30
Gambar 2.4 Use Case Diagram Rumah Sakit... 37
Gambar 2.5 Activity Diagram Rumah Sakit... 38
Gambar 2.6 Sequence Diagram Administrator ... 39
Gambar 2.7 Class Diagram Rumah Sakit ... 40
Gambar 2.8 Interface Rapidminer pada Data Mining Naive Bayes ... 43
Gambar 3.1 Kerangka Pemikiran ... 45
Gambar 3.2 Activity Diagram Diagnosa Prediksi Penyakit DBD ... 49
Gambar 3.3 Model Pengujian ... 55
Gambar 4.1 Model Algoritma Naïve Bayes ... 56
Gambar 4.2 Menu untuk menemukan performance algoritma ... 59
Gambar 4.3 Design Rapid Miner ... 65
Gambar 4.4 Hasil Prediksi Rapid Miner ... 65
Gambar 4.5 Simple Distribution Model ... 67
Gambar 4.6 Accuracy ... 69
Gambar 4.7 Precision... 70
Gambar 4.8 Recall ... 71
xi
DAFTAR TABEL
Tabel 3.1 Akuisisi Pengetahuan ... 50
Tabel 3.2 Data Pasien ... 54
Tabel 3.3 Pembagian Data ... 55
Tabel 4.1 Seleksi Data ... 58
Tabel 4.2 Data Training ... 60
Tabel 4.3 Data Testing ... 60
Tabel 4.4 Evaluasi Pengujian ... 66
Tabel 4.5 Distribusi Label ... 67
Tabel 4.6 Accuracy ... 69
1
BAB I PENDAHULUAN
1.1 Latar belakang
Pada awal tahun 2018 wabah Demam Berdarah Dengue di Indonesia memang tengah memuncak. Berdasarkan data pasien di RS Budi Asih Kota Cikarang, Demam Berdarah Dengue memasuki 10 besar penyakit yang banyak terjadi selama tahun 2017 yaitu sebanyak 485 kasus dan menjadi urutan ketiga setelah penyakit Gastro Enteritis/Colitis dan Congestive Heart Failure/ Decompensatio Cordis. Terlepas dari masalah tersebut, dalam bidang kesehatan/kedokteran, ada salah satu teknik klasifikasi dalam data mining yang banyak diterapkan pada hal-hal yang berkenaan dengan diagnosis secara statistik yang berhubungan dengan probabilitas serta kemungkinan dari penyakit dan gejala-gejala yang berkaitan yaitu metode naïve bayes.
Beberapa penelitian pernah dilakukan oleh Krishnaiah, Narsimha, dan Chandra (2013) mengenai “Diagnosis of Lung Cancer Prediction System Using Data Mining Classification Techniques”, dalam penelitian tersebut digunakan metode association rules, dicision tree, naïve bayes dan artificial neural network dengan tujuan untuk mengusulkan model untuk deteksi dini dan diagnosis yang benar dari penyakit yang akan membantu seorang dokter dalam menyelamatkan hidup seorang pasien. Hasil analisisnya tersebut menyatakan bahwa model yang paling efektif untuk memprediksi pasien dengan penyakit paru-paru tampaknya adalah naïve bayes diikuti association rules, decision trees dan neural network.
Peneliti lainnya dilakukan oleh Iyer, Jeyalatha, dan Sumbaly (2015) dengan judul “Diagnosis of Diabetes Using Classification Mining Technique”, penelitian tersebut bertujuan mencari solusi untuk mendiagnosis penyakit dengan menganalisis pola yang ditemukan dalam data melalui analisis klasifikasi dengan menggunakan decision tree dan naïve bayes. Hasil analisisnya menunjukan bahwa kedua metode yang digunakan memiliki perbedaan yang memang relatif kecil ditingkat kesalahan. Meskipun demikian, jika dibandingkan tingkat kesalahan klasifikasinya, maka metode naïve bayes memiliki tingkat kesalahan yang yang lebih kecil dibandingkan metode decision tree pada kasus tersebut.
Rumah sakit Budi Asih merupakan sebuah badan usaha yang bergerak dibidang pelayanan kesehatan masyarakat dibawah naungan perusahaan perseroan terbatas yang bernama PT. Kyandra Jantera dan sudah mendapat izin dari Pemerintah Daerah Kabupaten Bekasi dan Dinas Kesehatan. Pada prinsipnya, keberadaan Rumah Sakit Budi Asih ini adalah untuk memfasilitasi perusahaan - perusahaan dalam melaksanakan salah satu kewajibannya sebagai sebuah badan usaha yaitu menjamin kesejahteraan kesehatan bagi karyawannya.
Penyakit Demam Berdarah Dengue (DBD) yang sering dialami masyarakat dapat terjadi pada pasien dengan usia berapapun. Penyakit ini paling banyak ditemui selama musim hujan dan setelah musim hujan di area tropis dan subtropis. Maka diharapkan dengan adanya diagnosa prediksi penyakit DBD menggunakan data mining akan memudahkan pasien untuk melihat hasil diagnosa dari gejala – gejala yang muncul dengan mudah.
Oleh karena itu kemajuan teknologi mendorong setiap instansi – instansi dalam dunia kesehatan yaitu Rumah Sakit untuk meningkatkan mutu pelayanan terhadap pasien melalui cara melibatkan kemajuan teknologi dalam dunia kesehatan. Dimana nantinya pihak Rumah Sakit Budi Asih mampu mendiagnosa penyakit menggunakan teknlogi.
Dengan adanya masalah tersebut serta ada solusi untuk mengatasi dan penerapan metode penelitian menggunakan data mining terhadap pasien untuk mendiagnosa penyakit tersebut maka penulis akan mengusulkan judul “Klasifikasi
Penyakit Demam Berdarah Dengue Menggunakan Algoritma Naïve Bayes Pada Rumah Sakit Budi Asih”.
1.2 Identifikasi Masalah
Setelah membaca literatur, melakukan wawancara dan melakukan observasi adapun identifikasi masalah dari latar belakang diatas yaitu :
1. Rumah sakit Budi Asih melakukan identifikasi penyakit Demam Berdarah Dengue secara manual dan memerlukan waktu yang cukup lama untuk mendiagnosa penyakit tersebut.
2. Rumah Sakit Budi Asih belum menerapkan sistem yang mampu mendeteksi secara akurat dan cepat tentang penyakit Demam Berdarah Dengue.
3. Kurangnya pemahaman masyarakat akan bahaya dari penyakit Demam Berdarah Dengue.
4. Sulit membedakan Demam Berdarah Dengue dengan penyakit demam biasa, karena penyakit DBD mempunyai gejala-gejala yang berjumlah cukup banyak dan terdapat kesamaan gejala yang dimiliki penyakit lain. 5. Keterbatasan pengetahuan masyarakat tentang cara mencegah dan
menangani penyakit Demam Berdarah Dengue.
Pasien yang terjangkit penyakit Demam Berdarah Dengue pada Rumah sakit Budi Asih mengalami peningkatan tiap tahun.
1.3 Rumusan Masalah
Dari identifikasi masalah yang terjadi, maka perumusan masalah yang akan dibahas dalam penulisan ini adalah bagaimana melakukan prediksi data minig untuk jenis data penyakit Demam Berdarah Dengue di Rumah Sakit Budi Asih sehingga dokter dapat melihat hasil diagnosa awal dari gejala dengan cepat dan akurat?
1.4 Batasan Masalah
Dari identifikasi masalah yang ada, penulis membatasi masalah dalam penelitian ini, agar dalam pembahasan dilaporan penelitian dapat terarah dan mencapai tujuan. Berikut batasan – batasan masalah antara lain :
1. Penggunaan rapid miner untuk mencari tingkat akurasi diagnosa dokter terhadap penyakit demam berdarah dengue di Rumah Sakit Budi Asih. 2. Memastikan tingkat akurasi dan prediksi diagnosa dokter sesuai dengan
3. Banyak pasien yang terjangkit demam berdarah dengue, bahkan gejala yang ditimbulkan menyerupai penyakit lain.
1.5 Tujuan Penelitian
Berdasarkan latar belakang dan rumusan masalah yang telah diuraikan diatas maka tujuan dari penelitian ini yaitu :
1. Membuat sistem yang mampu mendeteksi secara akurat dan cepat tentang penyakit Demam Berdarah Dengue.
2. Mengganti proses diagnosa penyakit Demam Berdarah Dengue secara komputerisasi agar tidak memakan waktu yang lama untuk mendiagnosa penyakit tersebut.
3. Membantu dokter dalam mendiagnosa penyakit Demam Berdarah Dengue pada Rumah sakit Budi Asih.
1.6 Manfaat Penelitian
Jika tujuan tercapai adapun manfaat dari penulisan tugas akhir ini dibagi menjadi beberapa bagian yaitu :
a. Bagi Penulis
Tercapainya tujuan penulis yaitu dapat mengimplementasikan ilmu pengetahuan yang telah didapatkan penulis selama masa perkuliahan dan dapat memahami penerapan data mining serta metode naïve bayes.
Manfaat bagi institusi yaitu dengan adanya penerapan data mining ini dapat membantu dokter dalam mendiagnosa penyakit Demam Berdarah Dengue (DBD) tersebut.
c. Bagi Instansi
Manfaat bagi instansi yaitu diharapkan dapat menjadi tambahan bagi peneliti selanjutnya untuk meneliti variable yang lain yang berkaitan dengan diagnosa penyakit Demam Berdarah Dengue (DBD) menggunakan data mining dengan metode naïve bayes classifier.
7
BAB II
LANDASAN TEORI
2.1 Kerangka Pemikiran
Kerangka pikir merupakan garis besar dari langkah – langkah penelitian yang dilakukan. Langkah – langkah tersebut disusun sedemikian rupa sebagai acuan untuk tahap – tahap yang dilakukan dalam proses penelitian. Kerangka pemikiran dalam penelitian ini berisi landasan teori yang menjadi dasar dalam menjawab tujuan penelitian. Teori yang diuraikan meliputi konsep dasar dari metode naïve bayes beserta teknik yang digunakan untuk mengetahui diagnosa penyakit Demam Berdarah Dengue yang dialami oleh pasien akibat terinfeksi virus serta penggunaan rapid miner untuk mengetahui akurasi prediksi penyakit tersebut.
Adapun data yang diperoleh merupakan data berupa lembaran file rekam medis pasien. Data tersebut berupa data kasus DBD. Selain itu juga terdapat data-data terkait dengan hal atau faktor-faktor yang mempengaruhi terkena DBD. Data rekam medis tersebut kemudian dianalisis guna mendapatkan data yang spesifik dan menuangkan data yang didapatkan dalam bentuk excel, guna mempermudah pengolahan data.
Berdasarkan kerangka teori yang telah dijelaskan pada gambaran umum objek, maka dikembangkan kerangka pemikiran penelitian diagnosa penyakit Demam Berdarah Dengue yang dipengaruhi oleh gejala – gejala yang ada pada penyakit Demam Berdarah Dengue.
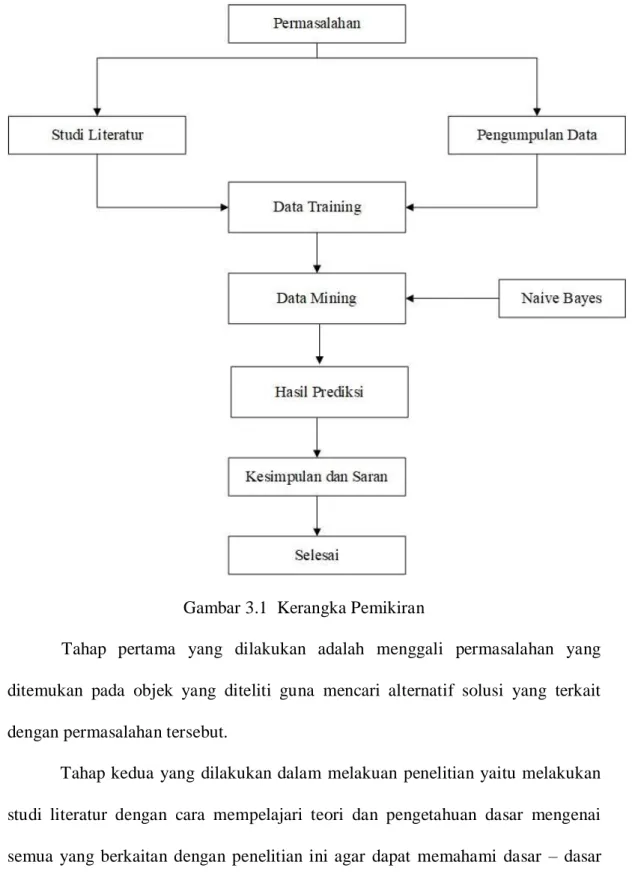
Gambar 3.1 Kerangka Pemikiran
Tahap pertama yang dilakukan adalah menggali permasalahan yang ditemukan pada objek yang diteliti guna mencari alternatif solusi yang terkait dengan permasalahan tersebut.
Tahap kedua yang dilakukan dalam melakuan penelitian yaitu melakukan studi literatur dengan cara mempelajari teori dan pengetahuan dasar mengenai semua yang berkaitan dengan penelitian ini agar dapat memahami dasar – dasar teori dan konsep – konsep yang mendukung penelitian.
Tahap ketiga yaitu pengumpulan data, setelah tahap studi literatur maka tahap selanjutnya yang harus dilakukan adalah mengumpulkan data. Data yang dibutuhkan adalah data pasien yang di dapatkan dari RS. Budi Asih.
Tahap keempat yaitu membuat data training / data latih dari data – data yang sudah dikumpulkan, karena tidak semua data dibutuhkan untuk pengujian model.
Tahap kelima adalah membuat data mining yang digunakan untuk memilih teknik dan algoritma yang sesuai untuk menemukan pola dari data pasien tersebut dengan menggunakan algoritma naive bayes.
Tahap keenam adalah hasil prediksi dari penerapan data mining dengan algoritma naive bayes.
Tahap ketujuh merupakan kesimpulan yang didapat dari penelitian tersebut serta saran.
2.1 Sistem Diagnosis 2.1.1 Pengertian Sistem
Sistem di definisikan sebagai suatu komponen yang saling berhubungan, dengan batas yang telah didefinisikan secara jelas, bekerja sama untuk mencapai sekumpulan tujuan yang umum dengan menerima input dan memproduksi output di sebuah proses transformasi yang teroganisir (James A. & George M, 2010 :25).
1. Input meliputi pengambilan dan perakitan komponen yang masuk ke sistem untuk di proses. Contohnya, bahan mentah, energy, data dan upaya manusia harus di jamin dan teroganisir untuk di proses.
2. Processing meliputi proses transformasi yang mengubah input menjadi output. Contohnya adalah proses pembuatan, proses pernafasan manusia, atau perhitungan matematika.
3. Output meliputi pemindahan komponen yang telah di produksi oleh proses transformasi ke tujuan akhir. Contohnya, produk jadi, pelayanan manusia, dan informasi manajemen harus di kirim ke user.
Sistem adalah kumpulan dari elemen – elemen yang berinteraksi untuk mencapai suatu tujuan tertentu yang menggambarkan suatu kejadian – kejadian dan kesatuan yang nyata adalah suatu objek nyata seperti tempat, benda dan orang – orang yang betul – betul ada dan terjadi (Jogianto, 2005:2).
Sistem adalah kumpulan – kumpulan dari komponen – komponen yang dimiliki unsur keterkaitan antara satu dengan lainnya (Indrajit, 2001:2).
Sistem adalah seperangkat elemen yang membentuk kumpulan atau prosedur – prosedur / bagan – bagan pengolahan yang mencari suatu tujuan bagian atau tujuan bersama dengan mengoperasikan data pada waktu tertentu untuk menghasilkan informasi (Murdick, R.G, 27).
2.1.2 Pengertian Diagnosis
Diagnosa adalah identifikasi sifat – sifat penyakit atau kondisi atau membedakan satu penyakit atau kondisi dari yang lainnya. Penilaian dapat dilakukan melalui pemeriksaan fisik, tes laboratorium atau sejenisnya. Dan dapat
dibantu oleh program komputer yang dirancang untuk memperbaiki proses pengambil keputusan. (Carpenito, L. J, 2013).
2.1.3 Pengertian Sistem Diagnosis
Sistem diagnosis adalah sistem yang mengadopsi pengetahuan manusia ke komputer agar dapat menyelesaikan masalah seperti yang biasa dilakukan oleh para ahli dan dirancang agar dapat menyelesaikan suatu permasalahan tertentu dengan meniru kerja dari para ahli (Kusumadewi, 2003).
Sistem diagnosis yang akan dibangun mengambil referensi literature sistem pakar sebagai dasar dalam perancangan pada penelitian ini. Perbedaan sistem pakar dengan sistem diagnosis adalah sistem diagnosis pada penelitian ini tidak menggunakan salah satu komponen sistem pakar yaitu mesin inferensi. Dengan demikian sistem ini belum dapat dikatakan sebagai sistem pakar (Kusrini, 2010).
2.2 Pengertian Penyakit Demam Berdarah Dengue (DBD)
Demam Dengue adalah penyakit yang disebabkan oleh virus dengue yang ditularkan kepada manusia melalui gigitan nyamuk Aedes Aegypti. Penyakit ini dapat dialami oleh semua golongan umur, terutama pada anak dan remaja, dengan tanda-tanda klinis berupa demam, nyeri otot dan atau nyeri sendi yang disertai leukopenia, dengan atau tanpa ruam, dan limfadenopati, demam bifasik, sakit kepala hebat, nyeri pergerakan bola mata, trombositopenia ringan dan petekie spontan. Sedangkan perbedaan dengan Demam Berdarah Dengue adalah pada kasus Demam Berdarah Dengue ditemukan tanda hemokonsentrasi dan trombositopenia, yang jika tidak ditangani dengan cepat dapat masuk dalam fase syok.
Penyakit ini merupakan salah satu masalah kesehatan utama karena dapat menyerang semua golongan usia dan meyebabkan kematian khususnya pada anak dan kejadian luar biasa (KLB, wabah). Saat ini terlihat adanya kecenderungan kenaikan proporsi penderita Demam Berdarah Dengue pada orang dewasa.
Secara umum, Demam Dengue dan Demam Berdarah Dengue akan ditandai dengan fase febril yaitu demam tinggi mendadak dan terusmenerus 2-7 hari, diikuti oleh fase afebril (demam mereda). Fase afebril ini merupakan fase kesembuhan untuk Demam Dengue, tetapi merupakan fase kritis pada Demam Berdarah Dengue. Pada awal sukar dibedakan berdasarkan gejala apakah akan terjadi Demam Dengue atau Demam Berdarah Dengue.
Ada beberapa gejala yang dapat menimbulkan penyakit DBD diantaranya suhu badan naik secara mendadak dan terus-menerus hingga 2-7 hari. Demam naik turun dan tidak mampu diobati dengan antireptik. Pendarahan yaitu pendarahan pada kulit, gusi berdarah, mimisan. Lalu mual hingga muntah,nafsu makan turun, pusing, kringat dingin, nyeri sendi dan otot (Sejati, E. W, 2015).
Tidak ada pengobatan spesifik untuk demam berdarah. Untuk demam berdarah yang berat, perawatan medis oleh dokter dan perawat yang berpengalaman dapat menyelamatkan nyawa hingga penurunan tingkat kematian lebih dari 20% menjadi kurang dari 1%. Pemeliharaan volume cairan tubuh pasien sangat penting untuk perawatan dengue yang parah (WHO, 2018).
Menurut World Health Organization (WHO), Dengue Hammorhagic Fever (DHF) atau Demam Berdarah Dengue (DBD) merupakan penyakit yang disebabkan oleh gigitan nyamuk Aedes yang terinfeksi salah satu dari empat tipe virus dengue
dengan manifestasi klinis demam, nyeri otot dan/atau nyeri sendi yang disertai leukopenia, ruam, limfadenopati, trombositopenia dan diathesis hemoragik (WHO, 2018).
Uji Hematologi atau Hitung Darah Lengkap (HDL) merupakan jenis pemeriksaan yang memberikan informasi tentang sel-sel darah pasien. HDL merupakan test laboratorium yang paling umum dilakukan. HDL memeriksa jenis sel dalam darah, termasuk sel darah merah (hemoglobin), sel darah putih (leukosit), kadar hematokrit, dan jumlah trombosit (Kumala, F, 2015).
2.3 Data Mining
2.3.1 Pengertian Data Mining
Data Mining merupakan istilah yang sering dikatakan sebagai suatu cara untuk menguraikan serta mencari penemuan berupa pengetahuan di dalam suatu database. Data mining adalah proses pemilihan atau “menambang” pengetahuan dari sekumpulan data dalam jumlah yang banyak (Han, Jiawei dan Kamber, 2006) Data Mining juga sering disebut sebagai kegiatan mengeksplorasi dan menganalisis data dalam jumlah yang besar untuk menemukan pattern dan rule yang berarti (Berry, M. & Gordon S, L, 2004)
Data mining digunakan untuk mencari informasi bisnis yang berharga dari basis data yang sangat besar, yang dipakai untuk memprediksi trend dan sifat – sifat bisnis serta menemukan pola – pola yang tidak diketahui sebelumnya.
Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Data mining adalah analisis otomatis dari data yang berjumlah besar atau
kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaannya.
Data mining didefinisikan sebagai proses menemukan pola – pola dalam data. Proses ini otomatis atau seringnya semi otomatis. Pola yang ditemukan harus penuh arti dan pola tersebut memberikan keuntungan, biasanya keuntungan secara ekonomi. Data yang dibutuhkan dalam jumlah besar.
Data mining adalah proses pengumpulan informasi penting dari sejumlah data besar yang tersimpan di dalam basis data, gudang data, atau tempat penyimpanan lainnya. Data mining merupakan proses yang tidak dapat dipisahkan dengan Knowledge Discovery in Database (KDD), Karena penambangan data adalah salah satu dari tahap dalam proses KDD. (Han, Jiawei dan Kamber, 2006)
2.3.2 Tugas – Tugas Data Mining
Menurut Larose (2005) tugas – tugas dalam data mining secara umum dibagi ke dalam beberapa kategori yaitu :
a. Prediktif
Tujuan dari tugas prediktif adalah untuk memprediksi nilai dari atribut tertentu berdasarkan pada nilai dari atribut – atribut lain. Atribut yang diprediksi umumnya dikenal sebagai target atau variabel tak bebas, sedangkan atribut – atribut yang digunakan untuk membuat prediksi dikenal sebagai explanatory atau variabel bebas.
b. Deskriptif
Tujuan dari tugas deskriptif adalah untuk menurunkan pola - pola (korelasi, trend, cluster, trayektori dan anomali) yang meringkas hubungan yang
pokok dalam data. Tugas data mining deskriptif sering merupakan penyelidikan dan seringkali memerlukan Teknik post processing untuk validasi dan penjelasan hasil.
Berikut adalah tugas – tugas dalam data mining (Larose, 2005) : a) Analisis Asosiasi (Korelasi dan Kausalitas)
Analisis Asosiasi adalah pencarian aturan – aturan asosiasi yang menunjukkan kondisi – kondisi nilai atribut yang sering terjadi bersama – sama dalam sekumpulan data. Analisis asosiasi sering digunakan untuk menganalisa market basket dan data transaksi.
b) Klasifikasi dan Prediksi
Klasifikasi adalah proses menemukan model (fungsi) yang menjelaskan dan membedakan kelas – kelas atau konsep, dengan tujuan agar model yang diperoleh dapat digunakan untuk memprediksi kelas atau objek yang memiliki label kelas tidak diketahui. Model yang diturunkan didasarkan pada analisis dari training data (yaitu objek data yang memiliki label kelas yang diketahui). Model yang diturunkan dapat direpresentasikan dalam berbagai bentuk seperti aturan IF – THEN klasifikasi, pohon keputusan, formula matematika atau jaringan syaraf tiruan. Dalam banyak kasus, pengguna ingin memprediksi nilai – nilai data yang tidak tersedia atau hilang (bukan label dari kelas). Dalam kasus ini biasanya nilai data yang akan diprediksi merupakan data numeric. Kasus ini seringkali dirujuk sebagai prediksi.
c) Analisis Cluster
Tidak seperti klasifikasi dan prediksi, yang menganalisis objek data yang diberi label kelas, clustering menganalisis objek data dimana label kelas tidak diketahui. Clustering dapat digunakan untuk menentukan label kelas tidak diketahui dengan cara mengkelompokkan data untuk membentuk kelas baru. Sebagai contoh Clutering rumah untuk menemukan pola distribusinya. Prinsip dalam clustering adalah memaksimumkan kemiripan intra – class dan meminimumkan kemiripan interclass.
d) Analisis Outlier
Outlier merupakan objek data yang tidak mengikuti perilaku umum dari data. Outlier dapat dianggap sebagai noise atau pengecualian. Analisis data outlier dinamakan outlier mining. Teknik ini berguna dalam fraud detection dan rare event analysis.
e) Analisis Trend dan Evolusi
Analisis evolusi data menjelaskan dan memodelkan trend dari objek yang memiliki perilaku yang berubah setiap waktu. Teknik ini dapat meliputi karakterisasi, deskriminasi, asosiasi, klasifikassi atau clustering dari data yang berkaitan dengan waktu.
2.4 Arsitektur Sistem Data Mining
Data mining merupakan proses pencarian pengetahuan yang menarik dari data berukuran besar yang disimpan dalam basis data, data warehouse atau tempat penyimpanan informasi lainnya. Dengan demikian menurut (Connoly. T & Begg. C 2005) arsitektur sistem data mining memiliki komponen – komponen utama yaitu :
a. Basis data, data warehouse atau tempat penyimpanan informasi lainnya. b. Basis data dan data warehouse server. Komponen ini bertanggung jawab
dalam pengambilan relevan data, berdasarkan permintaan pengguna. c. Basis pengetahuan. Komponen ini merupakan domain knowledge yang
digunakan untuk memandu pencarian atau mengevaluasi pola – pola yang dihasilkan. Pengetahuan tersebut meliputi hirarki konsep yang digunakan untuk mengorganisasikan atribut atau nilai atribut ke dalam level abstraksi yang berbeda. Pengetahuan tersebut juga dapat berupa kepercayaan pengguna (user belief) yang dapat digunakan untuk menentukan kemenarikan pola yang diperoleh.
d. Data Mining Engine. Bagian ini merupakan komponen penting dalam arsitektur sistem data mining. Komponen ini terdiri modul – modul fungsional data mining seperti karakterisasi, asosiasi, klasifikasi dan analisis cluster.
e. Modul Evaluasi Pola. Komponen ini menggunakan ukuran – ukuran kemenarikan dan berinteraksi dengan modul data mining dalam pencarian pola – pola menarik. Modul evaluasi pola dapat menggunakan threshold kemenaikan untuk memfilter pola – pola yang diperoleh.
f. Antarmuka Pengguna Grafis. Modul ini berkomunikasi dengan pengguna dan sistem data mining. Melalui modul ini, pengguna berinteraksi dengan sistem menentukan query atau task data mining. Antarmuka juga menyediakan informasi untuk memfokuskan pencarian dan melakukan eksplorasi data mining berdasarkan hasil data mining. Komponen ini juga
memungkinkan pengguna untuk mencari (browser) basis data dan skema data warehouse atau struktur data, evaluasi pola yang diperoleh dan visualisasi pola dalam berbagai bentuk.
2.5 Penyimpanan Data dalam Data Mining
Data mining dapat diaplikasikan pada berbagai jenis penyimpanan data seperti basis data relational, data warehouse, transactional database, object – oriented and object – relational databases, spatial databases, time – series data and temporal data, text databases and multimedia databases, heterogeneous and legacy databases dan WWW.
a. Basis Data Relasional
Merupakan kolekssi dari table. Setiap table berisi atribut (field) dan biasanya menyimpan sejumlah besar tuple (record). Setiap tuple dalam table relasional merepresentasikan sebuah objek yang diidentifikasikan oleh kunci unik dan dideskripsikan oleh sekumpulan nilai atribut. Data relasional dapat diakses oleh query basis data yang ditulis dalam bahasa query relasional seperti SQL atau dengan bantuan antarmuka pengguna grafis. b. Data Warehouse
Merupakan tempat penyimpanan informasi yang dikumpulkan dari berbagai sumber, disimpan dalam skema yang dipersatukan (unified schema) dan biasanya bertempat pada tempat penyimpanan tunggal. Data warehouse dikonstruksi melalui sebuah proses data cleaning, data transformation, data integration, data loading dan periodic data refreshing. Selain data warehouse, terdapat istilah penyimpanan data yang lain yaitu datamart.
Sebuah data warehouse mengumpulkan informasi mengenai subjek – subjek yang menjangkau seluruh organisasi, dengan demikian cakupannya enterprise-wide. Sedangkan datamart merupakan sub bagian dari data warehouse. Fokus datamart adalah pada subjek yang dipilih dan dengan demikian cakupannya adalah department-wide.
c. Basis Data Transaksional
Secara umum, basis data transaksional terdiri dari sebuah file dimana setiap record merepresentasikan transaksi.
2.6 Tahap – Tahap Data Mining
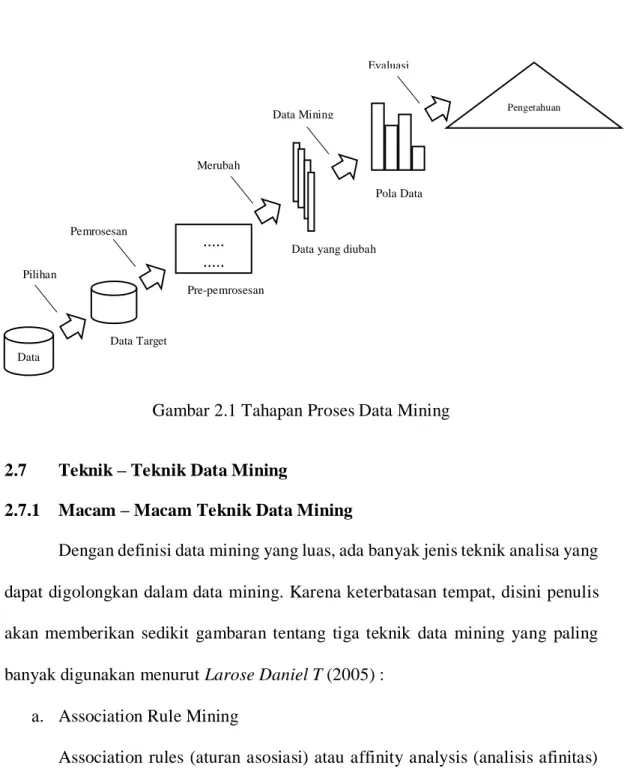
Istilah data mining dan knowledge discovery in databases (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Menurut Fayyad proses KDD secara garis besar dapat dijelaskan sebagai berikut :
1. Data Selection
Pemilihan (seleksi) dari data sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan suatu berkas, terpisah dari basis data operasional.
2. Pre – Processing (Cleaning)
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi focus KDD. Proses cleaning mencakup antara lain
membuang duplikasi data, memeriksa data yang inkonsisten, memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data Mining
Adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode atau algoritma dalam data mining sangat bervariasi pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation (Evaluation)
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
Gambar 2.1 Tahapan Proses Data Mining
2.7 Teknik – Teknik Data Mining
2.7.1 Macam – Macam Teknik Data Mining
Dengan definisi data mining yang luas, ada banyak jenis teknik analisa yang dapat digolongkan dalam data mining. Karena keterbatasan tempat, disini penulis akan memberikan sedikit gambaran tentang tiga teknik data mining yang paling banyak digunakan menurut Larose Daniel T (2005) :
a. Association Rule Mining
Association rules (aturan asosiasi) atau affinity analysis (analisis afinitas) berkenaan dengan studi tentang “apa bersama apa”. Karena awalnya berasal dari studi tentang database transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama produk apa, maka aturan asosiasi juga sering dinamakan market basket analysis. Analisis asosiasi dikenal juga sebagai salah satu metode data mining yang menjadi dasar dari berbagai metode data mining lainnya.
Data Data Target ... ... ... Pengetahuan Pilihan Pemrosesan Merubah Data Mining Evaluasi Pre-pemrosesan
Data yang diubah Pola Data
b. Classification
Dalam klasifikasi, terdapat target variable kategori. Sebagai contoh penggolongan pendapatan dapat dipisahkan dalam tiga kategori yaitu pendapatan tinggi, pendapatan sedang dan pendapatan rendah.
c. Clustering
Termasuk metode yang sudah cukup dikenal dan banyak dipakai dalam data mining. Sampai sekarang para ilmuwan dalam bidang data mining masih melakukan berbagai usaha untuk melakukan perbaikan model clustering karena metode yang dikembangankan sekarang masih bersifat heuristic. Tujuan utama dari metode clustering adalah pengelompokkan sejumlah data / objek ke dalam cluster (group) sehingga dalam setiap cluster akan berisi data yang semirip mungkin. Dalam metode ini tidak diketahui sebelumnya berapa jumlah cluster dan bagaimana pengelompokannya.
Berikut ini adalah 9 algoritma penggalian data yang paling sering digunakan berdasarkan konferensi ICDM ’06 :
1. C4.5 2. K-Means 3. SVM 4. Apriori 5. PageRank 6. AdaBoost 7. KNN 8. Naïve Bayes
2.7.2 Teknik Classification menggunakan Naïve Bayes
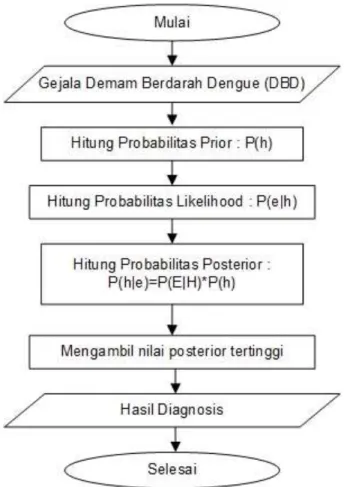
Naïve Bayes merupakan sebuah metoda klasifikasi menggunakan metode probabilitas dan statistic yang dikemukakan oleh ilmuwan Inggris Thomas Bayes. Naïve Bayes memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya sehingga dikenal sebagai Teorema Bayes.
Gambar diagram alir Naïve Bayes :
Gambar 2.2 Diagram Alir Naïve Bayes (Jurnal PPTIK Vol.2, No.8, Agustus 2018)
2.8 Implementasi (Penerapan Data Mining)
1. Analisa pasar dan manajemen
Solusi yang dapat diselesaikan dengan data mining, diantaranya : menembak target pasar, melihat pola beli pemakai dari waktu ke waktu, cross-market analysis, profil customer, identifikasi kebutuhan customer, menilai loyalitas customer, informasi summary.
2. Analisa perusahaan dan manajemen resiko
Solusi yang dapat diselesaikan dengan data mining, diantaranya : perencanaan dan evaluasi aset, perencanaan sumber daya (resource planning), persaingan (competition).
3. Telekomunikasi
Menerapkan data mining untuk melihat dari jutaan transaksi yang masuk dan transaksi mana sajakah yang harus ditangani secara manual.
4. Keuangan
Menggunakan data mining untuk menambang berbagai subyek seperti property, rekening bank dan transaksi keuangan lainnya untuk mendeteksi transaksi – transaksi keuangan yang mencurigakan seperti money laundry.
5. Asuransi
Menggunakan data mining untuk mengidentifikasi layanan kesehatan yang sebenarnya tidak perlu tetapi tetap dilakukan oleh peserta asuransi.
6. Olahraga
Menggunakan data mining untuk menganalisis statistic permainan NBA dalam rangka mecapai keunggulan bersaing.
2.9 Metode Penelitian Data Mining 2.9.1 Teori Naïve Bayes Classifier
Naïve Bayes merupakan sebuah pengklasifikasian probalistik sederhana yang menghitung sekumpulan probabilitas dengan menjumlahkan frekuensi dan kombinasi nilai dari dataset yang diberikan. Algoritma menggunakan Teorema Bayes dan mengasumsikan semua atribut independen atau tidak saling ketergantungan yang diberikan oleh nilai pada variable kelas. Naïve Bayes juga didefinisikan sebagai pengklasifikasian dengan metode probabilitas dan statistik yang dikemukakan oleh ilmuan inggris Thomas Bayes yaitu memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya (Saleh, 2015).
Menurut Prasetyo (2012), Naïve Bayes merupakan teknik prediksi berbasis probabilistik sederhana yang berdasar pada penerapan teorema bayes (aturan bayes) dengan asumsi independensi (ketidaktergantungan) yang kuat (naif). Dengan kata lain, dalam naive bayes model yang digunakan adalah “model fitur independen”.
Naïve Bayes didasarkan pada asumsi penyederhanaan bahwa nilai atribut secara kondisional saling bebas jika diberikan nilai output. Dengan kata lain diberikan nilai output, probabilitas mengamati secara bersama adalah produk dari probabilitas individu. Keuntungan penggunaan Naïve Bayes adalah bahwa metode ini hanya membutuhkan jumlah data pelatihan (Training Data) yang kecil untuk menentukan estimasi parameter yang diperlukan dalam proses pengklasifikasian. Naïve Bayes sering bekerja jauh lebih baik dalam kebanyakan situasi dunia nyata yang kompleks daripada yang diharapkan (Saleh, 2015).
Persamaan dari Teorema Bayes (aturan bayes) dapat dilihat dibawah ini :
𝑃 (𝐻 | 𝑋) = P(X|H). P(H) P(H) Dimana :
X : Data dengan class yang belum diketahui
H : Hipotesis data menggunakan suatu class spesifik
P(H|X) : Probabilitas hipotesis H berdasarkan kondisi X (parteriori probabilitas)
P(H) : Probabilitas hipotesis H (prior probabilitas)
P(X|H) : Probabilitas X berdasarkan kondisi pada hipotesis H P(X) : Probabilitas H
2.9.2 Naïve Bayes Untuk Klasifikasi
Menurut Prasetyo (2012), klasifikasi merupakan suatu pekerjaan menilai objek data untuk memasukkannya ke dalam kelas tertentu dari sejumlah kelas yang tersedia. Dalam klasifikasi terdapat dua proses yang dilakukan yaitu dengan membangun model untuk disimpan sebagai memori dan menggunakan model tersebut untuk melakukan pengenalan atau klasifikasi atau prediksi pada suatu data lain supaya diketahui di kelas mana objek data tersebut dimasukkan berdasarkan model yang telah disimpan dalam memori.
Sistem dalam klasifikasi diharapkan mampu melakukan klasifikasi semua set data dengan benar, namun tidak dapat dipungkiri bahwa kesalahan akan terjadi dalam proses pengklasifikasian tersebut sehingga perlunya dilakukan pengukuran kinerja dari sistem klasifikasi. Umumnya, pengukuran kinerja klasifikasi dilakukan
dengan matriks konfusi (confusion matrix). Matriks konfusi merupakan tabel pencatat hasil kerja klasifikasi.
Kaitan antara naïve bayes dengan klasifikasi, korelasi hipotesis dan bukti klasifikasi adalah bahwa hipotesis dalam teorema bayes merupakan label kelas yang menjadi target pemetaan dalam klasifikasi, sedangkan bukti merupakan fitur – fitur yang menjadikan masukkan dalam model klasifikasi. Jika X adalah vector masukkan yang berisi fitur dan Y adalah label kelas, naïve bayes dituliskan dengan P(X|Y). Notasi tersebut berarti probabilitas label kelas Y didapatkan setelah fitur – fitur X diamati. Notasi ini disebut juga probabilitas akhir (posterior probability) untuk Y, sedangkan P(Y) disebut probabilitas awal (prior probability) Y.
Konsep Klasifikasi merupakan suatu pekerjaan menilai objek data untuk memasukkannya ke dalam kelas tertentu dari sejumlah kelas yang tersedia. Dalam klasifikasi ada dua pekerjaan utama yang dilakukan, yaitu :
1. Pembangunan model seperti prototype untuk disimpan sebagai memori.
2. Penggunaan model tersebut untuk melakukan pengenalan / klasifikasi / prediksi pada suatu objek data lain agar diketahui di kelas mana objek data tersebut dalam model yang mudah disimpan.
Contohnya adalah bagaimana melakukan diagnosis penyakit kulit kanker melanoma (Amaliyah, 2011) yaitu dengan melakukan pembangunan model berdasarkan data latih yang ada, kemudian menggunakan model tersebut untuk mengidentifikasi penyakit pasien baru sehingga diketahui apakah pasien tersebut menderita kanker atau tidak.
2.9.3 Model Klasifikasi
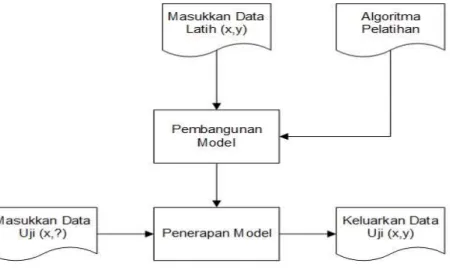
Model dalam klasifikasi mempunyai arti yang sama dengan kotak hitam, dimana ada suatu model yang menerima masukan, kemudian mampu melakukan pemikiran terhadap masukan tersebut dan memberikan jawaban sebagai keluaran dari hasil pemikirannya. Kerangka kerja (framework) klasifikasi ditunjukkan pada gambar 2.3, pada gambar tersebut disediakan sejumlah data latih (x,y) untuk digunakan sebagai data pembangunan model. Model tersebut kemudian dipakai untuk memprediksi kelas dari data uji (x,y) sehingga diketahui kelas y yang sesungguhnya. Menurut Amaliyah (2011) berikut adalah contoh proses klasifikasi data latih
Gambar 2.3 Proses Klasifikasi (Amaliyah, 2011)
Model yang sudah dibangun pada saat pelatihan kemudian dapat digunakan untuk memprediksi label kelas baru yang belum diketahui. Dalam pembangunan model selama proses pelatihan tersebut diperlukan suatu algoritma untuk membangunnya, yang disebut algoritma pelatihan (learning algorithm). Ada banyak algoritma pelatihan yang sudah dikembangkan oleh para peneliti seperti
K-Nearest Neighbor, Artificial Neural Network, Support Vector Machine dsb. Setiap algoritma mempunyai kelebihan dan kekurangan, tetapi semua algoritma berprinsip sama yaitu melakukan suatu pelatihan sehingga di akhir pelatihan model dapat memetakan (memprediksi) setiap vektor masukan ke label kelas keluaran dengan benar.
Contoh studi kasus hasil pengujian akurasi :
Hasil dari pengujian akurasi dengan sampel 40 data uji mendapat 35 hasil yang akurat dan 5 hasil tidak akurat. Untuk mencari nilai persentase akurasi sistem diperoleh dari menghitung jumlah data yang akurat dibagi jumlah seluruh data uji, setelah mendapat hasil pembagian kemudian dikali 100. Nilai akurasi dihitung dengan menggunakan persamaan 2 (Gardenia dkk, 2015) dan memperoleh hasil seperti berikut:
𝑎𝑘𝑢𝑟𝑎𝑠𝑖 =𝑗𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎 𝑦𝑎𝑛𝑔 𝑎𝑘𝑢𝑟𝑎𝑡
𝑗𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎 𝑥 100 = 35
40 𝑥 100 = 87,5%
Dari hasil perhitungan akurasi di dapatkan persentase sebesar 87,5%. Terdapat 5 kesalahan hasil diagnosis sistem, kesalahan terjadi disebabkan karena gejala dimiliki oleh dua penyakit sedangkan sistem hanya dapat menghasilkan satu output penyakit. Dapat dikatakan semakin banyak gejala spesifik yang digunakan maka akurasi semakin tinggi, semakin banyak gejala umum yang digunakan maka akurasi semakin rendah.
2.10 Metode – Metode Pilihan dan Klasifikasi
Berikut merupakan beberapa metode yang digunakan pada klasifikasi secara umum, diantaranya adalah :
1. Klasifikasi berdasarkan pohon keputusan (Decission Tree)
Pohon keputusan atau decission tree merupakan proses pelatihan data set yang memiliki atribut dengan dasaran nominal, yaitu bersifat kategoris dan setiap nilai tidak bisa dijumlahkan atau dikurangkan. Pada umumnya, ciri khusus berikut cocok untuk diterapkan pada decission tree :
a. Data / example dinyatakan dengan pasangan atribut dan nilainya b. Label / output data biasanya bernilai diskrit
c. Data mempunyai missing value 2. Klasifikasi Bayesian
Klasifikasi Bayesian merupakan klasifikasi berdasarkan statistic classifier. Ini dapat mengklasifikasikan sebuah kelas dengan probabilitas dari setiap klasifikasi Bayesian didasarkan pada Bayes Theorem. Beberapa penelitian yang membandingkan algoritma klasifikasi telah menemukan sebuah klasifikasi Bayesian sederhana yang dikenal dengan nama Naïve Bayes Classifier. Algoritma ini telah dibandingkan dengan decission tree dan selektif Neoral Network secara performansi. Klasifikasi Bayesian juga memiliki tingkat akurasi yang tinggi dan cepat jika diterapkan pada database yang besar. Naïve Bayes Classifier mengenali setiap atribut pada data set sebagai atribut yang independen, sehingga disebut algoritma yang naïve.
Propagasi Balik atau Back Propagation merupakan sebuah algoritma pembelajaran dari Neural Network. Secara umum, neural network merupakan satu set input / output yang terhubung pada setiap koneksi memiliki weight. Input / Output yang terhubung tersebut mengadopsi system syaraf manusia, yang pemrosesan utamanya adalah di otak. Bagian terkecil dari otak manusia adalah sel syaraf yang disebut Unit Dasar pemroses informasi atau neuron. Ada sekitar 10 miliar neuron dalam otak manusia dan sekitar 60 triliun koneksi dengan menggunakan neuron tersebut secara simultan, otak manusia dapat memproses informasi secara parallel dan cepat, bahkan lebih cepat dari komputer tercepat saat ini.
Dengan analogi system kinerja otak tersebut, neural network terdiri dari unit proses yang disebut neuron yang berisi penambah dan fungsi aktivasi, sejumlah bobot, sejumlah vector masukan. Fungsi aktivasi berguna untuk mengatur keluaran yang diberikan oleh neuron. Propagasi Balik mempelajari data dengan memprediksi setiap jaringan pada setiap atribut dan kemudian mengklasifikasikannya kedalam kelas target. Kelas target dapat diketahui melalui training pada data set.
4. Support Vector Machine (SVM)
SVM merupakan metode klasifikasi yang berakar dari teori pembelajaran statistik yang hasilnya sangat menjanjikan untuk memberikan hasil yang lebih baik daripada metode yang lain. SVM juga bekerja dengan baik pada set data berdimensi tinggi, bahkan SVM yang menggunakan teknik kernel yang harus memetakan data asli dari dimensi asalnya menjadi dimensi lain yang relative
lebih tinggi. Pada SVM, data latih yang akan dipelajari hanya data terpilih saja yang berkontribusi untuk membentuk model yang digunakan dalam klasifikasi yang akan dipelajari. Hal ini menjadi kelebihan SVM karena tidak semua data latih akan dipandang untuk dilibatkan dalam setiap iterasi pelatihannya. Data yang berkontribusi tersebut disebut Support Vector sehingga metodenya disebut Support Vector Machine.
2.11 Penelitian Terdahulu
Pada penelitian terdahulu terdapat 5 kajian jurnal yang di bahas adalah sebagai berikut :
2.11.1 Kajian jurnal pertama
Penelitian Dwi Nugroho, Fhira Nhita, Danang Trantoro. Pada tahun 2016 dengan judul “Prediksi Penyakit Menggunakan Genetic Algorithm (GA) dan Naive Bayes Untuk Data Berdimensi Tinggi”. Penelitian ini membahas tentang sebuah sistem yang mampu menganalisis dan mengidentifikasi seseorang terkena suatu penyakit. Data penyakit Kanker, Jantung, Diabetes, AIDS, dan TBC bersumber dari website Kent Ridge Bio-medical Repository, yang mana data tersebut adalah data berdimensi tinggi untuk setiap penyakit.
Data penyakit tersebut memiliki ribuan atribut yang akan dibagi menjadi dua data, yaitu data traning dan data testing selanjutnya dilakukan reduksi dengan Genetic Algorithm (GA) dan klasifikasi dengan Naïve Bayes Classifier. Kesimpulan hasil akhir yang didapat menunjukkan metode cross validation lebih baik dengan nilai akurasi dari data colon tumor 88.89% dan leukemia 100%
dibandingkan metode percentage split dengan akurasi dari data colon tumor 78.95% dan leukemia 77.27% (Dwi Nugroho, Fhira Nhita, Danang Trantoro, 2016).
2.11.2 Kajian jurnal kedua
Penelitian Diana Septiari pada tahun 2016 dengan judul “Implementasi Metode Naive Bayes Classification Dalam Klasifikasi Kelayakan Calon Pendonor Darah (Studi Kasus Pmi Kab. Demak)”. Penelitian ini membahas tentang kegiatan Palang Merah Indonesia (PMI) yaitu melakukan pelayanan kesehatan berupa donor darah. Pada penelitian ini digunakan metode naive bayes classifier untuk mengklasifikasikan calon pendonor darah berdasarkan input dari data calon pendonor darah.
Data pendonor akan dicari nilai mean, nilai standart deviasi, nilai densitas gaus, nilai likelihood dan kemudian akan dinormalisasi nilai probabilitasnya sehingga menghasilkan kelas BOLEH DONOR atau TIDAK BOLEH DONOR. Hasil dari sistem yang dibangun pada penelitian ini mempunyai akurasi kinerja sistem sebesar 81,6% sehingga sistem ini dirasa dapat diterapkan pada PMI Kabupaten Demak teempat penelitian ini berlangsung. (Diana Septiari, 2016).
2.11.3 Kajian jurnal ketiga
Penelitian Yudo Juni Hardiko, Nurul Hidayat, Imam Cholissodin pada tahun 2018 dengan judul “Diagnosis Penyakit Ikan Koi Menggunakan Metode Naive Bayes Classifier”. Penelitian ini membahas tentang penyakit yang sering menyerang ikan koi, yaitu disebabkan oleh pathogen yang berupa bakteri, jamur, atau virus. Dengan banyaknya penyakit yang mempunyai gejala yang sama tersebut sulit mendiagnosis penyakit pada ikan koi.
Dalam sistem ini menerima input berupa data gejala penyakit ikan koi dan data tersebut kemudian diolah menggunakan metode Naive Bayes yang hasil output sistem berupa diagnosis jenis penyakit dan pengobatan hasil penyakit yang didiagnosis. Berdasarkan pengujian akurasi dari 20 data menghasilkan tingkat akurasi sebesar 90%. (Yudo Juni Hardiko, Nurul Hidayat, Imam Cholissodin, 2018).
2.11.4 Kajian jurnal keempat
Penelitian Ela Nurelasari pada tahun 2018 tentang “Komparasi Algoritma Naive Bayes Dengan Support Vector Machine Berbasis Particle Swarm Optimization untuk Prediksi Kesuburan”. Penelitian ini membahas mengenai kesuburan pria yang telah mengalami penurunan, hal ini dapat disebabkan oleh beberapa faktor lingkungan dan gaya hidup, diantaranya seperti pecandu alkohol, rokok, usia, faktor genetik dan musim yang dapat berpengaruh pada sperma yang berkualitas.
Penelitian ini menguji kemampuan antara metode algoritma Naive Bayes dengan Support Vector Machine berbasis Particle Swarm Optimization, dimana dataset yang digunakan diambil dari dataset fertilitas UCI Machine Learning Repositori. Dataset terdiri dari 100 sample dan 10 field/atribut. Hasil dari komparasi kedua metode tersebut dimana klasifikasi Support Vector Machine berbasis Particle Swarm Optimization memperoleh nilai accuracy lebih tinggi 88.00% dibandingkan dengan algoritma naive bayes dengan nilai accuracy 85.00%. (Ela Nurelasari, 2018).
2.11.5 Kajian jurnal kelima
Penelitian Adhi Indra Irawan pada tahun 2016 dengan judul “Penerapan metode naïve bayes classifier dan algoritma adaboost untuk prediksi penyakit ginjal kronik”. Penelitian ini membahas penerapan metode Naïve Bayes dan AdaBoost dalam mengklasfikasikan penyakit ginjal kronik atau chronic kidney disease (CKD). Dari hasil dengan perhitungan confusion matrix didapatkan akurasi sebesar 0,95 dan F1-score sebesar 0,958 untuk metode Naïve Bayes. Sedangkan penggabungan dengan AdaBoost berhasil meningkatkan akurasi menjadi 0,98 dan F1-score sebesar 0,984.
Ketika dilakukan penggantian missing value, metode Naïve Bayes mengalami penurunan akurasi menjadi 0,945 dan F1-score 0,954, sedangkan algoritma AdaBoost berhasil meningkatkan akurasi menjadi 0,9825 dan F1-score sebesar 0,986. Hal ini menunjukkan bahwa metode Naïve Bayes memiliki kemampuan yang baik dalam menghadapi missing value dan algoritma AdaBoost berhasil meningkatkan kinerja dengan meningkatkan akurasi. (Adhi Indra Irawan, 2016).
2.12 Spesifikasi Kebutuhan Software dan Hardware
Suatu sistem yang baik tidak akan berhasil dengan baik apabila tidak didukung oleh sarana pendukung yang baik pula. Sarana pendukung yang dimaksud bukan harus menggunakan suatu unit komputer dengan merek tertentu dan harga yang mahal tetapi harus berintegrasi dengan baik antara satu dengan yang lainnya. Sistem dikatakan baik dan akan berhasil digunakan atau diterapkan jika didiukung dengan beberapa unsur atau beberapa aspek antara lain perangkay keras
(Hardware), perangkat lunak (Software) dan pemakai (Brainware). Diantara unsur tersebut yaitu prasarana atau peralatan pendukung yang dibutuhkan harus sesuai dengan spesifikasi sistem yang diusulkan untuk itu penulis menguraikan prasarana atau perangkat komputer yang harus tersedia pada sistem yang diusulkan. Adapun spsesifikasinya adalah sebagai berikut :
Perangkat lunak (Software) yang digunakan pada sistem usulan ini yaitu menggunakan :
a. Operating Sistem : Microsoft Windows 10
b. Menggunakan Rapidminer untuk data mining dengan metode algoritma naïve bayes classifier.
Rapidminer adalah aplikasi data mining yang tidak perlu dipertanyakan lagi dan berbasis sistem open-source dunia yang terkemuka dan ternama. Tersedia sebagai aplikasi yang berdiri sendiri untuk analisis data dan sebagai mesin data mining untuk integrasi ke dalam produk.
Contoh interface Rapidminer pada data mining naïve bayes classifier
Gambar 2.8 Interface Rapidminer pada data mining naïve bayes classifier Adapun perangkat keras yang digunakan sebagai berikut :
a. Micro Processor : AMD Quad-Core Processor E2-6110 / 1.50 Ghz
c. Hardisk : 500 GB HDD
d. Monitor : 16”
e. Keyboard / Mouse : Serial / PS2 / USB f. Printer : Epson Stylus Colour 460
2.13 Pengujian Confusion Matrix
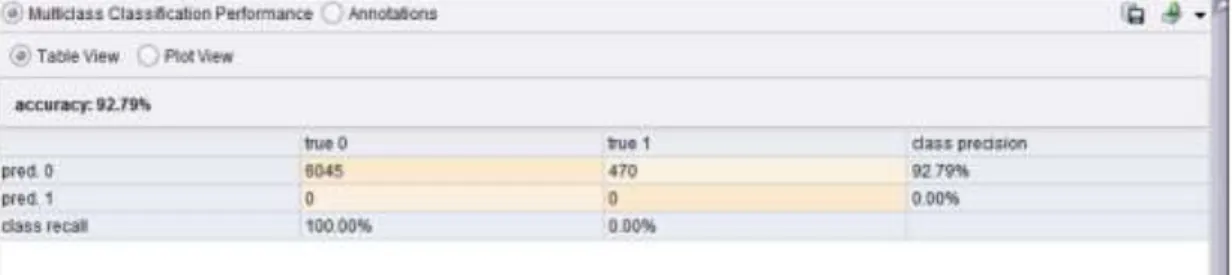
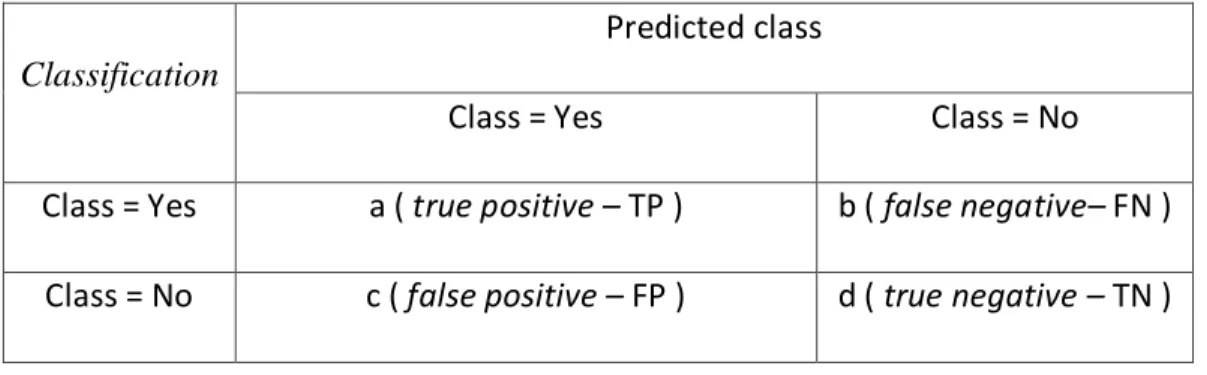
Confusion matrix merupakan salah satu metode yang dapat digunakan untuk mengukur kinerja suatu metode klasifikasi. Pada dasarnya confusion matrix mengandung informasi yang membandingkan hasil klasifikasi yang dilakukan oleh sistem dengan hasil klasifikasi yang seharusnya. Pada pengukuran kinerja menggunakan confusion matrix, terdapat 4 (empat) istilah sebagai representasi hasil proses klasifikasi. Keempat istilah tersebut adalah True Positive (TP), True Negative (TN), False Positive (FP) dan False Negative (FN). Nilai True Negative (TN) merupakan jumlah data negatif yang terdeteksi dengan benar, sedangkan False Positive (FP) merupakan data negatif namun terdeteksi sebagai data positif. Sementara itu, True Positive (TP) merupakan data positif yang terdeteksi benar. False Negative (FN) merupakan kebalikan dari True Positive, sehingga data posifit, namun terdeteksi sebagai data negatif.(Untari, 2010)
Pada jenis klasifikasi binary yang hanya memiliki 2 keluaran kelas, confusion matrix dapat disajikan seperti pada Tabel 2.1.
Tabel 0.1 Tabel Confusion matrix
Classification
Predicted class
Class = Yes Class = No
Class = Yes a ( true positive – TP ) b ( false negative– FN ) Class = No c ( false positive – FP ) d ( true negative – TN )
Pada tabel 2.1 berdasarkan nilai d (true negative –TN),c (false positive – FP),b (false negative – FN),a (True positive – TP) dapat diperoleh nilai akuras,presisi dan recall. Nilai akurasi menggambarkan seberapa akurasi sistem dapat mengklasifikasi data secara benar. Dengan kata lain, nilai akurasi merupakan perbandingan antara data yang terklasifikasi benar dengan keseluruhan data. Nilai akurasi dapat diperoleh dengan Persamaan . Nilai presisi menggambarkan jumlah data kategori positif yang diklasifikasikan secara benar dibagi dengan total data yang diklasifikasi positif . Presisi dapat diperoleh dengan Persamaan . Sementara itu, recall menunjukkan berapa persen data kategori positif yang terklasifikasikan dengan benar oleh sistem. Nilai recall diperoleh dengan Persamaan.
Akurasi = 𝑇𝑃+𝑇𝑁 𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁
*100%
Presisi = 𝑇𝑃 𝐹𝑃+𝑇𝑃*100%
Recall = 𝑇𝑃 𝐹𝑁+𝑇𝑃*100%
dimana:
TP adalah True Positive, yaitu jumlah data positif yang terklasifikasi dengan benar oleh sistem.
TN adalah True Negative, yaitu jumlah data negatif yang terklasifikasi dengan benar oleh sistem.
FN adalah False Negative, yaitu jumlah data negatif namun terklasifikasi salah oleh sistem.
FP adalah False Positive, yaitu jumlah data positif namun terklasifikasi salah oleh sistem.
Sementara itu, pada klasifikasi dengan jumlah keluaran kelas yang lebih dari dua (multi-class), cara menghitung akurasi, presisi dan recall dapat dilakukan dengan menghitung rata-rata dari nilai akurasi, presisi dan recall pada setiap kelas.
40
BAB III
METODE PENELITIAN
3.1 Sekilas Tentang Rumah Sakit Budi Asih
Rumah Sakit Budi Asih bertempat di Jl. Raya Serang-Cibarusah, Cikarang Selatan, Jawa Barat, merupakan pengembangan dari klinik yang sekarang menjadi Rumah Sakit yang di pimpin oleh dr. Anton. Rumah Sakit Budi Asih merupakan sebuah badan usaha yang bergerak dibidang pelayanan kesehatan masyarakat di bawah naungan perusahaan perseroan terbatas yang bernama PT. Kyandra Jantera dan sudah mendapatkan izin dari Pemerintah Kabupaten Bekasi dan Dinas Kesehatan.
Rumah Sakit Budi Asih didirikan pada September 2009 dengan status Klinik Utama, kemudian meningkat statusnya menjadi Rumah Sakit Ibu dan Anak pada akhir tahun 2014, dan menjadi Rumah Sakit Umum pada tahun 2015 yang di dukung oleh tenaga medis dan non medis professional sehingga dapat memberikan pelayanan kesehatan yang dibutuhkan pasien.
Terletak diantara pemukiman warga kampung serang, kebon kopi, cicau, perumahan – perumahan dan kawasan industri di Cikarang. Letaknya yang strategis sangat memudahkan masyarakat yang memerlukan pelayanan kesehatan baik penduduk setempat di perkampungan, diperumahan maupun para karyawan perusahaan yang berada di kawasan industri. Rumah Sakit Budi Asih terletak diantara kawasan industri Hyundai, EJIP, Delta Silicon, Green Land dan beberapa kawasan industri di Cikarang yang mulai ikut memadati kawasan Cikarang.
3.2 Metode Pengumpulan Data
Metode yang digunakan dalam penyusunan laporan skripsi ini adalah : 1. Metode Wawancara
Dilakukan terhadap narasumber yang mengerti konsep kesehatan khususnya mengenai gejala penyakit Demam Berdarah Dengue (DBD) dan jenisnya.
2. Observasi
Merupakan salah satu metode pengumpulan data yang cukup efektif untuk mempelajari suatu sistem. Penulis melakukan pengamatan langsung pada Dokter agar data yang di dapatkan lebih akurat.
3. Studi Pustaka (Library Research)
Metode ini memperoleh data – data yang berhubungan dengan penulisan skripsi dari berbagai sumber bacaan seperti buku, jurnal dan lain sebagainya sebagai acuan. 3 Searching (Browsing)
Melakukan pengumpulan jurnal yang bersumber dari internet.
3.3 Hasil Wawancara
Setelah melakukan penelitian dan wawancara dengan seorang pakar yang ahli di bidang kesahatan dan cara penanganan dapat disimpulkan bahwa penyakit Demam Berdarah Dengue dapat berakibat fatal jika tidak segera ditangani. Gejala penyakit Demam Berdarah Dengue bermacam – macam seperti demam, nyeri kepala, pusing dan sebagainya yang akan berakibat fatal apabila tidak segera ditangani. Cara penanganannya dengan rawat inap di rumah sakit tertentu dan sering mengkonsumsi makanan – makanan yang bergizi.
3.4 Desain Penelitian
Dalam melakukan suatu penelitian ini sangat perlu dilakukan perencanaan agar penelitian yang dilakukan dapat berjalan dengan baik dan sistematis. Desain penelitian menurut Moh. Nazir (2003:84) memaparkan bahwa desain penelitian adalah semua proses yang dilakukan dalam perencanaan dan pelaksanaan penelitian. Dari definisi diatas maka dapat disimpulkan bahwa desain penelitian merupakan semua proses penelitian yang dilakukan oleh penulis dalam melaksanakan penelitian mulai dari perencanaan sampai dengan pelaksanaan penelitian yang dilakukan pada waktu tertentu.
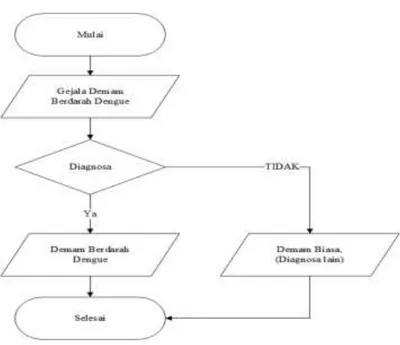
3.5 Analisa Sistem yang Berjalan
Sebelum melakukan penelitian sistem, terlebih dahulu dilakukan analisa sistem berjalan. Arus data pada sistem kerja dilihat pada gambar flowchart Diagnosa Prediksi Penyakit Demam Berdarah Dengue (DBD) berikut :
Gambar 3.2 Flowchart Diagnosa Prediksi Penyakit Demam Berdarah Dengue (DBD)
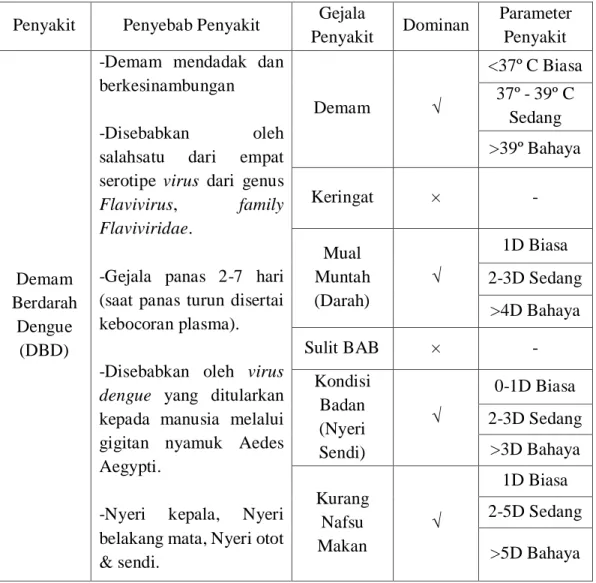
3.6 Akuisisi Pengetahuan
Selanjutnya setelah penyusunan basis pengetahuan dengan tabel keputusan diagnosa penyakit sesuai pengamatan pada penyakit Demam Berdarah Dengue. Hanya beberapa gejala yang paling nampak yang digunakan dalam tabel keputusan diagnosa, kemudian ditentukan hasil diagnosanya. Representasi pengetahuan dibuat dalam bentuk tabel yang akan digunakan dalam pembuatan aturan – aturan untuk melakukan pengambilan keputusan diagnosa pada penyakit Demam Berarah Dengue (DBD).
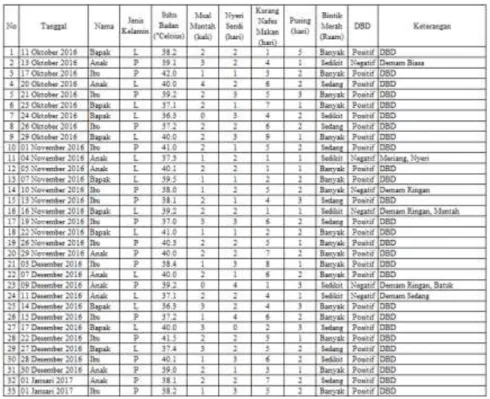
Tabel 3.1 Akuisisi Pengetahuan
Penyakit Penyebab Penyakit Gejala
Penyakit Dominan Parameter Penyakit Demam Berdarah Dengue (DBD)
-Demam mendadak dan berkesinambungan -Disebabkan oleh salahsatu dari empat serotipe virus dari genus Flavivirus, family Flaviviridae.
-Gejala panas 2-7 hari (saat panas turun disertai kebocoran plasma). -Disebabkan oleh virus dengue yang ditularkan kepada manusia melalui gigitan nyamuk Aedes Aegypti.
-Nyeri kepala, Nyeri belakang mata, Nyeri otot & sendi. Demam √ <37º C Biasa 37º - 39º C Sedang >39º Bahaya Keringat × - Mual Muntah (Darah) √ 1D Biasa 2-3D Sedang >4D Bahaya Sulit BAB × - Kondisi Badan (Nyeri Sendi) √ 0-1D Biasa 2-3D Sedang >3D Bahaya Kurang Nafsu Makan √ 1D Biasa 2-5D Sedang >5D Bahaya
-Terjadi pendarahan gusi,
bahkan sampai
pendarahan masif (butuh transfusi darah).
-Timbul gejala gastro intestinal, berupa diare dan gejala saluran napas atau batuk pilek.
-Gejala syok : korban gelisah hingga terjadi penurunan kesadaran, sianosis, nafas cepat, hingga tekanan darah turun. Pusing (Sakit Kepala) √ 1D Biasa 2-5D Sedang >5D Bahaya Bintik Merah √ 1 Biasa 2-5 Sedang >5 Bahaya Diare × - 3.7 Analisa Sistem
Pada bagian ini analisa dilakukan terhadap data dan permasalahan yang telah dirumuskan yang dapat menjawab permasalahan dan kendala yang ada. Adapun analisa yang dilakukan adalah :
a. Analisa kebutuhan sistem
Tahap ini dilakukan berdasarkan data yang diperoleh dari pakar kemudian data tersebut digunakan dalam membangun sistem.
b. Basis pengetahuan
Pada tahap ini dibangun basis pengetahuan berupa data gejala. Pada tahap ini digunakan table relasi gejala penyakit dengan memanfaatkan pengetahuan dari pakar yang bersangkutan.