KOMBINASI SELEKSI FITUR CHI SQUARE DENGAN
ALGORITMA NAIVE BAYES UNTUK ANALISIS SENTIMEN
KOMENTAR FACEBOOK
Riza HidayatProg. Studi Ilmu Komputer Fakultas MIPA Universitas Lambung Mangkurat, Jl. A. Yani Km 36 Banjarbaru, Kalimantan selatan,
Email : [email protected]
Abstract
Comments generated in the Facebook comment field have a diversity of sentiments. The diversity of these sentiments can produce implicit information, which can be either positive sentiments or negative sentiments. So it is necessary to do a sentiment analysis to understand and extract the information. In the research of sentiment analysis found many unique features and did not give the best results in the classification so to overcome this done the technique of feature selection. On feature selection is done the process of eliminating irrelevant features and using the relevant features to proceed to the classification stage. However, in some previous studies, there has been no research on the accuracy of sentiment analysis if done with the number of different features in the classification process. So it is necessary to do research related to the effect of feature selection with different amount to the result of accuracy of sentiment analysis. This research produces a classification process with a number of different features, resulting in different levels of classification accuracy depending on the effect of feature relevance to the class and the exact number of features. The highest accuracy performance in the Naive Bayes algorithm combination study with Chi Square feature selection for Facebook commented sentiment analysis is 91% obtained from 366 features or with a 25.52% percentage of all tokens.
Keywords: Sentiment Analysis, Data mining, Naive bayes, Feature Selection, Chi square
Abstrak
Komentar yang dihasilkan pada kolom komentar Facebook memiliki keragaman sentimen. Keragaman sentimen ini dapat menghasilkan informasi yang tersirat, dapat berupa sentiman positif atau sentimen negatif. Sehingga perlu dilakukan analisis sentimen untuk memahami dan mengekstrak informasi tersebut. Dalam penelitian analisis sentimen banyak ditemukan fitur yang unik dan tidak memberikan hasil terbaik dalam klasifikasi sehingga untuk mengatasi hal tersebut dilakukan teknik seleksi fitur. Pada seleksi fitur dilakukan proses menghilangkan fitur yang tidak relevan dan menggunakan fitur yang relevan untuk dilanjutkan ke tahap klasifikasi. Namun pada beberapa penelitian sebelumnya, belum dilakukan penelitian tentang hasil akurasi analisis sentimen jika dilakukan dengan jumlah fitur yang berbeda dalam proses klasifikasi. Sehingga perlu dilakukan penelitian terkait pengaruh seleksi fitur dengan jumlah yang berbeda terhadap hasil akurasi analisis sentimen. Penelitian ini menghasilkan proses klasifikasi dengan jumlah fitur yang berbeda, menghasilkan tingkat akurasi klasifikasi yang berbeda tergantung dari pengaruh relevansi fitur terhadap kelas dan jumlah fitur yang tepat. Performa akurasi tertinggi pada penelitian kombinasi algoritma Naive Bayes dengan seleksi fitur Chi Square untuk analisis sentimen komentar Facebook yaitu 91% yang diperoleh dari 366 fitur atau dengan persentase 25,52% dari seluruh jumlah token.
1. PENDAHULUAN
Media sosial saat ini telah menjadi media komunikasi yang sangat populer bagi kalangan masyarakat pengguna internet. Di Indonesia salah satu media sosial yang populer dan banyak digunakan adalah Facebook. Menurut data dari Webershandwick, untuk wilayah Indonesia terdapat sekitar 65 juta pengguna Facebook aktif. Sebanyak 33 juta pengguna aktif per harinya, sekitar 28 juta pengguna aktif yang memakai perangkat mobile per harinya. Konten yang dihasilkan Facebook dapat berupa gambar, status, video dan lain lain. Setiap konten tersebut dapat diberikan komentar oleh pengguna Facebook.
Adanya kesempatan pengguna Facebook memberikan komentar terhadap konten yang disajikan, membuat tidak jarang banyak sekali komentar-komentar yang beragam muncul baik berupa opini positif ataupun opini negatif, sehingga diperlukan analisis sentimen dalam pengolahan opini dari komentar tersebut. Salah satu contoh penelitian analisis sentimen telah dilakukan oleh Pamungkas [1] terkait pengolahan teks pada media sosial (Twitter) untuk melakukan penilaian sentimen masyarakat terhadap kata kunci kurikulum 2013.
Naive bayes adalah salah satu
algoritma dalam data mining yang digunakan untuk mengklasifikasikan data ke dalam satu atau beberapa kelas yaang sudah didefinisikan sebelumnya. Naive bayes banyak digunakan untuk klasifikasi teks dalam machine learning yang didasarkan pada fitur probabilitas [2]. Pada penelitian Rish [3] menunjukkan bahwa meskipun asumsi independensi antar kata dalam dokumen tidak sepenuhnya dapat dipenuhi, tetapi kinerja NBC dalam klasifikasi relatif sangat bagus. Pada penelitian Hamzah [4] menyimpulkan bahwa klasifikasi dokumen berita dengan menggunakan Naive bayes didapatkan akurasi yang lebih tinggi (maksimal 91%) dibandingkan dengan dokumen akademik (maksimal 82%). Namun, pada saran penelitian disampaikan bahwa diperlukan seleksi fitur kata yang digunakan sebagai dasar klasifikasi, karena ditemukan jumlah kata yang banyak dengan mengunakan seluruh kata unik dalam koleksi dokumen tidak memberikan hasil klasifikasi yang terbaik.
Pada penelitian Firqiani [5] menyampaikan bahwa seleksi fitur digunakan untuk mengurangi dimensi data dan fitur-fitur yang tidak relevan. Seleksi fitur digunakan
untuk meningkatkan efektifitas dan efisiensi kinerja dari algoritma klasifikasi. Pada penelitian Rahmad [6] menyampaikan bahwa pemilihan feature dengan menggunakan Chi
square dalam algoritma Naïve Bayes untuk
klasifikasi berita otomatis, berpengaruh terhadap pengurangan jumlah fitur yang diperoleh. Namun dari beberapa penelitian belum dilakukan penelitian tentang pengaruh seleksi fitur Chi square dengan jumlah yang berbeda terhadap hasil akurasi analisis sentimen menggunakan algoritma Naive bayes. Dari beberapa penelitian tersebut perlu dilakukan penelitian terkait pengaruh seleksi fitur Chi square dengan jumlah yang berbeda terhadap hasil akurasi analisis sentimen menggunakan algoritma Naive bayes. Jenis teks yang digunakan adalah komentar pada Facebook yang berupa opini-opini menggunakan bahasa Indonesia dengan kategori teks yang pendek, serta penggunaan bahasa yang unik.
2. METODOLOGI PENELITIAN
2.1 Alat Penelitian
Alat-alat yang digunakan dalam penelitian ini terbagi menjadi dua jenis meliputi perangkat keras meliputi processor Intel Core i5-820M, 2.4Ghz, RAM 4 GB, Harddisk 450 GB serta perangkat lunak meliputi Sistem Operasi Windows 10 Pro, Webserver Apache, Relational Database
Management System, MySQL, Bahasa
Pemrograman PHP, Notepad ++, Sastrawi Indonesian Stemming PHP Library, SublimeText, Facebook Graph API Online , dan OpenRefine
2.2 Bahan Penelitian
Bahan penelitian yang digunakan dalam penelitian ini berupa data yang diperoleh dari media sosial yaitu komentar pada status Facebook dengan format JSON
(Javascript Object Notation) atau microsoft
excel dengan topik terkait status olahraga yang terdapat pada halaman Kompas.
2.3 Variabel Penelitian
Variabel yang digunakan dalam penelitian ini yaitu pengujian berupa accuracy (akurasi)
2.4 Prosedur Penelitian
Adapun prosedur penelitian yang akan digunakan dalam penelitian ini adalah sebagai berikut:
2.4.1. Pengumpulan Data
Data diperoleh dengan menggunakan Facebook Graph API dengan melakukan filter kata kunci pencarian berupa topik yang terkait dengan status olahraga sebanyak 1000 komentar dengan pembagian 700 komentar untuk data latih dan 300 komentar untuk data uji, kemudian komentar pada topik tersebut disimpan dengan format JSON. Kemudian komentar tersebut akan diberikan label nilai positif dan negatif.
2.4.2 Pemrosesan Data
Data yang dihasilkan sebelumnya diproses dengan menerapkan prinsip
Knowledge Discovery in Database (KDD)
dengan tahapan sebagai berikut: 2.4.2.1 Data Preprocessing
Data cleaning, data integration, data selection, dan data transformation pada KDD juga dikenal dalam satu kesatuan dengan istilah data preprocessing [7]. Tahap
preprocessing dalam penelitian ini
menerapkan text preprocessing yang meliputi teknik sebagai berikut:
a. Penghapusan Data Duplikat
Penghapusan duplikat dilakukan agar dapat menanggulangi kurangnya kualitas dataset karena kondisi data yang tak seimbang akibat duplikasi data, atau data yang sama persis. Pada penelitian ini data dianggap duplikat apabila terdapat dari data komentar dengan nama pengguna yang sama, id pengguna yang sama dan teks komentar yang sama.
b. Penanganaan Negasi
Seperti halnya ilmu matematika, dalam bahasa terdapat kata yang dapat membalikan arti dari kata tersebut atau bersifat negasi. Kata-kata yang bersifat negasi adalah “kurang”, “tidak”, “enggak”, “ga”, “nggak”, “tak”, dan “gak” [8].
c. Cleansing
Cleansing merupakan proses membersihkan kata-kata yang tidak diperlukan untuk mengurangi noise. Kata yang dihilangkan adalah URL, hashtag (#),
username (@username), dan email. Selain
itu juga tanda baca seperti titik(.), koma(,), dan tanda baca yang lainnya akan dihilangkan [8].
d. Stemming
Stemming, yakni proses untuk
mendapatkan kata dasar dengan cara menghilangkan awalan, akhiran, sisipan,
dan confixes (kombinasi dari awalan dan akhiran). Algoritma stemming Nazief dan Adriani dikembangkan berdasarkan aturan bahasa Indonesia yang kata-katanya menggunakan imbuhan, awalan (prefix), sisipan (infix), akhiran (suffix), dan kombinasi awalan serta akhiran (confixes) [9].
e. Casefolding
Casefolding merupakan tahapan merubah
bentuk kata-kata menjadi sama bentuknya, baik semuanya menjadi lower case ataupun menjadi upper case [8].
f. Konversi Emoticon
Setiap emoticon akan dikonversikan ke dalam string yang bersesuaian. Jenis
emoticon yang akan diproses oleh adalah emoticon western style yang sudah
terdaftar di database, dikarenakan jenis tersebut banyak digunakan atau menjadi standar di semua platform seperti web ataupun mobile [8].
g. Tokenization
Tokenizing yaitu proses penguraian
deskripsi yang semula berupa kalimat-kalimat menjadi kata-kata dan menghilangkan delimiter-delimiter seperti tanda titik (.), koma (,), spasi dan karakter angka yang ada pada kata tersebut [10]. h. Konversi Slang
Pentingnya convert word atau slang adalah untuk mengkonversi kalimat yang tidak baku, saat ini penggunaan kalimat alay atau bahasa gaul mengakibatkan penggunaan Bahasa Indonesia tidak baku [11].
Setelah melalui beberapa teknik
preprocessing, untuk setiap dokumen pada
dataset diberikan label kelas (positif dan negatif) secara manual sesuai jenis sentimen yang dimiliki oleh dokumen. Hasil akhir pada tahap ini berupa dataset yang siap untuk diolah melalui data mining (text mining). 2.4.2.2. Data mining
Data mining adalah proses
mengeksplorasi dan menganalisa data dalam jumlah yang besar yang bertujuan untuk menemukan suatu pola atau informasi yang menarik dari data yang tersimpan dalam jumlah yang besar dengan menggunakan teknik atau metode tertentu.
Analisis sentimen adalah proses memahami, mengekstrak dan mengolah data tekstual untuk mendapatkan informasi [12]. Analisis sentimen dilakukan untuk melihat pendapat atau kecenderungan opini terhadap sebuah masalah atau objek oleh seseorang,
apakah cenderung berpandangan atau beropini negatif atau positif [13]. Pada penelitian ini dilakukan seleksi fitur Chi square dan klasifikasi menggunakan Naive bayes.
Naïve Bayes classifier merupakan
suatu metode klasifikasi yang menggunakan perhitungan probabilitas. Konsep dasar yang digunakan pada Naïve Bayes classifier adalah Teorema Bayes yang dinyatakan pertama kali oleh Thomas Bayes [14]. Hamzah [4] menjelaskan bahwa klasifikasi Naive bayes dilakukan dengan cara mencari probabilitas P(V=vj | D=di), yaitu probabilitas kategori vj jika diketahui dokumen di. Dokumen di dipandang sebagai tuple dari kata-kata dalam dokumen, yaitu <a1, a2,…,an>, yang frekuensi kemunculannya diasumsikan sebagai variable
random dengan distribusi probabilitas
Bernoulli.
Seleksi fitur adalah proses pemilihan subset dari term pada training set dan digunakan dalam klasifikasi teks. Seleksi fitur mempunyai 2 tujuan utama yaitu, membuat data latih yang digunakan untuk classifier lebih efisien dengan cara mengurangi ukuran kosakata, dan untuk meningkatkan akurasi klasifikasi dengan menghilangkan fitur noise [15].
Chi square adalah salah satu supervised feature selection yang mampu
menghilangkan banyak feature tanpa mengurangi tingkat akurasi [16]. Dalam seleksi fitur Chi square berdasarkan teori statistika, dua peristiwa di antaranya adalah, kemunculan dari fitur dan kemunculan dari kategori, yang kemudian setiap nilai term diurutkan dari yang tertinggi berdasarkan perhitungan berikut :
Dengan nilai oi adalah frekuensi observasi dan ei adalah frekuensi ekspektasi. Lalu hitung :
Dengan nilai Σfk adalah jumlah frekuensi pada kolom. Nilai Σfb adalah jumlah frekuensi pada baris. Nilai ΣT adalah jumlah keseluruhan baris atau kolom [17].
Dalam pengujian, dilakukan perbandingan antara tanpa seleksi fitur, dan dengan seleksi fitur. Pada pengklasifikasian
dengan seleksi fitur dilakukan percobaan berulang ulang dengan jumlah fitur yang berbeda. Hasil klasifikasi sistem dan nilai kelas sebenarnya pada data uji akan dibandingkan dan dicatat hasilnya dalam bentuk confusion
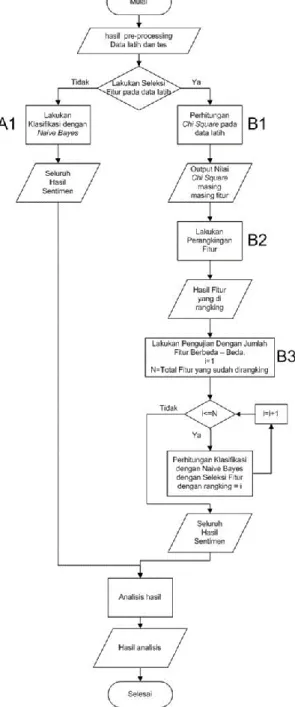
matrix. Alur tahap data mining dapat dilihat
pada gambar 1.
Gambar 1. Alur Data mining 2.4.2.3 Pattern evaluation
Pattern evaluation merupakan tahapan penilaian hasil dari teknik data mining yang telah dilakukan sebelumnya.
2.4.2.4 Knowledge presentation
Tahap memformulasikan keputusan atau aksi dari hasil analisis yang didapat. Tahapan ini dilakukan visualisasi dan presentasi hasil pengetahuan yang diperoleh. Visualisasi dapat disajikan dalam bentuk tabel dan grafik dari hasil yang didapat.
3. HASIL DAN PEMBAHASAN
3.1. Hasil
3.1.1 Pengumpulan Data
Data yang digunakan dalam penelitian ini merupakan data komentar berita olahraga yang diperoleh dengan menggunakan Facebook Graph API pada halaman Facebook Kompas.com. Pengambilan data dilakukan secara otomatis dan disimpan sebanyak 1000 data yang akan digunakan dalam penelitian. Data yang dihasilkan merupakan data mentah yang disimpan dalam format JSON. Data JSON yang dihasilkan belum berbentuk kolom, sehingga jika ingin mempermudah dalam pembacaan dan proses pelabelan, maka data tersebut di convert ke microsoft excel dengan memilih beberapa kolom yang dapat digunakan untuk penelitian. Data yang dihasilkan dengan Format JSON atau microsoft
excel memiliki struktur data yang dapat dilihat
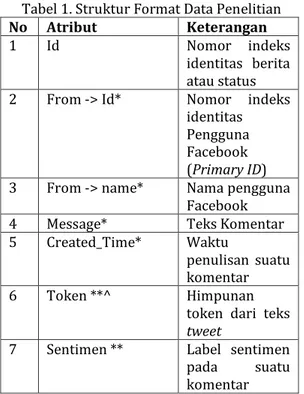
pada tabel 1.
Tabel 1. Struktur Format Data Penelitian
No Atribut Keterangan
1 Id Nomor indeks
identitas berita atau status 2 From -> Id* Nomor indeks
identitas Pengguna Facebook (Primary ID) 3 From -> name* Nama pengguna
Facebook 4 Message* Teks Komentar 5 Created_Time* Waktu
penulisan suatu komentar 6 Token **^ Himpunan
token dari teks
tweet
7 Sentimen ** Label sentimen pada suatu komentar Keterangan:
* atribut yang digunakan dalam penelitian
** atribut bentukan setelah pelabelan dan data
preprocessing
^ atribut bentukan yang hanya terdapat di file format JSON.
3.1.2 Preprocessing
Adapun beberapa tahapan yang dilakukan pada text preprocessing ini yaitu penanganaan negasi, cleansing, stemming, casefolding, konversi emoticon, tokenization dan konversi slang. Setelah melewati tahap
preprocessing, setiap data komentar diberikan
label kelas berupa data positif, negatif atau tidak dikenal secara manual. Data yang digunakan dalam penelitian merupakan data yang memiliki label kelas “positif”, dan “negatif”. Sedangkan data dengan label kelas “tak dikenal atau nonsentimen” tidak digunakan dalam penelitian karena sifatnya yang ambigu sehingga tidak dapat ditentukan jenis sentimen yang dimiliki.
1000 buah dataset dibagi menjadi dua bagian meliputi data latih (70%), dan data uji (30%). Pembagian data latih dan data uji untuk data yang sudah berlabel dilakukan secara seimbang antara label dengan sentimen positif dan sentimen negatif. Model pembagian data latih dan data uji yang dilakukan dapat dilihat pada tabel 2.
Tabel 2. Pembagian Data Latih dan Data Uji
No Jenis Data Label Sentimen Total
Positif Negatif
1 Data Latih 350 350 700 2 Data Uji 150 150 300
Total Data 500 500 1000
3.1.3 Data mining
Setelah teks komentar melalui tahap
preprocessing, proses selanjutnya dalam
penelitian adalah data mining yang berguna untuk menemukan suatu pola atau pengetahuan dalam data yang berjumlah besar. Pada penelitian ini proses data mining menggunakan algoritma klasifikasi Naive
bayes. Dalam pengujian, dilakukan
perbandingan antara tanpa seleksi fitur, dan dengan seleksi fitur. Pada pengklasifikasian dengan seleksi fitur dilakukan percobaan berulang ulang dengan jumlah fitur yang berbeda.
3.1.3.1. Naïve Bayes Tanpa Seleksi Fitur Chi
square.
Untuk menghitung hasil klasifikasi dengan algoritma Naïve Bayes diperlukan perhitungan nilai peluang kemunculan kata pada kelas. Pada konsep dasar Naïve Bayes nilai probabilitas dihitung dari kemunculan opini dengan perkalian nilai probabilitas kemunculan fitur dalam opini tersebut. Perhitungan Naive Bayes tanpa seleksi fitur untuk kalimat “ini baru keren” dapat dilihat pada tabel 3.
Tabel 3. Perhitungan Naive bayes pada salah satu kalimat
Dari perhitungan tersebut dibandingkan maka nilai positif lebih tinggi sehingga kalimat tersebut bernilai positif
Hasil seluruh perhitungan 300 data uji dihasilkan nilai akurasi klasifikasi dengan
Naive bayes tanpa menggunakan seleksi fitur
adalah sebesar 68,667%. Hasil ini didapatkan dari evaluasi menggunakan confusion matrix yang dapat dilihat pada tabel 4.
Tabel 4. Confusion matrix Naive bayes
Nilai Prediksi Nilai Sebenarnya Positif Negatif Positif 137 81 Negatif 13 69
Pada hasil confusion matrix yang disajikan terdapat 137 data positif yang terklasifikasi dengan benar, dan 69 data negatif yang terklasifikasi dengan benar. Namun masih terdapat sebanyak total 94 data yang terklasifikasi salah oleh sistem.
Nilai akurasi didapatkan dari evaluasi hasil sentimen secara keseluruhan, di mana akurasi merupakan jumlah klasifikasi yang benar dibagi dengan total klasifikasi. Perhitungan akurasi dapat dilihat pada tabel 5.
Tabel 5. Perhitungan Akurasi
3.1.3.2. Naïve Bayes Dengan Seleksi Fitur Chi
square.
Secara umum, seleksi fitur digunakan untuk mencari semua kemungkinan kombinasi dari kata dalam data untuk menemukan fitur kata yang terbaik untuk prediksi. Fitur kata terbaik dihasilkan berdasarkan nilai Chi square tertinggi.
Tahap pertama seperti pada 1 bagian B1, dilakukan proses nilai Chi square masing masing fitur yang terdapat di data latih. Fitur keseluruhan adalah 1434 fitur, lalu fitur itu dilakukan perhitungan Chi square masing masing fitur dengan menggunakan rumus x2
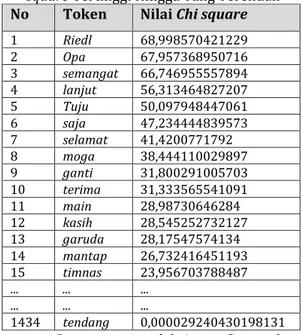
(Chi square) dengan terlebih dahulu mencari nilai frekuensi harapan, dimana total kemunculan token positif adalah 3317 dan total kemunculan token negatif adalah 4951. Setelah didapatkan nilai Chi square, nilai tersebut diurutkan dari nilai tertinggi hingga nilai terendah untuk masing masing fitur seperti yang dapat dilihat pada tabel 6.
Tabel 6. Pengurutan Fitur Kata dari Nilai Chi
square Tertinggi Hingga Yang Terendah
No Token Nilai Chi square
1 Riedl 68,998570421229 2 Opa 67,957368950716 3 semangat 66,746955557894 4 lanjut 56,313464827207 5 Tuju 50,097948447061 6 saja 47,234444839573 7 selamat 41,4200771792 8 moga 38,444110029897 9 ganti 31,800291005703 10 terima 31,333565541091 11 main 28,98730646284 12 kasih 28,545252732127 13 garuda 28,17547574134 14 mantap 26,732416451193 15 timnas 23,956703788487 ... ... ... ... ... ... 1434 tendang 0,000029240430198131 Proses penyeleksian fitur kata dilakukan dengan cara memilih fitur kata untuk digunakan dalam proses pengujian klasifikasi sedangkan data yang tidak terpilih akan dihapus dari proses klasifikasi. Pada penelitian ini pemilihan fitur ditentukan berdasarkan rangking nilai Chi-Square, sehingga hanya data data yang termasuk pada rangking tertentu yang akan digunakan dalam klasifikasi.
Pengujian dengan jumlah fitur yang berbeda beda berdasarkan jumlah rangking keseluruhan, misalkan pengambilan jumlah
fitur kata 1 maka rangking 1 saja yang diambil sebagai data latih, bila jumlah fitur kata 2 maka rangking 1 dan 2 yang diambil sebagai data latih, dan seterusnya. Pada penelitian ini seluruh fitur kata akan dicoba dari rangking ke-1 hingga rangking ke-1434.
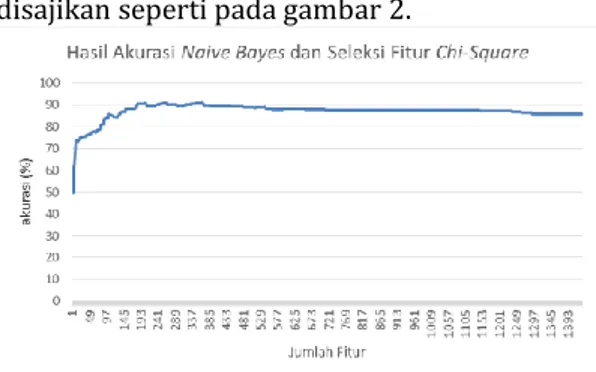
Grafik hasil akurasi klasifikasi Naive
bayes menggunakan seleksi fitur Chi square
dengan jumlah fitur yang berbeda beda disajikan seperti pada gambar 2.
Gambar 2. Grafik Hasil Akurasi Klasifikasi
Naive bayes Dengan Menggunakan Seleksi
Fitur Chi square
Hasil yang didapatkan dari pengujian dengan jumlah fitur berbeda beda, nilai akurasi terendah dihasilkan pada jumlah fitur ke-1 sampai dengan 5 dengan nilai akurasi 50%, Nilai akurasi pada jumlah fitur ke-1 sampai dengan 10 masih lebih rendah dari nilai akurasi klasifikasi tanpa seleksi fitur, pengujian dengan seluruh fitur yaitu 1434 menghasilkan nilai akurasi 85,666%, dan untuk fitur terbaik terdapat pada jumlah fitur ke-366 dengan nilai akurasi 91%.
3.2. Pembahasan
Pada penelitian ini klasifikasi komentar dilakukan dengan pengklasifikasian tanpa dilakukan seleksi fitur dan pengklasifikasian menggunakan seleksi fitur. Pada pengklasifikasian dengan seleksi fitur dilakukan percobaan berulang ulang dengan jumlah fitur yang berbeda. Percobaan ini dimaksudkan untuk mengetahui pengaruh pemilihan fitur dengan jumlah yang berbeda terhadap hasil akurasi dari klasifikasi. Pengklasifikasian pada penelitian ini dilakukan menggunakan algoritma Naïve Bayes dan seleksi fitur menggunakan metode Chi square. Pengujian dilakukan dengan menggunakan data sebanyak 1000 komentar Facebook yang sudah melewati proses preprocessing terlebih dahulu. Pembagian data menjadi 700 data latih dan 300 data uji. Dimana 700 data latih terdiri dari 350 data berlabel positif dan 350 data berlabel negatif. Begitupula dengan data uji yang terdiri dari 300 data, terdiri dari 150 data
berlabel positif dan 150 data berlabel negatif. Hal ini dilakukan agar data latih dan data uji memiliki data yang seimbang untuk label sentimen awal. Dengan jumlah data latih yang seimbang maka hasil klasifikasi hanya ditentukan dari jumlah dan kata-kata di data uji tanpa pengaruh jumlah sentimennya. Pada Penelitian oleh Saraswati [18] tentang Text Mining dengan metode Naïve Bayes Classifier dan Support Vector Machines untuk Sentiment Analysis, menyatakan bahwa dengan jumlah data latih positif yang lebih besar maka hasil klasifikasi akan cenderung menunjukkan sebagai opini positif. Demikian pula sebaliknya. Jika data latih negatif lebih besar hasil klasifikasi akan cenderung sebagai opini negatif. Dengan jumlah data latih yang seimbang maka hasil klasifikasi hanya ditentukan dari jumlah dan kata-kata di data uji tanpa pengaruh priori probability. Dari 700 data latih yang digunakan, setelah dilakukan proses preprocessing dihasilkan 1434 fitur dengan nilai kemunculan token yang berbeda beda. Jika dihitung keseluruhan kemunculan token maka jumlah token berlabel positif adalah 3317 token, dan jumlah token berlabel negatif adalah 4951 token. Namun dalam seluruh token masih banyak ditemukan kata-kata yang sering keluar dan dianggap tidak penting seperti waktu, penghubung, dan lain sebagainya. Salah satu solusi untuk penelitian selanjutnya dalam mengatasi hal tersebut yaitu dengan menerapkan penghapusan kata (stopword removal) pada kata kata tertentu yang dianggap tidak berhubungan dengan kelas, Faradhillah [19] pada penelitiannya menyatakan hasil penggunaan algoritma Naïve
Bayes dengan menggunakan metode praproses
penghapusan kata (stopword removal) mendapatkan hasil yang lebih tinggi dibanding yang tidak menggunakan.
Berdasarkan penelitian yang dilakukan dengan pengklasifikasian menggunakan algortima Naive bayes tanpa seleksi fitur menghasilkan nilai akurasi sebesar 68,667%. Pada hasil confusion matrix yang disajikan terdapat 137 data positif yang terklasifikasi dengan benar, dan 69 data negatif yang terklasifikasi dengan benar. Namun masih terdapat sebanyak total 94 data yang terklasifikasi salah oleh sistem. Hal ini terjadi dikarenakan masih banyaknya data yang memiliki fitur penggangu dan fitur tidak relevan dalam klasifikasi. Yang dimaksud fitur pengganggu adalah fitur yang tidak memberikan kontribusi dalam perhitungan
terdapat data token yang bernilai 0 atau tidak ada dalam data latih. Akibatnya hasil klasifikasi tidak dapat ditentukan atau menghasilkan representasi nilai yang berbeda dari kelas. Solusi yang dapat dilakukan pada penelitian selanjutnya adalah dengan menerapkan teknik Smoothing pada perhitungan Naive bayes untuk dapat mengatasi permasalahan nilai 0. Nugraha [20] penggunaan laplacian smoothing dengan konsep menambahkan nilai positif yang kecil pada setiap nilai probabilitas kondisional yang ada agar terhindarnya nilai nol pada model probabilitas sehingga meningkatkan tingkat akurasi Naïve Bayesian. Selain itu pada umumnya, atribut dari klasifikasi sentimen teks sangat besar, dan jika semua atribut tersebut digunakan, maka akan mengurangi kinerja dari classifier [21].
Penelitian yang dilakukan dengan pengklasifikasian menggunakan algoritma
Naive bayes dengan seleksi fitur Chi square
menghasilkan nilai akurasi yang berbeda beda tergantung jumlah fitur yang dipilih. Pada proses pengujian terlebih dahulu menentukan nilai Chi square dari fitur data latih keseluruhan. Sehingga 1434 fitur dari data latih menghasilkan 1434 rangking sesuai urutan nilai Chi square dari tertinggi hingga terendah. Setelah dilakukan nilai Chi square dan rangkingnya sudah diketahui, dilakukan proses klasifikasi menggunakan Algoritma
Naive bayes. Selanjutnya dilakukan pengujian
dengan jumlah fitur yang berbeda beda, pada penelitian ini seluruh fitur akan dicoba dari rangking ke-1 hingga rangking ke-1434.
Berdasarkan pengujian klasifikasi tanpa seleksi fitur Chi square dan dengan menggunakan seleksi fitur Chi square, tingkat akurasi pada klasifikasi menggunakan seleksi fitur dengan nilai tertentu lebih baik daripada tidak menggunakan seleksi fitur. Hal ini dibuktikan dengan tingkat akurasi yang dihasilkan, pada akurasi klasifikasi tanpa seleksi fitur dihasilkan 68,667% nilai akurasi. Sedangkan dengan menggunakan seleksi fitur dari 1434 kali pengujian dengan jumlah fitur yang berbeda beda, nilai akurasi pada pengujian dengan jumlah fitur sebanyak 11 fitur sampai dengan jumlah fitur sebanyak 1434 fitur, menghasilkan nilai akurasi yang lebih tinggi dari hasil akurasi klasifikasi tanpa seleksi fitur yaitu dengan hasil akurasi terendah 73,333% sampai dengan tertinggi 91%.
Dengan adanya seleksi fitur, jumlah fitur yang terlibat dalam menentukan suatu
nilai kelas target menjadi berkurang dengan menghilangkan fitur irrelevant, sehingga dapat mengurangi salah pengertian terhadap hasil kelas target klasifikasi. Hasilnya, seleksi fitur dengan jumlah fitur tertentu, dapat meningkatkan kinerja hasil akurasi. Namun tidak semua jumlah fitur menghasilkan nilai akurasi lebih baik dari nilai akurasi klasifikasi tanpa seleksi fitur, pada pengujian dengan jumlah fitur 1 sampai dengan jumlah fitur 10, akurasi yang dihasilkan adalah antara 50% sampai dengan 67,666%, tidak lebih baik dari klasifikasi tanpa seleksi fitur. Hal ini dikarenakan fitur yang digunakan terlalu sedikit sehingga kata kata yang akan dihitung propabilitasnya terlalu sedikit sehingga akurasi perhitungan untuk masing-masing kategori menjadi kurang akurat. Pada pengujian lain dilakukan dengan seluruh fitur pada data latih yaitu 1434 fitur, menghasilkan nilai akurasi sebesar 85,666%. Pada hasil
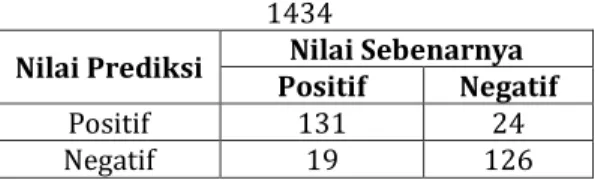
confusion matrix yang disajikan pada tabel 7,
terdapat 131 data positif yang terklasifikasi dengan benar, dan 126 data negatif yang terklasifikasi dengan benar. Namun masih terdapat sebanyak total 43 data yang terklasifikasi salah oleh sistem.
Tabel 7. Confusion matrix Pada Jumlah Fitur 1434
Nilai Prediksi Positif Nilai Sebenarnya Negatif
Positif 131 24
Negatif 19 126
Hasil ini lebih baik daripada klasifikasi tanpa seleksi fitur karena seleksi fitur telah mengurangi jumlah fitur yang terlibat dalam menentukan suatu nilai kelas target, namun hasil ini bukan merupakan nilai akurasi klasifikasi terbaik, hal ini disebabkan fitur yang diambil untuk perhitungan klasifikasi jumlahnya terlalu banyak sehingga kata-kata yang akan dihitung probabilitasnya sangat banyak, dan menyebabkan kata-kata yang umum yang berada disemua kategori ikut dihitung.
Dari hasil 1434 kali pengujian klasifikasi didapatkan nilai akurasi tertinggi yaitu 91% yang diperolah dari rangking fitur 366 atau dengan secara persentase yaitu 25,52% dari seluruh jumlah token. Sehingga ditarik kesimpulan bahwa jumlah fitur yang tepat dengan relevansi fitur yang tinggi terhadap kelas akan menghasilkan nilai akurasi yang tinggi, jika fitur terlalu sedikit ataupun terlalu banyak dapat menurunkan
klasifikasi hasil klasifikasi, karena kata yang digunakan tidak memiliki pengaruh yang baik terhadap kelas.
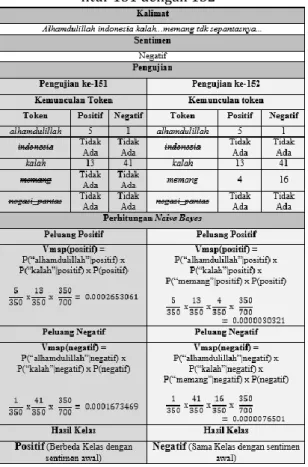
Pada pengujian klasifikasi dengan seleksi fitur dari 1434 kali pengujian dengan jumlah fitur yang berbeda beda, menghasilkan tingkat akurasi yang berbeda tergantung dari pengaruh relevansi fitur terhadap kelas. Contoh perubahan hasil klasifikasi akibat pengaruh relevansi fitur terhadap kelas terjadi pada pengujian ke 152 dengan fitur kata yaitu memang. Sebelum ada fitur kata memang pada pengujian ke 151 nilai akurasi yang dihasilkan adalah sebesar 87% namun setelah pengujian ke-152 nilai akurasi meningkat menjadi 88%. Perbandingan pengujian pada jumlah fitur 151 dengan 152 dapat dilihat pada tabel 8.
Tabel 8. Perbandingan pengujian pada jumlah fitur 151 dengan 152
Maka berdasarkan penjelasan diatas disimpulkan bahwa tingkat akurasi pada klasifikasi dengan algoritma Naïve Bayes menggunakan seleksi fitur Chi square lebih baik daripada tidak menggunakan seleksi fitur, hal ini menunjukkan bahwa keberadaan fitur mempengaruhi hasil klasifikasi. Fitur-fitur yang mempunyai relevansi terhadap kelas akan mempengaruhi terhadap hasil akurasi klasifikasi. Sehingga pengujian dengan
beberapa fitur yang berbeda menghasilkan nilai akurasi klasifikasi yang berbeda tergantung dari relevansi fitur terhadap kelas klasifikasi. Hasil terbaik pada pengujian klasifikasi dengan seleksi fitur Chi square terdapat pada pengujian dengan jumlah 366 fitur yaitu nilai akurasi sebesar 91%.
4. SIMPULAN
Kesimpulan yang dapat diambil dari penelitian ini adalah analisis sentimen dengan algoritma Naïve Bayes menggunakan seleksi fitur Chi square dengan jumlah fitur yang berbeda menghasilkan hasil akurasi yang berbeda tergantung dari pengaruh relevansi fitur terhadap kelas. Semakin tinggi relevansi fitur terhadap kelas dengan jumlah fitur yang tepat akan menghasilkan nilai akurasi yang tinggi, jika fitur terlalu sedikit ataupun terlalu banyak dengan relevansi fitur yang rendah dapat menurunkan hasil klasifikasi, karena fitur kata yang digunakan tidak memiliki pengaruh yang baik terhadap kelas. Performa akurasi terbaik menggunakan algoritma Naive
bayes dengan seleksi fitur Chi square diperoleh
pada pengujian klasifikasi dengan jumlah 366 fitur yaitu nilai akurasi sebesar 91%. Untuk penelitian lebih lanjut dapat dilakukan pula tahapan penghapusan kata (stopword removal) pada kata kata tertentu yang dianggap tidak berhubungan dengan kelas. Karena dalam seluruh token masih banyak ditemukan kata-kata yang sering keluar dan tidak penting seperti waktu, penghubung, dan lain sebagainya. Selain itu juga disarankan menambahkan tehnik Smoothing pada perhitungan Naive bayes untuk mengatasi fitur yang tidak memberikan kontribusi dalam perhitungan Naive bayes dan mengakibatkan hasil klasifikasi tidak dapat ditentukan atau menghasilkan representasi nilai yang berbeda dari kelas.
DAFTAR PUSTAKA
[1]. Pamungkas, D. S, et. Al. 2015. Analisis
Sentiment Pada Sosial Media Twitter Menggunakan Naive bayes Classifier Terhadap Kata Kunci “Kurikulum 2013”. Techno.COM, Vol. 14, No. 4,
November 2015: 299-314
[2]. Zhang, Lei, et. al. 2011. Combining
Lexicon-based and Learning-based
Methods for Twitter Sentiment
Analysis. HPL-2011-89 HP Laboratories
[3]. Rish, Irina, 2001 , An Empirical Study of
the Naïve Bayes Classifier, T.J. Watson
http://www.research.ibm.com/people/r /rish/papers/RC22230.pdf ).
[4]. Hamzah, A., 2012 Klasifikasi Teks
Dengan Naïve Bayes Classifier (NBC) Untuk Pengelompokan Teks Berita Dan Abstract Akademis, Prosiding
Seminar Nasional Aplikasi Sains & Teknologi (SNAST), ISSN:1979-911X, Nopember 2012.
[5]. Firqiani, Hida. N. 2007. Seleksi Fitur
Menggunakan Fast Correlation Based Filter pada Algoritma Voting Feature Intervals 5. Bogor : Institut Pertanian
Bogor.
[6]. Rahmad, A., Pribadi. 2015. Pemilihan
Feature Dengan Chi square Dalam
Algoritma Naïve Bayes Untuk
Klasifikasi Berita. Edu Komputika
Journal. Jurusan Teknik Elektro, Fakultas Teknik, Universitas Negeri Semarang, Indonesia.
[7]. Han, Jiawei, Michelin Kamber, Jian Pei. 2012. Data mining Concepts and
Techniques, 3rd Edition. Waltham:
Morgan Kaufmann.
[8]. Sentiaji, Aditia R dan Adam M Bachtiar. 2013. Analisis Sentimen Terhadap
Acara Televisi Berdasarkan Opini Publik. Jurnal Ilmiah Komputer dan
Informatika (KOMPUTA) ISSN : 2089-9033, halaman 1-6.
[9]. Ariadi, Dio. & Fithriasari, K. 2015.
Klasifikasi Berita Indonesia
Menggunakan Metode Naive bayesian Classification dan Support Vector Machine dengan Confix Stripping Stemmer. Jurnal Sains Dan Seni ITS Vol.
4, No.2, (2015) 2337-3520.
[10].Weiss, S.M., Indurkhya, N., Zhang, T., Damerau, F.J. 2005. Text Mining :
Predictive Methods fo Analyzing Unstructered Information. Springer :
New York.
[11].Mujilahwati, Siti. 2016. Pre-Processing
Text Mining Pada Data Twitter.
Seminar Nasional Teknologi Informasi dan Komunikasi 2016 (SENTIKA 2016). ISSN: 2089-9815.
[12].Ipmawati, J., et Al. 2016. Komparasi
Teknik Klasifikasi Teks Mining Pada Analisis Sentimen. Indonesian Journal
on Networking and Security, Vol 6 No 1. [13].Liu, B. 2010. Handbook of Natural
Language Processing, chapter Sentiment Analysis and Analysis, 2nd Edition. Chapman & Hall / CRC Press.
[14].Aldrich, J., 2008. R. A. Fisher on Bayes
and Bayes’ Theorem. Bayesian
Analysis, 3(1), pp. 161-170.
[15]. Manning C D, Raghavan P, Schütze H. 2009. Introduction to Information
Retrieval. Cambridge (GB): Cambridge
University Press. McAfee
[16]. Sun, C, X. Wang, and J. Xu, "Study on
Feature Selection in Finance Text
Categorization," Science And
Technology, 2009, pp. 5077-5082.
[17]. T.E. Dunning. (1993): Accurate Methods
for Statistics of suprise and
coincidence. In Computational Linguistic,
volume 19:1, Hal 61-74.
[18]. Saraswati, N. 2013. Naïve Bayes
Classifier Dan Support Vector
Machines Untuk Sentiment Analysis.
Seminar Nasional Sistem Informasi Indonesia, Desember 2013.
[19].Faradhillah, Nuke. Y. A, et. Al. 2016.
Eksperimen Sistem Klasifikasi Analisa Sentimen Twitter Pada Akun Resmi Pemerintah Kota Surabaya Berbasis Pembelajaran Mesin. Surabaya : Institut
Teknologi Sepuluh Nopember.
[20]. Nugraha, Praditio.A, et. al. 2013.
Perbandingan Metode Probabilistik Naive Bayesian Classifier dan Jaringan
Syaraf Tiruan Learning Vector
Quantization dalam Kasus Klasifikasi Penyakit Kandungan. JURNAL ITSMART
Vol 2. No 2. Desember 2013 ISSN : 2301– 7201
[21].Wang, S., Li, D., Zhao, L., & Zhang, J. (2013). Sample cutting method for
imbalanced text sentiment
classification based on BRC.
Knowledge-Based Systems, 37, 451–461. doi:10.1016/j.knosys.2012.09.003