BAB 2
LANDASAN TEORI
Pada bab ini akan diuraikan konsep-konsep yang berhubungan dengan penelitian yang menggunakan metode multidimensional scaling yaitu: klasifikasi
multidimensional scaling, prosedur analisis multidimensional scaling, Euclidean distance, Perceptual Map, RSQ (R Square), STRESS serta teori-teori pendukung
yang dibutuhkan dalam penelitian.
2.1 Multidimensional Scaling
Ada beberapa definisi penskalaan multidimensional (multidimensional scaling) yang diungkapkan oleh beberapa ahli antara lain, penskalaan multidimensional = PMD (Multidimensional Scaling) = MDS) merupakan suatu teknik yang biasa membantu peneliti untuk mengenali (mengidentifikasi) dimensi kunci yang mendasari evaluasi objek dari responden atau pelanggan (Supranto, 2010). Sebagai contoh, MDS sering dipergunakan di dalam pemasaran untuk mengenali dimensi kunci yang mendasari evaluasi objek atau produk (mobil, komputer, pasta gigi) dari responden. Penggunaan lain dari MDS meliputi perbandingan mutu fisik, persepsi kandidat politik atau isu dan bahkan penilaian mengenai perbedaan budaya (cultural) antara kelompok yang berbeda.
Analisis penskalaan multidimensional atau multidimensional scaling (MDS) ialah suatu kelas prosedur untuk menyajikan persepsi dan preferensi pelanggan secara spasial dengan menggunakan tayangan yang bisa dilihat (a visual display). Persepsi atau hubungan antara stimulus secara psikologis ditunjukkan sebagai hubungan geografis antara titik-titik di dalam ruang multidimensional. Sumbu dari peta spasial diasumsikan menunjukkan dasar psikologis atau dimensi yang mendasari yang dipergunakan oleh pelanggan/responden untuk membentuk persepsi dan preferensi untuk stimulus. Analisis penskalaan multidimensional dipergunakan di dalam pemasaran untuk mengenali (mengidentifikasi), hal-hal berikut:
1. Banyaknya dimensi dan sifat/cirinya yang dipergunakan untuk mempersiapkan merek yang berbeda di pasar.
2. Penempatan (positioning) merek yang diteliti dalam dimensi ini. 3. Penempatan merek ideal dari pelanggan dalam dimensi ini.
Sementara itu, Singgih (2015) menyatakan bahwa MDS berhubungan dengan pembuatan grafik (map) untuk menggambarkan posisi sebuah objek dengan objek yang lain, berdasarkan kemiripan (similarity) objek-objek tersebut. Di sisi lain, Hair dkk (2009) mengungkapkan bahwa MDS, atau yang juga diketahui sebagai
perceptual mapping adalah suatu cara yang memugkinkan peneliti untuk
menentukan gambar yang dirasa relatif terhadap suatu kumpulan objek (lembaga, produk atau hal lain yang berkaitan dengan persepsi secara umum). Perceptual
mapping akan menghasilkan perceptual map. Sedangkan Richard & Dean (2007)
menyatakan bahwa Multidimensional Scaling adalah sebuah metode untuk mentransformasikan data multivariat ke dalam ruang dimensi yang lebih rendah.
Tujuan dari MDS adalah untuk mentransformasikan penilaian konsumen terhadap kesamaan secara keseluruhan atau preferensi (misalnya preferensi terhadap toko atau merek) ke dalam jarak yang direpresentasikan pada ruang multidimensi.
Metode multidimensional scaling (MDS) banyak digunakan di berbagai disiplin ilmu. Beberapa aplikasi metode multidimensional scaling banyak ditemukan dibidang ekonomi khususnya manajemen pemasaran dan bisnis, teknik, psikologi dan lain-lain.
Sehingga dapat disimpulkan bahwa, multidimensional scaling adalah:
1. Kumpulan teknik-teknik statistika untuk menganalisis kemiripan dan ketakmiripan antar objek.
2. Memberikan hasil yang berupa plot titik-titik sehingga jarak antar titik menggambarkan tingkat kemiripan atau ketakmiripan.
3. Memberikan petunjuk untuk mengidentifikasi atribut tak diketahui atau faktor yang mempengaruhi munculnya kemiripan atau ketakmiripan.
Berdasarkan tipe datanya, Multidimensional Scaling dibagi menjadi dua, yaitu:
1. Multidimensional Scaling Metrik (Klasik)
Skala yang digunakan dalam Multidimensional Scaling Metrik adalah skala data interval atau rasio. Penskalaan Metrik dilakukan jika jarak dianggap bertipe rasio, missal: dAB = 2dBC. Multidimensional scaling (MDS) metrik
mengasumsikan bahwa data adalah kuantitatif (interval dan rasio). Dalam prosedur MDS metrik tidak dipermasalahkan apakah data input ini merupakan jarak yang sebenarnya atau tidak, prosedur ini hanya menyusun bentuk geometri dari titik-titik objek yang diupayakan sedekat mungkin dengan input jarak yang diberikan. Sehingga pada dasarnya adalah mengubah input jarak atau metrik kedalam bentuk geometrik sebagai outputnya.
2. Multidimensional Scaling non metrik.
Skala yang digunakan dalam Multidimensional Scaling Nonmetrik adalah skala data nominal atau ordinal. Penskalaan nonmetrik dilakukan jika jarak dianggap bertipe ordinal, missal: dAB > dBC, maka begitu juga jarak pada peta. Asalkan urutannya benar, walaupun rasionya tidak sesuai maka masih diperbolehkan. Multidimesional scaling nonmetrik mengasumsikan bahwa datanya adalah kualitatif (nominal dan ordinal). Pada kasus ini perhitungan kriteria adalah untuk menghubungkan nilai ketidaksamaan suatu jarak ke nilai ketidaksamaan yang terdekat. Program MDS nonmetrik menggunakan transformasi monoton (sama) ke data yang sebenarnya sehingga dapat dilakukan operasi aritmatika terhadap nilai ketidaksamaannya, untuk menyesuaikan jarak dengan nilai urutan ketidaksamaanya. Transformasi monoton akan memelihara urutan nilai ketidaksamaannya sehingga jarak antara objek yang tidak sesuai dengan urutan nilai ketidaksamaan dirubah sedemikian rupa sehingga akan tetap memenuhi urutan nilai ketidaksamaan tersebut dan mendekati jarak awalnya. Hasil perubahan ini disebut disparities.
Disparities ini digunakan untuk mengukur tingkat ketidaktepatan konfigurasi
ketidaksamaannya. Pendekatan yang sering digunakan saat ini untuk mencapai hasil yang optimal dari skala nonmetrik digunakan Kruskal’s Least-Square
Monotomic Transformation dimana disparities merupakan nilai rata-rata dari
jarak-jarak yang tidak sesuai dengan urutan ketidaksamaanya. Informasi ordinal kemudian dapat diolah dengan MDS nonmetrik sehingga menghasilkan konfigurasi dari objek-objek yang yang terdapat pada dimensi tertentu dan kemudian agar jarak antara objek sedekat mungkin dengan input nilai ketidaksamaan atau kesamaannya. Koordinat awal dari setiap subjek dapat diperoleh melalui cara yang sama seperti metode MDS metrik dengan asumsi bahwa meskipun data bukan jarak informasi yang sebenarnya tapi nilai urutan tersebut dipandang sebagai variabel interval.
Analisis data Multidimensional Scaling digunakan nilai-nilai yang menggambarkan tingkat kemiripan atau tingkat ketidakmiripan antar objek yang sering disebut proximity (Ginanjar, 2008). Proximity dibagi atas dua yaitu:
1. Similarity (kemiripan)
Yaitu jika semakin kecil nilai jaraknya, maka menunjukkan bahwa objeknya semakin mirip.
2. Dissimilarity (ketidakmiripan)
Yaitu jika semakin besar nilai jaraknya, maka menunjukkan bahwa objek semakin tidak mirip (berbeda).
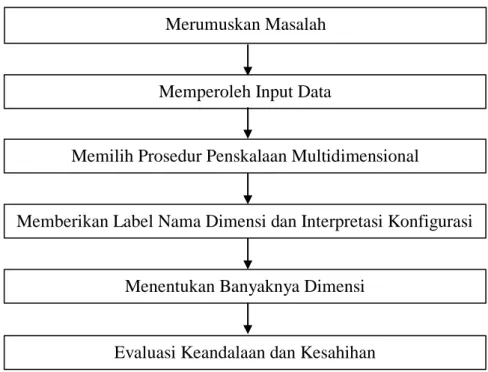
2.1.1 Prosedur Analisis Multidimensional Scaling
Gambar 2.1 Prosedur Analisis Multidimensional Scaling
2.1.2 Kemiripan (similarity)
Dalam beberapa metode yang berkaitan dengan kemiripan (similarity), jarak dimaksudkan sebagai ukuran kemiripan. Ukuran kemiripan ditentukan berdasarkan jarak (distance) antar titik. Ukuran jarak dalam bidang dua dimensi dapat ditentukan dengan menggunakan Jarak Euclidean (Euclidean Distance) adalah perhitungan jarak dari dua buah titik dalam Euclidean Space. Euclidean
Space diperkenalkan oleh Euclid, seorang matematikawan dari Yunani sekitar
tahun 300 sebelum masehi untuk mempelajari hubungan sudut dan jarak.
Euclidean ini berkaitan dengan Teorema Phytagoras.
Untuk menghitung nilai kedekatan jarak antar objek pada peta persepsi dapat diperoleh dengan menggunakan jarak Euclidean Distance antara objek ke-i dengan objek ke-j:
Merumuskan Masalah
Memperoleh Input Data
Memilih Prosedur Penskalaan Multidimensional
Memberikan Label Nama Dimensi dan Interpretasi Konfigurasi
Menentukan Banyaknya Dimensi
√∑ ∑ ∑
Dalam hal ini:
Jarak antar objek ke-i dan objek ke-j
Hasil pengukuran objek ke-i pada peubah/atribut h Hasil pengukuran objek ke-j pada peubah/atribut h
2.1.3 Perceptual Map
Hair dkk (2009) mendefinisikan peta persepsi adalah sebuah representasi visual dari persepsi seorang responden terhadap beberapa objek pada dua atau lebih dimensi. Tiap objek akan memiliki posisi spasial pada peta persepsi tersebut yang merefleksikan kesamaan atau preferensi (preference) ke objek lain dengan melihat dimensi-dimensi pada peta persepsi.
Perceptual map juga sering disebut peta spasial (spatial map). Peta spasial
(spatial map) ialah hubungan antara merek atau stimulus lain yang dipersepsikan, dinyatakan sebagai hubungan geometris antara titik-titik di alam ruang yang multidimensional koordinat (coordinates), menunjukkan posisi (letak) suatu merek atau suatu stimulus dalam suatu peta spasial (Supranto, 2010).
Untuk memperoleh peta persepsi, maka harus diperoleh stimulus koordinat. Algoritma MDS fokus pada fakta bahwa koordinat matriks X dapat diperoleh dengan dekomposisi eigenvalue dari produk skalar matriks . Masalah dalam mengkonstruksi D dari matriks proximity P diselesaikan dengan mengalikan kuadrat dari matriks proximity dengan matriks – . Prosedur ini dinamakan double centering.
Adapaun langkah-langkah dalam menentukan posisi atau koordinat stimulus dari objek-objek yang diteliti dengan menggunakan algoritma multidimensional
1. Membentuk sebuah matriks jarak (D)
2. Menghitung kuadrat dari matriks D yang disebut D2
3. Menentukan matriks B dengan menggunakan proses double centering :
yang menggunakan matriks , dimana A adalah matriks yang semuanya elemennya adalah 1, dan n adalah jumlah objek. 4. Ambil 2 mutlak terbesar dari nilai eigen (eigenvalue) … pada B serta m
vector eigen (eigenvector) yang sesuai … .
5. Sebuah konfigurasi ruang m-dimensi (stimulus koordinat) atas n objek diperoleh dari koordinat matriks dimana adalah matriks dari
m eigenvector dan adalah matriks diagonal dari masing-masing m
eigenvalue matriks B.
2.1.4 RSQ (R Square)
√ adalah koefien kolerasi berganda yang digunakan untuk mengukur kuatnya hubungan beberapa variable x dan y. yaitu koefisien determinasi berganda.
Koefisien determinasi ( ) merupakan ukuran yang paling sederhana yang digunakan untuk mengetahui sejauh mana kecocokan antara data dengan garis estimasi regresi. Apabila data hasil pengamatan terletak dalam garis regresi maka kita akan memperoleh kecocokan yang sempurna. Namun hal itu jarang terjadi. Umumnya hasil-hasil pengamatan itu menyebar di seputar garis estimasi regresi sehingga menghasilkan ̂ positif jika pengamatan-pengamatan di atas garis estimasi regresi, atau sebaliknya ̂ negatif jika pengamatan-pengamatan di bawah garis estimasi regresi. Total penyimpangan terdiri dari dua komponen yaitu: jumlah kuadrat yang dapat dijelaskan oleh model regresi (explained sum of
square, ESS) dan jumlah kuadrat penyimpangan residual (residual sumof square,
RSS), sehingga:
∑∑ ̂ ̅ ̂ ̅ ∑ ̅ ̅ ∑∑ ̂ ̅ ̂ ̅ Dimana :
R2 = besarnya koefisien determinasi
SSR = Sum Of Squares Regression (Explaind Variation) SST = Sum Of Squares Total (Total Variation)
= Titik potong kurva terhadap sumbu Y
= Slope garis estimasi yang paling baik (Best Fitting) n = Banyak nya data
x = Nilai variabel x y = Nilai variabel y
̅ = Nilai rata-rata variabel y
Semakin besar nilai , semakin dekat antara estimasi garis regresi dengan data sampelnya. Dua sifat yang terdapat dalam koefisien determinasi adalah (Sarwoko, 2007):
1. Nilainya tidak pernah negative (non negative quantity)
2. Memiliki nilai limit . Apabila berarti kecocokan yang sempurna, sehingga ̂ , di lain apabila berarti tidak ada hubungan antara regressand dengan regressor.
Koefisien determinasi mengukur proporsi atau persen total variasi variable Y yang dapat dijelaskan oleh model regresi. Dalam multidimensional scaling¸ koefisien determinasi dikenal dengan RSQ (R Square) atau R kuadrat ialah kuadrat dari koefisien korelasi yang menunjukkan proporsi varian dari the
multidimensional yang merupakan ukuran kecocokan/ketepatan (goodness of fit
measure).
Dalam multidimensional scaling (MDS), RSQ mengindikasikan proporsi ragam input data yang dapat dijelaskan oleh model MDS. Semakin tinggi RSQ, semakin baik model MDS. Menurut Malhotra (2005), model RSQ dapat diterima bila RSQ > 0,6.
2.1.5 STRESS (Standarized Residual Sum of Square)
Menurut Supranto (2010) Kesesuaian solusi MDS biasanya dikaji dengan ukuran STRESS. STRESS ialah ukuran ketidakcocokan (a lack of fit measure), makin tinggi nilai STRESS semakin tidak cocok. Pada multidimensional scaling nonmetrik, hanya informasi ordinal pada proximity yang digunakan untuk mengkonstruksi konfigurasi spasial. Sebuah transformasi monotonik dari
proximity dihitung, yang menghasilkan scaled proximities. Optimally scaled proximities disebut juga sebagai disparities ̂
Untuk mengetahui ukuran tingkat ketidakcocokan output dengan keadaan sebenarnya digunakan fungsi STRESS (Standarized Residual Sum of Square) sebagai berikut:
√∑ ∑ ̂ ∑ ̅
Di mana :
̅ = Rata-rata jarak dalam peta
̂ = Jarak turunan (derived distance) atau data kemiripan (similary data). = Data jarak yang diberikan responden
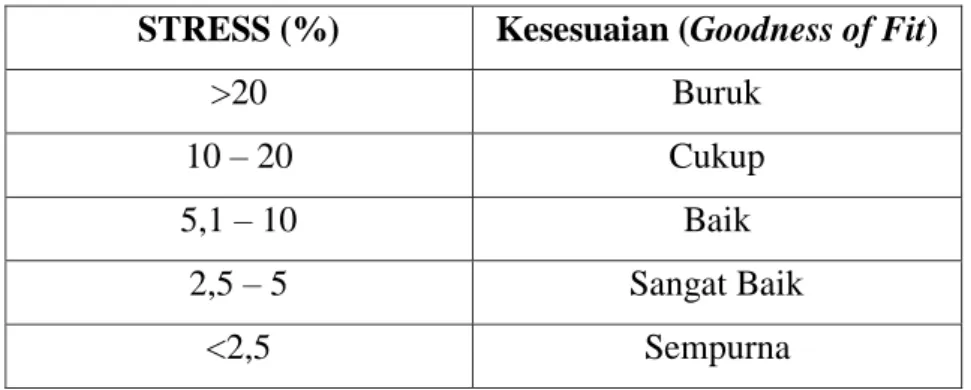
Perhitungan nilai STRESS juga dapat digunakan untuk menilai atau menentukan goodness of fit pada sebuah solusi MDS. Nilai STRESS yang kecil mengindikasikan sebuah kecocokan yang baik, sedangkan nilai STRESS yang tinggi mengindikasikan kecocokan yang buruk. Kruskal (1994) memberikan
beberapa panduan dalam hal interpretasi nilai STRESS mengenai goodness of
fit dari solusi yang ditunjukkan pada Tabel 2.1 berikut:
Tabel 2.1 Nilai Kesesuaian Fungsi STRESS
STRESS (%) Kesesuaian (Goodness of Fit)
>20 Buruk
10 – 20 Cukup
5,1 – 10 Baik
2,5 – 5 Sangat Baik
<2,5 Sempurna
Sumber; Masuku, Paendong, Langi (2014)
Semakin kecil nilai STRESS menunjukkan bahwa hubungan monoton yang terbentuk antara ketidaksamaan dengan disparities semakin baik (didapat kesesuaian) dan kriteria peta persepsi yang terbentuk semakin sempurna.
2.1.6 Positioning
Menurut Kotler (1988) positioning adalah suatu tindakan merancang nilai dan kesan yang ditawarkan perusahaan sehingga segmen pelanggan memahami dan mengapresiasi apa yang dilakukan perusahaan dalam kaitan dengan para pesaingnya.
Positioning didefinisikan sebagai seni dan ilmu pengetahuan dalam mencocokkan
produk atau jasa dengan satu atau lebih segmen pasar dalam rangka menetapkan bagian yang berarti dari produk atau jasa tersebut dari persaingan. Positioning juga merupakan upaya untuk mendesain produk agar menempati sebuah posisi yang unik di benak pelanggan. Positioning akan menjadi penting apabila persaingan sudah sangat sengit di segala bidang.
Menurut Pangerapan Sianipar (2010), Matriks adalah suatu susunan berbentuk persegi panjang dari elemen-elemen (bilangan-bilangan) yang terdiri dari beberapa baris dan kolom dibatasi dengan tanda kurung, seperti bentuk:
(
,
Atau disingkat dengan:
( )
Matriks A disebut matriks tingkat , atau disingkat matriks Karena terdiri dari m baris dan n kolom. Setiap disebut elemen (unsur) dari matriks itu, sedang indeks dan berturut-turut menyatakan baris dan kolom. Jadi elemen terdapat pada baris ke-i, kolom ke-j. pasangan bilangan disebut dimensi (ukuran atau bentuk) dari matriks itu. Suatu matriks tidak mempunyai harga numerik.
Pada umumnya martiks disingkat dan dinyatakan dengan huruf besar, sedang elemen-elemen matriks dengan huruf kecil. Untuk membeda-bedakan matriks ditulis dengan : atau misalnya untuk matriks .
2.2.1 Matriks Identitas dan Determinan Matriks
Matriks identitas adalah matriks diagonal dimana nilai elemen diagonal utamanya masing-masing adalah satu sedangkan nilai elemen off-diagonalnya adalah sama dengan nol. Matriks identitas memilki sifat seperti angka satu. Artinya, jika matriks identitas dikalikan dengan matriks lain (asal dimensinya terpenuhi) maka hasilnya akan tetap sama dengan nilai semua matriks tersebut. Dengan contoh matriks identitas berordo 3x3 tersebut dinotasikan dalam bentuk:
(
+
Determinan matriks A (det A atau |A|) adalah skalar yang dihitung melalui proses reduksi dan ekspansi dengan menggunakan minor dan kofaktor. Berikut langkah-langkah yang dapat dilakukan untuk memperoleh determinan matriks:
1. Pilih baris atau kolom yang akan diekspansi dan kemudian tentukan nilai minor matriks B dengan cara menghitung determinan submatriks yang tersisa setelah baris i dan kolom j dihilangkan.
2. Hitung matriks kofaktor ( ) sesuai dengan nilai minor terkait dengan menggunakan rumus .
3. Hitung ∑ dimana adalah nilai elemen baris (1) matriks B (baris yang di ekspansi).
Selain teknik tersebut ada alternatif yang mungkin lebih sederhana untuk menghitung determinan, yaitu dengan menjumlahkan hasil kali elemen-elemen yang sejajar dengan diagonal utama dan menguranginya dengan hasil kali elemen elemen yang berlawanan arah dengan diagonal utama.
2.3 Eigenvalue dan Eigenvector
Vektor kolom X merupakan eigenvector matriks A dan adalah eigenvalue atau sering disebut juga characteristic value. Jika A adalah sebuah matriks bujursangkar berukuran dan X adalah suatu vektor kolom, persamaan:
dimana adalah suatu bilangan, dapat ditulis sebagai:
( , ( , ( , Atau
Penyelesaian tersebut akan mempunyai persamaan tak trivial dan hanya jika
|
|
Yang dapat ditulis sebagai
yang merupakan suatu suku banyak berderajat n dalam . Akar dari persamaan suku banyak ini disebut eigenvalue (nilai eigen) dari atau nilai karakteristik dari matriks A. Untuk setiap eigenvalue (nilai eigen) akan ada penyelesaian X 0 yang merupakan suatu penyelesaian tak trivial yang dinamakan eigenvector (vector eigen) atau vektor karakteristik dari nilai eigennya.
2.4 Analisis Multivariat
Secara umum, Analisis Multivariat atau Metode Multivariat berhubungan dengan metode-metode statistik yang secara bersama-sama (simultan) melakukan analisis terhadap lebih dari dua variabel dari setiap objek (Singgih, 2015). Jadi bias dikatakan, analisis multivariat merupakan perluasan dari analisis univariat (seperti uji t) atau bivariat (seperti korelasi dan regresi sederhana).
Multidimensional Scaling adalah salah satu metode dari analisis data
multivariat. Analisis data multivariat secara sederhana dapat didefinisikan sebagai aplikasi metode-metode yang berhubungan dengan sejumlah besar pengukuran yang dibuat untuk setiap objek dalam satu atau lebih sampel secara simultan.Dengan kata lain, analisis data multivariat mengukur relasi simultan antar variabel. Secara umum, metode-metode dalam analisis data multivariat digolongkan menjadi dua kelompok. Kelompok pertama adalah metode-metode dependen. Metode-metode dependen terpusat pada mencari asosiasi dari dua
himpunan variabel dimana salah satu himpunan adalah realisasi dari suatu ukuran dependen. Dengan kata lain, metode-metode dependen berusaha mencari atau memprediksi ukuran satu atau lebih kriteria berdasar himpunan variabel prediktor. Yang termasuk dalam kelompok ini adalah Multiple Regression, Analisis Diskriminan, Analisis Logistik, Multivariate Analysis of Variance (MANOVA) dan Canonical Correlation Analysis.
Kelompok kedua adalah metode-metode interdepeden. Metode-metode interdependen terpusat pada asosiasi mutual antar variabel tanpa membedakan tipe -tipe variabel. Secara umum, metode-metode ini tidak memberikan prediksi melainkan mencoba memberikan gambaran mengenai struktur yang mendasari data dengan cara menyederhanakan kompleksitas atau dengan mereduksi data. Yang termasuk dalam kelompok ini adalah Principal Component Analysis, Analisis Faktor, Multidimensional Scaling (MDS), Analisis Kluster, Pemodelan Loglinear.
2.4.1 Analisis Faktor
Menurut J. Supranto (2004), analisis faktor merupakan teknik statistika yang utamanya dipergunakan untuk mereduksi atau meringkas data dari variabel yang banyak diubah menjadi sedikit variabel, misalnya dari 15 variabel yang lama diubah menjadi 4 atau 5 variabel yang baru yang disebut faktor dan masih memuat sebagian besar informasi yang terkandung dalam variabel asli (original variable). Dalam analisis faktor tidak ada variabel dependent dan independent, proses analisis faktor sendiri mencoba menemukan hubungan (interrelationship) antara sejumlah variabel yang saling dependent dengan yang lain sehingga bisa dibuat satu atau beberapa kumpulan variabel yang lebih sedikit dari jumlah awal. Analisis faktor digunakan di dalam situasi sebagai berikut:
a. Mengenali atau mengidentifikasi dimensi yang mendasari (underlying
dimensions) atau faktor yang menjelaskan korelasi antara suatu set variabel.
b. Mengenali dan mengidentifikasi suatu set variabel baru yang tidak berkorelasi (independent) yang lebih sedikit jumlahnya untuk menggantikan suatu set variabel asli yang saling berkorelasi di dalam analisis multivariat selanjutnya.
c. Mengenali atau mengidentifikasi suatu set variabel yang penting dari suatu set variabel yang lebih banyak jumlahnya untuk dipergunakan di dalam analisis multivariat selanjutnya.
Faktor yang unik tidak berkorelasi dengan sesama faktor yang unik dan juga tidak berkorelasi dengan common factor. Common factor sendiri bisa dinyatakan sebagai kombinasi linier dari variabel-variabel yang terlihat/terobservasi (the observed variables) hasil penelitian lapangan.
keterangan:
= Perkiraan Faktor ke-i (didasarkan pada nilai variabel X dengan koefisiennya Wi)
= Timbangan atau Koefisien Nilai Faktor ke-i k = Jumlah
Variabel
2.5 Jenis Data Menurut Cara Memperolehnya
Menurut cara memperolehnya, data terbagi menjadi 2, yaitu (Syafrizal & Muslich, 2012):
1. Data Primer
Data primer (primary data) yaitu data yang dikumpulkan sendiri oleh perorangan/suatu organisasi secara langsung dari objek yang diteliti dan untuk kepentingan studi yang bersangkutan yang dapat berupa interview (wawancaa), kuesioner (angket) maupun observasi.
2. Data Sekunder (Secondary Data)
Data sekunder (secondary data) yaitu data yang diperoleh atau dikumpulkan dan disatukan oleh studi-studi sebelumnya atau yang diterbitkan oleh berbagai instansi lain. Biasanya sumber tidak langsung berupa data dokumentasi dan arsip-arsip resmi.
2.6 Jenis Skala Pengukuran Data
Ada 4 jenis atau tipe skala pengukuran data, yaitu (Syafrizal & Muslich,2012): 1. Skala Nominal
Skala nominal merupakan tingkatan pengukuran yang paling sederhana. Dasar penggolongan ini agar kategori yang tidak tumpang tindih (mutually
exclusive) dan tuntas (exhaustive). “Angka” yang ditunjuk untuk suatu
kategori tidak merefleksikan bagaimana kedudukan kategori tersebut terhadap kategori lainnya, tetapi hanya sekedar label atau kode sehingga skala yang diterapkan pada data yang hanya bisa dibagi ke dalam kelompok-kelompok tertentu dan pengelompokan tersebut hanya dilakukan untuk tujuan identifikasi.
2. Skala Ordinal
Skala ordinal memungkinkan peneliti untuk mengurutkan respondennya dari tingkatan yang paling rendah ke tingkatan yang paling tinggi menurut atribut tertentu. Skala yang diterapkan pada data dapat dibagi dalam berbagai kelompok dan bisa dibuat peringkat di antara kelompok tersebut.
3. Skala Interval
Seperti halnya ukuran ordinal, ukuran interval adalah mengurutkan orang atau objek berdasarkan suatu atribut. Interval atau jarak yang sama pada skala interval dipandang sebagai mewakili interval atau jarak yang sama pula pada objek yang diukur. Skala yang diterapkan pada data dapat diranking dan peringkat tersebut bisa diketahui perbedaan diantara peringkat-peringkat tersebut dan bisa dihitung besarnya perbedaan itu. Namun harus diperhatika bahwa dalam skala ini perbandingan rasio yang ada tidak diperhitungkan.
4. Skala Rasio
Suatu bentuk interval yang jaraknya (interval) tidak dinyatakan sebagai perbedaan nilai antar responden, tetapi antara seorang dengan nilai nol absolut, karena ada titik nol maka perbandingan rasio dapat ditentukan.
2.7 Teknik Sampling
Teknik sampling adalah suatu cara untuk menentukan banyaknya sampel dan pemilihan calon anggota sampel, sehingga setiap sampel yang terpilih dalam penelitian dapat mewakili populasinya (representatif) baik dari aspek jumlah maupun dari aspek karakteristik yang dimiliki populasi. Sampling adalah proses pemilihan sejumlah elemen dari populasi sehingga dengan meneliti dan memahami karakteristik sampel dapat digeneralisir untuk karakteristik populasi. Jarang sekali suatu penelitian dilakukan dengan cara memeriksa semua objek yang diteliti (sensus), tetapi sering digunakan sampling (Teken, 1965), alasannya adalah:
1. Biaya, waktu dan tenaga untuk menyelidiki melalui sensus.
2. Populasi yang berukuran besar selain sulit untuk dikumpulkan, dicatat dan dianalisis, juga biasanya akan menghasilkan informasi yang kurang teliti. Dengan cara sampling jumlah objek yang harus diteliti menjadi lebih kecil, sehingga lebih terpusat perhatiannya.
3. Percobaan-percobaan yang berbahaya atau bersifat merusak hanya cocok dilakukan dengan sampling.
Keuntungan dengan menggunakan teknik sampling antara lain adalah mengurangi ongkos, mempercepat waktu penelitian dan dapat memperbesar ruang lingkup penelitian (Teken, 1965). Metode pengambilan sampel yang ideal memiliki sifat-sifat sebagai berikut:
1. Dapat menghasilkan gambaran yang dapat dipercaya dari seluruh populasi yang diteliti.
2. Dapat menentukan ketepatan hasil penelitian dengan menentukan penyimpangan baku dari taksiran yang diperoleh.
3. Sederhana dan mudah diperoleh.
4. Dapat memberikan keterangan sebanyak mungkin dengan biaya serendah mungkin.
Dalam menentukan besarnya sampel dalam suatu penelitian, ada empat faktor yang harus dipertimbangkan yaitu:
1. Derajat keseragaman populasi.
2. Ketepatan yang dikehendaki dari penelitian. 3. Rencana analisis.
4. Tenaga, biaya dan waktu.
Teknik sampling dapat dikelompokkan menjadi dua, yaitu: 1. Probability sampling, meliputi:
a. Simple random sampling (populasi homogen) yaitu pengambilan sampel dilakukan secara acak tanpa memperhatikan strata yang ada. Teknik ini hanya digunakan jika populasinya homogen.
b. Proportionale stratifiled random sampling (populasi tidak homogen)
yaitu pengambilan sampel dilakukan secara acak dengan memperhatikan strata yang ada. Artinya setiap strata terwakili sesuai proporsinya.
c. Disproportionate stratifiled random sampling yaitu teknik ini digunakan untuk menentukan jumlah sampel dengan populasi berstrata tetapi kurang proporsional, artinya ada beberapa kelompok strata yang ukurannya kecil sekali.
d. Cluster sampling (sampling daerah) yaitu teknik ini digunakan untuk menentukan jumlah sampel jika sumber data sangat luas. Pengambilan sampel didasarkan daerah populasi yang telah ditetapkan.
2. Non probability sampling, meliputi: sampling sistematis, sampling kuota, sampling incidental, purposive sampling, sampling jenuh, dan snowball sampling.
Pada penelitian ini, peneliti menggunakan sampling kuota yaitu jumlah sampel minimal adalah 10 kali dari jumlah variabel yang diteliti.
2.8 Uji Normalitas
Melakukan uji normalitas data terhadap setiap variabel bebas. Uji normalitas terhadap data dengan tujuan untuk mengetahui apakah data yang diambil berdistribusi normal atau tidak. Uji yang digunakan adalah uji Liliefors yang
dikemukaan oleh Sudjana (2005:466) dengan langkah-langkah pengujiannya sebagai berikut:
1. Mengurutkan setiap data pada vaiabel bebas dari data terbesar sampai data terendah.
2. Mengolah data menjadi bahan baku Z dengan menggunakan rumus: ∑ ̅ ̅ ∑ ∑ √ ∑ ∑ ̅ Keterangan: S = Simpangan Baku ̅ = Rata-rata
xij = Data setiap variabel n = Jumlah data
3. Dengan menggunakan distribusi normal baku, dihitung peluang dari F(Zi) = P(Z ≤ Zi). Dengan melihat table Z untuk nilai F(Zi).
4. Selanjutnya hitung prporsi Z1, Z2, …, Zn yang lebih kecil atau sama dengan Zi. Peluang ini deinyatakan dengan S(Zi), dengan menggunakan rumus:
5. Hitung selisih F(Z) – S(Z). Kemudian ditentukan harga mutlaknya dan harga mutlak terbesar dinyatakan dengan L0.
6. Untuk menerima atau menolak hipotesis nol dibandingkan antara L0 dengan nilai kritis L pada uji liliefors.
Ambil harga L0 dengan kritis L ( Ltabel pada taraf nyata α = 0,05 yang dipilih) jika L0 ≤ Ltabel berarti data pada variabel bebas diatas berdistribusi normal.
Kriteria pengujiannya :
Jika L0 > Ltabel berarti data tidak berdistribusi normal
2.9 Uji Validitas
Validitas merupakan alat ukur untuk melihat atau mengetahui apakah kuesioner dapat digunakan untuk mengukur keadaan responden sebenarnya. Untuk menguji validitas keadaan responden digunakan rumus kolerasi product Moment Pearson (Usman, 2013) yaitu: ∑ ∑ ∑ √ ∑ ∑ ∑ ∑ x = variabel bebas y = variabel tak bebas
n = banyaknya ukuran sampel
Sebelum menjabarkan tentang analisis data dalam bentuk perhitungan dengan menggunakan bantuan program SPSS, sebagaimana diketahui hipotesis penelitian sebagai berikut:
= Variabel valid = Variabel tidak valid
Validitas dapat diukur dengan membandingkan dengan . Kriteria penilaian uji validitas adalah:
a. Apabila > (pada taraf signifikan 5% atau 1%), maka diterima artinya butir pertanyaan tersebut valid.
b. Apabila (pada taraf signifikan 5% atau 1%), maka ditolak artinya butir pertanyaan tersebut tidak valid.
Setelah dilakukan uji validitas dan dinyatakan valid dilanjutkan dengan uji reliabilitas. Suatu variabel dikatakan reliabel apabila setelah dilakukan uji reliabel diperoleh nilai Cronbach Alpha > 0,60 atau nilai Cronbach Alpha > 0,80. Jika dihitung variansi itemnya akan diperoleh hasil sebagai berikut:
Mencari nilai variansi dari masing-masing variabel dengan rumus sebagai berikut:
∑ ∑
Keterangan: s = Variansi x = Variabel bebas
Mencari nilai Alpha
][1-∑
] Keterangan :
koefisien reliabilitas (alpha Cronbach) jumlah item tes
varians skor