Pendekatan Algoritma Heuristik dan Neural Network
untuk Screening Test pada Urinalysis
Abidatul Izzah
1), R.V. Hari Ginardi
2), Ahmad Saikhu
3)Teknik Informatika Institut Teknologi Sepuluh Nopember Surabaya
1
)[email protected],
2)[email protected],
3)[email protected]
ABSTRAK
Uji makro kandungan urin menggunakan dipstick urin telah dimanfaatkan untuk mengetahui potensi penyakit yang diderita oleh seorang pasien. Namun, pembacaan hasil tes dipstick urin masih sulit dipahami oleh sebagian masyarakat. Oleh karena itu perlu adanya suatu alat bantu untuk memberi informasi dari hasil yang diperoleh dipstick urin. Pada makalah ini, digunakan suatu metode yang mampu memberikan sebuah indikasi sebagai hasil screening test dari dipstick urin menggunakan pendekatan komputasi cerdas. Metode yang digunakan pada makalah ini adalah algoritma heuristik Gravitational Search Algorithm
(GSA) dan Artificial Neural Network (ANN). GSA digunakan sebagai algoritma pembelajaran sehingga diperoleh kombinasi bobot dan bias pada arsitektur ANN. Digunakan pula operator
disruption untuk menghindari konvergensi dini sebagai kekurangan yang dimiliko oleh GSA. Metode ini diimplementasikan untuk melakukan screening test pada penyakit Infeksi Saluran Kemih (ISK) pada data urinalysis dari 90 pasien. Data ini diperoleh dari hasil pemeriksaan urinalysis di Laboratorium Klinik Utama Popular, Surabaya sejak Januari 2012 sampai dengan September 2013. Hasil yang diperoleh menunjukkan bahwa dengan menggunakan metode yang diusulkan dapat memberikan hasil yang lebih baik daripada metode pembandingnya dengan nilai sensivitas dan spesifisitas yang menghasilkan nilai sebesar 100% dan sebesar 77%.
Kata Kunci
Gravitational Search Algorithm, Artificial Neural Network, Urinalysis, Disruption
1.
PENDAHULUAN
Pemeriksaan kesehatan berdasarkan urin atau yang sering disebut dengan urinalysis berdasarkan pada kandungan urin dapat menunjukkan potensi kelainan pada pasien. Variasi warna urin dapat disebabkan oleh jenis makanan atau obat yang dikonsumsi oleh pasien. Beberapa manfaat urinalysis adalah dapat digunakan untuk mengetahui adanya potensi gangguan hati, diabetes mellitus, infeksi pada ginjal atau saluran kemih. Uji urinalysis terdiri dari dua macam, yaitu uji makroskopik dan uji mikroskopik. Tes mikroskopik dilakukan dengan memutar (centrifuge) urin lalu mengamati endapan urin di bawah mikroskop. Sedangkan tes makroskopik dilakukan dengan cara visual yakni, pemeriksaan urin meliputi penaksiran dari kenampakan, bau, keadaan, dan fisik. Saat ini metode paling umum pada urinalysis adalah uji menggunakan dipstick urin. Uji ini dapat menunjukkan rentang kandungan kimia yang ada pada urin. Uji ini menggunakan reagen strip yang dicelupkan ke dalam urin lalu mengamati perubahan warna yang terjadi pada strip dan membandingkannya dengan grafik warna standar. Dari pengujian ini diperoleh sepuluh zat yang dikandung urin antara lain pH, berat jenis, glukosa, protein, bilirubin, urobilinogen, darah, keton, nitrit, dan lekosit. Dengan melakukan uji urinalysis menggunakan dipstick ini, pasien akan memperoleh nilai kandungan zat pada urin namun terkadang tidak
mengetahui makna dari nilai yang ditunjukkan. Jika pasien mengetahui bahwa kondisi urin memiliki kecenderungan abnormal, maka pasien bisa merubah dan memperbaiki pola hidup.
Penelitian tentang pemanfaatan dipstick urin untuk mengindikasikan suatu penyakit yang diderita pasien telah banyak dilakukan. Salah satunya adalah dipstick sebagai diagnosis untuk trypsin inhibitor (urinstatin) pada urin dan plasma pasien yang terinfeksi saluran kemih (Pugia, 2004). Pemeriksaan awal menggunakan dipstick urin sangat membantu untuk mengetahui apakah pasien perlu melakukan pemeriksaan tambahan. Namun, penerjemahan hasil kenampakan warna
dipstick urin masih sulit dipahami oleh para penggunanya. Oleh karena itu diperlukan sebuah alat bantu untuk menerjemahkan hasil pemeriksaan dipstick urin.
Di sisi lain, berkembangnya ilmu pengetahuan dan teknologi di bidang analisis data dapat dimanfaatkan dalam bidang kesehatan dalam pengambilan sistem pendukung keputusan. Data Mining (DM) adalah suatu disiplin ilmu yang melakukan pendekatan dalam analisis data dan penemuan informasi pada dataset yang kompleks (Yeh, 2012). Salah satu permasalahan yang dapat diatasi dalam pengolahan data adalah pemberian label dalam mendeskripsikan analisis komputasi yakni klasifikasi. Klasifikasi data merupakan proses pelabelan pada suatu dataset berdasarkan pembelajaran pada dataset sebelumnya (Mastrogiannis dkk, 2009). Metode yang digunakan untuk klasifikasi salah satunya adalah Neural Network (ANN). ANN adalah algoritma yang diinspirasi dari sistem syaraf manusia, dimana sistem syaraf manusia terdiri dari beberapa neuron yang menerima rangsangan dari luar tubuh untuk diteruskan menuju otak melalui dendrit. Algoritma ini merupakan algoritma supervised learning yang yang banyak digunakan dalam memecahkan permasalahan linear maupun non linear (Dias dkk, 2004). Di samping itu algoritma heuristik sebagai algoritma pencarian juga mengalami perkembangan yang pesat, salah satunya ditemukan Gravitational Search Algorithm (GSA) yakni algoritma yang diinspirasi dari hukum gravitasi dan hukum perpindahan benda menuju pada posisi seimbang. Sebagai algoritma heuristik, GSA memiliki kemampuan yang bagus dalam pencarian global. Namun jika konvergensi terlalu dini terjadi, algoritma ini kehilangan kemampuannya dalam pencarian (Sarafrazi, 2011). Untuk memperbaiki kemampuan GSA ditambahkan sebuah operator baru yakni disruption untuk lebih mengeksplorasi solusi yang didapatkan oleh GSA. Izzah (2013) telah melakukan uji coba pada GSA dengan penambahan operator disruption sebagai metode pembelajaran pada ANN untuk klasifikasi data. Hasil yang diperoleh menunjukkan bahwa metode ini memberikan hasil yang lebih baik daripada ANN dengan pembelajaran GSA (ANN-GSA) dan ANN dengan pembelajaran Genetic Algorithm (ANN-GA).
Paper ini bertujuan untuk melakukan klasifikasi data urinalysis menggunakan metode ANN dengan pembelajaran GSA dan
sebagai screening test pada uji dipstick urin sehingga pasien dapat mengetahui apakah ia memiliki potensi mengidap penyakit Infeksi Saluran Kemih (ISK).
2.
LANDASAN TEORI
2.1
Uji Urinalysis
Urine analysis (analisa terhadap kandungan urin) merupakan salah satu tes klinis yang paling sering dilakukan pada dunia pediatri. Hal ini didasari pada kemudahan pengumpulan urin dan kesederhanaan prosedur tes yang harus dilakukan (Whiting, 2006). Tes urin dapat digunakan untuk mendeteksi beberapa gangguan kesehatan. Deteksi ini dilakukan dengan menganalisa kandungan kimia yang terdapat pada urin. Beberapa kandungan kimia yang umum dianalisa adalah kandungan darah, protein, glukosa, leukosit esterase, nitrit, dan β-HCG. Beberapa kandungan lain juga dianalisa namun jarang dilakukan adalah kandungan keton, urobilin, bilirubin, berat jenis, dan pH (Barrat, 2007). Pada uji urinalysis menggunakan reagent strips, sepuluh kandungan urin yang terdeteksi antara lain: berat jenis, pH, leukosit, hemoglobin, nitrit, keton, bilirubin, urobilinogen, protein, dan glukosa. Warna yang dihasilkan oleh dipstick akan dibandingkan dengan urin chart sehingga dapat diperoleh estimasi nilai dari masing-masing warna. Gambar 1 memperlihatkan chart warna yang dihasilkan saat melakukan tes makroskopis urinalysis.
Gambar 1. Bagan Warna Dipstick Urinalysis Beberapa manfaat urinalysis adalah dapat digunakan untuk mengetahui adanya potensi gangguan hati, diabetes mellitus, infeksi pada ginjal atau saluran kemih. Infeksi saluran kemih adalah infeksi yang terjadi di sepanjang jalan saluran kemih, termasuk ginjal itu sendiri akibat proliferasi suatu mikroorganisme. Untuk menyatakan adanya infeksi saluran kemih harus ditemukan bakteri di dalam urin. Suatu infeksi dapat dikatakan jika terdapat 100.000 atau lebih bakteri/ml urin, namun jika hanya terdapat 10.000 atau kurang bakteri/ml urin, hal itu menunjukkan bahwa adanya kontaminasi bakteri.Bakteriuria bermakna yang disertai gejala pada saluran kemih disebut bakteriuria bergejala. Sedangkan yang tanpa gejala disebut bakteriuria tanpa gejala.
Dalam pemeriksaan laboratorium, pasien yang berpotensi mengidap ISK dapat dilihat dari hasil urinalisis yang meliputi “Leukosuria” (ditemukannya leukosit dalam urin) dimana dinyatakan positif jika terdapat 5 atau lebih leukosit (sel darah putih) per lapangan pandang dalam sedimen urin dan “Hematuria” (ditemukannya eritrosit dalam urin) yakni petunjuk adanya infeksi saluran kemih jika ditemukan eritrosit (sel darah merah) 5-10 per lapangan pandang sedimen urin.
Hematuria bisa juga karena adanya kelainan atau penyakit lain, misalnya batu ginjal dan penyakit ginjal lainnya. Di sisi lain, dengan memanfaatkan uji makroskopis, pasien mendapatkan informasi ada tidaknya kandungan zat pada urin. Majid (2010) menunjukkan bahwa pada urin pasien yang mengandung nitrit berindikasi mengidap penyakit ISK. Hal ini disebabkan adanya nitrit merupakan hasil perubahan asam nitrat oleh bakteri. Dengan demikian potensi mengidap ISK dapat diteliti dari ada atau tidaknya kandungan nitrit pada urin pasien.
2.2
Artificial Neural Network
ANN merupakan algoritma supervised learning yang memetakan data input terhadap target output dimana ANN mampu memodelkan permasalahan non linier kompleks yang sulit dipecahkan dengan menggunakan persamaan matematis biasa. Rojas (1996) menjelaskan bahwa secara biologis, sebuah informasi dapat disimpan pada titik-titik kontak antara neuron (sinapsis). Dalam arsitektur ANN, sebuah node adalah suatu elemen komputasi yang mengintrepretasikan suatu neuron. Informasi yang dikandung dalam node akan dilanjutkan ke node yang lain layaknya sinapsis pada jaringan syaraf manusia. Arsitektur ANN terdiri dari lapisan input, lapisan hidden, dan lapisan output. Jaringan syaraf yang tidak memiliki lapisan hidden disebut dengan ANN satu layer, sedangkan jaringan yang memiliki banyak lapisan hidden disebut dengan ANN multi layer. Masing-masing node antar lapisan dihubungkan dengan bobot 𝑤𝑖 dan dipengaruhi oleh bias 𝜃𝑖. ANN ditentukan oleh 3 hal, yakni pola hubungan antar neuron (disebut arsitektur jaringan), metode untuk menentukan bobot penghubung (disebut metode training/learning/algoritma), dan fungsi aktivasi (fungsi transfer). Contoh arsitektur jaringan ANN dapat dilihat pada Gambar 2. Sedangkaan macam-macam fungsi aktivasi dapat dilihat pada Gambar 3.
(a) (b)
Gambar 2. Arsitektur Neural Network (a) ANN Satu Layer (b) ANN Multi Layer
(a) (b)
(c) (d)
Gambar 3. Fungsi Aktivasi
2.3
GSA dan
Disruption
GSA adalah algoritma heuristik yang ditemukan oleh Rashedi (2009). Algoritma ini diinspirasi dari fenomena alam yakni hukum gravitasi dan tarik menarik massa. Hukum gravitasi menyatakan bahwa setiap partikel yang memiliki massa menarik satu sama lain dengan gaya gravitasi sehingga menyebabkan perpindahan partikel menuju massa yang lebih besar. Fenomena gravitasi yang menyebabkan perpindahan suatu benda menuju keseimbangan telah diadopsi menjadi sebuah algoritma yang disebut dengan GSA. Dalam GSA, posisi partikel yang memiliki massa merepresentasikan solusi permasalahan.
Gravitasi adalah kecenderungan sebuah benda untuk melakukan tarik-menarik dengan benda lain yang memiliki massa. Gaya ini adalah salah satu interaksi dasar di alam selain gaya elektromagnetik, gaya nuklir lemah, dan gaya nuklir kuat. Dalam hukum gravitasi Newton, setiap partikel menarik partikel lain dengan gaya gravitasi dan percepatan partikel ditentukan oleh gaya dan massa partikel tersebut (Rashedi, 2009). Konsep gaya tarik menarik antar benda dapat dilihat pada Gambar 4.
Gambar 4. Konsep gaya tarik menarik antar partikel Dari Gambar 4 dapat dilihat bahwa tarikan oleh massa yang lebih besar mampu mendominasi resultan gaya yang dialami sebuah benda (F1 sebagai resultan gaya yang dialami M1
menuju M3 dimana M3 adalah massa yang paling besar).
Semakin besar massa yang ditarik maka semakin besar gaya yang dibutuhkan. Di sisi lain, jika kedua benda dipisahkan semakin jauh, maka gaya yang ditimbulkan semakin kecil. Hukum gravitasi menyatakan bahwa setiap partikel yang memiliki massa saling menarik satu sama lain dengan gaya gravitasi sehingga menyebabkan perpindahan menuju massa yang lebih besar.
Rashedi (2009) menjelaskan bahwa langkah pertama dalam GSA adalah inisialisasi N solusi (agen) awal dengan m dimensi secara random. Posisi agen direpresentasikan sebagai berikut:
𝑋𝑖= (𝑥𝑖1, … , 𝑥𝑖𝑑, … , 𝑥𝑖𝑚)
dimana i= 1, 2, …, N dan 𝑥𝑖𝑑 adalah posisi agen ke-i dimensi ke-d. Untuk setiap iterasi, total gaya interaksi setiap agen F
dengan agen yang lain dihitung dengan persamaan (1) dan (2):
𝐹𝑖𝑑(𝑡) = 𝐺(𝑡)𝑀𝑖(𝑡) 𝑀𝑅𝑖𝑗(𝑡)𝑗(𝑡)(𝑥𝑗𝑑(𝑡) − 𝑥𝑗𝑑(𝑡)) (1)
𝐹𝑖𝑗𝑑(𝑡) = ∑ 𝑟𝑎𝑛𝑑𝑗𝐹𝑖𝑑(𝑡) 𝑁
𝑗𝜖𝐾𝐵𝑒𝑠𝑡 𝑗≠𝑖
(2)
dimana 𝐺(𝑡) adalah konstanta gravitasi pada saat t, Mi(t)
adalah massa agen i, 𝑅𝑖𝑗(𝑡) merupakan jarak euclid antar agen yang dihitung dengan persamaan (3):
𝑅𝑖𝑗(𝑡) = ‖𝑋𝑖(𝑡), 𝑋𝑗(𝑡)‖2 (3)
Update nilai G(t) yang berubah pada setiap iterasi yang dihitung dengan persamaan (4):
𝐺(𝑡) = 𝐺(𝐺0, 𝑡) (4)
dimana 𝐺(𝑡0) adalah konstanta gravitasi pada interval kuantum kosmik pada saat t0.
Untuk menghitung massa Mi(t) tiap agen dihitung melalui
persamaan (5) dan (6):
𝑚𝑖(𝑡) =𝑏𝑒𝑠𝑡(𝑡) − 𝑤𝑜𝑟𝑠𝑡(𝑡) (5)𝑓𝑖𝑡𝑖(𝑡) − 𝑤𝑜𝑟𝑠𝑡(𝑡)
𝑀𝑖(𝑡) =∑𝑚𝑖𝑚(𝑡) 𝑗(𝑡) 𝑁
𝑗=1 (6)
Agen best dan worst dipilih berdasarkan nilai fitness. dimana jika fungsi minimasi, best(t) dan worst(t) ditentukan sebagai berikut:
𝑏𝑒𝑠𝑡(𝑡) = min𝑗𝜖{1,…,𝑁}𝑓𝑖𝑡𝑗(𝑡) (7) 𝑤𝑜𝑟𝑠𝑡(𝑡) = max𝑗𝜖{1,…,𝑁}𝑓𝑖𝑡𝑗(𝑡) (8)
Namun, jika fungsi maksimasi ditentukan sebagai berikut:
𝑏𝑒𝑠𝑡(𝑡) = max𝑗𝜖{1,…,𝑁}𝑓𝑖𝑡𝑗(𝑡) (9) 𝑤𝑜𝑟𝑠𝑡(𝑡) = min𝑗𝜖{1,…,𝑁}𝑓𝑖𝑡𝑗(𝑡) (10)
Langkah selanjutnya adalah menghitung kecepatan dan percepatan yang dialami oleh agen dengan persamaan (11) dan (12).
𝑎𝑖𝑑(𝑡) =𝐹𝑖 𝑑(𝑡)
𝑀𝑖(𝑡) (11) 𝑣𝑖𝑑(𝑡 + 1) = 𝑟𝑎𝑛𝑑𝑖𝑣𝑖𝑑(𝑡) + 𝑎𝑖𝑑(𝑡) (12)
Langkah terakhir adalah update posisi agen menggunakan persamaan (13).
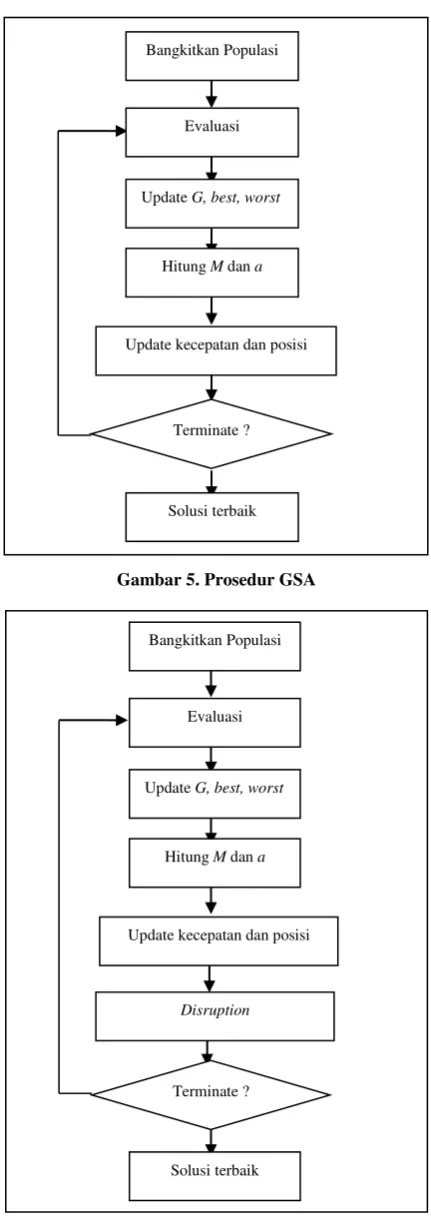
Sarafrazi (2011) menyebutkan bahwa jika konvergensi terlalu dini terjadi, algoritma ini kehilangan kemampuannya dalam pencarian. Untuk memperbaiki kemampuan GSA, ditambahkan sebuah operator baru yakni disruption untuk lebih mengeksplorasi solusi.
Disrupsi gaya gravitasi yang diinspirasi dari ilmu astronomi merupakan fenomena terjadinya guncangan pada sekumpulan partikel yang ada dibawah pengaruh gaya gravitasi. Disrupsi terjadi secara tiba-tiba pada sekumpulan partikel yang berada dalam medan gravitasi. Hal ini terjadi ketika gaya gravitasi tidak mampu memberikan keseimbangan. Konsep astronomi tentang gaya gravitasi menyatakan bahwa ketika sekumpulan partikel memiliki total massa (m) terlalu mendekati objek yang sangat besar (M), sekumpulan cenderung terpisah (Harwit, 1998).
Fenomena disrupsi dalam komputasi disimulasikan dengan solusi terbaik (partikel dengan massa yang paling besar) yang menjadi pusat partikel massa pada medan gravitasi. Dibawah pengaruh gaya gravitasi tersebut, solusi-solusi yang lain berpotensial untuk terguncang atau tersebar dalam ruang keadaan. Untuk menjaga diversitas dan bertambahnya kompleksitas, disruption dibatasi dengan persamaan (14).
𝑅𝑖,𝑗
𝑅𝑖,𝑏𝑒𝑠𝑡< 𝐶 (14)
dimana 𝑅𝑖,𝑗 adalah jarak euclid antara partikel i dengan sekitarnya sedangkan 𝑅𝑖,𝑏𝑒𝑠𝑡 adalah jarak euclid antara partikel i
dengan best. Disrupsi terjadi ketika rasio jarak antara partikel i
dengan partikel disekitarnya (𝑅𝑖,𝑗) dan jarak antara partikel i
dengan best (𝑅𝑖,𝑏𝑒𝑠𝑡) kurang dari suatu ambang batas. Berdasarkan konsep pencarian, dua solusi yang terlalu mirip tidak berguna dalam populasi. Oleh karena itu jika jarak tersebut terlalu dekat, operator disruption dijalankan. Gambar 6 menunjukkan diagram alir IGSA
Sarafrazi (2011) menjelaskan simulasi komputasi fenomena disruption secara sederhana dapat dilakukan sebagai berikut: a) Hitung rasio jarak antara partikel i dengan partikel
disekitarnya (𝑅𝑖,𝑗) danjarak antara partikel i dengan best (𝑅𝑖,𝑏𝑒𝑠𝑡)menggunakan persamaan (14).
b) Update posisi setiap partikel menggunakan persamaan berikut
𝐷 = {1 + 𝜌. 𝑈(−0.5,0.5) untuk yang lain𝑅𝑖,𝑗. 𝑈(−0.5,0.5) jika 𝑅𝑖,𝑏𝑒𝑠𝑡≥ 1
dengan 𝑈(−0.5,0.5) adalah bilangan acak uniform pada interval [-0.5,0.5].
c) Update xi(old)
Operator disruption akan mengeksplorasi dan mengeksploitasi solusi tergantung pada nilai D. Jika nilai 𝑅𝑖,𝑏𝑒𝑠𝑡 sangat besar maka solusi akan dieksplorasi sedangkan jika nilai 𝑅𝑖,𝑏𝑒𝑠𝑡 kecil dilakukan eksploitasi.
Gambar 5. Prosedur GSA
Gambar 6. Prosedur GSA dengan Operator Disruption
3.
ANN DAN IGSA UNTUK
SCREENING
TEST
PADA URINALYSIS
GSA dengan penambahan operator disruption yang kemudian disebut Integrated GSA (IGSA) pada ANN digunakan sebagai metode pembelajaran untuk menemukan bobot dan bias yang optimal. Langkah pertama adalah melakukan preprocessing data dan membagi data menjadi data latih dan data uji. Data tersebut
Bangkitkan Populasi
Update kecepatan dan posisi
Terminate ?
Solusi terbaik Disruption
Evaluasi
Update G, best, worst
Hitung M dan a Bangkitkan Populasi
Evaluasi
Update kecepatan dan posisi
Terminate ?
Solusi terbaik Update G, best, worst
kemudian dinormalisasi sehingga bernilai pada interval [0,1]. Parameter yang digunakan dalam ANN-IGSA adalah G, α,
jumlah agen, dan maxEpoh.
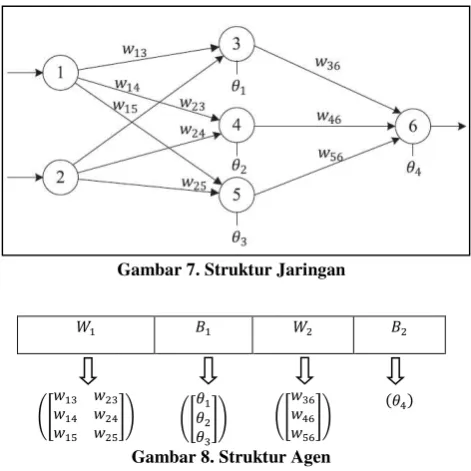
Dalam paper ini, struktur jaringan yang digunakan adalah ANN
double layer dengan jumlah node input sebanyak fitur data. Struktur jaringan ANN yang digunakan dapat dilihat pada Gambar 7. Langkah selanjutnya adalah membangkitkan agen yang merupakan kombinasi bobot dan bias. Node i di lapisan input dengan node j di lapisan hidden layer dihubungkan dengan bobot wij. Sedangkan node-node di hidden layer
dipengaruhi dengan 𝜃𝑘.
Pengkodean bobot dan bias yang digunakan adalah pengkodean matriks dimana agen i menyatakan solusi ke-i yang terdiri dari 𝑊1= [
. Fungsi aktivasi yang digunakan di hidden layer adalah fungsi sigmoid sesuai dengan Persamaan (16).
𝑓(𝑠𝑗) =1 + 𝑒− ∑(𝑤1 𝑖𝑗𝑥𝑖𝑗−𝜃𝑗); (16)
dimana 𝑠𝑗= ∑(𝑤𝑖𝑗𝑥𝑖𝑗− 𝜃𝑗), 𝑗 = 1,2, … , ℎ, n adalah jumlah node input, 𝑤𝑖𝑗 adalah bobot dari node i ke j, 𝑥𝑖𝑗 adalah data instance ke i fitur ke j, 𝜃𝑗 adalah bias node ke-j.
Sedangkan fungsi fitness yang digunakan adalah meminimumkan nilai Minimum Square Error (MSE) yang merupakan bias pada layer hidden.
Jika 𝑜𝑖𝑘 adalah output dari perhitungan aadalah sebagai berikut:
𝑜𝑘= ∑(𝑤𝑘𝑗𝑓(𝑠𝑗) − 𝜃𝑘) Laboratorium Klinik Utama Popular, Surabaya sejak Januari 2012 sampai dengan September 2013. Fitur yang diambil adalah sepuluh kandungan urin yang diperoleh dari hasil uji dipstick urin dan beberapa data pribadi seperti usia, jenis kelamin, dan penampakan warna urin. Karakteristik sampel data pasien dan fitur data urinalysis dari 90 pasien tersebut dapat dilihat pada Tabel 1 dan Tabel 2.
Tabel 1. Sebaran Sampel Data
Data Sebaran Sampel Data
Usia Min = 0; Max = 98; Mean = 49.1; StdDev = 19.4
Jenis Kelamin Wanita = 52; Pria = 38
Kekeruhan Jernih = 43; Agak Keruh = 25; Keruh = 22
Warna Kuning Muda = 78; Kuning Tua = 12
Tabel 2. Sebaran Fitur Data
Fitur
Data yang diperoleh dari Laboratorium Klinik Utama Popular adalah data yang tidak berlabel. Oleh karena itu, berdasarkan kajian dari Majid (2010) pelabelan dilakukan berdasarkan rule sebagai berikut:
IF “Nitrit” = “Positif” THEN “ISK” = YES” ELSE “ISK” = NO”
4.2
Hasil Percobaan
Pengujian pada makalah ini menggunakan ANN double layer
GSA yang digunakan adalah G = 100, α = 20, dan maxEpoh= 100. Nilai batas C yang digunakan berdasarkan pada persamaan (18) sedangkan G(t) dihitung dengan persamaan (19)
𝐶 = 𝜃(1 −𝑡𝑡
max) (18)
𝐺(𝑡) = 𝐺0𝑒−𝛼 𝑡𝑡max (19)
dengan nilai 𝜃 = 100.
Uji coba klasifikasi dataset urinalysis untuk screening test ISK dilakukan menggunakan metode 3 fold cross validation. Dalam setiap pengujian, dataset dibagi menjadi tiga kelompok untuk kemudian digunakan sebagai data latih dan data uji dengan komposisi 2:1. Gambaran mengenai 3 fold cross validation dalam pengujian ini dapat dilihat pada Gambar 9. Hasil dari tiga kali pengujian menggunakan 3 fold cross validation kemudian akan dicari rataan, simpangan baku, dan nilai terkecil. Masing-masing cross validation diterapkan dengan menggunakan kombinasi parameter nagen = 10, 30, dan 50 dan struktur
jaringan yang digunakan menggunakan neuron hidden s = 3,5, dan 7. Hasil uji coba klasifikasi untuk skenario pengujian ini dapat dilihat pada Tabel 3.
Gambar 9. Pembagian dataset untuk uji 3 fold cross validation
Tabel 3. Komputasi NN-IGSA untuk Klasifikasi Urinalysis
Parameter Neuron Hidden Mean Square Error Akurasi (%)
Mean Std. Dev Best hasil terbaik diperoleh pada saat nagen = 30 pada arsitektur
10-5-1 dan nagen = 50 pada arsitektur10-3-1. Nilai simpangan baku
dari 3 replikasi cross validation menunjukkan angka yang relatif kecil, sehingga nilai rataan tersebut memiliki keagaman kecil. Pengujian selanjutnya adalah dengan membandingkan performa ANN-IGSA urinalysis untuk screening test ISK dengan GSA. Parameter yang digunakan pada IGSA dan ANN-GSA adalah jumlah agen = 10, G = 100, α = 20, dan maxEpoh
= 100. Uji coba klasifikasi dataset urinalysis untuk screening test ISK juga dilakukan dengan menggunakan metode 3 fold cross validation dengan parameter yang telah ditentukan. Masing-masing cross validation dilakukan kombinasi struktur
jaringan yang digunakan menggunakan neuron hidden s = 3, 5, dan 7 Hasil uji coba klasifikasi dapat dilihat pada Tabel 4. Dari hasil tersebut, dapat dilihat bahwa rata-rata nilai MSE paling kecil dari 3 fold cross validation diperoleh menggunakan metode ANN-IGSA pada setiap neuron hidden yang berbeda.
Tabel 4. Perbandingan Komputasi NN-IGSA Neuron
Pada IGSA, adanya operator disruption untuk mengatasi kelemahan GSA menujukkan hasil yang baik pada klasifikasi dataset urinalysis untuk screening test ISK. Hasil komputasi IGSA memberikan nilai MSE minimum yang lebih cepat sekaligus terhindar dari konvergensi dini. Gambar 10 menunjukkan hasil komputasi pada ANN-IGSA dan ANN-GSA dengan parameter jumlah solusi = 30.
Gambar 10. Konvergensi ANN-IGSA dan ANN-GSA
Selain itu evaluasi juga dilakukan dengan menghitung sensitivitas dan spesifisitas dari sistem dalam memberikan hasil
screening test hasil penyakit ISK. Sensitivitas adalah ukuran keakuratan tes yaitu seberapa besar kemungkinan tes untuk mendeteksi positif orang-orang yang memiliki penyakit atau kondisi, sedangkan spesifisitas adalah ukuran statistik mengenai akurasi tes, yaitu seberapa baik tes mengidentifikasi negatif orang-orang yang tidak memiliki penyakit atau kondisi. Hasil komputasi dengan parameter nagen = 30 dan s = 7 memberikan
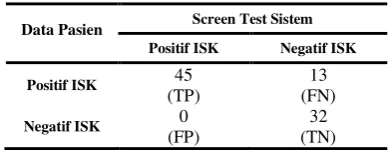
nilai seperti pada Tabel 5. Dari hasil tersebut diperoleh nilai sensitivitas sebesar 100% dan spesifisitas sebesar 77%.
Tabel 5. Matriks Confussion
Data Pasien Screen Test Sistem
Positif ISK Negatif ISK
5.
KESIMPULAN
Pada makalah ini, digunakan suatu metode yang mampu memberikan sebuah indikasi sebagai hasil screening test dari dipstick urin menggunakan pendekatan komputasi cerdas untuk penyakit ISK. Metode yang digunakan pada makalah ini adalah algoritma heuristik Gravitational Search Algorithm (GSA) dan
Artificial Neural Network (ANN) dengan penambahan operator
disruption. Uji coba klasifikasi dilakukan menggunakan 3 fold cross validation dengan parameter yang telah ditentukan. Hasil uji coba pada skenario pengujian ini menujukkan bahwa hasil terbaik diperoleh ketika nagen = 30 pada arsitektur 10-5-1 dan
nagen = 50 pada arsitektur 10-3-1. Hasil evaluasi juga
menggunakan sensivitas dan spesifisitas yang menghasilkan nilai sebesar 100% dan sebesar 77%.
Untuk penelitian selanjutnya, dapat dikembangkan screening tes pada penyakit lain yang memanfaatkan data urinalysis. Selain itu dapat pula dikembagkan ANN-GSA dengan konsep gerak dalam fisika seperti tumbukan dan momentum.
6.
REFERENSI
Barrat, J., “What to do with patients with abnormal dipstick
urinalysis”, Elsevier Ltd., 2007
Dias, F., Antunes, A., Mota A., “Artificial neural networks: a review of commercial hardware”, Engineering Applications of Artificial Intelligence, Vol. 17, 945–952, December 2004 Harwit, M. “The Astrophysical Concepts”, 3rd ed., NewYork, 1998
Izzah, A., Ginardi, R.V.H, Sarno, R., “Gravitational Search Algorithm dengan Operator Disruption sebagai Optimasi pada
Artificial Neural Network untuk Klasifikasi Data”, Prosiding
KNIF ITB, Vol 3, 102-107, November 2013
Majid, F.A., Buba, F., “The Predictive and Discriminant Values of Urine Nitrites in Urinary Tract Infection”, Biomedical Research, Vol 21(3), 297-299, 2010
Mastrogiannis, N., Boutsinasa, B., Giannikos, I., “A method for improving the accuracy of data mining classification algorithms”, Computers & Operations Research, Vol. 36, 2829–2839, October 2009
Pugia, “The uristatin dipstick is useful in distinguishing upper respiratory from urinary tract infections”, Clinica Chimica Acta, 341, 73–81, 2004
Rashedi, E., Nezamabadi-pour, H., Saryazdi, S., “GSA: A
Gravitational Search Algorithm”, Information Science, Vol. 179, 2232–2248, March 2009
Rojas, R., “Neural Networks : A Systematic Introduction”, Springer, Berlin, 1996
Sarafrazi S., Nezamabadi-pour∗H., Saryazdi S. “Disruption: A new operator in gravitational search algorithm”, Scientia Iranica D, Vol. 18(3), 539–548, February 2011
Whiting, P. Westwood, M. Bojke, L. dkk., “Clinical effectiveness and cost-effectiveness of tests for the diagnosis and investigation of urinary tract infection in children: a
systematic review and economic model”. Health Technol Assess; 10. iii-iv, xi-xiii, 1-154, 2006