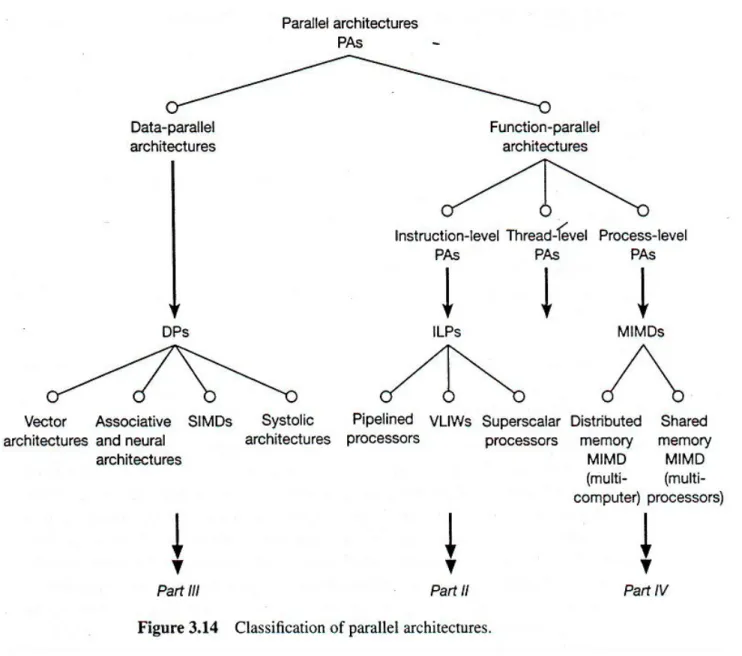
KLASIFIKASI ARSITEKTUR PARALEL
Arsitektur data-paralel
Arsitektur Fungsi-paralel
TEKNIK PARALEL DASAR
Pipelining
Replication
Table Pipelining and replication in parallel computer architecture
Pipelining
Replication
Vwctor processors
Systolic Arrays
SIMD (array) processors
Associative Processors
Pipelined Processors
VLIW Processors
Superscalar Processors
Multi-threaded Machines
Multicomputers
1Multiprocessors
PIPELINING
Pipelining adalah suatu teknik implementasi dengan mana berbagai
instruksi dapat dilaksanakan secara tumpang tindih (overlapped; hal ini
mengambil keuntungan paralelisme yang ada di antara tindakan yang
diperlukan untuk mengeksekusi suatu instruksi. Di dalam pipeline suatu
komputer, masing-masing langkah di dalam pipeline melengkapi
bagian-bagian dari suatu instruksi. Masing-masing langkah disebut
stage
atau
segment
.
Stage
dihubungkan satu terhadap lainnya sehingga
membentuk yang pipe-instruction pada bagian akhir
stage
. Mirip
dengan proses pada suatu industri manufaktur.
Pipelining menghasilkan reduksi untuk rata-rata waktu eksekusi per
instruksi.
Pipeline adalah suatu teknik implementasi yang memanfaatkan
paralelisme di antara instruksiinstruksi dalam laju instruksi sekuensial.
Hambatan utama terhadap Pipelining
Ada situasi yang menyebabkan hambatan dalam implementasi Pipeline
yang disebut
hazard
(resiko), yang akan mencegah instruksi yang
berikutnya dalam laju instruksi untuk diekseskusi selama siklus yang
ditunjuk.
Hazard
mereduksi laju kinerja ideal yang dihasilkan suatu
pipelining. Ada tiga kelas
hazard
:
1.
Structural Hazard
muncul akibat benturan sumberdaya manakala
perangkat keras tidak dapat mendukung semua kombinasi instruksi
secara serempak dalam eksekusi secara tumpang tindih.
2.
Data hazard
muncul manakala suatu instruksi tergantung pada hasil
dari suatu instruksi sebelumnya pada eksekusi instruksi tumpang
tindih.
3.
Control hazard
muncul pada pipelining dengan instruksi
pencabangan dan instruksi lain yang mengubah nilai
program
counter
.
Hazard
dalam pipeline dapat mengakibatkan diperlukannya
stall
terhadap pipeline. Pencegahan
hazard
seringkali memerlukan beberapa
instruksi ditunda, sementara lainnya diproses.
REPLICATION
Secara natural, paralelisme pada komputer adalah replikasi terhdap unit
fungsional (mis:prosesor).
Replicated Functional Units
dapat melakukan
eksekusi operasi yang sama secara simultan terhadap sejumlah data
elemen sesuai jumlah unit fungsional yang ada. Contoh klasikal dari
replikasi prosesor hádala
array processors
yang terdiri dari sejumlah
besar prosesor yang identik yang mengeksekusi operasi yang sama
pada sejumlah data.
Wafefront array
dan
2-dimensional systolic arrays
juga menggunakan
replikasi disamping pipelining.
Seluruh arsitektur MIMD menerapkan replikasi sebagai teknik
paralelismenya, demikian pula pada prosesor VLIW dan superscalar.
PENGUKURAN KINERJA PIPELINE
unpipeline processors :
-
cycle time
-
execution time
pipeline processors :
-
cycle time
-
latency
-
repetition rate
cycle time:
3-
waktu yang digunakan untuk setiap segmen/tahapan untuk
memenuhi operasi yang diperlukan. Cycle time dari prosesor
ditentukan oleh waktu terburuk pada segmen/tahapan terpanjang.
(2-20 nsec)
latency:
-
digunakan dalam konsteks pemrosesan instruksi ketergantungan
RAW berikutnya. Latency menetapkan jumlah waktu hasil dari suatu
instruksi tertentu yang tersedia dalam pipeline untuk instruksi
dependent
berikutnya
-
pada kasus
define-use latency
, merupakan waktu tunda
yang terjadi setelah decode hingga diperoleh hasil operasi
instruksi ketergantungan RAW
-
kasus
define-use latency
mul r1, r2, r3;
add r5, r1, r4;
-
pada kasus
define-use delay
merupakan waktu instruksi
ketergantungan RAW berikutnya yang stall dalam pipeline.
Besar define-use delay 1 cyle lebih keci dari define-use
latency.
-
kasus
define-use delay
load r1, x;
add r5, r1, r2;
Fetch Decode
Issue
Mult
Add
Round Writeback
F,D,I phase Execute phase Completion phase
LATENCY
repetition rate (throughput):
-
interval waktu terpendek yang mungkin terjadi atar dua instruksi
depedent dalam pipeline
-
pada basic pipeline besarnya 1 cycle
instr-3 instr-2 instr-1 hasil instr-1
4 Repetition rate
t
Performance Potential of Pipeline (P):
Skenario Aplikasi pipeline
Vector processors
General instruction
processing
Processing of
dedicated instruction
classes
Bab 13 Sub Bab 5.3 Sub Bab 5.4 Sub Bab 5.5
5
1 R = repetition rate (cycle)
P = tc = cycle time of pipeline
R * t c P = MFLOPS Pemrosesan instruksi FX Pemrosesan instruksi FP Pemrosesan instruksi L/S
6 RAW -dependencies Define-use dependencies Load-use dependencies
Muncul bila sebuah instruksi menggunakan hasil dari operasi sebelumnya sebagai operan sumber
Muncul bila sebuah instruksi menggunakan hasil dari instruksi
load sebelumnya sebagai operan sumber
Define-use dependencies
Load-use dependencies
Waktu yang berlalu setelah segeman decode, issue dan sebelum hasil sebuah operasi instruksi diperoleh dalam pipeline untuk instruksi RAW-dependent yang berikutnya
Bila nilainya 1 cycle, maka instruksi dependen immediate yang mengikutinya dapat diproses dalam pipeline tanpa delay.
Waktu yang sebelum hasil sebuah instruksi load diperoleh dalam pipeline untuk instruksi
RAW-dependent yang berikutnya Bila nilainya 1 cycle, maka instruksi dependen immediate yang mengikutinya dapat diproses dalam pipeline tanpa delay.
Define-use delay of an instruction
Load-use delay of an instruction
Waktu bahwa sebuah instruksi ketergantungan RAW-dependent harus mengalami stall dalam pipeline setelah operasi sebuah instruksi.
Define-use delay nilainya 1 cycle lebih kecil dari define-use latency.
Waktu bahwa sebuah instruksi ketergantungan RAW-dependent harus mengalami stall dalam pipeline setelah sebuah instruksi
load.
Load-use delay nilainya 1 cycle lebih kecil dari load-use latency.
LAYOUT DASAR PIPELINE
1. Jumlah segmen/stages/tahapan
2. Spesifikasi sub tugas yang harus ditampilkan pada tiap tahapan
3. Layout urutan tahapan
4. Penggunaan bypass 5. Waktu operasi pipeline
1. Jumlah segmen/stages/tahapan 2-stage pipeline tc1 tc2 tc3 i1 i2 4-stage pipeline tc1 tc2 tc3 tc4 tc5 tc6 tc7 tc8
i1
i2
i3
i4
8-stage pipeline tc : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15i1
i2
i3
i4
I5
I6
I7
I8
Beberapa masalah yang muncul bila pipeline dibuat lebih dalam :
Ketergantungan data & kontrol terjadi lebih sering, sehingga menurunkan kinerja. Lebih jauh bila tahapan pipeline ditingkatkan, partisi seluruh tugas menjadi kurang seimbang dan menumbuhkan clock yang tidak simetris. Akibat peningkatan kedalaman pipeline memerlukan peningkatan kinerja, namun suatu saat justru kinerja akan menurun.
7 PIPELINE DEPTH P E R F O R M A N C E
2. Spesifikasi sub tugas yang harus ditampilkan pada tiap tahapan
Setiap tahapan dapat mencakup detil yang berbeda, misalnya Fetch Instruction, Decode, Fetch Register, Execute Operation, Write back the result, dll.
3. Layout urutan tahapan
Pada kaus perkalian dan pembagian yang melakukan perulangan, recycling akan mengefektifkan penggunaan h/w, namun akan menghalangi laju paipeline.
4. Penggunaan bypass
Pengguanan bypass (data forwarding) dapat mereduksi atau meniadakan/mencegah stall. Akibat RAW-dependencies (define-use& load-use) akan menyebabkan stall 2 cycle.
5. Waktu operasi pipeline
Dapat dilakukan dengan pendekatan clocked(synchronous) dan self-timed (a synchronous). Prosesor komersial menggunakan pendekatan clokc baik 1 atau 2 fasa.
PEMROSESAN INSTRUKSI SECARA PIPELINE
Mencakup:
Deklarasi pipeline
Rincian spesifikasi subtask yang harus ditampilkan pada urutan eksekusi Jenis pipeline :
Pemrosesan data lojikal (FX Pipeline)
Pemrosesan data floating point (FP Pipeline)
Pemrosesan Load/Store (L/S Pipeline)
Pemrosesan pencabangan (B Pipeline) Branch Fetch Issue
FX Fetch Issue Execute Writeback
L/S Fetch Issue Address Generate Cache Writeback
FP Fetch Issue Decode Execute1 Execute2 Writeback
FX Fetch Issue Execute Writeback
Read referrenced registers Perform specified operation register contents
Pipeline pada PowerPC 601(1993) Physical Pipeline:
Multifuctional pipeline (MF pipelines):
-
MF for FX, FP,L/S, B - MF for FX, L/S, B - MF for FX, L/S Dedicated pipeline: FX, FP,L/S, B
VERY LONG INSTRUCTION WORD (VLIW)
Kesamaan dengan prosesor superskalar :
meningkatakan laju komputasi dengan mengeksploitasi paralel pada level instruksi,
menggunakan EU (execution unit) secara paralel
menggunakan unified register file atau split register file untuk data FX & FP
Perbedaan dengan prosesor superskalar :
formulasi /format instruksi penjadwalan instruksi
arsitektur superskalar dirancang untuk menerima instruksi konvensional untuk prosesor sekuensial, arsitektur VLIW dikontrol oleh long instructions words (gbr 6.2)
lebih memungkinkan untuk meningkatkan clock rate VLIW tidak dapat diprogram dalam assembly
penjadwalan pada prosesor skalar umumnya dilakukan secara dinamis, sedangkan pada VLIW secara statis
-
penjadwalan stastis: menyerahkan beban penjadwalan kepada compiler sehingga dapat menekan kompleksitas-
penjadwalan dinamis: karena jumlah instruksi yang banyak, maka penjadwalan dpat menimbulkan masalah dependensi data, penerbitan instruksi, penumpukan, penamaan ulang, dll.Panjang insruksi VLIW tergantung:
jumlah EU yang ada (5-30 buah)
panjang kode yang diperlukan untuk mengendalikan tiap EU (16-32 bit)
format intruksi 100-1024 bit (misalnya Trace7/200 memiliki panjang instruksi 256 bitdan mampu mengeksekusi 7 instruksi/cycle; Trace 28 memiliki panjang instruksi 1024 bit; ELI 512 memiliki panjang instruksi 512 bit)
Prosesor VLIW
Komersial:
1. Floating Point Systems, FPS-120B, yang memiliki 2 FP unit paralel -1976 2. FPS-164 – 1980
3. CDC AFP - 1980
4. TRACE (Multiflow) - 1987
5. CYDRA-5 TM-1 (Cydrome) 1989
6. TM-1 (Philips) - 1996 Prototype:
1. Polycyclic (ESL) – 1981 CYDRA-5 2. ELI-512 (Yale) – 1983 TRACE 3. iWARP (CMU) - 1988
4. LIFE (Philips) - 1989
5. StaCs 2.2 (ESPRIT IDPS) - 1993
TRACE 200 FAMILY
Dikembangkan di Yale menggunakan Trace compiler, sedang ELI-512 menggunakan Bulldog compiler (dibangun tahun 80-an dan perusahaannya bangkrut pada tahun 90-an.
Terdapat 3 model: Trace 7/200 (paralel 7 instruksi), Trace 14/200 (paralel 14 instruksi), Trace 28/200 (paralel 28 instruksi)
Harganya 6x lebih mahal dari VAX 8700
Memiliki split register 32-bit RICK kernel, 64 buag register integer, 2 buah EU
65 ns/cycle
bagian FP: 32*64-bit FP register file, 2 buah FP-EU (FADD, FMUL)
6 cycles FP Add; 7 cycles FP multiply; 25 cycles FP divide
Trace 7/200 dikendalikan oleh VLIW 256-bit, di mana sebuah kendali mengontrol eksekusi 7 buah instruksi
Kinerja Prosesor Tace vs prosesor DEC 8700 vs prosesor Cray XMP
Processor Instruction Issue rate (ns) Compiled Linpack (Full Precision) (MFLOPS) Trace 7/200 130 6 Trace 14/200 130 10 DEC 8700 45 0.97 Cray XMP 8 24 10
PROSESOR SUPERSCALAR
Perkembangan
IBM Cheetah project America Project
DEC Multititan Project
Stanford Univ MATCH TORCH
Kyushu Univ SIMP DSNS
1982 1983 1984 1985 1986 1987 1988 1989 1990
IBM:
-
1982 –83 dengan cheetah project, dilanjutkan 1985 dengan americ project, menghasilkan studi tentang eksekusi superskalar-
1990 menghasilkan RS/6000, selanjutnya diberi nama Power1DEC:
-
1985-87 dengan multitian project menghasilkan very high speed RISC processoryang menjadi konstributar prosesor (RISCy VAX)Stanford University:
-
1990 menghasilkan R200-based superscalar processor yang diberi nama TORCHKYUSHU University:
-
1989 menghasilkan SIMP dan DSNSProsesor RISC supersakalar :
-
Intel 960-
MC88000-
HP PA (Precision Architecture)-
Sun Sparc-
MIPS RProsesor CISC superskalar :
- Pentium
- MC 68060
- M1
- K5
- AMD Am29000