Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
BAB III
METODOLOGI PENELITIAN
A. Desain Penelitian
Penelitian ini merupakan penelitian eksplanatori mengenai pengukuran tingkat kesiapan peserta e-learning menggunakan model keterhubungan antar variabel yang merupakan hasil pengembangan dari penelitian-penelitian terdahulu serta teori yang ada. Penelitian eksplanatori atau disebut juga penelitian eksplanatif merupakan penelitian yang meneliti setiap variabelnya secara mendalam guna mendapatkan hasil mengenai ada tidaknya hubungan dari gejala-gejala yang didapatkan dari setiap variabel. Kategori kesiapan dalam model ini merupakan variabel-variabel yang akan diteliti secara mendalam hingga diharapkan menghasilkan sebuah hubungan terhadap kesiapan peserta secara keseluruhan.
Dalam penelitian ini, digunakan pendekatan kuantitatif dengan metode survei. Metode survei merupakan metode yang menggunakan angket sebagai alat pengumpul datanya. Pendekatan kuantitatif adalah :
Metode penelitian kuantitatif dapat diartikan sebagai metode penelitian yang berlandaskan pada filsafat positivism, digunakan untuk meneliti pada populasi atau sampel tertentu, teknik pengambilan sampel pada umumnya dilakukan secara random, pengumpulan data menggunakan instrument penelitian, analisis data bersifat kuantitatif/ statistik dengan tujuan untuk menguji hipotesis yang telah ditetapkan (Sugiyono,2013a:14).
Selanjutnya data dan fakta dari angket yang terkumpul akan diuji dengan teknik analisis data SEM. Tahapan analisis SEM sendiri setidaknya harus melalui lima tahapan (Latan,2013:42), yaitu: 1. spesifikasi model; 2. identifikasi model; 3. estimasi model; 4. evaluasi model; 5. modifikasi atau respesifikasi model.
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
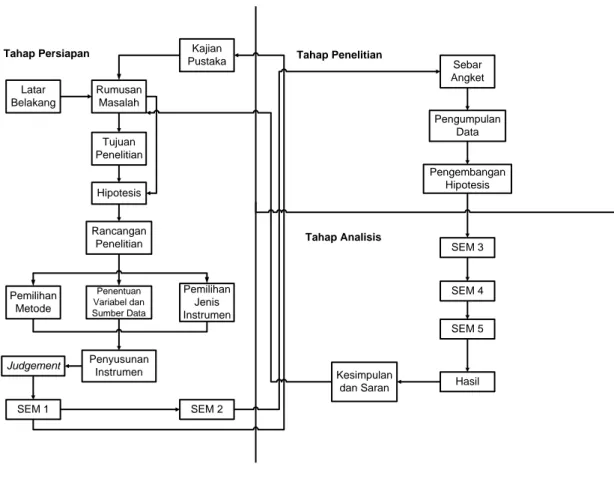
Latar Belakang Kajian Pustaka Rumusan Masalah Tujuan Penelitian Hipotesis Rancangan Penelitian Pemilihan Jenis Instrumen Penentuan Variabel dan Sumber Data Pemilihan Metode SEM 1 Penyusunan Instrumen Judgement Pengumpulan Data Sebar Angket SEM 3
Tahap Persiapan Tahap Penelitian
Tahap Analisis SEM 4 SEM 5 Hasil Kesimpulan dan Saran Pengembangan Hipotesis SEM 2
Pada dasarnya penelitian ini terdiri dari tiga tahapan dan berjalan dengan mengacu pada langkah-langkah SEM di atas serta penambahan beberapa langkah dasar di luar SEM. Adapun secara skematis langkah-langkah tersebut disajikan dalam gambar di bawah ini :
Gambar 3.1 Skema Penelitian
Adapun penjelasan dari skema di atas adalah sebagai berikut :
1. Tahap Persiapan
Tahap ini merupakan persiapan yang dilakukan peneliti sebelum melakukan sebuah penelitian. Dapat dilihat dari skema di atas, bahwa tahapan ini terdiri dari :
a. Penentuan latar belakang.
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
c. Menetapkan tujuan penelitian. d. Merumuskan hipotesis.
e. Menentukan rancangan penelitian.
1) Pemilihan metode.
2) Penentuan variabel dan sumber data. 3) Pemilihan jenis instrumen.
f. Penyusunan instrumen. g. Judgement instrumen.
h. Melakukan tahapan SEM pertama yaitu spesifikasi model berdasarkan kajian teori.
i. Melakukan tahapan SEM kedua yaitu identifikasi model.
2. Tahap Penelitian
Pada tahap ini peneliti memulai penelitian dengan tahapan : a. Penyebaran angket hasil judgement.
b. Proses pengumpulan data.
c. Mengembangkan hipotesis berdasarkan spesifikasi model.
3. Tahap Analisis
Setelah seluruh data diperoleh dan memenuhi syarat minimal sampel penelitian, maka data pun mulai dianalisis menggunakan SEM (melanjutkan tahapan SEM yaitu tahapan ketiga hingga kelima). Data yang terkumpul sebelum dianalisis, diperiksa terlebih dahulu telah memenuhi syarat atau belum, seperti tidak adanya data outliers. Selain data dianalisis menggunakan SEM, data pun diolah guna mengetahui kesiapan peserta e-learning. Setelah data berhasil diolah dan dianalisa, selanjutnya adalah penarikan kesimpulan yang mengacu pada rumusan masalah.
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
B. Variabel Penelitian
Variabel penelitian adalah segala sesuatu yang berbentuk apa saja yang ditetapkan oleh peneliti untuk dipelajari sehingga diperoleh informasi tentang hal tersebut, kemudian ditarik kesimpulannya (Sugiyono,2013a:60). Adapun variabel dalam penelitian kali ini yaitu:
1. Variabel laten
Merupakan variabel yang tidak dapat diukur secara langsung melainkan hanya dapat diukur dengan satu atau lebih variabel manifes. Variabel ini juga disebut sebagai unobserved variables. Dalam penelitian ini, setiap variabel endogen dan eksogen merupakan variabel laten, yaitu TA, COS, MOT, LS dan kesiapan peserta e-learning.
2. Variabel manifes
Sedangkan manifes, merupakan variabel yang dapat diukur secara langsung dan mengukur variabel laten. Variabel ini disebut juga observed variables. Dalam penelitian ini, setiap indikator yang menjelaskan variabel endogen dan eksogen, merupakan variabel manifes, yaitu indikator TA1, TA2, TA3, COS1, COS2, COS3, COS4, COS5, MOT1, MOT2, MOT3, MOT4,MOT5, LS1, LS2, LS3 dan LS4.
3. Variabel eksogen
Variabel eksogen atau sering juga dikenal dengan variabel independen, merupakan variabel yang tidak dipengaruhi variabel lain dan mempengaruhi variabel dependen. Dalam SEM, variabel ini ditunjukkan dengan adanya anak panah yang berasal dari variabel ini menuju variabel endogen. Pada penelitian kali ini yang termasuk variabel ini adalah TA. 4. Variabel endogen
Variabel endogen atau sering juga dikenal dengan variabel dependen, merupakan variabel yang dipengaruhi oleh variabel independen (eksogen). Dalam SEM, variabel ini ditunjukkan dengan adanya anak panah menuju variabel ini. Pada penelitian kali ini yang termasuk variabel ini adalah COS, MOT, LS dan kesiapan peserta e-learning.
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
C. Populasi dan Sampel
Populasi dalam penelitian ini adalah seluruh mahasiswa program sarjana tingkat tiga dan empat di Fakultas Pendidikan Matematika dan Ilmu Pengetahuan Alam Universitas Pendidikan Indonesia.Sampel yang diambil dari populasi penelitian ini menggunakan teknik stratified cluster random sampling, karena populasi terdiri dari 2 tingkat yaitu tingkat tiga dan empat, serta menaungi beberapa jurusan dengan beberapa program studi yang akan dibagi menjadi beberapa rumpun. Subjeknya adalah mahasiswa tingkat tiga dan empat, karena asumsinya mahasiswa tingkat tiga dan empat telah memiliki lebih banyak pengalaman dan juga telah melakukan pembelajaran menggunakan e-learning dibandingkan dengan mahasiswa tingkat satu dan dua.
Selanjutnya analisis statistik yang akan digunakan adalah SEM, maka untuk pengambilan sampel akan memperhatikan proporsi dari Joreskog dan Sorbom (Riduwan dan Kuncoro, 2012:56) serta proporsi menurut Bentler dan Chou (Latan,2013:44). Menurut Joreskog dan Sorbom, penentuan sampel minimal dapat dilihat pada tabel 3.1.
Tabel 3.1
Ukuran sampel minimal dan jumlah variabel Joreskog dan Sorbom (Riduwan dan Kuncoro, 2012:56)
Jumlah variabel Ukuran sampel minimal
3 200 5 200 10 200 15 360 20 630 25 975 30 1395
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
Sedangkan menurut Bentler dan Chou, jumlah sampel yang harus dipenuhi untuk proses estimasi adalah 5 kali (5:1) parameter yang akan di estimasi. Dari hasil identifikasi model (dijelaskan pada bab IV), penelitian ini memiliki 38 parameter. Melihat jumlah parameter tersebut maka sampel yang dibutuhkan sebanyak 190 orang dengan perhitungan berikut :
Jika melihat tabel 3.1 maka jumlah sampel pada penelitian ini adalah 200 responden karena menguji 5 variabel. Menimbang proporsi kedua ahli, peneliti menetapkan sampel minimal penelitian ini adalah 210 responden dikarenakan untuk mengantisipasi adanya data outliers atau data pencilan. Setelah menentukan jumlah sampel yang dibutuhkan, kemudian jumlah sampel tadi akan dihitung kembali berdasarkan tingkat (strata) dan rumpun (kluster) yang ada dengan persamaan (Riduwan dan Kuncoro, 2012:57):
dimana:
ni = jumlah sampel menurut rumpun/tingkat; n = jumlah sampel seluruhnya;
Ni = jumlah populasi menurut rumpun/tingkat; N = jumlah populasi seluruhnya.
Berdasarkan data rekapitulasi mahasiswa kontrak kuliah semester genap tahun ajaran 2013/2014 FPMIPA UPI yang terlampir pada lampiran 1, total mahasiswa FPMIPA UPI angkatan 2011 (tingkat tiga) adalah 525 orang, sedangkan total mahasiswa FPMIPA UPI angkatan 2010 (tingkat empat) adalah 582 orang. Maka populasinya adalah 1107 orang. Karena teknik pengambilan jumlah sampelnya berdasarkan tingkat dan rumpun, maka langkah pertama pengambilan sampel adalah penentuan jumlah sampel untuk masing-masing tingkat. Adapun perhitungan jumlah masing-masing sampel untuk setiap tingkat adalah:
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
Tabel 3.2
Perhitungan pengambilan sampel masing-masing tingkat (strata) Tingkat Pupulasi
tingkatan Perhitungan sampel Sampel Tingkat 3 (angkatan 2011) 525 orang 100 orang Tingkat 4 (angkatan 2010) 582 orang 110 orang Selanjutnya setelah menemukan angka sampel masing-masing tingkatan, langkah berikutnya adalah menghitung jumlah sampel sesuai daerah rumpun. Fakultas Pendidikan Matematika dan Ilmu Pengetahuan Alam menaungi 11 program studi yang selanjutnya dijadikan rumpun. Adapun pengambilan sampel untuk tingkat tiga disajikan pada tabel 3.3.
Tabel 3.3
Perhitungan pengambilan sampel tingkat (strata) tiga
No Program Studi
Populasi program studi
Perhitungan sampel Sampel
1 IPSE (International Program on Science Education) 19 4 orang 2 Pendidikan Ilmu Komputer 66 13 orang 3 Ilmu Komputer 38 7 orang 4 Pendidikan Matematika 72 14 orang 5 Matematika 28 5 orang
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
Tabel 3.3
Perhitungan pengambilan sampel tingkat (strata) tiga
No Program Studi
Populasi program studi
Perhitungan sampel Sampel
6 Pendidikan Biologi 70 13 orang 7 Biologi 28 5 orang 8 Pendidikan Kimia 76 15 orang 9 Kimia 34 6 orang 10 Pendidikan Fisika 66 13 orang 11 Fisika 28 5 orang Adapun pengambilan sampel untuk tingkat empat disajikan pada tabel 3.4.
Tabel 3.4
Perhitungan pengambilan sampel tingkat (strata) empat
No Program Studi
Populasi program studi
Perhitungan sampel Sampel
1 IPSE (International Program on Science Education) 17 3 orang 2 Pendidikan Ilmu Komputer 50 9 orang
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
Tabel 3.4
Perhitungan pengambilan sampel tingkat (strata) empat
No Program Studi
Populasi program studi
Perhitungan sampel Sampel
3 Ilmu Komputer 56 11 orang 4 Pendidikan Matematika 76 14 orang 5 Matematika 31 6 orang 6 Pendidikan Biologi 72 14 orang 7 Biologi 32 6 orang 8 Pendidikan Kimia 98 19 orang 9 Kimia 39 7 orang 10 Pendidikan Fisika 80 15 orang 11 Fisika 31 6 orang D. Definisi Operasional
Agar tidak terjadi perbedaan persepsi, maka berikut ini merupakan penjelasan dari beberapa istilah dalam penelitian kali ini, yaitu:
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
1. E-Learning (electronic learning)
E-learning adalah sebuah inovasi pembelajaran masa kini yang merupakan kesatuan instruksi dan informasi yang ditransmisikan dari pengajar dan atau peserta di tempat dan waktu yang berbeda melalui teknologi komputer menggunakan media internet, intranet, dan atau jaringan komputer lainnya.
2. Kesiapan e-learning
Kesiapan e-learning atau populer dengan e-learning readiness merupakan sebuah model yang diprakarsai oleh Samantha Chapnick. Model ini dirancang untuk mengetahui sejauh mana kesiapan sistem e-learning sebagai informasi mendasar dalam mengimplementasikan dan mengembangkan e-learning berdasarkan 8 kategori kesiapan. Sebagaimana dikatakan Chapnick (2000) :
My readiness model is designed to simplify the process of getting the basic information necessary to answerthe questions. Grouping together a wide variety of factors into eight categories allows practitioners to use thesame process to assess the vastly different stakeholders in the system.
Borotis & Poulymenakou dalam Priyanto (2008) mendefinisikan e-learning readiness (ELR) sebagai “kesiapan mental atau fisik suatu organisasi untuk suatu pengalaman pembelajaran”.
3. Kesiapan peserta e-learning
Kesiapan peserta e-learning merupakan kesiapan secara mental atau fisik sebuah implementasi sistem yang terfokus kepada peserta dalam pengalaman pembelajaran online. Pengukuran terhadap kesiapan peserta e-learning ini telah dilakukan oleh berbagai peneliti dengan berbagai macam modelnya, diantaranya dilakukan oleh University of Georgia, Hung et al.,, Watkins et al.,, dan Kriengsak.
4. Technology access (TA)
Merupakan variabel dalam model yang diasumsikan dapat mengukur kesiapan peserta e-learning berdasarkan ketersediaan akses teknologi peserta.
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
5. Computer and online skills (COS)
Merupakan variabel dalam model yang diasumsikan dapat mengukur kesiapan peserta e-learning berdasarkan kemampuan computer serta internet peserta.
6. Motivation (MOT)
Merupakan variabel dalam model yang diasumsikan dapat mengukur kesiapan peserta e-learning berdasarkan tinggi rendahnya motivasi peserta.
7. Learning style (LS)
Merupakan variabel dalam model yang diasumsikan dapat mengukur kesiapan peserta e-learning berdasarkan gaya belajar peserta.
8. Structural equation modelling (SEM)
Model persamaan struktural ini merupakan model untuk menganalisis hubungan sebab akibat antara variabel dimana setiap variabel terikat/ endogen secara unik keadaannya ditentukan oleh seperangkat variabel bebas/ eksogen (Riduwan dan Kuncoro,2012:5). SEM (Structural Equation Modelling) merupakan alat analisis statistik multivariat yang menggabungkan antara analisis faktor dengan analisis jalur, serta tepat untuk menguji hubungan yang rumit antar variabel.
9. AMOS
Merupakan salah satu dari sekian perangkat lunak analisis SEM yang akan dipakai pada penelitian ini. Adapun versi yang dipakai pada penelitian ini adalah AMOS 21.
E. Instrumen Penelitian
Instrumen adalah alat pada waktu peneliti menggunakan sesuatu metode (Arikunto, 1998:137). Terdapat 2 instrumen yang akan dipakai dalam penelitian ini yaitu instrumen pengumpulan data serta instrumen validasi dan verifikasi ahli. Instrumen untuk pengumpulan data yang digunakan adalah angket atau kuesioner. Arikunto (1998:140) mengungkapkan bahwa
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
“kuesioner adalah sejumlah pertanyaan tertulis yang digunakan untuk memperoleh informasi dari responden dalam arti laporan tentang pribadinya, atau hal-hal yang ia ketahui”. Sedangkan untuk validasi dan verifikasi ahli digunakan untuk judgement instrumen angket.
1. Instrumen Angket Penelitian
Angket pada penelitian ini menggunakan skala Likert yang biasa digunakan untuk mengukur sikap, pendapat, dan ataupun persepsi responden (Sugiyono,2013a:134). Angket ini diberi 5 pilihan jawaban yaitu untuk pernyataan positif adalah 1 (sangat tidak setuju), 2 (tidak setuju), 3 (kurang setuju), 4 (setuju) dan 5 (sangat setuju). Sedangkan untuk pernyataan negatif adalah 5 (sangat tidak setuju), 4 (tidak setuju), 3 (kurang setuju), 2 (setuju) dan 1 (sangat setuju). Skala tersebut dijadikan jawaban bagi instrumen pernyataan. Penelitian ini akan menggunakan angket dengan penyebaran secara online. Tujuannya agar data dapat langsung terkumpul dan lebih mudah untuk diolah.
2. Instrumen Judgement Angket oleh Ahli
Skala yang digunakan pada instrumen ini adalah rating scale. Skala tersebut memungkinkan data mentah berupa angka yang ditafsirkan menjadi kategori atau kriteria. Angket untuk responden akan dinilai oleh ahli dengan jawaban penilaian yg berbeda. Akan diberikan 4 jawaban pilihan yaitu 1 (tidak sesuai), 2 (kurang sesuai), 3 (cukup sesuai) dan 4 (sangat sesuai).
F. Teknik Analisis dan Pengolahan Data 1. Analisis Data Angket
Adapun skala yang akan dipakai mengacu pada pengukuran kesiapan e-learning oleh Aydin dan Tasci (2005) yaitu penskoran dengan skala Likert. Setiap pertanyaan yaitu setiap variabel manifes dalam variabel
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
laten akan diberi skor dengan rentang nilai 1 – 5. Jika direntangkan garis lurus mulai angka 1 hingga 5, akan menghasilkan 4 interval. Aydin dan Tasci telah memberikan nilai indeks untuk menilai kategori tingkat kesiapan. Adapun skala indeks Aydin dan Tasci telah disajikan dalam Gambar 2.2.
Adapun maksud skala Aydin dan Tasci yaitu:
a. Interval pertama yaitu indeks 1 – 2,59 berarti belum siap dan membutuhkan lebih banyak lagi persiapan untuk pembelajaran online. b. Interval kedua yaitu indeks 2,6 – 3,39 berarti belum siap namun hanya
memerlukan sedikit persiapan untuk pembelajaran online.
c. Interval ketiga yaitu indeks 3,4 - 4,19 berarti sudah siap namun masih membutuhkan sedikit peningkatan dalam pembelajaran online.
d. Interval keempat yaitu indeks 4,2 – 5 berarti sudah siap menjadi peserta e-learning.
Nilai indeks tersebut didapat dengan mencari mean (rerata) dari data yang terkumpul. Adapun mean atau rerata didapatkan dari hasil penjumlahan seluruh data lalu dibagi dengan banyaknya data. Adapun jika dirumuskan menjadi (Sugiyono, 2013b:49): ∑ dimana: Me = mean (rerata); Xi = jumlah data; n = banyaknya data.
Nilai indeks di atas dicari untuk mengetahui tingkat kesiapan peserta e-learning dimana hasilnya akan langsung dihitung pada angket online yang digunakan. Sehingga setiap responden akan langsung mendapatkan derajat kesiapannya setelah mengisi seluruh rangkaian angket.
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
2. Analisis Data Instrumen Judgement Ahli
Menurut Sugiyono (2013a:143) untuk mencari nilai dari rating scale maka dapat digunakan persamaan 3.3.
dimana:
P = persentase;
Skor ideal = skor tertinggi tiap butir x jumlah butir x jumlah responden.
Maka melihat rentang nilai 1 hingga 4, persentase dapat dikelompokkan menjadi :
Tabel 3.5 Persentase rating scale Persentase Kriteria 0 – 25 % Tidak sesuai 26 – 50 % Kurang sesuai 51 – 75 % Cukup sesuai 76 – 100 % Sangat sesuai
Proses penilaian dilakukan oleh 3 orang ahli dan dapat dilihat penilaiannya pada lampiran 2. Adapun hasil dari penilaian tersebut didapatkan skor hasil pengumpulan data sejumlah 171. Sedangkan skor ideal adalah 204, didapat dari perkalian antara skor tertinggi tiap butir, jumlah butir dan jumlah ahli. Skor tertinggi adalah 4, jumlah butir adalah 17 dan jumlah ahli adalah 3. Maka menentukan persentase sesuai rumus di atas adalah sebagai berikut :
Dari nilai yang didapatkan dan melihat tabel persentase rating scale, maka dapat didapatkan instrumen ini sangat sesuai. Melihat hasil tersebut,
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
dapat dikatakan instrumen layak dipakai, tentu dengan perbaikan yang dianjurkan oleh para ahli.
3. Structural Equation Modelling (SEM)
Sedangkan pengolahan statistik pada penelitian kali ini menggunakan SEM. Tahapan analisis SEM sendiri setidaknya harus melalui lima tahapan (Latan,2013:42-69) yaitu:
a. Spesifikasi model
Kegiatan pada langkah ini adalah mengembangkan suatu model berdasarkan kajian-kajian teoritik untuk mendukung penelitian terhadap masalah yang dikaji. Selanjutnya mendefinisikan model tersebut secara konseptual konstruk yang akan diteliti serta menentukan dimensionalitasnya. Arah hubungan yang dihipotesiskan pun haruslah jelas dan memiliki landasan teori.
b. Identifikasi model
Tahap ini merupakan tahap yang penting dalam SEM, karena model yang tidak dapat diidentifikasi, akan menjadi tidak dapat diestimasi atau dihitung. Penting bagi peneliti melakukan tahap ini guna mengetahui apakah model tersebut memiliki nilai unik atau tidak.Identifikasi ini dengan menghitung derajat kebebasan, dan nilai derajat kebebasan harus positif.Idealnya, setelah spesifikasi dan identifikasi model, tahap selanjutnya adalah penetuan jumlah sampel. c. Estimasi model
Setelah data terkumpul, model diestimasi, setelah sebelumnya ditentukan metode estimasinya. Umumnya metode estimasi yang dipakai adalah maximum likelihood (ML).
d. Evaluasi model
Kegiatan pada langkah ini adalah mengevaluasi dan interpretasi hasil analisis. Tahap ini bertujuan untuk mengevaluasi model secara keseluruhan. Proses ini diawali dengan uji normalitas data selanjutnya dilanjutkan dengan menguji model pengukuran (measurement model)
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
dengan menganalisis faktor konfirmasi untuk menguji validitas serta reliabilitas variabel laten, dilanjutkan dengan menguji struktural model serta terakhir menilai overall fit model dengan mengacu pada goodness of fit (GoF).
e. Modifikasi model
Kegiatan ini berkenaan dengan hasil evaluasi dan interpretasi model. Jika dari nilai GoF model tersebut tidak atau belum fit, maka perlu dilakukan modifikasi atau respesifikasi model.
4. Identifikasi Model
Identifikasi model dilakukan dengan cara menghitung degree of freedom (df) atau derajat kebebasan. Adapun rumusnya menurut Santoso (2012:60) adalah sebagai berikut:
[ ] dimana:
p = jumlah variabel manifes (observed variables) pada sebuah model; k = jumlah parameter yang akan diestimasi.
Menggunakan program analisis data AMOS telah menyajikan pula hasi perhitungan derajat kebebasan. Adapun untuk mengetahui model dapat diestimasi ataupun tidak, terdapat 3 jenis identifikasi (Santoso,2012;Latan,2013), yaitu:
a. Just Identified model atau saturated model
Jika hasil perhitungan df menghasilkan nilai 0, maka model tersebut termasuk just identified. Maka model sudah teridentifikasi sehingga estimasi dan penilaian model tidak perlu dilakukan.
b. Under Identified atau unidentified
Jika hasil df menghasilkan nilai negatif, maka model tersebut termasuk unidentified. Maka model tersebut tidak teridentifikasi, sehingga model juga tidak dapat diestimasi. Namun untuk
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
mengatasinya dapat dilakukan dengan menambah jumlah variabel manifes atau mengurangi parameter yang akan diestimasi.
c. Overidentified
Pada jenis ini nilai df akan menghasilkan bilangan positif, dan jika terjadi maka model ini dapat langsung diestimasi.
5. Uji Normalitas Data
Uji normalitas data dilakukan dengan menghitung distribusi data secara keseluruhan (multivariat). Adapun pengujian dilakukan dengan menghitung critical ratio (c.r) multivariat. Program AMOS telah menyajikan hasil penrhitungan normalitas data serta rincian sebaran data. Adapun untuk mencari nilai c.r dilakukan dengan 2 tahap, yaitu (Santoso,2012:86):
a. Menghitung standar error (s.e) multivariat.
√ dimana:
s.e = standar error; N
= jumlah sampel;
p = jumlah indikator (variabel manifes). b. Menghitung c.r multivariat.
Data dikatakan normal ketika tidak menceng ke kiri atau ke kanan serta memiliki keruncingan ideal. Nilai cut-off yang umumnya dipakai untuk menilai normalitas menurut Schumaker dan Lomax dalam Latan (2013:103) adalah nilai kemencengan (skewness) dan keruncingan (kurtosis) berkisar antara 1.0 hingga 1.5 atau nilai critical ratio (c.r) harus memenuhi syarat -2,58 < c.r < 2,58.
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
Jika didapatkan bahwa data belum terdistribusi normal, maka dapat dilakukan pendeteksian serta penghapusan data pencilan (outliers). Data pencilan dapat diketahui setidaknya dengan dua cara yaitu:
a. Melihat nilai probabilitas 1 (p1) atau probabilitas 2 (p2)
Nilai cut-off yang umumnya dipakai untuk mendeteksi data pencilan adalah melihat nilai p1 dan p2. Nilai tersebut disajikan pada tabel Mahalanobis Distance oleh AMOS. Nilai p1 atau p2 harus lebih besar dari 0,05 (Latan,2013:106).
b. Melihat nilai Mahalanobis Distance
Dikatakan oleh Santoso (2012:88) bahwa angka-angka pada tabel Mahalanobis Distance kolom Mahalanobis d-square menunjukkan seberapa jauh jarak data dengan titik pusat tertentu, jarak tersebut didapat dari perhitungan metode Mahalanobis. Semakin jauh jarak data dengan titik pusat data (centroid) maka semakin ada kemungkinan data tersebut adalah outliers.
Penelitian ini akan menggunakan cara pertama yaitu melihat nilai p1 atau p2.
6. Uji Model Pengukuran (Measurement Model)
Model pengukuran menunjukkan bagaimana variabel manifes (indikator) merepresentasikan variabel laten untuk diukur yaitu dengan menguji validitas dan reliabilitas variabel laten melalui analisis faktor konfirmatori. Penelitian ini akan menguji validitas konstruk dengan melihat validitas konvergen.
Validitas konvergen akan didapat dalam pengolahan SEM pada AMOS dengan melihat nilai factor loading atau disebut juga parameter lambda (λ). Nilai factor loading yang tinggi menunjukkan bahwa indikator konvergen pada satu titik. Selanjutnya dalam SEM, terdapat nilai squared multiple correlations yaitu kuadrat nilai korelasi antar variabel dengan indikatornya. Selanjutnya nilai tersebut dikalikan dengan 100%, hasil
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
persentase tersebut menunjukkan apakah indikator dapat menjelaskan konstruk atau tidak, sedangkan sisa persentase dijelaskan oleh unique factor, dalam hal ini adalah kesalahan pengukuran. Selanjutnya menurut Ferdinand dalam Wijaya (2009:138), ketika sebuah indikator memiliki nilai c.r pada tabel regression weights lebih besar dari dua kali standar kesalahan (s.e), maka indikator tersebut dapat dikatakan sahih mengukur variabel yang diukurnya.
Selain melihat nilai c.r, Santoso (2012:145) mengatakan bahwa kolom estimate pada tabel regression weights menunjukkan nilai kovarians antara variabel laten dengan indikatornya. Untuk mengetahui apakah indikator menjelaskan variabel laten atau tidak, selanjutnya dapat dilakukan uji hipotesis. Jika nilai probabilitas indikator lebih kecil dari 0,05, maka hipotesis nol ditolak. Adapun ringkasan acuan penentuan validitas dapat dilihat pada tabel 3.6.
Tabel 3.6
Ringkasan acuan validitas
Validitas Parameter Nilai Acuan
Validitas konvergen
Factor loading (λ) Lebih besar dari 0,5 c.r Lebih besar dari 2 kali s.e Probabilitas Lebih kecil dari 0,05
Selain menguji validitas konstruk, dilakukan juga uji reliabilitas konstruk. Uji ini berupaya untuk membuktkan akurasi, konsistensi dan ketepatan instrumen. Pada penelitian ini mencari reliabilitas dengan menggunakan teknik Alfa Cronbach. Nilai reliabilitas yang umumnya diterima dan menunjukkan ketepatan haruslah lebih besar dari 0,7. AMOS tidak menyajikan nilai untuk perhitungan ini, adapun untuk menghitungnya dengan persamaan 3.7 (Sugiyono,2013b:365).
{ ∑
} dimana:
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
ri = reliabilitas instrumen; k = banyaknya butir pernyataan;
si2 = jumlah varians butir; st2 = varians total;
Adapun untuk mencari varians butir dengan persamaan 3.8.
dimana:
si2 = varians butir;
JKi = jumlah kuadrat seluruh skor butir; JKs = jumlah kuadrat subyek;
n = jumlah responden.
Adapun untuk mencari varians total dengan persamaan 3.9. ∑ ∑ dimana:
st2 = varians total;
Xt2 = jumlah kuadrat X total; (Xt)2 = jumlah X total dikuadratkan; n = jumlah responden.
7. Uji Struktural Model (Structural Model)
Menguji model struktural bertujuan untuk mengetahui besarnya persentase variance setiap variabel endogen dalam model yang dijelaskan oleh variabel eksogen dengan melihat R-squares yang tidak lain adalah nilai squared multiple correlation. Selanjutnya selain nilai R-squares, evaluasi model struktural juga dapat dilakukan dengan melihat signifikansi nilai probabilitas sebagai dasar menerima atau menolak hipotesis nol. Nilai signifikansi yang digunakan yaitu 5% atau P < 0,05 serta nilai c.r > 1,96 (Latan,2013:208).
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
8. Kriteria Goodness of Fit (GoF)
Setelah menguji model pengukuran dan model struktural, selanjutnya adalah menguji model secara keseluruhan atau overall fit model berdasarkan nilai goodness of fit (GoF). GoF merupakan indikasi dari perbandingan antara model yang dispesifikasi dengan matrik kovarian antar indikator atau observed variables. Jika GoF yang dihasilkan baik, maka model tersebut dapat diterima dan sebaliknya jika GoF yang dihasilkan buruk, maka model tersebut harus ditolak atau dilakukan modifikasi model (Latan,2013:49). Kembali menurut Latan, seorang peneliti tidak harus memenuhi dan atau melaporkan semua kriteria GoF.Adapun kriteria GoF yang dilaporkan mengambil rekomendasi dari Garson dalam Latan (2013:49) yang tercantum pada tabel 3.7. Adapun program AMOS akan menampilkan hampir seluruh kriteria GoF.
Tabel 3.7
Kriteria goodness of fit (GoF)
Kriteria Indeks Ukuran Nilai Acuan Chi-Square (2) Probabilitas (P) > 0,05
CMIN/df 2,00
Root mean square error of approximation (RMSEA)
< 0,08
Comparative fit index (CFI) > 0,9 (mendekati 1) Parsimonious comparative fit
index (PCFI)
> 0,6
Akaike information criteria (AIC) AIC<AIC saturated model & independence model
Penjelasan dari kriteria di atas adalah sebagai berikut :
a. Chi-Squares (2)
Chi-Squares atau sering disebut juga -2 log likelihood merupakan kriteria fit indices yang menunjukkan adanya penyimpangan antara
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
sample covariance matrix dan model (fitted) covariance matrix. Fungsi chi-square dirumuskan sebagai berikut:
dimana: 2 = chi-square; N = besarnya sampel; F = discrepancy.
Sedangkan nilai discrepancy didapat dari nilai fo (observed frequency) dikurangi dengan nilai fe (frekuensi harapan) (Latan,2013:50).
b. CMIN/df
Adalah ukuran yang didapat dari pembagian nilai chi-squares (2 ) dengan degree of freedom (df). Nilai yang diajukan untuk mengetahui fit model adalah jika nilai CMIN/DF ≤ 2.
c. Root Mean Square Error of Approximation (RMSEA)
RMSEA mengukur penyimpangan nilai parameter model dengan matriks kovarians populasinya. Nilai RMSEA yang lebih kecil atau sama dengan 0,05 menunjukkan bahwa fit model sangat baik. Namun menurut Sugiyono (2013b:346), RMSEA dengan nilai lebih kecil dari 0.08 sudah dikatakan bahwa model fit. Adapun cara mencari RMSEA menurut Latan (2013:53) yaitu:
√
√̂
d. Comparative Fit Index (CFI)
CFI merupakan ukuran perbandingan antara model yang dihipotesiskan dengan null model. Pengukuran ini tidak dipengaruhi jumlah sampel dan merupakan ukuran fit yang sangat baik untuk
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
mengukur kesesuaian model. Nilai yang direkomendasikan adalah > 0,90. Adapun secara matematis dirumuskan sebagai berikut (Latan,2013:58): ( ̂ ) ̂ dimana: ̂ = discrepancy;
d = degree of freedom untuk model yang diuji; ̂ = discrepancy untuk baseline model;
db =degree of freedom untuk baselinemodel; NCP = nonconcentrality parameter model yang diuji; NCPb = nonconcentrality parameter untuk baseline model.
e. Parsimonious Comparative Fit Index (PCFI)
PCFI merupakan ukuran perbandingan antara df propose model / df null model. Angka yang disarankan untuk PCFI berkisar dari 0 hingga 1, namun menurut Latan (2013:64) jika PCFI > 0,60 sudah menunjukkan model mempunyai parsimony fit yang baik. Semakin tinggi nilai PCFI suatu model, maka semakin parsimony model tersebut. Adapun secara matematis dirumuskan sebagai berikut:
dimana:
d = degree of freedom untuk model yang diuji; db = degree of freedom untuk baselinemodel; CFI = nilai CFI.
f. Akaike Information Criteria (AIC)
AIC dipergunakan untuk membandingkan model dimana nilai AIC default model akan dibandingkan dengan AIC saturated model dan
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
independence model dengan nilai default model harus lebih kecil. Adapun secara matematis menurut Santoso (2012:125) dapat dirumuskan sebagai berikut:
dimana:
AIC = nilai akaike information criteria; 2
= chi-square hitung;
q = jumlah parameter estimasi.
9. Uji Hipotesis
Untuk mengetahui apakah hipotesis penelitian diterima atau ditolak, maka selanjutnya dilakukan uji hipotesis. Uji hipotesis yang dilakukan menggunakan kaidah pengujian signifikansi secara manual. Dilakukan dua tahap yaitu untuk menguji hipotesis keseluruhan model, dan hipotesis individual. Adapun hipotesis keseluruhan yaitu:
Ha = Keempat kategori kesiapan dari model ini berpengaruh secara
signifikan terhadap kesiapan peserta e-learning
H0 = Keempat kategori kesiapan dari model ini tidak berpengaruh
secara signifikan terhadap kesiapan peserta e-learning Atau secara statistiknya adalah :
H0 : = 0
Ha : 0
Sedangkan pengembangan hipotesis secara individu disampaikan pada bab 4 sesuai dengan spesifikasi model. Menurut Riduwan dan Kuncoro (2012:117), pengujian hipotesis secara keseluruhan dilakukan dengan membandingkan nilai F tabel (Ft) dengan F hitung (Fh). Jika Fh lebih besar atau sama dengan Ft, maka H0 ditolak, dan sebaliknya jika Fh kurang dari atau sama dengan Ft maka H0 diterima. Adapun menghitung
nilai Fh dapat digunakan persamaan 3.17.
( )
Siti Hasanah, 2014
Kajian Implementasi E-Learning Berdasarkan Tingkat Kesiapan Peserta E-Learning Universitas Pendidikan Indonesia | repository.upi.edu |perpustakaan.upi.edu
dimana:
n = jumlah sampel;
k = jumlah variabel eksogen; R2yxk = nilai R-square.
Selanjutnya untuk menguji signifikansi hubungan antar variabel laten dapat dilihat dari pengujian model pengukuran dan model struktural yang telah disampaikan sebelumnya. Untuk mengetahui besar tidaknya pengaruh hubungan variabel terhadap variabel lain, AMOS menyajikan pengaruh setiap variabel yang dirangkum dalam efek langsung (direct effect), efek tidak langsung (indirect effect) dan efek total (total effect). Adapun SEM sendiri yang terdiri dari analisis jalur memiliki beberapa simbol untuk mewakili pengaruh tersebut yaitu (Sugiyono,2013b:328): a. ξ (ksi) = mewakili variabel laten eksogen;
b. ε (eta) = mewakili variabel laten endogen; c. λ (lambda) = nilai factor loading;
d. β (beta) = koefisien pengaruh variabel endogen terhadap variabel endogen;
e. γ (gamma) = koefisien pengaruh variabel eksogen terhadap variabel endogen;
f. φ (phi) = koefisien pengaruh variabel eksogen terhadap variabel eksogen;
g. δ (zeta) = peluang galat model;
h. ε (epsilon) = kesalahan pengukuran variabel manifes untuk variabel laten endogen;
i. δ (delta) = kesalahan pengukuran variabel manifes untuk variabel laten eksogen.