7
LANDASAN TEORI
Dalam bab ini diuraikan beberapa landasan teori yang terkait, mencakup konsep neuro-fuzzy dan soft computing, logika fuzzy, teori himpunan fuzzy, aturan fuzzy dan penalaran fuzzy, fuzzy inference system ( FIS ), serta Adaptive Neuro-Fuzzy Inference System ( ANFIS ).
2.1 Neuro-Fuzzy dan Soft Computing
2.1.1 Pengertian Neuro-Fuzzy dan Soft Computing
Neuro-Fuzzy dan Soft Computing ( SC ) adalah integrasi dua pendekatan komplementer: jaringan saraf ( neural network, NN ) yang mengenali pola dan beradaptasi untuk menanggulangi keadaan yang berubah - ubah / acak; sistem inferensi fuzzy ( fuzzy inference system, FIS ) yang menggabungkan pengetahuan manusia serta melakukan inferensi dan pembuatan keputusan. Sinergi ini memungkinkan SC menggabungkan pengetahuan manusia secara efektif, menghadapi ketidakketepatan dan ketidakpastian (Linda, 2007).
2.1.2 Karakteristik Neuro-Fuzzy dan Soft Computing
a) Kepakaran manusia
SC menggunakan kepakaran manusia dalam bentuk aturan if - then fuzzy, sama baiknya seperti dalam representasi pengetahuan konvensional, untuk memecahkan masalah – masalah praktis.
b) Model – model komputasi biologically inspired
Diinspirasi oleh NN biologis, NN tiruan digunakan secara ekstensif dalam SC untuk menghadapi persepsi, pengenalan pola, dan regresi nonlinier serta masalah – masalah klasifikasi.
c) Teknik - teknik optimisasi baru
SC mengaplikasikan metode – metode optimisasi inovatif yang timbul dari berbagai sumber.
d) Komputasi numeris
Tidak seperti kecerdasan artifisial ( artificial intelligence, AI ) yang simbolik, SC terutama bergantung pada komputasi numeris.
e) Domain – domain aplikasi baru
Karena komputasi numerisnya, SC telah menemukan sejumlah domain aplikasi baru disamping domain – domain dengan pendekatan AI. Domain – domain aplikasi ini membutuhkan komputasi yang intensif. f) Pembelajaran bebas model
NN dan FIS adaptif mempunyai kemampuan untuk membangun model menggunakan hanya data contoh sistem target. Pengetahuan detil dalam sistem help targetmen-setstruktur model inisial, namun ini bukan suatu keharusan.
g) Komputasi intensif
Tanpa adanya asumsi yang banyak mengenai pengetahuan background dari masalah yang ingin diselesaikan, neuro-fuzzy dan SC sangat bergantung pada pengkomputasian menerka angka dalam kecepatan
tinggi untuk menemukan aturan – aturan atau susunan yang teratur dari dalam himpunan data.
h) Toleransi kesalahan
Penghancuran sebuah node / neuron dalam suatu NN atau sebuah aturan dalam suatu FIS, tidak akan menghancurkan sistem yang berjalan. Sistem akan tetap bekerja karena arsitektur paralel dan redundannya meskipun performa berangsur memburuk.
i) Karakteristik goal driven
Neuro-fuzzy dan SC adalah goal driver; jalan yang memimpin state kini ke solusi tidak terlalu penting selama bergerak menuju tujuan dalam long run. Pengetahuan domain spesifik menolong mengurangi waktu komputasi dan pencarian tetapi bukan menjadi suatu kebutuhan.
j) Aplikasi – aplikasi dunia rill
Semua masalah dunia riil mengandung ketidakpastian built-in yang tidak dapat dielakkan, sehingga terlalu cepat menggunakan pendekatan konvensional yang memerlukan deskripsi detil dari masalah yang sedang dipecahkan. SC adalah pendekatan terintegrasi yang seringkali dapat menggunakan teknik – teknik spesifik dalam subtugas – subtugas untuk membangun solusi umum yang memuaskan untuk masalah dunia riil (Jang, Jyh-Shing Roger, Chuen-Tsai Sun, Eiji Mizutani, 1997).
2.2 Logika Fuzzy
Dalam teori logika fuzzy menjelaskan sejarah, definisi dan terminologi dasar, teori operasi himpunan fuzzy, parameter dan formulasi fungsi keanggotaan ( membership function, MF ) serta konfigurasi dan desain sistem logika fuzzy.
Teori logika fuzzy dikemukakan pertama kali oleh Lotfi A. Zadech pada tahun 1965, yaitu suatu pendekatan komputasional dalam pengambilan keputusan sesuai dengan cara berpikir manusia yang mengijinkan adanya ketidakpastian dan memperlihatkan suatu logika yang bergradasi. Seperti yang dilakukan oleh manusia dalam mengambil keputusan, pengertian – pengertian yang ada di dalam pemikiran manusia diukur dengan kualitas daripada kuantitas (Kulkarni, 2001).
Menurut Sri Kusuma Dewi, logika fuzzy merupakan salah satu komponen pembentuk Soft Computing. Dasar logika fuzzy adalah teori himpunan fuzzy. Pada teori himpunan fuzzy, peranan derajat keanggotaan sebagai penentu keberadaan elemen dalam suatu himpunan sangatlah penting. Nilai keanggotaan atau derajat keanggotaan atau membership function menjadi ciri utama dari penalaran dengan logika fuzzy tersebut (Kusumadewi, 2006).
Dalam banyak hal, logika fuzzy digunakan sebagai suatu cara untuk memetakan permasalahan dari input menuju ke output yang diharapkan. Beberapa contoh yang dapat diambil antara lain:
1. Manajer pergudangan mengatakan pada manajer produksi seberapa banyak persediaan barang pada akhir minggu ini, kemudian manajer produksi akan menetapkan jumlah barang yang harus diproduksi esok hari.
2. Seorang pegawai melakukan tugasnya dengan kinerja yang sangat baik, kemudian atasan akan memberikan reward yang sesuai dengan kinerja pegawai tersebut (Kusumadewi dan Purnomo, 2004).
Logika fuzzy dapat dianggap sebagai kotak hitam yang menghubungkan antara input menuju ke ruang output. Kotak hitam tersebut berisi cara atau metode yang dapat digunakan untuk mengolah data input menjadi output dalam bentuk informasi yang baik.
Dalam logika klasik hanya mengenal dua nilai kebenaran yaitu benar atau salah yang disimbolkan oleh nilai 1 dan 0, serta perubahan keanggotaan pada himpunan klasik berubah secara drastis. Tetapi pada logika fuzzy, sesuatu dapat bernilai diantara 0 dan 1, serta nilai anggota himpunan diperbolehkan mempunyai gradiasi di antara menjadi anggota penuh atau hanya sebagian sehingga perubahan keanggotaan pada logika fuzzy berlangsung secara perlahan atau memberi nilai kebenaran yang bergradiasi.
Misalkan pada pengertian “tinggi” yang sering digunakan dalam kehidupan sehari – hari. Pada himpunan klasik hanya mengenal seseorang tinggi jika orang tersebut memiliki tinggi 180 cm, sedangkan dibawah 180 disebut “pendek”. Namun, pada himpunan fuzzy, orang yang memiliki tinggi badan 2 m mempunyai nilai kebenaran penuh atau 1. Sedangkan bila tingginya 175 cm maka seseorang dianggap misalnya 90% tinggi.
Menurut Sri Kusuma Dewi, ada beberapa alasan mengapa orang menggunakan logika fuzzy, antara lain :
1. Konsep logika fuzzy mudah dimengerti. Karena logika fuzzy menggunakan dasar teori himpunan, maka konsep matematis yang mendasari penalaran fuzzy tersebut cukup mudah untuk dimengerti.
2. Logika fuzzy sangat fleksibel, artinya mampu beradaptasi dengan perubahan - perubahan, dan ketidakpastian yang menyertai permasalahan.
3. Logika fuzzy memiliki toleransi terhadap data yang tidak tepat. Jika diberikan sekelompok data yang cukup homogen, dan kemudian ada beberapa data yang “ekslusif”, maka logika fuzzy memiliki kemampuan untuk menangani data eklusif tersebut.
4. Logika fuzzy mampu memodelkan fungsi - fungsi nonlinear yang sangat kompleks.
5. Logika fuzzy dapat membangun dan mengaplikasikan pengalaman - pengalaman para pakar secara langsung tanpa harus melalui proses pelatihan. Dalam hal ini, sering dikenal dengan nama Fuzzy Expert System menjadi bagian terpenting.
6. Logika fuzzy dapat bekerjasama dengan teknik - teknik kendali secara konvensional. Hal ini umumnya terjadi pada aplikasi di bidang teknik mesin maupun teknik elektro (Kusumadewi, 2006).
Logika fuzzy didasarkan pada bahasa alami. Logika fuzzy menggunakan bahasa sehari - hari sehingga mudah dimengerti.
2.3 Teori Himpunan Fuzzy 2.3.1 Himpunan Fuzzy
Teori himpunan fuzzy diperkenalkan oleh Zadeh pada tahun 1965 (Kulkarni, 2001). Beberapa definisi tentang himpunan fuzzy ( Yan; Ryan; power; 1994 ), yaitu :
• Jika U adalah objek - objek yang dinotasikan secara generik oleh u, maka suatu himpunan fuzzy F dalam U adalah suatu himpunan pasangan berurutan :
F = (2.1)
Dengan adalah derajat keanggotaan u di F yang memetakan U ke ruang keanggotaan yang terletak pada rentang [0,1].
• Support dari himpunan fuzzy F adalah himpunan klasik dari
sedemikian hingga . Untuk dimana = 0.5 disebut titik potong.
• Himpunan α-level dari himpunan fuzzy , , adalah himpunan klasik dari
sedemikian hingga .
• Biasanya derajat keanggotaan maksimum untuk elemen didalam himpunan fuzzy adalah 1. Pada kasus ini himpunan tersebut disebut ternomalisasi ( normalized ). Sebuah himpunan yang tidak ternomalisasi dapat dibuat menjadi begitu dengan mengubah semua nilai - nilai keanggotaan dalam proporsi sehingga membuat nilai terbesar menjadi 1.
Himpunan fuzzy adalah generalisasi konsep himpunan biasa ( ordiner ). Untuk semesta wacana X, himpunan fuzzy ditentukan oleh fungsi keanggotaan
yang memetakan anggota x ke rentang keanggotaan dalam interval [0, 1]. Sedangkan untuk himpunan biasa fungsi keanggotaan bernilai diskrit 0 dan 1.
Berikut didefinisikan beberapa kelas MF ( member function ) terparameter satu dimensi, yaitu MF dengan sebuah input tunggal (Kusumadewi, 2006).
MF segitiga dispesifikasikan oleh tiga parameter { a, b, c } seperti berikut :
µ
segitiga(x)
(2.2)Parameter { a, b, c } ( dengan a < b < c ) menentukan koordinat x dari ketiga corner yang mendasari MF segitiga.
MF trapesium dispesifikasikan oleh empat parameter { a, b, c, d } sebagai
berikut :
µ
trapesium(x, a, b, c, d)
(2.3)Parameter { a, b, c, d } ( dengan a < b ≤ c < d ) menentukan koordinat x dari keempat corner yang mendasari MF trapesium.
MF Gauss dispesifikasikan oleh dua parameter { c, σ } :
dimana c merepresentasikan pusat MF dan σ mendefinisikan lebar MF.
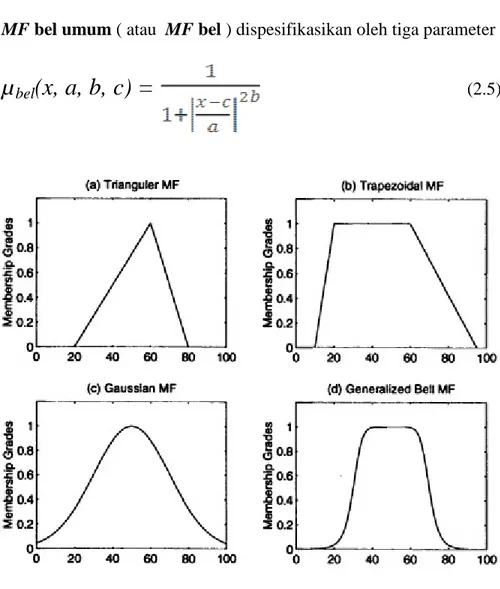
MF bel umum ( atau MF bel ) dispesifikasikan oleh tiga parameter {a, b, c} :
µ
bel(x, a, b, c) =
(2.5)Gambar 2.1 Contoh empat kelas MF terparameter : (a) µsegitiga(x; 20, 60, 80); (b) µtrapesium(x; 10, 20, 60, 95); (c) µgauss(x; 50, 20); (d) µbel(x; 20, 4, 50).
Gambar 2.2 Arti fisik dari parameter – parameter dalam suatu MF bel umum MF S berbentuk huruf S ( Gambar 2.3 ) dispesifikasikan oleh parameter { a, b }:
µs(x; a,b
) =
(2.6)Titik persilangan terjadi pada (a + b)/2.
Gambar 2.3 Grafik fungsi MFS
MF Z dispesifikasikan oleh dua parameter {a, b} (Gambar 2.4) :
Gambar 2.4 Grafik fungsi MF Z
MF pi dispesifikasikan oleh empat parameter { a, b, c, d } :
µ
phi(x; a,b) = µ
s(x; a,b) * µ
z(x; c,d)
(2.8)Parameter c menentukan titik tengah dan parameter b menentukan lebar bidang pada titik persilangan. Titik persilangan terdapat pada : u = c ± b/ 2.
Gambar 2.5 Grafik fungsi MFpi MF sigmoid didefinisikan oleh :
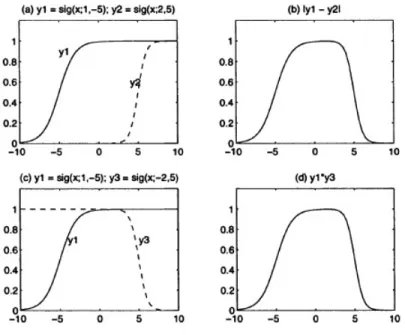
µ
sigmoid(x; a, c) =
(2.9)Gambar 2.6 Grafik fungsi MF sigmoid: (a) Dua fungsi sigmoid y1 dan y2; (b) sebuah close MF didapatkan dari | y1– y2|; (c) dua fungsi dari sigmoid y1 dan
y3; (d) sebuah close MF didapatkan dari y1y3.
2.3.2 Aturan Fuzzy dan Penalaran Fuzzy a) Aturan if – then Fuzzy
Suatu aturan if – then fuzzy atau aturan fuzzy mengasumsikan bentuk If x is A then y is B,
Dimana A dan B nilai linguistik yang didefinisikan himpunan fuzzy pada semesta X dan Y. “x is A” disebut anteseden, sedangkan “y is B” disebut konsekuen.
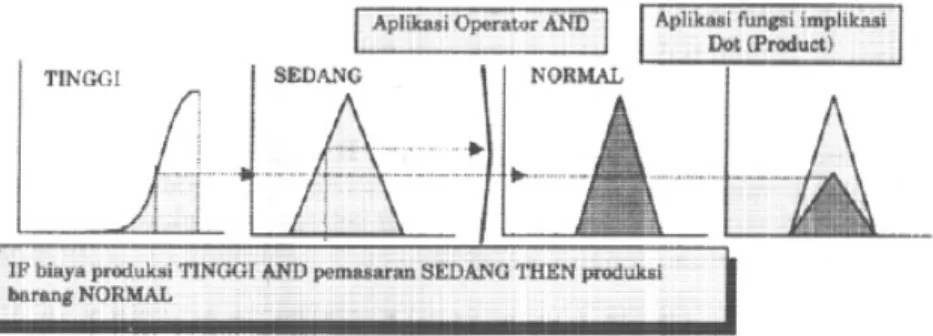
Dua fungsi implikasi yang banyak digunakan adalah min ( Mamdani ) karena kemudahannya dalam interpretasi grafis dan prod ( Larsen ) : 1) Min ( minimum ). Fungsi ini akan memotong output himpunan fuzzy.
Gambar di bawah ini menunjukkan salah satu contoh penggunaan fungsi min.
Gambar 2.7 Fungsi implikasi min
2) Dot ( dot product ). Fungsi ini akan menskala output himpunan fuzzy. Gambar dibawah ini menunjukkan salah satu contoh penggunaan fungsi dot.
Gambar 2.8 Fungsi Implikasi Dot
b) Penalaran Fuzzy
Aturan dasar inferensi dalam two - valued logic tradisional adalah modus ponens : menarik kebenaran proposisi B dari kebenaran A dan implikasi A→B.
Dalam penalaran manusia, modus ponen banyak digunakan dalam cara pendekatan ( approximate ). Ini dituliskan sebagai :
premis 1 ( fakta ) : x is A’.
konsekuensi ( konklusi ) : y is B’.
dimana A’ dekat dengan A dan B’ dekat dengan B. Prosedur inferensi di atas disebut approximate reasoning atau penalaran fuzzy; juga disebut
Generalized Modus Ponen ( GMP ) karena mengandung modus ponens
dalam kasus spesial.
A, A’, dan B adalah himpunan fuzzy pada X, X’, dan Y. Implikasi fuzzy A→B diekspresikan sebagai relasi fuzzy R pada X x Y. Maka himpunan fuzzy B yang ditarik dari “x is A” dan aturan fuzzy “if x is A then y is B” didefinisikan oleh
µB’(y) = maxx min[µA’( x ), µR(x, y)] (2.10) = vx[µA’ ( x ) ^ µR(x, y)],
atau ekuivalen dengan
B’ = A’ o R = A’ o ( A → B ). (2.11)
Ada tiga metode yang digunakan dalam melakukan komposisi aturan – aturan fuzzy untuk inferensi, yaitu: max, sum, dan probor. µsf(xi) = nilai keanggotaan solusi fuzzy sampai aturan ke – i; µkf(xi) = nilai keanggotaan konsekuen fuzzy aturan ke – i.
1) Metode Max ( Maximum )
Solusi himpunan fuzzy diperoleh dengan mengambil nilai maksimum aturan, menggunakannya untuk memodifikasi daerah fuzzy, dan mengaplikasikannya ke output dengan menggunakan operator OR ( union ).
µsf(xi) ←max(µsf(xi), µkf(xi)) (2.12) 2) Metode Additive ( Sum )
Solusi himpunan fuzzy diperoleh dengan melakukan penjumlahan terbatas terhadap semua output daerah fuzzy.
µsf(xi) ← min(1, 1 - µsf(xi) + µkf(xi)) (2.13) 3) Metode Probabilistic OR ( probor )
Solusi himpunan fuzzy diperoleh dengan melakukan produk terhadap semua output daerah fuzzy. Secara umum dituliskan :
µsf(xi) ← (µsf(xi) + µkf(xi)) – (µsf(xi) * µkf(xi)) (2.14)
Jadi, proses penalaran fuzzy dapat dibagi ke dalam empat langkah : a) Derajat kesepadanan / memasukkan input fuzzy
Bandingkan fakta yang diketahui dengan anteseden dari aturan fuzzy untuk menemukan derajat kesepadanan dengan memperhatikan setiap anteseden MF.
b) Kuat penyulutan / mengaplikasikan operator fuzzy
Gabungkan derajat – derajat kesepadanan dengan memperhatikan anteseden MF – MF dalam suatu aturan menggunakan operator fuzzy AND atau OR untuk membentuk kuat penyulutan yang mengindikasikan tingkat bagian anteseden dari aturan dipenuhi. c) MF konsekuen yang qualified ( terinduksi ) / mengaplikasikan
metode implikasi
Gunakan kuat penyulutan ke MF konsekuen dari suatu aturan untuk menemukan suatu MF konsekuen qualified.
Agresikan semua MF konsekuen qualified untuk mendapatkan suatu MF output keseluruhan.
2.3.3 Sistem Inferensi Fuzzy
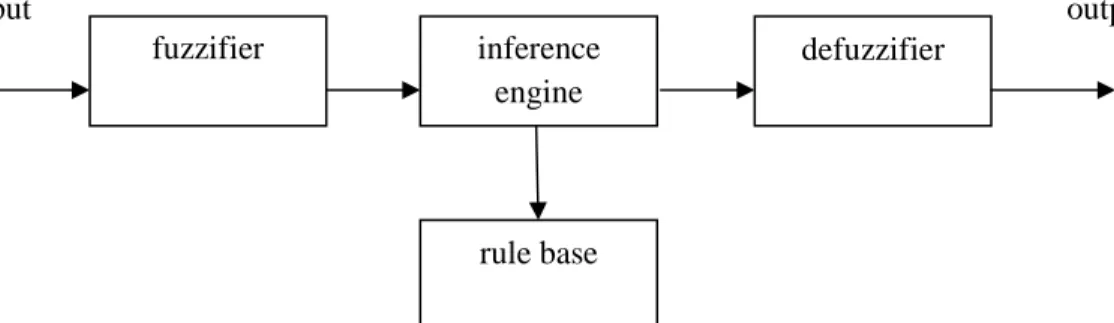
Sistem inferensi fuzzy (FIS) adalah sebuah framework komputasi populer berdasarkan pada konsep teori himpunan fuzzy, aturan if - then fuzzy, dan penalaran fuzzy (Kusumadewi, 2006).
Tiga komponen konsep FIS yaitu : baris aturan, mengandung seleksi dari aturan – aturan fuzzy; basis data, mendefinisikan MF – MF yang digunakan dalam aturan fuzzy; dan mekanisme penalaran, melakukan prosedur inferensi pada aturan – aturan dan fakta – fakta yang diberikan untuk menarik output atau konklusi yang reasonable.
FIS dapat mengambil input fuzzy maupun input tegas ( sebagai fuzzy singleton ), tapi output yang dihasilkan hampir selalu himpunan fuzzy. Kadang kala output tegas dibutuhkan, sehingga dibutuhkan metode defuzifikasi untuk mengekstrak nilai tegas paling baik merepresentasikan himpunan fuzzy.
Sistem inferensi fuzzy ( Fuzzy Inference System ) pada dasarnya mendefinisikan pemetaan nonlinear dari vektor data input menjadi skalar output. Proses pemetaan melibatkan input / output fungsi keanggotaan, operator - operator fuzzy, aturan fuzzy if - then, agregasi dari himpunan output dan defuzzification (Hartono, 2010). Model umum dari sistem inferensi fuzzy ditunjukkan pada gambar dibawah ini:
input output
x y
Gambar 2.9 Diagram Blok Sistem Inferensi Fuzzy
Sistem inferensi fuzzy memiliki empat komponen, yaitu: fuzzifier, inference engine, rule base dan defuzzifier. Rule base memiliki aturan linguistik yang diberikan oleh para ahli. Juga mungkin dapat mengambil aturan dari data numerik. Sekali aturan telah ditetapkan, sistem inferensi fuzzy dapat dilihat sebagai sebuah sistem yang memetakan sebuah vektor input ke vektor output. Fuzzifier memetakan angka - angka input kedalam keanggotaan fuzzy yang sesuai. Inference engine mendefinisikan pemetaan dari input himpunan fuzzy kedalam output himpunan fuzzy. Defuzzifier memetakan output himpunan fuzzy kedalam nomor crisp.
Metode Tsukamoto
Sistem inferensi fuzzy didasarkan pada konsep penalaran monoton. Pada metode penalaran monoton, nilai crisp pada daerah konsekuen dapat diperoleh secara langsung berdasarkan fire strength pada antesedennya. Salah satu syarat yang harus dipenuhi pada metode penalaran ini adalah himpunan fuzzy pada konsekuennya harus bersifat monoton ( baik monoton naik maupun monoton turun ) (Kusumadewi, 2006).
fuzzifier inference engine
defuzzifier
Model Fuzzy Sugeno
Model Fuzzy Sugeno ( model fuzzy TSK ) diajukan oleh Takagi, Sugeno, dan Kang ( Takagi dan Sugeno, 1985, hal. 116 – 132; Sugeno dan Kang, 1988, hal. 15 – 33 ) dalam upaya untuk membangun pendekatan sistematis untuk membangkitkan aturan – aturan fuzzy dari himpunan data input – output yang diberikan. Suatu aturan fuzzy khas dalam model fuzzy Sugeno dibentuk
if x is A and y is B then z = f(x,y),
dimana A dan B himpunan fuzzy dalam anteseden dan z = f(x,y) fungsi tegas dalam konsekuen. Jika f(x, y) polimonial orde satu, FIS yang dihasilkan disebut model fuzzy Sugeno orde satu. Jika f konstan, dihasilkan model fuzzy Sugeno orde nol.
Sistem inferensi fuzzy menggunakan metode Sugeno memiliki karakteristik, yaitu konsekuen tidak merupakan himpunan fuzzy, namun merupakan suatu persamaan linear dengan variabel - variabel sesuai dengan variabel - variabel inputnya. Ada 2 model sistem inferensi fuzzy dengan menggunakan metode TSK, yaitu:
1. Model Fuzzy Sugeno Orde-0
Secara umum bentuk model fuzzy sugeno orde-0 adalah:
IF( iS )° ( iS )° ( iS )°...° ( iS ) THEN z=k (2.15) dengan adalah himpunan fuzzy ke-i sebagai anteseden, ° adalah operator fuzzy ( seperti AND atau OR ), dan k adalah suatu konstanta ( tegas ) sebagai konsekuen.
2. Model Fuzzy Sugeno Orde-1
Secara umum bentuk model fuzzy Sugeno orde-1 adalah:
IF ( iS ) °...° ( iS ) THEN z= * +...+ * +q (2.16) dengan adalah himpunan fuzzy ke-i sebagai anteseden, ° adalah
operator fuzzy ( seperti AND atau OR ), adalah suatu konstanta ( tegas ) ke-i dan q juga merupakan konstanta dalam konsekuen. Proses agresasi dan defuzzy untuk mendapatkan nilai tegas sebagai output untuk M aturan fuzzy juga dilakukan dengan menggunakan rata - rata terbobot, yaitu:
z =
(2.17)2.4 Algoritma Pembelajaran Hybrid
Pada saat premise parameters ditemukan, output yang akan terjadi merupakan kombinasi linear dari consequent parameter, yaitu :
y = (2.18)
= =
Algoritma hybrid akan mengatur parameter – parameter cij secara maju (forward) dan akan mengatur parameter – parameter {ai, bi, ci} secara mundur ( backward).
Pada langkah maju (forward), input jaringan akan merambat maju sampai pada lapisan keempat, dimana parameter – parameter cij akan diidentifikasikan dengan menggunakan metode least-square. Sedangkan pada langkah mundur ( backward ), error sinyal akan merambat mundur dan parameter – parameter {ai, bi, ci} akan diperbaiki dengan menggunakan metode gradient descent.
Menurut Jang (1997), menggunakan algoritma backpropagation atau gradient descent untuk mengidentifikasikan parameter – parameter pada suatu jaringan adaptif biasanya membutuhkan waktu yang relatif lama untuk konvergen. Mengemukakan algoritma hybrid yang akan menggabungkan antara steepest descent (SD) dan least square estimator (LSE) untuk mengidentifikasikan parameter – parameter linear.
2.5 Least Square Estimator (LSE) Rekursif
Salah satu metode LSE adalah LSE rekursif. Pada LSE rekursif, dapat menambahkan suatu pasangan data [aT | y], sehingga memiliki sebanyak ( m+ 1) pasangan data. Dari sini dapat dihitung kembali LSE θk. Bentuk semacam ini dikenal dengan LSE Rekursif.
Karena jumlah parameter ada sebanyak n, maka matriks m x n dapat diselesaikan dengan menggunakan metode invers, sebagai berikut :
P
n= (A
n TA
n)
-1Θ
n= (P
nA
n Ty
n)
(2.20)Selanjutnya, iterasi dimulai dari data ke-(n + 1), dengan nilai Pk+1 dan ϴk+1 dapat dihitung sebagai berikut :
P
k+1= P
k–
(2.21)θ
k+1=
θ
k+ P
k+1a
k+1( y
k+1-
θ
k)
(2.22)2.6 Perambatan Balik Untuk Jaringan Feedforward
Perambatan balik adalah aturan pelatihan dasar untuk jaringan adaptif yang pada esensinya metode SD sederhana. Bagian inti adalah bagaimana secara rekursif memperoleh suatu vektor gradien dimana tiap elemen didefinisikan sebagai derivatif ukuran galat terhadap suatu parameter.
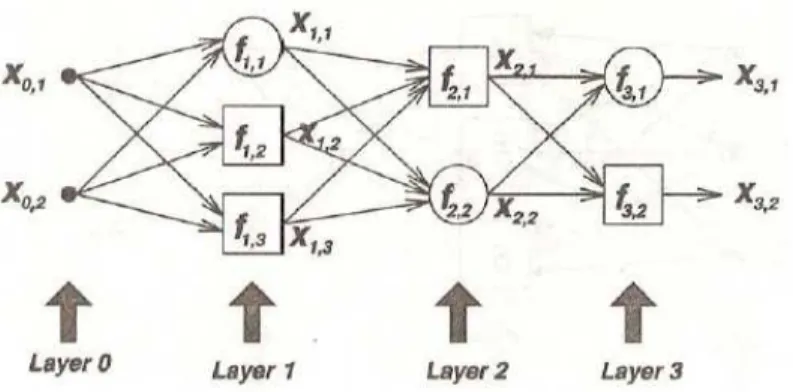
Misalkan sebuah jaringan adaptif feedforward yang diberikan mempunyai L lapis dan lapis l ( l = 0, 1, …., L; l = 0 merepresentasikan lapisan input) mempunyai N(I) node. Maka output dan fungsi node i [ i = 1,…, N(l)] dalam lapis l dapat direpresentasikan sebagai xl,i dan fl,i, seperti yang ditunjukkan pada gambar dibawah. Karena output suatu mode bergantung pada sinyal – sinyal yang masuk dan himpunan parameter dari node, maka ekspresi umum untuk fungsi node fl,i adalah sebagai berikut :
x
l,i= f
l,i(x
l-1,1, ….., x
l-1,N(l-1), α, β, γ,…)
(2.23)Gambar 2.10. Konvensi notasional : representasi lapis.
Asumsikan bahwa himpunan data pelatihan yang diberikan mempunyai P entri, dapat didefinisikan suatu ukuran galat untuk entri data pelatihan ke – p (1 ≤ p ≤ P) sebagai jumlah kuadrat galat :
,
(2.24)dimana dk adalah komponen ke – k dari vektor output yang diinginkan ke-p dan xL,k adalah komponen ke – k dari vektor output aktual yang dihasilkan dengan menggunakan vektor input ke – p ke jaringan. Karena untuk ANFIS hanya terdapat satu node output maka :
(2.25)
Sebelum mengkalkulasi vektor gradien, observasi hubungan kasual berikut :
Dengan kata lain, perubahan kecil pada parameter α akan mempengaruhi output node yang mengandung α; selanjutnya akan mempengaruhi output lapis akhir dan karenanya ukuran galat. Karena itu, konsep dasar dalam menghitung vektor
Change in parameter α Change in outputs of nodes containing α Change in network’s output Change in error measure
gradien adalah dengan melewatkan sebuah bentuk informasi derivatif dimulai dari lapis output dan berjalan mundur lapis demi lapis sampai lapis input dicapai. Sinyal galat
ϵ
l,i didefinisikan sebagai derivatif ukuran galat Ep terhadap output node i dalam lapis l, mengambil jalur baik langsung dan tak langsung.ϵ
l,i=
(2.26)
Ekspresi ini disebut derivatif beruntun oleh Werbos (1974), yang mempertimbangkan baik jalur langsung maupun tidak langsung yang membawa pada hubungan kausal.
Sinyal galat output node ke – i (pada lapis L) dapat dikalkulasi secara langsung :
ϵ
l,i=
=
(2.27)
Ini sama dengan
ϵ
L,i = -2(di – xL,i). Untuk node internal pada posisi ke – i dari lapis l, sinyal galat didapatkan dengan aturan berantai :ϵ
l,i=
=
(2.28)
=
dimana 0 ≤ l ≤ L-1.Vektor gradien didefinisikan sebagai derivatif ukuran galat terhadap masing – masing parameter. Jika α adalah suatu parameter dari node ke – i pada lapis l, maka
= ϵl,i
(2.29)Jika parameter α diijinkan untuk di-share di antara node – node berbeda, maka persamaan di atas diubah ke bentuk yang lebih umum :
(2.30)
dimana S adalah himpunan node yang mengandung α sebagai suatu parameter; dan x* dan f* adalah output dan fungsi dari suatu node generik dalam S.
Derivatif dari ukuran galat keseluruhan E terhadap α adalah
(2.31)
Karena itu, untuk penurunan tercuram sederhana tanpa minimisasi garis, formula update untuk parameter generik α (misalnya parameter a, b, atau c) adalah
dimana η adalah tingkat pelatihan, yang dapat diekspresian sebagai
dimana k adalah ukuran langkah, panjang setiap transisi sepanjang arah gradien dalam ruang parameter.
2.7 Aturan Pelatihan Hybrid : Mengkombinasikan SD dan LSE
(2.32)
Meski dapat menggunakan perambatan balik untuk mengidentifikasikan parameter jaringan adaptif, namun seringkali memakan waktu panjang sebelum konvergen. Output jaringan adaptif linier dalam beberapa parameter jaringannya; sehingga dapat diidentifikasi dengan metode kuadrat terkecil (MKT) linier. Pendekatan ini menghasilkan aturan pelatihan hybrid yang mengkombinasikan SD dan LSE untuk identifikasi cepat parameter.
Pelatihan Off-line (Pelatihan Batch)
Diasumsikan jaringan adaptif hanya mempunyai satu output yand direpresentasikan oleh
o = F(i, S)
(2.34)dimana i adalah vektor variabel – variabel input, S adalah himpunan parameter, dan F adalah fungsi keseluruhan yang diimplementasikan oleh jaringan adaptif. Jika terdapat sebuah fungsi H sehingga fungsi komposit H o F linier dalam beberapa elemen S, maka elemen – elemen ini dapat diidentifikasi oleh MKT. Secara lebih formal, jika himpunan parameter S dapat dibagi ke dalam dua himpunan
S = S
1⊕
S
2 (2.35)(dimana ⊕ merepresentasikan jumlah langsung) sehingga H o F linier dalam elemen – elemen S2 , maka dengan mengaplikasikan H ke persamaan (2.35), diperoleh
yang linier dalam S2. Jika diberikan nilai elemen – elemen S1, dapat dimasukkan P (data pelatihan) ke dalam persamaan (2.34) dan memperoleh persamaan matriks :
A
θθθθ
= y
(2.37)dimana
θ
adalah vektor yang tidak diketahui yang elemennya adalah parameter – parameter dalam S2. Solusi terbaik untukθ
yang meminimkan ||Aθ - y||2 adalah penduga kuadrat terkecil (LSE) θ*.Sekarang dapat dikombinasikan SD dan LSE untuk meng-update parameter jaringan adaptif. Untuk pelatihan hybrid yang diaplikasikan ke dalam mode batch, setiap epoch (periode pelatihan) tersusun atas forward pass dan backward pass. Dalam forward pass, setelah vektor input dihadirkan, dikalkulasikan output node lapis demi lapis sampai baris dalam matriks A dan y dalam persamaan (2.37) diperoleh. Lalu parameter – parameter dalam S2 diidentifikasi baik dengan formula LSE pseudoinverse atau formula LSE rekursif. Kemudian dihitung ukuran galat untuk setiap pasangan data pelatihan. Dalam backward pass, sinyal galat merambat dari akhir output menuju akhir input; vektor gradien diakumulasi untuk setiap entri data pelatihan. Pada akhir backward pass untuk semua data pelatihan, parameter – parameter dalam S1 di-update oleh SD dengan persamaan :
Untuk nilai parameter tetap dalam S1 yang diberikan, parameter dalam S2 yang ditemukan dijamin titik optimum global dalam ruang parameter S2 karena
pemilihan ukuran kuadrat galat. Bukan hanya aturan pelatihan hybrid ini mengurangi dimensi ruang pencarian metode SD, tetapi secara substansial juga mengurangi waktu yang dibutuhkan untuk mencapai konvergensi.
2.8 Adaptive Neuro - Fuzzy Inference System ( ANFIS )
Adaptive Neuro - Fuzzy Inference system adalah arsitektur yang secara fungsional sama dengan fuzzy rule base model Sugeno, dan juga sama dengan jaringan saraf dengan fungsi radial dengan sedikit batasan tertentu (Kusumadewi, 2006).
Adaptive Neuro - Fuzzy Inference System ( ANFIS ) merupakan jaringan saraf adaptif yang berbasis pada sistem kesimpulan fuzzy ( fuzzy inference system ). Dengan penggunaan suatu prosedur hybrid learning. ANFIS dapat membangun suatu mapping input - output yang keduanya berdasarkan pada pengetahuan manusia ( pada bentuk aturan fuzzy if – then ) dengan fungsi keanggotaan yang tepat.
Sistem kesimpulan fuzzy yang memanfaatkan aturan fuzzy if - then dapat memodelkan aspek pengetahuan manusia yang kualitatif dan memberi reasoning process tanpa memanfaatkan analisa kuantitatif yang tepat. Ada beberapa aspek dasar dalam pendekatan ini yang membutuhkan pemahaman yang lebih baik, secara rinci :
1) Tidak ada metode baku untuk men-transform pengetahuan atau pengalaman manusia ke dalam aturan dasar ( rule base ) dan database tentang fuzzy inference system.
2) Ada suatu kebutuhan bagi metode efektif untuk mengatur ( tuning ) fungsi keanggotaan ( Membership Function / MF ) untuk memperkecil ukuran kesalahan keluaran atau memaksimalkan indeks pencapaian.
ANFIS dapat bertindak sebagai suatu dasar untuk membangun satu kumpulan aturan fuzzy if - then dengan fungsi keanggotaan yang tepat, yang berfungsi untuk menghasilkan pasangan input – output yang tepat.
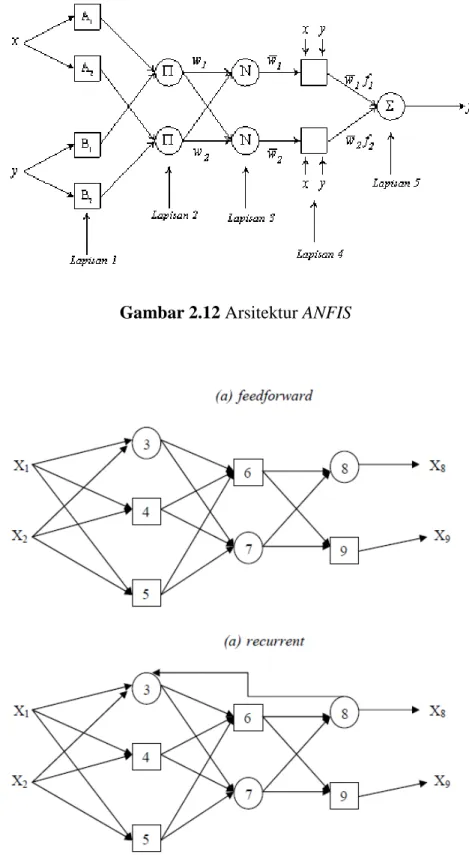
Sistem fuzzy inference yang digunakan adalah sistem inferensi fuzzy model Takagi – Sugeno - Kang ( TSK ) orde satu dengan pertimbangan kesederhanaan dan kemudahan komputasi.
Rule 1 : if x is A1 and y is B1 then z1 = ax + by + c premis konsekuen
Rule 2 : if x is A2 and y is B2 then z2 = px + qy + c premis konsekuen
Input adalah x dan y, konsekuen adalah z.
Langkah dari fuzzy reasoning dilakukan oleh sistem kesimpulan fuzzy terdiri dari 5 layer yaitu :
Layer 1 : Merupakan layer pertama setelah x dan y dimasukkan. Setiap node ke – I di dalam layer ini merupakan adaptive node dengan fungsi tersendiri.
O1,i = µAi (x) untuk tiap i = 1, 2, atau O1, i = µBi – 2(y) untuk tiap I = 3,4
Dimana x ( atau y ) merupakan data input ke dalam node i dan Ai ( atau Bi-2 ) berisi label linguistic ( misal “kecil” atau “besar” ) yang terkait dengan node ini. Fungsi yang digunakan, yaitu generalize bell function :
(2.39)
Dimana { ai , bi, ci } adalah parameter set. Selama parameter ini berubah, fungsi bentuk bell ini akan berubah, yang kemudian menunjukkan berbagai macam bentuk fungsi keanggotaan untuk set fuzzy A. Parameter dalam layer ini disebut sebagai premise parameters.
Layer 2 : Tiap node dalam layer ini merupakan node yang tetap ditandai sebagai Π, yang mana outputnya adalah produk keluaran dari semua signal yang masuk :
(2.40)
Tiap output node merepresentasikan kekuatan dari sebuah rule. Pada umumnya, Operasi T - norm yang mana saja yang dapat melakukan fuzzy logic dan dapat digunakan sebagai fungsi node dalam layer ini.
Layer 3 : Tiap node pada layer ini merupakan node yang ditandai dengan tetap sebagai N. Node ke - i mengkalkulasi rasio dari kekuatan rule ke – i ke semua jumlah yang didapat dari rule’s firing strengths:
(2.41)
Untuk penggunaannya, tiap output pada layer ini disebut sebagai
Layer 4 : Tiap node i dalam layer ini merupakan node adaptif dengan sebuah node fungsi
(2.42)
Dimana adalah normalisasi firing strength dimulai dari layer 3 dan {pi, qi, ri} yang merupakan set parameter dari node ini.
Layer 5 : Node yang tersendiri pada layer ini ditandai dengan tanda tetap sebagai Σ, yang mana menghitung keseluruhan output sebagai signal input yang dijumlahkan :
Output keseluruhan (2.43)
(Jang, 1997)
Gambar 2.12 Arsitektur ANFIS
2.9 Fuzzy Clustering
Clustering mempartisi suatu himpunan data ke dalam beberapa kelompok sehingga kemiripan di dalam kelompok lebih besar daripada antar kelompok. Karena itu diperlukan matriks kemiripan yang mengambil dua vektor input dan mengembalikan nilai kemiripannya. Karena matriks kemiripan sensitif terhadap rentang elemen – elemen dalam vektor input, maka setiap variabel input harus dinormalisasi, misalnya kedalam interval [ 0, 1 ]. Teknik – teknik clustering digunakan bersamaan dengan pemodelan fuzzy terutama untuk menentukan aturan – aturan if - then fuzzy.
2.10 Komoditi
Komoditi adalah sesuatu benda nyata yang relatif mudah diperdagangkan, dapat diserahkan secara fisik, dapat disimpan untuk jangka waktu tertentu dan dapat dipertukarkan dengan produk lainnya dengan jenis yang sama, yang biasa dapat dibeli atau dijual oleh investor melalui bursa berjangka. Secara umum, suatu produk yang diperdagangkan, termasuk valuta asing, instrumen keuangan dan indeks.
Komoditi disini berupa barang mineral dan produk pertanian, seperti batu bara, emas, timah, perak, minyak bumi, dan lain – lain untuk barang mineral, serta jagung, beras, gandum, kopi, gula, sapi, dan lain – lain untuk produk pertanian (Ferlianto, 2006). Ada juga barang yang disebut sebagai “commoditized” ( tidak lagi dibedakan berdasarkan merek ) seperti komputer.
Pasar komoditi sangatlah luas dan mendalam, menjanjikan peluang yang berpotensi untuk menghasilkan banyak uang serta terdapat tantangan tersendiri di dalamnya. Para investor kebanyakan seringkali kewalahan karena bingung untuk
memutuskan beli atau jual tiap – tiap transaksi mereka disebabkan oleh banyaknya jumlah komoditi yang bisa diperdagangkan. Untuk memutuskan apakah sang investor harus membeli atau menjual jagung, atau minyak mentah, atau juga mencari komoditi lainnya jika harga kesemua komoditi yang ada lebih murah dibandingkan dengan komoditi lainnya. Kesulitan untuk menentukan apakah keputusan beli atau jual itulah yang membuat para investor menjadi kewalahan dan juga ketakutan. Bahkan diantara dari mereka yang selalu senang mengambil resiko, pada akhirnya menjadi jatuh miskin karena terlalu sering rugi (Bouchentouf, 2007).
Berbeda dengan saham, yang mana tiap kali kita membeli sejumlah saham di dalam suatu perusahaan, kemudian kita akan menjadi bagian dari perusahaan tersebut, dalam pasar komoditi, tiap – tiap pembelian kita, maka yang kita miliki hanyalah barang yang telah dibeli, tidak ada kaitannya dengan perusahaan yang bersangkutan.
2.11 Prediksi dan Ramalan
Prediksi dan Peramalan adalah pernyataan tentang apa yang akan terjadi dimasa mendatang, biasanya didasari oleh pengalaman dan dasar ilmu pengetahuan yang dapat dipertanggungjawabkan namun tidak selamanya digunakan. Prediksi dan ramalan tampak sama namun pada dasarnya berbeda.
Penjelasan perbedaan kedua kata tersebut dapat kita gunakan dua istilah yang berbeda untuk menguraikan metodologi dalam memperkirakan permintaan masa datang: "Ramalan" dan "Prediksi". Ramalan merupakan istilah yang agak berbau nujum. Bila kita melakukan ramalan, maka kita menggabungkan sejumlah besar informasi subyektif maupun obyektif untuk membentuk perkiraan terbaik kita
tentang masa depan. Kita gunakan metode ramalan bila kita hanya memiliki sejumlah kecil pengalaman yang mendasari perkiraan kita tentang masa depan. Prediksi atau forecasting di lain pihak, akan diartikan sebagai penggunaan teknik - teknik statistik dalam membentuk gambaran masa depan berdasarkan pengolahan angka - angka historis. Prediksi tergantung kepada adanya data historis yang cukup agar dapat diuraikan secara statistik dan juga tergantung kepada faktor - faktor pembentuk pasar yang relatif stabil. Prediksi dan peramalan mempunyai kegunaan masing – masing (Buffa, 1994).
Prediksi tidak terlalu dibutuhkan dalam permintaan kondisi pasar yang stabil, karena perubahan permintaannya relatif kecil. Tetapi prediksi akan sangat dibutuhkan bila kondisi permintaan pasar bersifat kompleks dan dinamis.
Dalam kondisi pasar bebas, permintaan pasar lebih banyak bersifat kompleks dan dinamis karena permintaan tersebut akan tergantung dari keadaan sosial, ekonomi, politik, aspek teknologi, produk pesaing dan produk subtitusi. Oleh karena itu, prediksi yang akurat merupakan informasi yang sangat dibutuhkan dalam pengambilan keputusan manajemen.
Prediksi atau peramalan ini sendiri, seringkali digunakan pada perusahaan – perusahaan besar untuk mengetahui apa saja yang harus dilakukan agar suatu perusahaan dapat meraih apa yang mereka ingin capai semenjak mereka membangun perusahaan tersebut (Flyvbjerg, 2007). Ini memungkinkan suatu perusahaan untuk mendapatkan keuntungan lebih dan mencegah kerugian besar dikemudian harinya.
2.11.1 Prediksi dan Horison Waktu
Dalam hubungannya dengan horison waktu prediksi, maka kita bisa mengklasifikasikan prediksi tersebut kedalam 3 kelompok, yaitu :
1. Prediksi jangka panjang, umumnya 2 sampai 10 tahun. Prediksi ini digunakan untuk perencanaan produk dan perencanaan sumber daya. 2. Prediksi jangka menengah, umumnya 1 sampai 24 bulan. Prediksi ini
lebih khusus dibandingkan dengan prediksi jangka panjang, biasanya digunakan untuk menentukan aliran kas, perencanaan produksi, dan penentuan anggaran.
3. Prediksi jangka pendek, umumnya 1 sampai 5 minggu. Prediksi ini digunakan untuk mengambil keputusan dalam hal perlu tidaknya lembur, penjadwalan kerja, dan lain - lain keputusan kontrol jangka pendek (Herjanto, 2008).
2.11.2 Karakteristik Prediksi yang Baik
Prediksi yang baik mempunyai beberapa kriteria yang penting, antara lain akurasi biaya, dan kemudahan. Penjelasan dari criteria - kriteria tersebut adalah sebagai berikut :
1. AKURASI
Akurasi dari suatu hasil prediksi diukur dengan kebiasaan dan kekonsistenan prediksi tersebut. Hasil prediksi dikatakan bias bila prediksi tersebut terlalu tinggi atau terlalu rendah dibandingkan dengan
kenyataan yang sebenarnya terjadi. Hasil prediksi dikatakan konsisten bila besarnya kesalahan peramalan relatif kecil. Prediksi yang terlalu rendah akan mengakibatkan kekurangan persediaan, sehingga permintaan konsumen tidak dapat dipenuhi segera, akibatnya adalah perusahaan dimungkinkan kehilangan pelanggan dan kehilangan keuntungan penjualan. Prediksi yang terlalu tinggi akan mengakibatkan terjadinya penumpukkan persediaan, sehingga banyak modal yang terserap sia - sia. Keakuratan dari hasil prediksi ini berperan penting dalam menyeimbangkan persediaan yang ideal ( meminimasi penumpukan persediaan dan memaksimasi tingkat pelayanan ).
2. BIAYA
Biaya yang diperlukan dalam pembuatan suatu prediksi adalah tergantung dari jumlah item yang diramalkan, Lamanya periode prediksi, dan metode prediksi yang dipakai. Ketiga faktor pemicu biaya tersebut akan mempengaruhi berapa banyak data yang dibutuhkan, bagaimana pengolahan datanya ( manual atau komputerisasi ), bagaimana penyimpanan datanya dan siapa tenaga ahli yang diperbantukan. Pemilihan metode prediksi harus disesuaikan dengan dana yang tersedia dan tingkat akurasi yang ingin didapat, misalnya item - item yang penting akan diramalkan dengan metode yang canggih dan mahal, sedangkan item - item yang kurang penting bisa diramalkan dengan metode yang sederhana dan murah. Prinsip ini merupakan adopsi dari Hukum Pareto ( Analisa ABC ).
Penggunaan metode prediksi yang sederhana, dan mudah diaplikasikan akan memberikan keuntungan bagi perusahaan. Adalah percuma memakai metode yang canggih, tetapi tidak dapat diaplikasikan pada sistem perusahaan karena keterbatasan dana, sumberdaya manusia, maupun peralatan teknologi (Nasution, 2003).
2.11.3 Beberapa Sifat Hasil Peramalan
Dalam membuat peramalan atau menerapakan hasil suatu peramalan, maka ada beberapa hal yang harus dipertimbangkan, yaitu:
1. Peramalan pasti mengandung kesalahan, artinya peramal hanya bisa mengurangi ketidakpastian yang akan terjadi, tetapi tidak dapat menghilangkan ketidakpastian tersebut.
2. Peramalan seharusnya memberikan informasi tentang berapa ukuran kesalahan, artinya karena peramalan pasti mengandung kesalahan, maka adalah penting bagi peramal untuk menginformasikan seberapa besar kesalahan yang mungkin terjadi.
3. Peramalan jangka pendek lebih akurat dibandingkan peramalan jangka panjang. Hal ini disebabkan karena pada peramalan jangka pendek, faktor - faktor yang mempengaruhi permintaan relatif masih konstan, sedangkan semakin panjang periode peramalan, maka semakin besar pula
kemungkinan terjadinya perubahan faktor - faktor yang mempengaruhi permintaan (Nasution, 2003).
Banyak pengaplikasian dari prediksi dan ramalan ini yang tersebar di masyarakat, namun, kebanyakan prediksi tersebut digunakan bukan untuk urusan bisnis, melainkan untuk ramalan cuaca, ramalan pertumbuhan penduduk, dan beberapa ramalan dan prediksi lainnya yang menyangkut kehidupan pribadi masing – masing dari mereka.
Prediksi ini adalah apa yang akan kami capai dengan menggunakan ANFIS untuk mendapatkan hasil data yang diharapkan terjadi di masa mendatang nantinya dalam memprediksi harga komoditi bahan pangan.