ISSN: 1978-1520 11
Received June 1st,2012; Revised June 25th, 2012; Accepted July 10th, 2012
PEMANFAATAN METODE CLUSTER SOM – IDB SEBAGAI ANALISA
PENGELOMPOKAN PENERIMA BEASISWA
Lilia Rahmawati1, Andharini Dwi Cahyani2, Sigit Susanto Putro3
Program Studi Teknik Informatika, Fakultas Teknik, Universitas Trunojoyo. Jl. Raya Telang, PO BOX 2, Kamal, Bangkalan - 69162
e-mail: [email protected], [email protected], 3
Abstrak
Program beasiswa di khususkan untuk mahasiswa yang mempunyai kriteria yang sudah ditentukan. Jenis beasiswa yang diberikan pada mahasiswa yaitu Peningkatan Prestasi Akademik (PPA) dan Bantuan Belajar Mahasiswa (BBM). Penelitian ini bertujuan untuk mengelompokkan penerimaan beasiswa dengan teknik clustering untuk mendeteksi adanya adanya pencilan data (outlier). Teknik yang digunakan adalah menggunakan metode SOM (Self
Organizing Maps) yang hasilnya divalidasi dengan metode IDB (Indeks Davies-Bouldin).
Metode SOM mampu mengelompokkan data yang berdekatan untuk dicari kemiripan berdasarkan pola. Pada uji coba aplikasi dilakukan pengelompokan penerima beasiswa dengan menggunakan 2,3,4 dan 5 cluster dengan learning rate awal 0.6. Selanjutnya, hasil clustering diproses dengan IDB dan menunjukkan bahwa cluster 4 adalah cluster paling homogen dengan nilai IDB sebesar 0.098.
Kata kunci: Clustering, Self Organizing Maps, Indeks Davis Bouldin
Abstract
The scholarship program dedicated to students who have fulfilled pre-determined criteria. The types of scholarships which are given to students namely Improving Academic Achievement (PPA – Peningkatan Prestasi Akademik) and the Student Learning Assistance (BBM – Bantuan Belajar Mahasiswa). This study aims to group the scholarship recipients with clustering techniques to detect the presence of data outliers. The technique used is using SOM (Self Organizing Maps) whose results are validated with IDB method (Davies-Bouldin index). SOM method is able to classify the data that is adjacent to look for similarities in the patterns. In the experiment, the scholarship recipient is grouped into 2,3,4 and 5 clusters with the initial learning rate 0.6. Furthermore, those clustering results are validated by the IDB and presents that cluster 4 is the most homogeneous cluster with IDB value of 0.098.
Keywords: Clustering, Self Organizing Maps, Indeks Davis Bouldin
1. PENDAHULUAN
Pemberian Beasiswa merupakan program kerja yang ada di setiap Universitas atau perguruan tinggi. Program beasiswa diadakan untuk meringankan beban mahasiswa dalam menempuh masa studi kuliah khususnya dalam masalah biaya. Pemberian beasiswa kepada mahasiswa dilakukan secara selektif sesuai dengan jenis beasiswa yang diadakan. Pada studi kasus penelitian ini, ada dua jenis beasiswa yang ditawarkan yaitu beasiswa PPA dan BBM.
Dalam penelitian ini, penerapan data mining pada data penerimaan beasiswa untuk mengetahui adanya outlier dalam pengambilan keputusan penerimaan beasiswa. Selanjutnya dapat dilakukan analisa terhadap data outlier tersebut apakah diindikasikan sebagai kecurangan atau bukan. Metode data mining yang akan diterapkan dalam penelitian ini yaitu menggunakan
clustering dengan menggunakan algoritma Self Organizing Maps (SOM) [1]. Clustering ini
Received June 1st,2012; Revised June 25th, 2012; Accepted July 10th, 2012
digunakan untuk validasi cluster sehingga dihasilkan kelompok yang optimum atau paling homogen dari cluster-cluster yang sudah terbentuk.
Pada penelitian Hamiyah [1] menggunakan studi kasus mengelompokan data sesuai kemiripan data pada pengelompokan siswa. Cluster yang digunakan adalah 3 tiga cluster dengan learning rate = 0.6 serta epoch 10, 20, 30 dengan MSE terkecil = 41.42 di epoch 30 pada 245 data training. Sedangkan yang dijadikan tiga sampai dengan sembilan Cluster dengan
learning rate 0.6 serta epoch 10, 20, 30 dengan MSE terkecil = 25.04 di epoch 20 pada cluster
ke-4 dengan 245 data training. Nilai terkecil pada pemvalidasian Cluster dengan IDB menggunakan tiga sampai dengan sembilan Cluster pada 245 data training berada pada cluster ke-9 dengan nilai IDB = 37.44 dan hasilnya kurang akurat karena kelas yang terbentuk hanya dua kelompok [1].
2. METODE PENELITIAN
Flowchart penelitian ini gambaran dari alur sistem yang dikerjakan secara keseluruhan
dalam suatu proses tertentu dan menjelaskan prosedur – prosedur yang ada dalam sistem (Gambar 1).
Gambar 1 Alur sistem
Langkah-langkah pengelompokan penerima beasiswa adalah sebagai berikut : 1. Inputkan data beasiswa dengan 5 kriteria.
2. Hasil data yang sudah dinormalisasikan dijadikan untuk proses selanjutnya.
3. Data tersebut dicluster menggunakan SOM, yang diawali dengan inisilisasi bobot, menetapkan learning rate, sehingga menghasilkan data yang sudah tercluster.
4. Untuk setiap cluster yang terbentuk kemudian dilakukan pencarian nila rata-rata dari data yang tercluster, sehingga diperoleh hasil akhir nilai IDB.
5. Langkah 3 dan 4 dilakukan sebanyak yang diinginkan. Pada penelitian ini dilakukan analisa pengelompokan data penerima beasiswa dengan menggunakan 2, 3, 4 dan 5 cluster.
6. Nilai IDB yang paling kecil adalah nilai IDB menunjukkan bahwa pengelompokan data tersebut adalah jenis pengelompoka yang mampu menghasilkan cluster paling homogen.
Normalisasi
Langkah pertama yang dilakukan pada penelitian ini adalah normalisasi. Normalisasi ini diawali dengan pembacaan data yang kemudian dilakukan perhitungan terhadap nilai statistik dari data. Setelah data statistik didapatkan, maka selanjutnya dilakukan proses pengkonversian terhadapa tiap instance dari data ke bentuk normal Zscore. Hasilnya disimpan kembali kedalam file untuk digunakan pada proses selanjutnya.
Mulai
Normalisasi
Clustering dengan SOM
Dicari nilai IDB
Jumlah Cluster terbaik Data Beasiswa
ISSN: 1978-1520 13
Received June 1st,2012; Revised June 25th, 2012; Accepted July 10th, 2012
Z-Score adalah suatu metode normalisasi yang didapatkan dengan mengurangkan intensitas raw data untuk masing-masing gen dengan keseluruhan rata-rata intensitas gen, kemudian dibagi dengan standar deviasi dari keseluruhan intensitas yang diukur [2].
= ̅ (1)
Keterangan :
zi : Jarak Eucledian Distance s : Sampel data pelatihan x : data pelatihan
x : rata – rata sample data pelatihan Self Organizing Maps (SOM)
Jaringan kohonen diperkenalkan oleh Teuvo Kohonen seorang ilmuwan Finlandia pada tahun 1982. Jaringan kohonen memberikan sebuah tipe dari SOM kelas khusus dari jaringan syaraf tiruan [3].SOM merupakan metode berdasarkan model dari pendekatan jaringan syaraf tiruan [3]. SOM adalah metode terkemuka pendekatan jaringan syaraf tiruan untuk Clustering, setelah competitive learning [4]. SOM berbeda dengan competitive learning yaitu syaraf dalam satu lingkungan belajar untuk mengenali bagian lingkungan dari ruang input. SOM mengenali distribusi (seperti competitive learning) dan topologi dari vektor input yang melalui proses
training, SOM memperlihatkan tiga karakteristik: kompetisi yaitu setiap vektor bobot saling
berlomba untuk menjadi simpul pemenang, kooperasi yaitu setiap simpul pemenang bekerjasama dengan lingkungannya, dan adaptasi yaitu perubahan simpul pemenang.
Algoritma SOM
1. Inisialisasi bobot.
Pada tahap ini menentukan secara acak bobot awal secara random sebagai wij
2. Repeat
a. Menentukan data
Pada algoritma tahap ini adalah menetukan data selanjutnya b. Menentukan centroid dari obyek tersebut
Untuk setiap data terhadap bobot dihitung menggunakan Euclidean Distance matrix c. Menentukan bobot terbaru
Dalam menentukan bobot terbaru pada waktu t, maka diasumsikan obyek saat ini x(i) dan centroid yang terbentuk wj. Kemudian untuk menentukan centroid yang baru untuk waktu berikutnya t+1
( ) = ( ) + − ( ) (2)
α adalah learning rate, tiap kenaikan epoch (iterasi) maka learning rate = learning rate awal *0.5
3. Until tidak ada perubahan centroid atau threshold sudah terpenuhi.
4. Iterasi pada langkah ke-2 akan berhenti apabila threshold terpenuhi, untuk mencapai nilai
threshold terpenuhi dilakukan dengan menghitung nilai MSE.
5. Menetapkan setiap obyek terhadap centroid dan menentukan letak Cluster tersebut.
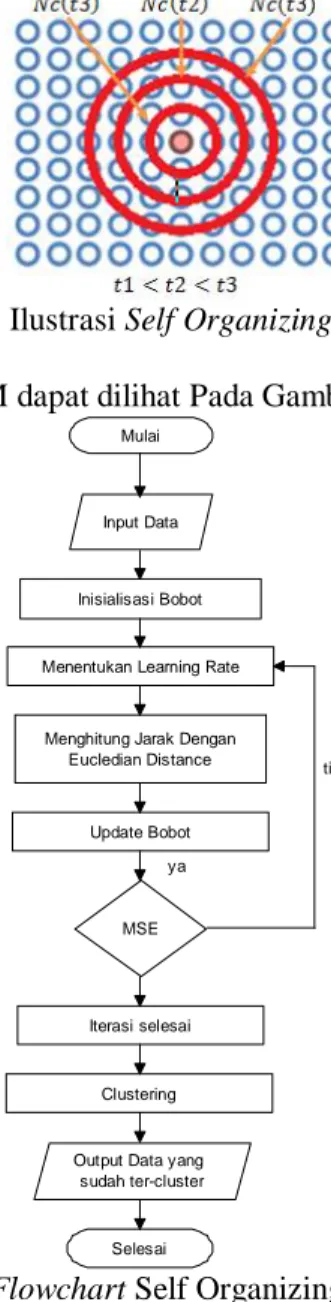
Pada Gambar 2 jika neuron/bobot yang di tengah adalah winner neuron untuk suatu
input vector/data, maka neighboring neuron untuk winner neuron ini adalah mereka yang
terletak di dalam lingkaran area, yang didefinisikan dengan Nc(t1), Nc(t2), …dst. Nc(t1) adalah batas area pada iterasi ke-1, Nc(t2) adalah batas area pada iterasi ke-2, dst. Neuron yang secara
Received June 1st,2012; Revised June 25th, 2012; Accepted July 10th, 2012
Gambar 2 Ilustrasi Self Organizing Map (SOM) Flowchart perhitungan SOM dapat dilihat Pada Gambar 3.
Gambar 3. Flowchart Self Organizing Maps (SOM)
Berikut ini adalah penjelasan Gambar 3:
1. Masukan data mahasiswa yang mendaftar beasiswa. Data yang digunakan adalah data yang berbentuk matrik ixj, dan selanjutnya dilakukan proses clustering menggunakan metode SOM
2. Pada perhitungan menggunakan metode SOM, diawali dengan inisialisasi bobot secara random (acak)
3. Menetapkan learning rate (α), untuk epoch ke-2 dst nilai learning rate menjadi 0.5 * learning rate awal.
4. Untuk setiap data dilakukan perhitungan terhadap bobot menggunakan rumus Euclidean Distance. Kemudian dipilih nilai terkecil.
5. Data yang memiliki nilai terkecil dari langkah 4 digunakan untuk proses update bobot. 6. Melakukan pengecekan syarat berhenti, disini menggunakan nilai MSE.
7. Apabila nila MSE 0,1 iterasi akan berhenti
8. Selanjutnya dilakukan proses pengelompokkan atau clusterisasi, disini menggunakan rumus Euclidean.
9. Hasil akhir dari proses ini yaitu data tercluster
Mulai
Input Data
Inisialisasi Bobot
Menentukan Learning Rate
Menghitung Jarak Dengan Eucledian Distance
Update Bobot
MSE
Iterasi selesai
Clustering
Output Data yang sudah ter-cluster
Selesai ya
ISSN: 1978-1520 15
Received June 1st,2012; Revised June 25th, 2012; Accepted July 10th, 2012 Eucledian Distance Eucledian Distance dianggap sebagai distance matrix yang mengadopsi prinsip Phytagoras. Hal ini dikarenakan pola perhitungannya yang menggunakan aturan pangkat dan akar kuadrat. Eucledian akan memberikan hasil jarak yang relatif kecil.[5] Jarak antara Nilai Random/ Bobot dan data dihitung dengan menggunakan rumus Euclidean Distance. = ∑ ( − ) (3)
Keterangan : d eucledian : Jarak Eucledian Distance pi : Titik Awal qi : Titik Awal N : Jumlah Data Indeks Davies-Bouldin (IDB) Indeks Davies-Bouldin (IDB) merupakan salah satu metode validasi cluster untuk evaluasi kuantitatif dari hasil clustering. Pengukuran ini bertujuan memaksimalkan jarak inter-cluster antara satu inter-cluster dengan inter-cluster yang lain. Dalam penelitian ini IDB akan digunakan untuk mendeteksi outlier pada masing-masing cluster yang terbentuk. ( ) = ( − ̅) (4)
= = 1, , , ≠ R … (5)
= ( ) (6)
= ∑ (7)
Dimana
DB : validasi davies bouldin Var : variance dari data N : Banyaknya data X : data ke-i
X : rata-rata dari tiap Cluster R : jarak antar Cluster
Skema clustering yang optimal adalah skema yang memiliki nilai IDB minimal [4]. Flowchart perhitungan IDB dapat dilihat pada Gambar 4.
Gambar 4. Flowchart Indeks Davies Bouldin (IDB)
Mulai
Input Data Hasil Clustering SOM
Menghitung rata-rata dari tiap cluster... pers (2.3)
Menghitung nilai variance dari setiap cluster..pers(2.4)
Hitung R max...pers(2.5)
Nilai IDB...pers(2.6)
Output Cluster Optimum
Received June 1st,2012; Revised June 25th, 2012; Accepted July 10th, 2012 Adapun penjelasannya Gambar 4. adalah sebagai berikut:
1. Data yang digunakan adalah data yang di dapat dari proses SOM, yaitu data yang sudah ter-cluster.
2. Cari nilai rata-rata dari masing-masing nilai cluster 3. Hitung variance data dari masing-masing dalam cluster 4. Cari R max dari langkah 2 dan 3
5. Hasil akhir adalah nilai IDB dari cluster
3. HASIL DAN PEMBAHASAN
Setiap data memiliki banyak persyaratan atau kriteria yang sudah ditentukan. Dari persyaratan yang sudah di tentukan, ada beberapa persyaratan di atas yang menjadi pertimbangan utama untuk proses seleksi beasiswa. Data training dibawah ini menggunakan 5 kriterian utama yaitu IPK, Jumlah Tanggungan, Gaji, Daya Listrik dan Semester yang akan dilakukan proses perhitungan menggunakan metode yang sudah ditentukan.
Tabel 1. Data Training
NRP IPK Jml Tanggungan Gaji Daya Listrik Semester
110471100020 3,13 2 Rp 2.500.000 1300 2 110471100014 3,14 5 Rp 4.124.500 450 2 110471100005 3,32 6 Rp 2.700.000 450 2 110471100012 3 2 Rp 750.000 450 4 100471100001 3,01 3 Rp 1.000.000 450 4 100471100002 3,43 3 Rp 2.000.000 900 6 090471100101 3,66 6 Rp 900.000 450 4 100471100062 3 5 Rp 750.000 450 2 110471100087 3,4 6 Rp 1.500.000 900 6 090471100009 3,13 2 Rp 2.500.000 1300 2
Cara menormalisasi data training menggunakan Z-Score contoh perhitungan Gaji orang tua (Persamaan 1):
1 =2977500 − 1920200
1141652,12 = 0,926 2 =2500000 − 1920200
1141652,12 = 0,507
Tabel 2. Data Training yang sudah ternormalisasi
NRP IPK Jml Tanggungan Gaji Daya Listrik Semester
110471100020 1,24 1,13 0,92 1,63 0,85 110471100014 0,55 1,13 0,5 1,63 0,85 110471100005 0,51 0,56 1,93 0,71 0,85 110471100012 0,22 1,13 0,68 0,71 0,85 100471100001 1,08 1,13 1,02 0,71 0,36 100471100002 1,04 0,56 0,8 0,71 0,36 090471100101 0,67 0,56 0,06 0,52 1,57 100471100062 1,61 1,13 0,89 0,71 0,36 110471100087 1,08 0,56 1,02 0,71 0,85 090471100009 0,54 1,13 0,36 0,52 1,57
a. Perhitungan SOM Eucledian Distance
Setelah data melalui normalisasi di dapat, maka tahapan SOM menggunakan Eucledian
Distance adalah sebagai berikut:
1. Menentukan Learning Rate secara Manual: diset 0.6 , Tiap kenaikan epoch (iterasi) learning rate = learning rate awal *0.5
2. Inisialisasi Bobot awal secara random. Pada Tabel 3 menunjukkan bobot awal dengan 2
ISSN: 1978-1520 17
Received June 1st,2012; Revised June 25th, 2012; Accepted July 10th, 2012
Tabel 3. Bobot Awal
Untuk setiap data dihitung menggunakan dengan Euclidean Distance. Berikut contoh perhitungan setiap data terhadap bobot menggunakan rumus Euclidean
Distance:
d2 = (0.78-1.24)2+(0.46-1.13) 2+(0.37-0.92) 2+(0.91-1.63) 2+(0.78-0.85) 2 =0.21 + 0.44 + 0.30 + 0.51 + 0.004 = 1.46
d2 = (0.28-0.55)2+(0.63-1.13) 2+(0.33-0.5) 2+(0.13-1.63) 2+(0.11-0.85) 2 =0.07 + 0.25 + 0.02 + 2.25 + 0.54 = 3.13 (winner)
3. Setelah didapat winner untuk setiap data, maka dilakukan update bobot dengan menggunakan rumus:
( ) = ( ) + − ( )
Berikut contoh perhitungan update bobot dari hasil winner (perhitungan setiap data menggunakan rumus Euclidean Distance):
UB = [(0.28 0.63 0.33 0.13 0.11) + 0.6[(1.24 1.13 0.92 1.63 0.85) - [(0.28 0.63 0.33 0.13 0.11)]] = [0.85 0.93 0.68 1.03 0.55]
Tabel 4. Hasil Update Bobot Awal
Hasil update bobot dengan menggunakan rumus Euclidean distance untuk 2 Cluster
Tabel 5. Hasil Clustering dengan Eucledian Distance
No NPM Jarak Cluster 1 100471100020 0,00181 1 2 110471100014 0,00119 2 3 110471100005 0,00592 2 4 110471100012 0,00116 1 5 100471100001 0,00324 1 6 100471100002 0,00168 2 7 090471100101 0,00104 2 8 100471100062 0,0016 2 9 110471100087 0,00489 1 10 090471100009 0,00261 2
Setelah data mengelompok maka langkah selanjutnya adalah mencari nilai IDB. Indeks
Davies Bouldien digunakan untuk validasi cluster yaitu prosedur yang mengevaluasi hasil
analisis cluster secara kuantitatif dan objektif sehingga dihasilkan kelompok optimum. Secara umum formulanya ditunjukan sebaga berikut:
1. Cari nilai rata-rata dari masing-masing nilai Cluster
Cluster 1=jumlah data/banyaknya data=(0.0111/4)=0.0027
Cluster2 =jumlah data/banyaknya data=(0.0140/6)=0.0023
2. Hitung variance data dari masing-masing dalam Cluster (persamaan 3)
Cluster 1 var (x) = 1/4 (0.00181-0.0027)2 + (0.00116-0.0027)2 + (0.00324-0.0027)2 + (0.00489-0.0027)2 = 0.25
Cluster 2 var(x) = 1/6 (0.00119-0.0023)2 + (0.00592-0.0023)2 + (0.00168-0.0023)2 + (0.00104-0.0023)2 + (0.0016-0.0023)2 + (0.00261-0.0023)2 = 0.16
3. Cari R max (persamaan 4 dan 5)
0,78 0,46 0,37 0,91 0,78
0,28 0,63 0,32 0,13 0,11
0,78 0,46 0,37 0,91 0,78
Received June 1st,2012; Revised June 25th, 2012; Accepted July 10th, 2012
R12= 0.25+0.16/||0.0027-0.0023||=0.41/0.0004=1.025
4. Hasil akhir adalah nilai IDB dari Cluster Secara umum formulanya ditunjukan sebaga berikut (persamaan 6):
DB=1/2(1.025)= 0.5125
Dengan langkah yang sama dilakukan dengan setting jumlah cluster 3,4 dan dilakukan pencarian IDB pada jumlah cluster 2,3,4 dan 5. Hasil Indeks Davies Bouldien pada studi kasus dengan penentuan jumlah cluster 2,3,4 dan 5 dapat dilihat pada Tabel 4. berikut:
Tabel 6. Nilai IDB
Jumlah
Cluster Nilai IDB
2 0.5125
3 0.340
4 0.098
5 0.197
Tabel 6 diatas menunjukkan nilai IDB pada jumlah cluster 2,3,4,5. Nilai IDB yang paling
homogen adalah nilai IDB yang paling kecil. Data akan homogen jika dikelompokkan menjadi 4
cluster.
4. KESIMPULAN DAN SARAN
Dari hasil uji coba dengan metode SOM mampu mengelompokkan data yang berdekatan untuk dicari kemiripan berdasarkan pola. kemiripan data pada pengelompokan beasiswa dilakukan dengan menggunakan jumlah cluster 2,3,4 dan 5 dengan learning rate awal 0.6. Hasil IDB Cluster 2 = 0.5125, Cluster 3 = 0.340, Cluster 4 = 0.098, Cluster 5 = 0.197 dari 10 data uji coba. Jadi jumlah cluster yang paling homogen adalah 4 cluster.
DAFTAR PUSTAKA
[1] Hamiyah, 2013, Pengelompokan Kualitas Kelas Pada Siswa Menggunakan Indeks
Davies Bouldin SOM ( Self Organizing Map), Teknik Informatika, Univ. Trunojoyo
Madura, Bangkalan.
[2] Cheadle, C., Vawter, M. P., Freed, W. J., & Becker, K. G. ,2003, Analysis of microarray data using Z score transformation, The Journal of molecular diagnostics, vol 5 no 2, hal. 73-81.
[3] Larose, D. T., 2014, Discovering knowledge in data: an introduction to data mining, John Wiley & Sons.
[4] Sitanggang, I. S., & Hermadi, I., 2007, Clustering menggunakan Self Organizing Maps studi kasus: data PPMB IPB, Jurnal Ilmu Komputer, vol. 5 no 2, 2007.
[5] Chaudhuri, S., & Dayal, U., 1997, An overview of data warehousing and OLAP technology, ACM Sigmod record, vol. 26 no. 1, hal 65-74.