BAB 2 LANDASAN TEORI
2.1 Teori Umum2.1.1 Definisi Data
M enurut Rob dan Coronel (2002, p11), data adalah fakta mentah atau fakta yang tidak pernah diproses sebelumnya untuk mengetahui artinya bagi end user. Sedangkan menurut Turban (2003, p15), data adalah fakta mentah atau deskripsi dasar dari suatu benda, acara, aktivitas dan transaksi yang ditangkap, direkam, dan disimpan, tetapi belum diolah untuk menyampaikan arti yang spesifik.
2.1.2 Definisi Database
M enurut Connolly dan Begg (2002, p14), database adalah kumpulan data yang saling berhubungan satu sama lain yang digunakan secara bersama-sama dan kumpulan data ini dirancang untuk memenuhi kebutuhan informasi suatu perusahaan. Sedangkan menurut Rob dan Coronel (2002, p11), database merupakan sebuah struktur komputer sebagai tempat dari koleksi data-data yang berhubungan.
2.1.3 Data Warehouse
M enurut Inmon (2005, p495), data warehouse adalah koleksi data yang mempunyai sifat berorientasi subjek, terintegrasi, rentang waktu, yang dirancan g untuk mendukung sistem pendukung keputusan dimana tiap data berhubungan dengan suatu kejadian pada suatu waktu. Sedangkan menurut Rob dan Coronel (2002, p812), data warehouse merupakan desain database dari sebuah informas i organisasi yang ditujukan untuk mendukung sistem pengambilan keputusan.
Hal-hal yang berkaitan dengan Data Warehouse
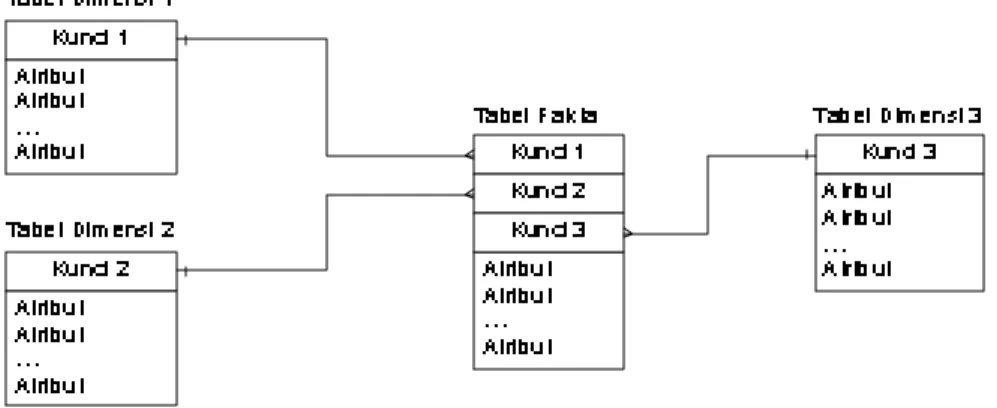
a. Fact Table
Tabel yang umumnya mengandung angka dan history data di mana key yang dihasilkan unik karena key-nya merupakan kumpulan foreign key dari primary key yang ada pada masing-masing tabel dimensi yang berhubungan.
b. Tabel Dimensi
Tabel yang berisikan kategori dengan ringkasan data detil yang dapat dilaporkan, seperti profit and loss report pada fact table dapat dilaporkan sebagai dimensi waktu (bisa per bulan, per kuartal, dan per tahun). Contoh : pusat dari star schema adalah pemesanan, dan yang mengelilinginya terdapat entity supplier, waktu, produk, entity inilah yang dinamakan tabel dimensi.
c. Star Schema
M enurut Connolly dan Begg (2002, p1079), star schema merupakan struktur logikal yang memiliki fact table yang berisi data fakta dan dikelilingi oleh tabel dimensi yang berisi data referensi (yang dapat didenormalisasikan).
2.1.4 Data Mart
M enurut Connolly dan Begg (2005, p1171), data mart adalah bagian dari data warehouse yang mendukung kebutuhan informasi dari suatu departemen atau fungsi bisnis tertentu. Sedangkan menurut Inmon (2005, p494), data mart diartikan sebagai struktur bagian dari data warehouse yang dibentuk berdasarkan kebutuhan informasi tiap departemen dan data tersebut tidak dinormalisasikan.
Sehingga, dari pengertian-pengertian tersebut dapat disimpulkan bahwa data mart adalah bagian dari data warehouse yang hanya menangani suatu departemen atau fungsi bisnis tertentu.
Karakteristik yang membedakan data mart dengan data warehouse :
1.
Data mart hanya berfokus pada kebutuhan pengguna yang berkaitan dengan suatu departemen atau fungsi bisnis.2.
Data mart tidak berisi data operasional yang bersifat detil.3.
Data mart lebih mudah dimengerti dan digunakan karena berisi data yang lebih sedikit dibanding data warehouseAlasan Pembuatan Data Mart :
1. Untuk memberi kemudahan bagi user untuk mengakses data yang sering digunakan untuk bahan analisis.
2. Data yang tersedia di data mart lebih sedikit dan spesifik per departemen tertentu sehingga memudahkan user dalam mencari data yang dibutuhkan. 3. Biaya yang dikeluarkan untuk membangun data mart lebih kecil
2.1.5 Analytical Report
Sebelum membahas analytical report, terlebih dahulu kita harus mengetahui pengertian dari report itu sendiri. Database Report merupakan bentuk tertulis yang menampilkan informasi dari query sebuah tabel yang ditampilkan dalam suatu bentuk yang terstruktur dan menarik.
Analytical report adalah laporan yang berisi summary informasi yang ditujukan untuk membantu proses pengambilan keputusan oleh pihak managerial. Informasi yang terkandung di dalam analytical report antara lain hasil analisis suatu permasalahan, dampak-dampak yang terjadi dan rekomendasi tindakan yang dapat diambil untuk menyelesaikan permasalahan yang timbul.
Elemen-elemen analytical report : • Judul Report
• Executive Summary berisi big picture yang memberi gambaran pokok permasalahan dari analytical report yang akan dibahas, sehingga pihak manager tidak perlu membaca keseluruhan report. • Daftar tabel, gambar dan istilah (jika perlu)
• Bagian isi report berisi informasi yang biasanya disajikan dalam bentuk tabel, grafik, gambar.
• Kesimpulan • Rekomendasi
Bagian ini merupakan bagian pemaparan alternatif solusi yang dapat diambil untuk mengantisipasi atau menanggulangi permasalahan.
2.1.6 Tools
2.1.6.1 Database Engine
Database Engine adalah suatu software (engine) yang dapat menyimpan, mengolah dan menampilkan data-data perusahaan. Database Engine yang digunakan dalam penelitian ini adalah Oracle Database 11g Enterprise Edition.
2.1.6.2 Database Administratition and Development Tools
Database Administration and Development Tools adalah tools yang dapat digunakan untuk meningkatkan produktivitas dari seorang administrator basis data (DBA) dan developer dengan menyediakan sebuah lingkungan development yang mudah digunakan. Fitur-fitur yang dapat digunakan dalam Database Administration and Development Tools yang paling umum digunakan adalah membuat, menjalankan, testing dan debug code serta dapat digunakan pula untuk memonitoring aktivitas database. Database Administration and Development Tools yang digunakan dalam penelitian ini adalah Toad TM.
2.1.6.3 Analytical Reporting Tools
Analytical Reporting Tools adalah alat (tools) yang digunakan untuk menghasilkan dan mengolah analytical report untuk mendukung proses pengambilan keputusan. Analytical reporting tools yang digunakan dalam penelitian ini adalah Business Object 6.0.
2.2 Teori Khusus
2.2.1 Definisi Performance
M enurut The Concise Oxford Dictionary (1999), Performance adalah tingkat kemampuan suatu mesin atau sistem. Sedangkan menurut Longman Dictionary of American English (2006), performance adalah tingkat bagus tidaknya seseorang atau sesuatu mengerjakan suatu tugas.
Sehingga dapat disimpulkan bahwa performance adalah tingkat kemampuan suatu sistem mengerjakan suatu tugas tertentu. Kecepatan merupakan salah satu indikator umum yang digunakan untuk menilai performance suatu sistem atau mesin.
2.2.2 Definisi Tuning
M enurut Chan pada e-book yang berjudul Performance Tuning Guide 11g Released 1 (2007, p34), tuning merupakan tindakan mengidentifikasikan hal-hal yang menyebabkan permasalahan pada performance dan membuat perubahan yang diperlukan untuk mengurangi dampak dari permasalahan tersebut. Sedangkan M enurut Edward Whalen pada White Paper yang berjudul Tuning Oracle on Windows for Maximum Performance (2004, p4), tuning adalah tindakan reconfigure atau modifikasi suatu sistem dengan tujuan untuk meningkatkan performance.
Sehingga, dapat disimpulkan bahwa tuning adalah suatu tindakan mengidentifikasi penyebab suatu permasalahan dan membuat suatu perubahan untuk mengurangi dampak dari permasalahan tersebut sehingga membentuk suatu kondisi yang efisien.
2.2.3 Manfaat Tuning
M enurut Connoly dan Begg (2002, p516), manfaat atau keuntungan yang akan diperoleh jika melakukan tuning adalah sebagai berikut :
1. Dengan tuning, kita dapat meminimalisasi penambahan hardware.
2. Tuning memungkinkan untuk menurunkan spesifikasi hardware minimum yang dibutuhkan.
3. M engurangi biaya maintenance yang mahal
4. Sebuah sistem yang di-tuning dengan baik akan menghasilkan response time yang cepat
5. Setelah di-tuning, suatu sistem dapat menghasilkan throughput yang lebih baik dibandingkan sebelumnya.
6. M engoptimalkan penggunaan hardware.
7. M eningkatnya response time dapat meningkatkan staff morale (semangat kerja dari para pegawai)
2.2.4 Jenis-jenis Tuning
M enurut Whalen pada White Paper yang berjudul Tuning Oracle on Windows for Maximum Performance (2001,p5), jenis–jenis tuning berdasarkan tujuannya, terdiri atas :
Tuning for response time
Tuning untuk waktu respon melibatkan perubahan dari komponen-komponen sistem untuk mengurangi keterlambatan (latency) pada transaksi dan mempercepat pemrosesan transaksi. Umumnya tuning untuk waktu respon dilakukan dengan tuning aplikasinya, menginstal hardware yang lebih cepat, atau melakukan tuning terhadap instance oracle. Waktu respon juga bisa ditingkatkan dengan melakukan tuning skema database oracle dengan index tuning, partitioning, dan lain-lain.
Tuning for throughput
Tuning untuk throughput melibatkan perubahan sistem untuk memungkinkan penyelesaian kerja yang lebih banyak tanpa perlu membuat proses/query individual berjalan lebih cepat. Throughput yang meningkat memungkinkan beberapa query untuk dapat menyelesaikan lebih banyak pekerjaan tanpa membuat salah satu query tersebut berjalan lebih cepat. Sebagai contoh, jika sebuah query memerlukan 10 detik untuk berjalan dan dengan melakukan tuning terhadap sistemnya kita dapat menjalankan dua buah query dalam 10 detik, dengan demikian kita telah meningkatkan throughput dari sistem tanpa meningkatkan waktu respon dari tiap query.
2.2.5 Tuning Methodology
Tuning Methodology adalah tahap-tahap dalam perencanaan mengoptimalkan performance suatu sistem. M enurut Whalen pada White Paper yang berjudul Tuning Oracle on Windows for Maximum Performance (2001,p4), Tuning Methodology adalah sebagai berikut :
1. Lakukan penilaian sementara mengenai current condition 2. Monitoring sistem yang sedang berjalan
3. Analisis hasil dari monitoring sistem 4. Buat sebuah hipotesis
5. Cari alternatif solusi masalah 6. Implementasikan solusi tersebut
7. Tes solusi dan kembali ke langkah ke-2 hingga performance menigkat sesuai dengan kebutuhan user.
M enurut M illsap (Optimizing Oracle Performance, pp6-7), Sebuah Perfomance Improvement Method yang bagus harus dapat memenuhi kriteria :
Impact
Suatu metodologi peningkatan performance yang bagus harus dapat menunjukkan peningkatan atau perubahan ke arah yang lebih baik.
Predictive capacity
Sebuah metode harus dapat memprediksikan dampak yang akan dihasilkan oleh suatu permasalahan, dan efek yang akan terjadi jika mengimplementasikan suatu solusi.
Measurability
Sebuah metode harus dapat menghasilkan peningkatan performance yang dapat diukur dengan satuan unit sehingga dapat di analisis lebih lanjut. Efficiency
Sebuah metode harus dapat meningkatkan performance dengan biaya minimum. Biaya yang dimaksud tidak hanya berupa uang, waktu dan effort juga harus dipertimbangkan. M etode yang bagus adalah metode yang meningkatkan performance secara signifikan dengan biaya minimum.
Reliability
Sebuah metode harus dapat mengindentifikasikan akar permasalahan, tak peduli apapun permasalahan tersebut.
Determinism
Sebuah metode harus memberikan suatu petunjuk yang jelas mengenai langkah-langkah yang ambigu sehingga tidak membingungkan user.
Practicality
Sebuah metode yang baik harus dapat di implementasikan pada berbagai kondisi. M isalnya : suatu metode tidak dapat diterima jika dapat di implementasikan pada lingkungan satu namun tidak dapat di implementasikan pada lingkungan lainnya.
Finiteness
Sebuah metode harus mempunyai batasan yang jelas mengenai kondisi akhir, misalnya pembuktian akan hasil yang optimal dengan menggunakan metode tersebut.
M enurut Oracle Perfomance Improvement Method Technical White Paper (2002,pp3-4), The Oracle Performance Improvement Method adalah :
1. Dapatkan feedback yang jelas dari user. Tentukan ruang lingkup beserta tujuan-tujuan dari proyek performance, juga tujuan masa mendatang performance. Proses ini merupakan kunci untuk perencanaan kapasitas masa mendatang.
2. Dapatkan set lengkap dari sistem operasi, database, dan statistik-statistik dari aplikasi baik pada saat performance-nya baik maupun tidak baik. Jika statistik yang diperoleh sedikit, maka dapatkan informasi apapun yang tersedia. Kehilangan statistik dapat dianalogikan seperti kehilangan barang bukti dari sebuah tindak kriminal – hal ini menyebabkan detektif bekerja lebih keras dan memakan waktu lebih banyak. Setiap bagian dari data memiliki nilai.
2. Lakukan pemeriksaan “kesehatan” sistem operasi dari seluruh mesin yang terlibat dengan performance user. Saat memeriksa sistem operasinya, cari tahu hardware atau sumber daya yang digunakan secara penuh. Daftarkan sumber daya apapun yang digunakan secara berlebihan untuk dianalisis. Serta periksa semua hardware untuk error atau informasi diagnostik.
4. Lihat Top Ten List of Oracle Performance Mistakes (lihat halaman 26) untuk mengetahui manakah dari skenario yang terdaftar merupakan masalah yang dihadapi. Daftarkan kesalahan-kesalahan yang cocok dengan skenario sebagai gejala untuk dianalisis. Untuk dijadikan kandidat permasalahan.
5. Bangun sebuah model konseptual dari apa yang terjadi pada sistem dengan menggunakan gejala-gejala sebagai petunjuk untuk memahami apa yang menyebabkan masalah-masalah performance.
6. Usulkan rangkaian tindakan perbaikan dan tindakan antisipasi untuk sistem, dan terapkan hal ini dengan maksud untuk mencari tindakan apa yang paling bermanfaat bagi sistem. Aturan emas pada kerja performance adalah kita hanya merubah satu hal pada satu satuan waktu dan kemudian mengukur perbedaannya. Sayangnya, keperluan downtime sistem mungkin melarang metode investigasi yang seteliti itu. Jika beberapa perubahan diterapkan pada waktu bersamaan, maka coba untuk memastikan bahwa mereka terisolasi.
7. Analisis apakah perubahan yang dilakukan telah memenuhi efek yang diinginkan, dan apakah performance telah meningkat. Jika belum, lakukan pencarian gejala yang lebih banyak, dan lanjutkan dengan memperbaiki model konseptual sehingga pemahaman terhadap aplikasi lebih akurat.
8. Ulang kembali 3 langkah terakhir hingga tujuan performance telah tercapai atau tidak mungkin dikarenakan keterbatasan yang lain.
2.2.6 Perfomance Tuning
M enurut Whalen (2001, p3), perfomance tuning adalah suatu tindakan untuk meningkatkan kinerja dari suatu sistem dengan merubah sistem parameter (tuning perangkat lunak) atau memperbaiki konfigurasi sistem (tuning perangkat keras).
M enurut Holmes pada Technology Conference dengan topik Oracle Perfomance Tuning Techniques (7-9 Oct 2001), tujuan dari perfomance tuning :
Meningkatkan kecepatan pemrosesan (row-time) Menghindari biaya upgrade hardware yang mahal Mendapatkan bukti nyata dari masalah performance Membuat performance predictions
Mengoptimalkan kegunaan dari tool execution_plan
M enurut Oracle Perfomance Improvement Method Technical White Paper (2002,pp5-6), The “Top Ten” List of Oracle Performance Mistakes :
1. M anajemen koneksi yang kurang baik : aplikasi melakukan koneksi dan menghentikan koneksi untuk setiap interaksi dengan database.
2. Penggunaan cursor dan shared pool yang kurang baik : code panjang yang tidak menggunakan cursor menyebabkan hard parsing untuk setiap SQL query.
3. I/O database yang salah : penentuan jumlah disk yang salah karena mengkonfigurasi disk-disk berdasarkan disk space bukan bandwidth I/O.
4. Permasalahan pada setup redo log : Ukuran redo log yang kecil akan mengakibatkan checkpoint akan terus berada di-load yang tinggi pada buffer
cache. Jumlah redo log yang terlalu sedikit, menyebabkan file archive tidak dapat disimpan terus sehingga terjadi kemacetan database.
5. Serialisasi dari blok-blok data pada buffer cache dikarenakan kekurangan dari free list, free list group, transaction slot, atau segmen rollback yang pendek.
6. Long Full Table Scans dapat mengindikasikan poor transaction design, missing indexes, atau poor SQL optimization.
7. Disk sorting untuk online operations dapat mengindikasikan poor transaction design, missing indexes, atau poor SQL optimization.
8. Banyaknya jumlah recursive SQL yang dieksekusi mengindikasikan kegiatan space management, seperti alokasi extent dan alokasi space. Hal ini berdampak terhadap user response time.
9. Schema Errors dan Optimizer Problems : Sebuah aplikasi menggunakan terlalu banyak resource karena schema yang memiliki tabel-tabel belum berhasil melakukan migrasi dari implementasi sebelumnya. Hal ini dapat disebabkan oleh missing indexes atau incorrect statistics. Error ini dapat menyebabkan sub-optimal execution plans dan poor interactive user performance.
10. Penggunaan initialization parameter yang tidak standar akibat asumsi yang tidak benar.
2.2.7 Application Tuning
M enurut Page (1999, p258), application tuning adalah suatu tindakan yang mayoritas berhubungan dengan perbaikan di sisi sintaks SQL. Sedangkan menurut Edward Whalen (2001, p4), application tuning melibatkan proses analisis sintaks SQL dan memastikan apakah sintaks query yang digunakan telah efisien dan optimal.
M enurut Holmes pada Technology Conference yang berjudul Oracle Perfomance Tuning Techniques (7-9 Oct 2001), kesalahan–kesalahan umum yang sering terjadi pada SQL code adalah:
1. Everything in One Statement
Multiple table join dan sub-query yang sangat kompleks pada satu SQL statement. Hal ini M engakibatkan :
✖ Proses yang lama meskipun dengan tuning
✖ Sulit untuk mengimplementasikan explain_plan
✖ Sulit untuk menyelesaikan masalah SQL yang kompleks
Solusi yang dapat diterapkan untuk mengantisipasinya :
✔ Pecah menjadi beberapa table joins
✔ INSERT & UPDATE menggunakan tabel temp
2. Desain dan coding yang kompleks
Desain dan coding SQL yang kompleks dapat menyebabkan masalah pada performance. Hal ini dapat disebabkan oleh:
✖ Terlalu banyak normalized tables, columns, views
✖ Indexing, triggers dan restraints yang berlebihan
✖ Logika yang terlalu rumit dan berbelit-belit
✖ SQL code tidak terstruktur sehingga sulit untuk dipahami
Solusi yang dapat diterapkan untuk mengantisipasinya :
✔ Usahakan tetap simple
✔ Lakukan hanya yang harus dilakukan
✔ Selalu meningkatkan kualitas secara terus menerus dan
berkelanjutan
✔ Selalu desain sesuatu yang dapat ditingkatkan di kemudian hari
✔ Standard coding style, neat, lined up
Berdasarkan http://www.tusc.com/oracle/training/course-apptune.html, beberapa hal yang perlu diperhatikan dalam melakukan application tuning :
SQL Tuning (mengoptimalkan code yang digunakan).
Indexing (penggunaan index yang tepat untuk mengakses data). Partitioning (penggunaan partisi untuk mengelompokkan data besar)
2.2.8 SQL Tuning
SQL tuning merupakan tindakan query optimization. Dimana definisi Query Optimization menurut Connoly dan Begg (2002, p606) adalah suatu tindakan memilih execution strategy yang efisien untuk mengeksekusi sebuah query. Terdapat banyak cara yang untuk menghasilkan data yang sama, namun tujuan dari query optimization adalah untuk memilih cara yang paling sedikit menggunakan resource.
M enurut Oracle Database Performance Tuning Guide 11g release 1(2007,p358), tujuan dari tuning adalah mengurangi response time bagi end user dari sebuah sistem dan mengurangi sumber daya yang digunakan untuk suatu pekerjaan yang sejenis dan untuk mencapai hal tersebut, beberapa cara dapat dilakukan, yaitu:
Mengurangi Workload
SQL Tuning pada umumnya melibatkan pencarian cara yang paling efektif untuk memproses beberapa workload yang sejenis. Hal ini dapat dilakukan dengan mengganti execution plan dari SQL statement tanpa harus mengubah fungsionalitasnya untuk mengurangi pemakaian sumber daya. Contoh: Jika ada SQL statement (query) yang sering dijalankan untuk mengakses sebagian kecil dari data dalam tabel, maka SQL statement tersebut dapat dijalankan lebih efisien dengan menggunakan index.
Menyeimbangkan Workload
Sistem cenderung akan berada dalam kondisi sibuk pada saat jam-jam operasional dan akan sedikit digunakan pada saat malam hari ketika kegiatan operasional sudah tidak dilakukan. Contoh: untuk pengambilan data dari OLTP menjadi data warehouse sebaiknya dilakukan malam hari. Paralelisasi Workload
Untuk melakukan query data dalam jumlah yang besar terutama pada data warehouse dapat dilakukan secara paralel untuk mengurangi response time pada data warehouse serta tidak menghentikan kegiatan transaksional secara keseluruhan pada OLTP.
Beberapa SQL Statement yang dapat mempercepat akses data : Penggunaan Equijoin
Untuk meningkatkan efisiensi SQL statement, lebih baik menggunakan equijoins jika memungkinkan. SQL statement yang menggunakan equijoins pada kolom yang tidak ditransformasikan nilainya lebih mudah untuk dilakukan tuning.
Hindari mengubah nilai column dalam WHERE clause Lebih baik menggunakan:
Daripada:
WHERE TO_NUMBER(SUBSTR(a.order_no,INSTR(b.order_no,'.')-1)) = TO_NUMBER(SUBSTR(a.order_no,INSTR(b.order_no,'.')-1)) WHERE a.order_no = b.order_no
Hindari penggunaan where clause untuk menggabungkan tabel Lebih baik menggunakan:
Daripada:
Karena untuk menggabungkan beberapa tabel dengan non-join clause (where clause), hasil akan dievaluasi setelah melakukan cross join seluruh tabel. Sedangkan dengan join clause, hasil akan dievaluasi setelah cross join antar 2 tabel. Sehingga dapat mengurangi jumlah row yang akan dicocokkan dengan tabel berikutnya.
Perhatikan processing time antara DELETE, INSERT dan UPDATE Operasi DELETE lebih cepat dari pada INSERT dan UPDATE karena sebenarnya oracle tidak menghapus datablock yang terpakai secara permanen, melainkan menandai datablock tersebut bahwa sudah tidak terpakai. Untuk INSERT, oracle akan memesan datablock untuk diisi dengan suatu nilai. Sedangkan UPDATE merupakan kegiatan yang lebih lama karena memerlukan waktu untuk pencarian data yang hendak di-update serta mengganti nilainya (terlebih jika melibatkan kalkukasi rumit dalam mengganti nilai).
SELECT last_name, job_name, department_name FROM employees a JOIN jobs b
ON a.job_id = b.job_id JOIN department c
ON a.department_id = c.department_id
SELECT last_name, job_name, department_name
FROM employees a, jobs b, department c
WHERE a.job_id = b.job_id AND
Hindari penggunaan data type convertion
Contoh:
Code di atas menggunakan explicit data type convertion (menyebutkan secara tertulis konversi tipe datanya). Hal ini akan menyebabkan performance menurun. Code di atas dapat juga ditulis sebagai berikut :
karena oracle akan mengubah WHERE clause di atas secara implicit menjadi:
Hindari penggunaan complex expressions
Complex expressions di atas mencegah SQL Optimizer untuk memberikan cardinality yang valid dan dapat menyebabkan perubahan pada execution plan dan join method. Hindarilah:
Lebih baik :
WHERE TO_NUMBER (char_col) = num_exp Keterangan :
char_col adalah varchar2 num_exp adalah number
WHERE TO_NUMBER(char_col) = num_exp
Contoh:
‐ col1 = NVL(:b1, col1) ‐ NVL(col1, -999) = ….
‐ TO_DATE(), TO_NUMBER(), TO_CHAR()
SELECT employee_num,full_name Name,employee_id FROM mtl_employees_current_view
WHERE (employee_num = NVL (:b1,employee_num)) AND (organization_id=:1)
ORDER BY employee num;
SELECT employee_num,full_name Name,employee_id FROM mtl_employees_current_view
WHERE (employee_num =:b1)AND(organization_id=:1) ORDER BY employee num;
Penggunaan EXISTS dan IN untuk subqueries
Dalam beberapa kondisi, lebih baik menggunakan IN daripada EXISTS. Contoh kasus :
a. Jika selective predicate berada di dalam subqueries maka gunakanlah IN Contoh:
b. Jika selective predicate di dalam parent query maka gunakan EXISTS Contoh:
Hindarilah mengakses data berulang-ulang untuk beberapa SQL
S tatement yang dapat digabung
Contoh: SELECT e.first_name,e.salary FROM employees e WHERE e.employee_id IN (SELECT o.sales_rep_id FROM orders o WHERE o.customer_id = 144);
SELECT e.first_name ,e.salary FROM employees e
WHERE e.department_id = 80 AND e.job_id = 'SA_REP' AND EXISTS (SELECT 1
FROM orders o
WHERE e.employee_id = o.sales_rep_id);
SELECT COUNT(*) FROM employees WHERE salary < 2000; SELECT COUNT(*) FROM employees WHERE salary > 4000; SELECT COUNT(*) FROM employees
Dapat digabungkan menjadi:
Mengendalikan Access Path dan Join Order dengan Hint
Kita dapat menggunakan hint dalam SQL statement untuk menginstruksikan kepada SQL optimizer bagaimana SQL statement ini seharusnya dijalankan. Join Order dapat memberikan efek yang sangat signifikan pada performance pengaksesan data dalam database. Hal-hal yang perlu diperhatikan ketika akan menentukan join order antara lain:
• Hindarilah full-table scan jika memungkinkan untuk mendapatkan data yang dibutuhkan melalui sebuah index.
• Hindarilah menggunakan index yang menarik 10.000 baris data dari sebuah tabel jika masih bisa menggunakan index lain yang menarik hanya 100 baris data.
• Pilihlah join order yang tepat sehingga menghasilkan lebih sedikit baris untuk di-join-kan dengan tabel berikutnya.
SELECT COUNT
(CASE WHEN salary<2000
THEN 1 ELSE null END) count_lt_2000,
COUNT (CASE WHEN salary BETWEEN 2001 AND 4000 THEN 1 ELSE null END) count_btwn_2001_4000, COUNT (CASE WHEN salary>4000
THEN 1 ELSE null END) count_gt_4000 FROM employees;
SELECT e.last_name FROM employees e
Rank Access Path
1 Single ROWID
2 Single row by cluster join
3 Single row by hash cluster key with unique or primary key
4 Single row by unique or prim ary key
5 Cluster Join
6 Hash cluster key
7 Indexed cluster key
8 Composite key
9 Single-Column indexes
10 Bounded range search on indexed colum s
11 Unbounded range search on indexed colum s
12 Sort-m erge join
13 Max or Min of indexed colum s
14 ORDER BY on indexed colum s
15 Full table scan
T abel 2-1 Rangking access path dari tercepat hingga paling lambat Berikut rangking access path dari tercepat hingga paling lambat:
Pada saat mengeksekusi suatu query, optimizer akan memilih execution plan berdasarkan access path yang tersedia. Jika terdapat lebih dari satu cara untuk
mengeksekusi SQL statement, optimizer selalu memilih cara dengan ranking terendah. Biasanya cara dengan ranking yang lebih rendah dieksekusi lebih cepat daripada ranking yang lebih tinggi. Berikut penjelasan mengenai setiap ranking nya :
1. Single ROWID
Access path ini tersedia jika pada statement where clause diidentifikasikan untuk menghasilkan data dengan dengan langsung menunjuk kepada ROWID nya. Contoh :
2. Single row by cluster join
Access path ini tersedia untuk statement yang menggabungkan beberapa tabel yang
tersimpan pada cluster yang sama dan jika memenuhi kedua kriteria berikut :
• Statement where clause mengandung kondisi yang menyamakan setiap kolom pada di cluster key dalam satu tabel dengan kolom pada tabel lain. • Statement where clause juga mengandung sebuah kondisi yang menjamin
bahwa hasil join hanya menghasilkan satu baris data. Contoh :
3. Single row by hash cluster key with unique or primary key
Access path ini tersedia jika memenuhi kriteria berikut :
• Query statem ent harus menjamin bahwa outputnya hanya satu baris data.
• Cluster key sekaligus primary key dari tabel tersebut SELECT *FROM emp, dept
WHERE emp.deptno = dept.deptno AND emp.empno = 7900;
• Statem ent where clause menggunakan semua kolom hash cluster key dalam
menyamakan kondisi antara tabel yang satu dengan yang lain.
Contoh : Pada statement dibawah, tabel orders tersimpan di hash cluster dan kolom orderno merupakan cluster key sekaligus primary key dari tabel orders.
4. Single row by unique or primary key
Access path ini akan tersedia jika statem ent where clause menggunakan semua kolom
yang merupakan unique atau prim ary key dalam penyamaan kondisi antara tabel yang satu dengan yang lain. Untuk mengeksekusi statem ent tersebut, oracle akan melakukan
scan index pada unique atau primary key untuk mendapatkan ROWID dan kemudian
tabel akan diakses menggunakan ROWID. Contoh :
5. Cluster Join
Access path ini tersedia jika :
• Statement menggabungkan beberapa tabel pada cluster yang sama
• Statement where clause mengandung kondisi yang menyamakan setiap kolom cluster key dalam satu tabel yang berhubungan dengan tabel lain. Contoh : Tabel emp dan dept dicluster pada kolom deptno :
SELECT * FROM orders WHERE orderno =1968;
SELECT * FROM emp
WHERE empno = 7900;
SELECT * FROM emp,dept
6. Hash cluster key
Access path ini hampir sama dengan single row by hash cluster key with unique or primary key (access path no.3), perbedaannya terletak pada cluster key tidak harus merupakan primary key dari tabel tersebut. Sehingga pada contoh dibawah ini, tabel line items disimpan di cluster dan orderno adalah cluster key namun bukan primary key dari tabel line items.
7. Indexed cluster key
Access path ini akan tersedia jika statem ent where clause menggunakan semua kolom
dari indexed cluster key untuk menyamakan kondisi satu tabel dengan tabel lain. Sebagai contoh : pada statement dibawah ini, tabel emp tersimpan di indexed cluster dan kolom deptno adalah cluster key.
8. Composite key
Access path ini akan tersedia jika statement where clause menggunakan semua kolom composite index dalam menyamakan kondisi tabel satu dengan tabel lainnya. Untuk mengeksekusi statement ini, oracle melakukan range scan pada index untuk mendapatkan ROWID dari selected row dan kemudian mengakses tabel tersebut dengan menggunakan ROWID yang didapatkan.
Contoh : Pada statement dibawah ini, terdapat composite index terhadap kolom job dan deptno :
SELECT * FROM line_items WHERE orderno = 65118968;
SELECT * FROM emp WHERE deptno = 10;
SELECT * FROM emp WHERE job = 'CLERK' AND deptno = 30;
9. Single-Column indexes
Access path ini tersedia jika statement where clause menggunakan satu atau lebih single column index dalam menyamakan kondisi antara tabel yang satu dengan yang lain. Sebagai contoh : di bawah ini, terdapat sebuah index pada kolom job :
Contoh lain jika terdapat beberapa single column index (kolom job dan deptno):
10. Bounded range search on indexed colums
Access path ini tersedia jika statement where clause mengandung kondisi yang menyangkut indexed column dan membatasi range output dengan menggunakan ekspresi sama dengan (=), lebih besar sama dengan dan lebih kecil dari ( > [=] AND < [=] ), BETWEEN …AND, dan ekspresi LIKE ‘c%’
Contoh :
11. Unbounded range search on indexed colums
Access path ini tersedia jika statement where clause mengandung kondisi yang menyangkut indexed column dan menggunakan ekspresi : Lebih besar dari >[=] atau kurang dari < [=].
Contoh :
SELECT * FROM emp
WHERE job = 'ANALYST';
SELECT * FROM emp
WHERE job = 'ANALYST'and deptno = 20;
SELECT * FROM emp
WHERE sal BETWEEN 2000 AND 3000;
SELECT * FROM emp WHERE sal > 2000;
12. Sort-merge join
Access path ini tersedia untuk statem ent yang menggabungkan beberapa tabel yang tidak
disimpan pada cluster yang sama sehingga oracle harus melakukan sort-merge join. Pada contoh dibawah ini, tabel emp dan dept tidak disimpan pada cluster yang sama :
13. Max or Min of indexed colums
Access path ini tersedia untuk select statement dan jika pada kondisi berikut ini :
• Hanya menggunakan fungsi MAX atau MIN pada SELECT statement • Tidak memiliki WHERE atau GROUP BY clause
Contoh :
14. ORDER BY on indexed colums
Access path ini tersedia untuk select statement dan jika pada kondisi berikut ini : • Mengandung ORDER BY clause
• Terdapat primary key atau NOT NULL constraint, sehingga menjamin kolom yang disort tidak mengandung nilai NULL.
Contoh :
15. Full table scan
Access path ini tersedia untuk berbagai jenis SQL statement jika tidak memiliki index atau tidak memenuhi empat belas access path sebelumnya. M isalnya : untuk mengeksekusi query yang bertujuan untuk menghasilkan jumlah data hampir atau seluruh data pada tabel tersebut :
SELECT * FROM emp, dept
WHERE emp.deptno = dept.deptno;
SELECT MAX(sal) FROM emp;
SELECT *FROM emp order by empno;
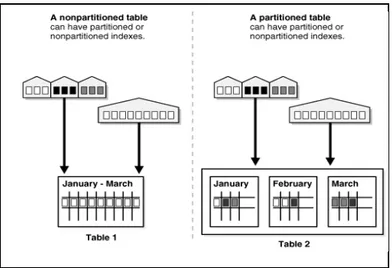
2.2.9 Partitioning
2.2.9.1 Mengenai Partitioning
M enurut Syamsiar (2006, p135), partisi pada tabel digunakan untuk membagi tabel yang mempunyai record data yang sangat besar menjadi segmen-segmen kecil yang terpisah. Aplikasi tetap mengakses dengan menggunakan nama tabel yang sama, tetapi secara fisik pembacaan data atau index dilakukan pada segmen-segmen tertentu. Partisi dapat meningkatkan performance query jika dilakukan pada tabel yang mempunyai data dalam jumlah besar.
M enurut Oracle Database Concepts 10g release 1 (10.1), partitioning adalah suatu metode yang membantu pembagian tabel yang memiliki data yang sangat banyak menjadi bagian yang lebih kecil yang disebut partition sehingga memudahkan untuk pengaturan (manageable). Setelah di partisi, DDL statements dapat mengakses atau memanipulasi data per-bagian tanpa perlu mengakses data pada tabel secara keseluruhan.
Setiap baris pada sebuah partitioned table dikelompokkan berdasarkan sebuah partition key yang merupakan bagian dari salah satu kolom pada tabel tersebut. Oracle akan secara otomatis mengelompokkan data ke dalam group-group partisi sesuai dengan kriteria pada tiap partisi tersebut.
Kriteria partition key adalah sebagai berikut :
• Merupakan salah satu kolom yang terdapat pada tabel tersebut • Dapat merupakan kolom yang berisi NULL value
• Tidak bisa berupa ROWID
Ketentuan Partitioned Table adalah sebagai berikut :
• Sebuah tabel dapat berisi hingga 64.000 partisi.
• Tidak dapat membuat partisi pada tabel yang berisi data bertipe RAW dan LONGRAW.
• Tabel yang mengandung data bertipe CLOB dan BLOB dapat dipartisi
• Setiap partisi yang terbentuk harus memiliki logical attribute yang sama, misalnya : Nama kolom, tipe data dan constraint.
Suatu tabel harus dipartisi jika memenuhi kriteria :
• Data yang terkandung dalam tabel tersebut sudah mencapai atau lebih dari 2 GB .
2.2.9.2 Manfaat Partitioning
M enurut Oracle Database Concepts 10g release 1 (10.1), manfaat yang diperoleh jika menerapkan partitioning antara lain ;
a. M emungkinkan Data Management Operations seperti : loading data, creating atau rebuilding index dan backup atau recovery pada partisi tertentu saja sehingga tidak perlu melakukan semua hal tersebut pada keseluruhan tabel. Hal ini mengurangi operation time untuk melakukan tugas-tugas tersebut.
b. M eningkatkan performance, manageability, dan availability. Sehingga selain kinerja meningkat, dengan menerapkan partitioning data dapat lebih mudah untuk diatur dan menjaga tingkat availability agar data selalu tersedia pada saat dibutuhkan. c. M engurangi dampak scheduled downtime for maintenance
d. M eningkatkan availability of mission-critical databases jika critical tabel dan index dibagi menjadi partisi untuk mengurangi maintenance windows, waktu recovery.
e. M emungkinkan penerapan Information Lifecycle Management yang simple dan efisien untuk data yang besar.
f. Salah satu keuntungan partitioning adalah dapat diimplementasikan tanpa perlu melakukan modifikasi pada aplikasi. M isalnya : kita dapat mengubah sebuah nonpartitioned menjadi partitioned table tanpa perlu mengubah select atau DM L statement yang mengakses tabel tersebut.
2.2.9.3 Jenis-jenis Partitioning
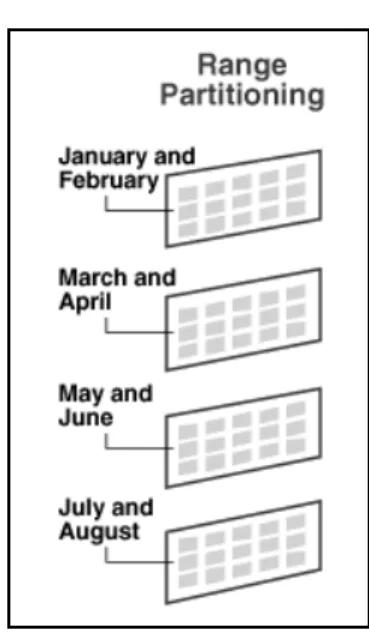
M enurut Syamsiar (2006, pp138-142), jenis-jenis partisi : a. Range Partitioning
Jenis partisi ini membagi data secara terpisah berdasarkan nilai cakupan tertentu. Biasanya digunakan pada kolom dengan tipe tanggal. M isalnya, data tahun 2007 diletakkan pada partisi P2007, data tahun 2008 diletakkan pada partisi P2008, dan seterusnya. Berikut contoh tabel penjualan yang dipartisi secara per tahun.
SQL > create table penjualan (
2 kode_sales varchar2(5),
3 tanggal date,
4 kode_item varchar2 (30),
5 qty number )
6 Partition by range (tanggal)
7 (
8 partition p2000 values less than (to_date(‘01/01/2001’,’dd/mm/yy’)),
9 partition p2001 values less than (to_date(‘01/01/2002’,’dd/mm/yy’)),
10 partition p2002 values less than (to_date(‘01/01/2003’,’dd/mm/yy’)),
11 partition p2003 values less than (to_date(‘01/01/2004’,’dd/mm/yy’)),
12 partition p2004 values less than (to_date(‘01/01/2005’,’dd/mm/yy’)),
13 partition p2005 values less than (to_date(‘01/01/2006,’dd/mm/yy’)),
14 partition p2006 values less than (to_date(‘01/01/2007,’dd/mm/yy’)),
15 partition p2007 values less than (to_date(‘01/01/2008’,’dd/mm/yy’)),
16 partition pmax values less than (maxvalue)
17 );
Data yang mempunyai nilai kolom kurang dari tanggal 1 Januari 2001, akan dimasukkan kedalam partisi P2000. Data yang mempunyai nilai kolom kurang dari tanggal 1 Januari 2002, dimasukkan kedalam partisi P2001, demikian seterusnya. Jika terdapat data yang tidak sesuai kriteria, misalnya data pada tanggal 16 Juli 2008 maka akan masuk ke partisi PM AX.
Setiap partisi pada tabel di atas diletakkan pada tablespace yang sama. Partisi juga dapat diletakkan pada tablespace yang berbeda, yaitu dengan menambahkan klausa TABLESPACE.
….
partition p2000 values less than (to_date(‘01/01/2001’,’dd/mm/yy’))
tablespace ts_2000,
partition p2001 values less than (to_date(‘01/01/2002’,’dd/mm/yy’))
tablespace ts_2001,
partition p2000 values less than (to_date(‘01/01/2003’,’dd/mm/yy’))
tablespace ts_2002,
partition p2000 values less than (to_date(‘01/01/2004’,’dd/mm/yy’))
tablespace ts_2003,
…..
M anfaat menyimpan partitions pada tablespace yang terpisah antara lain :
• Mengurangi kemungkinan terjadinya data corruption • Backup dan recover tiap partisi dapat dilakukan terpisah • Meningkatkan manageability, availability dan performance • Mengontrol proses mapping partitions ke disk drives (penting
untuk balancing I/O load)
b. Hash Partitioning
Partisi secara hash membagi data sesuai algoritma fungsi hash, yaitu setiap data dibagi secara merata sesuai dengan jumlah partisi yang sudah didefinisikan. Partisi secara hash lebih efektif digunakan untuk mendistribusikan data secara acak tanpa harus memperhatikan nilai pada kolom data tersebut. Berikut contoh partition by hash :
CREATE TABLE sales_hash(
salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), week_no NUMBER(2) ) PARTITION BY HASH(salesman_id)(
Partition sales1 tablespace ts1, Partition sales2 tablespace ts2, Partition sales3 tablespace ts3, Partition sales4 tablespace ts4 );
Data pada tabel sales_hash akan diletakkan pada masing-masing partisi secara acak berdasarkan kolom salesman_id. Partisi tersebut dapat juga dibuat tanpa menyebutkan nama partisinya.
CREATE TABLE sales_hash(
salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), week_no NUMBER(2) ) PARTITION BY HASH(salesman_id) PARTITIONS 4;
Oracle akan membuat partisi sebayak 4 buah dengan nama yang telah ditentukan oleh oracle. M isalnya SYS_P001, SYS_P002, dan seterusnya
SQL > select segment_name, partition_name 2 from user_segments
3 where segment_name in (‘sales’);
SEGMENT_NAME PARTITION_NAME --- SALES SYS_P25 SALES SYS_P26 SALES SYS_P27 SALES SYS_P28
Partitioning by hash lebih baik daripada by range bila :
• Kita tidak tahu sebelumnya ada berapa data berupa range. • Size partition by range akan sulit untuk di balance manually • Partitioning by range akan menyebabkan undesirably
clustered bila diimplementasikan
• Fitur perfomance seperti parallel DML, partition pruning, partition-wise joins menjadi sangat penting.
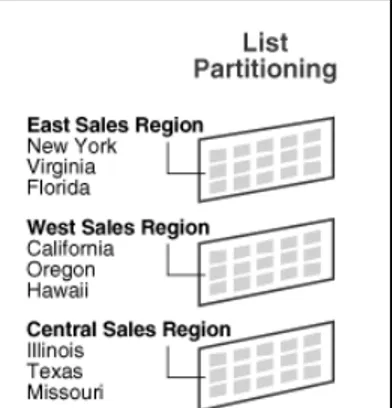
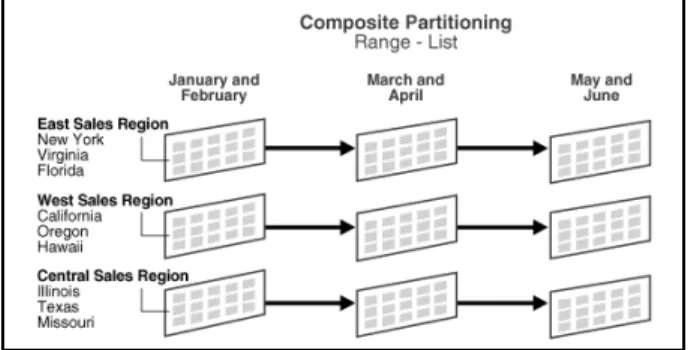
c. List Partitioning
Data dibagi berdasarkan daftar nilai tertentu, misalnya pada kolom KODE, dimana data dengan kode A, B diletakkan pada partisi pertama, data dengan kode C diletakkan pada partisi kedua, dan seterusnya. Partisi dengan jenis list hanya dapat digunakan pada satu kolom saja. Contoh penggunaan partition by list :
CREATE TABLE sales_list(
salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_state VARCHAR2(20), sales_amount NUMBER(10), sales_date DATE ) PARTITION BY LIST(sales_state)( west VALUES('California','Hawaii'),
east VALUES ('New York', 'Florida'), central VALUES('Texas', 'Illinois'), other VALUES(DEFAULT)
);
Tabel sales_list mencatat informasi masing-masing kota dan dikelompokkan menjadi empat wilayah, yaitu wilayah West terdiri dari California dan Hawaii, wilayah East terdiri dari New York dan Florida, wilayah Central terdiri dari Texas dan Illionis, serta wilayah other untuk menampung data pada wilayah lainnya.
d. Composite Partitioning
Partisi secara composite digunakan untuk membuat partisi dengan menggabungkan beberapa partisi dalam tabel yang sama.
• Composite Range-Hash Partitioning.
Artinya : pada mulanya data dipartisi terlebih dahulu by range, kemudian dipartisi lagi secara hash. Berikut contoh penggunaan Composite Range-Hash Partitioning :
CREATE TABLE sales_composite ( salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), sales_date DATE ) PARTITION BY RANGE(sales_date) SUBPARTITION BY HASH(salesman_id) SUBPARTITION TEMPLATE( SUBPARTITION sp1 TABLESPACE ts1, SUBPARTITION sp2 TABLESPACE ts2, SUBPARTITION sp3 TABLESPACE ts3, SUBPARTITION sp4 TABLESPACE ts4 )
(PARTITION jan2000 VALUES LESS THAN (TO_DATE('02/01/2000','DD/MM/YYYY')) PARTITION feb2000 VALUES LESS THAN
(TO_DATE('03/01/2000','DD/MM/YYYY')) PARTITION mar2000 VALUES LESS THAN
(TO_DATE('04/01/2000','DD/MM/YYYY')) PARTITION apr2000 VALUES LESS THAN
(TO_DATE('05/01/2000','DD/MM/YYYY')) PARTITION may2000 VALUES LESS THAN
(TO_DATE('06/01/2000','DD/MM/YYYY')) );
Tabel di atas dipartisi secara range berdasarkan kolom sales_date. Kemudian setiap partisinya akan dipartisi lagi by hash berdasarkan kolom salesman_id. Partisi berdasarkan
kolom salesman_id ini disebut sebagai subpartisi dari partisi berdasarkan kolom sales_date. Oracle akan membuat segmen terpisah untuk setiap subpartisi. Sehingga jika jumlah partisi secara RANGE adalah 7 dan jumlah partisi berdasarkan HASH adalah 4, maka total partisi yang terbentuk adalah 28 partisi.
• Composite Range-List Partitioning
Artinya : pada mulanya data dipartisi terlebih dahulu by range, kemudian dipartisi lagi secara list. Contoh penggunaanya adalah : partisi pertama (secara range) digunakan untuk mengelompokkan bulan, dan subpartisinya digunakan untuk mengelompokkan region.
Gambar 2-6 Com posite Range-Hash Partitioning
d. Interval Partitioning
Berdasarkan Oracle White Paper yang berjudul Partitioning in Oracle Database 11g (2007,p9), terdapat partitioning extentions yang merupakan fitur baru pada oracle 11g, salah satunya adalah interval partitioning :
Interval partitioning merupakan kemampuan tambahan dari range partitioning. Kelebihannya terdapat pada kemampuan membuat partisi baru secara otomatis ketika terdapat data baru yang tidak memenuhi kriteria partisi yang sudah ada. Partisi baru yang dihasilkan akan sesuai dengan kriteria partisi interval yang sudah didefinisikan sebelumnya dan terbentuk pada saat data tersebut masuk untuk pertama kalinya.
Berikut merupakan batasan-batasan interval partitioned table : • Interval partitioning terbatas untuk satu partition key yang
harus berupa numeric atau date range.
• M inimal satu partisi telah terbentuk pada saat tabel dibuat
• Tidak bisa assign nilai M AXVALUE
• Kolom yang dipartisi tidak boleh bernilai NULL
• Interval partitioning hanya dapat digunakan sebagai partisi utama pada composite partitioning, tidak dapat menjadi subpartition level.
Berikut contoh code interval partitioned : CREATE TABLE interval_tab ( id NUMBER,
created_date DATE )
PARTITION BY RANGE (created_date) INTERVAL(NUMTOYMINTERVAL(1,'MONTH'))( PARTITION part_01 values LESS THAN
(TO_DATE('01-NOV-2007','DD-MON-YYYY')) );
Code di atas membuat suatu tabel yang menggunakan interval partition, klausa yang berwarna merah adalah kriteria interval yang berarti sistem akan secara otomatis membuat partisi per bulan untuk data yang tidak memenuhi kriteria partisi yang sudah ada (sebelum tanggal 1 November 2007).
SELECT partition_name, high_value,num_rows FROM user_tab_partitions
ORDER BY table_name, partition_name;
PARTITION_NAME HIGH_VALUE NUM_ROWS --- --- --- PART 01 2007-11-01 0
Code di atas menunjukkan jumlah partisi yang terbentuk baru satu, yakni yang di-define pada saat create table yaitu
PART_01. Karena belum ada data yang di-insert kedalam tabel,
maka num_rows masih bernilai 0.
INSERT INTO interval_tab VALUES
(1,TO_DATE('16-OCT-2007', 'DD-MON-YYYY')); INSERT INTO interval_tab VALUES
(2,TO_DATE('31-OCT-2007', 'DD-MON-YYYY')); COMMIT;
SELECT partition_name,high_value,num_rows FROM user_tab_partitions
ORDER BY table_name, partition_name;
PARTITION_NAME HIGH_VALUE NUM_ROWS --- --- --- PART 01 2007-11-01 2
Code di atas menunjukkan tabel interval_tab telah memiliki 2 data pada partisi PART_01, karena sebelumnya telah di-insert 2 data yang kolom created_date-nya di bawah tanggal 1 November 2007.
INSERT INTO interval_tab VALUES (5,01-JAN-2008); INSERT INTO interval_tab VALUES (4,31-JAN-2008); COMMIT;
SELECT partition_name,high_value,num_rows FROM user_tab_partitions
ORDER BY table_name, partition_name;
Code di atas melakukan insert data ke tabel interval_tab dengan nilai created_date 1 hingga 31 JAN 2008.
Data di atas menunjukkan tabel interval_tab telah memiliki 2 partisi yakni PART_01 yang di-define pada saat create table dan
SYS_P44 yang merupakan partisi interval yang di-create secara
otomatis oleh sistem karena data baru yang dimasukkan, nilai created_date nya 1 hingga 31 JAN 2008 (yang berarti tidak memenuhi kriteria partisi yang pertama).
2.2.10 Indexing
2.2.10.1 Mengenai Index
M enurut Connoly dan Begg (2002, p1155), index adalah data structure yang memungkinkan DBM S mengakses record-record secara lebih cepat dan meningkatkan speed response dari suatu query. Index pada database mirip dengan index pada buku, untuk menemukan suatu topik pada sebuah buku tebal akan memakan waktu yang cukup lama, namun dengan adanya index yang menampilkan pada halaman berapa topik-topik khusus tersebut dibahas, proses pencarian akan menjadi sangat cepat karena kita tidak perlu membaca seluruh buku untuk mendapatkan apa yang kita cari.
M enurut Syamsiar (2004,p139), index merupakan faktor yang sangat menentukan performance aplikasi. Terlalu banyak index yang di-create dapat menyebabkan lambatnya performance DML namun terlalu sedikit index akan menyebabkan turunnya performance pada sebuah query.
2.2.10.2 Alasan Menggunakan Index
• M engandung banyak data (lebih dari 100.000 record)
• Field yang akan diberi index mengandung nilai range yang luas • Field yang akan diberi index mengandung banyak NULL values • Field yang akan diberi index sering diakses atau sering dijadikan
conditional statement di where clause atau di join clause.
• Tabel mengandung banyak data namun umumnya query hanya menampilkan kurang dari 2 – 4% baris data pada tabel tersebut.
2.2.10.3 Jenis-jenis Indexing
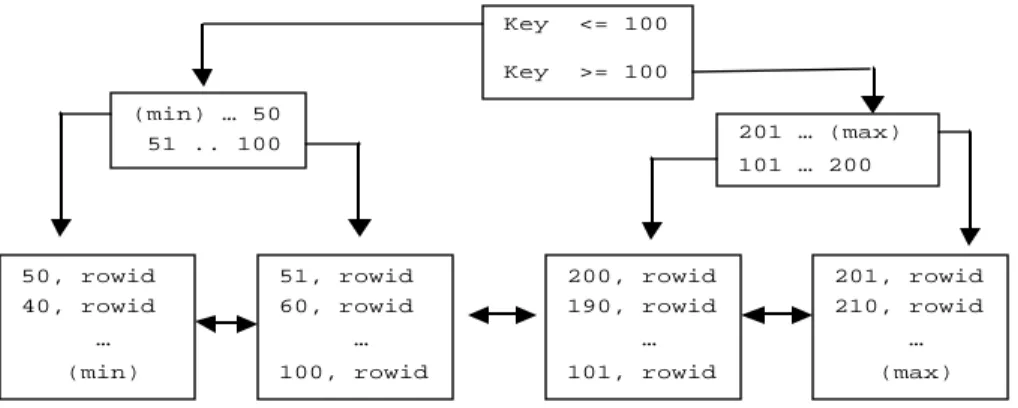
a. B*Tree Index
B*Tree index adalah struktur index yang dimiliki oleh banyak database-database yang lain. Disebut juga sebagai conventional index karena merupakan index default yang di-create oleh oracle dengan proses pencarian berdasarkan binary search tree. Sebagai contoh pada tabel yang mempunyai primary key :
Tabel transaksi mempunyai primary index dengan menggunakan kolom ID. Jika kolom ID mempunyai data dari 1 – 200 maka struktur index pada kolom ID tersebut adalah :
Blok paling bawah pada struktur tree di atas disebut leaf nodes yang berisi index key dan row id. Index key adalah data pada kolom ID sesuai dengan yang telah didefinisikan sedangkan row id adalah physical address yang menunjukkan pada blok mana record tersebut berada. Blok di atas leaf nodes disebut branch block.
Contoh : M encari data dengan nilai 52 menggunakan index :
create table tsx (id int primary key, … )
select *from tsx where id = 52;
Key <= 100 Key >= 100 (min) … 50 51 .. 100 201 … (max) 101 … 200 201, rowid 210, rowid … (max) 200, rowid 190, rowid … 101, rowid 51, rowid 60, rowid … 100, rowid 50, rowid 40, rowid … (min)
Oracle akan mulai mencari data dari block paling atas dan menuju branch blok sebelah kiri yang menunjukkan nilai lebih kecil sama dengan 100. Pada branch block kedua, oracle menuju block dengan nilai antara 51 dan 100, sampai akhirnya menemukan leaf node yang berisi index key dengan nilai 52, dan di dalamnya terdapat rowid letak record data sebenarnya di dalam tabel. Dari leaf node ini oracle akan mendapatkan record yang diminta. Cara pencarian data seperti ini disebut sebagai INDEX SCAN.
b. Bitmap Index
Bitmap index sangat tepat digunakan pada aplikasi yang berjenis data warehousing atau pada tabel-tabel yang serin g menggunakan ad-hoc query. M isalnya untuk mengetahui jumlah karyawan yang berkelamin laki-laki dan menjabat sebagai pimpinan cabang. Tabel employees mempunyai kolom gender dan jabatan. Kolom gender dapat berisi laki-laki atau perempuan. Sedangkan jabatan dapat berisi pimpinan, sekretaris atau bendahara.
M aka ketika ada query :
Oracle akan melihatnya sebagai :
select *from employees where gender =’Laki-Laki’ and jabatan =‘Bendahara’;
Emp_No Gender Jabatan
E001 Laki – Laki Pimpinan
E002 Perempuan Sekretaris E003 Perempuan Bendahara
E004 Laki-Laki Bendahara
Emp_No Gender Jabatan E001 1 0 E002 0 0 E003 0 1 E004 1 1
Berdasarkan query, oracle akan menginterpretasikan kolom gender laki-laki sebagai 1 sedangkan perempuan sebagai 0, begitu pula dengan kolom jabatan, bendahara akan bernilai 1, yang lainnya bernilai 0. Sehingga untuk menghasilkan data yang diperlukan, oracle hanya perlu mencari record data yang memiliki bitmap=1 pada kolom gender dan jabatan.
Proses pencarian data yang dilakukan menggunakan bitmap index menjadi lebih cepat, karena oracle hanya melihat nilai bitmap-nya saja. Jika bitmap bukan 1, pasti 0. Jika bukan 0, pasti 1. Hal ini membuat bitmap index sangat efisien untuk memenuhi kebutuhan ad-hoc query, terutama query-query yang sering melibatkan banyak kolom dengan berbagai macam kombinasi yang berbeda.
Akan tetapi, bitmap index tidak tepat jika digunakan pada tabel yang sering menggunakan transaksi DM L (insert, update, delete) secara bersama-sama dalam satu waktu karena bitmap index sangat potensial menyebabkan dead lock.
Bitmap index menyimpan beberapa record data dalam satu index entries, artinya dalam satu key tersimpan beberapa row id. Jika terjadi transaksi insert dengan nilai sesuai dengan key value tertentu, semua record yang memiliki key value yang sama akan mengalami locking.