Computing with DNA by operating on plasmids
T. Head
a,*, G. Rozenberg
b,c, R.S. Bladergroen
c,d, C.K.D. Breek
d,
P.H.M. Lommerse
d, H.P. Spaink
c,daDepartment of Mathematical Sciences,Binghamton Uni6ersity,Binghamton,NY13902-6000, USA
bLeiden Center for Ad6anced Computer Sciences,Leiden Uni6ersity,Niels Bohrweg1,2333CA Leiden,The Netherlands cLeiden Center for Natural Computing,Leiden Uni6ersity,Niels Bohrweg1,2333CA Leiden,The Netherlands dInstitute for Molecular Plants Sciences,Leiden Uni6ersity,Wassenaarseweg64,2333AL Leiden,The Netherlands
Received 28 March 2000; received in revised form 31 May 2000; accepted 2 June 2000
Abstract
A new method of computing using DNA plasmids is introduced and the potential advantages are listed. The new method is illustrated by reporting a laboratory computation of an instance of the NP-complete algorithmic problem of computing the cardinal number of a maximal independent subset of the vertex set of a graph. A circular DNA plasmid, specifically designed for this method of molecular computing, was constructed. This computational plasmid contains a specially inserted series of DNA sequence segments, each of which is bordered by a characteristic pair of restriction enzyme sites. For the computation reported here, the DNA sequence segments of this series were used to represent the vertices of the graph being investigated. By applying a scheme of enzymatic treatments to the computational plasmids, modified plasmids were generated from which the solution of the computational problem was selected. This new method of computing is applicable to a wide variety of algorithmic problems. Further computations in this style are in progress. © 2000 Elsevier Science Ireland Ltd. All rights reserved.
Keywords:DNA computing; Biomolecular computing; Molecular computing
www.elsevier.com/locate/biosystems
1. Introduction
Adleman (1994) introduced the application of the laboratory techniques of molecular biology to the solution of computational problems. He solved an instance of an algorithmic problem, the directed Hamiltonian path problem (Garey and Johnson, 1979) using the annealing and ligation of linear single-stranded DNA molecules. From
the molecules having the appropriate length, the solution was selected using a small number of biochemical separation steps. Adleman’s paper set off an explosion of interest in procedures for
computing by using DNA and other
biomolecules. A thriving international multidisci-plinary research area, known as ‘DNA comput-ing’, has resulted. One can survey this area using Paun et al. (1998), Hagiya (1999) and Rubin and Wood (1999) and the references they contain.
The results reported here belong to this general context, but they represent a new approach to * Corresponding author.
biomolecular computing that is entirely distinct from that of Adleman (1994). Our results are more easily related to the work of Ouyang et al. (1997), in which an instance of the algorithmic problem, known as the maximum clique problem (Garey and Johnson, 1979), was solved. These authors began by expressing the maximum clique problem as a maximum independent set problem. For their solu-tion of the resulting maximum independent set problem, they used 64 specially constructed linear double stranded DNA molecules, which were selec-tively cut by restriction enzymes in successive pairs of test tubes. From the shortest DNA molecule remaining, the solution was read off.
We describe and demonstrate here a systematic approach that is applicable in a uniform manner to a wide variety of algorithmic problems. Our method of computation is based on the use of one single, circular, double-stranded DNA molecular variety. Our molecule contains an origin for repli-cation, which allows the production, using bacteria, of copies of the molecule whenever needed. Such circular molecules are called plasmids. We compute by making molecular modifications, in parallel in distinct test tubes, beginning with a test tube containing a vast number of copies of the original plasmid.
We report here the laboratory solution of pre-cisely the same instance of the maximum indepen-dent set problem to which Ouyang et al. (1997) reduced, and then solved their chosen instance of the maximum clique problem. We include a brief comparison of our approach with the computation given in Ouyang et al. (1997). The laboratory success of the computation reported here supports the contention made in Head (1999) and Head et al. (1999) that several of the widely studied algorith-mic problems, such as the minimal vertex cover problem, the union of directed Hamiltonian sub-graphs problem and the satisfiability of sets of disjunctive clauses, will admit laboratory solutions using precisely the same pattern of protocols.
2. The plasmid computing concept
The plasmid computing concept can be explained as follows. LetPbe a plasmid, k, a positive integer
and s1,s2, . . . ,sk be k pairwise non-overlapping subsegments ofP. Suppose also that, for eachi, the nucleotide sequence of sioccurs nowhere else in the
plasmidP. Subsegments chosen in this way will be called ‘stations’ of the plasmid. The method of computing is to begin each computation with a test tube of water (or appropriate buffer) that contains a vast number of identical k-station plasmids. During a computation, the plasmids are modified in such a way as to be readable later. Modification takes place only at the stations. Each stationsi, at
any time during a computation, is in one of two states, which we regard as a representation of one of the bits: 1 or 0. Consequently, each plasmid plays a role comparable to that of a k-bit data register in a conventional computer. The memory in plas-mid computing is simply the body of water with its plasmid content. Water allows rapid partitioning of memory into subsets. Stirring, or diffusion, allows the assumption that each of the members of such a partition contains the same variety of molecules. Distinct members of the partition can be modified in different ways and reunited again into a single test tube. The design of a plasmid computation will include a procedure for reading the solution from the final condition of the memory. It is important to observe that the choice of procedures for mod-ifying the plasmid molecules is not specified in the concept of plasmid computing. Many choices for modifying the plasmids are being considered. For our initial effort, reported here, we have chosen the most classical method of genetic engineering: cut and paste.
3. Advantages of the plasmid computing concept
The following are three positive features of the plasmid method:
1. A user purchases and possibly perfects to his/
2. The plasmid (in buffer) is the computer. The user can develop a thorough familiarity with this single plasmid and its behaviors in the presence of a variety of enzymes in various buffers under various temperatures and salt concentrations. The user’s experience with this plasmid is cumulative. The user is not continu-ally adjusting to the idiosyncrasies presented by molecules with new sequences.
3. The plasmids are kept in double-stranded form at all times and throughout all computations. There is no tangled self-annealed single-stranded DNA or PCR amplification step to cause trouble. This use of DNA follows nature. During both replication and transcription, DNA is not pulled apart into long single strands. In-stead, small portions of the DNA are opened up and carefully controlled by associated proteins that prevent the occurrence of undesired anneal-ing as encountered in some current forms of DNA
computing. (We are, however, content to use PCR near the end of a computation to ‘read off’ linear segments from the plasmids.)
4. A sketch of the computational plasmid used here
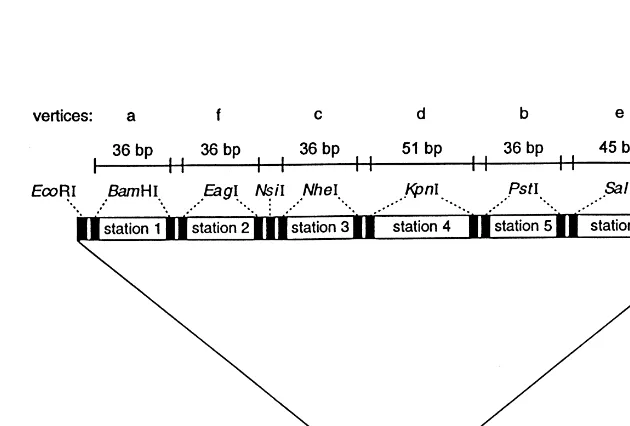
Fig. 1 gives a sketch of the computational plasmid used here. Its construction is based on plasmid pOK12 (Vieira and Messing, 1991) which was opened up and a specially constructed seg-ment of 297 base pairs (bps) was inserted before recircularizing to form the final plasmid, pMP6079, used in computation here. The six sta-tions of pMP6079 are all included in the specially designed insert (Fig. 1). A unique restriction en-zyme is associated with each of the stations. Each station is bounded by a pair of sites for its associ-ated restriction enzyme.
In computations, one is free to consider the initial state of each station of the computational plasmid to represent either the bit 0 or the bit 1, whichever is convenient. Here, we consider the initial condition of each station to represent the bit 1. The bit 1 represented at a specific station can be rewritten as a 0 by the following technique. At the two bounding sites of the station, the plasmid is cut with the restriction enzyme associ-ated with the station. The short segment in this station consisting of half of each restriction site, together with the portion of pMP6079 they bound, drops out. The longer segment of pMP6079 is then recircularized using a ligase en-zyme. One of the two original bounding restric-tion sites is reconstituted in the ligarestric-tion process. After the deletion of the specified material from the station, the station is regarded as representing the bit 0. For the reading process used here it is fundamental that, each time a bit is set to 0, the circumference of the plasmid is reduced by the length in base pairs (bps) of the segment deleted. The enzymes and the segment lengths associated with the stations of the computational plasmid used here are given in Fig. 1. The variation in the lengths of the stations of the plasmid is suffi-ciently small, so that from the shortening pro-duced by any combination of deletions at the stations, the number of deletions made is uniquely determined. This property is necessary for the reading procedure used here.
5. The maximum independent set problem
Each undirected graph G=(V,E), having ver-tex setV and edge set E, provides an instance of the fundamental algorithmic problem, known as the maximum independent set (MIS) problem (Garey and Johnson, 1979). A subsetS of the set Vof vertices of G=(V,E) is said to be indepen-dent if, for each edge in E, S does not contain both vertices belonging to that edge. The MIS problem associated with G requires the calcula-tion of the largest cardinal number that occurs as the cardinality of an independent subset ofV. The calculation of this cardinal number is known to be NP-complete (Garey and Johnson, 1979). It is
also natural to request that a specific independent subset of maximum cardinality be exhibited.
A laboratory solution by plasmid computing is given for the MIS problem associated with the graph G=(V,E) having as its vertex set V=
{a,b,c,d,e,f} and having as its set E of edges the set of four unordered pairs: {a,b}, {b,c}, {c,d} and {d,e}. Note that, for instances of the MIS problem, it is not required to place an isolated vertex (such as f in the present instance) in corre-spondence with a station, since an isolated vertex must certainly be included in any maximum inde-pendent set. (In further laboratory computations now in progress all six stations of the present computational plasmid are required.)
With each of the six vertices of the graph we associated a station of our computational plasmid as shown in Fig. 1. The computation began with a test tube T0 containing 80 ng of the computa-tional plasmid. Conceptually, this plasmid repre-sents the entire vertex set {a,b,c,d,e,f}. If there were no edges in E, this set would be the unique independent subset of maximum cardinality. Re-call, for reference below, that the length of the specially inserted segment that contains all six stations is 297 bps.
The presence of edge {a,b} in the setEof edges ofGrequires that no independent subset ofVcan contain both a and b, although an independent subset might contain either a or b. To incorporate this requirement chemically, the content ofT0was divided equally into test tubes T1andT2. Each of the plasmids in T1 was cut at the two bounding sites of the station representing vertex a, with BamHI and was then ligated back into circular form resulting in plasmids having a circumference reduced by 36 bps. Each of the plasmids inT2was cut, at the two bounding sites of the station representing vertex b, with PstI and was then ligated back into circular form resulting in plas-mids having a circumference reduced by 36 bps. Amplification of the resulting plasmids from tubes T1 and T2 was done by transformation into Es
-cherichia coli (Fig. 1). The plasmids amplified
from tubesT1andT2were united into a new tube T0.
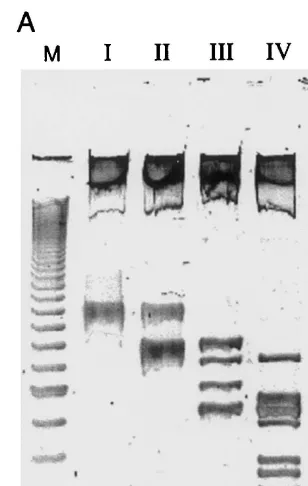
Fig. 2. Polyacrylamide gel electrophoresis of DNA samples treated with restriction enzymes as described in text. The resulting plasmids were digested with the enzymesEcoRI and HindIII which border the 297 base pairs fragment used for the calculations. The column marked M shows a marker DNA ladder increasing 20 bp in length starting from the lowest band visible of 100 bp. DNA samples were run on an 8% polyacry-lamide gel for 15 h at 45 V. Visualization was done by CyberGreen (Molecular Probes Europe, Leiden, The Nether-lands).
The final tube T0, obtained after each of the four edges in E were taken into account chemi-cally, were predicted to contain only plasmids having inserts of the appropriate length to repre-sent independent sets. A careful analysis (taking into account the small variation in the number of base pairs deleted as each station is set to zero) predicted that the lengths of the inserts occurring in the plasmids in tube T0 should be:
After only {a,b} has been accommodated: Tube T0 was expected to contain plasmids having inserts of the following length: 261 bps. After only {a,b} and {b,c} have been accom-modated: Tube T0 was expected to contain plasmids having inserts of the following lengths: 261, 225 bps.
After only {a,b}, {b,c}, and {c,d} have been accommodated: Tube T0 was expected to con-tain plasmids having inserts of the following lengths: 225, 210, 189 174 bps.
After {a,b}, {b,c}, {c,d} and {d,e} have all been accommodated: Tube T0 was expected to contain plasmids having inserts of the following lengths: 210, 180, 174, 165, 144, 138, 129 bps. A gel separation of the inserts cut from the plasmids remaining inT0after all four edges were taken into account was a required step of the computational procedure. It provides our current choice of technology for reading the solution of the problem. However, as a test on the quality of the biochemical protocols used in the computa-tion, a portion of the contents ofT0was removed at each of these four stages of T0 and all four samples were analyzed on a polyacrylamide gel. The resulting gel separation is presented as Fig. 2. Leftmost is a calibration column. Columns I – IV exhibit (in the lower two-thirds) the locations on the gel of the inserts cut from the plasmids resid-ing in T0 at the conclusion of each of the four stages of the computation for which lengths were predicted in the paragraph above. The long residues remaining from the plasmids after the inserts were cut out occupy the top portion of the gel. In each of the four columns the match be-tween the expected lengths of the linear segments and the lengths associated with the bands on the gel are faultless. No extraneous bands appear. We concluded from this gel that the protocols used were entirely successful.
regions of the same length: 297−36=261 bps. These two molecules represent the subsets {b,c,d,e,f} and {a,c,d,e,f}. If there had been no further edges inE, each of these sets would have been an independent set having maximum cardi-nality. (These inserts of length 261 are seen above in Column I of Fig. 2.)
As the final step of the computation, the length in base pairs (bps) of the longest remaining frag-ment of the insert was read from Column IV of the gel in Fig. 2. This gave 210 bps. From this length, it was concluded that the minimum number of stations of PMP6079 that were required to be set to zero in order to meet the requirement of indepen-dence was two. Hence, the largest cardinal number that occurs as the cardinal number of an indepen-dent set is 6−2=4. Thus, the solution of this instance of the NP-complete MIS problem is 4. If it is also desired to exhibit an independent set having this maximum cardinal number, this can be accomplished in two ways. The molecules consti-tuting the band on the gel having length 210 encode independent sets having this cardinality. This band can be cut out and the molecules it contains can be cloned and sequenced. In the present case there is only one maximum independent set, namely {a,c,e,f}. If desired, the sequencing step can be replaced by partitioning the molecules from a single clone into six tubes in which the continued presence of each of the station fragments is tested.
6. Comparison with published DNA computing methods
We make a brief comparison with the results of Ouyang et al. (1997). The laboratory work reported by these authors consisted of four steps that are parallel to the four steps taken above. In our procedure the number of distinct molecular vari-eties in Tube 0 proceeds through the values 1, 2, 4, 7 and 12. Exactly one of the final 12 provided the solution (the longest). In Ouyang et al. (1997), the 64 distinct molecular varieties that correspond to the complete set of 64 six bit strings that constitute the potential solutions were first constructed. Tube 0 was then initialized to contain these 64 molecular varieties. During the four steps used by Ouyang et al. (1997), molecules that cannot represent a solu-tion were systematically destroyed. The number of distinct molecular varieties in Tube 0 then pro-ceeded through the values 64, 48, 40, 32 and 26. Exactly one of the final 26 provided the solution (the shortest).
Notice that we avoid the strategy of beginning
with the construction all the molecular varieties that represent potential solutions. We prefer to keep the number of distinct molecular varieties present as small as possible at each stage of a computation.
7. Conclusions
We have reported in this paper a prototype computation that has been carried out successfully using the plasmid alternative for DNA computing. We emphasize that the plasmid-computing concept is not wedded to the specific biochemical techniques used here. The natural domain for computing in this style may be an aqueous solution of a vast number of initially identical molecules (or molecu-lar complexes) which can be altered at fixed loca-tions (staloca-tions) either chemically, magnetically, electrically, or by use of electromagnetic radiation. The constraining features of the specific procedures used here were: (i) the time required for the enzymatic processes to go sufficiently near to completion; (ii) the diminution of DNA during the separation of the plasmids from the enzymes that have acted on them; and (iii) the need for amplifi-cation steps due to the diminution of the DNA. It may seem that the application of our procedure to larger problems is limited by the available number of restriction enzymes. However, techniques have been described in which specifically designed protein nucleic acid (PNA) sequences can suppress restriction of particular restriction sites (Nielsen et al., 1993), thereby allowing the use of the same restriction enzyme for multiple stations. The results reported here have encouraged us to continue the development and exploration of these and further techniques for computing based on the plasmid concept. Additional plasmid computations that explore additional technologies are nearing com-pletion.
Acknowledgements
Organization for Scientific Research (NWO), and the Leiden Center for Natural Computing is gratefully acknowledged. We thank Dr N. Stuur-man and Dr W.R.M. SchlaStuur-man (Leiden Univer-sity) for valuable advice.
References
Adleman, L., 1994. Molecular computation of solutions to combinatorial problems. Science 266, 1021 – 1024. Garey, M.R., Johnson, D.S., 1979. Computers and
Intractabil-ity — A Guide to the Theory of NP-Completeness. Free-man, New York.
Hagiya, M., 1999. Perspectives on molecular computing. New. Generat. Comput. 17, 131 – 151.
Head, T., 1999. Circular suggestions for DNA computing. In: Carbone, A., Gromov, M., Pruzinkiewcz, P. (Eds.), Pattern
Formation in Biology, Vision and Dynamics. World Scien-tific, Singapore and London, pp. 325 – 335.
Head, T., Yamamura, M., Gal, S., 1999. Aqueous computing: writing on molecules. Proceedings of the Congress on Evolutionary Computing, IEEE Service Center, Piscataway, NJ, pp. 1006 – 1010.
Nielsen, P.E., Egholm, M., Berg, R.H., Buchardt, O., 1993. Sequence specific inhibition of DNA restriction enzyme cleavage by PNA. Nucleic Acids Res. 21, 197 – 200. Ouyang, Q., Kaplan, P.D., Liu, S., Libchaber, A., 1997. DNA
solution of the maximal clique problem. Science 278, 446 – 449.
Paun, Gh., Rozenberg, S., Salomaa, A., 1998. DNA Computing — New Computing Paradigms. Springer Verlag, Berlin. Rubin, H., Wood, D., 1999. DNA Based Computers III.
American Mathematical Society, Providence, Rhode Island. Vieira, J., Messing, J., 1991. New pUC-derived cloning vectors with different selectable markers and DNA replication origins. Gene 100, 189 – 194.