SNASTIA 201 4
ISSN 19 79-3960
CLASSIFICATION DENGAN
UNTUK DATA
MAHASISWA DAN
DI PERGURUAN TINGGI
Mewati Maresha Caroline3), Tjio Marvin Christian4)
Teknologi Informasi, Universitas Kristen Maranatha [email protected],
Abstract
The existence of historical data in universities, for the data of lecturer and student academic process, is valuable because of the fact that historical data can be analyzed to extract the implicit knowledge with the use of various analysis methods, which in turn can be used as a basis for improving education system. This research is aimed to analyze the historical data of students and lecturers using predictive methods as a continuation previous research that had been managed to produce a data warehouse schema for both types of data. In addition, the research is focused on three datasets, which are of research and community services and also the of graduates that were extracted using the methods of decision tree, especially J48 with some confidence factor parameter settings as well as several minimum numbers of instances for the leaves that will produce optimal analysis model. Research methodology began with the formation of derived data star schema of the previous research results, followed by the determination of attributes of the that would be used as training data and test data. Furthermore, those analyzed using some models before they finally were evaluated. The results of some test cases indicated that the decreasing in the value of the and also the increasing of minimum number of instances on leaves in J48 classifcation, both were the resulting tree pruning. For research and community datasets, the convergence on the number of leaves in the tree would be more quickly achieved along with the increase of minimum value of instances when compared to the case of the decrease of confidence factor value. Meanwhile, for the graduate in cases of classes, the convergence of the leaves number was influenced by the distribution of the data in the class attribute, either by adding the minimum value of the instance on the leaves as well as by lowering the confidence factor value.
kunci: data mining, decision tree, J48, universities historical data.
1.
Pendahuluan
Penelitian Ranjan (Ranjan Khalil, 2008) menyebutkan pengetahuan yang diperoleh dari data mining dapat dimanfaatkan untuk meningkatkan pendidikan. Berdasarkan data yang institusi, dapat
pengumpulan data yang dilanjutkan dengan menggunakan sebagai untuk mengevaluasi data histori. Dari hasil tersebut, dapat diperoleh pengetahuan yang bermanfaat untuk
perbaikan dalam sistem pendidikan.
Berbagai penelitian data mining telah untuk terhadap data yang dimiliki institusi. penelitian (Bhardwaj Pal, 2012) digunakan klasifikasi dengan Naive Bayes untuk memprediksi
mahasiswa. Sedangkan penelitian (Radaideh Nagi, 2012) menggunakan klasifikasi ID3, C4.5 Naive Bayes untuk memprediksi karyawan. (Gibert, 2010) juga memanfaatkan klasifikasi untuk
data yang berhubungan dengan masalah
Dari penelitian sebelumnya (Ayub 2013) (Ayub, Kristanti, Caroline, telah dihasilkan skema data warehouse untuk data mahasiswa dan data yang dapat diterapkan di perguruan tinggi. Berbasis skema data warehouse yang dihasilkan, pada makalah ini, akan dipaparkan hasil data dengan klasifikasi untuk menghasilkan model terhadap data dan data mahasiswa. Studi kasus data mining akan dilakukan terhadap penelitian pengabdian dan lulusan. klasifikasi yang digunakan
decision tree dengan J48 Weka yang dilengkapi dengan pengaturan parameter confidence factor dan jumlah
instance pada daun untuk dapat menghasilkan model yang optimal. J48 merupakan klasifikasi C4.5 yang paling berpengaruh dalam dengan data mining (Wu, Kumar, Ghosh, Yang, Motoda, 2008).
2.
Teori
Data Mining
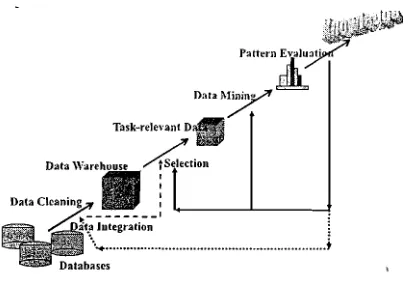
Data mining Knowledge Discovely in Databases (KDD). KDD merupakan prosedur yang interaktif mengekstraksi pengetahuan yang belum diketahui (implisit) menjadi pengetahuan yang data. Tahapan yang terjadi dalam dapat dilihat pada Gambar
SNASTIA 2014
ISSN 1979-3960
Gambar Knowledge in Databases (Han, Kamber, Pei, 2012)
Berdasarkan tujuan pemanfaatannya, data mining dapat dibedakan 1. prediktif
Dalam ini, data mining menggunakan beberapa untuk memprediksi variabel lain yang belum diketahui. data mining yang termasuk prediksi antara lain classification dan regresi.
2.
Dalam data digunakan untuk menggambarkan karakteristik dari sekumpulan data dalam juga untuk menggambarkan pola pengetahuan yang di dalam kumpulan data data yang termasuk adalah clustering dan aturan asosiasi.
2.2
Pada teknik classification, sekumpulan setiap akan dari beberapa atribut, salah satu dari atribut akan menentukan kelae (class). akan mencari suatu model untuk atribut kelas sebagai dari nilai atribut lainnya. Berdasarkan model tersebut, suatu data baru harus dapat ditempatkan ke dalam suatu kelas setepat
Dalam membangun model akan digunakan kumpulan yang disebut sebagai data training. Berdasarkan data training, untuk menentukan atribut kelas akan Untuk model tersebut, akan digunakan sekumpulan yang disebut data tes. Model diuji dengan data tes, kemudian ditinjau persentase keberhasilannya di dalam data tes.
Classification yang akan digunakan dalam makalah ini adalah dengan pohon keputusan. Pohon keputusan (decision tree) digambarkan dengan suatu pohon, dimana setiap node menyatakan pemeriksaan terhadap suatu atribut,
mengklasifikasi sampel yang belum nilai atribut sampel terhadap pohon keputusan. Suatu (path) ditelusuri dari akar sampai ke suatu node sehingga diketahui kelas dari sampel tersebut.
setiap menyatakan hasil (outcome) dari pemeriksaan tersebut, dan node daun menyatakan kelas. Pada saat
Pada saat dilakukan mining data, terdapat dua kelompok data, yaitu data training dan data test. Data training digunakan untuk membentuk model melalui suatu teknik data mining. data test digunakan untuk
sejauh mana akurasi dari model tersebut. Dengan hasil yang diperoleh dari suatu data mining perlu dievaluasi dengan mengukur tingkat kesalahan (error rate) dari model yang dihasilkan
Frank, Hall, 201 1) Kamber, Pei, 2012).
Untuk memprediksi performansi pada data baru, perlu dilakukan dahulu penilaian error rate pada sebuah yang bersifat independen dan tidak ada kaitannya dengan formasi classifier. yang independen
disebut juga test set. Baik training data maupun test data merupakan contoh-contoh dari permasalahan yang akan dianggap penting dan representatif Frank, Hall, 201 1).
Umumnya, semakin besar sampel training, akan baik classifier-nya, hasilnya berkurang volume data training berlebih. Semakin besar sampel test, maka semakin akurat estimasi error-nya. Masalah muncul ketika data yang tersedia tidaklah besar. Pada seperti ini, data training diklasifikasi secara dan begitu pula data test hams mengandung estimasi error. Hal akan membatasi jumlah data yang digunakan untuk training, validation, dan testing.
Jika semua contoh dengan class dihilangkan dari data training, maka data classifier akan dipakai pengujian pada class dan akan diperburuk dengan fakta bahwa class perlu pada data test karena tidak ada satu pun instance-nya yang diperlukan untuk data training. Namun, hams
SNASTIA 201 4
19 79-3960
bahwa random sampling dilakukan setiap class disiapkan untuk training set dan test set
Frank, Hall, 201 1).
Cara umum untuk mengurangi setiap bias yang disebabkan tertentu adalah dengan mengulangi proses, training and testing berulang kali dengan random sample yang berbeda. Dalam setiap iterasi, dapat digunakan misalnya dua per tiga data untuk training, dengan dan sisanya dapat digunakan untuk testing. Error rate pada setiap iterasi yang berbeda akan dirata-rata untuk menghasilkan keseluruhan error rate.
Prosedur ini disebut repeated holdout method untuk melakukan estimasi error rate.
Namun, dapat juga digunakan teknik statistik yaitu cross-validation. Dalam cross-validation, dapat dipilih
number untuk fold atau partisi dari data tersebut. contoh memakai tiga partisi, maka data akan dibagi tiga dengan pembagian yang hampir sama, sepertiga data akan digunakan untuk testing dan sisanya digunakan untuk training dan akan diulangi sebanyak tiga kali sehingga pada proses, setiap instance akan digunakan sekali untuk pengujian. Prosedur ini disebut threefold cross-validation Frank, Hall, 201 1).
Standar yang digunakan untuk memprediksi error rate pada klasifikasi dengan single, sample data adalah
tenfold cross-validation dimana data dibagi secara acak menjadi sepuluh bagian dimana class direpresentasikan dalam dengan proporsi yang sama. Setiap bagian diuji dan error rate-nya akan dikalkulasi. klasifikasi dieksekusi sebanyak sepuluh kali pada training set yang berbeda (setiap set kesamaan). kesepuluh error estimate yang didapatkan akan untuk
keseluruhan error estimate. sepuluh karena berdasarkan teoritis yang melatarbelakanginya, angka dianggap nilai fold yang tepat untuk mendapatkan estimate yang
argumen masih menuai sejumlah perdebatan, namun tenfold cross-validation telah menjadi metoda yang dilakukan. pengujian juga telah bahwa penggunaan stratifikasi akan meningkatkan hasil demi Oleh karenanya evaluasi standar dalam situasi dimana data terbatas akan memerlukan stratified tenfod cross-validation. data untuk stratifikasi juga 10 fold tidak perlu sama, dengan membaginya menjadi sepuluh set dengan yang hampir sama dengan representasi keragaman nilai- nilai class yang hampir sarna, jadi perbandingan fold atau cross-validation.
Stratifikasi mengurangi variasi, tidak mengurangi keseluruhan data Frank, Hall, 201 1).
Selain training error, model hasil klasifikasi juga ditentukan oleh generalization error. Generalization error adalah kesalahan yang ditimbulkan oleh data baru yang tidak muncul dalam proses klasifikasi. Model klasifikasi yang tidak hanya dapat memetakan data training dengan tepat, tetapi juga dapat data baru yang tidak muncul dalam data training. Apabila suatu model klasifikasi memetakan data training dengan tepat,
tidak dapat mengklasifikasi data baru dengan benar, maka model bersifat (Tan, Steinbach, Kumar, 2006).
dapat diatasi dengan melakukan pemangkasan (pruning) terhadap tree hasil klasifikasi. Terdapat pemangkasan, yaitu pre-pruning dan post-pruning. Model tree hasil klasifikasi yang telah
pemangkasan, bersifat lebih umum (general) dalam mengklasifikasi data baru, sehingga kesalahan dapat (Tan, Steinbach, Kumar, 2006) Frank, Hall, 201 1).
3.
Penelitian
yang dilakukan dalam pembahasan makalah ini adalah sebagai
a. Membentuk yang berasal dari skema data yang berbentuk star hasil penelitian
Menentukan atribut yang akan digunakan sebagai data training dan data test dalam dengan classification.
Melakukan dengan model classification untuk dengan parameter nilai confidence factor yang jumlah minimum instance tertentu pada daun menggunakan fold cross validation.
Melakukan dengan model classification untuk dengan parameter nilai jumlah minimum instance
pada daun yang diubah-ubah nilai factor tertentu menggunakan 10 fold cross validation. Melakukan evaluasi terhadap model hasil di
di digunakan untuk menganalisis penelitian pengabdian dan
Dan Pembahasan
SNASTIA 2014
19 79-3960
algoritma revisi ke-8 yang disediakan oleh Frank, Hall, 201 1). Algoritma akan menggunakan Gain Ratio sebagai nilai heuristic untuk dalam decision tree yang dibentuk.
4.1 Penelitian
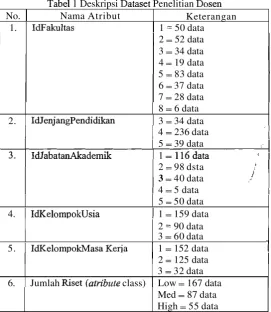
penelitian terdiri dari 309 instances. dari dapat dilihat pada
2 = 52 data
Gain Ratio yang diperoleh berdasarkan data pada 1 dan diurutkan dari nilai sarnpai nilai terendah dapat dilihat 2.
2 Nilai Gain Ratio Penelitian
No. Gain Ratio
1. 0.0491
Hasil klasifikasi dari pada ldengan Masifikasi dapat dilihat pada 3. Pada model awal yang dihasilkan dari percobaan dengan factor = atribut penentu dalam tree mengikuti urutan dihasilkan dari gain ratio pada 2. Tree awal yang dihasilkan bersifat karena menggambarkan data training yang digunakan. Sifat menyebabkan tree spesifik dan model yang dihasilkan
digunakan untuk generalisasi data (Tan, Steinbach, Kumar, 2006). karena dilakukan beberapa kali dengan nilai confidence factor yang diubah-ubah, mulai dengan nilai confidence factor = sampai dengan Nilai confidence factor yang mengecil menyebabkan dilakukan pemangkasan terhadap tree yang dihasilkan. Pada akhir percobaan, diperoleh tree dengan jumlah daun 26. Pada tree akhir yang dihasilkan, hanya tiga atribut menjadi penentu dalam tree.
3 Penelitian dengan Confidence Factor
SNASTIA 201
4
ISSN 1979-3960
Selanjutnya dilakukan juga klasifikasi dengan Confidence Factor tetap sebesar dan ada variasi pada minimum instance pada daun, mulai dengan jumlah instance = 2 sampai dengan 30. Hasilnya dapat pada 4. Pada
percobaan diperoleh tree dengan jumlah daun = 3, adapun atribut penentu yang digunakan hanya satu. No.
4 Hasil Klasifikasi Penelitian dengan Confidence Factor = dengan Variasi Minimum Instance pada daun
Karena IdFakultas atribut dengan 8 variasi nilai, maka untuk memperoleh yang umurn, percobaan selanjutnya dilakukan dengan menghilangkan atribut IdFakultas dari pada 1. Hasil klasifikasi J48 untuk penelitian IdFakultas dapat dilihat pada 5. Dari percobaan diperoleh tree yang sama dengan tree yang diperoleh pada 4.
No.
5 Hasil Klasifikasi Penelitian IdFakultas Confidence Daun Instance yang terklasifikasi
Jumlah Daun dalam
Dari hasil eksperimen pada 4 dan 5, class: High untuk atribut Jumlah Riset tidak muncul dalam tree, disebabkan distribusi data yang tidak seimbang untuk atribut Jumlah Riset, seperti tampak pada 1.
SNASTIA 2014
ISSN 19 79-3960
percobaan yang dilakukan untuk 6, diperoleh tree dengan 3 daun, di mana class muncul dalam tree, dengan persentase instance yang terklasifikasi dengan benar
6 Desknpsi Penelitian
4.2 Pengabdian
pengabdian terdiri dari 282 instances. dari pengabdian dapat dilihat pada 7.
3.
4.
5.
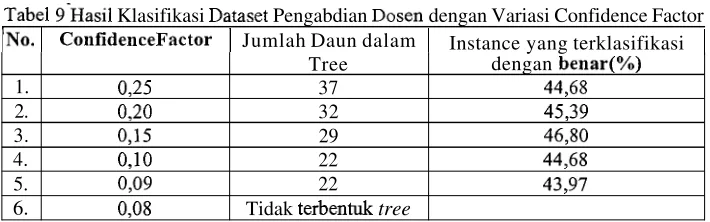
Pada 9 berisi J48 terhadap dari 7 dengan variasi Confidence Factor, mulai dari sampai dengan Pada model awal yang dihasilkan dari percobaan dengan confidence factor
penentu dalam tree mengikuti urutan yang dihasilkan dari gain ratio pada 8. Pada percobaan model dengan jumlah daun 22 dengan tiga atribut penentu dalam tree.
Ke rja
Jumlah Riset (atribut class)
Gain Ratio yang terbentuk berdasarkan data pada 7 dari nilai tertinggi sampai nilai dapat dilihat pada 8.
8 Nilai Gain Ratio Pengabdian 1 : 88 data 2 : 41 data
3 : 36 data 1 : 71 data 2 : 71 data 3 : 23 data Low : 55 data Med : 55 data High : 55 data
Gain Ratio 0,0392 0,0388 19 0,0154 0,0146
No. 1 .
2.
3.
4. 5.
SNASTIA 2014
1979-3960
Klasifikasi Pengabdian dengan Variasi Confidence Factor Jumlah Daun dalam Instance yang terklasifikasi
, Sesuai dengan percobaan yang dilakukan pada penelitian maka pengabdian juga
dengan nilai Confidence Factor tetap sebesar dan adanya variasi pada minimum instance pada daun, mulai dengan jumlah instance = 2 sampai dengan 90. dapat dilihat pada 10. Pada model yang dlhasilkan, terdapat satu atribut dalam tree.
1.
itu dilakukan juga percobaan dengan menghilangkan dari pengabdian hasilnya dapat pada 1 Dari percobaan diperoleh tree yang sama dengan tree yang diperoleh pada
7 Hasil Klasifikasi Pengabdian dengan Confidence Factor = dan dengan Variasi Minimum Instance pada daun
11 Hasil Klasifikasi Pengabdian
No. Confidence Daun Instance yang
Factor Tree dengan
201 4
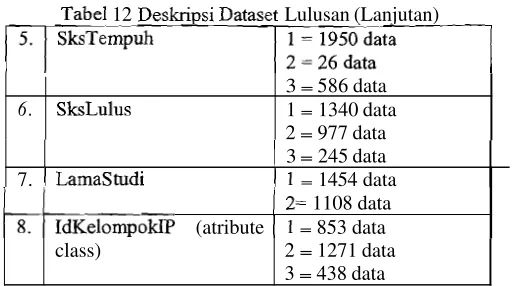
12 Lulusan (Lanjutan)
3 = 245 data
7. = 1454 data
6 .
1108 data (atribute = 853 data
Klasifikasi untuk Lulusan, dilakukan dalam dua kelompok percobaan, kelompok percobaan dengan IdKelompokIP sebagai class kelompok percobaan dengan sebagai class.
3 = 586 data 1 = 1340 data 2 = 977 data
class)
Gain Ratio untuk kelompok percobaan dengan IdKelompokIP sebagai class yang berdasarkan data pada 12 dan dari nilai sampai nilai terendah dapat dilihat pada 13.
2 = 1271 data 3 = 438 data
Nama Atribut
0,2582 0,1564 0,1515 0,0970
Hasil Lulusan dengan IdKelompokIP sebagai class dapat dilihat pada 14.
Sesuai dengan percobaan yang dilakukan pada maka juga dengan nilai Confidence Factor sebesar dan adanya variasi pada minimum instance pada daun. Hasilnya dapat dilihat pada
15.
14 Hasil Lulusan dengan Variasi Co dence Factor
1. 2. 3.
15 Hasil Klasifikasi Lulusan dengan Confidence Factor = dan dengan Variasi Minimum Instance pada daun
No.
Daun Tree
46 33 26
Minimum Instance pada Daun
Instance yang terklasilkasi dengan
Jumlah Daun dalam Tree
SNASTIA 2014
1979-3960
Gain Ratio untuk pada 12 dengan LamaStudi sebagai class pada 16 yang nilai gain ratio dari nilai tertinggi sampai dengan nilai terendah.
15 Hasil Klasifikasi Lulusan dengan Confidence Factor = dan dengan Variasi Minimum Instance pada daun
16 Nilai Gain Ratio Lulusan denean LamaStudi Class
11. 80
No. Nama Atribut Gain Ratio
12. 90 10 68.11
18
Hasil klasifikasi terhadap Lulusan dengan class LamaStudi dapat dilihat pada 17 dengan variasi nilai confidence factor mulai dari sampai dengan
1. 2. 3.
Variasi Confidence Factor
Hasil klasifikasi terhadap Lulusan dengan class Lama dapat dilihat pada 18 dengan confidence factor = dan minimum instance pada bervariasi dari 2 daun sampai dengan 100 daun.
0,173823 0,080082 0.053 162
Hasil
2 ditampilkan grafik yang hasil pada 3 dan 9, yaitu klasifikasi Penelitian dan Pengabdian dengan nilai confidence factor pada nilai minimum instance pada daun = 2.
18 Hasil Klasifikasi Lulusan (Class LamaStudi) dengan Confidence Factor = dan Minimum Instance pada Daun
No. Minimum Instance pada Daun
Jumlah Daun Tree
Instance yang
SNASTIA 201 4
ISSN 19 79-3960
I
Percobaan
Penelitian Pengabdian
Gambar 2 Hasil Percobaan Penelitian dan Pengabdian dengan Variasi Confidence Factor
Pada Gambar 3 ditampilkan yang menunjukkan hasil percobaan pada 4 10, yaitu klasifikasi Penelitian Pengabdian dengan variasi nilai minimum instance pada daun co
nfi
dence factor = ...
1 2 3 4 5 6 7
Nomor Percobaan
Penelitian Pengabdian
Gambar 3 Hasil Percobaan Klasifikasi Penelitian dan dengan Variasi Minimum Instance pada
Dari Gambar 2, terlihat penurunan jumlah daun berhenti pada percobaan ke-6, yaitu pada confidence factor Sedangkan pada Gambar 3, terlihat bahwa penurunan daun berhenti pada percobaan ke-7, yaitu pada nilai instance pada daun = 40. perbandingan grafik pada Gambar 2 dan Gambar 3, dapat disimpulkan
bahwa penambahan nilai minimum instance pada daun menyebabkan penurunan jumlah daun dalam tree yang dihasilkan lebih cepat dibandingkan penurunan nilai confidence factor. Dengan demiluan tree yang dihasilkan penambahan nilai minimum instance lebih ramping dan bersifat lebih (general) dibandingkan tree yang dihasilkan dari penurunan confidence factor.
Pada Gambar 4 ditampilkan grafik yang menunjukkan hasil percobaan pada 14 dan 17, yaitu Lulusan dengan variasi nilai confidence factor pada nilai minimum instance 2.
Nomor percobaan
Gambar 4 Hasil Percobaan Klasifikasi Lulusan dengan Variasi Factor
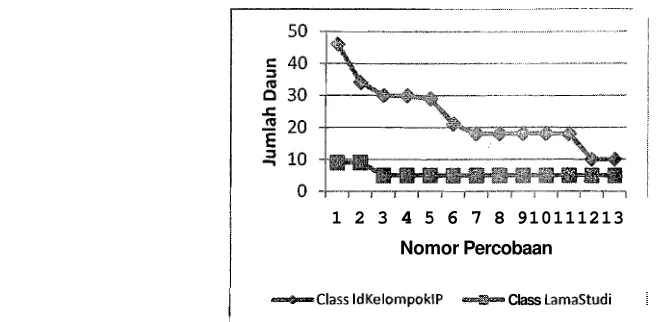
Pada Gambar 5 ditampilkan grafik yang menunjukkan hasil percobaan pada 15 dan 18, yaitu Lulusan dengan variasi nilai minimum instance pada daun untuk confidence factor =
SNASTIA 2 01
4
ISSN 1979-3960
1 2 3 4 5 6 7 8 910111213
Nomor Percobaan
Class
Gambar 5 Hasil Percobaan Klasifikasi Lulusan dengan Variasi Minimum Instance pada Daun
Dari Gambar 4, terlihat bahwa penurunan jumlah daun untuk Class berhenti pada percobaan ke-6, yaitu pada nilai confidence factor = Sedangkan untuk Class LamaStudi, jumlah daun pada tree yang dihasilkan mulai konvergen pada percobaan ke-3, yaitu pada nilai confidence factor =
Pada Gambar 5, terlihat bahwa jumlah daun untuk Class pada percobaan ke-13, yaitu untuk nilai minimum instance pada daun = 100. Sedangkan untuk Class daun pada tree dihasilkan mulai konvergen pada percobaan ke-4, yaitu untuk nilai minimum instance pa& = 15.
Dari perbandingan grafik pada Gambar 4 dan Gambar 5, dapat disimpulkan bahwa konvergensi jurnlah dalam tree yang dihasilkan lebih cepat untuk klasifikasi dengan Class LamaStudi dibandingkan klasifikasi dengan Class Distribusi data dalam Class LamaStudi pada 12 lebih merata dibandingkan dengan distribusi data dalam Class
5. Kesimpulan
Kesimpulan yang dapat dari percobaan yang telah dipaparkan dalam makalah ini adalah:
1. nilai confidence factor dalam klasifikasi dengan J48 berpengaruh dalam pemangkasan (pruning) tree yang dihasilkan.
2. Penambahan nilai minimum instance pada daun dalam klasifikasi dengan berpengaruh dalam pemangkasan (pruning) tree yang dihasilkan.
Dari percobaan terhadap penelitian dan pengabdian konvergensi jumlah daun dalam tree yang dihasilkan dengan cara penambahan nilai minimum instance pada daun lebih cepat dicapai dibandingkan dengan cara penurunan nilai confidence factor.
Dari percobaan terhadap Lulusan dengan atribut class yang berbeda, distribusi data dalam atribut class berpengaruh terhadap konvergensi jurnlah daun dalam tree yang dihasilkan, dengan cara penambahan nilai minimum instance pada daun, maupun dengan cara nilai confidence factor.
Ucapan Terima Kasih
kasih Hibah penelitian yang oleh DIPA Kopertis Wilayah IV, Kementrian Pendidikan melalui LPPM Universitas Kristen Maranatha untuk tahun anggaran 2014.
6. Daftar
Ayub, M., Kristanti. T. (2013). Model clustering untuk data mahasiswa dan diperguruan tinggi. Hibah Bersaing Tahun Anggaran 201 3.
Ayub, M., Kristanti, T., Caroline, M. (2013). Data warehouse sebagai basis data akademik perguruan tinggi. Seminar Nasional Teknologi Informasi (pp. 18-25). Jakarta:
Informasi Universitas Tarumanegara.
Bhardwaj, B., Pal, S. (2012). Data mining : Aprediction improvement using
Retrieved Maret 14, from http://arxiv.org/ftp/arxiv/papers/120 20 1.34
Ganganwar, V. (2012). overview of classification algorithms for imbalanced datasets. International Journal of Emerging Technology and Advanced Engineering
SNASTIA 201 4
ISSN 19 79-3960
,
/
Gibert, K., M., Codina, V. (2010). Choosing technique : of methods and intelligent recommendation. Februari 20, 2014, from http://www.iemss.org/iemss20
Han, J., Kamber, M., Pei, J. (2012). Data mining concepts and techniques. Waltham: Morgan Kaufmann Publisher.
Radaideh, Q., Nagi, E. (2012). Using data mining techniques to build a classification model for predicting employees performance. International Journal Advanced Computer Science and Applications ,
Ranjan, J., Khalil, S. (2008). Conceptual framework of data mining process in management education in India : An institutional perspective. Information Technology Journal 16-23.
Tan, P. N., Steinbach, M., Kumar, V. (2006). Introduction to data mining. Boston: International Ed. I. H., Frank, E., Hall, M. (201 1). Data machine learning tools and techniques.
Morgan Kaufmann Publisher.
Wu, X., Kumar, V., Quinlan, J., Ghosh, J., Q., Motoda, H. (2008). Top 10 algorithms in data mining.
Knowledge Information System
,
Volume 14, 1-37.,
Universitas Surabaya
I
, ,
,
!
!
i
I , ,