APLIKASI CLUSTERING UNTUK PENGELOMPOKAN MAHASISWA
STMIK ASIA BERDASARKAN USIA DAN DATA AKADEMIK
MENGGUNAKAN METODE K-MEANS
Rochmah Hidayati
STMIK ASIA Malang
Email: [email protected] ABSTRAK
Masalah ketidakseimbangan antara jumlah mahasiswa baru dan mahasiswa yang menyelesaikan studi tepat waktu merupakan permasalahan yang penting untuk diperhatikan. Karena salah satu factor yang menentukan kualitas perguruan tinggi adalah presentase kemampuan mahasiswa untuk menyelesaikan studi tepat waktu. Ketidakseimbangan tersebut bisa jadi karena mahasiswa menempuh studi tidak tepat waktu, memiliki status non-aktif atau bahkan dropout.
Pada penelitian ini penulis mencoba membangun sistem untuk mengelompokkan mahasiswa menjadi dua cluster yaitu cluster pertama (rawan dropout) dan cluster kedua (tidak dropout), dengan mengambil dataset mahasiswa STMIK ASIA jurusan teknik informatika angkatan 2006-2008 pada tahun ajaran 2012/2013. Total record dataset dari angkatan 2006-2008 adalah 576 record. Data tersebut dibagi menjadi 2 berdasarkan angkatan , yaitu untuk angkatan 2006-2007 adalah 315 record sebagai data training dan angkatan 2008 adalah 261 record sebagai data testing. Dalam penelitian ini menggunakan teknik clustering dengan metode K-Means untuk pengelompokan data. Tahap pertama pengujian terhadap data training dengan mengambil centroid awal secara random, pengujian ini bertujuan untuk mencari centroid awal yang tepat untuk disimpan dan digunakan pada saat pengujian data testing. Pemilihan pusat cluster yang tepat pada pengujian data training akan memberikan hasil dengan tingkat kebenaran pengelompokan yang lebih tinggi saat pengujian data testing.
Hasil pengujian terhadap data testing dengan 261 record data dan setelah tahap preprocessing menjadi 174 record, menggunakan centroid awal C1= 42, 8, 0.59 dan C2= 24, 4, 2.56 menghasilkan 10 iterasi dengan hasil akhir cluster 1 (rawan dropout) sebanyak 40 anggota atau sebesar 23% dan Cluster 2 (tidak dropout) sebanyak 134 anggota atau sebesar 77%. Dengan tingkat kebenaran/ketepatan pengelompokan berkisar antara 70% sampai dengan 73.13%.
Kata Kunci:Clustering, Data akademik,, Usia, K-Means
PENDAHULUAN
Perguruan Tinggi ASIA Malang merupakan salah satu perguruan tinggi yang cukup menarik banyak mahasiswa. Namun ada beberapa hal yang tidak seimbang antara masuk dan keluarnya mahasiswa yang telah menyelesaikan studinya. Mahasiswa yang masuk dalam jumlah besar, tetapi mahasiswa yang lulus tepat waktu sesuai dengan ketentuan jauh sangat kecil dibandingkan masuknya. Artinya terdapat mahasiswa yang tidak diketahui statusnya. Ketidakjelasan status tersebut bisa jadi karena mahasiswa menempuh studi tidak tepat waktu, memiliki status non-aktif atau bahkan drop out.
Beberapa penyebab kegagalan studi mahasiswa diantaranya adalah rendahnya kemampuan akademik, faktor pembiayaan, domisili saat menempuh studi dan faktor lainnya.
Tingginya presentasi mahasiswa yang memiliki status non aktif juga menyebabkan tingginya mahasiswa lulus tidak tepat waktu. Hal tersebut menjadi sangat penting bagi manajemen perguruan tinggi mengingat presentase mahasiswa lulus tepat waktu adalah salah satu elemen penilaian akreditasi yang ditetapkan oleh Badan Akreditasi.
mining. Data mining memecahkan masalah dengan menganalisis data yang telah ada dalam database. Clustering merupakan salah satu metode data mining yang bersifat tanpa arahan (unsupervised). KMeans merupakan salah satu metode clustering
non hirarki yang berusaha mempartisi data kedalam bentuk satu/lebih cluster/kelompok. Metode ini mempartisi data ke dalam cluster sehingga karakteristik yang sama dikelompokkan
kedalam satu cluster yang sama.
LANDASAN TEORI
1. Knowledge Discovery in Database
Menurut Jiawei Han Secara garis besar proses KDD dapat direpresentasikan dengan gambar sebagai berikut :
1.1 Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
1.2 Preprocessing
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses awal pada data yang menjadi fokus KDD untuk meyakinkan kualitas dari data yang telah dipilih pada tahapan sebelumnya.
A. Alasan pentingnya preprocessing
1. Jika data tidak berkualitas, maka hasil Mining juga tidak berkualitas
a. Kualitas keputusan harus didasarkan kepada kualitas data (misal, duplikasi data atau data hilang bisa menyebabkan ketidak-benaran atau bahkan statistik yang menyesatkan.
b. Data warehouse memerlukan kualitas integrasi data yang konsisten
2. Ekstraksi data, pembersihan dan transformasi merupakan kerja utama dari pembuatan suatu data warehouse
3. Data preprocessing membantu didalam
memperbaiki presisi dan kinerja data Mining dan mencegah kesalahan didalam data Mining
B. Data yang harus dikoreksi 1. Data Incomplete
Berisi nilai yang salah yang disebabkan karena :
a. Tidak tercatat (not recorded) b. Tidak tersedia (not available)
c. Sengaja dihapus karena dianggap salah atau tidak penting
2. Data Noisy
Berisi data salah yang tidak wajar (Anomalies/outliers) karena :
a. Instrumen pengumpulan data yang digunakan mungkin salah
b. Kesalahan manusia atau komputer yang terjadi pada saat entri data.
c. Kesalahan dalam transmisi data. 3. Data Inconsistent
Berisi data yang tidak konsisten dan berbeda dari sewajarnya disebabkan oleh : Perubahan kode di sistem yang menjadikan data tidak konsisten
1.3 Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode dan algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
1.4 Interpretation/Evalution
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
2. Data Mining
2.1 Pengertian Data Mining
Tan (2006) mendefinisikan data Mining sebagai proses untuk mendapatkan informasi yang berguna dari gudang basis data yang besar. Data Mining juga dapat diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data
besar yang membantu dalam pengambilan keputusan. Istilah data Mining kadang disebut juga knowledge discovery.
membangun sebuah model, kemudian menggunakan model tersebut agar dapat mengenali pola data yang lain yang tidak berada dalam basis data yang tersimpan. Kebutuhan untuk prediksi juga dapat memanfaatkan teknik ini. Dalam data Mining, pengelompokan data juga bisa dilakukan. Tujuannya adalah agar kita dapat mengetahui pola universal data-data yang ada.
Anomali data transaksi juga perlu dideteksi untuk dapat mengetahui tindak lanjut berikutnya yang dapat diambil. Semua hal tersebut bertujuan mendukung kegiatan operasional perusahaan sehingga tujuan akhir perusahaan diharapkan dapat tercapai.
(Prasetyo,2012:2)
2.2 Pekerjaan Data Mining
Pekerjaan yang berkaitan dengan data mining dapat dibagi menjadi empat kelompok, yaitu model prediksi (prediction modeling), analisis kelompok (cluster analysis), analisis asosiasi (association analysis), dan deteksi anomaly (anomaly detection).
1. Model prediksi
Model prediksi berkaitan dengan pembuatan sebuah model yang dapat melakukan pemetaan dari setiap himpunan variabel ke setiap targetnya, kemudian menggunakan model tersebut untuk memberikan nilai target pada himpunan baru yang didapat. Ada dua jenis model prediksi, yaitu klasifikasi dan regresi. Klasifikasi digunakan untuk variabel target diskret, sedangkan regresi untuk variabel target kontinu.
2. Analisis kelompok
Analisis kelompok melakukan pengelompokan data-data ke dalam sejumlah kelompok (cluster) berdasarkan kesamaan karakteristik masing-masing data pada kelompok-kelompok yang ada. Data-data yang masuk dalam batas
kesamaan dengan kelompoknya akan
bergabung dalam kelompok tersebut, dan akan terpisah dalam kelompok yang berbeda jika keluar dari batas kesamaan dengan kelompok tersebut.
3. Analisis asosiasi
Analisis asosiasi (association analysis) digunakan untuk menemukan pola yang menggambarkan kekuatan hubungan fitur dalam data. Pola yang ditemukan biasanya merepresentasikan bentuk aturan implikasi atau subset fitur. Tujuannya adalah untuk menemukan pola yang menarik dengan cara yang efisien.
4. Deteksi anomali
Pekerjaan deteksi anomali (anomaly detection) berkaitan dengan pengamatan sebuah data dari sejumlah data yang secara signifikan mempunyai karakteristik yang berbeda dari sisa data yang lain. Data-data yang karakteristiknya menyimpang (berbeda) dari data yang lain disebut outlier. Algoritma deteksi anomali yang baik harus mempunyai laju deteksi yang tinggi dan laju eror yang rendah. (Prasetyo, 2012:5)
3. Clustering
Salah satu metode yang diterapkan dalam KDD adalah clustering. Clustering adalah membagi data ke dalam grup-grup yang mempunyai obyek yang karakteristiknya sama. Garcia-Molina et al menyatakan clustering adalah mengelompokkan item data ke dalam sejumlah kecil grup sedemikian sehingga masing-masing grup mempunyai sesuatu persamaan yang esensial.
Clustering memegang peranan penting dalam aplikasi data Mining, misalnya eksplorasi data ilmu pengetahuan, pengaksesan informasi dan text mining, aplikasi basis data spasial, dan analisis web. Clustering diterapkan dalam mesin pencari di Internet. Web mesin pencari akan mencari ratusan dokumen yang cocok dengan kata kunci yang
dimasukkan. Dokumen-dokumen tersebut
dikelompokkan dalam cluster-cluster sesuai dengan kata-kata yang digunakan.
Tan, dkk membagi clustering dalam dua kelompok, yaitu hierarchical and partitional clustering. Partitional Clustering disebutkan sebagai pembagian obyek-obyek data ke dalam kelompok yang tidak saling overlap sehingga setiap
data berada tepat di satu cluster. Hierarchical clustering adalah sekelompok cluster yang bersarang seperti sebuah pohon berjenjang (hirarki).
William membagi algoritma clustering ke dalam kelompok besar seperti berikut:
1. Partitioning algorithms: algoritma dalam kelompok ini membentuk bermacam partisi dan kemudian mengevaluasinya dengan berdasarkan beberapa criteria.
2. Hierarchy algorithms: pembentukan dekomposisi hirarki dari sekumpulan data menggunakan beberapa criteria.
3. Density-based: pembentukan cluster berdasarkan pada koneksi dan fungsi densitas. 4. Grid-based: pembentukan cluster berdasarkan
pada struktur multiple-level granularity
5. Model-based: sebuah model dianggap sebagai hipotesa untuk masing-masing cluster dan model yang baik dipilih diantara model hipotesa tersebut.
4. K-Means
Algoritma K-Means adalah algoritma clustering yang paling popular dan banyak digunakan dalam dunia industry. Algoritma ini disusun atas dasar ide yang sederhana. Ada awalnya ditentukan berapa cluster yang akan dibentuk. Sebarang obyek atau elemen pertama dalam cluster dapat dipilih untuk dijadikan sebagai titik tengah (centroid point) cluster. Algoritma K-Means selanjutnya akan melakukan pengulangan langkah-langkah berikut sampai terjadi kestabilan (tidak ada obyekyang dapat dipindahkan):
1. Menentukan koordinat titik tengah setiap cluster
2. Menentukan jarak setiap obyek terhadap koordinat titik tengah
3. Mengelompokkan obyek-obyek tersebut berdasarkan pada jarak minimumnya.
(Andayani, 2007)
PEMBAHASAN & HASIL 1. Deskripsi Sistem
Pada subbab ini menjelaskan tentang aplikasi clustering untuk pengelompokan mahasiswa STMIK ASIA berdasarkan usia dan data akademik menggunakan metode K-Means, atau singkatnya bisa disebut dengan aplikasi clustering untuk pengelompokkan mahasiswa STMIK ASIA. Aplikasi ini menggunakan dataset mahasiswa jurusan teknik informatika angkatan 2006-2008 pada tahun ajaran 2012/2013.
Aplikasi ini menggunakan teknik clustering dengan metode K-Means dalam mengolah data, menghasilkan 2 cluster/kelompok. cluster pertama (C1) yaitu mahasiswa rawan dropout, cluster kedua (C2) yaitu mahasiswa tidak dropout. Hasil akhir dari aplikasi ini berupa presentase dan anggota dari masing-masing cluster.
Tujuan dibangunnya aplikasi ini dan penelitian dengan pemilihan dataset mahasiswa jurusan TI angkatan 2006-2008 diharapkan program dapat mendeskripsikan pengelompokan mahasiswa dengan benar dan menghasilkan kesimpulan yang dapat memberikan gambaran dari masing-masing cluster agar dapat digunakan untuk pengelompokan data mahasiswa angkatan selanjutnya. Sehingga dengan adanya gambaran pada masing-masing cluster tersebut kemungkinan dapat memberikan solusi khususnya untuk kelompok/cluster mahasiswa rawan dropout.
2. Analisa
Analisa data yang ada dalam bagian ini merupakan analisa data pada sistem clustering untuk pengelompokan mahasiswa, berdasarkan
masukan, proses dan keluaran yang ada pada sistem.
a) Analisa Kebutuhan Masukan
Data masukan adalah data yang mengalir ke dalam sistem. Sedangkan kebutuhan masukan pada sistem clustering untuk mengelompokan mahasiswa adalah pemilihan data (Data Selection) yaitu biodata mahasiswa dan data akademik mahasiswa STMIK ASIA jurusan teknik informatika angkatan 2006-2008 pada tahun ajaran 2012/2013. Total record dataset dari angkatan 2006-2008 adalah 576 record. Data tersebut dibagi menjadi 2 berdasarkan angkatan, yaitu untuk angkatan 2006-2007 adalah 315 record sebagai data training dan angkatan 2008 berjumlah 261 record sebagai data testing.
Data mahasiswa yang akan diclustering yaitu berdasarkan usia, masa studi minimal dan nilai IPK
b) Analisa Kebutuhan Proses
Proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan metode K-Means, akan tetapi sebelumnya perlu dilakukan praproses data terlebih dahulu seperti sinkronisasi data, menampilkan atribut, dan cleaning data. Setelah tahap praproses, baru dilakukan proses clustering dengan metode K-means.
c) Analisa Kebutuhan Keluaran
3. Diagram Context
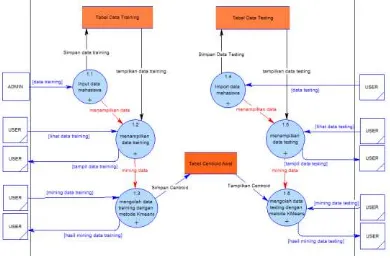
Diagram konteks (Context Diagram) aplikasi clustering untuk mengelompokkan mahasiswa STMIK ASIA adalah diagram arus data (DAD) yang menjelaskan proses sistem clustering untuk mengelompokkan mahasiswa STMIK ASIA secara menyeluruh. Diagram ini dimaksudkan untuk menggambarkan dengan pihak mana saja sistem ini berinteraksi, dan data apa saja yang mengalir di antaranya. Berikut diagram konteks sistem clustering untuk pengelompokan mahasiswa :
Pertama tama programmer yang juga merangkap sebagai database administrator (admin) memasukkan dataset data training mahasiswa jurusan TI angkatan 2006-2007 ke dalam sistem. kemudian data training mahasiswa dapat dilihat atau ditampilkan oleh user untuk diproses lebih lanjut yaitu proses mining data training dan user dapat melihat hasil proses mining data training. Pada sistem ini user dapat
melakukan banyak kegiatan seperti
memasukkan/import data mahasiswa (data testing), sampai proses mining data testing dan melihat hasil dari proses mining data.
4. Data Flow Diagram
Diagram level nol adalah diagram yang menggambarkan keseluruhan proses yang ada dalam suatu sistem. Diagram ini menggambarkan proses dan urutan-urutannya sebagai komponen yang menyusun keseluruhan sistem. Diagram level nol sistem clustering untuk pengelompokan mahasiswa adalah sebagai berikut:
Keterangan:
Gambar 3 diatas terdiri dari dua proses utama yaitu proses training meliputi proses input data training yang dilakukan oleh admin, menampilkan data training yang dilakukan oleh user dan mengolah data training menggunakan metode K-Means. Proses yang kedua yaitu proses testing alurnya sama dengan proses training.
Pada gambar 3.4 diatas terdapat dua tabel yaitu tabel data training dan tabel data testing yang mewakili dua proses yaitu proses mining data training dan proses mining data testing. Pada proses data training menggunakan data pada tabel data training dan saat proses mining data training, pusat cluster/centroid awal dapat disimpan di tabel data centroid, dan centroid tersebut ditampilkan untuk digunakan saat melakukan proses mining data testing.
5. Studi Kasus a. Persiapan Data
Setelah data terkumpul maka tahap selanjutnya adalah mempersiapkan data tersebut agar dapat digunakan untuk proses data mining. Data mentah yang akan digunakan pada aplikasi ini diperoleh dari beberapa sumber penyimpanan data yaitu :
1. Biodata mahasiswa jurusan teknik informatika angkatan/tahun masuk 2006, 2007 dan 2008, dengan rincian data sebagai berikut:
a. Biodata angkatan 2006 total data 174 record
b. Biodata angkatan 2007 total data 205 record
c. Biodata angkatan 2008 total data 290 record
2. Data status mahasiswa jurusan teknik informatika angkatan/tahun masuk 2006, 2007 dan 2008 pada tahun ajaran 2012/2013 semester ganjil, dengan rincian data sebagai berikut:
a. Data status angkatan 2006 total data 174 record
b. Data status angkatan 2007 total data 205 record
c. Data status angkatan 2008 total data 290 record
3. Data IPK mahasiswa jurusan teknik informatika angkatan 2006, 2007 dan 2008 pada tahun ajaran 2012/2013 semester ganjil.
a. Data IPK angkatan 2006 total data 138 record
b. Data IPK angkatan 2007 total data 178 record
c. Data IPK angkatan 2008 total data 262 record
Setelah tahap sinkronisasi data total record dataset dari angkatan 2006-2008 adalah 576 record. Data tersebut dibagi menjadi 2 berdasarkan angkatan, yaitu untuk angkatan 2006-2007 adalah 315 record sebagai data training dan angkatan 2008 berjumlah 261 record sebagai data testing.
b. Proses Data Mining
Record data training awal adalah 315 record, dan setelah tahap preprocessing data yang siap diproses mining adalah 262 record data. Selanjutnya akan
digunakan algoritma K-Means untuk
mengelompokkan data. Data yang ada akan dikelompokkan menjadi 2 kelompok yaitu :
1. Rawan Dropout (C1) 2. Tidak Dropout (C2)
Parameter hitung / atribut yang digunakan ada 3 atribut yaitu : usia, masa studi minimal dan IPK. Langkah-langkah yang dilakukan adalah inisialisasi dan iterasi 1,2,3,4 dan seterusnya sampai data cluster tidak mengalami perubahan. Banyaknya
cluster = 2, yaitu C1 yang diartikan sebagai kelompok rawan drop out dan C2 sebagai kelompok tidak drop out.
1. Langkah pertama adalah inisialisasi atau mengalokasikan semua data dengan membuat asumsi pusat cluster/centroid secara acak:
2. Hitung jarak setiap data yang ada terhadap setiap pusat cluster. Dengan mengunakan rumus Euclidian Distance :
Misalkan untuk menghitung jarak data mahasiswa pertama dengan pusat cluster pertama adalah :
Hasil perhitungan selengkapnya pada tabel
3. Suatu data akan menjadi anggota dari suatu cluster yang memiliki jarak terkecil dari pusat clusternya. Misalkan untuk data pertama, jarak terkecil diperoleh pada cluster pertama, maka data tersebut akan masuk pada cluster pertama. Demikian juga
PUSAT
CLUSTER
/
CENTROID
AWAL
C1 =
29
7
1.81
C2 =
26
4
2.79
NO USIA MASA IPK d1 d2 C1 C2
1 27 7 2.69 2.19 3.16 *
2 26 4 3.16 4.45 0.37 **
3 26 4 2.76 4.35 0.03 **
4 27 4 2.06 3.61 1.24 **
5 28 7 0.63 1.55 4.20 *
6 29 7 1.81 0.00 4.35 *
7 25 4 2.71 5.08 1.00 **
8 28 4 2.86 3.33 2.00 **
Tabel Proses Mining Iterasi 1 � � , � = ‖� − � ‖ = √∑ � − �
�
=
d1= √ − 2+ − 2 + . − . 2= .
untuk data kedua, jarak terkecil ada pada cluster kedua, maka data tersebut akan masuk pada data cluster kedua. Posisi cluster dapat dilihat di tabel sebelah kanan.
4. Hitung pusat cluster baru a. Untuk cluster pertama (C1) :
Contoh pada iterasi ke-1 jumlah data pada cluster 1 (C1) = 81 data maka untuk menghitung pusat cluster baru adalah sebagai berikut:
Selanjutnya untuk atribut masa studi minimal (C1.2), IPK (C1.3) rumus perhitungannya sama seperti diatas yaitu rata-rata dari jumlah data pada atribut yang termasuk dalam C1 dan jumlah data pada C1 b. Untuk cluster kedua (C2) :
Contoh pada iterasi ke-1 jumlah data pada cluster 2 (C2) = 181 data
maka untuk menghitung pusat cluster baru adalah sebagai berikut:
Selanjutnya untuk atribut masa studi minimal (C2.2), IPK (C2.3) rumus perhitungannya sama seperti diatas yaitu rata-rata dari jumlah data pada atribut yang termasuk dalam C2 dan jumlah data pada C2 Maka diperoleh pusat cluster baru dari
perhitungan rata-rata pada iterasi ke-1 sebagai berikut :
PUSAT CLUSTER / CENTROID AWAL
C1 = 28.91 6.28 2.07 C2 = 25.66 5.17 2.56
5. Ulangi langkah 2 hingga posisi data sudah tidak
mengalami perubahan.
c. Pengujian Data Training
Dengan dilakukan pengujian akan diketahui alur proses mining menggunakan metode K-Means dan kualitas dari sistem.
Pengujian dilakukan pada data training dengan 315 record data, setelah tahap preprocessing data training menjadi 262 record data. Pengujian ini bertujuan untuk mencari pusat cluster yang dapat memberikan hasil yang tepat untuk pengelompokan mahasiswa. Pusat cluster tersebut akan disimpan dalam tabel data centroid. Pengujian dilakukan beberapa kali sampai menemukan centroid awal dengan kebenaran pengelompokan yang cukup tinggi. Parameter yang
digunakan untuk menguji kebenaran hasil sistem adalah status mahasiswa.
Hasil clustering dinyatakan sudah benar jika anggota cluster rawan dropout (C1) tidak terdapat mahasiswa dengan status telah ujian (TU) dan lulus (L), dan pada anggota cluster tidak dropout (C2) tidak terdapat mahasiswa dengan status non aktif (NA).
Setelah pengujian beberapa kali penulis menyimpan centroid-centroid awal yang memiliki kebenaran pengelompokan diatas 50%. Tabel 4.1 adalah centroid awal yang telah disimpan pada saat pengujian data training.
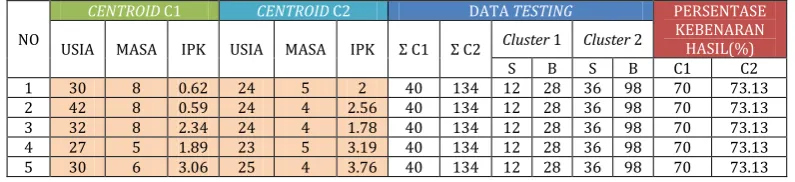
d. Pengujian Data Testing
Pengujian dilakukan pada data testing dengan 261 record data, setelah tahap preprocessing data testing yang siap di mining menjadi 174 record data. Pengujian ini bertujuan untuk menguji data test dan untuk mendapatkan kesimpulan presentase kebenaran pengelompokan.
Centroid-centroid awal pada tabel 4.2 adalah centroid awal yang telah disimpan saat pengujian data training. Pada tabel tersebut dapat diketahui bahwa presentase kebenaran pengelompokan lebih konsisten daripada saat pengujian data training.
NO
CENTROID C1 CENTROID C2 DATA TRAINING PERSENTASE
KEBENARAN HASIL(%)
USIA MASA IPK USIA MASA IPK Ʃ C Ʃ C
Cluster
1 Cluster 2
S B S B C1 C2 1 30 8 0.62 24 5 2 54 208 17 37 82 126 68.52 60.58 2 42 8 0.59 24 4 2.56 4 258 1 3 112 146 75 56.59 3 32 8 2.34 24 4 1.78 54 208 17 37 82 126 68.52 60.58 4 27 5 1.89 23 5 3.19 118 144 52 66 57 87 55.93 60.42 5 30 6 3.06 25 4 3.76 69 193 32 37 82 111 53.62 57.51
. = ∑ ∑ � � � �
. = ∑ ∑ � � � �
. = + + +⋯ = = .
. = + + +⋯ = = .
e. Hasil Pengujian
Tabel 4.3 di bawah ini merupakan
perbandingan presentase kebenaran
pengelompokan setelah dilakukan pengujian terhadap data training dan data testing. Pengujian terhadap data training bertujuan untuk menemukan pusat cluster/centroid awal yang
tepat, dimana centroid awal tersebut diambil secara random dan keakuratan pengelompokan metode K-Means tergantung pada ketepatan pemilihan pusat cluster awal. Sedangkan pengujian terhadap data testing bertujuan untuk menguji
data testing dengan presentase
kebenaran/ketepatan yang paling tinggi.
Pada tabel 4.3 dapat membuktikan bahwa pemilihan pusat cluster awal yang tepat pada saat pengujian data training akan memberikan hasil dengan tingkat kebenaran pengelompokan yang lebih tinggi pada pengujian data testing.
Hasil pengujian program terhadap data testing dengan jumlah record data setelah tahap preprocessing yaitu 174 record, menggunakan pusat cluster awal : C1 = 42, 8, 0.59 dan C2 = 24, 4, 2.56
Proses mining tersebut menghasilkan 10 iterasi dengan hasil :
a) Cluster 1 (rawan dropout) sebanyak 40 anggota atau 23% dari 174 record data b) Cluster 2 (tidak dropout) sebanyak 134
anggota atau 77 % dari 174 record data Gambar 4.11 dibawah ini adalah diagram presentase hasil pengelompokan dengan tingkat kebenaran/ketepatan pengelompokan berkisar antara 70% sampai dengan 73.13%.
PENUTUP 1. Kesimpulan
Berdasarkan implementasi dan
pengujian dari aplikasi clustering untuk
pengelompokkan mahasiswa STMIK ASIA
berdasarkan usia & data akademik menggunakan metode K-Means, dapat diperoleh kesimpulan sebagai berikut:
1. Algoritma K-Means ini dapat digunakan untuk mengelompokkan mahasiswa berdasarkan usia, masa studi dan nilai ipk menjadi 2 cluster, yaitu cluster 1 (rawan dropout) dan cluster 2 (tidak dropout). Akan tetapi untuk keakuratan dari algoritma ini masih kurang efektif. Hal ini dapat dibuktikan dengan melihat cluster yang
dihasilkan oleh sistem bergantung pada pemilihan pusat cluster awal harus tepat. 2. Untuk mengatasi hasil yang tidak konsisten dari
metode K-Means, dilakukan pengujian dengan cara yang berbeda yaitu mencari dan menyimpan pusat cluster awal yang tepat pada pengujian data training dan menggunakan pusat cluster tersebut untuk pengujian data testing.
3. Pemilihan pusat cluster awal yang tepat pada saat pengujian data training akan memberikan hasil dengan tingkat kebenaran pengelompokan yang lebih tinggi pada pengujian data testing. 4. Pada penelitian ini mahasiswa yang cenderung
dalam kelompok rawan dropout antara lain adalah mahasiswa yang memiliki status non
NO
CENTROID C1 CENTROID C2 DATA TESTING PERSENTASE
KEBENARAN HASIL(%)
USIA MASA IPK USIA MASA IPK Ʃ C Ʃ C Cluster 1 Cluster 2
S B S B C1 C2 1 30 8 0.62 24 5 2 40 134 12 28 36 98 70 73.13 2 42 8 0.59 24 4 2.56 40 134 12 28 36 98 70 73.13 3 32 8 2.34 24 4 1.78 40 134 12 28 36 98 70 73.13 4 27 5 1.89 23 5 3.19 40 134 12 28 36 98 70 73.13 5 30 6 3.06 25 4 3.76 40 134 12 28 36 98 70 73.13
NO
CENTROID C1 CENTROID C2 PERSENTASE KEBENARAN HASIL(%)
USIA MASA IPK USIA MASA IPK DATA TRAINING DATA TESTING
C1 C2 C1 C2
1 30 8 0.62 24 5 2 68.52 60.58 70 73.13
2 42 8 0.59 24 4 2.56 75 56.59 70 73.13
3 32 8 2.34 24 4 1.78 68.52 60.58 70 73.13 4 27 5 1.89 23 5 3.19 55.93 60.42 70 73.13 5 30 6 3.06 25 4 3.76 53.62 57.51 70 73.13
Tabel 4.2 Tabel Pengujian Pada Data Testing
aktif yang berdampak pada penambahan masa studi, dan mahasiswa yang memiliki ipk rendah. 5. Hasil pengujian program terhadap data testing
dengan jumlah record data setelah tahap preprocessing yaitu 174 record, menggunakan pusat cluster awal : C1 = 42, 8, 0.59 dan C2 = 24, 4, 2.56 menghasilkan 10 iterasi dengan hasil akhir :
c) Cluster 1 (rawan dropout) sebanyak 40 anggota atau sebesar 23%
d) Cluster 2 (tidak dropout) sebanyak 134 anggota atau sebesar 77 %
Dengan tingkat kebenaran/ketepatan pengelompokan berkisar antara 70% sampai dengan 73.13%.
2. Saran
Saran yang sekiranya bermanfaat untuk mengembangkan sistem clustering lebih lanjut adalah:
1. Untuk mengantisipasi besarnya presentase mahasiswa rawan dropout diharapkan ada
batasan maksimal dari pihak akademik untuk mahasiswa yang berstatus nonaktif, dan untuk mahasiswa yang memiliki ipk rendah seharusnya diwajibkan mengikuti program perbaikan nilai tanpa harus menambah masa studi, misalnya program perbaikan nilai pada perkuliahan semester pendek.
2. Beberapa kemungkinan alternatif cara untuk meningkatkan ketepatan pengelompokan adalah dengan menggunakan metode tertentu untuk seleksi/pemilihan atribut dengan kriteria lain seperti gini index, gain ratio atau untuk optimasi centroid menggunakan algoritma genetika.
3. Menggunakan dataset dan atribut yang lebih banyak terutama untuk data training, semakin banyak atribut dan dataset saat pengujian data training, semakin tinggi tingkat ketepatan pengelompokan.
4. Menggunakan teknik praproses yang tepat untuk menjaga keaslian data.
DAFTAR PUSTAKA
a. Agusta, Yudi, PhD. K-Means – Penerapan, Permasalahan dan Metode terkait. Jurnal Sistem dan Informatika Vol.3. 2007
b. Andayani, Sri. Pembentukan cluster dalam Knowledge Discovery in Database dengan algoritma K-Means. SEMNAS Jurdik Matematika FMIPA UNY. Yogyakarta. 2007
c. Arbie, Manajamen Database dengan MYSQL, Yogyakarta: ANDI, 2004
d. Arief, M. Rudianto, Pemrograman Web Dinamis Menggunakan PHP & MYSQL , Yogyakarta: ANDI, 2011
e. Han, Jiawei; Kamber, Micheline, Data Preprocessing, http://lecturer.eepis-its.edu/~entin/Data%20Mining/Minggu%204 %20Data%20Preprocessing.pdf, ( 26 Juli 2013) f. Hermawati, Fajar Astuti, Data Mining,
Yogyakarta: ANDI, 2013
g. HM, Jogiyanto, Analisis & Desain Sistem Informasi: Pendekatan Terstruktur Teori & Praktik Aplikasi Bisnis, Yogyakarta: ANDI, 2005 h. Kadir, Abdul, Dasar Pemrograman Web Dinamis
Menggunakan PHP, Yogyakarta: ANDI, 2008
i. Kadir, Abdul, Tuntunan Praktis: Belajar Database Menggunakan MySQL, Yogyakarta: ANDI, 2008
j. Kendall, Kenneth E. and Kendall, Julie E., System Analysis and Design, Fifth Edition, New Jersey: Prentice Hall, 2002
k. Kristanto, Harianto, Konsep dan Perancangan DATABASE, Yogyakarta: ANDI, 1994
l. Mata-Toledo, Ramon A. and Chusman, Pauline
K., Scaum’s Outliners of Fundamentals of
Relational Database, New York: Mc. Graw-Hill, 1999
m. Nugroho, Bunafit, Database Relasional dengan MySQL, Yogyakarta: ANDI, 2005
n. Prasetyo, Eko, Data Mining – Konsep dan Aplikasi Menggunakan MATLAB, Yogyakarta: ANDI, 2012
o. Pressman, Roger S., REKAYASA PERANGKAT LUNAK-BUKU SATU: Pendekatan Praktisi, Edisi 7, Yogyakarta: ANDI, 2012
p. Santosa, Budi,Data Mining Teknik pemanfaatan Data Untuk Keperluan Bisnis, 1st ed, Yogyakarta: