PENGELOMPOKAN DATA SATELIT DENGAN
GAUSSIAN MEANS CLUSTERING
Lay Stefanny
Teknik Informatika Universitas Tarumanagara
Jl. Let. Jen. S Parman 1, Jakarta 11440 Indonesia
email : [email protected]
ABSTRACT
This systemuses a Gaussian Means clustering for which the method is trying to determine the number of clusters either gradually or in stages to see if a cluster is in a state normally distributed or not. If the data considered not normal, it will be seen whether the cluster is still possible to be split two cluster. The workings of the G-Means method begins with determining the alpha error for testing and to determine the number of clusters to be formed in the initial clustering have two centroids. Anderson darling test to see if the cluster necessary splitting or not. The test results show that the Gaussian Means method has a clustering waters can do well, but the green areas and the woke up area not. Weaknesses contained in this application is the image that will adversely affect the clustering results.
Key Words
:Anderson darling Test, Clustering, Gaussian Means, Remote sensing, Satelit
1.
Pendahuluan
Pada era ini, bidang ilmu pengetahuan akan terus berkembang, salah satu diantaranya adalah bidang teknologi komputer. Komputer itu sendiri sudah menjadi kebutuhan bahkan gaya hidup manusia jaman ini. Oleh karena itu dengan kemajuan teknologi informasi ini, komputer akan memudahkan manusia dalam melakukan pekerjaannya. Semua pengumpulan data tentang objek di muka bumi dapat dilakukan secara manual atau melakukan pengukuran langsung ke lapangan tetapi hal ini akan menjadi tidak efisien, karena akan membuang waktu dan tenaga. Oleh karena itu untuk mempermudah, dilakukan penginderaan jauh atau remote sensing.
Remote sensing adalah ilmu pengetahuan untuk
memperoleh informasi tentang suatu obyek di muka bumi tanpa kontak langsung dengan obyek atau daerah yang dikaji dengan menggunakan sensor perekam. Alat perekam yang digunakan dalam aplikasi remote sensing ini yaitu satelit. Pengenalan objek atau target pada
remote sensing bertujuan untuk mengklasifikasi dan
mendeskripsikan pola atau objek melalui pengukuran sifat-sifat atau ciri-ciri objek bersangkutan. Clustering
adalah suatu cara menganalisa data dengan cara mengelompokkan objek ke dalam kelompok-kelompok berdasar suatu kesamaan tertentu. Dalam sistem ini sendiri akan memakai Gaussian Means yang dimana metode ini berusaha menentukan jumlah cluster secara gradual atau secara bertingkat dengan melihat apakah suatu cluster sudah dalam keadaan terdistribusi secara normal atau tidak. Jika dianggap belum normal, maka akan dilihat apakah cluster tersebut masih bisa dilakukan pembelahan untuk dijadikan dua cluster. Dalam metode ini juga terdapat hipotesis yang akan berguna sebagai penguji kebenaran dalam distribusi Gaussian.
Cara kerja metode G-Means ini dimulai dari menentukan kesalahan alpha untuk testing dan juga menentukan jumlah cluster yang akan dibentuk dalam
clustering. Setelah semua ditentukan, dilakukan proses
pencarian centroid baru yang akan memakai metode K-Means. Centroid-centroid baru tersebut akan dihubungkan dengan vektor v. Kemudian data satelit tersebut di proyeksikan ke dalam vektor v, setelah itu normalisasi menggunakan zscore untuk melihat data seberapa jauh menyimpang dari rata-rata dengan mengukur berdasarkan simpangan bakunya. Setelah mendapatkan zscore lalu kita mencari CDF, CDF merupakan jumlah data kira-kira yang berada dalam rentang z. Lalu akan dihitung kesalahan alpha untuk dilihat apakah cluster telah terdistribusi normal atau belum.
2. Landasan Teori
2.1 Pengertian Remote sensing
Berikut adalah pendapat para ahli mengenai Remote
sensing:[1]
1. Penginderaan jauh (remote sensing), yaitu suatu pengukuran atau perolehan data pada objek di permukaan bumi dari satelit atau instrumen lain di atas, jauh dari objek yang diindera.
2. Penginderaan jauh adalah ilmu untuk memperoleh, mengolah dan menginterpretasi citra yang telah direkam yang berasal dari interaksi antara gelombang elektromagnetik dengan sutau objek.
3. Penginderaan jauh adalah ilmu dan seni untuk memperoleh informasi tentang suatu objek, daerah atau fenomena melalui analisis data yang diperoleh dengan suatu alat tanpa kontak langsung dengan objek, daerah atau fenomena yang dikaji.
4. Penginderaan jauh (remote sensing) adalah ilmu untuk mendapatkan informasi mengenai permukaan bumi seperti lahan dan air dari citra yang diperoleh dari jarak jauh.
2.1.1 Satelit Landsat
Satelit Landsat pertama diluncurkan pada tahun 1972, satelit ini terkenal dengan kemampuannya merekam permukaan bumi dari angkasa [2]. Program ini dulunya disebut Earth Resources Observation Satellites Program ketika dimulai tahun 1966, namun diubah menjadi Landsat pada tahun 1975. Yang paling akhir Landsat 7, diluncurkan tanggal 15 April 1999. Landsat-7 ini dilengkapi dengan Enhanced Thematic Mapper Plus (ETM+), yang merupakan kelanjutan dari program Thematic Mapper (TM) yang diusung sejak Landsat-5. Saluran pada satelit ini pada dasarnya adalah sama dengan 7 saluran pada TM, namun diperluas dengan saluran 8 yaitu Pankromatik. Saluran 8 ini merupakan saluran berresolusi tinggi yaitu seluas 15 meter. Berikut adalah urutan peluncuran satelit landsat [3] :
1. Landsat 1 (mulanya dinamakan Earth Resources Technology Satellite 1) - diluncurkan 23 Juli 1972, operasi berakhir tahun 1978
2. Landsat 2 - diluncurkan 22 Januari 1975, berakhir 1981
3. Landsat 3 - diluncurkan 5 Maret 1978, berakhir 1983 4. Landsat 4 - diluncurkan 16 Juli 1982, berakhir 1993 5. Landsat 5 - diluncurkan 1 Maret 1984, masih
berfungsi.
6. Landsat 6 - diluncurkan 5 Oktober 1993, gagal mencapai orbit.
7. Landsat 7 - diluncurkan 15 April 1999, masih berfungsi.
Didalam penelitian ini, data atau citra multispectral yang digunakan memakai channel 1,2,3,4,5,7 dapat dilihat pada gambar 1, gambar 2, gambar 3, gambar
4, gambar 5, gambar 6
Gambar 1 Citra Band 1
Gambar 2 Citra Band 2
Gambar 3 Citra Band 3
Gambar 4 Citra Band 4
Gambar 5 Citra Band 5
2.2 Clustering
Tujuan utama pengelompokkan citra penginderaan jauh adalah untuk menghasilkan peta tematik, yang suatu warna mewakili suatu objek tertentu [5]. Contoh objek yang berkaitan dengan permukaan bumi antara lain air, hutan, sawah, kota, jalan, dan lain-lain. Sedangkan pada citra satelit meteorologi, proses klasifikasi dapat menghasilkan peta awan yang memperlihatkan distribusi awan di atas suatu wilayah.
Data Clustering merupakan salah satu metode Data
Mining yang bersifat tanpa arahan (unsupervised).
Proses unsupervised clustering melakukan pembagian data set dengan mengelompokkan seluruh piksel pada feature space (ruang ciri) ke dalam sejumlah cluster secara alami.
2.2.1 Metode K-Means
Metode K-Means merupakan salah satu metode data
clustering yang berusaha mempartisi data yang ada ke
dalam bentuk satu atau lebih cluster/kelompok [6]. Metode ini mempartisi data ke dalam cluster/kelompok sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke dalam kelompok yang lain. Adapun tujuan dari data clustering ini adalah untuk mengelompokkan objek sedemikian hingga jarak tiap-tiap objek ke pusat kelompok di dalam suatu kelompok adalah minimum.
Proses pengelompokkan menggunakan metode K-Means yang secara umum dilakukan dengan algoritma dasar sebagai berikut:
1. Tentukan jumlah cluster
2. Alokasikan data ke dalam cluster secara random 3. Hitung centroid/rata-rata dari data yang ada di
masing-masing cluster
4. Alokasikan masing-masing data ke centroid/rata-rata terdekat. Dengan rumus sebagai berikut:
C = [C1,C2,C3,...,Cn] C =
(1) C = centroid M = dimensi objek K = banyak objek {k=1,2,3,....,M} Xki = feature vector ke-i {i=1,2,...,n}
5. Kembali ke Step 3, perhitungan akan selesai jika nilai cluster yang lama sama dengan nilai cluster baru.
Metode K-Means memiliki karakteristik sebagai berikut:
1. K-Means sangat cepat dalam proses
clustering dan sangat sensitif pada pembangkitan
centroid awal secara acak.
2. Memungkinkan suatu cluster tidak punya anggota 3. Hasil clustering dengan K-Means bersifat tidak unik
(selalu berubah-ubah), terkadang baik atau juga buruk.
2.2.2 Metode Gaussian Means
G-Means berusaha menentukan jumlah cluster secara gradual dengan melihat apakah suatu cluster sudah dalam keadaan terdistribusi secara normal atau tidak. Kalau masih dianggap belum normal, maka akan dilihat apakah cluster tersebut masih bisa di split untuk dijadikan dua cluster. Hipotesis yang digunakan adalah [7]:
1. H0: Data di sekitar centroid disample dari suatu distribusi Gaussian.
2. H1: Data di sekitar centroid tidak disample dari suatu distribusi Gaussian.
Adapun algoritma yang digunakan untuk menentukan split atau tidak adalah sebagai berikut: 1. Tentukan dua centroid baru c1 dan c2.
2. Jalankan k-means terhadap dua centroid baru tersebut.
3. Tentukan confidence level Alpha untuk testing 4. Tentukan vektor v yang menghubungkan antara
centroid c1 dan c2 dimana:
v = c1 – c2 (2) 5. Kemudian proyeksikan data X ke v dengan rumus:
x’ = (x,v)/||v||^2 (3) Hitung Zscore adalah bentuk normalisasi x’ untuk melihat data seberapa jauh menyimpang dari rata-rata, diukur berdasarkan ukuran simpangan bakunya. Normalisasi ini menggunakan rumus sebagai berikut:
Zscore = (X1’ - µ) / σ (4) Keterangan :
v = vektor cluster c = centroid
X’ = representasi satu dimensi dari data yang diproyeksikan ke v.
Z = normalisasi Xi’ = data proyeksi µ = rata-rata hasil proyeksi σ = simpangan baku hasil proyeksi
Hitung Cumulative Distribution Function(CDF) dari zscore. CDF(zscore) = n adalah jumlah data yang bernilai zscore dalam data ada di antara (-∞ sampai zscoe). Berikut rumus CDF:
ERF merupakan "kesalahan fungsi" yang akan ditemukan dalam mengintegrasikan distribusi normal (yang merupakan bentuk normalisasi dari fungsi Gaussian) yang mempunyai 6 konstanta tetap yaitu: 1. a1 = 0.254829592 2. a2 = -0.284496736 3. a3 = 1.421413741; 4. a4 = -1.453152027; 5. a5 = 1.061405429; 6. p = 0.3275911;
Cara untuk mendapatkan nilai ERF yaitu: 1. sign = 1 jika x > 0, -1 jika x < 0 2. nilai absolute dari x
3. t = 1 / (1 + p * x) (6) 4. y = 1.0 - (((((a5*t + a4)*t) + a3)*t + a2)*t +
a1)*t*Exp(-x*x) (7) 5. hasil akhirnya sign * y
6. Hitung nilai A_2*(Z) dengan rumus di bawah dengan menggunakan Apabila A_2*(Z) berada di wilayah nilai non-critical pada confidence level Alpha, maka H0 diterima, dan centroid awal tetap digunakan dan centroid baru c1 dan c2 dihapus. Untuk keadaan sebaliknya, H0 harus ditolak dan
centroid baru c1 dan c2 digunakan sebagai
pengganti centroid awal berikut rumus yang digunakan:
A_2*(Z)=A_2(Z)(1+(4/n)-(25/(n^2))) (8)
A_2(Z) = (-1/n) * SUM (i=1 to n)((2*i– 1)(log(z_i)+log(1-z_(n+1-i))) – n (9) Keterangan :
x = data
A_2*(Z) = normalisasi dari Z n = jumlah data
A_2(Z) = standar normal
Jika H0 ditolak, maka akan dilakukan proses splitting. Dalam men-split centroid ini akan dilakukan dengan cara c±σ, karena centroid baru dicari berdasarkan kedekatan dengan centroid yang akan di split dengan menggunkan simpangan bakunya, dimana c adalah centroid yang akan di split dan σ adalah simpangan baku dari data yang akan di split.
2.2.3 Euclidean Distance
Metode Euclidean Distance ini dipakai untuk menghitung jarak antar data dan centroid. Pengukuran ini didasarkan pada nilai objek pada setiap k dimensi dalam pembelajaran. Euclidean Distance menggunakan theorem phytagoras dan pengukuran objek tidak terbatas hanya 2 dimensi bahkan lebih. Untuk Euclidean Distance dengan 2 objek (d12), jarak antara 2 objek tersebut tidak
lebih dari panjang hipotenusa segitiga [8]. Gambar Euclidean dapat dilihat pada Gambar 7.
Gambar 7 Euclidean Distance
Keterangan :
D12 = jarak antar objek
X1,Y1= dimensi pertama objek pertama X2,Y2= dimensi pertama objek kedua
Euclidean Distance 2 atau lebih dari 2 dimensi untuk n dimensi dapat dinyatakan dengan rumus :
D (x,y) = (11) Keterangan :
D(x,y)= banyak dimensi objek Xi = dimensi pertama dari objek x Yi = dimensi pertama dari objek
3.
Rancangan & Pembuatan
3.1
Rancangan
Program aplikasi yang dirancang bertujuan untuk mengelompokkan data satelit ke dalam sebuah kelas/cluster dengan menggunakan metode Gaussian
Means. Program aplikasi clustering ini menggunakan
tahapan SDLC (System Development Life Cycle). Software Development Life Cycle (SDLC) merupakan metodologi pengembangan aplikasi yang berisi tahapan-tahapan dalam pembuatan aplikasi. Tahapan pengembangan dan perancangan suatu sistem informasi. Kelebihan dalam metode tahapan SDLC ini ialah dalam urutan langkah-langkah perancangan yang sistematis, terstruktur, efisien dan mudah dimengerti.
Dalam perancangan program aplikasi, tahap tahap metode SDLC ini yaitu:
1. Perencanaan 2. Analisis 3. Perancangan 4. Pengkodean
5. Pengujian dan perawatan
3.2 Pembuatan Sistem
Setelah tahap perancangan selesai, tahap selanjutnya adalah pembuatan program aplikasi yang dirancang. Tahapan yang dilalui dalam pembuatan program pengelompokan citra remote sensing dengan G-Means
1. Mencari berbagai sumber teori yang berhubungan dengan
K-Means, G-Means, dan algoritma Euclidean Distance. Sumber teori dapat berasal dari buku, jurnal, maupun internet.
2. Merancang Diagram Hirarki, State Transition Diagram, dan modul yang digunakan. Perancangan diagram hirarki ini dapat diihat pada Lampiran. 3. Membuat program Gaussian Means Clustering
dengan menggunakan bahasa pemrograman Microsoft Visual Studio 2010 dan mencari perangkat lunak pendukung untuk mendapatkan informasi keaslian gambar peta..
4. Melakukan pengujian terhadap setiap modul untuk mengecek apakah semua modul sudah berjalan dengan baik sesuai dengan fungsinya masing-masing. Pengujian tersebut terlebih dahulu dilakukan dengan menjalankan program aplikasi G-Means Clustering lalu jalankan semua pilihan dan tombol-tombol yang tersedia, untuk penjelasan lebih lanjut akan dibahas pada Bab IV.
5. Melakukan pengujian program untuk melihat apakah program yang dibuat dapat melakukan clustering dengan baik atau tidak. Pengujian dilakukan dengan memasukan gambar grayscale pada channel 1,2,3,4,5, dan 7. Setelah gambar dimasukan, proses gambar-gambar tersebut melalui proses K-Means
Clustering lalu dilanjutkan dengan proses G-Means Clustering. Hasil pengujian dilanjutkan dengan
melihat hasil perhitungan dari proses K-Means
Clustering dan G-means Clustering.
6. Membuat buku manual yang bertujuan membantu pengguna menggunakan program aplikasi tersebut.
4.
Hasil Pengujian
Pengujian terhadap data citra Satelit bertujuan untuk melakukan pengujian terhadap metode G-means dengan tampilan yang mudah ditetapkan jumlah cluster dan kemiripan warna. Pengujian ditujukan untuk mendapatkan hasil melalui data citra yang mudah untuk dibandingkan sehingga kelebihan dan kekurangan masing-masing metode dapat terlihat dengan jelas. Pengukuran keberhasilan hasil clustering dilakukan dengan menampilkan output jumlah cluster pada
G-means clustering.
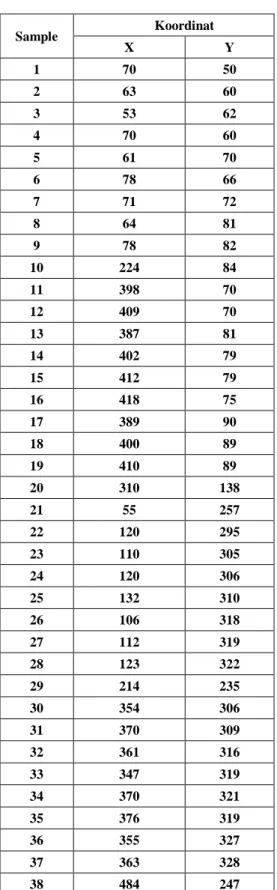
Dalam melakukan pengujian, program ini akan dilakukan percobaan dengan data dummy, percobaan ini dilakukan agar dapat mengetahui apakah aplikasi ini sudah berjalan sesuai dengan teori yang telah didapat. Data dummy tersebut dapat dilihat pada gambar 8.
Gambar 8 Data Dummy
Titik koordinat dari sample diatas terdapat dalam
tabel 1 berikut:
Tabel 1 Titik Koordinat Sample Data Dummy dengan Metode
G-means Clustering. Sample Koordinat X Y 1 70 50 2 63 60 3 53 62 4 70 60 5 61 70 6 78 66 7 71 72 8 64 81 9 78 82 10 224 84 11 398 70 12 409 70 13 387 81 14 402 79 15 412 79 16 418 75 17 389 90 18 400 89 19 410 89 20 310 138 21 55 257 22 120 295 23 110 305 24 120 306 25 132 310 26 106 318 27 112 319 28 123 322 29 214 235 30 354 306 31 370 309 32 361 316 33 347 319 34 370 321 35 376 319 36 355 327 37 363 328 38 484 247
Berdasarkan hasil percobaan di atas dengan menggunakan data dummy, program aplikasi ini telah
mengcluster dengan baik sesuai dengan apa yang
ditentukan. Hasil pengujian terhadap program aplikasi ini dengan data dummy dapat dilihat pada gambar 30.
Gambar 9 Hasil pengujian data dummy
Adapun data pengujian dengan menggunakan data Landsat dapat dilihat pada gambar 10, gambar 11,
gambar 12, gambar 13, gambar 14, gambar 15
dibawah ini:
Gambar 10 Pengujian data 2 Landsat channel 1
Gambar 11 Pengujian data 2 Landsat channel 2
Gambar 12 Pengujian data 2 Landsat channel 3
Gambar 13 Pengujian data 2 Landsat channel 4
Gambar 14 Pengujian data 2 Landsat channel 5
Gambar 15 Pengujian data 1 Landsat channel 7
Hasil pengujian diatas dari data Landsat dapat dilihat pada gambar 16, gambar 17, gambar 18.
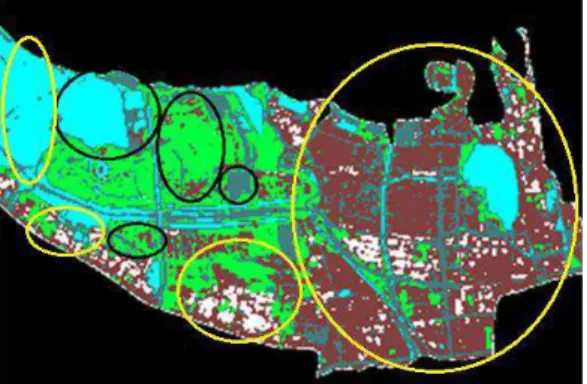
Gambar 16 Hasil 3 clustering kota Jakarta Utara 2000
Keterangan: 1. biru: perairan
3. hijau: daerah hijau
4. lingkaran hitam: hasil clustering yang salah
Gambar 17 Hasil 4 clustering kota Jakarta Utara 2000
Keterangan: 1. biru: perairan 2. hijau: daerah hijau 3. coklat: pemukiman
4. putih: komplek industri (komersil)
5. lingkaran hitam: hasil clustering yang salah
Gambar 18 Hasil 5 clustering kota Jakarta Utara 2000
Keterangan:
1. biru muda: perairan 2. hijau muda: bukan taman 3. hijau tua: taman
4. coklat: pemukiman 5. putih: komplek industri
6. lingkaran hitam: hasil clustering yang salah Gambar google earth dapat dilihat pada gambar 19.
Gambar 19 Google Earth Jakarta Utara 2000
4.
Kesimpulan & Saran
Berdasarkan pengujian yang telah dilakukan terhadap program aplikasi clustering data pada remote sensing dengan Gaussian Means, dapat disimpulkan beberapa hal sebagai berikut :
1. Clustering yang sudah dilakukan dapat mengelompokan setiap pixel yang mempunyai kemiripan ciri yang sama. Untuk melihat perbedaan antara satu cluster dengan cluster yang lain maka setiap cluster diberikan warna yang berbeda.
2. Hasil clustering dengan jumlah initial cluster 5 lebih akurat daripada jumlah cluster 3 dan 4.
3. Citra yang tidak terdapat banyak awan yang hanya dapat dipakai. Ini dikarenakan awan yang tampak akan masuk ke dalam cluster yang nantinya akan membuat hasil clustering tidak begitu jelas. Berdasarkan hasil pembuatan dan pengujian terhadap program aplikasi pengelompokan citra satelit ini, saran yang dapat disampaikan berkaitan dengan pengembangan program ini, ialah penggabungan dengan metode radiometri yang dapat mengkoreksi image yang akan diinput, sehingga semua image satelit Landsat7 dapat digunakan.
REFERENSI
[1] Wahid., 2011, “Kualitas Data Citra Landsat ETM Pada Perubahan Guna Lahan RTH”,
http://awhasyim.wordpress.com/2011/02/06/kualitas-data- citra-landsat-etm-pada-perubahan-guna-lahan-rth-dengan- menggunakan-scattergram-studi-kasus-pemukiman-kotamadya-surabaya/.
[2] Universitas Muhammadiyah Surakarta., 20 Agustus 2012, “Penginderaan Jauh”,
http://geografi.ums.ac.id//ebook/GIS/arcview_3x_Analisis _Citra_Arcview.pdf.
[3] SearchSoftwareQuality., 2012, “What is systems development life cycle (SDLC)?”,
http://searchsoftwarequality.techtarget.com/sDefinition/0,sid92_ gci755068,00.html.
[4] J.B., MacQueen., 31 juli 2011, ”K-Means Clustering”,
http://home.dei.polimi.it/
matteucc/Clustering/tutorial_html/kmeans.html. [5] Wikipedia., 2012, “ Penginderaan Jauh”,
http://id.wikipedia.org/wiki/Penginderaan_jauh.
[6] Hasniawati, Helmy., 2007, “Image Clustering Berdasarkan Warna”, Institut Teknologi Sepuluh Nopember, Surabaya.
[7] Harul Alam Wijaya, Jauh. Pengertian Pixel.
http://dreammaster38.blogspot.com/2009/08/pengertian-pixel-piksel.html, 4 Agustus 2011.
Penulis Pertama, memperoleh gelar S.Kom Universitas