Self-Learning System With
Natural Question-Guided Search
For Narration In Indonesian Language
Edwin Wibowo Sampurna#1, Esther Irawati Setiawan*2 #Global Business, Chinese Culture University
55, Hwa-Kang Road, Taipei, Taiwan R.O.C 11114
Sekolah Tinggi Teknik Surabaya
Ngagel Jaya Tengah 73-77, Surabaya, Indonesia
2
Abstract The need of self-learning education is quite high recently. Peoples find how to do learning education using the Natural Question-Guided Search algorithm to make a question that can form a question along with answers that can be used to improve the self-learning understanding. Natural Question-Guided Search is an algorithm used to make a question from a narrative sentence.
This Natural Question-Guided Search utilizes a Dependency Parser to process a sentence. Dependency Parser is a syntactical analysis process of a sentence which assume that a word is dependent on other words (head). This relation shows grammatical function between words which cannot be shown by constituency-based parser that can only identify phrase. By knowing grammatical function between those words, it will ease the creation of a question.
A test is done to determine the accuracy of the application of this Natural Question-Guided Search algorithm with applying it to the school reading text book to create a question.
Keywords natural language processing, natural question-guided search, dependency parser, constituency parser, bahasa Indonesia
1. I
NTRODUCTIONNowadays, the knowledge obtained from the learning process is really important. In addition to reading, comprehension of the text can be reader's understanding of the text.
With the technology that we know is increasing everyday, it is needed a system that can make such a question directly from an existing narrative texts, so that the reader will get a question and can answer any questions after reading the narrative text in order to improve understanding and comprehension of the content of the text. With that way, the reader can study or learn a text easily by themselves.
Natural Question-Guided Search algorithm is require to generate a question. Natural Question-Guided Search is an algorithm developed by Alexander Kotov and ChengXiangZai by using Dependency Parsing to process a sentence and generate a tree as the output. This output is Dependency Tree which further will be processed by Natural Question-Guided Search algorithm to generate a question. Those questions can be use for self-learning education that can help reader to study or learn a text by themselves.
2. F
UNDAMENTAL2.1. Indonesian Language Pattern
The same with English, Indonesian Language Pattern also consist of phrase, clause and sentence.
Clause is consist of two or more words that make up a construction containing elements of the predicative, and has the potential to be a sentence.
Sentence is a group of words that are put together to mean something which expresses a complete thought. It does this by following the grammatical rules of syntax. There are four type of Sentence: Simple Sentence, Compound Sentence, Complex Sentence and Complex-Compound Sentence. But on this research, it is focus only on Simple Sentence.
2.2. Natural Language Processing
Natural Language Processing (NLP) that is a part of computer science, Artificial Intelligence (AI), and Linguistics which deals with the interaction between human and computer so that the computer has the ability to be able to understand natural human language.
There are four NLP that used for this research : Part-of-Speech Tagging (POS Tagging), Named Entity Recognition, Constituency Parsing dan Dependency Parsing.
2.2.1. Part-Of-Speech Tagging
Part-of-Speech Tagging (POS Tagging) is the process of determining the words according to the grammar for each of the words in the sentences of natural language. POS Tagging is also can provide information of the word from syntactic or morphology of a sentence.
This research use Indonesian Language POS Tagging (iPOSTagger) that made by Alfan Farizki Wicaksono and Ayu Purwarianti. iPOSTagger is very important in this research, especially in classified and tagging the words on a sentence.
2.2.2. Named Entity Recognition
Named Entity Recognition (NER) is one of the components of information extraction to detect and classify the named-entity in a text. NER is generally used to detect people's names, place names and organization of a document.
This research use LingPipe NER for English.
in this reasearch, so that LingPipe NER can be use. While for detect the other names will be use some addition rules for categorizing.
2.2.3. Constituency Parsing
Constituency Parsing or Phrase Structure Grammar is a parser used in NLP to parse a
Grammar Pattern). Constituency Parser using the grammar rules to generate Constituency Tree of a sentence so that it becomes a model of grammar patterns.
But Constituency Parsing is not developed in this research. This research use Constituency Parsing by Stanford Parser to generate a Constituency Tree. Stanford Parser is an English parser. Since Indonesian Language has the similarities with English in terms of sentence structure, the Stanford Parser can be used.
2.2.4. Dependency Parsing
Dependency Parsing is a parser which generates a grammar that describes the dependence between the components which one is the head and the other is dependent. Head also called modifier as a determinant for the partner.
Dependency Parsing will be done using the method of mapping from Constituent Structure to Dependencies Structure, because the input to this parser is a constituent-based sentence that is output from last process.
2.3. Natural Question-Guided Search
Natural Question-Guided Search is an algorithm that can transform a narrative text into a question. The first idea of development this and faster result. In general, it is conceivable that Natural Question-Guided Search algorithm is very useful to for search an information by generate a good question.
But in this research, Natural Question-Guided Search algorithm not use to generate a question that use to search an information to get a better and faster result, but this algorithm is only use to generate a question with the answer, so it can be use for self-learning study.
There are two early stage should be done before running this algorithm, Pre-processing stage, and the second is Dependency Parsing. Furthermore, Dependency Tree (output from Dependency Parsing) will be processed by Question-Guided Natural Search algorithm.
Fig. 1 Question Form Phase Processing Diagram
3. Q
UESTIONF
ORMP
ROCESSINGThe process of Question Form Processing is processed through two main stages, Analysis Solution Dependency Parsing and Natural Question-Guided Search.
The first stage of Question Form Processing is Analysis Solution Dependency Parsing. On this stage the system will be mapping a Constituent Tree Structure into Dependency Tree Structure. This stage can be described in a process diagram as illustrated in Fig. 2.
Fig. 2 Analysis Solution Dependency Parsing Process Diagram
Can be seen in Fig. 2, the input process is an Indonesian Language which will be processed by the Pre-processing Module. The results of that module is a Constituency Tree which will be processed by the Dependency Parsing Module. The result of this system is the Dependency Tree.
The first process Analysis Solution Dependency Parsing is Pre-processing that consisting of POS Tagging and Parsing Constituency.
Fig. 3 Example Input and Output POS Tagging
Furthermore, the output of POS Tagging will be processed using Constituency Parsing to produce Constituency Tree.
Fig. 4 Example Input and Output Constituency Parsing
The next process is Dependency Parsing module that mapping the Constituent Structure. There are two phase to process and mapping it into Dependency Tree:
1. Dependency Extraction
This phase requires a Head Rule for each phrase structure. This module uses Head Rule of Collin Head Rule which can be implemented using the following algorithm:
FOR EACH cfg IN cfg_list
IF NOT pos(cfg.lhs) THEN
head get_head_pos(cfg.lhs)
FOR EACH node IN cfg.rhs
IF node <> head THEN
IF NOT pos(node) THEN
dependent get_head_pos (node)
ELSE
dependent node
add_relation(head,dependent)
2. Dependency Typing
This phase requires a Dependencies Label. This module uses the label of Stanford dependencies that have been adapted to Indonesian Language.
The result of this process is in the form of a Dependency tree is Dependency Tree with a label that shows the relationship between words.
Input:
Di/IN Indonesia/NNP terdapat/VBT sekitar/CDI 665/CDP bahasa/NN daerah./.
Output:
(ROOT (S
(NP (NNP Di) (NNP Indonesia)) (VP (VBP terdapat)
(NP
(QP (CD sekitar) (CD 665)) (NN bahasa) (NN daerah))) (. .)))
Input:
Di Indonesia terdapat sekitar 665 bahasa daerah.
Output:
Di/IN Indonesia/NNP terdapat/VBT sekitar/CDI 665/CDP bahasa/NN daerah./.
Fig. 5 Dependency Tree
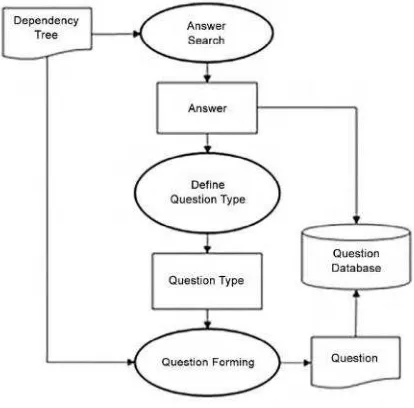
The second stage of Question Form Processing is Natural Question-Guided Search that will generate a question and the answer.
On this stage the system will do some process such as Answer Searching, Define Question Type, and the last is Question Forming. This stage can be described in a process diagram as illustrated in Fig. 6.
Fig. 6 Natural Question-Guided Search Process Diagram
Can be seen in Fig. 5, the input process Question-Guided Natural Search is a Dependency Tree that is output of the previous stage, Analysis Solution Dependency Parsing.
Natural Question-Guided Search process can be implemented using the following algorithm:
[Answer Search]
FOR EACH child IN root_left_child /
root_right_child answer get_deepest_child()
[Question Forming]
FOR EACH word IN sentence
IF word <> answer THEN
question question_mark + word +
The first process is the process to finding answers by tracing each of the left and right child of the root in the Dependency Tree that obtained from the previous stage. The process will be done after the system got the deepest node of both side. The results of the Answer Searching Process can be seen in Table 1.
TABLE 1
ANSWERSEARCHRESULT
L/R Deepest Node Head Answer
Left Di Indonesia Di
Indonesia
Right sekitar 665 Sekitar 665
The second process is to define the Question Type. The system will categorize each answer that obtained from the first process to get the question type. This categorization process is done by using Named Entity Recognition that using some addition rules to recognize the word category of each answer and get the question type. The results of the Define Question Type can be seen in Table 2.
TABLE 2
DEFINEQUESTIONTYPERESULT
L/R Answer Category Question Type
Left Di
Indonesia
Places Dimana
Right sekitar
665
Numeric Berapa
TABLE 3
QUESTIONFORMINGRESULT
Question Answer
Dimana terdapat sekitar 665 bahasa
daerah?
Di Indonesia
Berapa di Indonesia terdapat bahasa
daerah?
sekitar 665
From those process will obtained two question resulting from the left side and the right side of the answers. Each question always have an answer to that question.
4. C
ONCLUSIONSThis research obtained some conclusions that will be explained as follows:
1. Constituency Tree can be mapped to be Dependency Tree using Constituency Parser, Dependency Label and Head Rule. 2. Question Type error due to the lack of
rules at the process of categorizing the answer that obtained on Define Question Type process.
3. Dependency Parsing using mapping method relies heavily on the Constituency Tree that generated from Constituency Parser with the input from POS Tagger. 4. Dependency Parser error using mapping
method from phrase structure to dependency structure occurs in two phase: Constituency Parser and CFG. Error on the Constituency Parser phase is because the parser using a parser for English by giving a sentence that have been tagged with Indonesian Language structure as an input. Error on the CFG phase is because the CFG is a Constituency Tree generated from the Constituency Parser.
A
CKNOWLEDGMENTThis research can be used for further research. Here are some suggestions regarding the development of this research.
1. One of the obstacle on this research is the limited of Constituency Parser for Indonesian Language, so that errors happen dominoly from the Pre-process phase until the result of this research. The possible solution is to develop more for Constituency Parser for Indonesian Language start from Indonesian Language
Tree Bank to obtain a good Indonesian CFG rule.
2. The limited resource and paper about Natural Question-Guided Search also one of the obstacle to do this research. Research for this Natural Question-Guided Search algorithm still need to develop more in the future.
3. Head Rule that used for mapping from Phrase Structure into Dependency Structure still need more testing and validation by an Indonesian Language expert. Because Head Rule that used on this research is Collin Head Rule for English.
4. Labeling rules need to be more specific to avoid ambiguitous, not only for POS Tagging labelling process, but also need special handling for passive verbs.
R
EFERENCES[1] Afif, Irfan, Studi Perbandingan Kinerja Algoritma CYK dan Algoritma Earley pada Pengurai Kalimat Menggunakan Probabilistic Context Free Grammar Bahasa Indonesia Sederhana, Tugas Akhir Sarjana Teknik Informatika Institut Teknologi Bandung. 2011.
[2] Alexander Kotov, ChengXiang Zhai. Towards Natural Question-Guided Search, 2010.
[3] Alfan Farizki Wicaksono dan Ayu Purwarianti. HMM Based Part-of-Speech Tagger for Bahasa Indonesia, Tugas Akhir Sarjana Teknik Informatika Institut Teknologi Bandung, 2010.
[4] Bies, Ann et. Al., Bracketing Guidelines for Treebank II Style Penn Treebank Project. Linguistic Data Consortium, 1995.
[5] Covington, Michael A, Important Additional Notes about Dependency Parsing. The University of Georgia, 2004.
[6] Debusmann, Ralph, An Introduction to Dependency Grammar. Universitat des Saarlandes, 2000.
[7]
Concordance untuk Alkitab Perjanjian Baru Bahasa Indonesia, Sekolah Tinggi Teknik Surabaya, 2008.
[8] Jessica Felani Wijoyo, Natural Language Processing: Lecture 1. Introduction to Natural Language Processing, Sekolah Tinggi Teknik Surabaya, 2011.
[10] Keraf, Gorys, Tatabahasa Indonesia untuk SMK dan Umum. Penerbit Nusa Indah, 1991.
[11] Robinson, J., Dependency structure and tranformational rules. Language, 2/46. 1970. [12] Sukamto, Rosa Ariani, Penguraian Bahasa Indonesia dengan Menggunakan Pengurai
http://www.cs.columbia.edu/~mcollins/pape rs/heads, 1995.
[14] _______, Stanford Parser,