Aplikasi Pengenalan Ucapan
Berdasarkan Suku Kata Konsonan-Vokal Menggunakan Algoritma Hidden Markov Model
Syafaat Pradipta (L2F 005 581)
Jurusan Teknik Elektro, Fakultas Teknik, Universitas Diponegoro, Semarang, Indonesia
Abstract – There are a lot of speech recognition methods; the simplest one is by recognize every single word. But, this method has a weakness which is it needs a big memory to be used with various words. This can happen because of numbers of words which can be recognized are the same as numbers of words which are used to get recognition parameters. To handle this problem, we build recognition system based on their syllables. By using this system, speech will be recognized based on their syllables so speech inputs which are used to get recognition parameters are fewer than recognition system which are used words to get recognition parameters.
In this thesis we build a system to recognized speech based on their syllables with Hidden Markov Model (HMM) algorithm. First of all, words which have consonant-vocal syllables are recorded. Those words will be segmented for every syllable, so we get consonant-vocal syllables. Then those syllables trained by HMM algorithm to get recognition parameters. Next process, same as the first process—recording words which are have consonant- vocal syllables, then segmenting those words into syllables. Every syllable by segmentation process will be counted their recognition probabilities with HMM algorithm. Syllable with the highest probability score is the recognized syllable. Output of this system is text based on speech recognition.
After do some tests for this program, the results are the highest speech recognition percentage for speech recognition is happen when recognize trained speech and the score is 85,25 %. The speech recognition percentage for recognize outside trained speech is 61,65 % and the speech recognition percentage for recognize speech which is recorded by this program is 53,9 %. For recognition system which used syllable as its recognition parameters, segmentation process will influence system’s ability to recognize speech.
Keywords: Speech Recognition, Hidden Markov Model, Segmentation, Syllable.
I. Pendahuluan
Dunia teknologi komunikasi sudah berkembang begitu pesat. Berbagai penemuan penting telah diciptakan dengan tujuan untuk membantu kehidupan manusia. Salah satu aplikasi tersebut adalah pengenalan ucapan manusia (speech recognition).
1.1 Latar Belakang
Dengan aplikasi pengenalan ucapan manusia seorang sekretaris bisa membuat laporan lebih cepat, tanpa harus mengetik berlembar-lembar kertas. Atau lebih baik lagi untuk membantu mereka yang memiliki kekurangan fisik, dengan masukan berupa ucapan dan kemudian dikenali, sehingga mereka bisa lebih terbantu dalam kehidupan sehari-hari.
Teknologi pengenalan ucapan manusia atau yang lebih dikenal dengan speech recognition telah dirintis sejak lama. Penelitian terus dilakukan untuk meningkatkan efektifitas serta kehandalan sistem itu sendiri. Berbagai permasalahan yang muncul dalam membangun suatu sistem ini diantaranya adalah pemodelan ucapan agar nantinya dapat dikenali, kemampuan untuk mengenali ucapan pada suatu lingkungan yang berderau, ketepatan sistem dalam mengenali ucapan dan lain sebagainya.
Algoritma HMM (Hidden Markov Model) merupakan salah satu algoritma yang digunakan dalam sistem pengenalan ucapan manusia. Algoritma HMM
menggunakan prinsip-prinsip rantai markov yaitu ucapan masukan akan dibandingkan (dihitung probabilitasnya) dengan parameter ucapan yang sudah dimodelkan. Nilai probabilitas tertinggi akan menunjukan dikenal sebagai apa, ucapan masukan tersebut.
1.2 Tujuan
Tujuan dari tugas akhir ini adalah untuk membuat suatu program untuk mengenali ucapan manusia dengan menggunakan algoritma Hidden Markov Model sebagai algoritma pembelajaran dan pengenalan berdasarkan suku kata konsonan-vokal.
1.3 Batasan Masalah
Agar pembahasan atau analisis tidak melebar dan lebih terarah, maka permasalahan dibatasi pada :
1. Data masukan untuk pemodelan dan pembelajaran algoritma Hidden Markov Model berupa runtun kata Bahasa Indonesia, yang memiliki suku kata konsonan-vokal yang diambil dari 20 orang responden dan masing- masing responden diambil datanya sebanyak 10 buah contoh ucapan untuk setiap runtun kata.
2. Data yang digunakan untuk pengujian dari 10 contoh ucapan untuk setiap runtun kata.
Sebanyak 5 buah ucapan yang direkam untuk
pelatihan serta pengujian data pelatihan, sedangkan 5 buah ucapan lainnya untuk pengujian data di luar data pelatihan, serta tambahan 5 buah ucapan rekaman untuk pengujian ucapan rekaman langsung.
3. Analisis sinyal dilakukan dengan ekstraksi ciri menggunakan LPC (Linier Predictive Coding).
4. Proses pengenalan ucapan dilakukan dengan metode HMM (Hidden Markov Model).
5. Ucapan yang dapat dikenali berupa kata dalam Bahasa Indonesia yang memiliki suku kata konsonan-vokal.
II. Landasan Teori 2.1 Pengenalan Suara
Pengenalan suara merupakan salah satu upaya untuk dapat mengenali atau mengidentifikasi suara sehingga dapat dimanfaatkan untuk berbagai aplikasi.
Salah satu bentuk pendekatan untuk pengenalan suara, yakni dengan dengan pendekatan pengenalan pola.
Pendekatan pengenalan pola terdiri dari dua langkah yaitu pembelajaran pola suara dan pengenalan suara melalui perbandingan pola. Tahap perbandingan pola adalah tahap saat suara yang akan dikenali dibandingkan polanya dengan setiap kemungkinan pola yang telah dipelajari dalam fase pembelajaran, untuk kemudian diklasifikasikan dengan pola terbaik yang cocok. Blok diagram pembelajaran pola dan pengenalan suara ditunjukan pada gambar 1 di bawah ini. [8]
(a) Blok diagram pembelajaran pola.
(b) Blok diagram pengenalan suara.
Gambar 1 Blok Diagram Pembelajaran Pola dan Pengenalan Suara.
Pengenalan suara secara umum dapat dibagi menjadi tiga tahap, yaitu tahap ekstraksi ciri, tahap pemodelan atau pembelajaran, dan tahap pengenalan suara. Ekstraksi ciri adalah upaya untuk memperoleh ciri dari sinyal suara yang diproses. Salah satu metode yang dapat digunakan untuk proses ekstraksi ciri adalah LPC. Setelah didapatkan ciri dari sinyal suara tersebut, kemudian dilakukan pemodelan. Untuk pemodelan sinyal suara, dapat dilakukan dengan pelatihan menggunakan algoritma HMM (Hidden Markov Model). Keluaran dari pemodelan akan didapatkan parameter-parameter yang selanjutnya digunakan dalam proses pengenalan. [8]
2.2 Segmentasi Suara
Segmentasi suara merupakan proses memisahkan satu set elemen, seperti sinyal, suara atau gambar, ke dalam suatu daerah berhingga. Kumpulan setiap elemen yang terpisah tersebut akan memiliki karakteristik yang sama. Secara tradisional, segmentasi suara manusia dapat dilakukan secara langsung oleh
seorang phonetician menggunakan pendengaran dan gambaran sinyal secara visual. Akan tetapi, hal ini membutuhkan waktu lama, bersifat subjektif dan rawan terjadi kesalahan.[11]
Segmentasi bisa dilakukan dengan metode pendeteksian besarnya amplitudo suara ucapan.[11]
Sinyal ucapan masukan yang berisi informasi akan memiliki amplitudo yang lebih besar dibandingkan dengan jeda antar kata maupun antar suku kata. Dengan memberikan nilai ambang pada sinyal ucapan, maka jeda pada suara ucapan tersebut dapat dideteksi sehingga hasil dari proses segmentasi antar kata atau antar suku kata bisa diperoleh. Keluaran dari segmentasi suku kata ini kemudian dilatih agar mendapatkan parameter HMM pada proses pelatihan parameter HMM atau dihitung probabilitas maksimumnya untuk kemudian dikenali pada proses pengenalan kata.
2.3 Konsep Pengekstraksian Ciri Suara Ucapan dengan LPC
Ciri-ciri sinyal ucapan sangat berguna pada sistem pengenalan suara. Salah satu metode yang digunakan untuk proses ekstraksi ciri adalah LPC.
Analisis prediksi linier adalah suatu metode yang digunakan untuk mendapatkan sebuah pendekatan mengenai sinyal suara. Tujuan penggunaan metode ini adalah untuk mencari nilai koefisien LPC dari suatu sinyal suara. Nilai koefisien LPC tersebut selanjutnya akan digunakan oleh algoritma HMM untuk dimodelkan, sehingga masing-masing suara ucapan akan mempunyai model dengan karakteristik tertentu.[9]
Gambar 2 menunjukan blok diagram ekstraksi ciri menggunakan LPC untuk menghasilkan runtun vektor ciri. [9]
)
~ n(
s Xt(n) ~()
n Xt
) (t rm
) (t sm )
(t cm )
ˆ t( cm
∆
) ˆ t( cm
Gambar 2 Ekstraksi Ciri Menggunakan LPC
2.4 Pemodelan dengan HMM
HMM didefinisikan sebagai kumpulan lima parameter (N, M, A, B, π). Ciri-ciri HMM adalah[7]:
• Observasi diketahui tetapi urutan keadaan (state) tidak diketahui sehingga disebut hidden.
• Observasi adalah fungsi probabilitas keadaan.
• Perpindahan keadaan adalah dalam bentuk probabilitas.
2.4.1 Tiga Masalah Dasar HMM
Terdapat tiga permasalahan mendasar yang harus diselesaikan untuk menerapkan HMM dalam aplikasi kehidupan, yakni: [1], [4], [7], [12], [13]
Masalah 1: Perhitungan
Diberikan suatu deret yang diamati (deret pengujian), O
= (o1 o ... oT) dan sebuah model λ = (A, B, π), bagaimana menghitung P(O|λ) secara efisien?
Solusi: Masalah pertama dapat diselesaikan dengan algoritma maju-mundur.
Masalah 2: Pengkodean
Diberikan suatu deret yang diamati (deret pengujian atau pelatihan), O = (o1 o ... oT) dan sebuah model λ = (A, B, π), bagaimana mencari deret keadaan paling optimal q = (q1 q2...qT) yang akan menghasilkan deret observasi yang paling mendekati deret pengamatan O = (o1 o ... oT), menggunakan model yang telah diberikan?
Solusi: Masalah kedua dapat diselesaikan dengan algoritma viterbi.
Masalah 3: Pelatihan
Diberikan deret pelatihan Ok = O1k, O2k, O3k, .... , OT-1k, OTk dimana k adalah jumlah contoh dari model pelatihan. Bagaimana memilih model parameter λ = (A, B, π) untuk memaksimalkan P(O|λ)?
Solusi: Masalah ketiga dapat diselesaikan dengan metode Baum-Welch.
2.4.2 Penentuan Parameter secara Umum
Suatu sinyal suara dapat direpresentasikan ke dalam dua bentuk:[7]
• Representasi sinyal suara dalam bentuk gelombang
• Representasi sinyal suara dalam bentuk parameter
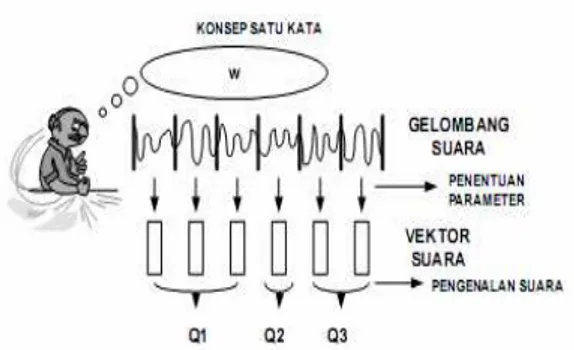
Untuk representasi suara dalam bentuk gelombang dengan menampilkan pola-pola gelombang suara yang ada. Sedangkan representasi sinyal suara dalam bentuk parameter merupakan cara representasi sinyal yang cukup rumit karena dari sinyal yang ada akan dihitung secara matematis parameter sinyal yang mengandung informasi sinyal. Representasi sinyal suara ke dalam parameter memberikan hasil yang lebih baik daripada representasi sinyal suara dalam bentuk gelombang. Penentuan parameter HMM secara umum dapat dilihat pada gambar 3, [7]
Gambar 3 Penentuan Parameter secara Umum
III. Perancangan dan Implementasi Sistem Secara umum pembuatan program ini mengikuti alur sesuai yang ditunjukan dalam gambar 4 berikut:
Gambar 4 Alur Perancangan Program Pengenalan Ucapan Manusia
3.1 Akuisisi Data
Data berupa sinyal ucapan diperoleh dengan cara merekam ucapan melalui mikrofon yang dihubungkan dengan komputer. Runtun kata diucapkan oleh 20 orang responden dimana untuk setiap runtun diulang sebanyak 10 kali. Pada Tugas Akhir ini menggunakan runtun kata sebagai masukan untuk menyederhanakan proses akuisisi data.
3.2 Segmentasi Ucapan untuk Memisahkan Tiap Suku Katanya
Setelah ucapan tersebut direkam, kemudian suara ucapan disegmentasi untuk dipisahkan tiap suku katanya. Proses segmentasi ini secara umum ditunjukan pada gambar 5.
Gambar 5 Diagram Alir Segmentasi Ucapan
Segmentasi dilakukan dua kali, yakni segmentasi pertama untuk memisahkan tiap kata
kemudian tiap kata tersebut melalui segmentasi kedua, untuk dipisahkan tiap suku katanya. Segmentasi pertama dilakukan dengan mencari letak amplitudo- amplitudo yang memiliki nilai diantara 0,01 dan 1. Jika jarak antar amplitudo yang berurutan lebih dari 375 ms maka dianggap sebagai jeda antar kata. Besar jarak antar amplitudo yang berurutan ini, didapat dengan asumsi 3000 cuplikan dibagi frekuensi cuplik 8000 Hz.
Jeda antar kata ini digunakan sebagai pemisah antar satu kata dengan yang lainnya.
Segmentasi kedua memiliki proses yang hampir sama dengan segmentasi pertama. Sinyal ucapan hasil segmentasi pertama, yang berupa satu kata dihilangkan bagian awal dan akhir sinyal. Sinyal dibagi menjadi beberapa daerah kecil, kemudian tiap-tiap daerah dihitung nilai amplitudo rata-ratanya. Dengan asumsi daerah yang memiliki nilai rata-rata amplitudo di atas suatu nilai ambang adalah daerah yang berisi sinyal informasi ucapan, maka daerah yang nilai rata- rata amplitudonya di bawah nilai ambang akan dihilangkan. Selanjutnya sinyal ucapan tersebut dipisahkan berdasarkan suku katanya dengan asumsi daerah dengan amplitudo terkecil merupakan jeda antar suku kata. Kemudian fungsi ini akan memisahkan sinyal tersebut menjadi suku kata pertama, begitu selanjutnya.
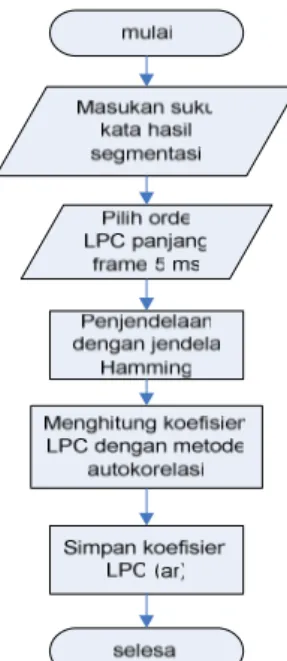
3.3 Analisis LPC untuk Mendapatkan Koefisien LPC
Hasil segmentasi ucapan yang berupa suku kata konsonan-vokal selanjutnya dianalisis untuk memperoleh koefisien LPC. Secara garis besar diagram alir analisis LPC ditunjukan pada gambar 6.
Gambar 6 Diagram Alir Analisis LPC
Untuk melakukan analisis LPC maka sesuai dengan karakteristik sinyal ucapan yang berubah terhadap waktu, analisis harus dilakukan pada selang waktu yang singkat. Pengolahan data sinyal ucapan diawali dengan pengambilan sinyal suara ucapan yang akan dianalisis, kemudian pemilihan orde LPC dan panjang frame. Panjang frame yang digunakan dalam program ini adalah 5 ms.
Selain itu, frame tersebut harus dijendelakan untuk memperkecil kesalahan peramalan atau
meminimisasi diskontinuitas pada awal dan akhir frame, yaitu dengan meratakan sinyal menuju nol pada awal dan akhir frame. Penjendelaan (windowing) dilakukan dengan menggunakan jendela Hamming yang memiliki bentuk seperti pada persamaan 2.3:
1 1 0
cos 2 46 , 0 54 , 0 )
( ≤ ≤ −
−
− Π
= n N
N n n
w ...(2.3)
3.4 Pelatihan Pemodelan HMM
Proses untuk mendapatkan parameter HMM ditunjukan pada gambar 7:
Gambar 7 Diagram Alir Pelatihan Pemodelan HMM
3.4.1 Runtun Observasi
Data pelatihan yang digunakan pada program simulasi ini adalah vektor ciri ucapan dari semua responden, setiap suku kata terdiri dari 5 ucapan untuk tiap responden. Jadi data pelatihan untuk masing- masing suku kata terdiri dari 100 vektor ciri suara ucapan yang kemudian dijadikan dalam satu vektor.
3.4.2 Inisialisasi Parameter HMM
Untuk tahap ini akan dilakukan inisialisasi parameter HMM.
3.4.3 Pelatihan Parameter HMM
Dalam proses pelatihan ini parameter yang sudah didapatkan dari hasil inisialisasi parameter akan diestimasi sampai NIT.
3.4.4 Penyimpanan Parameter
Penyimpanan parameter diperlukan karena parameter ini akan berfungsi untuk proses pengenalan kata.
3.5 Pengenalan Kata
Diagram pengenalan kata ditunjukan pada gambar 8:
Gambar 8 Diagram Alir Pengenalan Kata Sinyal ucapan s(n) disegmentasi suku kata terlebih dahulu, kemudian dimasukan ke dalam ekstraksi ciri sehingga didapatkan vektor ciri tiap suku kata, nilai-nilai vektor ciri ini kemudian dihitung probabilitas terhadap semua suku kata dengan menggunakan nilai-nilai yang terdapat dalam parameter HMM hasil pelatihan dan dipilih nilai probabilitas maksimum. Nilai probabilitas maksimum tersebut akan menunjukan suku kata yang paling sesuai dengan ucapan masukan.
IV. Pengujian dan Analisis
Pengujian dibagi menjadi dua, yakni pengujian offline dan pengujian online. Pengujian offline dibagi menjadi dua yakni pengujian terhadap data latih dan pengujian terhadap data di luar data pelatihan.
Pengujian online merupakan pengujian terhadap data rekaman ucapan yang direkam langsung melalui program, kemudian dikenali.
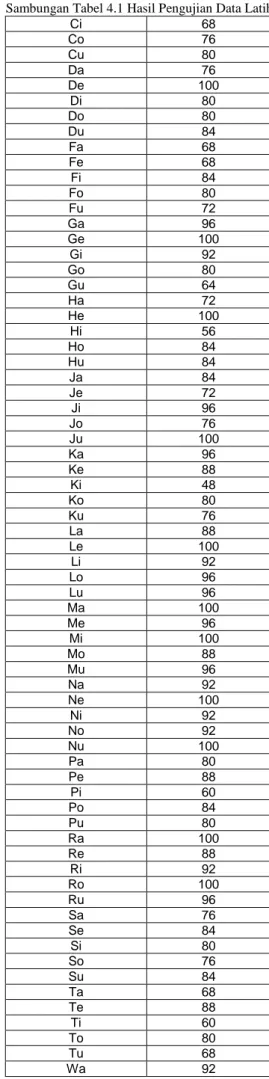
4.1 Analisis Hasil Pengujian Data Latihan
Data pelatihan merupakan data berupa suara ucapan yang digunakan untuk mendapatkan parameter HMM. Berikut ini adalah hasil pengujian terhadap data latihan:
Tabel 4.1 Hasil Pengujian Data Latih Suku Kata yang Persentase
Diujikan Pengenalan (…%)
Ba 100
Be 100
Bi 96
Bo 84
Bu 96
Ca 76
Ce 84
Sambungan Tabel 4.1 Hasil Pengujian Data Latih
Ci 68
Co 76
Cu 80
Da 76
De 100
Di 80
Do 80
Du 84
Fa 68
Fe 68
Fi 84
Fo 80
Fu 72
Ga 96
Ge 100
Gi 92
Go 80
Gu 64
Ha 72
He 100
Hi 56
Ho 84
Hu 84
Ja 84
Je 72
Ji 96
Jo 76
Ju 100
Ka 96
Ke 88
Ki 48
Ko 80
Ku 76
La 88
Le 100
Li 92
Lo 96
Lu 96
Ma 100
Me 96
Mi 100
Mo 88
Mu 96
Na 92
Ne 100
Ni 92
No 92
Nu 100
Pa 80
Pe 88
Pi 60
Po 84
Pu 80
Ra 100
Re 88
Ri 92
Ro 100
Ru 96
Sa 76
Se 84
Si 80
So 76
Su 84
Ta 68
Te 88
Ti 60
To 80
Tu 68
Wa 92
Sambungan Tabel 4.1 Hasil Pengujian Data Latih
Wi 92
Ya 96
Yo 96
Za 88
Rata- rata 85.25
Pengenalan
Hasil pengujian data pelatihan dengan tingkat pengenalan tertinggi sebesar 100 % yakni untuk suku kata Ba, Be, De, Ge, He, Ju, Le, Ma, Mi, Ne, Nu, Ra dan Ro. Pengenalan rata-rata seluruh suku kata untuk data latih adalah sebesar 85,25%.
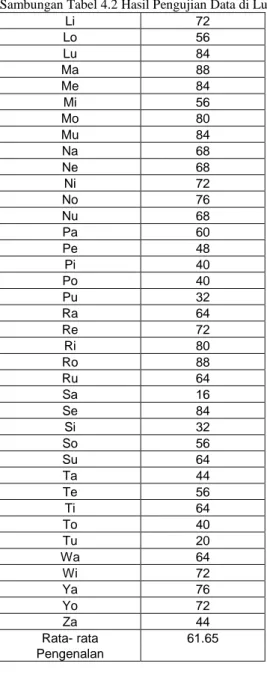
4.2 Analisis Hasil Pengujian Data di Luar Data Pelatihan
Data di luar data pelatihan merupakan data yang tidak digunakan untuk mendapatkan parameter HMM. Berikut ini adalah hasil pengujian terhadap data di luar data latihan:
Tabel 4.2 Hasil Pengujian Data di Luar Data Latih Suku Kata yang Persentase
Diujikan Pengenalan (…%)
Ba 52
Be 92
Bi 64
Bo 52
Bu 48
Ca 60
Ce 60
Ci 36
Co 64
Cu 64
Da 76
De 84
Di 24
Do 68
Du 44
Fa 56
Fe 60
Fi 84
Fo 36
Fu 24
Ga 96
Ge 96
Gi 32
Go 60
Gu 40
Ha 56
He 92
Hi 44
Ho 60
Hu 52
Ja 64
Je 64
Ji 68
Jo 60
Ju 100
Ka 84
Ke 56
Ki 36
Ko 76
Ku 36
La 72
Le 92
Sambungan Tabel 4.2 Hasil Pengujian Data di Luar Data Latih
Li 72
Lo 56
Lu 84
Ma 88
Me 84
Mi 56
Mo 80
Mu 84
Na 68
Ne 68
Ni 72
No 76
Nu 68
Pa 60
Pe 48
Pi 40
Po 40
Pu 32
Ra 64
Re 72
Ri 80
Ro 88
Ru 64
Sa 16
Se 84
Si 32
So 56
Su 64
Ta 44
Te 56
Ti 64
To 40
Tu 20
Wa 64
Wi 72
Ya 76
Yo 72
Za 44
Rata- rata 61.65
Pengenalan
Hasil pengujian pengenalan data di luar data latih, suku kata dengan persentase pengenalan tertinggi sebesar 100% yakni untuk suku kata Ju. Rata-rata persentase pengenalan seluruh suku kata untuk data di luar data latih adalah sebesar 61,65 %.
Persentase Pengenalan Total Data Pengujian
85.25
61.65
0 10 20 30 40 50 60 70 80 90
Data Latih Data di Luar Data Latih Data Pengujian
Persentase Pengenalan
Gambar 9 Grafik Persentase Pengenalan Total Data Pengujian.
Gambar 9 menunjukan persentase pengenalan antara data latih dan data di luar data latih. Dari gambar tersebut diketahui bahwa data latih memiliki tingkat pengenalan yang lebih tinggi daripada data di luar data
latih. Hal ini sudah sesuai dengan teori bahwa tingkat pengenalan tertinggi adalah pada data latih. Terdapat beberapa hal yang mempengaruhi tingkat pengenalan, yakni:
1. Derau
Derau sangat mempengaruhi hasil pengenalan ucapan. Agar sistem dapat mengenali ucapan dengan baik, maka diperlukan ruangan dengan derau yang rendah atau dapat ditambahkan tapis adaptif untuk mengatasi derau.
2. Segmentasi
Pada program dengan penyimpanan parameter berupa suku kata maupun fonem, segmentasi memegang peranan penting karena segmentasi yang menentukan tingkat keberhasilan pengenalan program. Mulai proses pelatihan untuk mendapatkan parameter HMM hingga pengujian melewati proses segmentasi.
3. Pengaruh bunyi yang berbeda untuk suku kata yang sama
Dalam bahasa Indonesia, terdapat istilah homograf yakni bentuk tulisan sama tetapi bunyinya berbeda. Hal ini banyak ditemukan pada suku kata yang konsonannya digandeng dengan vokal e, sebagai contoh kata teta dan tepi.
V. Penutup 5.1 Kesimpulan
Dari hasil penelitian dan pembahasan dapat disimpulkan bahwa:
1. Keluaran dari analisis LPC adalah koefisien ciri yang merupakan vektor berisi nilai-nilai yang mewakili sinyal ucapan pada suatu waktu n, s(n). Koefisien ciri ini didapat dari kombinasi linier sebanyak p sampel sebelumnya.
2. Keluaran dari algoritma HMM adalah berupa runtun observasi. Runtun observasi ini merupakan suku kata yang dilatih dan atau akan dikenali. Setelah proses analisis LPC didapat koefisien ciri yang mewakili masing- masing suku kata, kemudian dengan algoritma HMM koefisien LPC tersebut dijadikan sebagai parameter hasil dari pelatihan dan digunakan untuk proses pengenalan ucapan.
3. Hasil pengujian pengenalan terhadap data pelatihan, suku kata dengan persentase pengenalan tertinggi sebesar 100 % yakni untuk suku kata Ba, Be, De, Ge, He, Ju, Le, Ma, Mi, Ne, Nu, Ra dan Ro. Pengenalan rata- rata seluruh suku kata untuk data latih adalah sebesar 85,25%.
4. Hasil pengujian pengenalan terhadap data di luar data latih, suku kata dengan persentase pengenalan tertinggi sebesar 100% yakni untuk suku kata Ju. Persentase pengenalan rata-rata seluruh suku kata untuk data di luar data latih adalah sebesar 61,65 %.
5. Pada sistem pengenalan ucapan dengan parameter pengenalan berupa suku kata, proses segmentasi akan sangat mempengaruhi kemampuan sistem dalam mengenali ucapan.
5.2 Saran
Adapun saran yang dapat diberikan sehubungan dengan pelaksanaan penelitian ini adalah :
1. Karena sistem sangat peka terhadap sinyal derau, maka agar dapat dipertahankan keberhasilan pengenalannya, diperlukan suatu ruangan yang cukup tenang dan bersih terhadap sinyal derau.
2. Untuk memperkecil jumlah parameter yang disimpan, dapat digunakan fonem sebagai parameter pengenalan ucapan. Tetapi perlu diperhatikan pula proses segmentasinya agar kinerja sistem pengenalan ucapan tersebut baik.
Daftar Pustaka
[1] Abdulla, H. Waleed, and Nikola K. Kasabov.
The Concept of Hidden Markov Model in Speech Recognition, Knowledge Engineering Lab. Information Science Department
University of Otago, New Zealand, 1999.
[2] Ahmad Syarip, Iip, Penerapan Model Markov Tersembunyi dan Penyandian Linier untuk Pengenalan Kata Terisolasi, Skripsi S-1, Universitas Diponegoro, Semarang, 2004.
[3] Cappe, O., H2M : A Set of Matlab/Octave
Functions for The EM Estimation of Mixtures and Hidden Markov Model, ENST dpt.
TSI/LCTI (CNRS-URA 820), Paris, 2001.
[4] Furui, S., Digital Speech Processing, Synthesis, and Recognition, Marcel Dekker, Inc., New York, 1989.
[5] Gold, B., and Morgan, N., Speech and Audio Signal Processing : Processing and Perception of Speech and Music, John Wiley & Sons, Inc., New York, 1999.
[6] Hestiyaningsih, Lika Dwi, Pengenalan Ucapan Kata Berkorelasi Tinggi Menggunakan Metode Hidden Markov Model Melalui Ekstraksi Ciri Penyandian Prediktif Linier, Skripsi S-1, Universitas Diponegoro, Semarang, 2005.
[7] Hidayatno, Achmad. “Teori Umum Proses Markov”. http://achmad.blog.undip.ac.id.
Diakses 31 Agustus 2009.
[8] Hidayatno, Achmad, dan Sumardi. Pengenalan Ucapan Kata Terisolasi dengan Metode Hidden Markov Model (HMM) melalui Ekstraksi Ciri Linear Predictive Coding (LPC).
Universitas Diponegoro, Semarang. 2006.
[9] Irvandi, Mahmud, Aplikasi Pengenalan Ucapan dengan Jaringan Syaraf Tiruan Propagasi Balik untuk Pengendalian Robot Bergerak, Skripsi S-1, Universitas Diponegoro, Semarang, 2009.
[10] Kanungo, Tapas. “Hidden Markov Model”.
http://cfar.umd.edu. Diakses 2009.
[11] N.L. Li, Bavy, and James N.K. Liu. “A
Comparative Study of Speech Segmentation and Preprocessing for Automatic Multi- Lingual Recognition”.
[12] Rabiner, L., Biing-Hwang Juang. A Tutorial on Hidden Markov Models And Selected Applications in Speech Recognition, vol. 77,
no.2, pp. 257-286, 1989.
http://comp.polyu.edu.hk. Diakses 2009.
[13] Rabiner, L., Biing-Hwang Juang. Fundamentals Of Speech Recognition, New Jersey: Prentice Hall, 1993.
[14] R. Eddy, Sean. What is Hidden Markov Model?
Howard Hughes Medical Institute and Department of Genetics, Washington University School of Medicine, Missouri, 2004.
Biodata Penulis
Syafaat Pradipta, terlahir di kota Jakarta pada 16 Maret 1987.
Telah menjalani pendidikan di Taman Kanak-kanak Bani Saleh II, Sekolah Dasar Bani Saleh II Bekasi, Sekolah Lanjutan Tingkat Pertama Negeri 16 Bekasi, Sekolah Menengah Umum Negeri 1 Bekasi. Dan sekarang tengah menyelesaikan pendidikan Strata Satu di konsentrasi Elektronika dan Telekomunikasi, Jurusan Teknik Elektro, Fakultas Teknik, Universitas Diponegoro, Semarang, Indonesia.
Menyetujui, Dosen Pembimbing I,
Achmad Hidayatno, S.T., M.T.
NIP. 19691221 199512 1 001 Dosen Pembimbing II,
Ajub A. Zahra, S.T., M.T.
NIP. 19710719 199802 2 001