EKSTRAKSI DATA PADA WEBSTE PERPUSTAKAAN UNTUK PEMBUATAN KNOWLEDGE BASE MENGGUNAKAN ALGORITMA DEPTH-FIRST SEARCH
SEBAGAI METODE PENELUSURAN HALAMAN PAGE
USULAN SKRIPSI
Oleh : Musyfiq Luthfi
(09650183)
JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI MAULANA MALIK IBRAHIM MALANG
LEMBAR ENGESAHAN
REVISI USULAN SKRIPSI
EKSTRAKSI HALAMAN WEB DIGITAL LIBRARY MENGGUNAKAN METODE DEPTH-FIRST SEARCH GUNA MEMPERMUDAH PEMBENTUKAN RESOURCE
DESCRIPTION FRAMEWORK (RDF)
Musyfiq Luthfi (09650183)
Pada Tanggal : ……….2014
Telah diperiksa, disetujui, dan disahkan oleh :………..
Penguji I : (Zainal Abidin, M.Kom)NIP.19760613 200501 1 004 (...)
Penguji II : ( Fachurrochman, M.Kom)NIP.19700731 200501 1 002 (...)
BAB I PENDAHULUAN 1. Latar Belakang
Teknologi Informasi adalah suatu teknologi yang digunakan untuk mengolah data, Termasuk memproses, mendapatkan, menyusun, menyimpan, memanipulasi data dalam berbagai cara untuk menghasilkan informasi yang berkualitas, yaitu informasi yang relevan, akurat dan tepat waktu, yang digunakan untuk keperluan pribadi, bisnis, dan pemerintahan dan merupakan informasi yang strategis untuk pengambilan keputusan. Teknologi ini menggunakan seperangkat komputer untuk mengolah data, sistem jaringan untuk menghubungkan satu komputer dengan komputer yang lainnya sesuai dengan kebutuhan, dan teknologi telekomunikasi digunakan agar data dapat disebar dan diakses secara global.
Peran yang dapat diberikan oleh aplikasi teknologi informasi ini adalah mendapatkan informasi untuk kehidupan pribadi seperti informasi tentang kesehatan, hobi, rekreasi, dan rohani. Kemudian untuk profesi seperti sains, teknologi, perdagangan, berita bisnis, dan asosiasi profesi. Sarana kerjasama antara pribadi atau kelompok yang satu dengan pribadi yang lainnya atau kelompok yang lainnya tanpa mengenal batas jarak dan waktu, negara, ras, kelas ekonomi, ideologi atau faktor lainnya yang dapat menghambat bertukar pikiran yang sering disebut jejaring sosial .
Perkembangan Teknologi Informasi memacu suatu cara baru dalam kehidupan, dari kehidupan dimulai sampai dengan berakhir, kehidupan seperti ini dikenal dengan elife, artinya kehidupan ini sudah dipengaruhi oleh berbagai kebutuhan secara elektronik. Dan sekarang ini sedang semarak dengan berbagai huruf yang dimulai dengan awalan e seperti ecommerce, e-government, e-education, e-library, e-journal, e-medicine, elaboratory, ebiodiversitiy, dan yang lainnya lagi yang berbasis elektronika.
World Wide Web atau lebih dikenal sebagai WWW atau Web adalah suatu ruang informasi dimana setiap resource didalamnya diidentifikasi dengan suatu pengenal global yang disebut Unified Resource Indentifiers (URI) (Berners-Lee, 2004). Teknologi ini muncul pada tahun 1990 ketika Tim Berners-Lee mengimplementasikan sistem manajemen informasi untuk mencegah hilangnya data yang dimiliki institusi European Organization for Nuclear Investigation. Konsorsium World Wide Web sendiri mulai didirikan pada bulan Oktober 1994. Tugasnya adalah menstandarisasi dan mengimplementasikan protokol-protokol serta untuk mempromosikan evolusi dari teknologi World Wide Web yang memungkinkan bentuk mutakhir dari dokumentasi informasi maupun komunikasi manusia. Sejak saat itu, teknologi WWW terus dikembangkan dan kini telah menjadi paradigma yang paling berpengaruh dalam arena sistem informasi (Polo luciano, 2003)
Website merupakan bagian yang terpenting dalam era informasi saat ini. Hampir 80% layanan di internet tersedia dalam bentuk website sebagai media dalam menyebarkan informasi. Ini menandakan bahwa peran website sangat penting. Dilain pihak, statistik pengguna internet didunia terus naik secara signifikan, seperti terlihat dalam pernyatan Sammy (2013) selaku Ketua Umum Asosiasi Penyelenggara Jasa Internet Indonesia (APJII) bersama Badan Pusat Statistik (BPS) mengungkapkan jumlah pengguna internet di Indonesia mencapai 71,19 juta orang hingga akhir tahun 2013. Jumlah tersebut berarti tumbuh 13 persen dibandingkan catatan akhir 2012 yang sebanyak 63 juta orang. Dengan jumlah tersebut bila dibandingkan dengan total populasi jumlah penduduk Indonesia, maka penetrasi internet di Indonesia adalah meningkat sekitar 28 persen
Dengan meningkatnya perkembagan internet saat ini, tentu menimbulkan pesatnya kamajuan sarana informasi serta ilmu pengetahuan. Salah satu contoh pemamfaatan dari kemajuan teknologi adalah transformasi media penyimpanan teks. Penyimpanan berupa teks sudah tidak lagi selalu tersimpan dalam media cetak seperti kertas. Orang sudah mulai cenderung menyimpan informasi secara digital. Karena lebih mudah dalam penyimpanan dan cepat. Tuntutan dari gerakan anti global warming juga mendukung penyimpanan informasi secara digital,
membayar mahal, baik dalam waktu maupun uang demi mendapatkan informasi, keakuratan dari informasi yang mereka butuhkan, supaya mereka mendapatkan dengan cepat. Tidak hanya kecepatan mendapatkan informasi, keakuratan dari informasi juga menjadi harapan semua orang..
Namun demikian, ketersediaan data dalam jumlah besar pada web tidak menjamin bahwa seorang pengguna web dapat menemukan data yang dibutuhkannya dengan mudah. Pada kenyataannya, data dalam jumlah besar tersebut sudah melampaui kemampuan manusia untuk menemukan informasi yang dibutuhkan. Menurut hasil observasi, 99% data yang diperoleh oleh 99% pengguna web ternyata tidak sesuai dengan kebutuhannya (Berners-Lee, 2004). Tetapi, data web dalam jumlah besar dengan berbagai macam properti tersebut memang menunjukkan bahwa ada pengetahuan yang tersembunyi di balik data pada web yang tidak dapat diinterpretasikan dengan mudah dengan menggunakan intuisi manusia.
Informasi yang didapat dari internet biasanya berupa dokumen web yang memiliki elemen-elemen teks yang dapat diproses lebih lanjut untuk membantu penemuan dokumen yang relevan. Suatu dokumen web memiliki metadata berupa teks yang terstruktur yang dapat membantu dalam menentukan dokumen web yang relevan. Meskipun memiliki nilai yang sangat penting, metadata pada umumnya diabaikan dan kalaupun ada seringkali isinya tidak lengkap, karena menemukan, membuat atau memelihara metadata pada suatu halaman web secara manual ini terbilang sulit. Hal ini tentu saja menghambat efektivitas pelayanan atau pemberian informasi yang relevan.
Kemajuan teknologi informasi juga berdampak positif pada Perkembangan Digital library yang selama ini dirasa semakin mengalami banyak kemajuan, Digital library menjadi sumber pustaka yang dipandang sebagai peluang potensial bagi dunia akademik untuk menyimpan koleksi yang ada diperpustakaan seperti buku, jurnal ilmiah, majalah, tugas akhir maupun skripsi. Dengan demikian pemamfaatan teknologi yang tepat untuk mengembangkan, membangun dan mengelola koleksi dokumen perpustakaan yang benar-benar diinginkan pengguna merupakan tujuan kedepan semua pihak.
menggunakan pendekatan teknologi sematic web. Sehingga pencarian yang yang dihasilkan terkadang belum sesuai dengan persepsi pengguna dalam mencari informasi skripsi atau karya ilmiah lainya.
Tujuan perpustakaan, pengarsipan, yang ada di institusi adalah untuk memelihara dokumen yang memiliki harga keilmuan yang dapat diakses dimasa depan sama mudahnya diakses pada saat ini. Dengan semakin kecilnya media data, penyimpanan menggunakan media digital menjadi sangat menarik. Keuntungan penyimpanan menggunakan media digital adalah pencarian dapat dilakukan tidak hanya diantara masukan katalog elektronik, tetapi dapat menampilkan sepanjang keseluruhan isi dokumen.
Peneliti dan pengembang web mengusulkan tambahan informasi bagi konten web yang sering diistilahkan dengan metadata. istilah metadata ini sering dipakai dalam semantic web, yang menggambarkan pendekatan dalam menangani dan menyimpan dokumen. Saat ini dokumen mulai disajikan dalam format XML (Extensible Markup Language). Bahasa lain yang digunakan dalam mendukung visi Semantic Web selain XML adalah ontologi.
Ontologi adalah salah satu konsep yang ideal untuk menggambarkan struktur dan semantik dari tipe dokumen.Visi untuk masa depan dimana informasi diberikan secara eksplisit yang membuat mesin atau komputer dapat mengerti dan mampu memproses informasi itu secara otomatis dan mampu mengintegrasikan informasi yang tersedia di web. Komputer diharapkan mampu melakukan proses penalaran (reasoning) sebagaimana yang dilakukan manusia.
Terjemah :
1). Bacalah dengan (menyebut) nama Tuhanmu yang Menciptakan, 2). Dia Telah menciptakan manusia dari segumpal darah. 3). Bacalah, dan Tuhanmulah yang Maha pemurah, 4). Yang mengajar (manusia) dengan perantaran kalam, 5). Dia mengajar kepada manusia apa yang tidak diketahuinya. (Al-qur’an Surat Al - Alaq ayat 1-5)
Secara subtansial ayat diatas dapat dianalogikan bahwa dengan membaca maka akan banyak tahu dan mengerti, dengan membaca manusia akan terus mengalami proses pembelajaran Namun hal ini akan lebih bermamfaat jika dari proses pembelajaran kemudian diimplementasikan dalam kehidupan sehingga kemudian menjadi sebuah ilmu pengetahuan. Dengan ilmu pengetahuan peradaban manusiaakan terus mengalami dinamisasi. Dengan ilmu pengetahuan Allah SWT juga menjadikan barometer masing-masing derarjat manusia.
Berdasarkan latar belakang diatas maka tujuan dalam penelitian ini adalah untuk mengekstraksikan dokumen yang berupa metadata kemudian mentransformasikan hasil ekstraksi yang sebelumnya tidak terstruktur menjadi data yang lebih terstruktur sehingga nantinya data yang sudah terstruktur dapat disimpan dalam suatu data atau lembar kerja tertentu untuk lebih memudahkan dalam pemrosesan data yang dibutuhkan untuk pembuatan ontologi selanjutnya.
2. Rumusan Masalah
Dalam penelitian ini memiliki beberapa rumusan masalah yaitu :
a) Bagaimana membangun sebuah aplikasi ekstraksi halaman skripsi pada Digital Library UIN Maliki Malang?
c) Sejauh mana efektifitas aplikasi yang dibangun untuk ekstraksi halaman skripsi pada Digital Library dalam pembuatan Resource Description Framework (RDF) ?
3. Batasan Masalah
Batasan masalah pada penelitian ini adalah sebagai berikut :
a) Halaman skripsi yang akan diekstraksi berdasarkan dari halaman website http://lib.uinmalang.ac.id
b) Algortima yang digunakan dalam proses penelusuran menggunakan lgoritma Depth-First search (DFS)
c) Data yang akan diekstraksi adalah data skripsi yang ada pada Digital Library UIN Maliki Malang.
d) Data Ontologi skripsi meliputi Nama Penulis, Tahun Pembuatan, Fakultas, Jurusan, Dosen Pembimbing dan Abstrak.
e) Pembuatan Resource Description Framework (RDF) berdasarkan data dari hasil ekstraksi.
4. Tujuan Penelitian
Tujuan penelitian ini adalah sebagai berikut:
a) Membuat aplikasi yang mampu mengekstraksi halaman website Digital Library UIN Maliki Malang.
b) Mengetahui kinerja ekstraksi dokumen web dalam pembuatan Resource Description Framework (RDF)
5. Manfaat Penelitian
Manfaat yang diharapakan dari penelitian ini adalah :
a) Bagi mahasiswa dapat dijadikan referensi untuk pengembangan obyek penelitian selanjutnya.
b) Bagi universitas dapat djadikan sebagai pengembangan dari sistem digital library sebelumnya.
BAB II
STUDI LITERATUR
yang ingin diproses. Use case dan aktor dari sebuah perangkat lunak yang akan dibangun dapat ditemukan pada bagian kebutuhan fungsional pada dokumen SRS.
Penelitian dilakukan oleh Nava’atul Fadillah, Novrido Caribaldi, dan Herlina Jayadianti (2010). Penelitian bertujuan mengelola secara semantis informasi pustaka sehingga nantinya pengguna dapat melakukan pencarian berdasarkan persepsi dan tingkat pengetahuan yang dimilikinya untuk mencari koleksi pustaka.
Dalam penelitian ini, pengetahuan koleksi perpustakaan disimpan dalam bentuk ontology berbasis Web Ontology Language yang memiliki class Jurusan, Koleksi, Penulis, dan Penerbit. Model ontology yang dibangun diimplementasikan untuk aplikasi berbasis web dengan menggunakan Protege 3.4, NetBeans IDE 6.5.1 dengan bahasa pemrograman Java Server Pages (JSP), Jena API sebagai library pendukung dan bahasa query Sparql.
Penelitian oleh Ferdila (2010) tentang Aplikasi Web Semantik Untuk Pencarian Materi Perkuliahan. Penelitian ini bertujuan mengelola secara semantis informasi materi perkuliahan di Gunadarma dengan menggunakan staffsite gundarama. Pada halaman staffsite dapat melakukan pencarían materi perkuliahan sesuai dengan nama dosen yang mengajar suatu mata kuliah. sehingga pengguna dapat melakukan pencarian berdasarkan persepsi dan tingkat pengetahuan yang dimilikinya untuk mencari mata kuliah.
BAB III
METODE PENELITIAN 1. Desain Penelitian
a) Objek Penelitian
Pada usulan penelitian ini, peneliti akan melakukan penelitian mengenai Pemodelan Resource Description Framework (RDF) Menggunakan Aplikasi Ekstraksi Dokumen Skripsi Studi Kasus Digital Library UIN Maliki Malang. Objek penelitian ini adalah sebagai berikut:
1) Data yang akan diekstraksi berasal dari laman http://lib.uin-malang.ac.id
2) Pembuatan RDF berdasarkan ontologi dari hasil ekstraksi.
b) Sumber Data
Data yang digunakan adalah url pada laman di http://lib.uin-malang.ac.id UIN Maulana Malik Ibrahim Malang.
2. Instrumen Penelitian 1) Variabel Bebas
Dalam penelitian ini varianbel bebas adalah halaman di http://lib.uin-malang.ac.id.
2) Variabel Penghubung
3) Variabel Terikat
Dalam Penelitian ini variabel terikat adalah hasil uji coba meliputi :
1) Hasil ekstraksi.
2) Sejauh mana efektifitas penerapan algoritma Depth-First search (DFS) dalam proses penelusuran.
3) Data waktu dan konsumsi sumber daya komputer yang dibutuhkan untuk melakukan ekstraksi.
3. Prosedur Penelitian
Dalam melakukan penelitian ini, peneliti akan membagi beberapa tahap pengerjaan yang digunakan sebagai workplan dalam penyelesaian penelitian. Berikut beberapa tahapan dalam melakukan penelitian:
a) Perancangan dan Desain Aplikasi
Perancangan merupakan thapan yang penting dalam pembuatn suatu sistem, sehingga dengna perancangan yang baik diharapkan akan menghasilkan suatu sistem dengan perancangan yang sesuai dengan fungsi dan tujuan dari dibuatnya sistem tersebut.
Pada perancangan ini umumunya terdiri dari beberapa tahapan seperti menentukan cara kerja sistem, pengindentifikasian hal-hal yang dibutuhkan sistem dan menentukan tools atau alat bantu yang akan digunakan untuk pembuatan sistem. Untuk membangun sistem ini, dibutuhksn tahapan perancangan yang terdiri dari ontologi, penentuan algoritma dan desain sistem.
b) Deskripsi Sistem
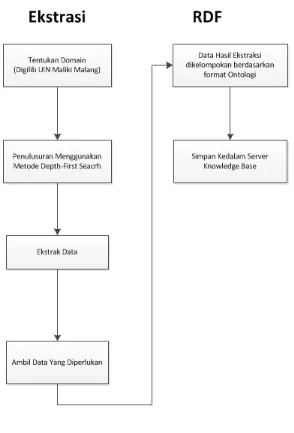
Sistem bekerja dengan cara mengekstraksi data yang berasal dari halaman website dengan cara menelusuri metadata yang terkandung dalam html. Teknik penulsuran adalah dengan mencari data informasi dengan menggunakan metode Depth-first search (DFS), kemudian setelah menemukan data yang dicari proses selanjutnya adalah pembuatan ontologi. Ontologi disini merupakan langkah awal dari pembuaatan Resource Description Framework (RDF). Untuk lebih jelasnya dapat dilihat dari ilustrasi gambar 3.1 alur kerja sistem dibawah ini :
c) Algoritma Depth-First Search (DFS)
A. Pengertian Algoritma Depth-First Search (DFS)
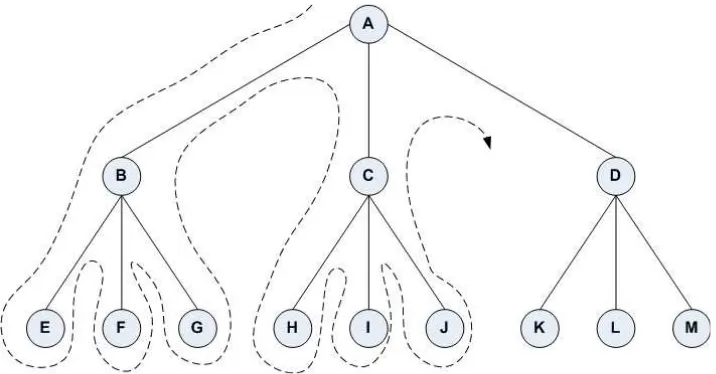
Gambar 3.2 : Diagram pohon dari DFS.
Pencarian dilakukan pada satu node dalam setiap level dari yang paling kiri. Jika pada level yang paling dalam, solusi belum ditemukan, maka pencarian dilanjutkan pada node sebelah kanan. Node yang kiri dapat dihapus dari memori. Jika pada level yang paling dalam tidak ditemukan solusi, maka pencarian dilanjutkan pada level sebelumnya. Demikian seterusnya sampai ditemukan solusi. Jika solusi ditemukan maka tidak diperlukan proses backtracking (penelusuran balik untuk mendapatkan jalur yang dinginkan)
B. Kelebihan dan Kekurangan Algortima Depth-First Search (DFS) Kelebihan DFS adalah:
Pemakain memori hanya sedikit, berbeda jauh dengan BFS yang harus menyimpan semua node yang pernah dibangkitkan.
Jika solusi yang dicari berada pada level yang dalam dan paling kiri, maka DFS akan menemukannya secara cepat.
Kelemahan DFS adalah:
Jika terdapat lebih dari satu solusi yang sama tetapi berada pada level yang berbeda, maka pada DFS tidak ada jaminan untuk menemukan solusi yang paling baik (Tidak Optimal).
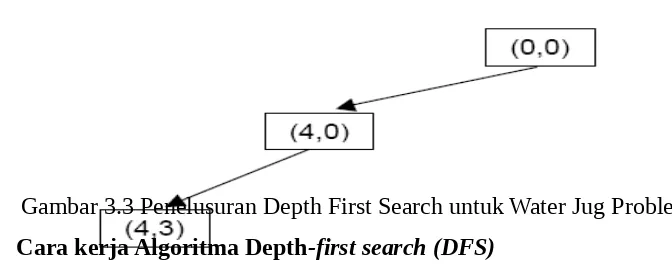
Gambar 3.3 Penelusuran Depth First Search untuk Water Jug Problem. C. Cara kerja Algoritma Depth-first search (DFS)
Pencarian rute terpendek dilakukan dengan cara membuat simpul-simpul yang menjadi titik awal, titik-titik yang akan dilalui dan juga titik akhir sebagai akhir dari tujuan atau sebagai simpul yang dicari.
Dalam algoritma DFS, simpul yang telah dikunjungi disimpan dalam suatu tumpukan (stack). Antrian ini digunakan untuk mengacu simpul-simpul yang akan dikunjungi sesuai urutan tumpukan (masuk terakhir, keluar pertama) dan mempermudah proses runut-balik jika simpul sudah tidak mempunyai anak (simpul pada kedalaman maksimal).
Untuk memperjelas cara kerja algoritma DFS beserta tumpukan yang digunakannya, berikut langkah-langkah algoritma DFS:
1) Masukkan simpul ujung (akar) ke dalam tumpukan
2) Ambil simpul dari tumpukan teratas, lalu cek apakah simpul merupakan solusi
3) Jika simpul merupakan solusi, pencarian selesai dan hasil dikembalikan.
5) Jika tumpukan kosong dan setiap simpul sudah dicek, pencarian selesai dan mengembalikan hasil solusi tidak ditemukan
6) Ulangi pencarian dari langkah kedua
d) Domain dan ruang lingkup Ontology
Perancangan ontologi memberikan informasi mengenai tahapan- tahapan dalam pembangunan ontologi dan menjelaskan mengenai komponen apa saja yang dibutuhkan dalam penggambaran sebuah informasi
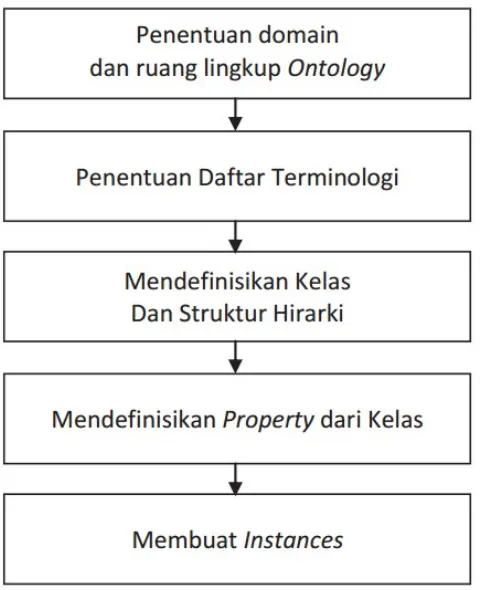
Tahapan-tahapan dalam pembangunan ontologi adalah sebagai berikut:
1) Penentuan domain. Domain yang melingkupi ontologi adalah digital library UIN Maliki Malang
2) Mendefinisikan class ontologi dan menyusun class tersebut dalam hirarki taksonomi (subclass-superclass) dengan menggunakan proses top-down dimulai dengan mendefinisikan concept umum dalam domain dilanjutkan dengan concept yang lebih spesifik.
3) Mendefinisikan slot atau property
4) Mendefinisikan facets pada slot atau axiom pada properties. Properties memiliki domain dan range yang spesifik. Properties menghubungkan individu pada domain dan individu pada range.
Untuk ilustrasi pemodelan ontolgy ini dapat dilihat pada gambar 3.3 dibawah ini.
Gambar 3.4 Ilustrasi proses pemodelan ontology
Domain ontology yang akan dibangun adalah Skripsi. Ontology ini akan digunakan untuk aplikasi yang dapat memberikan informasi mengenai skripsi pada Digital Library UIN Maliki Malang. Untuk melengkapi ruang lingkup dari domain tersebut dibutuhkan dokumen0dokumen seperti berikut:
Class Nama Penulis
Class Tahun Pembuatan
Class Fakultas (mempunyai subclass Tarbiyah, Ekonomi, Humaniora, Syariah, Saintek, dan Psikologi)
Class Jurusan (mempunyai subclass Teknik Informatika, Matematika, Biologi, Fisika, Kimia, Teknik Arsitektur, Bahasa Inggris, Psikologi dst).
Class Dosen Pembimbing (mempunyai subclass Pembimbing 1 dan pembimbing 2).
Class Abstract.
e) Resource Description Framework (RDF)
Gambar 3.5 Contoh RDF
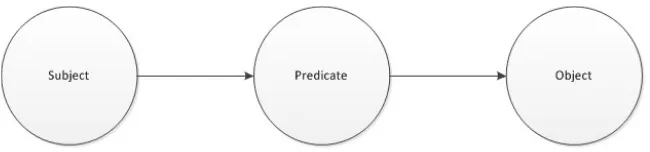
Resource Description Framework (RDF) merupakan representasi dari suatu model metadata dokumen yang mengandung subjek, predikat, dan objek. Subjek merupakan bagian dari kalimat yang menjelaskan tentang sesuatu yang menjadi pusat kalimat. Predikat merupakan bagian dari kalimat yang menjelaskan property atau karakteristik dari subject yang dibicarakan yang berisikan hubungan antar resource. Dan objek merupakan bagian dari kalimat yang menjelaskan value dari property. Sehingga apabila digambarkan dalam bentuk graph akan terlihat seperti Gambar 3.3
Gambar 3.6 Graph Data Model
Dokumen Resource Description Framework (RDF) direpresentasikan dalam bentuk objek seperti berikut :
properti, maupun Object, yang merupakan range dari suatu properti dari suatu kalimat.
2) Property, merupakan predikat dari suatu kalimat, yang menjelaskan value (range) dari suatu pokok permasalahan (domain).
3) Datatype, merupakan subClass dari Literal, yang memiliki atribut label XMLLiteral, Literal (string dan integer). subClass, subProperties, Domain, type, dan range menunjukkan relasi yang terjadi antar object, yaitu menurut pada rules RDF.
4) Literal, merupakan sesuatu yang bukan termasuk resource. Objek class, property, datatype, memiliki beberapa atribut yaitu, label, fragmennya,yaitu http://www.w3.org/1999/02/22-rdf- syntax-ns#nil. isDefinedBy, berisikan URIref tanpa label, dibatasi oleh karakter “#”,yaitu http://www.w3.org/1999/02/ 22- rdf-syntax-ns#.
4. Pembuatan Aplikasi
Pembuatan aplikasi dilakukan dengan menggunakan bahasa pemrograman PHP dimana sistem yang dibuat berbasiskan website. Terdapat beberapa tahap preprocessing sistem.
5. Uji coba dan evaluasi
Uji coba dan evaluasi dilakukan terhadap tahapan aplikasi dan hasil dari ekstraksi yang menggunakan Algoritma Knuth Morris Prath serta hasil dari proses pembuatan Resource Description Framework (RDF).
Uji sumber daya juga dilakukan pada tahap ini dengan mengukur tingkat kecepatan pencarian melalui jumlah waktu yang dibutuhkan algoritma dalam melakukan proses pencarian dan menampilkan hasil. Begitu pula dengan jumlah memori yang digunakan akan menunjukkan kinerja algoritma pencarian
6. 6) Penyusunan laporan
BAB IV
DAFTAR PUSTAKA
Berners-Lee, T., Hendler, J., Lasilla, O., 2001, The Semantic Web, American Scientific
Pollock, Jefray T.2009 Semantic Web for Dummies. Indiana Polis:Wiley Publishing Suteja,
Bernard Renaldy dkk. 2008. Ontology e-Learning Content Berbasis Web Semantic. Yogyakarta: Universitas Gadjah Mada
Saryo, Riyanarto, dkk. 2012. Semantic Search: Pencarian berdasarkan konten. Yogyakarta:Penerbit ANDI.
Wahyono, Teguh. 2004. Sistem Informasi (Konsep Dasar, Analisis Desain dan Implementasi). Yogyakarta: Graha Ilmu.
Nava’atul Fadillah, Novrido Charibaldi, Herlina Jayadianti.2010.Penerapan Teknologi Semantic Web Pada Aplikasi Pencarian Koleksi Perpustakaan(Studi Kasus:Perpustakaan Fti Upn ”Veteran” Yogyakarta).Tersedia di http://repository.upnyk.ac.id/461/1/DAFTAR_ISI.pdf diakses pada 27 februari 2014.
Nadya Sabyla Fitrya. 2012. Perancangan Dan Implementasi Search Engine Menggunakan Teknologi Semantic Web Pada Aplikasi Digital Library.Tersedia di http://lib.uin-malang.ac.id/?mod=th_detail&id=07650026 diakses pada 27 februari 2014.
Nisa Hidayani, Juni Nurma Sari, Rahmat Suhatman. 2013. Perancangan dan Implementasi Algoritma Brute Force Untuk Pencarian String Pada Website PCR. Tersedia di https://journal.pcr.ac.id/student- journal/page/read_pdf.php? name=Jurnal_NisaHidayani.pdf&id=57 27 februari 2014.
Andi Nugroho Moh. 2013. Ensiklopedia Objek Wisata Jawa Timur Menggunakan Semantic
Web.
Dian Farisah Ristanti. 2013, Mesin Pencari Berbasis Semantic Search Menggunakan
Algoritma Boyer-Moore pada Ensiklopedia Masjid Bersejarah Di Indonesia
Bing Liu, Robert Grossman, and Yanhong Zhai, Mining Data Records in Web Pages,
University of Illinois at Chicago, 2003, http://www.cs.uic.edu/~liub/publications/kdd
2003-dataRecord.pdf,
Bing Liu, Web Content Mining, University of Illinois at Chicago, 2005, http://www.frenchlane.com/Web-ContentMining-4.pdf,
Bing Liu, and Yanhong Zhai, Extracting Web Data Using Instance-Based Learning, University of Illinois at Chicago, 2007.
C-H. Chang, S-L. Lui, S-L., C. Pu, IEPAD: Information Extraction based on Pattern
Discovery, WWW-10, 2001, http://www10.org/cdrom/papers/pdf/p223.pdf,
Cris Yang, SEG5120-Web Mining, http://www.se.cuhk.edu.hk/~seg5120/note/Le
c%201%20Web%20Mining.pdf
David Buttler, Ling Liu, and Calton Pu, A Fully Automated Object Extraction System for