BAB 2
TINJAUAN PUSTAKA
2.1. Citra
Citra adalah suatu representasi (gambaran), kemiripan, atau imitasi dari suatu objek. Citra sebagai keluaran suatu sistem perekaman data dapat bersifat optik berupa foto, bersifat sinyal-sinyal video seperti gambar pada monitor televisi, atau bersifat digital yang dapat langsung disimpan pada media penyimpanan (Sutoyo, Et al. 2009).
2.1.1. Citra Analog
Citra analog adalah citra yang bersifat kontinu, seperti gambar pada monitor televisi, foto sinar X, foto yang dicetak di kertas foto, lukisan, pemandangan alam, hasil computerized tomography scanner (CT-scanner), gambar-gambar yang terekam pada pita kaset, dan lain sebagainya. Citra analog tidak dapat direpresentasikan dalam komputer sehingga tidak dapat diproses di komputer secara langsung, oleh sebab itu agar citra ini dapat diproses di komputer, proses konversi analog ke digital harus dilakukan terlebih dahulu.
Gambar 2.1. Contoh Citra Analog Sensor Rontgen Untuk Foto Thorax
Gambar 2.1 merupakan salah satu contoh dari citra analog, citra analog dihasilkan dari alat-alat analog, webcam, computerized tomography scanner (CT-scanner), sensor rontgen untuk foto thorax, sensor gelombang pendek pada sistem radar, sensor ultra sound pada sistem ultrasonografi (USG), dan lain-lain (Sutoyo, Et al. 2009).
2.1.2. Citra Digital
Citra digital adalah citra yang dapat diolah oleh komputer. Citra digital disebut juga citra diskrit di mana citra tersebut dihasilkan melalui proses digitalisasi terhadap citra kontinu.
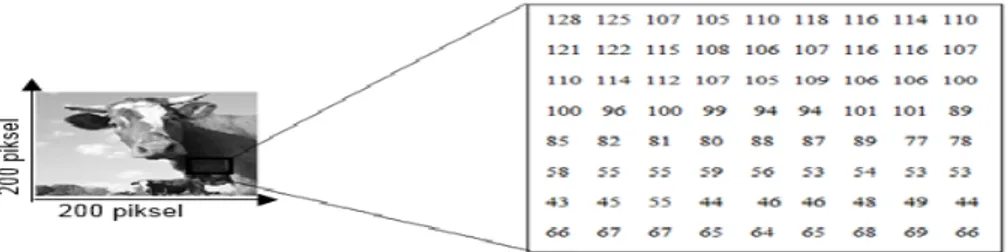
Gambar 2.2. Ilustrasi Citra dengan Matrix 200 x 200
Pada Gambar 2.2 terdapat sebuah ilustrasi citra grayscale berukuran 200x200 piksel diambil sebagian (kotak kecil) berukuran 8x9. Setelah itu monitor akan menampilkan sebuah kotak kecil, namun yang disimpan dalam memori komputer hanyalah angka-angka yang menunjukkan besar intensitas pada masing-masing piksel tersebut (Sutoyo, Et al. 2009).
Citra digital merupakan sebuah matriks di mana indeks baris dan kolomnya menyatakan suatu titik pada citra tersebut dan elemen matriksnya (yang disebut sebagai elemen gambar/piksel/pixel/picture elemen/pels) menyatakan tingkat keabuan pada titik tersebut. Sebuah citra mungkin dapat didefinisikan sebagai fungsi f(x,y) berukuran M baris dan N kolom, dengan x dan y adalah koordinat spasial, dan amplitudo f di titik koordinat (x,y) disebut intensitas atau tingkat keabuan dari citra pada titik tersebut. Apabila nilai x, y dan nilai amplitudo f secara keseluruhan berhingga (finite) dan bernilai diskrit maka dapat dikatakan bahwa citra tersebut adalah citra digital.
Gambar 2.3. Fungsi Citra Digital dengan Matriks N x M (Putra, 2010)
Gambar 2.3 menunjukkan posisi koordinat citra digital yang ditulis dalam bentuk matriks berukuran NxM (PU, 2006).
2.2. Format File Citra
Format file merupakan cara standar bagaimana informasi itu dikodekan untuk disimpan di dalam file komputer. Format file merupakan sebuah identitas file, di mana file tersebut dibedakan oleh software apa saja yang dapat membaca file tersebut serta sistem operasi apa saja yang mendukung file tersebut. Menurut (Sutoyo, et al. 2009:25) ada dua jenis format file citra yang sering digunakan dalam pengolahan citra, yaitu citra vektor dan citra bitmap.
Citra vektor adalah citra yang dihasilkan dari perhitungan matematis dan tidak berdasarkan piksel, di mana data tersebut tersimpan dalam bentuk vektor posisi, yang disimpan adalah informasi vektor posisi dalam bentuk sebuah fungsi. Mengubah warna pada citra vektor sulit untuk dilakukan, tetapi membentuk objek dengan cara mengubah nilai lebih mudah dilakukan. Yang termasuk dalam format citra vektor adalah AutoCAD Drawing Format(DWG), microstation Drawing Format(DGN), Dan lain-lain (Sutoyo, Et al. 2009).
Citra bitmap atau sering disebut citra raster merupakan kumpulan bit yang tersusun di dalam baris-baris dan kolom-kolom yang membentuk sebuah citra. Citra Bitmap menyimpan data kode citra secara digital dan lengkap, di mana citra tersebut memiliki kandungan satuan titik atau piksel (cara penyimpanannya adalah per piksel). Piksel merupakan satuan terkecil dari citra raster berupa kotak yang berisi satu warna. Citra Bitmap direpresentasikan dalam bentuk matriks atau dipetakan dengan menggunakan bilangan biner atau system bilangan lain. Citra ini memiliki kelebihan dalam memanipulasi warna, tetapi sulit untuk mengubah objek. Sehingga bitmap sering digunakan untuk gambar warna yang rumit, seperti foto dan lukisan digital. Citra bitmap umumnya diperoleh melalui media seperti camera digital, scanner, video capture, dll. Beberapa format citra raster yang digunakan adalah (bmp) Microsoft Windows bitmap format, (gif) compuserve graphics interchange format, Aldus tagged image file format (TIF), AT & T targa format (TGA) (Sutoyo, Et al. 2009).
2.2.1. Aldus Tagged Image File Format (TIF)
Aldus Tagged Image File Format (TIF) Merupakan format kompleks dan multiguna yang dikembangkan oleh Aldus bersama Microsoft (Sutoyo, Et al. 2009). Format file TIF (ekstensi .tif) merupakan file untuk format graphic yang tinggi. TIF adalah format
file yang umumnya berasal dari scanner, program pengubah foto, dari beberapa kamera tipe prosumer, dll. TIF merupakan salah satu dari format citra raster yang paling banyak disupport atau didukung oleh aplikasi-aplikasi image printing, baik yang berbasis pc maupun mac. TIF tersedia dalam bentuk bilevel, grayscale, dan palette color image. TIF merupakan format fleksibel yang dapat digunakan untuk
lossless compression atau lossy compression. Format ini biasanya dapat menyimpan 8
bit atau 16 bit perwarna (red, green, blue) untuk 24-bit dan 48-bit total, berturut-turut. File TIF tidak digunakan dalam gambar web. File jenis TIF merupakan file-file dengan ukuran yang besar, sehingga sebagian besar web browser tidak akan menampilkan file TIF (Shindu & Rajkamal, 2009).
2.2.2. AT & T Targa Format (TGA)
TGA merupakan format file citra yang digunakan untuk 16-bit dan 24-bit citra warna penuh diciptakan untuk sistem truevision. Format file ini mampu menyimpan gambar dengan mode warna RGB dalam 32 bit serta 1 alpha, channel, juga Grayscale, Indexed Color, dan RGB dalam 16 atau 24 bit tanpa alpha channel (Sutoyo, Et al. 2009).
2.3. Kompresi Citra
Kompresi citra merupakan proses untuk mereduksi atau mengurangi ukuran suatu data untuk menghasilkan representasi digital yang padat atau mampat namun tetap mewakili kuantitas informasi yang terkandung pada data tersebut (Putra, 2010).
Pemampatan citra atau kompresi bertujuan untuk meminimalkan kebutuhan memori dalam merepresentasikan citra digital dengan mengurangi duplikasi data di dalam citra sehingga memori yang dibutuhkan menjadi lebih sedikit daripada representasi citra semula.
2.3.1 Teknik Kompresi Citra
Ada dua teknik yang dapat dilakukan dalam melakukan kompresi citra yaitu: 1. Lossless Compression
Lossless Compression merupakan kompresi citra di mana hasil dekompresi
hilang. Akan tetapi rasio kompresi dengan metode ini umumnya sangat rendah. Banyak aplikasi yang memerlukan kompresi tanpa cacat atau berkehilangan seperti aplikasi radiografi, hasil diagnosis medis, satelit, dll. Contoh dari algoritma ini adalah Run Length Encoding (RLE), Entropy Encoding (Huffman, Arithmetic coding), Deflate dan Adaptive Dictionary Based (LZW) (Sutoyo, Et al. 2009).
2. Lossy Compression
Lossy Compression adalah kompressi citra di mana hasil dekompresi dari citra
yang terkompresi tidak sama dengan citra aslinya karena ada informasi yang hilang, tetapi masih dapat ditolerir oleh persepsi mata. Mata tidak dapat membedakan perubahan kecil pada gambar. Metode ini menghasilkan ratio kompresi yang lebih tinggi dari metode lossless. Contoh dari algoritma lossless adalah Color Reduction, Chroma Subsampling, dan Transform Coding (Sutoyo, Et al. 2009).
2.3.2. Kriteria Kompresi Citra
Dalam kompresi citra biasanya kriteria yang digunakan untuk mengukur pemampatan citra adalah:
1. Waktu kompresi dan waktu dekompresi
Proses kompresi merupakan proses mengkodekan citra (encode) sehingga diperoleh citra dengan representasi kebutuhan memori yang minimum. Citra terkompresi disimpan dalam file dengan format tertentu. Sedangkan proses dekompresi adalah proses untuk menguraikan citra yang dimampatkan untuk dikembalikan lagi (decoding) menjadi citra yang tidak mampat (mengembalikan ke bentuk semula). Algoritma pemampatan yang baik adalah algoritma yang membutuhkan waktu untuk kompresi dan dekompresi paling sedikit (paling cepat).
Gambar 2.4 merupakan gambar mengenai proses kompresi dan dekompresi citra (Sutoyo, Et al. 2009).
2. Kebutuhan memori
Suatu metode kompresi kompresi yang mampu mengompresi file citra menjadi file yang berukuran paling minimal adalah metode kompresi yang baik. Di mana memori yang dibutuhkan untuk menyimpan hasil kompresi berkurang secara berarti. Akan tetapi biasanya semakin besar persentase pemampatan, semakin kecil memori yang diperlukan sehingga kualitas citra makin berkurang. Sebaliknya semakin kecil persentase yang dimampatkan, semakin bagus kualitas hasil pemampatan tersebut (Sutoyo, Et al. 2009).
3. Kualitas pemampatan
Metode kompresi yang baik adalah metode yang dapat mengembalikan citra hasil kompresi menjadi citra semula tanpa kehilangan informasi apapun. Walaupun ada informasi yang hilang akibat pemampatan, sebaiknya hal tersebut ditekan seminimal mungkin. Semakin berkualitas hasil pemampatan, semakin besar memori yang dibutuhkan, sebaliknya semakin jelek kualitas pemampatan, semakin kecil kebutuhan memori yang harus disediakan (Sutoyo, Et al. 2009).
2.3.3. Rasio Kompresi Citra
Rasio kompresi citra adalah ukuran persentasi citra yang telah berhasil dimampatkan. Secara matematis pemampatan citra dituliskan sebagai berikut.
= 100% −
100%
Misalnya rasio kompresi adalah 20%, berarti 20% dari citra tersebut telah berhasil dimampatkan.
2.4. Arithmetic Coding
Arithmetic Coding adalah salah satu metode kompresi lossless yang memakai statistikal modeling yang mengodekan suatu barisan karakter/pesan dengan floating
point. Pada umumnya, suatu algoritma kompresi citra melakukan penggantian satu
satu deretan input dengan sebuah bilangan floating point. Apabila pesan yang dikodekan semakin panjang dan kompleks, maka semakin banyak bit yang diperlukan (Shindu & Rajkamal, 2009). Arithmetic Coding memiliki output yaitu satu angka yang lebih kecil dari 1 dan lebih besar sama dengan 0. Agar didapat hasil angka output tersebut, tiap simbol/karakter yang diencode diberikan 1 set nilai probabilitas. Sebagai contoh terdapat citra warna dengan ukuran 2x2 pixel dalam bentuk matriks seperti yang terdapat pada Gambar 2.5.
255 0 0 255 192 203 255 192 203 0 255 0
Gambar 2.5. Matrix Citra Warna RGB Ukuran 2x2 pixel
Simbol pada gambar di atas akan diencode sehingga didapat tabel probabilitas seperti pada Tabel 2.1.
Tabel 2.1. Tabel Nilai Probabilitas
Simbol Frekuensi Probabilitas
255 0 192 203 4 4 2 2 4/12 = 0.33 4/12 = 0.33 2/16 = 0.17 2/16 = 0.17
Setelah probabilitas tiap–tiap simbol/karakter diketahui, maka tiap simbol/karakter diberikan range tertentu dengan nilainya berkisar antara 0 dan 1, sesuai dengan probabilitas yang ada. Dalam hal ini tidak ada ketentuan urut–urutan dalam penentuan segmen, asalkan antara encoder dan decode melakukan hal yang sama. Setelah itu akan diperoleh Tabel 2.2 berikut.
Tabel 2.2. Tabel Probabilitas dan Range Simbol
Karakter Frekuensi Probabilitas Range
255 0 192 203 4 4 2 2 4/12 = 0.33 4/12 = 0.33 2/16 = 0.17 2/16 = 0.17 0.0 ≤ 255≤0.33 0.33≤0≤0.66 0.66≤192≤0.83 0.83≤203≤1.0
Satu hal yang perlu diperhatikan dalam tabel ini adalah tiap karakter melingkupi range yang disebutkan, kecuali bilangan yang tinggi. Jadi, simbol 128 sesungguhnya mempunyai range mulai dari 0.9 – 0.9999... (Sutoyo, et al. 2009) (lidya, 20120). Berikut ini adalah algoritma yang dipakai untuk proses encoding (PU, 2006): 1. Set low = 0.0 (kondisi awal)
2. Set high = 1.0 (kondisi awal) 3. While (symbol input masih ada) do 4. Ambil symbol input
5. CR = high - low
6. High = low + CR*high_range(simbol) 7. Low = low + CR*low_range(simbol) 8. End while
9. Cetak low
Pada algoritma encoder di atas dimulai dengan mengkondisikan nilai awal low = 0 dan high = 1, kemudian ambil simbol input pertama yaitu 255. Kemudian tentukan nilai CR (Code Range) pada simbol 255, di mana CR = high(kondisi awal)-low(kondisi awal) atau CR = high(hasil perhitungan sebelumnya)-low(hasil perhitungan sebelumnya). Setelah didapat nilai CR, kemudian tentukan nilai high_range dan low_range pada simbol 255, di mana nilai tersebut dilihat berdasarkan nilai Range pada Tabel 2.2 di atas. Kemudian tentukan nilai high dan low yang baru dengan menggunakan rumus High = low(kondisi awal)+CR*high_range(255) dan Low = low(kondisi awal)+CR*low_range(255), lalu cetak nilai Low. Kemudian ambil simbol berikutnya yaitu 0 , tentukan nilai CR = high (hasil perhitungan sebelumnya)-low (hasil perhitungan sebelumnya). Setelah didapat nilai CR, kemudian tentukan nilai high_range dan low_range pada simbol 0, di mana nilai tersebut dilihat berdasarkan nilai Range simbol 0 pada Tabel 2.2 di atas. Kemudian tentukan nilai high dan low yang baru dengan menggunakan rumus yang sama, lalu cetak nilai Low. Ulangi langkah yang sama pada simbol berikutnya hingga semua simbol habis, kemudian didapatlah nilai Low pada simbol terakhir yaitu simbol 0. Nilai Low tersebutlah yang akan menjadi output Encoded Symbol (ES) sebagai hasil keluaran dari proses encoding pada algoritma Arithmetic Coding.
Berikut ini adalah algoritma yang dipakai untuk proses decoding (PU, 2006): 1. Ambil encoded symbol (ES)
2. Do
3. Cari range dari symbol yang melingkupi ES 4. Cetak symbol
5. CR = high_range - low_range 6. ES = ES - low_range
7. ES = ES/CR 8. Until symbol habis
Proses decoder dimulai dengan mengambil nilai Encoded Symbol (ES), kemudian cari range dari simbol yang melingkupi ES. Misalkan nilai ES adalah 0.154429213 maka nilai ES tersebut berada pada range 0.0≤255≤0.33, berdasarkan pada Tabel 2.2 di atas. Maka didapatlah simbol pertamanya adalah 255, lalu cetak simbol. Untuk menentukan simbol berikutnya hitung nilai Code Range (CR) pada simbol 255 di mana CR = high_range(255)-low_range(255), kemudian tentukan nilai Encoded Symbol (ES) berikutnya dengan rumus ES = ES-low_range(255) kemudian nilai ES yang didapat dibagi dengan nilai Code Range (CR), di mana ES = ES/CR. Nilai ES yang didapat inilah yang akan digunakan untuk menentukan simbol berikutnya yang dilihat dari nilai Range berdasarkan Tabel 2.2 di atas. Ulangi langkah di atas untuk mendapatkan simbol berikutnya, hingga didapat nilai ES = 0.0 (selesai).
2.5. Deflate
Algoritma Deflate merupakan algoritma yang dibuat berdasarkan variasi algoritma LZ77 dikombinasikan dengan algoritma Huffman yang didesain oleh Philip Katz sebagai bagian dari file format ZIP (Salomon, 2007).
LZ77 adalah algoritma lossless compression yang diperkenalkan oleh Abraham Lempel dan Jacob Ziv, di mana algoritma kompresi ini bekerja dengan mencari urutan data yang diulang. Isitilah sliding window atau jendela luncur digunakan pada algoritma ini yang berarti pada suatu titik tertentu dalam data, ada catatan tentang apa yang terjadi pada karakter-karakter sebelumnya (Salomon, 2007). Berikut ini adalah contoh simbol dari citra grayscale dapat dilihat pada Gambar 2.6.
3 3 1 1 2
1 5 4 1 1
2 1 7 1 1
2 1 6 3 3
4 5 4 1 5
Gambar 2.6. Contoh Citra Grayscale Ukuran 5 x 5 Pixel
Kemudian contoh citra di atas akan dikodekan ke dalam algoritma LZ77 seperti pada Gambar 2.7.
Gambar 2.7. Sliding Window (Salomon, 2007)
Pada gambar di atas encoder akan membaca semua simbol pada look-ahead buffer, lalu encoder akan memeriksa search buffer dari kanan ke kiri untuk menemukan karakter pertama pada look-ahead buffer yang sesuai dengan karakter/simbol pada
search buffer yaitu “1” pada jarak 2 simbol dari ujung search buffer, kemudian
encoder akan berusaha mencocokkan rangkaian simbol. Kemudian simbol kedua ditemukan pada jarak 3 simbol dari ujung search buffer, dan simbol ketiga dan keempat ditemukan pada jarak 4 dan 5 dari ujung search buffer yang sesuai dengan karakter pertama pada look-ahead buffer, kemudian encoder akan berusaha mencocokkan rangkain simbol dan menghasilkan token. Token ditulis dengan (f,l,c) di mana f merupakan offset atau urutan posisi terkecil pada search buffer, length(l) merupakan panjang karakter, dan c merupakan simbol pertama pada look-ahead buffer yang berada tepat di kanan rangkaian simbol yang sesuai dengan search buffer. Encoder akan mencatat nilai length terbesar dan offset terkecil. Hasil pencarian tersebut menemukan panjang rangkaian length(l) yang sesuai yaitu 4 simbol (“1121“). Pencarian terus dilakukan hingga search buffer menelusuri semua simbol tersebut. Kemudian simbol keempat ditemukan pada offset ke-8, simbol kelima, keenam, ketujuh dan kedelapan ditemukan pada offset ke-9, ke-10, dan ke-11 dengan panjang
rangkaian length(l) yang sesuai yaitu 4 simbol (“1121“). Setelah penelusuran selesai Encoder akan mencatat nilai length terbesar dan offset terkecil, kemudian simbol “3” akan dicatat sebagai code(c). Simbol “6” merupakan simbol pertama yang berada tepat di kanan rangkaian simbol yang sesuai pada look-ahead buffer (“1121“). Encoder kemudian menghasilkan token melalui proses di atas yaitu token (5,4,6). Proses kemudian diulang dengan menggeser sliding window sebanyak length+1 terhadap teks, sehingga search buffer akan berisi “3312154112171” dan look-ahead
buffer berisi “12163345415“. Jika tidak ada simbol yang sesuai atau simbol yang
sesuai hanya 1 maka akan dihasilkan token(0,0,c) (PU, 2006) (Sihombing, 2011). Untuk proses dekompresi LZ77, decoder akan membaca setiap rangkaian token. Apabila terdapat token (0,0,5) maka decoder akan menulis simbol 5 ke dalam output. Berikut ini adalah contoh bagaimana decoder lz77 bekerja dapat dilihat pada Gambar 2.8.
Gambar 2.8. Proses Decode Algoritma LZ77 Pada Citra Grayscale (Salomon, 2007)
Algoritma Huffman merupakan algoritma pemampatan yang menggunakan pendekatan statistik. Algoritma Huffman didesain oleh David A. Huffman di mana algoritma tersebut merupakan sebuah algoritma entropy encoding yang digunakan untuk algoritma lossless compression (Salomon, 2007). Metode ini dimulai dengan membuat daftar nilai-nilai simbol yang diurutkan berdasarkan probabilitas atau frekuensi kemunculannya.
Berikut ini adalah contoh algoritma Huffman dengan menggunakan input yang sama dengan Gambar 2.6. Langkah pertama yang dilakukan adalah membuat daftar frekuensi kemunculan tiap karakter di mana K merupakan simbol/karakter, nk merupakan frekuensi tiap simbol/karakter, dan P(k) merupakan nilai probabilitas di mana jumlah frekuensi tiap simbol dibagi dengan jumlah seluruh frekuensi simbol atau pixel, seperti pada Tabel 2.3.
Tabel 2.3. Tabel Nilai Probabilitas K nk P(k) = nk/n 1 10 0.4 2 3 0.12 3 4 0.16 4 3 0.12 5 3 0.12 6 1 0.04 7 1 0.04
Langkah berikutnya adalah urutkan simbol berdasarkan tabel di atas dari simbol yang memiliki frekuensi kemunculan terkecil hingga terbesar. Buat sebuah node, di mana node merupakan gabungan dari dua buah simbol paling kiri yang mempunyai frekuensi terkecil dengan simbol sebelah kanan dari simbol tersebut, gabungkan dua buah pohon yang mempunyai frekuensi kemunculan terkecil dan urutkan kembali, kemudian ulangi langkah tersebut sampai tersisa satu pohon biner. Beri label pohon biner tersebut, pada sisi sebelah kiri beri label 0 dan sisi kanan pohon diberi label 1. Telusuri pohon biner tersebut dari akar ke daun, sehingga didapat barisan label-label sisi dari akar ke daun adalah kode Huffman. Berdasarkan langkah-langkah di atas dihasilkan pohon Huffman seperti pada Gambar 2.9.
.
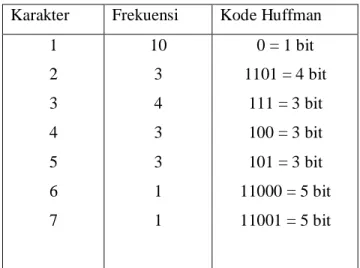
Dari penulusuran di atas maka dihasilkan kode Huffman seperti dalam Tabel 2.4.
Tabel 2.4. Tabel Kode Huffman Karakter Frekuensi Kode Huffman
1 2 3 4 5 6 7 10 3 4 3 3 1 1 0 = 1 bit 1101 = 4 bit 111 = 3 bit 100 = 3 bit 101 = 3 bit 11000 = 5 bit 11001 = 5 bit
Untuk proses decodingnya atau dekompresinya, pada rangkaian bit 111 111 0 0 1101 0 101 100 0 0 1101…..baca kode bit “1”, tidak ada kode bit “1”, selanjutnya baca kode bit “11”, tidak ada kode bit “11”, selanjutnya baca kode bit “111”, dari pemetaan disimpulkan bahwa kode bit “111” adalah 3, untuk bit selanjutnya baca kode bit “1”, tidak ada kode bit “1”, selanjutnya baca kode bit “11”, tidak ada kode bit “11”, selanjutnya kode bit “111” dari pemetaan disimpulkan bahwa kode bit “111” adalah 3, dan seterusnya (Sutoyo, Et al. 2009).
Dalam proses kompresinya, algoritma Deflate ini terlebih dahulu melakukan proses pengelompokan karakter dengan menggunakan algoritma LZ77. Kemudian hasil dari pengelompokan karakter tersebut dikompresi lagi dengan menggunakan algoritma Huffman (Huffman Tree). Algoritma Deflate ini merupakan algoritma
loseless compression. Karena algoritma Deflate ini merupakan gabungan dari dua
algoritma kompresi yang bersifat loseless (Dharmawan, 2008).
Proses encoding dari algoritma Deflate ini dilakukan pada dua tahap. Tahap pertama adalah melakukan proses pembuatan blok-blok atau penyingkatan karakter dengan menggunakan algoritma LZ77. Tahap kedua adalah mengambil hasil penyingkatan karakter dari algoritma LZ77 dan melakukan proses kompresi dengan menggunakan Huffman Tree terhadap karakter tersebut. Hasil dari proses encoding algoritma Deflate ini adalah berupa karakter yang telah disingkat yang merupakan hasil dari encoding algoritma LZ77 dan memiliki kode biner yang lebih pendek yang
merupakan hasil dari encoding algoritma Huffman (Dharmawan, 2008).
Proses decoding pada algoritma Deflate merupakan kebalikan dari proses encodingnya. Langkah pertama adalah melakukan proses decoding dengan menggunakan algoritma Huffman. Kemudian langkah kedua adalah mengambil hasil dari proses decoding dengan menggunakan algoritma Huffman dan melakukan proses decoding kembali dengan menggunakan algoritma LZ77.