ANALISIS KINERJA LOCAL BINARY PATTERN (LBP) DAN K-NEAREST NEIGHBOR (KNN) DALAM KLASIFIKASI
CITRA DAUN MENJARI (PALMINERVIS)
TESIS
ALYIZA DWI NINGTYAS 187038032
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2021
ANALISIS KINERJA LOCAL BINARY PATTERN (LBP) DAN K-NEAREST NEIGHBOR (KNN) DALAM KLASIFIKASI
CITRA DAUN MENJARI (PALMINERVIS)
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
ALYIZA DWI NINGTYAS 187038032
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2021
Telah diuji pada Tanggal : 25 Juni 2021
PANITIA PENGUJI TESIS
Ketua : Dr. Erna Budhiarti Nababan, M.IT.
Anggota : 1. Dr. Syahril Efendi, S.Si., M.IT.
2. Dr. Elviawaty Muisa Zamzami, ST.,MT.,MM.
3. Dr. Sutarman, M.Sc.
RIWAYAT HIDUP
DATA PRIBADI:
Nama Lengkap : Alyiza Dwi Ningtyas Tempat dan Tanggal Lahir : Medan, 12 Oktober 1995
Alamat Rumah : Jl. Dr. A. Sofyan No.84 Kampus USU Medan
Telp/HP : 081375809367
Email : [email protected]
DATA PENDIDIKAN
SD : SD IKAL MEDAN TAMAT: 2007
SLTP : SMP Harapan 1 Medan TAMAT : 2010
SLTA : SMA Harapan 1 Medan TAMAT : 2013
S1 : Ilmu Komputer USU TAMAT : 2017
S2 : Teknik Informatika USU TAMAT : 2021
UCAPAN TERIMA KASIH
Berkat karunia dan rahmat Tuhan Yang Maha Esa penulis dapat menyelesikan tesis yang berjudul “ANALISIS KINERJA LOCAL BINARY PATTERN (LBP) DAN K-NEAREST NEIGHBOR (KNN) DALAM KLASIFIKASI CITRA DAUN MENJARI (PALMINERVIS)” untuk memenuhi salah satu syarat dalam mencapai gelar Magister pada Jurusan Teknik Informatika Universitas Sumatera Utara Medan.
Dalam kesempatan ini, penulis menyadari bahwa banyak pihak yang ikut berperan dalam menyelesaikan tesis ini baik moril maupun materil. Oleh karena itu penulis ingin menyampaikan ucapan terima kasih kepada:
1. Bapak Dr. Muryanto Amin, S.Sos, M.Si selaku Rektor Universitas Sumatera Utara.
2. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc selaku Wakil Rektor IV Universitas Sumatera Utara
3. Ibu Dr. Maya Silvi Lydia, M.Sc selaku Dekan Fasilkom-TI Universitas Sumatera Utara.
4. Bapak Prof. Dr. Muhammad Zarlis, M.kom selaku Ketua Program Studi Pascasarjana Fasilkom-TI Universitas Sumatera Utara.
5. Ibu Dr. Erna Budiarti Nababan, M.Sc selaku pembimbing 1, atas bimbingannya dan arahannya selama pengerjaan tesis ini.
6. Bapak Dr. Syahril Efendi, M.IT selaku pembimbing 2 dan sekretaris Program Studi Magister Fasilkom-TI Universitas Sumatera Utara, serta sebagai pembimbing akademik, atas bimbingannya selama perkuliahan dan pengerjaan tesis ini.
7. Para penguji sidang Dr. Sutarman, M.Sc dan Dr. Elviawaty Zamzami, .MT, MM yang telah memberikan koreksi dan masukan yang sangat berarti guna perbaikan tesis.
8. Seluruh dosen serta tenaga pendidik Program Studi Sarjana dan Pascasarjana Fasilkom-TI Universitas Sumatera Utara.
9. Rekan-rekan mahasiswa Program Studi Pascasarjana Fasilkom-TI Universitas Sumatera Utara serta semua pihak yang tidak dapat disebutkan satu persatu.
Secara khusus penulis menyampaikan terima kasih kepada Ayahanda Dr. Suyanto, M.Kom dan Ibunda Sri Hariyani Harahap, Amd.Far yang telah mendidik arti kehidupan dan mendoakan agar penulis menjadi orang yang bermanfaat. Teristimewa, penulis menyampaikan
ABSTRAK
Sistem pengenalan suatu objek telah banyak diteliti oleh para peneliti, namun sebagian besar hanya menggunakan satu metode saja, yakni metode K-Nearest Neighbor (KNN).
Metode tersebut banyak digunakan untuk sistem pengenalan dikarenakan dapat memberikan jaminan tingkat akurasi yang relatif baik, namun memiliki kelemahan terhadap suatu noise.
Salah satu cara untuk mengatasi kelemahan tersebut yaitu dengan menggunakan metode ekstraksi ciri Local Binary Pattern (LBP). Untuk melihat sejauh mana kinerja kombinasi kedua metode tersebut, dilakukan juga proses pengenalan objek menggunakan kombinasi KNN dan Gray Level Co-Occurrence Matrix (GLCM). Adapun sebagai input untuk tahap pemrosesan ialah dengan menggunakan data berupa citra daun pepaya dan daun chaya (palminervis).
Perbandingan antara data pelatihan dan data pengujian dalam penelitian ini yakni 2:1.
Dari hasil eksperimen memperlihatkan bahwa tingkat akurasi menggunakan LBP-KNN untuk data latih lebih besar dibandingkan menggunakan GLCM-KNN, yakni selisih sebesar 12%
(95% berbanding 83%), sedangkan untuk data uji dengan selisih 18% (76% berbanding 58%).
Kata kunci: K-Nearest Neighbor (KNN), Local Binary Pattern (LBP), Gray Level Co- Occurrence Matrix (GLCM), ekstraksi ciri, daun menjari (palminervis), noise.
LOCAL BINARY PATTERN (LBP) AND K-NEAREST NEIGHBOR (KNN) ON IMAGE CLASSIFICATION ON FINGERS LEAVES’ PERFORMANCE ANALYSIS
ABSTRACT
The object recognition system have been studied by many researchers, but most of them only use one method, namely the K-Nearest Neighbor (KNN) method. This method is widely used for recognition systems because it can guarantee a relatively good level of accuracy, but has a weakness against noise. One way to overcome this weakness is to use the Local Binary Pattern (LBP) feature extraction method. To see how far the performance of the combination of the two methods is, an object recognition process is also carried out using a combination of KNN and Gray Level Co-Occurrence Matrix (GLCM). The input for the processing stage is to use data in the form of images of papaya leaves and chaya leaves (palminervis).
The comparison between training data and test data in this study is 2:1. The experimental results show that the level of accuracy using LBP-KNN for training data is greater than using GLCM-KNN, i.e. the difference is 12% (95% versus 83%), while for test data the difference is 18% (76% versus 58%).
Keywords: K-Nearest Neighbor (KNN), Local Binary Pattern (LBP), Gray Level Co- Occurrence Matrix (GLCM), feature extraction, finger leaves (palminervis), noise.
DAFTAR ISI
Halaman
Persetujuan ... ii
Pernyataan ... iii
Persetujuan Publikasi ... iv
Panitia Penguji Tesis ... v
Riwayat Hidup ... vi
Ucapan Terima Kasih ... vii
Abstrak ... ix
Abstract ... x
Daftar Isi ... xi
Daftar Tabel ... xiii
Daftar Gambar ... xiv
Daftar Lampiran ... xv
Bab 1 Pendahuluan ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Batasan Masalah ... 4
1.4 Tujuan Penelitian ... 4
1.5 Manfaat Penelitian ... 4
1.6 Sistematika Penulisan ... 5
Bab 2 Tinjauan Pustaka ... 7
2.1 Metode Ekstraksi Ciri ... 7
2.1.1 Metode Local Binary Pattern ... 7
2.1.2 Metode Gray Level Co-Occurrence Matrix (GLCM) ... 16
2.2 Metode Klasifikasi K-Nearest Neighbor (KNN) ... 19
2.3 Akurasi ... 22
2.4 Citra... 22
2.5 Daun Menjari ... 24
2.6 Penelitian-Penelitian Terkait ... 24
Bab 3 Metodologi Penelitian ... 28
3.1 Pengumpulan Data ... 28
3.2 Preprocessing ... 28
3.2.1 Mengubah Ukuran Citra (Resizing) ... 29
3.2.2 Pembentukan Citra Aras Keabuan (Grayscaling) ... 29
3.3 Ekstraksi Ciri ... 30
3.4 Klasifikasi ... 32
3.5 Arsitektur Sistem ... 33
Bab 4 Hasil dan Pembahasan ... 34
4.1 Pengumpulan Data ... 34
4.2 Hasil Preprocessing ... 35
4.3 Pelatihan dan Pengujian ... 36
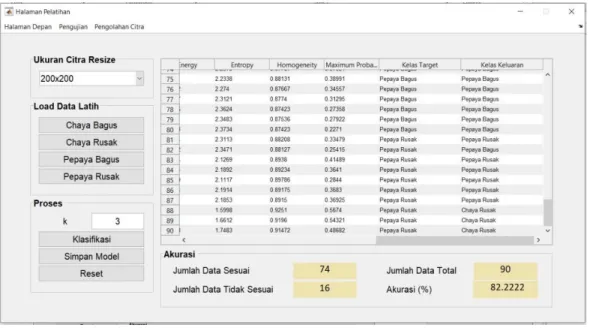
4.3.1 Hasil Pelatihan ... 37
4.3.1.1 Hasil Pelatihan LBP-KNN... 37
4.3.1.2 Hasil Pelatihan GLCM-KNN ... 41
4.3.2 Hasil Pengujian... 44
4.3.2.1 Hasil Pengujian LBP-KNN ... 45
4.3.2.2 Hasil Pengujian GLCM-KNN ... 47
4.4 Pembahasan ... 49
Bab 5 Kesimpulan dan Saran ... 53
5.1 Kesimpulan ... 53
5.2 Saran ... 53
Daftar Pustaka ... 54
DAFTAR TABEL
Halaman
Tabel 2.1 Konversi Citra Sudut Lancip Tenggara Menjadi Citra Grayscale 1 Bit ... 10
Tabel 2.2 Hasil Komputasi LBP Untuk Citra Sudut Lancip Tenggara ... 10
Tabel 2.3 Konversi Citra Sudut Lancip Timur Laut Menjadi Citra Grayscale 1 bit ... 11
Tabel 2.4 Hasil komputasi LBP Untuk Citra Sudut Lancip Timur Laut ... 12
Tabel 2.5 Penelitian Terkait ... 26
Tabel 4.1 Hasil Pelatihan 90 Citra LBP-KNN ... 37
Tabel 4.2 Hasil Pelatihan 90 Citra GLCM-KNN... 41
Tabel 4.3 Hasil Pengujian 45 Citra LBP-KNN ... 45
Tabel 4.4 Hasil Pengujian 45 Citra GLCM-KNN ... 47
Tabel L2.1 Label Daun Berdasarkan Fitur LBP ... 71
Tabel L2.2 Nilai Piksel Daun Chaya Matriks 5x5 ... 72
Tabel L2.3 Konversi Data Latih LBP ... 84
Tabel L2.4 Sampel Data Uji LBP ... 84
Tabel L2.5 Perhitungan Jarak Untuk Fitur LBP ... 85
Tabel L2.6 Hasil Perhitungan Jarak Terurut LBP-KNN ... 85
Tabel L2.6 Hasil Perhitungan Jarak Terurut LBP-KNN (Lanjutan)... 86
Tabel L2.7 Label Daun Berdasarkan Fitur GLCM ... 86
Tabel L2.7 Label Daun Berdasarkan Fitur GLCM (Lanjutan) ... 87
Tabel L2.8 Nilai Grayscale matriks Daun Chaya 5x5 ... 88
Tabel L2.9 Matriks co-occurrence GLCM [0 1] ... 88
Tabel L2.10 Matriks GLCM setelah normalisasi ... 89
Tabel L2.11 Konversi Data Latih GLCM ... 99
Tabel L2.12 Sampel Data Uji GLCM ... 99
Tabel L2.13 Perhitungan Jarak Untuk Fitur GLCM ... 100
Tabel L2.14 Hasil Perhitungan Jarak Terurut GLCM-KNN ... 100
Tabel L2.14 Hasil Perhitungan Jarak Terurut GLCM-KNN (Lanjutan) ... 101
DAFTAR GAMBAR
Halaman
Gambar 2.1 Piksel berada di sekitar ... 8
Gambar 2.2 Proses Komputasi Kode LBP ... 9
Gambar 3.1 Tahapan Preprocessing Citra ... 29
Gambar 3.2. (a) Diagram Ekstraksi Ciri LBP, (b) Diagram Ekstraksi Ciri GLCM ... 31
Gambar 3.3 Tahapan Klasifikasi Sistem ... 32
Gambar 3.4 Arsitektur Sistem... 33
Gambar 4.1 Daun Pepaya Bagus ... 34
Gambar 4.2 Daun Pepaya Rusak ... 34
Gambar 4.3 Daun Chaya Bagus ... 35
Gambar 4.4 Daun Chaya Rusak ... 35
Gambar 4.5 Citra Hasil Resize 200x200 ... 35
Gambar 4.6 Citra Hasil Grayscale ... 36
Gambar 4.7 Citra Hasil Preprocessing ... 36
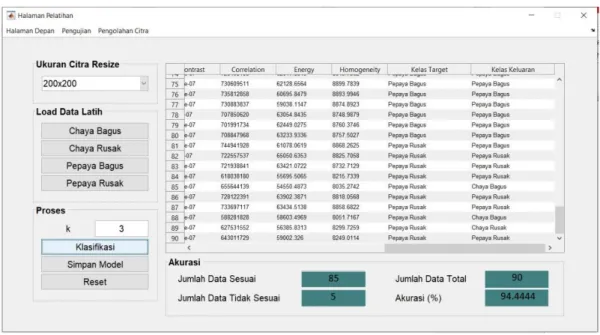
Gambar 4.8 Tampilan Hasil Pelatihan LBP-KNN ... 37
Gambar 4.9 Tampilan Hasil Pelatihan GLCM-KNN ... 41
Gambar 4.10 Tampilan Hasil Pengujian Citra LBP-KNN... 45
Gambar 4.11 Tampilan Hasil Pengujian Citra GLCM-KNN ... 47
Gambar 4.12 Tampilan Hasil Pengolahan Citra LBP ... 49
Gambar 4.13 Tampilan Hasil Pengolahan Citra GLCM ... 50
Gambar L2.1 Daun Chaya yang dibagi menjadi Matriks 3x3 ... 73
Gambar L2.2 Pencarian Nilai Piksel Tengah ... 73
Gambar L2.3 Konversi Nilai Piksel ke Biner ... 73
Gambar L2.4 Membentuk Bilangan Biner 8 Bit (Sumber: Petrou & Sevilla, 2006) ... 74
Gambar L2.5 Nilai Tengah Piksel 183 yang Berubah Menjadi Kode LBP ... 74
Gambar L2.6 Perhitungan nilai piksel daun Chaya selanjutnya ... 74
Gambar L2.7 Nilai Tengah Piksel 100 yang Berubah Menjadi Kode LBP ... 75
Gambar L2.8 Nilai Piksel Akhir Hasil Perhitungan LBP ... 75
DAFTAR LAMPIRAN
Halaman LAMPIRAN 1: DATA LATIH DAN DATA UJI ... 61 LAMPIRAN 2: KOMPUTASI MANUAL ... 71 LAMPIRAN 3:DAFTAR PUBLIKASI ILMIAH PENULIS... 102
BAB 1 PENDAHULUAN
Bab ini menjelaskan mengenai latar belakang, rumusan masalah, Batasan masalah, tujuan penelitian, manfaat penelitian, dan sistematika penulisan yang diuraikan sebagai berikut:
1.1 Latar Belakang
Teknologi akan terus dikembangkan dengan tujuan untuk membantu mempermudah pekerjaan yang dilakukan manusia. Saat ini manusia sangat bergantung dengan teknologi, dikarenakan otak manusia memiliki kerterbatasan dalam mengolah atau mengingat informasi tertentu. Tidak selamanya kemampuan berpikir manusia dapat menampung informasi yang banyak untuk waktu yang lama, oleh karena itu dibutuhkan peralihan pengetahuan manual ke suatu sistem digital. Perkembangan teknologi pada dunia digital memiliki potensi yang berpengaruh terhadap efisiensi kegiatan manusia. Salah satu teknologi yang berkembang saat ini adalah sistem yang melibatkan pengenalan secara komputerisasi menggunakan metode dan konsep untuk mengidentifikasi terhadap suatu objek.
Menurut Kamus Besar Bahasa Indonesia (KBBI) mengidentifikasi adalah menentukan atau menetapkan identitas (misal: orang, benda, dan sebagainya).
Identifikasi merupakan sinonim dari kata pengenalan, ditentukan berdasarkan pada ciri suatu pola dalam citra. Proses identifikasi atau pengenalan objek dimulai dari pembacaan citra, pengubahan citra asli menjadi citra biner, ekstraksi ciri dan proses klasifikasi objek (Khrisna et al., 2016).
Penelitian mengenai pengenalan pola sudah banyak dilakukan oleh para peneliti, salah satu terapannya di bidang botanical seperti identifikasi spesies tanaman. Pola yang dapat diolah dan dijadikan identifikasi terhadap tanaman salah satunya pada daun.
Pengidentifikasi yang digunakan ialah dilihat dari berbedanya pola sebuah daun (Bowo et al., 2011).
Klasifikasi jenis tanaman bertujuan agar sistem dapat mengenali citra dari jenis daun yang disajikan dengan melihat karakteristik yang meliputi bentuk serta tekstur dari sebuah daun (Saputra dan Wahyuni, 2018). Sistem pengenalan berdasarkan klasifikasi pada daun dapat berguna dalam memberikan sekumpulan informasi tentang suatu tanaman yang ditemui dan sumber informasi bagi orang awam. Klasifikasi sistem untuk dapat mengenali tanaman berupa daun harus melalui proses pembelajaran panjang yang tidak cukup diselesaikan hanya dengan melalui algoritma saja (Lianto & Lestari, 2011).
Adanya sistem yang mampu mengklasifikasi daun tumbuhan secara otomatis dapat membantu pengguna untuk mengenali tanaman dengan cepat (Liantoni, 2015). Metode klasifikasi yang paling banyak digunakan oleh para peneliti adalah metode K-Nearest Neighbor (KNN), dikarenakan metode ini memiliki tingkat akurasi yang relatif lebih baik (Miladiah, 2019) daripada metode Support Vector Machine (SVM) (Wahid, 2019) dan metode Learning Vector Quantization (LVQ) (Santoso, 2016). Penelitian dengan metode K-Nearest Neighbor (KNN) telah dilakukan sebelumnya oleh Sari (2015) yang menyatakan bahwa metode KNN dapat mengklasifikasi banyak kelas yang memiliki ciri yang hampir sama. Metode KNN juga dapat mampu mengenali objek berdasarkan karakteristik tekstur gambar objek tersebut (Adepoju, 2018). Di dalam proses pengenalan objek dengan metode klasifikasi KNN, digunakan pula metode jarak yaitu Euclidean distance. Menurut Paramita (2019), metode Euclidean distance dipilih karena metode ini memiliki tingkat akurasi yang relatif lebih baik daripada metode lain (misal: cityblock). Menurut Liantoni (2015), tahapan yang harus dilakukan ialah tahapan preprocessing citra dan tahapan ekstraksi ciri citra tepi daun, dilanjutkan ke tahapan klasifikasi. Dan ketepatan dalam mengekstraksi ciri objek sangat berpengaruh terhadap baik buruknya hasil klasifikasi tanaman.
Adepoju et al. (2018) meneliti tentang pengenalan karakteristik tekstur gambar wajah dengan metode LBP sebagai metode ekstraksi ciri dan metode klasifikasi KNN, menyimpulkan bahwa metode LBP dengan hanya menggunakan 1 buah fitur menghasilkan akurasi pengenalan sebesar 92%. Kusuma & Kartika (2017) mendeteksi jenis gambar dengan menggunakan metode KNN sebagai klasifikasi, menyimpulkan bahwa diperoleh akurasi sebesar 92,24%. Ahad, et al.( 2016) meneliti tentang
pegenalan sejarah manusia berdasarkan aksi manusia dalam video memggunakan metode LBP dan proses klasifikasi menggunakan SVM, menyimpulkan bahwa metode LBP memiliki ketahanan terhadap perubahan grayscale yang disebabkan oleh noises (seperti: variasi pencahayaan, dan kesederhanaannya dalam melakukan komputasi).
Hastuti et al. (2018) meneliti tentang identifikasi kondisi kesehatan ayam petelur menggunakan metode ekstraksi GLCM dan metode klasifikasi KNN, menyimpulkan bahwa GLCM dengan sudut 0 derajat menghasilkan akurasi hampir mencapai 100%, sedangkan sudut 135 derajat menghasilkan 70%. Metre dan Ghorpade (2013) meneliti tentang pengenalan tekstur berdasarkan klasifikasi daun tanaman menggunakan metode ekstraksi GLCM dengan 5 fitur dan metode klasifikasi LVQ plus RBF, dan memperoleh akurasi sebesar 98,7 %. Gustiawidi et al. (2018) meneliti tentang identifikasi kualitas kesegaran susu sapi dengan membandingkan metode ekstraksi GLCM dengan 4 fitur dan jarak d=1 pada nilai sudut 0, 45, 90, 135 dan LBP dengan 3 buah fitur, sedang metode klasifikasi yang digunakan metode KNN, menyimpulkan bahwa metode GLCM memiliki akurasi yang relatif lebih tinggi sebesar 100% dibandingkan dengan metode LBP yang akurasinya sebesar 97,5%.
Berdasarkan berbagai penelitian yang telah diuraikan pada paragraf sebelumnya, penulis tertarik untuk melakukan penelitian menggunakan metode ekstraksi ciri Local Binary Pattern (LBP), dan sebagai pembanding digunakan metode Gray Level Co- Occurrence Matrix (GLCM) dengan metode klasifikasi KNN. Citra yang akan diklasifikasi adalah daun menjari yakni daun pepaya dan daun Chaya, karena daun ini paling sering ditemukan dan masih banyak orang awam yang belum dapat membedakan kedua jenis daun menjari tersebut, dan memiliki kemiripan yang relatif tinggi. Adapun judul penelitian dalam tesis ini adalah “Analisis Kinerja Local Binary Pattern (LBP) dan K-Nearest Neighbor (KNN) dalam Pengenalan Citra Daun Menjari (Palminervis)”.
1.2 Rumusan Masalah
Umumnya sulit membedakan beberapa daun yang memiliki kemiripan yang relatif tinggi. Untuk membedakan kemiripan citra, banyak peneliti menggunakan berbagai metode klasifikasi, salah satu metode yang sering digunakan adalah metode
K-Nearest Neighbor . Metode ini memiliki efektivitas yang relatif tinggi untuk data pelatihan yang besar, namun sensitif terhadap citra yang memiliki noise yang mana menyebabkan akurasi terhadap klasifikasi relatif kurang memuaskan, namun dapat diatasi dengan menggunakan metode ekstraksi citra, seperti metode LBPdan GLCM.
1.3 Batasan Masalah
Batasan masalah pada penelitian ini adalah sebagai berikut:
1. Penelitian ini menggunakan metode ekstraksi ciri, yaitu LBP dan GLCM dengan masing-masing 10 fitur ciri, serta metode KNN sebagai klasifikasi.
2. Pada penelitian ini akan dilakukan klasifikasi jenis daun yang terdiri dari 2 jenis yaitu:
Daun Pepaya
Daun Chaya (Cnidoscolus acontifolius) atau daun pepaya jepang 3. Citra dari setiap jenis daun diambil menggunakan kamera DSLR.
4. File citra daun yang digunakan yaitu format JPG dengan piksel ukuran 200x200
1.4 Tujuan Penelitian
Berdasarkan rumusan masalah di atas, tujuan dari penelitian ini adalah untuk melihat kinerja metode KNN didalam melakukan klasifikasi citra daun menjari dengan metode ekstraksi LBP dan membandingkannya dengan metode GLCM.
1.5 Manfaat Penelitian
Manfaat penelitian ini, yaitu sebagai berikut:
1. Memberikan kontribusi bagi dunia ilmu pengetahuan dan teknologi dalam bidang pertanian sehingga sistem untuk pengenalan pola daun lebih memiliki keakuratan tinggi dalam waktu yang singkat dan durasi yang lama.
2. Memberikan sumber informasi bagi peneliti selanjutnya untuk mengetahui tingkat keakurasian dalam mengenali citra daun dengan menggunakan metode klasifikasi K-Nearest Neighbour.
3. Menambah pengetahuan bagi masyarakat khususnya petani untuk mengetahui perbedaan daun pepaya dan daun Chaya meskipun kondisi daun telah rusak.
4. Menambah pengetahuan penulis mengenai metode Local Binary Pattern, Gray Level Co-Occurrence Matrix dan K-Nearest Neighbour dalam mengenali sebuah citra daun menjari.
5. Mengetahui metode ekstraksi ciri dengan akurasi terbaik antara metode LBP dan GLCM.
1.6 Sistematika Penulisan
Sistematika penulisan meliputi:
Bab 1 (Pendahuluan) meliputi berisi latar belakang yang merupakan penjelasan secara garis beras pada penelitian yang akan dilakukan berdasarkan atas pola pikiran yang dituangkan dan dirangkum dalam konteks yang jelas dan padat. Penjelasan yang ada dalam ini terdapat hal tentang alasan memilih judul dan bagaimana pokok permasalahannya. Dengan penggambaran yang dirangkum secara singkat, padat dan jelas, maka dapat ditangkap substansi tesis. Berdasarkan dari rangkuman tersebut, selanjutnya akan dikemukakan tujuan dan manfaat penelitian yang akan ditinjau secara teoritis maupun praktis.
Begitu juga akan dijelaskan hasil dari beberapa penelitian terdahulu yang menjadi dasar ide penelitian dalam membuat tesis ini, sehingga tidak terjadi pengulangan dan plagiarisme penelitian. Dengan demikian, bab ini merupakan rangkuman garis besar penelitian yang akan dikerjakan yang menjadi pedoman untuk bab selanjutnya.
Bab 2 (Tinjauan Pustaka) berisi penjelasan beberapa metode yang digunakan, yaitu metode ekstraksi, metode klasifikasi, serta mengenai jenis daun yang akan digunakan untuk dilakukan pengujian pengenalan daun.
Bab 3 (Metodelogi Penelitian) berisi tahapan-tahapan dari metode yang digunakan dalam penelitian ini berdasarkan rumusan metode yang terkait.
Bab 4 berisi hasil dan pembahasan dari pengujian pengenalan citra yang dilakukan untuk kemudian melihat perbandingan metode ekstraksi antara LBP dengan GLCM , selanjutnya dilakukan kalsifikasi menggunakan metode KNN.
Bab 5 (Kesimpulan dan Saran) berisi simpulan dari hasil penelitian yang telah dilakukan dan memberikan saran untuk dapat digunakan pada penelitian lanjut.
BAB 2
TINJAUAN PUSTAKA
Bab ini mendiskusikan mengenai metode ekstraksi ciri yakni Local Binary Pattern (LBP) dan Gray Level Co-Occurrence Matrix (GLCM), Metode K-Nearest Neighbor (KNN), Euclidean distance, citra digital, daun menjari, dan penelitian terkait.
2.1 Metode Ekstraksi Ciri
Ekstraksi ciri merupakan hal yang sangat penting dan langkah penting dalam pengolahan citra untuk mendeteksi dan mengklasifikasi objek (Chan et al., 2018).
Langkah ekstraksi ini mengekstraksi informasi signifikan dari konten gambar, yang memaksimalkan kesamaan intra-class dan meminimalkan kesamaan inter-class. Vektor yang diperoleh dengan ekstraksi ciri digunakan untuk melatih dan menguji data pada tahap klasifikasi (Haghnegahdar et al., 2018).
Ekstraksi ciri mengacu pada proses pemetaan gambar dari ruang n-dimensi ke dimensi yang lebih rendah dengan menerapkan beberapa fungsi ke gambar asli.
Dimensi yang lebih kecil ini membantu dalam klasifikasi yang lebih baik dan lebih cepat. Terdapat beberapa cara ekstraksi ciri, yaitu ekstraksi berdasarkan bentuk, tekstur, tepi, dst. (SreeVidya dan Chandra, 2018).
2.1.1 Metode Local Binary Pattern
Ojala et al. (1996) mengajukan Local Binary Pattern (LBP) untuk menggambarkan fitur tekstur. LBP memiliki banyak keuntungan, yaitu sederhana, dan memiliki kompleksitas komputasi yang lebih sedikit daripada algoritma lainnya, serta tidak sensitif (intensitive) terhadap intensitas pencahayaan yang berbeda, sehingga LBP
mampu menggambarkan fitur tekstur lokal dari gambar. Ahad et al, (2016) menyatakan bahwa LBP merupakan metode yang efektif karena dapat menyesuaikan antara statistik tradisional yang berbeda dan model struktural analisis tekstur. LBP memperoleh popularitas karena kekokohannya terhadap perubahan gray-scale yang disebabkan oleh noises, seperti varian pencahayaan, dan kesederhanaan komputasi. Pietikainen et al.
(2011) menyatakan bahwa untuk mendapatkan label baru piksel tengah atau kode LBP, maka diberikan threshold di piksel tengah setelah piksel terbagi atau bekerja dalam blok 3x3, kemudian dilakukan perhitungan perkalian kuadrat dua, setelah itu dijumlahkan keseluruhan nilainya dari nilai biner berubah menjadi nilai desimal. Semua tetangga yang memiliki nilai lebih tinggi atau sama dari nilai piksel pusat diberi nilai 1 dan semua tetangga yang memiliki nilai lebih rendah dengan nilai piksel pusat diberi nilai 0.
LBP memiliki 8 (delapan) angka biner yang terkait dengan delapan tetangga tersebut kemudian dibaca berurutan dalam arah searah jarum jam untuk membentuk angka biner. Angka biner ini (atau setara dalam sistem desimal) dapat ditetapkan ke piksel pusat dan dapat digunakan untuk mengkarakterisasi tekstur lokal. Ini setara dengan menetapkan bobot ke delapan piksel tetangga sesuai dengan posisi relatifnya sehubungan dengan piksel tengah. Bobot ini adalah 27, 26, 25, 24, 23, 22, 21, 20, dengan yang pertama ditugaskan ke tetangga yang memeberikan digit yang paling signifikan, yang kedua ditugaskan ke tetangga yang memberikan digit paling signifikan kedua, dan seterusnya. Kemudian, beberapa tetangga diberikan lebih signifikan daripada lainnya dan hal ini membuat representasi ini peka (sensitif) terhadap rotasi, yaitu peka terhadap tetangga mana yang dianggap sebagai yang pertama (Petrou & Sevilla, 2006).
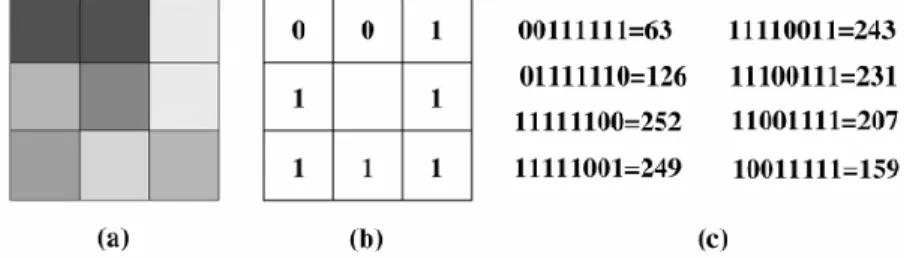
Gambar 2.1 merupakan contoh dari local binary pattern, dimana piksel berada disekitar piksel pusat.
Gambar 2.1 Piksel berada di sekitar piksel pusat pada (a) diberikan nilai 1, jika mereka lebih terang daripada piksel tengah dan akan diberikan nilai 0, jika mereka lebih gelap daripada piksel tengah. Nilainya ditunjukkan pada (b). jika kita membaca
nilai-nilai ini secara berurutan dalam arah searah jarum jam, tergantung pada piksel
mana yang merupakan piksel awal, kita dapat membentuk bilangan biner dan ekivalen desimalnya yang ditunjukkan pada (c). (Petrou & Sevilla, 2006)
Ali et al. (2017) menyatakan bahwa operator LBP digunakan untuk mencari nilai piksel tengah dari suatu gambar dan mengambil nilai ini sebagai ambang (threshold), seperti diperlihatkan dengan persamaan berikut:
𝐿𝐵𝑃𝐵𝑖𝑛𝑎𝑟𝑦𝐶𝑜𝑑𝑒 = {1 ; 𝐽𝑖𝑘𝑎 𝑝𝑖𝑘𝑠𝑒𝑙 𝑡𝑒𝑡𝑎𝑛𝑔𝑔𝑎 ≥ 𝑇ℎ𝑟𝑒𝑠ℎ𝑜𝑙𝑑
0 ; 𝐽𝑖𝑘𝑎 𝑝𝑖𝑘𝑠𝑒𝑙 𝑡𝑒𝑡𝑎𝑛𝑔𝑔𝑎 < 𝑇ℎ𝑟𝑒𝑠ℎ𝑜𝑙𝑑………...…..(2.1) Jika piksel tetangga nilainya lebih tinggi atau sama dengan nilai piksel tengah, maka piksel diberi nilai 1, jika tidak maka diberi nilai 0. Operator LBP adalah titik dari kode biner dan bobot yang sesuai (Tianyu, et al, 2018). Contoh proses komputasi kode LBP dan bagaimana menghitung sebuah kode biner dapat dilihat pada Gambar 2.2.
Gambar 2.2 Proses Komputasi Kode LBP
Gambar 2.2 memperlihatkan bahwa pada piksel tengah diberi nilai 4, sehingga setiap piksel tetangga yang nilainya lebih tinggi atau sama dengan nilai piksel tengah, maka diberi nilai 1, sebaliknya akan diberi nilai 0. Ketika nilai ambang (threshold) sudah didapatkan yaitu nilai biner 11011001, kemudian tiap nilai dikalikan kuadrat dua, setelah itu dijumlahkan sehingga didapatkan hasil nilai piksel tengah yang baru yaitu bernilai 217.
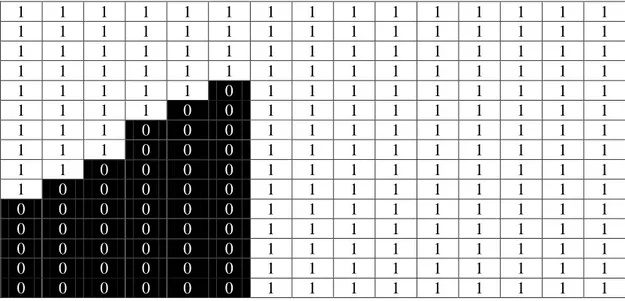
Berikut diberikan dua buah contoh citra yang memiliki sudut lancip sekitar 45 derajat, dimana yang satunya mengarah ke tenggara dan satunya lagi mengarah ke timur laut. Kedua citra tersebut akan dilakukan pencarian nilai tengah dengan proses komputasi menggunakan LBP. Contoh pertama yaitu citra sudut lancip yang mengarah ke tenggara setelah dikonversikan menjadi citra grayscale 1 bit yang dapat dilihat pada Tabel 2.1.
Tabel 2.1 Konversi Citra Sudut Lancip Tenggara Menjadi Citra Grayscale 1 Bit
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
1 0 0 0 0 0 1 1 1 1 1 1 1 1 1
1 1 0 0 0 0 1 1 1 1 1 1 1 1 1
1 1 1 0 0 0 1 1 1 1 1 1 1 1 1
1 1 1 1 0 0 1 1 1 1 1 1 1 1 1
1 1 1 1 0 0 1 1 1 1 1 1 1 1 1
1 1 1 1 1 0 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Ketika citra dikonversikan menjadi citra grayscale 1 bit, maka citra akan memiliki nilai biner yaitu 0 atau 1, yang kemudian akan menampilkan gambar yang pada setiap pikselnya diberi nilai 0 atau 1. Nilai 0 untuk piksel yang berwarna hitam, dan nilai 1 untuk yang berwarna putih, sedangkan nilai yang berada di luar frame diberikan nilai 1 (putih).
Setelah itu dilakukan perhitungan kode biner menggunakan LBP, dimana LBP bekerja pada blok 3x3 dari sebuah citra piksel di blok, yang kemudian diberikan threshold oleh piksel tengah, lalu dikalikan kuadrat dua, dan kemudian dijumlahkan untuk mendapatkan label baru untuk piksel tengah. Hasil dari komputasi LBP untuk contoh pertama dapat dilihat pada Tabel 2.2.
Tabel 2.2 Hasil Komputasi LBP Untuk Citra Sudut Lancip Tenggara
227 224 224 224 224 248 252 255 255 255 255 255 255 255 255 131 0 0 0 0 56 124 255 255 255 255 255 255 255 255 131 0 0 0 0 56 124 255 255 255 255 255 255 255 255 131 0 0 0 0 56 124 255 255 255 255 255 255 255 255 135 2 0 0 0 56 124 255 255 255 255 255 255 255 255 143 7 2 0 0 56 124 255 255 255 255 255 255 255 255 223 143 7 2 0 56 124 255 255 255 255 255 255 255 255 255 223 143 7 2 56 124 255 255 255 255 255 255 255 255 255 255 223 143 7 56 124 255 255 255 255 255 255 255 255 255 255 255 223 143 63 126 255 255 255 255 255 255 255 255 255 255 255 255 223 191 127 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255
255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 Dengan demikian diperoleh tepi dari citra sudut lancip yang mengarah tenggara, dengan hasil citra yang berubah menjadi sudut tumpul.
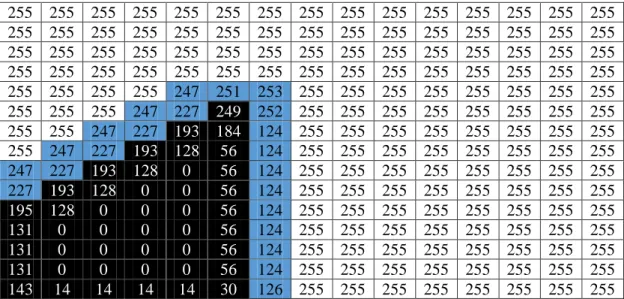
Contoh kedua yaitu citra sudut lancip yang mengarah ke timur laut setelah dikonversikan menjadi citra grayscale 1 bit yang dapat dilihat pada Tabel 2.3.
Tabel 2.3 Konversi Citra Sudut Lancip Timur Laut Menjadi Citra Grayscale 1 bit
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 0 1 1 1 1 1 1 1 1 1
1 1 1 1 0 0 1 1 1 1 1 1 1 1 1
1 1 1 0 0 0 1 1 1 1 1 1 1 1 1
1 1 1 0 0 0 1 1 1 1 1 1 1 1 1
1 1 0 0 0 0 1 1 1 1 1 1 1 1 1
1 0 0 0 0 0 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
Ketika citra dikonversikan menjadi citra grayscale 1 bit, maka citra akan memiliki nilai biner yaitu 0 dan 1, yang kemudian akan menampilkan gambar yang pada setiap pikselnya diberi nilai 0 dan 1. Nilai 0 untuk piksel yang berwarna hitam, dan nilai 1 untuk yang berwarna putih, sedangkan nilai yang berada di luar frame diberikan nilai 1 (putih).
Setelah itu dilakukan perhitungan kode biner menggunakan LBP, dimana LBP bekerja pada blok 3x3 dari sebuah citra piksel di blok, yang kemudian diberikan threshold oleh piksel tengah, lalu dikalikan kuadrat dua, dan kemudian dijumlahkan untuk mendapatkan label baru untuk piksel tengah. Hasil dari komputasi LBP untuk contoh kedua dapat dilihat pada tabel 2.4.
Tabel 2.4 Hasil komputasi LBP Untuk Citra Sudut Lancip Timur Laut 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 247 251 253 255 255 255 255 255 255 255 255 255 255 255 247 227 249 252 255 255 255 255 255 255 255 255 255 255 247 227 193 184 124 255 255 255 255 255 255 255 255 255 247 227 193 128 56 124 255 255 255 255 255 255 255 255 247 227 193 128 0 56 124 255 255 255 255 255 255 255 255 227 193 128 0 0 56 124 255 255 255 255 255 255 255 255 195 128 0 0 0 56 124 255 255 255 255 255 255 255 255 131 0 0 0 0 56 124 255 255 255 255 255 255 255 255 131 0 0 0 0 56 124 255 255 255 255 255 255 255 255 131 0 0 0 0 56 124 255 255 255 255 255 255 255 255 143 14 14 14 14 30 126 255 255 255 255 255 255 255 255
Maka didapatkanlah tepi dari citra sudut lancip yang mengarah timur laut, dengan hasil citra yang berubah menjadi sudut tumpul.
Oleh karena itu, dapat diambil kesimpulan hasil komputasi LBP dari kedua contoh citra bahwa metode LBP memiliki kelemahan dalam melakukan proses pengenalan tepi citra yang memiliki sudut yang lancip sekitar 45 derajat, yang menunjukan hasil citra berubah menjadi cacat atau citra yang semulanya merupakan citra dengan sudut yang lancip berubah menjadi citra dengan sudut yang tumpul. Namun, kelemahan tersebut tidak akan mengganggu penelitian dalam mengenali sebuah citra daun.
Dapat pula dilihat fungsi LBP yang didefinisikan pada persamaan 2.2 (Hakimi et al., 2015; Pietikainen M. et al., 2011):
𝐿𝐵𝑃𝑃,𝑅(𝑥, 𝑦) = ∑𝑝−1𝑖=0 𝑠(𝑝𝑖− 𝑝𝑐)2𝑖 ... (2.2) Dimana fungsi s(x) didefinisikan sebagai berikut:
𝑠(𝑝𝑖− 𝑝𝑐) = {1, 𝑝𝑖− 𝑝𝑐 ≥ 0
0, 𝑝𝑖− 𝑝𝑐 < 0 ... (2.3) dengan:
P : banyaknya piksel tetangga yang terlibat
R : nilai jarak/radius dari blok piksel 3x3
(x, y) : lokasi piksel di gambar atau koordinator pusat dari blok piksel 3x3 s( ) : fungsi threshold
pi : nilai tingkat keabuan dari setiap piksel tetangga. pi nilai koordinatnya bisa didapatkan dari (−𝑅𝑠𝑖𝑛(2𝜋𝑖/𝑃), 𝑅𝑐𝑜𝑠(2𝜋𝑖/𝑃)) apabila koordinat dari pc bernilai (0,0) melalui radius R
pc : nilai tingkat keabuan dari piksel tengah (pixel x dan y)
Proses LBP yang pertama adalah dengan dilakukan pengurangan piksel tetangga dengan piksel tengah menggunakan persamaan (2.2). Selanjutnya hasil perhitungannya di-threshold menggunakan persamaan (2.3). Jika nilai piksel tetangga kurang dari nilai tengah, maka didapatkan nilai 0 dan jika nilai piksel tetangga lebih tinggi atau sama dengan nilai piksel tengah, maka didapatkan nilai 1. Kemudian digit biner tetangga disatukan untuk membangun kode biner, dimana nilai biner piksel tetangga akan disusun berlawanan searah jarum jam dan 8 (delapan) bit biner tersebut akan dikonversikan ke dalam nilai decimal untuk menggantikan nilai piksel tengah pc. Metode LBP memiliki kelebihan yaitu memberikan kemudahan ketika diimplementasi, serta memiliki tingkat komputasi yang lebih rendah, sehingga ketika sedang menjalankan tahapan ekstraksi ciri tidak akan membutuhkan waktu yang lama (Amat et al., 2017).
Dalam operator LBP menghitung kode LBP dari nilai threshold dari lingkungan biner 8, dimana delapan (8) merupakan angka biner dari pola 3x3 dan 28 (256) merupakan jumlah dari kode LBP (Khan et al., 2017).
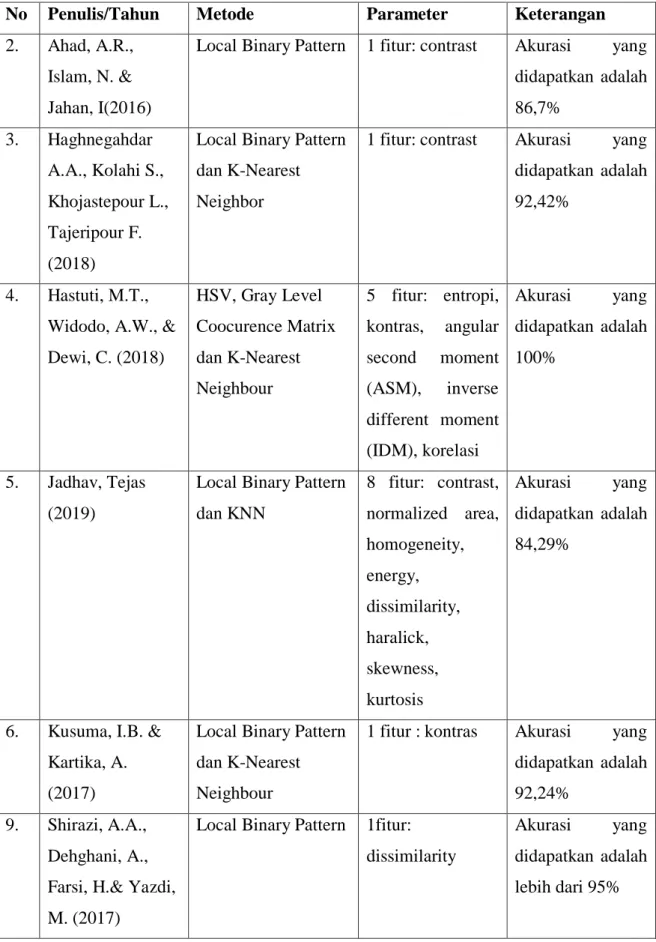
Pada penelitian ini digunakan 10 fitur ciri dalam ekstraksi fitur Local Binary Pattern (LBP), yaitu Mean, Standar Deviasi, Skewness, Kurtosis, Entropy, Variance, Contrast, Correlation, Energy dan Homogeneity. Berikut rumusan dari 10 fitur dalam ekstraksi fitur LBP, yaitu:
1) Mean adalah momen urutan pertama dan memberikan nilai warna rata-rata gambar (Bhole, 2020), serta menjelaskan nilai intensitas rata-rata dari semua piksel (Peng, 2017). Persamaan perhitungan mean dapat dilihat pada persamaan (2.4) berikut (Hidayat, 2019):
𝜇 = ∑ 𝑓𝑛 𝑃(𝑓𝑛)𝑛 ... (2.4)
dimana:
fn = nilai intensitas keabuan
P(fn) = nilai histogram (probabilitas dari munculnya intensitas pada citra)
2) Standar Deviasi. Standar deviasi menunjukkan menjelaskan variasi dari nilai piksel rata-rata (Peng, 2017). Persamaan perhitungan standar deviasi dapat dilihat pada persamaan (2.4) berikut (Hidayat, 2019):
𝜎 = ∑ |𝑓𝑛 − 𝜇| (𝑓𝑛)𝑛 ... (2.5) 3) Skewness. Skewness adalah momen urutan ketiga dan skewness tentang mean memberikan kontribusi setiap nilai piksel untuk gambar dan memberi tahu apakah distribusi data miring kiri, miring kanan atau simetri (Bhole, 2020), serta menunjukkan asimetri (Peng, 2017). Persamaan perhitungan skewness dapat dilihat pada persamaan (2.6) berikut (Hidayat, 2019):
𝛼3 = 1
𝜎3∑ (𝑓𝑛 − 𝜇)𝑛 3 𝑃(𝑓𝑛) ... (2.6) 4) Kurtosis. Kurtosis adalah momen urutan keempat dan menggambarkan tingkat outlier dalam distribusi (Bhole, 2020), serta menunjukkan keruncingan atau puncaknya (Peng, 2017). Persamaan perhitungan kurtosis dapat dilihat pada persamaan (2.7) berikut (Hidayat, 2019):
𝛼4 = 1
𝜎4∑ (𝑓𝑛 − 𝜇)𝑛 4. 𝑃(𝑓𝑛) − 3 ... (2.7) 5) Entropy. Entropy adalah banyaknya informasi gambar yang diperlukan untuk kompresi (Sachar dan Kumar, 2020), serta menjelaskan keacakan dan ketidakteraturan semua intensitas piksel (Peng, 2017). Entropy dari citra grayscale merupakan pengukuran statistic dari keacakan piksel citra yang dapat dimanfaatkan untuk mengkarakterisasi inputan citra tekstur (Gonzales, 2003). Persamaan perhitungan entropy dapat dilihat pada persamaan (2.8) berikut (Hidayat, 2019):
𝐻 = − ∑ 𝑃(𝑓𝑛)𝑛 2𝑙𝑜𝑔 𝑃(𝑓𝑛) ... (2.8) 6) Variance. Variance adalah momen urutan kedua dan menggunakan varians dapat mengetahui standar deviasi yang memberi tahu jumlah banyaknya piksel yang menyebar atau menyimpang dari piksel tengah (Bhole, 2020). Variance adalah kuadrat dari standar deviasi. Variance memberikan ukuran deviasi(penyimpangan)
sinyal dari nilai rata-ratanya (Damarjati, 2017). Persamaan perhitungan variance dapat dilihat pada persamaan (2.9) berikut (Hidayat, 2019):
𝜎2 = ∑ (𝑓𝑛 − 𝜇)𝑛 2𝑃(𝑓𝑛) ... (2.9) 7) Contrast. Contrast adalah penjumlahan perbedaan intensitas lokal membantu pertolongan dari P(i,j) jauh dari diagonal (dimana i≠j) (Sachar dan Kumar, 2020).
Contrast menunjukkan muatan variasi lokal dari citra. semakin tinggi kontrastnya semakin tinggi kontrasnya (Damarjati, 2017). Persamaan perhitungan contrast dapat dilihat pada persamaan (2.10) berikut (Damarjati, 2017):
𝐶𝑜𝑛𝑡𝑟𝑎𝑠𝑡 = ∑𝑁𝑖,𝑗𝑔𝑃(𝑖, 𝑗)(𝑖 − 𝑗)2 ... (2.10) 8) Correlation. Correlation menunjukkan ketergantungan linier dari tingkat keabuan piksel tetangga (Sachar dan Kumar, 2020). Correlation menunjukkan ukuran dari hubungan linear antara tingkat keabuan dari tingkat piksel tetangga (Damarjati, 2017). Persamaan perhitungan correlation dapat dilihat pada persamaan (2.11) berikut (Hidayat, 2019):
𝐶𝑂𝑅 = ∑ (𝑖−𝜇)(𝑗−𝜇).𝑃(𝑖,𝑗) 𝜎𝑖𝜎𝑦 𝑁𝑔
𝑖,𝑗 ... (2.11) 9) Energy. Energy adalah tingkat keseragaman piksel suatu gambar. Semakin tinggi nilai energinya, maka teksturnya akan semakin seragam (Damarjati, 2017).
Persamaan perhitungan energy dapat dilihat pada persamaan (2.12) berikut (Hidayat, 2019):
𝐸𝑛𝑒𝑟𝑔𝑦 = ∑𝑁𝑖=1𝑔 𝑃2(𝑖, 𝑗) ... (2.12) 10) Homogeneity. Homogeneity menyatakan besarnya kedekatan setiap elemen daratu matriks co-occurrence (Damarjati, 2017). Homogeneity menunjukkan suatu kedekatan dari citra berderajat keabuan yang memiliki sifat yang homogeny (Hidayat, 2019). Persamaan perhitungan homogeneity dapat dilihat pada persamaan (2.13) berikut (Hidayat, 2019):
𝐻𝑜𝑚𝑜𝑔𝑒𝑛𝑒𝑖𝑡𝑦 = ∑𝑁𝑖=1𝑔 𝑃(𝑖, 𝑗)/[1 + |𝑖 − 𝑗|] ... (2.13) dengan:
𝑖, 𝑗 = sifat keabuan dari resolusi 2 piksel yang berdekatan 𝑃(𝑖, 𝑗) = probabilitas kolom (i,j)
2.1.2 Metode Gray Level Co-Occurrence Matrix (GLCM)
Pada awalnya GLCM dikembangkan oleh seorang ilmuwan komputer yang benama Robert Haralick pada tahun 1973 dengan 28 fitur untuk menjelaskan pola spasial (Haralick et al., 1973). GLCM mengekstrak tekstur secara efektif serta memiliki akurasi dan waktu komputasi yang lebih baik dari metode ekstraksi lainnya. Gray level menghasilkan jarak (mempresentasikan pixels) dan sudut (mempresentasikan derajat) citra (Sinaga, 2020). GLCM merupakan martiks yang memiliki bentuk berupa persegi panjang atau bujur sangkar dan memiliki panjang sisi setara dengan jumlah tingkat keabuan gambar. Di dalam matriksnya terdapat nilai-nilai probabilitas yang tersusun atas dua buah piksel, yaitu piksel-i dan piksel-j. Setiap nilai piksel dibatasi oleh jarah dan arah (Amanullah,2018).
Setiap indeks dapat menyoroti properti tekstur tertentu, seperti kehalusan, kekakuan, dan ketidakteraturan. Tekstur adalah istilah yang digunakan untuk mencirikan variasi tonal atau tingkat abu-abu pada gambar (Hall-Beyer, 2017). Arah yang digunakan untuk melakukan analisis GLCM adalah horizontal (0 derajat), vertical (90 derajat) dan diagonal (45 dan 135 derajat) (Kevin, Hendryli & Herwindiati, 2019).
Namun pada penelitian ini, sudut yang digunakan adalah semua sudut 0, 45, 90 dan 135 yang kemudian diambil rata-ratanya. Sedangkan, nilai jarak (d) yang diambil adalah 1.
GLCM terbagi dalam tiga tahapan, yaitu (Zahro, 2016):
1. Menyalin citra grayscale untuk mendapatkan derajat keabuannya, 2. Membentuk matriks co-occurrence,
3. Menormalisasi matriks co-occurrence untuk mendapatkan nilai probabilitas hubungan ketetanggan antara dua piksel.
Perhitungan nilai dari GLCM dimulai dengan menentukan arah dan jarak yang akan digunakan untuk menghitung nilai citra, lalu menghitung jumlah piksel yang berpasangan yang terbentuk dan kemudian membentuk matriks GLCM, selanjutnya dinormalisasi menggunakan persamaan (2.14) sebagai berikut:
𝑀𝑎𝑡𝑟𝑖𝑥𝐺𝐿𝐶𝑀𝑁𝑜𝑟𝑚 = 1
∑ 𝑀𝑎𝑡𝑟𝑖𝑥𝐺𝐿𝐶𝑀𝑀𝑎𝑡𝑟𝑖𝑥𝐺𝐿𝐶𝑀 ... (2.14) Pada penelitian ini metode GLCM menggunakan 10 fitur ciri yang dipilih diantara 14 fitur GLCM, yaitu Autocorrelation, Contrast, Correlation, Cluster Prominence,
Cluster Shade, Dissimilarity, Energy, Entropy, Homogeneity dan Maximum Probability. Berikut rumusan dari 10 fitur dalam ekstraksi fitur GLCM, yaitu (Griethuysen, 2017):
1) Autocorrelation. Autocorrelation adalah ukuran besarnya kehalusan dan kekasaran tekstur, semakin tinggi nilai menunjukkan bahwa teksturnya lebih banyak pasangan dengan tingkat keabuan yang tinggi. Persamaan perhitungan autocorrelation dapat dilihat pada persamaan (2.15) berikut:
𝐴𝑢𝑡𝑜𝑐𝑜𝑟𝑟𝑒𝑙𝑎𝑡𝑖𝑜𝑛 = ∑𝑁𝑔𝑖 ∑𝑁𝑔𝑗 𝑖𝑗 𝑃(𝑖, 𝑗) ... (2.15) 2) Contrast. Contrast adalah penjumlahan perbedaan intensitas lokal membantu
pertolongan dari P(i,j) jauh dari diagonal (dimana i≠j) (Sachar dan Kumar, 2020).
Contrast menunjukkan muatan variasi lokal dari citra. semakin tinggi kontrastnya semakin tinggi kontrasnya (Damarjati, 2017). Persamaan perhitungan contrast dapat dilihat pada persamaan (2.16) berikut (Damarjati, 2017):
𝐶𝑜𝑛𝑡𝑟𝑎𝑠𝑡 = ∑𝑁𝑖,𝑗𝑔𝑃(𝑖, 𝑗)(𝑖 − 𝑗)2 ... (2.16) 3) Correlation. Correlation adalah nilai antara 0 (tidak berkorelasi) dan 1 (berkorelasi sempurna) yang menunjukkan linier ketergantungan nilai tingkat abu-abu ke voxelnya masing-masing di GLCM. Persamaan perhitungan correlation dapat dilihat pada persamaan (2.17) berikut (Hidayat, 2019):
𝐶𝑂𝑅 = ∑ (𝑖−𝜇)(𝑗−𝜇).𝑃(𝑖,𝑗) 𝜎𝑖𝜎𝑦 𝑁𝑔
𝑖,𝑗 ... (2.17) 4) Cluster Prominence. Cluster Prominence adalah ukuran kemiringan dan asimetri GLCM. Nilai yang lebih tinggi menyiratkan lebih banyak asimetri tentang rata-rata, sedangkan nilai yang lebih rendah menunjukkan puncak yang mendekati nilai rata- rata dan variasi yang lebih sedikit tentang rata-rata. Persamaan perhitungan cluster prominence dapat dilihat pada persamaan (2.18) berikut:
𝐶𝑙𝑢𝑠𝑡𝑒𝑟 𝑃𝑟𝑜𝑚𝑖𝑛𝑒𝑛𝑐𝑒 = ∑𝑁𝑔𝑖 ∑𝑁𝑔𝑗 𝑀𝑖𝑗(𝑖 + 𝑗 − 𝜇𝑖− 𝜇𝑗)4 ... (2.18) 5) Cluster Shade. Cluster Shade adalah ukuran kemiringan dan keseragaman GLCM.
Cluster shade yang lebih tinggi menyiratkan asimetri yang lebih besar tentang mean. Persamaan perhitungan cluster shade dapat dilihat pada persamaan (2.19) berikut:
𝐶𝑙𝑢𝑠𝑡𝑒𝑟 𝑆ℎ𝑎𝑑𝑒 = ∑𝑁𝑔𝑖 ∑𝑁𝑔𝑗 𝑀𝑖𝑗 (𝑖 + 𝑗 − 𝜇𝑖− 𝜇𝑗)3 ... (2.19)
6) Dissimilarity. Dissimilarity adalah ukuran variasi intensitas lokal yang didefinisikan sebagai perbedaan absolut rata-rata antara pasangan yang bertetangga.
Nilai yang lebih besar berkorelasi dengan perbedaan yang lebih besar dalam intensitas diantara voxel tetangga. Persamaan perhitungan dissimilarity dapat dilihat pada persamaan (2.20) berikut:
𝐷𝑖𝑠𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 = ∑𝑁𝑔𝑖 ∑𝑁𝑔𝑗 𝑀𝑖𝑗 |𝑖 − 𝑗| ... (2.20) 7) Energy. Energy adalah tingkat keseragaman piksel suatu gambar. Semakin tinggi
nilai energinya, maka teksturnya akan semakin seragam (Damarjati, 2017).
Persamaan perhitungan energy dapat dilihat pada persamaan (2.21) berikut (Hidayat, 2019):
𝐸𝑛𝑒𝑟𝑔𝑦 = ∑𝑁𝑖=1𝑔 𝑃2(𝑖, 𝑗) ... (2.21) 8) Entropy. Entropy adalah banyaknya informasi gambar yang diperlukan untuk kompresi (Sachar dan Kumar, 2020), serta menjelaskan keacakan dan ketidakteraturan semua intensitas piksel (Peng, 2017). Entropy dari citra grayscale merupakan pengukuran statistic dari keacakan piksel citra yang dapat dimanfaatkan untuk mengkarakterisasi inputan citra tekstur (Gonzales, 2003). Persamaan perhitungan entropy dapat dilihat pada persamaan (2.22) berikut (Hidayat, 2019):
𝐻 = − ∑ 𝑃(𝑖, 𝑗)𝑛 2𝑙𝑜𝑔 𝑃(𝑖, 𝑗) ... (2.22) 9) Homogeneity. Homogeneity menyatakan besarnya kedekatan setiap elemen dari suatu matriks co-occurrence (Damarjati, 2017). Homogeneity menunjukkan suatu kedekatan dari citra berderajat keabuan yang memiliki sifat yang homogeny (Hidayat, 2019). Persamaan perhitungan homogeneity dapat dilihat pada persamaan (2.23) berikut (Hidayat, 2019):
ℎ𝑜𝑚𝑜𝑔𝑒𝑛𝑒𝑖𝑡𝑦 = ∑𝑁𝑖=1𝑔 𝑃(𝑖, 𝑗)/[1 + |𝑖 − 𝑗|] ... (2.23) Dimana:
𝑖, 𝑗 = sifat keabuan dari resolusi 2 piksel yang berdekatan 𝑃(𝑖, 𝑗) = probabilitas kolom (i,j)
10) Maximum Probability. Maximum Probability adalah terjadinya pasangan paling dominan dari nilai intensitas bertetangga. Persamaan perhitungan maximum probability dapat dilihat pada persamaan (2.24) berikut:
𝑀𝑎𝑥𝑖𝑚𝑢𝑚 𝑃𝑟𝑜𝑏𝑎𝑏𝑖𝑙𝑖𝑡𝑦 = max
𝑖,𝑗 (𝑃𝑖𝑗) ... (2.24)
2.2 Metode Klasifikasi K-Nearest Neighbor (KNN)
Klasifikasi merupakan proses pelabelan inputan gambar ke dalam kategori tertentu (Saha et al., 2018). Klasifikasi adalah proses dimana atribut yang disebutkan digunakan untuk mengidentifikasi artefak. Hal tersebut dilakukan dengan menggunakan berbagai pengklasifikasi (Gilberet et al., 2017). Pengklasifikasian harus dilatih dengan contoh gambar yang sebelumnya agar dapat berhasil melakukan proses klasifikasi. Pengklasifikasian yang digunakan penelitian ini, yaitu pertama-tama dilatih untuk dapat mengidentifikasi perbedaan atau jenis di antara sampel yang dipisahkan (Cetiner et al., 2016).
KNN merupakan metode yang paling sederhana dari semua skema dan algoritma machine learning atau algoritma klasifikasi, dan menyimpan semua case yang tersedia dan mengklasifikasikan case baru yang dilihat berdasarkan pada ukuran yang sama (Beli dan Guo, 2017). KNN merupakan algoritma yang paling sering digunakan untuk proses klasifikasi, bahkan juga dapat digunakan untuk estimasi dan prediksi.
Penggunaan metode KNN dinyatakan mampu menghasilkan akurasi diatas 80%
(Huliman et al., 2013). Pengklasifikasian KNN memiliki dua fase, yaitu fase latih dan fase uji. Pada fase latih, vektor fitur global dari semua sampel latih disimpan dalam database latih. Pada fase uji, vektor fitur global dari setiap sampel uji ditemukan dan diberikan sebagain inputan ke KNN, yang menemukan label kelas dari sampel uji yang dibandingkan antara vektor fitur global sampel uji dan sampel latih (Suruliandi dan Jenicka, 2015). KNN merupakan metode klasifikasi untuk mengklasifikasikan objek berdasarkan pada contoh latih terdekat di zona fitur/ciri. Klasifikasi dilakukan dalam KNN dengan menganalisis dan mengevaluasi fitur-fitur dari berbagai titik di masing- masing zona ruang (Gilberet et al., 2017). Klasifikasi KNN bekerja dengan mencari database dari fitur yang diidentifikasi sebelumnya, hal ini sama halnya dengan menemukan jarak antara koordinat parameter fitur saat ini dan fitur lainnya (Russ, 2007). Terdapat pula fungsi jarak pada metode KNN untuk melakukan klasifikasi. Salah satu contoh metode jarak, yaitu metode Euclidean Distance yang berguna untuk melakukan perbandingan antara sampel data yang lebih dekat dengan sampel data lain pada kelas tertentu (Amynarto, et al, 2018). KNN digunakan untuk mengklasifikasikan objek berdasarkan pada perhitungan Euclidean distance antara dua buah vektor (Dutta et al., 2018). Pada umumnya, algoritma klasifikasi membutuhkan dua (2) jenis dataset,
yaitu dataset latih dan dataset uji. Dataset latih didiguanakn untuk melatih proses klasifikasi, dan kemudian pengklasifikasian yang dilatih untuk mengetahui label kelas (Shukla dan Desai, 2016). Dalam klasifikasi KNN, digunakan Euclidean distance antara fitur data latih dan fitur data uji diidentifikasi untuk membentuk matriks jarak. Nilai penjumlahan dari matriks jarak diestimasi dengan urutan yang meningkat (Ellaban et al., 2017). Setiap data uji, melakukan perhitungan Euclidean Distance antara anggota terdekat dari kumpulan data latih.
Euclidean Distance
Euclidean distance merupakan peralatan yang bekerja pada gambar biner untuk menghasilkan gambar grayscale. Definisi sederhana Euclidean distance adalah setiap titik di latar depan diberi nilai kecerahan yang sama dengan garis lurus (karenanya disebut “Euclidean”) jarak dari titik terdekat dari latar belakang. Pada sebagian gambar, jarak diambil dari setiap piksel dalam fitur ke piksel terdekat di latar belakang (Russ, 2007). Euclidean distance dihitung antara sampel uji dan k neighbours (Cetiner et al., 2016). Euclidean distance merupakan sebuah metode yang paling sering digunakan untuk mengukur jarak dari dua titik vektor atau lebih (Hartono dan Lusiana, 2017).
Metode jarak Euclidean diukur dengan menggunakan rumus perhitungan akar kuadrat dua atau lebih perbedaan vektor. Kegunaan dari metode ini adalah untuk dapat mengetahui nilai kemiripan citra dengan cara melakukan pengisian dua atau lebih vektor yang memiliki perbedaan terhadap suatu nilai fitur citra yang ingin diketahui nilai kemiripannya (Amynarto, et al, 2018). Hasil yang paling kecil dari pengukuran tersebut menandakan jarak terdekat ataupun dapat dikatakan memiliki nilai kemiripan yang besar. Pengukuran Euclidean Distance dilakukan dengan menerapkan persamaan (2.25) (Al Faqih, 2018; Retnoningrum et al., 2019 ), sebagai berikut:
𝑑(𝑥, 𝑦) = √∑𝑛𝑟−1(𝑥𝑖− 𝑦𝑖)2 ... (2.25) dengan:
d(x, y) : Jarak Euclidean antara xi dengan yi.
xi : Data pada x ke-i yang akan dilakukan proses perhitungan.
yi : Data pada y ke-i yang akan dilakukan proses perhitungan.
Menurut persamaan (2.24), objeknya ditugaskan ke kelas tetangga terdekat (Hlaing, 2016). Awalnya, himpunan vektor fitur/ciri dibagi menjadi dua himpunan bagian individu (misalkan k=2 kali lipat validasi silang) dengan cara ganjil dan genap, yang merupakan rangkaian data latih dan uji (Dutta et al., 2018). Pada data latih biasanya diambil lebih dari satu tetangga terdekat dengan data uji kemudian akan digunakan algoritma KNN untuk ditentukan kelasnya (Aksoy, 2008).
Walaupun metode KNN merupakan metode yang cukup sederhana, namun KNN juga memiliki kelebihan yang mampu melakukan proses konvergensi (penggabungan) dengan kecepatan yang relatif tinggi. Hal ini dikarenakan pengaksesan seluruh data latih yang harus dilakukan setiap kali data uji yang baru akan diklasifikasi (Amynarto et al., 2018). Berikut tahapan algoritma KNN (Retnoningrum et al., 2019), sebagai berikut:
1. Mendefinisikan nilai parameter k atau tetangga terdekat dari data latih terhadap data yang diuji.
2. Menentukan/menghitung jarak berdasarkan data latih dan data uji (yang akan dievaluasi/diinput).
3. Mengurutkan data berdasarkan hasil penentuan jarak, mulai dari yang paling kecil hingga yang paling besar. Data yang dipakai yaitu telah dilakukan proses perhitungan jarak antara data latih dan data uji.
4. Menentukan jarak terdekat sampai urutan k.
5. Mencocokkan atau menentukan kelas yang sesuai dengan nilai dari masing-masing tetangga terdekat.
6. Membentuk kelompok berdasarkan nilai dengan ketetanggaan terdekat dan memilih/menetapkan nilai dengan kemunculan paling sering sebagai kelas yang akan dievaluasi.
Algoritma K-Nearest Neighbor (KNN) bertujuan untuk mengklasifikasi sebuah objek baru yang didasarkan dari ciri sampel data yang dilatih. Cara kerja KNN berdasarkan jarak yang paling dekat dari data baru ke data latih (Sultoni et al., 2019).
2.3 Akurasi
Amynarto et al. (2018) menyatakan bahwa akurasi adalah nilai ukur untuk validasi pada suatu metode. Akurasi juga dapat dianggap sebagai sebuah presentase Tingkat keberhasilan pengujian dapat diketahui dengan melakukan perhitungan akurasi.
Perhitungannya adalah dengan membagikan nilai total data yang benar dengan jumlah seluruh data yang diuji, kemudian dikali dengan 100 persen.
Rumus perhitungan akurasi dapat dilihat di persamaan (2.25) (Retnoningrum et al., 2009).
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = ∑ 𝐵𝑒𝑛𝑎𝑟
∑ 𝐷𝑎𝑡𝑎 𝑈𝑗𝑖× 100% ... (2.25)
2.4 Citra
Definisi citra secara harfiah adalah gambar (picture) dua dimensi (2-D) yang dapat ditampilkan (di layar monitor, dicetak, difoto, dan lainnya), seperti: foto, lukisan, dan dapat juga dalam tampilan tiga dimensi (3-D) seperti: patung. Definisi citra secara matematis adalah fungsi kontinyu dari intensitas cahaya pada bidang 2-D. Citra merupakan kombinasi antara titik, garis, bidang, dan warna untuk menciptakan suatu bentuk tiruan dari sebuah objek, yang diperoleh dari hasil perekeman perangkat pengindera jarak jauh (remote sensing). Berdasarkan penggunaan sensor, citra dibagi menjadi 2, yakni citra foto dan citra non foto. Citra foto merupakan foto yang menampilkan berbagai objek dari hasil perekaman penginderaan jarak jauh dengan pemakaian sensor kamera, sedangkan citra non foto merupakan gambar yang dihasilkan dari sensor selain kamera, seperti: gelombang elektromagnetik (sinar X, sinar infrared, dan lainnya (Gonzales R.C. dan Wood R. E. (2003). Citra dapat bersifat analog atau digital. Citra analog berupa sinyal video seperti gambar pada monitor televisi, sedangkan citra digital dapat langsung disimpan pada alat penympanan data.
Ada tiga bidang studi yang berkaitan dengan citra yaitu grafika computer, pengolahan citra, dan pengenalan pola. Grafika komputer bertujuan menghasilkan citra atau lebih tepat disebut gambar dengan primitive geometri seperti garis, lingkaran, dan lainnya. Meskipun sebuah citra kaya informasi, namun sering mengalami penurunan mutu, misalnya: cacat atau derau (noise) sehingga sulit diinterpretasi karena informasi