2. TEORI PENUNJANG
2.1. Dasar-Dasar Pengolahan Gambar
Dalam suatu sistem pengenalan gambar tidak terlepas dari adanya pengolahan gambar itu sendiri. Hal ini antara lain dikarenakan gambar yang memiliki beragam format warna (RGB, gray-scale, black-white), mutu dari gambar yang kurang baik, dan ukuran dari gambar yang akan menentukan lama dari proses pengenalan itu sendiri. Dalam sub bab setelah ini akan dijelaskan tentang dasar pengolahan gambar mulai dari sistem warna, histogram equalization, dan stretch.
2.1.1. Sistem Warna
Warna dari suatu obyek merupakan suatu fungsi dari panjang gelombang yang tak dapat diserap dari cahaya yang dipantulkan dari obyek tersebut. Teori tentang cahaya ini diperoleh dari teori optik Isaac Newton, yang menyatakan bahwa sensasi dari warna dapat terpancar karena perbedaan panjang gelombang sehingga menghasilkan perbedaan efek visual dan Isaac Newton mengambil kesimpulan bahwa warna yang dimunculkan oleh suatu obyek diakibatkan oleh panjang gelombang selektif yang dipantulkan dari transmisi cahaya tampak.
Newton menyatakan juga bahwa terdapat 7 warna utama ( merah, oranye, kuning, hijau, biru, violet ) yang dipakai untuk menghitung warna dari spektrum panjang gelombang yang lainnya.
2.1.1.1. Sistem RGB
Sistem warna RGB adalah kombinasi aditif dari ketiga warna utama merah, hijau dan biru yang biasanya disebut dengan warna primer. Ketiga warna ini jika dicampur bersamaan maka akan diperoleh warna putih atau warna hitam tergantung nilai dari RGB dari pixel-pixel tersebut. Sistem warna RGB merupakan sistem warna yang standar dipakai.
Gambar pada sistem digital dapat diwakili dengan format RBG untuk setiap titiknya, dimana setiap komponen warna diwakili dengan satu byte. Jadi untuk masing- masing komponen R,G dan B mempunyai variasi dari 0 sampai 255. total variasi yang dihasilkan untuk sistem warna digital ini adalah 256 x 256 x 256 atau sama dengan 16.777.216 jenis warna yang disebut juga 24 bit dikarenakan satu byte adalah 8 bit maka dengan tiga warna primer jumlah total bit yang digunakan adalah 8 + 8 + 8 atau 24 bit.
2.1.1.2. Sistem Gray-Scale
Pada pengolahan gambar, kalkulasi mengunakan sistem warna RGB seperti dijelaskan diatas sangatlah memboroskan memory dan waktu maka diperlukan adanya reduksi warna. Selain itu dalam pemrosesan gambar dengan tujuan untuk pengenalan objek, system RGB sendiri tidaklah memberikan respon yang baik, oleh karena hal- hal tersebut maka digunakan sistem format gray-scale atau gray level, dimana format gambar warna dikonversi menjadi format gambar abu-abu. Sistem gray-scale hanya memiliki data sebanyak satu byte (delapan bit) dengan kemungkinan warna dari 0 (hitam) sampai dengan 255 (putih).
Konversi dari sistem warna RGB menjadi gray-scale ini ada beberapa macam diantaranya adalah :
a. Dengan merata-rata setiap komponen warna pada RGB
3 ) (R G B
GRAY = + + (2.1)
b. Menggunakan nilai maksimal dari komponen RGB
GRAY = MAX{R,G,B} (2.2)
c. Menggunakan system YUV (sistem warna pada NTSC), yaitu dengan cara mengambil komponen Y (iluminasi).
Komponen Y sendiri dapat diperoleh dari system warna RGB dengan konversi :
GRAY = Y = (0.30x R) + (0.59 x G) + (0.11 x B) (2.3)
Cara yang paling terakhir paling sering digunakan untuk konversi sistem warna ke sistem gray-scale karena memiliki hasil gambar gray-scale yang paling baik.
2.1.1.3. Sistem Black - White
Sistem warna black-white merupakan sistem warna biner dimana dapat diperoleh melalui reduksi dari sistem gray-scale yang memiliki nilai antara 0 sampai 255 yang setelah direduksi menjadi hanya dua macam nilai saja yaitu 0 dan 1 (biner). Sistem reduksi ini dapat dilakukan dengan hanya mengambil suatu nilai dari 0 sampai 255 sebagai batas untuk menentukan lebar range dari nilai komponen pixel yang dijadikan 0 (hitam) ataupun 1 (putih). Untuk memperoleh gambar black-white dari gray-scale biasanya diambil nilai batas tengah yaitu 127.
2.1.2. Histogram Equalization
Histogram adalah fungsi yang menampilkan untuk setiap gray level warna dan jumlah titik pada gambar yang menggunakan gray level tersebut.
Histogram untuk gray-scale berupa array dengan elemen sebanyak 256 buah, dimana elemen ke 0 menunjukkan tingkat untuk warna hitam dan elemen ke 255 menunjukkan tingkat untuk warna putih.
Histogram biasanya hanya hanya berupa informasi global tentang gambar. Histogram digunakan untuk mencari kondisi iluminasi optimum pada gambar, transformasi gray-scale dan segmentasi objek dari backgroundnya. Perlu diperhatikan bahwa perubahan posisi objek dalam gambar tidak akan mengubah nilai dari histogram. Histogram sangat berguna untuk objek dimana objek dan backgroundnya adalah homogen.
Teknik histogram equalization adalah transformasi gray-scale untuk meningkatkan kontras pada gambar. Pada gambar dapat saja diperoleh histogram dimana tidak semua komponen gray level digunakan dalam gambar tersebut.
Histogram equalization dapat didefinisikan sebagai
g(x,y) = c . f(x,y) + b (2.4)
dimana f(x,y) adalah gray level dari titik gambar asli dan g(x, y) adalah gray level dengan titik yang sama pada gambar hasil egualization, c adalah konstanta kontras dan b adalah konstanta keterangan (brightness). c dan b dapat diperoleh dari histogram gambar asli dengan
) min(
) max(
255 f c f
= − dan b= min( f) (2.5)
dimana min(f) dan max(f) adalah nilai minimum dan maksimum elemen histogram. Penyesuaian dilakukan baik dalam mencari min(f) dan max(f) ataupun pada konstanta c dan b seperti dengan menggunakan error minimum dalam mencari min(f) dan max(f) dan juga dalam memberi faktor skala pada konstanta c dan b.
2.1.3. Stretch
Dalam suatu pengolahan gambar umumnya tidak terlepas dari perlu adanya perubahan ukuran gambar, baik diperbesar maupun diperkecil dari ukuran sebenarnya. Dalam bahasa pemrograman Delphi 6.0 sudah terdapat fungsi stretch , sehingga dapat dengan mudah langsung digunakan. Perubahan ukuran ini dapat menghasilkan gambar yang proporsional ataupun tidak tergantung pada bentuk gambar, apakah sama sisi atau tidak dan juga terga ntung pada perbandingan dari pembesaran sisi lebar dan sisi tinggi.
2.2. Pola Pada Sidik Jari
Sidik jari telah dipergunakan lebih dari 100 tahun dan merupakan tanda pengenal tertua yang dikenal oleh manusia. Pada sidik jari manusia terdapat daerah terang yang disebut ridges dan daerah gelap yang disebut valleys. Sidik jari dibedakan menjadi enam kelas yaitu Right Loop, Left Loop, Whorl, Arch, Tented Arch, Twin Loop.
Pada sidik jari terdapat dua titik khusus yang disebut titik core dan titik delta. Titik ini selalu menjadi acuan dalam pengenalan sidik jari.
Core
Delta
Arch Tented Arch Left Loop
Right Loop Whorl Twin Loop Gambar 2.1. Titik Core dan Enam Kelas Sidik Jari
1 . Karu, K. and A.K. Jain. Fingerprint Classification. 1995 hal 2
Umumnya cara konvensional yang digunakan untuk mendapatkan jejak sidik jari adalah dengan menggunakan tinta dan media kertas yang kemudian sidik jari pada kertas tersebut dimasukkan dalam komputer dengan menggunakan media scanner. Cara seperti ini me nghasilkan gambar yang kurang sempurna dikarenakan berbagai hal, antara lain mutu kertas, mutu tinta dan yang terutama adalah besar gaya penekanan pada pada kertas oleh sidik jari.
Cara lain yang dapat digunakan adalah dengan menggunakan kamera CCD (Charge Couple Device). Penggunaan kamera CCD juga masih memungkinkan gangguan yang dikarenakan kulit kering, penyakit kulit, keringat, kotor dan kelembapan.
2.3. Sistem Pengenalan Sidik Jari
Pengenalan sidik jari atau secara umum pengenalan gambar memiliki beberapa macam metode atau sistem, yang masing- masing memiliki kelebihan, kekurangan, dan fungsi tersendiri yang diukur baik dari akurasi, waktu proses, dan rumitnya perhitungan. Dalam sub bab setelah ini akan diuraikan 5 metode sistem pengenalan gambar.
2.3.1. Template Matching
Matching atau pencocokan adalah pendekatan paling dasar pada pengenalan gambar. Matching dapat digunakan untuk mencari posisi dari objek yang sudah diketahui dalam suatu gambar dan juga untuk mencari pola tertentu.
Template atau pola dasar matching bisa saja memiliki ukuran yang sangat kecil ataupun memiliki ukuran yang mewakili seluruh objek. Segmentasi berdasarkan matching akan sangat mudah apabila objek yang dicari sama persis dengan template-nya.
Template matching yang pertama adalah mencari bagian dari suatu gambar yang cocok dengan template-nya. Sedangkan template matching yang kedua adalah membandingkan suatu gambar dengan beberapa template yang memiliki dimensi sama antara gambar dan template. Template matching yang kedua ini sering digunakan dalam pengenalan tulisan atau OCR (Optical Character Recognition), dimana setiap bagian huruf akan disegmentasi terlebih
dulu, kemudian setiap huruf ini akan dibandingkan dengan template yang ada.
Hasil dari pembandingan ini berupa nilai- nilai kemiripan (similarity) untuk setiap template dengan huruf yang akan dikenali, dimana template dengan nilai similarity paling tinggi menunjukkan tingkat kecocokan yang tinggi pula.
Template matching paling sederhana (gambar black-white) dapat didefinisikan sebagai
∑
= I(x,y).T(x,y)
S (2.6)
dimana I adalah gambar, dan T adalah template.
Misalkan template berupa matrik
111 111 111
dengan gambar berupa
101 111 111
maka nilai
untuk S menurut persamaan 2.6 adalah 8.
Untuk matching pada gambar gray-scale didefinisikan sebagai
Y X L
y x T y x I S
X
X Y
Y
. .
) , ( ) , ( 1
1
0 1
∑∑
− 0=
−
=
−
−
= (2.7)
dimana L adalah gray level maksimal (255), X dan Y adalah panjang dan lebar dari template.
S akan bervariasi dari 0 sampai 1, maka untuk gambar I yang sama dengan template-nya maka S akan bernilai 1.
2.3.2. Fuzzy Logic (Matching)
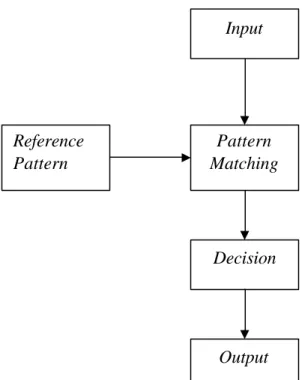
Pada tugas akhir ini dicoba menggunakan Fuzzy Logic dalam pengenalan pattern tertentu yaitu sidik jari. Sistem Fuzzy Matching didasarkan pada pendekatan pengenalan pattern tradisional, di mana elemen utamanya diperlihatkan pada blok diagram dari gambar di bawah ini.
Gambar 2.2. Blok Diagram Pattern Recognition
2.3.2.1. Dasar Fuzzy Logic
Seringkali masyarakat mengelompokkan ilmu menjadi 2 macam yaitu ilmu pasti (mis: matematika) dan ilmu sosial. Ilmu pasti menghasilkan output sebanyak 2 kemungkinan yaitu benar atau salah, 1 atau 0, high atau low, dan yang sejenisnya. Sedangkan ilmu sosial menghasilkan output berupa pandangan- pandangan yang jumlah kemungkinannya tidak hanya 2 tetapi bisa lebih.
Bagi mereka yang menekuni ilmu pasti bisa berbangga karena jawaban mereka sangat menyakinkan, tetapi akan menjadi masalah apabila menghadapi suatu sistem yang kompleks dan tidak stabil. Dalam kenyataannya tidak selalu suatu hal yang benar 100% atau salah 100%.
Input
Pattern Matching Reference
Pattern
Decision
Output
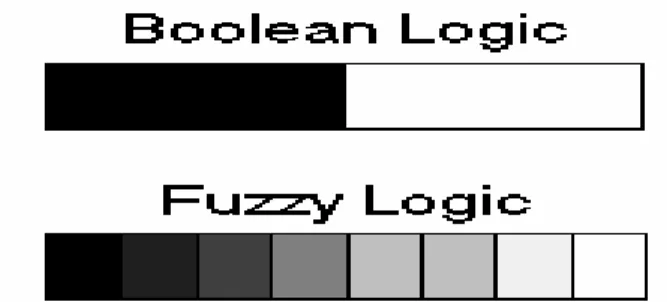
Pada tahun 1965, Profesor Lotfi Zadeh dari University of California at Berkeley mengemukakan pendapat bahwa pernyataan "true" atau "false" dari logika Boolean tidak dapat merepresentasikan pernyataan yang tidak pasti yang berada di antara pernyataan "true" dan "false" , seperti yang terdapat pada banyak hal dalam dunia nyata. Untuk merepresentasikan ketidakpastian di antara "true"
dan "false", Profesor Lotfi Zadeh mengembangkan suatu teori yang berdasarkan pada teori classical set atau conventional set yang disebutnya sebagai fuzzy set.
Tidak seperti logika boolean, logika fuzzy memiliki banyak nilai (multivalue).
Sebagai ganti dari pernyataan dengan nilai seluruhnya "true" atau semuanya "false", logika fuzzy menggunakan derajat dari membership (degrees of membership) dan derajat dari kebenaran (degrees of truth), sehingga suatu pernyataan dapat sebagian true atau sebagian false pada waktu yang bersamaan.
Gambar 2.3. Logika Boolean dan Logika Fuzzy
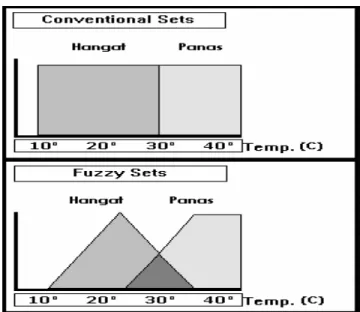
Contohnya saja apabila kita memasuki ruangan ber-AC dengan suhu 24 oC, mungkin kita mengatakan ruangan tersebut dingin. Tetapi belum tentu seseorang yang sehabis berolahraga memasuki ruangan tersebut dan mengatakan ruangan tersebut dingin. Dalam conventional set, suatu elemen merupakan anggota dari satu membership function saja. Misalnya: anggota dari membership function "Hangat" yaitu suhu antara 10 oC dan 30 oC, sedangkan anggota dari membership function "Panas" yaitu suhu antara 30 oC dan 40 oC. Jadi sangat sulit menentukan apakah suhu 30 oC termasuk hangat atau panas, karena transisi dari hangat ke panas terjadi secara langsung. Dalam logika fuzzy, suhu 30 oC mungkin termasuk hangat atau panas, hal ini sesuai dengan keadaan pada dunia nyata bahwa suhu 30 oC termasuk di antara hangat dan panas.
Dengan membership function yang saling tumpang tindih, menyebabkan transisi dari hangat ke panas terjadi secara bertahap.
Gambar 2.4. Conventional Sets dan Fuzzy Sets
Logika fuzzy tidak hanya mengenali batasan yang jelas dari membership function sebagai alternatif dari keanggotaan hitam atau putih, tetapi juga gradasi tanpa batas yang ada di antaranya. Hal ini tampaknya tidak jelas, tetapi logika fuzzy menguranginya dengan memberikan nilai yang spesifik dari setiap gradasi tersebut. Untuk lebih memahami sebuah sistem fuzzy, maka harus diketahui konsep dasar yang berhubungan dengan logika fuzzy. Untuk lebih jelasnya perhatikan gambar berikut ini.
Gambar 2.5. Bagian – Bagian Membership Function
Negatif Zero Positif
Membership Function
Universe Of Discourse Degree
Of Member ship
Bagian-bagian yang terdapat dalam gambar diatas dapat dijelaskan sebagai berikut :
• Label
Merupakan deskripsi dari nama yang digunakan untuk mengidentifikasi membership function.
• Degree of Membership
Merupakan pernyatakan derajat dari crisp input yang sesua i dengan membership function antara 0 sampai 1. Juga disebut sebagai Membership Grade, truth value, atau Fuzzy input.
• Membership Function
Mendefinisikan Fuzzy Set dengan memetakan crisp inputs dari nilai domainnya ke dalam derajat keanggotaannya.
• Universe of Discourse
Adalah range dari semua nilai yang mungkin dipakai dalam variabel sistem, merupakan semesta dari himpunan input.
2.3.2.2. Logika Fuzzy Logic
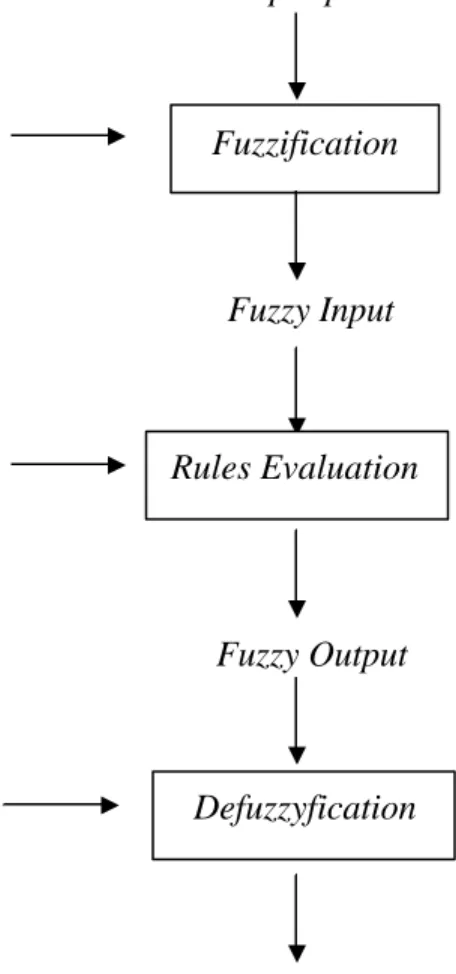
Konsep dari logika Fuzzy dapat digambarkan dalam bentuk blok diagram seperti gambar berikut :
Gambar 2.6. Konsep Logika Fuzzy
Pada blok diagram di atas terdapat 9 komponen penting yang dibutuhkan dalam suatu proses Fuzzy Logic antara lain seperti yang dijelaskan dibawah ini:
• Crisp Input
Merupakan nilai input dari proses Fuzzy yang merupakan besaran suatu kondisi, misalnya 24 °C.
• Membership function
Logika fuzzy selalu menyatakan suatu perubahan secara gradual sehingga setiap kondisi mempunyai derajat yang disebut sebagai Degree Of Membership. Fungsi yang menyatakan hubungan antara suatu kondisi dengan derajatnya disebut sebagai Fungsi Keanggotaan (Membership Function).
Crisp Input
Fuzzification
Fuzzy Input
Rules Evaluation
Fuzzy Output
Defuzzyfication
Crisp Output Input
Membership Function
If_Then Rules
Output Membership Function
Membership Function ini bisa berbentuk segitiga, trapezium, singleton maupun bentuk kurva. Tetapi Membership Function yang berbentuk kurva sangat jarang digunakan karena sulit implementasinya.
• Fuzzification
Langkah pertama yang dilakukan dalam proses logika fuzzy yaitu proses fuzzifikasi (Fuzzification). Tujuan utamanya adalah mentransformasikan nilai crisp input menjadi fuzzy input, sebelumnya dengan menentukan membership function untuk tiap input.
Setelah menentukan membership function - nya, maka proses fuzzifikasi mulai mengambil nilai input dan membandingkan dengan membership function yang telah ada untuk menghasilkan harga fuzzy input.
• Fuzzy Input
Untuk mendapatkan harga dari fuzzy input maka dilakukan pemetaan dari nilai crisp input pada membership function dengan cara seperti di bawah ini:
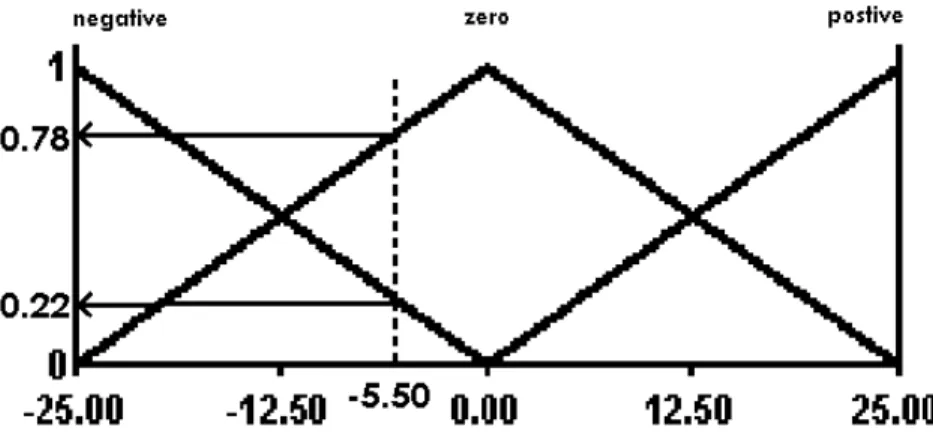
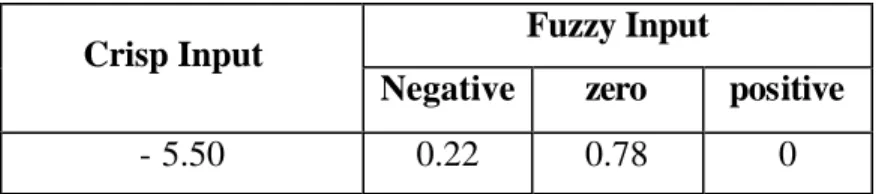
Gambar 2.7. Membership Function
Tabel 2.1. Crisp Input Fuzzy Input Crisp Input
Negative zero positive
- 5.50 0.22 0.78 0
Tabel di atas memperlihatkan hasil fuzzy input yang didapatkan dari crisp input dan membership seperti yang ditunjukkan pada gambar 2.7.
• If Then Rules
Untuk menyatakan hubungan antara input dengan output sistem, logika fuzzy menggunakan ekspresi pernyataan jika- maka (If_then) dimana pernyataan –pernyataan ini dapat diperoleh berdasarkan nilai yang masuk diakal berupa pengalaman, pengetahuan atau intuisi (common sense) manusia.
Pernyataan – pernyataan if_then tersebur dalam logika fuzzy dinamakan dengan Rules (aturan–aturan), dimana pernyataan “If” digunakan untuk menggambarkan dari kondisi sistem yang terjadi dan kondisi “Then”
digunakan untuk menggambarkan aksi yang akan dilakukan pada sistem jika kondisi sistem pernyataan yang dibuat dapat terdiri dari satu antecedent. Jika menggunakan lebih dari satu antecedent maka digunakan pernyataan “and”
sebagai penghubung, sehingga bentuk pernyataannya adalah : “If antecedent1 and antecedent2 then consequent”.
Dengan menggunakan aturan – aturan seperti diatas sangat mempermudah untuk melakukan kontrol sistem dibandingkan jika menggunakan suatu perhitungan matematis yang rumit untuk menggambarkan suatu proses kontrol. Tetapi dalam logika fuzzy pernyataan if_then harus terlebih dahulu dimasukkan ke dalam suatu tabel yang disebut Fuzzy Associative Memory (FAM).
• Rules Evaluations
Tahap kedua dari proses fuzzy adalah rule evaluation, dimana proses fuzzy akan menggunakan aturan – aturan (Rules) yang telah dibuat untuk menentukan aksi kontrol yang harus dilakukan sesuai dengan nilai input yang dihasilkan (fuzzy input). Pada tahap ini akan dilakukan evaluasi tiap – tiap rule dengan input yang dihasilkan dari proses sebelumnya (Fuzzification).
Aturan–aturan ini pada umumnya merupakan statement if_then yang menggambarkan aksi yang harus dilakukan sebagai respon dari berbagai macam fuzzy input.
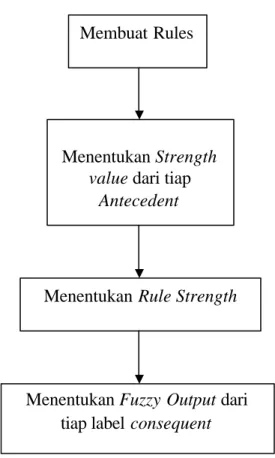
Untuk meringkas yang terjadi pada tahap rule evaluasi ini dapat digambarkan melalui blok diagram dibawah ini:
Gambar 2.8. Diagram Alir Proses Evaluation Rules
• Fuzzy Output
Untuk mendapatkan Fuzzy Output dilakukan defuzzyfikasi. Pada proses defuzzifikasi ini semua nilai fuzzy output yang dihasilkan dari proses rule evaluation dikombinasikan dengan output membership function untuk menghasilkan suatu nilai output yang sesuai dengan sistem yang diinginkan.
Membuat Rules
Menentukan Strength value dari tiap
Antecedent
Menentukan Rule Strength
Menentukan Fuzzy Output dari tiap label consequent
• Defuzzyfication
Metode proses defuzzifikasi secara umum yang digunakan ada dua macam yaitu :
a. Metode maximizer. Metode maximizer ini mengambil lokasi dari nilai fuzzy output yang tertinggi (maksimum value) sebagai hasil akhir.
Gambar 2.9. Metode Maximizer
b. Metode centroid (Center Of Area). Pada metode Center Of Area (COA) ini setiap output Membership Function yang mempunyai nilai diatas nilai fuzzy output dipotong. Pemotongan ini disebut dengan istilah Lambda Cut. Hasil dari membership function yang telah dipotong digabungkan lalu dihitung Center Of Area keseluruhannya. Dibawah ini gambar dari pemotongan output membership function (lambda cut).
Gambar 2.10. Lambda Cut - - -
Nilai Fuzzy Output
- - - Max
Value
Membership function yang telah dipotong dan digabungkan dengan membership function yang lain lalu diambil Center Of Area– nya dapat dilihat pada gambar di bawah ini:
Gambar 2.11. Metode Center Of Area
• Output membership function
Output membership function yang berbentuk singleton dapat menggunakan metode Center Of Area dalam proses defuzzifikasinya, dimana output ini merupakan sebuah garis vertikal tunggal yang tidak mempunyai bobot. Contoh dapat dilihat sepeti gambar dibawah ini:
Gambar 2.12. Lambda Cut pada Singleton
• Crisp Output
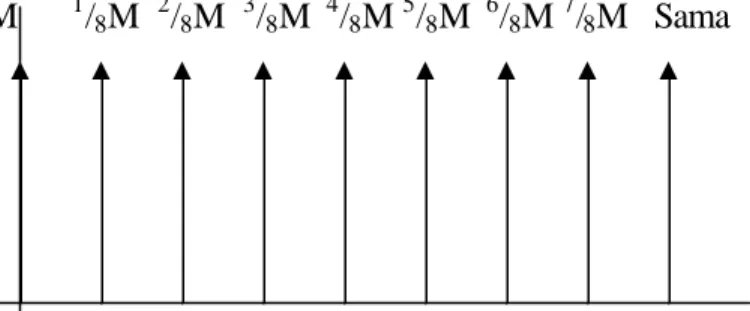
Untuk mendapatkan harga crisp output yaitu dengan cara menjumlahkan hasil perkalian dari koordinat fuzzy output dari posisi singleton dan kemudian hasilnya dibagi dengan jumlah fuzzy output.
Tdk M 1/8M 2/8M 3/8M 4/8M 5/8M 6/8M 7/8M Sama
0 1/8 1/4 3/8 1/2 5/8 3/4 7/8 1
2.3.3. Nearest Neighbour, Mean dan k-Neighbour
Metode- metode ini merupakan metode pengenalan yang umum, lazim dan mudah digunakan. Pada dasarnya ketiga metode tersebut memiliki prinsip yang sama yaitu adalah mencari jarak atau distance dari suatu gambar dengan template-nya.
Distance disini adalah jarak antara 2 titik dalam ruang multidimensi.
Persamaan untuk mengukur distance ini didapat dari penurunan teori Phytagoras untuk n buah dimensi, yaitu sebagai berikut :
∑ −
== n
i
b
ia
ib a de
1
)
2(
) ,
( (2.8)
Fungsi de adalah jarak antara titik a dan titik b dalam ruang dengan n buah dimensi,dalam hal ini adalah jumlah feature yang diambil.
2.3.3.1. Nearest Neighbour
Metode nearest neighbour adalah metode yang paling lazim digunakan oleh karena memiliki kecepatan proses yang sederhana dan recognition percentage yang cukup tinggi. Metode ini mencari distance dari feature Ix terhadap feature yang telah disimpan dari data image- image training. Setelah didapat distance-nya maka kemudian dicari distance yang minimum dari semua distance yang didapat. Distance minimum tersebut yang kemudian digunakan untuk mencari identitas dari Ix. Dari proses ini hanya diambil satu nilai distance, yaitu nilai distance yang paling kecil.
2.3.3.2. Nearest Mean
Pada metode nearest mean, Ix tidak dibandingkan pada tiap feature pada database, melainkan pada rata-rata feature yang berada di satu kelas. Metode ini memiliki proses yang lebih cepat, namun recognition percentage-nya rendah.
Sebelum dicari perbandingan distance, dicari terlebih dahulu rata-rata tiap kelas.
Setelah itu Ix dibandingkan dengan setiap rata-rata kelas tersebut. Sebagai contoh, bila kita memiliki image dari 12 orang dengan masing- masing 10 image,
dengan menggunakan metode nearest neighbour kita akan mendapatkan 120 nilai distance tetapi jika kita menggunakan metode nearest mean kita hanya mendapatkan 12 nilai distance. Pengenalan didapat dari distance yang minimum dari tiap kelas.
2.3.3.3. Nearest k-Neighbours
Metode ini memiliki recognition percentage yang paling tinggi, namun perhitungannya cenderung lebih rumit. Prinsip dasarnya hampir sama dengan metode nearest neighbour, tetapi distance yang didapat tidak hanya 1. pada metode ini diambil k buah nilai distance minimum. Dari k buah nilai itu dicari kelas mana yang paling banyak jumlahnya maka kelas tersebutlah yang diambil untuk mengidentifikasi Ix.
Pertimbangan dari metode ini adalah nilai distance minimum saja tidaklah cukup untuk mengidentifikasi Ix, karena belum tentu nilai distance minimum itu merepresentasikan kelas dimana image Ix sesungguhnya berada.
2.4. Principal Component Analysis (PCA)
Prinsip dasar dari PCA adalah memproyeksikan image kedalam bidang ruang eigen-nya. Caranya adalah dengan mencari eigen vektor yang dimiliki setiap image dan memproyeksikannya kedalam ruang eigen yang didapat tersebut.
Besar dari dimensi ruang eigen tergentung dari jumlah image yang dimiliki oleh program training. Langkah–langkah penggunaan PCA seperti yang dijelaskan di sub bab dibawah ini.
2.4.1. Memasukkan Data Pixels Image Kedalam Matriks
Jika kita memiliki image training sebanyak m dan masing- masing berdimensi 50 x 50 pixels atau 2500 pixels maka matriks yang merepresentasikan image- image tersebut adalah berdimensi 2500 x m (matriks u), jadi satu image training menempati satu kolom dari matriks dimana baris dari matriks mewakili besar dari dimensi image training tersebut.
2.4.2. Mencari Image Rata-Rata
Image rata-rata adalah besarnya rata-rata per- pixel dari image- image training, jadi komponen perbaris dari matriks dijumlahkan dan dibagi dengan jumlah image (jumlah colom) sehingga menghasilkan matriks rata-rata PCA yang berdimensi 2500 x 1 (matriks u ).
∑
== m
k k n
n
u
u
m1 , 1
,
1 (2.9)
2.4.3. Mencari Matriks Eigen Vector
Untuk dapat memperoleh matriks eigen vector maka harus diperoleh dahulu covariance matriksnya. covariance matrix dicari dengan mengalikan matriks u (2500 x m) dengan transpose-nya (m x 2500) sehingga menghasilkan matriks yang berdimensi 2500 x 2500. jadi :
u u
C = × ′ (2.10)
selanjutnya dilakukan dekomposisi eigen sehingga berlaku rumusan sebagai berikut :
V V
C× =λ× (2.11)
dimana V (matriks eigen vector) dan λ (matriks eigen value) adalah matriks berdimensi n x n (n adalah jumlah pixel image).
Pencarian eigen value dan eigen vector ini dapat dibantu dengan menggunakan metode Jacobi. Eigen value yang didapat diurutkan mulai yang terbesar sampai yang terkecil, dan eigen vector yang bersesuaian dengan eigen value tersebut juga diurutkan. Hasil dari operasi ini adalah matriks V yang berdimensi 2500 x 2500.
Agar dapat lebih memahami dalam perhitungan pencarian eigen vector ini akan diberikan satu contoh perhitungannya yang hasilnya akan dibandingkan dengan program PCA (bagian eigen) yang telah dibuat, untuk mengetahui kebenarannya.
Misalnya kita mempunyai matriks X berdimensi 3x3 yang akan kita cari eigen value dan eigen vectornya.
−
−
−
−
−
=
9340 , 0 0017 , 0 0
0017 , 0 4659 , 0 1598 , 0
0 1598
, 0 9681 , 20 X
Pada iterasi pertama kita ambil p=1,q=2
0
0017 . 0, ) 1 ( ) 0017 . 0, ( 0
0 0078 . 0, ) 0017 . 0, ( 0
4647 . 0,
) 0078 . 0, ( ) 1598 . 0, ( 2 ) 1 ( 4659 . 0, 0078 . 0, 9681 . 20,
97 . 20,
) 0078 . 0, ( ) 1598 . 0, ( 2 0078 . 0, 4659 . 0, ) 1 ( 9681 . 20,
0078 . 50 0, . 20, 1
1598 . sin 0,
1
50 . 20, 2
4659 . 0, 9681 . 5 20, . 0, cos
50 . 20, 44 . 420,
44 . 420,
) 1598 . 0, ( 4 ) 4659 . 0, 9681 . 20, (
21 12
23 13
2 2
22
2 2
11
2 2
2
=
=
=
−
⋅
− +
=
≈
⋅
− +
=
=
−
⋅
−
⋅
−
−
⋅ +
⋅
=
=
−
⋅
−
⋅ +
⋅ +
−
⋅
=
⋅ =
− −
=
−
= ⋅
+ −
=
=
=
=
− +
−
=
x x x x x x r r
α α
Sehingga didapat matriks N1 sebagai berikut
−
−
−
=
1 0
0
0 1 0078
, 0
0 0078 , 0 1
N1
dan matriks X yang baru
−
=
9340 , 0 0017 , 0 0
0017 . 0 4647 , 0 0
0 0
97 , 20 X
Pada iterasi ke 2 ambil p=2, q=3 dan lakukan tiap langkah seperti diatas maka akan didapat matriks N2 dan matrix X sebagai berikut:
−
=
8157 . 0 5784 . 0 0
5784 , 0 8157 , 0 0
0 0
1 N2
−
=
9340 , 0 0
0
0 4647
, 0 0
0 0
97 , 20 X
Karena semua komponen non diagonal sudah 0 berarti didapat eigen value dari matriks X adalah 20,97, 0,4647, -0,9340. Sedangkan eigen vectornya didapat dengan mengalikan N iterasi pertama dan N iterasi kedua.
2 1N N Q =
−
−
−
=
8157 , 0 5784 , 0 0
5784 , 0 8157 , 0 0078 , 0
0045 , 0 0064 , 0 1
Q
Hasil dari perhitungan pencarian matriks eigen vector ini sesuai dengan hasil dari program PCA yang telah dibuat.
2.4.4. Mencari Feature PCA
Feature adalah komponen-komponen penting dari image–image training yang didapatkan dari proses PCA secara keseluruhan. Feature inilah yang akan digunakan untuk mengidentifikasikan suatu image yang akan dikenali dengan membandingkannya terhadap hasil feature image tersebut. Feature dapat dicari dengan mentransformasikan image asal kedalam ruang eigen dengan menggunakan persamaan sebagai berikut :
i V f
m
i
T
I u
×=
∑ −
=1
( )
(2.12)dimana I adalah data tiap pixel dari image training ke-I, m adalah jumlah dari image training, dan V adalah matriks eigen vector. Hasil dari perhitungan feature ini adalah matrik feature (m x 2500).
2.5. Algoritma PCA Yang Lebih Efisien
Sebagai ilustrasi, misalkan kita memiliki m buah image dengan dimensi 100 x 100 atau 10.000 pixels, maka untuk mendapatkan eigen vector adalah dengan mencari matriks covariance (C = u x uT) yang berdimensi 10.000 x 10.000. perhitungan matriks ini tentunya akan sangat memakan waktu lama, dikarenakan dimensinya yang sangat besar. Oleh karena itu digunakan suatu algoritma yang lebih efisien yang dikenalkan oleh Murakami and Kumar dalam papernya yang menyimpulkan bahwa eigen vector dari matriks covariance (C = u x uT) dengan dimensi n x n (n adalah jumlah pixel dalam image) adalah sama dengan matriks M (M = uT x u) dengan dimensi m x m (m adalah jumlah image), sehingga proses akan lebih cepat. Untuk lebih jelasnya algoritma PCA- nya dapat dilihat pada sub bab dibawah ini.
2.5.1. Memasukkan Data Pixels Image Kedalam Matriks
Jika kita memiliki image training sebanyak m dan masing- masing berdimensi 50 x 50 pixels atau 2500 pixels maka matriks yang merepresentasikan image- image tersebut adalah berdimensi 2500 x m (matriks u), jadi satu image training menempati satu kolom dari matriks dimana baris dari matriks mewakili besar dari dimensi image training tersebut.
2.5.2. Mencari Image Rata-Rata
Image rata-rata adalah besarnya rata-rata per- pixel dari image- image training, jadi komponen perbaris dari matriks dijumlahkan dan dibagi dengan jumlah image (jumlah colom) sehingga menghasilkan matriks rata-rata PCA yang berdimensi 2500 x 1 (matrik s u ).
∑
== m
k k n
n
u
u
m1 , 1
,
1 (2.13)
2.4.3. Mencari Matriks Eigen Vector
Untuk dapat memperoleh matriks eigen vector maka harus diperoleh dahulu matriks M-nya. Matrix M dicari dengan mengalikan matriks transpose (m x 2500) dengan matriks u (2500 x m) sehingga menghasilkan matriks yang berdimensi m x m. jadi :
u u
M = ′× (2.14)
selanjutnya dilakukan dekomposisi eigen sehingga berlaku rumusan sebagai berikut :
V V
M× =λ× (2.15)
dimana V (matriks eigen vector) dan λ (matriks eigen value) adalah matriks berdimensi m x m dan m x 1. Pencarian eigen value dan eigen vector ini dapat dibantu dengan menggunakan metode Jacobi. Eigen value yang didapat diurutkan mulai yang terbesar sampai yang terkecil, dan eigen vector yang bersesuaian dengan eigen value tersebut juga diurutkan. Hasil dari operasi ini adalah matriks V yang berdimensi m x m.
2.4.4. Mencari Feature PCA
Feature adalah komponen-komponen penting dari image–image training yang didapatkan dari proses PCA secara keseluruhan. Feature inilah yang akan digunakan untuk mengidentifikasikan suatu image yang akan dikenali dengan membandingkannya terhadap hasil feature image tersebut.
Feature dapat dicari dengan mentransformasikan image asal kedalam ruang eigen dengan menggunakan persamaan sebagai berikut :
and i V
f
m
i
T
I u
exp1
( )
×=
∑ −
=
(2.16)
dimana I adalah data tiap pixel dari image training ke-I, m adalah jumlah dari image training, dan Vexpand diperoleh dari :
∑ −
×= V
and
Vexp
( Ii u )
(2.17)Vexpand adalah matriks dengan dimensi 2500 x m. Hasil dari perhitungan feature ini adalah matrik feature dengan dimensi m x m.