Timur Menggunakan Teknik Data Mining
SKRIPSI
Disusun Oleh :
Citr a Ar um Sar i
1032010048
J URUSAN TEKNIK INDUSTRI
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL “VETERAN”
J AWA TIMUR
PEMBANGUNAN NASIONAL “VETERAN” J AWA TIMUR
MENGGUNAKAN TEKNIK DATA MINING
Disusun oleh :
CITRA ARUM SARI 1032010048
Telah dipertahankan dihadapan dan diterima oleh Tim Penguji Skr ipsi J ur usan Teknik Industri Fakultas Teknologi Industr i
Univer sitas Pembangunan Nasional “Veteran” J awa Timur Pada Tanggal 20 J anuar i 2014
Tim Penguji : Pembimbing :
Univer sitas Pembangunan Nasional “Veteran” J awa Timur Sur abaya
PEMBANGUNAN NASIONAL “VETERAN” J AWA TIMUR
MENGGUNAKAN TEKNIK DATA MINING
Disusun oleh :
CITRA ARUM SARI 1032010048
Telah dipertahankan dihadapan dan diterima oleh Tim Penguji Skr ipsi J ur usan Teknik Industri Fakultas Teknologi Industr i
Univer sitas Pembangunan Nasional “Veteran” J awa Timur Pada Tanggal 20 J anuar i 2014
Tim Penguji : Pembimbing : NIP. 19591228 198803 2 001
Mengetahui
Ketua J ur usan Teknik Industri Fakultas Teknologi Industri
Univer sitas Pembangunan Nasional “Veteran” J awa Timur Sur abaya
sehingga penulis dapat menyelesaikan penyusunan Tugas Akhir ini.
Tugas Akhir ini disusun untuk memenuhi persyaratan kelulusan Program
Sarjana Strata-1 (S-1) di Jurusan Teknik Industri Fakultas Teknologi Industri
Universitas Pembangunan Nasional “Veteran” Jawa Timur dengan judul :
“ Analisa Dat a M ahasisw a Baru Terhadap Program St udi Yang Dipilih Di Universit as Pem bangunan Nasional “ Vet eran” Jaw a Timur M enggunakan Teknik Dat a M ining”
Penyelesaian penyusunan Tugas Akhir ini tentunya tidak terlepas dari
peran serta berbagai pihak yang telah memberikan bimbingan dan bantuan baik
secara langsung maupun tidak langsung. Oleh karena itu tidak berlebihan bila
pada kesempatan kali ini penulis mengucapkan terima kasih kepada :
1. Kedua orang tua yang telah memberikan banyak dukungan secara moril,
materil serta doa, sehingga penyelesaian laporan ini dapat segera
terselesaiakan.
2. Bapak Ir. Sutiyono, MT, selaku Dekan Fakultas Teknologi Industri
Universitas Pembangunan Nasional “Veteran” Jawa Timur.
3. Bapak Dr. Minto Waluyo, MM, selaku Ketua Jurusan Teknik Industri
Universitas Pembangunan Nasional “Veteran” Jawa Timur.
7. Ir. Iriani, MMT, selaku Dosen Penguji Skripsi.
8. Ir. Nisa Masruroh, MT, selaku Dosen Penguji Skripsi.
9. Ibu Ir. Erlina P., MT selaku Dosen Penguji Skripsi
10. Bapak Ir. Rusindiyanto, MT, selaku Dosen Penguji Skripsi.
11. Teman-teman angkatan 2010 khususnya asisten laboratorium Optimasi dan
Pemrograman Komputer yang telah memberikan semangat dalam
penyelesaian Tugas Akhir ini. Serta untuk Diska dan Intan yang bersedia
menemani dan selalu membantu ketika penulis mengalami kendala selama
perkuliahan hingga penyelesaian Tugas Akhir.
12. Pihak-pihak lain yang terkait baik secara langsung maupun tidak langsung
dalam penyelesaian Tugas Akhir ini yang tidak dapat disebutkan satu per
satu.
Penulis menyadari sepenuhnya bahwa penyusunan Tugas Akhir ini
terdapat kekurangan, maka dengan segala kerendahan hati penulis mengharapkan
saran dan kritik yang bersifat membangun.
Akhir kata semoga Tugas Akhir ini dapat bermanfaat bagi semua pihak
yang membaca. Terima Kasih.
KATA PENGANTAR ... i
DAFTAR ISI ... iii
DAFTAR GAMBAR ... v
DAFTAR TABEL ... vi
DAFTAR LAMPIRAN ... vii
BAB I PENDAHULUAN 1.1 Latar Belakang ... 1
1.2 Perumusan Masalah ... 2
1.3 Batasan Masalah... 3
1.4 Asumsi ... 3
1.5 Tujuan Penelitian ... 4
1.6 Manfaat Penelitian... 4
1.7 Sistematika Penulisan ... 4
BAB II TINJ AUAN PUSTAKA 2.1 Data Mining ... 6
2.1.1 Tahapan Data Mining ... 9
2.1.2 Pengelompokkan Data Mining ... 12
2.2 Clustering ... 16
2.2.1 Metode Clustering ... 19
2.3 Algoritma K-Means ... 20
BAB III METODE PENELITIAN
3.1 Pengamatan Obyek ... 35
3.2 Identifikasi Variabel ... 35
3.3 Pengumpulan Data ... 36
3.4 Pengolahan Data... 36
3.5 Langkah-Langkah Penelitian dan Pemecahan Masalah ... 37
BAB IV HASIL PENELITIAN DAN PEMBAHASAN 4.1 Pengumpulan Data ... 41
4.2 Pengolahan Data... 44
4.3 Pembahasan ... 48
BAB V KESIMPULAN DAN SARAN 5.1 Kesimpulan ... 50
5.2 Saran ... 50
Gambar 2.2 Tahap-Tahap Data Mining ... 9
Gambar 2.3 Contoh Clustering ... 18
Gambar 2.4 Grafik Hasil Klasterisasi Nilai Kompetensi Kualifikasi Akademik Dan Perencanaan & Pelaksanaan Pembelajaran .. 23
Gambar 2.5 Cara Kerja Algoritma K-Means ... 25
Gambar 2.6 Hasil Uji Coba Penelitian ... 31
Gambar 2.7 Hasil Clustering Menggunakan Algoritma K-Means ... 33
Baru ... 29
Tabel 2.2 Hasil Kluster Kota Asal Mahasiswa Baru ... 29
Tabel 4.1 Pengumpulan Data Mahasiswa Baru Universitas Pembangunan Nasional “Veteran” Jawa Timur ... 42
Tabel 4.2 Jarak Setiap Data dengan Pusat Kluster Iterasi 1 ... 45
Tabel 4.3 Hasil Kluster Data Berdasar Jarak Minimum Iterasi 1 ... 45
Tabel 4.4 Jarak Setiap Data dengan Pusat Kluster Iterasi 2 ... 46
Tabel 4.5 Hasil Kluster Data Berdasar Jarak Minimum Iterasi 2 ... 46
Tabel 4.6 Jarak Setiap Data dengan Pusat Kluster Iterasi 3 ... 47
Tabel 4.7 Hasil Kluster Data Berdasar Jarak Minimum Iterasi 3 ... 47
LAMPIRAN I.2 Hasil Pengolahan Data Mahasiswa Baru Universitas Pembangunan Nasional “Veteran” Jawa Timur Iterasi 1
LAMPIRAN II.1 Nilai Pusat Kluster Iterasi 2
LAMPIRAN II.2 Hasil Pengolahan Data Mahasiswa Baru Universitas
Pembangunan Nasional “Veteran” Jawa Timur Iterasi 2
LAMPIRAN III.1 Nilai Pusat Kluster Iterasi 2
KATA PENGANTAR ... i
DAFTAR ISI ... iii
DAFTAR GAMBAR... v
DAFTAR TABEL ... vi
DAFTAR LAMPIRAN ... vii
BAB I PENDAHULUAN 1.1 Latar Belakang ... 1
1.2 Perumusan Masalah ... 2
1.3 Batasan Masalah ... 3
1.4 Asumsi ... 3
1.5 Tujuan Penelitian ... 4
1.6 Manfaat Penelitian ... 4
1.7 Sistematika Penulisan ... 4
BAB II TINJ AUAN PUSTAKA 2.1 Data Mining ... 6
2.1.1 Tahapan Data Mining... 9
2.1.2 Pengelompokkan Data Mining ... 12
2.2 Clustering... 16
2.2.1 Metode Clustering... 19
2.3 Algoritma K-Means ... 20
BAB III METODE PENELITIAN
3.1 Pengamatan Obyek... 35
3.2 Identifikasi Variabel ... 35
3.3 Pengumpulan Data ... 36
3.4 Pengolahan Data ... 36
3.5 Langkah-Langkah Penelitian dan Pemecahan Masalah ... 37
BAB IV HASIL PENELITIAN DAN PEMBAHASAN 4.1 Pengumpulan Data ... 41
4.2 Pengolahan Data ... 44
4.3 Pembahasan ... 50
BAB V KESIMPULAN DAN SARAN 5.1 Kesimpulan ... 54
5.2 Saran ... 54
Gambar 2.2 Tahap-Tahap Data Mining ... 9
Gambar 2.3 Contoh Clustering ... 18
Gambar 2.4 Grafik Hasil Klasterisasi Nilai Kompetensi Kualifikasi Akademik Dan Perencanaan & Pelaksanaan Pembelajaran . 23 Gambar 2.5 Cara Kerja Algoritma K-Means ... 25
Gambar 2.6 Hasil Uji Coba Penelitian ... 31
Gambar 2.7 Hasil Clustering Menggunakan Algoritma K-Means ... 33
Baru ... 29
Tabel 2.2 Hasil Kluster Kota Asal Mahasiswa Baru ... 29
Tabel 4.1 Pengumpulan Data Mahasiswa Baru Universitas Pembangunan Nasional “Veteran” Jawa Timur ... 42
Tabel 4.2 Jarak Setiap Data dengan Pusat Kluster Iterasi 1 ... 45
Tabel 4.3 Hasil Kluster Data Berdasar Jarak Minimum Iterasi 1 ... 45
Tabel 4.4 Jarak Setiap Data dengan Pusat Kluster Iterasi 2 ... 46
Tabel 4.5 Hasil Kluster Data Berdasar Jarak Minimum Iterasi 2 ... 47
Tabel 4.6 Jarak Setiap Data dengan Pusat Kluster Iterasi 3 ... 48
Tabel 4.7 Hasil Kluster Data Berdasar Jarak Minimum Iterasi 3... 49
Hasil Pengolahan Data Program Studi Universitas Pembangunan Nasional “Veteran” Jawa Timur Iterasi 1
LAMPIRAN II Nilai Pusat Kluster Iterasi 2
Hasil Pengolahan Data Program Studi Universitas
Pembangunan Nasional “Veteran” Jawa Timur Iterasi 2
LAMPIRAN III Nilai Pusat Kluster Iterasi 2
Hasil Pengolahan Data Program Studi Universitas
Abstr ak
Universitas Pembangunan Nasional “Veteran” Jawa Timur berlokasi di Surabaya merupakan Perguruan Tinggi Swasta di Indonesia yang memiliki 6 Fakultas dengan 19 Program Studi (Progdi) sarjana.
Banyaknya peminat dari setiap program studi di Universitas Pembangunan Nasional “Veteran” Jawa Timur dapat dipengaruhi oleh asal SMA, pendapatan orang tua dan asal kota. Berdasarkan hal tersebut, maka penelitian ini akan mengelompokkan program studi berdasarkan data mahasiswa yang ada dengan tujuan memberikan informasi kepada pihak Universitas untuk memprioritaskan program studi dengan sedikit peminat.
Untuk proses pencarian informasi dari data mahasiswa baru UPN “Veteran” Jawa Timur digunakan teknik data mining, sedangkan clustering
K-Means digunakan untuk mengelompokkan program studi dalam beberapa kelas
berdasarkan kemiripan data.
Berdasarkan hasil clustering dengan metode algoritma K-Means telah terdapat 3 kluster, dimana kluster 1 merupakan program studi dengan sedikit peminat sebanyak 10 program studi, kluster 2 banyak peminat sebanyak 5 program studi dan kluster 3 cukup peminat sebanyak 4 program studi.
Abstr act
Universitas Pembangunan Nasional "Veteran" East Java is located in East Java, Surabaya is Indonesia's Private University which has 6 faculties with 19 courses.
The number of applicants from each courses at the Universitas Pembangunan Nasional "Veteran" East Java can be affected by SMA origin, parental income and home town. Based on this, the study will be categorize courses based on existing student data with the purpose of providing information to the University to prioritize programs with little interest.
For information search process of the new student data UPN "Veteran" East Java is used data mining techniques, while the K-Means clustering is used to group the courses into classes based on similar data.
Based on the results of the clustering method K-Means algorithm has been there 3 clusters, where cluster 1 is a courses with little interest in as many as 10 courses, cluster 2 of enthusiasts as much as 5 courses and cluster 3 is quite interested as much as 4 courses.
BAB I
PENDAHULUAN
1.1 Latar Belakang
Universitas Pembangunan Nasional “Veteran” Jawa Timur, disingkat UPN
“Veteran” Jatim atau UPN VJT berlokasi di Surabaya merupakan Perguruan
Tinggi Swasta di Indonesia yang berdiri sejak 5 Juli 1959. UPN “Veteran” Jawa
Timur hingga tahun 2013, memiliki 6 Fakultas dengan 19 Program Studi (Progdi)
sarjana, yaitu Fakultas Ekonomi Bisnis dengan 3 Program Studi, yaitu Progdi
Ilmu Ekonomi dan Pembangunan, Progdi Akuntansi dan Progdi Manajemen,
Fakultas Petanian dengan 2 Program Studi, yaitu Progdi Agroteknologi dan
Progdi Agribisnis, Fakultas Teknologi Industri dengan 5 Program Studi, yaitu
Progdi Teknik Kimia, Progdi Teknik Industri, Progdi Teknologi Pangan, Progdi
Teknik Informatika dan Progdi Sistem Informasi, Fakultas Ilmu Sosial dan Ilmu
Politik dengan 4 Program Studi, yaitu Progdi Administrasi Negara, Progdi
Administrasi Bisnis, Progdi Ilmu Komunikasi dan Progdi Hubungan
Internasional, Fakultas Teknik Sipil dan Perencanaan dengan 4 Program Studi,
yaitu Progdi Teknik Sipil, Progdi Teknik Arsitektur, Progdi Teknik Lingkungan
dan Progdi Desain Komunikasi Visual, serta Fakultas Hukum dengan 1 Program
Studi yaitu Progdi Ilmu Hukum.
Jumlah mahasiswa baru di Universitas Pembangunan Nasional “Veteran”
Jawa Timur mengalami pertumbuhan dan perkembangan yang cukup signifikan.
dimana ada yang banyak peminat dan kurang peminat. Besarnya peminat dari
setiap program studi dapat dipengaruhi oleh asal kota, pendapatan orang tua, asal
wilayah dan lain – lain. Berdasarkan hal tersebut, maka dalam penelitian ini akan
mengelompokkan program studi berdasarkan data mahasiswa yang ada dengan
tujuan memberikan informasi kepada pihak Universitas untuk memprioritaskan
program studi yang memiliki sedikit peminat.
Untuk metode yang akan digunakan dalam penelitian ini adalah teknik
data mining. Data mining berperan sebagai pencarian informasi yang berharga
dari basis data yang sangat besar. Data mining adalah suatu proses dalam
menemukan berbagai model, ringkasan data dan nilai – nilai yang berharga dari
sekumpulan data. Pada penelitian ini, metode data mining digunakan untuk proses
pencarian informasi dari data mahasiswa baru semester 1 UPN “Veteran” Jawa
Timur. Selain data mining juga menggunakan teknik clustering K-Means, dimana
clustering K-Means digunakan untuk mengelompokkan program studi
berdasarkan jarak minimum setiap data ke kluster.
Dengan demikian, diharapkan dapat memberikan informasi yang
bermanfaat bagi pihak Universitas dalam melakukan promosi mengenai program
studi sarjana yang ada di Universitas Pembangunan Nasional “Veteran” Jawa
Timur ini.
1.2 Perumusan Masalah
Berdasarkan latar belakang diatas, maka dapat dirumuskan suatu
Bagaimana hasil pengelompokkan program studi sarjana berdasarkan data
mahasiswa baru menggunakan clustering K-Means?
1.3 Batasan Masalah
Agar penulisan dapat berjalan dengan baik dan sesuai dengan alurnya
maka perlu diberikan batasan-batasan masalah sebagai berikut :
1. Data yang digunakan adalah data mahasiswa program studi sarjana UPN
“Veteran” Jatim, yaitu data mahasiswa semester 1 meliputi: program studi,
kota asal, pendapatan orang tua dan jenis SMA.
2. Menggunakan algoritma K-Means untuk pengelompokan data.
3. Pengerjaan dengan software matlab untuk membantu proses klasterisasi
dan analisis data.
1.4 Asumsi
Sedangkan beberapa asumsi yang digunakan dalam penelitian ini adalah
sebagai berikut :
1. Data tidak berubah selama penelitian.
2. Data yang digunakan merupakan data yang siap diolah dengan clustering
1.5 Tujuan Penelitian
Adapun tujuan penelitian dalam penyusunan tugas akhir ini adalah untuk
mengetahui hasil kelompok program studi sarjana yang perlu mendapat prioritas
utama dari pihak Universitas.
1.6 Manfaat Penelitian
Manfaat yang dapat diambil dari penelitian ini adalah :
1. Diharapkan dapat menjadi referensi untuk penggunaan Algoritma
K-Means bagi praktisi atau peneliti lain untuk diterapkan pada kasus
penelitian yang lain.
2. Dengan menggunakan data mining dengan clustering K-Means,
diharapkan dapat membantu pihak Universitas untuk mengetahui
kelompok program studi yang perlu diprioritaskan di Universitas
Pembangunan Nasional “Veteran” Jawa Timur.
1.7 Sistematika Penulisan
Adapun sistematika penulisan dari tugas akhir ini adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisi latar belakang, perumusan masalah, batasan
masalah, asumsi yang digunakan, tujuan penelitian, manfaat
BAB II TINJ AUAN PUSTAKA
Pada bab ini akan menguraikan mengenai landasan-landasan
teori atau literatur yang digunakan untuk menyelesaikan
laporan penelitian ini dan digunakan sebagai landasan peneliti
untuk menjalankan penelitian.
BAB III METODE PENELITIAN
Bab ini berisi langkah-langkah dalam melakukan penelitian
yaitu hal-hal yang dilakukan untuk mencapai tujuan dari
penelitian atau urutan kerja menyeluruh selama pelaksanaan
penelitian.
BAB IV HASIL PENELITIAN DAN PEMBAHASAN
Bab ini berisi pengolahan dari data yang telah dikumpulkan,
langkah-langkah pemecahan masalah dan metode analisis serta
pembahasan penelitian.
BAB V KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan dan saran dari hasil penelitian yang
telah dilakukan yang didapatkan dari tujuan dan permasalahan
yang ada.
DAFTAR PUSTAKA
BAB II
TINJ AUAN PUSTAKA
2.1 Data Mining
Istilah data mining memiliki beberapa padanan seperti knowledge
discovery atau pattern recognition. Istilah knowledge discovery atau penemuan
pengetahuan digunakan kerena tujuan utama dari data mining memang untuk
mendapatkan pengetahuan yang masih tersembunyi di dalam bongkahan data.
Istilah pattern recognition atau pengenalan pola pun tepat digunakan kerena
pengetahuan yang hendak digali memang berbentuk pola-pola yang mungkin juga
masih perlu digali dari dalam bongkahan data yang tengah dihadapi. (Susanto,
2010 dalam tesis Budiman, 2012)
Data Mining sebagai salah satu cabang ilmu yang relatif baru mempunyai
potensi pengembangan yang sangat besar dan diprediksi akan menjadi salah satu
yang paling revolusioner pada dekade ini (Larose, 2006 dalam tesis Budiman,
2012). Data Mining sendiri merupakan sebuah proses ekstraksi informasi untuk
menemukan pola (pattern recognition) yang penting pada tumpukan data dalam
database sehingga menjadi pengetahuan (knowledge discovery). Fungsi-fungsi
dalam data mining antara lain: fungsi deskripsi, fungsi estimasi, fungsi Prediksi,
fungsi Klasifikasi, fungsi Clustering dan fungsi asosiasi (Larose, 2005 dalam tesis
Budiman, 2012).
Data mining adalah serangkaian proses untuk menggali nilai tambah dari
manual (Moertini, 2002). Secara umum data mining memiliki beberapa kajian.
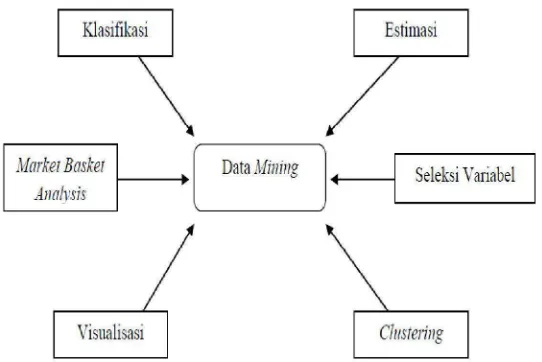
Seperti yang dapat dilihat pada Gambar 2.1, data mining merupakan pusat dari
beberapa kajian. Diantaranya adalah estimasi, seleksi variabel, clustering,
visualisasi, market basket analysis dan klasifikasi. Semua kajian tersebut
termasuk ke dalam data mining.
Gambar 2.1 Kajian Umum Data Mining
(Sumber : Santosa, 2007)
Data mining merupakan bidang dari beberapa bidang keilmuan yang
menyatukan teknik dari pembelajaran mesin, pengenalan pola, statistik, database
dan visualisasi untuk penanganan permasalahan pengambilan informasi dari
database yang besar (Larose, 2005). Data mining adalah analisis otomatis dari data
yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau
kecenderungan yang penting yang biasanya tidak disadari keberadaannya
(Moertini, 2002). Hal-hal penting yang terkait dengan data mining adalah (Luthfi
1. Data mining merupakan suatu proses otomatis terhadap data yang sudah
ada.
2. Data yang akan diproses berupa data yang sangat besar.
3. Tujuan data mining adalah mendapatkan hubungan atau pola yang
mungkin memberikan indikasi yang bermanfaat.
Hubungan yang dicari dalam data mining dapat berupa hubungan antara
dua atau lebih objek dalam satu dimensi yang sama. Misalnya dalam dimensi
produk dapat melihat keterkaitan pembelian suatu produk dengan produk yang
lain. Selain itu, hubungan juga dapat dilihat antara dua atau lebih atribut dan dua
atau lebih objek (Ponniah, 2001). Masalah-masalah yang sesuai untuk
diselesaikan dengan teknik data mining dapat dicirikan dengan (Piatetsky &
Shapiro, 2006):
1. Memerlukan keputusan yang bersifat knowledge-based.
2. Mempunyai lingkungan yang berubah.
3. Metode yang ada sekarang bersifat sub-optimal.
4. Tersedia data yang bisa diakses, cukup dan relevan.
5. Memberikan keuntungan yang tinggi jika keputusan yang diambil tepat.
Kata mining mempunyai arti yaitu usaha untuk mendapatkan sedikit
barang berharga dari sejumlah besar material dasar. Data mining memiliki akar
yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelegent),
machine learning, statistik dan database. Beberapa metode yang sering
disebut-sebut dalam literatur data mining antara lain clustering, classification, association
Data mining sering digunakan untuk membangun model prediksi/ inferensi
yang bertujuan untuk memprediksi tren masa depan atau perilaku berdasarkan
analisis data terstruktur. Dalam konteks ini, prediksi adalah pembangunan dan
penggunaan model untuk menilai kelas dari contoh tanpa label, atau untuk menilai
jangkauan nilai atau contoh yang cenderung memiliki nilai atribut. Klasifikasi dan
regresi adalah dua bagian utama dari masalah prediksi, dimana klasifikasi
digunakan untuk memprediksi nilai diskrit atau nominal sedangkan regresi
digunakan untuk memprediksi nilai terus-menerus atau nilai yang ditentukan
(Larose, 2005).
2.1.1 Tahapan Data Mining
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi
beberapa tahap yang diilustrasikan di Gambar 2.2. Tahap-tahap tersebut bersifat
interaktif, pemakai terlibat langsung atau dengan perantaraan knowledge base.
Tahap-tahap data mining ada 7, yaitu :
1. Pembersihan data (data cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang
tidak konsisten atau data tidak relevan. Pada umumnya data yang
diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen,
memiliki isian-isian yang tidak sempurna seperti data yang hilang, data
yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga
atribut-atribut data yang tidak relevan dengan hipotesa data mining yang
dimiliki. Data-data yang tidak relevan itu juga lebih baik dibuang.
Pembersihan data juga akan mempengaruhi performasi dari teknik data
mining karena data yang ditangani akan berkurang jumlah dan
kompleksitasnya.
2. Integrasi data (data integration)
Integrasi data merupakan penggabungan data dari berbagai database ke
dalam satu database baru. Tidak jarang data yang diperlukan untuk data
mining tidak hanya berasal dari satu database tetapi juga berasal dari
beberapa database atau file teks. Integrasi data dilakukan pada
atribut-aribut yang mengidentifikasikan entitas-entitas yang unik seperti atribut
nama, jenis produk, nomor pelanggan dan lainnya. Integrasi data perlu
dilakukan secara cermat karena kesalahan pada integrasi data bisa
menghasilkan hasil yang menyimpang dan bahkan menyesatkan
jenis produk ternyata menggabungkan produk dari kategori yang berbeda
maka akan didapatkan korelasi antar produk yang sebenarnya tidak ada.
3. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh
karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari
database. Sebagai contoh, sebuah kasus yang meneliti faktor
kecenderungan orang membeli dalam kasus market basket analysis, tidak
perlu mengambil nama pelanggan, cukup dengan id pelanggan saja.
4. Transformasi data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses
dalam data mining. Beberapa metode data mining membutuhkan format
data yang khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa
metode standar seperti analisis asosiasi dan clustering hanya bisa
menerima input data kategorikal. Karenanya data berupa angka numerik
yang berlanjut perlu dibagi-bagi menjadi beberapa interval. Proses ini
sering disebut transformasi data.
5. Proses mining,
Merupakan suatu proses utama saat metode diterapkan untuk menemukan
pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi pola (pattern evaluation),
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang
ditemukan. Dalam tahap ini hasil dari teknik data mining berupa pola-pola
hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh
tidak sesuai hipotesa ada beberapa alternatif yang dapat diambil seperti
menjadikannya umpan balik untuk memperbaiki proses data mining,
mencoba metode data mining lain yang lebih sesuai, atau menerima hasil
ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat.
7. Presentasi pengetahuan (knowledge presentation),
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang
digunakan untuk memperoleh pengetahuan yang diperoleh pengguna.
Tahap terakhir dari proses data mining adalah bagaimana
memformulasikan keputusan atau aksi dari hasil analisis yang didapat.
Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami
data mining. Karenanya presentasi hasil data mining dalam bentuk
pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang
diperlukan dalam proses data mining. Dalam presentasi ini, visualisasi
juga bisa membantu mengkomunikasikan hasil data mining (Han, 2006
dalam skripsi Masykur, 2010).
2.1.2 Pengelompokkan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang
dapat dilakukan, yaitu (Larose, 2005):
1. Deskripsi
Terkadang penelitian analisis secara sederhana ingin mencoba mencari
cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam
menemukan keterangan atau fakta bahwa siapa yang tidak cukup
profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi
dari pola dan kecenderungan sering memberikan kemungkinan penjelasan
untuk suatu pola atau kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi
lebih ke arah numerik daripada ke arah kategori. Model dibangun
menggunakan record lengkap yang menyediakan nilai dari variabel target
sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi
nilai dari variabel target dibuat berdasarkan nilai variabel prediksi. Sebagai
contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah
sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan
level sodium darah. Hubungan antara tekanan darah sistolik dan nilai
variabel prediksi dalam proses pembelajaran akan menghasilkan model
estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus
baru lainnya.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa
dalam prediksi nilai dari hasil akan ada di masa datang. Contoh prediksi
dalam bisnis dan penelitian adalah :
a. Prediksi harga beras dalam tiga bulan yang akan datang.
b. Prediksi presentase kenaikan kecelakaan lalu lintas tahun depan jika batas
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan
estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh,
penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu
pendapatan tinggi, pendapatan sedang, dan pendapatan rendah. Contoh
lain klasifikasi dalam bisnis dan penelitian adalah :
a. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang
curang atau bukan.
b. Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan
suatu kredit yang baik atau buruk.
c. Mendiagnosis penyakit seorang pasien untuk mendapatkan kategori
penyakit apa.
5. Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau
memperhatikan dan membentuk kelas objek-objek yang memiliki
kemiripan. Cluster adalah kumpulan record yang memiliki kemiripan satu
dengan yang lainnya dan memiliki ketidakmiripan dengan record-record
dalam cluster lain. Pengklusteran berbeda dengan klasifikasi yaitu tidak
adanya variabel target dalam pengklusteran. Pengklusteran tidak mencoba
untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari
variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk
kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan
record dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan
dengan record dalam kelompok lain akan bernilai minimal. Contoh
pengklusteran dalam bisnis dan penelitian adalah:
a. Melakukan pengklusteran terhadap ekspresi dari gen, untuk mendapatkan
kemiripan perilaku dari gen dalam jumlah besar.
b. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari
suatu produk bagi perusahaan yang tidak memiliki dana pemasaran yang
besar.
c. Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap
perilaku finansial dalam baik dan mencurigakan.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul
dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis
keranjang belanja. Contoh asosiasi dalam bisnis dan penelitian adalah :
a. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan
barang yang tidak pernah dibeli secara bersamaan.
b. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang
diharapkan untuk memberikan respons positif terhadap penawaran
2.2 Clustering
Clustering adalah studi formal metode dan algoritma untuk partisi atau
pengelompokan. Analisis clustering tidak menggunakan pelabelan kategori
sebelumnya. Clustering bersifat unsupervised learning atau tidak mempunyai
tahap pelatihan data, berbeda dengan klasifikasi (Jain, 2009 dalam tesis Budiman,
2012).
Clustering adalah alat penemuan mengungkapkan hubungan dan struktur
di dalam data yang sebelumnya tidak jelas menjadi pengetahuan yang bermanfaat
ketika ditemukan.
Tujuan utama dari metode clustering adalah pengelompokan sejumlah
data/ obyek ke dalam cluster (group) sehingga dalam setiap cluster akan berisi
data yang semirip mungkin. Clustering adalah metode yang berusaha untuk
menempatkan obyek yang mirip (jaraknya dekat) dalam satu cluster dan membuat
jarak antar cluster sejauh mungkin. Ini berarti obyek dalam satu cluster sangat
mirip satu sama lain dan berbeda dengan obyek dalam cluster-cluster yang lain.
Clustering digunakan untuk menganalisis pengelompokkan berbeda
terhadap data, mirip dengan klasifikasi, namun pengelompokkan belum
didefinisikan sebelum dijalankannya tool data mining. Clustering membagi item
menjadi kelompok-kelompok berdasarkan yang ditemukan tool data mining.
Prinsip dari clustering adalah memaksimalkan kesamaan antar anggota satu kelas
dan meminimumkan kesamaan antar cluster. Clustering dapat dilakukan pada data
yang memiliki beberapa atribut yang dipetakan sebagai ruang multidimensi
Clustering adalah sebuah proses pengelompokan data ke dalam beberapa
kelas berdasarkan kemiripan data. Tujuannya adalah untuk menemukan cluster
yang berkualitas dalam waktu yang layak. Clustering merupakan suatu alat untuk
analisa data, yang memecahkan permasalahan penggolongan. Clustering dalam
data mining berguna untuk menemukan pola distribusi di dalam sebuah data set
yang berguna untuk proses analisa data. Kesamaan objek biasanya diperoleh dari
kedekatan nilai – nilai atribut yang menjelaskan objek – objek data, sedangkan
objek – objek data biasanya dipresentasikan sebagai sebuah titik dalam ruang
multidimensi.
Terdapat dua pendekatan dalam metode dalam metode ini diantaranya
adalah Hierarchical dan Partitioning. Clustering dengan dengan pendekatan
hirarki atau sering disebut dengan hierarchical clustering merupakan
pengelompokkan data dengan membuat suatu hirarki berupa dendogram dimana
data yang mirip akan ditempatkan pada hirarki yang berdekatan dan yang tidak
pada hirarki yang berjauhan. Sedangkan, clustering dengan pendekatan partisi
atau sering disebut dengan partition – based clustering merupakan
pengelompokkan data dengan memilah – milah data yang dianalisa ke dalam
cluster – cluster yang ada.
Baskoro (2010) dalam skripsi Nango Dwi (2012) menyatakan bahwa
Clustering atau clusterisasi adalah salah satu alat bantu pada data mining yang
bertujuan mengelompokkan obyek-obyek ke dalam cluster-cluster. Cluster adalah
sekelompok atau sekumpulan obyek-obyek data yang similar satu sama lain
cluster. Obyek akan dikelompokkan ke dalam satu atau lebih cluster sehingga
obyek-obyek yang berada dalam satu cluster akan mempunyai kesamaan yang
tinggi antara satu dengan lainnya. Obyek-obyek dikelompokkan berdasarkan
prinsip memaksimalkan kesamaan obyek pada cluster yang sama dan
memaksimalkan ketidaksamaan pada cluster yang berbeda. Kesamaan obyek
biasanya diperoleh dari nilai-nilai atribut yang menjelaskan obyek data,
sedangkan obyek-obyek data biasanya direpresentasikan sebagai sebuah titik
dalam ruang multidimensi.
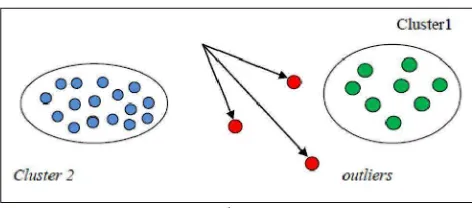
Dengan menggunakan clusterisasi, kita dapat mengidentifikasi daerah
yang padat, menemukan pola-pola distribusi secara keseluruhan, dan menemukan
keterkaitan yang menarik antara atribut-atribut data. Dalam data mining, usaha
difokuskan pada metode-metode penemuan untuk cluster pada basis data
berukuran besar secara efektif dan efisien. Beberapa kebutuhan clusterisasi dalam
data mining meliputi skalabilitas, kemampuan untuk menangani tipe 12 atribut
yang berbeda, mampu menangani dimensionalitas yang tinggi, menangani data
yang mempunyai noise, dan dapat diterjemahkan dengan mudah.
Gambar 2.3 Contoh Clustering (Baskoro 2010)
Adapun tujuan dari data clustering ini adalah untuk meminimalisasikan
berusaha meminimalisasikan variasi di dalam suatu cluster dan
memaksimalisasikan variasi antar cluster.
2.2.1 Metode Clustering
Menurut Baskoro (2010) dalam skripsi Nango Dwi (2012), secara garis
besar, terdapat beberapa metode clusterisasi data. Pemilihan metode clusterisasi
bergantung pada tipe data dan tujuan clusterisasi itu sendiri. Metode-metode
beserta algoritma yang termasuk didalamnya meliputi :
a. Partitioning Method
Membangun berbagai partisi dan kemudian mengevaluasi partisi tersebut
dengan beberapa kriteria, yang termasuk metode ini meliputi algoritma
K-Means, K-Medoid, PROCLUS, CLARA, CLARANS, dan PAM.
b. Hierarchical Methods
Membuat suatu penguraian secara hierarkikal dari himpunan data dengan
menggunakan beberapa kriteria. Metode ini terdiri atas dua macam, yaitu
Agglomerative yang menggunakan strategi bottom-up dan Disisive yang
menggunakan strategi top-down. Metode ini meliputi algoritma BIRCH,
AGNES, DIANA, CURE, dan CHAMELEON.
c. Density-based Methods
Metode ini berdasarkan konektivitas dan fungsi densitas. Metode ini
meliputi algoritma DBSCAN, OPTICS, dan DENCLU.
d. Grid-based Methods
Metode ini berdasarkan suatu struktur granularitas multi-level. Metode
e. Model-based Methods
Suatu model dihipotesakan untuk masing-masing cluster dan ide untuk
mencari best fit dari model tersebut untuk masing-masing yang lain.
Metode klusterisasi ini meliputi pendekatan statitik, yaitu algoritma
COBWEB dan jaringan syaraf tiruan, yaitu SOM.
2.3 Algoritma K-Means
Menurut Widyawati (2010) dalam skripsi Nango Dwi (2012), algoritma
k-means merupakan algoritma yang membutuhkan parameter input sebanyak k dan
membagi sekumpulan n objek kedalam k cluster sehingga tingkat kemiripan antar
anggota dalam satu cluster tinggi sedangkan tingkat kemiripan dengan anggota
pada cluster lain sangat rendah. Kemiripan anggota terhadap cluster diukur
dengan kedekatan objek terhadap nilai mean pada cluster atau dapat disebut
sebagai centroid cluster atau pusat massa.
Berikut rumus pengukuran jarak menurut Santosa (2007) dalam skripsi
Nango Dwi (2012) :
d(x,y) = ||x-y||2 = ∑ ( − )
Adapun rumus perhitungan jarak lainnya didefinisikan sebagai berikut :
d(x,y) = ( − ) + ( − )
Keterangan :
d = titik dokumen
x = data record
Jarak yang terpendek antara centroid dengan dokumen menentukan posisi
cluster suatu dokumen. Misalnya dokumen A mempunyai jarak yang paling
pendek ke centroid 1 dibanding ke yang lain, maka dokumen A masuk ke group 1.
Hitung kembali posisi centroid baru untuk tiap-tiap centroid (Ci..j) dengan
mengambil rata – rata dokumen yang masuk pada cluster awal (Gi..j ). Iterasi
dilakukan terus hingga posisi group tidak berubah. Berikut rumus dari penentuan
centroid :
C (i) =
| | ∑ ∈ ̅
Adapun rumus iterasi lainnya didefinisikan sebagai berikut :
C(i) =
K-Means merupakan algoritma clustering yang bersifat partitional yaitu
membagi himpunan objek data ke dalam sub himpunan (cluster) yang tidak
overlap, sehingga setiap objek data berada tepat dalam satu cluster. Strategi
partitional-clustering yang paling sering digunakan adalah berdasarkan kriteria
square error. Secara umum, tujuan kriteria square error adalah untuk
memperoleh partisi (jumlah cluster tetap) yang meminimalkan total square error.
SSE (Sum Squared of Error) menyatakan total kesalahan kuadarat yang terjadi
bila n data i n x ,..., x dikelompokkan kedalam k cluster dengan pusat tiap cluster
dikelompokkan ke dalam cluster-cluster tersebut. Semakin kecil nilai SSE,
semakin bagus hasil clustering-nya. Adapun rumus SSE adalah sebagai berikut :
SSE = (Ci)2 + (Ci)2 + (C..)2 + (C..)2
Keterangan :
Ci = nilai centroid
Untuk lebih memahami mengenai algoritma K-Means dapat dilihat pada
contoh berikut :
Guru sebagai tenaga profesional dapat berfungsi untuk meningkatkan
martabat dan peran guru sebagai agen pembelajaran danberfungsi untuk
meningkatkan mutu pendidikan nasional. Dengan terlaksananya sertifikasi guru,
diharapkan akan berdampak pada meningkatnya mutu pembelajaran dan mutu
pendidikan secara berkelanjutan.
Untuk mendapatkan informasi dan pengetahuan tentang profil kompetensi
guru diperlukan adanya suatu metode penggalian data (data mining) dan
klasifikasi yang tepat dengan jalan mengolah dan menggali variabel hasil
penilaian portofolio dan aspek lain dari profil guru. Dimana tujuan dari studi
kasus ini adalah :
a. Memberikan gambaran dan analisa kelebihan dan kekurangan kompetensi
guru dengan pemilihan data yang variatif.
b. Bagaimana memanfaatkan data berupa angka-angka hasil penilaian
portofolio menjadi sebuah informasi dan pengetahuan tentang kompetensi
c. Menerapkan proses data mining untuk pengolahan nilai portofolio guru
dengan metode K-mean clustering untuk mengelompokan kompetensi
yang relatif homogen.
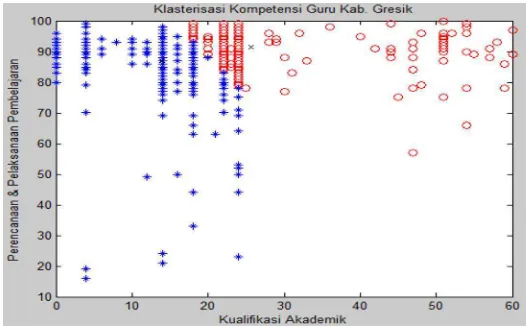
Gambar 2.4 Grafik Hasil Klasterisasi Nilai Kompetensi Kualifikasi Akademik Dan Perencanaan & Pelaksanaan Pembelajaran
Pada gambar adalah hasil klasterisasi nilai kompetensi kualifikasi
akademik dan perencanaan & Pelaksanaan Pembelajaran. Terbangun 2 kelompok
dan bisa disimpulkan bahwa :
1. Kompetensi guru di Kab. Gresik dalam membuat RPP tergolong bagus
dan merata dari berbagai kualifikasi akademik.
2. Tanda (*) adalah kelompok guru-guru yang perlu mendapat perhatian
berkaitan dengan kualifikasi akademik yang dibawah rata-rata.
2.3.1 Tahapan Algoritma K-Means
Widyawati (2010) dalam skripsi Nango Dwi (2012), menyatakan proses
algoritma K-Means adalah sebagai berikut :
a. Pilih secara acak objek sebanyak k, objek – objek tersebut akan
b. Untuk setiap objek dimasukan kedalam cluster yang tingkat kemiripan
objek terhadap cluster tersebut tinggi. Tingkat kemiripan ditentukan
dengan jarak objek terhadap mean atau centroid cluster tersebut.
c. Hitung nilai centroid yang baru pada masing-masing cluster.
d. Proses tersebut diulang hingga anggota pada kumpulan cluster tersebut
tidak berubah.
Sedangkan menurut Adiningsih (2007) dalam skripsi Nango Dwi (2012)
tahap penyelesaian algoritma K-Means adalah sebagai berikut :
a. Menentukan K buah titik yang merepresentasikan obyek pada setiap
cluster (centroid awal).
b. Menetapkan setiap obyek pada cluster dengan posisi centroid terdekat.
c. Jika semua obyek sudah dikelompokkan maka dilakukan perhitungan
ulang dalam menentukan centroid yang baru.
d. Ulangi langkah ke-2 dan ke-3 sampai centroid tidak berubah.
Menurut Kurniawan dkk (2010) dalam skripsi Nango Dwi (2012),
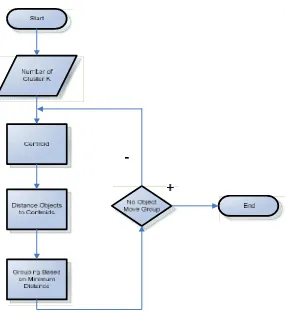
Gambar 2.5 Cara Kerja Algoritma K-Means (Kurniawan dkk 2010)
Berikut penjelasan dari gambar, dengan algoritma K-means dilakukan cara
berikut hingga ditemukan hasil iterasi yang stabil :
a. Menentukan data centroid, pada sistem ini, ditentukan bahwa centroid
pertama adalah n data pertama dari data-data yang akan di-cluster.
b. Menghitung jarak antara centroid dengan masing-masing data.
c. Mengelompokkan data berdasarkan jarak minimum.
d. Jika penempatan data sudah sama dengan sebelumnya, maka stop. Jika
2.3.2 Euclidean Distance
Euclidean distance merupakan salah satu metode penghitungan jarak yang
paling sederhana. Jika terdapat n buah variabel maka perhitungan jarak
menggunakan metode Euclidean dinyatakan sebagai berikut:
Dimana x dan y merupakan dua objek yang dihitung jaraknya, x1, x2, ... ,
xn dan y1, y2, ... , yn merupakan atribut-atribut sebanyak n buah dari objek x dan y.
2.3.3 Beberapa Per masalah yang Ter kait dengan K-Means
Beberapa permasalahan yang sering muncul pada saat menggunakan
metode K-Means untuk melakukan pengelompokkan data adalah :
1. Ditemukannya beberapa model clustering yang berbeda.
2. Pemilihan jumlah clustering yang paling tepat.
3. Kegagalan untuk converge.
4. Pendeteksian outliers.
5. Bentuk masing – masing cluster.
6. Masalah overlapping.
Hal – hal diatas perlu diperhatikan pada saat penggunaan K-Means.
Permasalah pertama umumnya disebabkan oleh perbedaan proses inisialisasi
anggota masing – masing cluster. Proses inisialisasi yang sering digunakan adalah
2.3.4 Kelemahan dan Kelebihan Algoritma K-Means
Dalam penggunaan algoritma K-Means memiliki beberapa kelemahan dan
kelebihan, yaitu :
A. Kelebihan K-Means :
1. Selalu konvergen atau mampu melakukan klusterisasi.
2. Tidak membutuhkan operasi matematis yang rumit, bisa dibilang
operasinya sederhana.
3. Beban komputasi relatif lebih ringan, sehingga klusterisasi bisa dilakukan
dengan cepat walaupun relatif tergantung pada banyak jumlah data dan
jumlah cluster yang ingin dicapai.
B. Kekurangan K-Means
K-means memiliki banyak kelemahan, antara lain:
1. Jumlah cluster sebanyak K, harus ditentukan sebelum dilakukan
perhitungan.
2. Nilai centroids yang diberikan di awal bisa mempengaruhi hasil
klusterisasi apabila nilainya berbeda (sensitif terhadap nilai centroids
awal).
3. Solusi cluster yang dihasilkan hanya bersifat local optima, sehingga kita
tidak tahu apakah itu sudah merupakan konfigurasi optimal atau belum.
4. Tergantung pada mean ( rata – rata).
5. Algoritma K-Means hanya bisa digunakan untuk data yang atributnya
6. Tidak pernah mengetahui real cluster dengan menggunakan data yang
sama, namun jika dimasukkan dengan cara yang berbeda mungkin dapat
memproduksi cluster yang berbeda jika jumlah datanya sedikit.
7. Tidak tahu kontribusi dari atribut dalam proses pengelompokan karena
dianggap bahwa setiap atribut memiliki bobot yang sama.
Salah satu cara untuk mengatasi kelemahan itu adalah dengan
menggunakan K-means clustering namun hanya jika tersedia banyak data.
2.4 Penelitian Terdahulu
Berikut adalah tiga penelitian lain mengenai algoritma K-Means yang
terkait dengan penelitian ini adalah :
a. Analisa Pr ofil Data Mahasiswa Baru Univer sitas Stikubank
(UNISBANK) Semarang Tahun 2005-2010 Dengan Teknik Data
Mining
Universitas Stikubank (Unisbank) merupakan salah satu perguruan tinggi
yang sudah cukup lama berkembang dengan jumlah mahasiswa baru yang
diterima setiap tahun cukup banyak. Namun demikian ternyata data mengenai
mahasiswa baru belum banyak dimanfaatkan untuk kepentingan yang saling
berkait, diantaranya adalah mengenai objek dan wilayah tujuan promosi.
Dengan adanya teknik data mining, salah satunya adalah metode
klustering dengan K-means, diharapkan data mahasiswa baru dapat diolah
satu dasar dalam pengambilan keputusan, yaitu menentukan wilayah promosi
yang tepat.
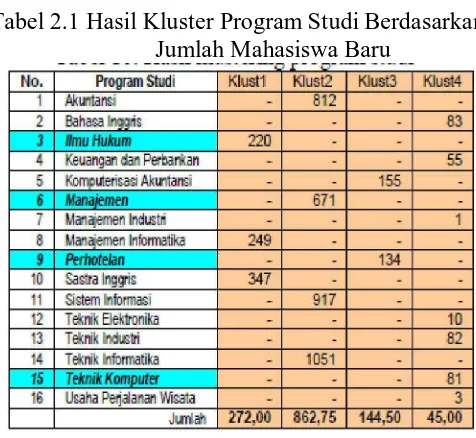
Berikut adalah tabel hasil kluster program studi berdasarkan jumlah
mahasiswa baru :
Tabel 2.1 Hasil Kluster Program Studi Berdasarkan Jumlah Mahasiswa Baru
Berikut juga ditunjukkan tabel hasil kluster kota asal mahasiswa baru :
Tabel 2.2 Hasil Kluster Kota Asal Mahasiswa Baru
Dari sejumlah 173 kota asal mahasiswa baru, setelah melalui proses
klustering diperoleh tiga buah kluster dengan jumlah mahasiswa terbanyak dan
penerimaan mahasiswa baru dan promosi dalam menentukan kota tujuan promosi.
(J ur nal : Wahyudi, Eko Nur.Dkk. 2011.)
b. Penggunaan Metode Pengklasteran Untuk Menentukan Bidang Tugas
Akhir Mahasiswa Teknik Infor matika PENS Berdasar kan Nilai
Tugas Akhir merupakan salah satu kewajiban mahasiswa, khususnya di
PENS-ITS, yang harus dikerjakan sebagai syarat kelulusan. Namun tidak jarang
mahasiswa mengalami kesulitan dalam penyelesaian tugas akhir tersebut. Salah
satu penyebabnya adalah faktor kemampuan mahasiswa dalam bidang Tugas Akhir
yang dikerjakannya.
Penelitian ini membahas penggunaan metode clustering dan inner product
untuk menentukan bidang Tugas Akhir mahasiswa Teknik Informatika PENS-ITS
berdasarkan nilai yang didapat mulai dari semester pertama sampai dengan
semester sebeum penentuan judul TA. Tiap bidang disusun oleh mata kuliah-mata
kuliah tertentu. Nilai mata kuliah-mata kuliah tersebutlah yang digunakan sebagai
atribut data dalam sistem ini.
Metode clustering yang digunakan adalah Single Linkage Hierarchical,
Centroid Linkage Hierarchical, dan K-Means. Metode-metode clustering tersebut
digunakan untuk melakukan training data sehingga terbentuk cluster-cluster.
Cluster-cluster yang terbentuk kemudian dilabelkan dengan Inner Product. Inner
Product dilakukan dengan mengalikan centroid tiap cluster dengan nilai minimum
(dari data training) untuk atribut centroid (mata kuliah) yang tidak mempengaruhi
bidang TA dan mengalikan dengan nilai maximum (dari data training) untuk
diproses. Hasil Inner Product yang paling besar menunjukkan bahwa cluster
tersebut memiliki label bidang TA yang sedang diproses.
Pengujian dilakukan dengan data baru (data uji) yang memiliki atribut
(mata kuliah) yang sama dengan data training. Data uji tersebut dihitung jaraknya
menggunakan Euclidean Distance dengan masing-masing cluster yang telah
berlabel (bidang TA). Jarak yang terdekat menujukkan data tersebut merupakan
anggota cluster yang dimaksud yang berarti data baru tersebut termasuk ke bidang
yang diwakili cluster yang berjarak paling dekat tersebut. Dan berikut adalah hasil
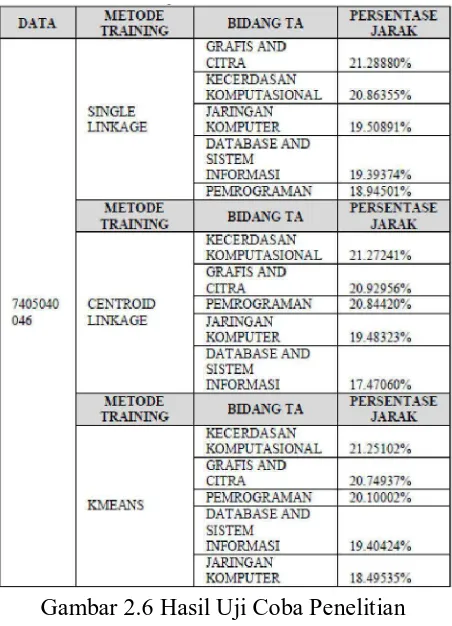
uji coba penelitian dengan metode yang berbeda :
Gambar 2.6 Hasil Uji Coba Penelitian
Hasil percobaan menunjukkan bahwa metode centroid linkage memiliki
nilai variance (Vw/ Vb) paling kecil yang menandakan bahwa metode tersebut
K-Means pada kasus ini. (J urnal : Entin Martiana S.Kom, M.Kom, Nur Rosyid
Mubtada’i S. Kom, Edi Pur nomo.2009.)
c. Implementasi Algoritma K-Means Clustering Untuk Menentukan
Strategi Marketing President University
President University merupakan salah satu Universitas swasta yang cukup
terkenal di Indonesia. President University berlokasi di Kawasan Industri
Jababeka yang didalamnya beroperasi lebih dari 1000 perusahaan nasional dan
internasional. President University tumbuh sangat pesat setiap tahunnya.
Mahasiswa President University sangat banyak yang berasal dari berbagai daerah
di Indonesia. Tidak hanya berasal dari Indonesia, mahasiswa President University
pun banyak yang berasal dari luar Indonseia, seperti Vietnam, China, Korea dan
beberapa negara lainnya.
Oleh karena mahasiswa President University berasal dari berbagai daerah
bahkan hingga berbagai negara, maka dibutuhkan strategi khusus oleh bagian
marketing dalam melakukan pemasaran untuk mencari calon mahasiswa agar
promosi yang dilakukan lebih efektif dan effisien. Untuk dapat melakukan
promosi promosi yang lebih efektif dan effisien, maka dalam penelitian ini
dilakukan dengan cara mengolahan data-data yang telah didapatkan dari
mahasiswa yang telah lulus seperti nama mahasiswa, kota asal, jurusan yang
diambil dan yang terkahir adalah nilai IPK. Data-data yang telah didapatkan tadi
kemudian diolah untuk mengetahui pola dari data-data tersebut sehingga kita
dapat mengambil informasi-informasi yang tersembunyi dari data-data tersebut.
penelitian ini analisa data mining dilakukan dengan menggunakan metode
K-Means clustering. Dengan menggunakan metode ini, data – data yang telah
didapatkan dapat dikelompokan kedalam beberapa cluster berdasarkan kemiripan
dari data-data tersebut, sehingga data-data yang memiliki karakteristik yang sama
dikelompokan dalam satu cluster dan yang memliki karakteristik yang berbeda
dikelompokan dalam cluster yang lain yang memiliki karakteristik yang sama.
Berdasarkan hasil pengelompokan data menggunakan metode k-means
clustering, di dapatkan hasil clustering hingga iterasi ke-7, dimana titik pusat
tidak lagi berubah dan tidak ada data yang berpindah antar cluster. Hasil dari
clustering tersebut seperti pada tabel berikut :
Gambar 2.7 Hasil Clustering Menggunakan Algoritma K-Means
Dari hasil cluster 1, terlihat bahwa karakteristik mahasiswa pada cluster 1
didominasi oleh mahasiswa yang berasal dari jurusan Information Technology dan
Marketing. Sedangkan, berdasarkan kota asal didominasi oleh mahasiswa yang
disimpulkan bahwa rata-rata mahasiswa pada cluster 1 yang berasal dari wilayah
kota asal DKI Jakarta dan Jawa Barat mengambil jurusan Infromation Technology
dan Marketing.
Kemudian, dari hasil cluster 2 di atas dapat dilihat bahwa karakteristik
mahasiswa pada cluster 2 didominasi oleh mahasiswa yang berasal dari jurusan
Accounting dan International Business. Sedangkan, berdasarkan kota asal
didominasi oleh mahasiswa yang berasal dari wilayah kota asal DKI Jakarta dan
Jawa Barat, sehingga dapat disimpulkan bahwa rata-rata mahasiswa pada cluster 2
yang berasal dari wilayah kota asal DKI Jakarta dan Jawa Barat mengambil
jurusan Infromation Technology dan Marketing.
Sedangkan, dari hasil cluster 3 di atas dapat dilihat bahwa karakteristik
mahasiswa pada cluster 3 didominasi oleh mahasiswa yang berasal dari jurusan
Public Relation, Accounting dan International Business. Sedangkan, berdasarkan
kota asal didominasi oleh mahasiswa yang berasal dari wilayah kota asal
Sulawesi, Jawa Timur dan Sumatera Selatan, sehingga dapat disimpulkan bahwa
rata-rata mahasiswa pada cluster 3 yang berasal dari wilayah kota asal Sulawesi,
Jawa Timur dan Sumatera Selatan mengambil jurusan Public Relation,
BAB III
METODE PENELITIAN
Perencanaan penelitian yang baik dan sistematis akan memudahkan
meningkatkan efektifitas penelitian dalam mencapai tujuan secara efisien.
Langkah-langkah dalam penelitian ini dapat dijelaskan secara urut sebagai
berikut:
3.1 Pengamatan Obyek
Pengamatan obyek ini dilakukan di Universitas Pembangunan Nasional
“Veteran” Jawa Timur. Waktu penelitian dilaksanakan pada bulan September
hingga data yang dibutuhkan tercukupi.
3.2 Identifikasi Variabel
Variabel adalah faktor yang mempunyai besaran dan variasi nilai. Variabel
itu sendiri terbagi menjadi dua yaitu variabel bebas dan variabel terikat.
a. Variabel Bebas
Variabel bebas merupakan variabel yang menjadi sebab timbulnya atau
berubahnya variabel dependen (terikat). Sehingga variabel independen dapat
dikatakan sebagai variabel yang mempengaruhi. Adapun variabel bebas dalam
penelitian ini adalah :
1. Program Studi
3. Jenis SMA
4. Pendapatan Orang Tua
b. Variabel Terikat
Variabel terikat adalah variabel yang berubahnya ditentukan oleh variabel
bebas. Adapun variabel terikat dalam penelitian ini adalah kelompok program
studi di Universitas Pembangunan Nasional “Veteran” Jawa Timur.
3.3 Pengumpulan Data
Data yang diperlukan disini adalah data-data yang dapat digunakan
sebagai variabel input yang diperlukan dalam pengolahan data nantinya yaitu data
sekunder.
Data sekunder diperoleh melalui Biro Admik UPN “Veteran” Jawa Timur.
Data yang didapat berupa program studi, asal kota, pendapatan orang tua dan jenis
SMA.
3.4 Pengolahan Data
Setelah data terkumpul langkah selanjutnya adalah melakukan pengolahan
data, sehingga diperoleh hasil yang dapat dipergunakan untuk memecahkan
masalah. Pengolahan data akan dilakukan dengan metode kualitatif dengan
menggunakan algoritma k-means untuk pengelompokkan data dan
3.5 Langkah-Langkah Penelitian dan Pemecahan Masalah
Berikut adalah flowchart langkah – langkah penelitian dan pemecahan
masalah :
Rumusan Masalah
Tujuan Penelitian
Identifikasi Variabel
Variabel Bebas Variabel Terikat
Pengumpulan Data :
Program Studi, Asal Kota, Pendapatan Orang Tua dan Jenis SMA
Menentukan Jumlah Kluster K
Hitung Nilai Centroid
A Mulai
Ya
Tidak
Gambar 3.1 Langkah-langkah Penelitian dan Pemecahan Masalah
Adapun tahapan penelitian yang akan dilakukan dalam proses penelitian
ini adalah sebagai berikut :
1. Studi Pustaka
Dengan mengumpulkan dan mempelajari literatur yang berkaitan dengan
konsep Data Mining clustering, yang menggunakan algoritma K-Means. Sumber
literatur berupa buku teks, paper, jurnal, karya ilmiah, dan situs-situs penunjang.
A
Menghitung jarak antara setiap record data dengan centroid awal
Mengelompokkan data record data dengan centroid awal
Analisa dan Pembahasan
Kesimpulan dan Saran
2. Studi Lapangan
Dengan mengumpulkan data dan informasi yang dibutuhkan dalam
penelitian ini. Data dan informasi didapat dari Biro Admik UPN Veteran Jawa
Timur. Setelah dilakukan studi pustaka dan studi lapangan, maka membuat suatu
perumusan masalah.
3. Tujuan Penelitian
Membuat tujuan berdasarkan penelitian yang akan dilakukan.
4. Identifikasi Variabel
Melakukan identifikasi variabel berdasarkan penelitian yang dilakukan,
yaitu program studi, asal kota, pendapatan orang tua dan jenis SMA.
5. Pengumpulan Data
Setelah melakukan identifikasi variabel, maka dilakukan pengumpulan
data mahasiswa baru yang meliputi: program studi, kota asal, pendapatan orang
tua dan jenis SMA.
6. Clustering Menggunakan Algoritma K-Means
Pada tahap ini terdapat beberapa proses sebagai berikut :
a. Tentukan k sebagai jumlah cluster yang ingin dibentuk.
b. Bangkitkan k centroids (titik pusat cluster) awal secara random.
c. Hitung masing-masing jarak setiap data ke masing-masing centroids.
d. Setiap data memilih centroids yang terdekat.
e. Tentukan posisi centroids baru dengan cara menghitung nilai rata-rata dari
f. Kembali ke langkah 3 jika posisi centroids baru dengan centroids lama
tidak sama.
7. Analisis dan Pembahasan
Tahapan untuk menganalisa hasil yang sudah diperoleh pada proses
clustering.
8. Kesimpulan dan Saran
Setelah pengolahan dan analisa data, maka langkah selanjutnya adalah
menarik kesimpulan, kemudian diberikan juga saran sebagai rekomendasi yang
dapat memberikan manfaat bagi peneliti maupun pihak UPN Veteran Jawa Timur.
BAB IV
HASIL PENELITIAN DAN PEMBAHASAN
Pada bab ini akan dijelaskan secara rinci mengenai pengumpulan data-data
yang diperlukan dalam penelitian dan juga proses pengolahan data hingga
diperoleh hasil yang diinginkan sesuai kerangka kerja yang telah ditetapkan. Bab
ini juga berisikan mengenai analisa dan pembahasan dari hasil pengolahan data
yang telah dilakukan sebelumnya.
4.1 Pengumpulan Data
Data yang digunakan untuk pengolahan data nantinya yaitu data sekunder
yang diperoleh melalui Biro Admik UPN “Veteran” Jawa Timur, yang berupa
data program studi, pendapatan orang tua, asal kota dan jenis SMA. Berikut
merupakan hasil pengumpulan data mahasiswa baru semester 1 yang telah
Tabel 4.1 Pengumpulan Data Mahasiswa Baru Universitas Pembangunan Nasional “Veteran” Jawa Timur
Sumber : Data Sekunder Biro Admik Universitas Pembangunan Nasional “Veteran” Jawa Timur
Berdasarkan tabel di atas, untuk program studi hanya dilakukan
pengkodean. Untuk keterangan dapat dilihat sebagai berikiut :
11 : Ekonomi Pembangunan
32 : Teknik Industri
33 : Teknik Pangan
34 : Teknik Informatika
35 : Sistem Informasi
41 : Ilmu Admin Negara
42 : Ilmu Admin Niaga
43 : Ilmu Komunikasi
44 : Hubungan Internasional
51 : Teknik Arsitektur
52 : Teknik Lingkungan
53 : Teknik Sipil
54 : Desain Komunikasi Visual
71 : Ilmu Hukum
Untuk memudahkan dalam mengetahui jumlah asal kota mahasiswa dari
setiap program studi, maka dari kota yang ada akan dikelompokkan menjadi
beberapa wilayah sebagai berikut :
Wilayah I : yaitu Indonesia bagian Timur yang mencakup pulau Jawa, Sumatra,
serta Kalimantan.
Wilayah II : yaitu Indonesia bagian Tengah yang mencakup Sulawesi, Kepulauan
Sunda Kecil.
Wilayah III : yaitu Indonesia bagian Barat yang mencakup Maluku, Papua.
Untuk pendapatan orang tua mahasiswa dari setiap program studi juga
Pendapatan Orang Tua I = 1 jt – 2,5 jt
Pendapatan Orang Tua II = 2,6jt – 5 jt
Pendapatan Orang Tua 3 = < 5jt
Berdasarkan tabel 4.1, dapat dilihat bahwa telah terjadi ketidakseimbangan
peminat antara program studi satu dengan yang lain dimana ada program studi
yang memiliki banyak peminat dan sedikit peminat. Selain itu, ketidakseimbangan
peminat juga tidak terjadi pada program studi saja, melainkan dari jenis SMA dan
asal kota mahasiswa.
4.2 Pengolahan Data
Dari hasil pengumpulan data tersebut, maka dilakukan suatu pengolahan
data dimana data yang ada akan dikelompokkan ke dalam beberapa cluster dengan
menggunakan Algoritma K-Means dengan bantuan software Matlab. Berikut akan
dijelaskan mengenai langkah – langkah pengolahan data dari penelitian yang
dilakukan :
1. Menentukan jumlah cluster yang akan dibuat. Dalam penelitian ini jumlah
cluster yang akan dibuat yaitu sebanyak 3.
2. Menentukan nilai pusat cluster. Dalam penelitian ini nilai pusat awal
ditentukan secara random dan didapat nilai pusat dari setiap cluster. Untuk
nilai pusat cluster awal dapat dilihat pada lampiran I.1.
3. Menghitung jarak antara centroid dengan masing-masing data. Dalam
dekat antara satu data dengan satu cluster tertentu akan menentukan suatu
data masuk dalam cluster mana, hasil dapat dilihat pada tabel 4.2 berikut :
Tabel 4.2 Jarak Setiap Data dengan Pusat Kluster Iterasi 1
Jarak 1 Jarak 2 Jarak 3
4. Memasukkan data ke dalam setiap kluster. Setelah menghitung jarak setiap
data, langkah selanjutnya adalah mengelompokkan data berdasarkan hasil
minimum jarak. Hasil kluster data dapat dilihat pada tabel 4.3. Untuk hasil
pengolahan data lebih jelasnya dapat dilihat pada lampiran I.2.
Tabel 4.3 Hasil Kluster Data Berdasar Jarak Minimum Iterasi 1
Kluster Program Studi Keterangan
1
Ekonomi Pembangunan
Mahasiswa yang berasal dari SMA 489 mahasiswa, SMK 188 mahasiswa, pendapatan orang tua I 245 mahasiswa, pendapatan orang tua
II 235 mahasiswa, pendapatan orang tua III 197 mahasiswa, Wilayah I 651 mahasiswa, Wilayah II
5. Menghitung pusat cluster baru. Dengan diketahuinya anggota cluster,
kemudian dilakukan perhitungan kembali pusat cluster baru dengan
keanggotaan cluster yang sekarang. Pusat cluster adalah rata-rata dari
semua obyek dalam masing-masing cluster. Untuk hasil pusat kluster
iterasi 2 dapat dilihat pada lampiran II.1
6. Menghitung jarak dari masing-masing data. Dari hasil perhitungan
menggunakan pusat cluster iterasi 2 maka diperoleh jarak sebagaiberikut:
Tabel 4.4 Jarak Setiap Data dengan Pusat Kluster Iterasi 2
Jarak 1 Jarak 2 Jarak 3
Kluster Program Studi Keterangan
2
Manajemen Mahasiswa yang berasal dari SMA 1047
mahasiswa, SMK 364 mahasiswa, pendapatan orang tua I 302 mahasiswa, pendapatan orang tua
II 523 mahasiswa, pendapatan orang tua III 586 mahasiswa, Wilayah I 1381 mahasiswa, Wilayah
II 17 mahasiswa, wilayah III 13 mahasiswa. Akuntansi
Teknik Industri Teknik Informatika Ilmu Komunikasi
3
Teknik Kimia Mahasiswa yang berasal dari SMA 408
mahasiswa, SMK 55 mahasiswa, pendapatan orang tua I 149 mahasiswa, pendapatan orang tua
II 221 mahasiswa, pendapatan orang tua III 93 mahasiswa, Wilayah I 450 mahasiswa, Wilayah II
9 mahasiswa, wilayah III 4 mahasiswa. Ilmu Admin Niaga