ANTARMUKA BAHASA INDONESIA PENGAKSES BASIS DATA DENGAN PEMBANGKITAN INPUT QUERY ALTERNATIF
MENGGUNAKAN KAIDAH SINTAKSIS DAN SEMANTIK
KOMPETENSI KOMPUTASI
SKRIPSI
I WAYAN SAFIRA SRI ARTHA NIM. 1208605040
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS UDAYANA
iii
Judul : Antarmuka Bahasa Indonesia Pengakses Basis Data dengan Pembangkitan Input Query Alternatif Menggunakan Kaidah Sintaksis dan Semantik
Nama : I Wayan Safira Sri Artha NIM : 1208605040
Pembimbing I : I Gede Santi Astawa, S.T., M.Cs.
Pembimbing II : I Dewa Made Bayu Atmaja Darmawan, S.Kom., M.Cs. ABSTRAK
Instansi-instansi kesekretariatan menggunakan basis data untuk menyimpan data-data arsip surat. Untuk mengakses dan mengolah data pada basis data diperlukan pemahaman mengenai bahasa kode terstruktur SQL. Namun, tidak semua orang mampu memahami dan memiliki waktu untuk mempelajarinya. Antarmuka form memudahkan end user seperti sekretaris ataupun pegawai administrasi surat untuk mengakses basis data arsip surat tanpa perlu memahami sintaks kode SQL. Bidang ilmu Natural Language Processing menjadi akar pengembangan antarmuka bahasa alami pengakses basis data/Natural Language Interface to Database (NLIDB) untuk mempermudah pencarian data dengan hanya mengetikkan sebuah kalimat perintah bahasa alami dan tanpa perlu mengisi form satu-persatu seperti pada antarmuka form. Dalam penelitian ini, dikembangkan sebuah NLIDB berbahasa Indonesia untuk domain basis data arsip persuratan. NLIDB Bahasa Indonesia ini bekerja dengan tahapan utama: (1) mengenali bahasa query input; (2) Membentuk logic form; (3) translasi ke SQL; (4) eksekusi untuk mendapatkan data pada database. Tahap pengenalan bahasa dilakukan dengan analisis sintaksis menggunakan kaidah-kaidah gramatikal Bahasa Indonesia. Sedangkan, tahap pembentukan logic form menggunakan kaidah-kaidah semantik kata. Pada proses translasi menjadi SQL, diterapkan pula fitur pembangkitan query alternatif untuk mengurangi risiko kesalahan output. Sejumlah 57 query Bahasa Indonesia diujikan terhadap sistem, mulai dari query dengan hanya SELECT expression, WHERE expression, hingga query beroperator. Hasilnya adalah precision sebesar 89,7 % dan recall 77,2 %.
Kata Kunci: Natural Language Processing, Natural Language Interface to Database, Bahasa Indonesia, SQL, basis data, kaidah sintaksis &
iv
Title : An Indonesian Language Interface to Database with Alternative Input Query Generation using Syntactic and Semantic Rules
Name : I WayanSafira Sri Artha Student Number : 1208605040
Main Supervisor : I GedeSantiAstawa, S.T., M.Cs.
Co-Supervisor : I Dewa Made BayuAtmajaDarmawan, S. Kom., M.Cs. ABSTRACT
Secretariatal agencies use databases to store data of archival letters. To access and process data in the database requires understanding regarding structured code language called SQL. However, not every people is able to understand the language and has time to learn it. A form interface allows end users such as secretaries or administrative staff to access databases and archives without the need of understanding the syntax of SQL code. Natural Language Processing instantiates an interface that translates the natural language into SQL language so can access the database, known as Natural Language Interface to Database (NLIDB). The aim is to facilitate the data search by simply typing a command/sentence in natural language without the need of filling out the form one by one like on the form interface. This study develops an Indonesian NLIDB for the domain of correspondence archive database. The Indonesian NLIDB works with the following major phases: (1) recognition of the input query language; (2) Establishment of the logic forms; (3) translation to SQL; (4) the execution to obtain data on the database. The introduction stage of language syntactic analysis is done by using the rules of Indonesian grammar. Meanwhile, logic formation stage form uses the rules of semantic words. In the process of translation into SQL, it also applied the features of alternative query generation to reduce the risk of error output. A number of Indonesian 57 queries were tested against the system, starting from only a SELECT query expression, WHERE expression, and query with operators. The result was a precision of 89.7% and recall of 77.2%.
v
KATA PENGANTAR
Penelitian yang berjudul “Antarmuka Bahasa Indonesia Pengakses Basis Data dengan Pembangkitan Input Query Alternatif Menggunakan Kaidah Sintaksis dan Semantik” ini disusun dalam rangkaian kegiatan pelaksanaan Tugas Akhir di jurusan Ilmu Komputer FMIPA UNUD.
Penulis mengucapkan terimakasih kepada pihak-pihak yang telah membantu dalam terselesaikannya penelitian ini, antara lain:
1. Bapak I Gede Santi Astawa, S.T., M.Cs. sebagai Pembimbing I yang telah banyak membantu menyempurnakan penelitian ini.
2. Bapak I Dewa Made Bayu Atmaja Darmawan, S.Kom, M.Cs. sebagai Pembimbing II yang telah banyak membantu penulisan laporan penelitian ini.
3. Bapak Agus Muliantara, S.Kom, M.Kom., sebagai Ketua Jurusan Ilmu Komputer Universitas Udayana sekaligus pembimbing akademik yang yang selalu membimbing, memberi masukan dan saran.
4. Bapak/Ibu para dosen di lingkungan Ilmu Komputer Universitas Udayana yang telah memberikan ilmu yang sangat berguna bagi penyusunan proposal ini.
5. Teman-teman yang telah mendukung secara moral dan material.
Tugas akhir ini masih jauh dari sempurna, untuk itu penulis mengharapkan masukan dan saran demi kesempurnaan tugas akhir ini.
Bukit Jimbaran, Januari 2016 Penyusun
vi DAFTAR ISI
LEMBAR PENGESAHAN TUGAS AKHIR ... ii
ABSTRAK ... iii
ABSTRACT ... iv
KATA PENGANTAR ... v
DAFTAR ISI ... vi
DAFTAR TABEL ... ix
DAFTAR GAMBAR ... x
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Batasan Masalah ... 3
1.4 Tujuan Penelitian ... 4
1.5 Manfaat Penelitian ... 4
1.6 Metodologi Penelitian ... 5
1.6.1 Desain Penelitian ... 5
1.6.2 Pengumpulan Data ... 5
1.6.3 Persiapan Query Input ... 6
1.6.4 Metode yang Digunakan ... 6
BAB II TINJAUAN PUSTAKA ... 7
2.1 Tinjauan Empiris ... 7
2.2 Tinjauan Teoritis ... 9
2.2.1 Basis Data ... 9
2.2.2 Structured Query Language ... 10
vii
2.2.4 Natural Language Processing ... 13
2.2.5 Natural Language Interface to Database (NLIDB) ... 17
BAB III PERANCANGAN DAN IMPLEMENTASI ... 21
3.1 Konsep Dasar ... 21
3.2 Arsitektur Sistem ... 21
3.3 Kebutuhan Fungsional Sistem ... 22
3.3.1 Filtering ... 23
3.3.2 Membedakan Tipe Kata ... 23
3.3.3 Pelabelan Kelas Kata... 23
3.3.4 Mengenali Bahasa ... 24
3.3.5 Membentuk Logic Form ... 24
3.3.6 Translasi ke Format SQL dan Eksekusi ... 25
3.4 Rancangan Basis Data Arsip Surat ... 25
3.5 Rancangan Aturan Gramatikal ... 26
3.6 Rancangan Aturan Semantik ... 26
3.7 Rancangan Query Input Bahasa Indonesia ... 27
3.8 Rancangan Antarmuka Sistem ... 27
3.9 Pengolahan Query Bahasa Indonesia ... 28
3.9.1 Filtering ... 28
3.9.2 Pelabelan Tipe dan Kelas Kata ... 29
3.9.3 Pengenalan Bahasa ... 31
3.9.4 Pembentukan Logic Form ... 36
3.9.5 Translasi ke Format SQL dan Eksekusi Query ... 37
3.10 Pengujian dan Evaluasi ... 37
3.10.1 Skenario Pengujian... 37
viii
BAB IV HASIL DAN PEMBAHASAN ... 39
4.1 Pengumpulan Dataset ... 39
4.2 Persiapan Awal ... 39
4.3 Implementasi Filtering ... 39
4.4 Implementasi Pelabelan Kata ... 40
4.5 Implementasi Pengenalan Bahasa ... 41
4.6 Implementasi Parsing ... 43
4.7 Implementasi Pemetaan Semantik ... 44
4.8 Implementasi Translasi ke Format SQL dan Eksekusi ... 47
4.9 Tampilan Antarmuka Sistem ... 48
4.10 Hasil dan Pengujian Sistem ... 50
4.10.1 Analisis Sintaksis ... 50
4.10.2 Analisis Semantik ... 53
4.10.3 Pembangkitan Query Input Alternatif ... 58
4.10.4 Pengujian Query Bahasa Indonesia ... 59
4.10.5 Analisis Faktor Kesalahan Lain ... 60
BAB V KESIMPULAN DAN SARAN ... 62
5.1 Kesimpulan ... 62
5.2 Saran ... 62
DAFTAR PUSTAKA ... 63
ix
DAFTAR TABEL
Tabel 2.1 Pseudocode Levenshtein Edit Distance ... 11
Tabel 2.2 Algoritma Stemming Nazief & Adriani ... 12
Tabel 2.3 Algoritma Cocke-Younger-Kasami (CYK) ... 16
Tabel 3.1 Kelas kata dan frase penyusun pola kalimat inversi ... 26
Tabel 3.2 Cuplikan aturan semantik yang digunakan sistem ... 27
Tabel 4.1 Sintaks filtering query input ... 39
Tabel 4.2 Sintaks pelabelan kelas dan tipe kata ... 40
Tabel 4.3 Sintaks stemming (algoritma Nazief-Adriani) ... 41
Tabel 4.4 Sintaks pengenalan bahasa metode CYK... 41
Tabel 4.5 Sintaks parsing ... 43
Tabel 4.6 Sintaks pemetaan semantik-1 ... 44
Tabel 4.7 Sintaks pemetaan semantik-2 ... 46
Tabel 4.8 Sintaks translasi logic form ke format SQL ... 47
Tabel 4.9 Grammar bantu ... 51
Tabel 4.10 Aturan semantik untuk SELECT expression ... 53
Tabel 4.11 Aturan semantik untuk WHERE expression ... 55
Tabel 4.12 Aturan semantik pada operator untuk SELECT expression ... 56
Tabel 4.13 Aturan semantik pada operator untuk WHERE expression ... 57
Tabel 4.14 Macam-macam format tanggal ... 58
Tabel 4.15 Perbedaan makna kata konjungsi ... 59
Tabel 4.16 Hasil pengujian dengan pembangkitan query alternatif ... 59
x
DAFTAR GAMBAR
Gambar 2.1 Alur mendapatkan informasi pada basis data ... 10
Gambar 2.2 Dua Fase Utama NLP ... 13
Gambar 2.3 Contoh parse tree ... 18
Gambar 2.4 Contoh semantic parse tree ... 19
Gambar 2.5 Arsitektur Intermediate Representation Language System ... 19
Gambar 3.1 Arsitektur Sistem NLIDB Bahasa Indonesia ... 21
Gambar 3.2 Skema basis data arsip surat ... 25
Gambar 3.3 Struktur tabel view_surat ... 25
Gambar 3.4 Rancangan antarmuka sistem NLIDB Bahasa Indonesia ... 28
Gambar 3.5 Flowchart proses filtering... 29
Gambar 3.6 Flowchart proses pelabelan kata ... 30
Gambar 3.7 Proses CYK tahap inisialisasi ... 31
Gambar 3.8 Proses CYK hingga mencapai root ... 33
Gambar 3.9 Hasil trace dari proses CYK ... 34
Gambar 3.10 Parse tree ... 34
Gambar 3.11 Flowchart proses CYK ... 35
Gambar 3.12 State pemrosesan query ... 38
Gambar 4.1 Ilustrasi parsing ... 44
Gambar 4.2 Antarmuka sistem NLIDB Bahasa Indonesia ... 48
Gambar 4.3 Contoh tampilan input sistem ... 49
Gambar 4.4 Contoh tampilan informasi proses translasi ... 49
Gambar 4.5 Contoh tampilan query alternatif ... 49
1 BAB I PENDAHULUAN 1.1 Latar Belakang
Basis data merupakan kumpulan data yang berisi informasi yang sesuai bagi sebuah institusi/perusahaan (Silberschatz, 2002). Data-data yang disimpan dalam basis data dapat memberikan informasi yang dibutuhkan bagi orang-orang dalam institusi tersebut. Untuk dapat mengakses dan mengolah basis data, dibutuhkan suatu sistem yang disebut sistem manajemen basis data atau Database Management System (DBMS). Sistem manajemen basis data diperkenalkan pada
tahun 1960 dan memiliki tujuan utama untuk menyediakan cara menyimpan dan mengambil informasi basis data secara mudah dan efisien (Silberschatz, 2002). Contoh DBMS adalah dBase, Microsoft Access, LibreOffice Base.
Seiring pesatnya perkembangan teknologi informasi, basis data menjadi semakin besar dan kompleks sehingga DBMS menjadi tidak cukup cepat dalam membaca data. Pada tahun 1970 diperkenalkan RDBMS, singkatan dari Relational Database Management System. Contohnya adalah MySQL, MariaDB,
SQLite. RDBMS mendukung relasional antar tabel menggunakan primary key, foreign key, dan index. Hal ini menjadikan RDBMS lebih cepat dalam menyimpan
dan mengambil data pada basis data. Hingga kini RDBMS paling banyak digunakan karena mampu mengolah data yang besar dan kompleks.
2
Seiring kemajuan ilmu kecerdasan buatan, pengolahan bahasa alami (Natural Language Processing/NLP) mulai banyak diaplikasikan pada berbagai bidang, salah satunya adalah pada pengolahan basis data. NLP merupakan bidang ilmu kecerdasan buatan yang secara khusus mempelajari bagaimana
mesin/komputer mampu “memahami” bahasa alami manusia (Bahasa Inggris,
Bahasa Indonesia, dsb.) dengan memberlakukan berbagai macam pendekatan (Androutsopoulos, 1995). Dengan mengaplikasikan NLP pada pengolahan basis data, pencarian data dapat dilakukan hanya dengan menggunakan sebuah perintah tertulis dalam bahasa alami. Konsep ini dikenal dengan istilah Natural Language Interface to Database (NLIDB). NLIDB adalah suatu antarmuka yang mampu
mengolah bahasa alami manusia menjadi SQL shingga dapat dieksekusi pada suatu database tertentu yang diperuntukkan (Androutsopoulos, 1995). Hadirnya NLIDB memberikan opsi lain bagi end user untuk mengakses basis data selain pengisian form pada antarmuka berbasis form.
NLIDB pertama kali dikembangkan pada tahun 60 hingga 70an. NLIDB yang terkenal terbaik pada saat itu adalah LUNAR, yang merupakan antarmuka bahasa alami untuk mengakses basis data analisis kimia bebatuan di Bulan. Beberapa NLIDB lainnya yang populer diantaranya adalah: INTELLECT, LOQUI, PRECISE, MASQUE, dll. Kebanyakan NLIDB tersebut menggunakan antarmuka Bahasa Inggris ke bahasa SQL.
Di Indonesia sendiri, penelitian mengenai NLIDB untuk Bahasa Indonesia telah dilakukan sejak lebih dari sedekade terakhir. Andiyani (2002) menerapkan query Bahasa Indonesia untuk basis data akademik, Hartati dan Zuliarso (2008) dan Wibisono (2013) menerapkan aturan produksi pada pengolahan bahasa alami untuk query basis data XML. Publikasi NLIDB Bahasa Indonesia dari tahun ke tahun mengalami pasang surut. Hal ini disebabkan karena kompleksnya bahasa/linguistik, seperti gramatikal, morfologi (pembentukan kata), sintaksis, semantik, pragmatik, serta ambiguitas (kerancuan) atau makna ganda dari suatu kata atau kalimat. Hingga saat ini, ambiguitas memang menjadi permasalahan utama dalam NLP yang masih sulit ditangani (Pusphak, 2010).
3
dengan template tertentu seperti yang telah dilakukan pada penelitian-penelitian berbahasa Indonesia sebelumnya, akan lebih sulit untuk menangani kesalahan-kesalahan struktural maupun makna. Oleh karena itu, penulis memberikan solusi berupa fitur pembangkitan query alternatif yang dapat memberikan opsi query yang lebih benar. Pembangkitan query alternatif ini akan mengurangi risiko kesalahan output sistem dalam mentranslasikan query Bahasa Indonesia menjadi SQL. Sebelum ditranslasikan, terlebih dahulu query input dianalisis menggunakan kaidah-kaidah sintaksis dan semantik. Analisis sintaksis memastikan struktur penulisan perintah yang diinputkan user sesuai dengan aturan gramatikal/ ketatabahasaan yang benar. Sedangkan, analisis semantik memetakan makna lain yang terkandung dalam suatu kata sehingga arah translasi SQL tidak jauh dari basis data yang digunakan.
Penelitian ini mengangkat ruang lingkup (domain) basis data administrasi arsip surat yang digeneralisasi (secara umum digunakan oleh sebagian besar instansi). Basis data arsip surat ini dipilih mengingat sistem pengarsipan surat bagi instansi merupakan hal yang sangat penting. Banyak data yang tersimpan sehingga banyak informasi penting yang bisa didapatkan oleh instansi tersebut dan orang-orang di dalamnya, seperti sekretaris, pegawai administrasi surat, tata usaha, dan lainnya.
1.2 Rumusan Masalah
Adapun rumusan masalah yang diangkat dalam penelitian ini adalah sebagai berikut.
1. Bagaimana tahapan dan metode pengembangan NLIDB Bahasa Indonesia dengan kaidah sintaksis dan semantik agar mampu mentranslasikan query input menjadi SQL?
2. Bagaimana peranan fitur pembangkitan query alternatif pada sistem NLIDB?
1.3 Batasan Masalah
4
1. Bahasa alami yang digunakan pada penelitian ini dibatasi pada Bahasa Indonesia baku yang sesuai dengan Ejaan Yang Disempurnakan (EYD). 2. Bahasa alami yang diolah menjadi format SQL dalam penelitian ini
dibatasi pada expression SELECT, FROM, dan WHERE, karena ketiga expression ini dapat menjadi fungsi yang bisa mewakili fungsi lainnya
serta merupakan expression dasar yang paling sering digunakan.
3. Perintah bahasa alami yang digunakan dibatasi pada perintah untuk menampilkan/menyeleksi data karena perintah ini dapat digunakan oleh semua tingkatan user. Berbeda dengan perintah penambahan (insert), pengubahan (update), maupun penghapusan (delete) yang umumnya hanya bisa dilakukan oleh golongan user tertentu saja.
4. Bahasa alami yang akan diolah menjadi SQL berupa sebuah kalimat perintah sederhana (kalimat diawali dengan kata kerja), baik perintah bersyarat ataupun tidak, tidak berupa kalimat bertingkat/majemuk, serta berpola kalimat inversi (predikat mendahului subjek).
5. Semantik yang digunakan pada penelitian ini terbatas pada domain arsip surat. Kata-kata yang merepresentasikan data-data pada basis data surat dibuatkan daftar padanan katanya untuk dijadikan rule semantik, semisal
“tanggal” dapat direpresentasikan dengan kata “pada”, alamat
direpresentasikan dengan kata “dari”, “tujuan”, “pengirim”, dan lain sebagainya.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah sebagai berikut.
1. Mengetahui tahapan dan metode pengembangan NLIDB Bahasa Indonesia menggunakan kaidah sintaksis dan semantik agar sistem mampu mentranslasikan query input menjadi SQL.
2. Mengetahui peranan fitur pembangkitan query alternatif pada sistem NLIDB.
1.5 Manfaat Penelitian
5
1. Membantu end user yang awam dengan bahasa SQL untuk dapat memperoleh data surat pada basis data dengan hanya menginputkan perintah dalam Bahasa Indonesia.
1.6 Metodologi Penelitian
Pada subbab metodelogi penelitian ini akan dijelaskan langkah-langkah dalam penelitian. Adapun subbab bahasan yang akan dijelaskan adalah desain penelitian, pengumpulan data, persiapan query input, dan metode yang digunakan. 1.6.1 Desain Penelitian
Penelitian ini dilakukan untuk mengetahui bagaimana langkah-langkah dalam mentranslasikan suatu perintah Bahasa Indonesia menjadi query SQL sehingga dapat mengakses basis data untuk mendapatkan data-data tertentu yang diinginkan. Perintah bahasa alami yang diperlukan adalah perintah yang sesuai aturan EYD yang benar.
Dalam proses pengolahan query bahasa alami tersebut akan diarahkan menuju output yang diharapkan dengan memberikan opsi query alternatif jika terdapat kesalahan baik pada pengejaan kata, struktur kalimat, maupun maknanya. Pendekatan yang digunakan adalah dengan penerapan kaidah-kaidah sintaksis dan semantik.
1.6.2 Pengumpulan Data
Data-data yang diperlukan dalam penelitian ini meliputi data kearsipan surat masuk dan surat keluar, kamus kata (lexicon), daftar penggolongan kata, aturan gramatikal, dan beberapa daftar sinonim kata. Semua data ini dikumpulkan dari berbagai sumber literatur dan internet. Khusus data arsip surat diambil sampel sejumlah 60 data yang terdiri dari 30 surat masuk dan 30 surat keluar yang bersumber dari arsip surat Jurusan Ilmu Komputer Universitas Udayana pada bulan Januari, September, dan Oktober tahun 2015.
6
gramatikal yang digunakan dikhususkan untuk kalimat perintah, yakni dengan pola kalimat inversi.
1.6.3 Persiapan Query Input
Query-query input yang akan diujikan pada sistem disusun atas dasar perintah-perintah yang lumrah digunakan untuk mencari data surat di berbagai instansi. Semua query tersebut diterjemahkan ke dalam format SQL secara manual oleh penulis untuk kemudian dijadikan sebagai output goal yang harus dipenuhi oleh sistem. Keberhasilan sistem menerjemahkan query bahasa Indonesia menjadi SQL dapat diketahui dengan mengacu pada kesesuaiannya terhadap goal SQL tersebut.
1.6.4 Metode yang Digunakan
Metode-metode yang digunakan pada sistem NLIDB Bahasa Indonesia ini diantaranya: tokenizing, stemming, spell correction, CYK language understanding, syntactic parsing, semantic mapping, dan beberapa metode tertentu yang dikembangkan sendiri.
7 BAB II
TINJAUAN PUSTAKA 2.1 Tinjauan Empiris
Penulis melakukan penelitian ini dengan terlebih dahulu mengkaji beberapa publikasi penelitian yang sudah pernah dilakukan dalam kurun waktu lima tahun terakhir, diantaranya adalah sebagai berikut.
a) Natural Language Interface to Database Using Semantic Matching. (Neelu Nihalani, 2011)
Penelitian ini menggunakan aturan-aturan semantik pada pre-processor yang di-generate secara otomatis. Administrator juga dapat melakukan pengaturan terhadap aturan-aturan tersebut. Aturan semantik didapatkan dari WordNet yang berisi sinonim ataupun arti kata. Dengan menggunakan database Northwind peneliti berhasil membuat NLIDB yang performanya lebih baik dari pada Microsoft English Query.
b) NaLIR (Natural Language Interface to Relational Database). (Fei Li, 2014)
Pada penelitian ini, dikembangkan NLIDB yang interaktif dengan modul interactive communicator yang ditonjolkan. Modul tersebut memberikan pilihan-pilihan alternatif query kepada user saat ditemukan kesalahan saat memproses query input.
c) Antarmuka Bahasa Alami Untuk Melakukan Query Terhadap Terjemahan Al-Quran. (Suwanto Raharjo, 2014)
Penelitian ini menggunakan aturan-aturan produksi untuk menghasilkan SQL dari query bahasa alami. Aturan produksi tersebut digunakan untuk mencocokkan pola-pola sintaksis tertentu terhadap query Bahasa Indonesia yang diawali dengan kata tanya 5W 1H.
d) Aplikasi Pengolah Bahasa Alami untuk Aplikasi Query Database. (Taryadi, 2010)
8
Pada penelitian-penelitian sebelumnya, NLIDB yang memproses Bahasa Inggris sudah mampu melakukan translasi dengan baik menggunakan kaidah-kaidah sintaksis dan semantik, bahkan dengan menggunakan lebih dari satu tabel pada basis datanya. Sementara, penelitian-penelitian dengan query Bahasa Indonesia masih banyak menggunakan aturan produksi ataupun pencocokan terhadap pola kalimat tertentu sehingga akan banyak ditemukan kesalahan output jika diberikan input query yang tidak sesuai dengan aturan pola yang telah disiapkan.
Pada penelitian yang dilakukan penulis, digunakan aturan-aturan sintaksis dan semantik untuk mentranslasikan query Bahasa Indonesia menjadi SQL dengan memberikan opsi query input alternatif sebagai respon terhadap kesalahan input yang dilakukan user, sehingga SQL yang dihasilkan diharapkan lebih tepat dan output yang dihasilkan sistem sesuai dengan yang dimaksudkan oleh user. Tantangan yang dihadapi penulis dalam mengembangkan sistem NLIDB menggunakan Bahasa Indonesia adalah sebagai berikut.
1. Bidang NLP merupakan bidang yang sangat luas. Oleh karena itu, penelitian-penelitian mengenai NLIDB saat ini kebanyakan dibatasi pada domain-domain tertentu. Walaupun, beberapa penelitian menggunakan Bahasa Inggris sudah ada yang menggunakan basis data universal yang bisa bebas digunakan seperti NORTHWIND, namun tidak demikian dengan NLIDB yang menggunakan Bahasa Indonesia. Sistem NLIDB Bahasa Indonesia yang pernah dikembangkan oleh penelitian terdahulu masih sebatas menggunakan domain-domain tertentu yang dispesifikasikan sendiri.
2. Belum ada sistem NLIDB Bahasa Indonesia yang dapat digunakan oleh publik, sehingga tidak ada cara untuk membandingkan performa sistem yang dikembangkan penulis dengan sistem lainnya yang berbahasa Indonesia.
9
Sedangkan, Indonesian Lemmatizer (Derwin Suhartono, 2014) yang memberikan akurasi yang lebih baik dari metode stemming, saat ini masih sedang dikembangkan. Akan tetapi, mengingat perintah-perintah yang digunakan pada penelitian yang dilakukan penulis terbatas pada perintah sederhana yang tidak terlalu banyak menggunakan kata berimbuhan yang kompleks, sehingga penulis memutuskan untuk menggunakan metode stemming.
4. Bahasa Indonesia sebenarnya sudah memiliki kamus sinonim ataupun arti kata seperti halnya WordNet dan Thesaurus pada Bahasa Inggris, namun masih dalam tahap penyempurnaan. Pada penelitian yang dilakukan penulis, daftar kelas kata dan sinonimnya disusun secara manual dengan acuan kamus Kamus Besar Bahasa Indonesia online (www.kbbi.web.id). Dengan melihat keterbatasan-keterbatasan yang ada saat ini, penulis melakukan pengujian performa sistem melalui referensi penelitian-penelitian sebelumnya yang menggunakan Bahasa Indonesia, yakni dengan mengujicobakan sejumlah dataset perintah Bahasa Indonesia kepada sistem yang sebelumnya sudah disusun goal SQLnya terlebih dahulu. Hasil dari pengujian tersebut berupa nilai precision dan recall.
2.2 Tinjauan Teoritis 2.2.1 Basis Data
Basis data atau database didefinisikan sebagai kumpulan data yang terintegrasi dan diatur sedemikian rupa sehingga data tersebut dapat dimanipulasi, diambil, dan dicari secara cepat (Budi Raharjo, 2011). Selain berisi data, basis data juga memiliki metadata, yakni berisi data penjelasan dari struktur basis data, seperti nama relasi (tabel), nama kolom (field), dan tipe data.
Ada beberapa operasi dasar yang dapat dilakukan berkenaan dengan basis data (Fathansyah, 1999), antara lain:
1. Pembuatan basis data baru (create database) 2. Penghapusan basis data (drop database)
10
5. Penambahan/pengisian data baru ke sebuah file/tabel (insert) 6. Pengambilan/pencarian data dari sebuah file/tabel (retrieve/search) 7. Pengubahan data dari sebuah file/tabel (update)
8. Penghapusan data dari sebuah file/tabel (delete).
End-user biasanya hanya bisa melakukan poin nomor 5, 6, 7, dan 8 saja, selain itu
perlu hak istimewa (seperti administrator) untuk melakukan poin nomor 1, 2, 3, dan 4. Pada penelitian ini, sistem NLIDB Bahasa Indonesia yang dikembangkan hanya mengolah perintah untuk mengambil/menampilkan data saja (poin 6). 2.2.2 Structured Query Language
Structured Query Language (SQL) merupakan sebuah bahasa standar yang
digunakan untuk berinteraksi dengan basis data relasional (Budi Raharjo, 2011). Bahasa SQL dibutuhkan untuk dapat melaksanakan semua pekerjaan yang berhubungan dengan manipulasi, definisi, dan administrasi sebuah basis data.
Untuk melihat informasi dengan kriteria tertentu dalam suatu database dengan menggunakan SQL, maka pemakai harus memahami struktur SQL,
dimana setelah diolah dalam “SQL Engine”, informasi pada basis data dapat dikeluarkan sebagai hasil query seperti pada skema berikut:
Format penulisan SQL untuk menampilkan data adalah sebagai berikut. SELECT nama_tabel.nama_atribut FROM nam_tabel
WHERE <condition>;
SQL memiliki operator-operator dan fungsi-fungsi dasar seperti <, >, <=, >=, MIN, MAX, LIKE, NOT LIKE, BETWEEN, AND, OR, COUNT, dan lain sebagainya. Operator-operator tersebut digunakan untuk menspesifikasikan penyeleksian data.
2.2.3 Text Processing 2.2.3.1 Tokenizing
Tokenizing adalah proses mensegmentasi/membagi suatu dokumen teks atau string kalimat menjadi token (serangkaian karakter yang merepresentasikan
SQL Engine Basis Data
SQL Hasil query
11
kata) oleh tokenizer. Tokenizer membagi suatu string menjadi token-token berdasarkan karakter tertentu. Biasanya karakter spasi, tab, new row (white space character) yang dijadikan panduan segmentasi menjadi token. Selain itu, tanda
baca (punctuation) juga dapat digunakan sebagai pemisah antar token, seperti
tanda “-“. Berikut contoh tokenizing pada kalimat “surat masuk dari MIPA”. Input: surat masuk dari MIPA
Output: [surat] [masuk] [dari] [MIPA] 2.2.3.2 Spell Check/Correction
Spell checking atau spell correction merupakan suatu fitur tambahan yang
dapat dimiliki oleh sebuah aplikasi temu kembali informasi di mana query yang diinputkan user akan dikoreksi pengejaan/penulisannya mengacu pada penulisan pada kamus. Jika terdapat kesalahan ejaan, aplikasi dapat memberikan peringatan bahwa terjadi kesalahan penulisan dan akan dicarikan alternatif penulisan yang mungkin dimaksudkan oleh pengguna. Situs pencarian Google menerapkan
koreksi kesalahan query dengan memberikan alternatif query, seperti pada “Did you mean”.
Tabel 2.1 Pseudocode Levenshtein Edit Distance No. Pseudocode Levenshtein Edit Distance
1 2 3 4 5 6 7 8 9 10 11 12 13 14
function LevenshteinDistance(char s[1..m], char t[1..n]): declare int d[0..m, 0..n]
set each element in d to zero for i from 1 to m:
d[i, 0] := i for j from 1 to n: d[0, j] := j for j from 1 to n: for i from 1 to m: if s[i] = t[j]:
d[i, j] := d[i-1, j-1] //no operation required else:
d[i, j] := minimum(d[i-1, j] + 1, //a deletion d[i, j-1] + 1, //an insertion
d[i-1, j-1] + 1) //a substitution return d[m, n]
12
tiap calon koreksi ejaan yang salah. Pseudocode Levenstein Edit Distance dapat dilihat pada Tabel 2.1.
2.2.3.3 Stemming
Stemming merupakan proses mengembalikan token ke bentuk semula atau
root word (kata dasar). Proses stemming biasanya dilakukan untuk mencari tahu arti kata ataupun kelas kata yang terdapat dalam kamus kata dasar. Terdapat aturan-aturan tertentu dalam proses stemming. Setiap bahasa memiliki aturan stemming yang berbeda-beda tergantung morfologi/pembentukan katanya.
Sebagai contoh, dalam Bahasa Indonesia dikenal terdapat algoritma stemming Mirna Adriani dan Bobby Nazief. Algoritma tersebut memiliki aturan imbuhan dengan model sebagai berikut.
[[[AW+]AW+]AW+] Kata-Dasar [[+AK][+KK][+P]]
AW: Awalan
AK: Akhiran
KK: Kata ganti kepunyaan
P: Partikel
Tanda kurung besar ([ ]) menandakan bahwa imbuhan tersebut opsional. Contoh stemming dengan algoritma M. Adriani dan B.Nazief:
Input: “Perlihatkan nomor pendaftaran surat ini”
Output: “Lihat nomor daftar surat ini”
Tabel 2.2 merupakan algortima dari metode stemming M. Adriani dan B.Nazief (disadur dari laman https://liyantanto.wordpress.com):
Tabel 2.2 Algoritma Stemming Nazief & Adriani No. Algoritma Stemming Nazief & Adriani
1. Pertama, cari kata yang akan di-stem pada kamus kata dasar. Jika ada di kamus, maka diasumsikan kata tersebut merupakan kata dasar, dan algoritma berhenti.
2. Eliminasi akhiran partikel, seperti “-lah”, “-kah”, “-pun”, dan akhiran
kepemilikan, seperti “-ku”, “-mu”, atau “-nya” jika ada. 3. Eliminasi akhiran “-i”, “-an”, atau “-kan” jika ada. 4. Eliminasi awalan jika ada.
5. Melakukan recording.
13
2.2.4 Natural Language Processing
Natural language processing (NLP) atau pengolahan bahasa alami adalah
cabang ilmu kecerdasan buatan (artificial intelligence/AI) dengan ilmu linguistik (Pushpak, 2010). Yang menjadi perhatian dalam NLP adalah bagaimana membuat komputer/mesin mengerti bahasa alami manusia sehingga antara manusia dan komputer dapat berinteraksi dengan perantara bahasa alami, baik itu berupa teks ataupun pesan suara (speech). NLP banyak memberi kemudahan kepada manusia, diantaranya: aplikasi penerjemah bahasa (natural language translation), aplikasi question answering/personal assistant, peringkasan dokumen teks otomatis (tex
summarization), dan masih banyak lagi.
Secara garis besar, NLP terbagi menjadi dua bidang, yakni: Natural Language Understanding (NLU) merupakan bidang yang mengertikan
(understanding) input bahasa alami, dan Natural Language Generation (NLG) yang menyusun teks bahasa alami.
2.2.4.1 NLP dalam Bahasa Indonesia
Pengolahan bahasa alami mengenal beberapa tingkat pengolahan, yaitu: a) Fonetik dan fonologi
Sering digunakan dalam sistem berbasis suara (speech based system). Berhubungan dengan suara yang menghasilkan kata yang dapat dikenali. b) Morfologi
Pengetahuan tentang kata dan pembentukannya. Digunakan untuk membedakan satu kata dengan lainnya.
c) Sintaksis
Pembentukan kalimat oleh kata-kata yang saling berhubungan/berurutan. Pengaturan tata letak suatu kata dalam kalimat akan membentuk kalimat yang dapat dikenali.
Natural Language Processing Komputer
Input bahasa alami Output bahasa alami
14
d) Semantik
Pemetaan dari struktur sintaksis yang mempelajari arti suatu kata dalam kalimat (belum mencangkup konteks dari kalimat tersebut).
e) Pragmatik
Pengetahuan pada tingkatan ini berkaitan dengan masing-masing konteks yang berbeda tergantung pada situasi dan tujuan pembuatan sistem.
NLIDB Bahasa Indonesia yang dikembangkan dalam penelitian ini mengolah input berupa teks (tertulis), sehingga pengolahan NLP yang digunakan hanyalah morfologi, sintaksis, dan semantik.
Terdapat sembilan kelas kata yang secara umum digunakan dalam Bahasa Indonesia (Abdul Chaer, 2008), yakni:
1. Kata benda (nomina) 2. Kata kerja (verba) 3. Kata sifat (adjektiva)
4. Kata kerja tambahan (adverbia) 5. Kata bilangan (numeralia) 6. Kata depan (preposisi)
7. Kata penghubung (konjungsi) 8. Kata ganti (pronomina) 9. Kata ungkapan (interjeksi)
Namun, dalam penelitian ini, penulis tidak menggunakan kata ganti dan kata ungkapan karena kedua kelas kata tersebut tidak dapat diterapkan sebagai perintah untuk menyeleksi data pada basis data arsip surat.
Kumpulan kata dapat membentuk frase. Secara sintaksis/gramatikal Bahasa Indonesia, terdapat beberapa kelas kata yang jika disatukan akan membentuk frase (Abdul Chaer, 2009), diantaranya adalah:
1. Frase nominal
Nomina + nomina; nomina + verba; nomina + adjektiva; adverbial + nomina; numeralia + nomina.
2. Frase verbal
15
3. Frase adjektival
Adjektiva + nomina; adjektiva + adjektiva; adjektiva + adverbia; 4. Frase preposisional
Preposisi + nomina. 5. Frase numeralia
numeralia + nomina.
Frase-frase tersebut akan membantu dalam menyusun kalimat dengan menggunakan pola-pola kalimat tertentu. Frase-frase ini juga menjadi landasan penyusunan aturan-aturan sintaksis dalam sistem NLIDB Bahasa Indonesia.
Pada sistem NLIDB Bahasa Indonesia yang dikembangkan penulis, input sistem adalah berupa kalimat perintah dasar. Menurut Abdul Chaer (2009), Pola kalimat perintah dasar dalam Bahasa Indonesia menggunakan pola inversi, yang artinya predikat mendahului subjek. Pola kalimat inversi dapat berupa: P-S, P-S-K, atau P-S-O-K. Di mana, subjek dan objek dapat disusun oleh kata nomina, frase preposisional, atau frase nominal. Sedangkan, predikat dapat disusun oleh kata kerja, kata sifat, kata kerja tambahan, frase verbal, frase numeralia, frase adjektiva, maupun frase adverbial.
2.2.4.2 Context-Free Grammar (CFG)
Dalam bahasa, grammar adalah aturan-aturan yang menjelaskan bagaimana merangkai kata-kata menjadi kalimat. Context-Free Grammar (CFG/ Phrase-Structure Grammar/Backus-Naur Form) adalah suatu notasi matematis
yang menyatakan aturan sebuah bahasa berdasarkan constituency (Ruli Manurung, 2008). CFG terdiri dari dua bagian, yakni:
1. Sehimpunan rule atau production, yang menyatakan bagaimana symbol dalam bahasa dikelompokkan.
2. Lexicon (daftar symbol/kata)
Symbol-symbol dalam CFG terbagai dua kelas, yaitu:
1. Terminal symbols: symbol yang merepresentasikan kata dalam bahasa. 2. Non-terminal symbols: symbol yang merepresentasikan kelompok/
generalisasi terminal.
Contoh CFG adalah sebagai berikut.
16
Contoh lexicon: verba tampilkan; nomina surat CFG secara simbolik dapat dutuliskan sebagai berikut (Altshuler, 2007).
G = (N, Σ, P, S)
dimana:
N = himpunan non-terminal symbol
Σ = himpunan terminal symbol (token) P = himpunan production / rule
S = start symbol
Rule (grammar) pada CFG biasanya ditulis dengan format Chomsky Normal Form (CNF), dimana terminal symbol ditulis di sisi kiri (left hand side) dan non-terminal symbol ditulis di sisi kanan (right hand side).
Contoh penulisan grammar CNF:
A a A BC
Untuk melakukan parsing terhadap suatu bahasa (berupa kalimat) dapat dilakukan dengan dua cara, yaitu top-down parsing dan bottom-up parsing.
a) Top-down parsing adalah metode parsing yang berhaluan tujuan (goal-driven), dilakukan dari atas (start symbol) ke bawah. Contoh: Earley
parsing.
b) Bottom-up parsing adalah kebalikan dari top-down parsing yang dimulai dari bawah ke atas (data-driven). Contoh: CYK.
Pada penelitian ini digunakan metode bottom-up parsing dengan algoritma Cocke-Younger-Kasami (CYK). CYK mampu mengenali apakah suatu CFG dapat dikategorikan sebagai bahasa atau tidak. CYK menggunakan grammar CNF secara langsung. Tabel 2. adalah algoritma dari CYK parsing.
Tabel 2.3 Algoritma Cocke-Younger-Kasami (CYK) No. Algoritma CYK
1 2 3 4
Buat tabel n x n, dimana n adalah jumlah kata.
Untuk semua cell yang index baris dan kolomnya sama, inisialisasi dengan kelas kata (terminal symbol) yang diperoleh dari lexicon.
Mulai dari index kolom terkecil dan index baris = index kolom -1
17
5 6
Lakukan poin 3 dan 4 hingga mencapai cell root (index baris terkecil, index kolom terbesar).
Jika cell root memiliki non-terminal symbol „Kal‟, maka dikatakan CFG tersebut sesuai dengan bahasa.
2.2.5 Natural Language Interface to Database (NLIDB)
Natural Language Interfaces to Databases (NLIDB) adalah suatu sistem
yang mampu mentranslasikan perintah (senctence) bahasa alami manusia menjadi query basis data (Androutsopoulos dkk, 1995). Terdapat beberapa arsitektur NLIDB yang pernah dikembangkan di dunia, diantaranya adalah:
a) Pattern-matching systems
Pada arsitektur ini digunakan metode pattern-matching untuk menjawab pertanyaan/perintah user. Sebagai contoh:
pattern: … “capital” … <country>
action: Report CAPITAL of row where COUNTRY = <country>
b) Syntax-based systems
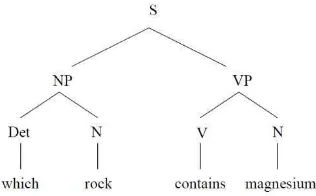
Pada arsitektur ini, inputan user di-parsing (dianalisis secara sintaksis), kemudian hasil dari parse tree langsung dipetakan ke bahasa query basis data. Syntax-based system menggunakan grammar yang dapat mendeskripsikan kemungkinan struktur sintaksis pada pertanyaan user. Sebagai contoh: sistem grammar pada NLIDB LUNAR:
S NP VP
NP Det N
Det “what” | “which”
N “rock”| “specimen” | “magnesium” | “radiation” | “light”
VP V N
V “contains” | “emits”
Keterangan:
18
Gambar 2.3 Contoh parse tree
NLIDB dapat memetakan parse tree di atas menjadi query basis data berikut.
(for every X (is_rock X)
(contains X magnesium) ;
(printout X))
c) Semantic grammar systems
Pada arsitektur semantic grammar systems, tanya-jawab masih dilakukan dengan mem-parsing input lalu memetakan parse tree ke query basis data. Perbedaannya terletak pada kategori grammar (node yang bukan leaf pada parse tree) tidak begitu sesuai dengan konsep sintaksis. Contoh semantic
grammar:
S Specimen_question | spacecraft_question
Specimen_question Specimen Emits_info | Specimen Contains_info
Specimen “which rock” | “which specimen”
Emits_info “emits” Radiation
Radiation “radiation” | “light”
Contains_info “contains” Substance
Substance “magnesium” | “calcium”
Spacecraft_question Spacecraft Depart_info | Spacecraft Arrive_info
Spacecraft “which vessel” | “which spacecraft”
Depart_info “was launched on” Date | “departed on” Date
19
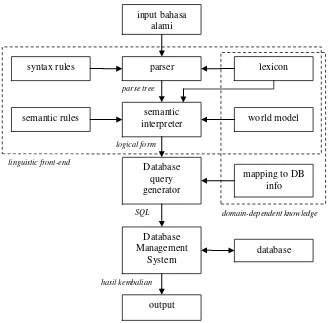
Gambar 2.4 Contoh semantic parse tree d) Intermediate representation languages system
Kebanyakan NLIDB saat ini menggunakan arsitektur ini. Pertama-tama pertanyaan bahasa alami ditransformasikan ke intermediate logical query (query peralihan). Query ini mengekspresikan arti dari pertanyaan user dalam high level world concepts yang tidak bergantung pada struktur basis data.
logical form parse tree
hasil kembalian SQL
input bahasa alami
parser
syntax rules lexicon
semantic interpreter
semantic rules world model
mapping to DB info Database
query generator
Database Management
System
output
database linguistic front-end
domain-dependent knowledge
20
Kelebihan dan kekurangan NLIDB menurut Androutsopoulus adalah sebagai berikut.
2.2.5.1 Kelebihan NLIDB
a) Pengguna (user) sistem NLIDB tidak perlu mempelajari bahasa query basis data (SQL, dll.) melainkan cukup melakukan perintah dengan bahasa alami.
b) Perintah negasi (tidak, bukan, dll.) lebih mudah diekspresikan dalam bahasa alami dibandingkan dengan menggunakan antarmuka form.
2.2.5.2 Kekurangan NLIDB
a) Perintah-perintah yang dapat dilakukan user bersifat terbatas dan user sulit mengetahui perintah seperti apa yang tidak boleh diinputkan ke sistem. b) Ketika sistem NLIDB tidak mengerti perintah user, seringkali sistem
langsung menolak perintah tersebut sehingga user tidak mengetahui dengan jelas pada bagian mana dari inputan perintahnya yang salah/tidak diterima sistem.