LANDASAN TEORI
2.1 Pengertian dan Kegunaan Peramalan (Forecasting)
Dalam melakukan analisis di bidang ekonomi, sosial dan sebagainya, diperlukan suatu perkiraan apa yang akan terjadi atau gambaran tentang masa yang akan datang. Kegiatan untuk memperkirakan apa yang akan terjadi pada masa yang akan datang, dikenal dengan peramalan (forecasting) (Assauri, 1984, p1). Sedangkan menurut Webster (1986, p3), peramalan adalah dugaan yang dibuat secara sederhana tentang apa yang akan terjadi di masa depan berdasarkan informasi yang tersedia saat ini.
Dalam usaha untuk melihat dan mengkaji situasi dan kondisi di masa depan maka harus dilakukan peramalan. Oleh karena itu perlu diperkirakan atau diramalkan situasi apa dan kondisi bagaimana yang akan terjadi pada masa depan, karena hal ini dibutuhkan untuk menentukan langkah-langkah yang perlu dilakukan untuk mencapai hasil yang diinginkan. Peramalan diperlukan karena adanya kebutuhan untuk mengetahui apa yang mungkin akan terjadi pada masa yang akan datang. Jadi dalam menentukan langkah-langkah itu perlu diperkirakan hal-hal apa saja yang akan terjadi sehingga dapat mengetahui ancaman yang mungkin terjadi.
Kegunaan dari peramalan terjadi pada waktu pengambilan keputusan. Setiap orang selalu dihadapkan pada masalah pengambilan keputusan. Keputusan yang baik adalah keputusan yang didasarkan atas pertimbangan-pertimbangan yang matang dan perkiraan tentang kejadian yang mungkin akan terjadi. Apabila ramalan yang dihasilkan kurang tepat, maka keputusan yang diambil tidak akan mencapai hasil yang memuaskan. Dengan meramalkan kejadian yang akan datang, tindakan-tindakan yang akan datang
dapat direncanakan dengan matang sehingga dapat mengurangi kerugian atau menambah keuntungan serta dapat mengantisipasi hal-hal yang tidak diinginkan.
Dengan demikian dapat dilihat bahwa peramalan memiliki peranan yang sangat penting, baik dalam penelitian, perencanaan maupun dalam pengambilan keputusan. Tetapi dapat diperhatikan bahwa peramalan memiliki tujuan untuk memperkecil kemungkinan kesalahan. Baik tidaknya suatu ramalan sangat tergantung pada faktor data dan metode serta kebenaran asumsi yang digunakan.
2.2 Jenis-jenis Peramalan
Pada umumnya peramalan dapat dibedakan dari beberapa segi tergantung dari cara melihatnya. Apabila dilihat dari sifat penyusunannya, maka peramalan dapat dibedakan atas dua macam, yaitu (Assauri, 1984, p3) :
1) Peramalan yang subjektif, yaitu peramalan yang didasarkan atas perasaan atau intuisi dari orang yang menyusunnya.
2) Peramalan yang objektif, adalah peramalan yang didasarkan atas data yang relevan pada masa lalu, dengan menggunakan teknik-teknik dan metode-metode dalam penganalisisan data tersebut.
Disamping itu, jika dilihat dari jangka waktu ramalan yang disusun, maka peramalan dapat dibedakan atas dua macam pula, yaitu (Assauri, 1984, p4) :
1) Peramalan jangka panjang, yaitu peramalan yang dilakukan untuk penyusunan hasil ramalan yang jangka waktunya lebih dari satu setengah tahun atau tiga semester.
2) Peramalan jangka pendek, yaitu peramalan yang dilakukan untuk penyusunan hasil ramalan dengan waktu yang kurang dari satu setengah tahun, atau tiga
semester. Oleh karena itu, peramalan jangka pendek menggunakan teknik analisa hubungan dimana satu-satunya variabel yang mempengaruhi adalah waktu. Dalam peramalan jangka pendek selalu ditemui adanya pola musiman. Jadi pada bulan-bulan atau triwulan yang sama setiap tahun mempunyai nilai variabel cukup tinggi, dan pada bulan-bulan atau triwulan tertentu lainnya mempunyai nilai variabel yang cukup rendah. Oleh karena itu dalam peramalan jangka pendek perlu ditinjau dahulu apakah deret data yang ada memiliki pola musiman.
Berdasarkan sifat ramalan yang telah disusun, maka peramalan dapat dibedakan atas dua macam, yaitu (Assauri, 1984, p4) :
1) Peramalan kualitatif, yaitu peramalan yang didasarkan atas data kualitatif pada masa lalu. Hasil peramalan yang dibuat sangat tergantung pada orang yang membuatnya, karena ditentukan berdasarkan pemikiran yang bersifat intuisi, judgment atau pendapat, dan pengetahuan serta pengalaman dari penyusunnya.
2) Peramalan kuantitatif, yaitu peramalan yang didasarkan atas data kuantitatif pada masa lalu. Hasil peramalan yang dibuat sangat tergantung pada metode yang dipergunakan dalam peramalan tersebut. Menurut Makridakis, Wheelwright dan McGee (1999, p20), tiga kondisi penerapan peramalan ini adalah : tersedia informasi tentang masa lalu, informasi tersebut dapat dikuantitatifkan dalam bentuk data numerik dan dapat diasumsikan bahwa beberapa aspek pola masa lalu akan terus berlanjut di masa mendatang. Menurut Reksohadiprodjo (1989, p5), peramalan kuantitatif dapat dibagi lagi menjadi deret waktu, kausalitas dan pemantauan.
2.3 Langkah-langkah Peramalan
Peramalan yang baik adalah peramalan yang dilakukan dengan mengikuti langkah-langkah atau prosedur penyusunan yang baik yang akan menentukan kualitas atau mutu dari hasil peramalan yang disusun. Pada dasarnya ada tiga langkah peramalan yang penting, yaitu (Assauri, 1984, p5):
1) Menganalisis data yang lalu, tahap ini berguna untuk pola yang terjadi pada masa lalu.
2) Menentukan metode yang dipergunakan. Metode yang baik adalah metode yang memberikan hasil ramalan yang tidak jauh berbeda dengan kenyataan yang terjadi.
3) Memproyeksikan data yang lalu dengan menggunakan metode yang dipergunakan, dan mempertimbangkan adanya beberapa faktor perubahan (perubahan kebijakan-kebijakan yang mungkin terjadi, termasuk perubahan kebijakan pemerintah, perkembangan potensi masyarakat, perkembangan teknologi dan penemuan-penemuan baru).
2.4 Metode Pemulusan (Smoothing) Eksponensial
Metode ini disebut eksponensial karena menggunakan pembobotan menurun secara eksponensial terhadap nilai pengamatan yang lebih lama. Metode pemulusan eksponensial terdiri atas tunggal, ganda, dan metode yang lebih rumit lainnya. Semuanya mempunyai sifat yang sama, yaitu nilai yang lebih baru diberikan bobot yang relatif lebih besar dibandingkan nilai pengamatan yang lebih lama.
2.4.1 Pemulusan Eksponensial Tunggal
Metode pemulusan eksponensial tunggal (Single Exponential Smooting/SES) minimal membutuhkan dua buah data untuk meramalkan nilai yang akan terjadi pada masa yang akan datang. Berikut ini rumusan dalam pemulusan eksponensial tunggal (Makridakis et al., 1999, p101) : ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − + = − + N X N X F F t t N t t 1 (2-1)
Jika pengamatan yang lama Xt−N tidak tersedia maka nilainya harus digantikan dengan
suatu nilai pendekatan. Salah satu pengganti yang mungkin adalah nilai ramalan periode sebelumnya F . Dengan melakukan subsitusi ini, persamaan (2-1) menjadi persamaan t
(2-2) kemudian ditulis kembali menjadi persamaan (2-3) (Makridakis et al., 1999, p102). ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − + = + N F N X F F t t t t 1 (2-2) t t t F N X N F ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ = + 1 1 1 1 (2-3)
(Perhatikan bahwa jika datanya stasioner, maka subsitusi di atas merupakan pendekatan yang cukup baik, namun bila terdapat trend, metode SES yang dijelaskan di sini tidak cukup baik).
Dari persamaan (2-3) dapat dilihat bahwa ramalan ini (F ) didasarkan atas t+1
pembobotan pada observasi yang terakhir dengan suatu nilai bobot (1/N) dan pembobotan ramalan yang terakhir sebelumnya (F ) dengan suatu bobot [1-(1-N)]. Oleh t
karena N merupakan suatu bilangan positif, 1/N akan menjadi suatu konstanta antara nol (jika N tak terhingga) dan 1 (jika N=1). Dengan mengganti 1/N dengan α , persamaan (2-3) menjadi (Makridakis et al., 1999, p103) :
t t
t X F
F+1 =α +(1−α) (2-4)
Metode ini banyak mengurangi masalah tentang penyimpanan data, karena kita tidak perlu lagi menyimpan semua data historis yang ada sebelumnya. Data-data yang perlu disimpan hanya pengamatan terakhir (Xt), ramalan terakhir (Ft) dan suatu nilai α
yang harus disimpan.
Persamaan pemulusan eksponensial dapat dilihat dengan lebih baik bila persamaan (2-4) diperluas dengan mengganti F dengan komponennya sebagai berikut
(Makridakis et al., 1999, p 103) :
(
)
[
1(
)
1]
1 1 − 1 − − = t + − t + − t t X X F F α α α α(
)
(
)
1 2 1 1 1 − 1 − − = t + − t + − t t X X F F α α α α (2-5)Jika proses subsitusi ini diulang dengan mengganti F dengan komponennya, t−1
2 −
t
F dengan komponennya, dan seterusnya, hasilnya adalah persamaan (3-6) (Makridakis et al., 1999, p103) :
(
)
(
)
(
)
3(
)
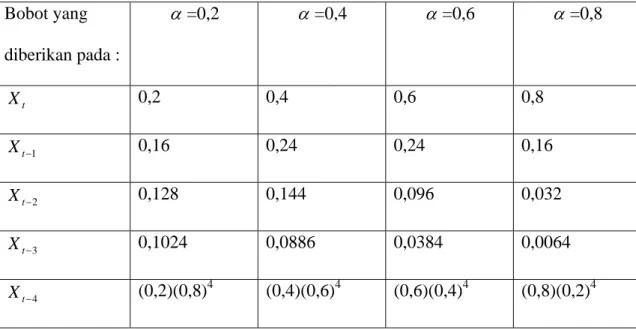
( 1) 3 2 2 1 1 1 1 1 1 − − − − − + − + • • • + − + − + − + = N t N t t t t t F X X X X F α α α α α α α α (2-6)Misalkan α =0,2; 0,4; 0,6; 0,8. Maka bobot yang diberikan pada nilai pengamatan observasi masa lalu akan menjadi sebagai berikut :
Tabel 2.1 Pembobotan Nilai Pengamatan (Makridakis et al., 1999, p103) Bobot yang diberikan pada : α =0,2 α =0,4 α =0,6 α =0,8 t X 0,2 0,4 0,6 0,8 1 − t X 0,16 0,24 0,24 0,16 2 − t X 0,128 0,144 0,096 0,032 3 − t X 0,1024 0,0886 0,0384 0,0064 4 − t X (0,2)(0,8)4 (0,4)(0,6)4 (0,6)(0,4)4 (0,8)(0,2)4 2.5 Pengertian Regresi
Metode regresi didasarkan pada penetapan suatu persamaan estimasi menggunakan teknik ”least squares”. Hubungan yang ada pertama-tama dianalisa secara
statistik. Ketepatan peramalan dengan metode ini sangat baik untuk peramalan jangka pendek. Metode ini banyak digunakan untuk peramalan penjualan, perncanaan keuntungan, peramalan permintaan dan peramalan keadaan ekonomi. Data yang dibutuhkan untuk penggunaan metode peramalan ini adalah data kuartalan dari beberapa tahun yang lalu.
2.5.1 Regresi Linear Sederhana
Untuk analisis regresi (Sudjana, 2003, p6) akan dibedakan dua jenis variabel yaitu variabel bebas atau variabel prediktor dan variabel tak bebas atau variabel respon. Penentuan variabel mana yang bebas dan mana yang tak bebas dalam beberapa hal tidak
mudah dapat dilaksanakan. Studi yang cermat, diskusi yang seksama, berbagai pertimbangan, kewajaran masalah yang dihadapai dan pengalaman akan membantu memudahkan penentuan. Variabel yang mudah didapat atau tersedia sering dapat digolongkan ke dalam variabel bebas, sedangkan variabel yang terjadi karena variabel bebas itu merupakan variabel tak bebas. Untuk keperluan analisis, variabel bebas akan dinyatakan dengan X1,X2,...,Xk
(
k ≥1)
sedangkan variabel tak bebas akan dinyatakan dengan Y.Misalnya, untuk fenomena yang meliputi hasil panen padi dan volume pupuk yang digunakan, sebaiknya diambil variabel bebas atau prediktor X = volume pupuk dan
variabel tak bebas atau respon Y = hasil panen. Untuk tiga variabel yang meliputi
pertumbuhan bakteri, seperti macam zat perantara tempat bakteri hidup dan waktu, dapat diambil respon Y = pertumbuhan bakteri, prediktor X1 =macam zat perantara dan
prediktor X2 =waktu. Tetapi untuk dua variabel tentang berat dan tinggi badan, salah satu dapat dipilih sebagai variabel bebas. Demikian pula jika masalah yang dipelajari itu berhubungan dengan hasil uji untuk matematika, fisika, biologi dan kimia.
Karena antara respon Y sebenarnya dan respon yang diperoleh dari regresi pada
umumnya harganya berbeda, maka untuk respon yang didapat dari regresi akan diberi lambang Y dengan topi, yakni Y). Model atau persamaan regresi linear sederhana Y atas X, secara umum berbentuk :
Y
)
= +
a bX
(2-7)Bentuk persamaan diatas akan dicari dengan menggunakan data hasil pengamatan (tepatnya pasangan data X dan i Y ) sehingga regresi yang diperoleh merupakan bentuk i
atau diduga dari grafik data pengamatan yang digambarkan menggunakan sumbu datar X
dan sumbu tegak Y. Gambar tiap pasang data X dan i Y pada sistem sumbu ini akan i
berupa titik-titik sehingga terjadi kumpulan titik-titik yang terpencar. Oleh karena itu, grafiknya sering disebut pula diagram pencar. Apabila letak titik-titik pada diagram pencar itu cenderung mengikuti pola lurus, diduga regresi Y atas X akan lurus atau linear
dan untuk itu persamaan umumnya seperti dalam persamaan (2-7). Dalam hal lain, yakni bila letak titik-titik pada diagram pencar jauh dari kecenderungan mengikuti pola lurus, diduga regresinya non linear dan persamaannya tidak berbentuk seperti dalam persamaan (2-7) melainkan bentuk lain.
2.6 Metode Theta
Dinyatakan
{
X1,...,Xn}
sebagai data deret waktu univariat yang diamati. Dari deret tersebut dibentuk sebuah deret{
Y1( )
θ ,...,Yn( )
θ}
sehingga"( )Yt θ =θXt" (2-8)
dimana "Xt adalah selisih kedua dari X dan t Yt"
( )
θ adalah selisih kedua dari Yt( )
θ . Dari persamaan (2-8) merupakan rumus selisih kedua dan menurut Box (1994) menghasilkan( ) = + ( 1)
t t
Y θ aθ b tθ − +θX (2-9)
dimana aθdan bθadalah konstan. Sehingga ( )Yt θ ekuivalen dengan fungsi linear dari
t
X dengan menambahkan sebuah trend linear. Assimakopoulos dan Nikolopoulos (2000)
menyatakan ( )Yt θ sebagai sebuah “garis theta”. Untuk sebuah θ yang tetap, diketahui
( )
2(
)
(
)
2 1 1 1 1 t t t t t i i X Y θ θ X aθ b tθ = = − = − − − − ⎡ ⎤ ⎡ ⎤ ⎣ ⎦ ⎣ ⎦∑
∑
(2-10)Persamaan ini ekuivalen untuk menyederhanakan jumlah kuadrat di atas dengan mengingat aθ dan bθ . Sehingga ini menjadi sebuah regresi sederhana antara
(
1−θ)
Xtdengan waktu t−1. Oleh karena itu, solusinya adalah
(
)
(
)
, 2 1 6 1 2 1 1 n n t t b tX n X n n θ θ = − ⎛ ⎞ = ⎜ − + ⎟ − ⎝∑
⎠ $ (2-11) dan a$θ,n = −(
1 θ)
X −b$θ,n(
n−1 2)
(2-12)Diingat bahwa nilai rata – rata (nilai tengah) dari deret waktu yang baru adalah
( )
$ ,n ,n(
1 2)
Y θ =aθ +b$θ n− +θX = X (2-13)
Selanjutnya, mudah dilihat bahwa 1
(
)
(
)
2⎡⎣Yt 1+ p +Yt 1−p ⎦⎤=Xtkarena
$1 p n, $1 p n, 0
a+ +a− = dan b$1+p n, +b$1−p n, =0.
Peramalan dengan metode Theta didapat melalui rata – rata bobot dari peramalan dari
( )
t
Y θ untuk nilai – nilai berbeda dari θ . Assimakopoulos dan Nikolopoulos (2000)
menjelaskan bagaimana mendapatkan nilai ramalan untuk θ = 0 dan θ = 2. Mereka mendefinisikan
( )
( )
1 2 0 2 n h n h n h X + = ⎡⎣Y + +Y + ⎤⎦ (2-14)dimana : Xn h+ = nilai peramalan (Ft)
( )
0n h
Y + = nilai peramalan dari theta berbobot 0
( )
2n h
( )
0n h
Y + didapat dengan mengekstrapolasikan linear dari persamaan (2-9) dan Yn h+
( )
2 didapat dengan menggunakan metode pemulusan eksponensial tunggal (SES) pada deret waktu{
Yt( )
2}
. Sehingga,( )
0 $0, 0,(
1)
n h n n
Y + =a +b$ n+ −h (2-15)
Pendekatan Makridakis, et al (1999) menyatakan
( )
1(
)
( ) (
) ( )
1 0 2 1 2 1 2 n i n n h n i i Y α α Y α Y − + − = =∑
− + − (2-16)dimana α adalah koefisien pemulusan untuk SES.
Melalui hasil di atas dapat dikombinasikan untuk mendapatkan penjelasan sederhana untuk peramalan Xn h+ . Dari persamaan (2-15) didapat
( )
1(
)
$2, 2,(
)
(
)
(
$2, 1)
0 2 1 1 2 1 2 n i n n h n n n i n i Y α α a b n i X α a X − + − = ⎡ ⎤ =∑
− ⎣ +$ − − + ⎦+ − + $2, 2,(
)
1 1 2 n n h n n a b n α X α α + ⎡ − ⎤ = + ⎢ − + ⎥+ ⎢ ⎥ ⎣ ⎦ $ (2-17)dimana Xn h+ adalah peramalan SES untuk deret waktu
{ }
Xt . Dengan mengingat bahwa$2,n $0,n
a = −a dan b$2,n = −b$ , maka diperoleh 0,n
(
)
1 0, 2 1 1 1 n n h n h n X X b h α α α + + ⎛ − ⎞ = + ⎜⎜ − + − ⎟⎟ ⎝ ⎠ $ (2-18)Untuk n yang besar, maka dapat ditulis menjadi
(
)
1 0, 2 1 1 n h n h n X + = X + + b$ h− + α (2-19)Sehingga ini adalah SES dengan menambahkan trend dimana slope dari trend ini adalah setengah dari garis trend yang disesuaikan dengan deret waktu asli.
2.7 Autokorelasi (ACF)
Autokorelasi di antara nilai-nilai yang berturut-turut dari data merupakan suatu alat penentu atau kunci dari identifikasi pola dasar yang menggambarkan data itu. Seperti telah diketahui bahwa konsep korelasi di antara dua variabel menyatakan asosiasi atau hubungan diantara dua variabel. Nilai korelasi menunjukkan apa yang terjadi atas salah satu variabel, terdapat perubahan dalam variabel lainnya.
Tingkat korelasi ini diukur dengan koefisien korelasi yang besarnya bervariasi di antara +1 dan -1. Suatu nilai koefisien yang mendekati +1 menunjukkan kuatnya hubungan positif diantara dua variabel itu. Ini berarti bahwa bila nilai dari salah satu variabel meningkat atau bertambah, maka nilai daripada variabel lainnya juga cenderung bertambah. Demikian pula halnya dengan nilai koefisien korelasi yang mendekati -1, menunjukkan bertambahnya nilai salah satu variabel akan mengakibatkan turunnya atau kurangnya nilai dari variabel lainnya. Suatu nilai koefisien korelasi nol menunjukkan bahwa kedua variabel secara statistik adalah bebas, tidak tergantung satu dengan lainnya, sehingga tidak ada perubahan dalam satu variabel, bila variabel lainnya berubah. Suatu koefisien autokorelasi adalah sama dengan suatu koefisien korelasi hanya bedanya bahwa koefisien ini menggambarkan assosiasi atau hubungan antara nilai-nilai dari variabel yang sama, tetapi pada periode waktu yang berbeda.
Autokorelasi memberikan informasi yang penting tentang susunan atau struktur data dan polanya. Dalam suatu kumpulan data acak yang lengkap, autokorelasi diantara nilai-nilai data dari ciri musiman dan siklus akan mempunyai autokorelasi yang kuat. Sebagai contoh, informasi yang menunjukkan suatu hubungan yang positif di antara temperatur setiap dua belas bulan berturut-turut merupakan informasi yang diperoleh dengan perhitungan autokorelasi yang dapat dipergunakan dalam pendekatan
Box-Jenkins untuk mengidentifikasikan model peramalan yang optimal. Dengan mengetahui nilai koefisien autokorelasi dapat diketahui pula ciri, pola dan jenis data, sehingga dapat memenuhi maksud untuk mengidentifikasikan suatu model tentatif atau percobaan yang dapat disesuaikan dengan data.
Menurut Makridakis (Makridakis et al., 1999, p 309-402), autokorelasi untuk
time-lag 1,2,3,4,..,k dapat dicarikan dan dinotasikan sebagai berikut:
(
)(
)
(
)
1 2 1 n k t t k t k n t t t Y Y Y Y r Y Y − + = = − − = −∑
∑
(2-20)Dengan koefisien autokorelasi dari data acak mempunyai sebaran penarikan contoh yang mendekati kurva normal dengan nilai tengah nol dan galat standar
2.8 Statistik Durbin-Watson
Uji statistik Durbin-Watson menguji hipotesis bahwa tidak terdapat autokorelasi pada nilai sisa/galat. Statistik Durbin-Watson adalah sebagai berikut (Supranto, 2001,
p270) :
∑
∑
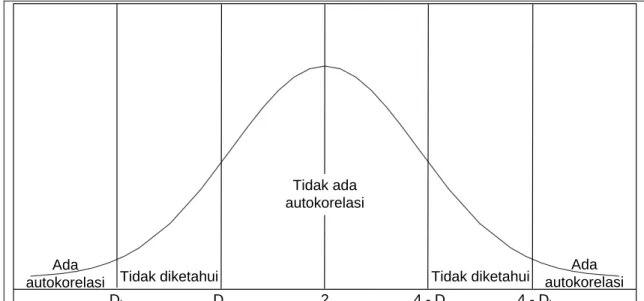
= − = − = − n t t t n t t e e e W D 1 2 2 1 2 ) ( (2-21) dimana : et adalah Xt – FtDistribusi Durbin-Watson adalah simetrik di sekitar 2, yaitu nilai tengahnya. Dengan demikian selang kepercayaan dapat dibentuk yang melibatkan lima wilayah seperti yang ditunjukkan pada gambar dibawah ini.
Tidak diketahui Tidak diketahui Tidak ada autokorelasi Ada autokorelasi Ada autokorelasi DL Du 2 4 - Du 4 - DL
Gambar 2.1 Grafik Distribusi Durbin-Watson (Makridakis et al., 1999, p 340)
Lima selang yang dimaksudkan adalah (Reksohadiprodjo, 1989, p 94) : 1. Kurang dari DL maka ada autokorelasi positif.
2. Antara DL dan DU maka tidak dapat disimpulkan.
3. Antara DU dan 4 – DU maka tidak ada autokorelasi.
4. Antara 4 – DU dan 4 – DL maka tidak dapat disimpulkan.
5. Lebih dari 4 – DL maka ada autokorelasi negatif.
2.9 Pemeriksaan Outlier
Walaupun terdapat banyak definisi, outlier biasanya dianggap sebagai sebuah titik data yang terletak jauh di luar batas normal atau selang kepercayaan dari variabel atau data populasi. Outlier dapat memberikan pengaruh besar dalam analisa statistika, seperti meningkatkan keragaman dan mengurangi kepercayaan saat pengujian. Outlier dapat muncul dari penyebab yang berbeda, misalnya kesalahan pencatatan dan pengukuran serta kesalahan pendugaan.
Terdapat berbagai macam cara dalam menentukan outlier dari populasi, salah satunya adalah dengan menentukan distribusi normal dari data. Hal ini dilakukan dengan menentukan selang kepercayaan sebesar 95% dari standar deviasi data tersebut, kemudian menambahkan dan mengurangkannya pada rata – rata data sehingga diperoleh batas bawah dan batas atas dari data. Kemudian jika diperoleh nilai yang berada di luar batas tersebut maka nilai tersebut dapat dinyatakan sebagai outlier.
2 / 2 1 t t t X X t X Z t t α ⎛ ⎞ − ⎜ ⎟ ⎝ ⎠ ± −
∑
∑
∑
(2-22)Selain menentukan outlier, dibutuhkan cara mengatasi outlier tersebut. Cara yang mudah dan sering digunakan adalah dengan menggunakan metode rata – rata berdekatan yaitu mengubah nilai yang dinyatakan sebagai outlier dengan nilai rata – rata dari nilai yang terdapat sesudah (t+1) dan sebelum (t-1) dari nilai tersebut. Dalam hal ini terdapat beberapa kasus tertentu dimana diperlukan cara mengatasi yang khusus, yaitu apabila
outlier terdeteksi berada di data pertama atau data terakhir. Maka hal ini diatasi dengan
mengubah nilai outlier tersebut dengan nilai sesudah outlier (t+1) apabila terdapat pada data pertama sedangkan apabila terdapat pada data terakhir maka nilai outlier tersebut diganti dengan nilai sebelum outlier (t-1)
2.10 Ketepatan Metode Peramalan
Makridakis, Wheelwright, dan McGee (1999, p 57-58) menyatakan bahwa dalam banyak hal, kata ”ketepatan” (accuracy), menunjuk ke ”kebaikan suai”, yang pada akhirnya penunjukkan seberapa jauh model peramalan tersebut mampu mereproduksi data yang telah diketahui. Dalam pemodelan deret berkala, sebagian data yang diketahui
dapat digunakan untuk meramalkan sisa data berikutnya sehingga memungkinkan orang untuk mempelajari ketepatan ramalan secara lebih langsung. Bagi pemakai ramalan, ketepatan ramalan yang akan datang adalah yang paling penting. Bagi pembuat model, kebaikan suai model untuk fakta yang diketahui harus diperhatikan. Berikut akan dijelaskan mengenai beberapa metode yang digunakan untuk mengetahui ketepatan sebuah metode peramalan
2.10.1 Mean Squared Error (MSE)
Makridakis, Wheelwright, dan McGee (1999, p58) mempunyai beberapa ukuran statistik standar untuk mengukur ketepatan hasil peramalan. Ukuran berikut menunjukkan pencocokan suatu model terhadap data historis. Perbandingan nilai MSE yang terjadi selama tahap pencocokan peramalan mungkin memberikan sedikit indikasi ketepatan model dalam peramalan.
t t t
e = X − F (2-22)
dimana : et = galat untuk periode ke-t.
Xt = data aktual untuk periode ke-t Ft = ramalan untuk periode ke-t
Jika terdapat nilai pengamatan dan ramalan untuk n periode waktu, maka akan terdapat n buah galat dan ukuran statistik standar berikut yang dapat didefinisikan Nilai Tengah Galat Kuadrat (Mean Squared Error)
MSE = 2 1 / n t i e n =
∑
(2-23)2.11 Aplikasi Rekayasa Perangkat Lunak
Rekayasa Perangkat lunak dapat diaplikasikan ke berbagai situasi di mana serangkaian langkah prosedural (seperti algoritma) telah didefinisikan (pengecualian-pengecualian yang dapat dicatat pada aturan ini adalah sistem pakar dan perangkat lunak jaringan syaraf kecerdasan buatan). Kandungan (content) informasi dan determinasi merupakan faktor terpenting dalam menentukan sifat aplikasi perangkat lunak. Content mengarah kepada arti dan bentuk dari informasi yang masuk dan yang keluar.
Pemrosesan informasi bisnis merupakan area aplikasi perangkat lunak yang paling luas. Aplikasi dalam area ini menyusun kembali struktur data yang ada dengan suatu cara tertentu untuk memperlancar operasi bisnis atau pengambilan keputusan manajemen.
Banyak perangkat lunak sistem (misal compiler, editor, dan utilitas pengatur file) memproses stuktur-struktur informasi yang lengkap namun tetap. Aplikasi-aplikasi sistem yang lain (komponen sistem operasi, driver, prosesor telekomunikasi) memproses secara luas data yang bersifat tetap. Di dalam setiap kasus tersebut, area perangkat lunak sistem ditandai dengan eratnya interaksi dengan perangkat keras komputer, penggunaan oleh banyak pemakai dan struktur-struktur data yang kompleks. Selanjutnya, ada empat tahapan dalam daur hidup perangkat lunak, yaitu :
1. Inception (kelahiran)
Tahapan dimana benih pemikiran membangun sistem mulai diterima, minimal secara internal organisasi.
Tahapan yang menghasilkan visi mengenai produk dan arsitekturnya. Tahapan ini juga menghasilkan sistem requirements berupa pernyataaan sederhana mengenai visi, bahkan sampai pada kriteria evaluasi untuk tiap perilaku fungsional maupun non-fungsional, sehingga masing-masing dapat menjadi “basis” untuk pengetesan.
3. Construction (pembangunan)
Pada tahapan ini software dibangun, diuji, diperbaiki dan disempurnakan 4. Transition (peralihan)
Dalam tahapan ini software diserahkan kepada komunitas user.
2.12 Basis Data (Database)
Menurut Farthansyah (2004,p7), Basis Data merupakan salah satu komponen dari Sistem Basis Data dan terdiri atas 3 hal yaitu kumpulan data yang terorganisir, relasi antar data dan objektifnya. Ada banyak pilihan dalam mengorganisasi data dan ada banyak pertimbangan dalam membentuk relasi antar data, namun pada akhirnya yang terpenting adalah objek utama yang harus selalu kita ingat yaitu kecepatan dan kemudahan berinteraksi dengan data yang dikelola/diolah.
Seperti telah dikemukakan di atas, bahwa Basis Data hanya merupakan satu komponen dari Sistem Basis Data, jadi masih ada komponen lainnya yaitu perangkat keras, perangkat lunak serta pemakai. Ketiga komponen ini saling ketergantungan. Basis Data tidak mungkin dapat dioperasikan tanpa adanya perangkat lunak yang mengorganisasikannya. Begitupun pemakai tidak dapat berinteraksi dengan basis data tanpa melalui perangkat lunak yang sesuai.
Pada program aplikasi yang dibuat ini akan menggunakan input dari sebuah file
Microsoft Excel 2003 (ekstensi .xls). File ini akan diload 2 kolom pertama di dalamnya,
yang kolom pertama berisi periode dan kolom kedua berisi angka penjualan pada periode tersebut dengan minimal 30 baris di dalamnya agar tercipta peramalan yang baik.
2.13 Unified Modelling Language (UML) 2.13.1 Pengertian UML
UML adalah suatu bahasa pemodelan standar untuk menulis rancangan software. UML dapat digunakan untuk visualisasi, spesifikasi, konstruksi dan dokumentasi suatu software yang intensif dari suatu sistem. UML memungkinkan pembangunan sistem untuk membuat rencana yang memungkinkan untuk dimengerti dan berkomunikasi dengan yang lain. Komunikasi dalam hal pandangan adalah yang paling penting di dalam pembangunan sistem. Sistem analis akan mencoba untuk memperkirakan kebutuhan dari client mereka, membuat analisis permintaan di beberapa notasi yang dapat dimengerti oleh analis (namun tidak selalu dimengerti oleh client), memberikan hasil analisa tersebut kepada programmer atau kelompok programmer, dan berharap produk terakhir adalah sistem yang diinginkan oleh client. Dan dengan adanya UML, masalah-masalah di atas dapat diatasi.
UML adalah bahasa standar untuk mebuat cetak biru dari piranti lunak. UML dapat digunakan untuk visualisasi dan menentukan, membangun serta mendokumentasikan hasil kerja dari sistem yang dirancang untuk piranti lunak.(Booch, Rumbaugh, dan Jacobson, 1998, p13). UML memiliki tiga unsur utama, yaitu :
a. Blok-blok bangunan, terdiri dari tiga jenis, yaitu Things, Relationship dan
Diagrams.
b. Aturan yang mengatur bagaimana bok-blok itu dihubungkan. c. Mekanisme yang dapat digunakan.
Untuk memahami UML, perlu diketahui tiga karakteristik penting dari UML, yaitu :
a. Use case Driven
Use case digunakan sebagai awalan untuk membuat perilaku, verifikasi dan
validasi arsitektur sistem. Selanjutnya use case digunakan untuk pengetesan sistem dan sebagai alat komunikasi antara pihak-pihak yang berkepentingan dengan pembangunan sistem ini.
b. Architecture centric
Arsitektur sistem digunakan sebagai pegangan utama untuk membuat konsep, mengkonstruksi, mengatur (manage) dan menyusun sistem yang Sedang dikembangkan.
c. Iterative dan Incremental process
Iterative berarti proses itu menyangkut pernyataan/keputusan yang dapat
dikerjakan secara berkelanjutan. Sedangkan incremental process adalah suatu proses yang melibatkan integrasi terus menerus dan arsitektur sistem untuk menghasilkan pernyataan / keputusan yang diikuti oleh pernyataan/keputusan berikutnya yang lebih baik dari sebelumnya.
Iterative dan incremental process adalah risk driven, artinya
pernyataan/keputusan yang baru difokuskan untuk mengatasi atau mengurangi risiko yang paling besar untuk suksesnya sistem yang dibangun.
2.13.2 Diagram-diagram UML
UML memiliki beberapa diagram yang digunakan untuk menggambarkan suatu sistem. Tujuan pembuatan diagram ini adalah agar sistem mudah dimengerti oleh semua pihak, baik yang teknis maupun non teknis. Berikut diagram dalam UML:
1. Class Diagram, menggambarkan hubungan antar objek.
2. Object Diagram, adalah objek dan hubungan sebagai pencerminan dari prototipe. 3. Component Diagram, adalah komponen dan hubungan yang mengilustrasikan
implementasi sistem.
4. Deployment Diagram, konfigurasi waktu kerja dari node dan objek yang memiliki node.
5. Use case Diagram. Diagram ini digunakan untuk mengorganisasikan use case dan behaviour (sifat).
6. Sequence Diagram. Diagram ini menggambarkan waktu urutan message dan object lifeline.
7. Collaboration Diagram, menggambarkan waktu urutan message dan organisasi objek dalam interaksi.
8. Flow Diagram, menggambarkan arus kerja dari aktivitas, difokuskan pada operasi yang dilewatkan antar objek.
9. Activity Diagram. Merupakan diagram yang menggambarkan life cycle dari objek sebagai perubahan dari satu state ke state lain, dibangkitkan oleh message. Untuk perancangan ini, tipe UML yang penulis gunakan antara lain:
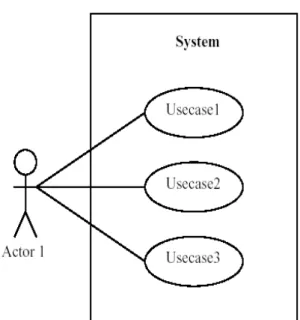
1. Use Case Diagram
Menggambarkan sekumpulan use case dan actor dan hubungan antara mereka (Booch, Rumbaugh, dan Jacobson, 1998, p97). Use case diagram
mempunyai peranan penting dalam pengorganisasian dan pemodelan behavior dari sistem.
Gambar 2.2 Use case diagram dalam UML 2. Activity Diagram
Merupakan gambaran dari perubahan keadaan (state) suatu objek (Booch, Rumbaugh, dan Jacobson, 1998, p98).
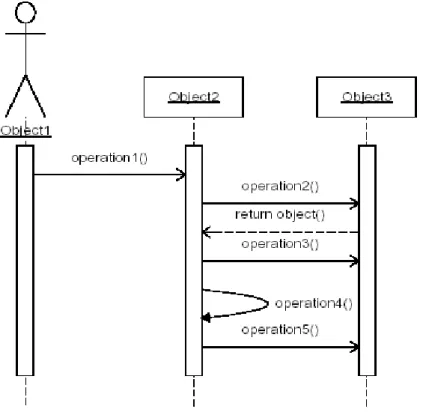
3. Sequence Diagram
Merupakan diagram interaksi yang menekankan pada urutan waktu dari pertukaran message. (Booch, Rumbaugh, dan Jacobson, 1998, p97).
Gambar 2.4 Sequence diagram dalam UML
2.14 Interaksi Manusia dengan Komputer
Untuk memperbaiki kegunaan suatu aplikasi, penting untuk mempunyai sebuah tampilan muka yang direncanakan dengan baik. “Delapan Aturan Emas Rencana Tampilan Muka” Shneiderman adalah sebuah panduan untuk rancangan interaksi yang baik. Delapan aturan tersebut yaitu (Shneiderman, 1998, pp74-75) :
1. Berusaha untuk konsisten.
Urutan tindakan yang sesuai harus diwajibkan dalam situasi-situasi yang sama, istilah serupa harus digunakan secara tepat, menu dan layar bantu.
2. Memungkinkan pemakai untuk menggunakan shortcut.
Seiring dengan frekuensi penggunaan yang meningkat, begitu juga hasrat atau keinginan pemakai untuk mengurangi jumlah interaksi dan untuk meningkatkan kecepatan interaksi.
3. Memberikan umpan balik yang informatif.
Untuk setiap tindakan pemakai sebaiknya ada beberapa sistem umpan balik. Untuk hal-hal yang sering, responnya bisa bermacam-macam, sementara untuk tindakan-tindakan yang jarang, responnya harus lebih besar.
4. Merancang dialog untuk hasil akhir.
Urutan tindakan harus diatur ke dalam kelompok-kelompok dengan sebuah permulaan, pertengahan dan akhir. Umpan balik yang informatif dalam penyelesaian tindakan-tindakan suatu kelompok memberikan kepuasan hasil akhir kepada pemakai, sebuah rasa lega.
5. Menawarkan penanganan kesalahan secara sederhana.
Sebanyak mungkin, merancang sistem sehingga pemakai tidak membuat kesalahan yang serius. Jika sebuah kesalahan dibuat, sistem harus mampu menemukan kesalahan dan menawarkan cara yang sederhana untuk menangani kesalahan tersebut.
6. Mengizinkan pembalikan tindakan yang mudah.
Fitur ini meringankan kecemasan, karena pemakai tahu bahwa kesalahan-kesalahan dapat dilepaskan, jadi hal itu mendorong penyelidikan pilihan-pilihan yang asing. Satuan perubahan mungkin sebuah tindakan tunggal, sebuah pemasukan data atau sebuah kelompok tindakan yang lengkap.
Pemakai-pemakai yang berpengalaman menginginkan bahwa mereka dapat mengendalikan sistem tersebut dan sistem tersebut dapat merespon tindakan mereka. Merancang sistem untuk membuat pemakai sebagai pengambil tindakan. 8. Mengurangi ingatan jangka pendek.
Batasan informasi pada manusia dalam memproses ingatan jangka pendek memerlukan tampilan secara sederhana, tampilan halaman-halaman dapat digabungkan, sehingga pergerakan windows dapat dikurangi.
Suatu program yang interaktif dan baik harus bersifat user friendly. (Shneiderman, 1998, p15) menjelaskan 5 kriteria yang harus dipenuhi oleh suatu program yang user friendly yaitu :
1. Waktu belajar yang tidak lama
2. Kecepatan penyajian informasi yang tepat 3. Tingkat kesalahan pemakaian rendah
4. Penghafalan sesudah melampaui jangka waktu 5. Kepuasan pribadi dari user yang menggunakannya
Suatu program yang interaktif dapat dengan mudah dibuat dan dirancang dengan suatu perangkat bantu pengembang sistem user interface, seperti C# (baca: C Sharp), Visual Basic, Borland Delphi dan sebagainya.
Keuntungan penggunaan perangkat bantu untuk mengembangkan user interface menurut Sentosa (1997, p7) yaitu :
1. User interface yang dihasilkan lebih baik.
2. Program user interface-nya menjadi mudah ditulis dan lebih ekonomis untuk dipelihara.
2.15 Spesifikasi Perangkat Program Aplikasi
Program aplikasi yang dirancang dalam penelitian ini adalah untuk menghitung penjualan mobil. Semua data penjualan terlebih dahulu dimasukkan ke dalam database yang dirancang dengan perangkat lunak (software) Microsoft Excel 2003. Semua data dalam database itu selanjutnya akan dihubungkan ke dalam suatu program aplikasi untuk menampilkan perhitungan peramalan penjualan mobil yang dirancang dengan perangkat lunak (software) bahasa pemrograman Visual C# dari paket Visual Studio
.NET.
Untuk perangkat keras (hardware) yang mendukung program aplikasi dengan
software yaitu Processor Intel Pentium 4, Memori 512 MB dengan sistem operasi