PENERAPAN ALGORITMA K-MEANS UNTUK
CLUSTERING DATA ANGGARAN PENDAPATAN
BELANJA DAERAH DI KABUPATEN XYZ
SKRIPSI
Oleh
Dwi Noviati Nango
531408022JURUSAN TEKNIK INFORMATIKA PROGRAM STUDI SISTEM INFORMASI
FAKULTAS TEKNIK
UNIVERSITAS NEGERI GORONTALO JULI 2012
PENERAPAN ALGORITMA K-MEANS UNTUK
CLUSTERING DATA ANGGARAN PENDAPATAN
BELANJA DAERAH DI KABUPATEN XYZ
SKRIPSI
Diajukan untuk memenuhi salah satu syarat memperoleh Gelar Sarjana pada Program Studi Sistem Informasi
Oleh
Dwi Noviati Nango
531408022JURUSAN TEKNIK INFORMATIKA
PROGRAM STUDI SISTEM INFORMASI
FAKULTAS TEKNIK
UNIVERSITAS NEGERI GORONTALO
JULI 2012
vi
KATA PENGANTAR
Syukur Alhamdulilah penulis panjatkan kehadirat Allah SWT, karena hanya dengan rahmat dan hidayah-Nya, penulis dapat menyusun dan menyelesaikan laporan akhir Skripsi ini dalam waktu yang telah ditetapkan.
Teriring ucapan terima kasih serta penghargaan yang setinggi-tingginya kepada semua pihak yang telah banyak membantu dan mendukung demi rampungnya laporan ini, terutama kepada :
1. Kedua orang tua tercinta atas doa dan dukungannya.
2. Bapak Syafrudin K. Lamusu, SE, MM, selaku sekretaris Kepala Badan Pengelola Keuangan dan Aset Daerah.
3. Ibu Ir. Rawiyah Husnan, MT, selaku Dekan Fakultas Teknik Universitas Negeri Gorontalo.
4. Pembantu Dekan I, Pembantu Dekan II dan Pembantu Dekan III Fakultas Teknik, Universitas Negeri Gorontalo.
5. Bapak Arip Mulyanto, M.Kom, selaku Ketua Jurusan Teknik Informatika Fakultas Teknik Universitas Negeri Gorontalo.
6. Bapak Agus Lahinta, ST, M.Kom, selaku Ketua Program Studi S1 Sistem Informasi Universitas Negeri Gorontalo, sekaligus pembimbing I.
7. Ibu Lillyan Hadjaratie, S.Kom, M.Si, selaku pembimbing II.
8. Seluruh staf dosen pengajar S1 Sistem Informasi Teknik Informatika Universitas Negeri Gorontalo, yang telah mendidik dan memberikan berbagai bekal
vii
pengetahuan yang tak ternilai harganya kepada penulis selama mengikuti perkuliahan.
9. Semua teman-teman senasib dan seperjuangan, khususnya Angkatan 2008 S1 Sistem Informasi Teknik Informatika Fakultas Teknik universitas Negeri Gorontalo.
10. Seluruh keluargaku tercinta
11. Serta semua orang yang telah mendukung dalam penyusunan ini yang tidak bisa disebutkan satu persatu.
Sebagai manusia yang tidak luput dari kesalahan, penulis menyadari bahwa dalam penyusunan laporan ini tetap saja masih terdapat kekurangan. Untuk itu penulis sangat mengharapkan saran dan kritik yang sifatnya membangun demi kesempurnaan laporan ini. Akhir kata semoga laporan ini dapat bermanfaat. Amin.
Gorontalo, Juli 2012
viii Intisari
Penelitian ini bertujuan untuk mengelompokkan data APBD tahun 2006-2011 yang memiliki kemiripan karakteristik berdasarkan kedekatan jarak, menggunakan teknik
clustering dengan algoritma K-Means. Pembentukan cluster diuji dengan 3 nilai
centroid dan 2 nilai centroid, yang dilanjutkan dengan menghitung nilai SSE (Sum of Squared Error). Hasil cluster dengan nilai SSE terkecil dijadikan sebagai parameter untuk mengestimasi data anggaran belanja yang akan datang. Berdasarkan penelitian yang dilakukan dapat diketahui bahwa pembentukan cluster dengan 3 nilai centroid adalah cluster yang terbaik, karena memiliki nilai SSE terkecil yaitu 6.235.940.663,88,. Untuk nilai pendapatan tahun 2012 sebesar Rp 394.083.451.404,-, diperoleh hasil estimasi nilai belanja tidak langsung sebesar Rp 199.533.334.595,76,- sampai Rp 203.564.311.052,24. Serta estimasi nilai belanja langsung sebesar Rp 176.135.846.021,76,- sampai Rp 180.166.822.478,24,-.
ix Abstract
The objective of this research to group the data of Local Budget revenue and expenditure fiscal year 2006-2011 which has resemblance characteristics based on distance by using clustering technique with K-Means algorithm. Cluster formed tested by 3 value of centroid and 2 value of centroid which continued by calculation SSE (Sum of Squared Error) value. Cluster result with the smallest SSE value became a parameter to estimate the next budget expenditure. Based on the study, it can reveal that cluster formed by 3 centroid value is the best cluster because has SSE smallest 4 value that is 6.235.940.663, 88,. Revenue value on 2012 around Rp. 394.083.451.404,-, obtained estimation value indirect expenditure around Rp. 199.533.334.594,76 to Rp. 203.564.311.052,24. Direct estimation expenditure value around Rp. 176.135.846.021,76.- to Rp. 180.166.822.478,24,-.
x DAFTAR ISI
Halaman
HALAMAN SAMPUL ... i
HALAMAN JUDUL ... ii
LEMBAR PERNYATAAN ... iii
LEMBAR PERSETUJUAN ... iv
LEMBAR PENGESAHAN ... v
MOTTO DAN PERSEMBAHAN ... vi
KATA PENGANTAR ... vii
INTISARI ... ix
ABSTRACT ... x
DAFTAR ISI ... xi
DAFTAR TABEL ...xiii
DAFTAR GAMBAR ...xiv
DAFTAR LAMPIRAN ... xv
BAB I PENDAHULUAN ... 1
A.Latar Belakang ... 1
B.Rumusan Masalah ... 2
C.Ruang Lingkup Penulisan ... 2
D.Tujuan Penulisan ... 3
E. Manfaat Penulisan ... 3
BAB II TINJAUAN PUSTAKA ... 5
A.Knowledge Discovery in Database (KDD) dan Data Mining ... 5
1. Pengertian data mining ... 7
2. Tujuan data mining ... 7
3. Pengelompokkan data mining ... 8
B.Clustering ... 11
1. Pengertian clustering ... 11
2. Metode clustering... 12
3. Document clustering ... 14
4. Klasifikasi algoritma clustering ... 14
C.Penelitian Terkait ... 15
D.Algoritma K-Means ... 17
1. Pengertian K-Means ... 17
2. Algoritma K-Means ... 18
xi
BAB III METODOLOGI PENELITIAN. ... 23
A.Objek Penelitian ... 23
1. Gambaran umum badan pengelola keuangan dan aset daerah .. 23
2. Visi badan pengelola keuangan dan aset daerah ... 23
3. Misi badan pengelola keuangan dan aset daerah ... 24
4. Struktur organisasi badan pengelola keuangan dan aset daerah ... 25
B.Metode Penelitian ... 26
C.Teknik Pengumpulan Data ... 26
1. Studi literatur ... 26
2. Teknik pengumpulan data arsip ... 26
D.Tahapan Penelitian ... 27
1. Studi pustaka ... 28
2. Pengumpulan data arsip ... 28
3. Praproses data... 28
4. Clustering menggunakan algoritma K-Means ... 29
5. Analisis hasil clusterisasi ... 30
6. Selesai ... 30
E. Jadwal Penelitian ... 31
BAB IV HASIL DAN PEMBAHASAN ... 32
A.Tahapan Penelitian ... 32
1. Pra proses data... 32
2. Cleaning data ... 33
3. Clustering menggunakan algoritma K-Means ... 34
B.Tahap Analisis ... 35
1. Proses clustering dalam K-Means ... 35
2. Pola hasil clustering dengan K-Means ... 57
3. Flowchart clustering K-Means ... 62
C.Desain Hasil ... 63
1. Hasil implementasi input data parameter k dan x ... 63
2. Hasil implementasi input data nama k ... 64
3. Hasil implementasi input data APBD ... 65
4. Hasil implementasi tampilan proses hasil perhitungan centroid ... 66
5. Hasil implementasi perhitungan jarak data ke centroid ... 67
6. Hasil implementasi iterasi ... 68
7. Hasil implementasi SSE ... 69
8. Hasil implementasi laporan data mining ... 70
xii BAB V PENUTUP ... 72 A.Kesimpulan ... 72 B.Saran ... 72 DAFTAR PUSTAKA ... 73 LAMPIRAN
xiii
DAFTAR TABEL
Tabel 4.1Contoh data yang redundant ... 33
Tabel 4.2Data APBD Kabupaten XYZ 6 tahun terakhir... 35
Tabel 4.3Hasil perhitungan centroid setiap cluster pada pengujian 2 parameter ... 38
Tabel 4.4Hasil perhitungan jarak data pada nilai k dengan masing-masing centroid setiap cluster ... 44
Tabel 4.5Perhitungan iterasi pertama pada cluster pendapatan ... 44
Tabel 4.6Perhitungan iterasi pertama pada cluster belanja tidak langsung ... 45
Tabel 4.7Perhitungan iterasi pertama pada cluster belanja langsung ... 46
Tabel 4.8Perhitungan iterasi pertama pada cluster pendapatan... 48
Tabel 4.9Perhitungan iterasi pertama pada cluster belanja tidak langsung ... 49
Tabel 4.10Perhitungan iterasi pertama pada cluster belanja langsung ... 50
Tabel 4.11Hasil perhitungan jarak data terhadap masing-masing nilai centroid untuk dijadikan seagai perhitungan ... 53
Tabel 4.12Perhitungan iterasi kedua pada cluster pendapatan ... 53
Tabel 4.13Perhitungan iterasi kedua pada cluster belanja tidak langsung ... 54
Tabel 4.14Perhitungan iterasi kedua pada cluster belanja langsung ... 55
Tabel 4.15Hasilakhirperhitungan iterasi dengan 3 nilai centroid dan 2 nilai centroid ... 56
Tabel 4.16Hasil perhitungan nilai SSE dengan 3 nilai centroid dan 2 nilai centroid ... 57
Tabel 4.17Data APBD sebelum di cluster ... 58
Tabel 4.18Nilai anggota pendapatan, belanja tidak langsung dan belanja langsung pada (C0) ... 58
Tabel 4.19Nilai anggota pendapatan, belanja tidak langsung dan belanja langsung pada (C1) ... 58
Tabel 4.20Nilai anggota pendapatan, belanja tidak langsung dan belanja langsung pada (C2) ... 59
Tabel 4.21Nilai anggota pendapatan 2012 ... 60
Tabel 4.22Contoh nilai outlier ... 60
xiv
DAFTAR GAMBAR
Gambar 2.1Tahapan dalam KDD ... 5
Gambar 2.2 Contoh clustering ... 12
Gambar 2.3Cara kerja algoritma K-Means ... 21
Gambar 3.1Tahapan penelitian ... 27
Gambar 4.1 Flow chart K-Means ... 62
Gambar 4.2Implementasi input data parameter k dan x dengan 3 nilai centroid ... 63
Gambar 4.3Implementasi input data parameter k dan x dengan 2 nilai centroid ... 63
Gambar 4.4Implementasiinput data nama k dengan 3 nilai centroid ... 64
Gambar 4.5Implementasiinput data nama k dengan 2 nilai centroid ... 64
Gambar 4.6Implementasi input data APBD dengan 3 nilai centroid... 65
Gambar 4.7Implementasi input data APBD dengan 2 nilai centroid... 65
Gambar 4.8 Implementasi tampilan proses hasil perhitungan dengan 3 nilai centroid ... 66
Gambar 4.9 Implementasi tampilan proses hasil perhitungan dengan 2 nilai centroid ... 66
Gambar 4.10Implementasitampilan perhitungan jarak data dengan 3 nilai centroid ... 67
Gambar 4.11 Implementasitampilan perhitungan jarak data dengan 2 nilai centroid ... 67
Gambar 4.12 Implementasi tampilan iterasi dengan 3 nilai centroid ... 68
Gambar 4.13Implementasi tampilan iterasi dengan 2 nilai centroid ... 68
Gambar 4.14 Implementasi tampilan akhir iterasi dengan 2 nilai centroid ... 69
Gambar 4.15 Implementasi tampilan nilai SSE dengan 3 nilai centroid ... 69
Gambar 4.16 Implementasi tampilan nilai SSE dengan 2 nilai centroid ... 69
Gambar 4.17 Implementasi laporan data mining dengan 3 nilai centroid ... 70
Gambar 4.18 Implementasi laporan data mining dengan 2 nilai centroid ... 70
xv
DAFTAR LAMPIRAN
Lampiran data APBD Kabupaten XYZ tahun 2006 (part 1) ... 1
Lampiran data APBD Kabupaten XYZ tahun 2006 (part 2) ... 2
Lampiran data APBD Kabupaten XYZ tahun 2007 ... 3
Lampiran data APBD Kabupaten XYZ tahun 2008 ... 4
Lampiran data APBD Kabupaten XYZ tahun 2009 ... 5
Lampiran data APBD Kabupaten XYZ tahun 2010 ... 6
Lampiran data APBD Kabupaten XYZ tahun 2011 ... 7
Lampiran surat ijin pengambilan data di Kabupaten XYZ ... 8
Lampiran surat pelaksanaan penelitian dari Kabupaten XYZ ... 9
1
BAB I
PENDAHULUAN
A. Latar Belakang Masalah
Saat ini begitu banyak data yang terdapat dalam sebuah organisasi, sehingga menimbulkan kesulitan dalam hal pengelompokkan data. Namun dengan perkembangan Teknologi Informasi (TI) terdapat berbagai macam solusi untuk mengatasi kesulitan tersebut, salah satunya adalah dengan menggunakan teknik Data
Mining (DM). “DM merupakan proses pencarian pola dan relasi-relasi yang
tersembunyi dalam sejumlah data yang besar dengan tujuan untuk melakukan klasifikasi, estimasi, prediksi, asosiasi rule, clustering, deskripsi dan visualisasi”
(Han dkk,2001, dalam Baskoro,2010).
Data Anggaran Pendapatan Belanja Daerah (APBD) yang dikelola oleh badan keuangan daerah di Kabupaten XYZ pada dasarnya sudah dikelompokkan berdasarkan pendapatan, belanja langsung dan tidak langsung. Akan tetapi karena data yang dikelola oleh badan pengelola keuangan daerah tersebut memiliki data yang begitu banyak, maka perlu diketahui bagaimana keterkaitan antar data pendapatan, belanja langsung dan tidak langsung dari lembaga tersebut. Salah satu metode yang digunakan yaitu clustering. Dengan clustering dimaksudkan untuk
2
Terdapat berbagai algoritma yang digunakan dalam teknik DM dengan metode
clustering salah satunya adalah algoritma K-Means. “Algoritma K-Means adalah
salah satu algoritma unsupervised learning yang paling sederhana yang dikenal dapat
menyelesaikan permasalahan clustering dengan baik” (Mac Queen, 1967). Dengan
diterapkannya algoritma K-Means dalam proses clusterisasi APBD maka diharapkan
dapat mengelompokkan dan menentukan jumlah cluster yang paling tepat/akurat
juga memprediksi nilai belanja tidak langsung serta nilai belanja langsung yang akan datang terhadap data APBD Kabupaten XYZ. Berdasarkan permasalahan tersebut maka penulis mengusulkan sebuah penulisan yang berjudul “Penerapan Algoritma K-Means Untuk Clustering Data Anggaran Pendapatan Belanja Daerah di
Kabupaten XYZ”.
B. Rumusan Masalah
Berdasarkan latar belakang permasalahan yang ada, maka rumusan masalahnya adalah bagaimana menerapkan algoritma K-Means untuk mengclustering data APBD
yang dikelola oleh badan pengelola keuangan daerah di Kabupaten XYZ ?
C. Ruang Lingkup Penulisan
Ruang lingkup penulisan meliputi :
a. Dataset yang digunakan adalah data APBD 6 tahun terakhir (2006 – 2011).
3
c. Atribut belanja tidak langsung yang digunakan dalam dataset ini adalah belanja pegawai.
d. Atribut belanja langsung yang digunakan dalam dataset ini adalah seluruh item pembelanjaan disetiap instansi.
D. Tujuan Penulisan
Adapun tujuan dari penulisan ini adalah :
a. Membangun protipe clusterisasi data APBD Kabupaten XYZ.
b. Menerapkan algoritma K-Means untuk mengelompokkan dan menentukan
jumlah cluster yang paling tepat/akurat terhadap data APBD Kabupaten XYZ.
c. Menganalisa hasilnya untuk menentukan parameter-parameter batasan berdasarkan karakteristik pada masing-masing cluster.
d. Dapat mengestimasi nilai belanja tidak langsung dan belanja langsung di masa yang akan datang.
E. Manfaat Penulisan
Manfaat yang diperoleh dalam penulisan ini yaitu :
a. Memberikan gambaran langkah-langkah penerapan algoritma K-Means pada
data APBD kabupaten XYZ.
b. Dapat memberikan suatu informasi penting bagi organisasi tentang bagaimana mengelompokkan data APBD dengan cara clustering menggunakan algoritma
4
c. Dengan adanya clustering dapat memperoleh pengetahuan tentang estimasi nilai
5 BAB II
TINJAUAN PUSTAKA
A. Knowledge Discovery in Database (KDD) dan Data Mining
Banyak orang menggunakan istilah data mining dan knowledge discovery in
databases (KDD) secara bergantian untuk menjelaskan proses penggalian informasi
tersembunyi dalam suatu kumpulan data yang besar. Akan tetapi kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. ”Salah satu tahapan dalam proses KDD adalah data mining” (Han & Kamber,2006 dalam Baskoro,2010).
Han and Kamber (2006) menyatakan :
Knowledge Discovery in Database (KDD) adalah proses menentukan informasi
yang berguna serta pola-pola yang ada dalam data. Informasi ini terkandung dalam basis data yang berukuran besar yang sebelumnya tidak diketahui dan potensial bermanfaat. Data Mining merupakan salah satu langkah dari
serangkaian proses iterative KDD. Tahapan proses KDD dapat dilihat pada
gambar dibawah ini.
6 Tahapan proses KDD terdiri dari :
a. Data Selection
Pada proses ini dilakukan pemilihah himpunan data, menciptakan himpunan data target, atau memfokuskan pada subset variabel (sampel data) dimana penemuan (discovery) akan dilakukan. Hasil seleksi disimpan dalam suatu berkas yang
terpisah dari basis data operasional. b. Pre-Processing dan Cleaning Data
Pre-Processing dan Cleaning Data dilakukan membuang data yang tidak
konsisten dan noise, duplikasi data, memperbaiki kesalahan data, dan bisa
diperkaya dengan data eksternal yang relevan.
c. Transformation
Proses ini mentransformasikan atau menggabungkan data ke dalam yang lebih tepat untuk melakukan proses mining dengan cara melakukan peringkasan
(agregasi).
d. Data Mining
Proses data mining yaitu proses mencari pola atau informasi menarik dalam data
terpilih dengan menggunakan teknik, metode atau algoritma tertentu sesuai dengan tujuan dari proses KDD secara keseluruhan.
e. Interpretation / Evaluasi
Proses untuk menerjamahkan pola-pola yang dihasilkan dari data mining.
Mengevaluasi (menguji) apakah pola atau informasi yang ditemukan bersesuaian atau bertentangan dengan fakta atau hipotesa sebelumnya. Pengetahuan yang
7
diperoleh dari pola-pola yang terbentuk dipresentasikan dalam bentuk visualisasi.
1. Pengertian data mining.
Santosa (2007) menyatakan bahwa data mining merupakan suatu kegiatan yang
meliputi pengumpulan, pemakaian data historis untuk menentukan keteraturan, pola atau hubungan dalam set data berukuran besar. Salah satu tugas utama dari data mining adalah pengelompokan clustering dimana data yang dikelompokkan belum
mempunyai contoh kelompok.
Larose (2005) menyatakan bahwa data mining adalah suatu proses pencarian
korelasi, pola dan tren baru yang berguna dalam media penyimpanan data berukuran besar menggunakan teknologi pengenalan pola seperti teknik-teknik statistik dan matematis. Istilah lain yang sering digunakan antara lain knowledge mining from
data, knowledge extraction, data/pattern analysis, data archeology, dan data
dredging.
2. Tujuan data mining.
Baskoro (2010) menyatakan bahwa adapun tujuan dari adanya data mining
adalah :
a. Explanatory, yaitu untuk menjelaskan beberapa kegiatan observasi atau suatu
kondisi.
b. Confirmatory, yaitu untuk mengkonfirmasikan suatu hipotesis yang telah ada.
8
3. Pengelompokkan data mining.
Tan et. al. (2005), menyatakan :
Secara garis besar data mining dapat dikelompokkan menjadi 2 kategori utama :
a. Descriptive mining, yaitu proses untuk menemukan karakteristik penting dari
data dalam suatu basis data. Teknik data mining yang termasuk dalam
descriptive mining adalah clustering, association, dan sequential mining.
b. Predictive mining, yaitu proses untuk menemukan pola dari data dengan
menggunakan beberapa variabel lain di masa depan. Salah satu teknik yang terdapat dalam predictive mining adalah klasifikasi.
Larose and Daniel (2005), menyatakan :
Pengelompokkan data mining berdasarkan tugas yang dapat dilakukan yaitu :
a. Deskripsi
Deskripsi adalah menggambarkan pola dan kecenderungan yang terdapat dalam data yang memungkinkan memberikan penjelasan dari suatu pola atau kecenderungan tersebut.
b. Estimasi
Estimasi hampir sama dengan klasifikasi, akan tetapi variabel target estimasi lebih ke arah numerik daripada ke arah kategori.
c. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, akan tetapi dalam prediksi nilai dari hasil akan terwujud di masa yang akan datang.
9 d. Klasifikasi
Klasifikasi adalah proses untuk menemukan model atau fungsi yang menggambarkan dan membedakan kelas data atau konsep dengan tujuan memprediksikan kelas untuk data yang tidak diketahui kelasnya (Han and Kamber, 2006).
e. Clustering
Clustering atau analisis cluster adalah proses pengelompokan satu set
benda-benda fisik atau abstrak ke dalam kelas objek yang sama (Han & Kamber, 2006).
f. Asosiasi
Asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu
waktu.
Kusrini dkk (2009), menyatakan bahwa :
Pengelompokkan data mining diatas dijadikan sebagai teknik dari data mining
berdasarkan tugas yang bisa dilakukan, yaitu : a. Deskripsi
Para penulis/analis biasanya mencoba menemukan cara untuk mendeskripsikan pola dan trend yang tersembunyi dalam data.
b. Estimasi
Estimasi mirip dengan klasifikasi, kecuali variabel tujuan yang lebih ke arah
numerik daripada kategori. Misalnya, akan dilakukan estimasi tekanan systolic
dari pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah.
10 c. Prediksi
Prediksi memiliki kemiripan dengan estimasi dan klasifikasi. Hanya saja,
prediksi hasilnya menunjukkan sesuatu yang belum terjadi (mungkin terjadi dimasa depan). Misalnya, ingin diketahui prediksi harga beras tiga bulan yang akan datang.
d. Klasifikasi
Dalam klasifikasi variable, tujuan bersifat kategorik. Misalnya, kita akan
mengklasifikasikan pendapatan dalam tiga kelas, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
e. Clustering
Clustering lebih kearah pengelompokan record, pengamatan, atau kasus dalam
kelas yang memiliki kemiripan. Sebuah cluster adalah kumpulan record yang
memiliki kemiripan satu dengan yang lain dan memiliki ketidak miripan dengan
record-record dalam cluster yang lain, misalnya untuk tujuan audit akuntasi
akan dilakukan segmentasi perilaku financial dalam kategori dan mencurigakan. f. Asosiasi
Mengidentifikasi hubungan antara berbagai peristiwa yang terjadi pada satu waktu. Pendekatan asosiasi tersebut menekankan sebuah kelas masalah yang dicirikan dengan analisis keranjang pasar.
11 B. Clustering
1. Pengertian clustering.
“Clustering atau analisis cluster adalah proses pengelompokan satu set benda-benda fisik atau abstrak ke dalam kelas objek yang sama” (Han and Kamber, 2006). Baskoro (2010) menyatakan bahwa :
Clustering atau clusterisasi adalah salah satu alat bantu pada data mining yang
bertujuan mengelompokkan obyek-obyek ke dalam cluster-cluster. Cluster
adalah sekelompok atau sekumpulan obyek-obyek data yang similar satu sama
lain dalam cluster yang sama dan dissimilar terhadap obyek-obyek yang berbeda
cluster. Obyek akan dikelompokkan ke dalam satu atau lebih cluster sehingga
obyek-obyek yang berada dalam satu cluster akan mempunyai kesamaan yang
tinggi antara satu dengan lainnya. Obyek-obyek dikelompokkan berdasarkan prinsip memaksimalkan kesamaan obyek pada cluster yang sama dan
memaksimalkan ketidaksamaan pada cluster yang berbeda. Kesamaan obyek
biasanya diperoleh dari nilai-nilai atribut yang menjelaskan obyek data, sedangkan obyek-obyek data biasanya direpresentasikan sebagai sebuah titik dalam ruang multidimensi.
Dengan menggunakan clusterisasi, kita dapat mengidentifikasi daerah yang
padat, menemukan pola-pola distribusi secara keseluruhan, dan menemukan keterkaitan yang menarik antara atribut-atribut data. Dalam data mining, usaha
difokuskan pada metode-metode penemuan untuk cluster pada basis data berukuran besar secara efektif dan efisien. Beberapa kebutuhan clusterisasi
12
atribut yang berbeda, mampu menangani dimensionalitas yang tinggi, menangani data yang mempunyai noise, dan dapat diterjemahkan dengan
mudah.
Gambar 2.2 Contoh Clustering (Baskoro 2010)
Adapun tujuan dari data clustering ini adalah untuk meminimalisasikan
objective function yang diset dalam proses clustering, yang pada umumnya
berusaha meminimalisasikan variasi di dalam suatu cluster dan
memaksimalisasikan variasi antar cluster.
2. Metode clustering.
Secara garis besar, terdapat beberapa metode clusterisasi data. Pemilihan metode
clusterisasi bergantung pada tipe data dan tujuan clusterisasi itu sendiri.
Metode-metode beserta algoritma yang termasuk didalamnya meliputi (Baskoro, 2010): Cluster1
Cluster 2 outliers
13 a. Partitioning Method
Membangun berbagai partisi dan kemudian mengevaluasi partisi tersebut dengan beberapa kriteria, yang termasuk metode ini meliputi algoritma Means,
K-Medoid, PROCLUS, CLARA, CLARANS, dan PAM.
b. Hierarchical Methods
Membuat suatu penguraian secara hierarkikal dari himpunan data dengan menggunakan beberapa kriteria. Metode ini terdiri atas dua macam, yaitu
Agglomerative yang menggunakan strategi bottom-up dan Disisive yang
menggunakan strategi top-down. Metode ini meliputi algoritma BIRCH, AGNES,
DIANA, CURE, dan CHAMELEON.
c. Density-based Methods
Metode ini berdasarkan konektivitas dan fungsi densitas. Metode ini meliputi algoritma DBSCAN, OPTICS, dan DENCLU.
d. Grid-based Methods
Metode ini berdasarkan suatu struktur granularitas multi-level. Metode clusterisasi ini meliputi algoritma STING, WaveCluster, dan CLIQUE.
e. Model-based Methods
Suatu model dihipotesakan untuk masing-masing cluster dan ide untuk mencari
best fit dari model tersebut untuk masing-masing yang lain. Metode clusterisasi
ini meliputi pendekatan statitik, yaitu algoritma COBWEB dan jaringan syaraf
14 Sadaaki et. al. (2008) menyatakan :
Sebelum memutuskan berapa jumlah cluster yang akan dibentuk bahwa
terdapat dua pendekatan yang dapat digunakan yaitu : a. supervised (jika jumlah cluster ditentukan).
b. unsupervised (jika jumlah cluster tidak ditentukan/alami).
3. Documentclustering.
“Document clustering merupakan suatu teknik untuk mengelompokkan dokumen-dokumen berdasarkan kemiripannya dengan tujuan mendapatkan sekumpulan dokumen yang tepat” (Widyawati, 2010). Dokumen-dokumen tersebut dikelompokan ke dalam cluster berdasarkan tingkat kemiripannya. Suatu cluster
dapat dikatakan bagus apabila tingkat kemiripan antar anggota cluster sangat tinggi
dan tingkat kemiripan antar cluster sangat rendah. Sedangkan kualitas suatu
cluster dapat diukur melalui kemampuannya dalam menemukan pola-pola yang
tersembunyi.
4. Klasifikasi algoritma clustering.
“Algoritma clustering secara luas diklasifikasikan menjadi dua algoritma, yaitu
hierarchical clustering, dan non-hierarchical clustering” (Henjaya, 2010).
Han and Kamber (2006) menyatakan bahwa hierarchical clustering adalah
sebuah metode hierarkis yang menciptakan komposisi hierarkis yang diterapkan pada objek data, sehingga akan menghasilkan cluster-cluster yang bersarang. Algoritma
15
hubungan antara setiap objek (Henjaya, 2010). “Contoh algoritma Hierarchical
clustering adalah HAC (Hierarchical Agglomerative Clustering)” (Karhendana,
2008).
Non-hierarchical clustering, pada umumnya disebut algoritma partitional
clustering, memberikan sejumlah n objek dan k yang merupakan jumlah dari cluster
yang terbentuk. Algoritma partitional clustering mengolah objek ke dalam k
-kelompok berdasarkan kriteria optimasi tertentu, dimana setiap -kelompok merupakan representasi sebuah cluster. Han and Kamber (2006) menyatakan bahwa contoh
algoritma partitional clustering antara lain K-Means.
C. Penulisan Terkait
Berdasarkan penulisan yang dilakukan oleh Firdausi dkk pada tahun 2011 tentang Analisis Financial Distress Dengan Pendekatan Data Mining Pada Industri
Manufaktur Go-Public Di Indonesia, dikemukakan bahwa penulisan tersebut berisi
tentang perbandingan algoritma K-Means dan Fuzzy C-Means (FCM). Cara kerja
algoritma K-Means dalam pengelompokan data keuangan dan data perusahaan yang
akan mengalami kebangkrutan lebih baik dari cara kerja algoritma FCM, dimana
dalam penulisan itu menggunakan rumus sum squared error (SSE) serta icdrate
(internal cluster disprersion rate). Dimana dari penulisan ini didapatkan nilai SSE
terkecil pada K-Means, menunjukkan bahwa total kesalahan kuadrat yang terjadi
pada pengelompokkan metode tersebut kecil. Sehingga metode itu dapat dikatakan memiliki nilai error terkecil dan lebih baik dibandingkan metode FCM.
16
Pada metode FCM, keragaman dalam cluster (Sum of Squared Within) SSW
bernilai tertinggi serta keragaman antar cluster (Sum of Squared Between) SSB
bernilai paling rendah sehingga metode FCM memiliki nilai icdrate tertinggi
dibandingkan K-Means. Hal ini menunjukkan pada pengelompokkan dengan
menggunakan metode FCM, terdapat banyak data berbeda dalam tiap cluster yang
terbentuk dan tercermin pada nilai SSW yang tinggi. Serta sedikitnya perbedaan data antar cluster yang terbentuk dapat dikatakan perbedaan antar cluster 1 dan 2 tidak
jauh beda yang tercermin pada nilai SSB yang rendah. Nilai terkecil pada seluruh
metode K-Means tercipta karena keragaman dalam cluster SSW yang terbentuk
sangat kecil dan keragaman antar cluster SSB sangat tinggi. Oleh karena itu antara
metode K-Means dengan FCM setelah dibandingkan dengan mempertimbangkan
nilai SSE dan icdrate, didapatkan metode K-Means sebagai metode terbaik.
Penulisan lain yang dilakukan oleh Wahyuni pada tahun 2009 dalam jurnalnya yang berjudul Penggunaan Cluster-Based Sampling Untuk Penggalian Kaidah
Asosiasi Multi Obyektif, menjelaskan bahwa algoritma K-Means lebih baik
dibandingkan algoritma FCM. Dalam penulisan ini berisi tentang dua pembandingan
metode clustering yaitu K-Means dan FCM. Adapun penulisan ini membahas hasil
penggalian kaidah asosiasi multi obyektif dengan menggunakan sampel yang dilakukan proses clustering terlebih dahulu akan menghasilkan kaidah-kaidah
asosiasi yang lebih baik. Hal ini ditunjukkan dengan nilai rata-rata yang diperoleh mempunyai nilai yang lebih besar dibandingkan data yang tidak melalui proses
clustering terlebih dahulu. Perbandingan metode clustering yang digunakan yaitu
17
dengan nilai rata-rata confidence yang dihasilkan menggunakan metode K-Means
mempunyai nilai yang lebih besar dibandingkan dengan metode FCM.
Penulisan yang dilakukan oleh Widyawati pada tahun 2010 dalam skripsinya yang berjudul Perbandingan Clustering Based On Frequent Word Sequence (CFWS)
Dan K-Means Untuk Pengelompokkan Dokumen Berbahasa Indonesia menjelaskan
bahwa didapatkan nilai F-Measure dan Purity hasil implementasi menggunakan
algoritma K-Means lebih tinggi dibandingkan dengan implementasi menggunakan
algoritma CFWS. Hal ini membuktikan bahwa algoritma K-Means lebih tepat
digunakan untuk pengelompokkan dokumen berbahasa Indonesia.
D. Algoritma K-Means
1. Pengertian K-Means.
“K-Means merupakan algoritma yang umum digunakan untuk clustering
dokumen. Prinsip utama K-Means adalah menyusun k prototype atau pusat massa
(centroid) dari sekumpulan data berdimensi n” (Aryan, 2010). Sebelum diterapkan
proses algoritma K-means, dokumen akan di preprocessing terlebih dahulu.
Kemudian dokumen direpresentasikan sebagai vektor yang memiliki term dengan nilai tertentu.
Agusta (2007) menyatakan bahwa K-Means merupakan salah satu metode data
clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu
atau lebih cluster/kelompok. Metode ini mempartisi data ke dalam cluster/kelompok
sehingga data yang memiliki karakteristik sama dikelompokkan ke dalam satu
18
2. Algoritma K-Means.
Algoritma k-means merupakan algoritma yang membutuhkan parameter input
sebanyak k dan membagi sekumpulan n objek kedalam k cluster sehingga tingkat
kemiripan antar anggota dalam satu cluster tinggi sedangkan tingkat kemiripan
dengan anggota pada cluster lain sangat rendah. Kemiripan anggota terhadap cluster
diukur dengan kedekatan objek terhadap nilai mean pada cluster atau dapat disebut
sebagai centroid cluster atau pusat massa (Widyawati, 2010).
Berikut rumus pengukuran jarak menurut (Santosa, 2007) :
d(x,y)
= ||x-y||
2=
𝑛𝑖=1(𝑥𝑖 − 𝑦𝑖) 2
Adapun rumus perhitungan jarak lainnya didefinisikan sebagai berikut :
d(x,y) =
√
( xi – yi )2 + ( xi – yi )2Keterangan :
d = titik dokumen x = data record
y = data centroid
Jarak yang terpendek antara centroid dengan dokumen menentukan posisi
cluster suatu dokumen. Misalnya dokumen A mempunyai jarak yang paling pendek
ke centroid 1 dibanding ke yang lain, maka dokumen A masuk ke group 1. Hitung
kembali posisi centroid baru untuk tiap-tiap centroid (C
i..j)dengan mengambil
rata-... ( 1 )
19 rata dokumen yang masuk pada cluster awal (G
i..j ). Iterasi dilakukan terus hingga
posisi group tidak berubah. Berikut rumus dari penentuan centroid.
C (i) = 1
𝐺𝑖 𝑥𝜖𝑐
𝑑𝑥
Adapun rumus iterasi lainnya didefinisikan sebagai berikut :
C(i) = x1+ x2+ x..+ x…
𝑥 Keterangan :
x1 = nilai data record ke-1
x2 = nilai data record ke-2
∑x = jumlah data record
K-Means merupakan algoritma clustering yang bersifat partitional yaitu
membagi himpunan objek data ke dalam sub himpunan (cluster) yang tidak overlap,
sehingga setiap objek data berada tepat dalam satu cluster. Strategi
partitional-clustering yang paling sering digunakan adalah berdasarkan kriteria square error.
Secara umum, tujuan kriteria square error adalah untuk memperoleh partisi (jumlah
cluster tetap) yang meminimalkan total square error.
SSE (Sum Squared of Error) menyatakan total kesalahan kuadarat yang terjadi
bila n data i n x ,..., x dikelompokkan kedalam k cluster dengan pusat tiap cluster
adalah k m ,...,m 1 . Nilai SSE tergantung pada jumlah cluster dan bagaimana data
dikelompokkan ke dalam cluster-cluster tersebut. Semakin kecil nilai SSE, semakin
bagus hasil clustering-nya.
... ( 3 )
20 Adapun rumus SSE adalah sebagai berikut :
SSE = (Ci)2 + (Ci)2 + (C..)2 + (C..)2
Keterangan :
Ci = nilai centroid
3. Tahapan algoritma K-Means.
Widyawati (2010), menyatakan :
Proses algoritma K-Means sebagai berikut :
a. Pilih secara acak objek sebanyak k, objek-objek tersebut akan direpresentasikan sebagai mean pada cluster.
b. Untuk setiap objek dimasukan kedalam cluster yang tingkat kemiripan objek
terhadap cluster tersebut tinggi. Tingkat kemiripan ditentukan dengan jarak
objek terhadap mean atau centroid cluster tersebut.
c. Hitung nilai centroid yang baru pada masing-masing cluster.
d. Proses tersebut diulang hingga anggota pada kumpulan cluster tersebut tidak
berubah.
Sedangkan menurut Adiningsih (2007) tahap penyelesaian algoritma K-Means
adalah sebagai berikut :
a. Menentukan K buah titik yang merepresentasikan obyek pada setiap cluster
(centroid awal).
b. Menetapkan setiap obyek pada cluster dengan posisi centroid terdekat.
c. Jika semua obyek sudah dikelompokkan maka dilakukan perhitungan ulang dalam menentukan centroid yang baru.
21
d. Ulangi langkah ke-2 dan ke-3 sampai centroid tidak berubah.
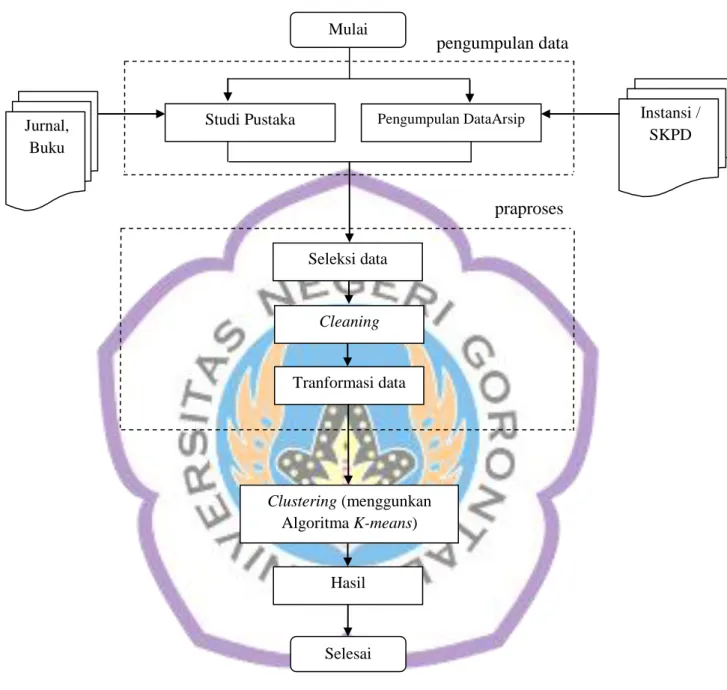
Kurniawan dkk (2010) menyatakan :
Langkah-langkah dari algoritma K-Means yaitu :
.
Berikut penjelasan dari gambar 2.3, dengan algoritma K-means dilakukan cara
berikut hingga ditemukan hasil iterasi yang stabil :
a. Menentukan data centroid, pada sistem ini, ditentukan bahwa centroid pertama
adalah n data pertama dari data-data yang akan di-cluster.
b. Menghitung jarak antara centroid dengan masing-masing data.
c. Mengelompokkan data berdasarkan jarak minimum.
Start Number of cluster K Centroid Distance objects to centroids Grouping based on minimum distance End
Gambar 2.3 Cara Kerja Algoritma K-Means (Kurniawan dkk 2010)
No object move group
22
d. Jika penempatan data sudah sama dengan sebelumnya, maka stop. Jika tidak, kembali ke cara yang ke-2.
23
BAB III
METODOLOGI PENELITIAN
A. Objek Penelitian
Penelitian ini dilakukan di salah satu Kabupaten yang ada di Provinsi Gorontalo, yaitu di Badan Pengelola Keuangan Dan Aset Daerah (BPKAD).
1. Gambaran umum badan pengelola keuangan dan aset daerah (BPKAD).
Berdasarkan PP nomor 8 tahun 2003 tentang Pedoman Organisasi Perangkat Daerah mengamanatkan adanya penataan kembali Organisasi Perangkat Daerah. Sehingga Bagian Keuangan Sekretariat Daerah Kabupaten XYZ mengalami perubahan nama menjadi Badan Pengelola Keuangan dan Aset Daerah disingkat (BPKAD), yang dibentuk berdasarkan Peraturan Daerah Kabupaten XYZ nomor 15 tahun 2005 sampai dengan sekarang. Organisasinya terdiri dari Kepala Badan, Bagian Tata Usaha, Bidang Pendapatan, Bidang Belanja, Bidang Kekayaan dan Aset, Bidang Pembukuan dan Pelaporan, Kelompok Jabatan Fungsional, dan Unit Pelaksana Teknis (UPT)
Badan Pengelola Keuangan dan Aset Daerah dipimpin oleh seorang Kepala Badan yang berada dibawah dan bertanggung jawab kepada Bupati melalui Sekretaris Daerah, mempunyai tugas menyelenggarakan kewenangan pemerintah dalam bidang Pengelolaan Keuangan dan Aset Daerah.
24
2. Visi badan pengelola keuangan dan aset daerah (BPKAD).
Perencanaan pengendalian manajemen pengelolaan keuangan daerah serta optimalisasi penerimaan pendapatan dan pengelolaan aset daerah dalam rangka mendukung pencapaian program pemerintah daerah Kabupaten XYZ.
3. Misi badan pengelola keuangan dan aset daerah (BPKAD).
a. Merumuskan kebijakan teknis pengelolaan keuangan. b. Optimalisasi dan diversifikasi potensi penerimaan.
c. Penataan dan pengembangan sistem pengelolaan keuangan.
d. Peningkatan kemampuan sumber daya aparatur pengelola keuangan daerah. e. Diversifikasi pemanfaatan dan pengamanan aset daerah dalam menunjang
pelaksanaan program.
25
4. Struktur organisasi badan pengelola keuangan dan aset daerah (BPKAD). STRUKTUR ORGANISASI
BADAN PENGELOLA KEUANGAN DAN ASET DAERAH KABUPATEN XYZ
SUB BID. PENDAPATAN DAERAH LAINNYA
SUB BID. PERBENDAHARAAN
SUB BID. PEMANFAATAN
DAN PENGENDALIAN SUB BID. PEMBUKUAN
DAN PELAPORAN SUB BIDANG PAD
BIDANG PENDAPATAN
SUB BID. ANGGARAN DAN PERMODALAN
BIDANG BELANJA
SUB BIDANG PENGADAAN DAN
PERAWATAN BIDANG KEKAYAAN DAN
ASSET
SUB BIDANG VERIVIKASI BIDANG PEMBUKUAN
DAN PELAPORAN SUB BAGIAN KEUANGAN
SUB BAGIAN PENYUSUNAN
PROGRAM
SUB BAGIAN UMUM & KEPEGAWAIAN KEPALA BADAN
UPT
26
B. Metode Penelitian
Metode penelitian yang digunakan pada penulisan kali ini adalah metode eksperimen. “Metode eksperimen merupakan rancangan penelitian yang mengidentifikasi hubungan kausal” (Sudaryono dkk:45, 2011).
C. Teknik Pengumpulan Data
Adapun teknik yang dilakukan oleh penulis yaitu :
1. Studi literatur.
Dengan mengumpulkan dan mempelajari literatur yang berkaitan dengan konsep DM clustering, yang menggunakan algoritma K-Means. Sumber literatur berupa
buku teks, paper, jurnal, karya ilmiah, dan situs-situs penunjang.
2. Teknik pengumpulan data arsip.
Dengan mengumpulkan data arsip yang berkaitan dengan data APBD Kabupaten XYZ serta data tentang analisis isi yang digunakan.
27
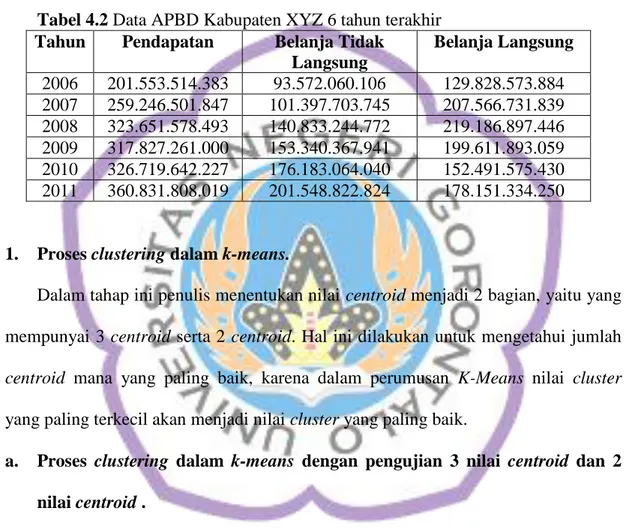
D. Tahapan Penelitian
pengumpulan data
praproses
Gambar 3.1 Tahapan penelitian Mulai
Studi Pustaka Pengumpulan DataArsip Instansi /
SKPD Jurnal, Buku Seleksi data Cleaning Tranformasi data Clustering (menggunkan Algoritma K-means) Hasil Selesai
28
Adapun tahapan penelitian yang akan dilakukan penulis dalam proses penelitian ini adalah sebagai berikut :
1. Studi pustaka.
Dengan mengumpulkan dan mempelajari literatur yang berkaitan dengan konsep DM clustering, yang menggunakan algoritma K-Means. Sumber literatur berupa
buku teks, paper, jurnal, karya ilmiah, dan situs-situs penunjang.
2. Pengumpulan data arsip.
Untuk mengetahui informasi yang dibutuhkan, penulis melakukan pengumpulan data arsip (laporan APBD dari tahun 2006-2011).
3. Praproses data.
Praproses data meliputi :
a. Seleksi data.
Untuk memilih himpunan data (dataset) yang akan digunakan pada penulisan ini, yaitu data pendapatan, belanja langsung dan tidak langsung.
b. Cleaning.
Untuk membersihkan data, yaitu melengkapi data, menghapus data duplikat, menghilangkan noise.
c. Transformasi data.
Untuk memformat data agar siap di cluster.
4. Clustering menggunakan algoritma k-means.
Tahapan proses dimana data yang sudah dipraproses di cluster dengan
29
a. Pilih jumlah cluster k. Inisialisasi k pusat cluster ini dapat dilakukan dengan
berbagai cara. Cara random sering digunakan, pusat-pusat cluster diberi nilai
awal dengan angka-angka random dan digunakan sebagai pusat cluster awal.
b. Tempatkan setiap data/obyek ke cluster terdekat, kedekatan kedua obyek
ditentukan berdasarkan jarak kedua obyek tersebut. Demikian juga kedekatan suatu data ke cluster tertentu ditentukan jarak antara data dengan pusat cluster.
Dalam tahap ini perlu dihitung jarak tiap data ke tiap pusat cluster. Jarak paling
dekat antara satu data dengan satu cluster tertentu akan menentukan suatu data
masuk dalam cluster mana. Adapun penghitungan jarak menggunakan rumus
Eulidean.
c. Hitung kembali pusat cluster dengan keanggotaan cluster yang sekarang. Pusat
cluster adalah rata-rata dari semua data/obyek dalam cluster tertentu.
Penghitungannya melalui penentuan centroid/pusat cluster.
Jarak yang terpendek antara pusat cluster dengan data/obyek menentukan posisi
cluster suatu data/obyek. Misalnya data/obyek A mempunyai jarak yang paling
pendek ke pusat cluster 1 dibanding ke yang lain, maka data/obyek A masuk ke
cluster 1.
d. Tugaskan kembali setiap obyek dengan menggunakan pusat cluster yang baru.
Jika pusat cluster sudah tidak berubah lagi, maka proses pengclusteran selesai. C(i) = x1+ x2+ x..+ x…
∑x
30
Bila berubah, maka kembali ke langkah no.3 hingga pusat cluster tidak berubah
lagi.
e. Setelah proses pengclusteran selesai, maka akan di hitung nilai SSE dari setiap
cluster. Nilai SSE tergantung pada jumlah cluster dan bagaimana data
dikelompokkan ke dalam cluster-cluster tersebut. Tujuannya untuk memperoleh
partisi (jumlah cluster tetap) yang meminimalkan total square error. Semakin
kecil nilai SSE, semakin bagus hasil clustering-nya. Berikut cara kerja dari SSE.
5. Analisis hasil clusterisasi.
Tahapan untuk menganalisa hasil yang sudah diperoleh pada proses clustering.
6. Selesai.
31
E. Jadwal Penelitian
NO KEGIATAN
BULAN
Maret April Mei Juni Juli
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1. Penyusunan Proposal 2. Pengumpulan Data 3. Praproses data 4. Clusterisasi Data 5. Analisis Hasil Clusterisasi 6. Penyusunan Laporan 7. Ujian Skripsi
32 BAB IV
HASIL DAN PEMBAHASAN
A. Tahapan Penelitian
1. Praproses data.
Data yang digunakan dalam penelitian ini yaitu 6 tahun terakhir (2006-2011) yang terdiri dari beberapa tabel antara lain tabel tahun, nama instansi, uraian, rincian item, dan rincian biaya. Adapun atribut tersebut yaitu :
a. Tahun.
Merupakan atribut yang berisi laporan tiap tahun di setiap laporan data anggaran dan pendapatan.
b. Nama instansi.
Merupakan atribut yang berisi nama-nama badan pemerintah yang tercantum pada kabupaten tersebut.
c. Uraian.
Merupakan atribut yang berisi item pendapatan, belanja tidak langsung dan belanja langsung.
d. Rincian item.
Merupakan atribut yang berisi rincian pembelanjaan dari transaksi pendapatan, belanja tidak langsung dan belanja langsung dari setiap instansi.
e. Rincian biaya.
33
Hasil akhir dari seleksi atribut didapatkan 4 atribut yang telah relevan dan konsisten, tetapi hanya 2 atribut saja yang digunakan dalam proses clustering yaitu
atribut uraian ( pendapatan, belanja langsung dan belanja tidak langsung ) dan rincian biaya. Karena informasi yang terkandung di dalamnya sudah mewakili informasi yang dibutuhkan untuk dijadikan indikator penentu dalam proses clustering
menggunakan algoritma K-Means.
2. Cleaning data.
Dilakukan pembersihan data terhadap data yang memiliki redundant. Dalam dataset terdapat tabel tahun, nama instansi, rincian item dan rincian biaya, atribut yang dihapus yaitu (tabel tahun, nama instansi dan rincian item). Hal itu dilakukan karena data tersebut tidak akan memberikan informasi apapun jika dipertahankan.
Tabel 4.1 Contoh data yang redundant
3. Clustering menggunakan algoritma K-Means.
Berikut cara algoritma K-Means mempartisi dataset ke dalam cluster.
a. Algoritma menerima jumlah cluster untuk mengelompokkan data. Dataset yang
akan dicluster dijadikan sebagai nilai input.
Tahun Nama Instansi Rincian Item
2007 Dinas Pendidikan o Hasil retribusi daerah
o Belanja pegawai
o Program pelayanan administrasi perkantoran
o Program peningkatan sarana dan prasarana aparatur
o Program peningkatan disiplin aparatur
o Program peningkatan kapasitas sumber daya aparatur
34
b. Algoritma membuat sebanyak k cluster awal (k = jumlah cluster yang terbentuk)
dari dataset.
c. Algoritma K-Means menghitung nilai rata-rata dari setiap cluster yang dibentuk
dalam dataset. Sebagai contoh jika di dalam dataset terdapat record Q yang menerima nilai pendapatan, belanja tidak langsung dan belanja langsung, maka ditulis Q = {pendapatan, belanja tidak langsung, belanja langsung}. Jika nilai pendapatan 201.553, belanja tidak langsung 93.572, belanja langsung 129.828. Maka ditulis Q = {201.553, 93.572, 129.828},
d. K-Means menghitung ulang rata-rata dari semua cluster. Rata-rata dari setiap
cluster adalah rata-rata dari semua record dalam cluster. Sebagai contoh, sebuah
cluster berisi 3 record Q = {201.553, 93.572, 129.828}, dan R = {259.246,
101.397, 207.566}. Maka rata-rata dalam sebuah record dinyatakan sebagai,
nilai rata-rata pendapatan pada record Q ditambahkan nilai rata-rata pendapatan pada record R, kemudian dibagi 2. Rata-rata pada pendapatan = (201.553 +
259.246)/2. rata pada belanja tidak langsung = (93.572 + 101.397)/2. Rata-rata pada belanja langsung = (129.828 + 207.566)/2. Rataan nilai itu akan menjadi pusat dari cluster yang baru.
e. K-Means mengirimkan lagi setiap data record di dalam dataset ke salah satu dari
cluster yang baru terbentuk.
f. Hitung kembali pusat cluster dengan anggota cluster sebelumnya, hingga
terbentuk cluster yang stabil dan prosedur K-Means selesai. Cluster stabil
terbentuk saat iterasi dari K-Means tidak membuat cluster baru sebagai pusat
35 g. Menghitung nilai SSE.
B. Tahap Analisis
Dalam penelitian ini penulis menentukan dahulu jumlah k, yaitu ada 3
(pendapatan, belanja tidak langsung dan belanja langsung).
Tabel 4.2 Data APBD Kabupaten XYZ 6 tahun terakhir
1. Proses clustering dalam k-means.
Dalam tahap ini penulis menentukan nilai centroid menjadi 2 bagian, yaitu yang
mempunyai 3 centroid serta 2 centroid. Hal ini dilakukan untuk mengetahui jumlah
centroid mana yang paling baik, karena dalam perumusan K-Means nilai cluster
yang paling terkecil akan menjadi nilai cluster yang paling baik.
a. Proses clustering dalam k-means dengan pengujian 3 nilai centroid dan 2
nilai centroid .
Tahun Pendapatan Belanja Tidak
Langsung Belanja Langsung 2006 201.553.514.383 93.572.060.106 129.828.573.884 2007 259.246.501.847 101.397.703.745 207.566.731.839 2008 323.651.578.493 140.833.244.772 219.186.897.446 2009 317.827.261.000 153.340.367.941 199.611.893.059 2010 326.719.642.227 176.183.064.040 152.491.575.430 2011 360.831.808.019 201.548.822.824 178.151.334.250
36
1) Perhitungan centroid awal.
Tahapan clusterisasi menggunakan algoritma K-Means, diawali dengan
pembentukan cluster pada dataset yaitu 3 cluster dengan pengujian 2 parameter
berupa 3 nilai centroid dan 2 nilai centroid.
a) Perhitungan centroid awal dengan 3 nilai centroid.
Cluster Nilai Pendapatan :
(C0) 201.553 + 259.246 = 230.399,5 2 (C1) 323.651 + 317.827 = 320.739 2 (C2) 326.719 + 360.831 = 343.775 2
Cluster Nilai Belanja Tidak Langsung :
(C0) 93.572 + 101.397 = 97.484,5 2 (C1) 140.833 + 153.340 = 147.086,5 2 (C2) 176.183 + 201.548 = 188.865,5 2
37
Cluster Nilai Belanja Langsung :
(C0) 129.828 + 207.566 = 168.697 2 (C1) 219.186 + 199.611 = 209.398,5 2 (C2) 152.491 + 178.151 = 165.321 2
b) Perhitungan centroid awal dengan 2 nilai centroid.
Cluster Nilai Pendapatan :
(C0) 201.553 + 259.246 + 323.651 = 261.483,34 3
(C1) 317.827 + 326.719 + 360.831 = 335.125,67 3
Cluster Nilai Belanja Tidak Langsung :
(C0) 93.572 + 101.397 + 140.833 = 111.934 3
(C1) 153.340 + 176.183 + 201.548 = 177.023,67 3
38
Cluster Nilai Belanja Langsung :
(C0) 129.828 + 207.566 + 219.186 = 185.526,67 3
(C1) 199.611 + 152.491 + 178.151 = 176.751 3
Tabel 4.3 Hasil perhitungan centroid setiap cluster pada pengujian 2 parameter
Cluster 3 centroid 2 centroid C0 C1 C2 C0 C1 Pendapatan 230.399,5 320.739 343.775 261.483,34 335.125,67 Belanja Tidak Langsung 97.484,5 147.086,5 188.865,5 111.934 177.023,67 Belanja Langsung 168.697 209.398,5 165.321 185.526,67 176.751
2) Proses perhitungan jarak.
Dalam langkah ini dilakukan proses perhitungan jarak untuk mengetahui masing – masing hasil jarak data pada jumlah k di setiap centroid.
Melakukan penghitungan untuk menentukan jarak setiap data dengan centroid awal, menggunakan rumus euclidiance distance.
a) Perhitungan jarak dengan 3 nilai centroid.
Jarak antara data pertama dengan centroid pertama (C0) :
d 1,0 = (201.553 – 230.399,5)2 + (93.572 – 97.484,5)2 + (129.828 – 168.697)2 = 48.561,58
39
Jarak antara data pertama dengan centroid kedua (C1) :
d 1,1 = (201.553 – 320.739)2 + (93.572 – 147.086,5)2 + (129.828 – 209.398,5)2 = 152.972,44
Jarak antara data pertama dengan centroid ketiga (C2) :
d 1,2 = (201.553 – 343.775)2 + (93.572 – 188.865,5)2 + (129.828 – 165.321)2 = 174.836,21
Jarak antara data kedua dengan centroid pertama (C0) :
d 1,0 = (259.246 – 230.399,5)2 + (101.397 – 97.484,5)2 + (207.566 – 168.697)2 = 48.561,58
Jarak antara data kedua dengan centroid kedua (C1) :
d 1,1 = (259.246 – 320.739)2 + (101.397 – 147.086,5)2 + (207.566 – 209.398,5)2 = 76.630,79
Jarak antara data kedua dengan centroid ketiga (C2) :
d 1,2 = (259.246 – 343.775)2 + (101.397 – 188.865,5)2 + (207.566 – 165.321)2 = 128.765,41
Jarak antara data ketiga dengan centroid pertama (C0) :
d 1,0 = (323.651 – 230.399,5)2 + (140.833 – 97.484,5)2 + (219.186 – 168.697)2 = 114.560,35
40
Jarak antara data ketiga dengan centroid kedua (C1) :
d 1,1 = (323.651 – 320.739)2 + (140.833 – 147.086,5)2 + (219.186 – 209.398,5)2 = 11.974,19
Jarak antara data ketiga dengan centroid ketiga (C2) :
d 1,2 = (323.651 – 343.775)2 + (140.833 – 188.865,5)2 + (219.186 – 165.321)2 = 74.923,53
Jarak antara data keempat dengan centroid pertama (C0) :
d 1,0 = (317.827 – 230.399,5)2 + (153.340 – 97.484,5)2 + (199.611 – 168.697)2 = 108.254,7
Jarak antara data keempat dengan centroid kedua (C1) :
d 1,1 = (317.827 – 320.739)2 + (153.340 – 147.086,5)2 + (199.611 – 209.398,5)2 = 11.974,19
Jarak antara data keempat dengan centroid ketiga (C2) :
d 1,2 = (317.827 – 343.775)2 + (153.340 – 188.865,5)2 + (199.611 – 165.321)2 = 55.777,81
Jarak antara data kelima dengan centroid pertama (C0) :
d 1,0 = (326.719 – 230.399,5)2 + (176.183 – 97.484,5)2 + (152.491 – 168.697)2 = 125.433,39
41
Jarak antara data kelima dengan centroid kedua (C1) :
d 1,1 = (326.719 – 320.739)2 + (176.183 – 147.086,5)2 + (152.491 – 209.398,5)2 = 64.193,69
Jarak antara data kelima dengan centroid ketiga(C2) :
d 1,2 = (326.719 – 343.775)2 + (176.183 – 188.865,5)2 + (152.491 – 165.321)2 = 24.826,64
Jarak antara data keenam dengan centroid pertama (C0) :
d 1,0 = (360.831 – 230.399,5)2 + (201.548 – 97.484,5)2 + (178.151 – 168.697)2 = 167.125,6
Jarak antara data keenam dengan centroid kedua (C1) :
d 1,1 = (360.831 – 320.739)2 + (201.548 – 147.086,5)2 + (178.151 – 209.398,5)2 = 74.497,18
Jarak antara data keenam dengan centroid ketiga (C2) :
d 1,2 = (360.831 – 343.775)2 + (201.548 – 188.865,5)2 + (178.151 – 165.321)2 = 24.826,64
b) Perhitungan jarak dengan 2 nilai centroid.
Jarak antara data pertama dengan centroid pertama (C0) :
d 1,0 = (201.553 – 261.483,34)2 + (93.572 – 111.934)2 + (129.828 – 185.526,67)2 = 83.851,95
42
Jarak antara data pertama dengan centroid kedua (C1) :
d1,1 = (201.553 – 335.125,67)2 + (93.572 – 177.023,67)2 + (129.828 – 176.751)2 = 164.339,91
Jarak antara data kedua dengan centroid pertama (C0) :
d1,0= (259.246 – 261.483,33)2 + (101.397 – 111.934)2 + (207.566 – 185.526,67)2 = 24.530,92
Jarak antara data kedua dengan centroid kedua (C1) :
d1,1= (259.246 – 335.125,67)2 + (101.397 – 177.023,67)2 + (207.566 – 176.751)2 = 111.475.03
Jarak antara data ketiga dengan centroid pertama (C0) :
d1,0= (323.651 – 261.483,33)2 + (140.833 – 111.934)2 + (219.186 – 185.526,67)2 = 76.373,57
Jarak antara data ketiga dengan centroid kedua (C1) :
d1,1 = (323.651 – 335.125,67)2 + (140.833 – 177.023,67)2 + (219.186 – 176.751)2 = 56.939,98
Jarak antara data keempat dengan centroid pertama (C0) :
d1,0 = (317.827 – 261.483,33)2 + (153.340 – 111.934)2 + (199.611 – 185.526,67)2 = 71.326,25
43
Jarak antara data keempat dengan centroid kedua (C1) :
d1,1= (317.827 – 335.125,67)2 + (153.340 – 177.023,67)2 + (199.611 – 176.751)2 = 37.185,21
Jarak antara data kelima dengan centroid pertama (C0) :
d1,0= (326.719 – 261.483,33)2 + (176.183 – 111.934)2 + (152.491 – 185.526,67)2 = 97.339,52
Jarak antara data kelima dengan centroid kedua (C1) :
d1,1= (326.719 – 335.125,67)2 + (176.183 – 177.023,67)2 + (152.491 – 176.751)2 = 25.689,03
Jarak antara data keenam dengan centroid pertama (C0) :
d1,0 = (360.831 – 261.483,33)2 + (201.548 – 111.934)2 + (178.151– 185.526,67)2 = 133.996,38
Jarak antara data keenam dengan centroid kedua (C1) :
d1,1 = (360.831 – 335.125,67)2 + (201.548 – 177.023,67)2 + (178.151– 176.751)2 = 35.555,12
44
Tabel 4.4 Hasil perhitungan jarak data pada nilai k dengan masing-masing
centroidsetiap cluster
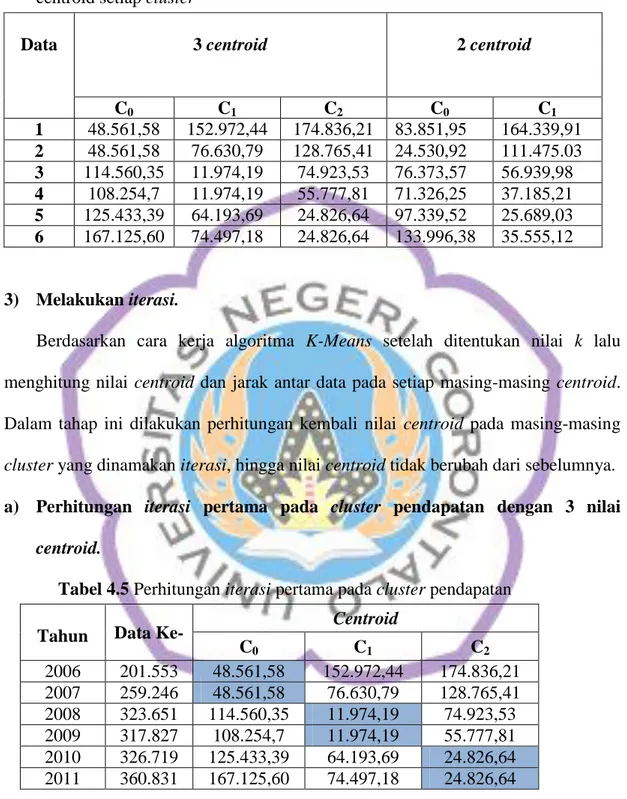
3) Melakukan iterasi.
Berdasarkan cara kerja algoritma K-Means setelah ditentukan nilai k lalu
menghitung nilai centroid dan jarak antar data pada setiap masing-masing centroid.
Dalam tahap ini dilakukan perhitungan kembali nilai centroid pada masing-masing
cluster yang dinamakan iterasi, hingga nilai centroid tidak berubah dari sebelumnya.
a) Perhitungan iterasi pertama pada cluster pendapatan dengan 3 nilai
centroid.
Tabel 4.5 Perhitungan iterasi pertama pada cluster pendapatan
Data 3 centroid 2 centroid
C0 C1 C2 C0 C1 1 48.561,58 152.972,44 174.836,21 83.851,95 164.339,91 2 48.561,58 76.630,79 128.765,41 24.530,92 111.475.03 3 114.560,35 11.974,19 74.923,53 76.373,57 56.939,98 4 108.254,7 11.974,19 55.777,81 71.326,25 37.185,21 5 125.433,39 64.193,69 24.826,64 97.339,52 25.689,03 6 167.125,60 74.497,18 24.826,64 133.996,38 35.555,12
Tahun Data
Ke-Centroid C0 C1 C2 2006 201.553 48.561,58 152.972,44 174.836,21 2007 259.246 48.561,58 76.630,79 128.765,41 2008 323.651 114.560,35 11.974,19 74.923,53 2009 317.827 108.254,7 11.974,19 55.777,81 2010 326.719 125.433,39 64.193,69 24.826,64 2011 360.831 167.125,60 74.497,18 24.826,64
45 Hitung kembali centroid
o centroid pertama (C0) = 201.553 + 259.246 2 = 230.399,5 o centroid kedua (C1) = 323.651 + 317.827 2 = 320.739 o centroid ketiga (C2) = 326.719 + 360.831 2 = 343.755
b) Perhitungan iterasi pertama pada cluster belanja tidak langsung dengan 3
nilai centroid.
Tabel 4.6 Perhitungan iterasi pertama pada cluster belanja tidak langsung
Tahun Data Ke- Centroid
C0 C1 C2 2006 93.572 48.561,58 152.972,44 174.836,21 2007 101.397 48.561,58 76.630,79 128.765,41 2008 140.833 114.560,35 11.974,19 74.923,53 2009 153.340 108.254,7 11.974,19 55.777,81 2010 176.183 125.433,39 64.193,69 24.826,64 2011 201.548 167.125,60 74.497,18 24.826,64
46 Hitung kembali centroid
o centroid pertama (C0) = 93.572 + 101.397 2 = 97.484,5 o centroid kedua (C1) = 140.833 + 153.340 2 = 147.086,5 o centroid ketiga (C2) = 176.183 + 201.548 2 = 188.865,5
c) Perhitungan iterasi pertama pada cluster belanja langsung dengan 3 nilai
centroid.
Tabel 4.7 Perhitungan iterasi pertama pada cluster belanja langsung
Tahun Data
Ke-Centroid C0 C1 C2 2006 129.828 48.561,58 152.972,44 174.836,21 2007 207.566 48.561,58 76.630,79 128.765,41 2008 219.186 114.560,35 11.974,19 74.923,53 2009 199.611 108.254,7 11.974,19 55.777,81 2010 152.491 125.433,39 64.193,69 24.826,64 2011 178.151 167.125,60 74.497,18 24.826,64
47 Hitung kembali centroid
o centroid pertama (C0) = 129.828 + 207.566 2 = 168.697 o centroid kedua (C1) = 219.186 + 199.611 2 = 209.398,5 o centroid ketiga (C2) = 152.491 + 178.151 2 = 165.321
Karena pada iterasi pertama nilai centroid pusat tidak berubah sama dengan nilai
48
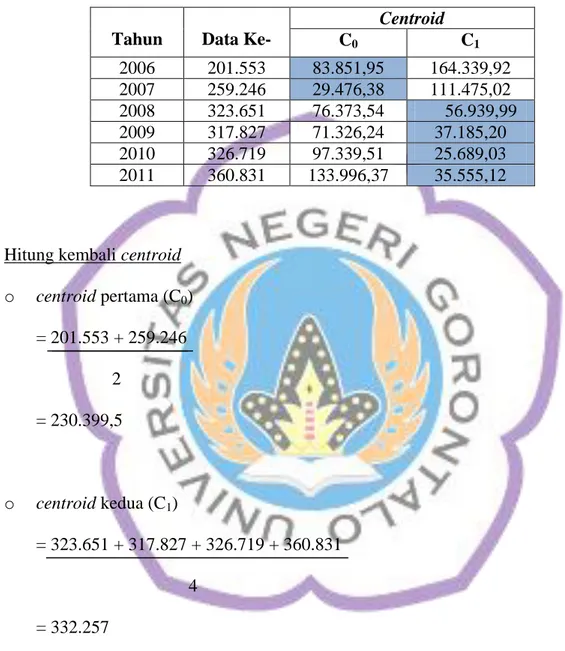
d) Perhitungan iterasi pertama pada cluster pendapatan dengan 2 nilai
centroid.
Tabel 4.8 Perhitungan iterasi pertama pada cluster pendapatan
Hitung kembali centroid
o centroid pertama (C0) = 201.553 + 259.246 2 = 230.399,5 o centroid kedua (C1) = 323.651 + 317.827 + 326.719 + 360.831 4 = 332.257
Tahun Data
Ke-Centroid C0 C1 2006 201.553 83.851,95 164.339,92 2007 259.246 29.476,38 111.475,02 2008 323.651 76.373,54 56.939,99 2009 317.827 71.326,24 37.185,20 2010 326.719 97.339,51 25.689,03 2011 360.831 133.996,37 35.555,12
49
e) Perhitungan iterasi pertama pada cluster belanja tidak langsung dengan 2
nilai centroid.
Tabel 4.9 Perhitungan iterasi pertama pada cluster belanja tidak langsung
Hitung kembali centroid
o centroid pertama (C0) = 93.572 + 101.397 2 = 97.484,5 o centroid kedua (C1) = 140.833 + 153.340 + 176.183 + 201.548 4 = 167.976
Tahun Data
Ke-Centroid C0 C1 2006 93.572 83.851,95 164.339,92 2007 101.397 29.476,38 111.475,02 2008 140.833 76.373,54 56.939,99 2009 153.340 71.326,24 37.185,20 2010 176.183 97.339,51 25.689,03 2011 201.548 133.996,37 35.555,12