INDEXING AND RETRIEVAL ENGINE
UNTUK DOKUMEN BERBAHASA INDONESIA
DENGAN MENGGUNAKAN INVERTED INDEX
Wahyu Hidayat1
1
Departemen Teknologi Informasi, Fakultas Ilmu Terapan, Telkom University
1
Abstrak
Dokumen teks tergolong dalam data tidak terstruktur. Jika dibandingkan dengan informasi yang tersimpan dalam bentuk yang terstruktur (misalnya pada tabel dalam sebuah database), maka data tidak terstruktur relatif lebih sulit dalam hal pengelolaan, penyimpanan, pencarian ulang maupun pengamanannya. Dalam paper ini dipaparkan sebuah metode indexing dan retrieval yang mampu menyimpan dokumen teks sebagai inverted index yang memiliki berbagai keunggulan penyimpanan data terstruktur.
Proses indexing melibatkan beberapa tahap yaitu parsing, stopping, stemming, sorting dan merging. Proses indexing dilakukan terhadap 6464 buah file txt dalam Alquran Terjemahan Indonesia. Setelah itu indeks yang dihasilkan digunakan dalam proses pencarian dokumen yang hasilnya dibandingkan dengan hasil pencarian dokumen konvensional secara full text search. Baik hasil pencarian maupun waktu yang dibutuhkan semuanya dicatat untuk mengukur performa retrieval engine dengan parameter precision, recall dan waktu.
Hasil pengujian menunjukkan bahwa proses indexing tidak mengurangi nilai recall, namun menurunkan nilai precision hingga 41,88% demi meningkatkan kecepatan pencarian hingga 3800 kali lipat.
Kata kunci : inverted index, indexing and retrieval, precision, recall
1. Pendahuluan
Informasi yang tersimpan dalam bentuk dokumen dikategorikan sebagai informasi yang tersimpan dalam bentuk yang tidak terstruktur. Jika dibandingkan dengan informasi yang tersimpan dalam bentuk yang terstruktur (misalnya pada tabel dalam sebuah database), maka jenis informasi ini relatif lebih sulit dalam hal pengelolaan, penyimpanan, pencarian uang maupun pengamanannya.
Untuk mencari informasi tertentu dari sekumpulan dokumen, biasanya dilakukan dengan mengumpulkan dokumen-dokumen yang mengandung kata kunci tertentu. Sayangnya, bila proses ini dilakukan secara manual akan memerlukan waktu yang cukup lama apalagi jika jumlah dan atau ukuran dokumen cukup besar. Pencarian data secara full text search juga melibatkan proses pembacaan disk secara intensif yang relatif lebih lama dibanding pembacaan pada memory utama (RAM). Hal ini akan memperlambat kinerja sistem.
Salah satu solusi yang dapat diterapkan untuk menangani permasalahan tersebut adalah dengan membuat indeks kata dari himpunan dokumen tersebut. Dengan demikian proses pencarian cukup dilakukan terhadap indeks sehingga dapat
menghindari proses pembacaan ke disk yang tidak perlu.
Dalam paper ini dipaparkan tentang sebuah indexing and retrieval engine untuk dokumen berbahasa Indonesia. Proses indexing akan melalui serangkaian tahap yang memungkinkan data tidak terstruktur yang ada dalam dokumen disimpan dalam bentuk indeks yang terstruktur dan dapat memiliki kelebihan-kelebihan data terstruktur dalam hal kemudahan pengelolaan, penyimpanan, pencarian uang maupun pengamanan data.
2. Tinjauan Pustaka
2.1 Indexing dan Retrieval
Information retrieval adalah proses mencari
materi (biasanya dalam bentuk dokumen) dalam bentuk yang tidak terstruktur (biasanya dalam bentuk teks) dari koleksi yang berukuran sangat besar (yang biasanya tersimpan dalam bentuk
elektronik) sesuai dengan informasi yang
dibutuhkan. Tidak hanya untuk membantu proses pencarian data dalam bentuk yang tidak terstruktur,
information retrieval juga dapat digunakan dalam
proses penelusuran dan penyaringan koleksi dokumen untuk diproses lebih lanjut [1].
Dalam domain information retrieval, proses
indexing adalah sebuah proses yang sangat penting.
Indexing terhadap dokumen dilakukan untuk
mengubah dokumen menjadi bentuk yang lebih
terstruktur serta memungkinkan proses retrieval,
yaitu proses menampilkan dokumen yang
mengandung elemen informasi yang dicari.
Langkah-langkah dalam proses indexing adalah
sebagai berikut [1]:
1. Mengumpulkan dokumen yang akan
di-indeks kemudian memberikan ID yang unik pada tiap dokumen
2. Tokenizing, yaitu proses memecah dokumen
menjadi serangkaian token atau unit-unit yang
lebih kecil
3. Normalisasi token secara linguistik, misalnya
dengan melakukan stopping (mengabaikan
stopwords) dan stemming (ekstraksi kata
dasar)
4. Mengindeks dokumen dengan struktur
inverted index yang terdiri dari dictionary dan
posting.
Proses indexing biasanya melibatkan proses
sorting dan grouping antara tiap token. Indeks yang
dihasilkan merupakan pemetaan antara token dan id
dokumen tempat token tersebut ditemukan, biasanya
disertai pula dengan frekuensi kemunculan token
pada dokumen tersebut.
Senada dengan [1], dalam [3] disebutkan
bahwa indexing dokumen dengan inverted index
dapat dilakukan melalui beberapa tahap berikut:
1. Parsing Dokumen
Dokumen dipecah-pecah menjadi kata-kata dan tiap kata disimpan dalam tabel bersama ID dokumen dimana kata tersebut muncul.
2. SortingToken
Tabel diurutkan berdasarkan kata.
3. MergingToken
Kata-kata yang sama dan terdapat pada dokumen yang sama digabungkan dalam satu entri.
4. Hitung Frekuensi
Pada tahap ini frekuensi kemunculan kata dihitung dan ditambahkan ke dalam tabel
Proses indexing dapat dilakukan secara
otomatis maupun secara manual. Indexing secara
otomatis (automatic indexing), umumnya meliputi
alphabet normalization, stopping dan stemming,
seperti yang dijelaskan dalam [5]
1. Alphabet Normalization
Dalam proses indexing biasanya karakter
alfabet dikonversikan ke dalam uppercase atau lowercase sedangkan karakter-karakter lain dapat dianggap sebagai separator atau diabaikan. Angka dapat diabaikan atau
diikutsertakan dalam proses indexing,
tergantung pada kebutuhan sistem.
2. Stopping
Kata-kata yang sering muncul dan tidak membantu mendeskripsikan dokumen disebut
stopwords. Proses stopping atau mengabaikan
stopwords akan dapat mengurangi daftar kata
yang diindeks. Masing-masing sistem
biasanya menentukan sendiri daftar stopwords
yang digunakan [5]
3. Stemming
Stemming adalah proses mengekstrak stem
atau kata dasar dari sebuah kata. Proses
stemming dapat memperkecil ukuran indeks
sehingga mempercepat proses pencarian.
Metode stemming yang umum digunakan
adalah stemming dengan berbasis kamus dan
aturan morfologi.
Daftar kata yang dihasilkan dari proses
stoppping dan stemming dapat digunakan untuk
mendeskripsikan isi dokumen. Salah satu cara untuk
menentukan apakah sebuah kata merupakan
indikator yang baik terhadap isi dokumen adalah dengan memperhatikan frekuensi kemunculan kata dalam dokumen [5].
2.2 Precision dan Recall
Untuk mengukur performa sebuah retrieval
engine biasanya minimal digunakan 2 parameter
yaitu precision dan recall. Keduanya merupakan
besaran yang dapat menunjukkan performa dari
sebuah retrieval engine. Semakin tinggi nilai
keduanya maka semakin baik kinerja retrieval
engine tersebut
.
2.2.1 Precision
Precision adalah salah satu besaran yang
umum digunakan untuk mengukur performa sebuah
information retrieval engine. Precision tidak sama
dengan tingkat akurasi. Precision merupakan
persentase relevant document dari seluruh hasil
query yang ditampilkan. Semakin tinggi nilai
precision, maka semakin besar pula peluang bahwa
hasil pencarian yang ditampilkan adalah hasil pencarian yang relevan [2].
di mana
tp = truepositive
fp = falsepositive
Nilai precision yang tinggi menunjukkan
tingginya komposisi true positive pada hasil
pencarian. Oleh karena itu, sebuah retrieval engine
yang memiliki nilai precision yang tinggi akan
semakin jarang salah mengklaim sebuah dokumen sebagai relevan, padahal dokumen tersebut tidak relevan.
2.2.2 Recall
Recall merupakan persentase relevant
documents yang berhasil ditampilkan dalam hasil
pencarian. Recall biasanya digunakan untuk
mengukur sensitivitas sebuah retrieval engine.
Semakin tinggi nilai recall, maka semakin besar
pula peluang bahwa dokumen yang relevan berhasil ditampilkan dalam hasil pencarian [2]
(2)
di mana:
tp = truepositive
fn = falsenegative
Nilai recall yang tinggi menunjukkan semakin
“sensitif”nya retrieval engine tersebut dalam
mendeteksi dokumen yang relevan. Oleh karena itu,
sebuah retrieval engine yang memiliki nilai recall
yang tinggi akan semakin banyak menemukan
dokumen yang relevan. Nilai recall yang tinggi juga
menunjukkan bahwa engine tersebut semakin jarang
mengklaim bahwa dokumen tersebut adalah tidak relevan padahal sebenarnya dokumen tersebut
relevan.
3. Cara Kerja Indexing and RetrievalEngine
Berikut ini adalah gambaran umum dalam
proses indexing dan retrieval:
Gambar 1. Gambaran Indexing & RetrievalEngine
Berdasarkan Gambar 1, urutan langkah kerja
pada proses indexing dokumen adalah sebagai
berikut:
1. Parsing
Pada proses parsing, dokumen dipecah menjadi
token berdasarkan daftar karakter separator
yang telah ditentukan oleh user. Semua token
yang dihasilkan kemudian dikonversikan ke
dalam bentuk lowercase dan dipasangkan
dengan identifier dokumen dimana token itu
ditemukan.
2. Stopping
Pada proses stopping, token-token yang
dihasilkan proses parsing dibandingkan dengan
daftar stopwords dan akan diabaikan bila
ternyata token tersebut ada di dalam daftar
stopwords. Proses ini bertujuan mengabaikan
token-token yang tidak perlu di-indeks. Adapun
detail dari proses stopping dapat dilihat pada
bagan berikut:
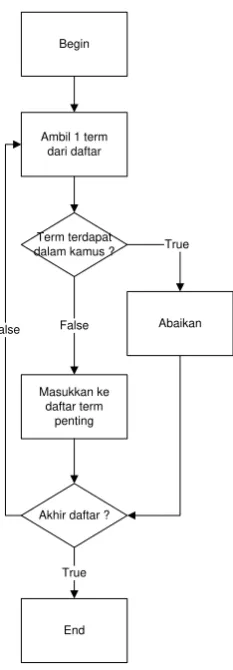
Gambar 2. Proses Stopping
Hasil Query Query Softcopy
Dokumen (*.txt)
User Inverted
Files Sorting
& Merging Stopping Stemming
Parsing
Query Kamus
StopWords (*.txt)
Kamus KataDasar (*.txt)
Begin
Term terdapat dalam kamus ? Ambil 1 term dari daftar
Masukkan ke daftar term
penting
Abaikan
End Akhir daftar ?
True
False
3. Stemming
Token yang dihasilkan dari proses stopping
diekstrak menjadi kata dasarnya. Proses
stemming bertujuan untuk mengelompokkan
token yang memiliki kata dasar yang sama.
Algoritma stemming yang digunakan
merupakan algoritma stemming berbasis aturan
morfologi. Adapun aturan morfologi yang digunakan adalah sesuai dengan 35 kombinasi
imbuhan dalam bahasa Indonesia yang
dijelaskan dalam [4]. Detail dari proses
stemming dapat dilihat pada bagan berikut:
Gambar 3. Proses Stemming
4. Sorting & Merging
Gambar diberi judul dengan “Gambar” dan “Tabel” dan diberi nomor, contoh, Gambar 1,
gambar 2, tabel 1, tabel 2, dan seterusnya. Judul Gambar ditempatkan dirata tengah bawah gambar. Judul table ditempatkan di rata tengah atas table. Baik gambar dan table ditempatkan di rata tengah antara margin kanan dan kiri halaman. Table/gambar harus ditempatkan pada halaman yang sama dengan
judul table/gambar..
4. Uji Performa Indexing and RetrievalEngine
4.1 Parameter dan Skenario Pengujian
Untuk menguji performa indexing and rerieval engine yang dibangun maka dilakukan indexing terhadap 6464 buah dokumen teks (*.txt) berahasa Indonesia dalam Alquran Terjemahan Bahasa Indonesia. Dalam proses indexing ditetapkan bahwa tidak akan mengindex angka dan untuk setiap kata yang diindex minimal memiliki panjang 3 karakter. Adapun stemming yang digunakan adalah stemming berbasis aturan morfologi dalam bahasa indonesia yang dijelaskan dalam [4].
Untuk mengukur performa indexing engine digunakan 2 parameter yaitu
1. Persentase penghematan ukuran index Rasio diperoleh dari membagi jumlah token setelah dilakukan proses stopping dan stemming dengan jumlah token sebelum prosesn stopping dan setemming. Hasilnya dikali dengan 100% sehingga persentase penghematan ukuran index dihitung dalam satuan persen (%)
2. Waktu indexing
Waktu yang dibutuhkan untuk setiap proses indexing akan diukur dan dicatat untuk melihat tahap mana yang membutuhkan waktu paling lama
Setelah index berhasil dibangun maka sekumpulan kata kunci yang dipilih secara acak akan digunakan sebagai kata kunci untuk pencarian dengan menggunakan retrieval engine dan pencarian dengan menggunakan full text search. Adapun pencaian dengan full text search diwaliki oleh fitur pencarian dokumen pada Microsoft Windows dengan service indexing yang sudah dinonaktifkan. Masing-masing hasil pencarian dan waktu yang dibutuhkan dicatat untuk mengukur performa retrieval engine dengan parameter berikut ini:
Begin
Ambil 1 term dari daftar
Term ada di kamus?
Catat term tersebut sebagai
kata dasar
Lakukan pembuangan imbuhan secara
bertahap
Ambigu stem?
Catat stem yang dihasilkan sebagai
kata dasar term
Lakukan penanganan ambigu stem
End Akhir daftar ?
Menemukan stem ? True
False
False
True
False
True True
1. Precision
Precision diukur dengan membagi jumlah dokumen relevan yang ditemukan dalam hasil pencarian dengan jumlah dokumen hasil pencarian seperti pada persamaan (1).
Nilai precision merupakan bilangan bulat dengan antara 0 sampai 1. Semakin tinggi nilai precision, berarti semakin rendah tingkat false positive nya, artinya semakin jarang menemukan dokumen yang tidak relevan dalam hasil pencarian.
2. Recall
Recall diukur dengan membagi jumlah dokumen relevan yang ditemukan pada hasil pencarian dengan jumlah seluruh dokumen relevan seperti pada persamaan (2). Nilai recall merupakan bilangan bulat dengan antara 0 sampai 1. Semakin tinggi nilai recall, berarti semakin tinggi tingkat sensitivitas retreival engine tersebut, artinya semakin besar peluang bahwa dokumen relevan berhasil ditemukan dalam hasil pencarian. 3. Waktu
Waktu yang dibutuhkan untuk menampilkan hasil pencarian akan diukur untuk membandingkan performa indexing and retrieval engine dengan full text search. Waktu dihitung dalam satuan detik mulai dari kata kunci dimasukan sampai daftar dokumen hasil pencarian ditampilkan.
4.2 Hasil Pengujian
Dari proses indexing diperoleh hasil bahwa proses stopping mengurangi jumlah token yang akan diindeks sebesar 44,49 % dari jumlah token hasil proses parsing. Proses stemming yang dapat mengurangi jumlah token yang akan diindeks sebesar 33,37% dari jumlah token hasil proses stopping. Dengan demikian, secara keseluruhan proses stopping dan stemming dapat mengurangi ukuran indeks sebesar 55,51%. Detailnya adalah sebagai sebagai berikut:
Tabel 1. Hasil Proses Indexing
Proses Keterangan
Parsing 227.160 token Stopping 126.094 token
Stemming stem dari 126.094 token
Sorting dan
Merging 94.541 entri indeks
Penulisan Indeks
menuliskan 94.541 entri indeks ke disk
Terlihat pula bahwa waktu yang paling banyak dibutuhkan adalah saat proses penulisan indeks, yaitu selama 214 detik atau sekitar 59,27% dari total waktu proses indexing. Berikut adalah detail catatan waktu tiap tahapnya:
Tabel 2. Catatan Waktu Proses Indexing
Proses
Waktu yang
dibutuhkan
(detik)
Parsing 36
Stopping 22
Stemming 74
Sorting dan Merging 15
Penulisan Indeks 214
Untuk menguji performa retrieval engine digunakan keyword-keyword yang telah diketahui jumlah dokumen relevan nya dan dipilih secara acak:
Tabel 3. Contoh Daftar Keyword dan Jumlah Dokumen yang Relevan
Keyword
Jumlah dokumen yang relevan
sekutu 45
mempersekutukan 60
mempersekutukan
tuhannya 4
malaikat yang terdekat 1
makan minum 21
ayah 30
zuhur 1
Tabel 4. Contoh Hasil Pencarian dengan Retrieval Engine
Keyword
Pencarian dengan
inverted index
Waktu pencarian
(detik)
Hasil Pencarian (dokumen)
sekutu 0,043 130
mempersekutukan 0,042 130 mempersekutukan
tuhannya 0,078 305
malaikat yang
terdekat 0,061 220
makan and minum 0,048 152
ayah 0,010 31
zuhur 0,001 1
Terlihat bahwa untuk pecarian dengan inverted index jumlah hasil pencarian melebihi jumlah dokumen yang relevan, hal ini menyebabkan penurunan pada nilai precision hingga 41.88%. Namun demikian, seluruh dokumen yang relevan ditemukan dalam proses pencarian sehingga nilai recallnya tetap !00%.
Sebagai pembandingnya, hasil pengujian terhadap pencarian dengan full text search pada Windows menunjukkan bahwa jumlah hasil pencarian sama persis dengan jumlah dokumen yang relevan, selain itu semua dokumen yang relevan ditemukan dalam hasil pencarian. Hal ini menyebabkan pencarian dengan full text search memiliki nilai precision sebesar 100% dan nilai recall sebanyak 100%.
Ditinjau dari sisi waktu, pencarian dengan retrieval engine membutuhkan waktu yang jauh lebih sedikit dibanding pencarian konvensional dengan full text search. yaitu sekitar 3800 kali lebih cepat. Berikut adalah detail contoh hasil pencarian full text search:
Tabel 5. Contoh Hasil Pencarian Full text search
Keyword
Pencarian dengan fasilitas search pada
Windows Waktu
pencarian (detik)
Hasil Pencarian (dokumen)
sekutu 21,13 45
mempersekutukan 21,09 60 mempersekutukan
tuhannya 20,51 4
Malaikat yang
terdekat 20,43 1
makan minum 20,36 21
ayah 20,95 30
zuhur 22,85 45
5. Kesimpulan
Dari uraian sebelumnya maka dapat disimpulkan bahwa proses indexing memakan waktu paling lama saat proses penulisan indeks yaitu sekitar 59,27% dari total waktu indexing. Namun demikian, saat dilakukan pencarian, index tersebut dapat mempercepat proses pencarian hingga 3800 kali lipat dibandingkan dengan pencarian konvensional dengan menggunakan full text search.
Adapun performa retrieval engine ditinjau dari parameter recall adalah 100%, setara dengan pencarian dengan full text search, Namun demikian, ditinjau dari parameter precision, pencarian dengan retrieval engine mengalami penurunan precision hingga 41,88%.
Akhirnya dapat disimpulkan bahwa proses indexing tidak mengurangi nilai recall, namun menurunkan nilai precision hingga 41,88% demi meningkatkan kecepatan pencarian hingga 3800 kali lipat.
Daftar Pustaka:
[1] Manning, C.D., Raghavan, P., and Schutze, H. 2009, An Introduction to Information Retrieval, Cambridge University Press
[2] Olson, David L.; Delen, Dursun, 2008 Advanced Data Mining Techniques, Springer [3] Ramakhrishnan Raghu and Gehrke Johannes,
2000 Database Management System, NewYork, McGraw Hill
[4] Suhendar and Supinah, 1995, Mata Kuliah Dasar Umum Bahasa Indonesia, Balai Pustaka [5] Wilkinson, Ross, 1997 Document Database,