TEKNIK PENGAMBILAN SAMPEL
3.1 Mengapa kita melakukan pengambilan contoh ?
Ide dasar pengambilan contoh adalah bahwa beberapa elemen atau anggota dalam suatu populasi bisa menyediakan informasi yang bermanfaat untuk menyimpulkan karakteristik populasi secara keseluruhan. Elemen tersebut merupakan subyek pengukuran yang dilakukan dalam penelitian atau disebut juga satuan pengamatan. Sebagai contoh, setiap pekerja yang ditanyai mengenai jadwal kerja merupakan elemen populasi. Populasi itu sendiri adalah kumpulan seluruh elemen dimana seorang peneliti akan melakukan kesimpulan mengenai variabel tertentu terhadap populasi tersebut.
Secara sederhana, pengambilan contoh adalah pengambilan sebagai elemen dari populasi untuk diamati atau diteliti. Tetapi jika pengamatan atau penelititan dilakukan terhadap seluruh elemen atau anggota populasi maka kegiatan tersebut mempunyai istilah khusus, yaitu sensus. Keuntungan ekonomis pengambilan sebagian elemen tersebut dibandingkan sensus adalah sangat besar, dan hal ini merupakan salah satu faktor penting yang menjadi pertimbangan mengapa kita melakukan pengmabilan contoh tersebut. Kita tidak perlu mengeluarkan biaya yang sangat besar dengan melakukan sensus terhadap seluruh karyawan di Jakarta jika dengan mengamati sebagian kecil tenaga kerja saja kita bisa memperoleh informasi yang bisa digunakan untuk menyimpulkan suatu karakteristik tenaga kerja keseluruhan. Misalkan untuk mengetahui motivasi kerja di suatu perusahaan yang mempunyai tenaga kerja sebanyak 1000 orang, kita bisa melakukan survai hanya kepada 100 orang diantaranya. Atau jejak pendapat di kalangan profesional dapat dilakukan kepada sebagaian saja diantaranya.
Deming (1960) di dalam Emory dan Cooper (1992) menyatakan bahwa kualitas penelitian sering lebih baik dibandingkan dengan melakukan sensus. Dengan pengambilan contoh kita bisa melakukan investigasi yang lebih lengkap, pengawasan dan pengolahan data yang lebih baik. Hal ini ditunjukkan dengan hasil penelitian bahwa 90 persen galat (error) penelitian disebabkan oleh kesalahan non sampling dan hanya 10 persen yang disebakan kesalahan sampling.
Pengambilan contoh juga bisa menyediakan informasi secara cepat dibandingkan sensus. Kecepatan ini bisa meminimalkan waktu antara kebutuhan akan suatu informasi dengan ketersediaan informasi tersebut. Sebagai gambaran, sensus penduduk di Indonesia mungkin memerlukan beberapa tahun sebelum diperoleh data lengkap yang kemungkinan besar sudah tidak relevan lagi untuk variabel-variabel tertentu, misalnya tingkat pendapatan. Pengambilan contoh juga mutlak diperlukan jika populasi sasarannya bersifat tak terhingga, misalnya, penelitian terhadap kualitas barang yang terus diproduksi atau uji kualitas lingkungan sepanjang waktu.
cenderung terjadi kompensasi satu sama lain sehingga nilai statistik tersebut secara umum mendekati nilai parameter. Masalah ini terkait dengan berapa jumlah elemen dalam sampel yang cukup mewakili dan bagaiman cara pengambilan contohnya. Sedangkan penjelasan teoritis mengenai keterwakilan ini adalah prinsip peluang (probability) dan distribusi sampling.
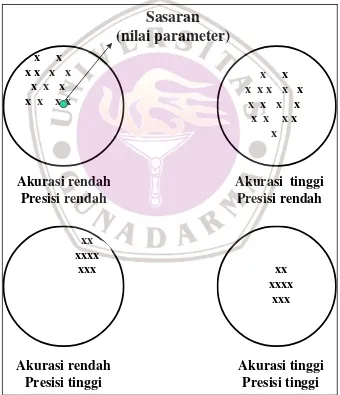
3.2 Sampel yang baik
Penilaian suatu rancangan penarikan contoh yang terpenting adalah seberapa baikkah sampel tersebut mewakili karaktaristik populasinya. Dalam istilah yang lebih terukur, suatu sampel harus bersifat valid. Validitas sampel ini tergantung dua faktor, yaitu ketepatan (accuracy) dan ketelitian (precision).
x x x x x x
x x x x x x x
x x x x x x x
x x x x x x x x
x
xx xxxx
xxx xx
xxxx xxx
Akurasi rendah
Presisi rendah
Akurasi tinggi
Presisi rendah
Akurasi rendah
Presisi tinggi
Akurasi tinggi
Presisi tinggi
Sasaran
(nilai parameter)
3.3 Pengertian-Pengertian dalam Penarikan Sampel
Pengertian dan prinsip dasar dalam proses pengambilan sampel perlu dibahas terlebih dahulu, terutama mengenai beberapa terminologi dan teori peluang dan distribusinya. Beberapa pengertian tersebut adalah sebegai berikut:
Populasi
Populasi adalah keseluruhan obyek psikologis yang dibatasi kriteria-kriteria tertentu. Obyek psikologis bisa merupakan obyek yang bisa diraba atau konkret (tangible) maupun obyek abstrak (intangible). Misalnya, barang-barang manufakturing dan fisik orang merupakan contoh obyek yang bersifat konkret, sedangkan motivasi kerja, kesadaran hukum, atau kredibilitas seorang pemimpin merupakan contoh-contoh obyek yang bersifat abstrak. Dalam ilmu sosial, misalnya bisnis atau manajemen, obyek psikologis yang sering diteliti relatif lebih banyak bersifat abstrak.
Banyak obyek psikologis dalam populasi disebut ukuran populasi (population sample) yang biasanya dilambangkan dengan N. Ukuran populasi ini besarnya bisa terhitung (countable) maupun tidak terhitung (uncountable). Apabila ukuran populasi berapapun besarnya tapi masih bisa dihitung maka populasi tersebut dinamakan populasi terhingga (finite population) sedangkan jika tidak bisa dihitung disebut populasi tak hingga (infinite population). Contohnya, himpunan bilangan merupakan populasi tak hingga sedangkan orang merupakan populasi hingga. Dalam penelitian ilmu sosial, populasi yang dihadapi adalah populasi hingga, misalnya perusahaan-perusahaan dalam suatu wilayah tertentu, para konsumen, karyawan, barang dan jasa yang ditawarkan, dan lain-lain.
Seorang peneliti pada langkah pertama strateginya harus menentukan secara tegas dan jelas populasi yang menjadi sasaran penelitiannya. Identifikasi populasi ini menyangkut penjelasan atau batasan kriteria yang digunakan salam populasi tersebut. Populasi sasaran adalah populasi yang nantinya akan menjadi cakupan kesimpulan penelitian. Jadi apabila dalam sebuah hasil penelitian dikeluarkan kesimpulan maka menurut etika penelitian, kesimpulan tersebut hanya terbatas pada populasi sasaran yang telah ditentukan. Beberapa contoh populasi sasaran yang dengan tegas didefinisikan dalam sebuah penelitan adalah sebagai berikut:
1. Populasi karyawan yang akan diteliliti dengan kriteria (1) karyawan tetap yang telah bekerja selama minimal satu tahun, (20) berusia antara 17 sampai 55 tahun, dan (3) bekerja di perusahaan berbadan hukum yang lokasi prabriknya di wilayah Jabotabek 2. Populasi keluarga dengan kriteria (1) termasuk kelompok prasejahtera, yang harus
didefinisikan secara tegas, misal berdasarkan definisi dari departemen sosial atau BKKBN dan (2) mempunyai tempat tinggal atau identitas di wilayah DKI Jakarta
3. Populasi konsumen dengan kriteria (1) Wanita berumur 17 sampai 25 tahun, (3) belum berkeluarga, (3) mempunyai pendidikan formal minimal SMU, dan (4) tempat tinggal di wilayah propinsi Jawa Barat.
Satuan Sampling
obyek pemilihan tersebut disebut satuan sampling (sampling unit). Satuan sampling bentuknya bisa individu yang berdiri sendiri atau kumpulan individu. Misalnya, seorang konsumen, karyawan, keluarga, perusahaan, desa atau kelurahan, kota besar, dan sebagainya.
Kerangka Sampling (Sampling frame)
Kerangka sampling adalah suatu daftar yang memuat semua seluruh anggota populasi yang telah ditentukan secara tegas satuan-satuannya. Daftar tersebut meliputi nomor urut (yang sangat diperlukan untuk proses pemilihan anggota sampel), nama atau identitas setiap satuan sampling, atau atribut lainyya. Kerangka sampling bisa berbentuk daftar perusahaan yang tercatat di Departemen Perindustria, daftar mahasiswa yang tercatat di sebuah perguruan tinggi, daftar karyawan tetap di sebuah perusahaan, dan sebagainya. Contoh bentuk kerangka sampling dengan satuan samplingnya adalah mahasiswa sebuah perguruan tinggi disajikan pada data editor SPSS adalah sebagai berikut:
SPSS
Penjelasan :
Kita akan membuat kerangka sampling yang memuat seluruh peserta kursus riset bisnis dengan menggunakan Data Editor pada SPSS. Kerangka sampling ini akan digunakan selanjutnya pada proses pemilihan beberapa satuan pengamatan dengan teknik sampling tertentu dan memanfaatkan fasilitas program SPSS
Menu : Data Define
Kita akan mendefinisikan 4 variabel, yaitu nomor, nama, jurusan, dan tingkat. Ketikkan nama variabel tersebut pada Variable name
dan klik Type lalu pilih String. Klik continue atau OK lalu mulailah mengetikan datanya pada data editor.
File Save
Gunakan menu ini jika semua data sudah dimasukkan dan simpanlah kerangka sampling tersebut dengan nama Frame.sav
Tampilan Data editor :
Nomor Nama Jurusan Tingkat
01 Pak A Akuntansi 3
02 Pak B Manajemen 4
…. ……… …
…. ……… …
N ……… …. ………
Tipe-Tipe Sampling
Proses memilih satuan sampling dari sebuah populasi, atau disebut sampling, bisa dikelompokkan ke dalam beberapa tipe, yaitu:
1. Berdasarkan aspek cara memilih dibagi menjadi (a) sampling dengan pengembalian dan (b) sampling tanpa pengembalian. Sampling dengan pengembalian apabila dalam proses pemilihannya, satuan sampling yang sudah terpilih dikembalikan lagi ke dalam populasi sebelum pemilihan berikutnya sehingga ada kemungkinan terpilih lebih dari sekali. Sampling tanpa pengembalian apabila satuan sampling yang sudah terpilih tidak dikembalikan ke populasi sehingga tidak mungkin terpilih lebih dari sekali. Dalam prakteknya, yang paling digunakan tipe sampling tanpa pengembalian inilah yang digunakan
2. Berdasarkan aspek peluang pemilihannya, sampling dikelompokkan menjadi dua tipe yaitu (a) sampling non peluang atau non probability sampling dan (b) sampling peluang atau probability sampling/random sampling. Sampling dikatakan sampling non peluang jika dalam proses memilih satuan-satuan sampling tidak dilibatkan unsur peluang. Proses ini sangat sederhana dan tidak rumit tetapi mempunyai kerugian relatif besar yaitu tidak bisa dilakukan uji signifikansinya, artinya analisis inferensial secara statistik tidak valid. Sedangkan sampling peluang adalah sampling yang dalam proses pemilihan satuan-satuan samplingnya didasarkan pada unsur peluang sedemikian hingga peluang setiap satuan sampling untuk terpilih diketahui besarnya.
3.4 Prinsip Dasar Sampling
Prinsip dasar pengambilan sampel dari sebuah populasi yang bersifat probabilistik mencakup konsep peluang dan distribusi peluang, pendugaan parameter populasi oleh statistik sampel, serta standar error pendugaannya. Untuk memahami semua prinsip tersebut, kita lihat ilustrisi berikut. Misalnya diketahui sebuah populasi dengan ukuran N=5 dengan satuan sampling lengkapnya adalah A, B, C, D, dan E. Variabel yang diukur dari setiap satuan sampling tersebut adalah X dengan nilai-nilai X untuk setiap satuan sampling dapat dilihat pada Gambar 5 berikut.
Misalnya kita akan mengambil contoh dengan ukuran sampel n=2 yang diambil dari populasi tersebut. Peluang masing-masing satuan sampling untuk terpilih ke dalam sampel adalah sebesar 1/5. Sedangkan banyaknya kemungkinan sampel yang bisa dibentuk adalah sebanyak 10 atau dengan rumus N!/(n!x(N-n)!). Tapi ingat, kita hanya bekerja dengan satu sampel saja atau kita tidak mencoba semua kemungkinan sampel tersebut. Jika kita melakukan sensus terhadap populasi, artinya mengukur nilai X untuk semua anggota populasi sebanyak 5 buah, maka diperoleh nilai parameter μ (rata-rata X) sebesar 3 dengan
D
Gambar 5. Prinsip pengambilan sampel acak
Dari tabel tersebut terlihat bahwa rata-rata X dari sebuah sampel yang diambil seorang peneliti mungkin lebih kecil, sama dengan atau lebih besar dari rata-rata populasi (μ =3). Artinya berdasarkan analisis statistik kita bisa menghitung seberapa besar tingkat kesalahan pendugaan parameter populasi untuk sampel tersebut. Untuk singkatnya, tingkat kesalahan tersebut disebut dengan standar error, yaitu dengan notasi dan rumus perhitungannya adalah sex = √[(N-n)/N)x(s2/n)], dan untuk populasi tak hingga atau
persentase ukuran sampel terhadap ukuran populasi relatif sangat kecil rumus yang digunakan adalah sex = √(s2/n). Berdasarkan rumus standar error tersebut secara
umum bisa disimpulkan bahwa presisi penelitian bisa ditingkat (atau standar error semakin kecil) jika keragaman (heterogenitas populasi) semakin kecil dan atau ukuran sampel semakin besar.
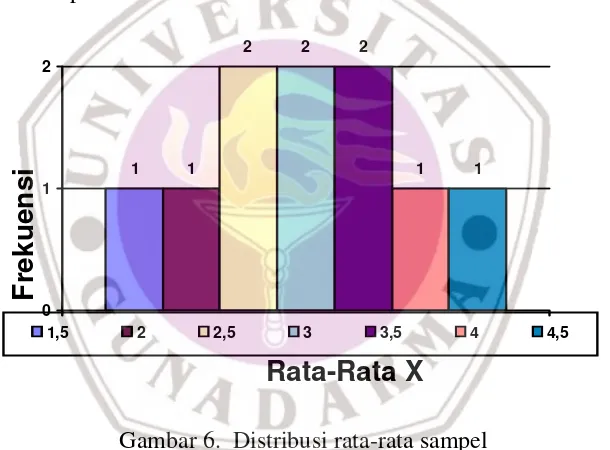
Ditinjau dari konsep peluang, kita bisa menghitung seberapa besar kemungkinan bahwa statistik sampel (misalnya rata-rata X di atas) mendekati nilai parameter populasi (untuk contoh diatas adalah μ=3). Hal ini bisa dijalaskan dengan distribusi sampling yang menunjukan distribusi peluang rata-rata X untuk keseluruhan sampel. Distribusi sampling tersebut dapat dilihat pada Gambar 6 berikut.
1 1
2 2 2
1 1
0 1 2
1,5 2 2,5 3 3,5 4 4,5
Frekuensi
Rata-Rata X
Gambar 6. Distribusi rata-rata sampel
Distribusi sampling tersebut menunjukkan bahwa rata-rata X dari sebuah sampling cukup besar peluangnya berada di sekitar rata-rata populasi. Konsep distribusi sampling ini digunakan dalam menganalisi secara statistika seberapa jauh tingkat kepercayaan sebuah penelitian.
3.5 Pengambilan sampel non probabilistik
Haphazard
Voluntary
Teknik ini dilakukan jika satuan sampling dikumpulkan atas dasar sukarela. Contohnya banyak digunakan di bidang kedokteran.
Purposive
Taknik pengambilan sampel yang dilakukan dengan memilih satuan sampling atas dasar pertimbangan sekelompok pakar di bidang ilmu yang sedang diteliti. Contohnya, penelitan untuk mengetahui indeks biaya hidup yang dilakukan oleh para pakar ekonomi.
Snowball
Teknik pengambilan sampel dimana satuan pengamatan diambil berdasarkan informasi dari satuan pengamatan sebelumnya yang sudah terpilih. Contohnya adalah penelitian mengenai penyebaran penyakit AIDS, yaitu dengan menelusuri orang-orang yang diduga mengidap penyekit ini berdasarkan informasi dari si penderiat pertama yang ditemukan. Informasi tersebut bisa berupa siapa-siapa saja yang pernah berhubungan dengan si yang sangat diperlukan untuk melacak penyebaran virus HIV.
Kuota
Teknik pengambilan sampel ini banyak diterapkan pada penelitian pasar dan penelitian pengumpulan pendapat (opinion poll) atau jejak pendapat. Teknik dilakukan dengan melakukan penjatahan terhadap kelompok satuan pengamatan secara berjenjang. Misalnya peneliti menetapkan Kuota 1 yaitu 100 orang eksekutif muda di Jakarta sebagai jumlah sampelnya. Kuota 1 tersebut selanjutnya dikelompokkan lagi dengan Kuota 2, misalnya 50 eksekutif pria dan 50 eksekutif wanita. Demikian seterusnya pengelompokkan dilakukan sesuai dengan tujuan penelitiannya.
3.6 Pengambilan sampel probabilistik
Simple Random Sampling (SRS)
1. Tentukan populasi sasaran secara tegas
2. Tentukan ukuran populasi secara tepat, contohnya 100 satuan pengamatan
3. Tentukan bentuk satuan sampling dan susun kerangka samplingnya secara lengkap. 4. Tentukan ukuran sampel melalui perhitungan tertentu. Ukuran ini bisa ditentukan
berdasarkan pertimbangan statisis (statistical aspect) atau oleh pertimbangan non statistis (nonstatistical aspect). Aspek statistik ditentukan oleh bentuk parameter (frekuensi, rata-rata, atau proporsi), teknik sampling yang digunakan, tujuan penelitian (menaksir atau menguji parameter), sifat penelitian (nonkomparatif atau komparataif), kedalaman analisis (overall atau elaborasi), variabilitas variabel yang diteliti (homogen atau heterogen), serta batas kesalahan dan derajat kepercayaan. Aspek nonstatistis biasanya mempertimbangkan biaya, waktu, tenaga, dan kepraktisan atau ketersediaan satuan pengamatan di lapangan.
5. Proses pemilihan 10 dari 100 satuan pengamatan secara acak. Proses yang melibatkan kerangka sampling yang kecil bisa dilakukan dengan cara undian (seperti pengocokan pemenang arisan). Tetapi yang paling banyak digunakan, terutama untuk kerangka sampling dan ukuran sampel yang relatif lebih besar, digunakan tabel angka acak.
SPSS
Data (Open) : frame.sav {kerangka sampling yang akan digunakan} Menu : Data Select cases
Klik Random sample of cases dan sample. Pada kotak dialog yang muncul, masukkan ukuran sampel yang akan diambil yang bisa dalam dua cara, yaitu persentase ukuran sampel terhadap populasi (approximately …. Of cases) atau besarnya sampel (Exactly …. Cases from the cases).
Output :
Jika sebuah kasus (cases) terpilih maka nomornya tidak dicoret dan variabel Filter_$ bernilai 1 atau selected, sedangkan kasus yang tidak terpilih akan dicoret nomornya dan variabel Filter_$ bernilai 0 atau not selected.
Contoh: Kasus yang terpilih
Nama Jurusan Tingkat Filter_$
1 Ujang Ak III 0
2 Otong Ma III 1
3 Teteh Ak IV 0
Systematic Random Sampling (SyRS)
Teknik ini digunakan apabila (1) bisa disusun kerangka sampling yang lengkap dan (2) keadaan variabel yang diteliti relatif homogen dan tersebar di seluruh populasi. Pemilihan satuan pengamatan kedalam sampel dengan menggunakan SyRS bisa dilakukan melalui dua pendekatan, yaitu (1) Linear systematic selection (LSS) dan (2) Circular systematic selection (CSS).
a. LSS
Langkah kerja:
1. Tentukan populasi sasaran dan tentukan satuan-satuan samplingnya yang menunjukkan ukuran populasi sasaran, misalnya N=1500
2. Susun kerangka sampling
3. Tentukan ukuran sampel, misalnya n=20 4. Sediakan tabel angka random
5. Proses pemilihan 20 dari 1500 satuan samplingnya adalah sebagai berikut: a. Tentukan interval pemulihan dengan rumus : I = N/n =1500/20 = 75
b. Tentukan secara random sebuah bilangan acak (disebut rendom start (RS) atau random seed) yang besanrnya memenuhi persyaratan 1< RS < I, atau untuk contoh 1 < RS < 75. Misalnya terpilih angka random 07 (baris ke2, kolom ke1 dan 2 pada tabel angka acak). Oleh karena nomor satuaan pengamatan pada kerangka samplingnya terdiri dari 4 digit (0001 sampai 1500), maka SR=0007. RS ini merupakan satuan sampling pertama yang terpilih.
c. Satuan pengamatan berikutnya dipilih dengan cara menambahkan I=75 kepada nomor terpilih. Jadi satuan pengamatan yang terpilih kedua adalah 0007 + 75 = 0082, ketiga adalah 0082 + 75 = 0157, demikian seterusnya sampai terpilih sebanyak 20 satuan pengamatan
2. CSS
Langkah kerja:
1. Tentukan populasi sasaran dan tentukan ukuran populasi, misalnya N=2111
2. Untuk setiap satuan sampling yang ada dalam populasi sasaran disusun dalam kerangka sampling
3. Tentukan ukuran sampel (dengan menggunakan rumus atau pertimbangan tertentu), misalnya n= 13
4. Sediakan tabel angka random
5. Proses pemilihan 13 dari 2111 satuan sampling, yaitu:
a. Tentukan interval (I) dengan rumus I = N/n. Bulatkan ke bilangan bulat terdekat, yaitu 2111/13 = 162
b. Dari tabel angka acak dipilih RS yang memenuhi persyaratan 1 < RS < N, misalnya terpilih RS=1842. RS ini adalah satuan pertama yang terpilih ke dalam sampel
c. Satuan sampling berikutnya dipilih dengan cara menambahkan I secara sistematik kepada RS, yaitu:
2. 2004 (1842+162)
3. 2166 (tidak dipakai karena melebihi nomor dalam kerangka sampling (2111) maka satuan sampling yang terpilih adalah 2166 - 2111 atau 0055
4. 0217 (0055 + 162), demikianlah setrusnya sampai nomor ke 13
Dibandingkan dengan teknik SRS, SySR mempunyai kelebihan, yaitu:
1. Standar error yang didasarkan pada sampling sistematis paling sedikit sama presisinya dengan SRS
2. Mudah dilakukan
3. Pada konidisi tertentu, sampling sistematik bisa dilakukan sekalipun tidak ada kerangka sampling. Contohnya pada traffic survey yaitu dengan mengamati pergerakaan lalu lintas pada jam-jam tertentu atau urutan pergerakan kendaraan, atau pada penelitian tingkat laku konsumen, misalnya pengambilan satuan pengamatan dalam pola antrian tertentu
Sedangkan kerugiannya adalah jika dalam kerangka samplingnya mempunyai periodisitas yang berimpit dengan interval pemilihan.
SPSS
Data (Open) : frame.sav {kerangka sampling} Menu : Data Select cases
Langkah-langkahnya sama seperti simple random tetapi kita hanya memilih 1 kasus dari I (besarnya interval) kasus yang pertama (aproximately …. Cases from the first I cases). Kasus kedua, ketiga dan seterusnya diperoleh dengan menambahkan I ke nomor kasus pertama.
Stratified Random Sampling (StRS)
Sifat homegintas populasi kadang tidak bisa dijamin sepenunya di lapangan. Semakin tinggi tingkat keragaman (heterogenitas) populasi maka ukuran sampel yang harus diambil dengan SRS akan semakin besar untuk tingkat ketelitian tertentu. Masalah ini bisa diatasi dengan membuat sub-sub populasi yang bersifat homogen dan terhadap subpopulasi itulah proses pengambilan sampel secara SRS dilakukan. Proses pengambilan sampel setelah populasi keseluruhan yang relatif heterogen dipilah-pilah ke dalam sub populasi itulah yang dilakukan oleh Teknik StRS. Jadi langkah utama yang membedakan teknik ini dengan teknik SRS adalah proses pembentukan sub populasi, disebut strata. Sedangkan proses pemilihan dari setiap strata tersebut bisa dilakukan sama seperti proses pemilihan satuan sampling dengan teknik SRS. Langkah kerja selengkapnya adalah sebagai berikut: 1. Tentukan populasi sasaran dan tentukan anggota populasi secara keseluruhan (N)
2. Berdasarkan variabel tertentu (kriteria tertentu), populasi dibagi ke dalam strata-strata. Misal kelompok responden dibagi sesuai jenis kelamin (laki atau perempuan) jika secara teoritis respon akan berbeda karena perbedaan jenis kelamin, atau populasi perusahaan dibagia menjadi sub populasi perusahaan kecil, menengah, dan besar
4. Dari sebuah populasi selanjutnya kita menentukan ukuran sampel keseluruhan yang disebut overall sample size.
5. Ukuran sampel sebesar n selanjutnya dialokasikan kesetiap strata (n1, n2, dan seterusnya) dimana n = n1 + n2 + …. + ni. Penyebaran ini disebut alokasi sampel yang bisa dilakukan dengan 4 cara yaitu:
a. Alokaso sembarang dimana ukuran sampel masing-masing strata ditentukan secara sembarang dengan syarat minimal dari sebuah strata adalah harus ada dua satuan pengamatan yang dipilih. Dalam praktek, alokasi seperti ini jarang dan tidak disarankan untuk digunakan karena menyebabkan standar error membesar.
b. Alokasi sama besar tanpa melihat perbedaan ukuran masing-masing strata atau n1=n2=….= ni
c. Alokasi proporsional yaitu ukuran sampel untuk setiap strata sesuai dengan proporsi ukuran strata tersebut terhadap ukuran sampel keseluruhan, misal n1=N1/N, n2=N2/N, dan seterusnya
d. Alokasi Newton
6. Dari setiap strata kemudian dipilih satuan sampling melalui teknik SRS. Oleh karena pemilihan satuan sampling dari setiap strata dilakukan dengan SRS maka keseluruhan prosesnya disebut stratified random sampling. Jika pemilihan dari setiap strata dilakukan dengan SyRS maka disebut stratified systematic random sampling.
Jadi teknik ini digunakan apabila (1) keadaan variabel yang kita teliti sangat heterogen sehingga menimbulkan standar error yang tinggi (atau presisi yang rendah). Stratifikasi populasi dilakukan untuk memperbesar presisi (atau memperkecil standar error) ini, dan (2) apabila kita bisa menyusun kerangka sampling yang lengkap dan langsung mengenai satuan pengamatan.
SPSS
File (Open) : Frame.sav
Menu : Data Sort Cases
untuk mengelompokkan atau mengurutkan data berdasarkan kategori variabel tertentu sehingga kelompok kasus tersebut relatif homogen dilihat dari kategori tertentu. Misalkan kerangka sampling peserta kursus sebanyak 40 akan disort berdasarkan jurusan, maka hasilnya adalah peserta jurusan akuntansi akan menempati nomor-nomor awal dari 1 sampai, misalnya 19 dan peserta jurusan manajemen menempati nomor 20 sampai 40. Jadi 19 nomor pertama adalah strata 1 dan kelompok kedua adalah strata 2 yang bersifat homogen berdasarkan variabel jurusan. Data Select cases
Cluster Random Sampling (CSR)
Kita kadang-kadang tidak bisa menysun kerangka sampling yang lenngkap mengenai populasi sasaran baik karena kondisi tertentu atau pertimbangan kepraktisannya. Sebagai contoh, seorang peneliti melakukan penelitian mengenai tingkat konsumsi rata-rata keluarga prasejahtera di seluruh Indonesia. Masalahnya adalah dari mana sumber informasi untuk mendata keluarga pra sejahtera seluruh Indonesia dalam bentuk kerangka sampling yang lengkap. Kalaupun bisa disusun, proses penyusunannyapun memerlukan waktu, administrasi, dan biaya yang sangat besar. Selain itu, jika telah dilakukan pemilihan satuan sampling (dalam hal ini sebuah keluarga) maka ada kemungkinan sebaran wilayahnyapun cukup luas, misalnya keluarga pertama diamati berada di kota Sabang, keluarga kedua berada di kota Merauke, Keluarga ketiga berada di Menado, demikian seterusnya sampai keluarga ke n berada di Gunung Kidul. Jadi penggunaan teknik sampling tersebut sangat sulit dilakukan. Teknik CRS digunakan untuk mengatasi masalah tersebut.
CSR didasarkan pada prinsip bahwa satuan pengamatan bisa dikumpulkan dalam kelompok yang lebih besar, misalnya kumpula keluarga prasejahtera dalam satu desa, kecamatan, kabupaten, demikian seterusnya sampai propinsi sehingga terbentuk kelompok-kelompok untuk seluruh Indonesia. Kelompok satuan pengamatan tersebut disebut Cluster. Pemilihan satuan sampling dengan CSR tidak dilakukan secara langsung terhadap keluarga prasejahtera, tetapi secara bertahap dimulai dari pemilihan kelompok yang terbesar. Misalkan memilih beberapa propinsi dari 27 propinsi di Indonesia, kemudian dilanjutkan memilih beberapa kabupaten dari propinsi yang terpilih, demikian seterusnya sampai diperoleh keluarga prasejahtera. Jadi proses pemilihan secara bertahap tersebut bisa satu tahap (single stage cluster sampling), dua tahap (Two stage cluster sampling), dan seterusnya. Dalam prakteknya, disarankan tingkat pemilihan tersebut tidak lebih dari dua kali untuk menghindari rumus yang kompleks.
a. Single Stage Cluster Sampling (SSCS)
Proses memilih dengan SSCS secara umum dilakukan dengan memilih beberapa kluster dan untuk kluster yang terpilih tersebut diamati semua satuan sampling yang ada di dalamnya. Langkah-langkah kerja selengkapnya adalah sebagai berikut:
1. Populasi dibagi-bagi menjadi N buah cluster atau satuan sampling primer (SSP) yang bersifat heterogen. Misalkan Indonesai terdiri dari 27 propinsi
2. Dipilih n buah cluster dengan menggunakan simple random sampling. Misalkan terpilih propinsi Jawa Barat dan Timor Timur.
3. Seluruh satuan sampling dari SSP tersebut diteliti. Jadi seluruh keluarga prasejahtera yang berada di Jawa Barat dan Timor Timur harus diteliti
b. Two Stage Cluster Sampling (TSCS)
satuan sampling sekunder (SSS). Jika secara acak terpilih 2 kabupaten di Jawa Barat dan kabupaten di Timor Timur maka pengamatan dilakukan pada seluruh keluarga prasejahtera yang berada di ke 4 kabupaten tersebut.
Salah satu keunggulan CSR adalah pada saat membentuk kerangka sampling. Dengan teknik ini, kita tidak perlu mempunyai kerangka sampling lengkap untuk satua pengamatan sebab kerangka sampling tersebut bisa disusun kemudian. Keunggulan inilah yang menyebabkan teknik ini, terutama two stage cluster sampling, banyak digunakan dalam survai. Kerugiannya adalah presisinya kurang baik. Presisi ini bisa ditingkatkan dengan dengan cara membentuk cluster yang didalamnya bersifat seheterogen mungkin. Dalam praktek survai pembentukan cluster ini biasanya adalah daerah administratif (desa, kecamatan, kabupaten, dan setrusnya). Pembentukan cluster berdasarkan wilayah tersebut menyebabkan teknik tersebut disebut area sampling.
Berdasarkan penjelasan teknik-teknik sampling probabilistik diatas, terlihat bahwa masing-masing teknik mempunyai kelebihan dan kekurangan. Emory dan Coper menjelaskan deskripsi, keunggulan, dan kelemahan dari keempat teknik tersebut, seperti disajikan pada Tabel berikut.
Tipe Deskripsi Keunggulan Kelemahan
Simple random Setiap elemen populasi mempunyai
Systematic Pemilihan elemen populasi dimulai
Jika daftar anggota populasi cenderung monotonik, akan menghasilkan estimasi bias berdasarkan titik mulainya
Stratified Populasi dibagi menjadi subpopulasi atau strata dan dari setiap strata tersebut metode berbeda dalam strata
Kesalahan meningkat jika subgrup dipilih pada ukuran berbeda
Cluster Populasi dibagi menjadi sub populasi yang bersifat heterogen. Beberapa
subpopulasi dipilih secara random untuk diteliti lebih lanjut
Memberikan estimasi parameter tak bias jika dikerjakan sempurna
Lebih efisien secara ekonomis dibandingkan simple random
Biaya termurah per sampel, terutama kluster geografis Mudah dilaksanakan tanpa daftar anggota populasi